

Experimental Research Design — 6 mistakes you should never make!
Since school days’ students perform scientific experiments that provide results that define and prove the laws and theorems in science. These experiments are laid on a strong foundation of experimental research designs.
An experimental research design helps researchers execute their research objectives with more clarity and transparency.
In this article, we will not only discuss the key aspects of experimental research designs but also the issues to avoid and problems to resolve while designing your research study.
Table of Contents
What Is Experimental Research Design?
Experimental research design is a framework of protocols and procedures created to conduct experimental research with a scientific approach using two sets of variables. Herein, the first set of variables acts as a constant, used to measure the differences of the second set. The best example of experimental research methods is quantitative research .
Experimental research helps a researcher gather the necessary data for making better research decisions and determining the facts of a research study.
When Can a Researcher Conduct Experimental Research?
A researcher can conduct experimental research in the following situations —
- When time is an important factor in establishing a relationship between the cause and effect.
- When there is an invariable or never-changing behavior between the cause and effect.
- Finally, when the researcher wishes to understand the importance of the cause and effect.
Importance of Experimental Research Design
To publish significant results, choosing a quality research design forms the foundation to build the research study. Moreover, effective research design helps establish quality decision-making procedures, structures the research to lead to easier data analysis, and addresses the main research question. Therefore, it is essential to cater undivided attention and time to create an experimental research design before beginning the practical experiment.
By creating a research design, a researcher is also giving oneself time to organize the research, set up relevant boundaries for the study, and increase the reliability of the results. Through all these efforts, one could also avoid inconclusive results. If any part of the research design is flawed, it will reflect on the quality of the results derived.
Types of Experimental Research Designs
Based on the methods used to collect data in experimental studies, the experimental research designs are of three primary types:
1. Pre-experimental Research Design
A research study could conduct pre-experimental research design when a group or many groups are under observation after implementing factors of cause and effect of the research. The pre-experimental design will help researchers understand whether further investigation is necessary for the groups under observation.
Pre-experimental research is of three types —
- One-shot Case Study Research Design
- One-group Pretest-posttest Research Design
- Static-group Comparison
2. True Experimental Research Design
A true experimental research design relies on statistical analysis to prove or disprove a researcher’s hypothesis. It is one of the most accurate forms of research because it provides specific scientific evidence. Furthermore, out of all the types of experimental designs, only a true experimental design can establish a cause-effect relationship within a group. However, in a true experiment, a researcher must satisfy these three factors —
- There is a control group that is not subjected to changes and an experimental group that will experience the changed variables
- A variable that can be manipulated by the researcher
- Random distribution of the variables
This type of experimental research is commonly observed in the physical sciences.
3. Quasi-experimental Research Design
The word “Quasi” means similarity. A quasi-experimental design is similar to a true experimental design. However, the difference between the two is the assignment of the control group. In this research design, an independent variable is manipulated, but the participants of a group are not randomly assigned. This type of research design is used in field settings where random assignment is either irrelevant or not required.
The classification of the research subjects, conditions, or groups determines the type of research design to be used.

Advantages of Experimental Research
Experimental research allows you to test your idea in a controlled environment before taking the research to clinical trials. Moreover, it provides the best method to test your theory because of the following advantages:
- Researchers have firm control over variables to obtain results.
- The subject does not impact the effectiveness of experimental research. Anyone can implement it for research purposes.
- The results are specific.
- Post results analysis, research findings from the same dataset can be repurposed for similar research ideas.
- Researchers can identify the cause and effect of the hypothesis and further analyze this relationship to determine in-depth ideas.
- Experimental research makes an ideal starting point. The collected data could be used as a foundation to build new research ideas for further studies.
6 Mistakes to Avoid While Designing Your Research
There is no order to this list, and any one of these issues can seriously compromise the quality of your research. You could refer to the list as a checklist of what to avoid while designing your research.
1. Invalid Theoretical Framework
Usually, researchers miss out on checking if their hypothesis is logical to be tested. If your research design does not have basic assumptions or postulates, then it is fundamentally flawed and you need to rework on your research framework.
2. Inadequate Literature Study
Without a comprehensive research literature review , it is difficult to identify and fill the knowledge and information gaps. Furthermore, you need to clearly state how your research will contribute to the research field, either by adding value to the pertinent literature or challenging previous findings and assumptions.
3. Insufficient or Incorrect Statistical Analysis
Statistical results are one of the most trusted scientific evidence. The ultimate goal of a research experiment is to gain valid and sustainable evidence. Therefore, incorrect statistical analysis could affect the quality of any quantitative research.
4. Undefined Research Problem
This is one of the most basic aspects of research design. The research problem statement must be clear and to do that, you must set the framework for the development of research questions that address the core problems.
5. Research Limitations
Every study has some type of limitations . You should anticipate and incorporate those limitations into your conclusion, as well as the basic research design. Include a statement in your manuscript about any perceived limitations, and how you considered them while designing your experiment and drawing the conclusion.
6. Ethical Implications
The most important yet less talked about topic is the ethical issue. Your research design must include ways to minimize any risk for your participants and also address the research problem or question at hand. If you cannot manage the ethical norms along with your research study, your research objectives and validity could be questioned.
Experimental Research Design Example
In an experimental design, a researcher gathers plant samples and then randomly assigns half the samples to photosynthesize in sunlight and the other half to be kept in a dark box without sunlight, while controlling all the other variables (nutrients, water, soil, etc.)
By comparing their outcomes in biochemical tests, the researcher can confirm that the changes in the plants were due to the sunlight and not the other variables.
Experimental research is often the final form of a study conducted in the research process which is considered to provide conclusive and specific results. But it is not meant for every research. It involves a lot of resources, time, and money and is not easy to conduct, unless a foundation of research is built. Yet it is widely used in research institutes and commercial industries, for its most conclusive results in the scientific approach.
Have you worked on research designs? How was your experience creating an experimental design? What difficulties did you face? Do write to us or comment below and share your insights on experimental research designs!
Frequently Asked Questions
Randomization is important in an experimental research because it ensures unbiased results of the experiment. It also measures the cause-effect relationship on a particular group of interest.
Experimental research design lay the foundation of a research and structures the research to establish quality decision making process.
There are 3 types of experimental research designs. These are pre-experimental research design, true experimental research design, and quasi experimental research design.
The difference between an experimental and a quasi-experimental design are: 1. The assignment of the control group in quasi experimental research is non-random, unlike true experimental design, which is randomly assigned. 2. Experimental research group always has a control group; on the other hand, it may not be always present in quasi experimental research.
Experimental research establishes a cause-effect relationship by testing a theory or hypothesis using experimental groups or control variables. In contrast, descriptive research describes a study or a topic by defining the variables under it and answering the questions related to the same.

good and valuable
Very very good
Good presentation.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Publishing Research
- Reporting Research
How to Optimize Your Research Process: A step-by-step guide
For researchers across disciplines, the path to uncovering novel findings and insights is often filled…

- Industry News
- Trending Now
Breaking Barriers: Sony and Nature unveil “Women in Technology Award”
Sony Group Corporation and the prestigious scientific journal Nature have collaborated to launch the inaugural…

Achieving Research Excellence: Checklist for good research practices
Academia is built on the foundation of trustworthy and high-quality research, supported by the pillars…

- Promoting Research
Plain Language Summary — Communicating your research to bridge the academic-lay gap
Science can be complex, but does that mean it should not be accessible to the…

Science under Surveillance: Journals adopt advanced AI to uncover image manipulation
Journals are increasingly turning to cutting-edge AI tools to uncover deceitful images published in manuscripts.…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right…
Research Recommendations – Guiding policy-makers for evidence-based decision making

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What should universities' stance be on AI tools in research and academic writing?
Experimental Design: Types, Examples & Methods
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs.
Probably the most common way to design an experiment in psychology is to divide the participants into two groups, the experimental group and the control group, and then introduce a change to the experimental group, not the control group.
The researcher must decide how he/she will allocate their sample to the different experimental groups. For example, if there are 10 participants, will all 10 participants participate in both groups (e.g., repeated measures), or will the participants be split in half and take part in only one group each?
Three types of experimental designs are commonly used:
1. Independent Measures
Independent measures design, also known as between-groups , is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group.
Independent measures involve using two separate groups of participants, one in each condition. For example:

- Con : More people are needed than with the repeated measures design (i.e., more time-consuming).
- Pro : Avoids order effects (such as practice or fatigue) as people participate in one condition only. If a person is involved in several conditions, they may become bored, tired, and fed up by the time they come to the second condition or become wise to the requirements of the experiment!
- Con : Differences between participants in the groups may affect results, for example, variations in age, gender, or social background. These differences are known as participant variables (i.e., a type of extraneous variable ).
- Control : After the participants have been recruited, they should be randomly assigned to their groups. This should ensure the groups are similar, on average (reducing participant variables).
2. Repeated Measures Design
Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants.
Repeated Measures design is also known as within-groups or within-subjects design .
- Pro : As the same participants are used in each condition, participant variables (i.e., individual differences) are reduced.
- Con : There may be order effects. Order effects refer to the order of the conditions affecting the participants’ behavior. Performance in the second condition may be better because the participants know what to do (i.e., practice effect). Or their performance might be worse in the second condition because they are tired (i.e., fatigue effect). This limitation can be controlled using counterbalancing.
- Pro : Fewer people are needed as they participate in all conditions (i.e., saves time).
- Control : To combat order effects, the researcher counter-balances the order of the conditions for the participants. Alternating the order in which participants perform in different conditions of an experiment.
Counterbalancing
Suppose we used a repeated measures design in which all of the participants first learned words in “loud noise” and then learned them in “no noise.”
We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
The sample would be split into two groups: experimental (A) and control (B). For example, group 1 does ‘A’ then ‘B,’ and group 2 does ‘B’ then ‘A.’ This is to eliminate order effects.
Although order effects occur for each participant, they balance each other out in the results because they occur equally in both groups.

3. Matched Pairs Design
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group .
One member of each matched pair must be randomly assigned to the experimental group and the other to the control group.

- Con : If one participant drops out, you lose 2 PPs’ data.
- Pro : Reduces participant variables because the researcher has tried to pair up the participants so that each condition has people with similar abilities and characteristics.
- Con : Very time-consuming trying to find closely matched pairs.
- Pro : It avoids order effects, so counterbalancing is not necessary.
- Con : Impossible to match people exactly unless they are identical twins!
- Control : Members of each pair should be randomly assigned to conditions. However, this does not solve all these problems.
Experimental design refers to how participants are allocated to an experiment’s different conditions (or IV levels). There are three types:
1. Independent measures / between-groups : Different participants are used in each condition of the independent variable.
2. Repeated measures /within groups : The same participants take part in each condition of the independent variable.
3. Matched pairs : Each condition uses different participants, but they are matched in terms of important characteristics, e.g., gender, age, intelligence, etc.
Learning Check
Read about each of the experiments below. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design.
1 . To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period.
The researchers attempted to ensure that the patients in the two groups had similar severity of depressed symptoms by administering a standardized test of depression to each participant, then pairing them according to the severity of their symptoms.
2 . To assess the difference in reading comprehension between 7 and 9-year-olds, a researcher recruited each group from a local primary school. They were given the same passage of text to read and then asked a series of questions to assess their understanding.
3 . To assess the effectiveness of two different ways of teaching reading, a group of 5-year-olds was recruited from a primary school. Their level of reading ability was assessed, and then they were taught using scheme one for 20 weeks.
At the end of this period, their reading was reassessed, and a reading improvement score was calculated. They were then taught using scheme two for a further 20 weeks, and another reading improvement score for this period was calculated. The reading improvement scores for each child were then compared.
4 . To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page.
Experiment Terminology
Ecological validity.
The degree to which an investigation represents real-life experiences.
Experimenter effects
These are the ways that the experimenter can accidentally influence the participant through their appearance or behavior.
Demand characteristics
The clues in an experiment lead the participants to think they know what the researcher is looking for (e.g., the experimenter’s body language).
Independent variable (IV)
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable.
Dependent variable (DV)
Variable the experimenter measures. This is the outcome (i.e., the result) of a study.
Extraneous variables (EV)
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible.
Confounding variables
Variable(s) that have affected the results (DV), apart from the IV. A confounding variable could be an extraneous variable that has not been controlled.
Random Allocation
Randomly allocating participants to independent variable conditions means that all participants should have an equal chance of taking part in each condition.
The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effects
Changes in participants’ performance due to their repeating the same or similar test more than once. Examples of order effects include:
(i) practice effect: an improvement in performance on a task due to repetition, for example, because of familiarity with the task;
(ii) fatigue effect: a decrease in performance of a task due to repetition, for example, because of boredom or tiredness.
- Experimental Research Designs: Types, Examples & Methods

Experimental research is the most familiar type of research design for individuals in the physical sciences and a host of other fields. This is mainly because experimental research is a classical scientific experiment, similar to those performed in high school science classes.
Imagine taking 2 samples of the same plant and exposing one of them to sunlight, while the other is kept away from sunlight. Let the plant exposed to sunlight be called sample A, while the latter is called sample B.
If after the duration of the research, we find out that sample A grows and sample B dies, even though they are both regularly wetted and given the same treatment. Therefore, we can conclude that sunlight will aid growth in all similar plants.
What is Experimental Research?
Experimental research is a scientific approach to research, where one or more independent variables are manipulated and applied to one or more dependent variables to measure their effect on the latter. The effect of the independent variables on the dependent variables is usually observed and recorded over some time, to aid researchers in drawing a reasonable conclusion regarding the relationship between these 2 variable types.
The experimental research method is widely used in physical and social sciences, psychology, and education. It is based on the comparison between two or more groups with a straightforward logic, which may, however, be difficult to execute.
Mostly related to a laboratory test procedure, experimental research designs involve collecting quantitative data and performing statistical analysis on them during research. Therefore, making it an example of quantitative research method .
What are The Types of Experimental Research Design?
The types of experimental research design are determined by the way the researcher assigns subjects to different conditions and groups. They are of 3 types, namely; pre-experimental, quasi-experimental, and true experimental research.
Pre-experimental Research Design
In pre-experimental research design, either a group or various dependent groups are observed for the effect of the application of an independent variable which is presumed to cause change. It is the simplest form of experimental research design and is treated with no control group.
Although very practical, experimental research is lacking in several areas of the true-experimental criteria. The pre-experimental research design is further divided into three types
- One-shot Case Study Research Design
In this type of experimental study, only one dependent group or variable is considered. The study is carried out after some treatment which was presumed to cause change, making it a posttest study.
- One-group Pretest-posttest Research Design:
This research design combines both posttest and pretest study by carrying out a test on a single group before the treatment is administered and after the treatment is administered. With the former being administered at the beginning of treatment and later at the end.
- Static-group Comparison:
In a static-group comparison study, 2 or more groups are placed under observation, where only one of the groups is subjected to some treatment while the other groups are held static. All the groups are post-tested, and the observed differences between the groups are assumed to be a result of the treatment.
Quasi-experimental Research Design
The word “quasi” means partial, half, or pseudo. Therefore, the quasi-experimental research bearing a resemblance to the true experimental research, but not the same. In quasi-experiments, the participants are not randomly assigned, and as such, they are used in settings where randomization is difficult or impossible.
This is very common in educational research, where administrators are unwilling to allow the random selection of students for experimental samples.
Some examples of quasi-experimental research design include; the time series, no equivalent control group design, and the counterbalanced design.
True Experimental Research Design
The true experimental research design relies on statistical analysis to approve or disprove a hypothesis. It is the most accurate type of experimental design and may be carried out with or without a pretest on at least 2 randomly assigned dependent subjects.
The true experimental research design must contain a control group, a variable that can be manipulated by the researcher, and the distribution must be random. The classification of true experimental design include:
- The posttest-only Control Group Design: In this design, subjects are randomly selected and assigned to the 2 groups (control and experimental), and only the experimental group is treated. After close observation, both groups are post-tested, and a conclusion is drawn from the difference between these groups.
- The pretest-posttest Control Group Design: For this control group design, subjects are randomly assigned to the 2 groups, both are presented, but only the experimental group is treated. After close observation, both groups are post-tested to measure the degree of change in each group.
- Solomon four-group Design: This is the combination of the pretest-only and the pretest-posttest control groups. In this case, the randomly selected subjects are placed into 4 groups.
The first two of these groups are tested using the posttest-only method, while the other two are tested using the pretest-posttest method.
Examples of Experimental Research
Experimental research examples are different, depending on the type of experimental research design that is being considered. The most basic example of experimental research is laboratory experiments, which may differ in nature depending on the subject of research.
Administering Exams After The End of Semester
During the semester, students in a class are lectured on particular courses and an exam is administered at the end of the semester. In this case, the students are the subjects or dependent variables while the lectures are the independent variables treated on the subjects.
Only one group of carefully selected subjects are considered in this research, making it a pre-experimental research design example. We will also notice that tests are only carried out at the end of the semester, and not at the beginning.
Further making it easy for us to conclude that it is a one-shot case study research.
Employee Skill Evaluation
Before employing a job seeker, organizations conduct tests that are used to screen out less qualified candidates from the pool of qualified applicants. This way, organizations can determine an employee’s skill set at the point of employment.
In the course of employment, organizations also carry out employee training to improve employee productivity and generally grow the organization. Further evaluation is carried out at the end of each training to test the impact of the training on employee skills, and test for improvement.
Here, the subject is the employee, while the treatment is the training conducted. This is a pretest-posttest control group experimental research example.
Evaluation of Teaching Method
Let us consider an academic institution that wants to evaluate the teaching method of 2 teachers to determine which is best. Imagine a case whereby the students assigned to each teacher is carefully selected probably due to personal request by parents or due to stubbornness and smartness.
This is a no equivalent group design example because the samples are not equal. By evaluating the effectiveness of each teacher’s teaching method this way, we may conclude after a post-test has been carried out.
However, this may be influenced by factors like the natural sweetness of a student. For example, a very smart student will grab more easily than his or her peers irrespective of the method of teaching.
What are the Characteristics of Experimental Research?
Experimental research contains dependent, independent and extraneous variables. The dependent variables are the variables being treated or manipulated and are sometimes called the subject of the research.
The independent variables are the experimental treatment being exerted on the dependent variables. Extraneous variables, on the other hand, are other factors affecting the experiment that may also contribute to the change.
The setting is where the experiment is carried out. Many experiments are carried out in the laboratory, where control can be exerted on the extraneous variables, thereby eliminating them.
Other experiments are carried out in a less controllable setting. The choice of setting used in research depends on the nature of the experiment being carried out.
- Multivariable
Experimental research may include multiple independent variables, e.g. time, skills, test scores, etc.
Why Use Experimental Research Design?
Experimental research design can be majorly used in physical sciences, social sciences, education, and psychology. It is used to make predictions and draw conclusions on a subject matter.
Some uses of experimental research design are highlighted below.
- Medicine: Experimental research is used to provide the proper treatment for diseases. In most cases, rather than directly using patients as the research subject, researchers take a sample of the bacteria from the patient’s body and are treated with the developed antibacterial
The changes observed during this period are recorded and evaluated to determine its effectiveness. This process can be carried out using different experimental research methods.
- Education: Asides from science subjects like Chemistry and Physics which involves teaching students how to perform experimental research, it can also be used in improving the standard of an academic institution. This includes testing students’ knowledge on different topics, coming up with better teaching methods, and the implementation of other programs that will aid student learning.
- Human Behavior: Social scientists are the ones who mostly use experimental research to test human behaviour. For example, consider 2 people randomly chosen to be the subject of the social interaction research where one person is placed in a room without human interaction for 1 year.
The other person is placed in a room with a few other people, enjoying human interaction. There will be a difference in their behaviour at the end of the experiment.
- UI/UX: During the product development phase, one of the major aims of the product team is to create a great user experience with the product. Therefore, before launching the final product design, potential are brought in to interact with the product.
For example, when finding it difficult to choose how to position a button or feature on the app interface, a random sample of product testers are allowed to test the 2 samples and how the button positioning influences the user interaction is recorded.
What are the Disadvantages of Experimental Research?
- It is highly prone to human error due to its dependency on variable control which may not be properly implemented. These errors could eliminate the validity of the experiment and the research being conducted.
- Exerting control of extraneous variables may create unrealistic situations. Eliminating real-life variables will result in inaccurate conclusions. This may also result in researchers controlling the variables to suit his or her personal preferences.
- It is a time-consuming process. So much time is spent on testing dependent variables and waiting for the effect of the manipulation of dependent variables to manifest.
- It is expensive.
- It is very risky and may have ethical complications that cannot be ignored. This is common in medical research, where failed trials may lead to a patient’s death or a deteriorating health condition.
- Experimental research results are not descriptive.
- Response bias can also be supplied by the subject of the conversation.
- Human responses in experimental research can be difficult to measure.
What are the Data Collection Methods in Experimental Research?
Data collection methods in experimental research are the different ways in which data can be collected for experimental research. They are used in different cases, depending on the type of research being carried out.
1. Observational Study
This type of study is carried out over a long period. It measures and observes the variables of interest without changing existing conditions.
When researching the effect of social interaction on human behavior, the subjects who are placed in 2 different environments are observed throughout the research. No matter the kind of absurd behavior that is exhibited by the subject during this period, its condition will not be changed.
This may be a very risky thing to do in medical cases because it may lead to death or worse medical conditions.
2. Simulations
This procedure uses mathematical, physical, or computer models to replicate a real-life process or situation. It is frequently used when the actual situation is too expensive, dangerous, or impractical to replicate in real life.
This method is commonly used in engineering and operational research for learning purposes and sometimes as a tool to estimate possible outcomes of real research. Some common situation software are Simulink, MATLAB, and Simul8.
Not all kinds of experimental research can be carried out using simulation as a data collection tool . It is very impractical for a lot of laboratory-based research that involves chemical processes.
A survey is a tool used to gather relevant data about the characteristics of a population and is one of the most common data collection tools. A survey consists of a group of questions prepared by the researcher, to be answered by the research subject.
Surveys can be shared with the respondents both physically and electronically. When collecting data through surveys, the kind of data collected depends on the respondent, and researchers have limited control over it.
Formplus is the best tool for collecting experimental data using survey s. It has relevant features that will aid the data collection process and can also be used in other aspects of experimental research.
Differences between Experimental and Non-Experimental Research
1. In experimental research, the researcher can control and manipulate the environment of the research, including the predictor variable which can be changed. On the other hand, non-experimental research cannot be controlled or manipulated by the researcher at will.
This is because it takes place in a real-life setting, where extraneous variables cannot be eliminated. Therefore, it is more difficult to conclude non-experimental studies, even though they are much more flexible and allow for a greater range of study fields.
2. The relationship between cause and effect cannot be established in non-experimental research, while it can be established in experimental research. This may be because many extraneous variables also influence the changes in the research subject, making it difficult to point at a particular variable as the cause of a particular change
3. Independent variables are not introduced, withdrawn, or manipulated in non-experimental designs, but the same may not be said about experimental research.
Conclusion
Experimental research designs are often considered to be the standard in research designs. This is partly due to the common misconception that research is equivalent to scientific experiments—a component of experimental research design.
In this research design, one or more subjects or dependent variables are randomly assigned to different treatments (i.e. independent variables manipulated by the researcher) and the results are observed to conclude. One of the uniqueness of experimental research is in its ability to control the effect of extraneous variables.
Experimental research is suitable for research whose goal is to examine cause-effect relationships, e.g. explanatory research. It can be conducted in the laboratory or field settings, depending on the aim of the research that is being carried out.
Connect to Formplus, Get Started Now - It's Free!
- examples of experimental research
- experimental research methods
- types of experimental research
- busayo.longe
You may also like:
Experimental Vs Non-Experimental Research: 15 Key Differences
Differences between experimental and non experimental research on definitions, types, examples, data collection tools, uses, advantages etc.
Simpson’s Paradox & How to Avoid it in Experimental Research
In this article, we are going to look at Simpson’s Paradox from its historical point and later, we’ll consider its effect in...
What is Experimenter Bias? Definition, Types & Mitigation
In this article, we will look into the concept of experimental bias and how it can be identified in your research
Response vs Explanatory Variables: Definition & Examples
In this article, we’ll be comparing the two types of variables, what they both mean and see some of their real-life applications in research
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Types of Research Designs Compared | Guide & Examples
Types of Research Designs Compared | Guide & Examples
Published on June 20, 2019 by Shona McCombes . Revised on June 22, 2023.
When you start planning a research project, developing research questions and creating a research design , you will have to make various decisions about the type of research you want to do.
There are many ways to categorize different types of research. The words you use to describe your research depend on your discipline and field. In general, though, the form your research design takes will be shaped by:
- The type of knowledge you aim to produce
- The type of data you will collect and analyze
- The sampling methods , timescale and location of the research
This article takes a look at some common distinctions made between different types of research and outlines the key differences between them.
Table of contents
Types of research aims, types of research data, types of sampling, timescale, and location, other interesting articles.
The first thing to consider is what kind of knowledge your research aims to contribute.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
The next thing to consider is what type of data you will collect. Each kind of data is associated with a range of specific research methods and procedures.
Finally, you have to consider three closely related questions: how will you select the subjects or participants of the research? When and how often will you collect data from your subjects? And where will the research take place?
Keep in mind that the methods that you choose bring with them different risk factors and types of research bias . Biases aren’t completely avoidable, but can heavily impact the validity and reliability of your findings if left unchecked.
Choosing between all these different research types is part of the process of creating your research design , which determines exactly how your research will be conducted. But the type of research is only the first step: next, you have to make more concrete decisions about your research methods and the details of the study.
Read more about creating a research design
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Ecological validity
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, June 22). Types of Research Designs Compared | Guide & Examples. Scribbr. Retrieved April 15, 2024, from https://www.scribbr.com/methodology/types-of-research/
Is this article helpful?

Shona McCombes
Other students also liked, what is a research design | types, guide & examples, qualitative vs. quantitative research | differences, examples & methods, what is a research methodology | steps & tips, what is your plagiarism score.
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Experimental Research: What it is + Types of designs

Any research conducted under scientifically acceptable conditions uses experimental methods. The success of experimental studies hinges on researchers confirming the change of a variable is based solely on the manipulation of the constant variable. The research should establish a notable cause and effect.
What is Experimental Research?
Experimental research is a study conducted with a scientific approach using two sets of variables. The first set acts as a constant, which you use to measure the differences of the second set. Quantitative research methods , for example, are experimental.
If you don’t have enough data to support your decisions, you must first determine the facts. This research gathers the data necessary to help you make better decisions.
You can conduct experimental research in the following situations:
- Time is a vital factor in establishing a relationship between cause and effect.
- Invariable behavior between cause and effect.
- You wish to understand the importance of cause and effect.
Experimental Research Design Types
The classic experimental design definition is: “The methods used to collect data in experimental studies.”
There are three primary types of experimental design:
- Pre-experimental research design
- True experimental research design
- Quasi-experimental research design
The way you classify research subjects based on conditions or groups determines the type of research design you should use.
0 1. Pre-Experimental Design
A group, or various groups, are kept under observation after implementing cause and effect factors. You’ll conduct this research to understand whether further investigation is necessary for these particular groups.
You can break down pre-experimental research further into three types:
- One-shot Case Study Research Design
- One-group Pretest-posttest Research Design
- Static-group Comparison
0 2. True Experimental Design
It relies on statistical analysis to prove or disprove a hypothesis, making it the most accurate form of research. Of the types of experimental design, only true design can establish a cause-effect relationship within a group. In a true experiment, three factors need to be satisfied:
- There is a Control Group, which won’t be subject to changes, and an Experimental Group, which will experience the changed variables.
- A variable that can be manipulated by the researcher
- Random distribution
This experimental research method commonly occurs in the physical sciences.
0 3. Quasi-Experimental Design
The word “Quasi” indicates similarity. A quasi-experimental design is similar to an experimental one, but it is not the same. The difference between the two is the assignment of a control group. In this research, an independent variable is manipulated, but the participants of a group are not randomly assigned. Quasi-research is used in field settings where random assignment is either irrelevant or not required.
Importance of Experimental Design
Experimental research is a powerful tool for understanding cause-and-effect relationships. It allows us to manipulate variables and observe the effects, which is crucial for understanding how different factors influence the outcome of a study.
But the importance of experimental research goes beyond that. It’s a critical method for many scientific and academic studies. It allows us to test theories, develop new products, and make groundbreaking discoveries.
For example, this research is essential for developing new drugs and medical treatments. Researchers can understand how a new drug works by manipulating dosage and administration variables and identifying potential side effects.
Similarly, experimental research is used in the field of psychology to test theories and understand human behavior. By manipulating variables such as stimuli, researchers can gain insights into how the brain works and identify new treatment options for mental health disorders.
It is also widely used in the field of education. It allows educators to test new teaching methods and identify what works best. By manipulating variables such as class size, teaching style, and curriculum, researchers can understand how students learn and identify new ways to improve educational outcomes.
In addition, experimental research is a powerful tool for businesses and organizations. By manipulating variables such as marketing strategies, product design, and customer service, companies can understand what works best and identify new opportunities for growth.
Advantages of Experimental Research
When talking about this research, we can think of human life. Babies do their own rudimentary experiments (such as putting objects in their mouths) to learn about the world around them, while older children and teens do experiments at school to learn more about science.
Ancient scientists used this research to prove that their hypotheses were correct. For example, Galileo Galilei and Antoine Lavoisier conducted various experiments to discover key concepts in physics and chemistry. The same is true of modern experts, who use this scientific method to see if new drugs are effective, discover treatments for diseases, and create new electronic devices (among others).
It’s vital to test new ideas or theories. Why put time, effort, and funding into something that may not work?
This research allows you to test your idea in a controlled environment before marketing. It also provides the best method to test your theory thanks to the following advantages:

- Researchers have a stronger hold over variables to obtain desired results.
- The subject or industry does not impact the effectiveness of experimental research. Any industry can implement it for research purposes.
- The results are specific.
- After analyzing the results, you can apply your findings to similar ideas or situations.
- You can identify the cause and effect of a hypothesis. Researchers can further analyze this relationship to determine more in-depth ideas.
- Experimental research makes an ideal starting point. The data you collect is a foundation for building more ideas and conducting more action research .
Whether you want to know how the public will react to a new product or if a certain food increases the chance of disease, experimental research is the best place to start. Begin your research by finding subjects using QuestionPro Audience and other tools today.
LEARN MORE FREE TRIAL
MORE LIKE THIS

Top 7 DEI Software Solutions to Empower Your Workplace
Apr 16, 2024

The Power of AI in Customer Experience — Tuesday CX Thoughts

Employee Lifecycle Management Software: Top of 2024
Apr 15, 2024

Top 15 Sentiment Analysis Software That Should Be on Your List
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Experimental design: Guide, steps, examples
Last updated
27 April 2023
Reviewed by
Miroslav Damyanov
Experimental research design is a scientific framework that allows you to manipulate one or more variables while controlling the test environment.
When testing a theory or new product, it can be helpful to have a certain level of control and manipulate variables to discover different outcomes. You can use these experiments to determine cause and effect or study variable associations.
This guide explores the types of experimental design, the steps in designing an experiment, and the advantages and limitations of experimental design.
Make research less tedious
Dovetail streamlines research to help you uncover and share actionable insights
- What is experimental research design?
You can determine the relationship between each of the variables by:
Manipulating one or more independent variables (i.e., stimuli or treatments)
Applying the changes to one or more dependent variables (i.e., test groups or outcomes)
With the ability to analyze the relationship between variables and using measurable data, you can increase the accuracy of the result.
What is a good experimental design?
A good experimental design requires:
Significant planning to ensure control over the testing environment
Sound experimental treatments
Properly assigning subjects to treatment groups
Without proper planning, unexpected external variables can alter an experiment's outcome.
To meet your research goals, your experimental design should include these characteristics:
Provide unbiased estimates of inputs and associated uncertainties
Enable the researcher to detect differences caused by independent variables
Include a plan for analysis and reporting of the results
Provide easily interpretable results with specific conclusions
What's the difference between experimental and quasi-experimental design?
The major difference between experimental and quasi-experimental design is the random assignment of subjects to groups.
A true experiment relies on certain controls. Typically, the researcher designs the treatment and randomly assigns subjects to control and treatment groups.
However, these conditions are unethical or impossible to achieve in some situations.
When it's unethical or impractical to assign participants randomly, that’s when a quasi-experimental design comes in.
This design allows researchers to conduct a similar experiment by assigning subjects to groups based on non-random criteria.
Another type of quasi-experimental design might occur when the researcher doesn't have control over the treatment but studies pre-existing groups after they receive different treatments.
When can a researcher conduct experimental research?
Various settings and professions can use experimental research to gather information and observe behavior in controlled settings.
Basically, a researcher can conduct experimental research any time they want to test a theory with variable and dependent controls.
Experimental research is an option when the project includes an independent variable and a desire to understand the relationship between cause and effect.
- The importance of experimental research design
Experimental research enables researchers to conduct studies that provide specific, definitive answers to questions and hypotheses.
Researchers can test Independent variables in controlled settings to:
Test the effectiveness of a new medication
Design better products for consumers
Answer questions about human health and behavior
Developing a quality research plan means a researcher can accurately answer vital research questions with minimal error. As a result, definitive conclusions can influence the future of the independent variable.
Types of experimental research designs
There are three main types of experimental research design. The research type you use will depend on the criteria of your experiment, your research budget, and environmental limitations.
Pre-experimental research design
A pre-experimental research study is a basic observational study that monitors independent variables’ effects.
During research, you observe one or more groups after applying a treatment to test whether the treatment causes any change.
The three subtypes of pre-experimental research design are:
One-shot case study research design
This research method introduces a single test group to a single stimulus to study the results at the end of the application.
After researchers presume the stimulus or treatment has caused changes, they gather results to determine how it affects the test subjects.
One-group pretest-posttest design
This method uses a single test group but includes a pretest study as a benchmark. The researcher applies a test before and after the group’s exposure to a specific stimulus.
Static group comparison design
This method includes two or more groups, enabling the researcher to use one group as a control. They apply a stimulus to one group and leave the other group static.
A posttest study compares the results among groups.
True experimental research design
A true experiment is the most common research method. It involves statistical analysis to prove or disprove a specific hypothesis .
Under completely experimental conditions, researchers expose participants in two or more randomized groups to different stimuli.
Random selection removes any potential for bias, providing more reliable results.
These are the three main sub-groups of true experimental research design:
Posttest-only control group design
This structure requires the researcher to divide participants into two random groups. One group receives no stimuli and acts as a control while the other group experiences stimuli.
Researchers perform a test at the end of the experiment to observe the stimuli exposure results.
Pretest-posttest control group design
This test also requires two groups. It includes a pretest as a benchmark before introducing the stimulus.
The pretest introduces multiple ways to test subjects. For instance, if the control group also experiences a change, it reveals that taking the test twice changes the results.
Solomon four-group design
This structure divides subjects into two groups, with two as control groups. Researchers assign the first control group a posttest only and the second control group a pretest and a posttest.
The two variable groups mirror the control groups, but researchers expose them to stimuli. The ability to differentiate between groups in multiple ways provides researchers with more testing approaches for data-based conclusions.
Quasi-experimental research design
Although closely related to a true experiment, quasi-experimental research design differs in approach and scope.
Quasi-experimental research design doesn’t have randomly selected participants. Researchers typically divide the groups in this research by pre-existing differences.
Quasi-experimental research is more common in educational studies, nursing, or other research projects where it's not ethical or practical to use randomized subject groups.
- 5 steps for designing an experiment
Experimental research requires a clearly defined plan to outline the research parameters and expected goals.
Here are five key steps in designing a successful experiment:
Step 1: Define variables and their relationship
Your experiment should begin with a question: What are you hoping to learn through your experiment?
The relationship between variables in your study will determine your answer.
Define the independent variable (the intended stimuli) and the dependent variable (the expected effect of the stimuli). After identifying these groups, consider how you might control them in your experiment.
Could natural variations affect your research? If so, your experiment should include a pretest and posttest.
Step 2: Develop a specific, testable hypothesis
With a firm understanding of the system you intend to study, you can write a specific, testable hypothesis.
What is the expected outcome of your study?
Develop a prediction about how the independent variable will affect the dependent variable.
How will the stimuli in your experiment affect your test subjects?
Your hypothesis should provide a prediction of the answer to your research question .
Step 3: Design experimental treatments to manipulate your independent variable
Depending on your experiment, your variable may be a fixed stimulus (like a medical treatment) or a variable stimulus (like a period during which an activity occurs).
Determine which type of stimulus meets your experiment’s needs and how widely or finely to vary your stimuli.
Step 4: Assign subjects to groups
When you have a clear idea of how to carry out your experiment, you can determine how to assemble test groups for an accurate study.
When choosing your study groups, consider:
The size of your experiment
Whether you can select groups randomly
Your target audience for the outcome of the study
You should be able to create groups with an equal number of subjects and include subjects that match your target audience. Remember, you should assign one group as a control and use one or more groups to study the effects of variables.
Step 5: Plan how to measure your dependent variable
This step determines how you'll collect data to determine the study's outcome. You should seek reliable and valid measurements that minimize research bias or error.
You can measure some data with scientific tools, while you’ll need to operationalize other forms to turn them into measurable observations.
- Advantages of experimental research
Experimental research is an integral part of our world. It allows researchers to conduct experiments that answer specific questions.
While researchers use many methods to conduct different experiments, experimental research offers these distinct benefits:
Researchers can determine cause and effect by manipulating variables.
It gives researchers a high level of control.
Researchers can test multiple variables within a single experiment.
All industries and fields of knowledge can use it.
Researchers can duplicate results to promote the validity of the study .
Replicating natural settings rapidly means immediate research.
Researchers can combine it with other research methods.
It provides specific conclusions about the validity of a product, theory, or idea.
- Disadvantages (or limitations) of experimental research
Unfortunately, no research type yields ideal conditions or perfect results.
While experimental research might be the right choice for some studies, certain conditions could render experiments useless or even dangerous.
Before conducting experimental research, consider these disadvantages and limitations:
Required professional qualification
Only competent professionals with an academic degree and specific training are qualified to conduct rigorous experimental research. This ensures results are unbiased and valid.
Limited scope
Experimental research may not capture the complexity of some phenomena, such as social interactions or cultural norms. These are difficult to control in a laboratory setting.
Resource-intensive
Experimental research can be expensive, time-consuming, and require significant resources, such as specialized equipment or trained personnel.
Limited generalizability
The controlled nature means the research findings may not fully apply to real-world situations or people outside the experimental setting.
Practical or ethical concerns
Some experiments may involve manipulating variables that could harm participants or violate ethical guidelines .
Researchers must ensure their experiments do not cause harm or discomfort to participants.
Sometimes, recruiting a sample of people to randomly assign may be difficult.
- Experimental research design example
Experiments across all industries and research realms provide scientists, developers, and other researchers with definitive answers. These experiments can solve problems, create inventions, and heal illnesses.
Product design testing is an excellent example of experimental research.
A company in the product development phase creates multiple prototypes for testing. With a randomized selection, researchers introduce each test group to a different prototype.
When groups experience different product designs , the company can assess which option most appeals to potential customers.
Experimental research design provides researchers with a controlled environment to conduct experiments that evaluate cause and effect.
Using the five steps to develop a research plan ensures you anticipate and eliminate external variables while answering life’s crucial questions.
Get started today
Go from raw data to valuable insights with a flexible research platform
Editor’s picks
Last updated: 21 December 2023
Last updated: 16 December 2023
Last updated: 6 October 2023
Last updated: 5 March 2024
Last updated: 25 November 2023
Last updated: 15 February 2024
Last updated: 11 March 2024
Last updated: 12 December 2023
Last updated: 6 March 2024
Last updated: 10 April 2023
Last updated: 20 December 2023
Latest articles
Related topics.
- Types of experimental
Log in or sign up
Get started for free
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
14.1 What is experimental design and when should you use it?
Learning objectives.
Learners will be able to…
- Describe the purpose of experimental design research
- Describe nomethetic causality and the logic of experimental design
- Identify the characteristics of a basic experiment
- Discuss the relationship between dependent and independent variables in experiments
- Identify the three major types of experimental designs
Pre-awareness check (Knowledge)
What are your thoughts on the phrase ‘experiment’ in the realm of social sciences? In an experiment, what is the independent variable?
The basics of experiments
In social work research, experimental design is used to test the effects of treatments, interventions, programs, or other conditions to which individuals, groups, organizations, or communities may be exposed to. There are a lot of experiments social work researchers can use to explore topics such as treatments for depression, impacts of school-based mental health on student outcomes, or prevention of abuse of people with disabilities. The American Psychological Association defines an experiment as:
a series of observations conducted under controlled conditions to study a relationship with the purpose of drawing causal inferences about that relationship. An experiment involves the manipulation of an independent variable , the measurement of a dependent variable , and the exposure of various participants to one or more of the conditions being studied. Random selection of participants and their random assignment to conditions also are necessary in experiments .
In experimental design, the independent variable is the intervention, treatment, or condition that is being investigated as a potential cause of change (i.e., the experimental condition ). The effect, or outcome, of the experimental condition is the dependent variable. Trying out a new restaurant, dating a new person – we often call these things “experiments.” However, a true social science experiment would include recruitment of a large enough sample, random assignment to control and experimental groups, exposing those in the experimental group to an experimental condition, and collecting observations at the end of the experiment.
Social scientists use this level of rigor and control to maximize the internal validity of their research. Internal validity is the confidence researchers have about whether the independent variable (e.g, treatment) truly produces a change in the dependent, or outcome, variable. The logic and features of experimental design are intended to help establish causality and to reduce threats to internal validity , which we will discuss in Section 14.5 .
Experiments attempt to establish a nomothetic causal relationship between two variables—the treatment and its intended outcome. We discussed the four criteria for establishing nomothetic causality in Section 4.3 :
- plausibility,
- covariation,
- temporality, and
- nonspuriousness.
Experiments should establish plausibility , having a plausible reason why their intervention would cause changes in the dependent variable. Usually, a theory framework or previous empirical evidence will indicate the plausibility of a causal relationship.
Covariation can be established for causal explanations by showing that the “cause” and the “effect” change together. In experiments, the cause is an intervention, treatment, or other experimental condition. Whether or not a research participant is exposed to the experimental condition is the independent variable. The effect in an experiment is the outcome being assessed and is the dependent variable in the study. When the independent and dependent variables covary, they can have a positive association (e.g., those exposed to the intervention have increased self-esteem) or a negative association (e.g., those exposed to the intervention have reduced anxiety).
Since researcher controls when the intervention is administered, they can be assured that changes in the independent variable (the treatment) happens before changes in the dependent variable (the outcome). In this way, experiments assure temporality .
Finally, one of the most important features of experiments is that they allow researchers to eliminate spurious variables to support the criterion of nonspuriousness . True experiments are usually conducted under strictly controlled conditions. The intervention is given in the same way to each person, with a minimal number of other variables that might cause their post-test scores to change.
The logic of experimental design
How do we know that one phenomenon causes another? The complexity of the social world in which we practice and conduct research means that causes of social problems are rarely cut and dry. Uncovering explanations for social problems is key to helping clients address them, and experimental research designs are one road to finding answers.
Just because two phenomena are related in some way doesn’t mean that one causes the other. Ice cream sales increase in the summer, and so does the rate of violent crime; does that mean that eating ice cream is going to make me violent? Obviously not, because ice cream is great. The reality of that association is far more complex—it could be that hot weather makes people more irritable and, at times, violent, while also making people want ice cream. More likely, though, there are other social factors not accounted for in the way we just described this association.
As we have discussed, experimental designs can help clear up at least some of this fog by allowing researchers to isolate the effect of interventions on dependent variables by controlling extraneous variables . In true experimental design (discussed in the next section) and quasi-experimental design, researchers accomplish this w ith a control group or comparison group and the experimental group . The experimental group is sometimes called the treatment group because people in the experimental group receive the treatment or are exposed to the experimental condition (but we will call it the experimental group in this chapter.) The control/comparison group does not receive the treatment or intervention. Instead they may receive what is known as “treatment as usual” or perhaps no treatment at all.

In a well-designed experiment, the control group should look almost identical to the experimental group in terms of demographics and other relevant factors. What if we want to know the effect of CBT on social anxiety, but we have learned in prior research that men tend to have a more difficult time overcoming social anxiety? We would want our control and experimental groups to have a similar portions of men, since ostensibly, both groups’ results would be affected by the men in the group. If your control group has 5 women, 6 men, and 4 non-binary people, then your experimental group should be made up of roughly the same gender balance to help control for the influence of gender on the outcome of your intervention. (In reality, the groups should be similar along other dimensions, as well, and your group will likely be much larger.) The researcher will use the same outcome measures for both groups and compare them, and assuming the experiment was designed correctly, get a pretty good answer about whether the intervention had an effect on social anxiety.
Random assignment [/pb_glossary], also called randomization, entails using a random process to decide which participants are put into the control or experimental group (which participants receive an intervention and which do not). By randomly assigning participants to a group, you can reduce the effect of extraneous variables on your research because there won’t be a systematic difference between the groups.
Do not confuse random assignment with random sampling . Random sampling is a method for selecting a sample from a population and is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other related fields. Random sampling helps a great deal with external validity, or generalizability , whereas random assignment increases internal validity .
Other Features of Experiments that Help Establish Causality
To control for spuriousness (as well as meeting the three other criteria for establishing causality), experiments try to control as many aspects of the research process as possible: using control groups, having large enough sample sizes, standardizing the treatment, etc. Researchers in large experiments often employ clinicians or other research staff to help them. Researchers train their staff members exhaustively, provide pre-scripted responses to common questions, and control the physical environment of the experiment so each person who participates receives the exact same treatment. Experimental researchers also document their procedures, so that others can review them and make changes in future research if they think it will improve on the ability to control for spurious variables.
An interesting example is Bruce Alexander’s (2010) Rat Park experiments. Much of the early research conducted on addictive drugs, like heroin and cocaine, was conducted on animals other than humans, usually mice or rats. The scientific consensus up until Alexander’s experiments was that cocaine and heroin were so addictive that rats, if offered the drugs, would consume them repeatedly until they perished. Researchers claimed this behavior explained how addiction worked in humans, but Alexander was not so sure. He knew rats were social animals and the experimental procedure from previous experiments did not allow them to socialize. Instead, rats were kept isolated in small cages with only food, water, and metal walls. To Alexander, social isolation was a spurious variable, causing changes in addictive behavior not due to the drug itself. Alexander created an experiment of his own, in which rats were allowed to run freely in an interesting environment, socialize and mate with other rats, and of course, drink from a solution that contained an addictive drug. In this environment, rats did not become hopelessly addicted to drugs. In fact, they had little interest in the substance. To Alexander, the results of his experiment demonstrated that social isolation was more of a causal factor for addiction than the drug itself.
One challenge with Alexander’s findings is that subsequent researchers have had mixed success replicating his findings (e.g., Petrie, 1996; Solinas, Thiriet, El Rawas, Lardeux, & Jaber, 2009). Replication involves conducting another researcher’s experiment in the same manner and seeing if it produces the same results. If the causal relationship is real, it should occur in all (or at least most) rigorous replications of the experiment.
Replicability
[INSERT A PARAGRAPH ABOUT REPLICATION/REPRODUCTION HERE. CAN USE/REFERENCE THIS IF IT’S HELPFUL; include glossary definition as well as other general info]
To allow for easier replication, researchers should describe their experimental methods diligently. Researchers with the Open Science Collaboration (2015) [1] conducted the Reproducibility Project , which caused a significant controversy regarding the validity of psychological studies. The researchers with the project attempted to reproduce the results of 100 experiments published in major psychology journals since 2008. What they found was shocking. Although 97% of the original studies reported significant results, only 36% of the replicated studies had significant findings. The average effect size in the replication studies was half that of the original studies. The implications of the Reproducibility Project are potentially staggering, and encourage social scientists to carefully consider the validity of their reported findings and that the scientific community take steps to ensure researchers do not cherry-pick data or change their hypotheses simply to get published.
Generalizability
Let’s return to Alexander’s Rat Park study and consider the implications of his experiment for substance use professionals. The conclusions he drew from his experiments on rats were meant to be generalized to the population. If this could be done, the experiment would have a high degree of external validity , which is the degree to which conclusions generalize to larger populations and different situations. Alexander argues his conclusions about addiction and social isolation help us understand why people living in deprived, isolated environments may become addicted to drugs more often than those in more enriching environments. Similarly, earlier rat researchers argued their results showed these drugs were instantly addictive to humans, often to the point of death.
Neither study’s results will match up perfectly with real life. There are clients in social work practice who may fit into Alexander’s social isolation model, but social isolation is complex. Clients can live in environments with other sociable humans, work jobs, and have romantic relationships; does this mean they are not socially isolated? On the other hand, clients may face structural racism, poverty, trauma, and other challenges that may contribute to their social environment. Alexander’s work helps understand clients’ experiences, but the explanation is incomplete. Human existence is more complicated than the experimental conditions in Rat Park.
Effectiveness versus Efficacy
Social workers are especially attentive to how social context shapes social life. This consideration points out a potential weakness of experiments. They can be rather artificial. When an experiment demonstrates causality under ideal, controlled circumstances, it establishes the efficacy of an intervention.
How often do real-world social interactions occur in the same way that they do in a controlled experiment? Experiments that are conducted in community settings by community practitioners are less easily controlled than those conducted in a lab or with researchers who adhere strictly to research protocols delivering the intervention. When an experiment demonstrates causality in a real-world setting that is not tightly controlled, it establishes the effectiveness of the intervention.
The distinction between efficacy and effectiveness demonstrates the tension between internal and external validity. Internal validity and external validity are conceptually linked. Internal validity refers to the degree to which the intervention causes its intended outcomes, and external validity refers to how well that relationship applies to different groups and circumstances than the experiment. However, the more researchers tightly control the environment to ensure internal validity, the more they may risk external validity for generalizing their results to different populations and circumstances. Correspondingly, researchers whose settings are just like the real world will be less able to ensure internal validity, as there are many factors that could pollute the research process. This is not to suggest that experimental research findings cannot have high levels of both internal and external validity, but that experimental researchers must always be aware of this potential weakness and clearly report limitations in their research reports.
Types of Experimental Designs
Experimental design is an umbrella term for a research method that is designed to test hypotheses related to causality under controlled conditions. Table 14.1 describes the three major types of experimental design (pre-experimental, quasi-experimental, and true experimental) and presents subtypes for each. As we will see in the coming sections, some types of experimental design are better at establishing causality than others. It’s also worth considering that true experiments, which most effectively establish causality , are often difficult and expensive to implement. Although the other experimental designs aren’t perfect, they still produce useful, valid evidence and may be more feasible to carry out.
Key Takeaways
- Experimental designs are useful for establishing causality, but some types of experimental design do this better than others.
- Experiments help researchers isolate the effect of the independent variable on the dependent variable by controlling for the effect of extraneous variables .
- Experiments use a control/comparison group and an experimental group to test the effects of interventions. These groups should be as similar to each other as possible in terms of demographics and other relevant factors.
- True experiments have control groups with randomly assigned participants; quasi-experimental types of experiments have comparison groups to which participants are not randomly assigned; pre-experimental designs do not have a comparison group.
TRACK 1 (IF YOU ARE CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
- Think about the research project you’ve been designing so far. How might you use a basic experiment to answer your question? If your question isn’t explanatory, try to formulate a new explanatory question and consider the usefulness of an experiment.
- Why is establishing a simple relationship between two variables not indicative of one causing the other?
TRACK 2 (IF YOU AREN’T CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
Imagine you are interested in studying child welfare practice. You are interested in learning more about community-based programs aimed to prevent child maltreatment and to prevent out-of-home placement for children.
- Think about the research project stated above. How might you use a basic experiment to look more into this research topic? Try to formulate an explanatory question and consider the usefulness of an experiment.
- Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349 (6251), aac4716. Doi: 10.1126/science.aac4716 ↵
an operation or procedure carried out under controlled conditions in order to discover an unknown effect or law, to test or establish a hypothesis, or to illustrate a known law.
treatment, intervention, or experience that is being tested in an experiment (the independent variable) that is received by the experimental group and not by the control group.
Ability to say that one variable "causes" something to happen to another variable. Very important to assess when thinking about studies that examine causation such as experimental or quasi-experimental designs.
circumstances or events that may affect the outcome of an experiment, resulting in changes in the research participants that are not a result of the intervention, treatment, or experimental condition being tested
causal explanations that can be universally applied to groups, such as scientific laws or universal truths
as a criteria for causal relationship, the relationship must make logical sense and seem possible
when the values of two variables change at the same time
as a criteria for causal relationship, the cause must come before the effect
an association between two variables that is NOT caused by a third variable
variables and characteristics that have an effect on your outcome, but aren't the primary variable whose influence you're interested in testing.
the group of participants in our study who do not receive the intervention we are researching in experiments with random assignment
the group of participants in our study who do not receive the intervention we are researching in experiments without random assignment
in experimental design, the group of participants in our study who do receive the intervention we are researching
The ability to apply research findings beyond the study sample to some broader population,
This is a synonymous term for generalizability - the ability to apply the findings of a study beyond the sample to a broader population.
performance of an intervention under ideal and controlled circumstances, such as in a lab or delivered by trained researcher-interventionists
The performance of an intervention under "real-world" conditions that are not closely controlled and ideal
the idea that one event, behavior, or belief will result in the occurrence of another, subsequent event, behavior, or belief
Doctoral Research Methods in Social Work Copyright © by Mavs Open Press. All Rights Reserved.
Share This Book
Research Design 101
Everything You Need To Get Started (With Examples)
By: Derek Jansen (MBA) | Reviewers: Eunice Rautenbach (DTech) & Kerryn Warren (PhD) | April 2023

Navigating the world of research can be daunting, especially if you’re a first-time researcher. One concept you’re bound to run into fairly early in your research journey is that of “ research design ”. Here, we’ll guide you through the basics using practical examples , so that you can approach your research with confidence.
Overview: Research Design 101
What is research design.
- Research design types for quantitative studies
- Video explainer : quantitative research design
- Research design types for qualitative studies
- Video explainer : qualitative research design
- How to choose a research design
- Key takeaways
Research design refers to the overall plan, structure or strategy that guides a research project , from its conception to the final data analysis. A good research design serves as the blueprint for how you, as the researcher, will collect and analyse data while ensuring consistency, reliability and validity throughout your study.
Understanding different types of research designs is essential as helps ensure that your approach is suitable given your research aims, objectives and questions , as well as the resources you have available to you. Without a clear big-picture view of how you’ll design your research, you run the risk of potentially making misaligned choices in terms of your methodology – especially your sampling , data collection and data analysis decisions.
The problem with defining research design…
One of the reasons students struggle with a clear definition of research design is because the term is used very loosely across the internet, and even within academia.
Some sources claim that the three research design types are qualitative, quantitative and mixed methods , which isn’t quite accurate (these just refer to the type of data that you’ll collect and analyse). Other sources state that research design refers to the sum of all your design choices, suggesting it’s more like a research methodology . Others run off on other less common tangents. No wonder there’s confusion!
In this article, we’ll clear up the confusion. We’ll explain the most common research design types for both qualitative and quantitative research projects, whether that is for a full dissertation or thesis, or a smaller research paper or article.

Research Design: Quantitative Studies
Quantitative research involves collecting and analysing data in a numerical form. Broadly speaking, there are four types of quantitative research designs: descriptive , correlational , experimental , and quasi-experimental .
Descriptive Research Design
As the name suggests, descriptive research design focuses on describing existing conditions, behaviours, or characteristics by systematically gathering information without manipulating any variables. In other words, there is no intervention on the researcher’s part – only data collection.
For example, if you’re studying smartphone addiction among adolescents in your community, you could deploy a survey to a sample of teens asking them to rate their agreement with certain statements that relate to smartphone addiction. The collected data would then provide insight regarding how widespread the issue may be – in other words, it would describe the situation.
The key defining attribute of this type of research design is that it purely describes the situation . In other words, descriptive research design does not explore potential relationships between different variables or the causes that may underlie those relationships. Therefore, descriptive research is useful for generating insight into a research problem by describing its characteristics . By doing so, it can provide valuable insights and is often used as a precursor to other research design types.
Correlational Research Design
Correlational design is a popular choice for researchers aiming to identify and measure the relationship between two or more variables without manipulating them . In other words, this type of research design is useful when you want to know whether a change in one thing tends to be accompanied by a change in another thing.
For example, if you wanted to explore the relationship between exercise frequency and overall health, you could use a correlational design to help you achieve this. In this case, you might gather data on participants’ exercise habits, as well as records of their health indicators like blood pressure, heart rate, or body mass index. Thereafter, you’d use a statistical test to assess whether there’s a relationship between the two variables (exercise frequency and health).
As you can see, correlational research design is useful when you want to explore potential relationships between variables that cannot be manipulated or controlled for ethical, practical, or logistical reasons. It is particularly helpful in terms of developing predictions , and given that it doesn’t involve the manipulation of variables, it can be implemented at a large scale more easily than experimental designs (which will look at next).
That said, it’s important to keep in mind that correlational research design has limitations – most notably that it cannot be used to establish causality . In other words, correlation does not equal causation . To establish causality, you’ll need to move into the realm of experimental design, coming up next…
Need a helping hand?
Experimental Research Design
Experimental research design is used to determine if there is a causal relationship between two or more variables . With this type of research design, you, as the researcher, manipulate one variable (the independent variable) while controlling others (dependent variables). Doing so allows you to observe the effect of the former on the latter and draw conclusions about potential causality.
For example, if you wanted to measure if/how different types of fertiliser affect plant growth, you could set up several groups of plants, with each group receiving a different type of fertiliser, as well as one with no fertiliser at all. You could then measure how much each plant group grew (on average) over time and compare the results from the different groups to see which fertiliser was most effective.
Overall, experimental research design provides researchers with a powerful way to identify and measure causal relationships (and the direction of causality) between variables. However, developing a rigorous experimental design can be challenging as it’s not always easy to control all the variables in a study. This often results in smaller sample sizes , which can reduce the statistical power and generalisability of the results.
Moreover, experimental research design requires random assignment . This means that the researcher needs to assign participants to different groups or conditions in a way that each participant has an equal chance of being assigned to any group (note that this is not the same as random sampling ). Doing so helps reduce the potential for bias and confounding variables . This need for random assignment can lead to ethics-related issues . For example, withholding a potentially beneficial medical treatment from a control group may be considered unethical in certain situations.
Quasi-Experimental Research Design
Quasi-experimental research design is used when the research aims involve identifying causal relations , but one cannot (or doesn’t want to) randomly assign participants to different groups (for practical or ethical reasons). Instead, with a quasi-experimental research design, the researcher relies on existing groups or pre-existing conditions to form groups for comparison.
For example, if you were studying the effects of a new teaching method on student achievement in a particular school district, you may be unable to randomly assign students to either group and instead have to choose classes or schools that already use different teaching methods. This way, you still achieve separate groups, without having to assign participants to specific groups yourself.
Naturally, quasi-experimental research designs have limitations when compared to experimental designs. Given that participant assignment is not random, it’s more difficult to confidently establish causality between variables, and, as a researcher, you have less control over other variables that may impact findings.
All that said, quasi-experimental designs can still be valuable in research contexts where random assignment is not possible and can often be undertaken on a much larger scale than experimental research, thus increasing the statistical power of the results. What’s important is that you, as the researcher, understand the limitations of the design and conduct your quasi-experiment as rigorously as possible, paying careful attention to any potential confounding variables .

Research Design: Qualitative Studies
There are many different research design types when it comes to qualitative studies, but here we’ll narrow our focus to explore the “Big 4”. Specifically, we’ll look at phenomenological design, grounded theory design, ethnographic design, and case study design.
Phenomenological Research Design
Phenomenological design involves exploring the meaning of lived experiences and how they are perceived by individuals. This type of research design seeks to understand people’s perspectives , emotions, and behaviours in specific situations. Here, the aim for researchers is to uncover the essence of human experience without making any assumptions or imposing preconceived ideas on their subjects.
For example, you could adopt a phenomenological design to study why cancer survivors have such varied perceptions of their lives after overcoming their disease. This could be achieved by interviewing survivors and then analysing the data using a qualitative analysis method such as thematic analysis to identify commonalities and differences.
Phenomenological research design typically involves in-depth interviews or open-ended questionnaires to collect rich, detailed data about participants’ subjective experiences. This richness is one of the key strengths of phenomenological research design but, naturally, it also has limitations. These include potential biases in data collection and interpretation and the lack of generalisability of findings to broader populations.
Grounded Theory Research Design
Grounded theory (also referred to as “GT”) aims to develop theories by continuously and iteratively analysing and comparing data collected from a relatively large number of participants in a study. It takes an inductive (bottom-up) approach, with a focus on letting the data “speak for itself”, without being influenced by preexisting theories or the researcher’s preconceptions.
As an example, let’s assume your research aims involved understanding how people cope with chronic pain from a specific medical condition, with a view to developing a theory around this. In this case, grounded theory design would allow you to explore this concept thoroughly without preconceptions about what coping mechanisms might exist. You may find that some patients prefer cognitive-behavioural therapy (CBT) while others prefer to rely on herbal remedies. Based on multiple, iterative rounds of analysis, you could then develop a theory in this regard, derived directly from the data (as opposed to other preexisting theories and models).
Grounded theory typically involves collecting data through interviews or observations and then analysing it to identify patterns and themes that emerge from the data. These emerging ideas are then validated by collecting more data until a saturation point is reached (i.e., no new information can be squeezed from the data). From that base, a theory can then be developed .
As you can see, grounded theory is ideally suited to studies where the research aims involve theory generation , especially in under-researched areas. Keep in mind though that this type of research design can be quite time-intensive , given the need for multiple rounds of data collection and analysis.

Ethnographic Research Design
Ethnographic design involves observing and studying a culture-sharing group of people in their natural setting to gain insight into their behaviours, beliefs, and values. The focus here is on observing participants in their natural environment (as opposed to a controlled environment). This typically involves the researcher spending an extended period of time with the participants in their environment, carefully observing and taking field notes .
All of this is not to say that ethnographic research design relies purely on observation. On the contrary, this design typically also involves in-depth interviews to explore participants’ views, beliefs, etc. However, unobtrusive observation is a core component of the ethnographic approach.
As an example, an ethnographer may study how different communities celebrate traditional festivals or how individuals from different generations interact with technology differently. This may involve a lengthy period of observation, combined with in-depth interviews to further explore specific areas of interest that emerge as a result of the observations that the researcher has made.
As you can probably imagine, ethnographic research design has the ability to provide rich, contextually embedded insights into the socio-cultural dynamics of human behaviour within a natural, uncontrived setting. Naturally, however, it does come with its own set of challenges, including researcher bias (since the researcher can become quite immersed in the group), participant confidentiality and, predictably, ethical complexities . All of these need to be carefully managed if you choose to adopt this type of research design.
Case Study Design
With case study research design, you, as the researcher, investigate a single individual (or a single group of individuals) to gain an in-depth understanding of their experiences, behaviours or outcomes. Unlike other research designs that are aimed at larger sample sizes, case studies offer a deep dive into the specific circumstances surrounding a person, group of people, event or phenomenon, generally within a bounded setting or context .
As an example, a case study design could be used to explore the factors influencing the success of a specific small business. This would involve diving deeply into the organisation to explore and understand what makes it tick – from marketing to HR to finance. In terms of data collection, this could include interviews with staff and management, review of policy documents and financial statements, surveying customers, etc.
While the above example is focused squarely on one organisation, it’s worth noting that case study research designs can have different variation s, including single-case, multiple-case and longitudinal designs. As you can see in the example, a single-case design involves intensely examining a single entity to understand its unique characteristics and complexities. Conversely, in a multiple-case design , multiple cases are compared and contrasted to identify patterns and commonalities. Lastly, in a longitudinal case design , a single case or multiple cases are studied over an extended period of time to understand how factors develop over time.
As you can see, a case study research design is particularly useful where a deep and contextualised understanding of a specific phenomenon or issue is desired. However, this strength is also its weakness. In other words, you can’t generalise the findings from a case study to the broader population. So, keep this in mind if you’re considering going the case study route.

How To Choose A Research Design
Having worked through all of these potential research designs, you’d be forgiven for feeling a little overwhelmed and wondering, “ But how do I decide which research design to use? ”. While we could write an entire post covering that alone, here are a few factors to consider that will help you choose a suitable research design for your study.
Data type: The first determining factor is naturally the type of data you plan to be collecting – i.e., qualitative or quantitative. This may sound obvious, but we have to be clear about this – don’t try to use a quantitative research design on qualitative data (or vice versa)!
Research aim(s) and question(s): As with all methodological decisions, your research aim and research questions will heavily influence your research design. For example, if your research aims involve developing a theory from qualitative data, grounded theory would be a strong option. Similarly, if your research aims involve identifying and measuring relationships between variables, one of the experimental designs would likely be a better option.
Time: It’s essential that you consider any time constraints you have, as this will impact the type of research design you can choose. For example, if you’ve only got a month to complete your project, a lengthy design such as ethnography wouldn’t be a good fit.
Resources: Take into account the resources realistically available to you, as these need to factor into your research design choice. For example, if you require highly specialised lab equipment to execute an experimental design, you need to be sure that you’ll have access to that before you make a decision.
Keep in mind that when it comes to research, it’s important to manage your risks and play as conservatively as possible. If your entire project relies on you achieving a huge sample, having access to niche equipment or holding interviews with very difficult-to-reach participants, you’re creating risks that could kill your project. So, be sure to think through your choices carefully and make sure that you have backup plans for any existential risks. Remember that a relatively simple methodology executed well generally will typically earn better marks than a highly-complex methodology executed poorly.

Recap: Key Takeaways
We’ve covered a lot of ground here. Let’s recap by looking at the key takeaways:
- Research design refers to the overall plan, structure or strategy that guides a research project, from its conception to the final analysis of data.
- Research designs for quantitative studies include descriptive , correlational , experimental and quasi-experimenta l designs.
- Research designs for qualitative studies include phenomenological , grounded theory , ethnographic and case study designs.
- When choosing a research design, you need to consider a variety of factors, including the type of data you’ll be working with, your research aims and questions, your time and the resources available to you.
If you need a helping hand with your research design (or any other aspect of your research), check out our private coaching services .

Psst… there’s more (for free)
This post is part of our dissertation mini-course, which covers everything you need to get started with your dissertation, thesis or research project.
You Might Also Like:

Is there any blog article explaining more on Case study research design? Is there a Case study write-up template? Thank you.

Thanks this was quite valuable to clarify such an important concept.

Thanks for this simplified explanations. it is quite very helpful.

This was really helpful. thanks

Thank you for your explanation. I think case study research design and the use of secondary data in researches needs to be talked about more in your videos and articles because there a lot of case studies research design tailored projects out there.
Please is there any template for a case study research design whose data type is a secondary data on your repository?

This post is very clear, comprehensive and has been very helpful to me. It has cleared the confusion I had in regard to research design and methodology.

This post is helpful, easy to understand, and deconstructs what a research design is. Thanks

how to cite this page

Thank you very much for the post. It is wonderful and has cleared many worries in my mind regarding research designs. I really appreciate .
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Athl Train
- v.45(1); Jan-Feb 2010
Study/Experimental/Research Design: Much More Than Statistics
Kenneth l. knight.
Brigham Young University, Provo, UT
The purpose of study, experimental, or research design in scientific manuscripts has changed significantly over the years. It has evolved from an explanation of the design of the experiment (ie, data gathering or acquisition) to an explanation of the statistical analysis. This practice makes “Methods” sections hard to read and understand.
To clarify the difference between study design and statistical analysis, to show the advantages of a properly written study design on article comprehension, and to encourage authors to correctly describe study designs.
Description:
The role of study design is explored from the introduction of the concept by Fisher through modern-day scientists and the AMA Manual of Style . At one time, when experiments were simpler, the study design and statistical design were identical or very similar. With the complex research that is common today, which often includes manipulating variables to create new variables and the multiple (and different) analyses of a single data set, data collection is very different than statistical design. Thus, both a study design and a statistical design are necessary.
Advantages:
Scientific manuscripts will be much easier to read and comprehend. A proper experimental design serves as a road map to the study methods, helping readers to understand more clearly how the data were obtained and, therefore, assisting them in properly analyzing the results.
Study, experimental, or research design is the backbone of good research. It directs the experiment by orchestrating data collection, defines the statistical analysis of the resultant data, and guides the interpretation of the results. When properly described in the written report of the experiment, it serves as a road map to readers, 1 helping them negotiate the “Methods” section, and, thus, it improves the clarity of communication between authors and readers.
A growing trend is to equate study design with only the statistical analysis of the data. The design statement typically is placed at the end of the “Methods” section as a subsection called “Experimental Design” or as part of a subsection called “Data Analysis.” This placement, however, equates experimental design and statistical analysis, minimizing the effect of experimental design on the planning and reporting of an experiment. This linkage is inappropriate, because some of the elements of the study design that should be described at the beginning of the “Methods” section are instead placed in the “Statistical Analysis” section or, worse, are absent from the manuscript entirely.
Have you ever interrupted your reading of the “Methods” to sketch out the variables in the margins of the paper as you attempt to understand how they all fit together? Or have you jumped back and forth from the early paragraphs of the “Methods” section to the “Statistics” section to try to understand which variables were collected and when? These efforts would be unnecessary if a road map at the beginning of the “Methods” section outlined how the independent variables were related, which dependent variables were measured, and when they were measured. When they were measured is especially important if the variables used in the statistical analysis were a subset of the measured variables or were computed from measured variables (such as change scores).
The purpose of this Communications article is to clarify the purpose and placement of study design elements in an experimental manuscript. Adopting these ideas may improve your science and surely will enhance the communication of that science. These ideas will make experimental manuscripts easier to read and understand and, therefore, will allow them to become part of readers' clinical decision making.
WHAT IS A STUDY (OR EXPERIMENTAL OR RESEARCH) DESIGN?
The terms study design, experimental design, and research design are often thought to be synonymous and are sometimes used interchangeably in a single paper. Avoid doing so. Use the term that is preferred by the style manual of the journal for which you are writing. Study design is the preferred term in the AMA Manual of Style , 2 so I will use it here.
A study design is the architecture of an experimental study 3 and a description of how the study was conducted, 4 including all elements of how the data were obtained. 5 The study design should be the first subsection of the “Methods” section in an experimental manuscript (see the Table ). “Statistical Design” or, preferably, “Statistical Analysis” or “Data Analysis” should be the last subsection of the “Methods” section.
Table. Elements of a “Methods” Section

The “Study Design” subsection describes how the variables and participants interacted. It begins with a general statement of how the study was conducted (eg, crossover trials, parallel, or observational study). 2 The second element, which usually begins with the second sentence, details the number of independent variables or factors, the levels of each variable, and their names. A shorthand way of doing so is with a statement such as “A 2 × 4 × 8 factorial guided data collection.” This tells us that there were 3 independent variables (factors), with 2 levels of the first factor, 4 levels of the second factor, and 8 levels of the third factor. Following is a sentence that names the levels of each factor: for example, “The independent variables were sex (male or female), training program (eg, walking, running, weight lifting, or plyometrics), and time (2, 4, 6, 8, 10, 15, 20, or 30 weeks).” Such an approach clearly outlines for readers how the various procedures fit into the overall structure and, therefore, enhances their understanding of how the data were collected. Thus, the design statement is a road map of the methods.
The dependent (or measurement or outcome) variables are then named. Details of how they were measured are not given at this point in the manuscript but are explained later in the “Instruments” and “Procedures” subsections.
Next is a paragraph detailing who the participants were and how they were selected, placed into groups, and assigned to a particular treatment order, if the experiment was a repeated-measures design. And although not a part of the design per se, a statement about obtaining written informed consent from participants and institutional review board approval is usually included in this subsection.
The nuts and bolts of the “Methods” section follow, including such things as equipment, materials, protocols, etc. These are beyond the scope of this commentary, however, and so will not be discussed.
The last part of the “Methods” section and last part of the “Study Design” section is the “Data Analysis” subsection. It begins with an explanation of any data manipulation, such as how data were combined or how new variables (eg, ratios or differences between collected variables) were calculated. Next, readers are told of the statistical measures used to analyze the data, such as a mixed 2 × 4 × 8 analysis of variance (ANOVA) with 2 between-groups factors (sex and training program) and 1 within-groups factor (time of measurement). Researchers should state and reference the statistical package and procedure(s) within the package used to compute the statistics. (Various statistical packages perform analyses slightly differently, so it is important to know the package and specific procedure used.) This detail allows readers to judge the appropriateness of the statistical measures and the conclusions drawn from the data.
STATISTICAL DESIGN VERSUS STATISTICAL ANALYSIS
Avoid using the term statistical design . Statistical methods are only part of the overall design. The term gives too much emphasis to the statistics, which are important, but only one of many tools used in interpreting data and only part of the study design:
The most important issues in biostatistics are not expressed with statistical procedures. The issues are inherently scientific, rather than purely statistical, and relate to the architectural design of the research, not the numbers with which the data are cited and interpreted. 6
Stated another way, “The justification for the analysis lies not in the data collected but in the manner in which the data were collected.” 3 “Without the solid foundation of a good design, the edifice of statistical analysis is unsafe.” 7 (pp4–5)
The intertwining of study design and statistical analysis may have been caused (unintentionally) by R.A. Fisher, “… a genius who almost single-handedly created the foundations for modern statistical science.” 8 Most research did not involve statistics until Fisher invented the concepts and procedures of ANOVA (in 1921) 9 , 10 and experimental design (in 1935). 11 His books became standard references for scientists in many disciplines. As a result, many ANOVA books were titled Experimental Design (see, for example, Edwards 12 ), and ANOVA courses taught in psychology and education departments included the words experimental design in their course titles.
Before the widespread use of computers to analyze data, designs were much simpler, and often there was little difference between study design and statistical analysis. So combining the 2 elements did not cause serious problems. This is no longer true, however, for 3 reasons: (1) Research studies are becoming more complex, with multiple independent and dependent variables. The procedures sections of these complex studies can be difficult to understand if your only reference point is the statistical analysis and design. (2) Dependent variables are frequently measured at different times. (3) How the data were collected is often not directly correlated with the statistical design.
For example, assume the goal is to determine the strength gain in novice and experienced athletes as a result of 3 strength training programs. Rate of change in strength is not a measurable variable; rather, it is calculated from strength measurements taken at various time intervals during the training. So the study design would be a 2 × 2 × 3 factorial with independent variables of time (pretest or posttest), experience (novice or advanced), and training (isokinetic, isotonic, or isometric) and a dependent variable of strength. The statistical design , however, would be a 2 × 3 factorial with independent variables of experience (novice or advanced) and training (isokinetic, isotonic, or isometric) and a dependent variable of strength gain. Note that data were collected according to a 3-factor design but were analyzed according to a 2-factor design and that the dependent variables were different. So a single design statement, usually a statistical design statement, would not communicate which data were collected or how. Readers would be left to figure out on their own how the data were collected.
MULTIVARIATE RESEARCH AND THE NEED FOR STUDY DESIGNS
With the advent of electronic data gathering and computerized data handling and analysis, research projects have increased in complexity. Many projects involve multiple dependent variables measured at different times, and, therefore, multiple design statements may be needed for both data collection and statistical analysis. Consider, for example, a study of the effects of heat and cold on neural inhibition. The variables of H max and M max are measured 3 times each: before, immediately after, and 30 minutes after a 20-minute treatment with heat or cold. Muscle temperature might be measured each minute before, during, and after the treatment. Although the minute-by-minute data are important for graphing temperature fluctuations during the procedure, only 3 temperatures (time 0, time 20, and time 50) are used for statistical analysis. A single dependent variable H max :M max ratio is computed to illustrate neural inhibition. Again, a single statistical design statement would tell little about how the data were obtained. And in this example, separate design statements would be needed for temperature measurement and H max :M max measurements.
As stated earlier, drawing conclusions from the data depends more on how the data were measured than on how they were analyzed. 3 , 6 , 7 , 13 So a single study design statement (or multiple such statements) at the beginning of the “Methods” section acts as a road map to the study and, thus, increases scientists' and readers' comprehension of how the experiment was conducted (ie, how the data were collected). Appropriate study design statements also increase the accuracy of conclusions drawn from the study.
CONCLUSIONS
The goal of scientific writing, or any writing, for that matter, is to communicate information. Including 2 design statements or subsections in scientific papers—one to explain how the data were collected and another to explain how they were statistically analyzed—will improve the clarity of communication and bring praise from readers. To summarize:
- Purge from your thoughts and vocabulary the idea that experimental design and statistical design are synonymous.
- Study or experimental design plays a much broader role than simply defining and directing the statistical analysis of an experiment.
- A properly written study design serves as a road map to the “Methods” section of an experiment and, therefore, improves communication with the reader.
- Study design should include a description of the type of design used, each factor (and each level) involved in the experiment, and the time at which each measurement was made.
- Clarify when the variables involved in data collection and data analysis are different, such as when data analysis involves only a subset of a collected variable or a resultant variable from the mathematical manipulation of 2 or more collected variables.
Acknowledgments
Thanks to Thomas A. Cappaert, PhD, ATC, CSCS, CSE, for suggesting the link between R.A. Fisher and the melding of the concepts of research design and statistics.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
10 Experimental research
Experimental research—often considered to be the ‘gold standard’ in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research—rather than for descriptive or exploratory research—where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalisability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments are conducted in field settings such as in a real organisation, and are high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favourably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receiving a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the ‘cause’ in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and ensures that each unit in the population has a positive chance of being selected into the sample. Random assignment, however, is a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group prior to treatment administration. Random selection is related to sampling, and is therefore more closely related to the external validity (generalisability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam.
Not conducting a pretest can help avoid this threat.
Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
Regression threat —also called a regression to the mean—refers to the statistical tendency of a group’s overall performance to regress toward the mean during a posttest rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest were possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-group experimental designs

Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest-posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement—especially if the pretest introduces unusual topics or content.
Posttest -only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

The treatment effect is measured simply as the difference in the posttest scores between the two groups:
![\[E = (O_{1} - O_{2})\,.\]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f2ce47275e7b35def5c5b52b7d7d45_l3.png "Rendered by QuickLaTeX.com")
The appropriate statistical analysis of this design is also a two-group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.

Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:
Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of posttest-only design, but with internal validity due to the controlling of covariates. Covariance designs can also be extended to pretest-posttest control group design.
Factorial designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each subdivision of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).

In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for three hours/week of instructional time than for one and a half hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid experimental designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomised bocks design, Solomon four-group design, and switched replications design.
Randomised block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full-time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between the treatment group (receiving the same treatment) and the control group (see Figure 10.5). The purpose of this design is to reduce the ‘noise’ or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.

Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs, but not in posttest-only designs. The design notation is shown in Figure 10.6.

Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organisational contexts where organisational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.

Quasi-experimental designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organisation is used as the treatment group, while another section of the same class or a different organisation in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impacted by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.

In addition, there are quite a few unique non-equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to the treatment or control group based on a cut-off score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardised test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program.

Because of the use of a cut-off score, it is possible that the observed results may be a function of the cut-off score rather than the treatment, which introduces a new threat to internal validity. However, using the cut-off score also ensures that limited or costly resources are distributed to people who need them the most, rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design do not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.

Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, say you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data is not available from the same subjects.

An interesting variation of the NEDV design is a pattern-matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique—based on the degree of correspondence between theoretical and observed patterns—is a powerful way of alleviating internal validity concerns in the original NEDV design.

Perils of experimental research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, often experimental research uses inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies, and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artefact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if in doubt, use tasks that are simple and familiar for the respondent sample rather than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
19+ Experimental Design Examples (Methods + Types)
Ever wondered how scientists discover new medicines, psychologists learn about behavior, or even how marketers figure out what kind of ads you like? Well, they all have something in common: they use a special plan or recipe called an "experimental design."
Imagine you're baking cookies. You can't just throw random amounts of flour, sugar, and chocolate chips into a bowl and hope for the best. You follow a recipe, right? Scientists and researchers do something similar. They follow a "recipe" called an experimental design to make sure their experiments are set up in a way that the answers they find are meaningful and reliable.
Experimental design is the roadmap researchers use to answer questions. It's a set of rules and steps that researchers follow to collect information, or "data," in a way that is fair, accurate, and makes sense.

Long ago, people didn't have detailed game plans for experiments. They often just tried things out and saw what happened. But over time, people got smarter about this. They started creating structured plans—what we now call experimental designs—to get clearer, more trustworthy answers to their questions.
In this article, we'll take you on a journey through the world of experimental designs. We'll talk about the different types, or "flavors," of experimental designs, where they're used, and even give you a peek into how they came to be.
What Is Experimental Design?
Alright, before we dive into the different types of experimental designs, let's get crystal clear on what experimental design actually is.
Imagine you're a detective trying to solve a mystery. You need clues, right? Well, in the world of research, experimental design is like the roadmap that helps you find those clues. It's like the game plan in sports or the blueprint when you're building a house. Just like you wouldn't start building without a good blueprint, researchers won't start their studies without a strong experimental design.
So, why do we need experimental design? Think about baking a cake. If you toss ingredients into a bowl without measuring, you'll end up with a mess instead of a tasty dessert.
Similarly, in research, if you don't have a solid plan, you might get confusing or incorrect results. A good experimental design helps you ask the right questions ( think critically ), decide what to measure ( come up with an idea ), and figure out how to measure it (test it). It also helps you consider things that might mess up your results, like outside influences you hadn't thought of.
For example, let's say you want to find out if listening to music helps people focus better. Your experimental design would help you decide things like: Who are you going to test? What kind of music will you use? How will you measure focus? And, importantly, how will you make sure that it's really the music affecting focus and not something else, like the time of day or whether someone had a good breakfast?
In short, experimental design is the master plan that guides researchers through the process of collecting data, so they can answer questions in the most reliable way possible. It's like the GPS for the journey of discovery!
History of Experimental Design
Around 350 BCE, people like Aristotle were trying to figure out how the world works, but they mostly just thought really hard about things. They didn't test their ideas much. So while they were super smart, their methods weren't always the best for finding out the truth.
Fast forward to the Renaissance (14th to 17th centuries), a time of big changes and lots of curiosity. People like Galileo started to experiment by actually doing tests, like rolling balls down inclined planes to study motion. Galileo's work was cool because he combined thinking with doing. He'd have an idea, test it, look at the results, and then think some more. This approach was a lot more reliable than just sitting around and thinking.
Now, let's zoom ahead to the 18th and 19th centuries. This is when people like Francis Galton, an English polymath, started to get really systematic about experimentation. Galton was obsessed with measuring things. Seriously, he even tried to measure how good-looking people were ! His work helped create the foundations for a more organized approach to experiments.
Next stop: the early 20th century. Enter Ronald A. Fisher , a brilliant British statistician. Fisher was a game-changer. He came up with ideas that are like the bread and butter of modern experimental design.
Fisher invented the concept of the " control group "—that's a group of people or things that don't get the treatment you're testing, so you can compare them to those who do. He also stressed the importance of " randomization ," which means assigning people or things to different groups by chance, like drawing names out of a hat. This makes sure the experiment is fair and the results are trustworthy.
Around the same time, American psychologists like John B. Watson and B.F. Skinner were developing " behaviorism ." They focused on studying things that they could directly observe and measure, like actions and reactions.
Skinner even built boxes—called Skinner Boxes —to test how animals like pigeons and rats learn. Their work helped shape how psychologists design experiments today. Watson performed a very controversial experiment called The Little Albert experiment that helped describe behaviour through conditioning—in other words, how people learn to behave the way they do.
In the later part of the 20th century and into our time, computers have totally shaken things up. Researchers now use super powerful software to help design their experiments and crunch the numbers.
With computers, they can simulate complex experiments before they even start, which helps them predict what might happen. This is especially helpful in fields like medicine, where getting things right can be a matter of life and death.
Also, did you know that experimental designs aren't just for scientists in labs? They're used by people in all sorts of jobs, like marketing, education, and even video game design! Yes, someone probably ran an experiment to figure out what makes a game super fun to play.
So there you have it—a quick tour through the history of experimental design, from Aristotle's deep thoughts to Fisher's groundbreaking ideas, and all the way to today's computer-powered research. These designs are the recipes that help people from all walks of life find answers to their big questions.
Key Terms in Experimental Design
Before we dig into the different types of experimental designs, let's get comfy with some key terms. Understanding these terms will make it easier for us to explore the various types of experimental designs that researchers use to answer their big questions.
Independent Variable : This is what you change or control in your experiment to see what effect it has. Think of it as the "cause" in a cause-and-effect relationship. For example, if you're studying whether different types of music help people focus, the kind of music is the independent variable.
Dependent Variable : This is what you're measuring to see the effect of your independent variable. In our music and focus experiment, how well people focus is the dependent variable—it's what "depends" on the kind of music played.
Control Group : This is a group of people who don't get the special treatment or change you're testing. They help you see what happens when the independent variable is not applied. If you're testing whether a new medicine works, the control group would take a fake pill, called a placebo , instead of the real medicine.
Experimental Group : This is the group that gets the special treatment or change you're interested in. Going back to our medicine example, this group would get the actual medicine to see if it has any effect.
Randomization : This is like shaking things up in a fair way. You randomly put people into the control or experimental group so that each group is a good mix of different kinds of people. This helps make the results more reliable.
Sample : This is the group of people you're studying. They're a "sample" of a larger group that you're interested in. For instance, if you want to know how teenagers feel about a new video game, you might study a sample of 100 teenagers.
Bias : This is anything that might tilt your experiment one way or another without you realizing it. Like if you're testing a new kind of dog food and you only test it on poodles, that could create a bias because maybe poodles just really like that food and other breeds don't.
Data : This is the information you collect during the experiment. It's like the treasure you find on your journey of discovery!
Replication : This means doing the experiment more than once to make sure your findings hold up. It's like double-checking your answers on a test.
Hypothesis : This is your educated guess about what will happen in the experiment. It's like predicting the end of a movie based on the first half.
Steps of Experimental Design
Alright, let's say you're all fired up and ready to run your own experiment. Cool! But where do you start? Well, designing an experiment is a bit like planning a road trip. There are some key steps you've got to take to make sure you reach your destination. Let's break it down:
- Ask a Question : Before you hit the road, you've got to know where you're going. Same with experiments. You start with a question you want to answer, like "Does eating breakfast really make you do better in school?"
- Do Some Homework : Before you pack your bags, you look up the best places to visit, right? In science, this means reading up on what other people have already discovered about your topic.
- Form a Hypothesis : This is your educated guess about what you think will happen. It's like saying, "I bet this route will get us there faster."
- Plan the Details : Now you decide what kind of car you're driving (your experimental design), who's coming with you (your sample), and what snacks to bring (your variables).
- Randomization : Remember, this is like shuffling a deck of cards. You want to mix up who goes into your control and experimental groups to make sure it's a fair test.
- Run the Experiment : Finally, the rubber hits the road! You carry out your plan, making sure to collect your data carefully.
- Analyze the Data : Once the trip's over, you look at your photos and decide which ones are keepers. In science, this means looking at your data to see what it tells you.
- Draw Conclusions : Based on your data, did you find an answer to your question? This is like saying, "Yep, that route was faster," or "Nope, we hit a ton of traffic."
- Share Your Findings : After a great trip, you want to tell everyone about it, right? Scientists do the same by publishing their results so others can learn from them.
- Do It Again? : Sometimes one road trip just isn't enough. In the same way, scientists often repeat their experiments to make sure their findings are solid.
So there you have it! Those are the basic steps you need to follow when you're designing an experiment. Each step helps make sure that you're setting up a fair and reliable way to find answers to your big questions.
Let's get into examples of experimental designs.
1) True Experimental Design

In the world of experiments, the True Experimental Design is like the superstar quarterback everyone talks about. Born out of the early 20th-century work of statisticians like Ronald A. Fisher, this design is all about control, precision, and reliability.
Researchers carefully pick an independent variable to manipulate (remember, that's the thing they're changing on purpose) and measure the dependent variable (the effect they're studying). Then comes the magic trick—randomization. By randomly putting participants into either the control or experimental group, scientists make sure their experiment is as fair as possible.
No sneaky biases here!
True Experimental Design Pros
The pros of True Experimental Design are like the perks of a VIP ticket at a concert: you get the best and most trustworthy results. Because everything is controlled and randomized, you can feel pretty confident that the results aren't just a fluke.
True Experimental Design Cons
However, there's a catch. Sometimes, it's really tough to set up these experiments in a real-world situation. Imagine trying to control every single detail of your day, from the food you eat to the air you breathe. Not so easy, right?
True Experimental Design Uses
The fields that get the most out of True Experimental Designs are those that need super reliable results, like medical research.
When scientists were developing COVID-19 vaccines, they used this design to run clinical trials. They had control groups that received a placebo (a harmless substance with no effect) and experimental groups that got the actual vaccine. Then they measured how many people in each group got sick. By comparing the two, they could say, "Yep, this vaccine works!"
So next time you read about a groundbreaking discovery in medicine or technology, chances are a True Experimental Design was the VIP behind the scenes, making sure everything was on point. It's been the go-to for rigorous scientific inquiry for nearly a century, and it's not stepping off the stage anytime soon.
2) Quasi-Experimental Design
So, let's talk about the Quasi-Experimental Design. Think of this one as the cool cousin of True Experimental Design. It wants to be just like its famous relative, but it's a bit more laid-back and flexible. You'll find quasi-experimental designs when it's tricky to set up a full-blown True Experimental Design with all the bells and whistles.
Quasi-experiments still play with an independent variable, just like their stricter cousins. The big difference? They don't use randomization. It's like wanting to divide a bag of jelly beans equally between your friends, but you can't quite do it perfectly.
In real life, it's often not possible or ethical to randomly assign people to different groups, especially when dealing with sensitive topics like education or social issues. And that's where quasi-experiments come in.
Quasi-Experimental Design Pros
Even though they lack full randomization, quasi-experimental designs are like the Swiss Army knives of research: versatile and practical. They're especially popular in fields like education, sociology, and public policy.
For instance, when researchers wanted to figure out if the Head Start program , aimed at giving young kids a "head start" in school, was effective, they used a quasi-experimental design. They couldn't randomly assign kids to go or not go to preschool, but they could compare kids who did with kids who didn't.
Quasi-Experimental Design Cons
Of course, quasi-experiments come with their own bag of pros and cons. On the plus side, they're easier to set up and often cheaper than true experiments. But the flip side is that they're not as rock-solid in their conclusions. Because the groups aren't randomly assigned, there's always that little voice saying, "Hey, are we missing something here?"
Quasi-Experimental Design Uses
Quasi-Experimental Design gained traction in the mid-20th century. Researchers were grappling with real-world problems that didn't fit neatly into a laboratory setting. Plus, as society became more aware of ethical considerations, the need for flexible designs increased. So, the quasi-experimental approach was like a breath of fresh air for scientists wanting to study complex issues without a laundry list of restrictions.
In short, if True Experimental Design is the superstar quarterback, Quasi-Experimental Design is the versatile player who can adapt and still make significant contributions to the game.
3) Pre-Experimental Design
Now, let's talk about the Pre-Experimental Design. Imagine it as the beginner's skateboard you get before you try out for all the cool tricks. It has wheels, it rolls, but it's not built for the professional skatepark.
Similarly, pre-experimental designs give researchers a starting point. They let you dip your toes in the water of scientific research without diving in head-first.
So, what's the deal with pre-experimental designs?
Pre-Experimental Designs are the basic, no-frills versions of experiments. Researchers still mess around with an independent variable and measure a dependent variable, but they skip over the whole randomization thing and often don't even have a control group.
It's like baking a cake but forgetting the frosting and sprinkles; you'll get some results, but they might not be as complete or reliable as you'd like.
Pre-Experimental Design Pros
Why use such a simple setup? Because sometimes, you just need to get the ball rolling. Pre-experimental designs are great for quick-and-dirty research when you're short on time or resources. They give you a rough idea of what's happening, which you can use to plan more detailed studies later.
A good example of this is early studies on the effects of screen time on kids. Researchers couldn't control every aspect of a child's life, but they could easily ask parents to track how much time their kids spent in front of screens and then look for trends in behavior or school performance.
Pre-Experimental Design Cons
But here's the catch: pre-experimental designs are like that first draft of an essay. It helps you get your ideas down, but you wouldn't want to turn it in for a grade. Because these designs lack the rigorous structure of true or quasi-experimental setups, they can't give you rock-solid conclusions. They're more like clues or signposts pointing you in a certain direction.
Pre-Experimental Design Uses
This type of design became popular in the early stages of various scientific fields. Researchers used them to scratch the surface of a topic, generate some initial data, and then decide if it's worth exploring further. In other words, pre-experimental designs were the stepping stones that led to more complex, thorough investigations.
So, while Pre-Experimental Design may not be the star player on the team, it's like the practice squad that helps everyone get better. It's the starting point that can lead to bigger and better things.
4) Factorial Design
Now, buckle up, because we're moving into the world of Factorial Design, the multi-tasker of the experimental universe.
Imagine juggling not just one, but multiple balls in the air—that's what researchers do in a factorial design.
In Factorial Design, researchers are not satisfied with just studying one independent variable. Nope, they want to study two or more at the same time to see how they interact.
It's like cooking with several spices to see how they blend together to create unique flavors.
Factorial Design became the talk of the town with the rise of computers. Why? Because this design produces a lot of data, and computers are the number crunchers that help make sense of it all. So, thanks to our silicon friends, researchers can study complicated questions like, "How do diet AND exercise together affect weight loss?" instead of looking at just one of those factors.
Factorial Design Pros
This design's main selling point is its ability to explore interactions between variables. For instance, maybe a new study drug works really well for young people but not so great for older adults. A factorial design could reveal that age is a crucial factor, something you might miss if you only studied the drug's effectiveness in general. It's like being a detective who looks for clues not just in one room but throughout the entire house.
Factorial Design Cons
However, factorial designs have their own bag of challenges. First off, they can be pretty complicated to set up and run. Imagine coordinating a four-way intersection with lots of cars coming from all directions—you've got to make sure everything runs smoothly, or you'll end up with a traffic jam. Similarly, researchers need to carefully plan how they'll measure and analyze all the different variables.
Factorial Design Uses
Factorial designs are widely used in psychology to untangle the web of factors that influence human behavior. They're also popular in fields like marketing, where companies want to understand how different aspects like price, packaging, and advertising influence a product's success.
And speaking of success, the factorial design has been a hit since statisticians like Ronald A. Fisher (yep, him again!) expanded on it in the early-to-mid 20th century. It offered a more nuanced way of understanding the world, proving that sometimes, to get the full picture, you've got to juggle more than one ball at a time.
So, if True Experimental Design is the quarterback and Quasi-Experimental Design is the versatile player, Factorial Design is the strategist who sees the entire game board and makes moves accordingly.
5) Longitudinal Design

Alright, let's take a step into the world of Longitudinal Design. Picture it as the grand storyteller, the kind who doesn't just tell you about a single event but spins an epic tale that stretches over years or even decades. This design isn't about quick snapshots; it's about capturing the whole movie of someone's life or a long-running process.
You know how you might take a photo every year on your birthday to see how you've changed? Longitudinal Design is kind of like that, but for scientific research.
With Longitudinal Design, instead of measuring something just once, researchers come back again and again, sometimes over many years, to see how things are going. This helps them understand not just what's happening, but why it's happening and how it changes over time.
This design really started to shine in the latter half of the 20th century, when researchers began to realize that some questions can't be answered in a hurry. Think about studies that look at how kids grow up, or research on how a certain medicine affects you over a long period. These aren't things you can rush.
The famous Framingham Heart Study , started in 1948, is a prime example. It's been studying heart health in a small town in Massachusetts for decades, and the findings have shaped what we know about heart disease.
Longitudinal Design Pros
So, what's to love about Longitudinal Design? First off, it's the go-to for studying change over time, whether that's how people age or how a forest recovers from a fire.
Longitudinal Design Cons
But it's not all sunshine and rainbows. Longitudinal studies take a lot of patience and resources. Plus, keeping track of participants over many years can be like herding cats—difficult and full of surprises.
Longitudinal Design Uses
Despite these challenges, longitudinal studies have been key in fields like psychology, sociology, and medicine. They provide the kind of deep, long-term insights that other designs just can't match.
So, if the True Experimental Design is the superstar quarterback, and the Quasi-Experimental Design is the flexible athlete, then the Factorial Design is the strategist, and the Longitudinal Design is the wise elder who has seen it all and has stories to tell.
6) Cross-Sectional Design
Now, let's flip the script and talk about Cross-Sectional Design, the polar opposite of the Longitudinal Design. If Longitudinal is the grand storyteller, think of Cross-Sectional as the snapshot photographer. It captures a single moment in time, like a selfie that you take to remember a fun day. Researchers using this design collect all their data at one point, providing a kind of "snapshot" of whatever they're studying.
In a Cross-Sectional Design, researchers look at multiple groups all at the same time to see how they're different or similar.
This design rose to popularity in the mid-20th century, mainly because it's so quick and efficient. Imagine wanting to know how people of different ages feel about a new video game. Instead of waiting for years to see how opinions change, you could just ask people of all ages what they think right now. That's Cross-Sectional Design for you—fast and straightforward.
You'll find this type of research everywhere from marketing studies to healthcare. For instance, you might have heard about surveys asking people what they think about a new product or political issue. Those are usually cross-sectional studies, aimed at getting a quick read on public opinion.
Cross-Sectional Design Pros
So, what's the big deal with Cross-Sectional Design? Well, it's the go-to when you need answers fast and don't have the time or resources for a more complicated setup.
Cross-Sectional Design Cons
Remember, speed comes with trade-offs. While you get your results quickly, those results are stuck in time. They can't tell you how things change or why they're changing, just what's happening right now.
Cross-Sectional Design Uses
Also, because they're so quick and simple, cross-sectional studies often serve as the first step in research. They give scientists an idea of what's going on so they can decide if it's worth digging deeper. In that way, they're a bit like a movie trailer, giving you a taste of the action to see if you're interested in seeing the whole film.
So, in our lineup of experimental designs, if True Experimental Design is the superstar quarterback and Longitudinal Design is the wise elder, then Cross-Sectional Design is like the speedy running back—fast, agile, but not designed for long, drawn-out plays.
7) Correlational Design
Next on our roster is the Correlational Design, the keen observer of the experimental world. Imagine this design as the person at a party who loves people-watching. They don't interfere or get involved; they just observe and take mental notes about what's going on.
In a correlational study, researchers don't change or control anything; they simply observe and measure how two variables relate to each other.
The correlational design has roots in the early days of psychology and sociology. Pioneers like Sir Francis Galton used it to study how qualities like intelligence or height could be related within families.
This design is all about asking, "Hey, when this thing happens, does that other thing usually happen too?" For example, researchers might study whether students who have more study time get better grades or whether people who exercise more have lower stress levels.
One of the most famous correlational studies you might have heard of is the link between smoking and lung cancer. Back in the mid-20th century, researchers started noticing that people who smoked a lot also seemed to get lung cancer more often. They couldn't say smoking caused cancer—that would require a true experiment—but the strong correlation was a red flag that led to more research and eventually, health warnings.
Correlational Design Pros
This design is great at proving that two (or more) things can be related. Correlational designs can help prove that more detailed research is needed on a topic. They can help us see patterns or possible causes for things that we otherwise might not have realized.
Correlational Design Cons
But here's where you need to be careful: correlational designs can be tricky. Just because two things are related doesn't mean one causes the other. That's like saying, "Every time I wear my lucky socks, my team wins." Well, it's a fun thought, but those socks aren't really controlling the game.
Correlational Design Uses
Despite this limitation, correlational designs are popular in psychology, economics, and epidemiology, to name a few fields. They're often the first step in exploring a possible relationship between variables. Once a strong correlation is found, researchers may decide to conduct more rigorous experimental studies to examine cause and effect.
So, if the True Experimental Design is the superstar quarterback and the Longitudinal Design is the wise elder, the Factorial Design is the strategist, and the Cross-Sectional Design is the speedster, then the Correlational Design is the clever scout, identifying interesting patterns but leaving the heavy lifting of proving cause and effect to the other types of designs.
8) Meta-Analysis
Last but not least, let's talk about Meta-Analysis, the librarian of experimental designs.
If other designs are all about creating new research, Meta-Analysis is about gathering up everyone else's research, sorting it, and figuring out what it all means when you put it together.
Imagine a jigsaw puzzle where each piece is a different study. Meta-Analysis is the process of fitting all those pieces together to see the big picture.
The concept of Meta-Analysis started to take shape in the late 20th century, when computers became powerful enough to handle massive amounts of data. It was like someone handed researchers a super-powered magnifying glass, letting them examine multiple studies at the same time to find common trends or results.
You might have heard of the Cochrane Reviews in healthcare . These are big collections of meta-analyses that help doctors and policymakers figure out what treatments work best based on all the research that's been done.
For example, if ten different studies show that a certain medicine helps lower blood pressure, a meta-analysis would pull all that information together to give a more accurate answer.
Meta-Analysis Pros
The beauty of Meta-Analysis is that it can provide really strong evidence. Instead of relying on one study, you're looking at the whole landscape of research on a topic.
Meta-Analysis Cons
However, it does have some downsides. For one, Meta-Analysis is only as good as the studies it includes. If those studies are flawed, the meta-analysis will be too. It's like baking a cake: if you use bad ingredients, it doesn't matter how good your recipe is—the cake won't turn out well.
Meta-Analysis Uses
Despite these challenges, meta-analyses are highly respected and widely used in many fields like medicine, psychology, and education. They help us make sense of a world that's bursting with information by showing us the big picture drawn from many smaller snapshots.
So, in our all-star lineup, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, the Factorial Design is the strategist, the Cross-Sectional Design is the speedster, and the Correlational Design is the scout, then the Meta-Analysis is like the coach, using insights from everyone else's plays to come up with the best game plan.
9) Non-Experimental Design
Now, let's talk about a player who's a bit of an outsider on this team of experimental designs—the Non-Experimental Design. Think of this design as the commentator or the journalist who covers the game but doesn't actually play.
In a Non-Experimental Design, researchers are like reporters gathering facts, but they don't interfere or change anything. They're simply there to describe and analyze.
Non-Experimental Design Pros
So, what's the deal with Non-Experimental Design? Its strength is in description and exploration. It's really good for studying things as they are in the real world, without changing any conditions.
Non-Experimental Design Cons
Because a non-experimental design doesn't manipulate variables, it can't prove cause and effect. It's like a weather reporter: they can tell you it's raining, but they can't tell you why it's raining.
The downside? Since researchers aren't controlling variables, it's hard to rule out other explanations for what they observe. It's like hearing one side of a story—you get an idea of what happened, but it might not be the complete picture.
Non-Experimental Design Uses
Non-Experimental Design has always been a part of research, especially in fields like anthropology, sociology, and some areas of psychology.
For instance, if you've ever heard of studies that describe how people behave in different cultures or what teens like to do in their free time, that's often Non-Experimental Design at work. These studies aim to capture the essence of a situation, like painting a portrait instead of taking a snapshot.
One well-known example you might have heard about is the Kinsey Reports from the 1940s and 1950s, which described sexual behavior in men and women. Researchers interviewed thousands of people but didn't manipulate any variables like you would in a true experiment. They simply collected data to create a comprehensive picture of the subject matter.
So, in our metaphorical team of research designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, and Meta-Analysis is the coach, then Non-Experimental Design is the sports journalist—always present, capturing the game, but not part of the action itself.
10) Repeated Measures Design

Time to meet the Repeated Measures Design, the time traveler of our research team. If this design were a player in a sports game, it would be the one who keeps revisiting past plays to figure out how to improve the next one.
Repeated Measures Design is all about studying the same people or subjects multiple times to see how they change or react under different conditions.
The idea behind Repeated Measures Design isn't new; it's been around since the early days of psychology and medicine. You could say it's a cousin to the Longitudinal Design, but instead of looking at how things naturally change over time, it focuses on how the same group reacts to different things.
Imagine a study looking at how a new energy drink affects people's running speed. Instead of comparing one group that drank the energy drink to another group that didn't, a Repeated Measures Design would have the same group of people run multiple times—once with the energy drink, and once without. This way, you're really zeroing in on the effect of that energy drink, making the results more reliable.
Repeated Measures Design Pros
The strong point of Repeated Measures Design is that it's super focused. Because it uses the same subjects, you don't have to worry about differences between groups messing up your results.
Repeated Measures Design Cons
But the downside? Well, people can get tired or bored if they're tested too many times, which might affect how they respond.
Repeated Measures Design Uses
A famous example of this design is the "Little Albert" experiment, conducted by John B. Watson and Rosalie Rayner in 1920. In this study, a young boy was exposed to a white rat and other stimuli several times to see how his emotional responses changed. Though the ethical standards of this experiment are often criticized today, it was groundbreaking in understanding conditioned emotional responses.
In our metaphorical lineup of research designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, and Non-Experimental Design is the journalist, then Repeated Measures Design is the time traveler—always looping back to fine-tune the game plan.
11) Crossover Design
Next up is Crossover Design, the switch-hitter of the research world. If you're familiar with baseball, you'll know a switch-hitter is someone who can bat both right-handed and left-handed.
In a similar way, Crossover Design allows subjects to experience multiple conditions, flipping them around so that everyone gets a turn in each role.
This design is like the utility player on our team—versatile, flexible, and really good at adapting.
The Crossover Design has its roots in medical research and has been popular since the mid-20th century. It's often used in clinical trials to test the effectiveness of different treatments.
Crossover Design Pros
The neat thing about this design is that it allows each participant to serve as their own control group. Imagine you're testing two new kinds of headache medicine. Instead of giving one type to one group and another type to a different group, you'd give both kinds to the same people but at different times.
Crossover Design Cons
What's the big deal with Crossover Design? Its major strength is in reducing the "noise" that comes from individual differences. Since each person experiences all conditions, it's easier to see real effects. However, there's a catch. This design assumes that there's no lasting effect from the first condition when you switch to the second one. That might not always be true. If the first treatment has a long-lasting effect, it could mess up the results when you switch to the second treatment.
Crossover Design Uses
A well-known example of Crossover Design is in studies that look at the effects of different types of diets—like low-carb vs. low-fat diets. Researchers might have participants follow a low-carb diet for a few weeks, then switch them to a low-fat diet. By doing this, they can more accurately measure how each diet affects the same group of people.
In our team of experimental designs, if True Experimental Design is the quarterback and Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, and Repeated Measures Design is the time traveler, then Crossover Design is the versatile utility player—always ready to adapt and play multiple roles to get the most accurate results.
12) Cluster Randomized Design
Meet the Cluster Randomized Design, the team captain of group-focused research. In our imaginary lineup of experimental designs, if other designs focus on individual players, then Cluster Randomized Design is looking at how the entire team functions.
This approach is especially common in educational and community-based research, and it's been gaining traction since the late 20th century.
Here's how Cluster Randomized Design works: Instead of assigning individual people to different conditions, researchers assign entire groups, or "clusters." These could be schools, neighborhoods, or even entire towns. This helps you see how the new method works in a real-world setting.
Imagine you want to see if a new anti-bullying program really works. Instead of selecting individual students, you'd introduce the program to a whole school or maybe even several schools, and then compare the results to schools without the program.
Cluster Randomized Design Pros
Why use Cluster Randomized Design? Well, sometimes it's just not practical to assign conditions at the individual level. For example, you can't really have half a school following a new reading program while the other half sticks with the old one; that would be way too confusing! Cluster Randomization helps get around this problem by treating each "cluster" as its own mini-experiment.
Cluster Randomized Design Cons
There's a downside, too. Because entire groups are assigned to each condition, there's a risk that the groups might be different in some important way that the researchers didn't account for. That's like having one sports team that's full of veterans playing against a team of rookies; the match wouldn't be fair.
Cluster Randomized Design Uses
A famous example is the research conducted to test the effectiveness of different public health interventions, like vaccination programs. Researchers might roll out a vaccination program in one community but not in another, then compare the rates of disease in both.
In our metaphorical research team, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, and Crossover Design is the utility player, then Cluster Randomized Design is the team captain—always looking out for the group as a whole.
13) Mixed-Methods Design
Say hello to Mixed-Methods Design, the all-rounder or the "Renaissance player" of our research team.
Mixed-Methods Design uses a blend of both qualitative and quantitative methods to get a more complete picture, just like a Renaissance person who's good at lots of different things. It's like being good at both offense and defense in a sport; you've got all your bases covered!
Mixed-Methods Design is a fairly new kid on the block, becoming more popular in the late 20th and early 21st centuries as researchers began to see the value in using multiple approaches to tackle complex questions. It's the Swiss Army knife in our research toolkit, combining the best parts of other designs to be more versatile.
Here's how it could work: Imagine you're studying the effects of a new educational app on students' math skills. You might use quantitative methods like tests and grades to measure how much the students improve—that's the 'numbers part.'
But you also want to know how the students feel about math now, or why they think they got better or worse. For that, you could conduct interviews or have students fill out journals—that's the 'story part.'
Mixed-Methods Design Pros
So, what's the scoop on Mixed-Methods Design? The strength is its versatility and depth; you're not just getting numbers or stories, you're getting both, which gives a fuller picture.
Mixed-Methods Design Cons
But, it's also more challenging. Imagine trying to play two sports at the same time! You have to be skilled in different research methods and know how to combine them effectively.
Mixed-Methods Design Uses
A high-profile example of Mixed-Methods Design is research on climate change. Scientists use numbers and data to show temperature changes (quantitative), but they also interview people to understand how these changes are affecting communities (qualitative).
In our team of experimental designs, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, Crossover Design is the utility player, and Cluster Randomized Design is the team captain, then Mixed-Methods Design is the Renaissance player—skilled in multiple areas and able to bring them all together for a winning strategy.
14) Multivariate Design
Now, let's turn our attention to Multivariate Design, the multitasker of the research world.
If our lineup of research designs were like players on a basketball court, Multivariate Design would be the player dribbling, passing, and shooting all at once. This design doesn't just look at one or two things; it looks at several variables simultaneously to see how they interact and affect each other.
Multivariate Design is like baking a cake with many ingredients. Instead of just looking at how flour affects the cake, you also consider sugar, eggs, and milk all at once. This way, you understand how everything works together to make the cake taste good or bad.
Multivariate Design has been a go-to method in psychology, economics, and social sciences since the latter half of the 20th century. With the advent of computers and advanced statistical software, analyzing multiple variables at once became a lot easier, and Multivariate Design soared in popularity.
Multivariate Design Pros
So, what's the benefit of using Multivariate Design? Its power lies in its complexity. By studying multiple variables at the same time, you can get a really rich, detailed understanding of what's going on.
Multivariate Design Cons
But that complexity can also be a drawback. With so many variables, it can be tough to tell which ones are really making a difference and which ones are just along for the ride.
Multivariate Design Uses
Imagine you're a coach trying to figure out the best strategy to win games. You wouldn't just look at how many points your star player scores; you'd also consider assists, rebounds, turnovers, and maybe even how loud the crowd is. A Multivariate Design would help you understand how all these factors work together to determine whether you win or lose.
A well-known example of Multivariate Design is in market research. Companies often use this approach to figure out how different factors—like price, packaging, and advertising—affect sales. By studying multiple variables at once, they can find the best combination to boost profits.
In our metaphorical research team, if True Experimental Design is the quarterback, Longitudinal Design is the wise elder, Factorial Design is the strategist, Cross-Sectional Design is the speedster, Correlational Design is the scout, Meta-Analysis is the coach, Non-Experimental Design is the journalist, Repeated Measures Design is the time traveler, Crossover Design is the utility player, Cluster Randomized Design is the team captain, and Mixed-Methods Design is the Renaissance player, then Multivariate Design is the multitasker—juggling many variables at once to get a fuller picture of what's happening.
15) Pretest-Posttest Design
Let's introduce Pretest-Posttest Design, the "Before and After" superstar of our research team. You've probably seen those before-and-after pictures in ads for weight loss programs or home renovations, right?
Well, this design is like that, but for science! Pretest-Posttest Design checks out what things are like before the experiment starts and then compares that to what things are like after the experiment ends.
This design is one of the classics, a staple in research for decades across various fields like psychology, education, and healthcare. It's so simple and straightforward that it has stayed popular for a long time.
In Pretest-Posttest Design, you measure your subject's behavior or condition before you introduce any changes—that's your "before" or "pretest." Then you do your experiment, and after it's done, you measure the same thing again—that's your "after" or "posttest."
Pretest-Posttest Design Pros
What makes Pretest-Posttest Design special? It's pretty easy to understand and doesn't require fancy statistics.
Pretest-Posttest Design Cons
But there are some pitfalls. For example, what if the kids in our math example get better at multiplication just because they're older or because they've taken the test before? That would make it hard to tell if the program is really effective or not.
Pretest-Posttest Design Uses
Let's say you're a teacher and you want to know if a new math program helps kids get better at multiplication. First, you'd give all the kids a multiplication test—that's your pretest. Then you'd teach them using the new math program. At the end, you'd give them the same test again—that's your posttest. If the kids do better on the second test, you might conclude that the program works.
One famous use of Pretest-Posttest Design is in evaluating the effectiveness of driver's education courses. Researchers will measure people's driving skills before and after the course to see if they've improved.
16) Solomon Four-Group Design
Next up is the Solomon Four-Group Design, the "chess master" of our research team. This design is all about strategy and careful planning. Named after Richard L. Solomon who introduced it in the 1940s, this method tries to correct some of the weaknesses in simpler designs, like the Pretest-Posttest Design.
Here's how it rolls: The Solomon Four-Group Design uses four different groups to test a hypothesis. Two groups get a pretest, then one of them receives the treatment or intervention, and both get a posttest. The other two groups skip the pretest, and only one of them receives the treatment before they both get a posttest.
Sound complicated? It's like playing 4D chess; you're thinking several moves ahead!
Solomon Four-Group Design Pros
What's the pro and con of the Solomon Four-Group Design? On the plus side, it provides really robust results because it accounts for so many variables.
Solomon Four-Group Design Cons
The downside? It's a lot of work and requires a lot of participants, making it more time-consuming and costly.
Solomon Four-Group Design Uses
Let's say you want to figure out if a new way of teaching history helps students remember facts better. Two classes take a history quiz (pretest), then one class uses the new teaching method while the other sticks with the old way. Both classes take another quiz afterward (posttest).
Meanwhile, two more classes skip the initial quiz, and then one uses the new method before both take the final quiz. Comparing all four groups will give you a much clearer picture of whether the new teaching method works and whether the pretest itself affects the outcome.
The Solomon Four-Group Design is less commonly used than simpler designs but is highly respected for its ability to control for more variables. It's a favorite in educational and psychological research where you really want to dig deep and figure out what's actually causing changes.
17) Adaptive Designs
Now, let's talk about Adaptive Designs, the chameleons of the experimental world.
Imagine you're a detective, and halfway through solving a case, you find a clue that changes everything. You wouldn't just stick to your old plan; you'd adapt and change your approach, right? That's exactly what Adaptive Designs allow researchers to do.
In an Adaptive Design, researchers can make changes to the study as it's happening, based on early results. In a traditional study, once you set your plan, you stick to it from start to finish.
Adaptive Design Pros
This method is particularly useful in fast-paced or high-stakes situations, like developing a new vaccine in the middle of a pandemic. The ability to adapt can save both time and resources, and more importantly, it can save lives by getting effective treatments out faster.
Adaptive Design Cons
But Adaptive Designs aren't without their drawbacks. They can be very complex to plan and carry out, and there's always a risk that the changes made during the study could introduce bias or errors.
Adaptive Design Uses
Adaptive Designs are most often seen in clinical trials, particularly in the medical and pharmaceutical fields.
For instance, if a new drug is showing really promising results, the study might be adjusted to give more participants the new treatment instead of a placebo. Or if one dose level is showing bad side effects, it might be dropped from the study.
The best part is, these changes are pre-planned. Researchers lay out in advance what changes might be made and under what conditions, which helps keep everything scientific and above board.
In terms of applications, besides their heavy usage in medical and pharmaceutical research, Adaptive Designs are also becoming increasingly popular in software testing and market research. In these fields, being able to quickly adjust to early results can give companies a significant advantage.
Adaptive Designs are like the agile startups of the research world—quick to pivot, keen to learn from ongoing results, and focused on rapid, efficient progress. However, they require a great deal of expertise and careful planning to ensure that the adaptability doesn't compromise the integrity of the research.
18) Bayesian Designs
Next, let's dive into Bayesian Designs, the data detectives of the research universe. Named after Thomas Bayes, an 18th-century statistician and minister, this design doesn't just look at what's happening now; it also takes into account what's happened before.
Imagine if you were a detective who not only looked at the evidence in front of you but also used your past cases to make better guesses about your current one. That's the essence of Bayesian Designs.
Bayesian Designs are like detective work in science. As you gather more clues (or data), you update your best guess on what's really happening. This way, your experiment gets smarter as it goes along.
In the world of research, Bayesian Designs are most notably used in areas where you have some prior knowledge that can inform your current study. For example, if earlier research shows that a certain type of medicine usually works well for a specific illness, a Bayesian Design would include that information when studying a new group of patients with the same illness.
Bayesian Design Pros
One of the major advantages of Bayesian Designs is their efficiency. Because they use existing data to inform the current experiment, often fewer resources are needed to reach a reliable conclusion.
Bayesian Design Cons
However, they can be quite complicated to set up and require a deep understanding of both statistics and the subject matter at hand.
Bayesian Design Uses
Bayesian Designs are highly valued in medical research, finance, environmental science, and even in Internet search algorithms. Their ability to continually update and refine hypotheses based on new evidence makes them particularly useful in fields where data is constantly evolving and where quick, informed decisions are crucial.
Here's a real-world example: In the development of personalized medicine, where treatments are tailored to individual patients, Bayesian Designs are invaluable. If a treatment has been effective for patients with similar genetics or symptoms in the past, a Bayesian approach can use that data to predict how well it might work for a new patient.
This type of design is also increasingly popular in machine learning and artificial intelligence. In these fields, Bayesian Designs help algorithms "learn" from past data to make better predictions or decisions in new situations. It's like teaching a computer to be a detective that gets better and better at solving puzzles the more puzzles it sees.
19) Covariate Adaptive Randomization

Now let's turn our attention to Covariate Adaptive Randomization, which you can think of as the "matchmaker" of experimental designs.
Picture a soccer coach trying to create the most balanced teams for a friendly match. They wouldn't just randomly assign players; they'd take into account each player's skills, experience, and other traits.
Covariate Adaptive Randomization is all about creating the most evenly matched groups possible for an experiment.
In traditional randomization, participants are allocated to different groups purely by chance. This is a pretty fair way to do things, but it can sometimes lead to unbalanced groups.
Imagine if all the professional-level players ended up on one soccer team and all the beginners on another; that wouldn't be a very informative match! Covariate Adaptive Randomization fixes this by using important traits or characteristics (called "covariates") to guide the randomization process.
Covariate Adaptive Randomization Pros
The benefits of this design are pretty clear: it aims for balance and fairness, making the final results more trustworthy.
Covariate Adaptive Randomization Cons
But it's not perfect. It can be complex to implement and requires a deep understanding of which characteristics are most important to balance.
Covariate Adaptive Randomization Uses
This design is particularly useful in medical trials. Let's say researchers are testing a new medication for high blood pressure. Participants might have different ages, weights, or pre-existing conditions that could affect the results.
Covariate Adaptive Randomization would make sure that each treatment group has a similar mix of these characteristics, making the results more reliable and easier to interpret.
In practical terms, this design is often seen in clinical trials for new drugs or therapies, but its principles are also applicable in fields like psychology, education, and social sciences.
For instance, in educational research, it might be used to ensure that classrooms being compared have similar distributions of students in terms of academic ability, socioeconomic status, and other factors.
Covariate Adaptive Randomization is like the wise elder of the group, ensuring that everyone has an equal opportunity to show their true capabilities, thereby making the collective results as reliable as possible.
20) Stepped Wedge Design
Let's now focus on the Stepped Wedge Design, a thoughtful and cautious member of the experimental design family.
Imagine you're trying out a new gardening technique, but you're not sure how well it will work. You decide to apply it to one section of your garden first, watch how it performs, and then gradually extend the technique to other sections. This way, you get to see its effects over time and across different conditions. That's basically how Stepped Wedge Design works.
In a Stepped Wedge Design, all participants or clusters start off in the control group, and then, at different times, they 'step' over to the intervention or treatment group. This creates a wedge-like pattern over time where more and more participants receive the treatment as the study progresses. It's like rolling out a new policy in phases, monitoring its impact at each stage before extending it to more people.
Stepped Wedge Design Pros
The Stepped Wedge Design offers several advantages. Firstly, it allows for the study of interventions that are expected to do more good than harm, which makes it ethically appealing.
Secondly, it's useful when resources are limited and it's not feasible to roll out a new treatment to everyone at once. Lastly, because everyone eventually receives the treatment, it can be easier to get buy-in from participants or organizations involved in the study.
Stepped Wedge Design Cons
However, this design can be complex to analyze because it has to account for both the time factor and the changing conditions in each 'step' of the wedge. And like any study where participants know they're receiving an intervention, there's the potential for the results to be influenced by the placebo effect or other biases.
Stepped Wedge Design Uses
This design is particularly useful in health and social care research. For instance, if a hospital wants to implement a new hygiene protocol, it might start in one department, assess its impact, and then roll it out to other departments over time. This allows the hospital to adjust and refine the new protocol based on real-world data before it's fully implemented.
In terms of applications, Stepped Wedge Designs are commonly used in public health initiatives, organizational changes in healthcare settings, and social policy trials. They are particularly useful in situations where an intervention is being rolled out gradually and it's important to understand its impacts at each stage.
21) Sequential Design
Next up is Sequential Design, the dynamic and flexible member of our experimental design family.
Imagine you're playing a video game where you can choose different paths. If you take one path and find a treasure chest, you might decide to continue in that direction. If you hit a dead end, you might backtrack and try a different route. Sequential Design operates in a similar fashion, allowing researchers to make decisions at different stages based on what they've learned so far.
In a Sequential Design, the experiment is broken down into smaller parts, or "sequences." After each sequence, researchers pause to look at the data they've collected. Based on those findings, they then decide whether to stop the experiment because they've got enough information, or to continue and perhaps even modify the next sequence.
Sequential Design Pros
This allows for a more efficient use of resources, as you're only continuing with the experiment if the data suggests it's worth doing so.
One of the great things about Sequential Design is its efficiency. Because you're making data-driven decisions along the way, you can often reach conclusions more quickly and with fewer resources.
Sequential Design Cons
However, it requires careful planning and expertise to ensure that these "stop or go" decisions are made correctly and without bias.
Sequential Design Uses
In terms of its applications, besides healthcare and medicine, Sequential Design is also popular in quality control in manufacturing, environmental monitoring, and financial modeling. In these areas, being able to make quick decisions based on incoming data can be a big advantage.
This design is often used in clinical trials involving new medications or treatments. For example, if early results show that a new drug has significant side effects, the trial can be stopped before more people are exposed to it.
On the flip side, if the drug is showing promising results, the trial might be expanded to include more participants or to extend the testing period.
Think of Sequential Design as the nimble athlete of experimental designs, capable of quick pivots and adjustments to reach the finish line in the most effective way possible. But just like an athlete needs a good coach, this design requires expert oversight to make sure it stays on the right track.
22) Field Experiments
Last but certainly not least, let's explore Field Experiments—the adventurers of the experimental design world.
Picture a scientist leaving the controlled environment of a lab to test a theory in the real world, like a biologist studying animals in their natural habitat or a social scientist observing people in a real community. These are Field Experiments, and they're all about getting out there and gathering data in real-world settings.
Field Experiments embrace the messiness of the real world, unlike laboratory experiments, where everything is controlled down to the smallest detail. This makes them both exciting and challenging.
Field Experiment Pros
On one hand, the results often give us a better understanding of how things work outside the lab.
While Field Experiments offer real-world relevance, they come with challenges like controlling for outside factors and the ethical considerations of intervening in people's lives without their knowledge.
Field Experiment Cons
On the other hand, the lack of control can make it harder to tell exactly what's causing what. Yet, despite these challenges, they remain a valuable tool for researchers who want to understand how theories play out in the real world.
Field Experiment Uses
Let's say a school wants to improve student performance. In a Field Experiment, they might change the school's daily schedule for one semester and keep track of how students perform compared to another school where the schedule remained the same.
Because the study is happening in a real school with real students, the results could be very useful for understanding how the change might work in other schools. But since it's the real world, lots of other factors—like changes in teachers or even the weather—could affect the results.
Field Experiments are widely used in economics, psychology, education, and public policy. For example, you might have heard of the famous "Broken Windows" experiment in the 1980s that looked at how small signs of disorder, like broken windows or graffiti, could encourage more serious crime in neighborhoods. This experiment had a big impact on how cities think about crime prevention.
From the foundational concepts of control groups and independent variables to the sophisticated layouts like Covariate Adaptive Randomization and Sequential Design, it's clear that the realm of experimental design is as varied as it is fascinating.
We've seen that each design has its own special talents, ideal for specific situations. Some designs, like the Classic Controlled Experiment, are like reliable old friends you can always count on.
Others, like Sequential Design, are flexible and adaptable, making quick changes based on what they learn. And let's not forget the adventurous Field Experiments, which take us out of the lab and into the real world to discover things we might not see otherwise.
Choosing the right experimental design is like picking the right tool for the job. The method you choose can make a big difference in how reliable your results are and how much people will trust what you've discovered. And as we've learned, there's a design to suit just about every question, every problem, and every curiosity.
So the next time you read about a new discovery in medicine, psychology, or any other field, you'll have a better understanding of the thought and planning that went into figuring things out. Experimental design is more than just a set of rules; it's a structured way to explore the unknown and answer questions that can change the world.
Related posts:
- Experimental Psychologist Career (Salary + Duties + Interviews)
- 40+ Famous Psychologists (Images + Biographies)
- 11+ Psychology Experiment Ideas (Goals + Methods)
- The Little Albert Experiment
- 41+ White Collar Job Examples (Salary + Path)
Reference this article:
About The Author
Free Personality Test

Free Memory Test

Free IQ Test

PracticalPie.com is a participant in the Amazon Associates Program. As an Amazon Associate we earn from qualifying purchases.
Follow Us On:
Youtube Facebook Instagram X/Twitter
Psychology Resources
Developmental
Personality
Relationships
Psychologists
Serial Killers
Psychology Tests
Personality Quiz
Memory Test
Depression test
Type A/B Personality Test
© PracticalPsychology. All rights reserved
Privacy Policy | Terms of Use
- Privacy Policy
Buy Me a Coffee
Home » Research Design – Types, Methods and Examples
Research Design – Types, Methods and Examples
Table of Contents

Research Design
Definition:
Research design refers to the overall strategy or plan for conducting a research study. It outlines the methods and procedures that will be used to collect and analyze data, as well as the goals and objectives of the study. Research design is important because it guides the entire research process and ensures that the study is conducted in a systematic and rigorous manner.
Types of Research Design
Types of Research Design are as follows:
Descriptive Research Design
This type of research design is used to describe a phenomenon or situation. It involves collecting data through surveys, questionnaires, interviews, and observations. The aim of descriptive research is to provide an accurate and detailed portrayal of a particular group, event, or situation. It can be useful in identifying patterns, trends, and relationships in the data.
Correlational Research Design
Correlational research design is used to determine if there is a relationship between two or more variables. This type of research design involves collecting data from participants and analyzing the relationship between the variables using statistical methods. The aim of correlational research is to identify the strength and direction of the relationship between the variables.
Experimental Research Design
Experimental research design is used to investigate cause-and-effect relationships between variables. This type of research design involves manipulating one variable and measuring the effect on another variable. It usually involves randomly assigning participants to groups and manipulating an independent variable to determine its effect on a dependent variable. The aim of experimental research is to establish causality.
Quasi-experimental Research Design
Quasi-experimental research design is similar to experimental research design, but it lacks one or more of the features of a true experiment. For example, there may not be random assignment to groups or a control group. This type of research design is used when it is not feasible or ethical to conduct a true experiment.
Case Study Research Design
Case study research design is used to investigate a single case or a small number of cases in depth. It involves collecting data through various methods, such as interviews, observations, and document analysis. The aim of case study research is to provide an in-depth understanding of a particular case or situation.
Longitudinal Research Design
Longitudinal research design is used to study changes in a particular phenomenon over time. It involves collecting data at multiple time points and analyzing the changes that occur. The aim of longitudinal research is to provide insights into the development, growth, or decline of a particular phenomenon over time.
Structure of Research Design
The format of a research design typically includes the following sections:
- Introduction : This section provides an overview of the research problem, the research questions, and the importance of the study. It also includes a brief literature review that summarizes previous research on the topic and identifies gaps in the existing knowledge.
- Research Questions or Hypotheses: This section identifies the specific research questions or hypotheses that the study will address. These questions should be clear, specific, and testable.
- Research Methods : This section describes the methods that will be used to collect and analyze data. It includes details about the study design, the sampling strategy, the data collection instruments, and the data analysis techniques.
- Data Collection: This section describes how the data will be collected, including the sample size, data collection procedures, and any ethical considerations.
- Data Analysis: This section describes how the data will be analyzed, including the statistical techniques that will be used to test the research questions or hypotheses.
- Results : This section presents the findings of the study, including descriptive statistics and statistical tests.
- Discussion and Conclusion : This section summarizes the key findings of the study, interprets the results, and discusses the implications of the findings. It also includes recommendations for future research.
- References : This section lists the sources cited in the research design.
Example of Research Design
An Example of Research Design could be:
Research question: Does the use of social media affect the academic performance of high school students?
Research design:
- Research approach : The research approach will be quantitative as it involves collecting numerical data to test the hypothesis.
- Research design : The research design will be a quasi-experimental design, with a pretest-posttest control group design.
- Sample : The sample will be 200 high school students from two schools, with 100 students in the experimental group and 100 students in the control group.
- Data collection : The data will be collected through surveys administered to the students at the beginning and end of the academic year. The surveys will include questions about their social media usage and academic performance.
- Data analysis : The data collected will be analyzed using statistical software. The mean scores of the experimental and control groups will be compared to determine whether there is a significant difference in academic performance between the two groups.
- Limitations : The limitations of the study will be acknowledged, including the fact that social media usage can vary greatly among individuals, and the study only focuses on two schools, which may not be representative of the entire population.
- Ethical considerations: Ethical considerations will be taken into account, such as obtaining informed consent from the participants and ensuring their anonymity and confidentiality.
How to Write Research Design
Writing a research design involves planning and outlining the methodology and approach that will be used to answer a research question or hypothesis. Here are some steps to help you write a research design:
- Define the research question or hypothesis : Before beginning your research design, you should clearly define your research question or hypothesis. This will guide your research design and help you select appropriate methods.
- Select a research design: There are many different research designs to choose from, including experimental, survey, case study, and qualitative designs. Choose a design that best fits your research question and objectives.
- Develop a sampling plan : If your research involves collecting data from a sample, you will need to develop a sampling plan. This should outline how you will select participants and how many participants you will include.
- Define variables: Clearly define the variables you will be measuring or manipulating in your study. This will help ensure that your results are meaningful and relevant to your research question.
- Choose data collection methods : Decide on the data collection methods you will use to gather information. This may include surveys, interviews, observations, experiments, or secondary data sources.
- Create a data analysis plan: Develop a plan for analyzing your data, including the statistical or qualitative techniques you will use.
- Consider ethical concerns : Finally, be sure to consider any ethical concerns related to your research, such as participant confidentiality or potential harm.
When to Write Research Design
Research design should be written before conducting any research study. It is an important planning phase that outlines the research methodology, data collection methods, and data analysis techniques that will be used to investigate a research question or problem. The research design helps to ensure that the research is conducted in a systematic and logical manner, and that the data collected is relevant and reliable.
Ideally, the research design should be developed as early as possible in the research process, before any data is collected. This allows the researcher to carefully consider the research question, identify the most appropriate research methodology, and plan the data collection and analysis procedures in advance. By doing so, the research can be conducted in a more efficient and effective manner, and the results are more likely to be valid and reliable.
Purpose of Research Design
The purpose of research design is to plan and structure a research study in a way that enables the researcher to achieve the desired research goals with accuracy, validity, and reliability. Research design is the blueprint or the framework for conducting a study that outlines the methods, procedures, techniques, and tools for data collection and analysis.
Some of the key purposes of research design include:
- Providing a clear and concise plan of action for the research study.
- Ensuring that the research is conducted ethically and with rigor.
- Maximizing the accuracy and reliability of the research findings.
- Minimizing the possibility of errors, biases, or confounding variables.
- Ensuring that the research is feasible, practical, and cost-effective.
- Determining the appropriate research methodology to answer the research question(s).
- Identifying the sample size, sampling method, and data collection techniques.
- Determining the data analysis method and statistical tests to be used.
- Facilitating the replication of the study by other researchers.
- Enhancing the validity and generalizability of the research findings.
Applications of Research Design
There are numerous applications of research design in various fields, some of which are:
- Social sciences: In fields such as psychology, sociology, and anthropology, research design is used to investigate human behavior and social phenomena. Researchers use various research designs, such as experimental, quasi-experimental, and correlational designs, to study different aspects of social behavior.
- Education : Research design is essential in the field of education to investigate the effectiveness of different teaching methods and learning strategies. Researchers use various designs such as experimental, quasi-experimental, and case study designs to understand how students learn and how to improve teaching practices.
- Health sciences : In the health sciences, research design is used to investigate the causes, prevention, and treatment of diseases. Researchers use various designs, such as randomized controlled trials, cohort studies, and case-control studies, to study different aspects of health and healthcare.
- Business : Research design is used in the field of business to investigate consumer behavior, marketing strategies, and the impact of different business practices. Researchers use various designs, such as survey research, experimental research, and case studies, to study different aspects of the business world.
- Engineering : In the field of engineering, research design is used to investigate the development and implementation of new technologies. Researchers use various designs, such as experimental research and case studies, to study the effectiveness of new technologies and to identify areas for improvement.
Advantages of Research Design
Here are some advantages of research design:
- Systematic and organized approach : A well-designed research plan ensures that the research is conducted in a systematic and organized manner, which makes it easier to manage and analyze the data.
- Clear objectives: The research design helps to clarify the objectives of the study, which makes it easier to identify the variables that need to be measured, and the methods that need to be used to collect and analyze data.
- Minimizes bias: A well-designed research plan minimizes the chances of bias, by ensuring that the data is collected and analyzed objectively, and that the results are not influenced by the researcher’s personal biases or preferences.
- Efficient use of resources: A well-designed research plan helps to ensure that the resources (time, money, and personnel) are used efficiently and effectively, by focusing on the most important variables and methods.
- Replicability: A well-designed research plan makes it easier for other researchers to replicate the study, which enhances the credibility and reliability of the findings.
- Validity: A well-designed research plan helps to ensure that the findings are valid, by ensuring that the methods used to collect and analyze data are appropriate for the research question.
- Generalizability : A well-designed research plan helps to ensure that the findings can be generalized to other populations, settings, or situations, which increases the external validity of the study.
Research Design Vs Research Methodology
About the author.

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Process – Steps, Examples and Tips

Institutional Review Board – Application Sample...
Leave a comment x.
Save my name, email, and website in this browser for the next time I comment.
Organizing Academic Research Papers: Types of Research Designs
- Purpose of Guide
- Design Flaws to Avoid
- Glossary of Research Terms
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Choosing a Title
- Making an Outline
- Paragraph Development
- Executive Summary
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tertiary Sources
- What Is Scholarly vs. Popular?
- Qualitative Methods
- Quantitative Methods
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Annotated Bibliography
- Dealing with Nervousness
- Using Visual Aids
- Grading Someone Else's Paper
- How to Manage Group Projects
- Multiple Book Review Essay
- Reviewing Collected Essays
- About Informed Consent
- Writing Field Notes
- Writing a Policy Memo
- Writing a Research Proposal
- Acknowledgements
Introduction
Before beginning your paper, you need to decide how you plan to design the study .
The research design refers to the overall strategy that you choose to integrate the different components of the study in a coherent and logical way, thereby, ensuring you will effectively address the research problem; it constitutes the blueprint for the collection, measurement, and analysis of data. Note that your research problem determines the type of design you can use, not the other way around!
General Structure and Writing Style
Action research design, case study design, causal design, cohort design, cross-sectional design, descriptive design, experimental design, exploratory design, historical design, longitudinal design, observational design, philosophical design, sequential design.
Kirshenblatt-Gimblett, Barbara. Part 1, What Is Research Design? The Context of Design. Performance Studies Methods Course syllabus . New York University, Spring 2006; Trochim, William M.K. Research Methods Knowledge Base . 2006.
The function of a research design is to ensure that the evidence obtained enables you to effectively address the research problem as unambiguously as possible. In social sciences research, obtaining evidence relevant to the research problem generally entails specifying the type of evidence needed to test a theory, to evaluate a program, or to accurately describe a phenomenon. However, researchers can often begin their investigations far too early, before they have thought critically about about what information is required to answer the study's research questions. Without attending to these design issues beforehand, the conclusions drawn risk being weak and unconvincing and, consequently, will fail to adequate address the overall research problem.
Given this, the length and complexity of research designs can vary considerably, but any sound design will do the following things:
- Identify the research problem clearly and justify its selection,
- Review previously published literature associated with the problem area,
- Clearly and explicitly specify hypotheses [i.e., research questions] central to the problem selected,
- Effectively describe the data which will be necessary for an adequate test of the hypotheses and explain how such data will be obtained, and
- Describe the methods of analysis which will be applied to the data in determining whether or not the hypotheses are true or false.
Kirshenblatt-Gimblett, Barbara. Part 1, What Is Research Design? The Context of Design. Performance Studies Methods Course syllabus . New Yortk University, Spring 2006.
Definition and Purpose
The essentials of action research design follow a characteristic cycle whereby initially an exploratory stance is adopted, where an understanding of a problem is developed and plans are made for some form of interventionary strategy. Then the intervention is carried out (the action in Action Research) during which time, pertinent observations are collected in various forms. The new interventional strategies are carried out, and the cyclic process repeats, continuing until a sufficient understanding of (or implement able solution for) the problem is achieved. The protocol is iterative or cyclical in nature and is intended to foster deeper understanding of a given situation, starting with conceptualizing and particularizing the problem and moving through several interventions and evaluations.
What do these studies tell you?
- A collaborative and adaptive research design that lends itself to use in work or community situations.
- Design focuses on pragmatic and solution-driven research rather than testing theories.
- When practitioners use action research it has the potential to increase the amount they learn consciously from their experience. The action research cycle can also be regarded as a learning cycle.
- Action search studies often have direct and obvious relevance to practice.
- There are no hidden controls or preemption of direction by the researcher.
What these studies don't tell you?
- It is harder to do than conducting conventional studies because the researcher takes on responsibilities for encouraging change as well as for research.
- Action research is much harder to write up because you probably can’t use a standard format to report your findings effectively.
- Personal over-involvement of the researcher may bias research results.
- The cyclic nature of action research to achieve its twin outcomes of action (e.g. change) and research (e.g. understanding) is time-consuming and complex to conduct.
Gall, Meredith. Educational Research: An Introduction . Chapter 18, Action Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Kemmis, Stephen and Robin McTaggart. “Participatory Action Research.” In Handbook of Qualitative Research . Norman Denzin and Yvonna S. Locoln, eds. 2nd ed. (Thousand Oaks, CA: SAGE, 2000), pp. 567-605.; Reason, Peter and Hilary Bradbury. Handbook of Action Research: Participative Inquiry and Practice . Thousand Oaks, CA: SAGE, 2001.
A case study is an in-depth study of a particular research problem rather than a sweeping statistical survey. It is often used to narrow down a very broad field of research into one or a few easily researchable examples. The case study research design is also useful for testing whether a specific theory and model actually applies to phenomena in the real world. It is a useful design when not much is known about a phenomenon.
- Approach excels at bringing us to an understanding of a complex issue through detailed contextual analysis of a limited number of events or conditions and their relationships.
- A researcher using a case study design can apply a vaiety of methodologies and rely on a variety of sources to investigate a research problem.
- Design can extend experience or add strength to what is already known through previous research.
- Social scientists, in particular, make wide use of this research design to examine contemporary real-life situations and provide the basis for the application of concepts and theories and extension of methods.
- The design can provide detailed descriptions of specific and rare cases.
- A single or small number of cases offers little basis for establishing reliability or to generalize the findings to a wider population of people, places, or things.
- The intense exposure to study of the case may bias a researcher's interpretation of the findings.
- Design does not facilitate assessment of cause and effect relationships.
- Vital information may be missing, making the case hard to interpret.
- The case may not be representative or typical of the larger problem being investigated.
- If the criteria for selecting a case is because it represents a very unusual or unique phenomenon or problem for study, then your intepretation of the findings can only apply to that particular case.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 4, Flexible Methods: Case Study Design. 2nd ed. New York: Columbia University Press, 1999; Stake, Robert E. The Art of Case Study Research . Thousand Oaks, CA: SAGE, 1995; Yin, Robert K. Case Study Research: Design and Theory . Applied Social Research Methods Series, no. 5. 3rd ed. Thousand Oaks, CA: SAGE, 2003.
Causality studies may be thought of as understanding a phenomenon in terms of conditional statements in the form, “If X, then Y.” This type of research is used to measure what impact a specific change will have on existing norms and assumptions. Most social scientists seek causal explanations that reflect tests of hypotheses. Causal effect (nomothetic perspective) occurs when variation in one phenomenon, an independent variable, leads to or results, on average, in variation in another phenomenon, the dependent variable.
Conditions necessary for determining causality:
- Empirical association--a valid conclusion is based on finding an association between the independent variable and the dependent variable.
- Appropriate time order--to conclude that causation was involved, one must see that cases were exposed to variation in the independent variable before variation in the dependent variable.
- Nonspuriousness--a relationship between two variables that is not due to variation in a third variable.
- Causality research designs helps researchers understand why the world works the way it does through the process of proving a causal link between variables and eliminating other possibilities.
- Replication is possible.
- There is greater confidence the study has internal validity due to the systematic subject selection and equity of groups being compared.
- Not all relationships are casual! The possibility always exists that, by sheer coincidence, two unrelated events appear to be related [e.g., Punxatawney Phil could accurately predict the duration of Winter for five consecutive years but, the fact remains, he's just a big, furry rodent].
- Conclusions about causal relationships are difficult to determine due to a variety of extraneous and confounding variables that exist in a social environment. This means causality can only be inferred, never proven.
- If two variables are correlated, the cause must come before the effect. However, even though two variables might be causally related, it can sometimes be difficult to determine which variable comes first and therefore to establish which variable is the actual cause and which is the actual effect.
Bachman, Ronet. The Practice of Research in Criminology and Criminal Justice . Chapter 5, Causation and Research Designs. 3rd ed. Thousand Oaks, CA: Pine Forge Press, 2007; Causal Research Design: Experimentation. Anonymous SlideShare Presentation ; Gall, Meredith. Educational Research: An Introduction . Chapter 11, Nonexperimental Research: Correlational Designs. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Trochim, William M.K. Research Methods Knowledge Base . 2006.
Often used in the medical sciences, but also found in the applied social sciences, a cohort study generally refers to a study conducted over a period of time involving members of a population which the subject or representative member comes from, and who are united by some commonality or similarity. Using a quantitative framework, a cohort study makes note of statistical occurrence within a specialized subgroup, united by same or similar characteristics that are relevant to the research problem being investigated, r ather than studying statistical occurrence within the general population. Using a qualitative framework, cohort studies generally gather data using methods of observation. Cohorts can be either "open" or "closed."
- Open Cohort Studies [dynamic populations, such as the population of Los Angeles] involve a population that is defined just by the state of being a part of the study in question (and being monitored for the outcome). Date of entry and exit from the study is individually defined, therefore, the size of the study population is not constant. In open cohort studies, researchers can only calculate rate based data, such as, incidence rates and variants thereof.
- Closed Cohort Studies [static populations, such as patients entered into a clinical trial] involve participants who enter into the study at one defining point in time and where it is presumed that no new participants can enter the cohort. Given this, the number of study participants remains constant (or can only decrease).
- The use of cohorts is often mandatory because a randomized control study may be unethical. For example, you cannot deliberately expose people to asbestos, you can only study its effects on those who have already been exposed. Research that measures risk factors often relies on cohort designs.
- Because cohort studies measure potential causes before the outcome has occurred, they can demonstrate that these “causes” preceded the outcome, thereby avoiding the debate as to which is the cause and which is the effect.
- Cohort analysis is highly flexible and can provide insight into effects over time and related to a variety of different types of changes [e.g., social, cultural, political, economic, etc.].
- Either original data or secondary data can be used in this design.
- In cases where a comparative analysis of two cohorts is made [e.g., studying the effects of one group exposed to asbestos and one that has not], a researcher cannot control for all other factors that might differ between the two groups. These factors are known as confounding variables.
- Cohort studies can end up taking a long time to complete if the researcher must wait for the conditions of interest to develop within the group. This also increases the chance that key variables change during the course of the study, potentially impacting the validity of the findings.
- Because of the lack of randominization in the cohort design, its external validity is lower than that of study designs where the researcher randomly assigns participants.
Healy P, Devane D. “Methodological Considerations in Cohort Study Designs.” Nurse Researcher 18 (2011): 32-36; Levin, Kate Ann. Study Design IV: Cohort Studies. Evidence-Based Dentistry 7 (2003): 51–52; Study Design 101 . Himmelfarb Health Sciences Library. George Washington University, November 2011; Cohort Study . Wikipedia.
Cross-sectional research designs have three distinctive features: no time dimension, a reliance on existing differences rather than change following intervention; and, groups are selected based on existing differences rather than random allocation. The cross-sectional design can only measure diffrerences between or from among a variety of people, subjects, or phenomena rather than change. As such, researchers using this design can only employ a relative passive approach to making causal inferences based on findings.
- Cross-sectional studies provide a 'snapshot' of the outcome and the characteristics associated with it, at a specific point in time.
- Unlike the experimental design where there is an active intervention by the researcher to produce and measure change or to create differences, cross-sectional designs focus on studying and drawing inferences from existing differences between people, subjects, or phenomena.
- Entails collecting data at and concerning one point in time. While longitudinal studies involve taking multiple measures over an extended period of time, cross-sectional research is focused on finding relationships between variables at one moment in time.
- Groups identified for study are purposely selected based upon existing differences in the sample rather than seeking random sampling.
- Cross-section studies are capable of using data from a large number of subjects and, unlike observational studies, is not geographically bound.
- Can estimate prevalence of an outcome of interest because the sample is usually taken from the whole population.
- Because cross-sectional designs generally use survey techniques to gather data, they are relatively inexpensive and take up little time to conduct.
- Finding people, subjects, or phenomena to study that are very similar except in one specific variable can be difficult.
- Results are static and time bound and, therefore, give no indication of a sequence of events or reveal historical contexts.
- Studies cannot be utilized to establish cause and effect relationships.
- Provide only a snapshot of analysis so there is always the possibility that a study could have differing results if another time-frame had been chosen.
- There is no follow up to the findings.
Hall, John. “Cross-Sectional Survey Design.” In Encyclopedia of Survey Research Methods. Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 173-174; Helen Barratt, Maria Kirwan. Cross-Sectional Studies: Design, Application, Strengths and Weaknesses of Cross-Sectional Studies . Healthknowledge, 2009. Cross-Sectional Study . Wikipedia.
Descriptive research designs help provide answers to the questions of who, what, when, where, and how associated with a particular research problem; a descriptive study cannot conclusively ascertain answers to why. Descriptive research is used to obtain information concerning the current status of the phenomena and to describe "what exists" with respect to variables or conditions in a situation.
- The subject is being observed in a completely natural and unchanged natural environment. True experiments, whilst giving analyzable data, often adversely influence the normal behavior of the subject.
- Descriptive research is often used as a pre-cursor to more quantitatively research designs, the general overview giving some valuable pointers as to what variables are worth testing quantitatively.
- If the limitations are understood, they can be a useful tool in developing a more focused study.
- Descriptive studies can yield rich data that lead to important recommendations.
- Appoach collects a large amount of data for detailed analysis.
- The results from a descriptive research can not be used to discover a definitive answer or to disprove a hypothesis.
- Because descriptive designs often utilize observational methods [as opposed to quantitative methods], the results cannot be replicated.
- The descriptive function of research is heavily dependent on instrumentation for measurement and observation.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 5, Flexible Methods: Descriptive Research. 2nd ed. New York: Columbia University Press, 1999; McNabb, Connie. Descriptive Research Methodologies . Powerpoint Presentation; Shuttleworth, Martyn. Descriptive Research Design , September 26, 2008. Explorable.com website.
A blueprint of the procedure that enables the researcher to maintain control over all factors that may affect the result of an experiment. In doing this, the researcher attempts to determine or predict what may occur. Experimental Research is often used where there is time priority in a causal relationship (cause precedes effect), there is consistency in a causal relationship (a cause will always lead to the same effect), and the magnitude of the correlation is great. The classic experimental design specifies an experimental group and a control group. The independent variable is administered to the experimental group and not to the control group, and both groups are measured on the same dependent variable. Subsequent experimental designs have used more groups and more measurements over longer periods. True experiments must have control, randomization, and manipulation.
- Experimental research allows the researcher to control the situation. In so doing, it allows researchers to answer the question, “what causes something to occur?”
- Permits the researcher to identify cause and effect relationships between variables and to distinguish placebo effects from treatment effects.
- Experimental research designs support the ability to limit alternative explanations and to infer direct causal relationships in the study.
- Approach provides the highest level of evidence for single studies.
- The design is artificial, and results may not generalize well to the real world.
- The artificial settings of experiments may alter subject behaviors or responses.
- Experimental designs can be costly if special equipment or facilities are needed.
- Some research problems cannot be studied using an experiment because of ethical or technical reasons.
- Difficult to apply ethnographic and other qualitative methods to experimental designed research studies.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 7, Flexible Methods: Experimental Research. 2nd ed. New York: Columbia University Press, 1999; Chapter 2: Research Design, Experimental Designs . School of Psychology, University of New England, 2000; Experimental Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Trochim, William M.K. Experimental Design . Research Methods Knowledge Base. 2006; Rasool, Shafqat. Experimental Research . Slideshare presentation.
An exploratory design is conducted about a research problem when there are few or no earlier studies to refer to. The focus is on gaining insights and familiarity for later investigation or undertaken when problems are in a preliminary stage of investigation.
The goals of exploratory research are intended to produce the following possible insights:
- Familiarity with basic details, settings and concerns.
- Well grounded picture of the situation being developed.
- Generation of new ideas and assumption, development of tentative theories or hypotheses.
- Determination about whether a study is feasible in the future.
- Issues get refined for more systematic investigation and formulation of new research questions.
- Direction for future research and techniques get developed.
- Design is a useful approach for gaining background information on a particular topic.
- Exploratory research is flexible and can address research questions of all types (what, why, how).
- Provides an opportunity to define new terms and clarify existing concepts.
- Exploratory research is often used to generate formal hypotheses and develop more precise research problems.
- Exploratory studies help establish research priorities.
- Exploratory research generally utilizes small sample sizes and, thus, findings are typically not generalizable to the population at large.
- The exploratory nature of the research inhibits an ability to make definitive conclusions about the findings.
- The research process underpinning exploratory studies is flexible but often unstructured, leading to only tentative results that have limited value in decision-making.
- Design lacks rigorous standards applied to methods of data gathering and analysis because one of the areas for exploration could be to determine what method or methodologies could best fit the research problem.
Cuthill, Michael. “Exploratory Research: Citizen Participation, Local Government, and Sustainable Development in Australia.” Sustainable Development 10 (2002): 79-89; Taylor, P. J., G. Catalano, and D.R.F. Walker. “Exploratory Analysis of the World City Network.” Urban Studies 39 (December 2002): 2377-2394; Exploratory Research . Wikipedia.
The purpose of a historical research design is to collect, verify, and synthesize evidence from the past to establish facts that defend or refute your hypothesis. It uses secondary sources and a variety of primary documentary evidence, such as, logs, diaries, official records, reports, archives, and non-textual information [maps, pictures, audio and visual recordings]. The limitation is that the sources must be both authentic and valid.
- The historical research design is unobtrusive; the act of research does not affect the results of the study.
- The historical approach is well suited for trend analysis.
- Historical records can add important contextual background required to more fully understand and interpret a research problem.
- There is no possibility of researcher-subject interaction that could affect the findings.
- Historical sources can be used over and over to study different research problems or to replicate a previous study.
- The ability to fulfill the aims of your research are directly related to the amount and quality of documentation available to understand the research problem.
- Since historical research relies on data from the past, there is no way to manipulate it to control for contemporary contexts.
- Interpreting historical sources can be very time consuming.
- The sources of historical materials must be archived consistentally to ensure access.
- Original authors bring their own perspectives and biases to the interpretation of past events and these biases are more difficult to ascertain in historical resources.
- Due to the lack of control over external variables, historical research is very weak with regard to the demands of internal validity.
- It rare that the entirety of historical documentation needed to fully address a research problem is available for interpretation, therefore, gaps need to be acknowledged.
Savitt, Ronald. “Historical Research in Marketing.” Journal of Marketing 44 (Autumn, 1980): 52-58; Gall, Meredith. Educational Research: An Introduction . Chapter 16, Historical Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007.
A longitudinal study follows the same sample over time and makes repeated observations. With longitudinal surveys, for example, the same group of people is interviewed at regular intervals, enabling researchers to track changes over time and to relate them to variables that might explain why the changes occur. Longitudinal research designs describe patterns of change and help establish the direction and magnitude of causal relationships. Measurements are taken on each variable over two or more distinct time periods. This allows the researcher to measure change in variables over time. It is a type of observational study and is sometimes referred to as a panel study.
- Longitudinal data allow the analysis of duration of a particular phenomenon.
- Enables survey researchers to get close to the kinds of causal explanations usually attainable only with experiments.
- The design permits the measurement of differences or change in a variable from one period to another [i.e., the description of patterns of change over time].
- Longitudinal studies facilitate the prediction of future outcomes based upon earlier factors.
- The data collection method may change over time.
- Maintaining the integrity of the original sample can be difficult over an extended period of time.
- It can be difficult to show more than one variable at a time.
- This design often needs qualitative research to explain fluctuations in the data.
- A longitudinal research design assumes present trends will continue unchanged.
- It can take a long period of time to gather results.
- There is a need to have a large sample size and accurate sampling to reach representativness.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 6, Flexible Methods: Relational and Longitudinal Research. 2nd ed. New York: Columbia University Press, 1999; Kalaian, Sema A. and Rafa M. Kasim. "Longitudinal Studies." In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 440-441; Ployhart, Robert E. and Robert J. Vandenberg. "Longitudinal Research: The Theory, Design, and Analysis of Change.” Journal of Management 36 (January 2010): 94-120; Longitudinal Study . Wikipedia.
This type of research design draws a conclusion by comparing subjects against a control group, in cases where the researcher has no control over the experiment. There are two general types of observational designs. In direct observations, people know that you are watching them. Unobtrusive measures involve any method for studying behavior where individuals do not know they are being observed. An observational study allows a useful insight into a phenomenon and avoids the ethical and practical difficulties of setting up a large and cumbersome research project.
- Observational studies are usually flexible and do not necessarily need to be structured around a hypothesis about what you expect to observe (data is emergent rather than pre-existing).
- The researcher is able to collect a depth of information about a particular behavior.
- Can reveal interrelationships among multifaceted dimensions of group interactions.
- You can generalize your results to real life situations.
- Observational research is useful for discovering what variables may be important before applying other methods like experiments.
- Observation researchd esigns account for the complexity of group behaviors.
- Reliability of data is low because seeing behaviors occur over and over again may be a time consuming task and difficult to replicate.
- In observational research, findings may only reflect a unique sample population and, thus, cannot be generalized to other groups.
- There can be problems with bias as the researcher may only "see what they want to see."
- There is no possiblility to determine "cause and effect" relationships since nothing is manipulated.
- Sources or subjects may not all be equally credible.
- Any group that is studied is altered to some degree by the very presence of the researcher, therefore, skewing to some degree any data collected (the Heisenburg Uncertainty Principle).
Atkinson, Paul and Martyn Hammersley. “Ethnography and Participant Observation.” In Handbook of Qualitative Research . Norman K. Denzin and Yvonna S. Lincoln, eds. (Thousand Oaks, CA: Sage, 1994), pp. 248-261; Observational Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Patton Michael Quinn. Qualitiative Research and Evaluation Methods . Chapter 6, Fieldwork Strategies and Observational Methods. 3rd ed. Thousand Oaks, CA: Sage, 2002; Rosenbaum, Paul R. Design of Observational Studies . New York: Springer, 2010.
Understood more as an broad approach to examining a research problem than a methodological design, philosophical analysis and argumentation is intended to challenge deeply embedded, often intractable, assumptions underpinning an area of study. This approach uses the tools of argumentation derived from philosophical traditions, concepts, models, and theories to critically explore and challenge, for example, the relevance of logic and evidence in academic debates, to analyze arguments about fundamental issues, or to discuss the root of existing discourse about a research problem. These overarching tools of analysis can be framed in three ways:
- Ontology -- the study that describes the nature of reality; for example, what is real and what is not, what is fundamental and what is derivative?
- Epistemology -- the study that explores the nature of knowledge; for example, on what does knowledge and understanding depend upon and how can we be certain of what we know?
- Axiology -- the study of values; for example, what values does an individual or group hold and why? How are values related to interest, desire, will, experience, and means-to-end? And, what is the difference between a matter of fact and a matter of value?
- Can provide a basis for applying ethical decision-making to practice.
- Functions as a means of gaining greater self-understanding and self-knowledge about the purposes of research.
- Brings clarity to general guiding practices and principles of an individual or group.
- Philosophy informs methodology.
- Refine concepts and theories that are invoked in relatively unreflective modes of thought and discourse.
- Beyond methodology, philosophy also informs critical thinking about epistemology and the structure of reality (metaphysics).
- Offers clarity and definition to the practical and theoretical uses of terms, concepts, and ideas.
- Limited application to specific research problems [answering the "So What?" question in social science research].
- Analysis can be abstract, argumentative, and limited in its practical application to real-life issues.
- While a philosophical analysis may render problematic that which was once simple or taken-for-granted, the writing can be dense and subject to unnecessary jargon, overstatement, and/or excessive quotation and documentation.
- There are limitations in the use of metaphor as a vehicle of philosophical analysis.
- There can be analytical difficulties in moving from philosophy to advocacy and between abstract thought and application to the phenomenal world.
Chapter 4, Research Methodology and Design . Unisa Institutional Repository (UnisaIR), University of South Africa; Labaree, Robert V. and Ross Scimeca. “The Philosophical Problem of Truth in Librarianship.” The Library Quarterly 78 (January 2008): 43-70; Maykut, Pamela S. Beginning Qualitative Research: A Philosophic and Practical Guide . Washington, D.C.: Falmer Press, 1994; Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, CSLI, Stanford University, 2013.
- The researcher has a limitless option when it comes to sample size and the sampling schedule.
- Due to the repetitive nature of this research design, minor changes and adjustments can be done during the initial parts of the study to correct and hone the research method. Useful design for exploratory studies.
- There is very little effort on the part of the researcher when performing this technique. It is generally not expensive, time consuming, or workforce extensive.
- Because the study is conducted serially, the results of one sample are known before the next sample is taken and analyzed.
- The sampling method is not representative of the entire population. The only possibility of approaching representativeness is when the researcher chooses to use a very large sample size significant enough to represent a significant portion of the entire population. In this case, moving on to study a second or more sample can be difficult.
- Because the sampling technique is not randomized, the design cannot be used to create conclusions and interpretations that pertain to an entire population. Generalizability from findings is limited.
- Difficult to account for and interpret variation from one sample to another over time, particularly when using qualitative methods of data collection.
Rebecca Betensky, Harvard University, Course Lecture Note slides ; Cresswell, John W. Et al. “Advanced Mixed-Methods Research Designs.” In Handbook of Mixed Methods in Social and Behavioral Research . Abbas Tashakkori and Charles Teddle, eds. (Thousand Oaks, CA: Sage, 2003), pp. 209-240; Nataliya V. Ivankova. “Using Mixed-Methods Sequential Explanatory Design: From Theory to Practice.” Field Methods 18 (February 2006): 3-20; Bovaird, James A. and Kevin A. Kupzyk. “Sequential Design.” In Encyclopedia of Research Design . Neil J. Salkind, ed. Thousand Oaks, CA: Sage, 2010; Sequential Analysis . Wikipedia.
- << Previous: Purpose of Guide
- Next: Design Flaws to Avoid >>
- Last Updated: Jul 18, 2023 11:58 AM
- URL: https://library.sacredheart.edu/c.php?g=29803
- QuickSearch
- Library Catalog
- Databases A-Z
- Publication Finder
- Course Reserves
- Citation Linker
- Digital Commons
- Our Website
Research Support
- Ask a Librarian
- Appointments
- Interlibrary Loan (ILL)
- Research Guides
- Databases by Subject
- Citation Help
Using the Library
- Reserve a Group Study Room
- Renew Books
- Honors Study Rooms
- Off-Campus Access
- Library Policies
- Library Technology
User Information
- Grad Students
- Online Students
- COVID-19 Updates
- Staff Directory
- News & Announcements
- Library Newsletter
My Accounts
- Interlibrary Loan
- Staff Site Login
FIND US ON

5 Chapter 5: Experimental and Quasi-Experimental Designs
Case stu dy: the impact of teen court.
Research Study
An Experimental Evaluation of Teen Courts 1
Research Question
Is teen court more effective at reducing recidivism and improving attitudes than traditional juvenile justice processing?
Methodology
Researchers randomly assigned 168 juvenile offenders ages 11 to 17 from four different counties in Maryland to either teen court as experimental group members or to traditional juvenile justice processing as control group members. (Note: Discussion on the technical aspects of experimental designs, including random assignment, is found in detail later in this chapter.) Of the 168 offenders, 83 were assigned to teen court and 85 were assigned to regular juvenile justice processing through random assignment. Of the 83 offenders assigned to the teen court experimental group, only 56 (67%) agreed to participate in the study. Of the 85 youth randomly assigned to normal juvenile justice processing, only 51 (60%) agreed to participate in the study.
Upon assignment to teen court or regular juvenile justice processing, all offenders entered their respective sanction. Approximately four months later, offenders in both the experimental group (teen court) and the control group (regular juvenile justice processing) were asked to complete a post-test survey inquiring about a variety of behaviors (frequency of drug use, delinquent behavior, variety of drug use) and attitudinal measures (social skills, rebelliousness, neighborhood attachment, belief in conventional rules, and positive self-concept). The study researchers also collected official re-arrest data for 18 months starting at the time of offender referral to juvenile justice authorities.
Teen court participants self-reported higher levels of delinquency than those processed through regular juvenile justice processing. According to official re-arrests, teen court youth were re-arrested at a higher rate and incurred a higher average number of total arrests than the control group. Teen court offenders also reported significantly lower scores on survey items designed to measure their “belief in conventional rules” compared to offenders processed through regular juvenile justice avenues. Other attitudinal and opinion measures did not differ significantly between the experimental and control group members based on their post-test responses. In sum, those youth randomly assigned to teen court fared worse than control group members who were not randomly assigned to teen court.
Limitations with the Study Procedure
Limitations are inherent in any research study and those research efforts that utilize experimental designs are no exception. It is important to consider the potential impact that a limitation of the study procedure could have on the results of the study.
In the current study, one potential limitation is that teen courts from four different counties in Maryland were utilized. Because of the diversity in teen court sites, it is possible that there were differences in procedure between the four teen courts and such differences could have impacted the outcomes of this study. For example, perhaps staff members at one teen court were more punishment-oriented than staff members at the other county teen courts. This philosophical difference may have affected treatment delivery and hence experimental group members’ belief in conventional attitudes and recidivism. Although the researchers monitored each teen court to help ensure treatment consistency between study sites, it is possible that differences existed in the day-to-day operation of the teen courts that may have affected participant outcomes. This same limitation might also apply to control group members who were sanctioned with regular juvenile justice processing in four different counties.
A researcher must also consider the potential for differences between the experimental and control group members. Although the offenders were randomly assigned to the experimental or control group, and the assumption is that the groups were equivalent to each other prior to program participation, the researchers in this study were only able to compare the experimental and control groups on four variables: age, school grade, gender, and race. It is possible that the experimental and control group members differed by chance on one or more factors not measured or available to the researchers. For example, perhaps a large number of teen court members experienced problems at home that can explain their more dismal post-test results compared to control group members without such problems. A larger sample of juvenile offenders would likely have helped to minimize any differences between the experimental and control group members. The collection of additional information from study participants would have also allowed researchers to be more confident that the experimental and control group members were equivalent on key pieces of information that could have influenced recidivism and participant attitudes.
Finally, while 168 juvenile offenders were randomly assigned to either the experimental or control group, not all offenders agreed to participate in the evaluation. Remember that of the 83 offenders assigned to the teen court experimental group, only 56 (67%) agreed to participate in the study. Of the 85 youth randomly assigned to normal juvenile justice processing, only 51 (60%) agreed to participate in the study. While this limitation is unavoidable, it still could have influenced the study. Perhaps those 27 offenders who declined to participate in the teen court group differed significantly from the 56 who agreed to participate. If so, it is possible that the differences among those two groups could have impacted the results of the study. For example, perhaps the 27 youths who were randomly assigned to teen court but did not agree to be a part of the study were some of the least risky of potential teen court participants—less serious histories, better attitudes to begin with, and so on. In this case, perhaps the most risky teen court participants agreed to be a part of the study, and as a result of being more risky, this led to more dismal delinquency outcomes compared to the control group at the end of each respective program. Because parental consent was required for the study authors to be able to compare those who declined to participate in the study to those who agreed, it is unknown if the participants and nonparticipants differed significantly on any variables among either the experimental or control group. Moreover, of the resulting 107 offenders who took part in the study, only 75 offenders accurately completed the post-test survey measuring offending and attitudinal outcomes.
Again, despite the experimental nature of this study, such limitations could have impacted the study results and must be considered.
Impact on Criminal Justice
Teen courts are generally designed to deal with nonserious first time offenders before they escalate to more serious and chronic delinquency. Innovative programs such as “Scared Straight” and juvenile boot camps have inspired an increase in teen court programs across the country, although there is little evidence regarding their effectiveness compared to traditional sanctions for youthful offenders. This study provides more specific evidence as to the effectiveness of teen courts relative to normal juvenile justice processing. Researchers learned that teen court participants fared worse than those in the control group. The potential labeling effects of teen court, including stigma among peers, especially where the offense may have been very minor, may be more harmful than doing less or nothing. The real impact of this study lies in the recognition that teen courts and similar sanctions for minor offenders may do more harm than good.
One important impact of this study is that it utilized an experimental design to evaluate the effectiveness of a teen court compared to traditional juvenile justice processing. Despite the study’s limitations, by using an experimental design it improved upon previous teen court evaluations by attempting to ensure any results were in fact due to the treatment, not some difference between the experimental and control group. This study also utilized both official and self-report measures of delinquency, in addition to self-report measures on such factors as self-concept and belief in conventional rules, which have been generally absent from teen court evaluations. The study authors also attempted to gauge the comparability of the experimental and control groups on factors such as age, gender, and race to help make sure study outcomes were attributable to the program, not the participants.
In This Chapter You Will Learn
The four components of experimental and quasi-experimental research designs and their function in answering a research question
The differences between experimental and quasi-experimental designs
The importance of randomization in an experimental design
The types of questions that can be answered with an experimental or quasi-experimental research design
About the three factors required for a causal relationship
That a relationship between two or more variables may appear causal, but may in fact be spurious, or explained by another factor
That experimental designs are relatively rare in criminal justice and why
About common threats to internal validity or alternative explanations to what may appear to be a causal relationship between variables
Why experimental designs are superior to quasi-experimental designs for eliminating or reducing the potential of alternative explanations
Introduction
The teen court evaluation that began this chapter is an example of an experimental design. The researchers of the study wanted to determine whether teen court was more effective at reducing recidivism and improving attitudes compared to regular juvenile justice case processing. In short, the researchers were interested in the relationship between variables —the relationship of teen court to future delinquency and other outcomes. When researchers are interested in whether a program, policy, practice, treatment, or other intervention impacts some outcome, they often utilize a specific type of research method/design called experimental design. Although there are many types of experimental designs, the foundation for all of them is the classic experimental design. This research design, and some typical variations of this experimental design, are the focus of this chapter.
Although the classic experiment may be appropriate to answer a particular research question, there are barriers that may prevent researchers from using this or another type of experimental design. In these situations, researchers may turn to quasi-experimental designs. Quasi-experiments include a group of research designs that are missing a key element found in the classic experiment and other experimental designs (hence the term “quasi” experiment). Despite this missing part, quasi-experiments are similar in structure to experimental designs and are used to answer similar types of research questions. This chapter will also focus on quasi-experiments and how they are similar to and different from experimental designs.
Uncovering the relationship between variables, such as the impact of teen court on future delinquency, is important in criminal justice and criminology, just as it is in other scientific disciplines such as education, biology, and medicine. Indeed, whereas criminal justice researchers may be interested in whether a teen court reduces recidivism or improves attitudes, medical field researchers may be concerned with whether a new drug reduces cholesterol, or an education researcher may be focused on whether a new teaching style leads to greater academic gains. Across these disciplines and topics of interest, the experimental design is appropriate. In fact, experimental designs are used in all scientific disciplines; the only thing that changes is the topic. Specific to criminal justice, below is a brief sampling of the types of questions that can be addressed using an experimental design:
Does participation in a correctional boot camp reduce recidivism?
What is the impact of an in-cell integration policy on inmate-on-inmate assaults in prisons?
Does police officer presence in schools reduce bullying?
Do inmates who participate in faith-based programming while in prison have a lower recidivism rate upon their release from prison?
Do police sobriety checkpoints reduce drunken driving fatalities?
What is the impact of a no-smoking policy in prisons on inmate-on-inmate assaults?
Does participation in a domestic violence intervention program reduce repeat domestic violence arrests?
A focus on the classic experimental design will demonstrate the usefulness of this research design for addressing criminal justice questions interested in cause and effect relationships. Particular attention is paid to the classic experimental design because it serves as the foundation for all other experimental and quasi-experimental designs, some of which are covered in this chapter. As a result, a clear understanding of the components, organization, and logic of the classic experimental design will facilitate an understanding of other experimental and quasi-experimental designs examined in this chapter. It will also allow the reader to better understand the results produced from those various designs, and importantly, what those results mean. It is a truism that the results of a research study are only as “good” as the design or method used to produce them. Therefore, understanding the various experimental and quasi-experimental designs is the key to becoming an informed consumer of research.
The Challenge of Establishing Cause and Effect
Researchers interested in explaining the relationship between variables, such as whether a treatment program impacts recidivism, are interested in causation or causal relationships. In a simple example, a causal relationship exists when X (independent variable) causes Y (dependent variable), and there are no other factors (Z) that can explain that relationship. For example, offenders who participated in a domestic violence intervention program (X–domestic violence intervention program) experienced fewer re-arrests (Y–re-arrests) than those who did not participate in the domestic violence program, and no other factor other than participation in the domestic violence program can explain these results. The classic experimental design is superior to other research designs in uncovering a causal relationship, if one exists. Before a causal relationship can be established, however, there are three conditions that must be met (see Figure 5.1). 2
FIGURE 5.1 | The Cause and Effect Relationship
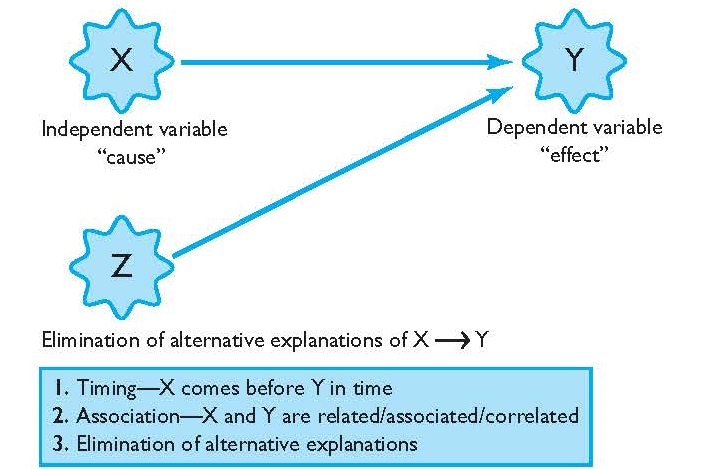
Timing The first condition for a causal relationship is timing. For a causal relationship to exist, it must be shown that the independent variable or cause (X) preceded the dependent variable or outcome (Y) in time. A decrease in domestic violence re-arrests (Y) cannot occur before participation in a domestic violence reduction program (X ), if the domestic violence program is proposed to be the cause of fewer re-arrests. Ensuring that cause comes before effect is not sufficient to establish that a causal relationship exists, but it is one requirement that must be met for a causal relationship.
Association In addition to timing, there must also be an observable association between X and Y, the second necessary condition for a causal relationship. Association is also commonly referred to as covariance or correlation. When an association or correlation exits, this means there is some pattern of relationship between X and Y —as X changes by increasing or decreasing, Y also changes by increasing or decreasing. Here, the notion of X and Y increasing or decreasing can mean an actual increase/decrease in the quantity of some factor, such as an increase/decrease in the number of prison terms or days in a program or re-arrests. It can also refer to an increase/decrease in a particular category, for example, from nonparticipation in a program to participation in a program. For instance, subjects who participated in a domestic violence reduction program (X) incurred fewer domestic violence re-arrests (Y) than those who did not participate in the program. In this example, X and Y are associated—as X change s or increases from nonparticipation to participation in the domestic violence program, Y or the number of re-arrests for domestic violence decreases.
Associations between X and Y can occur in two different directions: positive or negative. A positive association means that as X increases, Y increases, or, as X decreases, Y decreases. A negative association means that as X increases, Y decreases, or, as X decreases, Y increases. In the example above, the association is negative—participation in the domestic violence program was associated with a reduction in re-arrests. This is also sometimes called an inverse relationship.
Elimination of Alternative Explanations Although participation in a domestic violence program may be associated with a reduction in re-arrests, this does not mean for certain that participation in the program was the cause of reduced re-arrests. Just as timing by itself does not imply a causal relationship, association by itself does not imply a causal relationship. For example, instead of the program being the cause of a reduction in re-arrests, perhaps several of the program participants died shortly after completion of the domestic violence program and thus were not able to engage in domestic violence (and their deaths were unknown to the researcher tracking re-arrests). Perhaps a number of the program participants moved out of state and domestic violence re-arrests occurred but were not able to be uncovered by the researcher. Perhaps those in the domestic violence program experienced some other event, such as the trauma of a natural disaster, and that experience led to a reduction in domestic violence, an event not connected to the domestic violence program. If any of these situations occurred, it might appear that the domestic violence program led to fewer re-arrests. However, the observed reduction in re-arrests can actually be attributed to a factor unrelated to the domestic violence program.
The previous discussion leads to the third and final necessary consideration in determining a causal relationship— elimination of alternative explanations. This means that the researcher must rule out any other potential explanation of the results, except for the experimental condition such as a program, policy, or practice. Accounting for or ruling out alternative explanations is much more difficult than ensuring timing and association. Ruling out all alternative explanations is difficult because there are so many potential other explanations that can wholly or partly explain the findings of a research study. This is especially true in the social sciences, where researchers are often interested in relationships explaining human behavior. Because of this difficulty, associations by themselves are sometimes mistaken as causal relationships when in fact they are spurious. A spurious relationship is one where it appears that X and Y are causally related, but the relationship is actually explained by something other than the independent variable, or X.
One only needs to go so far as the daily newspaper to find headlines and stories of mere associations being mistaken, assumed, or represented as causal relationships. For example, a newspaper headline recently proclaimed “Churchgoers live longer.” 3 An uninformed consumer may interpret this headline as evidence of a causal relationship—that going to church by itself will lead to a longer life—but the astute consumer would note possible alternative explanations. For example, people who go to church may live longer because they tend to live healthier lifestyles and tend to avoid risky situations. These are two probable alternative explanations to the relationship independent of simply going to church. In another example, researchers David Kalist and Daniel Yee explored the relationship between first names and delinquent behavior in their manuscript titled “First Names and Crime: Does Unpopularity Spell Trouble?” 4 Kalist and Lee (2009) found that unpopular names are associated with juvenile delinquency. In other words, those individuals with the most unpopular names were more likely to be delinquent than those with more popular names. According to the authors, is it not necessarily someone’s name that leads to delinquent behavior, but rather, the most unpopular names also tend to be correlated with individuals who come from disadvantaged home environments and experience a low socio-economic status of living. Rightly noted by the authors, these alternative explanations help to explain the link between someone’s name and delinquent behavior—a link that is not causal.
A frequently cited example provides more insight to the claim that an association by itself is not sufficient to prove causality. In certain cities in the United States, for example, as ice cream sales increase on a particular day or in a particular month so does the incidence of certain forms of crime. If this association were represented as a causal statement, it would be that ice cream or ice cream sales causes crime. There is an association, no doubt, and let us assume that ice cream sales rose before the increase in crime (timing). Surely, however, this relationship between ice cream sales and crime is spurious. The alternative explanation is that ice cream sales and crime are associated in certain parts of the country because of the weather. Ice cream sales tend to increase in warmer temperatures, and it just so happens that certain forms of crime tend to increase in warmer temperatures as well. This coincidence or association does not mean a causal relationship exists. Additionally, this does not mean that warm temperatures cause crime either. There are plenty of other alternative explanations for the increase in certain forms of crime and warmer temperatures. 6 For another example of a study subject to alternative explanations, read the June 2011 news article titled “Less Crime in U.S. Thanks to Videogames.” 7 Based on your reading, what are some other potential explanations for the crime drop other than videogames?
The preceding examples demonstrate how timing and association can be present, but the final needed condition for a causal relationship is that all alternative explanations are ruled out. While this task is difficult, the classic experimental design helps to ensure these additional explanatory factors are minimized. When other designs are used, such as quasi-experimental designs, the chance that alternative explanations emerge is greater. This potential should become clearer as we explore the organization and logic of the classic experimental design.
CLASSICS IN CJ RESEARCH
Minneapolis Domestic Violence Experiment
The Minneapolis Domestic Violence Experiment (MDVE) 5
Which police action (arrest, separation, or mediation) is most effective at deterring future misdemeanor domestic violence?
The experiment began on March 17, 1981, and continued until August 1, 1982. The experiment was conducted in two of Minneapolis’s four police precincts—the two with the highest number of domestic violence reports and arrests. A total of 314 reports of misdemeanor domestic violence were handled by the police during this time frame.
This study utilized an experimental design with the random assignment of police actions. Each police officer involved in the study was given a pad of report forms. Upon a misdemeanor domestic violence call, the officer’s action (arrest, separation, or mediation) was predetermined by the order and color of report forms in the officer’s notebook. Colored report forms were randomly ordered in the officer’s notebook and the color on the form determined the officer response once at the scene. For example, after receiving a call for domestic violence, an officer would turn to his or her report pad to determine the action. If the top form was pink, the action was arrest. If on the next call the top form was a different color, an action other than arrest would occur. All colored report forms were randomly ordered through a lottery assignment method. The result is that all police officer actions to misdemeanor domestic violence calls were randomly assigned. To ensure the lottery procedure was properly carried out, research staff participated in ride-alongs with officers to ensure that officers did not skip the order of randomly ordered forms. Research staff also made sure the reports were received in the order they were randomly assigned in the pad of report forms.
To examine the relationship of different officer responses to future domestic violence, the researchers examined official arrests of the suspects in a 6-month follow-up period. For example, the researchers examined those initially arrested for misdemeanor domestic violence and how many were subsequently arrested for domestic violence within a 6-month time frame. They did the same procedure for the police actions of separation and mediation. The researchers also interviewed the victim(s) of each incident and asked if a repeat domestic violence incident occurred with the same suspect in the 6-month follow-up period. This allowed researchers to examine domestic violence offenses that may have occurred but did not come to the official attention of police. The researchers then compared official arrests for domestic violence to self-reported domestic violence after the experiment.
Suspects arrested for misdemeanor domestic violence, as opposed to situations where separation or mediation was used, were significantly less likely to engage in repeat domestic violence as measured by official arrest records and victim interviews during the 6-month follow-up period. According to official police records, 10% of those initially arrested engaged in repeat domestic violence in the followup period, 19% of those who initially received mediation engaged in repeat domestic violence, and 24% of those who randomly received separation engaged in repeat domestic violence. According to victim interviews, 19% of those initially arrested engaged in repeat domestic violence, compared to 37% for separation and 33% for mediation. The general conclusion of the experiment was that arrest was preferable to separation or mediation in deterring repeat domestic violence across both official police records and victim interviews.
A few issues that affected the random assignment procedure occurred throughout the study. First, some officers did not follow the randomly assigned action (arrest, separation, or mediation) as a result of other circumstances that occurred at the scene. For example, if the randomly assigned action was separation, but the suspect assaulted the police officer during the call, the officer might arrest the suspect. Second, some officers simply ignored the assigned action if they felt a particular call for domestic violence required another action. For example, if the action was mediation as indicated by the randomly assigned report form, but the officer felt the suspect should be arrested, he or she may have simply ignored the randomly assigned response and substituted his or her own. Third, some officers forgot their report pads and did not know the randomly assigned course of action to take upon a call of domestic violence. Fourth and finally, the police chief also allowed officers to deviate from the randomly assigned action in certain circumstances. In all of these situations, the random assignment procedures broke down.
The results of the MDVE had a rapid and widespread impact on law enforcement practice throughout the United States. Just two years after the release of the study, a 1986 telephone survey of 176 urban police departments serving cities with populations of 100,000 or more found that 46 percent of the departments preferred to make arrests in cases of minor domestic violence, largely due to the effectiveness of this practice in the Minneapolis Domestic Violence Experiment. 8
In an attempt to replicate the findings of the Minneapolis Domestic Violence Experiment, the National Institute of Justice sponsored the Spouse Assault Replication Program. Replication studies were conducted in Omaha, Charlotte, Milwaukee, Miami, and Colorado Springs from 1986–1991. In three of the five replications, offenders randomly assigned to the arrest group had higher levels of continued domestic violence in comparison to other police actions during domestic violence situations. 9 Therefore, rather than providing results that were consistent with the Minneapolis Domestic Violence Experiment, the results from the five replication experiments produced inconsistent findings about whether arrest deters domestic violence. 10
Despite the findings of the replications, the push to arrest domestic violence offenders has continued in law enforcement. Today many police departments require officers to make arrests in domestic violence situations. In agencies that do not mandate arrest, department policy typically states a strong preference toward arrest. State legislatures have also enacted laws impacting police actions regarding domestic violence. Twenty-one states have mandatory arrest laws while eight have pro-arrest statutes for domestic violence. 11
The Classic Experimental Design
Table 5.1 provides an illustration of the classic experimental design. 12 It is important to become familiar with the specific notation and organization of the classic experiment before a full discussion of its components and their purpose.
Major Components of the Classic Experimental Design
The classic experimental design has four major components:
1. Treatment
2. Experimental Group and Control Group
3. Pre-Test and Post-Test
4. Random Assignment
Treatment The first component of the classic experimental design is the treatment, and it is denoted by X in the classic experimental design. The treatment can be a number of things—a program, a new drug, or the implementation of a new policy. In a classic experimental design, the primary goal is to determine what effect, if any, a particular treatment had on some outcome. In this way, the treatment can also be considered the independent variable.
TABLE 5.1 | The Classic Experimental Design
Experimental Group = Group that receives the treatment
Control Group = Group that does not receive the treatment
R = Random assignment
O 1 = Observation before the treatment, or the pre-test
X = Treatment or the independent variable
O 2 = Observation after the treatment, or the post-test
Experimental and Control Groups The second component of the classic experiment is an experimental group and a control group. The experimental group receives the treatment, and the control group does not receive the treatment. There will always be at least one group that receives the treatment in experimental and quasi-experimental designs. In some cases, experiments may have multiple experimental groups receiving multiple treatments.
Pre-Test and Post-Test The third component of the classic experiment is a pre-test and a post-test. A pretest is a measure of the dependent variable or outcome before the treatment. The post-test is a measure of the dependent variable after the treatment is administered. It is important to note that the post-test is defined based on the stated goals of the program. For example, if the stated goal of a particular program is to reduce re-arrests, the post-test will be a measure of re-arrests after the program. The dependent variable also defines the pre-test. For example, if a researcher wanted to examine the impact of a domestic violence reduction program (treatment or X) on the goal of reducing re-arrests (dependent variable or Y), the pre-test would be the number of domestic violence arrests incurred before the program. Program goals may be numerous and all can constitute a post-test, and hence, the pre-test. For example, perhaps the goal of the domestic violence program is also that participants learn of different pro-social ways to handle domestic conflicts other than resorting to violence. If researchers wanted to examine this goal, the post-test might be subjects’ level of knowledge about pro-social ways to handle domestic conflicts other than violence. The pre-test would then be subjects’ level of knowledge about these pro-social alternatives to violence before they received the treatment program.
Although all designs have a post-test, it is not always the case that designs have a pre-test. This is because researchers may not have access or be able to collect information constituting the pre-test. For example, researchers may not be able to determine subjects’ level of knowledge about alternatives to domestic violence before the intervention program if the subjects are already enrolled in the domestic violence intervention program. In other cases, there may be financial barriers to collecting pre-test information. In the teen court evaluation that started this chapter, for example, researchers were not able to collect pre-test information on study participants due to the financial strain it would have placed on the agencies involved in the study. 13 There are a number of potential reasons why a pre-test might not be available in a research study. The defining feature, however, is that the pre-test is determined by the post-test.
Random Assignment The fourth component of the classic experiment is random assignment. Random assignment refers to a process whereby members of the experimental group and control group are assigned to the two groups through a random and unbiased process. Random assignment should not be mistaken for random selection as discussed in Chapter 3. Random selection refers to selecting a smaller but representative sample from a larger population. For example, a researcher may randomly select a sample from a larger city population for the purposes of sending sample members a mail survey to determine their attitudes on crime. The goal of random selection in this example is to make sure the sample, although smaller in size than the population, accurately represents the larger population.
Random assignment, on the other hand, refers to the process of assigning subjects to either the experimental or control group with the goal that the groups are similar or equivalent to each other in every way (see Figure 5.2). The exception to this rule is that one group gets the treatment and the other does not (see discussion below on why equivalence is so important). Although the concept of random is similar in each, the goals are different between random selection and random assignment. 14 Experimental designs all feature random assignment, but this is not true of other research designs, in particular quasi-experimental designs.
FIGURE 5.2 | Random Assignment
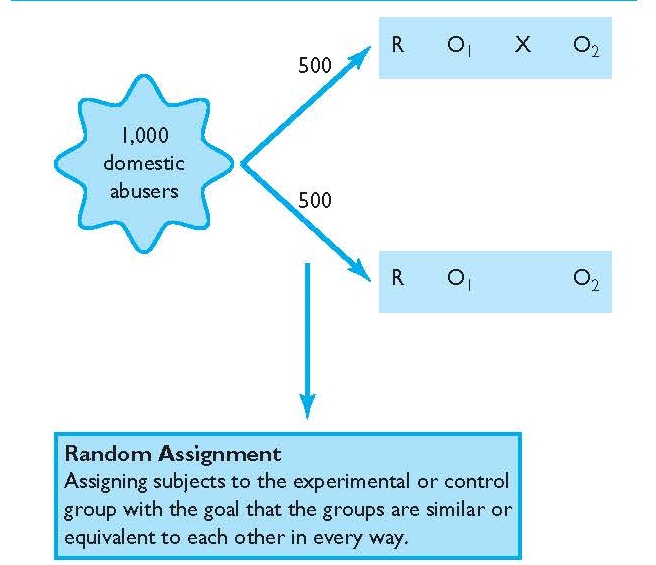
The classic experimental design is the foundation for all other experimental and quasi-experimental designs because it retains all of the major components discussed above. As mentioned, sometimes designs do not have a pre-test, a control group, or random assignment. Because the pre-test, control group, and random assignment are so critical to the goal of uncovering a causal relationship, if one exists, we explore them further below.
The Logic of the Classic Experimental Design
Consider a research study using the classic experimental design where the goal is to determine if a domestic violence treatment program has any effect on re-arrests for domestic violence. The randomly assigned experimental and control groups are comprised of persons who had previously been arrested for domestic violence. The pretest is a measure of the number of domestic violence arrests before the program. This is because the goal of the program is to determine whether re-arrests are impacted after the treatment. The post-test is the number of re-arrests following the treatment program.
Once randomly assigned, the experimental group members receive the domestic violence program, and the control group members do not. After the program, the researcher will compare the pre-test arrests for domestic violence of the experimental group to post-test arrests for domestic violence to determine if arrests increased, decreased, or remained constant since the start of the program. The researcher will also compare the post-test re-arrests for domestic violence between the experimental and control groups. With this example, we explore the usefulness of the classic experimental design, and the contribution of the pre-test, random assignment, and the control group to the goal of determining whether a domestic violence program reduces re-arrests.
The Pre-Test As a component of the classic experiment, the pre-test allows an examination of change in the dependent variable from before the domestic violence program to after the domestic violence program. In short, a pre-test allows the researcher to determine if re-arrests increased, decreased, or remained the same following the domestic violence program. Without a pre-test, researchers would not be able to determine the extent of change, if any, from before to after the program for either the experimental or control group.
Although the pre-test is a measure of the dependent variable before the treatment, it can also be thought of as a measure whereby the researcher can compare the experimental group to the control group before the treatment is administered. For example, the pre-test helps researchers to make sure both groups are similar or equivalent on previous arrests for domestic violence. The importance of equivalence between the experimental and control groups on previous arrests is discussed below with random assignment.
Random Assignment Random assignment helps to ensure that the experimental and control groups are equivalent before the introduction of the treatment. This is perhaps one of the most critical aspects of the classic experiment and all experimental designs. Although the experimental and control groups will be made up of different people with different characteristics, assigning them to groups via a random assignment process helps to ensure that any differences or bias between the groups is eliminated or minimized. By minimizing bias, we mean that the groups will balance each other out on all factors except the treatment. If they are balanced out on all factors prior to the administration of the treatment, any differences between the groups at the post-test must be due to the treatment—the only factor that differs between the experimental group and the control group. According to Shadish, Cook, and Campbell: “If implemented correctly, random assignment creates two or more groups of units that are probabilistically similar to each other on the average. Hence, any outcome differences that are observed between those groups at the end of a study are likely to be due to treatment, not to differences between the groups that already existed at the start of the study.” 15 Considered in another way, if the experimental and control group differed significantly on any relevant factor other than the treatment, the researcher would not know if the results observed at the post-test are attributable to the treatment or to the differences between the groups.
Consider an example where 500 domestic abusers were randomly assigned to the experimental group and 500 were randomly assigned to the control group. Because they were randomly assigned, we would likely find more frequent domestic violence arrestees in both groups, older and younger arrestees in both groups, and so on. If random assignment was implemented correctly, it would be highly unlikely that all of the experimental group members were the most serious or frequent arrestees and all of the control group members were less serious and/or less frequent arrestees. While there are no guarantees, we know the chance of this happening is extremely small with random assignment because it is based on known probability theory. Thus, except for a chance occurrence, random assignment will result in equivalence between the experimental and control group in much the same way that flipping a coin multiple times will result in heads approximately 50% of the time and tails approximately 50% of the time. Over 1,000 tosses of a coin, for example, should result in roughly 500 heads and 500 tails. While there is a chance that flipping a coin 1,000 times will result in heads 1,000 times, or some other major imbalance between heads and tails, this potential is small and would only occur by chance.
The same logic from above also applies with randomly assigning people to groups, and this can even be done by flipping a coin. By assigning people to groups through a random and unbiased process, like flipping a coin, only by chance (or researcher error) will one group have more of one characteristic than another, on average. If there are no major (also called statistically significant) differences between the experimental and control group before the treatment, the most plausible explanation for the results at the post-test is the treatment.
As mentioned, it is possible by some chance occurrence that the experimental and control group members are significantly different on some characteristic prior to administration of the treatment. To confirm that the groups are in fact similar after they have been randomly assigned, the researcher can examine the pre-test if one is present. If the researcher has additional information on subjects before the treatment is administered, such as age, or any other factor that might influence post-test results at the end of the study, he or she can also compare the experimental and control group on those measures to confirm that the groups are equivalent. Thus, a researcher can confirm that the experimental and control groups are equivalent on information known to the researcher.
Being able to compare the groups on known measures is an important way to ensure the random assignment process “worked.” However, perhaps most important is that randomization also helps to ensure similarity across unknown variables between the experimental and control group. Because random assignment is based on known probability theory, there is a much higher probability that all potential differences between the groups that could impact the post-test should balance out with random assignment—known or unknown. Without random assignment, it is likely that the experimental and control group would differ on important but unknown factors and such differences could emerge as alternative explanations for the results. For example, if a researcher did not utilize random assignment and instead took the first 500 domestic abusers from an ordered list and assigned them to the experimental group and the last 500 domestic abusers and assigned them to the control group, one of the groups could be “lopsided” or imbalanced on some important characteristic that could impact the outcome of the study. With random assignment, there is a much higher likelihood that these important characteristics among the experimental and control groups will balance out because no individual has a different chance of being placed into one group versus the other. The probability of one or more characteristics being concentrated into one group and not the other is extremely small with random assignment.
To further illustrate the importance of random assignment to group equivalence, suppose the first 500 domestic violence abusers who were assigned to the experimental group from the ordered list had significantly fewer domestic violence arrests before the program than the last 500 domestic violence abusers on the list. Perhaps this is because the ordered list was organized from least to most chronic domestic abusers. In this instance, the control group would be lopsided concerning number of pre-program domestic violence arrests—they would be more chronic than the experimental group. The arrest imbalance then could potentially explain the post-test results following the domestic violence program. For example, the “less risky” offenders in the experimental group might be less likely to be re-arrested regardless of their participation in the domestic violence program, especially compared to the more chronic domestic abusers in the control group. Because of imbalances between the experimental and control group on arrests before the program was implemented, it would not be known for certain whether an observed reduction in re-arrests after the program for the experimental group was due to the program or the natural result of having less risky offenders in the experimental group. In this instance, the results might be taken to suggest that the program significantly reduces re-arrests. This conclusion might be spurious, however, for the association may simply be due to the fact that the offenders in the experimental group were much different (less frequent offenders) than the control group. Here, the program may have had no effect—the experimental group members may have performed the same regardless of the treatment because they were low-level offenders.
The example above suggests that differences between the experimental and control groups based on previous arrest records could have a major impact on the results of a study. Such differences can arise with the lack of random assignment. If subjects were randomly assigned to the experimental and control group, however, there would be a much higher probability that less frequent and more frequent domestic violence arrestees would have been found in both the experimental and control groups and the differences would have balanced out between the groups—leaving any differences between the groups at the post-test attributable to the treatment only.
In summary, random assignment helps to ensure that the experimental and control group members are balanced or equivalent on all factors that could impact the dependent variable or post-test—known or unknown. The only factor they are not balanced or equal on is the treatment. As such, random assignment helps to isolate the impact of the treatment, if any, on the post-test because it increases confidence that the only difference between the groups should be that one group gets the treatment and the other does not. If that is the only difference between the groups, any change in the dependent variable between the experimental and control group must be attributed to the treatment and not an alternative explanation, such as significant arrest history imbalance between the groups (refer to Figure 5.2). This logic also suggests that if the experimental group and control group are imbalanced on any factor that may be relevant to the outcome, that factor then becomes a potential alternative explanation for the results—an explanation that reduces the researcher’s ability to isolate the real impact of the treatment.
WHAT RESEARCH SHOWS: IMPACTING CRIMINAL JUSTICE OPERATIONS
Scared Straight
The 1978 documentary Scared Straight introduced to the public the “Lifer’s Program” at Rahway State Prison in New Jersey. This program sought to decrease juvenile delinquency by bringing at-risk and delinquent juveniles into the prison where they would be “scared straight” by inmates serving life sentences. Participants in the program were talked to and yelled at by the inmates in an effort to scare them. It was believed that the fear felt by the participants would lead to a discontinuation of their problematic behavior so that they would not end up in prison themselves. Although originally touted as a success based on anecdotal evidence, subsequent evaluations of the program and others like it proved otherwise.
Using a classic experimental design, Finckenauer evaluated the original “Lifer’s Program” at Rahway State Prison. 16 Participating juveniles were randomly assigned to the experimental group or the control group. Results of the evaluation were not positive. Post-test measures revealed that juveniles who were assigned to the experimental group and participated in the program were actually more seriously delinquent afterwards than those who did not participate in the program. Also using an experimental design with random assignment, Yarborough evaluated the “Juvenile Offenders Learn Truth” (JOLT) program at the State Prison of Southern Michigan at Jackson. 17 This program was similar to that of the “Lifer’s Program” only with fewer obscenities used by the inmates. Post-test measurements were taken at two intervals, 3 and 6 months after program completion. Again, results were not positive. Findings revealed no significant differences between those juveniles who attended the program and those who did not.
Other experiments conducted on Scared Straight -like programs further revealed their inability to deter juveniles from future criminality. 18 Despite the intuitive popularity of these programs, these evaluations proved that such programs were not successful. In fact, it is postulated that these programs may have actually done more harm than good.
The Control Group The presence of an equivalent control group (created through random assignment) also gives the researcher more confidence that the findings at the post-test are due to the treatment and not some other alternative explanation. This logic is perhaps best demonstrated by considering how interpretation of results is affected without a control group. Absent an equivalent control group, it cannot be known whether the results of the study are due to the program or some other factor. This is because the control group provides a baseline of comparison or a “control.” For example, without a control group, the researcher may find that domestic violence arrests declined from pre-test to post-test. But the researcher would not be able to definitely attribute that finding to the program without a control group. Perhaps the single experimental group incurred fewer arrests because they matured over their time in the program, regardless of participation in the domestic violence program. Having a randomly assigned control group would allow this consideration to be eliminated, because the equivalent control group would also have naturally matured if that was the case.
Because the control group is meant to be similar to the experimental group on all factors with the exception that the experimental group receives the treatment, the logic is that any differences between the experimental and control group after the treatment must then be attributable only to the treatment itself—everything else occurs equally in both the experimental and control groups and thus cannot be the cause of results. The bottom line is that a control group allows the researcher more confidence to attribute any change in the dependent variable from pre- to post-test and between the experimental and control groups to the treatment—and not another alternative explanation. Absent a control group, the researcher would have much less confidence in the results.
Knowledge about the major components of the classic experimental design and how they contribute to an understanding of cause and effect serves as an important foundation for studying different types of experimental and quasi-experimental designs and their organization. A useful way to become familiar with the components of the experimental design and their important role is to consider the impact on the interpretation of results when one or more components are lacking. For example, what if a design lacked a pre-test? How could this impact the interpretation of post-test results and knowledge about the comparability of the experimental and control group? What if a design lacked random assignment? What are some potential problems that could occur and how could those potential problems impact interpretation of results? What if a design lacked a control group? How does the absence of an equivalent control group affect a researcher’s ability to determine the unique effects of the treatment on the outcomes being measured? The ability to discuss the contribution of a pre-test, random assignment, and a control group—and what is the impact when one or more of those components is absent from a research design—is the key to understanding both experimental and quasi-experimental designs that will be discussed in the remainder of this chapter. As designs lose these important parts and transform from a classic experiment to another experimental design or to a quasi-experiment, they become less useful in isolating the impact that a treatment has on the dependent variable and allow more room for alternative explanations of the results.
One more important point must be made before further delving into experimental and quasi-experimental designs. This point is that rarely, if ever, will the average consumer of research be exposed to the symbols or specific language of the classic experiment, or other experimental and quasi-experimental designs examined in this chapter. In fact, it is unlikely that the average consumer will ever be exposed to the terms pre-test, post-test, experimental group, or random assignment in the popular media, among other terms related to experimental and quasi-experimental designs. Yet, consumers are exposed to research results produced from these and other research designs every day. For example, if a national news organization or your regional newspaper reported a story about the effectiveness of a new drug to reduce cholesterol or the effects of different diets on weight loss, it is doubtful that the results would be reported as produced through a classic experimental design that used a control group and random assignment. Rather, these media outlets would use generally nonscientific terminology such as “results of an experiment showed” or “results of a scientific experiment indicated” or “results showed that subjects who received the new drug had greater cholesterol reductions than those who did not receive the new drug.” Even students who regularly search and read academic articles for use in course papers and other projects will rarely come across such design notation in the research studies they utilize. Depiction of the classic experimental design, including a discussion of its components and their function, simply illustrates the organization and notation of the classic experimental design. Unfortunately, the average consumer has to read between the lines to determine what type of design was used to produce the reported results. Understanding the key components of the classic experimental design allows educated consumers of research to read between those lines.
RESEARCH IN THE NEWS
“Swearing Makes Pain More Tolerable” 19
In 2009, Richard Stephens, John Atkins, and Andrew Kingston of the School of Psychology at Keele University conducted a study with 67 undergraduate students to determine if swearing affects an individual’s response to pain. Researchers asked participants to immerse their hand in a container filled with ice-cold water and repeat a preferred swear word. The researchers then asked the same participants to immerse their hand in ice-cold water while repeating a word used to describe a table (a non-swear word). The results showed that swearing increased pain tolerance compared to the non-swearing condition. Participants who used a swear word were able to hold their hand in ice-cold water longer than when they did not swear. Swearing also decreased participants’ perception of pain.
1. This study is an example of a repeated measures design. In this form of experimental design, study participants are exposed to an experimental condition (swearing with hand in ice-cold water) and a control condition (non-swearing with hand in ice-cold water) while repeated outcome measures are taken with each condition, for example, the length of time a participant was able to keep his or her hand submerged in ice-cold water. Conduct an Internet search for “repeated measures design” and explore the various ways such a study could be conducted, including the potential benefits and drawbacks to this design.
2. After researching repeated measures designs, devise a hypothetical repeated measures study of your own.
3. Retrieve and read the full research study “Swearing as a Response to Pain” by Stephens, Atkins, and Kingston while paying attention to the design and methods (full citation information for this study is listed below). Has your opinion of the study results changed after reading the full study? Why or why not?
Full Study Source: Stephens, R., Atkins, J., and Kingston, A. (2009). “Swearing as a response to pain.” NeuroReport 20, 1056–1060.
Variations on the Experimental Design
The classic experimental design is the foundation upon which all experimental and quasi-experimental designs are based. As such, it can be modified in numerous ways to fit the goals (or constraints) of a particular research study. Below are two variations of the experimental design. Again, knowledge about the major components of the classic experiment, how they contribute to an explanation of results, and what the impact is when one or more components are missing provides an understanding of all other experimental designs.
Post-Test Only Experimental Design
The post-test only experimental design could be used to examine the impact of a treatment program on school disciplinary infractions as measured or operationalized by referrals to the principal’s office (see Table 5.2). In this design, the researcher randomly assigns a group of discipline problem students to the experimental group and control group by flipping a coin—heads to the experimental group and tails to the control group. The experimental group then enters the 3-month treatment program. After the program, the researcher compares the number of referrals to the principal’s office between the experimental and control groups over some period of time, for example, discipline referrals at 6 months after the program. The researcher finds that the experimental group has a much lower number of referrals to the principal’s office in the 6 month follow-up period than the control group.
TABLE 5.2 | Post-Test Only Experimental Design
Several issues arise in this example study. The researcher would not know if discipline problems decreased, increased, or stayed the same from before to after the treatment program because the researcher did not have a count of disciplinary referrals prior to the treatment program (e.g., a pre-test). Although the groups were randomly assigned and are presumed equivalent, the absence of a pre-test means the researcher cannot confirm that the experimental and control groups were equivalent before the treatment was administered, particularly on the number of referrals to the principal’s office. The groups could have differed by a chance occurrence even with random assignment, and any such differences between the groups could potentially explain the post-test difference in the number of referrals to the principal’s office. For example, if the control group included much more serious or frequent discipline problem students than the experimental group by chance, this difference might explain the lower number of referrals for the experimental group, not that the treatment produced this result.
Experimental Design with Two Treatments and a Control Group
This design could be used to determine the impact of boot camp versus juvenile detention on post-release recidivism (see Table 5.3). Recidivism in this study is operationalized as re-arrest for delinquent behavior. First, a population of known juvenile delinquents is randomly assigned to either boot camp, juvenile detention, or a control condition where they receive no sanction. To accomplish random assignment to groups, the researcher places the names of all youth into a hat and assigns the groups in order. For example, the first name pulled goes into experimental group 1, the next into experimental group 2, and the next into the control group, and so on. Once randomly assigned, the experimental group youth receive either boot camp or juvenile detention for a period of 3 months, whereas members of the control group are released on their own recognizance to their parents. At the end of the experiment, the researcher compares the re-arrest activity of boot camp participants to detention delinquents to control group members during a 6-month follow-up period.
TABLE 5.3 | Experimental Design with Two Treatments and a Control Group
This design has several advantages. First, it includes all major components of the classic experimental design, and simply adds an additional treatment for comparison purposes. Random assignment was utilized and this means that the groups have a higher probability of being equivalent on all factors that could impact the post-test. Thus, random assignment in this example helps to ensure the only differences between the groups are the treatment conditions. Without random assignment, there is a greater chance that one group of youth was somehow different, and this difference could impact the post-test. For example, if the boot camp youth were much less serious and frequent delinquents than the juvenile detention youth or control group youth, the results might erroneously show that the boot camp reduced recidivism when in fact the youth in boot camp may have been the “best risks”—unlikely to get re-arrested with or without boot camp. The pre-test in the example above allows the researcher to determine change in re-arrests from pretest to post-test. Thus, the researcher can determine if delinquent behavior, as measured by re-arrest, increased, decreased, or remained constant from pre- to post-test. The pre-test also allows the researcher to confirm that the random assignment process resulted in equivalent groups based on the pre-test. Finally, the presence of a control group allows the researcher to have more confidence that any differences in the post-test are due to the treatment. For example, if the control group had more re-arrests than the boot camp or juvenile detention experimental groups 6 months after their release from those programs, the researcher would have more confidence that the programs produced fewer re-arrests because the control group members were the same as the experimental groups; the only difference was that they did not receive a treatment.
The one key feature of experimental designs is that they all retain random assignment. This is why they are considered “experimental” designs. Sometimes, however, experimental designs lack a pre-test. Knowledge of the usefulness of a pre-test demonstrates the potential problems with those designs where it is missing. For example, in the post-test only experimental design, a researcher would not be able to make a determination of change in the dependent variable from pre- to post-test. Perhaps most importantly, the researcher would not be able to confirm that the experimental and control groups were in fact equivalent on a pre-test measure before the introduction of the treatment. Even though both groups were randomly assigned, and probability theory suggests they should be equivalent, without a pre-test measure the researcher could not confirm similarity because differences could occur by chance even with random assignment. If there were any differences at the post-test between the experimental group and control group, the results might be due to some explanation other than the treatment, namely that the groups differed prior to the administration of the treatment. The same limitation could apply in any form of experimental design that does not utilize a pre-test for conformational purposes.
Understanding the contribution of a pre-test to an experimental design shows that it is a critical component. It provides a measure of change and also gives the researcher more confidence that the observed results are due to the treatment, and not some difference between the experimental and control groups. Despite the usefulness of a pre-test, however, perhaps the most critical ingredient of any experimental design is random assignment. It is important to note that all experimental designs retain random assignment.
Experimental Designs Are Rare in Criminal Justice and Criminology
The classic experiment is the foundation for other types of experimental and quasi-experimental designs. The unfortunate reality, however, is that the classic experiment, or other experimental designs, are few and far between in criminal justice. 20 Recall that one of the major components of an experimental design is random assignment. Achieving random assignment is often a barrier to experimental research in criminal justice. Achieving random assignment might, for example, require the approval of the chief (or city council or both) of a major metropolitan police agency to allow researchers to randomly assign patrol officers to certain areas of a city and/or randomly assign police officer actions. Recall the MDVE. This experiment required the full cooperation of the chief of police and other decision-makers to allow researchers to randomly assign police actions. In another example, achieving random assignment might require a judge to randomly assign a group of youthful offenders to a certain juvenile court sanction (experimental group), and another group of similar youthful offenders to no sanction or an alternative sanction as a control group. 21 In sum, random assignment typically requires the cooperation of a number of individuals and sometimes that cooperation is difficult to obtain.
Even when random assignment can be accomplished, sometimes it is not implemented correctly and the random assignment procedure breaks down. This is another barrier to conducting experimental research. For example, in the MDVE, researchers randomly assigned officer responses, but the officers did not always follow the assigned course of action. Moreover, some believe that the random assignment of criminal justice programs, sentences, or randomly assigning officer responses may be unethical in certain circumstances, and even a violation of the rights of citizens. For example, some believe it is unfair when random assignment results in some delinquents being sentenced to boot camp while others get assigned to a control group without any sanction at all or a less restrictive sanction than boot camp. In the MDVE, some believe it is unfair that some suspects were arrested and received an official record whereas others were not arrested for the same type of behavior. In other cases, subjects in the experimental group may receive some benefit from the treatment that is essentially denied to the control group for a period of time and this can become an issue as well.
There are other important reasons why random assignment is difficult to accomplish. Random assignment may, for example, involve a disruption of the normal procedures of agencies and their officers. In the MDVE, officers had to adjust their normal and established routine, and this was a barrier at times in that study. Shadish, Cook, and Campbell also note that random assignment may not always be feasible or desirable when quick answers are needed. 22 This is because experimental designs sometimes take a long time to produce results. In addition to the time required in planning and organizing the experiment, and treatment delivery, researchers may need several months if not years to collect and analyze the data before they have answers. This is particularly important because time is often of the essence in criminal justice research, especially in research efforts testing the effect of some policy or program where it is not feasible to wait years for answers. Waiting for the results of an experimental design means that many policy-makers may make decisions without the results.
Quasi-Experimental Designs
In general terms, quasi-experiments include a group of designs that lack random assignment. Quasi-experiments may also lack other parts, such as a pre-test or a control group, just like some experimental designs. The absence of random assignment, however, is the ingredient that transforms an otherwise experimental design into a quasi-experiment. Lacking random assignment is a major disadvantage because it increases the chances that the experimental and control groups differ on relevant factors before the treatment—both known and unknown—differences that may then emerge as alternative explanations of the outcomes.
Just like experimental designs, quasi-experimental designs can be organized in many different ways. This section will discuss three types of quasi-experiments: nonequivalent group design, one-group longitudinal design, and two-group longitudinal design.
Nonequivalent Group Design
The nonequivalent group design is perhaps the most common type of quasi-experiment. 23 Notice that it is very similar to the classic experimental design with the exception that it lacks random assignment (see Table 5.4). Additionally, what was labeled the experimental group in an experimental design is sometimes called the treatment group in the nonequivalent group design. What was labeled the control group in the experimental design is sometimes called the comparison group in the nonequivalent group design. This terminological distinction is an indicator that the groups were not created through random assignment.
TABLE 5.4 | Nonequivalent Group Design
NR = Not Randomly assigned
One of the main problems with the nonequivalent group design is that it lacks random assignment, and without random assignment, there is a greater chance that the treatment and comparison groups may be different in some way that can impact study results. Take, for example, a nonequivalent group design where a researcher is interested in whether an aggression-reduction treatment program can reduce inmate-on-inmate assaults in a prison setting. Assume that the researcher asked for inmates who had previously been involved in assaultive activity to volunteer for the aggression-reduction program. Suppose the researcher placed the first 50 volunteers into the treatment group and the next 50 volunteers into the comparison group. Note that this method of assignment is not random but rather first come, first serve.
Because the study utilized volunteers and there was no random assignment, it is possible that the first 50 volunteers placed into the treatment group differed significantly from the last 50 volunteers who were placed in the comparison group. This can lead to alternative explanations for the results. For example, if the treatment group was much younger than the comparison group, the researcher may find at the end of the program that the treatment group still maintained a higher rate of infractions than the comparison group—even after the aggression-reduction program! The conclusion might be that the aggression program actually increased the level of violence among the treatment group. This conclusion would likely be spurious and may be due to the age differential between the treatment and comparison groups. Indeed, research has revealed that younger inmates are significantly more likely to engage in prison assaults than older inmates. The fact that the treatment group incurred more assaults than the comparison group after the aggression-reduction program may only relate to the age differential between the groups, not that the program had no effect or that it somehow may have increased aggression. The previous example highlights the importance of random assignment and the potential problems that can occur in its absence.
Although researchers who utilize a quasi-experimental design are not able to randomly assign their subjects to groups, they can employ other techniques in an attempt to make the groups as equivalent as possible on known or measured factors before the treatment is given. In the example above, it is likely that the researcher would have known the age of inmates, their prior assault record, and various other pieces of information (e.g., previous prison stays). Through a technique called matching, the researcher could make sure the treatment and comparison groups were “matched” on these important factors before administering the aggression reduction program to the treatment group. This type of matching can be done individual to individual (e.g., subject #1 in treatment group is matched to a selected subject #1 in comparison group on age, previous arrests, gender), or aggregately, such that the comparison group is similar to the treatment group overall (e.g., average ages between groups are similar, equal proportions of males and females). Knowledge of these and other important variables, for example, would allow the researcher to make sure that the treatment group did not have heavy concentrations of younger or more frequent or serious offenders than the comparison group—factors that are related to assaultive activity independent of the treatment program. In short, matching allows the researcher some control over who goes into the treatment and comparison groups so as to balance these groups on important factors absent random assignment. If unbalanced on one or more factors, these factors could emerge as alternative explanations of the results. Figure 5.3 demonstrates the logic of matching both at the individual and aggregate level in a quasi-experimental design.
Matching is an important part of the nonequivalent group design. By matching, the researcher can approximate equivalence between the groups on important variables that may influence the post-test. However, it is important to note that a researcher can only match subjects on factors that they have information about—a researcher cannot match the treatment and comparison group members on factors that are unmeasured or otherwise unknown but which may still impact outcomes. For example, if the researcher has no knowledge about the number of previous incarcerations, the researcher cannot match the treatment and comparison groups on this factor. Matching also requires that the information used for matching is valid and reliable, which is not always the case. Agency records, for example, are notorious for inconsistencies, errors, omissions, and for being dated, but are often utilized for matching purposes. Asking survey questions to generate information for matching (for example, how many times have you been incarcerated?) can also be problematic because some respondents may lie, forget, or exaggerate their behavior or experiences.
In addition to the above considerations, the more factors a researcher wishes to match the group members on, the more difficult it becomes to find appropriate matches. Matching on prior arrests or age is less complex than matching on several additional pieces of information. Finally, matching is never considered superior to random assignment when the goal is to construct equitable groups. This is because there is a much higher likelihood of equivalence with random assignment on factors that are both measured and unknown to the researcher. Thus, the results produced from a nonequivalent group design, even with matching, are at a greater risk of alternative explanations than an experimental design that features random assignment.
FIGURE 5.3 | (a) Individual Matching (b) Aggregate Matching
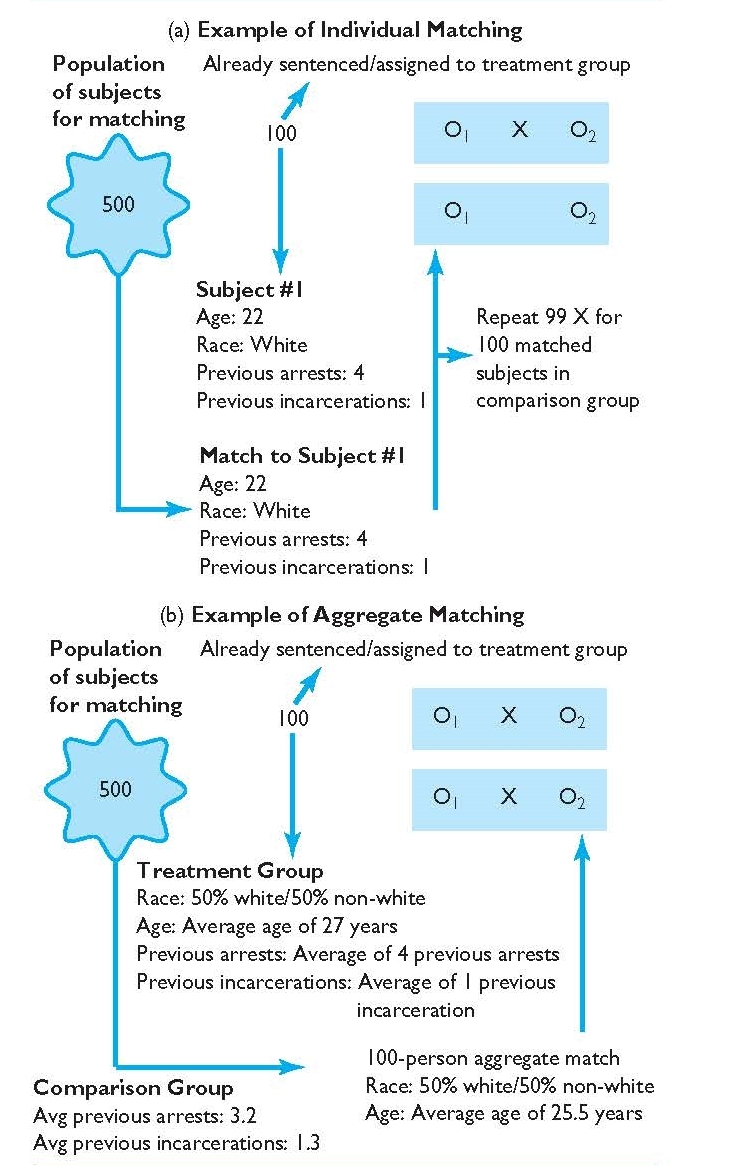
The previous discussion is not to suggest that the nonequivalent group design cannot be useful in answering important research questions. Rather, it is to suggest that the nonequivalent group design, and hence any quasi-experiment, is more susceptible to alternative explanations than the classic experimental design because of the absence of random assignment. As a result, a researcher must be prepared to rule out potential alternative explanations. Quasi-experimental designs that lack a pre-test or a comparison group are even less desirable than the nonequivalent group design and are subject to additional alternative explanations because of these missing parts. Although the quasi-experiment may be all that is available and still can serve as an important design in evaluating the impact of a particular treatment, it is not preferable to the classic experiment. Researchers (and consumers) must be attuned to the potential issues of this design so as to make informed conclusions about the results produced from such research studies.
The Effects of Red Light Camera (RLC) Enforcement
On March 15, 2009, an article appeared in the Santa Cruz Sentinel entitled “Ticket’s in the Mail: Red-Light Cameras Questioned.” The article stated “while studies show fewer T-bone crashes at lights with cameras and fewer drivers running red lights, the number of rear-end crashes increases.” 24 The study mentioned in the newspaper, which showed fewer drivers running red lights with cameras, was conducted by Richard Retting, Susan Ferguson, and Charles Farmer of the Insurance Institute for Highway Safety (IIHS). 25 They completed a quasi-experimental study in Philadelphia to determine the impact of red light cameras (RLC) on red light violations. In the study, the researchers selected nine intersections—six of which were experimental sites that utilized RLCs and three comparison sites that did not utilize RLCs. The six experimental sites were located in Philadelphia, Pennsylvania, and the three comparison sites were located in Atlantic County, New Jersey. The researchers chose the comparison sites based on the proximity to Philadelphia, the ability to collect data using the same methods as at experimental intersections (e.g., the use of cameras for viewing red light traffic), and the fact that police officials in Atlantic County had offered assistance selecting and monitoring the intersections.
The authors collected three phases of information in the RLC study at the experimental and comparison sites:
Phase 1 Data Collection: Baseline (pre-test) data collection at the experimental and comparison sites consisting of the number of vehicles passing through each intersection, the number of red light violations, and the rate of red light violations per 10,000 vehicles.
Phase 2 Data Collection: Number of vehicles traveling through experimental and comparison intersections, number of red light violations after a 1-second yellow light increase at the experimental sites (treatment 1), number of red light violations at comparison sites without a 1-second yellow light increase, and red light violations per 10,000 vehicles at both experimental and comparison sites.
Phase 3 Data Collection: Red light violations after a 1-second yellow light increase and RLC enforcement at the experimental sites (treatment 2), red light violations at comparison sites without a 1-second yellow increase or RLC enforcement, number of vehicles passing through the experimental and comparison intersections, and the rate of red light violations per 10,000 vehicles.
The researchers operationalized “red light violations” as those where the vehicle entered the intersection one-half of a second or more after the onset of the red signal where the vehicle’s rear tires had to be positioned behind the crosswalk or stop line prior to entering on red. Vehicles already in the intersection at the onset of the red light, or those making a right turn on red with or without stopping were not considered red light violations.
The researchers collected video data at each of the experimental and comparison sites during Phases 1–3. This allowed the researchers to examine red light violations before, during, and after the implementation of red light enforcement and yellow light time increases. Based on an analysis of data, the researchers revealed that the implementation of a 1-second yellow light increase led to reductions in the rate of red light violations from Phase 1 to Phase 2 in all of the experimental sites. In 2 out of 3 comparison sites, the rate of red light violations also decreased, despite no yellow light increase. From Phase 2 to Phase 3 (the enforcement of red light camera violations in addition to a 1-second yellow light increase at experimental sites), the authors noted decreases in the rate of red light violations in all experimental sites, and decreases among 2 of 3 comparison sites without red light enforcement in effect.
Concluding their study, the researchers noted that the study “found large and highly significant incremental reductions in red light running associated with increased yellow signal timing followed by the introduction of red light cameras.” Despite these findings, the researchers noted a number of potential factors to consider in light of the findings: the follow-up time periods utilized when counting red light violations before and after the treatment conditions were instituted; publicity about red light camera enforcement; and the size of fines associated with red light camera enforcement (the fine in Philadelphia was $100, higher than in many other cities), among others.
After reading about the study used in the newspaper article, has your impression of the newspaper headline and quote changed?
For more information and research on the effect of RLCs, visit the Insurance Institute for Highway Safety at http://www .iihs.org/research/topics/rlr.html .
One-Group Longitudinal Design
Like all experimental designs, the quasi-experimental design can come in a variety of forms. The second quasi-experimental design (above) is the one-group longitudinal design (also called a simple interrupted time series design). 26 An examination of this design shows that it lacks both random assignment and a comparison group (see Table 5.5). A major difference between this design and others we have covered is that it includes multiple pre-test and post-test observations.
TABLE 5.5 | One-Group Longitudinal Design
The one-group longitudinal design is useful when researchers are interested in exploring longer-term patterns. Indeed, the term longitudinal generally means “over time”—repeated measurements of the pre-test and post-test over time. This is different from cross-sectional designs, which examine the pre-test and post-test at only one point in time (e.g., at a single point before the application of the treatment and at a single point after the treatment). For example, in the nonequivalent group design and the classic experimental design previously examined, both are cross-sectional because pre-tests and post-tests are measured at one point in time (e.g., at a point 6 months after the treatment). Yet, these designs could easily be considered longitudinal if researchers took repeated measures of the pre-test and post-test.
The organization of the one-group longitudinal design is to examine a baseline of several pre-test observations, introduce a treatment or intervention, and then examine the post-test at several different time intervals. As organized, this design is useful for gauging the impact that a particular program, policy, or law has, if any, and how long the treatment impact lasts. Consider an example whereby a researcher is interested in gauging the impact of a tobacco ban on inmate-on-inmate assaults in a prison setting. This is an important question, for recent years have witnessed correctional systems banning all tobacco products from prison facilities. Correctional administrators predicted that there would be a major increase of inmate-on-inmate violence once the bans took effect. The one-group longitudinal design would be one appropriate design to examine the impact of banning tobacco on inmate assaults.
To construct this study using the one-group longitudinal design, the researcher would first examine the rate of inmate-on-inmate assaults in the prison system (or at an individual prison, a particular cellblock, or whatever the unit of analysis) prior to the removal of tobacco. This is the pre-test, or a baseline of assault activity before the ban goes into effect. In the design presented above, perhaps the researcher would measure the level of assaults in the preceding four months prior to the tobacco ban. When establishing a pre-test baseline, the general rule is that, in a longitudinal design, the more time utilized, both in overall time and number of intervals, the better. For example, the rate of assaults in the preceding month is not as useful as an entire year of data on inmate assaults prior to the tobacco ban. Next, once the tobacco ban is implemented, the researcher would then measure the rate of inmate assaults in the coming months to determine what impact the ban had on inmate-on-inmate assaults. This is shown in Table 5.5 as the multiple post-test measures of assaults. Assaults may increase, decrease, or remain constant from the pre-test baseline over the term of the post-test.
If assaults increased at the same time as the ban went into effect, the researcher might conclude that the increase was due only to the tobacco ban. But, could there be alternative explanations? The answer to this question is yes, there may be other plausible explanations for the increase even with several months of pre-test data. Unfortunately, without a comparison group there is no way for the researcher to be certain if the increase in assaults was due to the tobacco ban, or some other factor that may have spurred the increase in assaults and happened at the same time as the tobacco ban. What if assaults decreased after the tobacco ban went into effect? In this scenario, because there is no comparison group, the researcher would still not know if the results would have happened anyway without the tobacco ban. In these instances, the lack of a comparison group prevents the researcher from confidently attributing the results to the tobacco ban, and interpretation is subject to numerous alternative explanations.
Two-Group Longitudinal Design
A remedy for the previous situation would be to introduce a comparison group (see Table 5.6). Prior to the full tobacco ban, suppose prison administrators conducted a pilot program at one prison to provide insight as to what would happen once the tobacco ban went into effect systemwide. To conduct this pilot, the researcher identified one prison. At this prison, the researcher identified two different cellblocks, C-Block and D-Block. C-Block constitutes the treatment group, or the cellblock of inmates who will have their tobacco taken away. D-Block is the comparison group—inmates in this cellblock will retain their tobacco privileges during the course of the study and during a determined follow-up period to measure post-test assaults (e.g., 12-months). This is a two-group longitudinal design (also sometimes called a multiple interrupted time series design), and adding a comparison group makes this design superior to the one-group longitudinal design.
TABLE 5.6 | Two-Group Longitudinal Design
The usefulness of adding a comparison group to the study means that the researcher can have more confidence that the results at the post-test are due to the tobacco ban and not some alternative explanation. This is because any difference in assaults at the post-test between the treatment and comparison group should be attributed to the only difference between them, the tobacco ban. For this interpretation to hold, however, the researcher must be sure that C-Block and D-Block are similar or equivalent on all factors that might influence the post-test. There are many potential factors that should be considered. For example, the researcher will want to make sure that the same types of inmates are housed in both cellblocks. If a chronic group of assaultive inmates constitutes members of C-Block, but not D-Block, this differential could explain the results, not the treatment.
The researcher might also want to make sure equitable numbers of tobacco and non-tobacco users are found in each cellblock. If very few inmates in C-Block are smokers, the real effect of removing tobacco may be hidden. The researcher might also examine other areas where potential differences might arise, for example, that both cellblocks are staffed with equal numbers of officers, that officers in each cellblock tend to resolve inmate disputes similarly, and other potential issues that could influence post-test measure of assaults. Equivalence could also be ensured by comparing the groups on additional evidence before the ban takes effect: number of prior prison sentences, time served in prison, age, seriousness of conviction crime, and other factors that might relate to assaultive behavior, regardless of the tobacco ban. Moreover, the researcher should ensure that inmates in C-Block do not know that their D-Block counterparts are still allowed tobacco during the pilot study, and vice versa. If either group knows about the pilot program being an experiment, they might act differently than normal, and this could become an explanation of results. Additionally, the researchers might also try to make sure that C-Block inmates are completely tobacco free after the ban goes into effect—that they do not hoard, smuggle, or receive tobacco from officers or other inmates during the tobacco ban in or outside of the cellblock. If these and other important differences are accounted for at the individual and cellblock level, the researcher will have more confidence that any differences in assaults at the post-test between the treatment and comparison groups are related to the tobacco ban, and not some other difference between the two groups or the two cellblocks.
The addition of a comparison group aids in the ability of the researcher to isolate the true impact of a tobacco ban on inmate-on-inmate assaults. All factors that influence the treatment group should also influence the comparison group because the groups are made up of equivalent individuals in equivalent circumstances, with the exception of the tobacco ban. If this is the only difference, the results can be attributed to the ban. Although the addition of the comparison group in the two-group longitudinal design provides more confidence that the findings are attributed to the tobacco ban, the fact that this design lacks randomization means that alternative explanations cannot be completely ruled out—but they can be minimized. This example also suggests that the quasi-experiment in this instance may actually be preferable to an experimental design—noting the realities of prison administration. For example, prison inmates are not typically randomly assigned to different cellblocks by prison officers. Moreover, it is highly unlikely that a prison would have two open cellblocks waiting for a researcher to randomly assign incoming inmates to the prison for a tobacco ban study. Therefore, it is likely there would be differences among the groups in the quasi-experiment.
Fortunately, if differences between the groups are present, the researcher can attempt to determine their potential impact before interpretation of results. The researcher can also use statistical models after the ban takes effect to determine the impact of any differences between the groups on the post-test. While the two-group longitudinal quasi-experiment just discussed could also take the form of an experimental design, if random assignment could somehow be accomplished, the previous discussion provides one situation where an experimental design might be appropriate and desired for a particular research question, but would not be realistic considering the many barriers.
The Threat of Alternative Explanations
Alternative explanations are those factors that could explain the post-test results, other than the treatment. Throughout this chapter, we have noted the potential for alternative explanations and have given several examples of explanations other than the treatment. It is important to know that potential alternative explanations can arise in any research design discussed in this chapter. However, alternative explanations often arise because some design part is missing, for example, random assignment, a pre-test, or a control or comparison group. This is especially true in criminal justice where researchers often conduct field studies and have less control over their study conditions than do researchers who conduct experiments under highly controlled laboratory conditions. A prime example of this is the tobacco ban study, where it would be difficult for researchers to ensure that C-Block inmates, the treatment group, were completely tobacco free during the course of the study.
Alternative explanations are typically referred to as threats to internal validity. In this context, if an experiment is internally valid, it means that alternative explanations have been ruled out and the treatment is the only factor that produced the results. If a study is not internally valid, this means that alternative explanations for the results exist or potentially exist. In this section, we focus on some common alternative explanations that may arise in experimental and quasi-experimental designs. 27
Selection Bias
One of the more common alternative explanations that may occur is selection bias. Selection bias generally indicates that the treatment group (or experimental group) is somehow different from the comparison group (or control group) on a factor that could influence the post-test results. Selection bias is more often a threat in quasi-experimental designs than experimental designs due to the lack of random assignment. Suppose in our study of the prison tobacco ban, members of C-Block were substantially younger than members of D-Block, the comparison group. Such an imbalance between the groups would mean the researcher would not know if the differences in assaults are real (meaning the result of the tobacco ban) or a result of the age differential. Recall that research shows that younger inmates are more assaultive than older inmates and so we would expect more assaults among the younger offenders independent of the tobacco ban.
In a quasi-experiment, selection bias is perhaps the most prevalent type of alternative explanation and can seriously compromise results. Indeed, many of the examples above have referred to potential situations where the groups are imbalanced or not equivalent on some important factor. Although selection bias is a common threat in quasi-experimental designs because of lack of random assignment, and can be a threat in experimental designs because the groups could differ by chance alone or the practice of randomization was not maintained throughout the study (see Classics in CJ Research-MDVE above), a researcher may be able to detect such differentials. For example, the researcher could detect such differences by comparing the groups on the pre-test or other types of information before the start of the study. If differences were found, the researcher could take measures to correct them. The researcher could also use a statistical model that could account or control for differences between the groups and isolate the impact of the treatment, if any. This discussion is beyond the scope of this text but would be a potential way to deal with selection bias and estimate the impact of this bias on study results. The researcher could also, if possible, attempt to re-match the groups in a quasi-experiment or randomly assign the groups a second time in an experimental design to ensure equivalence. At the least, the researcher could recognize the group differences and discuss their potential impact on the results. Without a pre-test or other pre-study information on study participants, however, such differences might not be able to be detected and, therefore, it would be more difficult to determine how the differences, as a result of selection bias, influenced the results.
Another potential alternative explanation is history. History refers to any event experienced differently by the treatment and comparison groups in the time between the pre-test and the post-test that could impact results. Suppose during the course of the tobacco ban study several riots occurred on D-Block, the comparison group. Because of the riots, prison officers “locked down” this cellblock numerous times. Because D-Block inmates were locked down at various times, this could have affected their ability to otherwise engage in inmate assaults. At the end of the study, the assaults in D-Block might have decreased from their pre-test levels because of the lockdowns, whereas in C-Block assaults may have occurred at their normal pace because there was not a lockdown, or perhaps even increased from the pretest because tobacco was also taken away. Even if the tobacco ban had no effect and assaults remained constant in C-Block from pre- to post-test, the lockdown in D-Block might make it appear that the tobacco ban led to increased assaults in C-Block. Thus, the researcher would not know if the post-test results for the C-Block treatment group were attributable to the tobacco ban or the simple fact that D-Block inmates were locked down and their assault activity was artificially reduced. In this instance, the comparison group becomes much less useful because the lockdown created a historical factor that imbalanced the groups during the treatment phase and nullified the comparison.
Another potential alternative explanation is maturation. Maturation refers to the natural biological, psychological, or emotional processes we all experience as time passes—aging, becoming more or less intelligent, becoming bored, and so on. For example, if a researcher was interested in the effect of a boot camp on recidivism for juvenile offenders, it is possible that over the course of the boot camp program the delinquents naturally matured as they aged and this produced the reduction in recidivism—not that the boot camp somehow led to this reduction. This threat is particularly applicable in situations that deal with populations that rapidly change over a relatively short period of time or when a treatment lasts a considerable period of time. However, this threat could be eliminated with a comparison group that is similar to the treatment group. This is because the maturation effects would occur in both groups and the effect of the boot camp, if any, could be isolated. This assumes, however, that the groups are matched and equitable on factors subject to the maturation process, such as age. If not, such differentials could be an alternative explanation of results. For example, if the treatment and comparison groups differ by age, on average, this could mean that one group changes or matures at a different rate than the other group. This differential rate of change or maturation as a result of the age differential could explain the results, not the treatment. This example demonstrates how selection bias and maturation can interact at the same time as alternative explanations. This example also suggests the importance of an equivalent control or comparison group to eliminate or minimize the impact of maturation as an alternative explanation.
Attrition or Subject Mortality
Attrition or subject mortality is another typical alternative explanation. Attrition refers to differential loss in the number or type of subjects between the treatment and comparison groups and can occur in both experimental and quasi-experimental designs. Suppose we wanted to conduct a study to determine who is the better research methods professor among the authors of this textbook. Let’s assume that we have an experimental design where students were randomly assigned to professor 1, professor 2, or professor 3. By randomly assigning students to each respective professor, there is greater probability that the groups are equivalent and thus there are no differences between the three groups with one exception—the professor they receive and his or her particular teaching and delivery style. This is the treatment. Let’s also assume that the professors will be administering the same tests and using the same textbook. After the group members are randomly assigned, a pre-treatment evaluation shows the groups are in fact equivalent on all important known factors that could influence post-test scores, such as grade point average, age, time in school, and exposure to research methods concepts. Additionally, all groups scored comparably on a pre-test of knowledge about research methods, thus there is more confidence that the groups are in fact equivalent.
At the conclusion of the study, we find that professor 2’s group has the lowest final test scores of the three. However, because professor 2 is such an outstanding professor, the results appear odd. At first glance, the researcher thinks the results could have been influenced by students dropping out of the class. For example, perhaps several of professor 2’s students dropped the course but none did from the classes of professor 1 or 3. It is revealed, however, that an equal number of students dropped out of all three courses before the post-test and, therefore, this could not be the reason for the low scores in professor 2’s course. Upon further investigation, however, the researcher finds that although an equal number of students dropped out of each class, the dropouts in professor 2’s class were some of his best students. In contrast, those who dropped out of professor 1’s and professor 3’s courses were some of their poorest students. In this example, professor 2 appears to be the least effective teacher. However, this result appears to be due to the fact that his best students dropped out, and this highly influenced the final test average for his group. Although there was not a differential loss of subjects in terms of numbers (which can also be an attrition issue), there was differential loss in the types of students. This differential loss, not the teaching style, is an alternative explanation of the results.
Testing or Testing Bias
Another potential alternative explanation is testing or testing bias. Suppose that after the pre-test of research methods knowledge, professor 1 and professor 3 reviewed the test with their students and gave them the correct answers. Professor 2 did not. The fact that professor l’s and professor 3’s groups did better on the post-test final exam may be explained by the finding that students in those groups remembered the answers to the pre-test, were thus biased at the pre-test, and this artificially inflated their post-test scores. Testing bias can explain the results because students in groups 1 and 3 may have simply remembered the answers from the pre-test review. In fact, the students in professor l’s and 3’s courses may have scored high on the post-test without ever having been exposed to the treatment because they were biased at the pre-test.
Instrumentation
Another alternative explanation that can arise is instrumentation. Instrumentation refers to changes in the measuring instrument from pre- to post-test. Using the previous example, suppose professors 1 and 3 did not give the same final exam as professor 2. For example, professors 1 and 3 changed the final exam and professor 2 kept the final exam the same as the pretest. Because professors 1 and 3 changed the exam, and perhaps made it easier or somehow different from the pre-test exam, results that showed lower scores for professor 2’s students may be related only to instrumentation changes from pre- to post-test. Obviously, to limit the influence of instrumentation, researchers should make sure that instruments remain consistent from pre- to post-test.
A final alternative explanation is reactivity. Reactivity occurs when members of the treatment or experimental group change their behavior simply as a result of being part of a study. This is akin to the finding that people tend to change their behavior when they are being watched or are aware they are being studied. If members of the experiment know they are part of an experiment and are being studied and watched, it is possible that their behavior will change independent of the treatment. If this occurs, the researcher will not know if the behavior change is the result of the treatment, or simply a result of being part of a study. For example, suppose a researcher wants to determine if a boot camp program impacts the recidivism of delinquent offenders. Members of the experimental group are sentenced to boot camp and members of the control group are released on their own recognizance to their parents. Because members of the experimental group know they are part of the experiment, and hence being watched closely after they exit boot camp, they may artificially change their behavior and avoid trouble. Their change of behavior may be totally unrelated to boot camp, but rather, to their knowledge of being part of an experiment.
Other Potential Alternative Explanations
The above discussion provided some typical alternative explanations that may arise with the designs discussed in this chapter. There are, however, other potential alternative explanations that may arise. These alternative explanations arise only when a control or comparison group is present.
One such alternative explanation is diffusion of treatment. Diffusion of treatment occurs when the control or comparison group learns about the treatment its members are being denied and attempts to mimic the behavior of the treatment group. If the control group is successful in mimicking the experimental group, for example, the results at the end of the study may show similarity in outcomes between groups and cause the researcher to conclude that the program had no effect. In fact, however, the finding of no effect can be explained by the comparison group mimicking the treatment group. 28 In reality, there may be no effect of the treatment, but the researcher would not know this for sure because the control group effectively transformed into another experimental group—there is then no baseline of comparison. Consider a study where a researcher wants to determine the impact of a training program on class behavior and participation. In this study, the experimental group is exposed to several sessions of training on how to act appropriately in class and how to engage in class participation. The control group does not receive such training, but they are aware that they are part of an experiment. Suppose after a few class sessions the control group starts to mimic the behavior of the experimental group, acting the same way and participating in class the same way. At the conclusion of the study, the researcher might determine that the program had no impact because the comparison group, which did not receive the new program, showed similar progress.
In a related explanation, sometimes the comparison or control group learns about the experiment and attempts to compete with the experimental or treatment group. This alternative explanation is called compensatory rivalry. For example, suppose a police chief wants to determine if a new training program will increase the endurance of SWAT team officers. The chief randomly assigns SWAT members to either an experimental or control group. The experimental group will receive the new endurance training program and the control group will receive the normal program that has been used for years. During the course of the study, suppose the control group learns that the treatment group is receiving the new endurance program and starts to compete with the experimental group. Perhaps the control group runs five more miles per day and works out an extra hour in the weight room, in addition to their normal endurance program. At the end of the study, and due to the control group’s extra and competing effort, the results might show no effect of the new endurance program, and at worst, experimental group members may show a decline in endurance compared to the control group. The rivalry or competing behavior actually explains the results, not that the new endurance program has no effect or a damaging effect. Although the new endurance program may in reality have no effect, this cannot be known because of the actions of the control group, who learned about the treatment and competed with the experimental group.
Closely related to compensatory rivalry is the alternative explanation of comparison or control group demoralization. 29 In this instance, instead of competing with the experimental or treatment group, the control or comparison group simply gives up and changes their normal behavior. Using the SWAT example, perhaps the control group simply quits their normal endurance program when they learn about the treatment group receiving the new endurance program. At the post-test, their endurance will likely drop considerably compared to the treatment group. Because of this, the new endurance program might emerge as a shining success. In reality, however, the researcher will not know if any changes in endurance between the experimental and control groups are a result of the new endurance program or the control group giving up. Due to their giving up, there is no longer a comparison group of equitable others, the change in endurance among the treatment group members could be attributed to a number of alternative explanations, for example, maturation. If the comparison group behaves normally, the researcher will be able to exclude maturation as a potential explanation. This is because any maturation effects will occur in both groups.
The previous discussion suggests that when the control or comparison group learns about the experiment and the treatment they are denied, potential alternative explanations can arise. Perhaps the best remedy to protect from the alternative explanations just discussed is to make sure the treatment and comparison groups do not have contact with one another. In laboratory experiments this can be ensured, but sometimes this is a problem in criminal justice studies, which are often conducted in the field.
The previous discussion also suggests that there are numerous alternative explanations that can impact the interpretation of results from a study. A careful researcher would know that alternative explanations must be ruled out before reaching a definitive conclusion about the impact of a particular program. The researcher must be attuned to these potential alternative explanations because they can influence results and how results are interpreted. Moreover, the discussion shows that several alternative explanations can occur at the same time. For example, it is possible that selection bias, maturation, attrition, and compensatory rivalry all emerge as alternative explanations in the same study. Knowing about these potential alternative explanations and how they can impact the results of a study is what distinguishes a consumer of research from an educated consumer of research.
Chapter Summary
The primary focus of this chapter was the classic experimental design, the foundation for other types of experimental and quasi-experimental designs. The classic experimental design is perhaps the most useful design when exploring causal relationships. Often, however, researchers cannot employ the classic experimental design to answer a research question. In fact, the classic experimental design is rare in criminal justice and criminology because it is often difficult to ensure random assignment for a variety of reasons. In circumstances where an experimental design is appropriate but not feasible, researchers may turn to one of many quasi-experimental designs. The most important difference between the two is that quasi-experimental designs do not feature random assignment. This can create potential problems for researchers. The main problem is that there is a greater chance the treatment and comparison groups may differ on important characteristics that could influence the results of a study. Although researchers can attempt to prevent imbalances between the groups by matching them on important known characteristics, it is still much more difficult to establish equivalence than it is in the classic experiment. As such, it becomes more difficult to determine what impact a treatment had, if any, as one moves from an experimental to a quasi-experimental design.
Perhaps the most important lesson to be learned in this chapter is that to be an educated consumer of research results requires an understanding of the type of design that produced the results. There are numerous ways experimental and quasi-experimental designs can be structured. This is why much attention was paid to the classic experimental design. In reality, all experimental and quasi-experimental designs are variations of the classic experiment in some way—adding or deleting certain components. If the components and organization and logic of the classic experimental design are understood, consumers of research will have a better understanding of the results produced from any sort of research design. For example, what problems in interpretation arise when a design lacks a pre-test, a control group, or random assignment? Having an answer to this question is a good start toward being an informed consumer of research results produced through experimental and quasi-experimental designs.
Critical Thinking Questions
1. Why is randomization/random assignment preferable to matching? Provide several reasons with explanation.
2. What are some potential reasons a researcher would not be able to utilize random assignment?
3. What is a major limitation of matching?
4. What is the difference between a longitudinal study and a cross-sectional study?
5. Describe a hypothetical study where maturation, and not the treatment, could explain the outcomes of the research.
association (or covariance or correlation): One of three conditions that must be met for establishing cause and effect, or a causal relationship. Association refers to the condition that X and Y must be related for a causal relationship to exist. Association is also referred to as covariance or correlation. Although two variables may be associated (or covary or be correlated), this does not automatically imply that they are causally related
attrition or subject mortality: A threat to internal validity, it refers to the differential loss of subjects between the experimental (treatment) and control (comparison) groups during the course of a study
cause and effect relationship: A cause and effect relationship occurs when one variable causes another, and no other explanation for that relationship exists
classic experimental design or experimental design: A design in a research study that features random assignment to an experimental or control group. Experimental designs can vary tremendously, but a constant feature is random assignment, experimental and control groups, and a post-test. For example, a classic experimental design features random assignment, a treatment, experimental and control groups, and pre- and post-tests
comparison group: The group in a quasi-experimental design that does not receive the treatment. In an experimental design, the comparison group is referred to as the control group
compensatory rivalry: A threat to internal validity, it occurs when the control or comparison group attempts to compete with the experimental or treatment group
control group: In an experimental design, the control group does not receive the treatment. The control group serves as a baseline of comparison to the experimental group. It serves as an example of what happens when a group equivalent to the experimental group does not receive the treatment
cross-sectional designs: A measurement of the pre-test and post-test at one point in time (e.g., six months before and six months after the program)
demoralization: A threat to internal validity closely associated with compensatory rivalry, it occurs when the control or comparison group gives up and changes their normal behavior. While in compensatory rivalry the group members compete, in demoralization, they simply quit. Both are not normal behavioral reactions
dependent variable: Also known as the outcome in a research study. A post-test is a measure of the dependent variable
diffusion of treatment: A threat to internal validity, it occurs when the control or comparison group members learn that they are not getting the treatment and attempt to mimic the behavior of the experimental or treatment group. This mimicking may make it seem as if the treatment is having no effect, when in fact it may be
elimination of alternative explanations: One of three conditions that must be met for establishing cause and effect. Elimination of alternative explanations means that the researcher has ruled out other explanations for an observed relationship between X and Y
experimental group: In an experimental design, the experimental group receives the treatment
history: A threat to internal validity, it refers to any event experienced differently by the treatment and comparison groups—an event that could explain the results other than the supposed cause
independent variable: Also called the cause
instrumentation: A threat to internal validity, it refers to changes in the measuring instrument from pre- to post-test
longitudinal: Refers to repeated measurements of the pre-test and post-test over time, typically for the same group of individuals. This is the opposite of cross-sectional
matching: A process sometimes utilized in some quasi-experimental designs that feature treatment and comparison groups. Matching is a process whereby the researcher attempts to ensure equivalence between the treatment and comparison groups on known information, in the absence of the ability to randomly assign the groups
maturation: A threat to internal validity, maturation refers to the natural biological, psychological, or emotional processes as time passes
negative association: Refers to a negative association between two variables. A negative association is demonstrated when X increases and Y decreases, or X decreases and Y increases. Also known as an inverse relationship—the variables moving in opposite directions
operationalized or operationalization: Refers to the process of assigning a working definition to a concept. For example, the concept of intelligence can be operationalized or defined as grade point average or score on a standardized exam, among others
pilot program or test: Refers to a smaller test study or pilot to work out problems before a larger study and to anticipate changes needed for a larger study. Similar to a test run
positive association: Refers to a positive association between two variables. A positive association means as X increases, Y increases, or as X decreases, Y decreases
post-test: The post-test is a measure of the dependent variable after the treatment has been administered
pre-test: The pre-test is a measure of the dependent variable or outcome before a treatment is administered
quasi-experiment: A quasi-experiment refers to any number of research design configurations that resemble an experimental design but primarily lack random assignment. In the absence of random assignment, quasi-experimental designs feature matching to attempt equivalence
random assignment: Refers to a process whereby members of the experimental group and control group are assigned to each group through a random and unbiased process
random selection: Refers to selecting a smaller but representative subset from a population. Not to be confused with random assignment
reactivity: A threat to internal validity, it occurs when members of the experimental (treatment) or control (comparison) group change their behavior unnaturally as a result of being part of a study
selection bias: A threat to internal validity, selection bias occurs when the experimental (treatment) group and control (comparison) group are not equivalent. The difference between the groups can be a threat to internal validity, or, an alternative explanation to the findings
spurious: A spurious relationship is one where X and Y appear to be causally related, but in fact the relationship is actually explained by a variable or factor other than X
testing or testing bias: A threat to internal validity, it refers to the potential of study members being biased prior to a treatment, and this bias, rather than the treatment, may explain study results
threat to internal validity: Also known as alternative explanation to a relationship between X and Y. Threats to internal validity are factors that explain Y, or the dependent variable, and are not X, or the independent variable
timing: One of three conditions that must be met for establishing cause and effect. Timing refers to the condition that X must come before Y in time for X to be a cause of Y. While timing is necessary for a causal relationship, it is not sufficient, and considerations of association and eliminating other alternative explanations must be met
treatment: A component of a research design, it is typically denoted by the letter X. In a research study on the impact of teen court on juvenile recidivism, teen court is the treatment. In a classic experimental design, the treatment is given only to the experimental group, not the control group
treatment group: The group in a quasi-experimental design that receives the treatment. In an experimental design, this group is called the experimental group
unit of analysis: Refers to the focus of a research study as being individuals, groups, or other units of analysis, such as prisons or police agencies, and so on
variable(s): A variable is a concept that has been given a working definition and can take on different values. For example, intelligence can be defined as a person’s grade point average and can range from low to high or can be defined numerically by different values such as 3.5 or 4.0
1 Povitsky, W., N. Connell, D. Wilson, & D. Gottfredson. (2008). “An experimental evaluation of teen courts.” Journal of Experimental Criminology, 4, 137–163.
2 Hirschi, T., and H. Selvin (1966). “False criteria of causality in delinquency.” Social Problems, 13, 254–268.
3 Robert Roy Britt, “Churchgoers Live Longer.” April, 3, 2006. http://www.livescience.com/health/060403_church_ good.html. Retrieved on September 30, 2008.
4 Kalist, D., and D. Yee (2009). “First names and crime: Does unpopularity spell trouble?” Social Science Quarterly, 90 (1), 39–48.
5 Sherman, L. (1992). Policing domestic violence. New York: The Free Press.
6 For historical and interesting reading on the effects of weather on crime and other disorder, see Dexter, E. (1899). “Influence of weather upon crime.” Popular Science Monthly, 55, 653–660 in Horton, D. (2000). Pioneering Perspectives in Criminology. Incline Village, NV: Copperhouse.
7 http://www.escapistmagazine.com/news/view/111191-Less-Crime-in-U-S-Thanks-to-Videogames , retrieved on September 13, 2011. This news article was in response to a study titled “Understanding the effects of violent videogames on violent crime.” See Cunningham, Scott, Engelstätter, Benjamin, and Ward, (April 7, 2011). Available at SSRN: http://ssm.com/abstract= 1804959.
8 Cohn, E. G. (1987). “Changing the domestic violence policies of urban police departments: Impact of the Minneapolis experiment.” Response, 10 (4), 22–24.
9 Schmidt, Janell D., & Lawrence W. Sherman (1993). “Does arrest deter domestic violence?” American Behavioral Scientist, 36 (5), 601–610.
10 Maxwell, Christopher D., Joel H. Gamer, & Jeffrey A. Fagan. (2001). The effects of arrest on intimate partner violence: New evidence for the spouse assault replication program. Washington D.C.: National Institute of Justice.
11 Miller, N. (2005). What does research and evaluation say about domestic violence laws? A compendium of justice system laws and related research assessments. Alexandria, VA: Institute for Law and Justice.
12 The sections on experimental and quasi-experimental designs rely heavily on the seminal work of Campbell and Stanley (Campbell, D.T., & J. C. Stanley. (1963). Experimental and quasi-experimental designs for research. Chicago: RandMcNally) and more recently, Shadish, W., T. Cook, & D. Campbell. (2002). Experimental and quasi-experimental designs for generalized causal inference. New York: Houghton Mifflin.
13 Povitsky et al. (2008). p. 146, note 9.
14 Shadish, W., T. Cook, & D. Campbell. (2002). Experimental and quasi-experimental designs for generalized causal inference. New York: Houghton Mifflin Company.
15 Ibid, 15.
16 Finckenauer, James O. (1982). Scared straight! and the panacea phenomenon. Englewood Cliffs, N.J.: Prentice Hall.
17 Yarborough, J.C. (1979). Evaluation of JOLT (Juvenile Offenders Learn Truth) as a deterrence program. Lansing, MI: Michigan Department of Corrections.
18 Petrosino, Anthony, Carolyn Turpin-Petrosino, & James O. Finckenauer. (2000). “Well-meaning programs can have harmful effects! Lessons from experiments of programs such as Scared Straight.” Crime and Delinquency, 46, 354–379.
19 “Swearing makes pain more tolerable” retrieved at http:// www.livescience.com/health/090712-swearing-pain.html (July 13, 2009). Also see “Bleep! My finger! Why swearing helps ease pain” by Tiffany Sharpies, retrieved at http://www.time.com/time/health/article /0,8599,1910691,00.html?xid=rss-health (July 16, 2009).
20 For an excellent discussion of the value of controlled experiments and why they are so rare in the social sciences, see Sherman, L. (1992). Policing domestic violence. New York: The Free Press, 55–74.
21 For discussion, see Weisburd, D., T. Einat, & M. Kowalski. (2008). “The miracle of the cells: An experimental study of interventions to increase payment of court-ordered financial obligations.” Criminology and Public Policy, 7, 9–36.
22 Shadish, Cook, & Campbell. (2002).
24 Kelly, Cathy. (March 15, 2009). “Tickets in the mail: Red-light cameras questioned.” Santa Cruz Sentinel.
25 Retting, Richard, Susan Ferguson, & Charles Farmer. (January 2007). “Reducing red light running through longer yellow signal timing and red light camera enforcement: Results of a field investigation.” Arlington, VA: Insurance Institute for Highway Safety.
26 Shadish, Cook, & Campbell. (2002).
27 See Shadish, Cook, & Campbell. (2002), pp. 54–61 for an excellent discussion of threats to internal validity. Also see Chapter 2 for an extended discussion of all forms of validity considered in research design.
28 Trochim, W. (2001). The research methods knowledge base, 2nd ed. Cincinnati, OH: Atomic Dog.
Applied Research Methods in Criminal Justice and Criminology by University of North Texas is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book

Research Design | Importance, Types of Research Design Examples

Are you wondering about the concept of research design?
Do you need examples of research design or guidance on its elements and selecting the most suitable type for your study?
You’re in the right place!
This article will provide the information you’re looking for.
- Table of Contents
Research Design
Research design encompasses the overall plan or strategy that a researcher adopts to answer specific research questions or test hypotheses.
It includes the framework of methods and techniques chosen to collect, analyze, and interpret data.
Types of Research Design
Understanding the different types of research design is crucial for researchers as it enables them to develop an effective research methodology that aligns with their research objectives and facilitates timely completion of their studies.
While there are various research design types, the two most commonly utilized by researchers are quantitative and qualitative research methods.
1. Quantitative Research
Quantitative research is characterized by its objectivity and utilization of statistical approaches. It aims to establish cause-and-effect relationships among variables by employing various statistical and computational methods. Surveys, experiments, and observations are commonly used techniques in quantitative research, yielding numerical data that can be analyzed and expressed in numerical form.
Types of quantitative research designs and examples of quantitative research designs
Correlational research design.
Correlational research examines the strength and direction of relationships between variables. This design helps researchers establish connections between two variables without the researcher manipulating or controlling either variable.
For instance, a correlational study might investigate the relationship between the amount of time teenagers spend watching crime shows and their tendencies towards aggressive behavior.
Descriptive Research Design:
This quantitative research design is employed to identify characteristics, frequencies, trends, and categories within a study. It often does not start with a hypothesis and is focused on describing an identified variable.
Descriptive research aims to answer questions about “what,” “when,” “where,” or “how” phenomena occur, without going into the reasons or causes behind them.
For example, a study might examine the income levels of individuals who regularly use nutritional supplements.
This type of research aims to outline the features of a population or issues within the study area. It focuses primarily on answering the “what” of the research problem rather than going into the “why.” Researchers in descriptive or statistical research report facts precisely without attempting to influence variables.
Explanatory Research Design
In explanatory research design, a researcher delves deeper into their theories and ideas on a topic to gain a more thorough understanding. This design is employed when there is limited information available about a phenomenon, aiming to increase understanding of unexplored aspects of a subject. It serves as a foundation for future research.
Exploratory research is undertaken when a researcher encounters a research problem without past data or with limited existing studies. This type of research is often informal and lacks structure, serving as an initial exploration tool that generates hypothetical or theoretical ideas regarding the research problem.
It does not aim to provide definitive solutions but rather lays the groundwork for future research. Exploratory research is flexible and involves investigating various sources such as published secondary data, data from other surveys, and so on.
For instance, a researcher might develop hypotheses to guide future studies on how delaying school start times could positively impact the mental health of teenagers.
Causal Research Design
Causal research design, a subset of explanatory research, seeks to establish cause-and-effect relationships within its data. Unlike experimental research, causal research does not involve manipulating independent variables but rather observes naturally occurring or pre-existing groupings to define cause and effect.
For example, researchers might compare school dropout rates with instances of bullying to investigate potential causal relationships.
Diagnostic Research Design
In diagnostic design, researchers seek to understand the underlying causes of a specific issue or phenomenon, typically aiming to find effective solutions. This type of research involves diagnosing problems and identifying solutions based on thorough analysis. For example, a researcher might analyze customer feedback and reviews to pinpoint areas for improvement in an app.
Experimental Research Design
Experimental research design is utilized to study causal relationships by manipulating one or more independent variables and measuring their impact on one or more dependent variables. For instance, a study might assess the effectiveness of a new influenza vaccine plan by manipulating variables such as dosage or administration method and measuring their effects on vaccination outcomes.
2. Qualitative Research
In contrast, qualitative research takes a subjective and exploratory approach. It focuses on understanding the relationships between collected data and observations. Qualitative research is often conducted through interviews with open-ended questions, allowing participants to express their perspectives in words rather than numerical data.
Types of qualitative research designs and examples of qualitative research designs
- Grounded Theory
Grounded theory is a research design utilized to explore research questions that haven’t been extensively studied before. Also known as an exploratory design, it establishes sequential guidelines, provides inquiry strategies, and enhances the efficiency of data collection and analysis in qualitative research.
For instance, imagine a researcher studying how people adopt a particular app. They gather data through interviews and then analyze it to identify recurring patterns. These patterns are then used to formulate a theory regarding the adoption process of that app.
Thematic Analysis
Thematic analysis, another research design, involves comparing data collected from previous research to uncover common themes in qualitative research. For example, a researcher might analyze an interview transcript to identify recurring themes or topics.
Discourse Analysis
Discourse analysis is a research design focusing on language or social contexts within qualitative data collection. For instance, it might involve identifying the ideological frameworks and viewpoints expressed by authors in a series of policies.
3. Analytical Research
Analytical research uses established facts as a foundation for further investigation. Researchers seek supporting data that strengthens and validates their previous findings while also contributing to the development of new concepts related to the research topic.
Thus, analytical research combines minute details to generate more acceptable hypotheses. The analytical investigation clarifies the validity of a claim.
4. Applied Researc h
Applied research is aimed at addressing current issues faced by society or industrial organizations. It is characterized by non-systematic inquiry, typically conducted by businesses, government bodies, or individuals to solve specific problems or challenges.
5. Fundamental Research
Fundamental research is concerned with formulating theories and generalizations, making it the primary focus of this research type. It aims to discover new facts with broad applications, enhancing existing knowledge in specific fields or industries, and supplementing known ideas and theories.
6. Conclusive Research
Conclusive research, on the other hand, is designed to yield information crucial for reaching conclusions or making decisions, as implied by its name. It typically takes a quantitative approach and requires clearly defined research objectives and data requirements. The findings from conclusive research are specific and have practical applications.
Research Design Elements
Research design elements encompass several crucial components:
- Clear Research Question : Defining a clear research question or hypothesis is essential for clarity and direction.
- Research Methodology Type : Choosing the overall approach for the study is a fundamental aspect of research design.
- Sampling Strategy : Decisions regarding sample size, sampling methods, and criteria for inclusion or exclusion are important. Different research designs require different sampling approaches.
- Study Time Frame : Determining the study’s duration, timelines for data collection and analysis, and follow-up periods are critical considerations.
- Data Collection Methods : This involves gathering data from study participants or sources, including decisions on what data to collect, how to collect it, and the tools or instruments to use.
- Data Analysis Techniques : All research designs necessitate data analysis and interpretation. Decisions about statistical tests or methods, addressing confounding variables or biases, are key in this element.
- Resource : Planning for budget, staffing, and necessary resources is essential for effective study execution.
- Ethical Considerations: Research design must address ethical concerns such as informed consent, confidentiality, and participant protection.
Importance of research design
A good research design includes these key points:
- Guides decision-making at every study step.
- Identifies major and minor study tasks.
- Enhances research effectiveness and interest with detailed steps.
- Frames research objectives based on experiment design.
- Helps achieve study goals within set time and solve research issues efficiently.
- Improves task completion even with limited resources.
- Ensures research accuracy, reliability, consistency, and legitimacy.
Characteristics of research design
A well-planned research design is essential for carrying out a scientifically thorough study that produces reliable, neutral, valid, and generalizable results. At the same time, it should provide a certain level of flexibility.
Generalizability
The outcomes of a research design should be applicable to a broader population beyond the sample studied. A generalized approach allows for the study’s findings to be applied accurately to different segments of the population.
- Reliability
Research design should prioritize consistency in measurement across repeated measures and minimize random errors. A reliable research design produces consistent results with minimal chance-related errors.
Maintaining a neutral stance throughout the research process, from assumptions to study setup, is crucial. Researchers must avoid preconceived notions or biases that could influence findings or their interpretation. A good research design addresses potential sources of bias and ensures unbiased and neutral results.
Validity focuses on minimizing systematic errors or nonrandom errors in research. A reliable research design uses measurement tools that enhance the validity of results, ensuring accuracy and relevance.
Flexibility
Research design should allow for adaptability and adjustments based on collected data and study outcomes. Flexibility enables researchers to refine their approach and enhance the study’s effectiveness as it progresses.
How to Develop a research design?
The following provides guidance on developing a research design:
Step 1: Identify the Problem Statement
Choose a novel topic within your research field and clearly define the problem statement.
Step 2: Identify the Research Gap
Collect existing data and conduct an extensive literature review to identify gaps in current research.
This step provides insight into research methods, data collection, analysis techniques, and tools needed for your study.
Step 3: Develop the Research Hypothesis and Objectives
The next step is to formulate a strong research hypothesis, which plays a crucial role in guiding the remainder of your research process. Crafting a research hypothesis involves various strategies, such as evaluating data and conducting analysis.
If you’re struggling for ideas, consider listing potential objectives and then narrowing them down to focus on the most essential or critical ones.
Your research objectives can then be developed based on your hypothesis.
Step 4: Design the Research Methodology
When developing your research methodology, take into account several factors such as the type of study, sample location, sampling techniques, sample size, experimental setup, experimental procedures, software, and tools to be utilized.
By carefully considering these elements, you can craft a good research methodology that effectively addresses your research objectives and ensures the completion of your research work.
Step 5: Data analysis and results dissemination
It’s time to initiate the data analysis process, which can involve various techniques such as descriptive statistics, t-tests, and regression analysis. The initial step in this analysis phase is to determine the most appropriate method for your specific data.
Descriptive statistics are beneficial for summarizing data, while t-tests are effective for comparing means between two groups, and regression analysis aids in exploring relationships between variables.
Once the suitable analysis method is identified, you can proceed with analyzing the data. Subsequently, ensure to present your findings clearly and provide appropriate interpretations. Finally, document your findings in a research paper or thesis, accompanied by relevant discussions, and ensure that they align with your research objectives.
Benefits of Research Design
- A strong research design increases research efficiency by enabling researchers to choose appropriate designs, conduct statistical analyses effectively, and save time by outlining necessary data and data collection methods.
- Research design provides clear direction by guiding the choice of objectives, helping researchers focus on specific research questions or hypotheses.
- Proper research design allows researchers to control variables, identify confounding factors, and use randomization to minimize bias, enhancing the reliability of findings.
- Research designs enable replication, confirming study findings and ensuring results are not due to chance or external factors, thus reducing bias and errors.
- Research design reduces inaccuracies and ensures research reliability, maintaining consistent results over time, across different samples, and under varying conditions.
- Research design ensures the validity of research, ensuring results accurately reflect the phenomenon under investigation.
A well-chosen and executed research design facilitates high-quality research, meaningful conclusions, and contributes to knowledge advancement in the respective field.
A carefully planned research design improves the originality, reliability, and validity of your research results. It guides the researcher in the correct path without straying from the objectives. It’s crucial to note that a weak research design can lead to significant setbacks in terms of time, resources, and finances for the entire research project.
Other articles
Please read through some of our other articles with examples and explanations if you’d like to learn more about research methodology.
Citation Styles
- APA Reference Page
- MLA Citations
- Chicago Style Format
- “et al.” in APA, MLA, and Chicago Style
- Do All References in a Reference List Need to Be Cited in Text?
Comparision
- Basic and Applied Research
- Cross-Sectional vs Longitudinal Studies
- Survey vs Questionnaire
- Open Ended vs Closed Ended Questions
- Experimental and Non-Experimental Research
- Inductive vs Deductive Approach
- Null and Alternative Hypothesis
- Reliability vs Validity
- Population vs Sample
- Conceptual Framework and Theoretical Framework
- Bibliography and Reference
- Stratified vs Cluster Sampling
- Sampling Error vs Sampling Bias
- Internal Validity vs External Validity
- Full-Scale, Laboratory-Scale and Pilot-Scale Studies
- Plagiarism and Paraphrasing
- Research Methodology Vs. Research Method
- Mediator and Moderator
- Type I vs Type II error
- Descriptive and Inferential Statistics
- Microsoft Excel and SPSS
- Parametric and Non-Parametric Test
- Independent vs. Dependent Variable – MIM Learnovate
- Research Article and Research Paper
- Proposition and Hypothesis
- Principal Component Analysis and Partial Least Squares
- Academic Research vs Industry Research
- Clinical Research vs Lab Research
- Research Lab and Hospital Lab
- Thesis Statement and Research Question
- Quantitative Researchers vs. Quantitative Traders
- Premise, Hypothesis and Supposition
- Survey Vs Experiment
- Hypothesis and Theory
- Independent vs. Dependent Variable
- APA vs. MLA
- Ghost Authorship vs. Gift Authorship
- Research Methods
- Quantitative Research
- Qualitative Research
- Case Study Research
- Survey Research
- Conclusive Research
- Descriptive Research
- Cross-Sectional Research
- Theoretical Framework
- Conceptual Framework
- Triangulation
- Quasi-Experimental Design
- Mixed Method
- Correlational Research
- Randomized Controlled Trial
- Stratified Sampling
- Ethnography
- Ghost Authorship
- Secondary Data Collection
- Primary Data Collection
- Ex-Post-Facto
- Dissertation Topic
- Thesis Statement
- Research Proposal
- Research Questions
- Research Problem
- Research Gap
- Types of Research Gaps
- Operationalization of Variables
- Literature Review
- Research Hypothesis
- Questionnaire
- Measurement of Scale
- Sampling Techniques
- Acknowledgements
- PLS-SEM model
- Principal Components Analysis
- Multivariate Analysis
- Friedman Test
- Chi-Square Test (Χ²)
- Effect Size
- Critical Values in Statistics
- Statistical Analysis
- Calculate the Sample Size for Randomized Controlled Trials
- Covariate in Statistics
- Avoid Common Mistakes in Statistics
- Standard Deviation
- Derivatives & Formulas
- Build a PLS-SEM model using AMOS
- Principal Components Analysis using SPSS
- Statistical Tools
- One-tailed and Two-tailed Test

Related Posts
9 qualitative research designs and research methods, tips to increase your journal citation score, types of research quiz, difference between cohort study and case control study, convenience sampling: method and examples, difference between cohort and panel study, why is a pilot study important in research, panel survey: definition with examples, what is panel study, what is a cohort study | definition & examples, leave a reply cancel reply.
Save my name, email, and website in this browser for the next time I comment.
An experimental design for comparing interactive methods based on their desirable properties
- Original Research
- Open access
- Published: 17 April 2024
Cite this article
You have full access to this open access article
- Bekir Afsar ORCID: orcid.org/0000-0003-3643-2342 1 ,
- Johanna Silvennoinen ORCID: orcid.org/0000-0002-0763-0297 1 ,
- Francisco Ruiz ORCID: orcid.org/0000-0002-2612-009X 2 ,
- Ana B. Ruiz ORCID: orcid.org/0000-0003-0543-8055 2 ,
- Giovanni Misitano ORCID: orcid.org/0000-0002-4673-7388 1 &
- Kaisa Miettinen ORCID: orcid.org/0000-0003-1013-4689 1
In multiobjective optimization problems, Pareto optimal solutions representing different tradeoffs cannot be ordered without incorporating preference information of a decision maker (DM). In interactive methods, the DM takes an active part in the solution process and provides preference information iteratively. Between iterations, the DM can learn how achievable the preferences are, learn about the tradeoffs, and adjust the preferences. Different interactive methods have been proposed in the literature, but the question of how to select the best-suited method for a problem to be solved remains partly open. We propose an experimental design for evaluating interactive methods according to several desirable properties related to the cognitive load experienced by the DM, the method’s ability to capture preferences and its responsiveness to changes in the preferences, the DM’s satisfaction in the overall solution process, and their confidence in the final solution. In the questionnaire designed, we connect each questionnaire item to be asked with a relevant research question characterizing these desirable properties of interactive methods. We also conduct a between-subjects experiment to compare three interactive methods and report interesting findings. In particular, we find out that trade-off-free methods may be more suitable for exploring the whole set of Pareto optimal solutions, while classification-based methods seem to work better for fine-tuning the preferences to find the final solution.
Avoid common mistakes on your manuscript.
1 Introduction
Multiobjective optimization methods support a decision maker (DM) in finding the best balance among (typically conflicting) objective functions that must be optimized simultaneously. The DM’s preference information is required to find the most preferred solution (MPS) among the mathematically incomparable Pareto optimal solutions that have different tradeoffs (Hwang & Masud, 1979 ; Miettinen, 1999 ; Steuer, 1986 ). Based on the DM’s role in the solution process, multiobjective optimization methods can be classified into no-preference, a priori, a posteriori, and interactive ones, where the DM does not participate in the solution process or provides their preference information (preferences, for short) before, after or during the solution process, respectively (Hwang & Masud, 1979 ).
Interactive methods (Chankong & Haimes, 1983 ; Miettinen et al., 2008 , 2016 ; Steuer, 1986 ), in which the DM takes part in the solution process iteratively, have proven useful because the DM can learn about the tradeoffs among the objective functions and about the feasibility of their preferences (Belton et al., 2008 ). Accordingly, they can adjust their preferences between iterations until they find the MPS. Interactive methods are computationally and cognitively efficient because only solutions of interest are generated, and only a few solutions per iteration are shown to the DM during the solution process. Therefore, many interactive methods are available in the literature. They differ, e.g., in the type of preference information the DM specifies, the type of information shown to the DM, how new solutions are generated, what the stopping criterion is, etc.
Choosing an appropriate interactive method for one’s needs necessitates assessing and comparing their properties and performance. Since a DM plays an important role in interactive methods, the performance highly depends on human aspects. Experimental studies with human participants have been conducted in the literature to assess and compare interactive methods (see the survey (Afsar et al., 2021 ) and references therein). For example, the level of cognitive load experienced by the DM was assessed in Kok ( 1986 ) and the methods’ ability to capture the DM’s preferences in Buchanan ( 1994 ) and Narasimhan and Vickery ( 1988 ). Furthermore, the DM’s satisfaction was assessed in Brockhoff ( 1985 ), Buchanan ( 1994 ), Buchanan and Daellenbach ( 1987 ), Korhonen and Wallenius ( 1989 ), Narasimhan and Vickery ( 1988 ) and Wallenius ( 1975 ). According to Afsar et al. ( 2023 ), most papers lack information on experimental details, such as the questionnaire used (i.e., exact questions asked) and data collected. Thus, they cannot be replicated to compare other methods.
Recently, an experimental design and a questionnaire were proposed in Afsar et al. ( 2023 ) to assess the DM’s experienced level of cognitive load, the methods’ ability to capture preferences, and the satisfaction of the DM in the solution process. The questionnaire aimed at measuring some desirable properties characterizing the performance of interactive methods, according to Afsar et al. ( 2021 ). A proof-of-concept experiment was also conducted in Afsar et al. ( 2023 ) to compare the reference point method (RPM) (Wierzbicki, 1980 ) and synchronous NIMBUS (NIMBUS) (Miettinen & Mäkelä, 2006 ) with a within-subjects design, where a small number of participants solved the same problem with both methods (in different orders). This experiment demonstrated how the experimental setup worked, but no conclusions about the assessment of the methods compared could be derived, given that the results were not statistically significant.
Not all the desirable properties of interactive methods listed in Afsar et al. ( 2021 ) have been assessed before. In this paper, we design a questionnaire assessing multiple desirable properties. Its foundation is based on Afsar et al. ( 2023 ). We investigate the following aspects of interactive methods: cognitive load, capturing preferences, responsiveness to the changes in the DM’s preferences, overall satisfaction, and confidence in the final solution. To avoid tiring participants, we have selected a between-subjects design, in which each participant solves the problem with only one method. This allows comparing more methods with more questionnaire items offering a deeper understanding of users’ perceptions of applying different methods.
Besides conducting an experiment with the proposed design, one more contribution of this paper is reporting the insights gained. We compare three interactive methods: the E-NAUTILUS method (Ruiz et al., 2015 ), NIMBUS, and RPM. E-NAUTILUS is a trade-off-free method from the NAUTILUS family (Miettinen & Ruiz, 2016 ). In these methods, the DM starts from an inferior solution and gradually approaches Pareto optimal ones. This means that the DM gains in all objective functions simultaneously without trading off throughout the solution process. Including a tradeoff-free method in the experiment enables testing whether the proposed questionnaire can assess the above-mentioned aspects (e.g., a tradeoff-free method should place less cognitive load on the DM). On the other hand, NIMBUS uses the classification of the objective functions as the type of preference information. In each iteration, the DM examines the objective function values at the current solution and classifies each function into one of the five classes, indicating whether the function value (1) should improve, (2) should improve until a desired aspiration level is reached, (3) is currently acceptable, (4) may be impaired until some lower bound, or (5) can change freely. A classification is valid if at least one objective function should be improved and at least one is allowed to impair its current value. The DM provides aspiration levels and lower bounds for classes 2 and 4, respectively, and can specify the number of new Pareto optimal solutions to be generated for the next iteration. Finally, in each iteration of RPM, the DM provides preference information as a reference point consisting of aspiration levels. With this information, the method generates \(k+1\) Pareto optimal solutions, where k is the number of objective functions.
In the experiment conducted, we involve a high number of participants, which increases the reliability of the results. Having statistically significant results allows us to derive interesting conclusions about the behavior of the methods compared with respect to the desirable properties considered (which was not possible in Afsar et al. ( 2023 )). In addition, we also develop a user interface (UI) for E-NAUTILUS similar to those implemented for NIMBUS and RPM in Afsar et al. ( 2023 ).
To summarize, the main contribution of this paper is two-fold. First, we design a questionnaire that can be used for experiments both to assess the performance of an individual interactive method and to compare different ones. Second, we share findings and insights from our experiment comparing interactive methods of different types.
The remainder of the paper is organized as follows. In Sect. 2 , we outline general concepts of multiobjective optimization and briefly describe the considered aspects of interactive methods. We propose the extensive questionnaire in Sect. 3 . We then focus on the experiment and its analysis and results in Sect. 4 . In Sect. 5 , we discuss and summarize our findings. Finally, we draw conclusions in Sect. 6 .
2 Background
When a number of k (with \(k \ge 2\) ) conflicting objective functions \(f_i: S \rightarrow {\mathbb {R}}\) have to be optimized simultaneously over a feasible set \(S \subset {\mathbb {R}}^n\) of solutions or decision vectors \({\textbf {x}} = (x_1, \dots , x_n)^T\) , we have a multiobjective optimization problem (MOP) of the form Footnote 1 :
We have objective vectors \({{\textbf {f}}}({{\textbf {x}}}) = (f_1({{\textbf {x}}}), \dots , f_k({{\textbf {x}}}))^T\) for \({{\textbf {x}}} \in S\) and a feasible objective region Z , which is the image of S in the objective space \({\mathbb {R}}^k\) (i.e., \(Z={{\textbf {f}}}(S)\) ). Usually, finding a single optimal solution where all objective functions can reach their individual optima is not possible because of the degree of conflict among the objective functions. Instead, several Pareto optimal solutions exist, at which no objective function can be improved without deteriorating at least one of the others. A solution \({{\textbf {x}}} \in S\) is said to be Pareto optimal if there is no other \(\bar{{\textbf {x}}} \in S\) such that \(f_i(\bar{{\textbf {x}}}) \ge f_i({{\textbf {x}}})\) for all \(i = 1, \dots , k\) , and \(f_j(\bar{{\textbf {x}}}) > f_j({{\textbf {x}}})\) for at least one index j . Its objective vector \({{\textbf {f}}}({{\textbf {x}}})\) is called a Pareto optimal objective vector . All Pareto optimal solutions form a Pareto optimal set E , and the corresponding objective vectors form a Pareto optimal front \({{\textbf {f}}}(E)\) . The ranges of the objective function values in the Pareto optimal front are defined by the ideal and nadir points, denoted by \({\textbf {z}}^{\star } = (z_1^{\star },\dots , z_k^{\star })^T\) and \({{\textbf {z}}}^{\textrm{nad}} = (z_1^{\textrm{nad}}, \dots , z_k^{\textrm{nad}})^T\) , respectively. For \(i=1, \dots , k\) , their components are defined as follows: \(z_i^{\star } = \max _{{{\textbf {x}}} \in S} f_i({{\textbf {x}}}) = \max _{{{\textbf {x}}} \in E} f_i({{\textbf {x}}})\) , and \(z_i^{\textrm{nad}} = \min _{{{\textbf {x}}} \in E} f_i({{\textbf {x}}})\) .
Pareto optimal solutions are incomparable in a mathematical sense, and preference information from a DM is required to identify the MPS as the final solution. Different ways of expressing preferences can be used (Luque et al., 2011 ; Miettinen, 1999 ; Ruiz et al., 2012 ), such as e.g., selecting the most desired/undesired solution(s) among a set of alternatives, performing pairwise comparisons, giving a reference point formed by desirable objective function values (known as aspiration levels) or providing preferred ranges for the objective functions.
As stated in Miettinen et al. ( 2008 ), two phases can often be observed in interactive solutions processes, a learning phase and a decision phase, which are performed pursuing different purposes. In the learning phase, the DM learns about the problem, the available feasible solutions, and the feasibility of their own preferences. After exploring different solutions, the DM finds a region of interest (ROI) formed by Pareto optimal solutions that satisfy them the most. Then, a refined search within the ROI follows in the decision phase until finally finding the MPS.
A large variety of interactive methods have been developed, see e.g., Meignan et al. ( 2015 ), Miettinen ( 1999 ), Miettinen et al. ( 2016 ) and references therein. To find a suitable method for solving a problem, we need information about the properties and performance of different methods. Nevertheless, what “performance” means for an interactive method, i.e., how well it supports the DM in finding the MPS, is still an open question, given that different aspects must be considered. Desirable properties describing the performance of interactive methods have been proposed in Afsar et al. ( 2021 ). The authors also recognized the need of developing improved means for comparing interactive methods and provided general guidelines to conduct experiments with DMs. Since the quantitative assessment of interactive methods involving DMs is not trivial, further research is needed (Afsar et al., 2021 ; López-Ibáñez & Knowles, 2015 ).
Because of the central role of a DM in interactive methods, attention must be devoted to humans, and one aspect to be evaluated is the cognitive load set on the DM during the solution process. The cognitive load refers to the amount of working memory resources required and used (Sweller, 1988 ) with three types of cognitive load. Intrinsic cognitive load is the inherent level of difficulty and effort associated with a certain topic (Chandler & Sweller, 1991 ). The inherent levels of difficulty inducing cognitive load depend on an individual’s capacities in specific problem-solving contexts. Extraneous cognitive load is caused by the ways information is presented (Chandler & Sweller, 1991 ), and germane cognitive load refers to the effort in processing and creating a mental knowledge structures (i.e., schema) of the topic (Sweller et al., 1998 ).
Thus, cognitive effort should not be demanding, and tiredness or confusion should be avoided during the solution process. To this aim, a DM must be provided with easy-to-understand information, shown using comprehensive visualizations to decrease the possibility of extraneous cognitive load emerging. Avoiding long waiting times and assuring that the MPS is found in a reasonable number of iterations should also be promoted. In addition, the way the preference information is elicited and the method’s responsiveness (i.e., its ability to generate solutions reflecting the provided preferences even if they were changed drastically) influence the cognitive load.
The level of satisfaction of a DM when applying an interactive method in practice is also a determinant for evaluating its performance, given that the solution process usually stops when the DM is sufficiently satisfied (Afsar et al., 2021 ). Nevertheless, a DM may be satisfied with the final solution but may not be willing to interact with the method again if they found the interactive solution process e.g., too demanding or too difficult to be understood. Therefore, it is important to distinguish between the DM’s satisfaction with the overall solution process and their satisfaction and confidence with the final solution. To ensure that the DM is confident enough with a solution before stopping, the method must promote learning about the tradeoffs during the solution process to allow the DM to get convinced of having reached a solution reflecting their preferences.
When experimenting with humans, we need to validate that the measurement’s constructs measure the phenomenon being studied (Cook & Campbell, 1979 ). A validated measurement is a research instrument that has been tested to produce consistent results in terms of reliability and capture the issue intended to be measured, indicating the validity of the measurement. Many validated measurements have been developed to examine human perceptions, e.g., a validated measurement of the NASA Task Load Index (NASA TLX) has been developed for measuring cognitive load or level of experienced workload when interacting with technology (Hart & Staveland, 1988 ). NASA TLX has been created to evaluate six characteristics of cognitive load (mental, physical, and temporal demands, frustration, effort, and performance) in human-computer interaction. All of them are rated on a low to high scale, except performance, whose scale is from good to poor. To the best of our knowledge, validated measurements of cognitive load have not been developed for the specific characteristics of our experiment.
The after-scenario questionnaire (ASQ) (Lewis, 1995 ) is a validated measurement of a 3-item scale to measure user satisfaction with a computer system. The ASQ was developed within human-computer interaction for usability testing but can be applied to assess problem-solving with interactive multiobjective optimization methods due to its general nature. The measurement items are not restricted to specific contexts in humans interacting with technology.
The interactive methods used in our study have been implemented in the DESDEO framework (Misitano et al., 2021 ), a Python-based modular, open-source software framework for interactive methods. As a part of this study, we have developed appropriate web-based UIs. The details about the multiobjective optimization problem that participants solved in the experiment with the methods can be seen in Section S1 of the supplementary material available at http://www.mit.jyu.fi/optgroup/extramaterial.html . In addition, brief descriptions of the interactive methods used in the experiment (E-NAUTILUS, NIMBUS, and RPM) can be found in Section S2 of this supplementary material.
3 Questionnaire design
In this section, we first list our research questions with our reasoning behind them. We then describe the proposed questionnaire and discuss connections to the desirable properties of interactive methods, research questions, and existing validated measurements.
3.1 Research questions
In this paper, we aim to assess important aspects of interactive methods such as the level of cognitive load experienced by the DM, the method’s ability to capture preferences, the method’s responsiveness to changes in the DM’s preferences, the satisfaction of the DM in the overall solution process, and the DM’s confidence in the final solution. Accordingly, we have selected some desirable properties of interactive methods (Afsar et al., 2021 ) and connected them to our research questions (RQs) as presented in Table 1 .
Desirable properties related to the cognitive load are grouped into RQ1: Cognitive load , which covers how extensive the level of cognitive load experienced by the DM was in the whole solution process. RQ2: Capturing preferences and responsiveness examines the method’s ability to capture a DM’s preferences and the method’s responsiveness. With RQ3: Satisfaction and confidence , we aim to investigate a DM’s confidence in the final solution and the satisfaction of the DM with the overall solution process.
3.2 Questionnaire
In this section, we propose our questionnaire in Table 2 , classified based on the timing of asking the question (for short, timing is used in Table 2 ). Apart from the questions to be answered once the solution process is over, some questions are to be answered after some specific iterations of the solution process. This includes both statements to be graded on a given scale and open-ended questions to be answered in writing. For the sake of brevity, we will refer to them as items henceforth. In Table 2 , we list the desirable properties with RQs we have in Sect. 3.1 to show the corresponding item’s purpose in the column ‘purpose’ (i.e., which desirable property is being assessed). For example, item RQ2-1 investigates RQ2 and its first desirable property (in Table 1 ). We use a 7-point Likert scale (strongly disagree (1)–strongly agree (7)) (Joshi et al., 2015 ; Likert, 1932 ) or a 5-point semantic differential scale (e.g., very low (1)–very high (5)), enabling us to perform quantitative analysis. Moreover, in some items, participants first grade on a scale and then explain the reasoning behind their grades.
The first four items in Table 2 are to be asked during the solution process, while the remaining ones are to be asked after the solution process. We present the items in the order to be used in experiments. In the first iteration, items 1 and 2 are asked after the participants have provided their preference information for the first time and before seeing the corresponding solution(s) generated by the method, while items 3 and 4 are asked after they have seen the solution(s). Similarly, in the fourth iteration, item 2 is asked after they have provided the preferences, but before seeing the solution(s), and items 3 and 4 once they have seen the solution(s) computed based on the preferences provided (we do not ask these questions at every iteration to avoid overloading the participants). Note that item 1 is only asked in the first iteration. In what follows, we elaborate on the items according to the RQs we have in Sect. 3.1 .
In assessing the level of cognitive load experienced by the DM (RQ1), we get inspiration from the NASA-TLX questionnaire (Hart, 2006 ; Hart & Staveland, 1988 ) discussed in Sect. 2 . Items 14 and 25 assess the experienced level of mental demand; items 22 and 24 a DM’s mental effort, and item 23 the frustration level of the DM. Besides, we have item 13 to assess the level of performance of the DM in finding the final solution, similar to the NASA-TLX measuring one’s performance in a given task. NASA-TLX has two more measurements (physical demand concerning participants’ physical activity level and temporal demand concerning the time pressure placed on participants) that are inapplicable to our context—solving a multiobjective optimization problem does not require physical activity, and we do not set any time restrictions in our experiments.
As mentioned in Sect. 2 , another key aspect describing the performance of an interactive method is the method’s ability to reflect the preferences of the DM (RQ2). In particular, during the learning phase, the DM can provide preferences to explore different solutions. This means that the preferences may differ drastically from one iteration to the next. Thus, the method’s ability to generate solutions reflecting the DM’s preferences is crucial. Items 1 and 15 aim to assess whether the DM could articulate preferences well during the solution process. We have items 2, 16, 18, 19, and 20 to assess the method’s ability to capture the preferences in terms of making it easy for the DM to provide preferences and having the necessary functionalities so that the DM could feel in control during the solution process. Finally, items 3, 9, 17, and 21 assess the method’s responsiveness as the ability to react to the DM’s preferences.
In this paper, we consider the satisfaction in the overall solution process and the satisfaction (and confidence) in the final solution separately (RQ3). We first assess whether the DM has learned enough about tradeoffs among the objective functions in the problem considered. This is important since the DM cannot be confident in the final solution if they have not learned enough about the problem. Items 4, 6, 7, 10, and 11 evaluate whether the DM has gained insight into the problem (learned enough) or not. As mentioned, a DM typically stops the solution process when satisfied with the solution(s) found (Afsar et al., 2021 ). But overall satisfaction is also important, and they may stop for other reasons (e.g., being tired or not finding their preferred solution). We have items 5, 26, 27, and 28 to understand the overall satisfaction. Items 26, 27, and 28 come from ASQ (introduced in Sect. 2 ). Items 8, 12, and 29 assess whether the DM is satisfied and confident with the final solution.
In our questionnaire, we have developed new items and selected some proposed in Afsar et al. ( 2023 ) to investigate the aforementioned aspects of interactive methods. Besides the items listed in Table 2 , we assess the participants’ involvement as DMs with the questions “ The problem was easy to understand. Please describe why? ” and “ The problem was important for me to solve. Please describe why? ”, as in Afsar et al. ( 2023 ). These questions are important to understand whether the participants take the experiment seriously, which improves the reliability of the experiments.
4 The experiment
4.1 ui design.
We implemented the UIs of the three considered interactive methods following the same design principles as in Afsar et al. ( 2023 ) and utilizing the DESDEO framework (Misitano et al., 2021 ). The most notable difference from our previous work was the inclusion of a UI for E-NAUTILUS and the integration of the questionnaire items into the UIs. To illustrate the experimental setting, we give a brief description of the E-NAUTILUS UI in this section. More detailed descriptions of the UIs and their implementations are given in Section S3 of the supplementary material at http://www.mit.jyu.fi/optgroup/extramaterial.html .

Left: The UI of the E-NAUTILUS method. Right: Questionnaire items related to the given preferences as shown to the participant
The E-NAUTILUS UI is shown in Fig. 1 . On the left of the figure, the UI for E-NAUTILUS is shown, where the participants can explore the points generated by the method and choose the one they prefer. After choosing a point and iterating, the participant is shown questionnaire items related to the preferences (Table 2 , RQ2-1 and RQ2-2) as shown on the right of Fig. 1 . The questionnaire items are positioned so that they do not block the view of the UI, but while they are shown, interacting with the UI is not possible before each item is answered. Other questionnaire items presented during the solution process are shown in a similar way. The questionnaire items showed after the solution process (Table 2 ) are shown in the same environment as well.
4.2 Participants and procedure
The participants ( N = 164, 61% female, 39% male, age range 18–28, mean M = 19 years, standard deviation SD = 2.2) involved in this experiment were students from the Faculty of Economics and Business Studies of the University of Malaga. They all had very similar backgrounds in mathematics and multiobjective optimization. The participants were divided into three groups with one method assigned to each group, and the experiment was conducted in three separate sessions: one for E-NAUTILUS ( n = 64), another for NIMBUS ( n = 44), and another for RPM ( n = 56). The numbers of participants differ because some students did not attend the experiment sessions they were assigned to.
We conducted a pilot study online (using the Zoom platform) with six participants (three of the co-authors and three collaborators) before the actual experiment. One co-author acted as an observer and another one as an experimenter, who started by presenting the informed consent, briefly describing the study and the procedure to be followed, and performing a live demonstration of the UIs (this took approximately 15 min). Then the experimenter sent to each participant (via chat) the web address of the UI, their credentials to log in, and the method to be used. The correct method was chosen for each participant based on the credentials. Each method was tested by two participants. After this pilot study, we could estimate how long the experiment would take. The general procedure was carried out as planned, and no modifications were needed.
Two weeks before the experiment, two co-authors described the main purpose and procedure of our study to the participants in each group in separate informative sessions. In these sessions, the general purpose of interactive multiobjective optimization methods was briefly presented, including a detailed description of the method to be used by each group. In addition, the multiobjective optimization problem to be solved was introduced, and a live demonstration of the UI of each method was made in the corresponding group. To let them think carefully about their preferences before the day of the experiment, we provided the students with supplementary documentation consisting of detailed information about the problem and the interactive method to be used.
At the beginning of the experiment, in each separate session, the participants were presented with informed consent. The experiment procedure was shortly reminded, and a tutorial video was shown to demonstrate the UI again. Besides, a 2-page printed summary of the problem and of the interactive method to be used was provided to let the participants recall the details during the experiment if needed. Next, they received their credentials printed on paper to log into the system’s web address available on the course’s virtual campus. As in the pilot study, the credentials ensured that they interacted with the appropriate method. Overall, the experiment took approximately 45 min in each session. It should be noted that the questionnaire was implemented in English. However, we provided the option to respond to open-ended questions in Spanish if the students found it more convenient to ensure that they could express their responses in a language that felt most comfortable for them. The supplementary documentation, the 2-page summaries of the problem and the interactive methods, and the video tutorials of the UIs can be seen in Sections S4, S5, and S6, respectively, of the supplementary material at http://www.mit.jyu.fi/optgroup/extramaterial.html .
4.3 Analysis and results
In what follows, we perform a quantitative and qualitative analysis of the participants’ responses to the items of Sect. 3.2 . As described in Sect. 4.1 , they used radio buttons for the items answered in the Likert or semantic differential scales through the methods’ UIs. They did not need to switch to another window to respond to the items, which allowed them to stay focused on the solution process and the questionnaire.
We applied the Kruskal–Wallis test (Kruskal & Wallis, 1952 ), a non-parametric test detecting statistically significant differences between the results of three or more independent groups. The test was appropriate for our needs because the items were measured on an ordinal scale (e.g., Likert scale and semantic differential) rather than a continuous scale, and we used the between-subjects design with three independent groups. For the p -values, the significance level was set at 0.05. In Table 3 , we report the responses as mean scores (M) and standard deviations (SD) for each method, the latter in parentheses, along with the corresponding RQs. We also report the p -values of the Kruskal–Wallis test, with the statistically significant ones (less than 0.05) highlighted in bold in Table 3 (i.e., the corresponding item’s results for the three methods differ significantly).
We analyzed the responses to the open-ended questions with a data-driven approach of qualitative content analysis (Weber, 1990 ). This included identifying semantic analysis units to create categories with iterative analysis. Data-driven qualitative content analysis requires an in-depth reading of the textual data with analysis iterations to create categories representing the data contents (Weber, 1990 ). Conducting data-driven qualitative content analysis can be time-consuming, but it is highly important and beneficial in gaining an in-depth understanding of participants’ reasoning behind their numerical ratings. Next, we provide the quantitative and qualitative analysis for each RQ.
RQ1 – Cognitive load: In Table 3 , the responses to the items related to RQ1 indicated the participants’ experienced level of cognitive load for the whole solution process. The participants were significantly more satisfied with their performance in finding the final solution (item 13) using NIMBUS ( M = 5.49; SD = 1.05) than with E-NAUTILUS ( M = 5.21; SD = 1.15) or RPM ( M = 4.79; SD = 1.45). Qualitative content analysis showed similar contents in describing the reasons behind the numerical ratings (item 13) for the question: I am satisfied with my performance in finding the final solution. Please describe why? . All the methods were evaluated in terms of whether a satisfactory solution was reached or not. Reasons for NIMBUS ( N = 44) consisted of notions such as “Yes, because it shows you the results according to the restrictions” , for E-NAUTILUS ( N = 64) e.g., “I believe that I have been correctly evaluating the solutions as well as their possible consequences” , and for RPM ( N = 56) notions such as “I am more or less in agreement with the solution that I have obtained” . The only content-wise difference was that comments for RPM also included statements of how quick it was to obtain a solution (e.g., “It was quite easy and quick” ). However, according to the statistical results above, this did not lead to a higher level of performance satisfaction in the RPM participants.
According to the responses to the mental activity (item 14) and the efforts in finding the final solution (item 22), RPM required more mental activity ( M = 4.83; SD = 1.19) and effort ( M = 4.60; SD = 1.46) than the other two methods. E-NAUTILUS required slightly less mental activity ( M = 4.29; SD = 1.51) and significantly less effort ( M = 3.84; SD = 1.36). Similarly, participants reported less frustration in the solution process (item 23) with E-NAUTILUS ( M =3.51; SD = 1.64). However, even though RPM required more mental activity and effort, they were more frustrated with the NIMBUS solution process ( M = 4.22; SD = 1.52). The participants felt that they needed more iterations with NIMBUS and RPM to arrive at an acceptable solution (item 24), and their tiredness level (item 25) was nearly the same. On the other hand, even though all E-NAUTILUS users reached the 4th iteration while roughly 45% of NIMBUS users and 36% of RPM users did not, they felt that the solution process with E-NAUTILUS required significantly fewer iterations ( M = 3.21; SD = 1.46) and was less tiring ( M = 2.95; SD = 1.85). Besides, the average time spent (in seconds) with E-NAUTILUS ( M = 966.26; SD = 257.78) was higher than with NIMBUS ( M = 844.11; SD = 380.76) and with RPM ( M = 812.82; SD = 304.78). We can only report here the total time, but it is important in future experiments to record separately the time the DM spent interacting with the method, the computing time, and the time used in answering the questionnaire.
RQ2 – Capturing preferences and responsiveness: The ability of the methods to capture and respond to preferences was assessed using the RQ2 items in Table 3 . Item 1 was only asked once, after the first iteration. The mean scores for all methods indicate that the participants easily provided preferences in all methods. They did, however, find E-NAUTILUS ( M = 5.52; SD = 1.17) to be slightly easier than the others. Answers to the question I was able to reflect my actual preferences when providing the information required by the method. Please describe why? (item 16) were reasoned similarly for all the methods (e.g., E-NAUTILUS ( N = 64): “I have been able to choose according to my preferences at any moment” , NIMBUS ( N = 44): “The programme has been able to interpret the data that I have entered” , and RPM ( N = 56) “The method is good enough in order to represent user’s preferences in these three aspects” . All the methods also included notions of difficulties in reflecting preferences (e.g., E-NAUTILUS: “It wasn’t that easy to provide my preferences due to the conflicting objectives” , NIMBUS: “Because I wanted to increase the economic dimension, but the application did not increase it as I wanted it to” , and RPM: “Because the economic dimension affects too much the environmental one” ). One can say that these comments indicate a need to learn about trade-offs.
The participants found learning to use E-NAUTILUS significantly easier (item 15) ( M = 5.87; SD = 1.25) than the other methods. They felt in control (item 18) and comfortable (item 19) during the solution process with all methods, and the methods provided all the necessary functionalities (item 20). However, when they wanted to return to previous solutions (item 21), E-NAUTILUS ( M = 5.35; SD = 1.35) performed significantly better than the other two methods.
Written descriptions to the question What do you wish to achieve by providing this preference information? (item 2) were also analyzed with the qualitative content analysis (Weber, 1990 ) after the first and the fourth iteration. The answers of all the participants were similar. The focus was on either improving the preferred objective (e.g., for E-NAUTILUS and first iteration: “My objective is to improve in first place the economy, and in second place the environment” and same participant after the fourth iteration: “I want to improve the three objectives, specifically my preferences are the economy and the environment” ), or on not to emphasize one objective but to seek a more balanced solution between the objectives (e.g., for E-NAUTILUS, “I hope to find the best balanced solution” and after the fourth iteration: “I believe that a balance between the economic and environmental spheres represents an overall improvement for society” ). Overall, the rationale of what was wished to be achieved by providing preferences did not change between the first and the fourth iteration. The focus was more on fine-tuning the solution, either by increasing the value of one objective or by finding a more balanced solution.
The answers to the items related to the methods’ responsiveness when the preferences changed significantly. Item 3 was asked during the solution process (after the first and fourth iterations); NIMBUS was the best at generating solutions that reflected participants’ preferences well after the first iteration ( M = 5.34; SD = 1.22), and this situation did not change after the fourth iteration ( M = 5.29; SD = 1.30). Similarly, they felt that NIMBUS reacted best to their preferences (item 17) in general ( M = 5.46; SD = 1.31). On the other hand, they found E-NAUTILUS to be significantly easier ( M = 5.25; SD = 1.08) than the other methods in exploring solutions with different conflicting values (item 9).
RQ3 – Satisfaction and confidence: To determine which method was superior in terms of overall satisfaction and confidence in the final solution, we examined the responses given to the items for RQ3 in Table 3 . During the solution process, knowing more about the problem (item 4) was measured twice. The participants’ responses did not change significantly between the first and the fourth iterations, and they gained slightly more knowledge on the problem with E-NAUTILUS ( M = 5.23; SD = 1.31) and NIMBUS ( M = 5.21; SD = 1.14) than RPM ( M = 4.74; SD = 1.70). They obtained a clear idea of the values that the objectives could simultaneously achieve (item 10), as well as possible choices available similar to the solutions they were interested in (item 11) with all methods. Moreover, with all the methods, they discovered that the second and the third objectives were in conflict with one another (item 7). When it comes to satisfaction and confidence in the final solution (item 29), NIMBUS outperformed the other two methods significantly. From the written descriptions to the question I am satisfied with the solution I chose. Please describe why? (item 29); the positive and negative statements were similar across all the methods. All of the comments pertained to reaching or not reaching a satisfactory solution. Positive example statements were given, such as “Because it is the option I see as the best one of those obtained” . For the participants who were not satisfied with the chosen solution, the reason was in not obtaining a satisfactory solution, e.g., “I would have liked the environmental objective to be higher” . Furthermore, they felt that the solution they found with NIMBUS was the best (item 6). Regarding overall satisfaction with the entire solution process (items 26, 27, and 28), E-NAUTILUS was slightly better than NIMBUS, and NIMBUS was slightly better than RPM.
For the question If you imagined a desired solution in the beginning, how similar is it when compared to the final solution you obtained? Please describe why? (item 8), 26 participants applying E-NAUTILUS ( N = 64) stated that the final solution was similar to what they imagined (e.g., “Because I have achieved a social level and an economic level very close to the ideal levels, without the environmental level being too much compromised since it would remain relatively as it is now” ). Differences between the final solution and the solution imagined in the beginning were described in terms of lower value than expected in the economic objective ( n = 12/64), for example, with arguments such as “My aim was to find a solution that would improve the economic indicator but without creating a great harm to the environment, but it was the objective that has suffered the most. The last variable in rank of importance was the social one, and this is the one that has experienced the highest improvement” . The environment objective ( n = 9/64) was imagined to have a higher value (e.g., “The environmental dimension, whose range between the worst value and the best value is wider and therefore more difficult to approach to the most beneficial value, without considerably affecting the rest of the dimensions” ). The social objective ( n = 6/64) was also considered to have influenced the final solution differently than what was imagined in the beginning. It was either considered as the most preferred objective aiming to be increased as much as possible or tried to be decreased (e.g., “I wanted a low social factor, but it kept rising even if I tried keeping it low” ). Few participants ( n = 6/64) stated that the final solution was very different from the imagined one (e.g., “Because I would have liked to achieve higher values for all three objectives but, given the problem and the conflict between the objectives, this was not possible” ), and 5 participants stated that they were not able to imagine a solution in the beginning.
Imagined solutions that corresponded to the solutions obtained were described by 17 participants applying NIMBUS ( N = 44), with sentences such as “My aims as described at the beginning are in line with what has been achieved” . Differences compared to what was imagined were reported regarding higher values of the environment objective ( n = 5/44), higher values of the economic objective ( n = 4/44), and unexpected effects of the social objective to the other objectives ( n = 4/44), e.g., “I imagined that the social factor would remain between these values, which are very specific, and that the economic indicator would be quite dependent on the environmental one, and vice versa. That’s why I’m looking for a point where I can improve the economic dimension by reducing the environmental dimension a little bit” . Some participants ( n = 14/44) also stated that the solution was very different from what they imagined ( “Because I thought the other two objectives would be in a better situation” ), or they could not imagine a solution before starting the solution process.
The same categories emerged from the analysis of responses given for RPM. From the participants ( N = 56), only seven stated that the solution obtained was similar to the one they imagined. Differences between the imagined one and the obtained one were described according to unexpectedly low obtained values of the environment objective (n = 13/56), e.g., “The environmental factor has to be strongly sacrificed in order to increase the other two” , and of the economic objective (n = 12/56), e.g., “Because I wanted to maximize the economic objective and it was impossible” , and the social objective was considered as high ( n = 7/56). From the participants applying RPM, 17 found the obtained solution very different (e.g., “Since I wanted to maximize the economy, but I also wanted to have a high level of the environmental objective, but with high levels of economy, it’s very difficult to have high levels of the environmental objective” ), or unimaginable (e.g., “Because my imagined situation is not real” ).
Answers for the question Did some solution(s) surprise you, why? (item 12) were similar for all the methods. For E-NAUTILUS, a majority of the participants stated yes ( n = 44/64), and the main reasons were due to unexpected results pertaining to the social objective ( n = 18/44) (e.g., “The social dimension reached very high values at the solutions from the beginning” ). Surprises regarding the environmental objective ( n = 9/44) were described pertaining to its low value (e.g., “Yes, the environmental one, by sacrificing this level too much to increase the other two” ), and, especially in relation to the economic objective (e.g., “Yes, because I didn’t know that if I wanted to maximize the economy, the environmental objective was so low” ). Unexpected changes in the economic objective were the smallest category ( n = 4/44) (e.g., “The economic function was very difficult to keep constant or to maximize” ). The second biggest category ( n = 13/44) consisted of general statements depicting surprise of the interrelations of the objectives, such as “Yes, the solutions that improve the economic and the environmental objectives, while the social one worsened”. Participants who were not surprised ( n = 20/64) expressed their reasons, for example with the following words “No, in general, the solutions were within what I could expect” .
For NIMBUS, less than half of the participants answered yes ( N = 19/44), and 25 out of 44 participants said no. The reasons for encountering something unexpected pertained to lower values for the other objectives in increasing the social objective ( n = 4/19) (e.g., “Yes, in order to improve the social index, the economic one had to decrease a lot” ), to the low values of the environment objective ( n = 4/19) (e.g., “Improving the economy makes the environment worse” ), and due to the economic objective ( n = 4/19) (e.g., “Yes, for example, how the value of the economic index can change” ). The second biggest category ( n = 7/19) consisted of general statements “Yes, because I didn’t know that objectives could be so different from each other” .
From the participants applying RPM ( N = 56), 20 did not find surprises in the solutions, while the rest did ( n = 36/56). Reasons for encountering something unexpected pertained to the high values in the social objective ( n = 8/36) and were similar to the other methods, as well as lower values of the environment objective ( n = 9/36), and especially in relation to the economic objective, with statements such as “Yes, because the economic and environmental objectives are almost opposite in some cases” . Only two participants reported surprises solely in the economic objective. The second biggest category ( n = 17/36) of general statements included notions of surprises, such as “Yes. Because they change a lot with a small variation” , and “Yes, because they have nothing in common with the ones I wanted to get” .
Participants’ involvement as DMs: The responses given to the problem-related questions were not significantly different. The problem was easily understood by all three groups (mean scores were over 5 on the Likert scale). However, the E-NAUTILUS users felt slightly more involved and found the problem important for them to solve ( M = 5.27; SD = 1.18) than RPM ( M = 4.75; SD = 1.58) and NIMBUS users ( M = 4.83; SD = 1.45).
The written descriptions analyzed with qualitative content analysis revealed reasons behind the numerical scores given. Answers to the questions The problem was easy to understand. Please describe why? regarding: E-NAUTILUS were stated, such as “Because it is a problem that is well embedded in today’s society” and “Because the problem and its importance are very well explained” . For the question The problem was important for me to solve. Please describe why? , responses when applying E-NAUTILUS were stated, such as “Because it is something that affects everyone’s life, and individually, with projects like this one, the situation can be better understood and help to some extent to solve it” , for RPM e.g., “Because it is about important aspects” , and for NIMBUS e.g., “It’s a curious thing, it’s important to understand how sustainability works” .
Reasons for stopping iterating: The participants were asked to provide textual descriptions to the question: Why did you stop iterating? (item 5 in Table 2 ). The analysis resulted in two descriptive categories for all the methods: satisfactory solution found and misc/failure. The category of finding a satisfactory solution consists of descriptions of achieving the pursued goal as well as descriptions of reaching a good enough compromise between the objectives. The misc/failure category consists of notions of not being able to reach a satisfactory compromise and also utterances of not being able to apply the method correctly. In addition, for E-NAUTILUS, a third category was identified as a reason to stop iterating derived from the method: the number of iterations, in which reasons to stop iterating were defined according to the preset iteration rounds completed.
The majority of participants applying E-NAUTILUS ( N = 64) stopped iterating due to reaching a satisfactory solution ( n = 50/64). Justifications included statements such as “I have found the most satisfactory balance according to my criteria” . The number of iterations was stated as the stopping reason ( n = 8/64), with a rationale such as “Because I completed the number of iterations” . The third category, misc/failure ( n = 6/64), had reasons such as “I couldn’t get to the solution I was hoping for and I kept going in the same direction and found it difficult to straighten it out” . For NIMBUS ( N = 44), almost all the participants stopped iterating due to finding a satisfactory solution ( n = 40/44). Reasons were stated, for example, “I have managed to find the solution that most closely matches my preferences” . Few participants stopped iterating because they did not reach a satisfactory solution (misc/failure ( n = 4/44), with statements such as “With different values, it gave me the same solution” ). Participants applying RPM ( N = 56) mostly also stopped iterating due to finding a satisfactory solution ( n = 40/56). Reasons were described, such as “Because I have found a solution that, more or less, maximizes the economy without reducing a lot the social and environmental values” . Compared to E-NAUTILUS and NIMBUS, RPM gathered the most statements pertaining to misc/failure ( n = 16/56). Descriptions for this stopping reason were described, for example, with the following words “Because the program doesn’t work well and I couldn’t change the results” .
5 Discussion
The experiment was designed as a between-subjects study enabling the comparison of three interactive methods with questionnaire items focusing on different aspects. When compared to a within-subjects design, where all the participants would have applied all the methods in a randomized order, it would not have been possible to ask as many questions due to an excessive workload impacting the results. A between-subjects design enabled designing the questionnaire in a way that included the assessment of many desirable properties of interactive methods. From the responses obtained, we can derive some interesting findings about the methods considered. In what follows, we discuss them in further detail.
First, the overall impression is that the participants were more confident in the final solution provided by NIMBUS, while they found E-NAUTILUS easier to use and less demanding. On the other hand, the RPM method did not appear to excel in any of the aspects considered. Interestingly, the method applied also influenced the perception of the participants about the problem to be solved. When asked to describe their involvement with the problem, the responses corresponding to RPM were more negative than for the other methods, even though the numerical results did not differ much between the methods. Going into further detail, the following observations can be made:
The satisfaction with one’s own performance was high for E-NAUTILUS and NIMBUS (the highest one for the latter) and a bit lower for RPM. Paradoxically, the highest frustration level also occurred with NIMBUS, while frustration was the lowest with E-NAUTILUS. A possible reason is that a tradeoff-free method requires lower mental activity, while NIMBUS makes the users more aware of the tradeoffs, especially in the ROI around the final solution. Besides, RPM seemed to require more mental activity (although the reported mental activity levels were high for all the three methods) and more hard work than the others, E-NAUTILUS being the best in these respects. Therefore, while the preference information required by RPM (reference points) is, in principle, simple to provide, it seems that the participants struggled to decide which information to provide to obtain satisfactory solutions.
Surprisingly, despite the fact that all the participants iterated at least 4 iterations with E-NAUTILUS, while a significant percentage of them used fewer iterations with the other methods, and the overall time spent with E-NAUTILUS was longer, the impression of needing too many iterations and tiredness were much lower for E-NAUTILUS. These findings, once again, show that tradeoff-free iterations are cognitively less demanding and tiring. It must be said that the number of iterations is initially set in E-NAUTILUS (although it can be changed during the solution process). This may explain why the participants performed more iterations with this method, but their perceptions of time and tiredness are still interesting.
The participants considered that E-NAUTILUS made it easier to explore solutions with different tradeoffs, but NIMBUS was the method that best reacted to their preference information. In both cases, RPM was the worst one. Therefore, it seems that NIMBUS reflected preferences more accurately. The participants were able to correctly find the greatest conflict degree (between the economic \(f_2\) and the environmental \(f_3\) objective functions) with all three methods. In fact, many open-ended responses to the items I was able to reflect my actual preferences when providing the information required by the method. Please describe why? and Did some solution(s) surprise you, why? (see Sect. 4.3 ) prove this learning effect.
E-NAUTILUS users reported having a clearer idea of the values that the objective functions could simultaneously achieve in the whole set of solutions, while they felt that NIMBUS performed better for identifying these values in the ROI, close to the final solution.
A total of 43.2% of the participants applying NIMBUS re-started the solution process from the beginning, even more than once, while this percentage was 18% for RPM and just 9.4% for E-NAUTILUS. Maybe they did not understand properly what a feasible classification was in NIMBUS, although they reported that learning how to use this method was slightly harder than E-NAUTILUS but slightly easier than RPM. Better guidance in the NIMBUS UI could have been helpful.
Despite previous responses about tiredness, mental activity, easiness to use, etc., NIMBUS users were more convinced than others that they had found the best possible solution. This may be explained by the fact that NIMBUS allows fine-tuning the final solution better than the other two methods. This interpretation is supported by the fact that there was greater satisfaction with the final solution obtained with NIMBUS than with others.
The above findings lead to an interesting conclusion: a tradeoff-free method like E-NAUTILUS seems appropriate for the beginning of the solution process, i.e., the learning phase, to allow the DM to explore the set of solutions without getting tired and stressed, and to determine one’s ROI efficiently. On the other hand, a tradeoff-based method like NIMBUS, involving a classification, seems appropriate for the decision phase, where the DM can carry out a few more iterations to fine-tune the search and find one’s MPS. This conclusion reinforces the appropriateness of building computational systems for interactive multiobjective optimization enabling the DM switching among different methods during the solution process (Heikkinen et al., 2023 ).
One possible limitation of this study is that the experiments were carried out with students, who are not expected to have a strong involvement with the problem. Although it would be hard to find such a large number of real DMs to carry out this experiment, we believe it would also be convenient to know the opinions of real DMs when using different methods. Another limitation is that the responses to the open-ended questions in Spanish were translated into English, which may have influenced the results of the qualitative analysis.
6 Conclusions
In this paper, we have proposed a questionnaire to assess and compare interactive methods corresponding to the following aspects: the DM’s experienced level of cognitive load, the method’s ability to capture and respond to preferences, the DM’s overall satisfaction, and the DM’s confidence in the final solution. We have carefully designed the questionnaire, i.e., the content, order, and timing of each item. In particular, apart from the items to be answered once the solution process is over, some items have been added in some specific iterations of the process to measure, e.g., the participants’ learning about the tradeoffs during the solution process. Furthermore, we deliberately chose the experimental design to be a between-subjects design, which allows asking many questions to assess the aforementioned aspects.
To demonstrate the applicability of the questionnaire, we conducted an experiment by comparing an interactive tradeoff-free method E-NAUTILUS and two more typical interactive methods, NIMBUS and RPM, that are based on dealing with Pareto optimal solutions throughout the solution process and focus more on tradeoffs. The methods compared were chosen with care to analyze the questionnaire in terms of the aspects considered. We were able to acquire useful outcomes. E-NAUTILUS, for example, was cognitively less demanding than the other methods, supporting the claim made for tradeoff-free methods. NIMBUS users, on the other hand, were more satisfied with the final solutions because they thought NIMBUS responded well to their preferences.
The proposed questionnaire, along with the experimental design and results, demonstrated its suitability for assessing and comparing interactive methods. We fully shared the questionnaire, which can be applied to future studies. Based on the results of this paper, we plan to conduct experiments to study the switch from one method to another during the solution process (e.g., one method at the beginning of the solution process to find the ROI (i.e., in the learning phase), and another method when the DM wants to fine-tune the solutions in the ROI (i.e., in the decision phase)).
Moreover, while the scope of this paper is focused on assessing the desirable properties of interactive methods, we acknowledge the value of exploring the specific solutions discovered during and at the end of the solution process. Therefore, as part of our future research studies, we plan to incorporate the analysis of solutions found, providing a more comprehensive understanding of the interactive methods and further enhancing the applicability of our findings.
Other future research directions include studying the role of the UI design solutions more in-depth affecting interaction in the solution process to improve the proposed UIs by decreasing possibilities of inducing extraneous cognitive load, as well as extending the questionnaire to further desirable properties discussed in the literature. It will also be interesting to develop validated measurements that are applicable for assessing the performance of interactive multiobjective optimization methods.
7 Supplementary information.
The supplementary material associated with this manuscript can be found at http://www.mit.jyu.fi/optgroup/extramaterial.html .
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
For simplicity, all objectives are assumed to be maximized. In case any of them must be minimized, it can be transformed into the maximization form by multiplying by -1.
Afsar, B., Miettinen, K., & Ruiz, F. (2021). Assessing the performance of interactive multiobjective optimization methods: A survey. ACM Computing Surveys, 54 (4), 1–27. Art. no. 85.
Article Google Scholar
Afsar, B., Silvennoinen, J., Misitano, G., Ruiz, F., Ruiz, A. B., & Miettinen, K. (2023). Designing empirical experiments to compare interactive multiobjective optimization methods. Journal of the Operational Research Society, 74 (11), 2327–2338.
Belton, V., Branke, J., Eskelinen, P., Greco, S., Molina, J., Ruiz, F., & Słowiński, R. (2008). Interactive multiobjective optimization from a learning perspective. In J. Branke, K. Deb, K. Miettinen, & R. Slowinski (Eds.), Multiobjective Optimization: Interactive and Evolutionary Approaches (pp. 405–434). Berlin: Springer.
Chapter Google Scholar
Brockhoff, K. (1985). Experimental test of MCDM algorithms in a modular approach. European Journal of Operational Research, 22 (2), 159–166.
Buchanan, J. T. (1994). An experimental evaluation of interactive MCDM methods and the decision making process. Journal of the Operational Research Society, 45 (9), 1050–1059.
Buchanan, J. T., & Daellenbach, H. G. (1987). A comparative evaluation of interactive solution methods for multiple objective decision models. European Journal of Operational Research, 29 (3), 353–359.
Chandler, P., & Sweller, J. (1991). Cognitive load theory and the format of instruction. Cognition and Instruction, 8 (4), 293–332.
Chankong, V., & Haimes, Y. Y. (1983). Multiobjective Decision Making: Theory and Methodology . North-Holland.
Google Scholar
Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentation: Design and Analysis Issues for Field Settings . Houghton Mifflin Company.
Hart, S. G. (2006). NASA-task load index (NASA-TLX); 20 years later. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 50 , 904–908.
Hart, S. G., & Staveland, L. E. (1988). Development of NASA-TLX (task load index): Results of empirical and theoretical research. Advances in Psychology, 52 , 139–183.
Heikkinen, R., Sipila, J., Ojalehto, V., & Miettinen, K. (2023). Flexible data driven inventory management with interactive multiobjective lot size optimization. International Journal of Logistics Systems and Management, 46 (2), 206–235.
Hwang, C.-L., & Masud, A. S. M. (1979). Multiple Objective Decision Making - Methods and Applications: A State-of-the-Art Survey . Springer.
Book Google Scholar
Joshi, A., Kale, S., Chandel, S., & Pal, D. K. (2015). Likert scale: Explored and explained. British Journal of Applied Science & Technology, 7 (4), 396–403.
Kok, M. (1986). The interface with decision makers and some experimental results in interactive multiple objective programming methods. European Journal of Operational Research, 26 (1), 96–107.
Korhonen, P., & Wallenius, J. (1989). Observations regarding choice behaviour in interactive multiple criteria decision-making environments: An experimental investigation. In A. Lewandowski & I. Stanchev (Eds.), Methodology and Software for Interactive Decision Support (pp. 163–170). Berlin: Springer.
Kruskal, W. H., & Wallis, W. A. (1952). Use of ranks in one-criterion variance analysis. Journal of the American Statistical Association, 47 (260), 583–621.
Lewis, J. R. (1995). IBM computer usability satisfaction questionnaires: Psychometric evaluation and instructions for use. International Journal of Human-Computer Interaction, 7 (1), 57–78.
Likert, R. (1932). A technique for the measurement of attitudes. Archives of Psychology, 22 (140), 5–55.
López-Ibáñez, M., & Knowles, J. (2015). Machine decision makers as a laboratory for interactive EMO. In A. Gaspar-Cunha, C. Henggeler Antunes, & C. Coello Coello (Eds.) Evolutionary Multi-criterion Optimization, 8th International Conference, Proceedings, Part II (pp. 295–309). Springer.
Luque, M., Ruiz, F., & Miettinen, K. (2011). Global formulation for interactive multiobjective optimization. OR Spectrum, 33 (1), 27–48.
Meignan, D., Knust, S., Frayret, J. M., Pesant, G., & Gaud, N. (2015). A review and taxonomy of interactive optimization methods in operations research. ACM Transactions on Interactive Intelligent Systems, 5 (3), 17:1-17:43.
Miettinen, K. (1999). Nonlinear Multiobjective Optimization . Kluwer Academic Publishers.
Miettinen, K., Hakanen, J., & Podkopaev, D. (2016). Interactive nonlinear multiobjective optimization methods. In S. Greco, M. Ehrgott, & J. Figueira (Eds.), Multiple Criteria Decision Analysis: State of the Art Surveys (Vol. 2, pp. 931–980). Springer.
Miettinen, K., & Mäkelä, M. M. (2006). Synchronous approach in interactive multiobjective optimization. European Journal of Operational Research, 170 (3), 909–922.
Miettinen, K., & Ruiz, F. (2016). NAUTILUS framework: Towards trade-off-free interaction in multiobjective optimization. Journal of Business Economics, 86 (1), 5–21.
Miettinen, K., Ruiz, F., & Wierzbicki, A. P. (2008). Introduction to multiobjective optimization: Interactive approaches. In J. Branke, K. Deb, K. Miettinen, & R. Słowiński (Eds.), Multiobjective Optimization: Interactive and Evolutionary Approaches (pp. 27–57). Springer.
Misitano, G., Saini, B. S., Afsar, B., Shavazipour, B., & Miettinen, K. (2021). DESDEO: The modular and open source framework for interactive multiobjective optimization. IEEE Access, 9 , 148277–148295.
Narasimhan, R., & Vickery, S. K. (1988). An experimental evaluation of articulation of preferences in multiple criterion decision-making (MCDM) methods. Decision Sciences, 19 (4), 880–888.
Ruiz, A. B., Sindhya, K., Miettinen, K., Ruiz, F., & Luque, M. (2015). E-NAUTILUS: A decision support system for complex multiobjective optimization problems based on the NAUTILUS method. European Journal of Operational Research, 246 , 218–231.
Ruiz, F., Luque, M., & Miettinen, K. (2012). Improving the computational efficiency in a global formulation (GLIDE) for interactive multiobjective optimization. Annals of Operations Research, 197 (1), 47–70.
Steuer, R. E. (1986). Multiple Criteria Optimization: Theory, Computation, and Applications . Wiley.
Sweller, J. (1988). Cognitive load during problem solving: Effects on learning. Cognitive Science, 12 (2), 257–285.
Sweller, J., Van Merrienboer, J. J. G., & Paas, F. G. W. C. (1998). Cognitive architecture and instructional design. Educational Psychology Review, 10 (3), 251–296.
Wallenius, J. (1975). Comparative evaluation of some interactive approaches to multicriterion optimization. Management Science, 21 (12), 1387–1396.
Weber, R. P. (1990). Basic Content Analysis . Sage.
Wierzbicki, A. P. (1980). The use of reference objectives in multiobjective optimization. In G. Fandel & T. Gal (Eds.), Multiple Criteria Decision Making, Theory and Applications (pp. 468–486). Springer.
Download references
Acknowledgements
This research is related to the thematic research area Decision Analytics utilizing Causal Models and Multiobjective Optimization (DEMO, jyu.fi/demo) at the University of Jyvaskyla, and was partly funded by the Academy of Finland (project 322221). This research was partly supported by the Spanish Ministry of Science (projects PID2019-104263RB-C42 and PID2020-115429GB-I00), the Regional Government of Andalucía (projects SEJ-532 and P18-RT-1566), and the University of Málaga (grant B1-2020-18).
Open Access funding provided by University of Jyväskylä (JYU).
Author information
Authors and affiliations.
University of Jyvaskyla, Faculty of Information Technology, P.O. Box 35 (Agora), FI-40014, University of Jyvaskyla, Finland
Bekir Afsar, Johanna Silvennoinen, Giovanni Misitano & Kaisa Miettinen
Department of Applied Economics (Mathematics), Universidad de Málaga, C/ Ejido 6, 29071, Málaga, Spain
Francisco Ruiz & Ana B. Ruiz
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Bekir Afsar .
Ethics declarations
Conflict of interest.
The authors declare that they have no Conflict of interest.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Afsar, B., Silvennoinen, J., Ruiz, F. et al. An experimental design for comparing interactive methods based on their desirable properties. Ann Oper Res (2024). https://doi.org/10.1007/s10479-024-05941-6
Download citation
Received : 17 April 2023
Accepted : 09 March 2024
Published : 17 April 2024
DOI : https://doi.org/10.1007/s10479-024-05941-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Multiple criteria optimization
- Interactive methods
- Performance comparison
- Empirical experiments
- Human decision makers
- Find a journal
- Publish with us
- Track your research
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 15 April 2024
Experimental study on the interface characteristics of geogrid-reinforced gravelly soil based on pull-out tests
- Jie Liu 1 , 2 ,
- Jiadong Pan 1 , 2 ,
- Qi Liu 2 &
Scientific Reports volume 14 , Article number: 8669 ( 2024 ) Cite this article
27 Accesses
Metrics details
- Civil engineering
The factors influencing geogrid–soil interface characteristics are critical design parameters in some geotechnical designs. This study describes pull-out tests performed on gravelly soils commonly encountered in the Xinjiang region and reinforced with two types of geogrids. The factors affecting the geogrid–gravelly soil interface properties are investigated with different experimental loading methods (pull-out velocity, normal stress), geogrid types, and soil particle size distributions and water contents. The ultimate pull-out force increases with the normal stress and pull-out velocity. Furthermore, with increasing coarse particle content and water content, the ultimate pull-out force increases and then decreases sharply. Based on these research results, this paper provides reasonable parameters and recommendations for the design and pull-out testing of reinforced soil in engineering structures. In reinforced soil structure design, the grid depth should be increased appropriately, and the coarse particle content of the overlying soil should be between 30 and 40%. During construction, the gravelly soil should be compacted to the maximum compaction at the optimal water content, and the structure should have a reasonable waterproofing system. According to the calculation results of the interface strength parameters, the uniaxial geogrid–gravelly soil interface has a high cohesive force c sg , which should not be ignored in reinforced soil structure design.
Similar content being viewed by others

Physical and 3D numerical modelling of reinforcements pullout test
Ivan P. Damians, Aníbal Moncada, … Alejandro Josa

Sensitivity analysis of counterweight double-row pile deformation to weak stratum parameters
Qiongyi Wang, Yungang Niu, … Shasha Lu

Splitting tensile strength and microstructure of xanthan gum-treated loess
Tong Jiang, Jin-di Zhao & Jun-ran Zhang
Introduction
Geosynthetics have been widely used in the past two decades to protect retaining walls, slopes, and embankments. The interaction between the geosynthetic materials and the soil body mainly reflects the reinforcement effect 1 . At the geogrid–soil interface, the resisting shear force mainly arises from the friction between the soil and the surface of the geogrid 2 . The interface characteristics between the soil and reinforcing material, especially the shear strength of the reinforcing soil interface, directly affect the safety and stability of reinforced soil structures. Therefore, the parameters of this interaction must be considered in design calculations 3 , 4 , 5 .
Many scholars have performed experimental research to understand the interface characteristics between the soil and reinforcing materials in reinforced soil. The corresponding tests are mainly interface direct shear and pull-out tests 3 , 6 , 7 . Comparing direct shear test and pull-out test results, Xu et al. 8 found that the direct shear strength τs, interfacial shear strength τds, and pull-out shear strength τp of a geogrid-compacted soil interface were similar. However, since the direct shear test is used to study the interfacial characteristics of reinforced soil, it can reflect only the interfacial strength of the reinforcing material and the soil and not the tensile strength of the reinforcing material or the strength of the whole soil body 9 . Furthermore, the direct shear test cannot fully simulate the double-sided sliding of the reinforcing material and soil and the large deformation characteristics of the soil when it is damaged. However, the pull-out test can consider various factors, such as soil expansion, crowding, and reinforcement slippage, influencing the performance of the reinforcement. This approach can simulate the working conditions of the geogrid inside the soil with simultaneous forces above and below. It can reflect the evolution of the reinforced soil structure during loading 10 . Therefore, the pull-out test is one of the standard methods used to study the reinforcement characteristics of geogrids in soil and to deduce the residual strength and peak strength.
Some domestic and foreign scholars have used this experimental method to investigate the mechanism of reinforcement and the factors influencing the interfacial characteristics of geogrids. Ochiai et al. 11 conducted field and laboratory pull-out tests to determine the parameters required to design and analyze geogrid reinforcement structures and elucidate their pull-out mechanisms. They noted that geogrids may fracture or elongate under normal stress. In addition, they recommended that pull-out tests be performed at a low normal stress. Li et al. 12 conducted a series of pull-out tests to investigate and compare the load‒displacement characteristics of tire belts and uniaxial and biaxial geogrid-reinforced sandy soils under different normal stresses. The damage to the tire belt-reinforced sand was progressive, with the shear strength of each part of the sand depending on that of various other parts of the sand. The interlocking effect and pull-out resistance between a tire belt and sandy soil are extreme and significantly greater than those between geogrid and sandy soil. Cardile et al. 13 investigated the stability of a geosynthetic–soil interface under cyclic loading. Under specific conditions, pull-out resistance parameters should be considered when designing geosynthetic-reinforced soil structures. Derksen et al. 14 designed a test instrument where the interface between the reinforcing materials and the soil could be observed to study the interfacial interactions occurring along the direction of the reinforcing materials. Three regions were identified based on different interaction patterns. Chen et al. 15 conducted a comprehensive study of extensive box pull-out tests using the discrete element method. Moreover, large-scale pull-out tests were conducted on embedded biaxial and triaxial geogrid ballast samples. A discrete element model that can reasonably predict the pull-out resistance of geogrid-reinforced soil was developed. Furthermore, the test results indicate that the effect of the geogrid aperture on the tensile strength of the grid is greater than the effect of the geogrid thickness. Perkins and Edens 16 combined pull-out tests with finite element numerical calculations to establish a numerical finite element model for pull-out tests and simulated pull-out tests with geosynthetic materials. By comparing the results of the finite element analysis and pull-out tests, it was demonstrated that the creep of the geogrid has a slight effect on the deformation of the geosynthetic material. Mosallanezhad et al. 17 investigated the performance of a new reinforcement system through large-scale pull-out tests and numerical analysis. In the new system, they used cubic units attached to the geogrid with elastic strips. The results showed that the pull-out interaction coefficient of the new system was 100% greater than that of typical geogrid systems. The successful design of geosynthetic reinforcement for geotechnical structures, especially geogrid reinforcement, requires information about the interaction of geogrid–geogrid interfaces. Hajitaheriha et al. 18 conducted a series of indoor tests and finite element modeling analyses to investigate the significant effects of parameters such as the number of geogrids, burial depth and effective trench depth on the bearing capacity ratio (BCR). The above study suggests that experimental research can not only establish a research model and verify the reasonableness of the model but also provide reasonable design parameters for engineering applications 15 . In addition, the successful design of geosynthetic reinforcement, especially geogrid reinforcement, of geotechnical structures requires information related to the interaction of the reinforcement–soil interfaces.
Factors affecting the characteristics of geogrid–soil interfaces are critical parameters in geotechnical design, so domestic and foreign scholars have studied this topic. Jing et al. 19 used the discrete element method to simulate the pull-out testing of geogrid-reinforced ballast to demonstrate the effects of particle shape, geogrid size and friction on a ballasted geogrid system. Du et al. 20 conducted direct shear and pull-out tests on tailings reinforced with geogrids of different grid sizes to explore reasonable grid sizes. The results show that the ratio of the geogrid–tailings interface area to the shear surface area should be controlled between 0.47 and 0.55, within which the embedding and occlusion function of the transverse ribs of the geogrid can be fully exploited so that the reinforcement effect of the geogrid can be optimized. Abdi et al. 21 designed and developed a sizeable pull-out test apparatus to evaluate the interaction between clay and thin sand layers and geogrids. The effects of factors such as geogrid geometry and soil grain size on pull-out resistance were investigated to facilitate the use of poor-quality soils in engineering. Zhao et al. 22 investigated the frictional characteristics of biaxial geogrid-reinforced soil at different pull-out velocities and embedment lengths on self-developed test equipment. The test results show that the pull-out velocity has little effect on the shear strength of reinforced soil. However, the pull-out force increases with increasing embedment length. The obtained results are of reference value for the design of biaxial geogrids in engineering. To test the pull-out performance of uniaxial polypropylene geogrids, Baykal and Dadasbilge 23 conducted pull-out testing to analyze the effect of the geogrid displacement velocity, load magnitude, and specimen width on the specimen behavior. The results show that the boundary effect of the pull-out box affects the peak value of the pull-out test.
An overview of the above research shows that the experimental study of the interface characteristics of reinforced soil is an essential element in the study of the functional properties, damage mode, and reinforcement mechanism of reinforced soil structures, which is of great significance for reducing engineering costs and engineering accidents. The factors influencing the characteristics of the geogrid–gravelly soil interface are critical to understand for predicting the reinforcement–soil interface properties and reinforcement mechanism. There are currently only a few studies on the geogrid–gravelly soil interface characteristics in Xinjiang. This study investigated three categories of gravelly soils in Xinjiang via pull-out tests with different normal stresses, pull-out velocities, and soil water contents. Sandy soil was used to artificially formulate two types of gravelly soil with five gradations each. The influences of the particle shape and gradation of the gravelly soil on the interfacial characteristics of the geogrid were investigated. On this basis, reasonable parameters and suggestions were given for the structural design of the reinforced soil project and pull-out test. The findings of this study will hopefully promote the application of geogrids in gravelly soil roadbeds in Xinjiang.
Pull-out testing of the geogrid
Test device.
The laboratory instrument used in this study was a YT140 pull-out tester for geosynthetics at the Wuhan University of Technology, College of Transportation (Fig. 1 ). The YT140 instrument can perform pull-out tests for geogrids, geomembranes, geotextiles, and other geosynthetic materials. The horizontal loading system consists of a displacement sensor and a pull-out force sensor, which can adjust the pull-out force and displacement during the test. A hydraulic device loads the normal stress at constant pressure. The instrument can record the data changes at each stage during the pull-out test in detail.

YT140 pull-out tester for geosynthetics: ( a ) test apparatus, ( b ) loading box, ( c ) schematic diagram of the device.
Test materials
The round gravelly soil, angular gravelly soil, and sandy soil studied in this experiment were collected from three different areas in Xinjiang (Fig. 2 ). The round gravelly soil was from the soil extraction site of the road construction project of the Shawan section of the S101 line in the Tacheng area, Xinjiang. It is a widely used roadbed filler for mountain highways in Xinjiang. The angular gravelly soil was from the soil quarry in Aketao County, Kechu, Xinjiang, and is a poorly graded gravel; it is a typical angular gravelly soil. The sandy soil was from the territory of the Xinjiang Hami region, and the site is located on a piedmont impact plain. The parent rock of this sandy soil is dominated by sandstone and siliceous rock. The three-phase proportion indices of the three gravelly soils derived from compaction testing are shown in Table 1 .

Soil sampling location: ( a ) round gravelly soil, ( b ) angular gravelly soil, ( c ) sandy soil.
Due to the limitation of the instrument size, particles greater than 60 mm were removed from the gravelly soils. To maintain the skeletal role of such coarse particles, the continuity of the coarse grain gradation, and a performance similar to that with a natural gradation, the equal mass substitution method was used to convert the content of extralarge particles. That is, all coarse materials are described as a proportion of equal replacement of extralarge particles (to allow the maximum particle size to correspond to the 5 mm particle size content) 24 , 25 , 26 . The scale-reduced gradation curves of the three gravelly soils for the test are shown in Fig. 3 .

The soil gradation curves.
The uniaxial geogrid used in the test was TGDG50HDPE (Fig. 4 ), with 46 longitudinal ribs per meter, and the maximum thickness of the horizontal ribs was 1.38 mm. The biaxial geogrid used for the test was a polypropylene biaxially oriented geogrid, model TGSG15-15 (Fig. 4 ). The geometric and strength characteristics of the geogrids are shown in Table 2 .

Schematic diagram of geogrids: ( a ) uniaxial geogrids and ( b ) biaxial geogrids.
The geogrid was cut according to the dimensions of the YT140 geosynthetic material pull-out tester loading box. The geogrid specimen used in this pull-out test contained eight vertical ribs along the width direction. The total length was 255 mm, the net length after deducting the distance inside the fixture was 237.5 mm, and the initial width of the geogrid buried in the soil was 100 mm.
Test design
Before the start of testing, the YT140-type geosynthetic pull-out instrument was calibrated. The standard calibrator fixed in the equipment recorded the measured value during tensile testing, which was compared to the standard value; then, the instrument was adjusted so that the error was within a reasonable range. Following the operation method stipulated in the “Test Methods of Geosynthetics for Highway Engineering” (JTG E50-2006), the geogrid was sampled across 75% of the width of the test box. To ensure that the reinforcing material could not be pulled out of the loading box and that a sufficient anchorage length was reserved, 300 mm was considered along the length direction. First, the lower box was filled in layers and compacted according to the set degree of compaction, and the loose soil particles on the surface were brushed off with a wire brush after each layer of filling to ensure a rough surface and a tight bond between the soil layers, with the top layer of the filling surface initially reaching slightly higher than the lower edge of the seam opening. After the lower box was filled, the specimen was pre-pressurized. The surface was cleaned after the prepressurization treatment so that the fill surface was flush with the lower edge of the seam opening. Then, the buried length of the 10–15 cm geogrid was centered and flatly laid on the soil surface of the lower box. The tensile end of the geogrid aligned with the seam opening between the upper and lower boxes and connected to a horizontally oriented fixture. A plate with a narrow slit of an adjustable height was inserted so that the positive lower edge was on the specimen's surface to fix the plate's position. Subsequently, the filling of the test box was continued in layers, and the layers were compacted until the compacted soil surface was flat and slightly below the top of the box. Finally, the pressurized plate was placed on top, and prepressure was applied for consolidation; the consolidation time was at least 15 min.
After the specimen preparation, a small amount of horizontal load was applied so that the horizontal loading device became taut, and the pull-out force of the instrument was set to zero. The pull-out velocity was set, a horizontal force was applied, pulling started, and after the pull-out force reached the peak, the test continued until it stabilized and then stopped. The pull-out force gradually pulled out the geogrid from the system. If no peak pull-out force occurred or the specimen was pulled out of the box as a whole, the length of the geogrid buried in the soil was shortened, and the test was repeated. The test program is shown in Table 3 .
In a pull-out test, the boundary effect of the sidewall of the pull-out box cannot be neglected. Figure 5 shows the pull-out curve of the uniaxial geogrid in the S1 soil sample when the normal stress is 100 kPa. After the pull-out test starts, the curve exhibits an obvious upward trend, after which the pull-out force decreases sharply. This is due to the increase in the pull-out displacement; geogrid mesh holes on the soil body of the embedded fixation effect lead to movement of the soil particles to the pull-out outlet, resulting in an increase in the density of the region near the pull-out outlet until the final geogrid becomes stuck in the pull-out outlet, resulting in a sharp increase in the pull-out force and ultimately in geogrid fracture. In contrast, this situation does not occur in actual projects because there are no fixed sidewall constraints. If the pull-out box is large enough, the geogrid can also break before it is pulled out. Therefore, the elimination of the boundary effect can only be performed by correcting the pull-out force–pull-out displacement curve. If the pull-out curve shows an upward section with a sharp increase in the pull-out force, this section is removed.

Force‒displacement curves of the S1 soil samples at a normal stress of 100 kPa.
Pull-out test results and analysis
Analysis of the force‒displacement curves of the pull-out tests under various normal stresses.
To study the influence of normal stress on the characteristics of the geogrid–soil interface in the pull-out test, a TGDG50HDPE uniaxial geogrid was used as the reinforcing material, and the S1 soil was used as the filler. A total of 7 groups of geogrid–gravelly soil pull-out tests with different normal stresses were carried out with a pull-out velocity of 1.0 mm/min. As shown in Fig. 6 , the curve between the pull-out displacement and force varies widely under different normal stresses. The pull-out force increases with increasing pull-out displacement, and the relationship between the pull-out force and pull-out displacement corresponds to strain hardening. At the beginning of the pull-out tests, the curves of the relationship between the pull-out displacement and force under different loads all have a linear segment for small pull-out displacements. This segment is the static friction stage, and its slope increases with normal stress. The pull-out displacement in this section mainly reflects the deformation of the geogrid. The greater the normal stress is, the longer the static friction stage, and the greater the pull-out force. After the linear static friction stage ends, the curve between the pull-out displacement and force increases linearly. The analysis shows that the curves of the relationship between the pull-out displacement and force under different normal stresses can be separated into two groups at this stage. The slope of the curve under 90–110 kPa of normal stress is significantly larger than that under 50–80 kPa of normal stress, and the pull-out force increases faster with increasing pull-out displacement. Afterward, the curves of the relationship between the pull-out displacement and force enter a nonlinearly increasing phase, in which the pull-out force of the geogrid increases at a slower velocity with increasing pull-out displacement. When the pull-out displacement reaches a certain level, the pull-out force peaks. Finally, the each curve of the relationship between the pull-out displacement and force ends with the peak pull-out force remaining stable or the geogrid fracturing.

Force‒displacement curves of pull-out tests of S1 soil under various vertical loads.
The relationship between the normal stress and the peak pull-out force was analyzed by comparing the geogrid force‒displacement curves of the pull-out tests under various vertical loads. When the normal stress is low, the force between the soil particles and the force between the soil and geogrid are small, the movement of the soil particles is easier to achieve, the embedment effect on the horizontal ribs of the geogrid is small, and the friction between the soil and geogrid is also very small. Hence, the pull-out force increases slowly with the pull-out displacement at the late stage of the test. This increase is mainly due to the resistance of the soil particles embedded in the mesh and the horizontal ribs before the crowding of the horizontal ribs 27 . When the normal stress is high, the force transmitted between the soil particles and the soil particles to the geogrid is large, and the friction force is high 28 . The more significant shear dilation effect at the interface between the soil particles and the geogrid makes the soil particles continuously compact. The embedment effect between the soil and the geogrid is more prominent. As a result, the pull-out resistance continues to increase, and the pull-out displacement corresponding to the peak strength increases.
The above analysis shows that the interface strength parameters should differ under the different normal stresses and peak pull-out forces on the geogrid in different layers. At present, the relevant specification does not consider this pattern. Applying a specific vertical load on the upper part of the geogrid or appropriately increasing the overburden thickness can improve the stability of the lower geogrid-reinforced soil.
Analysis of the force–displacement curves of the pull-out tests under various pull-out velocities
The TGDG50HDPE uniaxial geogrid was used as the reinforcing material, and the S1 soil and S2 soil were used as fillers to conduct pull-out tests at different pull-out velocities under 100 kPa of normal stress to study the effect of the change in pull-out velocity on the mechanical characteristics of the geogrid-reinforced gravelly soil. The pull-out velocity of the geogrid–soil pull-out test can be selected according to the site soil material and drainage conditions, as well as the consolidation rate of the soil samples. According to the “Test Methods of Geosynthetics for Highway Engineering” (JTG E50-2006), the corresponding range for this study is generally 0.2–3.0 mm/min. Thus, four different pull-out velocities of 1.0, 1.5, 2.0, and 3.0 mm/min were considered, and the force‒displacement curves of the pull-out tests were determined under a normal stress of σ = 100 kPa.
Figure 7 a, b show the geogrid force‒displacement curves of the pull-out tests for the S1 soil and S2 soil at different pull-out velocities. The overall curves of both soil samples exhibit strain hardening for all four pull-out velocities considered.

Force‒displacement curves of pull-out tests under various pull-out velocities: ( a ) S1 soil, ( b ) S2 soil.
Figure 7 a shows that the greater the pull-out velocity is, the greater the rate of increase in the pull-out force in the middle of the pull-out stage. Moreover, the difference between the peak pull-out force and the corresponding pull-out displacement is relatively small at the tested pull-out velocities. Because the coarse particles of round gravelly soil are spherical, the particles are more likely to move and rotate when subjected to a pull-out force, which is more likely to dissipate the dilatancy effect. Therefore, the round gravelly soil particles will be rearranged after a specific pull-out displacement.
Figure 7 b shows that the larger the pull-out velocity, the more pronounced the strain hardening phenomenon of the angular gravelly soil is, the faster the pull-out force increases with the pull-out displacement, and the larger the peak pull-out force is 22 . Compared to the peak pull-out force at a pull-out rate of 1 mm/min, the peak pull-out force at rates of 1.5 mm/min, 2 mm/min, and 3 mm/min increases by 30.7%, 70.6%, and 83.3%, respectively. This means that when the pull-out velocity is small, the relative displacement of the geogrid–gravelly soil interface is small per unit of time, and the geogrid has a long travel time to complete the displacement. The soil particles in the interface range have a stress concentration at the horizontal ribs that dissipates continuously with the rearrangement of soil particles. The stress of the reinforcing material should be evenly distributed, and the required pull-out force should be small. The larger the pull-out velocity is, the larger the relative displacement at the geogrid–soil interface per unit time. Additionally, the soil particles within a specific range above and below the geogrid–soil interface cannot readjust. Thus, the stress concentration at the horizontal ribs cannot dissipate, causing the soil near the geogrid to undergo shear dilation 29 . A significant interfacial frictional resistance is generated, increasing the peak pull-out force as the pull-out velocity increases.
The interaction mechanism between the geogrid and soil is more complex and closely related to the loading rate. In engineering applications, the mechanical performance index parameters should be determined through tests according to the actual conditions of the project. The geogrid–gravelly soil reinforcement structure takes some time to stabilize. Considering the safety of the structure, it is recommended to select a pulling speed of 1.5–2 mm/min for round gravelly soils and 1 mm/min for angular gravelly soils when selecting structural calculation parameters.
Analysis of the force‒displacement curves of the pull-out tests under various particle shapes and gradations
To study the effect of the gravelly soil particle shape and gradation on the geogrid–gravelly soil interface characteristics, coarse particles larger than 5 mm were sieved out of the S3 sandy soil, and the remaining fine particles were retained as the fine particle fraction of the test soil material. Compaction tests were performed on the fraction of fine particles less than 5 mm, yielding a maximum dry density of 1.61 g/cm 3 and an optimum water content of 6.1% for the fine particles. Crushed stone and pebble stone of 1 to 2 cm were used as the coarse grains of the gravelly soils and mixed with fine-grained soils in different proportions to make five gradations ranging from fine to coarse and a total of ten different gradations of angular gravelly and round gravelly soils. The compaction of these ten soil gradations was converted using the maximum dry density and optimum water content of the fine-grained fraction less than 5 mm to ensure that the compaction remained consistent. The grading scheme and physical properties are shown in Table 4 . The gradation curves of the five artificially formulated gravelly soils and the gradation curves of the sandy soil are shown in Fig. 8 .

The gradation curves of artificially prepared gravelly soil.
A TGSG15-15 biaxial geogrid was used as the reinforcing material for these tests. The force‒displacement curves of the pull-out tests of round gravelly soil and angular gravelly soil with different gradations were obtained under a 50 kPa normal stress and a 2.0 mm/min pull-out velocity, as shown in Fig. 9 a, b.

Force‒displacement curves of pull-out tests: ( a ) round gravelly soil, ( b ) angular gravelly soil.
Figure 9 a shows that the peak pull-out force of the sandy soil (0.51 kN) at a normal stress of 50 kPa is greater than the peak pull-out force of gradation 1 (0.44 kN) and gradation 2 (0.31 kN) with a lower content of round gravel. Because the surfaces of the pebble-like coarse particles used in this test are smooth, the friction coefficient is lower than that of the sandy soil, which reduces the internal friction angle φ of the mix. Therefore, the coarse particles distributed in the sandy soil are separated from each other when the coarse particle content is low, it is difficult to achieve mutual occlusion, and the pull-out force is smaller than that of pure sandy soil. The peak strength of gradation four among the five round gravelly soils is the largest at 0.88 kN, 1.73 times that of the sandy soil, 2.0 times that of gradation 1, and 2.73 times that of gradation 2. The difference in peak strength between gradation 3 and gradation 5 is minor, and the peak strengths are 0.73 kN and 0.66 kN, respectively.
Figure 9 b shows that the peak pull-out forces of the angular gravelly soil at a normal stress of 50 kPa are greater than the peak pull-out forces of the sandy soil. Among the five angular gravelly soils, the peak pull-out force of gradation 3 is 1.22 kN, which is 2.41 times that of the sandy soil, 1.91 times that of gradation 1, and 1.77 times that of gradation 2. The difference in the peak pull-out forces between gradation 4, 1.17 kN, and gradation 5, 1.11 kN, is small.
Figure 9 a, b show that the sandy soils of gradations 1 and 2 have similar trends for the curve segments after the peak pull-out force. Round gravelly soil with a higher coarse particle content (gradation 3 to gradation 5) exhibits strain softening. Gradation 3 to gradation 5, with higher coarse-grained contents, of angular gravelly soil show strain hardening characteristics in the curve's rising section after the pull-out force reaches its peak value. For gradation 3 to gradation 5, the angular gravelly soil and round gravelly soil, the pull-out forces developed faster and peaked earlier than those of the other three groups of tests. This indicates that the coarse grains are involved in the embedded fixation effect earlier and that only a very small pull-out displacement is required to achieve a specific strength. Meanwhile, comparing the force‒displacement curves of the pull-out tests of the angular gravel and round gravelly soils, it can be seen that the more coarse-grained material there is, the more pronounced the curve fluctuation, showing a clear step-like shape. When more coarse particles are present, the rotation, locking, and movement of soil particles affect the pull-out force of the geogrid more. In addition, with 1–2 cm coarse grains, the gravel material gradation is not uniform, and the large particle distribution dramatically influences the curve during the pull-out test. The large particles at the nodes and horizontal ribs of the geogrid are pushed as the geogrid is pulled. The adjustment of the misaligned large particles in the mesh increases the resistance of the large particles after realignment. Thus, the fluctuation in the force‒displacement curve of the pull-out test is more pronounced, showing an apparent step-like shape 30 .
Figure 10 shows that when the content of particles larger than 5 mm in the test material is 30%, the pull-out friction effect is substantially greater than that of general sandy soils. When the gravel content is between 30 and 40%, the fine particles in the gravelly soil fill the pores between the coarse particles, making the material denser. The responses of the coarse and fine particles in this case are coupled, and the contact area with the geogrid surface will reach a maximum. Conversely, when the gravel content exceeds 40%, the large particles play a skeletal role, and the fines are too small to fill the pores between the large particles. The frictional effect between the soil and reinforcement is then reduced 31 . This shows that appropriately increasing the content of coarse particles in gravelly soils can improve the shear strength of the reinforcement–soil contact surface and its residual shear strength 32 .

Curves of the peak shear stress of specimens with coarse particles.
The peak strength of the coarse grains of the irregular angular gravelly soil is generally significantly greater than that of the round gravelly soil with rounded coarse grains under the same working conditions in the pull-out test, indicating that the reinforcement effect of angular gravelly soil is greater than that of the round gravelly soil. Generally, in pull-out tests, angular gravelly soil has a peak strength that is 30% to 40% greater than that of round gravelly soil of the same gradation.
The above analysis shows that when the content of coarse particles with particle sizes greater than or equal to 1 cm is greater than 30%, the peak strength of the pull-out test is the greatest observed in this work. To ensure a good reinforcement effect, the content of coarse particles in geogrid-reinforced gravelly soil is recommended to be 30% to 40% for structure design, and it is recommended that gravelly soil with angular particles is used as roadbed filler.
Analysis of the force‒displacement curves of the pull-out tests under various water contents
In engineering practice, rainfall is the cause of damage to reinforced structures, and the water content is the main factor affecting the stability of reinforced structures 33 . To study the influence of the water content in the reinforced soil on the geogrid–soil interface characteristics, a pull-out test of the S3 soil sample under a 50 kPa normal stress and a 2.0 mm/min pull-out velocity was carried out by using a YT140 pull-out tester for geosynthetics with TGDG50 uniaxial geogrids under six groups of different water contents. The ultimate pull-out force of the geogrid was tested for different water contents.
Figure 11 shows the force‒displacement curves of sandy soils with different water contents from the pull-out tests. A clear differentiation in the curve shapes occurs at a water content of 6.4%. When the water content ranges from 2% to 6.4%, the force‒displacement curves of the pull-out test overlap at the beginning of the pull-out displacement, and the pull-out force increases faster with increasing displacement. When the water content ranges from 2 to 6.4%, the higher the water content, the earlier the peak pull-out force appears. The force‒displacement curves of the pull-out test show strain softening after the peak value, and the curve has a decreasing trend. When the water content is more significant than 6.4%, the peak pull-out force is lower, and the pull-out force increases more slowly with increasing pull-out displacement. The force‒displacement curves of the pull-out tests show a peak followed by a flat section, reflecting strain hardening. The displacement required to reach a specific pull-out force is greater at a higher water content.

Force‒displacement curves of the pull-out tests of S3 soil with different water contents.
Figure 12 shows the relationship between the ultimate pull-out force and the water content of gravelly soil. Clearly, the ultimate pull-out force increases and then decreases with increasing water content. The role of geogrids in reinforcing gravelly soil is mainly related to friction and embedded fixation. At low water contents, pseudocohesion occurs in gravelly soils due to capillary water action at the edges. The pseudocohesion will initially increase with increasing water content, and the resistance of the surrounding soil particles to movement when the geogrid is pulled increases. When the pseudocohesion reaches its maximum value, the pull-out resistance also peaks. Subsequently, the pseudocohesion decreases as the water content increases until it disappears, and the pull-out resistance decreases. When the pseudocohesion disappears, the water content then increases. At this point, the water acts as a lubricating fluid between the soil particles and at the contact surface between the geogrid and the soil particles. The higher the water content is, the more pronounced the lubrication effect will be such that the pull-out resistance will decrease sharply with increasing water content.

Relationship between the ultimate pull-out force and water content of gravelly soil.
In addition, the sandy soil used in this test is a typical cohesionless soil. When the water content in the soil changes, the friction coefficient between the soil particles and between the geogrid and soil particles decreases with increasing water content, which leads to a decrease in the friction between the soil and grids. Moreover, when the water content approaches the optimum water content, the compaction of the fill gradually increases, and the embedment effect of soil particles on the mesh becomes more pronounced 34 . The resistance of the transverse rib to the soil particles gradually dominates. As the water content continues to increase, the friction between the soil and the geogrid continues to decrease, the compaction of the soil decreases, the resistance of the horizontal rib to the soil particles gradually decreases, and the ultimate pull-out force appears to decay sharply 35 .
According to the above analysis, during the construction of reinforced structures, attention should be given to selecting the two indicators: the water content and compaction degree of the fill soil. A suitable water content should be selected during the construction process and should be at most the optimum water content. The compaction degree should be as close as possible to the maximum for the fill material used. Reinforced structures should be designed to prevent rainwater immersion during the heavy rainfall flood season, as these processes reduce the strength of the structure and lead to structural instability.
On the basis of the above research results, the parameters of the likely cohesion ( c sg ) and likely interface friction angle ( φ sg ) are introduced for describing the strength of the geogrid–soil interface. For a given soil sample and a given grating, c sg and φ sg are constants, so c sg and φ sg are the recommended parameters for use in engineering design and testing. After determining the ultimate pull-out force under different normal stresses based on the pull-out curves of the uniaxial geogrids in three soil samples, the corresponding interface shear strength τ f is calculated from Eq. ( 1 ). On this basis, the interface strength indices c sg and φ sg can be obtained by plotting the τ f – σ relationship (Table 5 ).
where T d is the ultimate pull-out force (kN) and L 2 is the length of the part of the geogrid buried in the soil (m). B is the width of the geogrid specimen (m).
Table 5 shows that the interfacial friction angle is greater than 38° in all cases except for the case of S2 soil with a water content of 6.6%. The interfacial friction angle is not less than 40° at the optimum water content. The interface strength between the gravelly soil and the uniaxial grid is very high. Therefore, the water content at the time of rolling during roadbed construction is generally equal to or close to the optimum water content. In addition, the interfacial cohesion between uniaxial grids and gravelly soils is not equal to zero; instead, the interfacial cohesion is more than 10 kPa. Additionally, the c sg for S3 soil is even greater than 100 kPa (w = 6.4%) while the current specification 36 is ignored, which is on the conservative side. Because the cohesive force of the geogrid– gravelly soil interface is not between the two adhesive forces, the cohesive force c sg actually reflects the embedded fixation of the geogrid mesh and soil particles, particularly, that of the coarse particles in the gravelly soil and the geogrid holes and cross-ribs; this resistance is considerable, so ignoring it is too conservative.
This study used pull-out tests to study how four factors, namely, the normal stress, pull-out rate, particle shape and gradation, and water content, affect the geogrid–gravelly soil interface properties. According to the research results, reasonable parameters and suggestions are given for future engineering structure design and pull-out testing. In addition, in the design and construction of roadbeds, the type of geogrid should be selected based on the actual force and deformation of the roadbed. Uniaxial geogrids are suitable for resisting unidirectional forces, such as the reinforcement of high-fill roadbeds. Biaxial geogrids are suitable for resisting uneven settlement and deformation in weak roadbeds. However, this study investigated only the force‒displacement curves and peak pull-out forces of geogrid-reinforced coarse-grained soils under the above four factors, and the sample size was small. In the experimental design, not all three soil types were considered in the pull-out tests for each factor due to the limitations of the test conditions. For example, only the S1 soil was adopted in the tests that considered the effect of normal stress on the interfacial characteristics of the reinforced soil, and the S3 soil was not considered in the pull-out velocity tests. However, the patterns derived from these tests can be applied to other soils 3 , 37 , 38 . In the future, we will further expand our research on the factors influencing reinforced soils. Moreover, at the microscale, studies on the movement of gravelly soil particles under the action of different factors and changes in the influence zone of reinforcement have yet to be conducted. Using digital image correlation (DIC) or particle image velocimetry (PIV) to study the microscale motions at the reinforcement–soil interface allows for a better analysis of the evolution and distribution of the particle displacement field in the reinforcement influence zone of the soil 39 . At present, effective methods for studying the interfacial characteristics of reinforced soils include pull-out tests and direct shear tests. However, the two methods produce different test data, failure modes, and strength indices in practical tests 40 , 41 . This study used only the pull-out test to analyze geogrid–gravelly soil interface characteristics. In the future, the results of pull-out test under the same experimental conditions should be compared with the results of direct shear to explore the differences between and advantages and disadvantages of the two tests for studying the interfacial characteristics of reinforced soil.
In this study, a series of pull-out tests were conducted on geogrid-reinforced gravelly soils to determine the effects of different normal stresses, pull-out rates, soil particle shapes and gradations, and moisture content conditions on the interfacial properties of reinforced soils. Based on the pull-out test data, the interfacial strength parameters of the three types of soils reinforced by uniaxial geogrids were obtained for different normal stresses and water contents. Reasonable parameters and suggestions were given for the structural design of reinforced soil engineering and pull-out testing. The following conclusions were drawn:
The pull-out force increases with the pull-out displacement at each of the normal stresses tested, and the ultimate pull-out force increases continuously with the normal stress. Therefore, in the design and construction stage of reinforced soil structures, appropriately increasing the geogrid burial depth is helpful for improving the stability of the geogrid-reinforced soil.
The greater the pull-out velocity is, the more pronounced the strain-hardening behavior reflected in the force‒displacement curves of the pull-out tests. The faster the pull-out force continues to increase, the greater the peak pull-out force. Considering the safety of a structure, when choosing the structural calculation parameters, it is recommended to use a pull-out velocity of 1.5 –2 mm/min for the pull-out testing of geogrid-reinforced round gravelly soil and a pull-out velocity of 1 mm/min for the pull-out testing of angular gravelly soil.
Among the conditions tested, when the content of coarse particles with particle sizes greater than or equal to 1 cm is greater than 30%, the peak force of the pull-out test is the largest. To ensure a good reinforcement effect, the content of coarse particles in the geogrid–gravelly soil reinforcement structure design is recommended to be 30% to 40%, and it is recommended to prioritize gravelly soil with angular particles as roadbed filler.
When the water content in the sandy soil is less than the optimum, the trend of the force‒displacement curves and the peak pull-out forces of the pull-out tests are less different than when the water content is greater than the optimum. However, when the water content exceeds the optimum, the peak pull-out force decreases sharply. Therefore, in the design and construction of geogrid-reinforced soil engineering, special attention should be given to selecting and implementing the two indicators of the fill soil: the water content and compaction of the fill soil should be approximately the optimal water content and maximum compaction. During the construction and operation of geogrid-reinforced soil engineering structures, special attention should be given to the drainage system of the structure to avoid structural failure due to an excessive water content of the fill.
Uniaxial geogrid and gravelly soil interface cohesion c sg is larger; it is the grille cross rib end bearing resistance embodiment, is not a geogrid—soil interface viscous size of the reflection of the role of the actual engineering design to ignore the role of the c sg is unreasonable conservative practice.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Wang, J., Liu, F., Wang, P. & Cai, Y. Particle size effects on coarse soil-geogrid interface response in cyclic and post-cyclic direct shear tests. Geotext. Geomembr. 44 , 854–861. https://doi.org/10.1016/j.geotexmem.2016.06.011 (2016).
Article Google Scholar
Liu, C.-N., Ho, Y.-H. & Huang, J.-W. Large scale direct shear tests of soil/PET-yarn geogrid interfaces. Geotext. Geomembr. 27 , 19–30. https://doi.org/10.1016/j.geotexmem.2008.03.002 (2009).
Kayadelen, C., Önal, T. Ö. & Altay, G. Experimental study on pull-out response of geogrid embedded in sand. Measurement 117 , 390–396. https://doi.org/10.1016/j.measurement.2017.12.024 (2018).
Article ADS Google Scholar
Moraci, N. et al. Soil geosynthetic interaction: Design parameters from experimental and theoretical analysis. Transport. Infrastruct. Geotechnol. 1 , 165–227. https://doi.org/10.1007/s40515-014-0007-2 (2014).
Karnamprabhakara, B. K., Chennarapu, H. & Balunaini, U. Modified axial pullout resistance factors of geostrip and metal strip reinforcements in sand considering transverse pull effects. Geotech. Geol. Eng. 41 , 3847–3858. https://doi.org/10.1007/s10706-023-02485-7 (2023).
Makkar, F. M., Chandrakaran, S. & Sankar, N. Performance of 3-D geogrid-reinforced sand under direct shear mode. Int. J. Geotech. Eng. 13 , 227–235. https://doi.org/10.1080/19386362.2017.1336297 (2019).
Article CAS Google Scholar
Makkar, F. M., Chandrakaran, S. & Sankar, N. Experimental investigation of response of different granular soil-3D geogrid interfaces using large-scale direct shear tests. J. Mater. Civ. Eng. 31 , 04019012. https://doi.org/10.1061/(ASCE)MT.1943-5533.0002645 (2019).
Xu, Y., Williams, D. J. & Serati, M. Measurement of shear strength and interface parameters by multi-stage large-scale direct/interface shear and pull-out tests. Meas. Sci. Technol. 29 , 085601. https://doi.org/10.1016/j.geotexmem.2016.06.011 (2018).
Hai-long, Z., Yi-chuan, X., Ai-jun, Z. & Shao-hong, Z. Experimental investigation on shear strength of reinforced coarse-grained soil. J. China Inst. Water Resour. Hydropower Res. 11 , 41–47 (2013).
Google Scholar
Wen-bai, L. & Jian, Z. Experimental research on interface friction of geogrids and soil. Rock Soil Mech. 30 , 965–970 (2009).
Ochiai, H., Otani, J., Hayashic, S. & Hirai, T. The pull-out resistance of geogrids in reinforced soil. Geotextiles Geomembr. 14 , 19–42 (1996).
Li, L. H., Chen, Y. J., Ferreira, P. M. V., Liu, Y. & Xiao, H. L. Experimental investigations on the pull-out behavior of tire strips reinforced sands. Materials (Basel) https://doi.org/10.3390/ma10070707 (2017).
Article PubMed PubMed Central Google Scholar
Cardile, G., Pisano, M. & Moraci, N. The influence of a cyclic loading history on soil-geogrid interaction under pullout condition. Geotextiles Geomembr. 47 , 552–565. https://doi.org/10.1016/j.geotexmem.2019.01.012 (2019).
Derksen, J., Ziegler, M. & Fuentes, R. Geogrid–soil interaction: A new conceptual model and testing apparatus. Geotextiles Geomembr. 49 , 1393–1406. https://doi.org/10.1016/j.geotexmem.2021.05.011 (2021).
Chen, C., McDowell, G. R. & Thom, N. A study of geogrid-reinforced ballast using laboratory pull-out tests and discrete element modelling. Geomech. Geoeng. 8 , 244–253. https://doi.org/10.1080/17486025.2013.805253 (2013).
Perkins, S. & Edens, M. Finite element modeling of a geosynthetic pullout test. Geotech. Geol. Eng. 21 , 357–375. https://doi.org/10.1023/b:gege.0000006053.77489.c5 (2003).
Mosallanezhad, M., Taghavi, S. H. S., Hataf, N. & Alfaro, M. C. Experimental and numerical studies of the performance of the new reinforcement system under pull-out conditions. Geotextiles Geomembr. 44 , 70–80. https://doi.org/10.1016/j.geotexmem.2015.07.006 (2016).
Hajitaheriha, M. M., Akbarimehr, D., Hasani Motlagh, A. & Damerchilou, H. Bearing capacity improvement of shallow foundations using a trench filled with granular materials and reinforced with geogrids. Arab. J. Geosci. https://doi.org/10.1007/s12517-021-07679-y (2021).
Jing, G. Q., Luo, X. H. & Wang, Z. J. Micro-analysis ballast-geogrid pull out tests interaction. Appl. Mech. Mater. 548–549 , 1716–1720. https://doi.org/10.4028/www.scientific.net/AMM.548-549.1716 (2014).
Du, C., Niu, B., Wang, L., Yi, F. & Liang, L. Experimental study of reasonable mesh size of geogrid reinforced tailings. Sci. Rep. 12 , 10037. https://doi.org/10.1038/s41598-022-13980-x (2022).
Article ADS CAS PubMed PubMed Central Google Scholar
Abdi, M., Zandieh, A., Mirzaeifar, H. & Arjomand, M. Influence of geogrid type and coarse grain size on pull out behaviour of clays reinforced with geogrids embedded in thin granular layers. Eur. J. Environ. Civ. Eng. 25 , 2161–2180. https://doi.org/10.1080/19648189.2019.1619627 (2021).
Zhao, Y., Yang, G., Wang, Z. & Liang, X. Optimal configuration for the wind-solar complementary energy storage capacity based on improved harmony search algorithm J. Phys. Conf. Ser. 2598 , 012016 (2023) (IOP Publishing).
Baykal, G. & Dadasbilge, O. Geosynthetics in Civil and Environmental Engineering: Geosynthetics Asia 2008 Proceedings of the 4th Asian Regional Conference on Geosynthetics in Shanghai, China. 174–178 (Springer, 2008).
Hai-tao, L. & Xiao-hui, C. Discrete element analysis for size effects of coarse-grained soils. Rock Soil Mech. 30 , 287–292 (2009).
Tang, K., Xie, X. & Yang, L. Research on mechanical characteristics of gravel soil based on large-scale triaxial tests. Chin. J. Under Sp. Eng. 10 , 580–585 (2014).
Yong-zhen, Z., Wei, Z., Jia-jun, P. & Na, Z. Effects of gradation scale method on maximum dry density of coarse-grained soil. Rock Soil Mech. 36 , 417–422 (2015).
Ismail, M., Joohari, M., Habulat, A. & Azizan, F. Pull-out resistance of sand-geosynthetics reinforcement. Int. J. Integr. Eng. 13 , 87–93. https://doi.org/10.30880/ijie.2021.13.03.010 (2021).
Abdi, M. & Zandieh, A. Experimental and numerical analysis of large scale pull out tests conducted on clays reinforced with geogrids encapsulated with coarse material. Geotextiles Geomembr. 42 , 494–504. https://doi.org/10.1016/j.geotexmem.2014.07.008 (2014).
Liu, J., Wang, B. & Sun, Y. Mechanism and mesoscopic characteristics of indirectly reinforced gravelly soil by a geogrid. Adv. Mater. Sci. Eng. https://doi.org/10.1155/2022/8536258 (2022).
Guangqing, Y., Guangxin, L. & Baojian, Z. Experimental studies on interface friction characteristics of geogrids. Chin. J. Geotech. Eng. 28 , 948–952 (2006).
Shengyou, L. Theory and Technology of Modern Reinforced Soil . 75–81 (China Communication Press, 2006).
Jia-Quan, W., Biao, W. U., Hong, Z., Qi, Z. & Gang, K. E. Large direct shear test research of interface interaction characteristics of geogrid and coarse grained soil. J. Guangxi Univ. Sci. Technol. (2015).
Feng, X., Yang, Q., Li, S. & Luan, M. Influence of water content on pullout behavior of geogrid in red clay. Chin. J. Rock Mech. Eng. 28 , 4059–4064 (2009).
Altay, G., Kayadelen, C., Taşkıran, T. & Kaya, Y. Z. A laboratory study on pull-out resistance of geogrid in clay soil. Measurement 139 , 301–307. https://doi.org/10.1016/j.measurement.2019.02.065 (2019).
Chen, J.-N., Ren, X., Xu, H., Zhang, C. & Xia, L. Effects of grain size and moisture content on the strength of geogrid-reinforced sand in direct shear mode. Int. J. Geomech. 22 , 04022006. https://doi.org/10.1061/(ASCE)GM.1943-5622.0002309 (2022).
Giroud, J. P. From geotextiles to geosynthetics: A revolution in geotechnical engineering. Proc. 3rd Int. Conf. Geotextiles, Vienna, 1–18 (1986).
Cai, X. et al. Study on interface interaction between uniaxial geogrid reinforcement and soil based on tensile and pull-out tests. Sustainability. https://doi.org/10.3390/su141610386 (2022).
Zhao, Y., Yang, G., Wang, Z. & Yuan, S. Research on the effect of particle size on the interface friction between geogrid reinforcement and soil. Sustainability https://doi.org/10.3390/su142215443 (2022).
Liu, J. et al. Experimental study on the fine-scale characteristics of a geogrid-gravelly soil reinforcement influence zone. Front. Earth Sci. https://doi.org/10.3389/feart.2022.1053728 (2023).
Wang, Z., Jacobs, F. & Ziegler, M. Experimental and DEM investigation of geogrid–soil interaction under pullout loads. Geotextiles Geomembr. 44 , 230–246. https://doi.org/10.1016/j.geotexmem.2015.11.001 (2016).
Kim, D. & Ha, S. Effects of particle size on the shear behavior of coarse grained soils reinforced with geogrid. Materials (Basel) 7 , 963–979. https://doi.org/10.3390/ma7020963 (2014).
Article ADS PubMed Google Scholar
Download references
Acknowledgements
This study was funded by the Enterprise Commissioned Science and Technology Project of Xinjiang Traffic Design Institute Company (No. KY2022121902).
Author information
Authors and affiliations.
College of Civil Engineering and Architecture, Xinjiang University, Urumqi, 830047, China
Jie Liu & Jiadong Pan
Xinjiang Transportation Planning Survey and Design Institute Co. Ltd., Urumqi, 830006, China
Jie Liu, Jiadong Pan, Qi Liu & Yan Xu
You can also search for this author in PubMed Google Scholar
Contributions
JL: Writing–original draft. JP: Writing–original draft, Writing–review and Editing Pictures and Tables. QL: Writing–review and editing. YX: Writing–review and editing. All authors reviewed the manuscript.
Corresponding author
Correspondence to Yan Xu .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Liu, J., Pan, J., Liu, Q. et al. Experimental study on the interface characteristics of geogrid-reinforced gravelly soil based on pull-out tests. Sci Rep 14 , 8669 (2024). https://doi.org/10.1038/s41598-024-59297-9
Download citation
Received : 02 January 2024
Accepted : 09 April 2024
Published : 15 April 2024
DOI : https://doi.org/10.1038/s41598-024-59297-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Geogrid reinforcement
- Coarse-grained soil
- Pull-out tests
- Interface parameters
- Geogrid–soil interaction
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

- Computer Vision
- Federated Learning
- Reinforcement Learning
- Natural Language Processing
- New Releases
- AI Dev Tools
- Advisory Board Members
- 🐝 Partnership and Promotion
LLMs have demonstrated remarkable capabilities across various domains, including complex scientific fields like mathematics and medicine. While they excel at accelerating experimental validation, they have yet to be extensively used for identifying new research problems. Previous approaches to hypothesis generation have focused on linking two variables, limiting their ability to tackle multifaceted real-world issues. The researchers aim to generate comprehensive research ideas by leveraging accumulated knowledge from vast scientific literature, surpassing methods that solely rely on concepts. Unlike other efforts that use knowledge in fragments, they integrate broad knowledge from scientific papers. Inspired by human iterative refinement processes, they also explore LLMs’ potential for refining research ideas iteratively.
ResearchAgent automates research idea generation using LLMs. It follows a three-step process mirroring human research practices: problem identification, method development, and experiment design. LLMs leverage existing literature to formulate ideas, where a core paper is selected along with its related citations. ResearchAgent augments LLMs with entity-centric knowledge extracted from the scientific literature to enhance idea generation. Additionally, it employs iterative refinement with ReviewingAgents, evaluating generated ideas based on specific criteria. To align LLM judgments with human preferences, human-annotated evaluation criteria are used to guide LLM evaluations. This iterative approach ensures the continual improvement of research ideas.

Experimental results demonstrate the efficacy of ResearchAgent in generating high-quality research ideas. It outperforms baselines across various metrics, especially when augmented with relevant entities, enhancing creativity. Inter-annotator agreements and agreements between human and model-based evaluations validate the reliability of assessments. Iterative refinements improve idea quality, although diminishing returns are observed. Ablation studies show the importance of both relevant references and entities. Aligning model-based evaluations with human preferences enhances the reliability of assessments. Ideas generated from high-impact papers are of higher quality. Performance with weaker LLMs drops significantly, highlighting the importance of using powerful models like GPT-4.
In conclusion, ResearchAgent accelerates scientific research by automatically generating research ideas, encompassing problem identification, method development, and experiment design. It enhances LLMs by utilizing paper relationships from citation graphs and relevant entities extracted from diverse papers. Through iterative refinement based on feedback from multiple reviewing agents aligned with human preferences, ResearchAgent produces more creative, valid, and clear ideas than baselines. It is a collaborative partner, fostering synergy between researchers and AI in uncovering new research avenues.
Check out the Paper . All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter . Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup .
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here

Sana Hassan
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
- Sana Hassan https://www.marktechpost.com/author/sana-hassan/ Researchers from UNC-Chapel Hill Introduce CTRL-Adapter: An Efficient and Versatile AI Framework for Adapting Diverse Controls to Any Diffusion Model
- Sana Hassan https://www.marktechpost.com/author/sana-hassan/ The Rise of NeuroTechnology and Its Fusion with AI
- Sana Hassan https://www.marktechpost.com/author/sana-hassan/ GNNBench: A Plug-and-Play Deep Learning Benchmarking Platform Focused on System Innovation
- Sana Hassan https://www.marktechpost.com/author/sana-hassan/ Evaluating World Knowledge and Memorization in Machine Learning: A Study by the University of Tübingen
RELATED ARTICLES MORE FROM AUTHOR
Dataset reset policy optimization (dr-po): a machine learning algorithm that exploits a generative model’s ability to reset from offline data to enhance rlhf from..., meet zamba-7b: zyphra’s novel ai model that’s small in size and big on performance, researchers from unc-chapel hill introduce ctrl-adapter: an efficient and versatile ai framework for adapting diverse controls to any diffusion model, reka unleashes reka core: the next generation of multimodal language model across text, image, and video, the role and impact of the chief ai officer (caio) in modern business, amazon bedrock expands ai portfolio with anthropic’s groundbreaking claude 3 series, dataset reset policy optimization (dr-po): a machine learning algorithm that exploits a generative model’s..., reka unleashes reka core: the next generation of multimodal language model across text, image,..., researchers from unc-chapel hill introduce ctrl-adapter: an efficient and versatile ai framework for adapting..., emerging trends in reinforcement learning: applications beyond gaming, meet osworld: revolutionizing autonomous agent development with real-world computer environments, this ai paper from microsoft and tsinghua university introduces rho-1 model to boost language..., autocoderover: an automated artificial intelligence ai approach for solving github issues to autonomously achieve....
- AI Magazine
- Privacy & TC
- Cookie Policy
🐝 FREE AI Courses on RAG + Deployment of an Healthcare AI App + LangChain Colab Notebook all included
Thank You 🙌
Privacy Overview
- Reference Manager
- Simple TEXT file
People also looked at
Original research article, optimal design of gas injection development method for enhanced recovery in terrestrial shale oil reservoir.

- 1 Research Institute of Petroleum Exploration and Development, PetroChina, Beijing, China
- 2 PetroChina Daqing Oilfield Co., Ltd., Daqing, China
- 3 School of Energy Resources, China University of Geosciences (Beijing), Beijing, China
This study investigates the shale oil drainage characteristics from the Gulong Sag, The objective is to clarify the development method for effective recovery enhancement of terrestrial shale oil. The investigation employs elastic depletion, CO 2 displacement, and CO 2 huff and puff coupled with nuclear magnetic resonance (NMR) measurements and numerical simulation methods. The study found that the elastic depletion, CO 2 displacement, and CO 2 huff and puff utilization efficiencies were 17.4%, 18.87%, and 21%, respectively. The study evaluated the oil drainage efficiency of different pore sizes in elastic depletion and CO 2 huff and puff modes. The results demonstrated a clear trend in the order of micropore, mesoporous and macropore, with micropores exhibiting the highest oil drainage efficiency due to gas channeling during CO 2 displacement. The use of CO 2 huff and puff has been shown to improve oil drainage efficiency by 6.02%∼9.2% for different pore sizes. The numerical simulation optimization results suggest an injection volume of 3,000 t per round per well, an injection rate of 100 t/d, and a soaking time of 20 d for optimal CO 2 huff and puff injection. This will increase oil production by 65,000 m³, resulting in an overall improvement of 24%. The study results provide a strong theoretical foundation for improving the recovery rates of terrestrial shale oil and gas through injection.
1 Introduction
China’s terrestrial shale oil is mainly distributed in the Songliao Basin, Ordos Basin, Junggar Basin, Sichuan Basin and Jianghan Basin, etc., which are widely distributed and have huge resources, The use of natural energy development suffers from rapid pressure drop and diminishing producation. Gulong shale oil is the most typical in situ terrestrial shale oil and the reservoir is characterised by tight lithology and high clay mineral content compared to domestic and foreign shales dominated by marine or saline lake basin deposits; The storage space is a nano-matrix pore with a pore throat diameter of 10 nm–50 nm; Porosity ranges from 2.1% to 12.0% and permeability is less than 0.01 mD ( Wang et al., 2021 ; He et al., 2023 ). Due to the characteristics of tight lithology, low porosity and low permeability, effective development is a major challenge and studies have shown that unconventional reservoirs can be effectively developed by gas injection to improve recovery ( Fu et al., 2023 ).
Tao conducted an experimental study of cyclic gas injection in the Eagle Ford Shale using a simulation method, and the results showed that cyclic gas injection in hydraulically fractured shale reservoirs can increase the total oil recovery rate by 29% ( Tao et al., 2013 ). Ao carried out high pressure PVT tests and long thin tube alternation flooding experiments to carry out the indoor evaluation study of gas injection and CO 2 flooding to improve recovery. Through the analysis of crude oil physical properties and oil displacement efficiency, it shows that the continuous injection of rich gas and alternating injection can improve the recovery rate by more than 28% ( Ao et al., 2016 ). Zhao carried out CO 2 –formation crude oil contact experiments, core seepage experiments and indoor displacement experiments to describe the two-phase seepage characteristics of CO 2 –formation crude oil, to analyse the CO 2 flooding mechanism and displacement characteristics, and to conduct mine experiments in the Jingbian extra-low permeability oil reservoir. Research has shown that the gas injection capacity of extra-low permeability reservoirs is twice that of water injection, and that gas injection can quickly and effectively replenish formation energy and increase oil production, with daily liquid and oil production in the test area increasing overall ( Zhao et al., 2018 ). Yao carried out an experimental study of CO 2 displacement using one-dimensional and two-dimensional nuclear magnetic resonance (NMR) technology evaluation methods with Ordos Basin Chang 7 Shale core samples. The results show that the relative volume fraction of free oil in the replacement is over 50% ( Yao et al., 2023 ). Kong took Hailar oilfield as the research object to carry out CO 2 injection gravity oil repulsion experiments, and the CO 2 flooding efficiency could reach 55.9% when injecting 1.2 PV of CO 2 at the original formation pressure of 10.57 MPa ( Kong et al., 2023 ). In recent years, many scientists at home and abroad have conducted research on different injection media, influencing factors and the degree of shale oil recovery.
In this paper, the core samples of the Gulong Sag were taken as the research objects, and the indoor experiments of elastic depletion, CO 2 displacement and CO 2 huff and puff were carried out based on the formation temperature and pressure conditions, so as to clarify the degree of utilization of different pore spaces and the efficiency of different development methods. The effect of different huff and puff parameters on enhanced recovery were further investigated with numerical simulation methods to provide a theoretical basis for the efficient development of shale oil in the Gulong Sag.
2 Materials and methods
The indoor experiments in this paper are based on NMR experimental methods with elastic depletion, CO 2 displacement and CO 2 huff and puff co-examination. In order to simulate the actual reservoir conditions, the experimental temperatures and pressures were consistent with the formation, and the oil used for the experiments was wellhead degassed crude oil. The utilization efficiency and the percentage of utilization pores of different sizes under different development methods were quantitatively characterised by NMR T 2 spectral analysis. Numerical simulation experiments were carried out to determine the optimum values of each parameter by optimising the design of the three main parameters.
2.1 Sample information
The mineral composition of the shale in the Gulong Sag is mainly dominated by clay minerals, quartz and feldspar, followed by calcite and dolomite. The specific parameters of the core samples are given in Table 1 .

Table 1 . Parameters of shale cores in the Gulong Sag.
2.2 Experimental setup
The experimental setup includes a MesoMR3-060H-I NMR instrument, drying apparatus, saturation device, loading device, high temperature and high pressure MR-dd displacement device, data acquisition and RF device, and hand pump. Where the NMR experiments have an echo interval of 0.2 ms and a waiting time of 3,000 ms.
2.3 Experimental methods
The following three experimental scenarios are based on the parameters of 41 MPa boundary pressure, 35 MPa pore pressure, 118.5°C actual reservoir temperature, 38 MPa reservoir pressure, 30% RH humidity and CO 2 with a purity of 99.95% or more as the displacement/huff and puff medium.
2.3.1 Elastic depletion experiments
The samples were vacuumed and saturated with formation crude oil after deoiling and drying, and then the sample pore pressure was increased by injecting crude oil at both ends of the sample under 41 MPa confinement pressure conditions, and the depletion pressure were set to 5 MPa, 15 MPa, 25 MPa, and 35 MPa, respectively. During the oil-saturation process, the confinement pressure was maintained unchanged and the T 2 spectrum of the NMR signal was monitored in real time, and when the NMR T 2 spectrum was stable, the saturation pressure was stopped and the pore pressure released. Once the pore pressure had been completely released and the NMR T 2 spectrum had stabilized, the T 2 spectrum of the sample’s NMR signal was measured at this point and the experiment was terminated.
2.3.2 CO 2 displacement experiments
The dried core samples were vacuumed and saturated with formation crude oil until the cores were fully saturated with formation crude oil to test the NMR T 2 spectra at this point. The confinement pressure was kept constant by the core holder and the T 2 spectra of the NMR signals were measured at displacement pressures of 5 MPa, 10 MPa, 15 MPa, and 20 MPa respectively and the NMR maps were plotted and the results analysed.
2.3.3 CO 2 huff and puff experiments
After deoiling and drying, samples were treated with evacuated, saturated formation crude oil and tested for NMR signals at this point. The T 2 spectrum of the NMR signal was tested under 35 MPa pore pressure and reservoir temperature conditions for 10 h, followed by pressure release and oil drainage for 5 h. The steps of CO 2 huff and puff, soaking and pressure release and oil drainage were repeated to test the NMR T 2 spectra with different rounds and to analyse the experimental results.
2.4 Numerical simulation methods
The results of the indoor experiments demonstrate that the CO 2 huff and puff mode has a high utilization efficiency. A CO 2 huff and puff mode was established based on the real reservoir characteristics in the Gulong Sag to investigate the impact of individual CO 2 huff and puff parameters on recovery improvement. The CO 2 huff and puff mode is presented in the table below. The numerical simulation model parameters were formulated based on the optimised design of the single-round injection volume of a single well, the injection rate, the soaking time, and the three main parameters (as shown in Table 2 ), using the basic parameters from Table 3 . The analysis of huff and puff oil production was conducted under various parameter conditions with confidence.

Table 2 . Range of optimisation parameters.

Table 3 . Basic model parameters.
3 Results and discussion
Figures 1A–C clearly demonstrates the NMR T 2 spectra for different conditions: elastic depletion mode, CO 2 displacement mode, and CO 2 huff and puff mode. The results unequivocally indicate that the degree of oil drainage varies depending on the pore size and elasticity. Pores with greater elasticity are significantly more effective in promoting oil drainage. The spectral samples clearly demonstrate that the pore structure of core samples (a) is relatively simple, while that of core samples (b) and (c) is relatively complex, as evidenced by their classification into single-peak and double-peak states.

Figure 1 . (A–C) show the NMR T 2 spectra of the samples during elastic depletion, displacement, and huff and puff modes, respectively.
3.1 Utilization efficiency in utilizing various development models
Figure 2 displays the utilization efficiency of four samples exhibiting the elastic depletion mode under different differential pressures. The figure clearly demonstrates that all four samples exhibit an increasing trend in utilization efficiency with increasing differential pressure of the depletion. This indicates that as the differential pressure of the depletion increases, the compressed fluid’s expansion energy in the pore space also increases, thereby promoting oil discharge. The results demonstrate that the utilisation efficiency of the samples varies significantly with differential pressure. The lowest efficiency was observed at 5 MPa, while the highest was achieved at 35 MPa, reaching an impressive maximum of 21.2%. Notably, utilisation efficiency increased rapidly as the differential pressure increased from 5 MPa to 15 MPa, and continued to gradually increase from 15 MPa to 25 MPa. Although the increase in utilisation efficiency was slower and less pronounced when the differential pressure increased from 25 MPa to 35 MPa, the overall trend indicates a clear relationship between differential pressure and utilisation efficiency. The elastic depletion mode resulted in an average utilization efficiency of 17.4% at a differential pressure of 35 MPa.

Figure 2 . Shows the utilization efficiency of four core samples in the elastic depletion mode at differential pressures.
As shown in Figure 3 , the utilization efficiency of CO 2 displacement mode samples increases with the differential pressure. All four samples exhibit an increase in utilization efficiency, with a maximum of 24.94%. Specifically, the efficiency increases by 8.55% at 10 MPa, 4.81% at 15 MPa, and 1.73% at 20 MPa. Increasing the differential pressure of the displacement from 5 MPa to 20 MPa results in a significant increase in average utilization efficiency. Notably, the CO 2 displacement mode with a 20 MPa differential pressure achieves an impressive average utilization efficiency of 18.87%. Overall, these findings demonstrate the clear benefits of increasing differential pressure in displacement processes.

Figure 3 . Shows the utilization efficiency of four core samples in CO 2 displacement mode at differential pressure of the displacement.
Figure 4 displays the utilization efficiency of CO 2 huff and puff mode samples during various rounds. The figure illustrates a gradual increase in utilization efficiency during huff and puff rounds 1–4, with an average increase of 7.3%. Utilization efficiencies for rounds 5 and 6 are slightly higher or lower. It is evident that increasing the number of huff and puff rounds can expand the swept volume and effectively improve the recovery rate. However, after a certain number of rounds, a small amount of oil in the pore is displaced, and the remaining oil becomes difficult to use or may not be used at all. The average utilization efficiency was 21.67% for 4 rounds and 21.84% for 6 rounds.

Figure 4 . Shows the utilization efficiency of four core samples in CO 2 huff and puff mode with different huff and puff rounds.
3.2 Utilization efficiency of utilising pores of different sizes under various development modes
Numerous studies have shown that NMR T 2 values correspond well with pore size distribution ( Maniesh et al., 2019 ; Sun et al., 2022 ; Du et al., 2023 ). Liu analysed the frequency of pore throat distribution in Gulong shale cores using nuclear magnetic and mercury intrusion methods. They calculated a conversion factor of 0.008 μm/ms between shale nuclear magnetic T 2 value and pore throat radius through statistical analysis ( Liu et al., 2023 ). The experimental core pores were classified using the pore classification method of the International Union of Pure (Chemical) and Applied Chemistry (IUPAC) . This method defines pore sizes of less than 2 nm as micropore, 2 nm–50 nm as mesoporous, and greater than 50 nm as macropore ( Gregg and Sing, 1983 ; Sing, 1985 ), with a conversion factor of 0.008 μm/ms. Figure 5 the utilization efficiency of pores of different sizes follows the order of macropore > mesoporous > micropore, from large to small. The higher percentage of free crude oil in the large aperture pore is due to smaller capillary resistance and comparable thickness of the adsorption layer in the large and small aperture pores. The free oil is able to release elastic energy during compression, which facilitates effective discharge.

Figure 5 . Pore utilization efficiency of different pore sizes in elastic depletion mode.
Figure 6 demonstrates that macropores are the primary contributors to oil drainage during CO 2 displacement, followed by micropores and mesoporous, according to the pore classification basis. The oil discharge contribution rate is expected to increase in the order of micropores, mesoporous, and macropores. However, the gas channeling effect prevents oil discharge under air pressure. As a result, the inefficiency of oil discharge increases with pore size, In fact, in some cases, the discharge efficiency of oil from micropores is even higher than that of mesoporous. In the T 2 spectrum shown in Figure 1B , the signal of the peak on the right for a 5 MPa displacement pressure difference is higher than that of saturated oil, This confirms the occurrence of gas channeling.

Figure 6 . Pore utilization efficiency of different pore sizes in CO 2 displacement mode.
Figure 7 in CO 2 huff and puff mode, the utilization efficiencies of different pores are in descending order: macropore > mesoporous > micropore. In CO 2 huff and puff mode, the driving force of crude oil discharge relies on the elastic force generated by the expansion of compressed fluid in the pore space. The efficiency of oil discharge in different pore space sizes increases significantly by 6.02%, 9.2%, and 8.16%, respectively, compared to that of the elastic depletion mode. This is due to the expansion of crude oil volume and the decrease in fluid viscosity caused by CO 2 dissolution.

Figure 7 . Pore utilization efficiency of different pore sizes in CO 2 huff and puff mode.
3.3 Optimisation of parameters for the numerical simulation of CO 2 huff and puff
3.3.1 optimisation of the injection volume.
Tang took the Jimusar shale as a research object and used numerical simulation method to optimise the CO 2 huff and puff scheme, and the results showed that there is an optimum value which can both improve the oil production and maximise the economic benefits ( Tang et al., 2022 ). Figure 8 clearly demonstrates the relationship between injection volume and cumulative oil production and oil exchange rate for a single well. The data shows that increasing injection volumes from 600 t to 9,600 t results in a corresponding increase in both cumulative oil production and oil exchange rate. The graph of cumulative oil production clearly shows that increasing the injection volume leads to an increase in oil production. This indicates that a higher injection volume results in more gas being dissolved in the crude oil, leading to improved gas swept efficiency and supplementing formation energy. As a result, huff and puff oil production is significantly increased. However, there is a turning point at 2,400 t ∼3,000 t for single injection volume of a single well, and the increase slows down after that. The oil change rate curve shows that the oil change rate decreases as the injection volume increases, and the combined oil production and oil change rate suggests a single injection volume of 3,000 t for a single well in a single round.

Figure 8 . (A) Relationship between different injection volumes and oil production and oil change rate (B) Cumulative oil production curves at different injection volumes.
3.3.2 Optimising the injection speed
Accelerating the injection rate can significantly improve oil production by enhancing injection pressure, shortening injection time, and increasing the efficiency of smaller hole slit waves. It is important to note that a very high injection rate may lead to gas scrambling, which should be avoided. Cao analyzed different injection rates and recovery rates by simulation, and the results showed that as the injection rate increased, the recovery factor showed a tendency to increase and then decrease ( Cao et al., 2017 ). In this paper, seven different injection rates are set to compare and analyse with the corresponding oil production. As seen from Figure 9A , as the injection rate increases, the oil production shows a sharp increase and then a stable increase or slight decrease. The oil yield sharply increases and then stabilises before reaching an injection rate of 100 t/days. However, beyond this point, the oil yield plateaus or slightly decreases. Figure 9B shows that the oil production curve does not exhibit a significant increase beyond an injection rate of 100 t/days. Additionally, it is not expected that the oil production will increase after 2027, and an injection rate of 200 t/days displays a decreasing trend. Compared the cumulative oil production at different stages, it is suggested that the injection rate is 100 t/days, which corresponds to 30 days of gas injection time.

Figure 9 . (A) Relationship between different injection rates and oil production (B) Cumulative oil production curves at different injection rates.
3.3.3 Optimising soak time
The soaking time is a crucial aspect of huff and puff production, the purpose of which is to bring the injected gas into full contact with the crude oil on the one hand, and to increase the gas coverage on the other, and the appropriate soaking time can effectively improve oil production. As can be seen in Figure 10A , oil production tends to increase as the soaking time of the well increases, but after a certain node is reached, production no longer increases. Based on the data, it is clear that oil production experiences an increase before 20 days of well soaking time, but reaches a turning point at 20 days. Beyond this point, the increase in cumulative oil production slows or declines ( Figure 10B ). The production progress and oil production indicators strongly suggest that the optimal well soaking time is 20 days.

Figure 10 . (A) Relationship between different well soaking times and oil production (B) Cumulative oil production curve under different well soaking times.
3.3.4 Predicting the impact of huff and puff on development
The overall injection and extraction parameters were optimised for a single well with a single round injection volume of 3,000 t, an injection rate of 100 t/days and a soaking time of 20 days ( Table 4 ).

Table 4 . Parameter optimisation results.
Optimisation results in a 3% improvement in oil production compared to elastic depletion in the first year, as shown in Figure 11 . After 5 years, oil production can be increased by 36,000 m³ compared to depletion with CO 2 huff and puff, resulting in an overall improvement of 24%. It is expected that CO 2 huff and puff will increase oil production by a total of 65,000 m³. This method can extend the gas reach and effectively supplement formation energy, leading to improved recovery. Additionally, the combination of CO 2 flooding and geological storage is expected to be a future development trend, CO 2 injection strengthens oil and gas extraction while also promoting carbon capture, utilization, and storage (CCUS).

Figure 11 . Comparison of oil production between elastic depletion and CO 2 huff and puff mode.
4 Conclusion
The study clearly elucidated the exploitation efficiencies of various development modes through indoor experiments and numerical simulations. Additionally, it quantitatively characterized the exploitation efficiencies of pores of different sizes and investigated the impact of key parameters on huff and puff oil production. Based on the findings, the study established optimal injection and extraction parameters and drew definitive conclusions.
(1) The average utilization efficiency of 35 MPa depletion pressure in elastic depletion mode is 17.4%, the average utilization efficiency of 20 MPa differential pressure in CO 2 displacement mode is 18.87%, and the average utilization efficiency of 6 rounds in CO 2 huff and puff mode is 21.84%, which is comparatively higher among the three modes.
(2) Macropores exhibit the highest oil discharge efficiency in elastic depletion mode, followed by mesoporous and micropores. Similarly, in CO 2 displacement mode, macropores have the highest oil discharge efficiency, followed by micropores and mesoporous. It is worth noting that micropores have a greater oil discharge efficiency than mesoporous due to gas channeling. The study confidently recommends adopting CO 2 huff and puff mode for reservoirs with more developed mesoporous. This mode increases the utilization efficiency of different pore sizes by 6.02%–9.2% compared to elastic depletion. The contribution of different pore sizes to oil discharge is in the order of macropore > mesoporous > micropore, with the utilization efficiency of mesoporous being 9.2% higher than that of elastic depletion.
(3) Among the injection volume, injection rate and soaking time, the single-well single-round injection volume has the greatest influence on cumulative huff and puff oil production. In this study, the optimum single-well single-round injection volume is 3,000 t, the injection rate is 100 t/days and the soaking time is 20 days.
(4) Compared with depletion development, the total oil production of CO 2 huff and puff can be increased by 24%, and it is estimated that the oil can be increased by 65,000 m³, and the huff and puff can effectively improve the recovery rate.
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author contributions
XC: Writing–original draft, Data curation, Methodology. ZC: Writing–review and editing, Data curation. RW: Investigation, Writing–review and editing. YH: Methodology, Data curation, Writing–review and editing. XH: Writing–review and editing, Investigation. ZL: Methodology, Writing–review and editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Natural Science Foundation of China (No. U22B2075).
Conflict of interest
Author XC, ZC, XH, and ZL were employed by PetroChina. Author RW was employed by PetroChina Daqing Oilfield Co., Ltd.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ao, W. J., Kong, L. P., Wang, C. S., Chen, S. J., Tian, J. J., and Kan, L. (2016). Study on enhanced oil recovery in high water-cut reservoir by gas flooding (in Chinese). Complex Hydrocarb. Reserv. 9 (4), 52–57. doi:10.16181/j.cnki.fzyqc.2016.04.012
CrossRef Full Text | Google Scholar
Cao, M. J., Wu, X. D., An, Y. S., Zuo, Y., and Wang, R. H. (2017). “Numerical simulation and performance evaluation of CO 2 Huff-n-Puff processes in unconventional oil reservoirs,” in Proceedings of the USA carbon management technology conference , Houston, TX, USA .
Du, H. F., Hou, R. Q., Sun, X., Dong, Y. H., and Wang, C. W. (2023). Study on pore characteristics of shale based on NMR (in Chinese). Unconv. Oil gas 10 (5), 38–47. doi:10.19901/j.fcgyq.2023.05.06
Fu, J., Chen, H. Q., Yao, C. Q., Sakaida, S., Kerr, E., Johnson, A., et al. (2023). “Field application of a novel multi-resolution Multi-Well unconventional reservoir simulation: history matching and parameter identificationn,” in USA unconventional resources technology conference (Denver, CO: SPE/AAPG/SEG ).
Google Scholar
Gregg, S. J., Sing, K. S., and Salzberg, H. W. (1983). Adsorption, surface area, and porosity. J. Electrochem. Soc. 114, 279C. doi:10.1149/1.2426447
He, W. Y., Liu, B., Zhang, J. Y., Bai, L. H., Tian, S. S., and Chi, Y. A. (2023). Geological characteristics and key scientific and technological problems of Gulong shale oil in Songliao Basin (in Chinese). Earth Sci. 48 (1), 49–62. doi:10.3799/dqkx.2022.320
Kong, F. S., Li, Y. J., Guo, T. J., Liu, J. D., and Nan, J. H. (2023). Applicability of CO 2 gravity drainage technology for high⁃dip fault block reservoirs in Hailar Oilfield (in Chinese). Petroleum Geol. Oilfield Dev. Daqing. 42 (6), 75–81. doi:10.19597/J.ISSN.1000-3754.202302026
Liu, Y. S., Chen, Z. W., Ji, D. Q., Peng, Y. F., Hou, Y. N., and Lei, Z. D. (2023). Pore fluid movability in fractured shale oil reservoir based on Nuclear Magnetic Resonance. Processes. 11 (12), 3365. doi:10.3390/pr11123365
Maniesh, S., Swapan, K. D., Umer, F., and Ei, S. R. (2019). “A case study on reducing uncertainty by using correct procedure & desaturated reservoir fluid on NMR Core T 2 bound fluid Cut-Off analysis for gaint Abu Dhabi onshore carbonate to compute reliable field wide swirr analysis from NMR Logs,” in Proceedings of the Abu Dhabi International Petroleum Exhibition and Conference (Abu Dhabi, United Arab Emirates: SPE) , Abu Dhabi, UAE .
Sing, K. S. (1985). Reporting physisorption data for gas/solid systems with special reference to the determination of surface area and porosity (Recommendations 1984). Pure Appl. Chem. 57 (4), 603–619. doi:10.1351/pac198557040603
Sun, Z. L., Li, Z. M., Shen, B. J., Zhu, Q. M., and Li, C. X. (2022). NMR technology in reservoir evaluation for shale oil and gas. Petroleum Geol. Exp. 44 (5), 930–940. doi:10.11781/sysydz202205930
Tang, W. Y., Huang, Z. Y., Chen, C., Ding, Z. H., Sheng, J. P., Wang, X. K., et al. (2022). Optimization of CO 2 huff and puff scheme for Jimsar shale oil and evaluation of test effect. Spec. Oil Gas. Reserv. 29, 131–137. doi:10.3969/j.issn.1006-6535.2022.03.019
Tao, W., James, J., and Sheng, M. Y. (2013). “Evaluation of the EOR potential in shale oil reservoirs by cyclic gas injection,” in New orleans 54th annual logging symposium (Louisiana, New Orleans: One petro ).
Wang, F. L., Fu, Z. G., Wang, J. K., Tang, Z. G., and Jiang, R. G. (2021). Characteristics and classification evaluation of Gulong shale oil reservoir in Songliao Basin (in Chinese). Petroleum Geol. Oilfield Dev. Daqing. 40 (5), 144–156. doi:10.19597/J.ISSN.1000-3754.202107017
Yao, L. L., Yang, Z. M., Li, H. B., Zhou, T. Y., Zhang, Y. P., Du, M., et al. (2023). CO 2 displacement characteristics of interbedded shale reservoir: a case study of Chang 7 shale in Ordos Basin (in Chinese). Petroleum Geol. Oilf. Dev. Daqing , 1–7. doi:10.19597/J.ISSN.1000-3754.202302017
Zhao, Y. P., Zhao, X. S., Yao, Z. J., and Zhao, Y. (2018). Indoor experiment and field application of CO 2 flooding in ultra-low permeability oil reservoirs (in Chinese). Petroleum Geol. Oilfield Dev. Daqing. 37 (1), 128–133. doi:10.19597/J.ISSN.1000-3754.201706040
Zhu, G. W., Wang, X. J., Zhang, J. Y., Liu, Z., Bai, Y. F., Zhao, Y., et al. (2023). Enrichment conditions and favorable zones for exploration and development of terrestrial shale oil in Songliao Basin (in Chinese). Acta Pet. Sin. 44 (1), 110. doi:10.7623/syxb202301007
Keywords: terrestrial shale oil, gas injection, nuclear magnetic resonance (NMR), enhanced oil recovery, numerical simulation
Citation: Cui X, Chen Z, Wang R, Han Y, He X and Lei Z (2024) Optimal design of gas injection development method for enhanced recovery in terrestrial shale oil reservoir. Front. Energy Res. 12:1397417. doi: 10.3389/fenrg.2024.1397417
Received: 07 March 2024; Accepted: 25 March 2024; Published: 11 April 2024.
Reviewed by:
Copyright © 2024 Cui, Chen, Wang, Han, He and Lei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhengdong Lei, [email protected]
This article is part of the Research Topic
Production Technology for Deep Reservoirs
Search Cornell

Class Roster
Section menu.
- Toggle Navigation
- Summer 2024
- Spring 2024
- Winter 2024
- Archived Rosters
Last Updated
- Schedule of Classes - April 16, 2024 7:30PM EDT
- Course Catalog - April 16, 2024 7:07PM EDT
HD 2830 Research Methods in Human Development
Course description.
Course information provided by the Courses of Study 2023-2024 . Courses of Study 2024-2025 is scheduled to publish mid-June.
This course will introduce students to the basics of research design and will review several methodologies in the study of human development. The focus of the course will be on descriptive and experimental methods. Students will learn the advantages and challenges to different methodological approaches. The course also places an emphasis on developing students' scientific writing and strengthening their understanding of statistics.
When Offered Fall.
Permission Note Priority given to: HD majors. Prerequisites/Corequisites Recommended prerequisite: HD 1150.
Distribution Category (SBA-HE)
- The goals of the course are to encourage students to think critically, learn how to design basic research studies, and to develop their writing skills.
- Students will demonstrate their knowledge of course content, including theories, in areas of developmental and cognitive psychology in legal contexts.
View Enrollment Information
Regular Academic Session. Combined with: PSYCH 2830
Credits and Grading Basis
3 Credits Stdnt Opt (Letter or S/U grades)
Class Number & Section Details
7771 HD 2830 LEC 001
Meeting Pattern
- TR 10:10am - 11:25am To Be Assigned
- Aug 26 - Dec 9, 2024
Instructors
To be determined. There are currently no textbooks/materials listed, or no textbooks/materials required, for this section. Additional information may be found on the syllabus provided by your professor.
For the most current information about textbooks, including the timing and options for purchase, see the Cornell Store .
Additional Information
Instruction Mode: In Person Enrollment limited to Human Development and Psychology majors. Instructor permission required for all other students.
Or send this URL:
Available Syllabi
About the class roster.
The schedule of classes is maintained by the Office of the University Registrar . Current and future academic terms are updated daily . Additional detail on Cornell University's diverse academic programs and resources can be found in the Courses of Study . Visit The Cornell Store for textbook information .
Please contact [email protected] with questions or feedback.
If you have a disability and are having trouble accessing information on this website or need materials in an alternate format, contact [email protected] for assistance.
Cornell University ©2024
IMAGES
VIDEO
COMMENTS
Experimental Design. Experimental design is a process of planning and conducting scientific experiments to investigate a hypothesis or research question. It involves carefully designing an experiment that can test the hypothesis, and controlling for other variables that may influence the results. Experimental design typically includes ...
Pre-experimental research is of three types —. One-shot Case Study Research Design. One-group Pretest-posttest Research Design. Static-group Comparison. 2. True Experimental Research Design. A true experimental research design relies on statistical analysis to prove or disprove a researcher's hypothesis.
If your study system doesn't match these criteria, there are other types of research you can use to answer your research question. Step 3: Design your experimental treatments How you manipulate the independent variable can affect the experiment's external validity - that is, the extent to which the results can be generalized and applied ...
Three types of experimental designs are commonly used: 1. Independent Measures. Independent measures design, also known as between-groups, is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
The pre-experimental research design is further divided into three types. One-shot Case Study Research Design. In this type of experimental study, only one dependent group or variable is considered. The study is carried out after some treatment which was presumed to cause change, making it a posttest study.
You can also create a mixed methods research design that has elements of both. Descriptive research vs experimental research. Descriptive research gathers data without controlling any variables, while experimental research manipulates and controls variables to determine cause and effect.
Research study designs are of many types, each with its advantages and limitations. The type of study design used to answer a particular research question is determined by the nature of question, the goal of research, and the availability of resources. ... (experimental studies - e.g., administration of a drug). If a drug had been started in ...
The classic experimental design definition is: "The methods used to collect data in experimental studies.". There are three primary types of experimental design: The way you classify research subjects based on conditions or groups determines the type of research design you should use. 01. Pre-Experimental Design.
An experimental design is a detailed plan for collecting and using data to identify causal relationships. Through careful planning, the design of experiments allows your data collection efforts to have a reasonable chance of detecting effects and testing hypotheses that answer your research questions. An experiment is a data collection ...
There are three main types of experimental research design. The research type you use will depend on the criteria of your experiment, your research budget, and environmental limitations. Pre-experimental research design. A pre-experimental research study is a basic observational study that monitors independent variables' effects.
Types of Experimental Designs. Experimental design is an umbrella term for a research method that is designed to test hypotheses related to causality under controlled conditions. Table 14.1 describes the three major types of experimental design (pre-experimental, quasi-experimental, and true experimental) and presents subtypes for each.
Experimental Research Design. Experimental research design is used to determine if there is a causal relationship between two or more variables.With this type of research design, you, as the researcher, manipulate one variable (the independent variable) while controlling others (dependent variables). Doing so allows you to observe the effect of the former on the latter and draw conclusions ...
Study, experimental, or research design is the backbone of good research. It directs the experiment by orchestrating data collection, defines the statistical analysis of the resultant data, and guides the interpretation of the results. When properly described in the written report of the experiment, it serves as a road map to readers, 1 helping ...
Experimental research serves as a fundamental scientific method aimed at unraveling. cause-and-effect relationships between variables across various disciplines. This. paper delineates the key ...
10 Experimental research. 10. Experimental research. Experimental research—often considered to be the 'gold standard' in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different ...
1) True Experimental Design. In the world of experiments, the True Experimental Design is like the superstar quarterback everyone talks about. Born out of the early 20th-century work of statisticians like Ronald A. Fisher, this design is all about control, precision, and reliability.
This will guide your research design and help you select appropriate methods. Select a research design: There are many different research designs to choose from, including experimental, survey, case study, and qualitative designs. Choose a design that best fits your research question and objectives.
Experimental research is the most common. type of research design for people working in the sciences and a variety of other fields. Experimental design is an efficient method of optimizing the ...
Experimental research designs support the ability to limit alternative explanations and to infer direct causal relationships in the study. ... This type of research design draws a conclusion by comparing subjects against a control group, in cases where the researcher has no control over the experiment. There are two general types of ...
Although there are many types of experimental designs, the foundation for all of them is the classic experimental design. This research design, and some typical variations of this experimental design, are the focus of this chapter. Although the classic experiment may be appropriate to answer a particular research question, there are barriers ...
Causal research design, a subset of explanatory research, seeks to establish cause-and-effect relationships within its data. Unlike experimental research, causal research does not involve manipulating independent variables but rather observes naturally occurring or pre-existing groupings to define cause and effect.
of ans wering the research ques tion or testing from hypothesis. This type of research d esign. includes descriptive design, exploratory design, experimental design, longitudinal design, cross ...
There are 3 types of experimental research designs. These are pre-experimental research design, true experimental research design, and quasi experimental research design. 1. The assignment of the control group in quasi experimental research is non-random, unlike true experimental design, which is randomly assigned. 2.
In multiobjective optimization problems, Pareto optimal solutions representing different tradeoffs cannot be ordered without incorporating preference information of a decision maker (DM). In interactive methods, the DM takes an active part in the solution process and provides preference information iteratively. Between iterations, the DM can learn how achievable the preferences are, learn ...
The above study suggests that experimental research can not only establish a research model and verify the reasonableness of the model but also provide reasonable design parameters for engineering ...
Methods and Experimental Design 3.1. Methodology. ... Current research focuses on single vegetation types such as rigid plants (shrubs) or flexible plants (grasses), but little research has been conducted on the effects of combining rigid and flexible plant cover on soil erosion. Rigid and flexible plants each have unique mechanisms for ...
Scientific research, crucial for advancing human well-being, faces challenges due to its complexity and slow pace, requiring specialized expertise. Integrating AI, particularly LLMs, could revolutionize this process. LLMs are good at processing large amounts of data and identifying patterns, potentially accelerating research by suggesting ideas and aiding in experimental design.
The experimental setup includes a MesoMR3-060H-I NMR instrument, drying apparatus, saturation device, loading device, high temperature and high pressure MR-dd displacement device, data acquisition and RF device, and hand pump. Where the NMR experiments have an echo interval of 0.2 ms and a waiting time of 3,000 ms. 2.3 Experimental methods
This course will introduce students to the basics of research design and will review several methodologies in the study of human development. The focus of the course will be on descriptive and experimental methods. Students will learn the advantages and challenges to different methodological approaches. The course also places an emphasis on developing students' scientific writing and ...