Analyzing and Presenting Results from Descriptive Studies

Introduction
Disease surveillance systems and health data sources provide the raw information necessary to monitor trends in health and disease. Descriptive epidemiology provides a way of organizing and analyzing these data in order to understand variations in disease frequency geographically and over time, and how disease (or health) varies among people based on a host of personal characteristics (person, place, and time). This makes it possible to identify trends in health and disease and also provides a means of planning resources for populations. In addition, descriptive epidemiology is important for generating hypotheses (possible explanations) about the determinants of health and disease. By generating hypotheses, descriptive epidemiology also provides the starting point for analytic epidemiology, which formally tests associations between potential determinants and health or disease outcomes. Specific tasks of descriptive epidemiology are the following:
- Monitoring and reporting on the health status and health related behaviors in populations
- Identifying emerging health problems
- Alerting us to potential threats from bioterrorism
- Establishing public health priorities for a population
- Evaluating the effectiveness of intervention programs and
- Exploring potential associations between "risk factors" and health outcomes in order to generate hypotheses about the determinants of disease.
Key Questions:
How can I summarize data?
How do I produce basic figures and tables?
How can I analyze the correlation between two continuous variables?
How can I apply this to the analysis and description of an ecologic study?
How can I use R to do descriptive analyses?
Learning Objectives
After successfully completing this unit, the student will be able to:
- Identify the different classes of variables (discrete [dichotomous, categorical, ordinal], continuous, time to event)
- For continuous variables distinguish when to use mean and standard deviation versus median and interquartile range (IQR) to characterize the center and variability in data.
- Use R to compute mean, variance, standard deviation, median, and interquartile range (IQR).
- Use R to compute the correlation coefficient for an ecological study
Basic Concepts
Types of variables.
Procedures to summarize data and to perform subsequent analysis differ depending on the type of data (or variables) that are available. As a result, it is important to have a clear understanding of how variables are classified.
There are three general classifications of variables:
1) Discrete Variables: variables that assume only a finite number of values, for example, race categorized as non-Hispanic white, Hispanic, black, Asian, other. Discrete variables focus on the frequency of observations and can be presented as the number, the percentage, or the proportion of observations within a given category.
Discrete variables may be further subdivided into:
2) Continuous Variables: These are sometimes called quantitative or measurement variables; they can take on any value within a range of plausible values. For example, total serum cholesterol level, height, weight and systolic blood pressure are examples of continuous variables. Continuous variables (i.e., measurement variables) are summarized by finding a central measure, such as a mean or a median, as appropriate, and characterizing the variability of spread around the central measure .
3) Time to Event Variables: these reflect the time to a particular event such as a heart attack, cancer remission or death. This module will focus primarily on summarizing and presenting discrete variables and continuous variables; time to event variables will be addressed in a later module.
This module will introduce basic concepts for analyzing and presenting data from exploratory (descriptive) studies that are essential for disease surveillance, for assessing the health and health-related behaviors in a population, or for generating hypotheses about the determinants of health or disease. However, students may want to refer to other learning modules that address these concepts in greater detail. These can be found using the following links:
Link to module - Basic Concepts for Biostatistics
Link to module - Summarizing Data
Link to module - Data Presentation
Population Parameters versus Sample Statistics
A descriptive measure for an entire population is a ''parameter.'' There are many population parameters, for example, the population size (N) is one parameter, and the mean diastolic blood pressure or the mean body weight of a population would be other parameters that relate to continuous variables. Other population parameters focus on discrete variables, such as the percentage of current smokers in the population or the percentage of people with type 2 diabetes mellitus. Health-related behaviors can also be thought of this way, such as the percentage of the population that gets vaccinated against the flu each year or the percentage who routinely wear a seatbelt when driving.
However, it is generally not feasible to directly measure parameters, since it requires collecting information from all members of the population. We, therefore, take samples from the population, and the descriptive measures for a sample are referred to as ''sample statistics'' or simply ''statistics.'' For example, the mean diastolic blood pressure, the mean body weight, and the percentage of smokers in a sample from the population would be sample statistics. In the image below the true mean diastolic blood pressure for the population of adults in Massachusetts is 78 millimeters of mercury (mm Hg); this is a population parameter. The image also shows the mean diastolic blood pressure in three separate samples. These means are sample statistics which we might use in order to estimate the parameter for the entire population. However, note that the sample statistics are all a little bit different, and none of them are exactly the sample as the population parameter.

In order to illustrate some fundamentals, let's consider a very small sample with data shown in the table below.
Table - Data Values for a Small Sample
Note that the data table has continuous variables (age, length of stay in the hospital, body mass index) and discrete variables that are dichotomous (type 2 diabetes and current smoking). Let's focus first on the continuous variables which we will summarize by computing a central measure and an indication of how much spread there is around that central estimate.
Measures of Central Tendency and Variability
There are three sample statistics that describe the center of the data for a continuous variable. There are:
- The Mean : the average of all the values
- The Median : The "middle" value, such that half of the observations are below this value, and half are above.
- The Mode : The most frequently observed value.
The mean and the median will be most useful to us for analyzing and presenting the results of exploratory studies.
One way to summarize age for the small data set above would be to determine the frequency of subjects by age group as show in the table below.
This makes it easier to understand the age structure of the group. One could also summarize the age structure by creating a frequency histogram as shown in the figure below.

If there are no extreme or outlying values of the variable (as in this case), the mean is the most appropriate summary of a typical value.
The sample mean is computed by summing all of the values for a particular variable in the sample and dividing by the number of values in the sample.
So, the general formula is
The X with the bar over it represents the sample mean, and it is read as "X bar". The Σ indicates summation (i.e., sum of the X's or sum of the ages in this example).
Sample Variance and Standard Deviation
When the mean is appropriate to characterize the central values, the variability or spread of values around the mean can be characterized with the variance or the standard deviation. If all of the observed values in a sample are close to the sample mean, the standard deviation will be small (i.e., close to zero), and if the observed values vary widely around the sample mean, the standard deviation will be large. If all of the values in the sample are identical, the sample standard deviation will be zero.
To compute the sample standard deviation we begin by computing the variance (s 2 ) as follows:
The variance is essentially the mean of the squared deviations, although we divide by n-1 in order to avoid underestimating the population variance. We can compute this manually by first computing the deviations from the mean and then squaring them and adding the squared deviations from the mean as shown in the table below.
Table - Computation of Variance for Age
However, the more common measure of variability in a sample is the sample standard deviation (s) , defined as the square root of the sample variance:
Computing Mean, Variance, and Standard Deviation in R
These computations are easy using the R statistical package. First, I will create a data set with the ten observed ages in the example above using the concatenation function in R.
> agedata <- c(63, 74, 75, 74, 70, 72, 81, 68, 67, 77)
To calculate the mean:
> mean(agedata)
To calculate the variance:
> var(agedata)
[1] 27.65556
To calculate the standard deviation for age:
> sd(agedata)
[1] 5.258855
Next, we will examine length of stay in the hospital (days) which is also a continuous variable. As we did with age, we could summarize hospital length of stay by looking at the frequency, e.g., how many patients stayed 1, 2, 3, 4, etc. days.
And one again, we could also present the same information with a frequency histogram as shown below.

Here, most patients stayed in the hospital for only 2 or 3 days, but there were outliers who stayed 5, 7, and 9 days. This is a skewed distribution, and in this case the mean would be a misleading characterization of the central value. Rather than compute a mean, it would be more informative to compute the median value, i.e., the "middle" value, such that half of the observations are below this value, and half are above.
To compute the median one would first order the data.
- If the sample size is an odd number, the mean is the middle value.
- If the sample size is an even number, the median is the mean of the two middle values.
However, R is a more convenient way to do this, because it will also enable you to see the interquartile range (IQR) which is a useful way of characterizing the variability or spread of the data.
Computing Median and Interquartile Range with R
We can again create a small data set for hospital length of stay using the concatenation function in R:
> hospLOS <- c(2,2,2,2,3,3,3,5,7,9)
and we can then compute the median.
> median(hospLOS)
However, it is more useful to use the "summary()" command.
> summary(hospLOS)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.0 2.0 3.0 3.8 4.5 9.0
The quartiles divide the data into 4 roughly equal groups as illustrated below.

When a data set has outliers or extreme values, we summarize a typical value using the median as opposed to the mean. When a data set has outliers, variability is often summarized by a statistic called the interquartile range , which is the difference between the first and third quartiles. The first quartile, denoted Q 1 , is the value in the data set that holds 25% of the values below it. The third quartile, denoted Q 3 , is the value in the data set that holds 25% of the values above it.
To summarize:
• No outliers: sample mean and standard deviation summarize location and variability.
• When there are outliers or skewed data , median and interquartile range (IQR) best summarize location and variability, where IQR = Q3-Q1
Box-Whisker Plots
Box-whisker plots are very useful for comparing distributions. A box-whisker plot divides the observations into 4 roughly equal quartiles. The whiskers represent the minimum and maximum observed values. The right side of the box indicates Q1, below which are the lowest 25% of observations, and the left side of the box is Q3, above which are the highest 25% of observations. The lowest 25% of observations are below Q1 and the highest 25% are above Q3. The median value is shown within the box.

Data Presentation
There are two fundamental methods for presenting summary information: tables and graphs.
- Tables are generally best if you want to be able to look up specific information or if the values must be reported precisely.
- Graphics are best for illustrating trends and making comparisons
For examples of how to create effective tables and graphs and how to avoid pitfalls in data presentation, please refer to the following two online learning modules:
Case Series - Summary of Findings and Presentation
Nguyen Duc Hien, Nguyen Hong Ha, et al: Human infection with highly pathogenic avian influenza virus (H5N1) in Northern Vietnam, 2004–2005 . Emerg Infect Dis. 2009 Jan; 15(1): 19–23.
Link to the complete article
This is a small, but important case series reported in 2009. Shown below are the abstract and slightly modified versions of the two tables presented in the report.
Note that both continuous and discrete variables are reported, and note that the authors used the mean and standard deviation for variables like age, but they used median and IQR for many other variables because their distributions were skewed. Note also that discrete variables and continuous variables can be presented in the same table, but it is essential to specify how each characteristic is being presented.
Table 1. Characteristics of 29 patients infected with highly pathogenic avian influenza virus (H5N1), northern Vietnam, 2004–2005*
Table Legend: *IQR, interquartile range;
†Poultry, a history of exposure to sick or healthy poultry; sick poultry or person, a history of exposure to sick poultry or a family infected with avian influenza (H5N1).
Table 2 below shows selected laboratory findings among survivors versus patients who died. Leukocytes are white blood cells, and neutrophils are a specific type of white blood cell; the lower numbers of these two counts in those who died suggests that the immune system was overwhelmed. Hemoglobin is a measure of red blood cells and oxygen carrying capacity. Platelets are essential elements for blood clotting. Albumin is the most abundant protein in blood. AST is an abbreviation for aspartate aminotransferase, an enzyme that is abundant in the liver; high levels of AST in the blood frequently indicate liver damage. Urea nitrogen is a measure of kidney function; high levels of urea nitrogen suggest compromised kidney function but could also be indicative of dehydration.
Table 2. Initial laboratory results for 29 patients infected with highly pathogenic avian influenza virus
†p<0.05, by Wilcoxon test or Fisher exact test.
We will address p-values and statistical tests like the Wilcoxon test and the Fisher exact test in subsequent modules.
A Cross-Sectional Survey
In 2002 John Snow, Inc. (JSI) worked with the town of Weymouth, Massachusetts to identify unmet health needs in the town and devise a plan to prioritize unmet health needs and key risk factors that may be modified through lifestyle changes. The project conducted a mail survey of a random sample of 5,000 households as well as a survey of all 3,400 Weymouth public school students in grades nine through twelve. The information assisted the Town's decision-making about priorities for improving services and designing interventions that may prevent or reduce the incidence of ill health. Below you will find links to PDF versions of the full surveys and a link to a subset of the data and a key for identifying the variables and the coded responses.
Link to the Adult Survey Questionnaire
Link to a subset of the data from the Adult Survey
Link to description of the variable names and codes for the adult survey data
link to the Student Survey Questionnaire
Open the link to the Adult Survey Questionnaire and scan through it to get an idea of how a carefully constructed survey tool looks. Note the efforts to make the question explicit and clear.

Ecologic Studies
In ecologic studies the unit of observation for the exposure of interest is the average level of exposure in different populations or groups, and the outcome of interest is the overall frequency of disease for those populations or groups. In this regard, ecologic studies are different from all other epidemiologic studies, for which the unit of observation is exposure status and outcome status for individual people. As a result, ecologic studies need to be interpreted with caution. Nevertheless, they can be informative, and this module will focus on their analysis, interpretation, and presentation using correlation and simple linear regression.
Computing the Correlation Coefficient
The module on Descriptive Studies showed an ecologic study correlating per capita meat consumption and incidence of colon cancer in women from 22 countries. Investigators used commerce data to compute the overall consumption of meat by various nations. They then calculated the average (per capita) meat consumption per person by dividing total national meat consumption by the number of people in a given country. There is a clear linear trend; countries with the lowest meat consumption have the lowest rates of colon cancer, and the colon cancer rate among these countries progressively increases as meat consumption increases.

Note that in reality, people's meat consumption probably varied widely within nations, and the exposure that was calculated was an average that assumes that everyone ate the average amount of meat. This average exposure was then correlated with the overall disease frequency in each country. The example here suggests that the frequency of colon cancer increases as meat consumption increases.
How can we analyze and present this type of information?
As noted in the module on Descriptive Studies, ecologic studies invite us to assess the association between the the independent variable (in this case, per capita meat consumption) and the dependent variable (in this case, the outcome, incidence of colon cancer in women) by computing the correlation coefficient ("r"). This section will provide a brief outline of correlation analysis and demonstrate how to use the R statistical package to compute correlation coefficients. Correlation analysis and simple linear regression are described in a later module for this course.
Link to module on Correlation and Linear Regression.
The most commonly used type of correlation is Pearson correlation, named after Karl Pearson, introduced this statistic around the turn of the 20 th century. Pearson's r measures the linear relationship between two variables, say X and Y . A correlation of 1 indicates the data points perfectly lie on a line for which Y increases as X increases. A value of -1 also implies the data points lie on a line; however, Y decreases as X increases. The formula for r is:
where Cov(x,y) is the covariance of x and y defined as
The variances of x and y measure the variability of the x scores and y scores around their respective sample means of X and Y considered separately. The covariance measures the variability of the (x,y) pairs around the mean of x and mean of y, considered simultaneously.
We can combine all of this into the following equation:
In the "Other Resources" listed to the left of this page there is a link to a data file called "Meat-CancerEcologic.csv" which has three columns: Country, Grams (per capita meat consumption), and Incidence (Incidence of colon cancer per 100,000 women).
If I import this data set into the R Studio, I can compute the correlations coefficient and then plot the points using the following commands. First, I created a data frame called "meat,":and then I computed the correlation coefficient.
> meat <- Meat-CancerEcologic
> attach(meat)
> cor (grams, incidence)
[1] 0.9005721
The correlation coefficient of 0.9005721 indicates a strong positive correlation between national per capita meat consumption and national incidence of colon cancer in women.
Next, I created a scatter plot of the data.
> plot(grams, incidence, col="red", pch =24)

Visual inspection of the plot suggests a linear relationship with a strong positive correlation, and the correlation coefficient r=0.90 confirms this.
Download the data set and try it yourself.
Brief Comments About Data Presentation
In order to be useful, the data must be organized and analyzed in a thoughtful, structured way, and the results must be be communicated in a clear, effective way to both the public health workforce and the community at large. Some simple standards are useful to promote clear presentation. Compiled data are commonly summarized in tables, graphs, or some combination.
Simple guidelines for tables.
- Provide a concise descriptive title.
- Label the rows and columns.
- Provide the units in the column headers.
- Provide the column total, if appropriate.
- If necessary, additional explanatory information may be provided in a footnoted legend immediately beneath the title.
Table - Treatment with Anti-hypertensive Medication in Men and Women
Simple guidelines for figures:
- Include a concise descriptive title.
- Label the axes clearly showing units where appropriate.
- Use appropriate scales for the vertical and horizontal axes that display the results without exaggerating them with ranges that are either too expansive or too restrictive.
- For line graphs with multiple groups include a simple legend if necessary.
Figure - Relative Frequency of Anti-hypertensive Medication Use in Men and Women

Additional resources for summarizing and presenting data:
- Online learning module on "Data Presentation." (Link to Data Presentation module)
- Online learning module on "Summarizing Data". (Link the Summarizing Data module)
- The CDC also provides another good resource for advice about organizing data. (Link to CDC page on organizing data.)
Answer to Question on Page 3 Regarding Confidence Interval for the Body Mass Index
The Framingham Heart Study reported that in a sample of 3,326 subjects the mean body mass index was 28.15, and the standard deviation was 5.32. What was the 95% confidence interval for the population's mean body mass index?
So the 95% confidence interval is
Interpretation:
Our estimate of the mean BMI in the population is 28.15. With 95% confidence the true mean is likely to be between 27.97 and 28.33.
Answer to 95% Confidence Interval for the Case-Fatality Rate from Bird Flu - page 3
The point estimate is
There are 7 persons who died and 22 who did not, so we can use the following formula:
Substituting:
So, the 95% confidence interval is 0.085, 0.391.
Our best estimate of the case-fatality rate from bird flu is 24%. With 95% confidence the true case-fatality rate is likely to be between 8.5% to 39.1%.
Note that this 95% confidence interval is quite broad because of the small sample size (n=29).
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
- How to Write Discussions and Conclusions

The discussion section contains the results and outcomes of a study. An effective discussion informs readers what can be learned from your experiment and provides context for the results.
What makes an effective discussion?
When you’re ready to write your discussion, you’ve already introduced the purpose of your study and provided an in-depth description of the methodology. The discussion informs readers about the larger implications of your study based on the results. Highlighting these implications while not overstating the findings can be challenging, especially when you’re submitting to a journal that selects articles based on novelty or potential impact. Regardless of what journal you are submitting to, the discussion section always serves the same purpose: concluding what your study results actually mean.
A successful discussion section puts your findings in context. It should include:
- the results of your research,
- a discussion of related research, and
- a comparison between your results and initial hypothesis.
Tip: Not all journals share the same naming conventions.
You can apply the advice in this article to the conclusion, results or discussion sections of your manuscript.
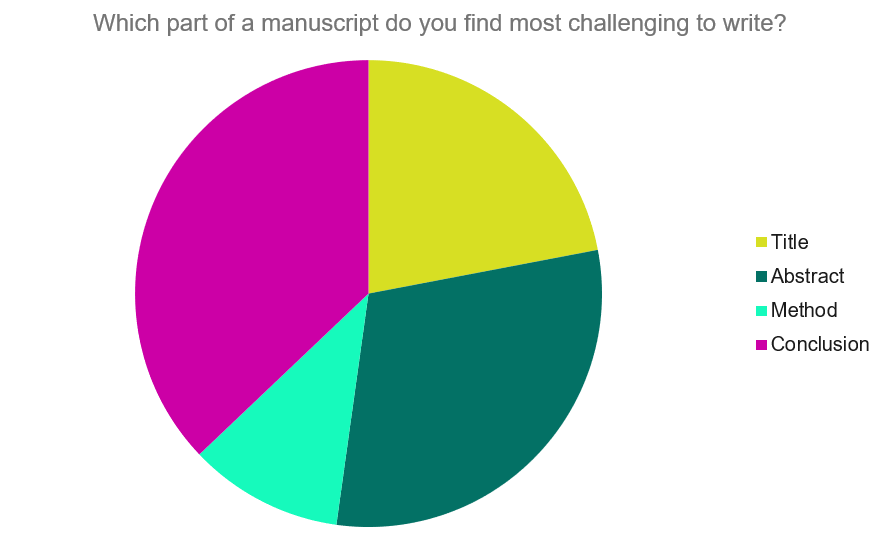
Our Early Career Researcher community tells us that the conclusion is often considered the most difficult aspect of a manuscript to write. To help, this guide provides questions to ask yourself, a basic structure to model your discussion off of and examples from published manuscripts.
Questions to ask yourself:
- Was my hypothesis correct?
- If my hypothesis is partially correct or entirely different, what can be learned from the results?
- How do the conclusions reshape or add onto the existing knowledge in the field? What does previous research say about the topic?
- Why are the results important or relevant to your audience? Do they add further evidence to a scientific consensus or disprove prior studies?
- How can future research build on these observations? What are the key experiments that must be done?
- What is the “take-home” message you want your reader to leave with?
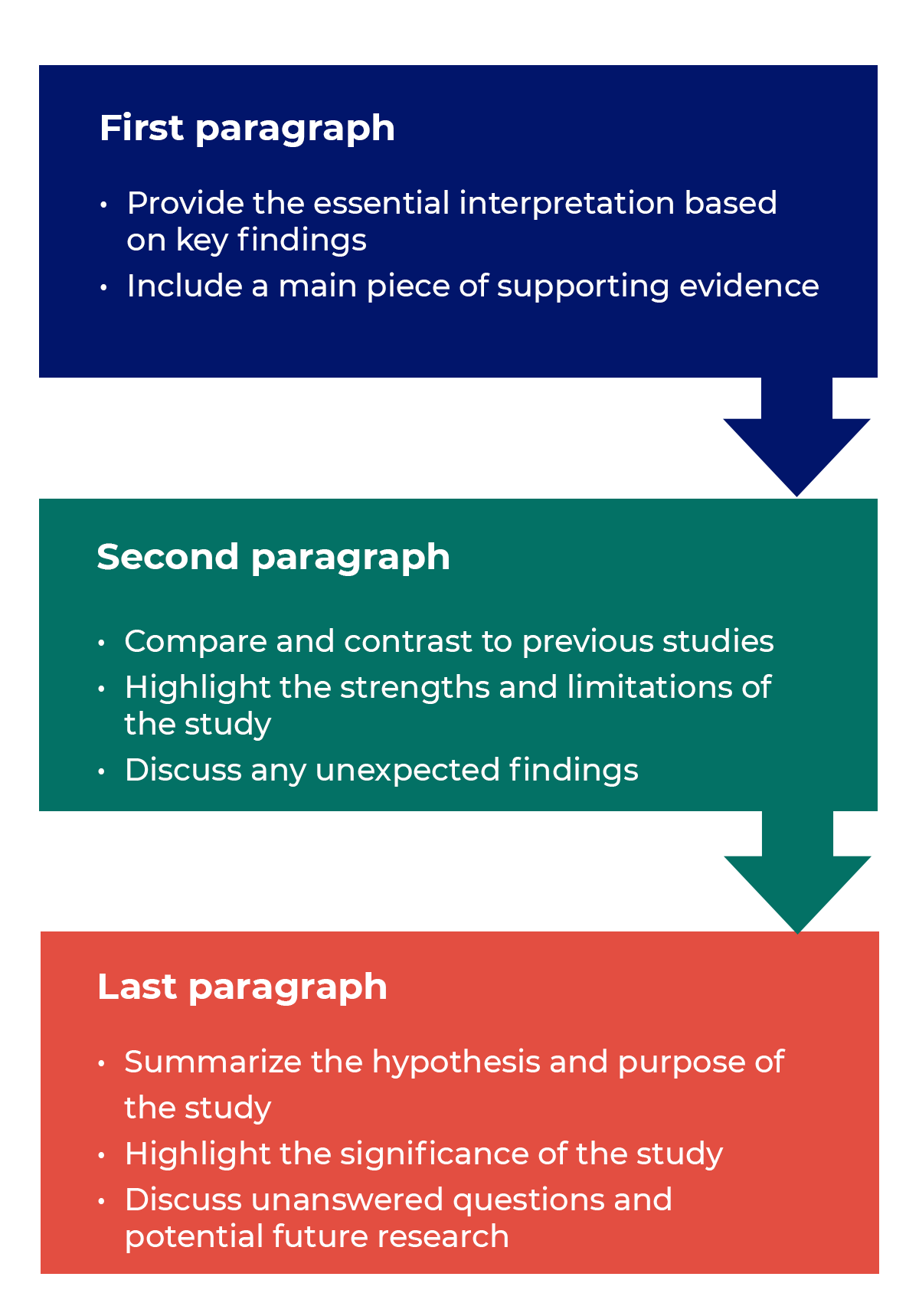
How to structure a discussion
Trying to fit a complete discussion into a single paragraph can add unnecessary stress to the writing process. If possible, you’ll want to give yourself two or three paragraphs to give the reader a comprehensive understanding of your study as a whole. Here’s one way to structure an effective discussion:
Writing Tips
While the above sections can help you brainstorm and structure your discussion, there are many common mistakes that writers revert to when having difficulties with their paper. Writing a discussion can be a delicate balance between summarizing your results, providing proper context for your research and avoiding introducing new information. Remember that your paper should be both confident and honest about the results!

- Read the journal’s guidelines on the discussion and conclusion sections. If possible, learn about the guidelines before writing the discussion to ensure you’re writing to meet their expectations.
- Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion.
- Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and limitations of the research.
- State whether the results prove or disprove your hypothesis. If your hypothesis was disproved, what might be the reasons?
- Introduce new or expanded ways to think about the research question. Indicate what next steps can be taken to further pursue any unresolved questions.
- If dealing with a contemporary or ongoing problem, such as climate change, discuss possible consequences if the problem is avoided.
- Be concise. Adding unnecessary detail can distract from the main findings.

Don’t
- Rewrite your abstract. Statements with “we investigated” or “we studied” generally do not belong in the discussion.
- Include new arguments or evidence not previously discussed. Necessary information and evidence should be introduced in the main body of the paper.
- Apologize. Even if your research contains significant limitations, don’t undermine your authority by including statements that doubt your methodology or execution.
- Shy away from speaking on limitations or negative results. Including limitations and negative results will give readers a complete understanding of the presented research. Potential limitations include sources of potential bias, threats to internal or external validity, barriers to implementing an intervention and other issues inherent to the study design.
- Overstate the importance of your findings. Making grand statements about how a study will fully resolve large questions can lead readers to doubt the success of the research.
Snippets of Effective Discussions:
Consumer-based actions to reduce plastic pollution in rivers: A multi-criteria decision analysis approach
Identifying reliable indicators of fitness in polar bears
- How to Write a Great Title
- How to Write an Abstract
- How to Write Your Methods
- How to Report Statistics
- How to Edit Your Work
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…
Child Care and Early Education Research Connections
Descriptive research studies.
Descriptive research is a type of research that is used to describe the characteristics of a population. It collects data that are used to answer a wide range of what, when, and how questions pertaining to a particular population or group. For example, descriptive studies might be used to answer questions such as: What percentage of Head Start teachers have a bachelor's degree or higher? What is the average reading ability of 5-year-olds when they first enter kindergarten? What kinds of math activities are used in early childhood programs? When do children first receive regular child care from someone other than their parents? When are children with developmental disabilities first diagnosed and when do they first receive services? What factors do programs consider when making decisions about the type of assessments that will be used to assess the skills of the children in their programs? How do the types of services children receive from their early childhood program change as children age?
Descriptive research does not answer questions about why a certain phenomenon occurs or what the causes are. Answers to such questions are best obtained from randomized and quasi-experimental studies . However, data from descriptive studies can be used to examine the relationships (correlations) among variables. While the findings from correlational analyses are not evidence of causality, they can help to distinguish variables that may be important in explaining a phenomenon from those that are not. Thus, descriptive research is often used to generate hypotheses that should be tested using more rigorous designs.
A variety of data collection methods may be used alone or in combination to answer the types of questions guiding descriptive research. Some of the more common methods include surveys, interviews, observations, case studies, and portfolios. The data collected through these methods can be either quantitative or qualitative. Quantitative data are typically analyzed and presenting using descriptive statistics . Using quantitative data, researchers may describe the characteristics of a sample or population in terms of percentages (e.g., percentage of population that belong to different racial/ethnic groups, percentage of low-income families that receive different government services) or averages (e.g., average household income, average scores of reading, mathematics and language assessments). Quantitative data, such as narrative data collected as part of a case study, may be used to organize, classify, and used to identify patterns of behaviors, attitudes, and other characteristics of groups.
Descriptive studies have an important role in early care and education research. Studies such as the National Survey of Early Care and Education and the National Household Education Surveys Program have greatly increased our knowledge of the supply of and demand for child care in the U.S. The Head Start Family and Child Experiences Survey and the Early Childhood Longitudinal Study Program have provided researchers, policy makers and practitioners with rich information about school readiness skills of children in the U.S.
Each of the methods used to collect descriptive data have their own strengths and limitations. The following are some of the strengths and limitations of descriptive research studies in general.
Study participants are questioned or observed in a natural setting (e.g., their homes, child care or educational settings).
Study data can be used to identify the prevalence of particular problems and the need for new or additional services to address these problems.
Descriptive research may identify areas in need of additional research and relationships between variables that require future study. Descriptive research is often referred to as "hypothesis generating research."
Depending on the data collection method used, descriptive studies can generate rich datasets on large and diverse samples.
Limitations:
Descriptive studies cannot be used to establish cause and effect relationships.
Respondents may not be truthful when answering survey questions or may give socially desirable responses.
The choice and wording of questions on a questionnaire may influence the descriptive findings.
Depending on the type and size of sample, the findings may not be generalizable or produce an accurate description of the population of interest.
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Descriptive Research: Definition, Characteristics, Methods + Examples

Suppose an apparel brand wants to understand the fashion purchasing trends among New York’s buyers, then it must conduct a demographic survey of the specific region, gather population data, and then conduct descriptive research on this demographic segment.
The study will then uncover details on “what is the purchasing pattern of New York buyers,” but will not cover any investigative information about “ why ” the patterns exist. Because for the apparel brand trying to break into this market, understanding the nature of their market is the study’s main goal. Let’s talk about it.
What is descriptive research?
Descriptive research is a research method describing the characteristics of the population or phenomenon studied. This descriptive methodology focuses more on the “what” of the research subject than the “why” of the research subject.
The method primarily focuses on describing the nature of a demographic segment without focusing on “why” a particular phenomenon occurs. In other words, it “describes” the research subject without covering “why” it happens.
Characteristics of descriptive research
The term descriptive research then refers to research questions, the design of the study, and data analysis conducted on that topic. We call it an observational research method because none of the research study variables are influenced in any capacity.
Some distinctive characteristics of descriptive research are:
- Quantitative research: It is a quantitative research method that attempts to collect quantifiable information for statistical analysis of the population sample. It is a popular market research tool that allows us to collect and describe the demographic segment’s nature.
- Uncontrolled variables: In it, none of the variables are influenced in any way. This uses observational methods to conduct the research. Hence, the nature of the variables or their behavior is not in the hands of the researcher.
- Cross-sectional studies: It is generally a cross-sectional study where different sections belonging to the same group are studied.
- The basis for further research: Researchers further research the data collected and analyzed from descriptive research using different research techniques. The data can also help point towards the types of research methods used for the subsequent research.
Applications of descriptive research with examples
A descriptive research method can be used in multiple ways and for various reasons. Before getting into any survey , though, the survey goals and survey design are crucial. Despite following these steps, there is no way to know if one will meet the research outcome. How to use descriptive research? To understand the end objective of research goals, below are some ways organizations currently use descriptive research today:
- Define respondent characteristics: The aim of using close-ended questions is to draw concrete conclusions about the respondents. This could be the need to derive patterns, traits, and behaviors of the respondents. It could also be to understand from a respondent their attitude, or opinion about the phenomenon. For example, understand millennials and the hours per week they spend browsing the internet. All this information helps the organization researching to make informed business decisions.
- Measure data trends: Researchers measure data trends over time with a descriptive research design’s statistical capabilities. Consider if an apparel company researches different demographics like age groups from 24-35 and 36-45 on a new range launch of autumn wear. If one of those groups doesn’t take too well to the new launch, it provides insight into what clothes are like and what is not. The brand drops the clothes and apparel that customers don’t like.
- Conduct comparisons: Organizations also use a descriptive research design to understand how different groups respond to a specific product or service. For example, an apparel brand creates a survey asking general questions that measure the brand’s image. The same study also asks demographic questions like age, income, gender, geographical location, geographic segmentation , etc. This consumer research helps the organization understand what aspects of the brand appeal to the population and what aspects do not. It also helps make product or marketing fixes or even create a new product line to cater to high-growth potential groups.
- Validate existing conditions: Researchers widely use descriptive research to help ascertain the research object’s prevailing conditions and underlying patterns. Due to the non-invasive research method and the use of quantitative observation and some aspects of qualitative observation , researchers observe each variable and conduct an in-depth analysis . Researchers also use it to validate any existing conditions that may be prevalent in a population.
- Conduct research at different times: The analysis can be conducted at different periods to ascertain any similarities or differences. This also allows any number of variables to be evaluated. For verification, studies on prevailing conditions can also be repeated to draw trends.
Advantages of descriptive research
Some of the significant advantages of descriptive research are:

- Data collection: A researcher can conduct descriptive research using specific methods like observational method, case study method, and survey method. Between these three, all primary data collection methods are covered, which provides a lot of information. This can be used for future research or even for developing a hypothesis for your research object.
- Varied: Since the data collected is qualitative and quantitative, it gives a holistic understanding of a research topic. The information is varied, diverse, and thorough.
- Natural environment: Descriptive research allows for the research to be conducted in the respondent’s natural environment, which ensures that high-quality and honest data is collected.
- Quick to perform and cheap: As the sample size is generally large in descriptive research, the data collection is quick to conduct and is inexpensive.
Descriptive research methods
There are three distinctive methods to conduct descriptive research. They are:
Observational method
The observational method is the most effective method to conduct this research, and researchers make use of both quantitative and qualitative observations.
A quantitative observation is the objective collection of data primarily focused on numbers and values. It suggests “associated with, of or depicted in terms of a quantity.” Results of quantitative observation are derived using statistical and numerical analysis methods. It implies observation of any entity associated with a numeric value such as age, shape, weight, volume, scale, etc. For example, the researcher can track if current customers will refer the brand using a simple Net Promoter Score question .
Qualitative observation doesn’t involve measurements or numbers but instead just monitoring characteristics. In this case, the researcher observes the respondents from a distance. Since the respondents are in a comfortable environment, the characteristics observed are natural and effective. In a descriptive research design, the researcher can choose to be either a complete observer, an observer as a participant, a participant as an observer, or a full participant. For example, in a supermarket, a researcher can from afar monitor and track the customers’ selection and purchasing trends. This offers a more in-depth insight into the purchasing experience of the customer.
Case study method
Case studies involve in-depth research and study of individuals or groups. Case studies lead to a hypothesis and widen a further scope of studying a phenomenon. However, case studies should not be used to determine cause and effect as they can’t make accurate predictions because there could be a bias on the researcher’s part. The other reason why case studies are not a reliable way of conducting descriptive research is that there could be an atypical respondent in the survey. Describing them leads to weak generalizations and moving away from external validity.
Survey research
In survey research, respondents answer through surveys or questionnaires or polls . They are a popular market research tool to collect feedback from respondents. A study to gather useful data should have the right survey questions. It should be a balanced mix of open-ended questions and close ended-questions . The survey method can be conducted online or offline, making it the go-to option for descriptive research where the sample size is enormous.
Examples of descriptive research
Some examples of descriptive research are:
- A specialty food group launching a new range of barbecue rubs would like to understand what flavors of rubs are favored by different people. To understand the preferred flavor palette, they conduct this type of research study using various methods like observational methods in supermarkets. By also surveying while collecting in-depth demographic information, offers insights about the preference of different markets. This can also help tailor make the rubs and spreads to various preferred meats in that demographic. Conducting this type of research helps the organization tweak their business model and amplify marketing in core markets.
- Another example of where this research can be used is if a school district wishes to evaluate teachers’ attitudes about using technology in the classroom. By conducting surveys and observing their comfortableness using technology through observational methods, the researcher can gauge what they can help understand if a full-fledged implementation can face an issue. This also helps in understanding if the students are impacted in any way with this change.
Some other research problems and research questions that can lead to descriptive research are:
- Market researchers want to observe the habits of consumers.
- A company wants to evaluate the morale of its staff.
- A school district wants to understand if students will access online lessons rather than textbooks.
- To understand if its wellness questionnaire programs enhance the overall health of the employees.
FREE TRIAL LEARN MORE
MORE LIKE THIS

Data Information vs Insight: Essential differences
May 14, 2024

Pricing Analytics Software: Optimize Your Pricing Strategy
May 13, 2024

Relationship Marketing: What It Is, Examples & Top 7 Benefits
May 8, 2024

The Best Email Survey Tool to Boost Your Feedback Game
May 7, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Jump to navigation
Cochrane Training
Chapter 15: interpreting results and drawing conclusions.
Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie A Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Key Points:
- This chapter provides guidance on interpreting the results of synthesis in order to communicate the conclusions of the review effectively.
- Methods are presented for computing, presenting and interpreting relative and absolute effects for dichotomous outcome data, including the number needed to treat (NNT).
- For continuous outcome measures, review authors can present summary results for studies using natural units of measurement or as minimal important differences when all studies use the same scale. When studies measure the same construct but with different scales, review authors will need to find a way to interpret the standardized mean difference, or to use an alternative effect measure for the meta-analysis such as the ratio of means.
- Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values, but report the confidence interval together with the exact P value.
- Review authors should not make recommendations about healthcare decisions, but they can – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences and other factors that determine a decision such as cost.
Cite this chapter as: Schünemann HJ, Vist GE, Higgins JPT, Santesso N, Deeks JJ, Glasziou P, Akl EA, Guyatt GH. Chapter 15: Interpreting results and drawing conclusions. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.4 (updated August 2023). Cochrane, 2023. Available from www.training.cochrane.org/handbook .
15.1 Introduction
The purpose of Cochrane Reviews is to facilitate healthcare decisions by patients and the general public, clinicians, guideline developers, administrators and policy makers. They also inform future research. A clear statement of findings, a considered discussion and a clear presentation of the authors’ conclusions are, therefore, important parts of the review. In particular, the following issues can help people make better informed decisions and increase the usability of Cochrane Reviews:
- information on all important outcomes, including adverse outcomes;
- the certainty of the evidence for each of these outcomes, as it applies to specific populations and specific interventions; and
- clarification of the manner in which particular values and preferences may bear on the desirable and undesirable consequences of the intervention.
A ‘Summary of findings’ table, described in Chapter 14 , Section 14.1 , provides key pieces of information about health benefits and harms in a quick and accessible format. It is highly desirable that review authors include a ‘Summary of findings’ table in Cochrane Reviews alongside a sufficient description of the studies and meta-analyses to support its contents. This description includes the rating of the certainty of evidence, also called the quality of the evidence or confidence in the estimates of the effects, which is expected in all Cochrane Reviews.
‘Summary of findings’ tables are usually supported by full evidence profiles which include the detailed ratings of the evidence (Guyatt et al 2011a, Guyatt et al 2013a, Guyatt et al 2013b, Santesso et al 2016). The Discussion section of the text of the review provides space to reflect and consider the implications of these aspects of the review’s findings. Cochrane Reviews include five standard subheadings to ensure the Discussion section places the review in an appropriate context: ‘Summary of main results (benefits and harms)’; ‘Potential biases in the review process’; ‘Overall completeness and applicability of evidence’; ‘Certainty of the evidence’; and ‘Agreements and disagreements with other studies or reviews’. Following the Discussion, the Authors’ conclusions section is divided into two standard subsections: ‘Implications for practice’ and ‘Implications for research’. The assessment of the certainty of evidence facilitates a structured description of the implications for practice and research.
Because Cochrane Reviews have an international audience, the Discussion and Authors’ conclusions should, so far as possible, assume a broad international perspective and provide guidance for how the results could be applied in different settings, rather than being restricted to specific national or local circumstances. Cultural differences and economic differences may both play an important role in determining the best course of action based on the results of a Cochrane Review. Furthermore, individuals within societies have widely varying values and preferences regarding health states, and use of societal resources to achieve particular health states. For all these reasons, and because information that goes beyond that included in a Cochrane Review is required to make fully informed decisions, different people will often make different decisions based on the same evidence presented in a review.
Thus, review authors should avoid specific recommendations that inevitably depend on assumptions about available resources, values and preferences, and other factors such as equity considerations, feasibility and acceptability of an intervention. The purpose of the review should be to present information and aid interpretation rather than to offer recommendations. The discussion and conclusions should help people understand the implications of the evidence in relation to practical decisions and apply the results to their specific situation. Review authors can aid this understanding of the implications by laying out different scenarios that describe certain value structures.
In this chapter, we address first one of the key aspects of interpreting findings that is also fundamental in completing a ‘Summary of findings’ table: the certainty of evidence related to each of the outcomes. We then provide a more detailed consideration of issues around applicability and around interpretation of numerical results, and provide suggestions for presenting authors’ conclusions.
15.2 Issues of indirectness and applicability
15.2.1 the role of the review author.
“A leap of faith is always required when applying any study findings to the population at large” or to a specific person. “In making that jump, one must always strike a balance between making justifiable broad generalizations and being too conservative in one’s conclusions” (Friedman et al 1985). In addition to issues about risk of bias and other domains determining the certainty of evidence, this leap of faith is related to how well the identified body of evidence matches the posed PICO ( Population, Intervention, Comparator(s) and Outcome ) question. As to the population, no individual can be entirely matched to the population included in research studies. At the time of decision, there will always be differences between the study population and the person or population to whom the evidence is applied; sometimes these differences are slight, sometimes large.
The terms applicability, generalizability, external validity and transferability are related, sometimes used interchangeably and have in common that they lack a clear and consistent definition in the classic epidemiological literature (Schünemann et al 2013). However, all of the terms describe one overarching theme: whether or not available research evidence can be directly used to answer the health and healthcare question at hand, ideally supported by a judgement about the degree of confidence in this use (Schünemann et al 2013). GRADE’s certainty domains include a judgement about ‘indirectness’ to describe all of these aspects including the concept of direct versus indirect comparisons of different interventions (Atkins et al 2004, Guyatt et al 2008, Guyatt et al 2011b).
To address adequately the extent to which a review is relevant for the purpose to which it is being put, there are certain things the review author must do, and certain things the user of the review must do to assess the degree of indirectness. Cochrane and the GRADE Working Group suggest using a very structured framework to address indirectness. We discuss here and in Chapter 14 what the review author can do to help the user. Cochrane Review authors must be extremely clear on the population, intervention and outcomes that they intend to address. Chapter 14, Section 14.1.2 , also emphasizes a crucial step: the specification of all patient-important outcomes relevant to the intervention strategies under comparison.
In considering whether the effect of an intervention applies equally to all participants, and whether different variations on the intervention have similar effects, review authors need to make a priori hypotheses about possible effect modifiers, and then examine those hypotheses (see Chapter 10, Section 10.10 and Section 10.11 ). If they find apparent subgroup effects, they must ultimately decide whether or not these effects are credible (Sun et al 2012). Differences between subgroups, particularly those that correspond to differences between studies, should be interpreted cautiously. Some chance variation between subgroups is inevitable so, unless there is good reason to believe that there is an interaction, review authors should not assume that the subgroup effect exists. If, despite due caution, review authors judge subgroup effects in terms of relative effect estimates as credible (i.e. the effects differ credibly), they should conduct separate meta-analyses for the relevant subgroups, and produce separate ‘Summary of findings’ tables for those subgroups.
The user of the review will be challenged with ‘individualization’ of the findings, whether they seek to apply the findings to an individual patient or a policy decision in a specific context. For example, even if relative effects are similar across subgroups, absolute effects will differ according to baseline risk. Review authors can help provide this information by identifying identifiable groups of people with varying baseline risks in the ‘Summary of findings’ tables, as discussed in Chapter 14, Section 14.1.3 . Users can then identify their specific case or population as belonging to a particular risk group, if relevant, and assess their likely magnitude of benefit or harm accordingly. A description of the identifying prognostic or baseline risk factors in a brief scenario (e.g. age or gender) will help users of a review further.
Another decision users must make is whether their individual case or population of interest is so different from those included in the studies that they cannot use the results of the systematic review and meta-analysis at all. Rather than rigidly applying the inclusion and exclusion criteria of studies, it is better to ask whether or not there are compelling reasons why the evidence should not be applied to a particular patient. Review authors can sometimes help decision makers by identifying important variation where divergence might limit the applicability of results (Rothwell 2005, Schünemann et al 2006, Guyatt et al 2011b, Schünemann et al 2013), including biologic and cultural variation, and variation in adherence to an intervention.
In addressing these issues, review authors cannot be aware of, or address, the myriad of differences in circumstances around the world. They can, however, address differences of known importance to many people and, importantly, they should avoid assuming that other people’s circumstances are the same as their own in discussing the results and drawing conclusions.
15.2.2 Biological variation
Issues of biological variation that may affect the applicability of a result to a reader or population include divergence in pathophysiology (e.g. biological differences between women and men that may affect responsiveness to an intervention) and divergence in a causative agent (e.g. for infectious diseases such as malaria, which may be caused by several different parasites). The discussion of the results in the review should make clear whether the included studies addressed all or only some of these groups, and whether any important subgroup effects were found.
15.2.3 Variation in context
Some interventions, particularly non-pharmacological interventions, may work in some contexts but not in others; the situation has been described as program by context interaction (Hawe et al 2004). Contextual factors might pertain to the host organization in which an intervention is offered, such as the expertise, experience and morale of the staff expected to carry out the intervention, the competing priorities for the clinician’s or staff’s attention, the local resources such as service and facilities made available to the program and the status or importance given to the program by the host organization. Broader context issues might include aspects of the system within which the host organization operates, such as the fee or payment structure for healthcare providers and the local insurance system. Some interventions, in particular complex interventions (see Chapter 17 ), can be only partially implemented in some contexts, and this requires judgements about indirectness of the intervention and its components for readers in that context (Schünemann 2013).
Contextual factors may also pertain to the characteristics of the target group or population, such as cultural and linguistic diversity, socio-economic position, rural/urban setting. These factors may mean that a particular style of care or relationship evolves between service providers and consumers that may or may not match the values and technology of the program.
For many years these aspects have been acknowledged when decision makers have argued that results of evidence reviews from other countries do not apply in their own country or setting. Whilst some programmes/interventions have been successfully transferred from one context to another, others have not (Resnicow et al 1993, Lumley et al 2004, Coleman et al 2015). Review authors should be cautious when making generalizations from one context to another. They should report on the presence (or otherwise) of context-related information in intervention studies, where this information is available.
15.2.4 Variation in adherence
Variation in the adherence of the recipients and providers of care can limit the certainty in the applicability of results. Predictable differences in adherence can be due to divergence in how recipients of care perceive the intervention (e.g. the importance of side effects), economic conditions or attitudes that make some forms of care inaccessible in some settings, such as in low-income countries (Dans et al 2007). It should not be assumed that high levels of adherence in closely monitored randomized trials will translate into similar levels of adherence in normal practice.
15.2.5 Variation in values and preferences
Decisions about healthcare management strategies and options involve trading off health benefits and harms. The right choice may differ for people with different values and preferences (i.e. the importance people place on the outcomes and interventions), and it is important that decision makers ensure that decisions are consistent with a patient or population’s values and preferences. The importance placed on outcomes, together with other factors, will influence whether the recipients of care will or will not accept an option that is offered (Alonso-Coello et al 2016) and, thus, can be one factor influencing adherence. In Section 15.6 , we describe how the review author can help this process and the limits of supporting decision making based on intervention reviews.
15.3 Interpreting results of statistical analyses
15.3.1 confidence intervals.
Results for both individual studies and meta-analyses are reported with a point estimate together with an associated confidence interval. For example, ‘The odds ratio was 0.75 with a 95% confidence interval of 0.70 to 0.80’. The point estimate (0.75) is the best estimate of the magnitude and direction of the experimental intervention’s effect compared with the comparator intervention. The confidence interval describes the uncertainty inherent in any estimate, and describes a range of values within which we can be reasonably sure that the true effect actually lies. If the confidence interval is relatively narrow (e.g. 0.70 to 0.80), the effect size is known precisely. If the interval is wider (e.g. 0.60 to 0.93) the uncertainty is greater, although there may still be enough precision to make decisions about the utility of the intervention. Intervals that are very wide (e.g. 0.50 to 1.10) indicate that we have little knowledge about the effect and this imprecision affects our certainty in the evidence, and that further information would be needed before we could draw a more certain conclusion.
A 95% confidence interval is often interpreted as indicating a range within which we can be 95% certain that the true effect lies. This statement is a loose interpretation, but is useful as a rough guide. The strictly correct interpretation of a confidence interval is based on the hypothetical notion of considering the results that would be obtained if the study were repeated many times. If a study were repeated infinitely often, and on each occasion a 95% confidence interval calculated, then 95% of these intervals would contain the true effect (see Section 15.3.3 for further explanation).
The width of the confidence interval for an individual study depends to a large extent on the sample size. Larger studies tend to give more precise estimates of effects (and hence have narrower confidence intervals) than smaller studies. For continuous outcomes, precision depends also on the variability in the outcome measurements (i.e. how widely individual results vary between people in the study, measured as the standard deviation); for dichotomous outcomes it depends on the risk of the event (more frequent events allow more precision, and narrower confidence intervals), and for time-to-event outcomes it also depends on the number of events observed. All these quantities are used in computation of the standard errors of effect estimates from which the confidence interval is derived.
The width of a confidence interval for a meta-analysis depends on the precision of the individual study estimates and on the number of studies combined. In addition, for random-effects models, precision will decrease with increasing heterogeneity and confidence intervals will widen correspondingly (see Chapter 10, Section 10.10.4 ). As more studies are added to a meta-analysis the width of the confidence interval usually decreases. However, if the additional studies increase the heterogeneity in the meta-analysis and a random-effects model is used, it is possible that the confidence interval width will increase.
Confidence intervals and point estimates have different interpretations in fixed-effect and random-effects models. While the fixed-effect estimate and its confidence interval address the question ‘what is the best (single) estimate of the effect?’, the random-effects estimate assumes there to be a distribution of effects, and the estimate and its confidence interval address the question ‘what is the best estimate of the average effect?’ A confidence interval may be reported for any level of confidence (although they are most commonly reported for 95%, and sometimes 90% or 99%). For example, the odds ratio of 0.80 could be reported with an 80% confidence interval of 0.73 to 0.88; a 90% interval of 0.72 to 0.89; and a 95% interval of 0.70 to 0.92. As the confidence level increases, the confidence interval widens.
There is logical correspondence between the confidence interval and the P value (see Section 15.3.3 ). The 95% confidence interval for an effect will exclude the null value (such as an odds ratio of 1.0 or a risk difference of 0) if and only if the test of significance yields a P value of less than 0.05. If the P value is exactly 0.05, then either the upper or lower limit of the 95% confidence interval will be at the null value. Similarly, the 99% confidence interval will exclude the null if and only if the test of significance yields a P value of less than 0.01.
Together, the point estimate and confidence interval provide information to assess the effects of the intervention on the outcome. For example, suppose that we are evaluating an intervention that reduces the risk of an event and we decide that it would be useful only if it reduced the risk of an event from 30% by at least 5 percentage points to 25% (these values will depend on the specific clinical scenario and outcomes, including the anticipated harms). If the meta-analysis yielded an effect estimate of a reduction of 10 percentage points with a tight 95% confidence interval, say, from 7% to 13%, we would be able to conclude that the intervention was useful since both the point estimate and the entire range of the interval exceed our criterion of a reduction of 5% for net health benefit. However, if the meta-analysis reported the same risk reduction of 10% but with a wider interval, say, from 2% to 18%, although we would still conclude that our best estimate of the intervention effect is that it provides net benefit, we could not be so confident as we still entertain the possibility that the effect could be between 2% and 5%. If the confidence interval was wider still, and included the null value of a difference of 0%, we would still consider the possibility that the intervention has no effect on the outcome whatsoever, and would need to be even more sceptical in our conclusions.
Review authors may use the same general approach to conclude that an intervention is not useful. Continuing with the above example where the criterion for an important difference that should be achieved to provide more benefit than harm is a 5% risk difference, an effect estimate of 2% with a 95% confidence interval of 1% to 4% suggests that the intervention does not provide net health benefit.
15.3.2 P values and statistical significance
A P value is the standard result of a statistical test, and is the probability of obtaining the observed effect (or larger) under a ‘null hypothesis’. In the context of Cochrane Reviews there are two commonly used statistical tests. The first is a test of overall effect (a Z-test), and its null hypothesis is that there is no overall effect of the experimental intervention compared with the comparator on the outcome of interest. The second is the (Chi 2 ) test for heterogeneity, and its null hypothesis is that there are no differences in the intervention effects across studies.
A P value that is very small indicates that the observed effect is very unlikely to have arisen purely by chance, and therefore provides evidence against the null hypothesis. It has been common practice to interpret a P value by examining whether it is smaller than particular threshold values. In particular, P values less than 0.05 are often reported as ‘statistically significant’, and interpreted as being small enough to justify rejection of the null hypothesis. However, the 0.05 threshold is an arbitrary one that became commonly used in medical and psychological research largely because P values were determined by comparing the test statistic against tabulations of specific percentage points of statistical distributions. If review authors decide to present a P value with the results of a meta-analysis, they should report a precise P value (as calculated by most statistical software), together with the 95% confidence interval. Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values , but report the confidence interval together with the exact P value (see MECIR Box 15.3.a ).
We discuss interpretation of the test for heterogeneity in Chapter 10, Section 10.10.2 ; the remainder of this section refers mainly to tests for an overall effect. For tests of an overall effect, the computation of P involves both the effect estimate and precision of the effect estimate (driven largely by sample size). As precision increases, the range of plausible effects that could occur by chance is reduced. Correspondingly, the statistical significance of an effect of a particular magnitude will usually be greater (the P value will be smaller) in a larger study than in a smaller study.
P values are commonly misinterpreted in two ways. First, a moderate or large P value (e.g. greater than 0.05) may be misinterpreted as evidence that the intervention has no effect on the outcome. There is an important difference between this statement and the correct interpretation that there is a high probability that the observed effect on the outcome is due to chance alone. To avoid such a misinterpretation, review authors should always examine the effect estimate and its 95% confidence interval.
The second misinterpretation is to assume that a result with a small P value for the summary effect estimate implies that an experimental intervention has an important benefit. Such a misinterpretation is more likely to occur in large studies and meta-analyses that accumulate data over dozens of studies and thousands of participants. The P value addresses the question of whether the experimental intervention effect is precisely nil; it does not examine whether the effect is of a magnitude of importance to potential recipients of the intervention. In a large study, a small P value may represent the detection of a trivial effect that may not lead to net health benefit when compared with the potential harms (i.e. harmful effects on other important outcomes). Again, inspection of the point estimate and confidence interval helps correct interpretations (see Section 15.3.1 ).
MECIR Box 15.3.a Relevant expectations for conduct of intervention reviews
15.3.3 Relation between confidence intervals, statistical significance and certainty of evidence
The confidence interval (and imprecision) is only one domain that influences overall uncertainty about effect estimates. Uncertainty resulting from imprecision (i.e. statistical uncertainty) may be no less important than uncertainty from indirectness, or any other GRADE domain, in the context of decision making (Schünemann 2016). Thus, the extent to which interpretations of the confidence interval described in Sections 15.3.1 and 15.3.2 correspond to conclusions about overall certainty of the evidence for the outcome of interest depends on these other domains. If there are no concerns about other domains that determine the certainty of the evidence (i.e. risk of bias, inconsistency, indirectness or publication bias), then the interpretation in Sections 15.3.1 and 15.3.2 . about the relation of the confidence interval to the true effect may be carried forward to the overall certainty. However, if there are concerns about the other domains that affect the certainty of the evidence, the interpretation about the true effect needs to be seen in the context of further uncertainty resulting from those concerns.
For example, nine randomized controlled trials in almost 6000 cancer patients indicated that the administration of heparin reduces the risk of venous thromboembolism (VTE), with a risk ratio of 43% (95% CI 19% to 60%) (Akl et al 2011a). For patients with a plausible baseline risk of approximately 4.6% per year, this relative effect suggests that heparin leads to an absolute risk reduction of 20 fewer VTEs (95% CI 9 fewer to 27 fewer) per 1000 people per year (Akl et al 2011a). Now consider that the review authors or those applying the evidence in a guideline have lowered the certainty in the evidence as a result of indirectness. While the confidence intervals would remain unchanged, the certainty in that confidence interval and in the point estimate as reflecting the truth for the question of interest will be lowered. In fact, the certainty range will have unknown width so there will be unknown likelihood of a result within that range because of this indirectness. The lower the certainty in the evidence, the less we know about the width of the certainty range, although methods for quantifying risk of bias and understanding potential direction of bias may offer insight when lowered certainty is due to risk of bias. Nevertheless, decision makers must consider this uncertainty, and must do so in relation to the effect measure that is being evaluated (e.g. a relative or absolute measure). We will describe the impact on interpretations for dichotomous outcomes in Section 15.4 .
15.4 Interpreting results from dichotomous outcomes (including numbers needed to treat)
15.4.1 relative and absolute risk reductions.
Clinicians may be more inclined to prescribe an intervention that reduces the relative risk of death by 25% than one that reduces the risk of death by 1 percentage point, although both presentations of the evidence may relate to the same benefit (i.e. a reduction in risk from 4% to 3%). The former refers to the relative reduction in risk and the latter to the absolute reduction in risk. As described in Chapter 6, Section 6.4.1 , there are several measures for comparing dichotomous outcomes in two groups. Meta-analyses are usually undertaken using risk ratios (RR), odds ratios (OR) or risk differences (RD), but there are several alternative ways of expressing results.
Relative risk reduction (RRR) is a convenient way of re-expressing a risk ratio as a percentage reduction:

For example, a risk ratio of 0.75 translates to a relative risk reduction of 25%, as in the example above.
The risk difference is often referred to as the absolute risk reduction (ARR) or absolute risk increase (ARI), and may be presented as a percentage (e.g. 1%), as a decimal (e.g. 0.01), or as account (e.g. 10 out of 1000). We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.2 Number needed to treat (NNT)
The number needed to treat (NNT) is a common alternative way of presenting information on the effect of an intervention. The NNT is defined as the expected number of people who need to receive the experimental rather than the comparator intervention for one additional person to either incur or avoid an event (depending on the direction of the result) in a given time frame. Thus, for example, an NNT of 10 can be interpreted as ‘it is expected that one additional (or less) person will incur an event for every 10 participants receiving the experimental intervention rather than comparator over a given time frame’. It is important to be clear that:
- since the NNT is derived from the risk difference, it is still a comparative measure of effect (experimental versus a specific comparator) and not a general property of a single intervention; and
- the NNT gives an ‘expected value’. For example, NNT = 10 does not imply that one additional event will occur in each and every group of 10 people.
NNTs can be computed for both beneficial and detrimental events, and for interventions that cause both improvements and deteriorations in outcomes. In all instances NNTs are expressed as positive whole numbers. Some authors use the term ‘number needed to harm’ (NNH) when an intervention leads to an adverse outcome, or a decrease in a positive outcome, rather than improvement. However, this phrase can be misleading (most notably, it can easily be read to imply the number of people who will experience a harmful outcome if given the intervention), and it is strongly recommended that ‘number needed to harm’ and ‘NNH’ are avoided. The preferred alternative is to use phrases such as ‘number needed to treat for an additional beneficial outcome’ (NNTB) and ‘number needed to treat for an additional harmful outcome’ (NNTH) to indicate direction of effect.
As NNTs refer to events, their interpretation needs to be worded carefully when the binary outcome is a dichotomization of a scale-based outcome. For example, if the outcome is pain measured on a ‘none, mild, moderate or severe’ scale it may have been dichotomized as ‘none or mild’ versus ‘moderate or severe’. It would be inappropriate for an NNT from these data to be referred to as an ‘NNT for pain’. It is an ‘NNT for moderate or severe pain’.
We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.3 Expressing risk differences
Users of reviews are liable to be influenced by the choice of statistical presentations of the evidence. Hoffrage and colleagues suggest that physicians’ inferences about statistical outcomes are more appropriate when they deal with ‘natural frequencies’ – whole numbers of people, both treated and untreated (e.g. treatment results in a drop from 20 out of 1000 to 10 out of 1000 women having breast cancer) – than when effects are presented as percentages (e.g. 1% absolute reduction in breast cancer risk) (Hoffrage et al 2000). Probabilities may be more difficult to understand than frequencies, particularly when events are rare. While standardization may be important in improving the presentation of research evidence (and participation in healthcare decisions), current evidence suggests that the presentation of natural frequencies for expressing differences in absolute risk is best understood by consumers of healthcare information (Akl et al 2011b). This evidence provides the rationale for presenting absolute risks in ‘Summary of findings’ tables as numbers of people with events per 1000 people receiving the intervention (see Chapter 14 ).
RRs and RRRs remain crucial because relative effects tend to be substantially more stable across risk groups than absolute effects (see Chapter 10, Section 10.4.3 ). Review authors can use their own data to study this consistency (Cates 1999, Smeeth et al 1999). Risk differences from studies are least likely to be consistent across baseline event rates; thus, they are rarely appropriate for computing numbers needed to treat in systematic reviews. If a relative effect measure (OR or RR) is chosen for meta-analysis, then a comparator group risk needs to be specified as part of the calculation of an RD or NNT. In addition, if there are several different groups of participants with different levels of risk, it is crucial to express absolute benefit for each clinically identifiable risk group, clarifying the time period to which this applies. Studies in patients with differing severity of disease, or studies with different lengths of follow-up will almost certainly have different comparator group risks. In these cases, different comparator group risks lead to different RDs and NNTs (except when the intervention has no effect). A recommended approach is to re-express an odds ratio or a risk ratio as a variety of RD or NNTs across a range of assumed comparator risks (ACRs) (McQuay and Moore 1997, Smeeth et al 1999). Review authors should bear these considerations in mind not only when constructing their ‘Summary of findings’ table, but also in the text of their review.
For example, a review of oral anticoagulants to prevent stroke presented information to users by describing absolute benefits for various baseline risks (Aguilar and Hart 2005, Aguilar et al 2007). They presented their principal findings as “The inherent risk of stroke should be considered in the decision to use oral anticoagulants in atrial fibrillation patients, selecting those who stand to benefit most for this therapy” (Aguilar and Hart 2005). Among high-risk atrial fibrillation patients with prior stroke or transient ischaemic attack who have stroke rates of about 12% (120 per 1000) per year, warfarin prevents about 70 strokes yearly per 1000 patients, whereas for low-risk atrial fibrillation patients (with a stroke rate of about 2% per year or 20 per 1000), warfarin prevents only 12 strokes. This presentation helps users to understand the important impact that typical baseline risks have on the absolute benefit that they can expect.
15.4.4 Computations
Direct computation of risk difference (RD) or a number needed to treat (NNT) depends on the summary statistic (odds ratio, risk ratio or risk differences) available from the study or meta-analysis. When expressing results of meta-analyses, review authors should use, in the computations, whatever statistic they determined to be the most appropriate summary for meta-analysis (see Chapter 10, Section 10.4.3 ). Here we present calculations to obtain RD as a reduction in the number of participants per 1000. For example, a risk difference of –0.133 corresponds to 133 fewer participants with the event per 1000.
RDs and NNTs should not be computed from the aggregated total numbers of participants and events across the trials. This approach ignores the randomization within studies, and may produce seriously misleading results if there is unbalanced randomization in any of the studies. Using the pooled result of a meta-analysis is more appropriate. When computing NNTs, the values obtained are by convention always rounded up to the next whole number.
15.4.4.1 Computing NNT from a risk difference (RD)
A NNT may be computed from a risk difference as

where the vertical bars (‘absolute value of’) in the denominator indicate that any minus sign should be ignored. It is convention to round the NNT up to the nearest whole number. For example, if the risk difference is –0.12 the NNT is 9; if the risk difference is –0.22 the NNT is 5. Cochrane Review authors should qualify the NNT as referring to benefit (improvement) or harm by denoting the NNT as NNTB or NNTH. Note that this approach, although feasible, should be used only for the results of a meta-analysis of risk differences. In most cases meta-analyses will be undertaken using a relative measure of effect (RR or OR), and those statistics should be used to calculate the NNT (see Section 15.4.4.2 and 15.4.4.3 ).
15.4.4.2 Computing risk differences or NNT from a risk ratio
To aid interpretation of the results of a meta-analysis of risk ratios, review authors may compute an absolute risk reduction or NNT. In order to do this, an assumed comparator risk (ACR) (otherwise known as a baseline risk, or risk that the outcome of interest would occur with the comparator intervention) is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the risk ratio is RR = 0.92, and an ACR = 0.3 (300 per 1000) is assumed. Then the effect on risk is 24 fewer per 1000:

The NNT is 42:

15.4.4.3 Computing risk differences or NNT from an odds ratio
Review authors may wish to compute a risk difference or NNT from the results of a meta-analysis of odds ratios. In order to do this, an ACR is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the odds ratio is OR = 0.73, and a comparator risk of ACR = 0.3 is assumed. Then the effect on risk is 62 fewer per 1000:

The NNT is 17:

15.4.4.4 Computing risk ratio from an odds ratio
Because risk ratios are easier to interpret than odds ratios, but odds ratios have favourable mathematical properties, a review author may decide to undertake a meta-analysis based on odds ratios, but to express the result as a summary risk ratio (or relative risk reduction). This requires an ACR. Then

It will often be reasonable to perform this transformation using the median comparator group risk from the studies in the meta-analysis.
15.4.4.5 Computing confidence limits
Confidence limits for RDs and NNTs may be calculated by applying the above formulae to the upper and lower confidence limits for the summary statistic (RD, RR or OR) (Altman 1998). Note that this confidence interval does not incorporate uncertainty around the ACR.
If the 95% confidence interval of OR or RR includes the value 1, one of the confidence limits will indicate benefit and the other harm. Thus, appropriate use of the words ‘fewer’ and ‘more’ is required for each limit when presenting results in terms of events. For NNTs, the two confidence limits should be labelled as NNTB and NNTH to indicate the direction of effect in each case. The confidence interval for the NNT will include a ‘discontinuity’, because increasingly smaller risk differences that approach zero will lead to NNTs approaching infinity. Thus, the confidence interval will include both an infinitely large NNTB and an infinitely large NNTH.
15.5 Interpreting results from continuous outcomes (including standardized mean differences)
15.5.1 meta-analyses with continuous outcomes.
Review authors should describe in the study protocol how they plan to interpret results for continuous outcomes. When outcomes are continuous, review authors have a number of options to present summary results. These options differ if studies report the same measure that is familiar to the target audiences, studies report the same or very similar measures that are less familiar to the target audiences, or studies report different measures.
15.5.2 Meta-analyses with continuous outcomes using the same measure
If all studies have used the same familiar units, for instance, results are expressed as durations of events, such as symptoms for conditions including diarrhoea, sore throat, otitis media, influenza or duration of hospitalization, a meta-analysis may generate a summary estimate in those units, as a difference in mean response (see, for instance, the row summarizing results for duration of diarrhoea in Chapter 14, Figure 14.1.b and the row summarizing oedema in Chapter 14, Figure 14.1.a ). For such outcomes, the ‘Summary of findings’ table should include a difference of means between the two interventions. However, when units of such outcomes may be difficult to interpret, particularly when they relate to rating scales (again, see the oedema row of Chapter 14, Figure 14.1.a ). ‘Summary of findings’ tables should include the minimum and maximum of the scale of measurement, and the direction. Knowledge of the smallest change in instrument score that patients perceive is important – the minimal important difference (MID) – and can greatly facilitate the interpretation of results (Guyatt et al 1998, Schünemann and Guyatt 2005). Knowing the MID allows review authors and users to place results in context. Review authors should state the MID – if known – in the Comments column of their ‘Summary of findings’ table. For example, the chronic respiratory questionnaire has possible scores in health-related quality of life ranging from 1 to 7 and 0.5 represents a well-established MID (Jaeschke et al 1989, Schünemann et al 2005).
15.5.3 Meta-analyses with continuous outcomes using different measures
When studies have used different instruments to measure the same construct, a standardized mean difference (SMD) may be used in meta-analysis for combining continuous data. Without guidance, clinicians and patients may have little idea how to interpret results presented as SMDs. Review authors should therefore consider issues of interpretability when planning their analysis at the protocol stage and should consider whether there will be suitable ways to re-express the SMD or whether alternative effect measures, such as a ratio of means, or possibly as minimal important difference units (Guyatt et al 2013b) should be used. Table 15.5.a and the following sections describe these options.
Table 15.5.a Approaches and their implications to presenting results of continuous variables when primary studies have used different instruments to measure the same construct. Adapted from Guyatt et al (2013b)
15.5.3.1 Presenting and interpreting SMDs using generic effect size estimates
The SMD expresses the intervention effect in standard units rather than the original units of measurement. The SMD is the difference in mean effects between the experimental and comparator groups divided by the pooled standard deviation of participants’ outcomes, or external SDs when studies are very small (see Chapter 6, Section 6.5.1.2 ). The value of a SMD thus depends on both the size of the effect (the difference between means) and the standard deviation of the outcomes (the inherent variability among participants or based on an external SD).
If review authors use the SMD, they might choose to present the results directly as SMDs (row 1a, Table 15.5.a and Table 15.5.b ). However, absolute values of the intervention and comparison groups are typically not useful because studies have used different measurement instruments with different units. Guiding rules for interpreting SMDs (or ‘Cohen’s effect sizes’) exist, and have arisen mainly from researchers in the social sciences (Cohen 1988). One example is as follows: 0.2 represents a small effect, 0.5 a moderate effect and 0.8 a large effect (Cohen 1988). Variations exist (e.g. <0.40=small, 0.40 to 0.70=moderate, >0.70=large). Review authors might consider including such a guiding rule in interpreting the SMD in the text of the review, and in summary versions such as the Comments column of a ‘Summary of findings’ table. However, some methodologists believe that such interpretations are problematic because patient importance of a finding is context-dependent and not amenable to generic statements.
15.5.3.2 Re-expressing SMDs using a familiar instrument
The second possibility for interpreting the SMD is to express it in the units of one or more of the specific measurement instruments used by the included studies (row 1b, Table 15.5.a and Table 15.5.b ). The approach is to calculate an absolute difference in means by multiplying the SMD by an estimate of the SD associated with the most familiar instrument. To obtain this SD, a reasonable option is to calculate a weighted average across all intervention groups of all studies that used the selected instrument (preferably a pre-intervention or post-intervention SD as discussed in Chapter 10, Section 10.5.2 ). To better reflect among-person variation in practice, or to use an instrument not represented in the meta-analysis, it may be preferable to use a standard deviation from a representative observational study. The summary effect is thus re-expressed in the original units of that particular instrument and the clinical relevance and impact of the intervention effect can be interpreted using that familiar instrument.
The same approach of re-expressing the results for a familiar instrument can also be used for other standardized effect measures such as when standardizing by MIDs (Guyatt et al 2013b): see Section 15.5.3.5 .
Table 15.5.b Application of approaches when studies have used different measures: effects of dexamethasone for pain after laparoscopic cholecystectomy (Karanicolas et al 2008). Reproduced with permission of Wolters Kluwer
1 Certainty rated according to GRADE from very low to high certainty. 2 Substantial unexplained heterogeneity in study results. 3 Imprecision due to wide confidence intervals. 4 The 20% comes from the proportion in the control group requiring rescue analgesia. 5 Crude (arithmetic) means of the post-operative pain mean responses across all five trials when transformed to a 100-point scale.
15.5.3.3 Re-expressing SMDs through dichotomization and transformation to relative and absolute measures
A third approach (row 1c, Table 15.5.a and Table 15.5.b ) relies on converting the continuous measure into a dichotomy and thus allows calculation of relative and absolute effects on a binary scale. A transformation of a SMD to a (log) odds ratio is available, based on the assumption that an underlying continuous variable has a logistic distribution with equal standard deviation in the two intervention groups, as discussed in Chapter 10, Section 10.6 (Furukawa 1999, Guyatt et al 2013b). The assumption is unlikely to hold exactly and the results must be regarded as an approximation. The log odds ratio is estimated as

(or approximately 1.81✕SMD). The resulting odds ratio can then be presented as normal, and in a ‘Summary of findings’ table, combined with an assumed comparator group risk to be expressed as an absolute risk difference. The comparator group risk in this case would refer to the proportion of people who have achieved a specific value of the continuous outcome. In randomized trials this can be interpreted as the proportion who have improved by some (specified) amount (responders), for instance by 5 points on a 0 to 100 scale. Table 15.5.c shows some illustrative results from this method. The risk differences can then be converted to NNTs or to people per thousand using methods described in Section 15.4.4 .
Table 15.5.c Risk difference derived for specific SMDs for various given ‘proportions improved’ in the comparator group (Furukawa 1999, Guyatt et al 2013b). Reproduced with permission of Elsevier
15.5.3.4 Ratio of means
A more frequently used approach is based on calculation of a ratio of means between the intervention and comparator groups (Friedrich et al 2008) as discussed in Chapter 6, Section 6.5.1.3 . Interpretational advantages of this approach include the ability to pool studies with outcomes expressed in different units directly, to avoid the vulnerability of heterogeneous populations that limits approaches that rely on SD units, and for ease of clinical interpretation (row 2, Table 15.5.a and Table 15.5.b ). This method is currently designed for post-intervention scores only. However, it is possible to calculate a ratio of change scores if both intervention and comparator groups change in the same direction in each relevant study, and this ratio may sometimes be informative.
Limitations to this approach include its limited applicability to change scores (since it is unlikely that both intervention and comparator group changes are in the same direction in all studies) and the possibility of misleading results if the comparator group mean is very small, in which case even a modest difference from the intervention group will yield a large and therefore misleading ratio of means. It also requires that separate ratios of means be calculated for each included study, and then entered into a generic inverse variance meta-analysis (see Chapter 10, Section 10.3 ).
The ratio of means approach illustrated in Table 15.5.b suggests a relative reduction in pain of only 13%, meaning that those receiving steroids have a pain severity 87% of those in the comparator group, an effect that might be considered modest.
15.5.3.5 Presenting continuous results as minimally important difference units
To express results in MID units, review authors have two options. First, they can be combined across studies in the same way as the SMD, but instead of dividing the mean difference of each study by its SD, review authors divide by the MID associated with that outcome (Johnston et al 2010, Guyatt et al 2013b). Instead of SD units, the pooled results represent MID units (row 3, Table 15.5.a and Table 15.5.b ), and may be more easily interpretable. This approach avoids the problem of varying SDs across studies that may distort estimates of effect in approaches that rely on the SMD. The approach, however, relies on having well-established MIDs. The approach is also risky in that a difference less than the MID may be interpreted as trivial when a substantial proportion of patients may have achieved an important benefit.
The other approach makes a simple conversion (not shown in Table 15.5.b ), before undertaking the meta-analysis, of the means and SDs from each study to means and SDs on the scale of a particular familiar instrument whose MID is known. For example, one can rescale the mean and SD of other chronic respiratory disease instruments (e.g. rescaling a 0 to 100 score of an instrument) to a the 1 to 7 score in Chronic Respiratory Disease Questionnaire (CRQ) units (by assuming 0 equals 1 and 100 equals 7 on the CRQ). Given the MID of the CRQ of 0.5, a mean difference in change of 0.71 after rescaling of all studies suggests a substantial effect of the intervention (Guyatt et al 2013b). This approach, presenting in units of the most familiar instrument, may be the most desirable when the target audiences have extensive experience with that instrument, particularly if the MID is well established.
15.6 Drawing conclusions
15.6.1 conclusions sections of a cochrane review.
Authors’ conclusions in a Cochrane Review are divided into implications for practice and implications for research. While Cochrane Reviews about interventions can provide meaningful information and guidance for practice, decisions about the desirable and undesirable consequences of healthcare options require evidence and judgements for criteria that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). In describing the implications for practice and the development of recommendations, however, review authors may consider the certainty of the evidence, the balance of benefits and harms, and assumed values and preferences.
15.6.2 Implications for practice
Drawing conclusions about the practical usefulness of an intervention entails making trade-offs, either implicitly or explicitly, between the estimated benefits, harms and the values and preferences. Making such trade-offs, and thus making specific recommendations for an action in a specific context, goes beyond a Cochrane Review and requires additional evidence and informed judgements that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). Such judgements are typically the domain of clinical practice guideline developers for which Cochrane Reviews will provide crucial information (Graham et al 2011, Schünemann et al 2014, Zhang et al 2018a). Thus, authors of Cochrane Reviews should not make recommendations.
If review authors feel compelled to lay out actions that clinicians and patients could take, they should – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences. Other factors that might influence a decision should also be highlighted, including any known factors that would be expected to modify the effects of the intervention, the baseline risk or status of the patient, costs and who bears those costs, and the availability of resources. Review authors should ensure they consider all patient-important outcomes, including those for which limited data may be available. In the context of public health reviews the focus may be on population-important outcomes as the target may be an entire (non-diseased) population and include outcomes that are not measured in the population receiving an intervention (e.g. a reduction of transmission of infections from those receiving an intervention). This process implies a high level of explicitness in judgements about values or preferences attached to different outcomes and the certainty of the related evidence (Zhang et al 2018b, Zhang et al 2018c); this and a full cost-effectiveness analysis is beyond the scope of most Cochrane Reviews (although they might well be used for such analyses; see Chapter 20 ).
A review on the use of anticoagulation in cancer patients to increase survival (Akl et al 2011a) provides an example for laying out clinical implications for situations where there are important trade-offs between desirable and undesirable effects of the intervention: “The decision for a patient with cancer to start heparin therapy for survival benefit should balance the benefits and downsides and integrate the patient’s values and preferences. Patients with a high preference for a potential survival prolongation, limited aversion to potential bleeding, and who do not consider heparin (both UFH or LMWH) therapy a burden may opt to use heparin, while those with aversion to bleeding may not.”
15.6.3 Implications for research
The second category for authors’ conclusions in a Cochrane Review is implications for research. To help people make well-informed decisions about future healthcare research, the ‘Implications for research’ section should comment on the need for further research, and the nature of the further research that would be most desirable. It is helpful to consider the population, intervention, comparison and outcomes that could be addressed, or addressed more effectively in the future, in the context of the certainty of the evidence in the current review (Brown et al 2006):
- P (Population): diagnosis, disease stage, comorbidity, risk factor, sex, age, ethnic group, specific inclusion or exclusion criteria, clinical setting;
- I (Intervention): type, frequency, dose, duration, prognostic factor;
- C (Comparison): placebo, routine care, alternative treatment/management;
- O (Outcome): which clinical or patient-related outcomes will the researcher need to measure, improve, influence or accomplish? Which methods of measurement should be used?
While Cochrane Review authors will find the PICO domains helpful, the domains of the GRADE certainty framework further support understanding and describing what additional research will improve the certainty in the available evidence. Note that as the certainty of the evidence is likely to vary by outcome, these implications will be specific to certain outcomes in the review. Table 15.6.a shows how review authors may be aided in their interpretation of the body of evidence and drawing conclusions about future research and practice.
Table 15.6.a Implications for research and practice suggested by individual GRADE domains
The review of compression stockings for prevention of deep vein thrombosis (DVT) in airline passengers described in Chapter 14 provides an example where there is some convincing evidence of a benefit of the intervention: “This review shows that the question of the effects on symptomless DVT of wearing versus not wearing compression stockings in the types of people studied in these trials should now be regarded as answered. Further research may be justified to investigate the relative effects of different strengths of stockings or of stockings compared to other preventative strategies. Further randomised trials to address the remaining uncertainty about the effects of wearing versus not wearing compression stockings on outcomes such as death, pulmonary embolism and symptomatic DVT would need to be large.” (Clarke et al 2016).
A review of therapeutic touch for anxiety disorder provides an example of the implications for research when no eligible studies had been found: “This review highlights the need for randomized controlled trials to evaluate the effectiveness of therapeutic touch in reducing anxiety symptoms in people diagnosed with anxiety disorders. Future trials need to be rigorous in design and delivery, with subsequent reporting to include high quality descriptions of all aspects of methodology to enable appraisal and interpretation of results.” (Robinson et al 2007).
15.6.4 Reaching conclusions
A common mistake is to confuse ‘no evidence of an effect’ with ‘evidence of no effect’. When the confidence intervals are too wide (e.g. including no effect), it is wrong to claim that the experimental intervention has ‘no effect’ or is ‘no different’ from the comparator intervention. Review authors may also incorrectly ‘positively’ frame results for some effects but not others. For example, when the effect estimate is positive for a beneficial outcome but confidence intervals are wide, review authors may describe the effect as promising. However, when the effect estimate is negative for an outcome that is considered harmful but the confidence intervals include no effect, review authors report no effect. Another mistake is to frame the conclusion in wishful terms. For example, review authors might write, “there were too few people in the analysis to detect a reduction in mortality” when the included studies showed a reduction or even increase in mortality that was not ‘statistically significant’. One way of avoiding errors such as these is to consider the results blinded; that is, consider how the results would be presented and framed in the conclusions if the direction of the results was reversed. If the confidence interval for the estimate of the difference in the effects of the interventions overlaps with no effect, the analysis is compatible with both a true beneficial effect and a true harmful effect. If one of the possibilities is mentioned in the conclusion, the other possibility should be mentioned as well. Table 15.6.b suggests narrative statements for drawing conclusions based on the effect estimate from the meta-analysis and the certainty of the evidence.
Table 15.6.b Suggested narrative statements for phrasing conclusions
Another common mistake is to reach conclusions that go beyond the evidence. Often this is done implicitly, without referring to the additional information or judgements that are used in reaching conclusions about the implications of a review for practice. Even when additional information and explicit judgements support conclusions about the implications of a review for practice, review authors rarely conduct systematic reviews of the additional information. Furthermore, implications for practice are often dependent on specific circumstances and values that must be taken into consideration. As we have noted, review authors should always be cautious when drawing conclusions about implications for practice and they should not make recommendations.
15.7 Chapter information
Authors: Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Acknowledgements: Andrew Oxman, Jonathan Sterne, Michael Borenstein and Rob Scholten contributed text to earlier versions of this chapter.
Funding: This work was in part supported by funding from the Michael G DeGroote Cochrane Canada Centre and the Ontario Ministry of Health. JJD receives support from the National Institute for Health Research (NIHR) Birmingham Biomedical Research Centre at the University Hospitals Birmingham NHS Foundation Trust and the University of Birmingham. JPTH receives support from the NIHR Biomedical Research Centre at University Hospitals Bristol NHS Foundation Trust and the University of Bristol. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health.
15.8 References
Aguilar MI, Hart R. Oral anticoagulants for preventing stroke in patients with non-valvular atrial fibrillation and no previous history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2005; 3 : CD001927.
Aguilar MI, Hart R, Pearce LA. Oral anticoagulants versus antiplatelet therapy for preventing stroke in patients with non-valvular atrial fibrillation and no history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2007; 3 : CD006186.
Akl EA, Gunukula S, Barba M, Yosuico VE, van Doormaal FF, Kuipers S, Middeldorp S, Dickinson HO, Bryant A, Schünemann H. Parenteral anticoagulation in patients with cancer who have no therapeutic or prophylactic indication for anticoagulation. Cochrane Database of Systematic Reviews 2011a; 1 : CD006652.
Akl EA, Oxman AD, Herrin J, Vist GE, Terrenato I, Sperati F, Costiniuk C, Blank D, Schünemann H. Using alternative statistical formats for presenting risks and risk reductions. Cochrane Database of Systematic Reviews 2011b; 3 : CD006776.
Alonso-Coello P, Schünemann HJ, Moberg J, Brignardello-Petersen R, Akl EA, Davoli M, Treweek S, Mustafa RA, Rada G, Rosenbaum S, Morelli A, Guyatt GH, Oxman AD, Group GW. GRADE Evidence to Decision (EtD) frameworks: a systematic and transparent approach to making well informed healthcare choices. 1: Introduction. BMJ 2016; 353 : i2016.
Altman DG. Confidence intervals for the number needed to treat. BMJ 1998; 317 : 1309-1312.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, Guyatt GH, Harbour RT, Haugh MC, Henry D, Hill S, Jaeschke R, Leng G, Liberati A, Magrini N, Mason J, Middleton P, Mrukowicz J, O'Connell D, Oxman AD, Phillips B, Schünemann HJ, Edejer TT, Varonen H, Vist GE, Williams JW, Jr., Zaza S. Grading quality of evidence and strength of recommendations. BMJ 2004; 328 : 1490.
Brown P, Brunnhuber K, Chalkidou K, Chalmers I, Clarke M, Fenton M, Forbes C, Glanville J, Hicks NJ, Moody J, Twaddle S, Timimi H, Young P. How to formulate research recommendations. BMJ 2006; 333 : 804-806.
Cates C. Confidence intervals for the number needed to treat: Pooling numbers needed to treat may not be reliable. BMJ 1999; 318 : 1764-1765.
Clarke MJ, Broderick C, Hopewell S, Juszczak E, Eisinga A. Compression stockings for preventing deep vein thrombosis in airline passengers. Cochrane Database of Systematic Reviews 2016; 9 : CD004002.
Cohen J. Statistical Power Analysis in the Behavioral Sciences . 2nd edition ed. Hillsdale (NJ): Lawrence Erlbaum Associates, Inc.; 1988.
Coleman T, Chamberlain C, Davey MA, Cooper SE, Leonardi-Bee J. Pharmacological interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2015; 12 : CD010078.
Dans AM, Dans L, Oxman AD, Robinson V, Acuin J, Tugwell P, Dennis R, Kang D. Assessing equity in clinical practice guidelines. Journal of Clinical Epidemiology 2007; 60 : 540-546.
Friedman LM, Furberg CD, DeMets DL. Fundamentals of Clinical Trials . 2nd edition ed. Littleton (MA): John Wright PSG, Inc.; 1985.
Friedrich JO, Adhikari NK, Beyene J. The ratio of means method as an alternative to mean differences for analyzing continuous outcome variables in meta-analysis: a simulation study. BMC Medical Research Methodology 2008; 8 : 32.
Furukawa T. From effect size into number needed to treat. Lancet 1999; 353 : 1680.
Graham R, Mancher M, Wolman DM, Greenfield S, Steinberg E. Committee on Standards for Developing Trustworthy Clinical Practice Guidelines, Board on Health Care Services: Clinical Practice Guidelines We Can Trust. Washington, DC: National Academies Press; 2011.
Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, Norris S, Falck-Ytter Y, Glasziou P, DeBeer H, Jaeschke R, Rind D, Meerpohl J, Dahm P, Schünemann HJ. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. Journal of Clinical Epidemiology 2011a; 64 : 383-394.
Guyatt GH, Juniper EF, Walter SD, Griffith LE, Goldstein RS. Interpreting treatment effects in randomised trials. BMJ 1998; 316 : 690-693.
Guyatt GH, Oxman AD, Vist GE, Kunz R, Falck-Ytter Y, Alonso-Coello P, Schünemann HJ. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ 2008; 336 : 924-926.
Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, Alonso-Coello P, Falck-Ytter Y, Jaeschke R, Vist G, Akl EA, Post PN, Norris S, Meerpohl J, Shukla VK, Nasser M, Schünemann HJ. GRADE guidelines: 8. Rating the quality of evidence--indirectness. Journal of Clinical Epidemiology 2011b; 64 : 1303-1310.
Guyatt GH, Oxman AD, Santesso N, Helfand M, Vist G, Kunz R, Brozek J, Norris S, Meerpohl J, Djulbegovic B, Alonso-Coello P, Post PN, Busse JW, Glasziou P, Christensen R, Schünemann HJ. GRADE guidelines: 12. Preparing summary of findings tables-binary outcomes. Journal of Clinical Epidemiology 2013a; 66 : 158-172.
Guyatt GH, Thorlund K, Oxman AD, Walter SD, Patrick D, Furukawa TA, Johnston BC, Karanicolas P, Akl EA, Vist G, Kunz R, Brozek J, Kupper LL, Martin SL, Meerpohl JJ, Alonso-Coello P, Christensen R, Schünemann HJ. GRADE guidelines: 13. Preparing summary of findings tables and evidence profiles-continuous outcomes. Journal of Clinical Epidemiology 2013b; 66 : 173-183.
Hawe P, Shiell A, Riley T, Gold L. Methods for exploring implementation variation and local context within a cluster randomised community intervention trial. Journal of Epidemiology and Community Health 2004; 58 : 788-793.
Hoffrage U, Lindsey S, Hertwig R, Gigerenzer G. Medicine. Communicating statistical information. Science 2000; 290 : 2261-2262.
Jaeschke R, Singer J, Guyatt GH. Measurement of health status. Ascertaining the minimal clinically important difference. Controlled Clinical Trials 1989; 10 : 407-415.
Johnston B, Thorlund K, Schünemann H, Xie F, Murad M, Montori V, Guyatt G. Improving the interpretation of health-related quality of life evidence in meta-analysis: The application of minimal important difference units. . Health Outcomes and Qualithy of Life 2010; 11 : 116.
Karanicolas PJ, Smith SE, Kanbur B, Davies E, Guyatt GH. The impact of prophylactic dexamethasone on nausea and vomiting after laparoscopic cholecystectomy: a systematic review and meta-analysis. Annals of Surgery 2008; 248 : 751-762.
Lumley J, Oliver SS, Chamberlain C, Oakley L. Interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2004; 4 : CD001055.
McQuay HJ, Moore RA. Using numerical results from systematic reviews in clinical practice. Annals of Internal Medicine 1997; 126 : 712-720.
Resnicow K, Cross D, Wynder E. The Know Your Body program: a review of evaluation studies. Bulletin of the New York Academy of Medicine 1993; 70 : 188-207.
Robinson J, Biley FC, Dolk H. Therapeutic touch for anxiety disorders. Cochrane Database of Systematic Reviews 2007; 3 : CD006240.
Rothwell PM. External validity of randomised controlled trials: "to whom do the results of this trial apply?". Lancet 2005; 365 : 82-93.
Santesso N, Carrasco-Labra A, Langendam M, Brignardello-Petersen R, Mustafa RA, Heus P, Lasserson T, Opiyo N, Kunnamo I, Sinclair D, Garner P, Treweek S, Tovey D, Akl EA, Tugwell P, Brozek JL, Guyatt G, Schünemann HJ. Improving GRADE evidence tables part 3: detailed guidance for explanatory footnotes supports creating and understanding GRADE certainty in the evidence judgments. Journal of Clinical Epidemiology 2016; 74 : 28-39.
Schünemann HJ, Puhan M, Goldstein R, Jaeschke R, Guyatt GH. Measurement properties and interpretability of the Chronic respiratory disease questionnaire (CRQ). COPD: Journal of Chronic Obstructive Pulmonary Disease 2005; 2 : 81-89.
Schünemann HJ, Guyatt GH. Commentary--goodbye M(C)ID! Hello MID, where do you come from? Health Services Research 2005; 40 : 593-597.
Schünemann HJ, Fretheim A, Oxman AD. Improving the use of research evidence in guideline development: 13. Applicability, transferability and adaptation. Health Research Policy and Systems 2006; 4 : 25.
Schünemann HJ. Methodological idiosyncracies, frameworks and challenges of non-pharmaceutical and non-technical treatment interventions. Zeitschrift für Evidenz, Fortbildung und Qualität im Gesundheitswesen 2013; 107 : 214-220.
Schünemann HJ, Tugwell P, Reeves BC, Akl EA, Santesso N, Spencer FA, Shea B, Wells G, Helfand M. Non-randomized studies as a source of complementary, sequential or replacement evidence for randomized controlled trials in systematic reviews on the effects of interventions. Research Synthesis Methods 2013; 4 : 49-62.
Schünemann HJ, Wiercioch W, Etxeandia I, Falavigna M, Santesso N, Mustafa R, Ventresca M, Brignardello-Petersen R, Laisaar KT, Kowalski S, Baldeh T, Zhang Y, Raid U, Neumann I, Norris SL, Thornton J, Harbour R, Treweek S, Guyatt G, Alonso-Coello P, Reinap M, Brozek J, Oxman A, Akl EA. Guidelines 2.0: systematic development of a comprehensive checklist for a successful guideline enterprise. CMAJ: Canadian Medical Association Journal 2014; 186 : E123-142.
Schünemann HJ. Interpreting GRADE's levels of certainty or quality of the evidence: GRADE for statisticians, considering review information size or less emphasis on imprecision? Journal of Clinical Epidemiology 2016; 75 : 6-15.
Smeeth L, Haines A, Ebrahim S. Numbers needed to treat derived from meta-analyses--sometimes informative, usually misleading. BMJ 1999; 318 : 1548-1551.
Sun X, Briel M, Busse JW, You JJ, Akl EA, Mejza F, Bala MM, Bassler D, Mertz D, Diaz-Granados N, Vandvik PO, Malaga G, Srinathan SK, Dahm P, Johnston BC, Alonso-Coello P, Hassouneh B, Walter SD, Heels-Ansdell D, Bhatnagar N, Altman DG, Guyatt GH. Credibility of claims of subgroup effects in randomised controlled trials: systematic review. BMJ 2012; 344 : e1553.
Zhang Y, Akl EA, Schünemann HJ. Using systematic reviews in guideline development: the GRADE approach. Research Synthesis Methods 2018a: doi: 10.1002/jrsm.1313.
Zhang Y, Alonso-Coello P, Guyatt GH, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Schünemann HJ. GRADE Guidelines: 19. Assessing the certainty of evidence in the importance of outcomes or values and preferences-Risk of bias and indirectness. Journal of Clinical Epidemiology 2018b: doi: 10.1016/j.jclinepi.2018.1001.1013.
Zhang Y, Alonso Coello P, Guyatt G, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Xie F, Schünemann HJ. GRADE Guidelines: 20. Assessing the certainty of evidence in the importance of outcomes or values and preferences - Inconsistency, Imprecision, and other Domains. Journal of Clinical Epidemiology 2018c: doi: 10.1016/j.jclinepi.2018.1005.1011.
For permission to re-use material from the Handbook (either academic or commercial), please see here for full details.
How To Write The Results/Findings Chapter
For quantitative studies (dissertations & theses).
By: Derek Jansen (MBA) | Expert Reviewed By: Kerryn Warren (PhD) | July 2021
So, you’ve completed your quantitative data analysis and it’s time to report on your findings. But where do you start? In this post, we’ll walk you through the results chapter (also called the findings or analysis chapter), step by step, so that you can craft this section of your dissertation or thesis with confidence. If you’re looking for information regarding the results chapter for qualitative studies, you can find that here .
Overview: Quantitative Results Chapter
- What exactly the results chapter is
- What you need to include in your chapter
- How to structure the chapter
- Tips and tricks for writing a top-notch chapter
- Free results chapter template
What exactly is the results chapter?
The results chapter (also referred to as the findings or analysis chapter) is one of the most important chapters of your dissertation or thesis because it shows the reader what you’ve found in terms of the quantitative data you’ve collected. It presents the data using a clear text narrative, supported by tables, graphs and charts. In doing so, it also highlights any potential issues (such as outliers or unusual findings) you’ve come across.
But how’s that different from the discussion chapter?
Well, in the results chapter, you only present your statistical findings. Only the numbers, so to speak – no more, no less. Contrasted to this, in the discussion chapter , you interpret your findings and link them to prior research (i.e. your literature review), as well as your research objectives and research questions . In other words, the results chapter presents and describes the data, while the discussion chapter interprets the data.
Let’s look at an example.
In your results chapter, you may have a plot that shows how respondents to a survey responded: the numbers of respondents per category, for instance. You may also state whether this supports a hypothesis by using a p-value from a statistical test. But it is only in the discussion chapter where you will say why this is relevant or how it compares with the literature or the broader picture. So, in your results chapter, make sure that you don’t present anything other than the hard facts – this is not the place for subjectivity.
It’s worth mentioning that some universities prefer you to combine the results and discussion chapters. Even so, it is good practice to separate the results and discussion elements within the chapter, as this ensures your findings are fully described. Typically, though, the results and discussion chapters are split up in quantitative studies. If you’re unsure, chat with your research supervisor or chair to find out what their preference is.

What should you include in the results chapter?
Following your analysis, it’s likely you’ll have far more data than are necessary to include in your chapter. In all likelihood, you’ll have a mountain of SPSS or R output data, and it’s your job to decide what’s most relevant. You’ll need to cut through the noise and focus on the data that matters.
This doesn’t mean that those analyses were a waste of time – on the contrary, those analyses ensure that you have a good understanding of your dataset and how to interpret it. However, that doesn’t mean your reader or examiner needs to see the 165 histograms you created! Relevance is key.
How do I decide what’s relevant?
At this point, it can be difficult to strike a balance between what is and isn’t important. But the most important thing is to ensure your results reflect and align with the purpose of your study . So, you need to revisit your research aims, objectives and research questions and use these as a litmus test for relevance. Make sure that you refer back to these constantly when writing up your chapter so that you stay on track.

As a general guide, your results chapter will typically include the following:
- Some demographic data about your sample
- Reliability tests (if you used measurement scales)
- Descriptive statistics
- Inferential statistics (if your research objectives and questions require these)
- Hypothesis tests (again, if your research objectives and questions require these)
We’ll discuss each of these points in more detail in the next section.
Importantly, your results chapter needs to lay the foundation for your discussion chapter . This means that, in your results chapter, you need to include all the data that you will use as the basis for your interpretation in the discussion chapter.
For example, if you plan to highlight the strong relationship between Variable X and Variable Y in your discussion chapter, you need to present the respective analysis in your results chapter – perhaps a correlation or regression analysis.
Need a helping hand?
How do I write the results chapter?
There are multiple steps involved in writing up the results chapter for your quantitative research. The exact number of steps applicable to you will vary from study to study and will depend on the nature of the research aims, objectives and research questions . However, we’ll outline the generic steps below.
Step 1 – Revisit your research questions
The first step in writing your results chapter is to revisit your research objectives and research questions . These will be (or at least, should be!) the driving force behind your results and discussion chapters, so you need to review them and then ask yourself which statistical analyses and tests (from your mountain of data) would specifically help you address these . For each research objective and research question, list the specific piece (or pieces) of analysis that address it.
At this stage, it’s also useful to think about the key points that you want to raise in your discussion chapter and note these down so that you have a clear reminder of which data points and analyses you want to highlight in the results chapter. Again, list your points and then list the specific piece of analysis that addresses each point.
Next, you should draw up a rough outline of how you plan to structure your chapter . Which analyses and statistical tests will you present and in what order? We’ll discuss the “standard structure” in more detail later, but it’s worth mentioning now that it’s always useful to draw up a rough outline before you start writing (this advice applies to any chapter).
Step 2 – Craft an overview introduction
As with all chapters in your dissertation or thesis, you should start your quantitative results chapter by providing a brief overview of what you’ll do in the chapter and why . For example, you’d explain that you will start by presenting demographic data to understand the representativeness of the sample, before moving onto X, Y and Z.
This section shouldn’t be lengthy – a paragraph or two maximum. Also, it’s a good idea to weave the research questions into this section so that there’s a golden thread that runs through the document.

Step 3 – Present the sample demographic data
The first set of data that you’ll present is an overview of the sample demographics – in other words, the demographics of your respondents.
For example:
- What age range are they?
- How is gender distributed?
- How is ethnicity distributed?
- What areas do the participants live in?
The purpose of this is to assess how representative the sample is of the broader population. This is important for the sake of the generalisability of the results. If your sample is not representative of the population, you will not be able to generalise your findings. This is not necessarily the end of the world, but it is a limitation you’ll need to acknowledge.
Of course, to make this representativeness assessment, you’ll need to have a clear view of the demographics of the population. So, make sure that you design your survey to capture the correct demographic information that you will compare your sample to.
But what if I’m not interested in generalisability?
Well, even if your purpose is not necessarily to extrapolate your findings to the broader population, understanding your sample will allow you to interpret your findings appropriately, considering who responded. In other words, it will help you contextualise your findings . For example, if 80% of your sample was aged over 65, this may be a significant contextual factor to consider when interpreting the data. Therefore, it’s important to understand and present the demographic data.
Step 4 – Review composite measures and the data “shape”.
Before you undertake any statistical analysis, you’ll need to do some checks to ensure that your data are suitable for the analysis methods and techniques you plan to use. If you try to analyse data that doesn’t meet the assumptions of a specific statistical technique, your results will be largely meaningless. Therefore, you may need to show that the methods and techniques you’ll use are “allowed”.
Most commonly, there are two areas you need to pay attention to:
#1: Composite measures
The first is when you have multiple scale-based measures that combine to capture one construct – this is called a composite measure . For example, you may have four Likert scale-based measures that (should) all measure the same thing, but in different ways. In other words, in a survey, these four scales should all receive similar ratings. This is called “ internal consistency ”.
Internal consistency is not guaranteed though (especially if you developed the measures yourself), so you need to assess the reliability of each composite measure using a test. Typically, Cronbach’s Alpha is a common test used to assess internal consistency – i.e., to show that the items you’re combining are more or less saying the same thing. A high alpha score means that your measure is internally consistent. A low alpha score means you may need to consider scrapping one or more of the measures.
#2: Data shape
The second matter that you should address early on in your results chapter is data shape. In other words, you need to assess whether the data in your set are symmetrical (i.e. normally distributed) or not, as this will directly impact what type of analyses you can use. For many common inferential tests such as T-tests or ANOVAs (we’ll discuss these a bit later), your data needs to be normally distributed. If it’s not, you’ll need to adjust your strategy and use alternative tests.
To assess the shape of the data, you’ll usually assess a variety of descriptive statistics (such as the mean, median and skewness), which is what we’ll look at next.

Step 5 – Present the descriptive statistics
Now that you’ve laid the foundation by discussing the representativeness of your sample, as well as the reliability of your measures and the shape of your data, you can get started with the actual statistical analysis. The first step is to present the descriptive statistics for your variables.
For scaled data, this usually includes statistics such as:
- The mean – this is simply the mathematical average of a range of numbers.
- The median – this is the midpoint in a range of numbers when the numbers are arranged in order.
- The mode – this is the most commonly repeated number in the data set.
- Standard deviation – this metric indicates how dispersed a range of numbers is. In other words, how close all the numbers are to the mean (the average).
- Skewness – this indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph (this is called a normal or parametric distribution), or do they lean to the left or right (this is called a non-normal or non-parametric distribution).
- Kurtosis – this metric indicates whether the data are heavily or lightly-tailed, relative to the normal distribution. In other words, how peaked or flat the distribution is.
A large table that indicates all the above for multiple variables can be a very effective way to present your data economically. You can also use colour coding to help make the data more easily digestible.
For categorical data, where you show the percentage of people who chose or fit into a category, for instance, you can either just plain describe the percentages or numbers of people who responded to something or use graphs and charts (such as bar graphs and pie charts) to present your data in this section of the chapter.
When using figures, make sure that you label them simply and clearly , so that your reader can easily understand them. There’s nothing more frustrating than a graph that’s missing axis labels! Keep in mind that although you’ll be presenting charts and graphs, your text content needs to present a clear narrative that can stand on its own. In other words, don’t rely purely on your figures and tables to convey your key points: highlight the crucial trends and values in the text. Figures and tables should complement the writing, not carry it .
Depending on your research aims, objectives and research questions, you may stop your analysis at this point (i.e. descriptive statistics). However, if your study requires inferential statistics, then it’s time to deep dive into those .

Step 6 – Present the inferential statistics
Inferential statistics are used to make generalisations about a population , whereas descriptive statistics focus purely on the sample . Inferential statistical techniques, broadly speaking, can be broken down into two groups .
First, there are those that compare measurements between groups , such as t-tests (which measure differences between two groups) and ANOVAs (which measure differences between multiple groups). Second, there are techniques that assess the relationships between variables , such as correlation analysis and regression analysis. Within each of these, some tests can be used for normally distributed (parametric) data and some tests are designed specifically for use on non-parametric data.
There are a seemingly endless number of tests that you can use to crunch your data, so it’s easy to run down a rabbit hole and end up with piles of test data. Ultimately, the most important thing is to make sure that you adopt the tests and techniques that allow you to achieve your research objectives and answer your research questions .
In this section of the results chapter, you should try to make use of figures and visual components as effectively as possible. For example, if you present a correlation table, use colour coding to highlight the significance of the correlation values, or scatterplots to visually demonstrate what the trend is. The easier you make it for your reader to digest your findings, the more effectively you’ll be able to make your arguments in the next chapter.

Step 7 – Test your hypotheses
If your study requires it, the next stage is hypothesis testing. A hypothesis is a statement , often indicating a difference between groups or relationship between variables, that can be supported or rejected by a statistical test. However, not all studies will involve hypotheses (again, it depends on the research objectives), so don’t feel like you “must” present and test hypotheses just because you’re undertaking quantitative research.
The basic process for hypothesis testing is as follows:
- Specify your null hypothesis (for example, “The chemical psilocybin has no effect on time perception).
- Specify your alternative hypothesis (e.g., “The chemical psilocybin has an effect on time perception)
- Set your significance level (this is usually 0.05)
- Calculate your statistics and find your p-value (e.g., p=0.01)
- Draw your conclusions (e.g., “The chemical psilocybin does have an effect on time perception”)
Finally, if the aim of your study is to develop and test a conceptual framework , this is the time to present it, following the testing of your hypotheses. While you don’t need to develop or discuss these findings further in the results chapter, indicating whether the tests (and their p-values) support or reject the hypotheses is crucial.
Step 8 – Provide a chapter summary
To wrap up your results chapter and transition to the discussion chapter, you should provide a brief summary of the key findings . “Brief” is the keyword here – much like the chapter introduction, this shouldn’t be lengthy – a paragraph or two maximum. Highlight the findings most relevant to your research objectives and research questions, and wrap it up.
Some final thoughts, tips and tricks
Now that you’ve got the essentials down, here are a few tips and tricks to make your quantitative results chapter shine:
- When writing your results chapter, report your findings in the past tense . You’re talking about what you’ve found in your data, not what you are currently looking for or trying to find.
- Structure your results chapter systematically and sequentially . If you had two experiments where findings from the one generated inputs into the other, report on them in order.
- Make your own tables and graphs rather than copying and pasting them from statistical analysis programmes like SPSS. Check out the DataIsBeautiful reddit for some inspiration.
- Once you’re done writing, review your work to make sure that you have provided enough information to answer your research questions , but also that you didn’t include superfluous information.
If you’ve got any questions about writing up the quantitative results chapter, please leave a comment below. If you’d like 1-on-1 assistance with your quantitative analysis and discussion, check out our hands-on coaching service , or book a free consultation with a friendly coach.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
Thank you. I will try my best to write my results.

Awesome content 👏🏾

this was great explaination
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

- LEARNING SKILLS
- Writing a Dissertation or Thesis
- Results and Discussion
Search SkillsYouNeed:
Learning Skills:
- A - Z List of Learning Skills
- What is Learning?
- Learning Approaches
- Learning Styles
- 8 Types of Learning Styles
- Understanding Your Preferences to Aid Learning
- Lifelong Learning
- Decisions to Make Before Applying to University
- Top Tips for Surviving Student Life
- Living Online: Education and Learning
- 8 Ways to Embrace Technology-Based Learning Approaches
- Critical Thinking Skills
- Critical Thinking and Fake News
- Understanding and Addressing Conspiracy Theories
- Critical Analysis
- Study Skills
- Exam Skills
- How to Write a Research Proposal
- Ethical Issues in Research
- Dissertation: The Introduction
- Researching and Writing a Literature Review
- Writing your Methodology
- Dissertation: Results and Discussion
- Dissertation: Conclusions and Extras
Writing Your Dissertation or Thesis eBook

Part of the Skills You Need Guide for Students .
- Research Methods
- Teaching, Coaching, Mentoring and Counselling
- Employability Skills for Graduates
Subscribe to our FREE newsletter and start improving your life in just 5 minutes a day.
You'll get our 5 free 'One Minute Life Skills' and our weekly newsletter.
We'll never share your email address and you can unsubscribe at any time.
Writing your Dissertation: Results and Discussion
When writing a dissertation or thesis, the results and discussion sections can be both the most interesting as well as the most challenging sections to write.
You may choose to write these sections separately, or combine them into a single chapter, depending on your university’s guidelines and your own preferences.
There are advantages to both approaches.
Writing the results and discussion as separate sections allows you to focus first on what results you obtained and set out clearly what happened in your experiments and/or investigations without worrying about their implications.This can focus your mind on what the results actually show and help you to sort them in your head.
However, many people find it easier to combine the results with their implications as the two are closely connected.
Check your university’s requirements carefully before combining the results and discussions sections as some specify that they must be kept separate.
Results Section
The Results section should set out your key experimental results, including any statistical analysis and whether or not the results of these are significant.
You should cover any literature supporting your interpretation of significance. It does not have to include everything you did, particularly for a doctorate dissertation. However, for an undergraduate or master's thesis, you will probably find that you need to include most of your work.
You should write your results section in the past tense: you are describing what you have done in the past.
Every result included MUST have a method set out in the methods section. Check back to make sure that you have included all the relevant methods.
Conversely, every method should also have some results given so, if you choose to exclude certain experiments from the results, make sure that you remove mention of the method as well.
If you are unsure whether to include certain results, go back to your research questions and decide whether the results are relevant to them. It doesn’t matter whether they are supportive or not, it’s about relevance. If they are relevant, you should include them.
Having decided what to include, next decide what order to use. You could choose chronological, which should follow the methods, or in order from most to least important in the answering of your research questions, or by research question and/or hypothesis.
You also need to consider how best to present your results: tables, figures, graphs, or text. Try to use a variety of different methods of presentation, and consider your reader: 20 pages of dense tables are hard to understand, as are five pages of graphs, but a single table and well-chosen graph that illustrate your overall findings will make things much clearer.
Make sure that each table and figure has a number and a title. Number tables and figures in separate lists, but consecutively by the order in which you mention them in the text. If you have more than about two or three, it’s often helpful to provide lists of tables and figures alongside the table of contents at the start of your dissertation.
Summarise your results in the text, drawing on the figures and tables to illustrate your points.
The text and figures should be complementary, not repeat the same information. You should refer to every table or figure in the text. Any that you don’t feel the need to refer to can safely be moved to an appendix, or even removed.
Make sure that you including information about the size and direction of any changes, including percentage change if appropriate. Statistical tests should include details of p values or confidence intervals and limits.
While you don’t need to include all your primary evidence in this section, you should as a matter of good practice make it available in an appendix, to which you should refer at the relevant point.
For example:
Details of all the interview participants can be found in Appendix A, with transcripts of each interview in Appendix B.
You will, almost inevitably, find that you need to include some slight discussion of your results during this section. This discussion should evaluate the quality of the results and their reliability, but not stray too far into discussion of how far your results support your hypothesis and/or answer your research questions, as that is for the discussion section.
See our pages: Analysing Qualitative Data and Simple Statistical Analysis for more information on analysing your results.
Discussion Section
This section has four purposes, it should:
- Interpret and explain your results
- Answer your research question
- Justify your approach
- Critically evaluate your study
The discussion section therefore needs to review your findings in the context of the literature and the existing knowledge about the subject.
You also need to demonstrate that you understand the limitations of your research and the implications of your findings for policy and practice. This section should be written in the present tense.
The Discussion section needs to follow from your results and relate back to your literature review . Make sure that everything you discuss is covered in the results section.
Some universities require a separate section on recommendations for policy and practice and/or for future research, while others allow you to include this in your discussion, so check the guidelines carefully.
Starting the Task
Most people are likely to write this section best by preparing an outline, setting out the broad thrust of the argument, and how your results support it.
You may find techniques like mind mapping are helpful in making a first outline; check out our page: Creative Thinking for some ideas about how to think through your ideas. You should start by referring back to your research questions, discuss your results, then set them into the context of the literature, and then into broader theory.
This is likely to be one of the longest sections of your dissertation, and it’s a good idea to break it down into chunks with sub-headings to help your reader to navigate through the detail.
Fleshing Out the Detail
Once you have your outline in front of you, you can start to map out how your results fit into the outline.
This will help you to see whether your results are over-focused in one area, which is why writing up your research as you go along can be a helpful process. For each theme or area, you should discuss how the results help to answer your research question, and whether the results are consistent with your expectations and the literature.
The Importance of Understanding Differences
If your results are controversial and/or unexpected, you should set them fully in context and explain why you think that you obtained them.
Your explanations may include issues such as a non-representative sample for convenience purposes, a response rate skewed towards those with a particular experience, or your own involvement as a participant for sociological research.
You do not need to be apologetic about these, because you made a choice about them, which you should have justified in the methodology section. However, you do need to evaluate your own results against others’ findings, especially if they are different. A full understanding of the limitations of your research is part of a good discussion section.
At this stage, you may want to revisit your literature review, unless you submitted it as a separate submission earlier, and revise it to draw out those studies which have proven more relevant.
Conclude by summarising the implications of your findings in brief, and explain why they are important for researchers and in practice, and provide some suggestions for further work.
You may also wish to make some recommendations for practice. As before, this may be a separate section, or included in your discussion.
The results and discussion, including conclusion and recommendations, are probably the most substantial sections of your dissertation. Once completed, you can begin to relax slightly: you are on to the last stages of writing!
Continue to: Dissertation: Conclusion and Extras Writing your Methodology
See also: Writing a Literature Review Writing a Research Proposal Academic Referencing What Is the Importance of Using a Plagiarism Checker to Check Your Thesis?
Library Guides
Dissertations 5: findings, analysis and discussion: home.
- Results/Findings
Alternative Structures
The time has come to show and discuss the findings of your research. How to structure this part of your dissertation?
Dissertations can have different structures, as you can see in the dissertation structure guide.
Dissertations organised by sections
Many dissertations are organised by sections. In this case, we suggest three options. Note that, if within your course you have been instructed to use a specific structure, you should do that. Also note that sometimes there is considerable freedom on the structure, so you can come up with other structures too.
A) More common for scientific dissertations and quantitative methods:
- Results chapter
- Discussion chapter
Example:
- Introduction
- Literature review
- Methodology
- (Recommendations)
if you write a scientific dissertation, or anyway using quantitative methods, you will have some objective results that you will present in the Results chapter. You will then interpret the results in the Discussion chapter.
B) More common for qualitative methods
- Analysis chapter. This can have more descriptive/thematic subheadings.
- Discussion chapter. This can have more descriptive/thematic subheadings.
- Case study of Company X (fashion brand) environmental strategies
- Successful elements
- Lessons learnt
- Criticisms of Company X environmental strategies
- Possible alternatives
C) More common for qualitative methods
- Analysis and discussion chapter. This can have more descriptive/thematic titles.
- Case study of Company X (fashion brand) environmental strategies
If your dissertation uses qualitative methods, it is harder to identify and report objective data. Instead, it may be more productive and meaningful to present the findings in the same sections where you also analyse, and possibly discuss, them. You will probably have different sections dealing with different themes. The different themes can be subheadings of the Analysis and Discussion (together or separate) chapter(s).
Thematic dissertations
If the structure of your dissertation is thematic , you will have several chapters analysing and discussing the issues raised by your research. The chapters will have descriptive/thematic titles.
- Background on the conflict in Yemen (2004-present day)
- Classification of the conflict in international law
- International law violations
- Options for enforcement of international law
- Next: Results/Findings >>
- Last Updated: Aug 4, 2023 2:17 PM
- URL: https://libguides.westminster.ac.uk/c.php?g=696975
CONNECT WITH US

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.
IMAGES
VIDEO
COMMENTS
Tips to Write the Results Section. Direct the reader to the research data and explain the meaning of the data. Avoid using a repetitive sentence structure to explain a new set of data. Write and highlight important findings in your results. Use the same order as the subheadings of the methods section.
Checklist: Research results 0 / 7. I have completed my data collection and analyzed the results. I have included all results that are relevant to my research questions. I have concisely and objectively reported each result, including relevant descriptive statistics and inferential statistics. I have stated whether each hypothesis was supported ...
Descriptive research methods. Descriptive research is usually defined as a type of quantitative research, though qualitative research can also be used for descriptive purposes. The research design should be carefully developed to ensure that the results are valid and reliable.. Surveys. Survey research allows you to gather large volumes of data that can be analyzed for frequencies, averages ...
Descriptive epidemiology provides a way of organizing and analyzing these data in order to understand variations in disease frequency geographically and over time, and how disease (or health) varies among people based on a host of personal characteristics (person, place, and time). This makes it possible to identify trends in health and disease ...
Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion. Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and ...
1. Context. The "results section" is the heart of the paper, around which the other sections are organized ().Research is about results and the reader comes to the paper to discover the results ().In this section, authors contribute to the development of scientific literature by providing novel, hitherto unknown knowledge ().In addition to the results, this section contains data and ...
Making scientific research available to others is a key part of academic integrity and open science. Interpretation or discussion of results; This belongs in your discussion section. Your results section is where you objectively report all relevant findings and leave them open for interpretation by readers.
Qualitative description (QD) is a label used in qualitative research for studies which are descriptive in nature, particularly for examining health care and nursing-related phenomena (Polit & Beck, 2009, 2014).QD is a widely cited research tradition and has been identified as important and appropriate for research questions focused on discovering the who, what, and where of events or ...
Descriptive research is a type of research that is used to describe the characteristics of a population. It collects data that are used to answer a wide range of what, when, and how questions pertaining to a particular population or group. For example, descriptive studies might be used to answer questions such as: What percentage of Head Start ...
Some distinctive characteristics of descriptive research are: Quantitative research: It is a quantitative research method that attempts to collect quantifiable information for statistical analysis of the population sample. It is a popular market research tool that allows us to collect and describe the demographic segment's nature.
The discussion of the results in the review should make clear whether the included studies addressed all or only some of these groups, and whether any important subgroup effects were found. 15.2.3 Variation in context . Some interventions, particularly non-pharmacological interventions, may work in some contexts but not in others; the situation ...
The "Results section" is the third most important anatomical structure of IMRAD (Introduction, Method and Material, Result, And Discussion) frameworks, the almost universally accepted framework in many journals in the late nineteenth century. 3 Before using a structured IMRAD format, research findings in scientific papers were presented in ...
The results chapter in a dissertation or thesis (or any formal academic research piece) is where you objectively and neutrally present the findings of your qualitative analysis (or analyses if you used multiple qualitative analysis methods ). This chapter can sometimes be combined with the discussion chapter (where you interpret the data and ...
As a general guide, your results chapter will typically include the following: Some demographic data about your sample; Reliability tests (if you used measurement scales); Descriptive statistics; Inferential statistics (if your research objectives and questions require these); Hypothesis tests (again, if your research objectives and questions require these); We'll discuss each of these ...
The results section of a research paper tells the reader what you found, while the discussion section tells the reader what your findings mean. The results section should present the facts in an academic and unbiased manner, avoiding any attempt at analyzing or interpreting the data. Think of the results section as setting the stage for the ...
The discussion section is where you delve into the meaning, importance, and relevance of your results.. It should focus on explaining and evaluating what you found, showing how it relates to your literature review and paper or dissertation topic, and making an argument in support of your overall conclusion.It should not be a second results section.. There are different ways to write this ...
Summarise your results in the text, drawing on the figures and tables to illustrate your points. The text and figures should be complementary, not repeat the same information. You should refer to every table or figure in the text. Any that you don't feel the need to refer to can safely be moved to an appendix, or even removed.
if you write a scientific dissertation, or anyway using quantitative methods, you will have some objective results that you will present in the Results chapter. You will then interpret the results in the Discussion chapter. B) More common for qualitative methods. - Analysis chapter. This can have more descriptive/thematic subheadings.
The discussion should also address the study's research questions and explain how the results contribute to the field of study. Limitations: This section should acknowledge any limitations of the study, such as sample size, data collection methods, or other factors that may have influenced the results.
Don't repeat results. Order simple to complex (building to conclusion); or may state conclusion first. Conclusion should be consistent with study objectives/research question. Explain how the results answer the question under study. Emphasize what is new, different, or important about your results.
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
chapter, data is interpreted in a descriptive form. This chapter comprises the analysis, presentation and interpretation of the findings resulting from this study. The analysis and interpretation of data is carried out in two phases. The first part, which is based on the results of the questionnaire, deals with a quantitative analysis of data.
This chapter 5 presents the results of the study. First, an outline of the informants included in the study and an overview of the statistical techniques employed in the data analyses are given ...