
- Ask a Librarian

Research: Overview & Approaches
- Getting Started with Undergraduate Research
- Planning & Getting Started
- Building Your Knowledge Base
- Locating Sources
- Reading Scholarly Articles
- Creating a Literature Review
- Productivity & Organizing Research
- Scholarly and Professional Relationships
Introduction to Empirical Research
Databases for finding empirical research, guided search, google scholar, examples of empirical research, sources and further reading.
- Interpretive Research
- Action-Based Research
- Creative & Experimental Approaches
Your Librarian

- Introductory Video This video covers what empirical research is, what kinds of questions and methods empirical researchers use, and some tips for finding empirical research articles in your discipline.
- Guided Search: Finding Empirical Research Articles This is a hands-on tutorial that will allow you to use your own search terms to find resources.
- Study on radiation transfer in human skin for cosmetics
- Long-Term Mobile Phone Use and the Risk of Vestibular Schwannoma: A Danish Nationwide Cohort Study
- Emissions Impacts and Benefits of Plug-In Hybrid Electric Vehicles and Vehicle-to-Grid Services
- Review of design considerations and technological challenges for successful development and deployment of plug-in hybrid electric vehicles
- Endocrine disrupters and human health: could oestrogenic chemicals in body care cosmetics adversely affect breast cancer incidence in women?

- << Previous: Scholarly and Professional Relationships
- Next: Interpretive Research >>
- Last Updated: May 23, 2024 11:51 AM
- URL: https://guides.lib.purdue.edu/research_approaches
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Module 2 Chapter 3: What is Empirical Literature & Where can it be Found?
In Module 1, you read about the problem of pseudoscience. Here, we revisit the issue in addressing how to locate and assess scientific or empirical literature . In this chapter you will read about:
- distinguishing between what IS and IS NOT empirical literature
- how and where to locate empirical literature for understanding diverse populations, social work problems, and social phenomena.
Probably the most important take-home lesson from this chapter is that one source is not sufficient to being well-informed on a topic. It is important to locate multiple sources of information and to critically appraise the points of convergence and divergence in the information acquired from different sources. This is especially true in emerging and poorly understood topics, as well as in answering complex questions.
What Is Empirical Literature
Social workers often need to locate valid, reliable information concerning the dimensions of a population group or subgroup, a social work problem, or social phenomenon. They might also seek information about the way specific problems or resources are distributed among the populations encountered in professional practice. Or, social workers might be interested in finding out about the way that certain people experience an event or phenomenon. Empirical literature resources may provide answers to many of these types of social work questions. In addition, resources containing data regarding social indicators may also prove helpful. Social indicators are the “facts and figures” statistics that describe the social, economic, and psychological factors that have an impact on the well-being of a community or other population group.The United Nations (UN) and the World Health Organization (WHO) are examples of organizations that monitor social indicators at a global level: dimensions of population trends (size, composition, growth/loss), health status (physical, mental, behavioral, life expectancy, maternal and infant mortality, fertility/child-bearing, and diseases like HIV/AIDS), housing and quality of sanitation (water supply, waste disposal), education and literacy, and work/income/unemployment/economics, for example.

Three characteristics stand out in empirical literature compared to other types of information available on a topic of interest: systematic observation and methodology, objectivity, and transparency/replicability/reproducibility. Let’s look a little more closely at these three features.
Systematic Observation and Methodology. The hallmark of empiricism is “repeated or reinforced observation of the facts or phenomena” (Holosko, 2006, p. 6). In empirical literature, established research methodologies and procedures are systematically applied to answer the questions of interest.
Objectivity. Gathering “facts,” whatever they may be, drives the search for empirical evidence (Holosko, 2006). Authors of empirical literature are expected to report the facts as observed, whether or not these facts support the investigators’ original hypotheses. Research integrity demands that the information be provided in an objective manner, reducing sources of investigator bias to the greatest possible extent.
Transparency and Replicability/Reproducibility. Empirical literature is reported in such a manner that other investigators understand precisely what was done and what was found in a particular research study—to the extent that they could replicate the study to determine whether the findings are reproduced when repeated. The outcomes of an original and replication study may differ, but a reader could easily interpret the methods and procedures leading to each study’s findings.
What is NOT Empirical Literature
By now, it is probably obvious to you that literature based on “evidence” that is not developed in a systematic, objective, transparent manner is not empirical literature. On one hand, non-empirical types of professional literature may have great significance to social workers. For example, social work scholars may produce articles that are clearly identified as describing a new intervention or program without evaluative evidence, critiquing a policy or practice, or offering a tentative, untested theory about a phenomenon. These resources are useful in educating ourselves about possible issues or concerns. But, even if they are informed by evidence, they are not empirical literature. Here is a list of several sources of information that do not meet the standard of being called empirical literature:
- your course instructor’s lectures
- political statements
- advertisements
- newspapers & magazines (journalism)
- television news reports & analyses (journalism)
- many websites, Facebook postings, Twitter tweets, and blog postings
- the introductory literature review in an empirical article
You may be surprised to see the last two included in this list. Like the other sources of information listed, these sources also might lead you to look for evidence. But, they are not themselves sources of evidence. They may summarize existing evidence, but in the process of summarizing (like your instructor’s lectures), information is transformed, modified, reduced, condensed, and otherwise manipulated in such a manner that you may not see the entire, objective story. These are called secondary sources, as opposed to the original, primary source of evidence. In relying solely on secondary sources, you sacrifice your own critical appraisal and thinking about the original work—you are “buying” someone else’s interpretation and opinion about the original work, rather than developing your own interpretation and opinion. What if they got it wrong? How would you know if you did not examine the primary source for yourself? Consider the following as an example of “getting it wrong” being perpetuated.
Example: Bullying and School Shootings . One result of the heavily publicized April 1999 school shooting incident at Columbine High School (Colorado), was a heavy emphasis placed on bullying as a causal factor in these incidents (Mears, Moon, & Thielo, 2017), “creating a powerful master narrative about school shootings” (Raitanen, Sandberg, & Oksanen, 2017, p. 3). Naturally, with an identified cause, a great deal of effort was devoted to anti-bullying campaigns and interventions for enhancing resilience among youth who experience bullying. However important these strategies might be for promoting positive mental health, preventing poor mental health, and possibly preventing suicide among school-aged children and youth, it is a mistaken belief that this can prevent school shootings (Mears, Moon, & Thielo, 2017). Many times the accounts of the perpetrators having been bullied come from potentially inaccurate third-party accounts, rather than the perpetrators themselves; bullying was not involved in all instances of school shooting; a perpetrator’s perception of being bullied/persecuted are not necessarily accurate; many who experience severe bullying do not perpetrate these incidents; bullies are the least targeted shooting victims; perpetrators of the shooting incidents were often bullying others; and, bullying is only one of many important factors associated with perpetrating such an incident (Ioannou, Hammond, & Simpson, 2015; Mears, Moon, & Thielo, 2017; Newman &Fox, 2009; Raitanen, Sandberg, & Oksanen, 2017). While mass media reports deliver bullying as a means of explaining the inexplicable, the reality is not so simple: “The connection between bullying and school shootings is elusive” (Langman, 2014), and “the relationship between bullying and school shooting is, at best, tenuous” (Mears, Moon, & Thielo, 2017, p. 940). The point is, when a narrative becomes this publicly accepted, it is difficult to sort out truth and reality without going back to original sources of information and evidence.

What May or May Not Be Empirical Literature: Literature Reviews
Investigators typically engage in a review of existing literature as they develop their own research studies. The review informs them about where knowledge gaps exist, methods previously employed by other scholars, limitations of prior work, and previous scholars’ recommendations for directing future research. These reviews may appear as a published article, without new study data being reported (see Fields, Anderson, & Dabelko-Schoeny, 2014 for example). Or, the literature review may appear in the introduction to their own empirical study report. These literature reviews are not considered to be empirical evidence sources themselves, although they may be based on empirical evidence sources. One reason is that the authors of a literature review may or may not have engaged in a systematic search process, identifying a full, rich, multi-sided pool of evidence reports.
There is, however, a type of review that applies systematic methods and is, therefore, considered to be more strongly rooted in evidence: the systematic review .
Systematic review of literature. A systematic reviewis a type of literature report where established methods have been systematically applied, objectively, in locating and synthesizing a body of literature. The systematic review report is characterized by a great deal of transparency about the methods used and the decisions made in the review process, and are replicable. Thus, it meets the criteria for empirical literature: systematic observation and methodology, objectivity, and transparency/reproducibility. We will work a great deal more with systematic reviews in the second course, SWK 3402, since they are important tools for understanding interventions. They are somewhat less common, but not unheard of, in helping us understand diverse populations, social work problems, and social phenomena.
Locating Empirical Evidence
Social workers have available a wide array of tools and resources for locating empirical evidence in the literature. These can be organized into four general categories.
Journal Articles. A number of professional journals publish articles where investigators report on the results of their empirical studies. However, it is important to know how to distinguish between empirical and non-empirical manuscripts in these journals. A key indicator, though not the only one, involves a peer review process . Many professional journals require that manuscripts undergo a process of peer review before they are accepted for publication. This means that the authors’ work is shared with scholars who provide feedback to the journal editor as to the quality of the submitted manuscript. The editor then makes a decision based on the reviewers’ feedback:
- Accept as is
- Accept with minor revisions
- Request that a revision be resubmitted (no assurance of acceptance)
When a “revise and resubmit” decision is made, the piece will go back through the review process to determine if it is now acceptable for publication and that all of the reviewers’ concerns have been adequately addressed. Editors may also reject a manuscript because it is a poor fit for the journal, based on its mission and audience, rather than sending it for review consideration.

Indicators of journal relevance. Various journals are not equally relevant to every type of question being asked of the literature. Journals may overlap to a great extent in terms of the topics they might cover; in other words, a topic might appear in multiple different journals, depending on how the topic was being addressed. For example, articles that might help answer a question about the relationship between community poverty and violence exposure might appear in several different journals, some with a focus on poverty, others with a focus on violence, and still others on community development or public health. Journal titles are sometimes a good starting point but may not give a broad enough picture of what they cover in their contents.
In focusing a literature search, it also helps to review a journal’s mission and target audience. For example, at least four different journals focus specifically on poverty:
- Journal of Children & Poverty
- Journal of Poverty
- Journal of Poverty and Social Justice
- Poverty & Public Policy
Let’s look at an example using the Journal of Poverty and Social Justice . Information about this journal is located on the journal’s webpage: http://policy.bristoluniversitypress.co.uk/journals/journal-of-poverty-and-social-justice . In the section headed “About the Journal” you can see that it is an internationally focused research journal, and that it addresses social justice issues in addition to poverty alone. The research articles are peer-reviewed (there appear to be non-empirical discussions published, as well). These descriptions about a journal are almost always available, sometimes listed as “scope” or “mission.” These descriptions also indicate the sponsorship of the journal—sponsorship may be institutional (a particular university or agency, such as Smith College Studies in Social Work ), a professional organization, such as the Council on Social Work Education (CSWE) or the National Association of Social Work (NASW), or a publishing company (e.g., Taylor & Frances, Wiley, or Sage).
Indicators of journal caliber. Despite engaging in a peer review process, not all journals are equally rigorous. Some journals have very high rejection rates, meaning that many submitted manuscripts are rejected; others have fairly high acceptance rates, meaning that relatively few manuscripts are rejected. This is not necessarily the best indicator of quality, however, since newer journals may not be sufficiently familiar to authors with high quality manuscripts and some journals are very specific in terms of what they publish. Another index that is sometimes used is the journal’s impact factor . Impact factor is a quantitative number indicative of how often articles published in the journal are cited in the reference list of other journal articles—the statistic is calculated as the number of times on average each article published in a particular year were cited divided by the number of articles published (the number that could be cited). For example, the impact factor for the Journal of Poverty and Social Justice in our list above was 0.70 in 2017, and for the Journal of Poverty was 0.30. These are relatively low figures compared to a journal like the New England Journal of Medicine with an impact factor of 59.56! This means that articles published in that journal were, on average, cited more than 59 times in the next year or two.
Impact factors are not necessarily the best indicator of caliber, however, since many strong journals are geared toward practitioners rather than scholars, so they are less likely to be cited by other scholars but may have a large impact on a large readership. This may be the case for a journal like the one titled Social Work, the official journal of the National Association of Social Workers. It is distributed free to all members: over 120,000 practitioners, educators, and students of social work world-wide. The journal has a recent impact factor of.790. The journals with social work relevant content have impact factors in the range of 1.0 to 3.0 according to Scimago Journal & Country Rank (SJR), particularly when they are interdisciplinary journals (for example, Child Development , Journal of Marriage and Family , Child Abuse and Neglect , Child Maltreatmen t, Social Service Review , and British Journal of Social Work ). Once upon a time, a reader could locate different indexes comparing the “quality” of social work-related journals. However, the concept of “quality” is difficult to systematically define. These indexes have mostly been replaced by impact ratings, which are not necessarily the best, most robust indicators on which to rely in assessing journal quality. For example, new journals addressing cutting edge topics have not been around long enough to have been evaluated using this particular tool, and it takes a few years for articles to begin to be cited in other, later publications.
Beware of pseudo-, illegitimate, misleading, deceptive, and suspicious journals . Another side effect of living in the Age of Information is that almost anyone can circulate almost anything and call it whatever they wish. This goes for “journal” publications, as well. With the advent of open-access publishing in recent years (electronic resources available without subscription), we have seen an explosion of what are called predatory or junk journals . These are publications calling themselves journals, often with titles very similar to legitimate publications and often with fake editorial boards. These “publications” lack the integrity of legitimate journals. This caution is reminiscent of the discussions earlier in the course about pseudoscience and “snake oil” sales. The predatory nature of many apparent information dissemination outlets has to do with how scientists and scholars may be fooled into submitting their work, often paying to have their work peer-reviewed and published. There exists a “thriving black-market economy of publishing scams,” and at least two “journal blacklists” exist to help identify and avoid these scam journals (Anderson, 2017).
This issue is important to information consumers, because it creates a challenge in terms of identifying legitimate sources and publications. The challenge is particularly important to address when information from on-line, open-access journals is being considered. Open-access is not necessarily a poor choice—legitimate scientists may pay sizeable fees to legitimate publishers to make their work freely available and accessible as open-access resources. On-line access is also not necessarily a poor choice—legitimate publishers often make articles available on-line to provide timely access to the content, especially when publishing the article in hard copy will be delayed by months or even a year or more. On the other hand, stating that a journal engages in a peer-review process is no guarantee of quality—this claim may or may not be truthful. Pseudo- and junk journals may engage in some quality control practices, but may lack attention to important quality control processes, such as managing conflict of interest, reviewing content for objectivity or quality of the research conducted, or otherwise failing to adhere to industry standards (Laine & Winker, 2017).
One resource designed to assist with the process of deciphering legitimacy is the Directory of Open Access Journals (DOAJ). The DOAJ is not a comprehensive listing of all possible legitimate open-access journals, and does not guarantee quality, but it does help identify legitimate sources of information that are openly accessible and meet basic legitimacy criteria. It also is about open-access journals, not the many journals published in hard copy.
An additional caution: Search for article corrections. Despite all of the careful manuscript review and editing, sometimes an error appears in a published article. Most journals have a practice of publishing corrections in future issues. When you locate an article, it is helpful to also search for updates. Here is an example where data presented in an article’s original tables were erroneous, and a correction appeared in a later issue.
- Marchant, A., Hawton, K., Stewart A., Montgomery, P., Singaravelu, V., Lloyd, K., Purdy, N., Daine, K., & John, A. (2017). A systematic review of the relationship between internet use, self-harm and suicidal behaviour in young people: The good, the bad and the unknown. PLoS One, 12(8): e0181722. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5558917/
- Marchant, A., Hawton, K., Stewart A., Montgomery, P., Singaravelu, V., Lloyd, K., Purdy, N., Daine, K., & John, A. (2018).Correction—A systematic review of the relationship between internet use, self-harm and suicidal behaviour in young people: The good, the bad and the unknown. PLoS One, 13(3): e0193937. http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0193937
Search Tools. In this age of information, it is all too easy to find items—the problem lies in sifting, sorting, and managing the vast numbers of items that can be found. For example, a simple Google® search for the topic “community poverty and violence” resulted in about 15,600,000 results! As a means of simplifying the process of searching for journal articles on a specific topic, a variety of helpful tools have emerged. One type of search tool has previously applied a filtering process for you: abstracting and indexing databases . These resources provide the user with the results of a search to which records have already passed through one or more filters. For example, PsycINFO is managed by the American Psychological Association and is devoted to peer-reviewed literature in behavioral science. It contains almost 4.5 million records and is growing every month. However, it may not be available to users who are not affiliated with a university library. Conducting a basic search for our topic of “community poverty and violence” in PsychINFO returned 1,119 articles. Still a large number, but far more manageable. Additional filters can be applied, such as limiting the range in publication dates, selecting only peer reviewed items, limiting the language of the published piece (English only, for example), and specified types of documents (either chapters, dissertations, or journal articles only, for example). Adding the filters for English, peer-reviewed journal articles published between 2010 and 2017 resulted in 346 documents being identified.
Just as was the case with journals, not all abstracting and indexing databases are equivalent. There may be overlap between them, but none is guaranteed to identify all relevant pieces of literature. Here are some examples to consider, depending on the nature of the questions asked of the literature:
- Academic Search Complete—multidisciplinary index of 9,300 peer-reviewed journals
- AgeLine—multidisciplinary index of aging-related content for over 600 journals
- Campbell Collaboration—systematic reviews in education, crime and justice, social welfare, international development
- Google Scholar—broad search tool for scholarly literature across many disciplines
- MEDLINE/ PubMed—National Library of medicine, access to over 15 million citations
- Oxford Bibliographies—annotated bibliographies, each is discipline specific (e.g., psychology, childhood studies, criminology, social work, sociology)
- PsycINFO/PsycLIT—international literature on material relevant to psychology and related disciplines
- SocINDEX—publications in sociology
- Social Sciences Abstracts—multiple disciplines
- Social Work Abstracts—many areas of social work are covered
- Web of Science—a “meta” search tool that searches other search tools, multiple disciplines
Placing our search for information about “community violence and poverty” into the Social Work Abstracts tool with no additional filters resulted in a manageable 54-item list. Finally, abstracting and indexing databases are another way to determine journal legitimacy: if a journal is indexed in a one of these systems, it is likely a legitimate journal. However, the converse is not necessarily true: if a journal is not indexed does not mean it is an illegitimate or pseudo-journal.
Government Sources. A great deal of information is gathered, analyzed, and disseminated by various governmental branches at the international, national, state, regional, county, and city level. Searching websites that end in.gov is one way to identify this type of information, often presented in articles, news briefs, and statistical reports. These government sources gather information in two ways: they fund external investigations through grants and contracts and they conduct research internally, through their own investigators. Here are some examples to consider, depending on the nature of the topic for which information is sought:
- Agency for Healthcare Research and Quality (AHRQ) at https://www.ahrq.gov/
- Bureau of Justice Statistics (BJS) at https://www.bjs.gov/
- Census Bureau at https://www.census.gov
- Morbidity and Mortality Weekly Report of the CDC (MMWR-CDC) at https://www.cdc.gov/mmwr/index.html
- Child Welfare Information Gateway at https://www.childwelfare.gov
- Children’s Bureau/Administration for Children & Families at https://www.acf.hhs.gov
- Forum on Child and Family Statistics at https://www.childstats.gov
- National Institutes of Health (NIH) at https://www.nih.gov , including (not limited to):
- National Institute on Aging (NIA at https://www.nia.nih.gov
- National Institute on Alcohol Abuse and Alcoholism (NIAAA) at https://www.niaaa.nih.gov
- National Institute of Child Health and Human Development (NICHD) at https://www.nichd.nih.gov
- National Institute on Drug Abuse (NIDA) at https://www.nida.nih.gov
- National Institute of Environmental Health Sciences at https://www.niehs.nih.gov
- National Institute of Mental Health (NIMH) at https://www.nimh.nih.gov
- National Institute on Minority Health and Health Disparities at https://www.nimhd.nih.gov
- National Institute of Justice (NIJ) at https://www.nij.gov
- Substance Abuse and Mental Health Services Administration (SAMHSA) at https://www.samhsa.gov/
- United States Agency for International Development at https://usaid.gov
Each state and many counties or cities have similar data sources and analysis reports available, such as Ohio Department of Health at https://www.odh.ohio.gov/healthstats/dataandstats.aspx and Franklin County at https://statisticalatlas.com/county/Ohio/Franklin-County/Overview . Data are available from international/global resources (e.g., United Nations and World Health Organization), as well.
Other Sources. The Health and Medicine Division (HMD) of the National Academies—previously the Institute of Medicine (IOM)—is a nonprofit institution that aims to provide government and private sector policy and other decision makers with objective analysis and advice for making informed health decisions. For example, in 2018 they produced reports on topics in substance use and mental health concerning the intersection of opioid use disorder and infectious disease, the legal implications of emerging neurotechnologies, and a global agenda concerning the identification and prevention of violence (see http://www.nationalacademies.org/hmd/Global/Topics/Substance-Abuse-Mental-Health.aspx ). The exciting aspect of this resource is that it addresses many topics that are current concerns because they are hoping to help inform emerging policy. The caution to consider with this resource is the evidence is often still emerging, as well.
Numerous “think tank” organizations exist, each with a specific mission. For example, the Rand Corporation is a nonprofit organization offering research and analysis to address global issues since 1948. The institution’s mission is to help improve policy and decision making “to help individuals, families, and communities throughout the world be safer and more secure, healthier and more prosperous,” addressing issues of energy, education, health care, justice, the environment, international affairs, and national security (https://www.rand.org/about/history.html). And, for example, the Robert Woods Johnson Foundation is a philanthropic organization supporting research and research dissemination concerning health issues facing the United States. The foundation works to build a culture of health across systems of care (not only medical care) and communities (https://www.rwjf.org).
While many of these have a great deal of helpful evidence to share, they also may have a strong political bias. Objectivity is often lacking in what information these organizations provide: they provide evidence to support certain points of view. That is their purpose—to provide ideas on specific problems, many of which have a political component. Think tanks “are constantly researching solutions to a variety of the world’s problems, and arguing, advocating, and lobbying for policy changes at local, state, and federal levels” (quoted from https://thebestschools.org/features/most-influential-think-tanks/ ). Helpful information about what this one source identified as the 50 most influential U.S. think tanks includes identifying each think tank’s political orientation. For example, The Heritage Foundation is identified as conservative, whereas Human Rights Watch is identified as liberal.
While not the same as think tanks, many mission-driven organizations also sponsor or report on research, as well. For example, the National Association for Children of Alcoholics (NACOA) in the United States is a registered nonprofit organization. Its mission, along with other partnering organizations, private-sector groups, and federal agencies, is to promote policy and program development in research, prevention and treatment to provide information to, for, and about children of alcoholics (of all ages). Based on this mission, the organization supports knowledge development and information gathering on the topic and disseminates information that serves the needs of this population. While this is a worthwhile mission, there is no guarantee that the information meets the criteria for evidence with which we have been working. Evidence reported by think tank and mission-driven sources must be utilized with a great deal of caution and critical analysis!
In many instances an empirical report has not appeared in the published literature, but in the form of a technical or final report to the agency or program providing the funding for the research that was conducted. One such example is presented by a team of investigators funded by the National Institute of Justice to evaluate a program for training professionals to collect strong forensic evidence in instances of sexual assault (Patterson, Resko, Pierce-Weeks, & Campbell, 2014): https://www.ncjrs.gov/pdffiles1/nij/grants/247081.pdf . Investigators may serve in the capacity of consultant to agencies, programs, or institutions, and provide empirical evidence to inform activities and planning. One such example is presented by Maguire-Jack (2014) as a report to a state’s child maltreatment prevention board: https://preventionboard.wi.gov/Documents/InvestmentInPreventionPrograming_Final.pdf .
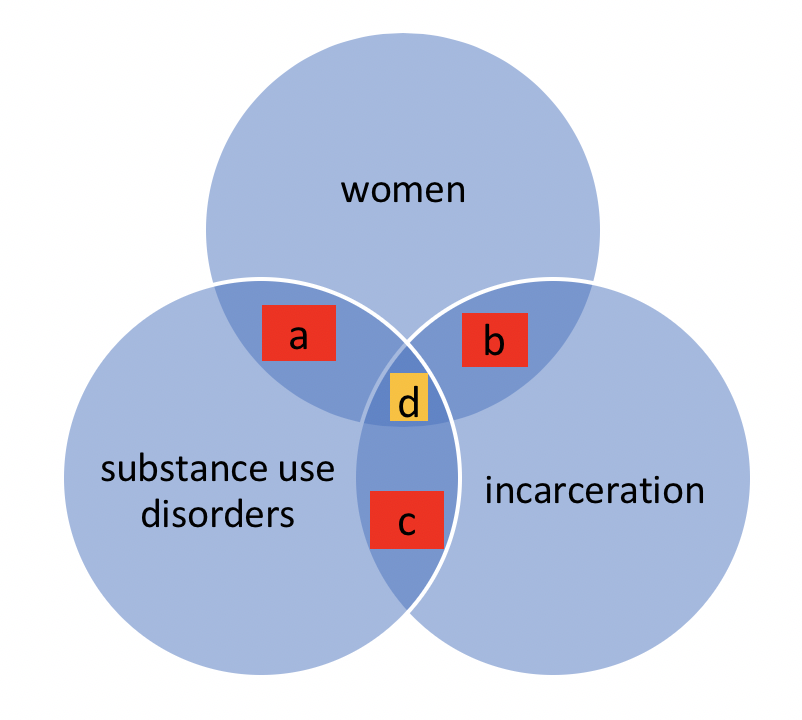
When Direct Answers to Questions Cannot Be Found. Sometimes social workers are interested in finding answers to complex questions or questions related to an emerging, not-yet-understood topic. This does not mean giving up on empirical literature. Instead, it requires a bit of creativity in approaching the literature. A Venn diagram might help explain this process. Consider a scenario where a social worker wishes to locate literature to answer a question concerning issues of intersectionality. Intersectionality is a social justice term applied to situations where multiple categorizations or classifications come together to create overlapping, interconnected, or multiplied disadvantage. For example, women with a substance use disorder and who have been incarcerated face a triple threat in terms of successful treatment for a substance use disorder: intersectionality exists between being a woman, having a substance use disorder, and having been in jail or prison. After searching the literature, little or no empirical evidence might have been located on this specific triple-threat topic. Instead, the social worker will need to seek literature on each of the threats individually, and possibly will find literature on pairs of topics (see Figure 3-1). There exists some literature about women’s outcomes for treatment of a substance use disorder (a), some literature about women during and following incarceration (b), and some literature about substance use disorders and incarceration (c). Despite not having a direct line on the center of the intersecting spheres of literature (d), the social worker can develop at least a partial picture based on the overlapping literatures.
Figure 3-1. Venn diagram of intersecting literature sets.
Take a moment to complete the following activity. For each statement about empirical literature, decide if it is true or false.
Social Work 3401 Coursebook Copyright © by Dr. Audrey Begun is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License , except where otherwise noted.
Share This Book
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Empirical Research: Definition, Methods, Types and Examples

Content Index
Empirical research: Definition
Empirical research: origin, quantitative research methods, qualitative research methods, steps for conducting empirical research, empirical research methodology cycle, advantages of empirical research, disadvantages of empirical research, why is there a need for empirical research.
Empirical research is defined as any research where conclusions of the study is strictly drawn from concretely empirical evidence, and therefore “verifiable” evidence.
This empirical evidence can be gathered using quantitative market research and qualitative market research methods.
For example: A research is being conducted to find out if listening to happy music in the workplace while working may promote creativity? An experiment is conducted by using a music website survey on a set of audience who are exposed to happy music and another set who are not listening to music at all, and the subjects are then observed. The results derived from such a research will give empirical evidence if it does promote creativity or not.
LEARN ABOUT: Behavioral Research
You must have heard the quote” I will not believe it unless I see it”. This came from the ancient empiricists, a fundamental understanding that powered the emergence of medieval science during the renaissance period and laid the foundation of modern science, as we know it today. The word itself has its roots in greek. It is derived from the greek word empeirikos which means “experienced”.
In today’s world, the word empirical refers to collection of data using evidence that is collected through observation or experience or by using calibrated scientific instruments. All of the above origins have one thing in common which is dependence of observation and experiments to collect data and test them to come up with conclusions.
LEARN ABOUT: Causal Research
Types and methodologies of empirical research
Empirical research can be conducted and analysed using qualitative or quantitative methods.
- Quantitative research : Quantitative research methods are used to gather information through numerical data. It is used to quantify opinions, behaviors or other defined variables . These are predetermined and are in a more structured format. Some of the commonly used methods are survey, longitudinal studies, polls, etc
- Qualitative research: Qualitative research methods are used to gather non numerical data. It is used to find meanings, opinions, or the underlying reasons from its subjects. These methods are unstructured or semi structured. The sample size for such a research is usually small and it is a conversational type of method to provide more insight or in-depth information about the problem Some of the most popular forms of methods are focus groups, experiments, interviews, etc.
Data collected from these will need to be analysed. Empirical evidence can also be analysed either quantitatively and qualitatively. Using this, the researcher can answer empirical questions which have to be clearly defined and answerable with the findings he has got. The type of research design used will vary depending on the field in which it is going to be used. Many of them might choose to do a collective research involving quantitative and qualitative method to better answer questions which cannot be studied in a laboratory setting.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
Quantitative research methods aid in analyzing the empirical evidence gathered. By using these a researcher can find out if his hypothesis is supported or not.
- Survey research: Survey research generally involves a large audience to collect a large amount of data. This is a quantitative method having a predetermined set of closed questions which are pretty easy to answer. Because of the simplicity of such a method, high responses are achieved. It is one of the most commonly used methods for all kinds of research in today’s world.
Previously, surveys were taken face to face only with maybe a recorder. However, with advancement in technology and for ease, new mediums such as emails , or social media have emerged.
For example: Depletion of energy resources is a growing concern and hence there is a need for awareness about renewable energy. According to recent studies, fossil fuels still account for around 80% of energy consumption in the United States. Even though there is a rise in the use of green energy every year, there are certain parameters because of which the general population is still not opting for green energy. In order to understand why, a survey can be conducted to gather opinions of the general population about green energy and the factors that influence their choice of switching to renewable energy. Such a survey can help institutions or governing bodies to promote appropriate awareness and incentive schemes to push the use of greener energy.
Learn more: Renewable Energy Survey Template Descriptive Research vs Correlational Research
- Experimental research: In experimental research , an experiment is set up and a hypothesis is tested by creating a situation in which one of the variable is manipulated. This is also used to check cause and effect. It is tested to see what happens to the independent variable if the other one is removed or altered. The process for such a method is usually proposing a hypothesis, experimenting on it, analyzing the findings and reporting the findings to understand if it supports the theory or not.
For example: A particular product company is trying to find what is the reason for them to not be able to capture the market. So the organisation makes changes in each one of the processes like manufacturing, marketing, sales and operations. Through the experiment they understand that sales training directly impacts the market coverage for their product. If the person is trained well, then the product will have better coverage.
- Correlational research: Correlational research is used to find relation between two set of variables . Regression analysis is generally used to predict outcomes of such a method. It can be positive, negative or neutral correlation.
LEARN ABOUT: Level of Analysis
For example: Higher educated individuals will get higher paying jobs. This means higher education enables the individual to high paying job and less education will lead to lower paying jobs.
- Longitudinal study: Longitudinal study is used to understand the traits or behavior of a subject under observation after repeatedly testing the subject over a period of time. Data collected from such a method can be qualitative or quantitative in nature.
For example: A research to find out benefits of exercise. The target is asked to exercise everyday for a particular period of time and the results show higher endurance, stamina, and muscle growth. This supports the fact that exercise benefits an individual body.
- Cross sectional: Cross sectional study is an observational type of method, in which a set of audience is observed at a given point in time. In this type, the set of people are chosen in a fashion which depicts similarity in all the variables except the one which is being researched. This type does not enable the researcher to establish a cause and effect relationship as it is not observed for a continuous time period. It is majorly used by healthcare sector or the retail industry.
For example: A medical study to find the prevalence of under-nutrition disorders in kids of a given population. This will involve looking at a wide range of parameters like age, ethnicity, location, incomes and social backgrounds. If a significant number of kids coming from poor families show under-nutrition disorders, the researcher can further investigate into it. Usually a cross sectional study is followed by a longitudinal study to find out the exact reason.
- Causal-Comparative research : This method is based on comparison. It is mainly used to find out cause-effect relationship between two variables or even multiple variables.
For example: A researcher measured the productivity of employees in a company which gave breaks to the employees during work and compared that to the employees of the company which did not give breaks at all.
LEARN ABOUT: Action Research
Some research questions need to be analysed qualitatively, as quantitative methods are not applicable there. In many cases, in-depth information is needed or a researcher may need to observe a target audience behavior, hence the results needed are in a descriptive analysis form. Qualitative research results will be descriptive rather than predictive. It enables the researcher to build or support theories for future potential quantitative research. In such a situation qualitative research methods are used to derive a conclusion to support the theory or hypothesis being studied.
LEARN ABOUT: Qualitative Interview
- Case study: Case study method is used to find more information through carefully analyzing existing cases. It is very often used for business research or to gather empirical evidence for investigation purpose. It is a method to investigate a problem within its real life context through existing cases. The researcher has to carefully analyse making sure the parameter and variables in the existing case are the same as to the case that is being investigated. Using the findings from the case study, conclusions can be drawn regarding the topic that is being studied.
For example: A report mentioning the solution provided by a company to its client. The challenges they faced during initiation and deployment, the findings of the case and solutions they offered for the problems. Such case studies are used by most companies as it forms an empirical evidence for the company to promote in order to get more business.
- Observational method: Observational method is a process to observe and gather data from its target. Since it is a qualitative method it is time consuming and very personal. It can be said that observational research method is a part of ethnographic research which is also used to gather empirical evidence. This is usually a qualitative form of research, however in some cases it can be quantitative as well depending on what is being studied.
For example: setting up a research to observe a particular animal in the rain-forests of amazon. Such a research usually take a lot of time as observation has to be done for a set amount of time to study patterns or behavior of the subject. Another example used widely nowadays is to observe people shopping in a mall to figure out buying behavior of consumers.
- One-on-one interview: Such a method is purely qualitative and one of the most widely used. The reason being it enables a researcher get precise meaningful data if the right questions are asked. It is a conversational method where in-depth data can be gathered depending on where the conversation leads.
For example: A one-on-one interview with the finance minister to gather data on financial policies of the country and its implications on the public.
- Focus groups: Focus groups are used when a researcher wants to find answers to why, what and how questions. A small group is generally chosen for such a method and it is not necessary to interact with the group in person. A moderator is generally needed in case the group is being addressed in person. This is widely used by product companies to collect data about their brands and the product.
For example: A mobile phone manufacturer wanting to have a feedback on the dimensions of one of their models which is yet to be launched. Such studies help the company meet the demand of the customer and position their model appropriately in the market.
- Text analysis: Text analysis method is a little new compared to the other types. Such a method is used to analyse social life by going through images or words used by the individual. In today’s world, with social media playing a major part of everyone’s life, such a method enables the research to follow the pattern that relates to his study.
For example: A lot of companies ask for feedback from the customer in detail mentioning how satisfied are they with their customer support team. Such data enables the researcher to take appropriate decisions to make their support team better.
Sometimes a combination of the methods is also needed for some questions that cannot be answered using only one type of method especially when a researcher needs to gain a complete understanding of complex subject matter.
We recently published a blog that talks about examples of qualitative data in education ; why don’t you check it out for more ideas?
Since empirical research is based on observation and capturing experiences, it is important to plan the steps to conduct the experiment and how to analyse it. This will enable the researcher to resolve problems or obstacles which can occur during the experiment.
Step #1: Define the purpose of the research
This is the step where the researcher has to answer questions like what exactly do I want to find out? What is the problem statement? Are there any issues in terms of the availability of knowledge, data, time or resources. Will this research be more beneficial than what it will cost.
Before going ahead, a researcher has to clearly define his purpose for the research and set up a plan to carry out further tasks.
Step #2 : Supporting theories and relevant literature
The researcher needs to find out if there are theories which can be linked to his research problem . He has to figure out if any theory can help him support his findings. All kind of relevant literature will help the researcher to find if there are others who have researched this before, or what are the problems faced during this research. The researcher will also have to set up assumptions and also find out if there is any history regarding his research problem
Step #3: Creation of Hypothesis and measurement
Before beginning the actual research he needs to provide himself a working hypothesis or guess what will be the probable result. Researcher has to set up variables, decide the environment for the research and find out how can he relate between the variables.
Researcher will also need to define the units of measurements, tolerable degree for errors, and find out if the measurement chosen will be acceptable by others.
Step #4: Methodology, research design and data collection
In this step, the researcher has to define a strategy for conducting his research. He has to set up experiments to collect data which will enable him to propose the hypothesis. The researcher will decide whether he will need experimental or non experimental method for conducting the research. The type of research design will vary depending on the field in which the research is being conducted. Last but not the least, the researcher will have to find out parameters that will affect the validity of the research design. Data collection will need to be done by choosing appropriate samples depending on the research question. To carry out the research, he can use one of the many sampling techniques. Once data collection is complete, researcher will have empirical data which needs to be analysed.
LEARN ABOUT: Best Data Collection Tools
Step #5: Data Analysis and result
Data analysis can be done in two ways, qualitatively and quantitatively. Researcher will need to find out what qualitative method or quantitative method will be needed or will he need a combination of both. Depending on the unit of analysis of his data, he will know if his hypothesis is supported or rejected. Analyzing this data is the most important part to support his hypothesis.
Step #6: Conclusion
A report will need to be made with the findings of the research. The researcher can give the theories and literature that support his research. He can make suggestions or recommendations for further research on his topic.

A.D. de Groot, a famous dutch psychologist and a chess expert conducted some of the most notable experiments using chess in the 1940’s. During his study, he came up with a cycle which is consistent and now widely used to conduct empirical research. It consists of 5 phases with each phase being as important as the next one. The empirical cycle captures the process of coming up with hypothesis about how certain subjects work or behave and then testing these hypothesis against empirical data in a systematic and rigorous approach. It can be said that it characterizes the deductive approach to science. Following is the empirical cycle.
- Observation: At this phase an idea is sparked for proposing a hypothesis. During this phase empirical data is gathered using observation. For example: a particular species of flower bloom in a different color only during a specific season.
- Induction: Inductive reasoning is then carried out to form a general conclusion from the data gathered through observation. For example: As stated above it is observed that the species of flower blooms in a different color during a specific season. A researcher may ask a question “does the temperature in the season cause the color change in the flower?” He can assume that is the case, however it is a mere conjecture and hence an experiment needs to be set up to support this hypothesis. So he tags a few set of flowers kept at a different temperature and observes if they still change the color?
- Deduction: This phase helps the researcher to deduce a conclusion out of his experiment. This has to be based on logic and rationality to come up with specific unbiased results.For example: In the experiment, if the tagged flowers in a different temperature environment do not change the color then it can be concluded that temperature plays a role in changing the color of the bloom.
- Testing: This phase involves the researcher to return to empirical methods to put his hypothesis to the test. The researcher now needs to make sense of his data and hence needs to use statistical analysis plans to determine the temperature and bloom color relationship. If the researcher finds out that most flowers bloom a different color when exposed to the certain temperature and the others do not when the temperature is different, he has found support to his hypothesis. Please note this not proof but just a support to his hypothesis.
- Evaluation: This phase is generally forgotten by most but is an important one to keep gaining knowledge. During this phase the researcher puts forth the data he has collected, the support argument and his conclusion. The researcher also states the limitations for the experiment and his hypothesis and suggests tips for others to pick it up and continue a more in-depth research for others in the future. LEARN MORE: Population vs Sample
LEARN MORE: Population vs Sample
There is a reason why empirical research is one of the most widely used method. There are a few advantages associated with it. Following are a few of them.
- It is used to authenticate traditional research through various experiments and observations.
- This research methodology makes the research being conducted more competent and authentic.
- It enables a researcher understand the dynamic changes that can happen and change his strategy accordingly.
- The level of control in such a research is high so the researcher can control multiple variables.
- It plays a vital role in increasing internal validity .
Even though empirical research makes the research more competent and authentic, it does have a few disadvantages. Following are a few of them.
- Such a research needs patience as it can be very time consuming. The researcher has to collect data from multiple sources and the parameters involved are quite a few, which will lead to a time consuming research.
- Most of the time, a researcher will need to conduct research at different locations or in different environments, this can lead to an expensive affair.
- There are a few rules in which experiments can be performed and hence permissions are needed. Many a times, it is very difficult to get certain permissions to carry out different methods of this research.
- Collection of data can be a problem sometimes, as it has to be collected from a variety of sources through different methods.
LEARN ABOUT: Social Communication Questionnaire
Empirical research is important in today’s world because most people believe in something only that they can see, hear or experience. It is used to validate multiple hypothesis and increase human knowledge and continue doing it to keep advancing in various fields.
For example: Pharmaceutical companies use empirical research to try out a specific drug on controlled groups or random groups to study the effect and cause. This way, they prove certain theories they had proposed for the specific drug. Such research is very important as sometimes it can lead to finding a cure for a disease that has existed for many years. It is useful in science and many other fields like history, social sciences, business, etc.
LEARN ABOUT: 12 Best Tools for Researchers
With the advancement in today’s world, empirical research has become critical and a norm in many fields to support their hypothesis and gain more knowledge. The methods mentioned above are very useful for carrying out such research. However, a number of new methods will keep coming up as the nature of new investigative questions keeps getting unique or changing.
Create a single source of real data with a built-for-insights platform. Store past data, add nuggets of insights, and import research data from various sources into a CRM for insights. Build on ever-growing research with a real-time dashboard in a unified research management platform to turn insights into knowledge.
LEARN MORE FREE TRIAL
MORE LIKE THIS

Top 10 Dynata Alternatives & Competitors
May 27, 2024
What Are My Employees Really Thinking? The Power of Open-ended Survey Analysis
May 24, 2024

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024

20 Best Customer Success Tools of 2024
May 20, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Penn State University Libraries
Empirical research in the social sciences and education.
- What is Empirical Research and How to Read It
- Finding Empirical Research in Library Databases
- Designing Empirical Research
- Ethics, Cultural Responsiveness, and Anti-Racism in Research
- Citing, Writing, and Presenting Your Work
Contact the Librarian at your campus for more help!

Introduction: What is Empirical Research?
Empirical research is based on observed and measured phenomena and derives knowledge from actual experience rather than from theory or belief.
How do you know if a study is empirical? Read the subheadings within the article, book, or report and look for a description of the research "methodology." Ask yourself: Could I recreate this study and test these results?
Key characteristics to look for:
- Specific research questions to be answered
- Definition of the population, behavior, or phenomena being studied
- Description of the process used to study this population or phenomena, including selection criteria, controls, and testing instruments (such as surveys)
Another hint: some scholarly journals use a specific layout, called the "IMRaD" format, to communicate empirical research findings. Such articles typically have 4 components:
- Introduction : sometimes called "literature review" -- what is currently known about the topic -- usually includes a theoretical framework and/or discussion of previous studies
- Methodology: sometimes called "research design" -- how to recreate the study -- usually describes the population, research process, and analytical tools used in the present study
- Results : sometimes called "findings" -- what was learned through the study -- usually appears as statistical data or as substantial quotations from research participants
- Discussion : sometimes called "conclusion" or "implications" -- why the study is important -- usually describes how the research results influence professional practices or future studies
Reading and Evaluating Scholarly Materials
Reading research can be a challenge. However, the tutorials and videos below can help. They explain what scholarly articles look like, how to read them, and how to evaluate them:
- CRAAP Checklist A frequently-used checklist that helps you examine the currency, relevance, authority, accuracy, and purpose of an information source.
- IF I APPLY A newer model of evaluating sources which encourages you to think about your own biases as a reader, as well as concerns about the item you are reading.
- Credo Video: How to Read Scholarly Materials (4 min.)
- Credo Tutorial: How to Read Scholarly Materials
- Credo Tutorial: Evaluating Information
- Credo Video: Evaluating Statistics (4 min.)
- Next: Finding Empirical Research in Library Databases >>
- Last Updated: Feb 18, 2024 8:33 PM
- URL: https://guides.libraries.psu.edu/emp
Empirical Research
Introduction, what is empirical research, attribution.
- Finding Empirical Research in Library Databases
- Designing Empirical Research
- Case Sudies
Empirical research is based on observed and measured phenomena and derives knowledge from actual experience rather than from theory or belief.
How do you know if a study is empirical? Read the subheadings within the article, book, or report and look for a description of the research "methodology." Ask yourself: Could I recreate this study and test these results?
Key characteristics to look for:
- Specific research questions to be answered
- Definition of the population, behavior, or phenomena being studied
- Description of the process used to study this population or phenomena, including selection criteria, controls, and testing instruments (such as surveys)
Another hint: some scholarly journals use a specific layout, called the "IMRaD" format, to communicate empirical research findings. Such articles typically have 4 components:
- Introduction : sometimes called "literature review" -- what is currently known about the topic -- usually includes a theoretical framework and/or discussion of previous studies
- Methodology: sometimes called "research design" -- how to recreate the study -- usually describes the population, research process, and analytical tools
- Results : sometimes called "findings" -- what was learned through the study -- usually appears as statistical data or as substantial quotations from research participants
- Discussion : sometimes called "conclusion" or "implications" -- why the study is important -- usually describes how the research results influence professional practices or future studies
Portions of this guide were built using suggestions from other libraries, including Penn State and Utah State University libraries.
- Next: Finding Empirical Research in Library Databases >>
- Last Updated: Jan 10, 2023 8:31 AM
- URL: https://enmu.libguides.com/EmpiricalResearch
Canvas | University | Ask a Librarian
- Library Homepage
- Arrendale Library
Empirical Research: Quantitative & Qualitative
- Empirical Research
Introduction: What is Empirical Research?
Quantitative methods, qualitative methods.
- Quantitative vs. Qualitative
- Reference Works for Social Sciences Research
- Contact Us!
Call us at 706-776-0111
Chat with a Librarian
Send Us Email
Library Hours
Empirical research is based on phenomena that can be observed and measured. Empirical research derives knowledge from actual experience rather than from theory or belief.
Key characteristics of empirical research include:
- Specific research questions to be answered;
- Definitions of the population, behavior, or phenomena being studied;
- Description of the methodology or research design used to study this population or phenomena, including selection criteria, controls, and testing instruments (such as surveys);
- Two basic research processes or methods in empirical research: quantitative methods and qualitative methods (see the rest of the guide for more about these methods).
(based on the original from the Connelly LIbrary of LaSalle University)

Empirical Research: Qualitative vs. Quantitative
Learn about common types of journal articles that use APA Style, including empirical studies; meta-analyses; literature reviews; and replication, theoretical, and methodological articles.
Academic Writer
© 2024 American Psychological Association.
- More about Academic Writer ...
Quantitative Research
A quantitative research project is characterized by having a population about which the researcher wants to draw conclusions, but it is not possible to collect data on the entire population.
- For an observational study, it is necessary to select a proper, statistical random sample and to use methods of statistical inference to draw conclusions about the population.
- For an experimental study, it is necessary to have a random assignment of subjects to experimental and control groups in order to use methods of statistical inference.
Statistical methods are used in all three stages of a quantitative research project.
For observational studies, the data are collected using statistical sampling theory. Then, the sample data are analyzed using descriptive statistical analysis. Finally, generalizations are made from the sample data to the entire population using statistical inference.
For experimental studies, the subjects are allocated to experimental and control group using randomizing methods. Then, the experimental data are analyzed using descriptive statistical analysis. Finally, just as for observational data, generalizations are made to a larger population.
Iversen, G. (2004). Quantitative research . In M. Lewis-Beck, A. Bryman, & T. Liao (Eds.), Encyclopedia of social science research methods . (pp. 897-898). Thousand Oaks, CA: SAGE Publications, Inc.
Qualitative Research
What makes a work deserving of the label qualitative research is the demonstrable effort to produce richly and relevantly detailed descriptions and particularized interpretations of people and the social, linguistic, material, and other practices and events that shape and are shaped by them.
Qualitative research typically includes, but is not limited to, discerning the perspectives of these people, or what is often referred to as the actor’s point of view. Although both philosophically and methodologically a highly diverse entity, qualitative research is marked by certain defining imperatives that include its case (as opposed to its variable) orientation, sensitivity to cultural and historical context, and reflexivity.
In its many guises, qualitative research is a form of empirical inquiry that typically entails some form of purposive sampling for information-rich cases; in-depth interviews and open-ended interviews, lengthy participant/field observations, and/or document or artifact study; and techniques for analysis and interpretation of data that move beyond the data generated and their surface appearances.
Sandelowski, M. (2004). Qualitative research . In M. Lewis-Beck, A. Bryman, & T. Liao (Eds.), Encyclopedia of social science research methods . (pp. 893-894). Thousand Oaks, CA: SAGE Publications, Inc.
- Next: Quantitative vs. Qualitative >>
- Last Updated: Mar 22, 2024 10:47 AM
- URL: https://library.piedmont.edu/empirical-research
- Ebooks & Online Video
- New Materials
- Renew Checkouts
- Faculty Resources
- Library Friends
- Library Services
- Our Mission
- Library History
- Ask a Librarian!
- Making Citations
- Working Online
Arrendale Library Piedmont University 706-776-0111

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Reviewing the research methods literature: principles and strategies illustrated by a systematic overview of sampling in qualitative research
Stephen j. gentles.
1 Department of Clinical Epidemiology and Biostatistics, McMaster University, Hamilton, Ontario Canada
4 CanChild Centre for Childhood Disability Research, McMaster University, 1400 Main Street West, IAHS 408, Hamilton, ON L8S 1C7 Canada
Cathy Charles
David b. nicholas.
2 Faculty of Social Work, University of Calgary, Alberta, Canada
Jenny Ploeg
3 School of Nursing, McMaster University, Hamilton, Ontario Canada
K. Ann McKibbon
Associated data.
The systematic methods overview used as a worked example in this article (Gentles SJ, Charles C, Ploeg J, McKibbon KA: Sampling in qualitative research: insights from an overview of the methods literature. The Qual Rep 2015, 20(11):1772-1789) is available from http://nsuworks.nova.edu/tqr/vol20/iss11/5 .
Overviews of methods are potentially useful means to increase clarity and enhance collective understanding of specific methods topics that may be characterized by ambiguity, inconsistency, or a lack of comprehensiveness. This type of review represents a distinct literature synthesis method, although to date, its methodology remains relatively undeveloped despite several aspects that demand unique review procedures. The purpose of this paper is to initiate discussion about what a rigorous systematic approach to reviews of methods, referred to here as systematic methods overviews , might look like by providing tentative suggestions for approaching specific challenges likely to be encountered. The guidance offered here was derived from experience conducting a systematic methods overview on the topic of sampling in qualitative research.
The guidance is organized into several principles that highlight specific objectives for this type of review given the common challenges that must be overcome to achieve them. Optional strategies for achieving each principle are also proposed, along with discussion of how they were successfully implemented in the overview on sampling. We describe seven paired principles and strategies that address the following aspects: delimiting the initial set of publications to consider, searching beyond standard bibliographic databases, searching without the availability of relevant metadata, selecting publications on purposeful conceptual grounds, defining concepts and other information to abstract iteratively, accounting for inconsistent terminology used to describe specific methods topics, and generating rigorous verifiable analytic interpretations. Since a broad aim in systematic methods overviews is to describe and interpret the relevant literature in qualitative terms, we suggest that iterative decision making at various stages of the review process, and a rigorous qualitative approach to analysis are necessary features of this review type.
Conclusions
We believe that the principles and strategies provided here will be useful to anyone choosing to undertake a systematic methods overview. This paper represents an initial effort to promote high quality critical evaluations of the literature regarding problematic methods topics, which have the potential to promote clearer, shared understandings, and accelerate advances in research methods. Further work is warranted to develop more definitive guidance.
Electronic supplementary material
The online version of this article (doi:10.1186/s13643-016-0343-0) contains supplementary material, which is available to authorized users.
While reviews of methods are not new, they represent a distinct review type whose methodology remains relatively under-addressed in the literature despite the clear implications for unique review procedures. One of few examples to describe it is a chapter containing reflections of two contributing authors in a book of 21 reviews on methodological topics compiled for the British National Health Service, Health Technology Assessment Program [ 1 ]. Notable is their observation of how the differences between the methods reviews and conventional quantitative systematic reviews, specifically attributable to their varying content and purpose, have implications for defining what qualifies as systematic. While the authors describe general aspects of “systematicity” (including rigorous application of a methodical search, abstraction, and analysis), they also describe a high degree of variation within the category of methods reviews itself and so offer little in the way of concrete guidance. In this paper, we present tentative concrete guidance, in the form of a preliminary set of proposed principles and optional strategies, for a rigorous systematic approach to reviewing and evaluating the literature on quantitative or qualitative methods topics. For purposes of this article, we have used the term systematic methods overview to emphasize the notion of a systematic approach to such reviews.
The conventional focus of rigorous literature reviews (i.e., review types for which systematic methods have been codified, including the various approaches to quantitative systematic reviews [ 2 – 4 ], and the numerous forms of qualitative and mixed methods literature synthesis [ 5 – 10 ]) is to synthesize empirical research findings from multiple studies. By contrast, the focus of overviews of methods, including the systematic approach we advocate, is to synthesize guidance on methods topics. The literature consulted for such reviews may include the methods literature, methods-relevant sections of empirical research reports, or both. Thus, this paper adds to previous work published in this journal—namely, recent preliminary guidance for conducting reviews of theory [ 11 ]—that has extended the application of systematic review methods to novel review types that are concerned with subject matter other than empirical research findings.
Published examples of methods overviews illustrate the varying objectives they can have. One objective is to establish methodological standards for appraisal purposes. For example, reviews of existing quality appraisal standards have been used to propose universal standards for appraising the quality of primary qualitative research [ 12 ] or evaluating qualitative research reports [ 13 ]. A second objective is to survey the methods-relevant sections of empirical research reports to establish current practices on methods use and reporting practices, which Moher and colleagues [ 14 ] recommend as a means for establishing the needs to be addressed in reporting guidelines (see, for example [ 15 , 16 ]). A third objective for a methods review is to offer clarity and enhance collective understanding regarding a specific methods topic that may be characterized by ambiguity, inconsistency, or a lack of comprehensiveness within the available methods literature. An example of this is a overview whose objective was to review the inconsistent definitions of intention-to-treat analysis (the methodologically preferred approach to analyze randomized controlled trial data) that have been offered in the methods literature and propose a solution for improving conceptual clarity [ 17 ]. Such reviews are warranted because students and researchers who must learn or apply research methods typically lack the time to systematically search, retrieve, review, and compare the available literature to develop a thorough and critical sense of the varied approaches regarding certain controversial or ambiguous methods topics.
While systematic methods overviews , as a review type, include both reviews of the methods literature and reviews of methods-relevant sections from empirical study reports, the guidance provided here is primarily applicable to reviews of the methods literature since it was derived from the experience of conducting such a review [ 18 ], described below. To our knowledge, there are no well-developed proposals on how to rigorously conduct such reviews. Such guidance would have the potential to improve the thoroughness and credibility of critical evaluations of the methods literature, which could increase their utility as a tool for generating understandings that advance research methods, both qualitative and quantitative. Our aim in this paper is thus to initiate discussion about what might constitute a rigorous approach to systematic methods overviews. While we hope to promote rigor in the conduct of systematic methods overviews wherever possible, we do not wish to suggest that all methods overviews need be conducted to the same standard. Rather, we believe that the level of rigor may need to be tailored pragmatically to the specific review objectives, which may not always justify the resource requirements of an intensive review process.
The example systematic methods overview on sampling in qualitative research
The principles and strategies we propose in this paper are derived from experience conducting a systematic methods overview on the topic of sampling in qualitative research [ 18 ]. The main objective of that methods overview was to bring clarity and deeper understanding of the prominent concepts related to sampling in qualitative research (purposeful sampling strategies, saturation, etc.). Specifically, we interpreted the available guidance, commenting on areas lacking clarity, consistency, or comprehensiveness (without proposing any recommendations on how to do sampling). This was achieved by a comparative and critical analysis of publications representing the most influential (i.e., highly cited) guidance across several methodological traditions in qualitative research.
The specific methods and procedures for the overview on sampling [ 18 ] from which our proposals are derived were developed both after soliciting initial input from local experts in qualitative research and an expert health librarian (KAM) and through ongoing careful deliberation throughout the review process. To summarize, in that review, we employed a transparent and rigorous approach to search the methods literature, selected publications for inclusion according to a purposeful and iterative process, abstracted textual data using structured abstraction forms, and analyzed (synthesized) the data using a systematic multi-step approach featuring abstraction of text, summary of information in matrices, and analytic comparisons.
For this article, we reflected on both the problems and challenges encountered at different stages of the review and our means for selecting justifiable procedures to deal with them. Several principles were then derived by considering the generic nature of these problems, while the generalizable aspects of the procedures used to address them formed the basis of optional strategies. Further details of the specific methods and procedures used in the overview on qualitative sampling are provided below to illustrate both the types of objectives and challenges that reviewers will likely need to consider and our approach to implementing each of the principles and strategies.
Organization of the guidance into principles and strategies
For the purposes of this article, principles are general statements outlining what we propose are important aims or considerations within a particular review process, given the unique objectives or challenges to be overcome with this type of review. These statements follow the general format, “considering the objective or challenge of X, we propose Y to be an important aim or consideration.” Strategies are optional and flexible approaches for implementing the previous principle outlined. Thus, generic challenges give rise to principles, which in turn give rise to strategies.
We organize the principles and strategies below into three sections corresponding to processes characteristic of most systematic literature synthesis approaches: literature identification and selection ; data abstraction from the publications selected for inclusion; and analysis , including critical appraisal and synthesis of the abstracted data. Within each section, we also describe the specific methodological decisions and procedures used in the overview on sampling in qualitative research [ 18 ] to illustrate how the principles and strategies for each review process were applied and implemented in a specific case. We expect this guidance and accompanying illustrations will be useful for anyone considering engaging in a methods overview, particularly those who may be familiar with conventional systematic review methods but may not yet appreciate some of the challenges specific to reviewing the methods literature.
Results and discussion
Literature identification and selection.
The identification and selection process includes search and retrieval of publications and the development and application of inclusion and exclusion criteria to select the publications that will be abstracted and analyzed in the final review. Literature identification and selection for overviews of the methods literature is challenging and potentially more resource-intensive than for most reviews of empirical research. This is true for several reasons that we describe below, alongside discussion of the potential solutions. Additionally, we suggest in this section how the selection procedures can be chosen to match the specific analytic approach used in methods overviews.
Delimiting a manageable set of publications
One aspect of methods overviews that can make identification and selection challenging is the fact that the universe of literature containing potentially relevant information regarding most methods-related topics is expansive and often unmanageably so. Reviewers are faced with two large categories of literature: the methods literature , where the possible publication types include journal articles, books, and book chapters; and the methods-relevant sections of empirical study reports , where the possible publication types include journal articles, monographs, books, theses, and conference proceedings. In our systematic overview of sampling in qualitative research, exhaustively searching (including retrieval and first-pass screening) all publication types across both categories of literature for information on a single methods-related topic was too burdensome to be feasible. The following proposed principle follows from the need to delimit a manageable set of literature for the review.
Principle #1:
Considering the broad universe of potentially relevant literature, we propose that an important objective early in the identification and selection stage is to delimit a manageable set of methods-relevant publications in accordance with the objectives of the methods overview.
Strategy #1:
To limit the set of methods-relevant publications that must be managed in the selection process, reviewers have the option to initially review only the methods literature, and exclude the methods-relevant sections of empirical study reports, provided this aligns with the review’s particular objectives.
We propose that reviewers are justified in choosing to select only the methods literature when the objective is to map out the range of recognized concepts relevant to a methods topic, to summarize the most authoritative or influential definitions or meanings for methods-related concepts, or to demonstrate a problematic lack of clarity regarding a widely established methods-related concept and potentially make recommendations for a preferred approach to the methods topic in question. For example, in the case of the methods overview on sampling [ 18 ], the primary aim was to define areas lacking in clarity for multiple widely established sampling-related topics. In the review on intention-to-treat in the context of missing outcome data [ 17 ], the authors identified a lack of clarity based on multiple inconsistent definitions in the literature and went on to recommend separating the issue of how to handle missing outcome data from the issue of whether an intention-to-treat analysis can be claimed.
In contrast to strategy #1, it may be appropriate to select the methods-relevant sections of empirical study reports when the objective is to illustrate how a methods concept is operationalized in research practice or reported by authors. For example, one could review all the publications in 2 years’ worth of issues of five high-impact field-related journals to answer questions about how researchers describe implementing a particular method or approach, or to quantify how consistently they define or report using it. Such reviews are often used to highlight gaps in the reporting practices regarding specific methods, which may be used to justify items to address in reporting guidelines (for example, [ 14 – 16 ]).
It is worth recognizing that other authors have advocated broader positions regarding the scope of literature to be considered in a review, expanding on our perspective. Suri [ 10 ] (who, like us, emphasizes how different sampling strategies are suitable for different literature synthesis objectives) has, for example, described a two-stage literature sampling procedure (pp. 96–97). First, reviewers use an initial approach to conduct a broad overview of the field—for reviews of methods topics, this would entail an initial review of the research methods literature. This is followed by a second more focused stage in which practical examples are purposefully selected—for methods reviews, this would involve sampling the empirical literature to illustrate key themes and variations. While this approach is seductive in its capacity to generate more in depth and interpretive analytic findings, some reviewers may consider it too resource-intensive to include the second step no matter how selective the purposeful sampling. In the overview on sampling where we stopped after the first stage [ 18 ], we discussed our selective focus on the methods literature as a limitation that left opportunities for further analysis of the literature. We explicitly recommended, for example, that theoretical sampling was a topic for which a future review of the methods sections of empirical reports was justified to answer specific questions identified in the primary review.
Ultimately, reviewers must make pragmatic decisions that balance resource considerations, combined with informed predictions about the depth and complexity of literature available on their topic, with the stated objectives of their review. The remaining principles and strategies apply primarily to overviews that include the methods literature, although some aspects may be relevant to reviews that include empirical study reports.
Searching beyond standard bibliographic databases
An important reality affecting identification and selection in overviews of the methods literature is the increased likelihood for relevant publications to be located in sources other than journal articles (which is usually not the case for overviews of empirical research, where journal articles generally represent the primary publication type). In the overview on sampling [ 18 ], out of 41 full-text publications retrieved and reviewed, only 4 were journal articles, while 37 were books or book chapters. Since many books and book chapters did not exist electronically, their full text had to be physically retrieved in hardcopy, while 11 publications were retrievable only through interlibrary loan or purchase request. The tasks associated with such retrieval are substantially more time-consuming than electronic retrieval. Since a substantial proportion of methods-related guidance may be located in publication types that are less comprehensively indexed in standard bibliographic databases, identification and retrieval thus become complicated processes.
Principle #2:
Considering that important sources of methods guidance can be located in non-journal publication types (e.g., books, book chapters) that tend to be poorly indexed in standard bibliographic databases, it is important to consider alternative search methods for identifying relevant publications to be further screened for inclusion.
Strategy #2:
To identify books, book chapters, and other non-journal publication types not thoroughly indexed in standard bibliographic databases, reviewers may choose to consult one or more of the following less standard sources: Google Scholar, publisher web sites, or expert opinion.
In the case of the overview on sampling in qualitative research [ 18 ], Google Scholar had two advantages over other standard bibliographic databases: it indexes and returns records of books and book chapters likely to contain guidance on qualitative research methods topics; and it has been validated as providing higher citation counts than ISI Web of Science (a producer of numerous bibliographic databases accessible through institutional subscription) for several non-biomedical disciplines including the social sciences where qualitative research methods are prominently used [ 19 – 21 ]. While we identified numerous useful publications by consulting experts, the author publication lists generated through Google Scholar searches were uniquely useful to identify more recent editions of methods books identified by experts.
Searching without relevant metadata
Determining what publications to select for inclusion in the overview on sampling [ 18 ] could only rarely be accomplished by reviewing the publication’s metadata. This was because for the many books and other non-journal type publications we identified as possibly relevant, the potential content of interest would be located in only a subsection of the publication. In this common scenario for reviews of the methods literature (as opposed to methods overviews that include empirical study reports), reviewers will often be unable to employ standard title, abstract, and keyword database searching or screening as a means for selecting publications.
Principle #3:
Considering that the presence of information about the topic of interest may not be indicated in the metadata for books and similar publication types, it is important to consider other means of identifying potentially useful publications for further screening.
Strategy #3:
One approach to identifying potentially useful books and similar publication types is to consider what classes of such publications (e.g., all methods manuals for a certain research approach) are likely to contain relevant content, then identify, retrieve, and review the full text of corresponding publications to determine whether they contain information on the topic of interest.
In the example of the overview on sampling in qualitative research [ 18 ], the topic of interest (sampling) was one of numerous topics covered in the general qualitative research methods manuals. Consequently, examples from this class of publications first had to be identified for retrieval according to non-keyword-dependent criteria. Thus, all methods manuals within the three research traditions reviewed (grounded theory, phenomenology, and case study) that might contain discussion of sampling were sought through Google Scholar and expert opinion, their full text obtained, and hand-searched for relevant content to determine eligibility. We used tables of contents and index sections of books to aid this hand searching.
Purposefully selecting literature on conceptual grounds
A final consideration in methods overviews relates to the type of analysis used to generate the review findings. Unlike quantitative systematic reviews where reviewers aim for accurate or unbiased quantitative estimates—something that requires identifying and selecting the literature exhaustively to obtain all relevant data available (i.e., a complete sample)—in methods overviews, reviewers must describe and interpret the relevant literature in qualitative terms to achieve review objectives. In other words, the aim in methods overviews is to seek coverage of the qualitative concepts relevant to the methods topic at hand. For example, in the overview of sampling in qualitative research [ 18 ], achieving review objectives entailed providing conceptual coverage of eight sampling-related topics that emerged as key domains. The following principle recognizes that literature sampling should therefore support generating qualitative conceptual data as the input to analysis.
Principle #4:
Since the analytic findings of a systematic methods overview are generated through qualitative description and interpretation of the literature on a specified topic, selection of the literature should be guided by a purposeful strategy designed to achieve adequate conceptual coverage (i.e., representing an appropriate degree of variation in relevant ideas) of the topic according to objectives of the review.
Strategy #4:
One strategy for choosing the purposeful approach to use in selecting the literature according to the review objectives is to consider whether those objectives imply exploring concepts either at a broad overview level, in which case combining maximum variation selection with a strategy that limits yield (e.g., critical case, politically important, or sampling for influence—described below) may be appropriate; or in depth, in which case purposeful approaches aimed at revealing innovative cases will likely be necessary.
In the methods overview on sampling, the implied scope was broad since we set out to review publications on sampling across three divergent qualitative research traditions—grounded theory, phenomenology, and case study—to facilitate making informative conceptual comparisons. Such an approach would be analogous to maximum variation sampling.
At the same time, the purpose of that review was to critically interrogate the clarity, consistency, and comprehensiveness of literature from these traditions that was “most likely to have widely influenced students’ and researchers’ ideas about sampling” (p. 1774) [ 18 ]. In other words, we explicitly set out to review and critique the most established and influential (and therefore dominant) literature, since this represents a common basis of knowledge among students and researchers seeking understanding or practical guidance on sampling in qualitative research. To achieve this objective, we purposefully sampled publications according to the criterion of influence , which we operationalized as how often an author or publication has been referenced in print or informal discourse. This second sampling approach also limited the literature we needed to consider within our broad scope review to a manageable amount.
To operationalize this strategy of sampling for influence , we sought to identify both the most influential authors within a qualitative research tradition (all of whose citations were subsequently screened) and the most influential publications on the topic of interest by non-influential authors. This involved a flexible approach that combined multiple indicators of influence to avoid the dilemma that any single indicator might provide inadequate coverage. These indicators included bibliometric data (h-index for author influence [ 22 ]; number of cites for publication influence), expert opinion, and cross-references in the literature (i.e., snowball sampling). As a final selection criterion, a publication was included only if it made an original contribution in terms of novel guidance regarding sampling or a related concept; thus, purely secondary sources were excluded. Publish or Perish software (Anne-Wil Harzing; available at http://www.harzing.com/resources/publish-or-perish ) was used to generate bibliometric data via the Google Scholar database. Figure 1 illustrates how identification and selection in the methods overview on sampling was a multi-faceted and iterative process. The authors selected as influential, and the publications selected for inclusion or exclusion are listed in Additional file 1 (Matrices 1, 2a, 2b).

Literature identification and selection process used in the methods overview on sampling [ 18 ]
In summary, the strategies of seeking maximum variation and sampling for influence were employed in the sampling overview to meet the specific review objectives described. Reviewers will need to consider the full range of purposeful literature sampling approaches at their disposal in deciding what best matches the specific aims of their own reviews. Suri [ 10 ] has recently retooled Patton’s well-known typology of purposeful sampling strategies (originally intended for primary research) for application to literature synthesis, providing a useful resource in this respect.
Data abstraction
The purpose of data abstraction in rigorous literature reviews is to locate and record all data relevant to the topic of interest from the full text of included publications, making them available for subsequent analysis. Conventionally, a data abstraction form—consisting of numerous distinct conceptually defined fields to which corresponding information from the source publication is recorded—is developed and employed. There are several challenges, however, to the processes of developing the abstraction form and abstracting the data itself when conducting methods overviews, which we address here. Some of these problems and their solutions may be familiar to those who have conducted qualitative literature syntheses, which are similarly conceptual.
Iteratively defining conceptual information to abstract
In the overview on sampling [ 18 ], while we surveyed multiple sources beforehand to develop a list of concepts relevant for abstraction (e.g., purposeful sampling strategies, saturation, sample size), there was no way for us to anticipate some concepts prior to encountering them in the review process. Indeed, in many cases, reviewers are unable to determine the complete set of methods-related concepts that will be the focus of the final review a priori without having systematically reviewed the publications to be included. Thus, defining what information to abstract beforehand may not be feasible.
Principle #5:
Considering the potential impracticality of defining a complete set of relevant methods-related concepts from a body of literature one has not yet systematically read, selecting and defining fields for data abstraction must often be undertaken iteratively. Thus, concepts to be abstracted can be expected to grow and change as data abstraction proceeds.
Strategy #5:
Reviewers can develop an initial form or set of concepts for abstraction purposes according to standard methods (e.g., incorporating expert feedback, pilot testing) and remain attentive to the need to iteratively revise it as concepts are added or modified during the review. Reviewers should document revisions and return to re-abstract data from previously abstracted publications as the new data requirements are determined.
In the sampling overview [ 18 ], we developed and maintained the abstraction form in Microsoft Word. We derived the initial set of abstraction fields from our own knowledge of relevant sampling-related concepts, consultation with local experts, and reviewing a pilot sample of publications. Since the publications in this review included a large proportion of books, the abstraction process often began by flagging the broad sections within a publication containing topic-relevant information for detailed review to identify text to abstract. When reviewing flagged text, the reviewer occasionally encountered an unanticipated concept significant enough to warrant being added as a new field to the abstraction form. For example, a field was added to capture how authors described the timing of sampling decisions, whether before (a priori) or after (ongoing) starting data collection, or whether this was unclear. In these cases, we systematically documented the modification to the form and returned to previously abstracted publications to abstract any information that might be relevant to the new field.
The logic of this strategy is analogous to the logic used in a form of research synthesis called best fit framework synthesis (BFFS) [ 23 – 25 ]. In that method, reviewers initially code evidence using an a priori framework they have selected. When evidence cannot be accommodated by the selected framework, reviewers then develop new themes or concepts from which they construct a new expanded framework. Both the strategy proposed and the BFFS approach to research synthesis are notable for their rigorous and transparent means to adapt a final set of concepts to the content under review.
Accounting for inconsistent terminology
An important complication affecting the abstraction process in methods overviews is that the language used by authors to describe methods-related concepts can easily vary across publications. For example, authors from different qualitative research traditions often use different terms for similar methods-related concepts. Furthermore, as we found in the sampling overview [ 18 ], there may be cases where no identifiable term, phrase, or label for a methods-related concept is used at all, and a description of it is given instead. This can make searching the text for relevant concepts based on keywords unreliable.
Principle #6:
Since accepted terms may not be used consistently to refer to methods concepts, it is necessary to rely on the definitions for concepts, rather than keywords, to identify relevant information in the publication to abstract.
Strategy #6:
An effective means to systematically identify relevant information is to develop and iteratively adjust written definitions for key concepts (corresponding to abstraction fields) that are consistent with and as inclusive of as much of the literature reviewed as possible. Reviewers then seek information that matches these definitions (rather than keywords) when scanning a publication for relevant data to abstract.
In the abstraction process for the sampling overview [ 18 ], we noted the several concepts of interest to the review for which abstraction by keyword was particularly problematic due to inconsistent terminology across publications: sampling , purposeful sampling , sampling strategy , and saturation (for examples, see Additional file 1 , Matrices 3a, 3b, 4). We iteratively developed definitions for these concepts by abstracting text from publications that either provided an explicit definition or from which an implicit definition could be derived, which was recorded in fields dedicated to the concept’s definition. Using a method of constant comparison, we used text from definition fields to inform and modify a centrally maintained definition of the corresponding concept to optimize its fit and inclusiveness with the literature reviewed. Table 1 shows, as an example, the final definition constructed in this way for one of the central concepts of the review, qualitative sampling .
Final definition for qualitative sampling , including methodological tradition-specific variations
Developed after numerous iterations in the methods overview on sampling [ 18 ]
We applied iteratively developed definitions when making decisions about what specific text to abstract for an existing field, which allowed us to abstract concept-relevant data even if no recognized keyword was used. For example, this was the case for the sampling-related concept, saturation , where the relevant text available for abstraction in one publication [ 26 ]—“to continue to collect data until nothing new was being observed or recorded, no matter how long that takes”—was not accompanied by any term or label whatsoever.
This comparative analytic strategy (and our approach to analysis more broadly as described in strategy #7, below) is analogous to the process of reciprocal translation —a technique first introduced for meta-ethnography by Noblit and Hare [ 27 ] that has since been recognized as a common element in a variety of qualitative metasynthesis approaches [ 28 ]. Reciprocal translation, taken broadly, involves making sense of a study’s findings in terms of the findings of the other studies included in the review. In practice, it has been operationalized in different ways. Melendez-Torres and colleagues developed a typology from their review of the metasynthesis literature, describing four overlapping categories of specific operations undertaken in reciprocal translation: visual representation, key paper integration, data reduction and thematic extraction, and line-by-line coding [ 28 ]. The approaches suggested in both strategies #6 and #7, with their emphasis on constant comparison, appear to fall within the line-by-line coding category.
Generating credible and verifiable analytic interpretations
The analysis in a systematic methods overview must support its more general objective, which we suggested above is often to offer clarity and enhance collective understanding regarding a chosen methods topic. In our experience, this involves describing and interpreting the relevant literature in qualitative terms. Furthermore, any interpretative analysis required may entail reaching different levels of abstraction, depending on the more specific objectives of the review. For example, in the overview on sampling [ 18 ], we aimed to produce a comparative analysis of how multiple sampling-related topics were treated differently within and among different qualitative research traditions. To promote credibility of the review, however, not only should one seek a qualitative analytic approach that facilitates reaching varying levels of abstraction but that approach must also ensure that abstract interpretations are supported and justified by the source data and not solely the product of the analyst’s speculative thinking.
Principle #7:
Considering the qualitative nature of the analysis required in systematic methods overviews, it is important to select an analytic method whose interpretations can be verified as being consistent with the literature selected, regardless of the level of abstraction reached.
Strategy #7:
We suggest employing the constant comparative method of analysis [ 29 ] because it supports developing and verifying analytic links to the source data throughout progressively interpretive or abstract levels. In applying this approach, we advise a rigorous approach, documenting how supportive quotes or references to the original texts are carried forward in the successive steps of analysis to allow for easy verification.
The analytic approach used in the methods overview on sampling [ 18 ] comprised four explicit steps, progressing in level of abstraction—data abstraction, matrices, narrative summaries, and final analytic conclusions (Fig. 2 ). While we have positioned data abstraction as the second stage of the generic review process (prior to Analysis), above, we also considered it as an initial step of analysis in the sampling overview for several reasons. First, it involved a process of constant comparisons and iterative decision-making about the fields to add or define during development and modification of the abstraction form, through which we established the range of concepts to be addressed in the review. At the same time, abstraction involved continuous analytic decisions about what textual quotes (ranging in size from short phrases to numerous paragraphs) to record in the fields thus created. This constant comparative process was analogous to open coding in which textual data from publications was compared to conceptual fields (equivalent to codes) or to other instances of data previously abstracted when constructing definitions to optimize their fit with the overall literature as described in strategy #6. Finally, in the data abstraction step, we also recorded our first interpretive thoughts in dedicated fields, providing initial material for the more abstract analytic steps.

Summary of progressive steps of analysis used in the methods overview on sampling [ 18 ]
In the second step of the analysis, we constructed topic-specific matrices , or tables, by copying relevant quotes from abstraction forms into the appropriate cells of matrices (for the complete set of analytic matrices developed in the sampling review, see Additional file 1 (matrices 3 to 10)). Each matrix ranged from one to five pages; row headings, nested three-deep, identified the methodological tradition, author, and publication, respectively; and column headings identified the concepts, which corresponded to abstraction fields. Matrices thus allowed us to make further comparisons across methodological traditions, and between authors within a tradition. In the third step of analysis, we recorded our comparative observations as narrative summaries , in which we used illustrative quotes more sparingly. In the final step, we developed analytic conclusions based on the narrative summaries about the sampling-related concepts within each methodological tradition for which clarity, consistency, or comprehensiveness of the available guidance appeared to be lacking. Higher levels of analysis thus built logically from the lower levels, enabling us to easily verify analytic conclusions by tracing the support for claims by comparing the original text of publications reviewed.
Integrative versus interpretive methods overviews
The analytic product of systematic methods overviews is comparable to qualitative evidence syntheses, since both involve describing and interpreting the relevant literature in qualitative terms. Most qualitative synthesis approaches strive to produce new conceptual understandings that vary in level of interpretation. Dixon-Woods and colleagues [ 30 ] elaborate on a useful distinction, originating from Noblit and Hare [ 27 ], between integrative and interpretive reviews. Integrative reviews focus on summarizing available primary data and involve using largely secure and well defined concepts to do so; definitions are used from an early stage to specify categories for abstraction (or coding) of data, which in turn supports their aggregation; they do not seek as their primary focus to develop or specify new concepts, although they may achieve some theoretical or interpretive functions. For interpretive reviews, meanwhile, the main focus is to develop new concepts and theories that integrate them, with the implication that the concepts developed become fully defined towards the end of the analysis. These two forms are not completely distinct, and “every integrative synthesis will include elements of interpretation, and every interpretive synthesis will include elements of aggregation of data” [ 30 ].
The example methods overview on sampling [ 18 ] could be classified as predominantly integrative because its primary goal was to aggregate influential authors’ ideas on sampling-related concepts; there were also, however, elements of interpretive synthesis since it aimed to develop new ideas about where clarity in guidance on certain sampling-related topics is lacking, and definitions for some concepts were flexible and not fixed until late in the review. We suggest that most systematic methods overviews will be classifiable as predominantly integrative (aggregative). Nevertheless, more highly interpretive methods overviews are also quite possible—for example, when the review objective is to provide a highly critical analysis for the purpose of generating new methodological guidance. In such cases, reviewers may need to sample more deeply (see strategy #4), specifically by selecting empirical research reports (i.e., to go beyond dominant or influential ideas in the methods literature) that are likely to feature innovations or instructive lessons in employing a given method.
In this paper, we have outlined tentative guidance in the form of seven principles and strategies on how to conduct systematic methods overviews, a review type in which methods-relevant literature is systematically analyzed with the aim of offering clarity and enhancing collective understanding regarding a specific methods topic. Our proposals include strategies for delimiting the set of publications to consider, searching beyond standard bibliographic databases, searching without the availability of relevant metadata, selecting publications on purposeful conceptual grounds, defining concepts and other information to abstract iteratively, accounting for inconsistent terminology, and generating credible and verifiable analytic interpretations. We hope the suggestions proposed will be useful to others undertaking reviews on methods topics in future.
As far as we are aware, this is the first published source of concrete guidance for conducting this type of review. It is important to note that our primary objective was to initiate methodological discussion by stimulating reflection on what rigorous methods for this type of review should look like, leaving the development of more complete guidance to future work. While derived from the experience of reviewing a single qualitative methods topic, we believe the principles and strategies provided are generalizable to overviews of both qualitative and quantitative methods topics alike. However, it is expected that additional challenges and insights for conducting such reviews have yet to be defined. Thus, we propose that next steps for developing more definitive guidance should involve an attempt to collect and integrate other reviewers’ perspectives and experiences in conducting systematic methods overviews on a broad range of qualitative and quantitative methods topics. Formalized guidance and standards would improve the quality of future methods overviews, something we believe has important implications for advancing qualitative and quantitative methodology. When undertaken to a high standard, rigorous critical evaluations of the available methods guidance have significant potential to make implicit controversies explicit, and improve the clarity and precision of our understandings of problematic qualitative or quantitative methods issues.
A review process central to most types of rigorous reviews of empirical studies, which we did not explicitly address in a separate review step above, is quality appraisal . The reason we have not treated this as a separate step stems from the different objectives of the primary publications included in overviews of the methods literature (i.e., providing methodological guidance) compared to the primary publications included in the other established review types (i.e., reporting findings from single empirical studies). This is not to say that appraising quality of the methods literature is not an important concern for systematic methods overviews. Rather, appraisal is much more integral to (and difficult to separate from) the analysis step, in which we advocate appraising clarity, consistency, and comprehensiveness—the quality appraisal criteria that we suggest are appropriate for the methods literature. As a second important difference regarding appraisal, we currently advocate appraising the aforementioned aspects at the level of the literature in aggregate rather than at the level of individual publications. One reason for this is that methods guidance from individual publications generally builds on previous literature, and thus we feel that ahistorical judgments about comprehensiveness of single publications lack relevance and utility. Additionally, while different methods authors may express themselves less clearly than others, their guidance can nonetheless be highly influential and useful, and should therefore not be downgraded or ignored based on considerations of clarity—which raises questions about the alternative uses that quality appraisals of individual publications might have. Finally, legitimate variability in the perspectives that methods authors wish to emphasize, and the levels of generality at which they write about methods, makes critiquing individual publications based on the criterion of clarity a complex and potentially problematic endeavor that is beyond the scope of this paper to address. By appraising the current state of the literature at a holistic level, reviewers stand to identify important gaps in understanding that represent valuable opportunities for further methodological development.
To summarize, the principles and strategies provided here may be useful to those seeking to undertake their own systematic methods overview. Additional work is needed, however, to establish guidance that is comprehensive by comparing the experiences from conducting a variety of methods overviews on a range of methods topics. Efforts that further advance standards for systematic methods overviews have the potential to promote high-quality critical evaluations that produce conceptually clear and unified understandings of problematic methods topics, thereby accelerating the advance of research methodology.
Acknowledgements
Not applicable.
There was no funding for this work.
Availability of data and materials
Authors’ contributions.
SJG wrote the first draft of this article, with CC contributing to drafting. All authors contributed to revising the manuscript. All authors except CC (deceased) approved the final draft. SJG, CC, KAB, and JP were involved in developing methods for the systematic methods overview on sampling.
Authors’ information
Competing interests.
The authors declare that they have no competing interests.
Consent for publication
Ethics approval and consent to participate, additional file.
Submitted: Analysis_matrices. (DOC 330 kb)
Cathy Charles is deceased
Contributor Information
Stephen J. Gentles, Email: moc.liamg@seltnegevets .
David B. Nicholas, Email: ac.yraglacu@salohcin .
Jenny Ploeg, Email: ac.retsamcm@jgeolp .
K. Ann McKibbon, Email: ac.retsamcm@bikcm .
Identifying Empirical Research Articles
Identifying empirical articles.
- Searching for Empirical Research Articles
What is Empirical Research?
An empirical research article reports the results of a study that uses data derived from actual observation or experimentation. Empirical research articles are examples of primary research. To learn more about the differences between primary and secondary research, see our related guide:
- Primary and Secondary Sources
By the end of this guide, you will be able to:
- Identify common elements of an empirical article
- Use a variety of search strategies to search for empirical articles within the library collection
Look for the IMRaD layout in the article to help identify empirical research. Sometimes the sections will be labeled differently, but the content will be similar.
- I ntroduction: why the article was written, research question or questions, hypothesis, literature review
- M ethods: the overall research design and implementation, description of sample, instruments used, how the authors measured their experiment
- R esults: output of the author's measurements, usually includes statistics of the author's findings
- D iscussion: the author's interpretation and conclusions about the results, limitations of study, suggestions for further research
Parts of an Empirical Research Article
Parts of an empirical article.
The screenshots below identify the basic IMRaD structure of an empirical research article.
Introduction
The introduction contains a literature review and the study's research hypothesis.

The method section outlines the research design, participants, and measures used.

Results
The results section contains statistical data (charts, graphs, tables, etc.) and research participant quotes.

The discussion section includes impacts, limitations, future considerations, and research.

Learn the IMRaD Layout: How to Identify an Empirical Article
This short video overviews the IMRaD method for identifying empirical research.
- Next: Searching for Empirical Research Articles >>
- Last Updated: Nov 16, 2023 8:24 AM
CityU Home - CityU Catalog

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
2.3 Reviewing the Research Literature
Learning objectives.
- Define the research literature in psychology and give examples of sources that are part of the research literature and sources that are not.
- Describe and use several methods for finding previous research on a particular research idea or question.
Reviewing the research literature means finding, reading, and summarizing the published research relevant to your question. An empirical research report written in American Psychological Association (APA) style always includes a written literature review, but it is important to review the literature early in the research process for several reasons.
- It can help you turn a research idea into an interesting research question.
- It can tell you if a research question has already been answered.
- It can help you evaluate the interestingness of a research question.
- It can give you ideas for how to conduct your own study.
- It can tell you how your study fits into the research literature.
What Is the Research Literature?
The research literature in any field is all the published research in that field. The research literature in psychology is enormous—including millions of scholarly articles and books dating to the beginning of the field—and it continues to grow. Although its boundaries are somewhat fuzzy, the research literature definitely does not include self-help and other pop psychology books, dictionary and encyclopedia entries, websites, and similar sources that are intended mainly for the general public. These are considered unreliable because they are not reviewed by other researchers and are often based on little more than common sense or personal experience. Wikipedia contains much valuable information, but the fact that its authors are anonymous and its content continually changes makes it unsuitable as a basis of sound scientific research. For our purposes, it helps to define the research literature as consisting almost entirely of two types of sources: articles in professional journals, and scholarly books in psychology and related fields.
Professional Journals
Professional journals are periodicals that publish original research articles. There are thousands of professional journals that publish research in psychology and related fields. They are usually published monthly or quarterly in individual issues, each of which contains several articles. The issues are organized into volumes, which usually consist of all the issues for a calendar year. Some journals are published in hard copy only, others in both hard copy and electronic form, and still others in electronic form only.
Most articles in professional journals are one of two basic types: empirical research reports and review articles. Empirical research reports describe one or more new empirical studies conducted by the authors. They introduce a research question, explain why it is interesting, review previous research, describe their method and results, and draw their conclusions. Review articles summarize previously published research on a topic and usually present new ways to organize or explain the results. When a review article is devoted primarily to presenting a new theory, it is often referred to as a theoretical article .
Figure 2.6 Small Sample of the Thousands of Professional Journals That Publish Research in Psychology and Related Fields

Most professional journals in psychology undergo a process of peer review . Researchers who want to publish their work in the journal submit a manuscript to the editor—who is generally an established researcher too—who in turn sends it to two or three experts on the topic. Each reviewer reads the manuscript, writes a critical review, and sends the review back to the editor along with his or her recommendations. The editor then decides whether to accept the article for publication, ask the authors to make changes and resubmit it for further consideration, or reject it outright. In any case, the editor forwards the reviewers’ written comments to the researchers so that they can revise their manuscript accordingly. Peer review is important because it ensures that the work meets basic standards of the field before it can enter the research literature.
Scholarly Books
Scholarly books are books written by researchers and practitioners mainly for use by other researchers and practitioners. A monograph is written by a single author or a small group of authors and usually gives a coherent presentation of a topic much like an extended review article. Edited volumes have an editor or a small group of editors who recruit many authors to write separate chapters on different aspects of the same topic. Although edited volumes can also give a coherent presentation of the topic, it is not unusual for each chapter to take a different perspective or even for the authors of different chapters to openly disagree with each other. In general, scholarly books undergo a peer review process similar to that used by professional journals.
Literature Search Strategies
Using psycinfo and other databases.
The primary method used to search the research literature involves using one or more electronic databases. These include Academic Search Premier, JSTOR, and ProQuest for all academic disciplines, ERIC for education, and PubMed for medicine and related fields. The most important for our purposes, however, is PsycINFO , which is produced by the APA. PsycINFO is so comprehensive—covering thousands of professional journals and scholarly books going back more than 100 years—that for most purposes its content is synonymous with the research literature in psychology. Like most such databases, PsycINFO is usually available through your college or university library.
PsycINFO consists of individual records for each article, book chapter, or book in the database. Each record includes basic publication information, an abstract or summary of the work, and a list of other works cited by that work. A computer interface allows entering one or more search terms and returns any records that contain those search terms. (These interfaces are provided by different vendors and therefore can look somewhat different depending on the library you use.) Each record also contains lists of keywords that describe the content of the work and also a list of index terms. The index terms are especially helpful because they are standardized. Research on differences between women and men, for example, is always indexed under “Human Sex Differences.” Research on touching is always indexed under the term “Physical Contact.” If you do not know the appropriate index terms, PsycINFO includes a thesaurus that can help you find them.
Given that there are nearly three million records in PsycINFO, you may have to try a variety of search terms in different combinations and at different levels of specificity before you find what you are looking for. Imagine, for example, that you are interested in the question of whether women and men differ in terms of their ability to recall experiences from when they were very young. If you were to enter “memory for early experiences” as your search term, PsycINFO would return only six records, most of which are not particularly relevant to your question. However, if you were to enter the search term “memory,” it would return 149,777 records—far too many to look through individually. This is where the thesaurus helps. Entering “memory” into the thesaurus provides several more specific index terms—one of which is “early memories.” While searching for “early memories” among the index terms returns 1,446 records—still too many too look through individually—combining it with “human sex differences” as a second search term returns 37 articles, many of which are highly relevant to the topic.
Depending on the vendor that provides the interface to PsycINFO, you may be able to save, print, or e-mail the relevant PsycINFO records. The records might even contain links to full-text copies of the works themselves. (PsycARTICLES is a database that provides full-text access to articles in all journals published by the APA.) If not, and you want a copy of the work, you will have to find out if your library carries the journal or has the book and the hard copy on the library shelves. Be sure to ask a librarian if you need help.
Using Other Search Techniques
In addition to entering search terms into PsycINFO and other databases, there are several other techniques you can use to search the research literature. First, if you have one good article or book chapter on your topic—a recent review article is best—you can look through the reference list of that article for other relevant articles, books, and book chapters. In fact, you should do this with any relevant article or book chapter you find. You can also start with a classic article or book chapter on your topic, find its record in PsycINFO (by entering the author’s name or article’s title as a search term), and link from there to a list of other works in PsycINFO that cite that classic article. This works because other researchers working on your topic are likely to be aware of the classic article and cite it in their own work. You can also do a general Internet search using search terms related to your topic or the name of a researcher who conducts research on your topic. This might lead you directly to works that are part of the research literature (e.g., articles in open-access journals or posted on researchers’ own websites). The search engine Google Scholar is especially useful for this purpose. A general Internet search might also lead you to websites that are not part of the research literature but might provide references to works that are. Finally, you can talk to people (e.g., your instructor or other faculty members in psychology) who know something about your topic and can suggest relevant articles and book chapters.
What to Search For
When you do a literature review, you need to be selective. Not every article, book chapter, and book that relates to your research idea or question will be worth obtaining, reading, and integrating into your review. Instead, you want to focus on sources that help you do four basic things: (a) refine your research question, (b) identify appropriate research methods, (c) place your research in the context of previous research, and (d) write an effective research report. Several basic principles can help you find the most useful sources.
First, it is best to focus on recent research, keeping in mind that what counts as recent depends on the topic. For newer topics that are actively being studied, “recent” might mean published in the past year or two. For older topics that are receiving less attention right now, “recent” might mean within the past 10 years. You will get a feel for what counts as recent for your topic when you start your literature search. A good general rule, however, is to start with sources published in the past five years. The main exception to this rule would be classic articles that turn up in the reference list of nearly every other source. If other researchers think that this work is important, even though it is old, then by all means you should include it in your review.
Second, you should look for review articles on your topic because they will provide a useful overview of it—often discussing important definitions, results, theories, trends, and controversies—giving you a good sense of where your own research fits into the literature. You should also look for empirical research reports addressing your question or similar questions, which can give you ideas about how to operationally define your variables and collect your data. As a general rule, it is good to use methods that others have already used successfully unless you have good reasons not to. Finally, you should look for sources that provide information that can help you argue for the interestingness of your research question. For a study on the effects of cell phone use on driving ability, for example, you might look for information about how widespread cell phone use is, how frequent and costly motor vehicle crashes are, and so on.
How many sources are enough for your literature review? This is a difficult question because it depends on how extensively your topic has been studied and also on your own goals. One study found that across a variety of professional journals in psychology, the average number of sources cited per article was about 50 (Adair & Vohra, 2003). This gives a rough idea of what professional researchers consider to be adequate. As a student, you might be assigned a much lower minimum number of references to use, but the principles for selecting the most useful ones remain the same.
Key Takeaways
- The research literature in psychology is all the published research in psychology, consisting primarily of articles in professional journals and scholarly books.
- Early in the research process, it is important to conduct a review of the research literature on your topic to refine your research question, identify appropriate research methods, place your question in the context of other research, and prepare to write an effective research report.
- There are several strategies for finding previous research on your topic. Among the best is using PsycINFO, a computer database that catalogs millions of articles, books, and book chapters in psychology and related fields.
- Practice: Use the techniques discussed in this section to find 10 journal articles and book chapters on one of the following research ideas: memory for smells, aggressive driving, the causes of narcissistic personality disorder, the functions of the intraparietal sulcus, or prejudice against the physically handicapped.
Adair, J. G., & Vohra, N. (2003). The explosion of knowledge, references, and citations: Psychology’s unique response to a crisis. American Psychologist, 58 , 15–23.
Research Methods in Psychology Copyright © 2016 by University of Minnesota is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.

- University of Memphis Libraries
- Research Guides
Empirical Research: Defining, Identifying, & Finding
Searching for empirical research.
- Defining Empirical Research
- Introduction
Where Do I Find Empirical Research?
How do i find more empirical research in my search.
- Database Tools
- Search Terms
- Image Descriptions
Because empirical research refers to the method of investigation rather than a method of publication, it can be published in a number of places. In many disciplines empirical research is most commonly published in scholarly, peer-reviewed journals . Putting empirical research through the peer review process helps ensure that the research is high quality.
Finding Peer-Reviewed Articles
You can find peer-reviewed articles in a general web search along with a lot of other types of sources. However, these specialized tools are more likely to find peer-reviewed articles:
- Library databases
- Academic search engines such as Google Scholar
Common Types of Articles That Are Not Empirical
However, just finding an article in a peer-reviewed journal is not enough to say it is empirical, since not all the articles in a peer-reviewed journal will be empirical research or even peer reviewed. Knowing how to quickly identify some types non-empirical research articles in peer-reviewed journals can help speed up your search.
- Peer-reviewed articles that systematically discuss and propose abstract concepts and methods for a field without primary data collection.
- Example: Grosser, K. & Moon, J. (2019). CSR and feminist organization studies: Towards an integrated theorization for the analysis of gender issues .
- Peer-reviewed articles that systematically describe, summarize, and often categorize and evaluate previous research on a topic without collecting new data.
- Example: Heuer, S. & Willer, R. (2020). How is quality of life assessed in people with dementia? A systematic literature review and a primer for speech-language pathologists .
- Note: empirical research articles will have a literature review section as part of the Introduction , but in an empirical research article the literature review exists to give context to the empirical research, which is the primary focus of the article. In a literature review article, the literature review is the focus.
- While these articles are not empirical, they are often a great source of information on previous empirical research on a topic with citations to find that research.
- Non-peer-reviewed articles where the authors discuss their thoughts on a particular topic without data collection and a systematic method. There are a few differences between these types of articles.
- Written by the editors or guest editors of the journal.
- Example: Naples, N. A., Mauldin, L., & Dillaway, H. (2018). From the guest editors: Gender, disability, and intersectionality .
- Written by guest authors. The journal may have a non-peer-reviewed process for authors to submit these articles, and the editors of the journal may invite authors to write opinion articles.
- Example: García, J. J.-L., & Sharif, M. Z. (2015). Black lives matter: A commentary on racism and public health .
- Written by the readers of a journal, often in response to an article previously-published in the journal.
- Example: Nathan, M. (2013). Letters: Perceived discrimination and racial/ethnic disparities in youth problem behaviors .
- Non-peer-reviewed articles that describe and evaluate books, products, services, and other things the audience of the journal would be interested in.
- Example: Robinson, R. & Green, J. M. (2020). Book review: Microaggressions and traumatic stress: Theory, research, and clinical treatment .
Even once you know how to recognize empirical research and where it is published, it would be nice to improve your search results so that more empirical research shows up for your topic.
There are two major ways to find the empirical research in a database search:
- Use built-in database tools to limit results to empirical research.
- Include search terms that help identify empirical research.
- << Previous: Discussion
- Next: Database Tools >>
- Last Updated: Apr 2, 2024 11:25 AM
- URL: https://libguides.memphis.edu/empirical-research
- Meriam Library
SWRK 330 - Social Work Research Methods
- Literature Reviews and Empirical Research
- Databases and Search Tips
- Article Citations
- Scholarly Journal Evaulation
- Statistical Sources
- Books and eBooks
What is a Literature Review?
Empirical research.
- Annotated Bibliographies
A literature review summarizes and discusses previous publications on a topic.
It should also:
explore past research and its strengths and weaknesses.
be used to validate the target and methods you have chosen for your proposed research.
consist of books and scholarly journals that provide research examples of populations or settings similar to your own, as well as community resources to document the need for your proposed research.
The literature review does not present new primary scholarship.
be completed in the correct citation format requested by your professor (see the C itations Tab)
Access Purdue OWL's Social Work Literature Review Guidelines here .
Empirical Research is research that is based on experimentation or observation, i.e. Evidence. Such research is often conducted to answer a specific question or to test a hypothesis (educated guess).
How do you know if a study is empirical? Read the subheadings within the article, book, or report and look for a description of the research "methodology." Ask yourself: Could I recreate this study and test these results?
These are some key features to look for when identifying empirical research.
NOTE: Not all of these features will be in every empirical research article, some may be excluded, use this only as a guide.
- Statement of methodology
- Research questions are clear and measurable
- Individuals, group, subjects which are being studied are identified/defined
- Data is presented regarding the findings
- Controls or instruments such as surveys or tests were conducted
- There is a literature review
- There is discussion of the results included
- Citations/references are included
See also Empirical Research Guide
- << Previous: Citations
- Next: Annotated Bibliographies >>
- Last Updated: Feb 6, 2024 8:38 AM
- URL: https://libguides.csuchico.edu/SWRK330
Meriam Library | CSU, Chico
What is Empirical Research? Definition, Methods, Examples
Appinio Research · 09.02.2024 · 36min read

Ever wondered how we gather the facts, unveil hidden truths, and make informed decisions in a world filled with questions? Empirical research holds the key.
In this guide, we'll delve deep into the art and science of empirical research, unraveling its methods, mysteries, and manifold applications. From defining the core principles to mastering data analysis and reporting findings, we're here to equip you with the knowledge and tools to navigate the empirical landscape.
What is Empirical Research?
Empirical research is the cornerstone of scientific inquiry, providing a systematic and structured approach to investigating the world around us. It is the process of gathering and analyzing empirical or observable data to test hypotheses, answer research questions, or gain insights into various phenomena. This form of research relies on evidence derived from direct observation or experimentation, allowing researchers to draw conclusions based on real-world data rather than purely theoretical or speculative reasoning.
Characteristics of Empirical Research
Empirical research is characterized by several key features:
- Observation and Measurement : It involves the systematic observation or measurement of variables, events, or behaviors.
- Data Collection : Researchers collect data through various methods, such as surveys, experiments, observations, or interviews.
- Testable Hypotheses : Empirical research often starts with testable hypotheses that are evaluated using collected data.
- Quantitative or Qualitative Data : Data can be quantitative (numerical) or qualitative (non-numerical), depending on the research design.
- Statistical Analysis : Quantitative data often undergo statistical analysis to determine patterns , relationships, or significance.
- Objectivity and Replicability : Empirical research strives for objectivity, minimizing researcher bias . It should be replicable, allowing other researchers to conduct the same study to verify results.
- Conclusions and Generalizations : Empirical research generates findings based on data and aims to make generalizations about larger populations or phenomena.
Importance of Empirical Research
Empirical research plays a pivotal role in advancing knowledge across various disciplines. Its importance extends to academia, industry, and society as a whole. Here are several reasons why empirical research is essential:
- Evidence-Based Knowledge : Empirical research provides a solid foundation of evidence-based knowledge. It enables us to test hypotheses, confirm or refute theories, and build a robust understanding of the world.
- Scientific Progress : In the scientific community, empirical research fuels progress by expanding the boundaries of existing knowledge. It contributes to the development of theories and the formulation of new research questions.
- Problem Solving : Empirical research is instrumental in addressing real-world problems and challenges. It offers insights and data-driven solutions to complex issues in fields like healthcare, economics, and environmental science.
- Informed Decision-Making : In policymaking, business, and healthcare, empirical research informs decision-makers by providing data-driven insights. It guides strategies, investments, and policies for optimal outcomes.
- Quality Assurance : Empirical research is essential for quality assurance and validation in various industries, including pharmaceuticals, manufacturing, and technology. It ensures that products and processes meet established standards.
- Continuous Improvement : Businesses and organizations use empirical research to evaluate performance, customer satisfaction, and product effectiveness. This data-driven approach fosters continuous improvement and innovation.
- Human Advancement : Empirical research in fields like medicine and psychology contributes to the betterment of human health and well-being. It leads to medical breakthroughs, improved therapies, and enhanced psychological interventions.
- Critical Thinking and Problem Solving : Engaging in empirical research fosters critical thinking skills, problem-solving abilities, and a deep appreciation for evidence-based decision-making.
Empirical research empowers us to explore, understand, and improve the world around us. It forms the bedrock of scientific inquiry and drives progress in countless domains, shaping our understanding of both the natural and social sciences.
How to Conduct Empirical Research?
So, you've decided to dive into the world of empirical research. Let's begin by exploring the crucial steps involved in getting started with your research project.
1. Select a Research Topic
Selecting the right research topic is the cornerstone of a successful empirical study. It's essential to choose a topic that not only piques your interest but also aligns with your research goals and objectives. Here's how to go about it:
- Identify Your Interests : Start by reflecting on your passions and interests. What topics fascinate you the most? Your enthusiasm will be your driving force throughout the research process.
- Brainstorm Ideas : Engage in brainstorming sessions to generate potential research topics. Consider the questions you've always wanted to answer or the issues that intrigue you.
- Relevance and Significance : Assess the relevance and significance of your chosen topic. Does it contribute to existing knowledge? Is it a pressing issue in your field of study or the broader community?
- Feasibility : Evaluate the feasibility of your research topic. Do you have access to the necessary resources, data, and participants (if applicable)?
2. Formulate Research Questions
Once you've narrowed down your research topic, the next step is to formulate clear and precise research questions . These questions will guide your entire research process and shape your study's direction. To create effective research questions:
- Specificity : Ensure that your research questions are specific and focused. Vague or overly broad questions can lead to inconclusive results.
- Relevance : Your research questions should directly relate to your chosen topic. They should address gaps in knowledge or contribute to solving a particular problem.
- Testability : Ensure that your questions are testable through empirical methods. You should be able to gather data and analyze it to answer these questions.
- Avoid Bias : Craft your questions in a way that avoids leading or biased language. Maintain neutrality to uphold the integrity of your research.
3. Review Existing Literature
Before you embark on your empirical research journey, it's essential to immerse yourself in the existing body of literature related to your chosen topic. This step, often referred to as a literature review, serves several purposes:
- Contextualization : Understand the historical context and current state of research in your field. What have previous studies found, and what questions remain unanswered?
- Identifying Gaps : Identify gaps or areas where existing research falls short. These gaps will help you formulate meaningful research questions and hypotheses.
- Theory Development : If your study is theoretical, consider how existing theories apply to your topic. If it's empirical, understand how previous studies have approached data collection and analysis.
- Methodological Insights : Learn from the methodologies employed in previous research. What methods were successful, and what challenges did researchers face?
4. Define Variables
Variables are fundamental components of empirical research. They are the factors or characteristics that can change or be manipulated during your study. Properly defining and categorizing variables is crucial for the clarity and validity of your research. Here's what you need to know:
- Independent Variables : These are the variables that you, as the researcher, manipulate or control. They are the "cause" in cause-and-effect relationships.
- Dependent Variables : Dependent variables are the outcomes or responses that you measure or observe. They are the "effect" influenced by changes in independent variables.
- Operational Definitions : To ensure consistency and clarity, provide operational definitions for your variables. Specify how you will measure or manipulate each variable.
- Control Variables : In some studies, controlling for other variables that may influence your dependent variable is essential. These are known as control variables.
Understanding these foundational aspects of empirical research will set a solid foundation for the rest of your journey. Now that you've grasped the essentials of getting started, let's delve deeper into the intricacies of research design.
Empirical Research Design
Now that you've selected your research topic, formulated research questions, and defined your variables, it's time to delve into the heart of your empirical research journey – research design . This pivotal step determines how you will collect data and what methods you'll employ to answer your research questions. Let's explore the various facets of research design in detail.
Types of Empirical Research
Empirical research can take on several forms, each with its own unique approach and methodologies. Understanding the different types of empirical research will help you choose the most suitable design for your study. Here are some common types:
- Experimental Research : In this type, researchers manipulate one or more independent variables to observe their impact on dependent variables. It's highly controlled and often conducted in a laboratory setting.
- Observational Research : Observational research involves the systematic observation of subjects or phenomena without intervention. Researchers are passive observers, documenting behaviors, events, or patterns.
- Survey Research : Surveys are used to collect data through structured questionnaires or interviews. This method is efficient for gathering information from a large number of participants.
- Case Study Research : Case studies focus on in-depth exploration of one or a few cases. Researchers gather detailed information through various sources such as interviews, documents, and observations.
- Qualitative Research : Qualitative research aims to understand behaviors, experiences, and opinions in depth. It often involves open-ended questions, interviews, and thematic analysis.
- Quantitative Research : Quantitative research collects numerical data and relies on statistical analysis to draw conclusions. It involves structured questionnaires, experiments, and surveys.
Your choice of research type should align with your research questions and objectives. Experimental research, for example, is ideal for testing cause-and-effect relationships, while qualitative research is more suitable for exploring complex phenomena.
Experimental Design
Experimental research is a systematic approach to studying causal relationships. It's characterized by the manipulation of one or more independent variables while controlling for other factors. Here are some key aspects of experimental design:
- Control and Experimental Groups : Participants are randomly assigned to either a control group or an experimental group. The independent variable is manipulated for the experimental group but not for the control group.
- Randomization : Randomization is crucial to eliminate bias in group assignment. It ensures that each participant has an equal chance of being in either group.
- Hypothesis Testing : Experimental research often involves hypothesis testing. Researchers formulate hypotheses about the expected effects of the independent variable and use statistical analysis to test these hypotheses.
Observational Design
Observational research entails careful and systematic observation of subjects or phenomena. It's advantageous when you want to understand natural behaviors or events. Key aspects of observational design include:
- Participant Observation : Researchers immerse themselves in the environment they are studying. They become part of the group being observed, allowing for a deep understanding of behaviors.
- Non-Participant Observation : In non-participant observation, researchers remain separate from the subjects. They observe and document behaviors without direct involvement.
- Data Collection Methods : Observational research can involve various data collection methods, such as field notes, video recordings, photographs, or coding of observed behaviors.
Survey Design
Surveys are a popular choice for collecting data from a large number of participants. Effective survey design is essential to ensure the validity and reliability of your data. Consider the following:
- Questionnaire Design : Create clear and concise questions that are easy for participants to understand. Avoid leading or biased questions.
- Sampling Methods : Decide on the appropriate sampling method for your study, whether it's random, stratified, or convenience sampling.
- Data Collection Tools : Choose the right tools for data collection, whether it's paper surveys, online questionnaires, or face-to-face interviews.
Case Study Design
Case studies are an in-depth exploration of one or a few cases to gain a deep understanding of a particular phenomenon. Key aspects of case study design include:
- Single Case vs. Multiple Case Studies : Decide whether you'll focus on a single case or multiple cases. Single case studies are intensive and allow for detailed examination, while multiple case studies provide comparative insights.
- Data Collection Methods : Gather data through interviews, observations, document analysis, or a combination of these methods.
Qualitative vs. Quantitative Research
In empirical research, you'll often encounter the distinction between qualitative and quantitative research . Here's a closer look at these two approaches:
- Qualitative Research : Qualitative research seeks an in-depth understanding of human behavior, experiences, and perspectives. It involves open-ended questions, interviews, and the analysis of textual or narrative data. Qualitative research is exploratory and often used when the research question is complex and requires a nuanced understanding.
- Quantitative Research : Quantitative research collects numerical data and employs statistical analysis to draw conclusions. It involves structured questionnaires, experiments, and surveys. Quantitative research is ideal for testing hypotheses and establishing cause-and-effect relationships.
Understanding the various research design options is crucial in determining the most appropriate approach for your study. Your choice should align with your research questions, objectives, and the nature of the phenomenon you're investigating.
Data Collection for Empirical Research
Now that you've established your research design, it's time to roll up your sleeves and collect the data that will fuel your empirical research. Effective data collection is essential for obtaining accurate and reliable results.
Sampling Methods
Sampling methods are critical in empirical research, as they determine the subset of individuals or elements from your target population that you will study. Here are some standard sampling methods:
- Random Sampling : Random sampling ensures that every member of the population has an equal chance of being selected. It minimizes bias and is often used in quantitative research.
- Stratified Sampling : Stratified sampling involves dividing the population into subgroups or strata based on specific characteristics (e.g., age, gender, location). Samples are then randomly selected from each stratum, ensuring representation of all subgroups.
- Convenience Sampling : Convenience sampling involves selecting participants who are readily available or easily accessible. While it's convenient, it may introduce bias and limit the generalizability of results.
- Snowball Sampling : Snowball sampling is instrumental when studying hard-to-reach or hidden populations. One participant leads you to another, creating a "snowball" effect. This method is common in qualitative research.
- Purposive Sampling : In purposive sampling, researchers deliberately select participants who meet specific criteria relevant to their research questions. It's often used in qualitative studies to gather in-depth information.
The choice of sampling method depends on the nature of your research, available resources, and the degree of precision required. It's crucial to carefully consider your sampling strategy to ensure that your sample accurately represents your target population.
Data Collection Instruments
Data collection instruments are the tools you use to gather information from your participants or sources. These instruments should be designed to capture the data you need accurately. Here are some popular data collection instruments:
- Questionnaires : Questionnaires consist of structured questions with predefined response options. When designing questionnaires, consider the clarity of questions, the order of questions, and the response format (e.g., Likert scale , multiple-choice).
- Interviews : Interviews involve direct communication between the researcher and participants. They can be structured (with predetermined questions) or unstructured (open-ended). Effective interviews require active listening and probing for deeper insights.
- Observations : Observations entail systematically and objectively recording behaviors, events, or phenomena. Researchers must establish clear criteria for what to observe, how to record observations, and when to observe.
- Surveys : Surveys are a common data collection instrument for quantitative research. They can be administered through various means, including online surveys, paper surveys, and telephone surveys.
- Documents and Archives : In some cases, data may be collected from existing documents, records, or archives. Ensure that the sources are reliable, relevant, and properly documented.
To streamline your process and gather insights with precision and efficiency, consider leveraging innovative tools like Appinio . With Appinio's intuitive platform, you can harness the power of real-time consumer data to inform your research decisions effectively. Whether you're conducting surveys, interviews, or observations, Appinio empowers you to define your target audience, collect data from diverse demographics, and analyze results seamlessly.
By incorporating Appinio into your data collection toolkit, you can unlock a world of possibilities and elevate the impact of your empirical research. Ready to revolutionize your approach to data collection?
Book a Demo
Data Collection Procedures
Data collection procedures outline the step-by-step process for gathering data. These procedures should be meticulously planned and executed to maintain the integrity of your research.
- Training : If you have a research team, ensure that they are trained in data collection methods and protocols. Consistency in data collection is crucial.
- Pilot Testing : Before launching your data collection, conduct a pilot test with a small group to identify any potential problems with your instruments or procedures. Make necessary adjustments based on feedback.
- Data Recording : Establish a systematic method for recording data. This may include timestamps, codes, or identifiers for each data point.
- Data Security : Safeguard the confidentiality and security of collected data. Ensure that only authorized individuals have access to the data.
- Data Storage : Properly organize and store your data in a secure location, whether in physical or digital form. Back up data to prevent loss.
Ethical Considerations
Ethical considerations are paramount in empirical research, as they ensure the well-being and rights of participants are protected.
- Informed Consent : Obtain informed consent from participants, providing clear information about the research purpose, procedures, risks, and their right to withdraw at any time.
- Privacy and Confidentiality : Protect the privacy and confidentiality of participants. Ensure that data is anonymized and sensitive information is kept confidential.
- Beneficence : Ensure that your research benefits participants and society while minimizing harm. Consider the potential risks and benefits of your study.
- Honesty and Integrity : Conduct research with honesty and integrity. Report findings accurately and transparently, even if they are not what you expected.
- Respect for Participants : Treat participants with respect, dignity, and sensitivity to cultural differences. Avoid any form of coercion or manipulation.
- Institutional Review Board (IRB) : If required, seek approval from an IRB or ethics committee before conducting your research, particularly when working with human participants.
Adhering to ethical guidelines is not only essential for the ethical conduct of research but also crucial for the credibility and validity of your study. Ethical research practices build trust between researchers and participants and contribute to the advancement of knowledge with integrity.
With a solid understanding of data collection, including sampling methods, instruments, procedures, and ethical considerations, you are now well-equipped to gather the data needed to answer your research questions.
Empirical Research Data Analysis
Now comes the exciting phase of data analysis, where the raw data you've diligently collected starts to yield insights and answers to your research questions. We will explore the various aspects of data analysis, from preparing your data to drawing meaningful conclusions through statistics and visualization.
Data Preparation
Data preparation is the crucial first step in data analysis. It involves cleaning, organizing, and transforming your raw data into a format that is ready for analysis. Effective data preparation ensures the accuracy and reliability of your results.
- Data Cleaning : Identify and rectify errors, missing values, and inconsistencies in your dataset. This may involve correcting typos, removing outliers, and imputing missing data.
- Data Coding : Assign numerical values or codes to categorical variables to make them suitable for statistical analysis. For example, converting "Yes" and "No" to 1 and 0.
- Data Transformation : Transform variables as needed to meet the assumptions of the statistical tests you plan to use. Common transformations include logarithmic or square root transformations.
- Data Integration : If your data comes from multiple sources, integrate it into a unified dataset, ensuring that variables match and align.
- Data Documentation : Maintain clear documentation of all data preparation steps, as well as the rationale behind each decision. This transparency is essential for replicability.
Effective data preparation lays the foundation for accurate and meaningful analysis. It allows you to trust the results that will follow in the subsequent stages.
Descriptive Statistics
Descriptive statistics help you summarize and make sense of your data by providing a clear overview of its key characteristics. These statistics are essential for understanding the central tendencies, variability, and distribution of your variables. Descriptive statistics include:
- Measures of Central Tendency : These include the mean (average), median (middle value), and mode (most frequent value). They help you understand the typical or central value of your data.
- Measures of Dispersion : Measures like the range, variance, and standard deviation provide insights into the spread or variability of your data points.
- Frequency Distributions : Creating frequency distributions or histograms allows you to visualize the distribution of your data across different values or categories.
Descriptive statistics provide the initial insights needed to understand your data's basic characteristics, which can inform further analysis.
Inferential Statistics
Inferential statistics take your analysis to the next level by allowing you to make inferences or predictions about a larger population based on your sample data. These methods help you test hypotheses and draw meaningful conclusions. Key concepts in inferential statistics include:
- Hypothesis Testing : Hypothesis tests (e.g., t-tests, chi-squared tests) help you determine whether observed differences or associations in your data are statistically significant or occurred by chance.
- Confidence Intervals : Confidence intervals provide a range within which population parameters (e.g., population mean) are likely to fall based on your sample data.
- Regression Analysis : Regression models (linear, logistic, etc.) help you explore relationships between variables and make predictions.
- Analysis of Variance (ANOVA) : ANOVA tests are used to compare means between multiple groups, allowing you to assess whether differences are statistically significant.
Inferential statistics are powerful tools for drawing conclusions from your data and assessing the generalizability of your findings to the broader population.
Qualitative Data Analysis
Qualitative data analysis is employed when working with non-numerical data, such as text, interviews, or open-ended survey responses. It focuses on understanding the underlying themes, patterns, and meanings within qualitative data. Qualitative analysis techniques include:
- Thematic Analysis : Identifying and analyzing recurring themes or patterns within textual data.
- Content Analysis : Categorizing and coding qualitative data to extract meaningful insights.
- Grounded Theory : Developing theories or frameworks based on emergent themes from the data.
- Narrative Analysis : Examining the structure and content of narratives to uncover meaning.
Qualitative data analysis provides a rich and nuanced understanding of complex phenomena and human experiences.
Data Visualization
Data visualization is the art of representing data graphically to make complex information more understandable and accessible. Effective data visualization can reveal patterns, trends, and outliers in your data. Common types of data visualization include:
- Bar Charts and Histograms : Used to display the distribution of categorical data or discrete data .
- Line Charts : Ideal for showing trends and changes in data over time.
- Scatter Plots : Visualize relationships and correlations between two variables.
- Pie Charts : Display the composition of a whole in terms of its parts.
- Heatmaps : Depict patterns and relationships in multidimensional data through color-coding.
- Box Plots : Provide a summary of the data distribution, including outliers.
- Interactive Dashboards : Create dynamic visualizations that allow users to explore data interactively.
Data visualization not only enhances your understanding of the data but also serves as a powerful communication tool to convey your findings to others.
As you embark on the data analysis phase of your empirical research, remember that the specific methods and techniques you choose will depend on your research questions, data type, and objectives. Effective data analysis transforms raw data into valuable insights, bringing you closer to the answers you seek.
How to Report Empirical Research Results?
At this stage, you get to share your empirical research findings with the world. Effective reporting and presentation of your results are crucial for communicating your research's impact and insights.
1. Write the Research Paper
Writing a research paper is the culmination of your empirical research journey. It's where you synthesize your findings, provide context, and contribute to the body of knowledge in your field.
- Title and Abstract : Craft a clear and concise title that reflects your research's essence. The abstract should provide a brief summary of your research objectives, methods, findings, and implications.
- Introduction : In the introduction, introduce your research topic, state your research questions or hypotheses, and explain the significance of your study. Provide context by discussing relevant literature.
- Methods : Describe your research design, data collection methods, and sampling procedures. Be precise and transparent, allowing readers to understand how you conducted your study.
- Results : Present your findings in a clear and organized manner. Use tables, graphs, and statistical analyses to support your results. Avoid interpreting your findings in this section; focus on the presentation of raw data.
- Discussion : Interpret your findings and discuss their implications. Relate your results to your research questions and the existing literature. Address any limitations of your study and suggest avenues for future research.
- Conclusion : Summarize the key points of your research and its significance. Restate your main findings and their implications.
- References : Cite all sources used in your research following a specific citation style (e.g., APA, MLA, Chicago). Ensure accuracy and consistency in your citations.
- Appendices : Include any supplementary material, such as questionnaires, data coding sheets, or additional analyses, in the appendices.
Writing a research paper is a skill that improves with practice. Ensure clarity, coherence, and conciseness in your writing to make your research accessible to a broader audience.
2. Create Visuals and Tables
Visuals and tables are powerful tools for presenting complex data in an accessible and understandable manner.
- Clarity : Ensure that your visuals and tables are clear and easy to interpret. Use descriptive titles and labels.
- Consistency : Maintain consistency in formatting, such as font size and style, across all visuals and tables.
- Appropriateness : Choose the most suitable visual representation for your data. Bar charts, line graphs, and scatter plots work well for different types of data.
- Simplicity : Avoid clutter and unnecessary details. Focus on conveying the main points.
- Accessibility : Make sure your visuals and tables are accessible to a broad audience, including those with visual impairments.
- Captions : Include informative captions that explain the significance of each visual or table.
Compelling visuals and tables enhance the reader's understanding of your research and can be the key to conveying complex information efficiently.
3. Interpret Findings
Interpreting your findings is where you bridge the gap between data and meaning. It's your opportunity to provide context, discuss implications, and offer insights. When interpreting your findings:
- Relate to Research Questions : Discuss how your findings directly address your research questions or hypotheses.
- Compare with Literature : Analyze how your results align with or deviate from previous research in your field. What insights can you draw from these comparisons?
- Discuss Limitations : Be transparent about the limitations of your study. Address any constraints, biases, or potential sources of error.
- Practical Implications : Explore the real-world implications of your findings. How can they be applied or inform decision-making?
- Future Research Directions : Suggest areas for future research based on the gaps or unanswered questions that emerged from your study.
Interpreting findings goes beyond simply presenting data; it's about weaving a narrative that helps readers grasp the significance of your research in the broader context.
With your research paper written, structured, and enriched with visuals, and your findings expertly interpreted, you are now prepared to communicate your research effectively. Sharing your insights and contributing to the body of knowledge in your field is a significant accomplishment in empirical research.
Examples of Empirical Research
To solidify your understanding of empirical research, let's delve into some real-world examples across different fields. These examples will illustrate how empirical research is applied to gather data, analyze findings, and draw conclusions.
Social Sciences
In the realm of social sciences, consider a sociological study exploring the impact of socioeconomic status on educational attainment. Researchers gather data from a diverse group of individuals, including their family backgrounds, income levels, and academic achievements.
Through statistical analysis, they can identify correlations and trends, revealing whether individuals from lower socioeconomic backgrounds are less likely to attain higher levels of education. This empirical research helps shed light on societal inequalities and informs policymakers on potential interventions to address disparities in educational access.
Environmental Science
Environmental scientists often employ empirical research to assess the effects of environmental changes. For instance, researchers studying the impact of climate change on wildlife might collect data on animal populations, weather patterns, and habitat conditions over an extended period.
By analyzing this empirical data, they can identify correlations between climate fluctuations and changes in wildlife behavior, migration patterns, or population sizes. This empirical research is crucial for understanding the ecological consequences of climate change and informing conservation efforts.
Business and Economics
In the business world, empirical research is essential for making data-driven decisions. Consider a market research study conducted by a business seeking to launch a new product. They collect data through surveys , focus groups , and consumer behavior analysis.
By examining this empirical data, the company can gauge consumer preferences, demand, and potential market size. Empirical research in business helps guide product development, pricing strategies, and marketing campaigns, increasing the likelihood of a successful product launch.
Psychological studies frequently rely on empirical research to understand human behavior and cognition. For instance, a psychologist interested in examining the impact of stress on memory might design an experiment. Participants are exposed to stress-inducing situations, and their memory performance is assessed through various tasks.
By analyzing the data collected, the psychologist can determine whether stress has a significant effect on memory recall. This empirical research contributes to our understanding of the complex interplay between psychological factors and cognitive processes.
These examples highlight the versatility and applicability of empirical research across diverse fields. Whether in medicine, social sciences, environmental science, business, or psychology, empirical research serves as a fundamental tool for gaining insights, testing hypotheses, and driving advancements in knowledge and practice.
Conclusion for Empirical Research
Empirical research is a powerful tool for gaining insights, testing hypotheses, and making informed decisions. By following the steps outlined in this guide, you've learned how to select research topics, collect data, analyze findings, and effectively communicate your research to the world. Remember, empirical research is a journey of discovery, and each step you take brings you closer to a deeper understanding of the world around you. Whether you're a scientist, a student, or someone curious about the process, the principles of empirical research empower you to explore, learn, and contribute to the ever-expanding realm of knowledge.
How to Collect Data for Empirical Research?
Introducing Appinio , the real-time market research platform revolutionizing how companies gather consumer insights for their empirical research endeavors. With Appinio, you can conduct your own market research in minutes, gaining valuable data to fuel your data-driven decisions.
Appinio is more than just a market research platform; it's a catalyst for transforming the way you approach empirical research, making it exciting, intuitive, and seamlessly integrated into your decision-making process.
Here's why Appinio is the go-to solution for empirical research:
- From Questions to Insights in Minutes : With Appinio's streamlined process, you can go from formulating your research questions to obtaining actionable insights in a matter of minutes, saving you time and effort.
- Intuitive Platform for Everyone : No need for a PhD in research; Appinio's platform is designed to be intuitive and user-friendly, ensuring that anyone can navigate and utilize it effectively.
- Rapid Response Times : With an average field time of under 23 minutes for 1,000 respondents, Appinio delivers rapid results, allowing you to gather data swiftly and efficiently.
- Global Reach with Targeted Precision : With access to over 90 countries and the ability to define target groups based on 1200+ characteristics, Appinio empowers you to reach your desired audience with precision and ease.

Get free access to the platform!
Join the loop 💌
Be the first to hear about new updates, product news, and data insights. We'll send it all straight to your inbox.
Get the latest market research news straight to your inbox! 💌
Wait, there's more

16.05.2024 | 30min read
Time Series Analysis: Definition, Types, Techniques, Examples

14.05.2024 | 31min read
Experimental Research: Definition, Types, Design, Examples

07.05.2024 | 29min read
Interval Scale: Definition, Characteristics, Examples
A systematic literature review of empirical research on ChatGPT in education
- Open access
- Published: 26 May 2024
- Volume 3 , article number 60 , ( 2024 )
Cite this article
You have full access to this open access article

- Yazid Albadarin ORCID: orcid.org/0009-0005-8068-8902 1 ,
- Mohammed Saqr 1 ,
- Nicolas Pope 1 &
- Markku Tukiainen 1
Over the last four decades, studies have investigated the incorporation of Artificial Intelligence (AI) into education. A recent prominent AI-powered technology that has impacted the education sector is ChatGPT. This article provides a systematic review of 14 empirical studies incorporating ChatGPT into various educational settings, published in 2022 and before the 10th of April 2023—the date of conducting the search process. It carefully followed the essential steps outlined in the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA 2020) guidelines, as well as Okoli’s (Okoli in Commun Assoc Inf Syst, 2015) steps for conducting a rigorous and transparent systematic review. In this review, we aimed to explore how students and teachers have utilized ChatGPT in various educational settings, as well as the primary findings of those studies. By employing Creswell’s (Creswell in Educational research: planning, conducting, and evaluating quantitative and qualitative research [Ebook], Pearson Education, London, 2015) coding techniques for data extraction and interpretation, we sought to gain insight into their initial attempts at ChatGPT incorporation into education. This approach also enabled us to extract insights and considerations that can facilitate its effective and responsible use in future educational contexts. The results of this review show that learners have utilized ChatGPT as a virtual intelligent assistant, where it offered instant feedback, on-demand answers, and explanations of complex topics. Additionally, learners have used it to enhance their writing and language skills by generating ideas, composing essays, summarizing, translating, paraphrasing texts, or checking grammar. Moreover, learners turned to it as an aiding tool to facilitate their directed and personalized learning by assisting in understanding concepts and homework, providing structured learning plans, and clarifying assignments and tasks. However, the results of specific studies (n = 3, 21.4%) show that overuse of ChatGPT may negatively impact innovative capacities and collaborative learning competencies among learners. Educators, on the other hand, have utilized ChatGPT to create lesson plans, generate quizzes, and provide additional resources, which helped them enhance their productivity and efficiency and promote different teaching methodologies. Despite these benefits, the majority of the reviewed studies recommend the importance of conducting structured training, support, and clear guidelines for both learners and educators to mitigate the drawbacks. This includes developing critical evaluation skills to assess the accuracy and relevance of information provided by ChatGPT, as well as strategies for integrating human interaction and collaboration into learning activities that involve AI tools. Furthermore, they also recommend ongoing research and proactive dialogue with policymakers, stakeholders, and educational practitioners to refine and enhance the use of AI in learning environments. This review could serve as an insightful resource for practitioners who seek to integrate ChatGPT into education and stimulate further research in the field.
Similar content being viewed by others

Empowering learners with ChatGPT: insights from a systematic literature exploration

Incorporating AI in foreign language education: An investigation into ChatGPT’s effect on foreign language learners

Large language models in education: A focus on the complementary relationship between human teachers and ChatGPT
Avoid common mistakes on your manuscript.
1 Introduction
Educational technology, a rapidly evolving field, plays a crucial role in reshaping the landscape of teaching and learning [ 82 ]. One of the most transformative technological innovations of our era that has influenced the field of education is Artificial Intelligence (AI) [ 50 ]. Over the last four decades, AI in education (AIEd) has gained remarkable attention for its potential to make significant advancements in learning, instructional methods, and administrative tasks within educational settings [ 11 ]. In particular, a large language model (LLM), a type of AI algorithm that applies artificial neural networks (ANNs) and uses massively large data sets to understand, summarize, generate, and predict new content that is almost difficult to differentiate from human creations [ 79 ], has opened up novel possibilities for enhancing various aspects of education, from content creation to personalized instruction [ 35 ]. Chatbots that leverage the capabilities of LLMs to understand and generate human-like responses have also presented the capacity to enhance student learning and educational outcomes by engaging students, offering timely support, and fostering interactive learning experiences [ 46 ].
The ongoing and remarkable technological advancements in chatbots have made their use more convenient, increasingly natural and effortless, and have expanded their potential for deployment across various domains [ 70 ]. One prominent example of chatbot applications is the Chat Generative Pre-Trained Transformer, known as ChatGPT, which was introduced by OpenAI, a leading AI research lab, on November 30th, 2022. ChatGPT employs a variety of deep learning techniques to generate human-like text, with a particular focus on recurrent neural networks (RNNs). Long short-term memory (LSTM) allows it to grasp the context of the text being processed and retain information from previous inputs. Also, the transformer architecture, a neural network architecture based on the self-attention mechanism, allows it to analyze specific parts of the input, thereby enabling it to produce more natural-sounding and coherent output. Additionally, the unsupervised generative pre-training and the fine-tuning methods allow ChatGPT to generate more relevant and accurate text for specific tasks [ 31 , 62 ]. Furthermore, reinforcement learning from human feedback (RLHF), a machine learning approach that combines reinforcement learning techniques with human-provided feedback, has helped improve ChatGPT’s model by accelerating the learning process and making it significantly more efficient.
This cutting-edge natural language processing (NLP) tool is widely recognized as one of today's most advanced LLMs-based chatbots [ 70 ], allowing users to ask questions and receive detailed, coherent, systematic, personalized, convincing, and informative human-like responses [ 55 ], even within complex and ambiguous contexts [ 63 , 77 ]. ChatGPT is considered the fastest-growing technology in history: in just three months following its public launch, it amassed an estimated 120 million monthly active users [ 16 ] with an estimated 13 million daily queries [ 49 ], surpassing all other applications [ 64 ]. This remarkable growth can be attributed to the unique features and user-friendly interface that ChatGPT offers. Its intuitive design allows users to interact seamlessly with the technology, making it accessible to a diverse range of individuals, regardless of their technical expertise [ 78 ]. Additionally, its exceptional performance results from a combination of advanced algorithms, continuous enhancements, and extensive training on a diverse dataset that includes various text sources such as books, articles, websites, and online forums [ 63 ], have contributed to a more engaging and satisfying user experience [ 62 ]. These factors collectively explain its remarkable global growth and set it apart from predecessors like Bard, Bing Chat, ERNIE, and others.
In this context, several studies have explored the technological advancements of chatbots. One noteworthy recent research effort, conducted by Schöbel et al. [ 70 ], stands out for its comprehensive analysis of more than 5,000 studies on communication agents. This study offered a comprehensive overview of the historical progression and future prospects of communication agents, including ChatGPT. Moreover, other studies have focused on making comparisons, particularly between ChatGPT and alternative chatbots like Bard, Bing Chat, ERNIE, LaMDA, BlenderBot, and various others. For example, O’Leary [ 53 ] compared two chatbots, LaMDA and BlenderBot, with ChatGPT and revealed that ChatGPT outperformed both. This superiority arises from ChatGPT’s capacity to handle a wider range of questions and generate slightly varied perspectives within specific contexts. Similarly, ChatGPT exhibited an impressive ability to formulate interpretable responses that were easily understood when compared with Google's feature snippet [ 34 ]. Additionally, ChatGPT was compared to other LLMs-based chatbots, including Bard and BERT, as well as ERNIE. The findings indicated that ChatGPT exhibited strong performance in the given tasks, often outperforming the other models [ 59 ].
Furthermore, in the education context, a comprehensive study systematically compared a range of the most promising chatbots, including Bard, Bing Chat, ChatGPT, and Ernie across a multidisciplinary test that required higher-order thinking. The study revealed that ChatGPT achieved the highest score, surpassing Bing Chat and Bard [ 64 ]. Similarly, a comparative analysis was conducted to compare ChatGPT with Bard in answering a set of 30 mathematical questions and logic problems, grouped into two question sets. Set (A) is unavailable online, while Set (B) is available online. The results revealed ChatGPT's superiority in Set (A) over Bard. Nevertheless, Bard's advantage emerged in Set (B) due to its capacity to access the internet directly and retrieve answers, a capability that ChatGPT does not possess [ 57 ]. However, through these varied assessments, ChatGPT consistently highlights its exceptional prowess compared to various alternatives in the ever-evolving chatbot technology.
The widespread adoption of chatbots, especially ChatGPT, by millions of students and educators, has sparked extensive discussions regarding its incorporation into the education sector [ 64 ]. Accordingly, many scholars have contributed to the discourse, expressing both optimism and pessimism regarding the incorporation of ChatGPT into education. For example, ChatGPT has been highlighted for its capabilities in enriching the learning and teaching experience through its ability to support different learning approaches, including adaptive learning, personalized learning, and self-directed learning [ 58 , 60 , 91 ]), deliver summative and formative feedback to students and provide real-time responses to questions, increase the accessibility of information [ 22 , 40 , 43 ], foster students’ performance, engagement and motivation [ 14 , 44 , 58 ], and enhance teaching practices [ 17 , 18 , 64 , 74 ].
On the other hand, concerns have been also raised regarding its potential negative effects on learning and teaching. These include the dissemination of false information and references [ 12 , 23 , 61 , 85 ], biased reinforcement [ 47 , 50 ], compromised academic integrity [ 18 , 40 , 66 , 74 ], and the potential decline in students' skills [ 43 , 61 , 64 , 74 ]. As a result, ChatGPT has been banned in multiple countries, including Russia, China, Venezuela, Belarus, and Iran, as well as in various educational institutions in India, Italy, Western Australia, France, and the United States [ 52 , 90 ].
Clearly, the advent of chatbots, especially ChatGPT, has provoked significant controversy due to their potential impact on learning and teaching. This indicates the necessity for further exploration to gain a deeper understanding of this technology and carefully evaluate its potential benefits, limitations, challenges, and threats to education [ 79 ]. Therefore, conducting a systematic literature review will provide valuable insights into the potential prospects and obstacles linked to its incorporation into education. This systematic literature review will primarily focus on ChatGPT, driven by the aforementioned key factors outlined above.
However, the existing literature lacks a systematic literature review of empirical studies. Thus, this systematic literature review aims to address this gap by synthesizing the existing empirical studies conducted on chatbots, particularly ChatGPT, in the field of education, highlighting how ChatGPT has been utilized in educational settings, and identifying any existing gaps. This review may be particularly useful for researchers in the field and educators who are contemplating the integration of ChatGPT or any chatbot into education. The following research questions will guide this study:
What are students' and teachers' initial attempts at utilizing ChatGPT in education?
What are the main findings derived from empirical studies that have incorporated ChatGPT into learning and teaching?
2 Methodology
To conduct this study, the authors followed the essential steps of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA 2020) and Okoli’s [ 54 ] steps for conducting a systematic review. These included identifying the study’s purpose, drafting a protocol, applying a practical screening process, searching the literature, extracting relevant data, evaluating the quality of the included studies, synthesizing the studies, and ultimately writing the review. The subsequent section provides an extensive explanation of how these steps were carried out in this study.
2.1 Identify the purpose
Given the widespread adoption of ChatGPT by students and teachers for various educational purposes, often without a thorough understanding of responsible and effective use or a clear recognition of its potential impact on learning and teaching, the authors recognized the need for further exploration of ChatGPT's impact on education in this early stage. Therefore, they have chosen to conduct a systematic literature review of existing empirical studies that incorporate ChatGPT into educational settings. Despite the limited number of empirical studies due to the novelty of the topic, their goal is to gain a deeper understanding of this technology and proactively evaluate its potential benefits, limitations, challenges, and threats to education. This effort could help to understand initial reactions and attempts at incorporating ChatGPT into education and bring out insights and considerations that can inform the future development of education.
2.2 Draft the protocol
The next step is formulating the protocol. This protocol serves to outline the study process in a rigorous and transparent manner, mitigating researcher bias in study selection and data extraction [ 88 ]. The protocol will include the following steps: generating the research question, predefining a literature search strategy, identifying search locations, establishing selection criteria, assessing the studies, developing a data extraction strategy, and creating a timeline.
2.3 Apply practical screen
The screening step aims to accurately filter the articles resulting from the searching step and select the empirical studies that have incorporated ChatGPT into educational contexts, which will guide us in answering the research questions and achieving the objectives of this study. To ensure the rigorous execution of this step, our inclusion and exclusion criteria were determined based on the authors' experience and informed by previous successful systematic reviews [ 21 ]. Table 1 summarizes the inclusion and exclusion criteria for study selection.
2.4 Literature search
We conducted a thorough literature search to identify articles that explored, examined, and addressed the use of ChatGPT in Educational contexts. We utilized two research databases: Dimensions.ai, which provides access to a large number of research publications, and lens.org, which offers access to over 300 million articles, patents, and other research outputs from diverse sources. Additionally, we included three databases, Scopus, Web of Knowledge, and ERIC, which contain relevant research on the topic that addresses our research questions. To browse and identify relevant articles, we used the following search formula: ("ChatGPT" AND "Education"), which included the Boolean operator "AND" to get more specific results. The subject area in the Scopus and ERIC databases were narrowed to "ChatGPT" and "Education" keywords, and in the WoS database was limited to the "Education" category. The search was conducted between the 3rd and 10th of April 2023, which resulted in 276 articles from all selected databases (111 articles from Dimensions.ai, 65 from Scopus, 28 from Web of Science, 14 from ERIC, and 58 from Lens.org). These articles were imported into the Rayyan web-based system for analysis. The duplicates were identified automatically by the system. Subsequently, the first author manually reviewed the duplicated articles ensured that they had the same content, and then removed them, leaving us with 135 unique articles. Afterward, the titles, abstracts, and keywords of the first 40 manuscripts were scanned and reviewed by the first author and were discussed with the second and third authors to resolve any disagreements. Subsequently, the first author proceeded with the filtering process for all articles and carefully applied the inclusion and exclusion criteria as presented in Table 1 . Articles that met any one of the exclusion criteria were eliminated, resulting in 26 articles. Afterward, the authors met to carefully scan and discuss them. The authors agreed to eliminate any empirical studies solely focused on checking ChatGPT capabilities, as these studies do not guide us in addressing the research questions and achieving the study's objectives. This resulted in 14 articles eligible for analysis.
2.5 Quality appraisal
The examination and evaluation of the quality of the extracted articles is a vital step [ 9 ]. Therefore, the extracted articles were carefully evaluated for quality using Fink’s [ 24 ] standards, which emphasize the necessity for detailed descriptions of methodology, results, conclusions, strengths, and limitations. The process began with a thorough assessment of each study's design, data collection, and analysis methods to ensure their appropriateness and comprehensive execution. The clarity, consistency, and logical progression from data to results and conclusions were also critically examined. Potential biases and recognized limitations within the studies were also scrutinized. Ultimately, two articles were excluded for failing to meet Fink’s criteria, particularly in providing sufficient detail on methodology, results, conclusions, strengths, or limitations. The review process is illustrated in Fig. 1 .

The study selection process
2.6 Data extraction
The next step is data extraction, the process of capturing the key information and categories from the included studies. To improve efficiency, reduce variation among authors, and minimize errors in data analysis, the coding categories were constructed using Creswell's [ 15 ] coding techniques for data extraction and interpretation. The coding process involves three sequential steps. The initial stage encompasses open coding , where the researcher examines the data, generates codes to describe and categorize it, and gains a deeper understanding without preconceived ideas. Following open coding is axial coding , where the interrelationships between codes from open coding are analyzed to establish more comprehensive categories or themes. The process concludes with selective coding , refining and integrating categories or themes to identify core concepts emerging from the data. The first coder performed the coding process, then engaged in discussions with the second and third authors to finalize the coding categories for the first five articles. The first coder then proceeded to code all studies and engaged again in discussions with the other authors to ensure the finalization of the coding process. After a comprehensive analysis and capturing of the key information from the included studies, the data extraction and interpretation process yielded several themes. These themes have been categorized and are presented in Table 2 . It is important to note that open coding results were removed from Table 2 for aesthetic reasons, as it included many generic aspects, such as words, short phrases, or sentences mentioned in the studies.
2.7 Synthesize studies
In this stage, we will gather, discuss, and analyze the key findings that emerged from the selected studies. The synthesis stage is considered a transition from an author-centric to a concept-centric focus, enabling us to map all the provided information to achieve the most effective evaluation of the data [ 87 ]. Initially, the authors extracted data that included general information about the selected studies, including the author(s)' names, study titles, years of publication, educational levels, research methodologies, sample sizes, participants, main aims or objectives, raw data sources, and analysis methods. Following that, all key information and significant results from the selected studies were compiled using Creswell’s [ 15 ] coding techniques for data extraction and interpretation to identify core concepts and themes emerging from the data, focusing on those that directly contributed to our research questions and objectives, such as the initial utilization of ChatGPT in learning and teaching, learners' and educators' familiarity with ChatGPT, and the main findings of each study. Finally, the data related to each selected study were extracted into an Excel spreadsheet for data processing. The Excel spreadsheet was reviewed by the authors, including a series of discussions to ensure the finalization of this process and prepare it for further analysis. Afterward, the final result being analyzed and presented in various types of charts and graphs. Table 4 presents the extracted data from the selected studies, with each study labeled with a capital 'S' followed by a number.
This section consists of two main parts. The first part provides a descriptive analysis of the data compiled from the reviewed studies. The second part presents the answers to the research questions and the main findings of these studies.
3.1 Part 1: descriptive analysis
This section will provide a descriptive analysis of the reviewed studies, including educational levels and fields, participants distribution, country contribution, research methodologies, study sample size, study population, publication year, list of journals, familiarity with ChatGPT, source of data, and the main aims and objectives of the studies. Table 4 presents a comprehensive overview of the extracted data from the selected studies.
3.1.1 The number of the reviewed studies and publication years
The total number of the reviewed studies was 14. All studies were empirical studies and published in different journals focusing on Education and Technology. One study was published in 2022 [S1], while the remaining were published in 2023 [S2]-[S14]. Table 3 illustrates the year of publication, the names of the journals, and the number of reviewed studies published in each journal for the studies reviewed.
3.1.2 Educational levels and fields
The majority of the reviewed studies, 11 studies, were conducted in higher education institutions [S1]-[S10] and [S13]. Two studies did not specify the educational level of the population [S12] and [S14], while one study focused on elementary education [S11]. However, the reviewed studies covered various fields of education. Three studies focused on Arts and Humanities Education [S8], [S11], and [S14], specifically English Education. Two studies focused on Engineering Education, with one in Computer Engineering [S2] and the other in Construction Education [S3]. Two studies focused on Mathematics Education [S5] and [S12]. One study focused on Social Science Education [S13]. One study focused on Early Education [S4]. One study focused on Journalism Education [S9]. Finally, three studies did not specify the field of education [S1], [S6], and [S7]. Figure 2 represents the educational levels in the reviewed studies, while Fig. 3 represents the context of the reviewed studies.

Educational levels in the reviewed studies

Context of the reviewed studies
3.1.3 Participants distribution and countries contribution
The reviewed studies have been conducted across different geographic regions, providing a diverse representation of the studies. The majority of the studies, 10 in total, [S1]-[S3], [S5]-[S9], [S11], and [S14], primarily focused on participants from single countries such as Pakistan, the United Arab Emirates, China, Indonesia, Poland, Saudi Arabia, South Korea, Spain, Tajikistan, and the United States. In contrast, four studies, [S4], [S10], [S12], and [S13], involved participants from multiple countries, including China and the United States [S4], China, the United Kingdom, and the United States [S10], the United Arab Emirates, Oman, Saudi Arabia, and Jordan [S12], Turkey, Sweden, Canada, and Australia [ 13 ]. Figures 4 and 5 illustrate the distribution of participants, whether from single or multiple countries, and the contribution of each country in the reviewed studies, respectively.

The reviewed studies conducted in single or multiple countries

The Contribution of each country in the studies
3.1.4 Study population and sample size
Four study populations were included: university students, university teachers, university teachers and students, and elementary school teachers. Six studies involved university students [S2], [S3], [S5] and [S6]-[S8]. Three studies focused on university teachers [S1], [S4], and [S6], while one study specifically targeted elementary school teachers [S11]. Additionally, four studies included both university teachers and students [S10] and [ 12 , 13 , 14 ], and among them, study [S13] specifically included postgraduate students. In terms of the sample size of the reviewed studies, nine studies included a small sample size of less than 50 participants [S1], [S3], [S6], [S8], and [S10]-[S13]. Three studies had 50–100 participants [S2], [S9], and [S14]. Only one study had more than 100 participants [S7]. It is worth mentioning that study [S4] adopted a mixed methods approach, including 10 participants for qualitative analysis and 110 participants for quantitative analysis.
3.1.5 Participants’ familiarity with using ChatGPT
The reviewed studies recruited a diverse range of participants with varying levels of familiarity with ChatGPT. Five studies [S2], [S4], [S6], [S8], and [S12] involved participants already familiar with ChatGPT, while eight studies [S1], [S3], [S5], [S7], [S9], [S10], [S13] and [S14] included individuals with differing levels of familiarity. Notably, one study [S11] had participants who were entirely unfamiliar with ChatGPT. It is important to note that four studies [S3], [S5], [S9], and [S11] provided training or guidance to their participants before conducting their studies, while ten studies [S1], [S2], [S4], [S6]-[S8], [S10], and [S12]-[S14] did not provide training due to the participants' existing familiarity with ChatGPT.
3.1.6 Research methodology approaches and source(S) of data
The reviewed studies adopted various research methodology approaches. Seven studies adopted qualitative research methodology [S1], [S4], [S6], [S8], [S10], [S11], and [S12], while three studies adopted quantitative research methodology [S3], [S7], and [S14], and four studies employed mixed-methods, which involved a combination of both the strengths of qualitative and quantitative methods [S2], [S5], [S9], and [S13].
In terms of the source(s) of data, the reviewed studies obtained their data from various sources, such as interviews, questionnaires, and pre-and post-tests. Six studies relied on interviews as their primary source of data collection [S1], [S4], [S6], [S10], [S11], and [S12], four studies relied on questionnaires [S2], [S7], [S13], and [S14], two studies combined the use of pre-and post-tests and questionnaires for data collection [S3] and [S9], while two studies combined the use of questionnaires and interviews to obtain the data [S5] and [S8]. It is important to note that six of the reviewed studies were quasi-experimental [S3], [S5], [S8], [S9], [S12], and [S14], while the remaining ones were experimental studies [S1], [S2], [S4], [S6], [S7], [S10], [S11], and [S13]. Figures 6 and 7 illustrate the research methodologies and the source (s) of data used in the reviewed studies, respectively.

Research methodologies in the reviewed studies

Source of data in the reviewed studies
3.1.7 The aim and objectives of the studies
The reviewed studies encompassed a diverse set of aims, with several of them incorporating multiple primary objectives. Six studies [S3], [S6], [S7], [S8], [S11], and [S12] examined the integration of ChatGPT in educational contexts, and four studies [S4], [S5], [S13], and [S14] investigated the various implications of its use in education, while three studies [S2], [S9], and [S10] aimed to explore both its integration and implications in education. Additionally, seven studies explicitly explored attitudes and perceptions of students [S2] and [S3], educators [S1] and [S6], or both [S10], [S12], and [S13] regarding the utilization of ChatGPT in educational settings.
3.2 Part 2: research questions and main findings of the reviewed studies
This part will present the answers to the research questions and the main findings of the reviewed studies, classified into two main categories (learning and teaching) according to AI Education classification by [ 36 ]. Figure 8 summarizes the main findings of the reviewed studies in a visually informative diagram. Table 4 provides a detailed list of the key information extracted from the selected studies that led to generating these themes.

The main findings in the reviewed studies
4 Students' initial attempts at utilizing ChatGPT in learning and main findings from students' perspective
4.1 virtual intelligent assistant.
Nine studies demonstrated that ChatGPT has been utilized by students as an intelligent assistant to enhance and support their learning. Students employed it for various purposes, such as answering on-demand questions [S2]-[S5], [S8], [S10], and [S12], providing valuable information and learning resources [S2]-[S5], [S6], and [S8], as well as receiving immediate feedback [S2], [S4], [S9], [S10], and [S12]. In this regard, students generally were confident in the accuracy of ChatGPT's responses, considering them relevant, reliable, and detailed [S3], [S4], [S5], and [S8]. However, some students indicated the need for improvement, as they found that answers are not always accurate [S2], and that misleading information may have been provided or that it may not always align with their expectations [S6] and [S10]. It was also observed by the students that the accuracy of ChatGPT is dependent on several factors, including the quality and specificity of the user's input, the complexity of the question or topic, and the scope and relevance of its training data [S12]. Many students felt that ChatGPT's answers were not always accurate and most of them believed that it requires good background knowledge to work with.
4.2 Writing and language proficiency assistant
Six of the reviewed studies highlighted that ChatGPT has been utilized by students as a valuable assistant tool to improve their academic writing skills and language proficiency. Among these studies, three mainly focused on English education, demonstrating that students showed sufficient mastery in using ChatGPT for generating ideas, summarizing, paraphrasing texts, and completing writing essays [S8], [S11], and [S14]. Furthermore, ChatGPT helped them in writing by making students active investigators rather than passive knowledge recipients and facilitated the development of their writing skills [S11] and [S14]. Similarly, ChatGPT allowed students to generate unique ideas and perspectives, leading to deeper analysis and reflection on their journalism writing [S9]. In terms of language proficiency, ChatGPT allowed participants to translate content into their home languages, making it more accessible and relevant to their context [S4]. It also enabled them to request changes in linguistic tones or flavors [S8]. Moreover, participants used it to check grammar or as a dictionary [S11].
4.3 Valuable resource for learning approaches
Five studies demonstrated that students used ChatGPT as a valuable complementary resource for self-directed learning. It provided learning resources and guidance on diverse educational topics and created a supportive home learning environment [S2] and [S4]. Moreover, it offered step-by-step guidance to grasp concepts at their own pace and enhance their understanding [S5], streamlined task and project completion carried out independently [S7], provided comprehensive and easy-to-understand explanations on various subjects [S10], and assisted in studying geometry operations, thereby empowering them to explore geometry operations at their own pace [S12]. Three studies showed that students used ChatGPT as a valuable learning resource for personalized learning. It delivered age-appropriate conversations and tailored teaching based on a child's interests [S4], acted as a personalized learning assistant, adapted to their needs and pace, which assisted them in understanding mathematical concepts [S12], and enabled personalized learning experiences in social sciences by adapting to students' needs and learning styles [S13]. On the other hand, it is important to note that, according to one study [S5], students suggested that using ChatGPT may negatively affect collaborative learning competencies between students.
4.4 Enhancing students' competencies
Six of the reviewed studies have shown that ChatGPT is a valuable tool for improving a wide range of skills among students. Two studies have provided evidence that ChatGPT led to improvements in students' critical thinking, reasoning skills, and hazard recognition competencies through engaging them in interactive conversations or activities and providing responses related to their disciplines in journalism [S5] and construction education [S9]. Furthermore, two studies focused on mathematical education have shown the positive impact of ChatGPT on students' problem-solving abilities in unraveling problem-solving questions [S12] and enhancing the students' understanding of the problem-solving process [S5]. Lastly, one study indicated that ChatGPT effectively contributed to the enhancement of conversational social skills [S4].
4.5 Supporting students' academic success
Seven of the reviewed studies highlighted that students found ChatGPT to be beneficial for learning as it enhanced learning efficiency and improved the learning experience. It has been observed to improve students' efficiency in computer engineering studies by providing well-structured responses and good explanations [S2]. Additionally, students found it extremely useful for hazard reporting [S3], and it also enhanced their efficiency in solving mathematics problems and capabilities [S5] and [S12]. Furthermore, by finding information, generating ideas, translating texts, and providing alternative questions, ChatGPT aided students in deepening their understanding of various subjects [S6]. It contributed to an increase in students' overall productivity [S7] and improved efficiency in composing written tasks [S8]. Regarding learning experiences, ChatGPT was instrumental in assisting students in identifying hazards that they might have otherwise overlooked [S3]. It also improved students' learning experiences in solving mathematics problems and developing abilities [S5] and [S12]. Moreover, it increased students' successful completion of important tasks in their studies [S7], particularly those involving average difficulty writing tasks [S8]. Additionally, ChatGPT increased the chances of educational success by providing students with baseline knowledge on various topics [S10].
5 Teachers' initial attempts at utilizing ChatGPT in teaching and main findings from teachers' perspective
5.1 valuable resource for teaching.
The reviewed studies showed that teachers have employed ChatGPT to recommend, modify, and generate diverse, creative, organized, and engaging educational contents, teaching materials, and testing resources more rapidly [S4], [S6], [S10] and [S11]. Additionally, teachers experienced increased productivity as ChatGPT facilitated quick and accurate responses to questions, fact-checking, and information searches [S1]. It also proved valuable in constructing new knowledge [S6] and providing timely answers to students' questions in classrooms [S11]. Moreover, ChatGPT enhanced teachers' efficiency by generating new ideas for activities and preplanning activities for their students [S4] and [S6], including interactive language game partners [S11].
5.2 Improving productivity and efficiency
The reviewed studies showed that participants' productivity and work efficiency have been significantly enhanced by using ChatGPT as it enabled them to allocate more time to other tasks and reduce their overall workloads [S6], [S10], [S11], [S13], and [S14]. However, three studies [S1], [S4], and [S11], indicated a negative perception and attitude among teachers toward using ChatGPT. This negativity stemmed from a lack of necessary skills to use it effectively [S1], a limited familiarity with it [S4], and occasional inaccuracies in the content provided by it [S10].
5.3 Catalyzing new teaching methodologies
Five of the reviewed studies highlighted that educators found the necessity of redefining their teaching profession with the assistance of ChatGPT [S11], developing new effective learning strategies [S4], and adapting teaching strategies and methodologies to ensure the development of essential skills for future engineers [S5]. They also emphasized the importance of adopting new educational philosophies and approaches that can evolve with the introduction of ChatGPT into the classroom [S12]. Furthermore, updating curricula to focus on improving human-specific features, such as emotional intelligence, creativity, and philosophical perspectives [S13], was found to be essential.
5.4 Effective utilization of CHATGPT in teaching
According to the reviewed studies, effective utilization of ChatGPT in education requires providing teachers with well-structured training, support, and adequate background on how to use ChatGPT responsibly [S1], [S3], [S11], and [S12]. Establishing clear rules and regulations regarding its usage is essential to ensure it positively impacts the teaching and learning processes, including students' skills [S1], [S4], [S5], [S8], [S9], and [S11]-[S14]. Moreover, conducting further research and engaging in discussions with policymakers and stakeholders is indeed crucial for the successful integration of ChatGPT in education and to maximize the benefits for both educators and students [S1], [S6]-[S10], and [S12]-[S14].
6 Discussion
The purpose of this review is to conduct a systematic review of empirical studies that have explored the utilization of ChatGPT, one of today’s most advanced LLM-based chatbots, in education. The findings of the reviewed studies showed several ways of ChatGPT utilization in different learning and teaching practices as well as it provided insights and considerations that can facilitate its effective and responsible use in future educational contexts. The results of the reviewed studies came from diverse fields of education, which helped us avoid a biased review that is limited to a specific field. Similarly, the reviewed studies have been conducted across different geographic regions. This kind of variety in geographic representation enriched the findings of this review.
In response to RQ1 , "What are students' and teachers' initial attempts at utilizing ChatGPT in education?", the findings from this review provide comprehensive insights. Chatbots, including ChatGPT, play a crucial role in supporting student learning, enhancing their learning experiences, and facilitating diverse learning approaches [ 42 , 43 ]. This review found that this tool, ChatGPT, has been instrumental in enhancing students' learning experiences by serving as a virtual intelligent assistant, providing immediate feedback, on-demand answers, and engaging in educational conversations. Additionally, students have benefited from ChatGPT’s ability to generate ideas, compose essays, and perform tasks like summarizing, translating, paraphrasing texts, or checking grammar, thereby enhancing their writing and language competencies. Furthermore, students have turned to ChatGPT for assistance in understanding concepts and homework, providing structured learning plans, and clarifying assignments and tasks, which fosters a supportive home learning environment, allowing them to take responsibility for their own learning and cultivate the skills and approaches essential for supportive home learning environment [ 26 , 27 , 28 ]. This finding aligns with the study of Saqr et al. [ 68 , 69 ] who highlighted that, when students actively engage in their own learning process, it yields additional advantages, such as heightened motivation, enhanced achievement, and the cultivation of enthusiasm, turning them into advocates for their own learning.
Moreover, students have utilized ChatGPT for tailored teaching and step-by-step guidance on diverse educational topics, streamlining task and project completion, and generating and recommending educational content. This personalization enhances the learning environment, leading to increased academic success. This finding aligns with other recent studies [ 26 , 27 , 28 , 60 , 66 ] which revealed that ChatGPT has the potential to offer personalized learning experiences and support an effective learning process by providing students with customized feedback and explanations tailored to their needs and abilities. Ultimately, fostering students' performance, engagement, and motivation, leading to increase students' academic success [ 14 , 44 , 58 ]. This ultimate outcome is in line with the findings of Saqr et al. [ 68 , 69 ], which emphasized that learning strategies are important catalysts of students' learning, as students who utilize effective learning strategies are more likely to have better academic achievement.
Teachers, too, have capitalized on ChatGPT's capabilities to enhance productivity and efficiency, using it for creating lesson plans, generating quizzes, providing additional resources, generating and preplanning new ideas for activities, and aiding in answering students’ questions. This adoption of technology introduces new opportunities to support teaching and learning practices, enhancing teacher productivity. This finding aligns with those of Day [ 17 ], De Castro [ 18 ], and Su and Yang [ 74 ] as well as with those of Valtonen et al. [ 82 ], who revealed that emerging technological advancements have opened up novel opportunities and means to support teaching and learning practices, and enhance teachers’ productivity.
In response to RQ2 , "What are the main findings derived from empirical studies that have incorporated ChatGPT into learning and teaching?", the findings from this review provide profound insights and raise significant concerns. Starting with the insights, chatbots, including ChatGPT, have demonstrated the potential to reshape and revolutionize education, creating new, novel opportunities for enhancing the learning process and outcomes [ 83 ], facilitating different learning approaches, and offering a range of pedagogical benefits [ 19 , 43 , 72 ]. In this context, this review found that ChatGPT could open avenues for educators to adopt or develop new effective learning and teaching strategies that can evolve with the introduction of ChatGPT into the classroom. Nonetheless, there is an evident lack of research understanding regarding the potential impact of generative machine learning models within diverse educational settings [ 83 ]. This necessitates teachers to attain a high level of proficiency in incorporating chatbots, such as ChatGPT, into their classrooms to create inventive, well-structured, and captivating learning strategies. In the same vein, the review also found that teachers without the requisite skills to utilize ChatGPT realized that it did not contribute positively to their work and could potentially have adverse effects [ 37 ]. This concern could lead to inequity of access to the benefits of chatbots, including ChatGPT, as individuals who lack the necessary expertise may not be able to harness their full potential, resulting in disparities in educational outcomes and opportunities. Therefore, immediate action is needed to address these potential issues. A potential solution is offering training, support, and competency development for teachers to ensure that all of them can leverage chatbots, including ChatGPT, effectively and equitably in their educational practices [ 5 , 28 , 80 ], which could enhance accessibility and inclusivity, and potentially result in innovative outcomes [ 82 , 83 ].
Additionally, chatbots, including ChatGPT, have the potential to significantly impact students' thinking abilities, including retention, reasoning, analysis skills [ 19 , 45 ], and foster innovation and creativity capabilities [ 83 ]. This review found that ChatGPT could contribute to improving a wide range of skills among students. However, it found that frequent use of ChatGPT may result in a decrease in innovative capacities, collaborative skills and cognitive capacities, and students' motivation to attend classes, as well as could lead to reduced higher-order thinking skills among students [ 22 , 29 ]. Therefore, immediate action is needed to carefully examine the long-term impact of chatbots such as ChatGPT, on learning outcomes as well as to explore its incorporation into educational settings as a supportive tool without compromising students' cognitive development and critical thinking abilities. In the same vein, the review also found that it is challenging to draw a consistent conclusion regarding the potential of ChatGPT to aid self-directed learning approach. This finding aligns with the recent study of Baskara [ 8 ]. Therefore, further research is needed to explore the potential of ChatGPT for self-directed learning. One potential solution involves utilizing learning analytics as a novel approach to examine various aspects of students' learning and support them in their individual endeavors [ 32 ]. This approach can bridge this gap by facilitating an in-depth analysis of how learners engage with ChatGPT, identifying trends in self-directed learning behavior, and assessing its influence on their outcomes.
Turning to the significant concerns, on the other hand, a fundamental challenge with LLM-based chatbots, including ChatGPT, is the accuracy and quality of the provided information and responses, as they provide false information as truth—a phenomenon often referred to as "hallucination" [ 3 , 49 ]. In this context, this review found that the provided information was not entirely satisfactory. Consequently, the utilization of chatbots presents potential concerns, such as generating and providing inaccurate or misleading information, especially for students who utilize it to support their learning. This finding aligns with other findings [ 6 , 30 , 35 , 40 ] which revealed that incorporating chatbots such as ChatGPT, into education presents challenges related to its accuracy and reliability due to its training on a large corpus of data, which may contain inaccuracies and the way users formulate or ask ChatGPT. Therefore, immediate action is needed to address these potential issues. One possible solution is to equip students with the necessary skills and competencies, which include a background understanding of how to use it effectively and the ability to assess and evaluate the information it generates, as the accuracy and the quality of the provided information depend on the input, its complexity, the topic, and the relevance of its training data [ 28 , 49 , 86 ]. However, it's also essential to examine how learners can be educated about how these models operate, the data used in their training, and how to recognize their limitations, challenges, and issues [ 79 ].
Furthermore, chatbots present a substantial challenge concerning maintaining academic integrity [ 20 , 56 ] and copyright violations [ 83 ], which are significant concerns in education. The review found that the potential misuse of ChatGPT might foster cheating, facilitate plagiarism, and threaten academic integrity. This issue is also affirmed by the research conducted by Basic et al. [ 7 ], who presented evidence that students who utilized ChatGPT in their writing assignments had more plagiarism cases than those who did not. These findings align with the conclusions drawn by Cotton et al. [ 13 ], Hisan and Amri [ 33 ] and Sullivan et al. [ 75 ], who revealed that the integration of chatbots such as ChatGPT into education poses a significant challenge to the preservation of academic integrity. Moreover, chatbots, including ChatGPT, have increased the difficulty in identifying plagiarism [ 47 , 67 , 76 ]. The findings from previous studies [ 1 , 84 ] indicate that AI-generated text often went undetected by plagiarism software, such as Turnitin. However, Turnitin and other similar plagiarism detection tools, such as ZeroGPT, GPTZero, and Copyleaks, have since evolved, incorporating enhanced techniques to detect AI-generated text, despite the possibility of false positives, as noted in different studies that have found these tools still not yet fully ready to accurately and reliably identify AI-generated text [ 10 , 51 ], and new novel detection methods may need to be created and implemented for AI-generated text detection [ 4 ]. This potential issue could lead to another concern, which is the difficulty of accurately evaluating student performance when they utilize chatbots such as ChatGPT assistance in their assignments. Consequently, the most LLM-driven chatbots present a substantial challenge to traditional assessments [ 64 ]. The findings from previous studies indicate the importance of rethinking, improving, and redesigning innovative assessment methods in the era of chatbots [ 14 , 20 , 64 , 75 ]. These methods should prioritize the process of evaluating students' ability to apply knowledge to complex cases and demonstrate comprehension, rather than solely focusing on the final product for assessment. Therefore, immediate action is needed to address these potential issues. One possible solution would be the development of clear guidelines, regulatory policies, and pedagogical guidance. These measures would help regulate the proper and ethical utilization of chatbots, such as ChatGPT, and must be established before their introduction to students [ 35 , 38 , 39 , 41 , 89 ].
In summary, our review has delved into the utilization of ChatGPT, a prominent example of chatbots, in education, addressing the question of how ChatGPT has been utilized in education. However, there remain significant gaps, which necessitate further research to shed light on this area.
7 Conclusions
This systematic review has shed light on the varied initial attempts at incorporating ChatGPT into education by both learners and educators, while also offering insights and considerations that can facilitate its effective and responsible use in future educational contexts. From the analysis of 14 selected studies, the review revealed the dual-edged impact of ChatGPT in educational settings. On the positive side, ChatGPT significantly aided the learning process in various ways. Learners have used it as a virtual intelligent assistant, benefiting from its ability to provide immediate feedback, on-demand answers, and easy access to educational resources. Additionally, it was clear that learners have used it to enhance their writing and language skills, engaging in practices such as generating ideas, composing essays, and performing tasks like summarizing, translating, paraphrasing texts, or checking grammar. Importantly, other learners have utilized it in supporting and facilitating their directed and personalized learning on a broad range of educational topics, assisting in understanding concepts and homework, providing structured learning plans, and clarifying assignments and tasks. Educators, on the other hand, found ChatGPT beneficial for enhancing productivity and efficiency. They used it for creating lesson plans, generating quizzes, providing additional resources, and answers learners' questions, which saved time and allowed for more dynamic and engaging teaching strategies and methodologies.
However, the review also pointed out negative impacts. The results revealed that overuse of ChatGPT could decrease innovative capacities and collaborative learning among learners. Specifically, relying too much on ChatGPT for quick answers can inhibit learners' critical thinking and problem-solving skills. Learners might not engage deeply with the material or consider multiple solutions to a problem. This tendency was particularly evident in group projects, where learners preferred consulting ChatGPT individually for solutions over brainstorming and collaborating with peers, which negatively affected their teamwork abilities. On a broader level, integrating ChatGPT into education has also raised several concerns, including the potential for providing inaccurate or misleading information, issues of inequity in access, challenges related to academic integrity, and the possibility of misusing the technology.
Accordingly, this review emphasizes the urgency of developing clear rules, policies, and regulations to ensure ChatGPT's effective and responsible use in educational settings, alongside other chatbots, by both learners and educators. This requires providing well-structured training to educate them on responsible usage and understanding its limitations, along with offering sufficient background information. Moreover, it highlights the importance of rethinking, improving, and redesigning innovative teaching and assessment methods in the era of ChatGPT. Furthermore, conducting further research and engaging in discussions with policymakers and stakeholders are essential steps to maximize the benefits for both educators and learners and ensure academic integrity.
It is important to acknowledge that this review has certain limitations. Firstly, the limited inclusion of reviewed studies can be attributed to several reasons, including the novelty of the technology, as new technologies often face initial skepticism and cautious adoption; the lack of clear guidelines or best practices for leveraging this technology for educational purposes; and institutional or governmental policies affecting the utilization of this technology in educational contexts. These factors, in turn, have affected the number of studies available for review. Secondly, the utilization of the original version of ChatGPT, based on GPT-3 or GPT-3.5, implies that new studies utilizing the updated version, GPT-4 may lead to different findings. Therefore, conducting follow-up systematic reviews is essential once more empirical studies on ChatGPT are published. Additionally, long-term studies are necessary to thoroughly examine and assess the impact of ChatGPT on various educational practices.
Despite these limitations, this systematic review has highlighted the transformative potential of ChatGPT in education, revealing its diverse utilization by learners and educators alike and summarized the benefits of incorporating it into education, as well as the forefront critical concerns and challenges that must be addressed to facilitate its effective and responsible use in future educational contexts. This review could serve as an insightful resource for practitioners who seek to integrate ChatGPT into education and stimulate further research in the field.
Data availability
The data supporting our findings are available upon request.
Abbreviations
- Artificial intelligence
AI in education
Large language model
Artificial neural networks
Chat Generative Pre-Trained Transformer
Recurrent neural networks
Long short-term memory
Reinforcement learning from human feedback
Natural language processing
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
AlAfnan MA, Dishari S, Jovic M, Lomidze K. ChatGPT as an educational tool: opportunities, challenges, and recommendations for communication, business writing, and composition courses. J Artif Intell Technol. 2023. https://doi.org/10.37965/jait.2023.0184 .
Article Google Scholar
Ali JKM, Shamsan MAA, Hezam TA, Mohammed AAQ. Impact of ChatGPT on learning motivation. J Engl Stud Arabia Felix. 2023;2(1):41–9. https://doi.org/10.56540/jesaf.v2i1.51 .
Alkaissi H, McFarlane SI. Artificial hallucinations in ChatGPT: implications in scientific writing. Cureus. 2023. https://doi.org/10.7759/cureus.35179 .
Anderson N, Belavý DL, Perle SM, Hendricks S, Hespanhol L, Verhagen E, Memon AR. AI did not write this manuscript, or did it? Can we trick the AI text detector into generated texts? The potential future of ChatGPT and AI in sports & exercise medicine manuscript generation. BMJ Open Sport Exerc Med. 2023;9(1): e001568. https://doi.org/10.1136/bmjsem-2023-001568 .
Ausat AMA, Massang B, Efendi M, Nofirman N, Riady Y. Can chat GPT replace the role of the teacher in the classroom: a fundamental analysis. J Educ. 2023;5(4):16100–6.
Google Scholar
Baidoo-Anu D, Ansah L. Education in the Era of generative artificial intelligence (AI): understanding the potential benefits of ChatGPT in promoting teaching and learning. Soc Sci Res Netw. 2023. https://doi.org/10.2139/ssrn.4337484 .
Basic Z, Banovac A, Kruzic I, Jerkovic I. Better by you, better than me, chatgpt3 as writing assistance in students essays. 2023. arXiv preprint arXiv:2302.04536 .
Baskara FR. The promises and pitfalls of using chat GPT for self-determined learning in higher education: an argumentative review. Prosiding Seminar Nasional Fakultas Tarbiyah dan Ilmu Keguruan IAIM Sinjai. 2023;2:95–101. https://doi.org/10.47435/sentikjar.v2i0.1825 .
Behera RK, Bala PK, Dhir A. The emerging role of cognitive computing in healthcare: a systematic literature review. Int J Med Inform. 2019;129:154–66. https://doi.org/10.1016/j.ijmedinf.2019.04.024 .
Chaka C. Detecting AI content in responses generated by ChatGPT, YouChat, and Chatsonic: the case of five AI content detection tools. J Appl Learn Teach. 2023. https://doi.org/10.37074/jalt.2023.6.2.12 .
Chiu TKF, Xia Q, Zhou X, Chai CS, Cheng M. Systematic literature review on opportunities, challenges, and future research recommendations of artificial intelligence in education. Comput Educ Artif Intell. 2023;4:100118. https://doi.org/10.1016/j.caeai.2022.100118 .
Choi EPH, Lee JJ, Ho M, Kwok JYY, Lok KYW. Chatting or cheating? The impacts of ChatGPT and other artificial intelligence language models on nurse education. Nurse Educ Today. 2023;125:105796. https://doi.org/10.1016/j.nedt.2023.105796 .
Cotton D, Cotton PA, Shipway JR. Chatting and cheating: ensuring academic integrity in the era of ChatGPT. Innov Educ Teach Int. 2023. https://doi.org/10.1080/14703297.2023.2190148 .
Crawford J, Cowling M, Allen K. Leadership is needed for ethical ChatGPT: Character, assessment, and learning using artificial intelligence (AI). J Univ Teach Learn Pract. 2023. https://doi.org/10.53761/1.20.3.02 .
Creswell JW. Educational research: planning, conducting, and evaluating quantitative and qualitative research [Ebook]. 4th ed. London: Pearson Education; 2015.
Curry D. ChatGPT Revenue and Usage Statistics (2023)—Business of Apps. 2023. https://www.businessofapps.com/data/chatgpt-statistics/
Day T. A preliminary investigation of fake peer-reviewed citations and references generated by ChatGPT. Prof Geogr. 2023. https://doi.org/10.1080/00330124.2023.2190373 .
De Castro CA. A Discussion about the Impact of ChatGPT in education: benefits and concerns. J Bus Theor Pract. 2023;11(2):p28. https://doi.org/10.22158/jbtp.v11n2p28 .
Deng X, Yu Z. A meta-analysis and systematic review of the effect of Chatbot technology use in sustainable education. Sustainability. 2023;15(4):2940. https://doi.org/10.3390/su15042940 .
Eke DO. ChatGPT and the rise of generative AI: threat to academic integrity? J Responsib Technol. 2023;13:100060. https://doi.org/10.1016/j.jrt.2023.100060 .
Elmoazen R, Saqr M, Tedre M, Hirsto L. A systematic literature review of empirical research on epistemic network analysis in education. IEEE Access. 2022;10:17330–48. https://doi.org/10.1109/access.2022.3149812 .
Farrokhnia M, Banihashem SK, Noroozi O, Wals AEJ. A SWOT analysis of ChatGPT: implications for educational practice and research. Innov Educ Teach Int. 2023. https://doi.org/10.1080/14703297.2023.2195846 .
Fergus S, Botha M, Ostovar M. Evaluating academic answers generated using ChatGPT. J Chem Educ. 2023;100(4):1672–5. https://doi.org/10.1021/acs.jchemed.3c00087 .
Fink A. Conducting research literature reviews: from the Internet to Paper. Incorporated: SAGE Publications; 2010.
Firaina R, Sulisworo D. Exploring the usage of ChatGPT in higher education: frequency and impact on productivity. Buletin Edukasi Indonesia (BEI). 2023;2(01):39–46. https://doi.org/10.56741/bei.v2i01.310 .
Firat, M. (2023). How chat GPT can transform autodidactic experiences and open education. Department of Distance Education, Open Education Faculty, Anadolu Unive . https://orcid.org/0000-0001-8707-5918
Firat M. What ChatGPT means for universities: perceptions of scholars and students. J Appl Learn Teach. 2023. https://doi.org/10.37074/jalt.2023.6.1.22 .
Fuchs K. Exploring the opportunities and challenges of NLP models in higher education: is Chat GPT a blessing or a curse? Front Educ. 2023. https://doi.org/10.3389/feduc.2023.1166682 .
García-Peñalvo FJ. La percepción de la inteligencia artificial en contextos educativos tras el lanzamiento de ChatGPT: disrupción o pánico. Educ Knowl Soc. 2023;24: e31279. https://doi.org/10.14201/eks.31279 .
Gilson A, Safranek CW, Huang T, Socrates V, Chi L, Taylor A, Chartash D. How does ChatGPT perform on the United States medical Licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med Educ. 2023;9: e45312. https://doi.org/10.2196/45312 .
Hashana AJ, Brundha P, Ayoobkhan MUA, Fazila S. Deep Learning in ChatGPT—A Survey. In 2023 7th international conference on trends in electronics and informatics (ICOEI) . 2023. (pp. 1001–1005). IEEE. https://doi.org/10.1109/icoei56765.2023.10125852
Hirsto L, Saqr M, López-Pernas S, Valtonen T. (2022). A systematic narrative review of learning analytics research in K-12 and schools. Proceedings . https://ceur-ws.org/Vol-3383/FLAIEC22_paper_9536.pdf
Hisan UK, Amri MM. ChatGPT and medical education: a double-edged sword. J Pedag Educ Sci. 2023;2(01):71–89. https://doi.org/10.13140/RG.2.2.31280.23043/1 .
Hopkins AM, Logan JM, Kichenadasse G, Sorich MJ. Artificial intelligence chatbots will revolutionize how cancer patients access information: ChatGPT represents a paradigm-shift. JNCI Cancer Spectr. 2023. https://doi.org/10.1093/jncics/pkad010 .
Househ M, AlSaad R, Alhuwail D, Ahmed A, Healy MG, Latifi S, Sheikh J. Large Language models in medical education: opportunities, challenges, and future directions. JMIR Med Educ. 2023;9: e48291. https://doi.org/10.2196/48291 .
Ilkka T. The impact of artificial intelligence on learning, teaching, and education. Minist de Educ. 2018. https://doi.org/10.2760/12297 .
Iqbal N, Ahmed H, Azhar KA. Exploring teachers’ attitudes towards using CHATGPT. Globa J Manag Adm Sci. 2022;3(4):97–111. https://doi.org/10.46568/gjmas.v3i4.163 .
Irfan M, Murray L, Ali S. Integration of Artificial intelligence in academia: a case study of critical teaching and learning in Higher education. Globa Soc Sci Rev. 2023;8(1):352–64. https://doi.org/10.31703/gssr.2023(viii-i).32 .
Jeon JH, Lee S. Large language models in education: a focus on the complementary relationship between human teachers and ChatGPT. Educ Inf Technol. 2023. https://doi.org/10.1007/s10639-023-11834-1 .
Khan RA, Jawaid M, Khan AR, Sajjad M. ChatGPT—Reshaping medical education and clinical management. Pak J Med Sci. 2023. https://doi.org/10.12669/pjms.39.2.7653 .
King MR. A conversation on artificial intelligence, Chatbots, and plagiarism in higher education. Cell Mol Bioeng. 2023;16(1):1–2. https://doi.org/10.1007/s12195-022-00754-8 .
Kooli C. Chatbots in education and research: a critical examination of ethical implications and solutions. Sustainability. 2023;15(7):5614. https://doi.org/10.3390/su15075614 .
Kuhail MA, Alturki N, Alramlawi S, Alhejori K. Interacting with educational chatbots: a systematic review. Educ Inf Technol. 2022;28(1):973–1018. https://doi.org/10.1007/s10639-022-11177-3 .
Lee H. The rise of ChatGPT: exploring its potential in medical education. Anat Sci Educ. 2023. https://doi.org/10.1002/ase.2270 .
Li L, Subbareddy R, Raghavendra CG. AI intelligence Chatbot to improve students learning in the higher education platform. J Interconnect Netw. 2022. https://doi.org/10.1142/s0219265921430325 .
Limna P. A Review of Artificial Intelligence (AI) in Education during the Digital Era. 2022. https://ssrn.com/abstract=4160798
Lo CK. What is the impact of ChatGPT on education? A rapid review of the literature. Educ Sci. 2023;13(4):410. https://doi.org/10.3390/educsci13040410 .
Luo W, He H, Liu J, Berson IR, Berson MJ, Zhou Y, Li H. Aladdin’s genie or pandora’s box For early childhood education? Experts chat on the roles, challenges, and developments of ChatGPT. Early Educ Dev. 2023. https://doi.org/10.1080/10409289.2023.2214181 .
Meyer JG, Urbanowicz RJ, Martin P, O’Connor K, Li R, Peng P, Moore JH. ChatGPT and large language models in academia: opportunities and challenges. Biodata Min. 2023. https://doi.org/10.1186/s13040-023-00339-9 .
Mhlanga D. Open AI in education, the responsible and ethical use of ChatGPT towards lifelong learning. Soc Sci Res Netw. 2023. https://doi.org/10.2139/ssrn.4354422 .
Neumann, M., Rauschenberger, M., & Schön, E. M. (2023). “We Need To Talk About ChatGPT”: The Future of AI and Higher Education. https://doi.org/10.1109/seeng59157.2023.00010
Nolan B. Here are the schools and colleges that have banned the use of ChatGPT over plagiarism and misinformation fears. Business Insider . 2023. https://www.businessinsider.com
O’Leary DE. An analysis of three chatbots: BlenderBot, ChatGPT and LaMDA. Int J Intell Syst Account, Financ Manag. 2023;30(1):41–54. https://doi.org/10.1002/isaf.1531 .
Okoli C. A guide to conducting a standalone systematic literature review. Commun Assoc Inf Syst. 2015. https://doi.org/10.17705/1cais.03743 .
OpenAI. (2023). https://openai.com/blog/chatgpt
Perkins M. Academic integrity considerations of AI large language models in the post-pandemic era: ChatGPT and beyond. J Univ Teach Learn Pract. 2023. https://doi.org/10.53761/1.20.02.07 .
Plevris V, Papazafeiropoulos G, Rios AJ. Chatbots put to the test in math and logic problems: A preliminary comparison and assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. arXiv (Cornell University) . 2023. https://doi.org/10.48550/arxiv.2305.18618
Rahman MM, Watanobe Y (2023) ChatGPT for education and research: opportunities, threats, and strategies. Appl Sci 13(9):5783. https://doi.org/10.3390/app13095783
Ram B, Verma P. Artificial intelligence AI-based Chatbot study of ChatGPT, google AI bard and baidu AI. World J Adv Eng Technol Sci. 2023;8(1):258–61. https://doi.org/10.30574/wjaets.2023.8.1.0045 .
Rasul T, Nair S, Kalendra D, Robin M, de Oliveira Santini F, Ladeira WJ, Heathcote L. The role of ChatGPT in higher education: benefits, challenges, and future research directions. J Appl Learn Teach. 2023. https://doi.org/10.37074/jalt.2023.6.1.29 .
Ratnam M, Sharm B, Tomer A. ChatGPT: educational artificial intelligence. Int J Adv Trends Comput Sci Eng. 2023;12(2):84–91. https://doi.org/10.30534/ijatcse/2023/091222023 .
Ray PP. ChatGPT: a comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys Syst. 2023;3:121–54. https://doi.org/10.1016/j.iotcps.2023.04.003 .
Roumeliotis KI, Tselikas ND. ChatGPT and Open-AI models: a preliminary review. Future Internet. 2023;15(6):192. https://doi.org/10.3390/fi15060192 .
Rudolph J, Tan S, Tan S. War of the chatbots: Bard, Bing Chat, ChatGPT, Ernie and beyond. The new AI gold rush and its impact on higher education. J Appl Learn Teach. 2023. https://doi.org/10.37074/jalt.2023.6.1.23 .
Ruiz LMS, Moll-López S, Nuñez-Pérez A, Moraño J, Vega-Fleitas E. ChatGPT challenges blended learning methodologies in engineering education: a case study in mathematics. Appl Sci. 2023;13(10):6039. https://doi.org/10.3390/app13106039 .
Sallam M, Salim NA, Barakat M, Al-Tammemi AB. ChatGPT applications in medical, dental, pharmacy, and public health education: a descriptive study highlighting the advantages and limitations. Narra J. 2023;3(1): e103. https://doi.org/10.52225/narra.v3i1.103 .
Salvagno M, Taccone FS, Gerli AG. Can artificial intelligence help for scientific writing? Crit Care. 2023. https://doi.org/10.1186/s13054-023-04380-2 .
Saqr M, López-Pernas S, Helske S, Hrastinski S. The longitudinal association between engagement and achievement varies by time, students’ profiles, and achievement state: a full program study. Comput Educ. 2023;199:104787. https://doi.org/10.1016/j.compedu.2023.104787 .
Saqr M, Matcha W, Uzir N, Jovanović J, Gašević D, López-Pernas S. Transferring effective learning strategies across learning contexts matters: a study in problem-based learning. Australas J Educ Technol. 2023;39(3):9.
Schöbel S, Schmitt A, Benner D, Saqr M, Janson A, Leimeister JM. Charting the evolution and future of conversational agents: a research agenda along five waves and new frontiers. Inf Syst Front. 2023. https://doi.org/10.1007/s10796-023-10375-9 .
Shoufan A. Exploring students’ perceptions of CHATGPT: thematic analysis and follow-up survey. IEEE Access. 2023. https://doi.org/10.1109/access.2023.3268224 .
Sonderegger S, Seufert S. Chatbot-mediated learning: conceptual framework for the design of Chatbot use cases in education. Gallen: Institute for Educational Management and Technologies, University of St; 2022. https://doi.org/10.5220/0010999200003182 .
Book Google Scholar
Strzelecki A. To use or not to use ChatGPT in higher education? A study of students’ acceptance and use of technology. Interact Learn Environ. 2023. https://doi.org/10.1080/10494820.2023.2209881 .
Su J, Yang W. Unlocking the power of ChatGPT: a framework for applying generative AI in education. ECNU Rev Educ. 2023. https://doi.org/10.1177/20965311231168423 .
Sullivan M, Kelly A, McLaughlan P. ChatGPT in higher education: Considerations for academic integrity and student learning. J ApplLearn Teach. 2023;6(1):1–10. https://doi.org/10.37074/jalt.2023.6.1.17 .
Szabo A. ChatGPT is a breakthrough in science and education but fails a test in sports and exercise psychology. Balt J Sport Health Sci. 2023;1(128):25–40. https://doi.org/10.33607/bjshs.v127i4.1233 .
Taecharungroj V. “What can ChatGPT do?” analyzing early reactions to the innovative AI chatbot on Twitter. Big Data Cognit Comput. 2023;7(1):35. https://doi.org/10.3390/bdcc7010035 .
Tam S, Said RB. User preferences for ChatGPT-powered conversational interfaces versus traditional methods. Biomed Eng Soc. 2023. https://doi.org/10.58496/mjcsc/2023/004 .
Tedre M, Kahila J, Vartiainen H. (2023). Exploration on how co-designing with AI facilitates critical evaluation of ethics of AI in craft education. In: Langran E, Christensen P, Sanson J (Eds). Proceedings of Society for Information Technology and Teacher Education International Conference . 2023. pp. 2289–2296.
Tlili A, Shehata B, Adarkwah MA, Bozkurt A, Hickey DT, Huang R, Agyemang B. What if the devil is my guardian angel: ChatGPT as a case study of using chatbots in education. Smart Learn Environ. 2023. https://doi.org/10.1186/s40561-023-00237-x .
Uddin SMJ, Albert A, Ovid A, Alsharef A. Leveraging CHATGPT to aid construction hazard recognition and support safety education and training. Sustainability. 2023;15(9):7121. https://doi.org/10.3390/su15097121 .
Valtonen T, López-Pernas S, Saqr M, Vartiainen H, Sointu E, Tedre M. The nature and building blocks of educational technology research. Comput Hum Behav. 2022;128:107123. https://doi.org/10.1016/j.chb.2021.107123 .
Vartiainen H, Tedre M. Using artificial intelligence in craft education: crafting with text-to-image generative models. Digit Creat. 2023;34(1):1–21. https://doi.org/10.1080/14626268.2023.2174557 .
Ventayen RJM. OpenAI ChatGPT generated results: similarity index of artificial intelligence-based contents. Soc Sci Res Netw. 2023. https://doi.org/10.2139/ssrn.4332664 .
Wagner MW, Ertl-Wagner BB. Accuracy of information and references using ChatGPT-3 for retrieval of clinical radiological information. Can Assoc Radiol J. 2023. https://doi.org/10.1177/08465371231171125 .
Wardat Y, Tashtoush MA, AlAli R, Jarrah AM. ChatGPT: a revolutionary tool for teaching and learning mathematics. Eurasia J Math, Sci Technol Educ. 2023;19(7):em2286. https://doi.org/10.29333/ejmste/13272 .
Webster J, Watson RT. Analyzing the past to prepare for the future: writing a literature review. Manag Inf Syst Quart. 2002;26(2):3.
Xiao Y, Watson ME. Guidance on conducting a systematic literature review. J Plan Educ Res. 2017;39(1):93–112. https://doi.org/10.1177/0739456x17723971 .
Yan D. Impact of ChatGPT on learners in a L2 writing practicum: an exploratory investigation. Educ Inf Technol. 2023. https://doi.org/10.1007/s10639-023-11742-4 .
Yu H. Reflection on whether Chat GPT should be banned by academia from the perspective of education and teaching. Front Psychol. 2023;14:1181712. https://doi.org/10.3389/fpsyg.2023.1181712 .
Zhu C, Sun M, Luo J, Li T, Wang M. How to harness the potential of ChatGPT in education? Knowl Manag ELearn. 2023;15(2):133–52. https://doi.org/10.34105/j.kmel.2023.15.008 .
Download references
The paper is co-funded by the Academy of Finland (Suomen Akatemia) Research Council for Natural Sciences and Engineering for the project Towards precision education: Idiographic learning analytics (TOPEILA), Decision Number 350560.
Author information
Authors and affiliations.
School of Computing, University of Eastern Finland, 80100, Joensuu, Finland
Yazid Albadarin, Mohammed Saqr, Nicolas Pope & Markku Tukiainen
You can also search for this author in PubMed Google Scholar
Contributions
YA contributed to the literature search, data analysis, discussion, and conclusion. Additionally, YA contributed to the manuscript’s writing, editing, and finalization. MS contributed to the study’s design, conceptualization, acquisition of funding, project administration, allocation of resources, supervision, validation, literature search, and analysis of results. Furthermore, MS contributed to the manuscript's writing, revising, and approving it in its finalized state. NP contributed to the results, and discussions, and provided supervision. NP also contributed to the writing process, revisions, and the final approval of the manuscript in its finalized state. MT contributed to the study's conceptualization, resource management, supervision, writing, revising the manuscript, and approving it.
Corresponding author
Correspondence to Yazid Albadarin .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
See Table 4
The process of synthesizing the data presented in Table 4 involved identifying the relevant studies through a search process of databases (ERIC, Scopus, Web of Knowledge, Dimensions.ai, and lens.org) using specific keywords "ChatGPT" and "education". Following this, inclusion/exclusion criteria were applied, and data extraction was performed using Creswell's [ 15 ] coding techniques to capture key information and identify common themes across the included studies.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Albadarin, Y., Saqr, M., Pope, N. et al. A systematic literature review of empirical research on ChatGPT in education. Discov Educ 3 , 60 (2024). https://doi.org/10.1007/s44217-024-00138-2
Download citation
Received : 22 October 2023
Accepted : 10 May 2024
Published : 26 May 2024
DOI : https://doi.org/10.1007/s44217-024-00138-2
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Large language models
- Educational technology
- Systematic review
Advertisement
- Find a journal
- Publish with us
- Track your research
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 May 2024
A double machine learning model for measuring the impact of the Made in China 2025 strategy on green economic growth
- Jie Yuan 1 &
- Shucheng Liu 2
Scientific Reports volume 14 , Article number: 12026 ( 2024 ) Cite this article
1 Altmetric
Metrics details
- Environmental economics
- Environmental impact
- Sustainability
The transformation and upgrading of China’s manufacturing industry is supported by smart and green manufacturing, which have great potential to empower the nation’s green development. This study examines the impact of the Made in China 2025 industrial policy on urban green economic growth. This study applies the super-slacks-based measure model to measure cities’ green economic growth, using the double machine learning model, which overcomes the limitations of the linear setting of traditional causal inference models and maintains estimation accuracy under high-dimensional control variables, to conduct an empirical analysis based on panel data of 281 Chinese cities from 2006 to 2021. The results reveal that the Made in China 2025 strategy significantly drives urban green economic growth, and this finding holds after a series of robustness tests. A mechanism analysis indicates that the Made in China 2025 strategy promotes green economic growth through green technology progress, optimizing energy consumption structure, upgrading industrial structure, and strengthening environmental supervision. In addition, the policy has a stronger driving effect for cities with high manufacturing concentration, industrial intelligence, and digital finance development. This study provides valuable theoretical insights and policy implications for government planning to promote high-quality development through industrial policy.
Similar content being viewed by others

The influence of AI on the economic growth of different regions in China

The trilemma of sustainable industrial growth: evidence from a piloting OECD’s Green city

Green technology advancement, energy input share and carbon emission trend studies
Introduction.
Since China’s reform and opening up, the nation’s economy has experienced rapid growth for more than 40 years. According to the National Bureau of Statistics, China’s per capita GDP has grown from 385 yuan in 1978 to 85,698 yuan in 2022, with an average annual growth rate of 13.2%. However, obtaining this growth miracle has come at considerable social and environmental costs 1 . Current pollution prevention and control systems have not yet fundamentally alleviated the structural and root causes, impairing China’s economic progress toward high-quality development 2 . The report of the 20th National Congress of the Communist Party of China proposed that the future will be focused on promoting the formation of green modes of production and lifestyles and advancing the harmonious coexistence of human beings and nature. This indicates that transforming the mode of economic development is now the focus of the government’s attention, calling for advancing the practices of green growth aimed at energy conservation, emissions reduction, and sustainability while continuously increasing economic output 3 . As a result, identifying approaches to balance economic growth and green environmental protection in the development process and realize green economic growth has become an arduous challenge and a crucially significant concern for China’s high-quality economic development.
An intrinsic driver of urban economic growth, manufacturing is also the most energy-intensive and pollution-emitting industry, and greatly constrains urban green development 4 . China’s manufacturing industry urgently needs to advance the formation of a resource-saving and environmentally friendly industrial structure and manufacturing system through transformation and upgrading to support for green economic growth 5 . As an incentive-based industrial policy that emphasizes an innovation-driven and eco-civilized development path through the development and implementation of an intelligent and green manufacturing system, Made in China 2025 is a significant initiative for promoting the manufacturing industry’s transformation and upgrading, providing solid economic support for green economic growth 6 . To promote the effective implementation of this industrial policy, fully mobilize localities to explore new modes and paths of manufacturing development, and strengthen the urban manufacturing industry’s influential demonstration role in advancing the green transition, the Ministry of Industry and Information Technology of China successively launched 30 Made in China 2025 pilot cities (city clusters) in 2016 and 2017. The Pilot Demonstration Work Program for “Made in China 2025” Cities specified that significant results should be achieved within three to 5 years. After several years of implementation, has the Made in China 2025 pilot policy promoted green economic growth? What are the policy’s mechanisms of action? Are there differences in green economic growth effects in pilot cities based on various urban development characteristics? This study’s theoretical interpretation and empirical examination of the above questions can add to the growing body of related research and provide valuable insights for cities to comprehensively promote the transformation and upgrading of manufacturing industry to advance China’s high-quality development.
This study constructs an analytical framework at the theoretical level to analyze the impact of the Made in China 2025 strategy on urban green economic growth, and uses the double machine learning (ML) model to test its green economic growth effect. The contributions of this study are as follows. First, focusing on the field of urban green development, the study incorporates variables representing the potential economic and environmental effects of the Made in China 2025 policy into a unified framework to systematically examine the impact of the Made in China 2025 pilot policy on the urban green economic growth, providing a novel perspective for assessing the effects of industrial policies. Second, we investigate potential transmission mechanisms of the Made in China 2025 strategy affecting green economic growth from the perspectives of green technology advancement, energy consumption structure optimization, industrial structure upgrading, and environmental supervision strengthening, establishing a useful supplement for related research. Third, leveraging the advantage of ML algorithms in high-dimensional and nonparametric prediction, we apply a double ML model assess the policy effects of the Made in China 2025 strategy to avoid the “curse of dimensionality” and the inherent biases of traditional econometric models, and improve the credibility of our research conclusions.
The remainder of this paper is structured as follows. Section “ Literature review ” presents a literature review. Section “ Policy background and theoretical analysis ” details our theoretical analysis and research hypotheses. Section “ Empirical strategy ” introduces the model setting and variables selection for the study. Section “ Empirical result ” describes the findings of empirical testing and analyzes the results. Section “ Conclusion and policy recommendation ” summarizes our conclusions and associated policy implications.
Literature review
Measurement and influencing factors of green economic growth.
The Green Economy Report, which was published by the United Nations Environment Program in 2011, defined green economy development as facilitating more efficient use of natural resources and sustainable growth than traditional economic models, with a more active role in promoting combined economic development and environmental protection. The Organization for Economic Co-operation and Development defined green economic growth as promoting economic growth while ensuring that natural assets continue to provide environmental resources and services; a concept that is shared by a large number of institutions and scholars 7 , 8 , 9 . A considerable amount of research has assessed green economic growth, primarily using three approaches. First, single-factor indicators, such as sulfur dioxide emissions, carbon dioxide emissions intensity, and other quantified forms; however, this approach neglects the substitution of input factors such as capital and labor for the energy factor, which has certain limitations 5 , 10 . Second, studies have been based on neoclassical economic growth theory, incorporating factors of capital, technology, energy, and the environment, and constructing a green Solow model to measure green total factor productivity (GTFP) 11 , 12 . Third, based on neoclassical economic growth theory, some studies have simultaneously considered desirable and undesirable output, applying Shepard’s distance function, the directional distance function, and data envelopment analysis to measure GTFP 13 , 14 , 15 .
Economic growth is an extremely complex process, and green economic growth is also subject to a combination of multiple complex factors. Scholars have explored the influence mechanisms of green economic growth from perspectives of resource endowment 16 , technological innovation 17 , industrial structure 18 , human capital 19 , financial support 20 , government regulation 21 , and globalization 22 . In the field of policy effect assessment, previous studies have confirmed the green development effects of pilot policies such as innovative cities 23 , Broadband China 24 , smart cities 25 , and low-carbon cities 26 . However, few studies have focused on the impact of Made in China 2025 strategy on urban green economic growth and identified its underlying mechanisms.
The impact of Made in China 2025 strategy
Since the industrial policy of Made in China 2025 was proposed, scholars have predominantly focused on exploring its economic effects on technological innovation 27 , digital transformation 28 , and total factor productivity (TFP) 29 , while the potential environmental effects have been neglected. Chen et al. (2024) 30 found that Made in China 2025 promotes firm innovation through tax incentives, public subsidies, convenient financing, academic collaboration and talent incentives. Xu (2022) 31 point out that Made in China 2025 policy has the potential to substantially improve the green innovation of manufacturing enterprises, which can boost the green transformation and upgrading of China’s manufacturing industry. Li et al. (2024) 32 empirically investigates the positive effect of Made in China 2025 strategy on digital transformation and exploratory innovation in advanced manufacturing firms. Moreover, Liu and Liu (2023) 33 take “Made in China 2025” as an exogenous shock and find that the pilot policy has a positive impact on the high-quality development of enterprises and capital markets. Unfortunately, scholars have only discussed the impact of Made in China 2025 strategy on green development and environmental protection from a theoretical perspective and lack empirical analysis. Li (2018) 27 has compared Germany’s “Industry 4.0” and China’s “Made in China 2025”, and point out that “Made in China 2025” has clear goals, measures and sector focus. Its guiding principles are to enhance industrial capability through innovation-driven manufacturing, optimize the structure of Chinese industry, emphasize quality over quantity, train and attract talent, and achieve green manufacturing and environment. Therefore, it is necessary to systematically explore the impact and mechanism of Made in China 2025 strategy on urban green economic growth from both theoretical and empirical perspectives.
Causal inference based on double ML
The majority of previous studies have used traditional causal inference models to assess policy effects; however, some limitations are inherent to the application of these models. For example, the parallel trend test of the difference-in-differences model has stringent requirements on appropriate sample data; the synthetic control method can construct a virtual control group that conforms to the parallel trend, but it requires that the treatment group does not have the extreme value characteristics, and it is only applicable to “one-to-many” circumstances; and the propensity score matching (PSM) method involves a considerable amount of subjectivity in selecting matching variables. To compensate for the shortcomings of traditional models, scholars have started to explore the application of ML in the field of causal inference 34 , 35 , 36 , and double ML is a typical representative.
Double ML was formalized in 2018 34 , and the relevant research falls into two main categories. The first strand of literature applies double ML to assess causality concerning economic phenomena. Yang et al. (2020) 37 applied double ML using a gradient boosting algorithm to explore the average treatment effect of top-ranked audit firms, verifying its robustness compared with the PSM method. Zhang et al. (2022) 38 used double ML to quantify the impact of nighttime subway services on the nighttime economy, house prices, traffic accidents, and crime following the introduction of nighttime subway services in London in 2016. Farbmacher et al. (2022) 39 combined double ML with mediating effects analysis to assess the causal relationship between health insurance coverage and youth wellness and examine the indirect mechanisms of regular medical checkups, based on a national longitudinal health survey of youth conducted by the US Bureau of Labor Statistics. The second strand of literature has innovated methodological theory based on double ML. Chiang et al. (2022) 40 proposed an improved multidirectional cross-fitting double ML method, obtaining regression results for high-dimensional parameters while estimating robust standard errors for dual clustering, which can effectively adapt to multidirectional clustered sampled data and improve the validity of estimation results. Bodory et al. (2022) 41 combined dynamic analysis with double ML to measure the causal effects of multiple treatment variables over time, using weighted estimation to assess the dynamic treatment effects of specific subsamples, which enriched the dynamic quantitative extension of double ML.
In summary, previous research has conducted some useful investigations regarding the impact of socioeconomic policies on green development, but limited studies have explored the relationship between the Made in China 2025 strategy and green economic growth. This study takes 281 Chinese cities as the research object, and applies the super-slacks-based measure (SBM) model to quantify Chinese cities’ green economic growth from 2006 to 2021. Based on a quasi-natural experiment of Made in China 2025 pilot policy implementation, we use the double ML model to test the impact and transmission mechanisms of the policy on urban green economic growth. We also conduct a heterogeneity analysis of cities based on different levels of manufacturing agglomeration, industrial intelligence, and digital finance. This study applies a novel approach and provides practical insights for research in the field of industrial policy assessment.
Policy background and theoretical analysis
Policy background.
The Made in China 2025 strategy aims to encourage and support local exploration of new paths and models for the transformation and upgrading of the manufacturing industry, and to drive the improvement of manufacturing quality and efficiency in other regions through demonstration effects. According to the Notice of Creating “Made in China 2025” National Demonstration Zones issued by the State Council, municipalities directly under the central government, sub-provincial cities, and prefecture-level cities can apply for the creation of demonstration zones. Cities with proximity and high industrial correlation can jointly apply for urban agglomeration demonstration zones. The Notice clarifies the goals and requirements for creating demonstration zones in areas such as green manufacturing, clean production, and environmental protection. In 2016, Ningbo became the first Made in China 2025 pilot city, and a total of 12 cities and 4 city clusters were included in the list of Made in China 2025 national demonstration zones. In 2018, the State Council issued the Evaluation Guidelines for “Made in China 2025” National Demonstration Zone, which further clarified the evaluation process and indicator system of the demonstration zone. Seven primary indicators and 29 secondary indicators were formulated, including innovation driven, quality first, green development, structural optimization, talent oriented, organizational implementation, and coordinated development of urban agglomerations. This indicator system can evaluate the creation process and overall effectiveness of pilot cities (city clusters), which is beneficial for the promotion of successful experiences and models in demonstration areas.
Advancing green urban development is a complex systematic project that requires structural adjustment and technological and institutional changes in the socioeconomic system 42 . The Made in China 2025 strategy emphasizes the development and application of smart and green manufacturing systems, which can unblock technological bottlenecks in the manufacturing sector in terms of industrial production, energy consumption, and waste emissions, and empower cities to operate in a green manner. In addition, the Made in China 2025 policy established requirements for promoting technological innovation to advance energy saving and environmental protection, improving the rate of green energy use, transforming traditional industries, and strengthening environmental supervision. For pilot cities, green economy development requires the support of a full range of positive factors. Therefore, this study analyzes the mechanisms by which the Made in China 2025 strategy affects urban green economic growth from the four paths of green technology advancement, energy consumption structure optimization, industrial structure upgrading, and environmental supervision strengthening.
Theoretical analysis and research hypotheses
As noted, the Made in China 2025 strategy emphasizes strengthening the development and application of energy-saving and environmental protection technologies to advance cleaner production. Pilot cities are expected to prioritize the driving role of green innovation, promote clustering carriers and innovation platforms for high-tech enterprises, and guide the progress of enterprises’ implementation of green technology. Specifically, pilot cities are encouraged to optimize the innovation environment by increasing scientific and technological investment and financial subsidies in key areas such as smart manufacturing and high-end equipment and strengthening intellectual property protection to incentivize enterprises to conduct green research and development (R&D) activities. These activities subsequently promote the development of green innovation technologies and industrial transformation 43 . Furthermore, since quality human resources are a core aspect of science and technology innovation 44 , pilot cities prioritize the cultivation and attraction of talent to establish a stable human capital guarantee for enterprises’ ongoing green technology innovation, transform and upgrade the manufacturing industry, and advance green urban development. Green technology advances also contribute to urban green economic growth. First, green technology facilitates enterprises’ adoption of improved production equipment and innovation in green production technology, accelerating the change of production mode and driving the transformation from traditional crude production to a green and intensive approach 45 , promoting green urban development. Second, green technology advancement accelerates green innovations such as clean processes, pollution control technologies, and green equipment, and facilitates the effective supply of green products, taking full advantage of the benefits of green innovations 46 and forming a green economic development model to achieve urban green economic growth.
The Made in China 2025 pilot policy endeavors to continuously increase the rate of green and low-carbon energy use and reduce energy consumption. Under target constraints of energy saving and carbon control, pilot cities will accelerate the cultivation of high-tech industries in green environmental protection and high-end equipment manufacturing with advantages of sustainability and low resource inputs 47 to improve the energy consumption structure. Pilot cities also advance new energy sector development by promoting clean energy projects, subsidizing new energy consumption, and supporting green infrastructure construction and other policy measures 48 to optimize the energy consumption structure. Energy consumption structure optimization can have a profound impact on green economy development. Optimization means that available energy tends to be cleaner, which can reduce the manufacturing industry’s dependence on traditional fossil energy and raise the proportion of clean energy 49 , ultimately promoting green urban development. Pilot cities also provide financial subsidies for new energy technology R&D, which promotes the innovation and application of new technologies, energy-saving equipment, efficient resource use, and energy-saving diagnostics, which allow enterprises to save energy and reduce consumption and improve energy use efficiency and TFP 50 , advancing the growth of urban green economy.
At its core, the Made in China 2025 strategy promotes the transformation and upgrading of the manufacturing sector. Pilot cities guide and develop technology-intensive high-tech industries, adjust the proportion of traditional heavy industry, and improve the urban industrial structure. Pilot cities also implement the closure, merger, and transformation of pollution-intensive industries; guide the fission of professional advantages of manufacturing enterprises 51 ; and expand the establishment and development of service-oriented manufacturing and productive service industries to promote the evolution of the industrial structure toward rationalization and high-quality development 52 . Upgrading the industrial structure can also contribute to urban green economic growth. First, industrial structure upgrading promotes the transition from labor- and capital-intensive industries to knowledge- and technology-intensive industries, which optimizes the industrial distribution patterns of energy consumption and pollutant emissions and promotes the transformation of economic growth dynamics and pollutant emissions control, providing a new impetus for cities’ sustainable development 53 . Second, changes in industrial structure and scale can have a profound impact on the type and quantity of pollutant emissions. By introducing high-tech industries, service-oriented manufacturing, and production-oriented service industries, pilot cities can promote the transformation of pollution-intensive industries, promoting the adjustment and optimization of industrial structure and scale 54 to achieve the purpose of driving green urban development.
The Made in China 2025 strategy proposes strengthening green supervision and conducting green evaluations, establishing green development goals for the manufacturing sector in terms of emissions and consumption reduction and water conservation. This requires pilot cities to implement stringent environmental regulatory policies, such as higher energy efficiency and emissions reduction targets and sewage taxes and charges, strict penalties for excess emissions, and project review criteria 55 , which consolidates the effectiveness of green development. Under the framework of environmental authoritarianism, strengthening environmental supervision is a key measure for achieving pollution control and improving environmental quality 56 . Therefore, environmental regulatory enhancement can help cities achieve green development goals. First, according to the Porter hypothesis 57 , strong environmental regulatory policies encourage firms to internalize the external costs of environmental supervision, stimulate technological innovation, and accelerate R&D and application of green technologies. This response helps enterprises improve input–output efficiency, achieve synergy between increasing production and emissions reduction, partially or completely offset the “environmental compliance cost” from environmental supervision, and realize the innovation compensation effect 58 . Second, strict environmental regulations can effectively mitigate the complicity of local governments and enterprises in focusing on economic growth while neglecting environmental protection 59 , urging local governments to constrain enterprises’ emissions, which compels enterprises to conduct technological innovation and pursue low-carbon transformation, promoting urban green economic growth.
Based on the above analysis, we propose the mechanisms that promote green economic growth through Made in China 2025 strategy, as shown in Fig. 1 . The proposed research hypotheses are as follows:

Mechanism analysis of Made in China 2025 strategy and green economic growth.
Hypothesis 1
The Made in China 2025 strategy promotes urban green economic growth.
Hypothesis 2
The Made in China 2025 strategy drives urban green economic growth through four channels: promoting green technology advancement, optimizing energy consumption structure, upgrading industrial structure, and strengthening environmental supervision.
Empirical strategy
Double ml model.
Compared with traditional causal inference models, double ML has unique advantages in variable selection and model estimation, and is also more applicable to the research problem of this study. Green economic growth is a comprehensive indicator of transformative urban growth that is influenced by many socioeconomic factors. To ensure the accuracy of our policy effects estimation, the interference of other factors on urban green economic growth must be controlled as much as possible; however, when introducing high-dimensional control variables, traditional regression models may face the “curse of dimensionality” and multicollinearity, rendering the accuracy of the estimates questionable. Double ML uses ML and regularization algorithms to automatically filter the preselected set of high-dimensional control variables to obtain an effective set of control variables with higher prediction accuracy. This approach avoids the “curse of dimensionality” caused by redundant control variables and mitigates the estimation bias caused by the limited number of primary control variables 39 . Furthermore, nonlinear relationships between variables are the norm in the evolution of economic transition, and ordinary linear regression may suffer from model-setting bias producing estimates that lack robustness. Double ML effectively overcomes the problem of model misspecification by virtue of the advantages of ML algorithms in handling nonlinear data 37 . In addition, based on the idea of instrumental variable functions, two-stage predictive residual regression, and sample split fitting, double ML mitigates the “regularity bias” in ML estimation and ensures unbiased estimates of the treatment coefficients in small samples 60 .
Based on the analysis above, this study uses the double ML model to assess the policy effects of the Made in China 2025 strategy. The partial linear double ML model is constructed as follows:
where i denotes the city, t denotes the year, and Y it represents green economic growth. Policy it represents the policy variable of Made in China 2025, which is set as 1 if the pilot is implemented and 0 otherwise. θ 0 is the treatment coefficient that is the focus of this study. X it denotes the set of high-dimensional control variables, and the ML algorithm is used to estimate the specific functional form \(\hat{g}(X_{it} )\) . U it denotes the error term with a conditional mean of zero.
Direct estimation of Eqs. ( 1 ) and ( 2 ) yields the following estimate of the treatment coefficient:
where n denotes the sample size.
Notably, the double ML model uses a regularization algorithm to estimate the specific functional form \(\hat{g}(X_{it} )\) , which prevents the variance of the estimate from being too large, but inevitably introduces a “regularity bias,” resulting in a biased estimate. To speed up the convergence of the \(\hat{g}(X_{it} )\) directions so that the estimates of the treatment coefficients satisfy unbiasedness with small samples, the following auxiliary regression is constructed:
where \(m(X_{it} )\) is the regression function of the treatment variable on the high-dimensional control variable, using ML algorithms to estimate the specific functional form \(\hat{m}(X_{it} )\) . V it is the error term with a conditional mean of zero.
The specific operation process follows three stages. First, we use the ML algorithm to estimate the auxiliary regression \(\hat{m}(X_{it} )\) and take its residuals \(\hat{V}_{it} = Policy_{it} - \hat{m}(X_{it} )\) . Second, we use the ML algorithm to estimate \(\hat{g}(X_{it} )\) and change the form of the main regression \(Y_{it} - \hat{g}(X_{it} ) = \theta_{0} Policy_{it} + U_{it}\) . Finally, we regress \(\hat{V}_{it}\) as an instrumental variable for Policy it , obtaining unbiased estimates of the treatment coefficients as follows:
Variable selection
- Green economic growth
We apply the super-SBM model to measure urban green economic growth. The super-SBM model is compatible with radial and nonradial characteristics, which avoids inflated results due to ignoring slack variables and deflated results due to ignoring the linear relationships between elements, and can truly reflect relative efficiency 61 . The SBM model reflects the nature of green economic growth more accurately compared with other models, and has been widely adopted by scholars 62 . The expression of the super-SBM model considering undesirable output is as follows:
where x is the input variable; y and z are the desirable and undesirable output variables, respectively; m denotes the number of input indicators; s 1 and s 2 represent the respective number of indicators for desirable and undesirable outputs; k denotes the period of production; i , r , and t are the decision units for the inputs, desirable outputs, and undesirable outputs, respectively; \(s^{ - }\) , \(s^{ + }\) , and \(s^{z - }\) are the respective slack variables for the inputs, desirable outputs, and undesirable outputs; and γ is a vector of weights. A larger \(\rho_{SE}\) value indicates greater efficiency. If \(\rho_{SE}\) = 1, the decision unit is effective; if \(\rho_{SE}\) < 1, the decision unit is relatively ineffective, indicating a loss of efficiency.
Referencing Sarkodie et al. (2023) 63 , the evaluation index system of green economic growth is constructed as shown in Table 1 .
Made in China 2025 pilot policy
The list of Made in China 2025 pilot cities (city clusters) published by the Ministry of Industry and Information Technology of China in 2016 and 2017 is matched with the city-level data to obtain 30 treatment group cities and 251 control group cities. The policy dummy variable of Made in China 2025 is constructed by combining the implementation time of the pilot policies.
Mediating variables
This study also examines the transmission mechanism of the Made in China 2025 strategy affecting urban green economic growth from four perspectives, including green technology advancement, energy consumption structure optimization, industrial structure upgrading, and strengthening of environmental supervision. (1) The number of green patent applications is adopted to reflect green technology advancement. (2) Energy consumption structure is quantified using the share of urban domestic electricity consumption in total energy consumption. (3) The industrial structure upgrading index is calculated using the formula \(\sum\nolimits_{i = 1}^{3} {i \times (GDP_{i} /GDP)}\) , where GDP i denotes the added value of primary, secondary, or tertiary industries. (4) The frequency of words related to the environment in government work reports is the proxy for measuring the intensity of environmental supervision 64 .
Control variables
Double ML can effectively accommodate the case of high-dimensional control variables using regularization algorithms. To control for the effect of other urban characteristics on green economic growth, this study introduces the following 10 control variables. We measure education investment by the ratio of education expenditure to GDP. Technology investment is the ratio of technology expenditure to GDP. The study measures urbanization using the share of urban built-up land in the urban area. Internet penetration is the number of internet users as a share of the total population at the end of the year. We measure resident consumption by the total retail sales of consumer goods per capita. The unemployment rate is the ratio of the number of registered unemployed in urban areas at the end of the year to the total population at the end of the year. Financial scale is the ratio of the balance of deposits and loans of financial institutions at the end of the year to the GDP. Human capital is the natural logarithm of the number of students enrolled in elementary school, general secondary schools, and general tertiary institutions per 10,000 persons. Transportation infrastructure is the natural logarithm of road and rail freight traffic. Finally, openness to the outside world is reflected by the ratio of actual foreign investment to GDP. Quadratic terms for the control variables are also included in the regression analysis to improve the accuracy of the model’s fit. We introduce city and time fixed effects as individual and year dummy variables to avoid missing information on city and time dimensions.
Data sources
This study uses 281 Chinese cities spanning from 2006 to 2021 as the research sample. Data sources include the China City Statistical Yearbook, the China Economic and Social Development Statistics Database, and the EPS Global Statistics Database. We used the average annual growth rate method to fill the gaps for the minimal missing data. To remove the effects of price changes, all data measured in monetary units are deflated using the consumer price index for each province for the 2005 base period. The descriptive statistics of the data are presented in Table 2 .
Empirical result
Baseline results.
The sample split ratio of the double ML model is set to 1:4, and we use the Lasso algorithm to predict and solve the main and auxiliary regressions, presenting the results in Table 3 . Column (1) does not control for fixed effects or control variables, column (2) introduces city and time fixed effects, and columns (3) and (4) add control variables to columns (1) and (2), respectively. The regressions in columns (1) and (2) are highly significant, regardless of whether city and time fixed effects are controlled. Column (4) controls for city fixed effects, time fixed effects, and the primary term of the control variable over the full sample interval, revealing that the regression coefficient of the Made in China 2025 pilot policy on green economic growth is positive and significant at the 1% level, confirming that the Made in China 2025 strategy significantly promotes urban green economic growth. Column (5) further incorporates the quadratic terms of the control variables and the regression coefficients remain significantly positive with little change in values. Therefore, Hypothesis 1 is verified.
Parallel trend test
The prerequisite for the establishment of policy evaluation is that the development status of cities before the pilot policy is introduced is similar. Referring to Liu et al. (2022) 29 , we adopt a parallel trend test to verify the effectiveness of Made in China 2025 pilot policy. Figure 2 shows the result of parallel trend test. None of the coefficient estimates before the Made in China 2025 pilot policy are significant, indicating no significant difference between the level of green economic growth in pilot and nonpilot cities before implementing the policy, which passes the parallel trend test. The coefficient estimates for all periods after the policy implementation are significantly positive, indicating that the Made in China 2025 pilot policy can promote urban green economic growth.

Parallel trend test.
Robustness tests
Replace explained variable.
Referencing Oh and Heshmati (2010) 65 and Tone and Tsutsui (2010) 66 , we use the Malmquist–Luenberger index under global production technology conditions (GML) and an epsilon-based measure (EBM) model to recalculate urban green economic growth. The estimation results in columns (1) and (2) of Table 4 show that the estimated coefficients of the Made in China 2025 pilot policy remain significantly positive after replacing the explanatory variables, validating the robustness of the baseline findings.
Adjusting the research sample
Considering the large gaps in the manufacturing development base between different regions in China, using all cities in the regression analysis may lead to biased estimation 67 . Therefore, we exclude cities in seven provinces with a poor manufacturing development base (Gansu, Qinghai, Ningxia, Xinjiang, Tibet, Yunnan, and Guizhou) and four municipalities with a better development base (Beijing, Tianjin, Shanghai, and Chongqing). The other city samples are retained to rerun the regression analysis, and the results are presented in column (3) of Table 4 . The first batch of pilot cities of the Made in China 2025 strategy was released in 2016, and the second batch of pilot cities was released in 2017. To exclude the effect of point-in-time samples that are far from the time of policy promulgation, the regression is also rerun by restricting the study interval to the three years before and after the promulgation of the policy (2013–2020), and the results are presented in column (4) of Table 4 . The coefficients of the Made in China 2025 pilot policy effect on urban green economic growth decrease after adjusting for the city sample and the time interval, but remain significantly positive at the 1% level. This, once again, verifies the robustness of the benchmark regression results.
Eliminating the impact of potential policies
During the same period of the Made in China 2025 strategy implementation, urban green economy growth may be affected by other relevant policies. To ensure the accuracy of the policy effect estimates, four representative policy categories overlapping with the sample period, including smart cities, low-carbon cities, Broadband China, and innovative cities, were collected and organized. Referencing Zhang and Fan (2023) 25 , dummy variables for these policies are included in the benchmark regression model and the results are presented in Table 5 . The estimated coefficient of the Made in China 2025 pilot policy decreases after controlling for the effects of related policies, but remains significantly positive at the 1% level. This suggests that the positive impact of the Made in China 2025 strategy on urban green economic growth, although overestimated, does not affect the validity of the study’s findings.
Reset double ML model
To avoid the impact of the double ML model imparting bias on the conclusions, we conduct robustness tests by varying the sample splitting ratio, the ML algorithm, and the model estimation form. First, we change the sample split ratio of the double ML model from 1:4 to 3:7 and 1:3. Second, we replace the Lasso ML algorithm with random forest (RF), gradient boosting (GBT), and BP neural network (BNN). Third, we replace the partial linear model based on the dual ML with a more generalized interactive model, using the following main and auxiliary regressions for the analysis:
among them, the meanings of each variable are the same as Eqs. ( 1 ) and ( 2 ).
The estimated coefficients for the treatment effects are obtained from the interactive model as follows:
Table 6 presents the regression results after resetting the double ML model, revealing that the sample split ratio, ML algorithm, and the model estimation form in double ML model did not affect the conclusion that the Made in China 2025 strategy promotes urban green economic growth, and only alters the magnitude of the policy effect, once again validating the robustness of our conclusions.
Difference-in-differences model
To further verify the robustness of the estimation results, we use traditional econometric models for regression. Based on the difference-in-differences (DID) model, a synthetic difference-in-differences (SDID) model is constructed by combining the synthetic control method 68 . It constructs a composite control group with a similar pre-trend to the treatment group by linearly combining several individuals in the control group, and compares it with the treatment group 69 . Table 7 presents the regression results of traditional DID model and SDID model. The estimated coefficient of the Made in China 2025 policy remains significantly positive at the 1% level, which once again verifies the robustness of the study’s findings.
Mechanism verification
This section conducts mechanism verification from four perspectives of green technology advancement, energy consumption structure, industrial structure, and environmental supervision. The positive impacts of the Made in China 2025 strategy on green technology advancement, energy consumption structure optimization, industrial structure upgrading, and strengthening environmental supervision are empirically examined using a dual ML model (see Table A.1 in the Online Appendix for details). Referencing Farbmacher et al. (2022) 39 for causal mediating effect analysis of double ML (see the Appendix for details), we test the transmission mechanism of the Made in China 2025 strategy on green economic growth based on the Lasso algorithm, presenting the results in Table 8 . The findings show that the total effects under different mediating paths are all significantly positive at the 1% level, verifying that the Made in China 2025 strategy positively promotes urban green economic growth.
Mechanism of green technology advancement
The indirect effect of green technological innovation is significantly positive for both the treatment and control groups. After stripping out the path of green technology advancement, the direct effects of the treatment and control groups remain significantly positive, indicating that the increase in the level of green technological innovation brought about by the Made in China 2025 strategy significantly promotes urban green economic growth. The Made in China 2025 strategy proposes to strengthen financial and tax policy support, intellectual property protection, and talent training systems. Through the implementation of policy incentives, pilot cities have fostered the concentration of high-technology enterprises and scientific and technological talent cultivation, exerting a knowledge spillover effect that further promotes green technology advancement. At the same time, policy preferences have stimulated the demand for innovation in energy conservation and emissions reduction, which raises enterprises’ motivation to engage in green innovation activities. Green technology advancement helps cities achieve an intensive development model, bringing multiple dividends such as lower resource consumption, reduced pollution emissions, and improved production efficiency, which subsequently promotes green economic growth.
Mechanism of energy consumption structure
The indirect effect of energy consumption structure is significantly positive for the treatment and control groups, while the direct effect of the Made in China 2025 pilot policy on green economic growth remains significantly positive, indicating that the policy promotes urban green economic growth through energy consumption structure optimization. The policy encourages the introduction of clean energy into production processes, reducing pressure on enterprise performance and the cost of clean energy use, which helps enterprises to reduce traditional energy consumption that is dominated by coal and optimize the energy structure to promote green urban development.
Mechanism of industrial structure
The indirect effects of industrial structure on the treatment and control groups are significantly positive. After stripping out the path of industrial structure upgrading, the direct effects remain significantly positive for both groups, indicating that the Made in China 2025 strategy promotes urban green economic growth through industrial structure optimization. Deepening the restructuring of the manufacturing industry is a strategic task specified in Made in China 2025. Pilot cities focus on transforming and guiding the traditional manufacturing industry toward high-end, intelligent equipment upgrades and digital transformation, driving the regional industrial structure toward rationalization and advancement to achieve rational allocation of resources. Upgrading industrial structure is a prerequisite for cities to advance intensive growth and sustainable development. By assuming the roles of “resource converter” and “pollutant controller,” industrial upgrading can continue to release the dividends of industrial structure, optimize resource allocation, and improve production efficiency, establishing strong support for green economic growth.
Mechanism of environmental supervision
The treatment and control groups of environmental supervision has a positive indirect effect in the process of the Made in China 2025 pilot policy affecting green economic growth that is significant at the 1% level, affirming the transmission path of environmental supervision. The Made in China 2025 strategy states that energy consumption, material consumption, and pollutant emissions per unit of industrial added value in key industries should reach the world’s advanced level by 2025. This requires pilot cities to consolidate and propagate the effectiveness of green development by strengthening environmental supervision while promoting the manufacturing sector’s green development. Strengthening environmental supervision promotes enterprises’ energy saving and emissions reduction through innovative compensation effects, while restraining enterprises’ emissions behaviors by tightening environmental protection policies, promoting environmental legislation, and increasing penalties to advance green urban development. Based on the above analysis, Hypothesis 2 is validated.
Heterogeneity analysis
Heterogeneity of manufacturing agglomeration.
To reduce production and transaction costs and realize economies of scale and scope, the manufacturing industry tends to accelerate its growth through agglomeration, exerting an “oasis effect” 70 . Cities with a high degree of manufacturing agglomeration are prone to scale and knowledge spillover effects, which amplify the agglomeration functions of talent, capital, and technology, strengthening the effectiveness of pilot policies. Based on this, we use the locational entropy of manufacturing employees to measure the degree of urban manufacturing agglomeration in the year (2015) before policy implementation, using the median to divide the full sample of cities into high and low agglomeration groups. Columns (1) and (2) in Table 9 reveal that the Made in China 2025 pilot policy has a stronger effect in promoting green economic growth in cities with high manufacturing concentration compared to those with low concentration. The rationale for this outcome may be that cities with a high concentration of manufacturing industries has large population and developed economy, which is conducive to leveraging agglomeration economies and knowledge spillover effects. Meanwhile, they are able to offer greater policy concessions by virtue of economic scale, public services, infrastructure, and other advantages. These benefits can attract the clustering of productive services and the influx of innovative elements such as R&D talent, accelerating the transformation and upgrading of the manufacturing industry and the integration and advancement of green technologies, empowering the green urban development.
Heterogeneity of industrial intelligence
As a landmark technology for the integration of the new scientific and technological revolution with manufacturing, industrial intelligence is a new approach for advancing the green transformation of manufacturing production methods. Based on this, we use the density of industrial robot installations to measure the level of industrial intelligence in cities in the year (2015) prior to policy implementation 71 , using the median to classify the full sample of cities into high and low level groups. Columns (3) and (4) in Table 9 reveals that the Made in China 2025 pilot policy has a stronger driving effect on the green economic growth of highly industrial intelligent cities. The rationale for this outcome may be that with the accumulation of smart factories, technologies, and equipment, a high degree of industrial intelligence is more likely to leverage the green development effects of pilot policies. For cities where the development of industrial intelligence is in its infancy or has not yet begun, the cost of information and knowledge required for enterprises to undertake technological R&D is higher, reducing the motivation and incentive to conduct innovative activities, diminishing the pilot policy’s contribution to green economic growth.
Heterogeneity of digital finance
As a fusion of traditional finance and information technology, digital finance has a positive impact on the development of the manufacturing industry by virtue of its advantages of low financing thresholds, fast mobile payments, and wide range of services 72 . Cities with a high degree of digital finance development have abundant financial resources and well-developed financial infrastructure that provide enterprises with more complete financial services, with subsequent influence on the effects of pilot policies. We use the Peking University Digital Inclusive Finance Index to measure the level of digital financial development in cities in the year (2015) prior to policy implementation, using the median to divide the full sample of cities into high and low level groups. Columns (5) and (6) in Table 9 reveal that the Made in China 2025 pilot policy has a stronger driving effect on the green economic growth of cities with highly developed digital finance. The rationale for this outcome may be that cities with a high degree of digital finance development can fully leverage the universality of financial resources, provide financial supply for environmentally friendly and technology-intensive enterprises, effectively alleviate the mismatch of financial capital supply, and provide financial security for enterprises to conduct green technology R&D. Digital finance also makes enterprises’ information more transparent through a rich array of data access channels, which strengthens government pollution regulation and public environmental supervision and compels enterprises to engage in green technological innovation to promote green economic growth.
Conclusion and policy recommendation
Conclusions.
This study examines the impact of the Made in China 2025 strategy on urban green economic growth using the double ML model based on panel data for 281 Chinese cities from 2006 to 2021. The relevant research results are threefold. First, the Made in China 2025 strategy significantly promotes urban green economic growth; a conclusion that is supported by a series of robustness tests. Second, regarding mechanisms, the Made in China 2025 strategy promotes urban green economic growth through green technology advancement, energy consumption structure optimization, industrial structure upgrading, and strengthening of environmental supervision. Third, the heterogeneity analysis reveals that the Made in China 2025 strategy has a stronger driving effect on green economic growth for cities with a high concentration of manufacturing and high degrees of industrial intelligence and digital finance.
policy recommendations
We next propose specific policy recommendations based on our findings. First, policymakers should summarize the experience of building pilot cities and create a strategic model to advance the transformation and upgrading of the manufacturing industry to drive green urban development. The Made in China 2025 pilot policy effectively promotes green economic growth and highlights the significance of the transformation and upgrading of the manufacturing industry to empower sustainable urban development. The government should strengthen the model and publicize summaries of successful cases of manufacturing development in pilot cities to promote the experience of manufacturing transformation and upgrading by producing typical samples to guide the transformation of the manufacturing industry to intelligence and greening. Policies should endeavor to optimize the industrial structure and production system of the manufacturing industry to create a solid real economy support for high-quality urban development.
Second, policymakers should explore the multidimensional driving paths of urban green economic growth and actively stimulate the green development dividend of pilot policies by increasing support for enterprise-specific technologies, subsidizing R&D in areas of energy conservation and emissions reduction, consumption reduction and efficiency, recycling and pollution prevention, and promoting the progress of green technologies. The elimination of outdated production capacity must be accelerated and the low-carbon transformation of traditional industries must be targeted, while guiding the clustering of high-tech industries, optimizing cities’ industrial structure, and driving industrial structure upgrading. Policymakers can regulate enterprises’ production practices and enhance the effectiveness of environmental supervision by improving the system of environmental information disclosure and mechanisms of rewards and penalties for pollution discharge. In addition, strategies should consider cities’ own resource endowment, promote large-scale production of new energy, encourage enterprises to increase the proportion of clean energy use, and optimize the structure of energy consumption.
Third, policymakers should engage a combination of urban development characteristics and strategic policy implementation to empower green urban development, actively promoting optimization of manufacturing industry structure, and accelerating the development of high-technology industries under the guidance of policies and the market to promote high-quality development and agglomeration of the manufacturing industry. At the same time, the government should strive to popularize the industrial internet, promote the construction of smart factories and the application of smart equipment, increase investment in R&D to advance industrial intelligence, and actively cultivate new modes and forms of industrial intelligence. In addition, new infrastructure construction must be accelerated, the application of information technology must be strengthened, and digital financial services must be deepened to ease the financing constraints for enterprises conducting R&D on green technologies and to help cities develop in a high-quality manner.
Data availability
The datasets used or analysed during the current study are available from the corresponding author on reasonable request.
Cheng, K. & Liu, S. Does urbanization promote the urban–rural equalization of basic public services? Evidence from prefectural cities in China. Appl. Econ. 56 (29), 3445–3459. https://doi.org/10.1080/00036846.2023.2206625 (2023).
Article Google Scholar
Yin, X. & Xu, Z. An empirical analysis of the coupling and coordinative development of China’s green finance and economic growth. Resour. Policy 75 , 102476. https://doi.org/10.1016/j.resourpol.2021.102476 (2022).
Fernandes, C. I., Veiga, P. M., Ferreira, J. J. M. & Hughes, M. Green growth versus economic growth: Do sustainable technology transfer and innovations lead to an imperfect choice?. Bus. Strateg. Environ. 30 (4), 2021–2037. https://doi.org/10.1002/bse.2730 (2021).
Orsatti, G., Quatraro, F. & Pezzoni, M. The antecedents of green technologies: The role of team-level recombinant capabilities. Res. Policy 49 (3), 103919. https://doi.org/10.1016/j.respol.2019.103919 (2020).
Lin, B. & Zhou, Y. Measuring the green economic growth in China: Influencing factors and policy perspectives. Energy 241 (15), 122518. https://doi.org/10.1016/j.energy.2021.122518 (2022).
Fang, M. & Chang, C. L. Nexus between fiscal imbalances, green fiscal spending, and green economic growth: Empirical findings from E-7 economies. Econ. Change Restruct. 55 , 2423–2443. https://doi.org/10.1007/s10644-022-09392-6 (2022).
Qian, Y., Liu, J. & Forrest, J. Y. L. Impact of financial agglomeration on regional green economic growth: Evidence from China. J. Environ. Plan. Manag. 65 (9), 1611–1636. https://doi.org/10.1080/09640568.2021.1941811 (2022).
Awais, M., Afzal, A., Firdousi, S. & Hasnaoui, A. Is fintech the new path to sustainable resource utilisation and economic development?. Resour. Policy 81 , 103309. https://doi.org/10.1016/j.resourpol.2023.103309 (2023).
Ahmed, E. M. & Elfaki, K. E. Green technological progress implications on long-run sustainable economic growth. J. Knowl. Econ. https://doi.org/10.1007/s13132-023-01268-y (2023).
Shen, F. et al. The effect of economic growth target constraints on green technology innovation. J. Environ. Manag. 292 (15), 112765. https://doi.org/10.1016/j.jenvman.2021.112765 (2021).
Zhao, L. et al. Enhancing green economic recovery through green bonds financing and energy efficiency investments. Econ. Anal. Policy 76 , 488–501. https://doi.org/10.1016/j.eap.2022.08.019 (2022).
Ferreira, J. J. et al. Diverging or converging to a green world? Impact of green growth measures on countries’ economic performance. Environ. Dev. Sustain. https://doi.org/10.1007/s10668-023-02991-x (2023).
Article PubMed PubMed Central Google Scholar
Song, X., Zhou, Y. & Jia, W. How do economic openness and R&D investment affect green economic growth?—Evidence from China. Resour. Conserv. Recycl. 149 , 405–415. https://doi.org/10.1016/j.resconrec.2019.03.050 (2019).
Xu, J., She, S., Gao, P. & Sun, Y. Role of green finance in resource efficiency and green economic growth. Resour. Policy 81 , 103349 (2023).
Zhou, Y., Tian, L. & Yang, X. Schumpeterian endogenous growth model under green innovation and its enculturation effect. Energy Econ. 127 , 107109. https://doi.org/10.1016/j.eneco.2023.107109 (2023).
Luukkanen, J. et al. Resource efficiency and green economic sustainability transition evaluation of green growth productivity gap and governance challenges in Cambodia. Sustain. Dev. 27 (3), 312–320. https://doi.org/10.1002/sd.1902 (2019).
Wang, K., Umar, M., Akram, R. & Caglar, E. Is technological innovation making world “Greener”? An evidence from changing growth story of China. Technol. Forecast. Soc. Change 165 , 120516. https://doi.org/10.1016/j.techfore.2020.120516 (2021).
Talebzadehhosseini, S. & Garibay, I. The interaction effects of technological innovation and path-dependent economic growth on countries overall green growth performance. J. Clean. Prod. 333 (20), 130134. https://doi.org/10.1016/j.jclepro.2021.130134 (2022).
Ge, T., Li, C., Li, J. & Hao, X. Does neighboring green development benefit or suffer from local economic growth targets? Evidence from China. Econ. Modell. 120 , 106149. https://doi.org/10.1016/j.econmod.2022.106149 (2023).
Lin, B. & Zhu, J. Fiscal spending and green economic growth: Evidence from China. Energy Econ. 83 , 264–271. https://doi.org/10.1016/j.eneco.2019.07.010 (2019).
Sohail, M. T., Ullah, S. & Majeed, M. T. Effect of policy uncertainty on green growth in high-polluting economies. J. Clean. Prod. 380 (20), 135043. https://doi.org/10.1016/j.jclepro.2022.135043 (2022).
Sarwar, S. Impact of energy intensity, green economy and blue economy to achieve sustainable economic growth in GCC countries: Does Saudi Vision 2030 matters to GCC countries. Renew. Energy 191 , 30–46. https://doi.org/10.1016/j.renene.2022.03.122 (2022).
Park, J. & Page, G. W. Innovative green economy, urban economic performance and urban environments: An empirical analysis of US cities. Eur. Plann. Stud. 25 (5), 772–789. https://doi.org/10.1080/09654313.2017.1282078 (2017).
Feng, Y., Chen, Z. & Nie, C. The effect of broadband infrastructure construction on urban green innovation: Evidence from a quasi-natural experiment in China. Econ. Anal. Policy 77 , 581–598. https://doi.org/10.1016/j.eap.2022.12.020 (2023).
Zhang, X. & Fan, D. Collaborative emission reduction research on dual-pilot policies of the low-carbon city and smart city from the perspective of multiple innovations. Urban Climate 47 , 101364. https://doi.org/10.1016/j.uclim.2022.101364 (2023).
Cheng, J., Yi, J., Dai, S. & Xiong, Y. Can low-carbon city construction facilitate green growth? Evidence from China’s pilot low-carbon city initiative. J. Clean. Prod. 231 (10), 1158–1170. https://doi.org/10.1016/j.jclepro.2019.05.327 (2019).
Li, L. China’s manufacturing locus in 2025: With a comparison of “Made-in-China 2025” and “Industry 4.0”. Technol. Forecast. Soc. Change 135 , 66–74. https://doi.org/10.1016/j.techfore.2017.05.028 (2018).
Wang, J., Wu, H. & Chen, Y. Made in China 2025 and manufacturing strategy decisions with reverse QFD. Int. J. Prod. Econ. 224 , 107539. https://doi.org/10.1016/j.ijpe.2019.107539 (2020).
Liu, X., Megginson, W. L. & Xia, J. Industrial policy and asset prices: Evidence from the Made in China 2025 policy. J. Bank. Finance 142 , 106554. https://doi.org/10.1016/j.jbankfin.2022.106554 (2022).
Chen, K. et al. How does industrial policy experimentation influence innovation performance? A case of Made in China 2025. Humanit. Soc. Sci. Commun. 11 , 40. https://doi.org/10.1057/s41599-023-02497-x (2024).
Article CAS Google Scholar
Xu, L. Towards green innovation by China’s industrial policy: Evidence from Made in China 2025. Front. Environ. Sci. 10 , 924250. https://doi.org/10.3389/fenvs.2022.924250 (2022).
Li, X., Han, H. & He, H. Advanced manufacturing firms’ digital transformation and exploratory innovation. Appl. Econ. Lett. https://doi.org/10.1080/13504851.2024.2305665 (2024).
Liu, G. & Liu, B. How digital technology improves the high-quality development of enterprises and capital markets: A liquidity perspective. Finance Res. Lett. 53 , 103683 (2023).
Chernozhukov, V. et al. Double/debiased machine learning for treatment and structural parameters. Econom. J. 21 (1), C1–C68. https://doi.org/10.1111/ectj.12097 (2018).
Article MathSciNet Google Scholar
Athey, S., Tibshirani, J. & Wager, S. Generalized random forests. Ann. Stat. 47 (2), 1148–1178. https://doi.org/10.1214/18-AOS1709 (2019).
Knittel, C. R. & Stolper, S. Machine learning about treatment effect heterogeneity: The case of household energy use. AEA Pap. Proc. 111 , 440–444 (2021).
Yang, J., Chuang, H. & Kuan, C. Double machine learning with gradient boosting and its application to the Big N audit quality effect. J. Econom. 216 (1), 268–283. https://doi.org/10.1016/j.jeconom.2020.01.018 (2020).
Zhang, Y., Li, H. & Ren, G. Quantifying the social impacts of the London Night Tube with a double/debiased machine learning based difference-in-differences approach. Transp. Res. Part A Policy Pract. 163 , 288–303. https://doi.org/10.1016/j.tra.2022.07.015 (2022).
Farbmacher, H., Huber, M., Lafférs, L., Langen, H. & Spindler, M. Causal mediation analysis with double machine learning. Econom. J. 25 (2), 277–300. https://doi.org/10.1093/ectj/utac003 (2022).
Chiang, H., Kato, K., Ma, Y. & Sasaki, Y. Multiway cluster robust double/debiased machine learning. J. Bus. Econ. Stat. 40 (3), 1046–1056. https://doi.org/10.1080/07350015.2021.1895815 (2022).
Bodory, H., Huber, M. & Lafférs, L. Evaluating (weighted) dynamic treatment effects by double machine learning. Econom. J. 25 (3), 628–648. https://doi.org/10.1093/ectj/utac018 (2022).
Waheed, R., Sarwar, S. & Alsaggaf, M. I. Relevance of energy, green and blue factors to achieve sustainable economic growth: Empirical study of Saudi Arabia. Technol. Forecast. Soc. Change 187 , 122184. https://doi.org/10.1016/j.techfore.2022.122184 (2023).
Taskin, D., Vardar, G. & Okan, B. Does renewable energy promote green economic growth in OECD countries?. Sustain. Account. Manag. Policy J. 11 (4), 771–798. https://doi.org/10.1108/SAMPJ-04-2019-0192 (2020).
Ding, X. & Liu, X. Renewable energy development and transportation infrastructure matters for green economic growth? Empirical evidence from China. Econ. Anal. Policy 79 , 634–646. https://doi.org/10.1016/j.eap.2023.06.042 (2023).
Ferguson, P. The green economy agenda: Business as usual or transformational discourse?. Environ. Polit. 24 (1), 17–37. https://doi.org/10.1080/09644016.2014.919748 (2015).
Pan, D., Yu, Y., Hong, W. & Chen, S. Does campaign-style environmental regulation induce green economic growth? Evidence from China’s central environmental protection inspection policy. Energy Environ. https://doi.org/10.1177/0958305X231152483 (2023).
Zhang, Q., Qu, Y. & Zhan, L. Great transition and new pattern: Agriculture and rural area green development and its coordinated relationship with economic growth in China. J. Environ. Manag. 344 , 118563. https://doi.org/10.1016/j.jenvman.2023.118563 (2023).
Li, J., Dong, K. & Dong, X. Green energy as a new determinant of green growth in China: The role of green technological innovation. Energy Econ. 114 , 106260. https://doi.org/10.1016/j.eneco.2022.106260 (2022).
Herman, K. S. et al. A critical review of green growth indicators in G7 economies from 1990 to 2019. Sustain. Sci. 18 , 2589–2604. https://doi.org/10.1007/s11625-023-01397-y (2023).
Mura, M., Longo, M., Zanni, S. & Toschi, L. Exploring socio-economic externalities of development scenarios. An analysis of EU regions from 2008 to 2016. J. Environ. Manag. 332 , 117327. https://doi.org/10.1016/j.jenvman.2023.117327 (2023).
Huang, S. Do green financing and industrial structure matter for green economic recovery? Fresh empirical insights from Vietnam. Econ. Anal. Policy 75 , 61–73. https://doi.org/10.1016/j.eap.2022.04.010 (2022).
Li, J., Dong, X. & Dong, K. Is China’s green growth possible? The roles of green trade and green energy. Econ. Res.-Ekonomska Istraživanja 35 (1), 7084–7108. https://doi.org/10.1080/1331677X.2022.2058978 (2022).
Zhang, H. et al. Promoting eco-tourism for the green economic recovery in ASEAN. Econ. Change Restruct. 56 , 2021–2036. https://doi.org/10.1007/s10644-023-09492-x (2023).
Article ADS Google Scholar
Ahmed, F., Kousar, S., Pervaiz, A. & Shabbir, A. Do institutional quality and financial development affect sustainable economic growth? Evidence from South Asian countries. Borsa Istanbul Rev. 22 (1), 189–196. https://doi.org/10.1016/j.bir.2021.03.005 (2022).
Yuan, S., Li, C., Wang, M., Wu, H. & Chang, L. A way toward green economic growth: Role of energy efficiency and fiscal incentive in China. Econ. Anal. Policy 79 , 599–609. https://doi.org/10.1016/j.eap.2023.06.004 (2023).
Capasso, M., Hansen, T., Heiberg, J., Klitkou, A. & Steen, M. Green growth – A synthesis of scientific findings. Technol. Forecast. Soc. Change 146 , 390–402. https://doi.org/10.1016/j.techfore.2019.06.013 (2019).
Wei, X., Ren, H., Ullah, S. & Bozkurt, C. Does environmental entrepreneurship play a role in sustainable green development? Evidence from emerging Asian economies. Econ. Res. Ekonomska Istraživanja 36 (1), 73–85. https://doi.org/10.1080/1331677X.2022.2067887 (2023).
Iqbal, K., Sarfraz, M. & Khurshid,. Exploring the role of information communication technology, trade, and foreign direct investment to promote sustainable economic growth: Evidence from Belt and Road Initiative economies. Sustain. Dev. 31 (3), 1526–1535. https://doi.org/10.1002/sd.2464 (2023).
Li, Y., Zhang, J. & Lyu, Y. Toward inclusive green growth for sustainable development: A new perspective of labor market distortion. Bus. Strategy Environ. 32 (6), 3927–3950. https://doi.org/10.1002/bse.3346 (2023).
Chernozhukov, V. et al. Double/Debiased/Neyman machine learning of treatment effects. Am. Econ. Rev. 107 (5), 261–265. https://doi.org/10.1257/aer.p20171038 (2017).
Chen, C. Super efficiencies or super inefficiencies? Insights from a joint computation model for slacks-based measures in DEA. Eur. J. Op. Res. 226 (2), 258–267. https://doi.org/10.1016/j.ejor.2012.10.031 (2013).
Article ADS MathSciNet Google Scholar
Tone, K., Chang, T. & Wu, C. Handling negative data in slacks-based measure data envelopment analysis models. Eur. J. Op. Res. 282 (3), 926–935 (2020).
Sarkodie, S. A., Owusu, P. A. & Taden, J. Comprehensive green growth indicators across countries and territories. Sci. Data 10 , 413. https://doi.org/10.1038/s41597-023-02319-4 (2023).
Jiang, Z., Wang, Z. & Lan, X. How environmental regulations affect corporate innovation? The coupling mechanism of mandatory rules and voluntary management. Technol. Soc. 65 , 101575 (2021).
Oh, D. H. & Heshmati, A. A sequential Malmquist-Luenberger productivity index: Environmentally sensitive productivity growth considering the progressive nature of technology. Energy Econ. 32 (6), 1345–1355. https://doi.org/10.1016/j.eneco.2010.09.003 (2010).
Tone, K. & Tsutsui, M. An epsilon-based measure of efficiency in DEA - A third pole of technical efficiency. Eur. J. Op. Res. 207 (3), 1554–1563. https://doi.org/10.1016/j.ejor.2010.07.014 (2010).
Lv, C., Song, J. & Lee, C. Can digital finance narrow the regional disparities in the quality of economic growth? Evidence from China. Econ. Anal. Policy 76 , 502–521. https://doi.org/10.1016/j.eap.2022.08.022 (2022).
Arkhangelsky, D., Athey, S., Hirshberg, D. A., Imbens, G. W. & Wager, S. Synthetic difference-in-differences. Am. Econ. Rev. 111 (12), 4088–4118 (2021).
Abadie, A., Diamond, A. & Hainmueller, J. Synthetic control methods for comparative case studies: Estimating the effect of California’s tobacco control program. J. Am. Stat. Assoc. 105 (490), 493–505 (2010).
Article MathSciNet CAS Google Scholar
Fang, J., Tang, X., Xie, R. & Han, F. The effect of manufacturing agglomerations on smog pollution. Struct. Change Econ. Dyn. 54 , 92–101. https://doi.org/10.1016/j.strueco.2020.04.003 (2020).
Yang, S. & Liu, F. Impact of industrial intelligence on green total factor productivity: The indispensability of the environmental system. Ecol. Econ. 216 , 108021. https://doi.org/10.1016/j.ecolecon.2023.108021 (2024).
Zhang, P., Wang, Y., Wang, R. & Wang, T. Digital finance and corporate innovation: Evidence from China. Appl. Econ. 56 (5), 615–638. https://doi.org/10.1080/00036846.2023.2169242 (2024).
Download references
Acknowledgements
This work was supported by the Major Program of National Fund of Philosophy and Social Science of China (20&ZD133).
Author information
Authors and affiliations.
School of Public Finance and Taxation, Zhejiang University of Finance and Economics, Hangzhou, 310018, China
School of Economics, Xiamen University, Xiamen, 361005, China
Shucheng Liu
You can also search for this author in PubMed Google Scholar
Contributions
J.Y.: Methodology, Validation. S.L.: Writing - Reviewing and Editing, Validation, Methodology. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Correspondence to Shucheng Liu .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary information., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Yuan, J., Liu, S. A double machine learning model for measuring the impact of the Made in China 2025 strategy on green economic growth. Sci Rep 14 , 12026 (2024). https://doi.org/10.1038/s41598-024-62916-0
Download citation
Received : 05 March 2024
Accepted : 22 May 2024
Published : 26 May 2024
DOI : https://doi.org/10.1038/s41598-024-62916-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Made in China 2025
- Industrial policy
- Double machine learning
- Causal inference
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Anthropocene newsletter — what matters in anthropocene research, free to your inbox weekly.

Position: Why We Must Rethink Empirical Research in Machine Learning
We warn against a common but incomplete understanding of empirical research in machine learning that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical machine learning research is fashioned as confirmatory research while it should rather be considered exploratory.
1 The Non-Replicable ML Research Enigma
In his Caltech commencement address “Cargo Cult Science” ∗ , 1 1 1 As our paper contains some jargon, we have included a glossary in the appendix; asterisks ( ∗ ) (*) ( ∗ ) in the text denote covered terms. Richard Feynman ( 1974 ) described how researchers employ practices that conflict with scientific principles to adhere to a certain way of doing things. This position paper warns against similar tendencies in empirical research in machine learning (ML) and calls for a mindset change to address methodological and epistemic challenges of experimentation. There is ML research that does not replicate. From an empirical scientific perspective, non-replicable research is a fundamental problem. As Karl Popper (p. 66 1959/2002 ) phrased it: “non-reproducible single occurrences are of no significance to science.” 2 2 2 Reproducible here does not refer to exact computational reproducibility ∗ but generally to arriving at the same scientific conclusions, termed replicability ∗ in this paper. Consequently, ML research that does not replicate has far-reaching epistemic ∗ and practical consequences. From an epistemological ∗ point of view, it means that research results are unreliable and, to some extent, it calls into question progress in the field. In practice, it may jeopardize applied empirical researchers’ confidence in experimental results and discourage them from applying ML methods, even though these novel approaches might be beneficial. For example, ML is increasingly being used in the medical domain, and this is often promising in terms of patient benefit. However, there are also examples indicating that applied researchers (are starting to) have concerns about ML being used in this high-stakes area. Consider, for example, this quite drastic warning by Dhiman et al. ( 2022 , p. 2) : “Machine learning is often portrayed as offering many advantages […]. However, these advantages have not yet materialised into patient benefit […]. Given the increasing concern about the methodological quality and risk of bias of prediction model studies [emphasis added], caution is warranted and the lack of uptake of models in medical practice is not surprising.” That is, if the ML community does not improve rigor in empirical methodological research, we think there may be a risk of a backlash against the use of ML in practice. In general, there is a growing body of empirical evidence showing that conclusions drawn from experimental results in ML were overly optimistic at the time of publication and could not be replicated in subsequent studies. For example, Melis et al. ( 2018 , p. 1) “arrive at the somewhat surprising conclusion that standard LSTM architectures, when properly regularized, outperform more recent models”; Henderson et al. ( 2018 , p. 3213) found for deep reinforcement learning “that both intrinsic (e.g. random seeds, environment properties) and extrinsic sources (e.g. hyperparameters, codebases) of non-determinism can contribute to difficulties in reproducing baseline algorithms”; Christodoulou et al. ( 2019 , p. 12) found in a systematic review “no performance benefit of machine learning over logistic regression for clinical prediction models”; Elor & Averbuch-Elor ( 2022 , p. 1) found in their study on data balancing in classification “that balancing does not improve prediction performance for the strong” classifiers; see also Lucic et al. ( 2018 ) , Riquelme et al. ( 2018 ) , Raff ( 2019 ) , Herrmann et al. ( 2020 ) , Ferrari Dacrema et al. ( 2021 ) , Marie et al. ( 2021 ) , Buchka et al. ( 2021 ) , Narang et al. ( 2021 ) , van den Goorbergh et al. ( 2022 ) , Mateus et al. ( 2023 ) , McElfresh et al. ( 2023 ) , or the surveys by Liao et al. ( 2021 ) and Kapoor & Narayanan ( 2023 ) for similar findings. In concrete terms, there is published ML research that is, as Popper would say, of no significance to science , but we do not know how much! We have been warned; don’t we listen? We are by no means the first to raise these and related issues, and the very fact that we are not the first is a matter of even graver concern. We think that empirical research in ML finds itself in a situation where practicing questionable research practices, such as state-of-the-art-hacking (SOTA-hacking; Gencoglu et al., 2019 ; Hullman et al., 2022 ), has sometimes become more rewarding than following the long line of literature warning against it. Langley wrote an editorial “Machine Learning as an Experimental Science” as early as 1988, and Drummond and Hand pointed out problems with experimental method comparison in ML already in 2006. Apart from these specific examples, there is a range of literature over the last decades dealing with similar issues (e.g., Hooker, 1995 ; McGeoch, 2002 ; Johnson, 2002 ; Drummond, 2009 ; Drummond & Japkowicz, 2010 ; Mannarswamy & Roy, 2018 ; Sculley et al., 2018 ; Lipton & Steinhardt, 2018 ; Bouthillier et al., 2019 ; Liao et al., 2021 ; D’Amour et al., 2022 ; Raff & Farris, 2022 ; Lones, 2023 ; Trosten, 2023 ) . Specifically relevant is the paper by Nakkiran & Belkin ( 2022 , p. 2) , in which they note a “perceived lack of legitimacy and real lack of community for good experimental science” (still) exists. If we continue not to take these warnings seriously the amount of non-replicable research will only continue to increase, as the cited very recent empirical findings indicate. We do not believe that deliberate actions on the part of individuals have led to this situation but that there is a general unawareness of the fact that, while “follow[ing] all the apparent precepts and forms of scientific investigation [in ML],” one can be “missing something essential.” In particular, this includes that “if you’re doing an experiment, you should report everything that you think might make it invalid—not only what you think is right about it: other causes that could possibly explain your results; and things you thought of that you’ve eliminated by some other experiment, and how they worked” (quotes from Feynman, 1974 , p. 11) . Misaligned incentives and pressure to publish positive results contribute to this situation (e.g., Smaldino & McElreath, 2016 ) . One of a kind? At the intersection of formal and empirical sciences. We believe that one of the main reasons for this is that ML stands, like few other disciplines, at the interface between formal sciences and real-world applications. Because ML has strong foundations in formal sciences such as mathematics, (theoretical) computer science (CS), and mathematical statistics, many ML researchers are accustomed to reasoning mathematically about abstract objects – ML methods – using formal proofs. On the other hand, ML can also very much be considered a (software) engineering science, to create practical systems that can learn and improve their performance by interacting with their environment. Lastly, and especially concerning experimentation in ML, there exists an applied statistical perspective with a focus on thorough inductive reasoning. With its tradition in data analysis and design of experiments, it emphasizes the empirical aspects of ML research. These different perspectives, with their specific objectives, methodology, and terminology, have their unique virtues, but they also have their blind spots. The formal science perspective aims at providing absolute certainty and deep insights through the definition of abstract concepts and mathematical proofs but is often not well suited to explain complex real-world phenomena, as these concepts and proofs very often have to be based on strongly simplifying assumptions. The engineering perspective brought us incredible application improvements, but at the same time, not all conducted experiments are optimally designed to generalize results beyond the specific application context (which is also often only implicitly defined), as the references provided at the beginning demonstrate. A statistical perspective , which we adopt here, is very sensitive to such empirical issues – explaining/analyzing real-world phenomena and generalizing beyond a specific context (inductive reasoning) – and thus particularly suited to explain 1) why ML is faced with non-replicable research, and 2) how a more complete and nuanced understanding of empirical research in ML can help to overcome this situation. With empirical ML we thus mean in a broad sense the systematic investigation of ML algorithms, techniques, and conceptual questions through simulations, experimentation, and observation. It deals with real objects: implementations of algorithms – which are usually more complex than their theoretical counterparts (e.g., Kriegel et al., 2017 ) – running on physical computers; data gathered and produced/simulated in the real world; and their interplay. Rather than focusing solely on theoretical analysis and proofs, empirical research emphasizes practical evaluations using real-world and/or synthetic data. Empirical ML, as understood here, requires a mindset very different from engineering and formal sciences and a different approach to methodology to allow for the full incorporation of the uncertainties inherent in dealing with real-world entities in experiments. In our view, the discussed literature, raising similar points, has two main shortcomings: 1) they address only specific aspects of the problem and do not provide a comprehensive picture; 2) there is a confusion of terminology. For example, Bouthillier et al. ( 2019 ) distinguish between exploratory and empirical research. Nakkiran & Belkin ( 2022 ) use the term good experimental research and contrast it in particular with improving applications . Sculley et al. ( 2018 ) talk about empirical advancements and empirical analysis that are not complemented by sufficient empirical rigor . And Drummond ( 2006 ) discusses ML as an experimental science hardly using the term empirical at all. To overcome these issues, we gather opinions and (empirical) evidence scattered across the literature and different domains and try to develop a comprehensive synthesis . For example, similar problems have been discussed in bioinformatics for some time (e.g., Yousefi et al., 2010 ; Boulesteix, 2010 ) . We also take into account literature from other, more distant fields facing related issues, such as psychology and medicine. We believe this comprehensive picture will allow for a broader and deeper understanding of the complexity of the situation, which may at first glance appear to be rather easy to solve, e.g., by more (rigorous) statistical machinery or more open research artifacts. It is our conviction that without this deeper understanding, a situation that has been warned about in vain for so long cannot be overcome.
2 The Status Quo of Empirical ML
Recent advances..
It is important to emphasize that there have been encouraging first steps in terms of empirical ML research recently. This includes the newly created publication formats Transactions on Machine Learning Research (TMLR), Journal of Data-centric Machine Learning Research (DMLR), or the NeurIPS Datasets and Benchmarks Track launched in 2021. These venues explicitly include in their scope, e.g., “reproducibility studies of previously published results or claims” ( TMLR, n.d. ) , “systematic analyses of existing systems on novel datasets or benchmarks that yield important new insight” ( DMLR, n.d. ) , and “systematic analyses of existing systems on novel datasets yielding important new insight” ( NeurIPS, n.d. ) . Further examples are the I Can’t Believe It’s Not Better! (ICBINB) workshop series (e.g., Forde et al., 2020 ) and Repository of Unexpected Negative Results ( ICBINB Initiative, n.d. ) and efforts towards preregistration (e.g., Albanie et al., 2021 ) and reproducibility (e.g., Sinha et al., 2023 , ) . These developments, while very important, are not sufficient in our view to overcome the problems empirical ML faces. For example, while computational reproducibility ∗ may be a necessary condition, it is not a sufficient condition for replicability (e.g., Bouthillier et al., 2019 ) . Furthermore, while the topics in the above formats cover many important aspects of empirical ML, we feel that they do not emphasize enough the importance of true replication of research, which is paramount from an empirical perspective. Most importantly, a situation in which a line of research warning us for a long time has been largely neglected will not be overcome by such practical changes alone. It also requires a change in awareness – of the importance of proper empirical ML but maybe even more of its limitations; and that there are different, equally valid types of proper empirical inquiry. We see this lack of awareness evidenced by TMLR (n.d.) itself: “TMLR emphasizes technical correctness over subjective significance, to ensure that we facilitate scientific discourse on topics that may not yet be accepted in mainstream venues [emphasis added] but may be important in the future.” This is expressed in the talk introducing TMLR, too. 3 3 3 TMLR - A New Open Journal For Machine Learning: https://youtu.be/Uc1r1LfJtds Judging by the example of other empirical sciences, this general lack of awareness of proper empirical ML is certainly the most difficult thing to overcome. Below we discuss problems we identified as symptoms of this lack.
Problem 1: Lack of unbiased experiments and scrutiny. Most method comparisons are carried out as part of a paper introducing a new method and are usually biased in favor of the new method (see Section 1 for examples). Sculley et al. ( 2018 , p. 1) found that “[l]ooking over papers from the last year, there seems to be a clear trend of multiple groups finding that prior work in fast moving fields may have missed improvements or key insights due to things as simple as hyperparameter tuning studies [∗] or ablation studies.” Moreover, for a neutral method comparison study of survival prediction methods, it has been shown that method rankings can vary considerably depending on design and analysis choices made at the meta-level (e.g., the selected set of datasets, performance metric, aggregation method) and that any method – even a simple baseline – can achieve almost any rank ( Nießl et al., 2022 ; see also Sonabend et al., 2022 ). We are convinced that it is not far-fetched to conclude that quite often results demonstrating the superiority of a newly proposed method are obtained by an experimental design favorable to that method. As in other disciplines (Munafò et al., 2017 ) , there are structural issues (e.g., publication bias, pressure to publish, lack of replication studies) and questionable practices (e.g., hypothesizing after the results are known [ Kerr, 1998 , HARKing, ] and p 𝑝 p italic_p -hacking [ Simonsohn et al., 2014 ]) that contribute to this lack of unbiased experiments and scrutiny. At the individual level, in particular, there is a lack of awareness that method comparisons performed as part of a paper introducing a new method are not well suited to draw reliable conclusions about a method beyond the datasets considered, especially if 1) the number of datasets considered is small (Dehghani et al., 2021 ; Koch et al., 2021 ) , 2) there is meta-level overfitting on a single benchmark design (Recht et al., 2019 ; Beyer et al., 2020 ) , 3) the set of datasets selected for the experiments is biased in favor of the newly proposed method, and 4) the authors are much more familiar with the new method than with its competitors, as is the case frequently (Johnson, 2002 ; Boulesteix et al., 2013 , 2017 ) . Furthermore, it is very easy to artificially make a method appear superior (e.g., Jelizarow et al., 2010 ; Norel et al., 2011 ; Nießl et al., 2022 ; Ullmann et al., 2023 ; Pawel et al., 2024 ; Nießl et al., 2024 ) , and publication bias towards positive results is a strong incentive to engage in SOTA-hacking and demonstrate the superiority of a newly proposed method (Sculley et al., 2018 ; Gencoglu et al., 2019 ) . At the system level there is a publication bias and a lack of replication and neutral method comparison studies (e.g., Boulesteix et al., 2013 , 2015b ) . Sculley et al. ( 2018 , p. 1) “observe that the rate of empirical advancement [larger and more complex experiments] may not have been matched by consistent increase in the level of empirical rigor across the field as a whole.” In unsupervised learning, the problem is more pronounced than in supervised learning because “there is much less of a benchmarking tradition in the clustering area than in the field of supervised learning” (Van Mechelen et al., 2023 , p. 2; see also Zimmermann, 2020 ) .
Problem 2: Lack of legitimacy. The second problem highlights a specific aspect of the lack of awareness of how different types of empirical research can contribute to ML. The problem was addressed by Nakkiran & Belkin ( 2022 ) and we completely agree with their description: “In mainstream ML venues, there is a perceived lack of legitimacy and a real lack of community for good experimental science – which neither proves a theorem nor improves an application. This effectively suppresses a mode of scientific inquiry which has historically been critical to scientific progress, and which has shown promise in both ML and in CS more generally” (Nakkiran & Belkin, 2022 , p. 2) . They identify a strong bias of the ML community towards mathematical proofs (formal science perspective) and application improvements (engineering perspective), while good experimental science that does not focus on one of the above is not incentivized nor encouraged. Nakkiran & Belkin ( 2022 ) see this evidenced by the lack of specific subject areas, the exclusion from recent calls for papers, the lack of explicit guidelines for reviewers, and the organization of separate workshops on experimental scientific investigation at major ML conferences. In particular, reviewers “often ask for application improvements” and “for ‘theoretical justification’ for purely experimental papers” (Nakkiran & Belkin, 2022 , pp. 2–3) . Together these factors point to a structural problem hindering the recognition and promotion of some sorts of experimental research in ML. We completely agree with this view but think it may not immediately be clear what distinguishes improving an application from good experimental science at first sight. 4 4 4 To avoid misunderstandings: we do consider mathematical proofs and application improvements very valuable research! As we understand it, the focus on application improvement means that much empirical/experimental research in ML focuses on developing a new method and demonstrating that it is superior to existing methods by improving some (predictive) performance metric on specific real-world benchmark datasets. Good experimental science, on the other hand, is not about improving performance. It is about improving understanding and knowledge of a problem, a (class of) methods, or a phenomenon. Sculley et al. ( 2018 , p. 2) emphasize that “[e]mpirical studies [in ML] have become challenges to be ‘won’, rather than a process for developing insight and understanding. Ideally, the benefit of working with real data is to tune and examine the behavior of an algorithm under various sampling distributions, to learn about the strengths and weaknesses of the algorithms, as one would do in controlled studies.” And Rendsburg et al. ( 2020 , p. 9) argue, “it is particularly important that our community actively attempts to understand the inherent inductive biases, strengths, and also the weaknesses of algorithms. Finding examples where an algorithm works is important – but maybe even more important is to understand under which circumstances the algorithm produces misleading results.”
Problem 3: Lack of conceptual clarity and operationalization. There is a perceived lack of clarity about some important abstract concepts that are the objects of ML research on the one side and a lack of clear operationalization ∗ in empirical investigations on the other side. Both aspects affect the validity of experiments in empirical ML. This problem is the most complex one and probably for that reason the most difficult to describe in precise terms (cf. Saitta & Neri, 1998 ) . However, since we think that this problem affects the validity of empirical research in ML in a fundamental way, an account of empirical ML that does not attempt to make it tangible would be incomplete. We aim to narrow down the problem by explicating examples for supervised learning and unsupervised learning. In other sciences such as psychology and physics, validity ∗ , the fact that the experimental measurement process actually measures what it is intended to measure, is fundamental. It inevitably depends on a strict and thorough operationalization in what way abstract concepts that are to be measured relate to measurable entities in the real world. Note that “[o]perational analysis is an excellent diagnostic tool for revealing where our knowledge is weak, in order to guide our efforts to strengthening it. The Bridgmanian ideal [∗] is always to back up concepts with operational definitions, that is, to ensure that every concept is independently measurable in every circumstance under which it is used” (Chang, 2004 , p. 147) . It is puzzling that validity and other quality criteria of empirical research have gained little attention in ML so far (e.g., Myrtveit et al., 2005 ; Segebarth et al., 2020 ; Raji et al., 2021 ) . Experimental validity in supervised learning. For supervised learning, the problem can be exemplified by the question of inference from experimental results on real data in method comparison and evaluation studies. 5 5 5 Another example independently affecting validity is underspecification, which “is common in modern ML pipelines, such as those based on deep learning” (D’Amour et al., 2022 , p. 2) . Typically, the goal is to generalize the observed performance difference between methods to datasets that were not included in a study, which would require specifying when datasets are from the same/different domain. The problem is that it is not at all clear in what sense results obtained from one set of real datasets can be generalized to any other set of datasets, as this would require a clear understanding of the distribution of the data-generating processes by which each dataset is generated (e.g., Aha, 1992 ; Salzberg, 1997 ; Boulesteix et al., 2015a ; Herrmann, 2022 ; Strobl & Leisch, 2024 ) . Without a definition of the population of data-generating processes, i.e., (some) clarity about an abstract concept, it can be argued that it is not clear what a real data comparison study actually measures. In other words, the collection of datasets considered “will not be representative of real data sets in any formal sense” (Hand, 2006 , p. 12) . Dietterich ( 1998 , p. 4) even went so far as claiming that how to perform benchmark experiments on real datasets properly is “perhaps the most fundamental and difficult question in machine learning.” Experimental validity in unsupervised learning. Arguably, the situation is even more involved in unsupervised learning (e.g., Kleinberg, 2002 ; von Luxburg et al., 2012 ; Zimek & Filzmoser, 2018 ; Herrmann, 2022 ) . First of all, “there is no […] direct measure of success. It is difficult to ascertain the validity of inferences drawn from the output of most unsupervised learning algorithms” (Hastie et al., 2009 , p. 487) . This is aggravated by an ambiguity about the abstract concepts of interest. Consider, for example, cluster analysis. 6 6 6 See also Herrmann et al. ( 2023b ) for outlier detection. Usually, clusters are conceptualized as the modes of a mixture of (normal) distributions. However, there is a different perspective that considers cluster analysis from a topological perspective and conceptualizes clusters as the connected components of a dataset (Niyogi et al., 2011 ) . It is not clear if these different notions of clusters 1) conceptualize clusters equally well, 2) can be related to the same real-world entities, and 3) whether clustering methods developed based on these different notions are equally suitable for all clustering problems. There is some evidence that suggests this is not the case (Herrmann et al., 2023a ) .
Problem summary. We argue that much empirical ML research is prone to overly optimistic, unreliable, and difficult-to-refute judgments and conclusions. Many experiments in empirical ML research are based on insufficiently operationalized experimental setups, partially due to ambiguous and inconclusive conceptualizations underlying the experiments. To draw more reliable conclusions, we need more explicit, context-specific operationalizations and clearer delineations of the abstract concepts that are to be investigated. Recall that “[o]perational analysis is an excellent diagnostic tool for revealing where our knowledge is weak, in order to guide our efforts in strengthening it” (Chang, 2004 , p. 147) . That sometimes good experimental research is not encouraged enough in ML (see Problem 2) and biased experiments still occur more often than desirable (see Problem 1), exacerbates the situation considerably. The former is an excellent approach for improving insight and understanding in the sense outlined above, biased experiments tend to make this more difficult. These aspects are becoming specifically important in deep learning where the sheer complexity of today’s models, especially of foundation models, makes mathematical analysis extremely difficult. Instead, the analysis often needs to be largely experimental and thus requires thorough experimentation at the highest possible level.
3 Improving the Status Quo: More Richness in Empirical Methodological Research
A unifying view: we need exploratory and confirmatory..
Confirmatory research ∗ , also known as hypothesis-testing research, aims to test preexisting hypotheses to confirm or refute existing theories. Researchers design specific studies to evaluate hypotheses derived from existing knowledge experimentally. Typically, this involves a structured and predefined research design, a priori hypotheses, and often statistical analyses to draw conclusive inferences. In contrast, exploratory research is an open-ended approach that aims to gain insight and understanding in a new or unexplored area. It is often conducted when little is known about the phenomenon under study. It involves gathering information, identifying patterns, and formulating specific hypotheses for further investigation. One of our main points is that to improve empirical ML towards more thorough, reliable, and insightful methodological research both exploratory and confirmatory research are needed in ML (cf. Tukey, 1980 ) . In general, the problems described can be placed in this broader epistemic context. We argue that most empirical research in ML is perceived as confirmatory research, when it should rather be considered to be exploratory from an epistemic perspective (see also Bouthillier et al., 2019 ) . At the same time, purely exploratory methodological research focusing on improving insight and understanding experimentally (cf. Dietterich, 1990 ) and research like neutral method comparison and replication studies, which can be considered more rigorous in the confirmatory sense, are not seen as an equally important contribution to the field. For the time being, it is worth making this distinction, yet, we discuss why it is an oversimplification from an epistemic perspective in Section 4 – even more so, because we distinguish two types of exploratory empirical methodological research in the following: 7 7 7 It is not our intention to establish a precise terminology, but we think this structure will be of assistance to the reader. insight-oriented exploratory research ∗ in contrast to method-developing exploratory research ∗ . We think insight-oriented exploratory research is what Nakkiran & Belkin ( 2022 ) mean by good experimental research, and what they mean by application improvements is a conflation of both method-developing exploratory and (supposedly) confirmatory research.
More insight-oriented exploratory research. In principle, the good thing about moving towards more insight-oriented exploratory methodological research in ML is that there are no epistemological obstacles to overcome. The neighboring field data mining and knowledge discovery clearly has an exploratory nature and is very much in the spirit of Tukey’s exploratory data analysis. There are also already some examples of influential ML research that can be considered insight-oriented and exploratory, e.g., Frankle & Carbin ( 2019 ) , Belkin et al. ( 2019 ) , Recht et al. ( 2019 ) , Rendsburg et al. ( 2020 ) , Zhang et al. ( 2021 ) , or Power et al. ( 2021 ) . So, rather than epistemic aspects, it is the incentives and attitudes in scientific practice towards this type of research that are an obstacle to its successful dissemination. In particular, an alleged lack of novelty and originality is often invoked, which leads to rejections. Yet, without the esteem expressed by acceptance for publication, in particular in major ML venues, there is simply little incentive to engage in exploratory ML research. More importantly, it reinforces the impression among students and young scientists that exploratory research is not an integral part of science. It is therefore necessary to stimulate, encourage, and provide opportunities to make such research visible. Nakkiran & Belkin ( 2022 , pp. 4–5) propose to establish a special subject area within ML conferences for “Experimental Science of Machine Learning,” focusing on “experimental investigation into the nature of learning and learning systems.” The types of papers outlined include those with “surprising experiments,” “empirical conjectures,” “refining existing phenomena,” “formalizing intuition,” and presentation of “new measurement tool[s],” all aiming to improve the understanding of ML empirically. They also provide guidelines specifically tailored to the review of this type of research.
More (actual) confirmatory research. As outlined, we believe most current empirical ML research (i.e., application improvements) is a mixture of method-developing exploratory research and (supposedly) confirmatory research. 8 8 8 In a sense, this limits the potential of the former and renders the latter largely useless, with biased experiments as a result. For this reason, we add a focus on well-designed, neutral method comparison and replication studies. The scrutiny and rigor these examples of (actual) confirmatory empirical research provide are sorely needed if we are to work toward more reliable and replicable research. Neutral method comparison studies include experiments that are less biased in favor of newly proposed methods (Boulesteix et al., 2013 ; Lim et al., 2000 ; Ali & Smith, 2006 ; Fernández-Delgado et al., 2014 ) . First, this includes prespecified, strictly adhered-to designs of the experimental setup, including in particular a clearly specified set of datasets and tasks. Ideally, neutral comparison studies focus on the comparison of already existing methods and are carried out by a group of authors approximately equally familiar with all the methods under consideration (Boulesteix et al., 2013 ) . Such studies ensure more neutrality and are less prone to overly optimistic conclusions than studies proposing a method, since there is much less of an incentive to promote a particular method. Second, proper uncertainty quantification is required when analyzing empirical results in ML, especially w.r.t. the different stages of inference (e.g., model fitting, model selection, pipeline construction, and performance estimation) (see Nadeau & Bengio, 2003 ; Bengio & Grandvalet, 2004 ; Hothorn et al., 2005 ; Bates et al., 2023 ) . Moreover, if statistical significance testing is to be conducted to test for statistically significant performance differences across different real-world datasets, as described, e.g., by Demšar ( 2006 ) , Eugster et al. ( 2012 ) , Boulesteix et al. ( 2015a ) , or Eisinga et al. ( 2017 ) , the methodological rigor established in other empirical domains should be applied (Munafò et al., 2017 ) , in particular, efforts towards prior sample size calculations are important (Boulesteix et al., 2017 ) . Moreover, we need more replication studies and meta-studies . These types of research face similar reservations as insight-oriented exploratory experimental research. However, replication studies are indispensable to assess the amount of non-replicable research and to prevent it from being increased. Such studies attempt to reach the same scientific conclusions as previous studies, to provide additional empirical evidence for observed phenomena. Meta-studies analyze and summarize the so accumulated evidence on a specific phenomenon. This process is the default to reach conclusions in other sciences and is important as single studies can be false and/or contradict each other. In ML, this can range from studies that attempt to replicate an experiment exactly (e.g., Lohmann et al., 2022 ) or slightly modify an experiment’s design (e.g., by using a different set of data in the replication of a neutral comparison study) to more comprehensive tuning and ablation studies of experiments conducted in method-developing research (e.g., Rendsburg et al., 2020 ; Kobak & Linderman, 2021 ) . The latter certainly overlaps with insight-oriented exploratory research. It is important to emphasize that it is in the nature of things that a replication is not an original or novel scientific contribution in the conventional sense, and not necessarily can important new insights be gained beyond the replication of previously observed results. Rather, it is an explicit attempt to arrive at the same results and conclusions as a previous study. The scientific relevance, which is well acknowledged in other empirical sciences such as physics or medicine, lies in gathering additional empirical evidence for a hypothesis through a successful replication. Moreover, a replication study may, but does not necessarily, also raise epistemic questions, point to experimental improvements, or provide refined concepts, especially in failed replications.
More infrastructure. To achieve this, practical limitations also need to be overcome. We require more dedicated infrastructure to make the proposed forms of research more (easily) realizable. In particular, there is a need for more and better open databases of well-curated and well-understood datasets such as OpenML (Vanschoren et al., 2013 ) or OpenML Benchmarking Suites (Bischl et al., 2021 ) . Moreover, well-maintained open-source software for systematic benchmark experiments, such as the AutoML Benchmark (Gijsbers et al., 2024 ) , HPOBench (Eggensperger et al., 2021 ) , NAS-Bench-Suite (Mehta et al., 2022 ) , or AlgoPerf (Dahl et al., 2023 ) , are needed. Platforms for public leaderboards and model sharing (e.g., Hugging Face) are another important aspect, although some of these platforms are geared towards horse racing based on predictive performance and therefore do not necessarily also provide scientific insights or interpretability. Yet, the standards and automatic nature of such platforms have the advantage that they offer concrete reference points for criticism and debate. Finally, reviewer guidelines implementing our suggestions and dedicated venues for currently hard-to-publish empirical work will allow the full potential of empirical ML to be realized (Sculley et al., 2018 ; Nakkiran & Belkin, 2022 ) . Moreover, without more education , none of this will be possible. Given the different perspectives – formal science, engineering, statistical – from which ML can be viewed, it is very difficult to include each in the appropriate depth in a single study program. While a recent survey of 101 undergraduate data science programs in the U.S. showed that all included an introductory course in statistics (Bile Hassan et al., 2021 ) , statistics has only recently (2023) been included as a core topic in the curriculum recommendations for CS ∗ (Joint Task Force on Computing Curricula, 2023 ) . It is also questionable if introductory courses are sufficient to avoid crucial gaps that can lead to the adoption of questionable research practices (cf. Gigerenzer, 2018 ) . Furthermore, nearly no study program contains a dedicated course on design and analysis of (computer) experiments (Santner et al., 2003 ; Box et al., 2005 ; Dean et al., 2017 ) , which we deem especially relevant for our context here. In general, we agree with De Veaux et al. ( 2017 , pp. 16–17) that many “courses traditionally found in computer science, statistics, and mathematics offerings should be redesigned for the data science [or ML] major in the interest of efficiency and the potential synergy that integrated courses would offer.”
Finally, we would like to offer concrete and practicable advice to specific target groups, in addition to the general recommendations above. Advice for junior researchers. (1) Read the positive examples of insight-oriented exploratory research in ML (listed above), about the design of experiments, the critical discussion on statistical testing, and the basics of philosophy of science. (2) Educate yourself in Open Science practices (e.g., see The Turing Way Community, 2023 ) . (3) Engage with researchers from other disciplines as data (the one on which ML models are trained) can only really be understood if one understands how it was generated. (4) Consider making empirical research in ML a (partial) research focus. Advice for senior researchers. (1) Allow your junior researchers to write (great) papers on empirical aspects of ML, even if those may be relatively difficult to publish in major venues for now. Our personal experience is that these papers can still be highly cited and become very influential. (2) Learn from other fields; what we are experiencing in terms of non-replicable research is not a new phenomenon. (3) Please do not perceive this paper as an attack on ML but rather as an honest attempt to improve it and, more importantly, to improve its impact. Advice for venue organizers and editors (see also Nakkiran & Belkin, 2022 ) . (1) Encourage all forms of proper empirical ML to be submitted (in particular, this includes insight-oriented exploratory research), e.g., by creating special tracks or adding keywords but also by allowing such work on main tracks. The idea is to create special measures for the topic to increase awareness but not to isolate or ban all such papers to special (workshop) tracks with (potentially) lower perceived value. (2) Consider giving out awards for positive examples of these types of research. (3) Consider establishing positions like reproducibility and replicability editors for venues and journals. (4) Give concrete advice for best practices, so authors and reviewers have clear guidelines to follow. Note that this should not be confined to asking “Were the empirical results subjected to statistical tests?” (without further information); this is close to the opposite of what we think is needed. 9 9 9 One anonymous reviewer also suggested that venues start collecting metadata on reasons for rejection. Such data could serve as a basis to evaluate if certain types of ML research face a systematic bias.
4 Beyond the Status Quo: Rethinking Empirical ML as a Maturing Science
The exploratory-confirmatory research continuum..
With ML’s strong foundation in formal sciences, where absolute certainty can be achieved by formal proofs, the clear distinction between exploratory and confirmatory research that has been invoked so far may seem natural. Yet, from an empirical perspective, i.e., whenever one deals with entities in the real world, it is itself an oversimplifying dichotomy, and empirical research is better thought of as a continuum from exploratory to confirmatory, with an ideal of purely exploratory research at one end and of strictly confirmatory research at the other (e.g., Wagenmakers et al., 2012 ; Oberauer & Lewandowsky, 2019 ; Szollosi & Donkin, 2021 ; Scheel et al., 2021 ; Devezer et al., 2021 ; Rubin & Donkin, 2022 ; Höfler et al., 2022 ; Fife & Rodgers, 2022 ) . Based on that notion, Fife & Rodgers ( 2022 ) argue that “psychology may not be mature enough to justify confirmatory research” (p. 453) and that “[t]he maturity of any science puts a cap on the exploratory/confirmatory continuum” (p. 462). Given the similarities between research in psychology and ML as described by Hullman et al. ( 2022 ) , we think similar holds for ML and we suggest ML should be considered as a maturing (empirical) science as well. 10 10 10 There are also differences between ML and psychology considerably simplifying our lives: we usually do not experiment on humans but algorithms on computers and have more control over experiments, larger sample sizes, and lower experimental costs. Hullman et al. ( 2022 , p. 355) “identify common themes in reform discussions, like overreliance on asymptotic theory and non-credible beliefs about real-world data-generating processes.” That said, confirmatory research in ML as advocated in Section 3 is still very different from strict confirmatory research in other disciplines. Rather it can be seen as rough confirmatory research (Fife & Rodgers, 2022 ; Tukey, 1973 ) that follows the same principles, but – as outlined – it is unclear how results can be generalized (e.g., using statistical tests) – a cornerstone of strict confirmatory research. But this should not be taken as a caveat. Rough confirmatory research allows for flexibility that strict confirmatory research does not (Fife & Rodgers, 2022 ) . The framework proposed by Heinze et al. ( 2024 , p. 1) can be seen as a way of mapping this rather abstract idea into more concrete guidelines for scientific practice. In the context of biostatistics, they propose to consider four phases of methodological research, analogous to clinical research in drug development: “(I) proposing a new methodological idea while providing, for example, logical reasoning or proofs, (II) providing empirical evidence, first in a narrow target setting, then (III) in an extended range of settings and for various outcomes, accompanied by appropriate application examples, and (IV) investigations that establish a method as sufficiently well-understood to know when it is preferred over others and when it is not; that is, its pitfalls.”
Statistical significance tests: Words of caution, revisited! The problem of empirical research as a continuum is more involved epistemologically and cannot be discussed in full detail here. An important aspect that needs to be discussed is its relation to the misguided use of statistical testing. This point has been made by Drummond ( 2006 ) before and in more detail. We revisit it here, enriching it with more recent literature on the issue. In particular, routinely adding statistical machinery to an (already underspecified and/or biased) experimental design to test for statistically significant differences in performance – as is frequently done and/or explicitly asked for (e.g., Henderson et al., 2018 ; Marie et al., 2021 ) – does not improve the epistemic relevance of the results by much nor does it add much additional insight over other data aggregations. In fact, “[s]tatistical significance was never meant to imply scientific importance,” and you should not “conclude anything about scientific or practical importance based on statistical significance (or lack thereof)” (Wasserstein et al., 2019 , pp. 2, 1) . On the contrary, the misguided beliefs in and use of statistical rituals (Gigerenzer, 2018 ) is largely responsible for the replication crisis in other empirical disciplines. The reasons are complex. First of all, the modern theory of statistical hypothesis testing (SHT) is a conflation of two historically distinct types of testing theory ∗ . Important epistemological questions about when statistical tests are appropriate are obscured by this mixed theory (e.g., Schneider, 2015 ; Gigerenzer & Marewski, 2015 ; Rubin, 2020 ) . More importantly, specifically for experiments in ML, both theories are developed for experimental designs based on samples randomly drawn from a population of interest (Schneider, 2015 ) . In general, the assumptions underlying the theory of statistical testing as an inferential tool are usually not met in many applications (Greenland, 2023 ) . In fact, the editors of the The American Statistician special issue “Statistical Inference in the 21st Century: A World Beyond p < 0.05 𝑝 0.05 p<0.05 italic_p < 0.05 ” went so far as to conclude, “based on [their] review of the articles in this special issue and the broader literature, that it is time to stop using the term ‘statistically significant’ entirely” (Wasserstein et al., 2019 , p. 2) . Note that we want to warn against an overemphasis on as well as an uncritical use of statistical tests; we do not argue against statistical testing in general. Quite the contrary, we argue for a more diverse set of analysis tools (applied with care and critical reflection), including but not limited to statistical testing. We also want to stress that statistical testing cannot remedy more fundamental problems such as poor experimental design. To summarize the main points, we emphasize:
Valid statistical testing inevitably depends on a thorough and well-designed experimental setup.
Statistical testing should not be applied routinely and requires thought and careful preparation to be valid and insightful.
Improper statistical testing and/or its uneducated interpretation are – widely acknowledged – a main driver for non-replicable results in other empirical sciences.
The discussion about these issues has been going on for decades and has resulted in a large body of literature, some of which is condensed in the mentioned special issue of The American Statistician .
So, while we argue for more experiments in a confirmatory spirit to improve the status quo of empirical ML (see Section 3 ), especially using neutral method comparison and replication studies, we also emphasize that it is important to keep in mind their current epistemic limitations. In particular, we warn against common misconceptions about and inappropriate use of SHT. The problem is that the underlying “misunderstandings stem from a set of interrelated cognitive biases that reflect innate human compulsions which even the most advanced mathematical training seems to do nothing to staunch, and may even aggravate: Dichotomania, the tendency to reduce quantitative scales to dichotomies; nullism, the tendency to believe or at least act as if an unrefuted null hypothesis is true; and statistical reification, the tendency to forget that mathematical arguments say nothing about reality except to the extent the assumptions they make (which are often implicit) can be mapped into reality in a way that makes them all correct simultaneously” (Greenland, 2023 , p. 911) .
Most current empirical ML research should rather be viewed as exploratory. As outlined, confirmatory research aims to test preexisting hypotheses, while exploratory research involves gathering information, identifying patterns, and formulating specific hypotheses for further investigation. We think, currently, most of the empirical research in ML is conducted as part of a paper introducing a new method and is fashioned as confirmatory research even though it is exploratory in nature. In our view, this is reflected especially in the routine use of statistical tests to aggregate benchmark results: the exploratory phase of method development (e.g., trying out different method variants) largely invalidates post hoc statistical tests. As Strobl & Leisch ( 2024 , p. 2) put it: “In methodological research, comparison studies are often published either with the explicit or implicit aim to promote a new method by means of showing that it outperforms existing methods.” In other words, the conducted experiments are set up to confirm the (implicit) hypothesis that the proposed method constitutes an improvement. Systemic pressures and conventions, as well as ML’s strong roots in formal sciences and focus on improving applications, encourage this mindset and the practice of invoking confirmatory arguments. This is expressed in statements such as that “[i]t is well-known that reviewers ask for application improvements” and “for ‘theoretical justification’ for purely experimental papers, even when the experiments alone constitute a valid scientific contribution” (Nakkiran & Belkin, 2022 , pp. 2–3) . The problem with not emphasizing the exploratory nature is that “exploratory findings have a slippery way of ‘transforming’ into planned findings as the research process progresses” (Calin-Jageman & Cumming, 2019 , p. 275) and “[a]t the bottom of that slippery slope one often finds results that don’t reproduce” (Wasserstein et al., 2019 , p. 3) . Shifting the focus to an exploratory notion of method development is an opportunity to fully allow “to understand under which circumstances the algorithm produces misleading results” (Rendsburg et al., 2020 , p. 9) and to “learn about [its] strengths and weaknesses” (Sculley et al., 2018 , p. 2) and clearly report them.
5 Conclusion
This work offers perspectives on ML that outline how it should move from a field being largely driven by mathematical proofs and application improvements to also becoming a full-fledged empirical field driven by multiple types of experimental research. By providing concrete practical guidance but at the same time moderating expectations of what empirical research can achieve, we wish to contribute to greater overall reliability and trustworthiness. For every don’t, there is a do. However, we are aware that our explanations may initially leave the reader unsatisfied when it comes to translating the conclusions into scientific practice. For example, those who were hoping for guidelines on the correct use of statistical tests may well be at a complete loss. However, we do not believe that this is actually the case. If you are inclined to perform statistical tests as described by Demšar ( 2006 ) , do so, but also be aware of the Do-lists described by Wasserstein et al. ( 2019 , Ch. 3, 7) . In this regard, we consider the following comment by Wasserstein et al. (ib., p. 6) very noteworthy: “Researchers of any ilk may rarely advertise their personal modesty. Yet, the most successful ones cultivate a practice of being modest throughout their research, by understanding and clearly expressing the limitations of their work.” Furthermore, do not only rely on real data, use simulated data as well. Simulations are an excellent tool for operationalization, i.e., mapping abstract concepts to measurable entities. Yet, the most important point is that we should be open to different ways of doing experimental research and should not penalize research just because it does not follow certain established conventions. As Nakkiran & Belkin ( 2022 , p. 6) put it: “Each paper must be evaluated on an individual basis”; this is challenging, but they suggest guidelines. The community should take them up to address this issue. Embracing inconclusiveness. Summarizing the perspectives on empirical ML covered here, and returning to the idea of mature sciences, we believe that for ML to mature as an (empirical) science, a greater awareness of some epistemic limitations, but also of the plurality of ways to gain insights, might be all it needs. We believe that if empirical research is one thing, it is not conclusive and no single empirical study can prove anything with absolute certainty. It must be scrutinized, repeated, and reassessed in a sense of epistemic iteration ∗ (Chang, 2004 ) . That said, we conclude by quoting Chang ’s thoughts (ib., p. 243) on science in general: “If something is actually uncertain, our knowledge is superior if it is accompanied by an appropriate degree of doubt rather than blind faith. If the reasons we have for a certain belief are inconclusive, being aware of the inconclusiveness prepares us better for the possibility that other reasons may emerge to overturn our belief. With a critical awareness of uncertainty and inconclusiveness, our knowledge reaches a higher level of flexibility and sophistication.”
Impact Statement
This position paper aims to advance machine learning by addressing practical challenges and epistemic constraints of empirical research that are often overlooked. We believe this has implications for machine learning research in general, as it can help to improve the reliability and credibility of research results. We also believe that our contribution can have a broader positive social and ethical impact by preventing misdirected efforts and resources.
Acknowledgments
We thank the four anonymous reviewers for their valuable comments and suggestions. Katharina Eggensperger is a member of the Machine Learning Cluster of Excellence, EXC number 2064/1 – Project number 390727645. Anne-Laure Boulesteix was partly funded by DFG grant BO3139/9-1.
- Aha (1992) Aha, D. W. Generalizing from case studies: A case study. In Sleeman, D. and Edwards, P. (eds.), Machine Learning Proceedings 1992 , pp. 1–10, San Francisco, CA, United States, 1992. Morgan Kaufmann. doi: 10.1016/B978-1-55860-247-2.50006-1 .
- Albanie et al. (2021) Albanie, S., Henriques, J., Bertinetto, L., Hernandez-Garcia, A., Doughty, H., and Varol, G. The pre-registration workshop: An alternative publication model for machine learning research [Workshop]. Thirty-Fifth Conference on Neural Information Processing Systems , Online, 2021. https://neurips.cc/Conferences/2021/Schedule?showEvent=21885 .
- Ali & Smith (2006) Ali, S. and Smith, K. A. On learning algorithm selection for classification. Applied Soft Computing , 6(2):119–138, 2006. doi: 10.1016/j.asoc.2004.12.002 .
- Barba (2018) Barba, L. A. Terminologies for reproducible research. arXiv:1802.03311 [cs.DL] , 2018. doi: 10.48550/arXiv.1802.03311 .
- Bates et al. (2023) Bates, S., Hastie, T., and Tibshirani, R. Cross-validation: What does it estimate and how well does it do it? Journal of the American Statistical Association , pp. 1–12, 2023. doi: 10.1080/01621459.2023.2197686 .
- Belkin et al. (2019) Belkin, M., Hsu, D., Ma, S., and Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proceedings of the National Academy of Sciences , 116(32):15849–15854, 2019. doi: 10.1073/pnas.1903070116 .
- Bengio & Grandvalet (2004) Bengio, Y. and Grandvalet, Y. No unbiased estimator of the variance of K-fold cross-validation. Journal of Machine Learning Research , 5:1089–1105, 2004. https://www.jmlr.org/papers/v5/grandvalet04a.html .
- Bergstra et al. (2011) Bergstra, J., Bardenet, R., Bengio, Y., and Kégl, B. Algorithms for hyper-parameter optimization. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K. (eds.), Advances in Neural Information Processing Systems , volume 24, Granada, Spain, 2011. Curran Associates, Inc. https://papers.neurips.cc/paper_files/paper/2011/hash/86e8f7ab32cfd12577bc2619bc635690-Abstract.html .
- Bergstra et al. (2013) Bergstra, J., Yamins, D., and Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Dasgupta, S. and McAllester, D. (eds.), Proceedings of the 30th International Conference on Machine Learning , pp. 115–123, Atlanta, GA, United States, 2013. PMLR. https://proceedings.mlr.press/v28/bergstra13.html .
- Beyer et al. (2020) Beyer, L., Hénaff, O. J., Kolesnikov, A., Zhai, X., and van den Oord, A. Are we done with ImageNet? arXiv:2006.07159 [cs.CV] , 2020. doi: 10.48550/arXiv.2006.07159 .
- Bile Hassan et al. (2021) Bile Hassan, I., Ghanem, T., Jacobson, D., Jin, S., Johnson, K., Sulieman, D., and Wei, W. Data science curriculum design: A case study. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education , pp. 529–534, Online, 2021. Association for Computing Machinery. doi: 10.1145/3408877.3432443 .
- Bischl et al. (2021) Bischl, B., Casalicchio, G., Feurer, M., Gijsbers, P., Hutter, F., Lang, M., Gomes Mantovani, R., van Rijn, J., and Vanschoren, J. OpenML benchmarking suites. In Vanschoren, J. and Yeung, S. (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , volume 1, Online, 2021. Curran Associates, Inc. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/hash/c7e1249ffc03eb9ded908c236bd1996d-Abstract-round2.html .
- Bischl et al. (2023) Bischl, B., Binder, M., Lang, M., Pielok, T., Richter, J., Coors, S., Thomas, J., Ullmann, T., Becker, M., Boulesteix, A.-L., Deng, D., and Lindauer, M. Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 13(2):e1484, 2023. doi: 10.1002/widm.1484 .
- Boulesteix (2010) Boulesteix, A.-L. Over-optimism in bioinformatics research. Bioinformatics , 26(3):437–439, 2010. doi: 10.1093/bioinformatics/btp648 .
- Boulesteix et al. (2013) Boulesteix, A.-L., Lauer, S., and Eugster, M. J. A. A plea for neutral comparison studies in computational sciences. PLoS ONE , 8(4):e61562, 2013. doi: 10.1371/journal.pone.0061562 .
- Boulesteix et al. (2015a) Boulesteix, A.-L., Hable, R., Lauer, S., and Eugster, M. J. A. A statistical framework for hypothesis testing in real data comparison studies. The American Statistician , 69(3):201–212, 2015a. doi: 10.1080/00031305.2015.1005128 .
- Boulesteix et al. (2015b) Boulesteix, A.-L., Stierle, V., and Hapfelmeier, A. Publication bias in methodological computational research. Cancer Informatics , 14(S5):11–19, 2015b. doi: 10.4137/CIN.S30747 .
- Boulesteix et al. (2017) Boulesteix, A.-L., Wilson, R., and Hapfelmeier, A. Towards evidence-based computational statistics: Lessons from clinical research on the role and design of real-data benchmark studies. BMC Medical Research Methodology , 17(1):138, 2017. doi: 10.1186/s12874-017-0417-2 .
- Bouthillier et al. (2019) Bouthillier, X., Laurent, C., and Vincent, P. Unreproducible research is reproducible. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning , pp. 725–734, Long Beach, CA, United States, 2019. PMLR. https://proceedings.mlr.press/v97/bouthillier19a.html .
- Bouthillier et al. (2021) Bouthillier, X., Delaunay, P., Bronzi, M., Trofimov, A., Nichyporuk, B., Szeto, J., Mohammadi Sepahvand, N., Raff, E., Madan, K., Voleti, V., Ebrahimi Kahou, S., Michalski, V., Arbel, T., Pal, C., Varoquaux, G., and Vincent, P. Accounting for variance in machine learning benchmarks. In Smola, A., Dimakis, A., and Stoica, I. (eds.), Proceedings of Machine Learning and Systems , volume 3, pp. 747–769, Online, 2021. https://proceedings.mlsys.org/paper_files/paper/2021/hash/0184b0cd3cfb185989f858a1d9f5c1eb-Abstract.html .
- Box et al. (2005) Box, G. E. P., Hunter, J. S., and Hunter, W. G. Statistics for Experimenters: Design, Innovation, and Discovery . Wiley Series in Probability and Statistics. John Wiley Wiley and Sons, 2nd edition, 2005.
- Bridgman (1927) Bridgman, P. W. The Logic of Modern Physics . Macmillan, 1927.
- Buchka et al. (2021) Buchka, S., Hapfelmeier, A., Gardner, P. P., Wilson, R., and Boulesteix, A.-L. On the optimistic performance evaluation of newly introduced bioinformatic methods. Genome Biology , 22(1):152, 2021. doi: 10.1186/s13059-021-02365-4 .
- Calin-Jageman & Cumming (2019) Calin-Jageman, R. J. and Cumming, G. The new statistics for better science: Ask how much, how uncertain, and what else is known. The American Statistician , 73(sup1):271–280, 2019. doi: 10.1080/00031305.2018.1518266 .
- Campell (1957) Campell, D. T. Factors relevant to the validity of experiments in social settings. Psychological Bulletin , 54(4):297–312, 1957. doi: 10.1037/h0040950 .
- Chang (2004) Chang, H. Inventing temperature: Measurement and scientific progress . Oxford University Press, 2004.
- Chang (2021) Chang, H. Operationalism. In Zalta, E. N. (ed.), The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, Fall 2021 edition, 2021. https://plato.stanford.edu/archives/fall2021/entries/operationalism/ .
- Christodoulou et al. (2019) Christodoulou, E., Ma, J., Collins, G. S., Steyerberg, E. W., Verbakel, J. Y., and Van Calster, B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. Journal of Clinical Epidemiology , 110:12–22, 2019. doi: 10.1016/j.jclinepi.2019.02.004 .
- Conference on Neural Information Processing Systems (n.d.) Conference on Neural Information Processing Systems. NeurIPS 2023 Datasets and Benchmarks Track, n.d. Retrieved January 31, 2024, from https://neurips.cc/Conferences/2023/CallForDatasetsBenchmarks .
- Dahl et al. (2023) Dahl, G. E., Schneider, F., Nado, Z., Agarwal, N., Sastry, C. S., Hennig, P., Medapati, S., Eschenhagen, R., Kasimbeg, P., Suo, D., Bae, J., Gilmer, J., Peirson, A. L., Khan, B., Anil, R., Rabbat, M., Krishnan, S., Snider, D., Amid, E., Chen, K., Maddison, C. J., Vasudev, R., Badura, M., Garg, A., and Mattson, P. Benchmarking neural network training algorithms. arXiv:2306.07179 [cs.LG] , 2023. doi: 10.48550/arXiv.2306.07179 .
- D’Amour et al. (2022) D’Amour, A., Heller, K., Moldovan, D., Adlam, B., Alipanahi, B., Beutel, A., Chen, C., Deaton, J., Eisenstein, J., Hoffman, M. D., Hormozdiari, F., Houlsby, N., Hou, S., Jerfel, G., Karthikesalingam, A., Lucic, M., Ma, Y., McLean, C., Mincu, D., Mitani, A., Montanari, A., Nado, Z., Natarajan, V., Nielson, C., Osborne, T. F., Raman, R., Ramasamy, K., Sayres, R., Schrouff, J., Seneviratne, M., Sequeira, S., Suresh, H., Veitch, V., Vladymyrov, M., Wang, X., Webster, K., Yadlowsky, S., Yun, T., Zhai, X., and Sculley, D. Underspecification presents challenges for credibility in modern machine learning. Journal of Machine Learning Research , 23:1–61, 2022. https://www.jmlr.org/papers/v23/20-1335.html .
- De Veaux et al. (2017) De Veaux, R. D., Agarwal, M., Averett, M., Baumer, B. S., Bray, A., Bressoud, T. C., Bryant, L., Cheng, L. Z., Francis, A., Gould, R., Kim, A. Y., Kretchmar, M., Lu, Q., Moskol, A., Nolan, D., Pelayo, R., Raleigh, S., Sethi, R. J., Sondjaja, M., Tiruviluamala, N., Uhlig, P. X., Washington, T. M., Wesley, C. L., White, D., and Ye, P. Curriculum guidelines for undergraduate programs in data science. Annual Review of Statistics and Its Application , 4:15–30, 2017. doi: 10.1146/annurev-statistics-060116-053930 .
- Dean et al. (2017) Dean, A., Voss, D., and Draguljić, D. Design and Analysis of Experiments . Springer Texts in Statistics. Springer, 2nd edition, 2017. doi: 10.1007/978-3-319-52250-0 .
- Dehghani et al. (2021) Dehghani, M., Tay, Y., Gritsenko, A. A., Zhao, Z., Houlsby, N., Diaz, F., Metzler, D., and Vinyals, O. The benchmark lottery. arXiv:2107.07002 [cs.LG] , 2021. doi: 10.48550/arXiv.2107.07002 .
- Demšar (2006) Demšar, J. Statistical comparisons of classifiers over multiple data sets. Journal of Machine Learning Research , 7:1–30, 2006. https://jmlr.org/papers/v7/demsar06a.html .
- Devezer et al. (2021) Devezer, B., Navarro, D. J., Vandekerckhove, J., and Buzbas, E. O. The case for formal methodology in scientific reform. Royal Society Open Science , 8(3):200805, 2021. doi: 10.1098/rsos.200805 .
- Dhiman et al. (2022) Dhiman, P., Ma, J., Andaur Navarro, C. L., Speich, B., Bullock, G., Damen, J. A. A., Hooft, L., Kirtley, S., Riley, R. D., Van Calster, B., Moons, K. G. M., and Collins, G. S. Risk of bias of prognostic models developed using machine learning: A systematic review in oncology. Diagnostic and Prognostic Research , 6:13, 2022. doi: 10.1186/s41512-022-00126-w .
- Dietterich (1990) Dietterich, T. G. Exploratory research in machine learning. Machine Learning , 5(1):5–9, 1990. doi: 10.1007/BF00115892 .
- Dietterich (1998) Dietterich, T. G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Computation , 10(7):1895–1923, 1998. doi: 10.1162/089976698300017197 .
- Drummond (2006) Drummond, C. Machine learning as an experimental science (revisited). In AAAI Workshop on Evaluation Methods for Machine Learning , Boston, MA, United States, 2006. https://aaai.org/papers/ws06-06-002-machine-learning-as-an-experimental-science-revisited/ .
- Drummond (2009) Drummond, C. Replicability is not reproducibility: Nor is it good science. In Proceedings of the Evaluation Methods for Machine Learning Workshop at the 26th Annual International Conference on Machine Learning , Montreal, Canada, 2009. https://www.site.uottawa.ca/~cdrummon/pubs/ICMLws09.pdf .
- Drummond & Japkowicz (2010) Drummond, C. and Japkowicz, N. Warning: Statistical benchmarking is addictive. Kicking the habit in machine learning. Journal of Experimental & Theoretical Artificial Intelligence , 22(1):67–80, 2010. doi: 10.1080/09528130903010295 .
- Eggensperger et al. (2021) Eggensperger, K., Müller, P., Mallik, N., Feurer, M., Sass, R., Klein, A., Awad, N., Lindauer, M., and Hutter, F. HPOBench: A collection of reproducible multi-fidelity benchmark problems for HPO. In Vanschoren, J. and Yeung, S. (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , volume 1, Online, 2021. Curran Associates, Inc. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/hash/93db85ed909c13838ff95ccfa94cebd9-Abstract-round2.html .
- Eisinga et al. (2017) Eisinga, R., Heskes, T., Pelzer, B., and Te Grotenhuis, M. Exact p -values for pairwise comparison of Friedman rank sums, with application to comparing classifiers. BMC Bioinformatics , 18(1):68, 2017. doi: 10.1186/s12859-017-1486-2 .
- Elor & Averbuch-Elor (2022) Elor, Y. and Averbuch-Elor, H. To SMOTE, or not to SMOTE? arXiv:2201.08528 [cs.LG] , 2022. doi: 10.48550/arXiv.2201.08528 .
- Eugster et al. (2012) Eugster, M. J. A., Hothorn, T., and Leisch, F. Domain-based benchmark experiments: Exploratory and inferential analysis. Austrian Journal of Statistics , 41(1):5–26, 2012. doi: 10.17713/ajs.v41i1.185 .
- Fernández-Delgado et al. (2014) Fernández-Delgado, M., Cernadas, E., Barro, S., and Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? Journal of Machine Learning Research , 15:3133–3181, 2014. https://jmlr.org/papers/v15/delgado14a.html .
- Ferrari Dacrema et al. (2021) Ferrari Dacrema, M., Boglio, S., Cremonesi, P., and Jannach, D. A troubling analysis of reproducibility and progress in recommender systems research. ACM Transactions on Information Systems , 39(2):1–49, 2021. doi: 10.1145/3434185 .
- Feurer & Hutter (2019) Feurer, M. and Hutter, F. Hyperparameter optimization. In Hutter, F., Kotthoff, L., and Vanschoren, J. (eds.), Automated Machine Learning: Methods, Systems, Challenges , The Springer Series on Challenges in Machine Learning, pp. 3–33. Springer, 2019. doi: 10.1007/978-3-030-05318-5_1 .
- Feynman (1974) Feynman, R. P. Cargo cult science. Engineering and Science , 37(7):10–13, 1974. Transcript of commencement address given at the California Institute of Technology. Available at http://calteches.library.caltech.edu/51/2/CargoCult.htm .
- Fife & Rodgers (2022) Fife, D. A. and Rodgers, J. L. Understanding the exploratory/confirmatory data analysis continuum: Moving beyond the “replication crisis”. American Psychologist , 77(3):453–466, 2022. doi: 10.1037/amp0000886 .
- Forde et al. (2020) Forde, J. Z., Ruiz, F., Pradier, M. F., and Schein, A. I can’t believe it’s not better! Bridging the gap between theory and empiricism in probabilistic machine learning [Workshop]. Thirty-Fourth Conference on Neural Information Processing Systems , Online, 2020. https://neurips.cc/virtual/2020/protected/workshop_16124.html .
- Foster (2024) Foster, C. Methodological pragmatism in educational research: From qualitative-quantitative to exploratory-confirmatory distinctions. International Journal of Research & Method in Education , 47(1):4–19, 2024. doi: 10.1080/1743727X.2023.2210063 .
- Frankle & Carbin (2019) Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In 7th International Conference on Learning Representations , New Orleans, LA, United States, 2019. https://openreview.net/forum?id=rJl-b3RcF7 .
- Franklin & Perovic (2023) Franklin, A. and Perovic, S. Experiment in physics. In Zalta, E. N. and Nodelman, U. (eds.), The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, Fall 2023 edition, 2023. https://plato.stanford.edu/archives/fall2023/entries/physics-experiment/ .
- Gencoglu et al. (2019) Gencoglu, O., van Gils, M., Guldogan, E., Morikawa, C., Süzen, M., Gruber, M., Leinonen, J., and Huttunen, H. HARK side of deep learning – From grad student descent to automated machine learning. arXiv:1904.07633 [cs.LG] , 2019. doi: 10.48550/arXiv.1904.07633 .
- Gigerenzer (2018) Gigerenzer, G. Statistical rituals: The replication delusion and how we got there. Advances in Methods and Practices in Psychological Science , 1(2):198–218, 2018. doi: 10.1177/2515245918771329 .
- Gigerenzer & Marewski (2015) Gigerenzer, G. and Marewski, J. N. Surrogate science: The idol of a universal method for scientific inference. Journal of Management , 41(2):421–440, 2015. doi: 10.1177/0149206314547522 .
- Gijsbers et al. (2024) Gijsbers, P., Bueno, M. L. P., Coors, S., LeDell, E., Poirier, S., Thomas, J., Bischl, B., and Vanschoren, J. AMLB: An AutoML benchmark. Journal of Machine Learning Research , 25:1–65, 2024. https://www.jmlr.org/papers/v25/22-0493.html .
- Greenland (2023) Greenland, S. Connecting simple and precise P -values to complex and ambiguous realities (includes rejoinder to comments on “Divergence vs. decision P -values”). Scandinavian Journal of Statistics , 50(3):899–914, 2023. doi: 10.1111/sjos.12645 .
- Gundersen (2021) Gundersen, O. E. The fundamental principles of reproducibility. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , 379(2197):20200210, 2021. doi: 10.1098/rsta.2020.0210 .
- Hand (2006) Hand, D. J. Classifier technology and the illusion of progress. Statistical Science , 21(1):1–14, 2006. doi: 10.1214/088342306000000060 .
- Hastie et al. (2009) Hastie, T., Tibshirani, R., and Friedman, J. H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction . Springer Series in Statistics. Springer, 2nd edition, 2009. doi: 10.1007/978-0-387-84858-7 .
- Heinze et al. (2024) Heinze, G., Boulesteix, A.-L., Kammer, M., Morris, T. P., White, I. R., and Simulation Panel of the STRATOS initiative. Phases of methodological research in biostatistics—building the evidence base for new methods. Biometrical Journal , 66(1):2200222, 2024. doi: 10.1002/bimj.202200222 .
- Henderson et al. (2018) Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., and Meger, D. Deep reinforcement learning that matters. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence , pp. 3207–3214, New Orleans, LA, United States, 2018. AAAI Press. doi: 10.1609/aaai.v32i1.11694 .
- Herrmann (2022) Herrmann, M. Towards more reliable machine learning: Conceptual insights and practical approaches for unsupervised manifold learning and supervised benchmark studies . PhD thesis, Ludwig-Maximilians-Universität München, Munich, Germany, 2022. doi: 10.5282/edoc.30789 .
- Herrmann et al. (2020) Herrmann, M., Probst, P., Hornung, R., Jurinovic, V., and Boulesteix, A.-L. Large-scale benchmark study of survival prediction methods using multi-omics data. Briefings in Bioinformatics , 22(3):bbaa167, 2020. doi: 10.1093/bib/bbaa167 .
- Herrmann et al. (2023a) Herrmann, M., Kazempour, D., Scheipl, F., and Kröger, P. Enhancing cluster analysis via topological manifold learning. Data Mining and Knowledge Discovery , pp. 1–48, 2023a. doi: 10.1007/s10618-023-00980-2 .
- Herrmann et al. (2023b) Herrmann, M., Pfisterer, F., and Scheipl, F. A geometric framework for outlier detection in high-dimensional data. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 13(3):e1491, 2023b. doi: 10.1002/widm.1491 .
- Höfler et al. (2022) Höfler, M., Scherbaum, S., Kanske, P., McDonald, B., and Miller, R. Means to valuable exploration: I. The blending of confirmation and exploration and how to resolve it. Meta-Psychology , 6, 2022. doi: 10.15626/MP.2021.2837 .
- Hooker (1995) Hooker, J. N. Testing heuristics: We have it all wrong. Journal of Heuristics , 1:33–42, 1995. doi: 10.1007/BF02430364 .
- Hothorn et al. (2005) Hothorn, T., Leisch, F., Zeileis, A., and Hornik, K. The design and analysis of benchmark experiments. Journal of Computational and Graphical Statistics , 14(3):675–699, 2005. doi: 10.1198/106186005X59630 .
- Hullman et al. (2022) Hullman, J., Kapoor, S., Nanayakkara, P., Gelman, A., and Narayanan, A. The worst of both worlds: A comparative analysis of errors in learning from data in psychology and machine learning. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society , pp. 335–348, Oxford, United Kingdom, 2022. Association for Computing Machinery. doi: 10.1145/3514094.3534196 .
- ICBINB Initiative (n.d.) ICBINB Initiative. ICBINB Repository of Unexpected Negative Results, n.d. Retrieved January 31, 2024, from http://icbinb.cc/icbinb-repository-of-unexpected-negative-results/ .
- Jaeger & Halliday (1998) Jaeger, R. G. and Halliday, T. R. On confirmatory versus exploratory research. Herpetologica , 54:S64–S66, 1998. https://www.jstor.org/stable/3893289 .
- Jelizarow et al. (2010) Jelizarow, M., Guillemot, V., Tenenhaus, A., Strimmer, K., and Boulesteix, A.-L. Over-optimism in bioinformatics: An illustration. Bioinformatics , 26(16):1990–1998, 2010. doi: 10.1093/bioinformatics/btq323 .
- Johnson (2002) Johnson, D. S. A theoretician’s guide to the experimental analysis of algorithms. In Goldwasser, M. H., Johnson, D. S., and McGeoch, C. C. (eds.), Data Structures, Near Neighbor Searches, and Methodology: Fifth and Sixth DIMACS Implementation Challenges , volume 59 of Series in Discrete Mathematics & Theoretical Computer Science , pp. 215–250. American Mathematical Society, 2002.
- Joint Task Force on Computing Curricula (2013) Joint Task Force on Computing Curricula. Computer Science Curricula 2013: Curriculum Guidelines for Undergraduate Degree Programs in Computer Science . Association for Computing Machinery and IEEE Computer Society, 2013. doi: 10.1145/2534860 .
- Joint Task Force on Computing Curricula (2023) Joint Task Force on Computing Curricula. Computer Science Curricula 2023 – The Final Report . Association for Computing Machinery, IEEE Computer Society, and Association for the Advancement of Artificial Intelligence, 2023. The report is not yet listed on the ACM curricula recommendation website. The final version is available at https://csed.acm.org/final-report/ .
- Journal of Data-centric Machine Learning Research (n.d.) Journal of Data-centric Machine Learning Research. Submission guidelines for authors, n.d. Retrieved January 31, 2024, from https://data.mlr.press/submissions.html .
- Kapoor & Narayanan (2023) Kapoor, S. and Narayanan, A. Leakage and the reproducibility crisis in machine-learning-based science. Patterns , 4(9):100804, 2023. doi: 10.1016/j.patter.2023.100804 .
- Kerr (1998) Kerr, N. L. HARKing: Hypothesizing after the results are known. Personality and Social Psychology Review , 2(3):196–217, 1998. doi: 10.1207/s15327957pspr0203_4 .
- Kimmelman et al. (2014) Kimmelman, J., Mogil, J. S., and Dirnagl, U. Distinguishing between exploratory and confirmatory preclinical research will improve translation. PLoS Biology , 12(5):e1001863, 2014. doi: 10.1371/journal.pbio.1001863 .
- Kleinberg (2002) Kleinberg, J. An impossibility theorem for clustering. In Becker, S., Thrun, S., and Obermayer, K. (eds.), Advances in Neural Information Processing Systems , volume 15, Vancouver, Canada, 2002. MIT Press. https://papers.neurips.cc/paper_files/paper/2002/hash/43e4e6a6f341e00671e123714de019a8-Abstract.html .
- Kobak & Linderman (2021) Kobak, D. and Linderman, G. C. Initialization is critical for preserving global data structure in both t -SNE and UMAP. Nature Biotechnology , 39(2):156–157, 2021. doi: 10.1038/s41587-020-00809-z .
- Koch et al. (2021) Koch, B., Denton, E., Hanna, A., and Foster, J. G. Reduced, reused and recycled: The life of a dataset in machine learning research. In Vanschoren, J. and Yeung, S. (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , volume 1, Online, 2021. Curran Associates, Inc. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/hash/3b8a614226a953a8cd9526fca6fe9ba5-Abstract-round2.html .
- Kriegel et al. (2017) Kriegel, H.-P., Schubert, E., and Zimek, A. The (black) art of runtime evaluation: Are we comparing algorithms or implementations? Knowledge and Information Systems , 52(2):341–378, 2017. doi: 10.1007/s10115-016-1004-2 .
- Langley (1988) Langley, P. Machine learning as an experimental science. Machine Learning , 3(1):5–8, 1988. doi: 10.1023/A:1022623814640 .
- Liao et al. (2021) Liao, T., Taori, R., Raji, I. D., and Schmidt, L. Are we learning yet? A meta review of evaluation failures across machine learning. In Vanschoren, J. and Yeung, S. (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , volume 1, Online, 2021. Curran Associates, Inc. https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/hash/757b505cfd34c64c85ca5b5690ee5293-Abstract-round2.html .
- Lim et al. (2000) Lim, T.-S., Loh, W.-Y., and Shih, Y.-S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Machine Learning , 40(3):203–228, 2000. doi: 10.1023/A:1007608224229 .
- Lindstrom (2023) Lindstrom, L. Cargo cults. In The Open Encyclopedia of Anthropology . Facsimile of the first edition in The Cambridge Encyclopedia of Anthropology , 2023. doi: 10.29164/18cargo .
- Lipton & Steinhardt (2018) Lipton, Z. C. and Steinhardt, J. Troubling trends in machine learning scholarship. arXiv:1807.03341 [stat.ML] , 2018. doi: 10.48550/arXiv.1807.03341 .
- Lohmann et al. (2022) Lohmann, A., Astivia, O. L. O., Morris, T. P., and Groenwold, R. H. H. It’s time! Ten reasons to start replicating simulation studies. Frontiers in Epidemiology , 2:973470, 2022. doi: 10.3389/fepid.2022.973470 .
- Lones (2023) Lones, M. A. How to avoid machine learning pitfalls: A guide for academic researchers. arXiv:2108.02497 [cs] , 2023. doi: 10.48550/arXiv.2108.02497 .
- Lucic et al. (2018) Lucic, M., Kurach, K., Michalski, M., Gelly, S., and Bousquet, O. Are GANs created equal? A large-scale study. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems , volume 31, Montréal, Canada, 2018. Curran Associates Inc. https://papers.neurips.cc/paper_files/paper/2018/hash/e46de7e1bcaaced9a54f1e9d0d2f800d-Abstract.html .
- Mannarswamy & Roy (2018) Mannarswamy, S. and Roy, S. Evolving AI from research to real life – Some challenges and suggestions. In Lang, J. (ed.), Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence , pp. 5172–5179, Stockholm, Sweden, 2018. AAAI Press. doi: 10.24963/ijcai.2018/717 .
- Marie et al. (2021) Marie, B., Fujita, A., and Rubino, R. Scientific credibility of machine translation research: A meta-evaluation of 769 papers. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp. 7297–7306, Online, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.566 .
- Mateus et al. (2023) Mateus, P., Volmer, L., Wee, L., Aerts, H. J. W. L., Hoebers, F., Dekker, A., and Bermejo, I. Image based prognosis in head and neck cancer using convolutional neural networks: A case study in reproducibility and optimization. Scientific Reports , 13:18176, 2023. doi: 10.1038/s41598-023-45486-5 .
- McElfresh et al. (2023) McElfresh, D., Khandagale, S., Valverde, J., C, V. P., Feuer, B., Hegde, C., Ramakrishnan, G., Goldblum, M., and White, C. When do neural nets outperform boosted trees on tabular data? In Oh, A., Neumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems , volume 36, New Orleans, LA, United States, 2023. Curran Associates Inc. https://papers.neurips.cc/paper_files/paper/2023/hash/f06d5ebd4ff40b40dd97e30cee632123-Abstract-Datasets_and_Benchmarks.html .
- McGeoch (2002) McGeoch, C. C. Experimental analysis of algorithms. In Pardalos, P. M. and Romeijn, H. E. (eds.), Handbook of Global Optimization: Volume 2 , pp. 489–513. Springer, 2002. doi: 10.1007/978-1-4757-5362-2_14 .
- Mehta et al. (2022) Mehta, Y., White, C., Zela, A., Krishnakumar, A., Zabergja, G., Moradian, S., Safari, M., Yu, K., and Hutter, F. NAS-Bench-Suite: NAS evaluation is (now) surprisingly easy. In 10th International Conference on Learning Representations , Online, 2022. https://openreview.net/forum?id=0DLwqQLmqV .
- Melis et al. (2018) Melis, G., Dyer, C., and Blunsom, P. On the state of the art of evaluation in neural language models. In 6th International Conference on Learning Representations , Vancouver, Canada, 2018. https://openreview.net/forum?id=ByJHuTgA- .
- Merriam-Webster (n.d.) Merriam-Webster. Epistemic. In Merriam-Webster.com dictionary , n.d. Retrieved May 1, 2024, from https://www.merriam-webster.com/dictionary/epistemic .
- Munafò et al. (2017) Munafò, M. R., Nosek, B. A., Bishop, D. V. M., Button, K. S., Chambers, C. D., du Sert, N. P., Simonsohn, U., Wagenmakers, E.-J., Ware, J. J., and Ioannidis, J. P. A. A manifesto for reproducible science. Nature Human Behaviour , 1(1):1–9, 2017. doi: 10.1038/s41562-016-0021 .
- Myrtveit et al. (2005) Myrtveit, I., Stensrud, E., and Shepperd, M. Reliability and validity in comparative studies of software prediction models. IEEE Transactions on Software Engineering , 31(5):380–391, 2005. doi: 10.1109/TSE.2005.58 .
- Nadeau & Bengio (2003) Nadeau, C. and Bengio, Y. Inference for the generalization error. Machine Learning , 52(3):239–281, 2003. doi: 10.1023/A:1024068626366 .
- Nakkiran & Belkin (2022) Nakkiran, P. and Belkin, M. Incentivizing empirical science in machine learning. In ML Evaluation Standards Workshop at ICLR 2022 , Online, 2022. https://ml-eval.github.io/assets/pdf/science_ml_proposal_2am.pdf .
- Narang et al. (2021) Narang, S., Chung, H. W., Tay, Y., Fedus, W., Fevry, T., Matena, M., Malkan, K., Fiedel, N., Shazeer, N., Lan, Z., Zhou, Y., Li, W., Ding, N., Marcus, J., Roberts, A., and Raffel, C. Do transformer modifications transfer across implementations and applications? In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pp. 5758–5773, Online and Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.465 .
- National Academies of Sciences, Engineering, and Medicine (2019) National Academies of Sciences, Engineering, and Medicine. Reproducibility and Replicability in Science . National Academies Press, 2019. doi: 10.17226/25303 .
- Nießl et al. (2022) Nießl, C., Herrmann, M., Wiedemann, C., Casalicchio, G., and Boulesteix, A.-L. Over-optimism in benchmark studies and the multiplicity of design and analysis options when interpreting their results. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 12(2):e1441, 2022. doi: 10.1002/widm.1441 .
- Nießl et al. (2024) Nießl, C., Hoffmann, S., Ullmann, T., and Boulesteix, A.-L. Explaining the optimistic performance evaluation of newly proposed methods: A cross-design validation experiment. Biometrical Journal , 66(1):2200238, 2024. doi: 10.1002/bimj.202200238 .
- Nilsen et al. (2020) Nilsen, E. B., Bowler, D. E., and Linnell, J. D. C. Exploratory and confirmatory research in the open science era. Journal of Applied Ecology , 57(4):842–847, 2020. doi: 10.1111/1365-2664.13571 .
- Niyogi et al. (2011) Niyogi, P., Smale, S., and Weinberger, S. A topological view of unsupervised learning from noisy data. SIAM Journal on Computing , 40(3):646–663, 2011. doi: 10.1137/090762932 .
- Norel et al. (2011) Norel, R., Rice, J. J., and Stolovitzky, G. The self‐assessment trap: Can we all be better than average? Molecular Systems Biology , 7(1):537, 2011. doi: 10.1038/msb.2011.70 .
- Nosek et al. (2018) Nosek, B. A., Ebersole, C. R., DeHaven, A. C., and Mellor, D. T. The preregistration revolution. Proceedings of the National Academy of Sciences , 115(11):2600–2606, 2018. doi: 10.1073/pnas.1708274114 .
- Oberauer & Lewandowsky (2019) Oberauer, K. and Lewandowsky, S. Addressing the theory crisis in psychology. Psychonomic Bulletin & Review , 26(5):1596–1618, 2019. doi: 10.3758/s13423-019-01645-2 .
- Pawel et al. (2024) Pawel, S., Kook, L., and Reeve, K. Pitfalls and potentials in simulation studies: Questionable research practices in comparative simulation studies allow for spurious claims of superiority of any method. Biometrical Journal , 66(1):2200091, 2024. doi: 10.1002/bimj.202200091 .
- Pineau et al. (2021) Pineau, J., Vincent-Lamarre, P., Sinha, K., Larivière, V., Beygelzimer, A., d’Alché Buc, F., Fox, E., and Larochelle, H. Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program). Journal of Machine Learning Research , 22:1–20, 2021. https://jmlr.org/papers/v22/20-303.html .
- Plesser (2018) Plesser, H. E. Reproducibility vs. replicability: A brief history of a confused terminology. Frontiers in Neuroinformatics , 11:76, 2018. doi: 10.3389/fninf.2017.00076 .
- Popper (2002) Popper, K. R. The Logic of Scientific Discovery . Routledge, 2002. The work was originally published in 1935 in German. The first English edition was published in 1959.
- Power et al. (2021) Power, A., Burda, Y., Edwards, H., Babuschkin, I., and Misra, V. Grokking: Generalization beyond overfitting on small algorithmic datasets. In Mathematical Reasoning in General Artificial Intelligence Workshop at ICLR 2021 , Online, 2021. https://mathai-iclr.github.io/papers/papers/MATHAI_29_paper.pdf .
- Raff (2019) Raff, E. A step toward quantifying independently reproducible machine learning research. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems , volume 32, Vancouver, Canada, 2019. Curran Associates, Inc. https://papers.neurips.cc/paper_files/paper/2019/hash/c429429bf1f2af051f2021dc92a8ebea-Abstract.html .
- Raff & Farris (2022) Raff, E. and Farris, A. L. A siren song of open source reproducibility. In ML Evaluation Standards Workshop at ICLR 2022 , Online, 2022. doi: 10.48550/arXiv.2204.04372 .
- Raji et al. (2021) Raji, D., Denton, E., Bender, E. M., Hanna, A., and Paullada, A. AI and the everything in the whole wide world benchmark. In Vanschoren, J. and Yeung, S. (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , volume 1, Online, 2021. Curran Associates, Inc. https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/084b6fbb10729ed4da8c3d3f5a3ae7c9-Abstract-round2.html .
- Recht et al. (2019) Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do ImageNet classifiers generalize to ImageNet? In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning , pp. 5389–5400, Long Beach, CA, United States, 2019. PMLR. https://proceedings.mlr.press/v97/recht19a.html .
- Rendsburg et al. (2020) Rendsburg, L., Heidrich, H., and von Luxburg, U. NetGAN without GAN: From random walks to low-rank approximations. In Daumé III, H. and Singh, A. (eds.), Proceedings of the 37th International Conference on Machine Learning , pp. 8073–8082, Online, 2020. PMLR. https://proceedings.mlr.press/v119/rendsburg20a.html .
- Riquelme et al. (2018) Riquelme, C., Tucker, G., and Snoek, J. Deep Bayesian bandits showdown: An empirical comparison of Bayesian deep networks for Thompson sampling. In 6th International Conference on Learning Representations , Vancouver, Canada, 2018. https://openreview.net/forum?id=SyYe6k-CW .
- Roettger (2021) Roettger, T. B. Preregistration in experimental linguistics: Applications, challenges, and limitations. Linguistics , 59(5):1227–1249, 2021. doi: 10.1515/ling-2019-0048 .
- Rubin (2020) Rubin, M. “Repeated sampling from the same population?” A critique of Neyman and Pearson’s responses to Fisher. European Journal for Philosophy of Science , 10:42, 2020. doi: 10.1007/s13194-020-00309-6 .
- Rubin & Donkin (2022) Rubin, M. and Donkin, C. Exploratory hypothesis tests can be more compelling than confirmatory hypothesis tests. Philosophical Psychology , pp. 1–29, 2022. doi: 10.1080/09515089.2022.2113771 .
- Saitta & Neri (1998) Saitta, L. and Neri, F. Learning in the “real world”. Machine Learning , 30(2–3):133–163, 1998. doi: 10.1023/A:1007448122119 .
- Salzberg (1997) Salzberg, S. L. On comparing classifiers: Pitfalls to avoid and a recommended approach. Data Mining and Knowledge Discovery , 1:317–328, 1997. doi: 10.1023/A:1009752403260 .
- Santner et al. (2003) Santner, T. J., Williams, B. J., and Notz, W. I. The Design and Analysis of Computer Experiments . Springer Series in Statistics. Springer, 2003. doi: 10.1007/978-1-4757-3799-8 .
- Scheel et al. (2021) Scheel, A. M., Tiokhin, L., Isager, P. M., and Lakens, D. Why hypothesis testers should spend less time testing hypotheses. Perspectives on Psychological Science , 16(4):744–755, 2021. doi: 10.1177/1745691620966795 .
- Schneider (2015) Schneider, J. W. Null hypothesis significance tests. A mix-up of two different theories: The basis for widespread confusion and numerous misinterpretations. Scientometrics , 102(1):411–432, 2015. doi: 10.1007/s11192-014-1251-5 .
- Schwab & Held (2020) Schwab, S. and Held, L. Different worlds confirmatory versus exploratory research. Significance , 17(2):8–9, 2020. doi: 10.1111/1740-9713.01369 .
- Sculley et al. (2018) Sculley, D., Snoek, J., Wiltschko, A., and Rahimi, A. Winner’s curse? On pace, progress, and empirical rigor. In 6th International Conference on Learning Representations – Workshop , Vancouver, Canada, 2018. https://openreview.net/forum?id=rJWF0Fywf .
- Segebarth et al. (2020) Segebarth, D., Griebel, M., Stein, N., von Collenberg, C. R., Martin, C., Fiedler, D., Comeras, L. B., Sah, A., Schoeffler, V., Lüffe, T., Dürr, A., Gupta, R., Sasi, M., Lillesaar, C., Lange, M. D., Tasan, R. O., Singewald, N., Pape, H.-C., Flath, C. M., and Blum, R. On the objectivity, reliability, and validity of deep learning enabled bioimage analyses. eLife , 9:e59780, 2020. doi: 10.7554/eLife.59780 .
- Simonsohn et al. (2014) Simonsohn, U., Nelson, L. D., and Simmons, J. P. P -curve: A key to the file-drawer. Journal of Experimental Psychology: General , 143(2):534–547, 2014. doi: 10.1037/a0033242 .
- Sinha et al. (2023, October 18) Sinha, K., Forde, J. Z., Samiei, M., Ghosh, A., Sutawika, L., and Panigrahi, S. S. Announcing MLRC 2023. ML Reproducibility Challenge, 2023, October 18. Retrieved January 31, 2024, from https://reproml.org/blog/announcing_mlrc2023/ .
- Smaldino & McElreath (2016) Smaldino, P. E. and McElreath, R. The natural selection of bad science. Royal Society Open Science , 3(9):160384, 2016. doi: 10.1098/rsos.160384 .
- Sonabend et al. (2022) Sonabend, R., Bender, A., and Vollmer, S. Avoiding c-hacking when evaluating survival distribution predictions with discrimination measures. Bioinformatics , 38(17):4178–4184, 2022. doi: 10.1093/bioinformatics/btac451 .
- Steup (2006) Steup, M. Epistemology. In Zalta, E. N. (ed.), The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, Spring 2006 edition, 2006. https://plato.stanford.edu/archives/spr2006/entries/epistemology/ .
- Steup & Neta (2020) Steup, M. and Neta, R. Epistemology. In Zalta, E. N. (ed.), The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, Fall 2020 edition, 2020. https://plato.stanford.edu/archives/fall2020/entries/epistemology/ .
- Strobl & Leisch (2024) Strobl, C. and Leisch, F. Against the “one method fits all data sets” philosophy for comparison studies in methodological research. Biometrical Journal , 66(1):2200104, 2024. doi: 10.1002/bimj.202200104 .
- Szollosi & Donkin (2021) Szollosi, A. and Donkin, C. Arrested theory development: The misguided distinction between exploratory and confirmatory research. Perspectives on Psychological Science , 16(4):717–724, 2021. doi: 10.1177/1745691620966796 .
- Tatman et al. (2018) Tatman, R., VanderPlas, J., and Dane, S. A practical taxonomy of reproducibility for machine learning research. In Reproducibility in Machine Learning Workshop at ICML 2018 , Stockholm, Sweden, 2018. https://openreview.net/forum?id=B1eYYK5QgX .
- The Turing Way Community (2023) The Turing Way Community. The Turing Way: A handbook for reproducible, ethical and collaborative research . Zenodo, 2023. doi: 10.5281/zenodo.7625728 .
- Transactions on Machine Learning Research (n.d.) Transactions on Machine Learning Research. Transactions on Machine Learning Research, n.d. Retrieved January 31, 2024, from https://jmlr.org/tmlr/index.html .
- Transactions on Machine Learning Research (n.d.) Transactions on Machine Learning Research. Submission guidelines and editorial policies, n.d. Retrieved January 31, 2024, from https://jmlr.org/tmlr/editorial-policies.html .
- Trosten (2023) Trosten, D. J. Questionable practices in methodological deep learning research. In Proceedings of the Northern Lights Deep Learning Workshop , volume 4, 2023. doi: 10.7557/18.6804 .
- Tukey (1973) Tukey, J. W. Exploratory data analysis as part of a larger whole. In Proceedings of the Eighteenth Conference on the Design of Experiments in Army Research, Development and Testing , pp. 1–10, Aberdeen, MD, United States, 1973. U.S. Army Research Office. https://apps.dtic.mil/sti/citations/AD0776910 .
- Tukey (1980) Tukey, J. W. We need both exploratory and confirmatory. The American Statistician , 34(1):23–25, 1980. doi: 10.2307/2682991 .
- Ullmann et al. (2023) Ullmann, T., Beer, A., Hünemörder, M., Seidl, T., and Boulesteix, A.-L. Over-optimistic evaluation and reporting of novel cluster algorithms: An illustrative study. Advances in Data Analysis and Classification , 17(1):211–238, 2023. doi: 10.1007/s11634-022-00496-5 .
- van den Goorbergh et al. (2022) van den Goorbergh, R., van Smeden, M., Timmerman, D., and Van Calster, B. The harm of class imbalance corrections for risk prediction models: Illustration and simulation using logistic regression. Journal of the American Medical Informatics Association , 29(9):1525–1534, 2022. doi: 10.1093/jamia/ocac093 .
- Van Mechelen et al. (2023) Van Mechelen, I., Boulesteix, A.-L., Dangl, R., Dean, N., Hennig, C., Leisch, F., Steinley, D., and Warrens, M. J. A white paper on good research practices in benchmarking: The case of cluster analysis. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 13(6):e1511, 2023. doi: 10.1002/widm.1511 .
- Vanschoren et al. (2013) Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. OpenML: Networked science in machine learning. SIGKDD Explorations , 15(2):49–60, 2013. doi: 10.1145/2641190.2641198 .
- von Luxburg et al. (2012) von Luxburg, U., Williamson, R. C., and Guyon, I. Clustering: Science or art? In Guyon, I., Dror, G., Lemaire, V., Taylor, G., and Silver, D. (eds.), Proceedings of ICML Workshop on Unsupervised and Transfer Learning , pp. 65–79, Bellevue, WA, United States, 2012. PMLR. https://proceedings.mlr.press/v27/luxburg12a.html .
- Wagenmakers et al. (2012) Wagenmakers, E.-J., Wetzels, R., Borsboom, D., van der Maas, H. L. J., and Kievit, R. A. An agenda for purely confirmatory research. Perspectives on Psychological Science , 7(6):632–638, 2012. doi: 10.1177/1745691612463078 .
- Wasserstein et al. (2019) Wasserstein, R. L., Schirm, A. L., and Lazar, N. A. Moving to a world beyond “ p < 0.05”. The American Statistician , 73(sup1):1–19, 2019. doi: 10.1080/00031305.2019.1583913 .
- Yousefi et al. (2010) Yousefi, M. R., Hua, J., Sima, C., and Dougherty, E. R. Reporting bias when using real data sets to analyze classification performance. Bioinformatics , 26(1):68–76, 2010. doi: 10.1093/bioinformatics/btp605 .
- Zhang et al. (2021) Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM , 64(3):107–115, 2021. doi: 10.1145/3446776 .
- Zimek & Filzmoser (2018) Zimek, A. and Filzmoser, P. There and back again: Outlier detection between statistical reasoning and data mining algorithms. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 8(6):e1280, 2018. doi: 10.1002/widm.1280 .
- Zimmermann (2020) Zimmermann, A. Method evaluation, parameterization, and result validation in unsupervised data mining: A critical survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , 10(2):e1330, 2020. doi: 10.1002/widm.1330 .
Bridgmanian ideal. Used by Chang ( 2004 ) to describe a specific notion of operationalization . Refers to Percy Williams Bridgman (1882–1961), Nobel laureate in physics for his work on high-pressure physics, who also made contributions to the philosophy of science. Operational analysis is the topic of his book The Logic of Modern Physics , in which he argues in particular that “[i]n general, we mean by any concept nothing more than a set of operations; the concept is synonymous with the corresponding set of operations ” (Bridgman, 1927 , p. 5) . This strict perspective on operationalization (also referred to as operationalism) has attracted a lot of criticism, see “Operationalism” in The Stanford Encyclopedia of Philosophy (Chang, 2021 ) . In particular, Chang ( 2004 , p. 148) points out that it builds on “an overly restrictive notion of meaning, which comes down to reduction of meaning to measurement, which [Chang] refer[s] to as Bridgman’s reductive doctrine of meaning .”
Cargo Cult Science. The term cargo cult refers to social movements that originated in Melanesia: “The modal cargo cult was an agitation or organised social movement of Melanesian villagers in pursuit of ‘cargo’ by means of renewed or invented ritual action that they hoped would induce ancestral spirits or other powerful beings to provide” (Lindstrom, 2023 , p. 1) . Richard Phillips Feynman (1918–1988), theoretical physicist and Nobel laureate, adapted the term to describe ritualized scientific practices which “follow all the apparent precepts and forms of scientific investigation, but [which are] missing something essential” (Feynman, 1974 , p. 11) .
Confirmatory research. Also known as hypothesis-testing research, aims to test preexisting hypotheses to confirm or refute existing theories. Researchers design specific studies to evaluate hypotheses derived from existing knowledge experimentally. Typically, this involves a structured and predefined research design, a priori hypotheses, and often statistical analyses to draw conclusive inferences. It is a well-established term in many fields other than ML. For example, general references are Schwab & Held ( 2020 ) , Nosek et al. ( 2018 ) , and Munafò et al. ( 2017 ) . Field-specific references include Jaeger & Halliday ( 1998 ) or Nilsen et al. ( 2020 ) for biology, Wagenmakers et al. ( 2012 ) for psychology, Kimmelman et al. ( 2014 ) for preclinical research, Roettger ( 2021 ) for linguistics, or Foster ( 2024 ) for educational research. The term confirmatory might appear to be in conflict with the principle of falsification established by Popper ( 1959/2002 ) . According to Popper, scientific theories cannot be conclusively confirmed, only falsified. It is important to emphasize that confirmatory research has a narrower scope rooted in Neyman-Pearson statistical testing theory (see the glossary entry on Two historically distinct types of testing theory ). This theory provides a framework for a statistically justified decision between a null hypothesis and an alternative hypothesis based on the available data. The hypothesis to be established (e.g., there is an effect) is usually stated as the alternative hypothesis and confirmation means rejecting the null hypothesis (e.g., there is no effect) for the alternative.
Curricula recommendations for CS. The report Computer Science Curricula 2013 lists “Intelligent Systems” (including basics in ML) as a Core (Tier2) topic but “still believe[s] it is not necessary for all CS programs to require a full course in probability theory [or statistics]” (Joint Task Force on Computing Curricula, 2013 , p. 50) . This has changed with the latest (2023) version insofar as statistics is now considered a CS Core topic in “Mathematical and Statistical Foundations”, which is one of several knowledge areas (Joint Task Force on Computing Curricula, 2023 ) .
Epistemic, epistemological. Both coming from the Greek word for knowledge or understanding, the terms are sometimes used synonymously and sometimes with distinct, more precise meanings. If the distinction is made, epistemic relates to knowledge itself, while epistemological relates to “the study of the nature and grounds of knowledge” (Merriam-Webster, n.d. ) , i.e., epistemology. For epistemology, an early edition of The Stanford Encyclopedia of Philosophy gives the following definition: “Defined narrowly, epistemology is the study of knowledge and justified belief. […] Understood more broadly, epistemology is about issues having to do with the creation and dissemination of knowledge in particular areas of inquiry” (Steup, 2006 ) . The most recent edition states in more abstract terms that “[m]uch recent work in formal epistemology is an attempt to understand how our degrees of confidence are rationally constrained by our evidence […]” and that “epistemology seeks to understand one or another kind of cognitive success […]” (Steup & Neta, 2020 ) .
Epistemic iteration. Chang ( 2004 ) introduced the concept and defined it in his glossary as a “process in which successive stages of knowledge, each building on the preceding one, are created in order to enhance the achievement of certain epistemic goals. It differs crucially from mathematical iteration in that the latter is used to approach a correct answer that is known, or at least in principle knowable, by other means” (p. 253). For thorough discussions, see Chapters 1 (pp. 46–48) and 5.
Exploratory research . As also specified in the main body of the paper, refers to an open-ended approach that aims to gain insight and understanding in a new or unexplored area (in contrast to confirmatory research ). It is often conducted when little is known about the phenomenon under study. It involves gathering information, identifying patterns, and formulating specific hypotheses for further investigation.
Hyperparameter tuning studies. Aim to find the best-performing configuration for an ML model class, including baselines (Feurer & Hutter, 2019 ; Bischl et al., 2023 ) . Tuned models can then be compared more objectively and fairly. Hyperparameter tuning (or the lack of it) is an important source of variation in benchmark studies (Bouthillier et al., 2021 ) and has been shown to have a strong effect on the outcome of results (see for example the references in Bouthillier et al., 2021 or our introduction). Treating the hyperparameter optimization as part of the problem of quantifying the performance of an algorithm has been suggested by Bergstra et al. ( 2011 ) and Bergstra et al. ( 2013 ) .
Insight-oriented exploratory research. Refers to experimental research in ML that aims to gain insight, rather than inventing/developing a new method. It does not necessarily involve a very specific hypothesis to be pursued, but it is about improving the understanding and knowledge of a problem, a (class of) existing methods, or a phenomenon.
Method-developing exploratory research. Refers to experimental research in ML carried out in the process of developing a new ML method. This can include method comparison experiments, but in particular, it refers to exploration that takes place during the development process. This may include, for example, trying different method variants or specifying hyperparameter configurations and implementation details.
Operationalization. Chang ( 2004 , p. 256) provides the following definition in his glossary: “The process of giving operational meaning to a concept where there was none before. Operationalization may or may not involve the specification of explicit measurement methods.” Operational meaning refers to “the meaning of a concept that is embodied in the physical operations whose description involves the concept.” For a thorough discussion, see Chapter 4 (pp. 197–219).
Replicability (vs. reproducibility). There is no consistent use of these terms in the broader literature (for discussions, e.g., see Barba, 2018 ; Plesser, 2018 ; Gundersen, 2021 ; Pineau et al., 2021 ) . We use the term reproducibility in a narrow technical sense (see the glossary entry on computational reproducibility ). In contrast, replicability here means arriving at the same scientific conclusions in a broad sense. This terminology is in line with the National Academies of Sciences, Engineering, and Medicine ( 2019 ) . In terms of the reliability of results, it means that replicability is more important than reproducibility. Note that Drummond ( 2009 ) , for example, uses the terms the reverse way.
Reproducibility (computational). Means that the provided code technically achieves the same result on the provided data, and not that code, experimental design, or analysis are error-free and that we can qualitatively reach the same conclusions for the same general question under slightly different technical conditions. It is thus not a sufficient condition for replicability. Note that Tatman et al. ( 2018 ) differentiate three levels of reproducibility.
Two historically distinct types of testing theory . This refers to two approaches to statistical testing developed by Ronald Aylmer Fisher (1890–1962) on the one side and Jerzy Neyman (1894–1981) and Egon Sharpe Pearson (1895–1980) on the other. Only the former includes p 𝑝 p italic_p -values and a single (null) hypothesis. The latter includes two hypotheses and hinges on statistical power and Type I and II errors (Schneider, 2015 , p. 413) . More generally, Fisher’s approach is “[b]ased on the concept of a ‘hypothetical infinite population’,” “[r]oots in inductive philosophy” and “[a]pplies to any single experiment (short run),” while Neyman-Pearson’s approach is “[b]ased on a clearly defined population,” “[r]oots in deductive philosophy,” and “[a]pplies only to ongoing, identical repetitions of an experiment, not to any single experiment (long run)” (Schneider, 2015 , p. 415, Table 1) .
Validity. Note that there is no concise definition of the term. In psychology, internal and external validity are differentiated in particular. According to Campell ( 1957 , p. 297) internal validity asks if “in fact the experimental stimulus make some significant difference in this specific instance?” External validity, on the other hand, asks “to what populations, settings, and variables can this effect be generalized?” The former appears to be closely related to in-distribution generalization performance in ML, the latter to out-of-distribution generalization. In contrast, The Stanford Encyclopedia of Philosophy states for experiments in physics (Franklin & Perovic, 2023 ) : “Physics, and natural science in general, is a reasonable enterprise based on valid [emphasis added] experimental evidence, criticism, and rational discussion.” Several strategies that may be used to validate observations are specified. These include the following: 1) “Experimental checks and calibration, in which the experimental apparatus reproduces known phenomena”; 2) “Reproducing artifacts that are known in advance to be present”; 3) “Elimination of plausible sources of error and alternative explanations of the result”; 4) “Using the results themselves to argue for their validity”; 5) “Using an independently well-corroborated theory of the phenomena to explain the results”; 6) “Using an apparatus based on a well-corroborated theory”; 7) “Using statistical arguments.” However, it is emphasized that “[t]here are many experiments in which these strategies are applied, but whose results are later shown to be incorrect […]. Experiment is fallible. Neither are these strategies exclusive or exhaustive. No single one of them, or fixed combination of them, guarantees the validity of an experimental result” (Franklin & Perovic, 2023 ) .
IMAGES
VIDEO
COMMENTS
This video covers what empirical research is, what kinds of questions and methods empirical researchers use, and some tips for finding empirical research articles in your discipline. ... Scopus Scopus is the largest abstract and citation database of peer-reviewed research literature. With over 19,000 titles from more than 5,000 international ...
In empirical literature, established research methodologies and procedures are systematically applied to answer the questions of interest. Objectivity.Gathering "facts," whatever they may be, drives the search for empirical evidence (Holosko, 2006). Authors of empirical literature are expected to report the facts as observed, whether or not ...
Empirical research is defined as any research where conclusions of the study is strictly drawn from concretely empirical evidence, and therefore "verifiable" evidence. ... Step #2 : Supporting theories and relevant literature. The researcher needs to find out if there are theories which can be linked to his research problem. He has to ...
Another hint: some scholarly journals use a specific layout, called the "IMRaD" format, to communicate empirical research findings. Such articles typically have 4 components: Introduction: sometimes called "literature review" -- what is currently known about the topic -- usually includes a theoretical framework and/or discussion of previous studies
Empirical research methodologies can be described as quantitative, qualitative, or a mix of both (usually called mixed-methods). Ruane (2016) (UofM login required) gets at the basic differences in approach between quantitative and qualitative research: Quantitative research -- an approach to documenting reality that relies heavily on numbers both for the measurement of variables and for data ...
Empirical research, in other words, involves the process of employing working hypothesis that are tested through experimentation or observation. Hence, empirical research is a method of uncovering empirical evidence. ... (1982). Empirical research in the literature class. English Journal, 71(3), 95-97. Article Google Scholar Heisenberg, W ...
Empirical research may explore, describe, or explain behaviors or phenomena in humans, animals, or the natural world. It may use any number of quantitative or qualitative methods, ranging from laboratory experiments to ... Literature Review empirical research papers. This section establishes the practical and scholarly significance of the ...
Empirical research is based on observed and measured phenomena and derives knowledge from actual experience rather than from theory or belief. ... Introduction: sometimes called "literature review" -- what is currently known about the topic -- usually includes a theoretical framework and/or discussion of previous studies;
A scientist gathering data for her research. Empirical research is research using empirical evidence. It is also a way of gaining knowledge by means of direct and indirect observation or experience. Empiricism values some research more than other kinds. Empirical evidence (the record of one's direct observations or experiences) can be analyzed ...
The empirical study of literature is an interdisciplinary field of research which includes the psychology, sociology, and philosophy of texts, the contextual study of literature, and the history of reading literary texts . The International Society for the Empirical Study of Literature and Media (IGEL) is one learned association which brings ...
Empirical research is based on phenomena that can be observed and measured. Empirical research derives knowledge from actual experience rather than from theory or belief. ... Learn about common types of journal articles that use APA Style, including empirical studies; meta-analyses; literature reviews; and replication, theoretical, and ...
The conventional focus of rigorous literature reviews (i.e., review types for which systematic methods have been codified, including the various approaches to quantitative systematic reviews [2-4], and the numerous forms of qualitative and mixed methods literature synthesis [5-10]) is to synthesize empirical research findings from multiple ...
Identifying Empirical Research Articles. Look for the IMRaD layout in the article to help identify empirical research.Sometimes the sections will be labeled differently, but the content will be similar. Introduction: why the article was written, research question or questions, hypothesis, literature review; Methods: the overall research design and implementation, description of sample ...
This is why the literature review as a research method is more relevant than ever. Traditional literature reviews often lack thoroughness and rigor and are conducted ad hoc, rather than following a specific methodology. ... By integrating findings and perspectives from many empirical findings, a literature review can address research questions ...
Discuss how the topic has been approached by empirical versus theoretical scholarship; Divide the literature into sociological, historical, and cultural sources; Theoretical. A literature review is often the foundation for a theoretical framework. You can use it to discuss various theories, models, and definitions of key concepts.
Reviewing the research literature means finding, reading, and summarizing the published research relevant to your question. An empirical research report written in American Psychological Association (APA) style always includes a written literature review, but it is important to review the literature early in the research process for several reasons.
Then compare your results to the literature that you referenced in your introduction section and to other research that has been conducted. In this section you will also want to address the generalizability and potential limitations of your study. Finally it is often recommended that a section on future research directions be included in your ...
Note: empirical research articles will have a literature review section as part of the Introduction, but in an empirical research article the literature review exists to give context to the empirical research, which is the primary focus of the article. In a literature review article, the literature review is the focus.
Empirical Research is research that is based on experimentation or observation, i.e. Evidence. Such research is often conducted to answer a specific question or to test a hypothesis (educated guess).. How do you know if a study is empirical? Read the subheadings within the article, book, or report and look for a description of the research "methodology."
Aside from including the typical parts from the introduction and literature view, up to the methods, analysis, and conclusions, the researcher should also make recommendations for further research on his or her topic. ... Empirical Research and Writing: A Political Science Student's Practical Guide. Thousand Oaks, CA: Sage, 1-19. https://dx ...
Empirical research is characterized by several key features: Observation and Measurement: It involves the systematic observation or measurement of variables, events, or behaviors. Data Collection: Researchers collect data through various methods, such as surveys, experiments, observations, or interviews.
To achieve this purpose, this research adopts systematic literature review methodology. A total of 60 empirical papers published during the period 2002 to 2021 was retrieved through exhaustive manual searches of online databases. A matrix table was developed to extract and organize information from the retrieved articles.
A systematic non-empirical research design was employed in this study. ... The analysed grey literature and primary research studies from peer-reviewed and published databases were restricted to ...
Over the last four decades, studies have investigated the incorporation of Artificial Intelligence (AI) into education. A recent prominent AI-powered technology that has impacted the education sector is ChatGPT. This article provides a systematic review of 14 empirical studies incorporating ChatGPT into various educational settings, published in 2022 and before the 10th of April 2023—the ...
During this process, theoretical essays, legal and literature reviews, and studies dealing exclusively with technical issues were excluded, as the goal was to synthesize empirical research on deepfakes. Emphasizing empirical research may inadvertently favor topics and regulatory challenges that are easier to investigate empirically, potentially ...
This study's theoretical interpretation and empirical examination of the above questions can add to the growing body of related research and provide valuable insights for cities to ...
We think that empirical research in ML finds itself in a situation where practicing questionable research practices, such as state-of-the-art-hacking (SOTA-hacking; Gencoglu et al., 2019; Hullman et al., 2022), has sometimes become more rewarding than following the long line of literature warning against it.
The Journal of Consumer Behaviour publishes theoretical and empirical research into consumer behaviour, advancing the fields of advertising and marketing research. ... An intensive evaluation of the existing literature on freemium models shows that many studies refer to online games without a contractual commitment ...
Read the latest articles of China Journal of Accounting Research at ScienceDirect.com, Elsevier's leading platform of peer-reviewed scholarly literature. Skip to main content. Journals & Books; Register Sign in. China Journal of Accounting Research ... An empirical study of rumor verification on investor Interactive platforms. https://doi.org ...