Critical Value Calculator
How to use critical value calculator, what is a critical value, critical value definition, how to calculate critical values, z critical values, t critical values, chi-square critical values (χ²), f critical values, behind the scenes of the critical value calculator.
Welcome to the critical value calculator! Here you can quickly determine the critical value(s) for two-tailed tests, as well as for one-tailed tests. It works for most common distributions in statistical testing: the standard normal distribution N(0,1) (that is when you have a Z-score), t-Student, chi-square, and F-distribution .
What is a critical value? And what is the critical value formula? Scroll down – we provide you with the critical value definition and explain how to calculate critical values in order to use them to construct rejection regions (also known as critical regions).
The critical value calculator is your go-to tool for swiftly determining critical values in statistical tests, be it one-tailed or two-tailed. To effectively use the calculator, follow these steps:
In the first field, input the distribution of your test statistic under the null hypothesis: is it a standard normal N (0,1), t-Student, chi-squared, or Snedecor's F? If you are not sure, check the sections below devoted to those distributions, and try to localize the test you need to perform.
In the field What type of test? choose the alternative hypothesis : two-tailed, right-tailed, or left-tailed.
If needed, specify the degrees of freedom of the test statistic's distribution. If you need more clarification, check the description of the test you are performing. You can learn more about the meaning of this quantity in statistics from the degrees of freedom calculator .
Set the significance level, α \alpha α . By default, we pre-set it to the most common value, 0.05, but you can adjust it to your needs.
The critical value calculator will display your critical value(s) and the rejection region(s).
Click the advanced mode if you need to increase the precision with which the critical values are computed.
For example, let's envision a scenario where you are conducting a one-tailed hypothesis test using a t-Student distribution with 15 degrees of freedom. You have opted for a right-tailed test and set a significance level (α) of 0.05. The results indicate that the critical value is 1.7531, and the critical region is (1.7531, ∞). This implies that if your test statistic exceeds 1.7531, you will reject the null hypothesis at the 0.05 significance level.
👩🏫 Want to learn more about critical values? Keep reading!
In hypothesis testing, critical values are one of the two approaches which allow you to decide whether to retain or reject the null hypothesis. The other approach is to calculate the p-value (for example, using the p-value calculator ).
The critical value approach consists of checking if the value of the test statistic generated by your sample belongs to the so-called rejection region , or critical region , which is the region where the test statistic is highly improbable to lie . A critical value is a cut-off value (or two cut-off values in the case of a two-tailed test) that constitutes the boundary of the rejection region(s). In other words, critical values divide the scale of your test statistic into the rejection region and the non-rejection region.
Once you have found the rejection region, check if the value of the test statistic generated by your sample belongs to it :
- If so, it means that you can reject the null hypothesis and accept the alternative hypothesis; and
- If not, then there is not enough evidence to reject H 0 .
But how to calculate critical values? First of all, you need to set a significance level , α \alpha α , which quantifies the probability of rejecting the null hypothesis when it is actually correct. The choice of α is arbitrary; in practice, we most often use a value of 0.05 or 0.01. Critical values also depend on the alternative hypothesis you choose for your test , elucidated in the next section .
To determine critical values, you need to know the distribution of your test statistic under the assumption that the null hypothesis holds. Critical values are then points with the property that the probability of your test statistic assuming values at least as extreme at those critical values is equal to the significance level α . Wow, quite a definition, isn't it? Don't worry, we'll explain what it all means.
First, let us point out it is the alternative hypothesis that determines what "extreme" means. In particular, if the test is one-sided, then there will be just one critical value; if it is two-sided, then there will be two of them: one to the left and the other to the right of the median value of the distribution.
Critical values can be conveniently depicted as the points with the property that the area under the density curve of the test statistic from those points to the tails is equal to α \alpha α :
Left-tailed test: the area under the density curve from the critical value to the left is equal to α \alpha α ;
Right-tailed test: the area under the density curve from the critical value to the right is equal to α \alpha α ; and
Two-tailed test: the area under the density curve from the left critical value to the left is equal to α / 2 \alpha/2 α /2 , and the area under the curve from the right critical value to the right is equal to α / 2 \alpha/2 α /2 as well; thus, total area equals α \alpha α .

As you can see, finding the critical values for a two-tailed test with significance α \alpha α boils down to finding both one-tailed critical values with a significance level of α / 2 \alpha/2 α /2 .
The formulae for the critical values involve the quantile function , Q Q Q , which is the inverse of the cumulative distribution function ( c d f \mathrm{cdf} cdf ) for the test statistic distribution (calculated under the assumption that H 0 holds!): Q = c d f − 1 Q = \mathrm{cdf}^{-1} Q = cdf − 1 .
Once we have agreed upon the value of α \alpha α , the critical value formulae are the following:
- Left-tailed test :
- Right-tailed test :
- Two-tailed test :
In the case of a distribution symmetric about 0 , the critical values for the two-tailed test are symmetric as well:
Unfortunately, the probability distributions that are the most widespread in hypothesis testing have somewhat complicated c d f \mathrm{cdf} cdf formulae. To find critical values by hand, you would need to use specialized software or statistical tables. In these cases, the best option is, of course, our critical value calculator! 😁
Use the Z (standard normal) option if your test statistic follows (at least approximately) the standard normal distribution N(0,1) .
In the formulae below, u u u denotes the quantile function of the standard normal distribution N(0,1):
Left-tailed Z critical value: u ( α ) u(\alpha) u ( α )
Right-tailed Z critical value: u ( 1 − α ) u(1-\alpha) u ( 1 − α )
Two-tailed Z critical value: ± u ( 1 − α / 2 ) \pm u(1- \alpha/2) ± u ( 1 − α /2 )
Check out Z-test calculator to learn more about the most common Z-test used on the population mean. There are also Z-tests for the difference between two population means, in particular, one between two proportions.
Use the t-Student option if your test statistic follows the t-Student distribution . This distribution is similar to N(0,1) , but its tails are fatter – the exact shape depends on the number of degrees of freedom . If this number is large (>30), which generically happens for large samples, then the t-Student distribution is practically indistinguishable from N(0,1). Check our t-statistic calculator to compute the related test statistic.

In the formulae below, Q t , d Q_{\text{t}, d} Q t , d is the quantile function of the t-Student distribution with d d d degrees of freedom:
Left-tailed t critical value: Q t , d ( α ) Q_{\text{t}, d}(\alpha) Q t , d ( α )
Right-tailed t critical value: Q t , d ( 1 − α ) Q_{\text{t}, d}(1 - \alpha) Q t , d ( 1 − α )
Two-tailed t critical values: ± Q t , d ( 1 − α / 2 ) \pm Q_{\text{t}, d}(1 - \alpha/2) ± Q t , d ( 1 − α /2 )
Visit the t-test calculator to learn more about various t-tests: the one for a population mean with an unknown population standard deviation , those for the difference between the means of two populations (with either equal or unequal population standard deviations), as well as about the t-test for paired samples .
Use the χ² (chi-square) option when performing a test in which the test statistic follows the χ²-distribution .
You need to determine the number of degrees of freedom of the χ²-distribution of your test statistic – below, we list them for the most commonly used χ²-tests.
Here we give the formulae for chi square critical values; Q χ 2 , d Q_{\chi^2, d} Q χ 2 , d is the quantile function of the χ²-distribution with d d d degrees of freedom:
Left-tailed χ² critical value: Q χ 2 , d ( α ) Q_{\chi^2, d}(\alpha) Q χ 2 , d ( α )
Right-tailed χ² critical value: Q χ 2 , d ( 1 − α ) Q_{\chi^2, d}(1 - \alpha) Q χ 2 , d ( 1 − α )
Two-tailed χ² critical values: Q χ 2 , d ( α / 2 ) Q_{\chi^2, d}(\alpha/2) Q χ 2 , d ( α /2 ) and Q χ 2 , d ( 1 − α / 2 ) Q_{\chi^2, d}(1 - \alpha/2) Q χ 2 , d ( 1 − α /2 )
Several different tests lead to a χ²-score:
Goodness-of-fit test : does the empirical distribution agree with the expected distribution?
This test is right-tailed . Its test statistic follows the χ²-distribution with k − 1 k - 1 k − 1 degrees of freedom, where k k k is the number of classes into which the sample is divided.
Independence test : is there a statistically significant relationship between two variables?
This test is also right-tailed , and its test statistic is computed from the contingency table. There are ( r − 1 ) ( c − 1 ) (r - 1)(c - 1) ( r − 1 ) ( c − 1 ) degrees of freedom, where r r r is the number of rows, and c c c is the number of columns in the contingency table.
Test for the variance of normally distributed data : does this variance have some pre-determined value?
This test can be one- or two-tailed! Its test statistic has the χ²-distribution with n − 1 n - 1 n − 1 degrees of freedom, where n n n is the sample size.
Finally, choose F (Fisher-Snedecor) if your test statistic follows the F-distribution . This distribution has a pair of degrees of freedom .
Let us see how those degrees of freedom arise. Assume that you have two independent random variables, X X X and Y Y Y , that follow χ²-distributions with d 1 d_1 d 1 and d 2 d_2 d 2 degrees of freedom, respectively. If you now consider the ratio ( X d 1 ) : ( Y d 2 ) (\frac{X}{d_1}):(\frac{Y}{d_2}) ( d 1 X ) : ( d 2 Y ) , it turns out it follows the F-distribution with ( d 1 , d 2 ) (d_1, d_2) ( d 1 , d 2 ) degrees of freedom. That's the reason why we call d 1 d_1 d 1 and d 2 d_2 d 2 the numerator and denominator degrees of freedom , respectively.
In the formulae below, Q F , d 1 , d 2 Q_{\text{F}, d_1, d_2} Q F , d 1 , d 2 stands for the quantile function of the F-distribution with ( d 1 , d 2 ) (d_1, d_2) ( d 1 , d 2 ) degrees of freedom:
Left-tailed F critical value: Q F , d 1 , d 2 ( α ) Q_{\text{F}, d_1, d_2}(\alpha) Q F , d 1 , d 2 ( α )
Right-tailed F critical value: Q F , d 1 , d 2 ( 1 − α ) Q_{\text{F}, d_1, d_2}(1 - \alpha) Q F , d 1 , d 2 ( 1 − α )
Two-tailed F critical values: Q F , d 1 , d 2 ( α / 2 ) Q_{\text{F}, d_1, d_2}(\alpha/2) Q F , d 1 , d 2 ( α /2 ) and Q F , d 1 , d 2 ( 1 − α / 2 ) Q_{\text{F}, d_1, d_2}(1 -\alpha/2) Q F , d 1 , d 2 ( 1 − α /2 )
Here we list the most important tests that produce F-scores: each of them is right-tailed .
ANOVA : tests the equality of means in three or more groups that come from normally distributed populations with equal variances. There are ( k − 1 , n − k ) (k - 1, n - k) ( k − 1 , n − k ) degrees of freedom, where k k k is the number of groups, and n n n is the total sample size (across every group).
Overall significance in regression analysis . The test statistic has ( k − 1 , n − k ) (k - 1, n - k) ( k − 1 , n − k ) degrees of freedom, where n n n is the sample size, and k k k is the number of variables (including the intercept).
Compare two nested regression models . The test statistic follows the F-distribution with ( k 2 − k 1 , n − k 2 ) (k_2 - k_1, n - k_2) ( k 2 − k 1 , n − k 2 ) degrees of freedom, where k 1 k_1 k 1 and k 2 k_2 k 2 are the number of variables in the smaller and bigger models, respectively, and n n n is the sample size.
The equality of variances in two normally distributed populations . There are ( n − 1 , m − 1 ) (n - 1, m - 1) ( n − 1 , m − 1 ) degrees of freedom, where n n n and m m m are the respective sample sizes.
I'm Anna, the mastermind behind the critical value calculator and a PhD in mathematics from Jagiellonian University .
The idea for creating the tool originated from my experiences in teaching and research. Recognizing the need for a tool that simplifies the critical value determination process across various statistical distributions, I built a user-friendly calculator accessible to both students and professionals. After publishing the tool, I soon found myself using the calculator in my research and as a teaching aid.
Trust in this calculator is paramount to me. Each tool undergoes a rigorous review process , with peer-reviewed insights from experts and meticulous proofreading by native speakers. This commitment to accuracy and reliability ensures that users can be confident in the content. Please check the Editorial Policies page for more details on our standards.

What is a Z critical value?
A Z critical value is the value that defines the critical region in hypothesis testing when the test statistic follows the standard normal distribution . If the value of the test statistic falls into the critical region, you should reject the null hypothesis and accept the alternative hypothesis.
How do I calculate Z critical value?
To find a Z critical value for a given confidence level α :
Check if you perform a one- or two-tailed test .
For a one-tailed test:
Left -tailed: critical value is the α -th quantile of the standard normal distribution N(0,1).
Right -tailed: critical value is the (1-α) -th quantile.
Two-tailed test: critical value equals ±(1-α/2) -th quantile of N(0,1).
No quantile tables ? Use CDF tables! (The quantile function is the inverse of the CDF.)
Verify your answer with an online critical value calculator.
Is a t critical value the same as Z critical value?
In theory, no . In practice, very often, yes . The t-Student distribution is similar to the standard normal distribution, but it is not the same . However, if the number of degrees of freedom (which is, roughly speaking, the size of your sample) is large enough (>30), then the two distributions are practically indistinguishable , and so the t critical value has practically the same value as the Z critical value.
What is the Z critical value for 95% confidence?
The Z critical value for a 95% confidence interval is:
- 1.96 for a two-tailed test;
- 1.64 for a right-tailed test; and
- -1.64 for a left-tailed test.
Books vs e-books
Flat vs. round earth, least to greatest.
- Biology (100)
- Chemistry (98)
- Construction (144)
- Conversion (292)
- Ecology (30)
- Everyday life (261)
- Finance (569)
- Health (440)
- Physics (509)
- Sports (104)
- Statistics (182)
- Other (181)
- Discover Omni (40)

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
S.3.1 hypothesis testing (critical value approach).
The critical value approach involves determining "likely" or "unlikely" by determining whether or not the observed test statistic is more extreme than would be expected if the null hypothesis were true. That is, it entails comparing the observed test statistic to some cutoff value, called the " critical value ." If the test statistic is more extreme than the critical value, then the null hypothesis is rejected in favor of the alternative hypothesis. If the test statistic is not as extreme as the critical value, then the null hypothesis is not rejected.
Specifically, the four steps involved in using the critical value approach to conducting any hypothesis test are:
- Specify the null and alternative hypotheses.
- Using the sample data and assuming the null hypothesis is true, calculate the value of the test statistic. To conduct the hypothesis test for the population mean μ , we use the t -statistic \(t^*=\frac{\bar{x}-\mu}{s/\sqrt{n}}\) which follows a t -distribution with n - 1 degrees of freedom.
- Determine the critical value by finding the value of the known distribution of the test statistic such that the probability of making a Type I error — which is denoted \(\alpha\) (greek letter "alpha") and is called the " significance level of the test " — is small (typically 0.01, 0.05, or 0.10).
- Compare the test statistic to the critical value. If the test statistic is more extreme in the direction of the alternative than the critical value, reject the null hypothesis in favor of the alternative hypothesis. If the test statistic is less extreme than the critical value, do not reject the null hypothesis.
Example S.3.1.1
Mean gpa section .
In our example concerning the mean grade point average, suppose we take a random sample of n = 15 students majoring in mathematics. Since n = 15, our test statistic t * has n - 1 = 14 degrees of freedom. Also, suppose we set our significance level α at 0.05 so that we have only a 5% chance of making a Type I error.
Right-Tailed
The critical value for conducting the right-tailed test H 0 : μ = 3 versus H A : μ > 3 is the t -value, denoted t \(\alpha\) , n - 1 , such that the probability to the right of it is \(\alpha\). It can be shown using either statistical software or a t -table that the critical value t 0.05,14 is 1.7613. That is, we would reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ > 3 if the test statistic t * is greater than 1.7613. Visually, the rejection region is shaded red in the graph.

Left-Tailed
The critical value for conducting the left-tailed test H 0 : μ = 3 versus H A : μ < 3 is the t -value, denoted -t ( \(\alpha\) , n - 1) , such that the probability to the left of it is \(\alpha\). It can be shown using either statistical software or a t -table that the critical value -t 0.05,14 is -1.7613. That is, we would reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ < 3 if the test statistic t * is less than -1.7613. Visually, the rejection region is shaded red in the graph.

There are two critical values for the two-tailed test H 0 : μ = 3 versus H A : μ ≠ 3 — one for the left-tail denoted -t ( \(\alpha\) / 2, n - 1) and one for the right-tail denoted t ( \(\alpha\) / 2, n - 1) . The value - t ( \(\alpha\) /2, n - 1) is the t -value such that the probability to the left of it is \(\alpha\)/2, and the value t ( \(\alpha\) /2, n - 1) is the t -value such that the probability to the right of it is \(\alpha\)/2. It can be shown using either statistical software or a t -table that the critical value -t 0.025,14 is -2.1448 and the critical value t 0.025,14 is 2.1448. That is, we would reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ ≠ 3 if the test statistic t * is less than -2.1448 or greater than 2.1448. Visually, the rejection region is shaded red in the graph.

Learn Math and Stats with Dr. G
A shortcut is the longest distance between two points.

Finding z Critical Values (zc)
In many cases, critical values are required.
A critical value often represents a rejection region cut-off value for a hypothesis test – also called a zc value for a confidence interval.
For confidence intervals and two-tailed z-tests, you can use the zTable to determine the critical values (zc).
Find the critical values for a 90% Confidence Interval.
NOTICE: A 90% Confidence Interval will have the same critical values (rejection regions) as a two-tailed z test with alpha = .10.
The Critical Values for a 90% confidence or alpha = .10 are +/- 1.645.
Example 2 Find the critical values for a 95% confidence interval. These are the same as the rejection region z-value cut-offs for a two-tailed z test with alpha = .05.
Note that when alpha = .05 we are using a 95% confidence interval.

10 Chapter 10: Hypothesis Testing with Z
Setting up the hypotheses.
When setting up the hypotheses with z, the parameter is associated with a sample mean (in the previous chapter examples the parameters for the null used 0). Using z is an occasion in which the null hypothesis is a value other than 0. For example, if we are working with mothers in the U.S. whose children are at risk of low birth weight, we can use 7.47 pounds, the average birth weight in the US, as our null value and test for differences against that. For now, we will focus on testing a value of a single mean against what we expect from the population.
Using birthweight as an example, our null hypothesis takes the form: H 0 : μ = 7.47 Notice that we are testing the value for μ, the population parameter, NOT the sample statistic ̅X (or M). We are referring to the data right now in raw form (we have not standardized it using z yet). Again, using inferential statistics, we are interested in understanding the population, drawing from our sample observations. For the research question, we have a mean value from the sample to use, we have specific data is – it is observed and used as a comparison for a set point.
As mentioned earlier, the alternative hypothesis is simply the reverse of the null hypothesis, and there are three options, depending on where we expect the difference to lie. We will set the criteria for rejecting the null hypothesis based on the directionality (greater than, less than, or not equal to) of the alternative.
If we expect our obtained sample mean to be above or below the null hypothesis value (knowing which direction), we set a directional hypothesis. O ur alternative hypothesis takes the form based on the research question itself. In our example with birthweight, this could be presented as H A : μ > 7.47 or H A : μ < 7.47.
Note that we should only use a directional hypothesis if we have a good reason, based on prior observations or research, to suspect a particular direction. When we do not know the direction, such as when we are entering a new area of research, we use a non-directional alternative hypothesis. In our birthweight example, this could be set as H A : μ ≠ 7.47
In working with data for this course we will need to set a critical value of the test statistic for alpha (α) for use of test statistic tables in the back of the book. This is determining the critical rejection region that has a set critical value based on α.
Determining Critical Value from α
We set alpha (α) before collecting data in order to determine whether or not we should reject the null hypothesis. We set this value beforehand to avoid biasing ourselves by viewing our results and then determining what criteria we should use.
When a research hypothesis predicts an effect but does not predict a direction for the effect, it is called a non-directional hypothesis . To test the significance of a non-directional hypothesis, we have to consider the possibility that the sample could be extreme at either tail of the comparison distribution. We call this a two-tailed test .
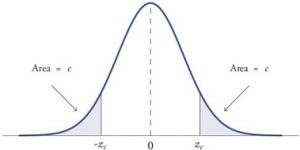
Figure 1. showing a 2-tail test for non-directional hypothesis for z for area C is the critical rejection region.
When a research hypothesis predicts a direction for the effect, it is called a directional hypothesis . To test the significance of a directional hypothesis, we have to consider the possibility that the sample could be extreme at one-tail of the comparison distribution. We call this a one-tailed test .
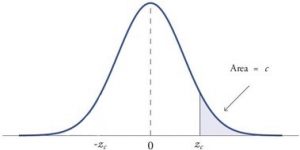
Figure 2. showing a 1-tail test for a directional hypothesis (predicting an increase) for z for area C is the critical rejection region.
Determining Cutoff Scores with Two-Tailed Tests
Typically we specify an α level before analyzing the data. If the data analysis results in a probability value below the α level, then the null hypothesis is rejected; if it is not, then the null hypothesis is not rejected. In other words, if our data produce values that meet or exceed this threshold, then we have sufficient evidence to reject the null hypothesis ; if not, we fail to reject the null (we never “accept” the null). According to this perspective, if a result is significant, then it does not matter how significant it is. Moreover, if it is not significant, then it does not matter how close to being significant it is. Therefore, if the 0.05 level is being used, then probability values of 0.049 and 0.001 are treated identically. Similarly, probability values of 0.06 and 0.34 are treated identically. Note we will discuss ways to address effect size (which is related to this challenge of NHST).
When setting the probability value, there is a special complication in a two-tailed test. We have to divide the significance percentage between the two tails. For example, with a 5% significance level, we reject the null hypothesis only if the sample is so extreme that it is in either the top 2.5% or the bottom 2.5% of the comparison distribution. This keeps the overall level of significance at a total of 5%. A one-tailed test does have such an extreme value but with a one-tailed test only one side of the distribution is considered.
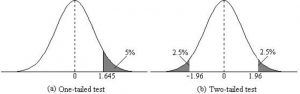
Figure 3. Critical value differences in one and two-tail tests. Photo Credit
Let’s re view th e set critical values for Z.
We discussed z-scores and probability in chapter 8. If we revisit the z-score for 5% and 1%, we can identify the critical regions for the critical rejection areas from the unit standard normal table.
- A two-tailed test at the 5% level has a critical boundary Z score of +1.96 and -1.96
- A one-tailed test at the 5% level has a critical boundary Z score of +1.64 or -1.64
- A two-tailed test at the 1% level has a critical boundary Z score of +2.58 and -2.58
- A one-tailed test at the 1% level has a critical boundary Z score of +2.33 or -2.33.
Review: Critical values, p-values, and significance level
There are two criteria we use to assess whether our data meet the thresholds established by our chosen significance level, and they both have to do with our discussions of probability and distributions. Recall that probability refers to the likelihood of an event, given some situation or set of conditions. In hypothesis testing, that situation is the assumption that the null hypothesis value is the correct value, or that there is no effec t. The value laid out in H 0 is our condition under which we interpret our results. To reject this assumption, and thereby reject the null hypothesis, we need results that would be very unlikely if the null was true.
Now recall that values of z which fall in the tails of the standard normal distribution represent unlikely values. That is, the proportion of the area under the curve as or more extreme than z is very small as we get into the tails of the distribution. Our significance level corresponds to the area under the tail that is exactly equal to α: if we use our normal criterion of α = .05, then 5% of the area under the curve becomes what we call the rejection region (also called the critical region) of the distribution. This is illustrated in Figure 4.

Figure 4: The rejection region for a one-tailed test
The shaded rejection region takes us 5% of the area under the curve. Any result which falls in that region is sufficient evidence to reject the null hypothesis.
The rejection region is bounded by a specific z-value, as is any area under the curve. In hypothesis testing, the value corresponding to a specific rejection region is called the critical value, z crit (“z-crit”) or z* (hence the other name “critical region”). Finding the critical value works exactly the same as finding the z-score corresponding to any area under the curve like we did in Unit 1. If we go to the normal table, we will find that the z-score corresponding to 5% of the area under the curve is equal to 1.645 (z = 1.64 corresponds to 0.0405 and z = 1.65 corresponds to 0.0495, so .05 is exactly in between them) if we go to the right and -1.645 if we go to the left. The direction must be determined by your alternative hypothesis, and drawing then shading the distribution is helpful for keeping directionality straight.
Suppose, however, that we want to do a non-directional test. We need to put the critical region in both tails, but we don’t want to increase the overall size of the rejection region (for reasons we will see later). To do this, we simply split it in half so that an equal proportion of the area under the curve falls in each tail’s rejection region. For α = .05, this means 2.5% of the area is in each tail, which, based on the z-table, corresponds to critical values of z* = ±1.96. This is shown in Figure 5.

Figure 5: Two-tailed rejection region
Thus, any z-score falling outside ±1.96 (greater than 1.96 in absolute value) falls in the rejection region. When we use z-scores in this way, the obtained value of z (sometimes called z-obtained) is something known as a test statistic, which is simply an inferential statistic used to test a null hypothesis.
Calculate the test statistic: Z
Now that we understand setting up the hypothesis and determining the outcome, let’s examine hypothesis testing with z! The next step is to carry out the study and get the actual results for our sample. Central to hypothesis test is comparison of the population and sample means. To make our calculation and determine where the sample is in the hypothesized distribution we calculate the Z for the sample data.
Make a decision
To decide whether to reject the null hypothesis, we compare our sample’s Z score to the Z score that marks our critical boundary. If our sample Z score falls inside the rejection region of the comparison distribution (is greater than the z-score critical boundary) we reject the null hypothesis.
The formula for our z- statistic has not changed:
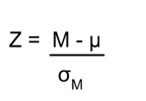
To formally test our hypothesis, we compare our obtained z-statistic to our critical z-value. If z obt > z crit , that means it falls in the rejection region (to see why, draw a line for z = 2.5 on Figure 1 or Figure 2) and so we reject H 0 . If z obt < z crit , we fail to reject. Remember that as z gets larger, the corresponding area under the curve beyond z gets smaller. Thus, the proportion, or p-value, will be smaller than the area for α, and if the area is smaller, the probability gets smaller. Specifically, the probability of obtaining that result, or a more extreme result, under the condition that the null hypothesis is true gets smaller.
Conversely, if we fail to reject, we know that the proportion will be larger than α because the z-statistic will not be as far into the tail. This is illustrated for a one- tailed test in Figure 6.

Figure 6. Relation between α, z obt , and p
When the null hypothesis is rejected, the effect is said to be statistically significant . Do not confuse statistical significance with practical significance. A small effect can be highly significant if the sample size is large enough.
Why does the word “significant” in the phrase “statistically significant” mean something so different from other uses of the word? Interestingly, this is because the meaning of “significant” in everyday language has changed. It turns out that when the procedures for hypothesis testing were developed, something was “significant” if it signified something. Thus, finding that an effect is statistically significant signifies that the effect is real and not due to chance. Over the years, the meaning of “significant” changed, leading to the potential misinterpretation.
Review: Steps of the Hypothesis Testing Process
The process of testing hypotheses follows a simple four-step procedure. This process will be what we use for the remained of the textbook and course, and though the hypothesis and statistics we use will change, this process will not.
Step 1: State the Hypotheses
Your hypotheses are the first thing you need to lay out. Otherwise, there is nothing to test! You have to state the null hypothesis (which is what we test) and the alternative hypothesis (which is what we expect). These should be stated mathematically as they were presented above AND in words, explaining in normal English what each one means in terms of the research question.
Step 2: Find the Critical Values
Next, we formally lay out the criteria we will use to test our hypotheses. There are two pieces of information that inform our critical values: α, which determines how much of the area under the curve composes our rejection region, and the directionality of the test, which determines where the region will be.
Step 3: Compute the Test Statistic
Once we have our hypotheses and the standards we use to test them, we can collect data and calculate our test statistic, in this case z . This step is where the vast majority of differences in future chapters will arise: different tests used for different data are calculated in different ways, but the way we use and interpret them remains the same.
Step 4: Make the Decision
Finally, once we have our obtained test statistic, we can compare it to our critical value and decide whether we should reject or fail to reject the null hypothesis. When we do this, we must interpret the decision in relation to our research question, stating what we concluded, what we based our conclusion on, and the specific statistics we obtained.
Example: Movie Popcorn
Let’s see how hypothesis testing works in action by working through an example. Say that a movie theater owner likes to keep a very close eye on how much popcorn goes into each bag sold, so he knows that the average bag has 8 cups of popcorn and that this varies a little bit, about half a cup. That is, the known population mean is μ = 8.00 and the known population standard deviation is σ =0.50. The owner wants to make sure that the newest employee is filling bags correctly, so over the course of a week he randomly assesses 25 bags filled by the employee to test for a difference (n = 25). He doesn’t want bags overfilled or under filled, so he looks for differences in both directions. This scenario has all of the information we need to begin our hypothesis testing procedure.
Our manager is looking for a difference in the mean cups of popcorn bags compared to the population mean of 8. We will need both a null and an alternative hypothesis written both mathematically and in words. We’ll always start with the null hypothesis:
H 0 : There is no difference in the cups of popcorn bags from this employee H 0 : μ = 8.00
Notice that we phrase the hypothesis in terms of the population parameter μ, which in this case would be the true average cups of bags filled by the new employee.
Our assumption of no difference, the null hypothesis, is that this mean is exactly
the same as the known population mean value we want it to match, 8.00. Now let’s do the alternative:
H A : There is a difference in the cups of popcorn bags from this employee H A : μ ≠ 8.00
In this case, we don’t know if the bags will be too full or not full enough, so we do a two-tailed alternative hypothesis that there is a difference.
Our critical values are based on two things: the directionality of the test and the level of significance. We decided in step 1 that a two-tailed test is the appropriate directionality. We were given no information about the level of significance, so we assume that α = 0.05 is what we will use. As stated earlier in the chapter, the critical values for a two-tailed z-test at α = 0.05 are z* = ±1.96. This will be the criteria we use to test our hypothesis. We can now draw out our distribution so we can visualize the rejection region and make sure it makes sense

Figure 7: Rejection region for z* = ±1.96
Step 3: Calculate the Test Statistic
Now we come to our formal calculations. Let’s say that the manager collects data and finds that the average cups of this employee’s popcorn bags is ̅X = 7.75 cups. We can now plug this value, along with the values presented in the original problem, into our equation for z:
So our test statistic is z = -2.50, which we can draw onto our rejection region distribution:

Figure 8: Test statistic location
Looking at Figure 5, we can see that our obtained z-statistic falls in the rejection region. We can also directly compare it to our critical value: in terms of absolute value, -2.50 > -1.96, so we reject the null hypothesis. We can now write our conclusion:
When we write our conclusion, we write out the words to communicate what it actually means, but we also include the average sample size we calculated (the exact location doesn’t matter, just somewhere that flows naturally and makes sense) and the z-statistic and p-value. We don’t know the exact p-value, but we do know that because we rejected the null, it must be less than α.
Effect Size
When we reject the null hypothesis, we are stating that the difference we found was statistically significant, but we have mentioned several times that this tells us nothing about practical significance. To get an idea of the actual size of what we found, we can compute a new statistic called an effect size. Effect sizes give us an idea of how large, important, or meaningful a statistically significant effect is.
For mean differences like we calculated here, our effect size is Cohen’s d :
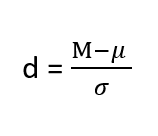
Effect sizes are incredibly useful and provide important information and clarification that overcomes some of the weakness of hypothesis testing. Whenever you find a significant result, you should always calculate an effect size
Table 1. Interpretation of Cohen’s d
Example: Office Temperature
Let’s do another example to solidify our understanding. Let’s say that the office building you work in is supposed to be kept at 74 degree Fahrenheit but is allowed
to vary by 1 degree in either direction. You suspect that, as a cost saving measure, the temperature was secretly set higher. You set up a formal way to test your hypothesis.
You start by laying out the null hypothesis:
H 0 : There is no difference in the average building temperature H 0 : μ = 74
Next you state the alternative hypothesis. You have reason to suspect a specific direction of change, so you make a one-tailed test:
H A : The average building temperature is higher than claimed H A : μ > 74

Now that you have everything set up, you spend one week collecting temperature data:
You calculate the average of these scores to be 𝑋̅ = 76.6 degrees. You use this to calculate the test statistic, using μ = 74 (the supposed average temperature), σ = 1.00 (how much the temperature should vary), and n = 5 (how many data points you collected):
z = 76.60 − 74.00 = 2.60 = 5.78
1.00/√5 0.45
This value falls so far into the tail that it cannot even be plotted on the distribution!

Figure 7: Obtained z-statistic
You compare your obtained z-statistic, z = 5.77, to the critical value, z* = 1.645, and find that z > z*. Therefore you reject the null hypothesis, concluding: Based on 5 observations, the average temperature (𝑋̅ = 76.6 degrees) is statistically significantly higher than it is supposed to be, z = 5.77, p < .05.
d = (76.60-74.00)/ 1= 2.60
The effect size you calculate is definitely large, meaning someone has some explaining to do!
Example: Different Significance Level
First, let’s take a look at an example phrased in generic terms, rather than in the context of a specific research question, to see the individual pieces one more time. This time, however, we will use a stricter significance level, α = 0.01, to test the hypothesis.
We will use 60 as an arbitrary null hypothesis value: H 0 : The average score does not differ from the population H 0 : μ = 50
We will assume a two-tailed test: H A : The average score does differ H A : μ ≠ 50
We have seen the critical values for z-tests at α = 0.05 levels of significance several times. To find the values for α = 0.01, we will go to the standard normal table and find the z-score cutting of 0.005 (0.01 divided by 2 for a two-tailed test) of the area in the tail, which is z crit * = ±2.575. Notice that this cutoff is much higher than it was for α = 0.05. This is because we need much less of the area in the tail, so we need to go very far out to find the cutoff. As a result, this will require a much larger effect or much larger sample size in order to reject the null hypothesis.
We can now calculate our test statistic. The average of 10 scores is M = 60.40 with a µ = 60. We will use σ = 10 as our known population standard deviation. From this information, we calculate our z-statistic as:
Our obtained z-statistic, z = 0.13, is very small. It is much less than our critical value of 2.575. Thus, this time, we fail to reject the null hypothesis. Our conclusion would look something like:
Notice two things about the end of the conclusion. First, we wrote that p is greater than instead of p is less than, like we did in the previous two examples. This is because we failed to reject the null hypothesis. We don’t know exactly what the p- value is, but we know it must be larger than the α level we used to test our hypothesis. Second, we used 0.01 instead of the usual 0.05, because this time we tested at a different level. The number you compare to the p-value should always be the significance level you test at. Because we did not detect a statistically significant effect, we do not need to calculate an effect size. Note: some statisticians will suggest to always calculate effects size as a possibility of Type II error. Although insignificant, calculating d = (60.4-60)/10 = .04 which suggests no effect (and not a possibility of Type II error).
Review Considerations in Hypothesis Testing
Errors in hypothesis testing.
Keep in mind that rejecting the null hypothesis is not an all-or-nothing decision. The Type I error rate is affected by the α level: the lower the α level the lower the Type I error rate. It might seem that α is the probability of a Type I error. However, this is not correct. Instead, α is the probability of a Type I error given that the null hypothesis is true. If the null hypothesis is false, then it is impossible to make a Type I error. The second type of error that can be made in significance testing is failing to reject a false null hypothesis. This kind of error is called a Type II error.
Statistical Power
The statistical power of a research design is the probability of rejecting the null hypothesis given the sample size and expected relationship strength. Statistical power is the complement of the probability of committing a Type II error. Clearly, researchers should be interested in the power of their research designs if they want to avoid making Type II errors. In particular, they should make sure their research design has adequate power before collecting data. A common guideline is that a power of .80 is adequate. This means that there is an 80% chance of rejecting the null hypothesis for the expected relationship strength.
Given that statistical power depends primarily on relationship strength and sample size, there are essentially two steps you can take to increase statistical power: increase the strength of the relationship or increase the sample size. Increasing the strength of the relationship can sometimes be accomplished by using a stronger manipulation or by more carefully controlling extraneous variables to reduce the amount of noise in the data (e.g., by using a within-subjects design rather than a between-subjects design). The usual strategy, however, is to increase the sample size. For any expected relationship strength, there will always be some sample large enough to achieve adequate power.
Inferential statistics uses data from a sample of individuals to reach conclusions about the whole population. The degree to which our inferences are valid depends upon how we selected the sample (sampling technique) and the characteristics (parameters) of population data. Statistical analyses assume that sample(s) and population(s) meet certain conditions called statistical assumptions.
It is easy to check assumptions when using statistical software and it is important as a researcher to check for violations; if violations of statistical assumptions are not appropriately addressed then results may be interpreted incorrectly.
Learning Objectives
Having read the chapter, students should be able to:
- Conduct a hypothesis test using a z-score statistics, locating critical region, and make a statistical decision including.
- Explain the purpose of measuring effect size and power, and be able to compute Cohen’s d.
Exercises – Ch. 10
- List the main steps for hypothesis testing with the z-statistic. When and why do you calculate an effect size?
- z = 1.99, two-tailed test at α = 0.05
- z = 1.99, two-tailed test at α = 0.01
- z = 1.99, one-tailed test at α = 0.05
- You are part of a trivia team and have tracked your team’s performance since you started playing, so you know that your scores are normally distributed with μ = 78 and σ = 12. Recently, a new person joined the team, and you think the scores have gotten better. Use hypothesis testing to see if the average score has improved based on the following 8 weeks’ worth of score data: 82, 74, 62, 68, 79, 94, 90, 81, 80.
- A study examines self-esteem and depression in teenagers. A sample of 25 teens with a low self-esteem are given the Beck Depression Inventory. The average score for the group is 20.9. For the general population, the average score is 18.3 with σ = 12. Use a two-tail test with α = 0.05 to examine whether teenagers with low self-esteem show significant differences in depression.
- You get hired as a server at a local restaurant, and the manager tells you that servers’ tips are $42 on average but vary about $12 (μ = 42, σ = 12). You decide to track your tips to see if you make a different amount, but because this is your first job as a server, you don’t know if you will make more or less in tips. After working 16 shifts, you find that your average nightly amount is $44.50 from tips. Test for a difference between this value and the population mean at the α = 0.05 level of significance.
Answers to Odd- Numbered Exercises – Ch. 10
1. List hypotheses. Determine critical region. Calculate z. Compare z to critical region. Draw Conclusion. We calculate an effect size when we find a statistically significant result to see if our result is practically meaningful or important
5. Step 1: H 0 : μ = 42 “My average tips does not differ from other servers”, H A : μ ≠ 42 “My average tips do differ from others”
Introduction to Statistics for Psychology Copyright © 2021 by Alisa Beyer is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
7.5: Critical values, p-values, and significance level
- Last updated
- Save as PDF
- Page ID 7117

- Foster et al.
- University of Missouri-St. Louis, Rice University, & University of Houston, Downtown Campus via University of Missouri’s Affordable and Open Access Educational Resources Initiative
A low probability value casts doubt on the null hypothesis. How low must the probability value be in order to conclude that the null hypothesis is false? Although there is clearly no right or wrong answer to this question, it is conventional to conclude the null hypothesis is false if the probability value is less than 0.05. More conservative researchers conclude the null hypothesis is false only if the probability value is less than 0.01. When a researcher concludes that the null hypothesis is false, the researcher is said to have rejected the null hypothesis. The probability value below which the null hypothesis is rejected is called the α level or simply \(α\) (“alpha”). It is also called the significance level. If α is not explicitly specified, assume that \(α\) = 0.05.
The significance level is a threshold we set before collecting data in order to determine whether or not we should reject the null hypothesis. We set this value beforehand to avoid biasing ourselves by viewing our results and then determining what criteria we should use. If our data produce values that meet or exceed this threshold, then we have sufficient evidence to reject the null hypothesis; if not, we fail to reject the null (we never “accept” the null).
There are two criteria we use to assess whether our data meet the thresholds established by our chosen significance level, and they both have to do with our discussions of probability and distributions. Recall that probability refers to the likelihood of an event, given some situation or set of conditions. In hypothesis testing, that situation is the assumption that the null hypothesis value is the correct value, or that there is no effect. The value laid out in H0 is our condition under which we interpret our results. To reject this assumption, and thereby reject the null hypothesis, we need results that would be very unlikely if the null was true. Now recall that values of z which fall in the tails of the standard normal distribution represent unlikely values. That is, the proportion of the area under the curve as or more extreme than \(z\) is very small as we get into the tails of the distribution. Our significance level corresponds to the area under the tail that is exactly equal to α: if we use our normal criterion of \(α\) = .05, then 5% of the area under the curve becomes what we call the rejection region (also called the critical region) of the distribution. This is illustrated in Figure \(\PageIndex{1}\).

The shaded rejection region takes us 5% of the area under the curve. Any result which falls in that region is sufficient evidence to reject the null hypothesis.
The rejection region is bounded by a specific \(z\)-value, as is any area under the curve. In hypothesis testing, the value corresponding to a specific rejection region is called the critical value, \(z_{crit}\) (“\(z\)-crit”) or \(z*\) (hence the other name “critical region”). Finding the critical value works exactly the same as finding the z-score corresponding to any area under the curve like we did in Unit 1. If we go to the normal table, we will find that the z-score corresponding to 5% of the area under the curve is equal to 1.645 (\(z\) = 1.64 corresponds to 0.0405 and \(z\) = 1.65 corresponds to 0.0495, so .05 is exactly in between them) if we go to the right and -1.645 if we go to the left. The direction must be determined by your alternative hypothesis, and drawing then shading the distribution is helpful for keeping directionality straight.
Suppose, however, that we want to do a non-directional test. We need to put the critical region in both tails, but we don’t want to increase the overall size of the rejection region (for reasons we will see later). To do this, we simply split it in half so that an equal proportion of the area under the curve falls in each tail’s rejection region. For \(α\) = .05, this means 2.5% of the area is in each tail, which, based on the z-table, corresponds to critical values of \(z*\) = ±1.96. This is shown in Figure \(\PageIndex{2}\).

Thus, any \(z\)-score falling outside ±1.96 (greater than 1.96 in absolute value) falls in the rejection region. When we use \(z\)-scores in this way, the obtained value of \(z\) (sometimes called \(z\)-obtained) is something known as a test statistic, which is simply an inferential statistic used to test a null hypothesis. The formula for our \(z\)-statistic has not changed:
\[z=\dfrac{\overline{\mathrm{X}}-\mu}{\bar{\sigma} / \sqrt{\mathrm{n}}} \]
To formally test our hypothesis, we compare our obtained \(z\)-statistic to our critical \(z\)-value. If \(\mathrm{Z}_{\mathrm{obt}}>\mathrm{Z}_{\mathrm{crit}}\), that means it falls in the rejection region (to see why, draw a line for \(z\) = 2.5 on Figure \(\PageIndex{1}\) or Figure \(\PageIndex{2}\)) and so we reject \(H_0\). If \(\mathrm{Z}_{\mathrm{obt}}<\mathrm{Z}_{\mathrm{crit}}\), we fail to reject. Remember that as \(z\) gets larger, the corresponding area under the curve beyond \(z\) gets smaller. Thus, the proportion, or \(p\)-value, will be smaller than the area for \(α\), and if the area is smaller, the probability gets smaller. Specifically, the probability of obtaining that result, or a more extreme result, under the condition that the null hypothesis is true gets smaller.
The \(z\)-statistic is very useful when we are doing our calculations by hand. However, when we use computer software, it will report to us a \(p\)-value, which is simply the proportion of the area under the curve in the tails beyond our obtained \(z\)-statistic. We can directly compare this \(p\)-value to \(α\) to test our null hypothesis: if \(p < α\), we reject \(H_0\), but if \(p > α\), we fail to reject. Note also that the reverse is always true: if we use critical values to test our hypothesis, we will always know if \(p\) is greater than or less than \(α\). If we reject, we know that \(p < α\) because the obtained \(z\)-statistic falls farther out into the tail than the critical \(z\)-value that corresponds to \(α\), so the proportion (\(p\)-value) for that \(z\)-statistic will be smaller. Conversely, if we fail to reject, we know that the proportion will be larger than \(α\) because the \(z\)-statistic will not be as far into the tail. This is illustrated for a one-tailed test in Figure \(\PageIndex{3}\).

When the null hypothesis is rejected, the effect is said to be statistically significant. For example, in the Physicians Reactions case study, the probability value is 0.0057. Therefore, the effect of obesity is statistically significant and the null hypothesis that obesity makes no difference is rejected. It is very important to keep in mind that statistical significance means only that the null hypothesis of exactly no effect is rejected; it does not mean that the effect is important, which is what “significant” usually means. When an effect is significant, you can have confidence the effect is not exactly zero. Finding that an effect is significant does not tell you about how large or important the effect is. Do not confuse statistical significance with practical significance. A small effect can be highly significant if the sample size is large enough. Why does the word “significant” in the phrase “statistically significant” mean something so different from other uses of the word? Interestingly, this is because the meaning of “significant” in everyday language has changed. It turns out that when the procedures for hypothesis testing were developed, something was “significant” if it signified something. Thus, finding that an effect is statistically significant signifies that the effect is real and not due to chance. Over the years, the meaning of “significant” changed, leading to the potential misinterpretation.
If you could change one thing about college, what would it be?
Graduate faster
Better quality online classes
Flexible schedule
Access to top-rated instructors

How To Find Critical Value In Statistics
10.28.2022 • 13 min read
Sarah Thomas
Subject Matter Expert
Learn how to find critical value, its importance, the different systems, and the steps to follow when calculating it.
In This Article
What Is a Critical Value?
The role of critical values in hypothesis tests, factors that influence critical values, critical values for one-tailed tests & two-tailed tests, commonly used critical values, how to find the critical value in statistics, how to find a critical value in r, don't overpay for college statistics.
Take Intro to Statistics Online with Outlier.org
From the co-founder of MasterClass, earn transferable college credits from the University of Pittsburgh (a top 50 global school). The world's best online college courses for 50% less than a traditional college.

In baseball, an ump cries “foul ball” any time a batter hits the ball into foul territory. In statistics, we have something similar to a foul zone. It’s called a rejection region. While foul lines, poles, and the stadium fence mark off the foul territory in baseball, in statistics numbers called critical values mark off rejection regions.
A critical value is a number that defines the rejection region of a hypothesis test. Critical values vary depending on the type of hypothesis test you run and the type of data you are working with.
In a hypothesis test called a two-tailed Z-test with a 95% confidence level, the critical values are 1.96 and -1.96. In this test, if the statistician’s results are greater than 1.96 or less than -1.96. We reject the null hypothesis in favor of the alternative hypothesis.
In Outlier's Intro to Statistics course, Dr. Gregory Matthews explains more about hypothesis testing and why to use it:
The figure below shows how the critical values mark the boundaries of two rejection regions (shaded in pink). Any test result greater than 1.96 falls into the rejection region in the distribution’s right tail, and any test result below -1.96 falls into the rejection region in the left tail of the distribution.

A two-tailed Z-test with a 95% confidence level (or a significance level of ɑ = 0.05) has two critical values 1.96 and -1.96.
Before we dive deeper, let’s do a quick refresher on hypothesis testing. In statistics, a hypothesis test is a statistical test where you test an “alternative” hypothesis against a “null” hypothesis. The null hypothesis represents the default hypothesis or the status quo. It typically represents what the academic community or the general public believes to be true. The alternative hypothesis represents what you suspect could be true in place of the null hypothesis.
For example, I may hypothesize that as times have changed, the average age of first-time mothers in the U.S. has increased and that first-time mothers, on average, are now older than 25. Meanwhile, conventional wisdom or existing research may say that the average age of first-time mothers in the U.S. is 25 years old.
In this example, my hypothesis is the alternative hypothesis, and the conventional wisdom is the null hypothesis.
Alternative Hypothesis H a H_a H a = Average age of first-time mothers in the U.S. > 25
Null Hypothesis H 0 H_0 H 0 = Average age of first-time mothers in the U.S. = 25
In a hypothesis test, the goal is to draw inferences about a population parameter (such as the population mean of first-time mothers in the U.S.) from sample data randomly drawn from the population.
The basic intuition behind hypothesis testing is this. If we assume that the null hypothesis is true, data collected from a random sample of first-time mothers should have a sample average that’s close to 25 years old. We don’t expect the sample to have the same average as the population, but we expect it to be pretty close. If we find this to be the case, we have evidence favoring the null hypothesis. If our sample average is far enough above 25, we have evidence that favors the alternative hypothesis.
A major conundrum in hypothesis testing is deciding what counts as “close to 25” and what counts as being “far enough above 25”? If you randomly sample a thousand first-time mothers and the sample mean is 26 or 27 years old, should you favor the null hypothesis or the alternative?
To make this determination, you need to do the following:
1. First, you convert your sample statistic into a test statistic.
In our first-time mother example, the sample statistic we have is the average age of the first-time mothers in our sample. Depending on the data we have, we might map this average to a Z-test statistic or a T-test statistic.
A test statistic is just a number that maps a sample statistic to a value on a standardized distribution such as a normal distribution or a T-distribution. By converting our sample statistic to a test statistic, we can easily see how likely or unlikely it is to get our sample statistic under the assumption that the null hypothesis is true.
2. Next, you select a significance level (also known as an alpha (ɑ) level) for your test.
The significance level is a measure of how confident you want to be in your decision to reject the null hypothesis in favor of the alternative. A commonly used significance level in hypothesis testing is 5% (or ɑ=0.05). An alpha-level of 0.05 means that you’ll only reject the null hypothesis if there is less than a 5% chance of wrongly favoring the alternative over the null.
3. Third, you find the critical values that correspond to your test statistic and significance level.
The critical value(s) tell you how small or large your test statistic has to be in order to reject the null hypothesis at your chosen significance level.
4. You check to see if your test statistic falls into the rejection region.
Check the value of the test statistic. Any test statistic that falls above a critical value in the right tail of the distribution is in the rejection region. Any test statistic located below a critical value in the left tail of the distribution is also in the rejection region. If your test statistic falls into the rejection region, you reject the null hypothesis in favor of the alternative hypothesis. If your test statistic does not fall into the rejection region, you fail to reject the null hypothesis.
Notice that critical values play a crucial role in hypothesis testing. Without knowing what your critical values are, you cannot make the final determination of whether or not to reject the null hypothesis.
Critical values vary with the following traits of a hypothesis test.
What test statistic are you using?
This will depend on the type of research question you have and the type of data you are working with. In a first-year statistics course, you will often conduct hypothesis tests using Z-statistics (these correspond to a standard normal distribution ), T-statistics (these correspond to a T-distribution), or chi-squared test statistics (these correspond to a chi-square distribution).
What significance level have you selected?
This is up to the person conducting the test. A significance level (or alpha level) is the probability of mistakenly rejecting the null hypothesis when it is actually true. By choosing a significance level, you are deciding how careful you want to be in avoiding such a mistake.
You might also hear a hypothesis test being described by a confidence level. Confidence levels are closely related to statistical significance. The confidence level of a test is equal to one minus the significance level or 1-ɑ.
Is it a one-tailed test or a two-tailed test?
Hypothesis tests can be one-tailed or two-tailed, depending on the alternative hypothesis. Null and alternative hypotheses are always mutually exclusive statements, but they can take different forms. If your alternative hypothesis is only concerned with positive effects or the right tail of the distribution, you will likely use a one-tailed upper-tail test.
If your alternative hypothesis is only concerned with negative effects or the left tail of the distribution, you will likely use a one-tailed lower-tail test. Finally, if your alternative hypothesis proposes a deviation in either direction from what the null hypothesis proposes, you’ll use a two-tailed test.
The number of critical values in a hypothesis test depends on whether the test is a one-tailed test or a two-tailed test.
Critical Values for Two-Tailed Tests
In a two-tailed test, we divide the rejection region into two equal parts: one in the right tail of the distribution and one in the left tail of the distribution. Each of these rejection regions will contain an area of the distribution equal to ɑ/2. For example, in a two-tailed test with a significance level of 0.05, each rejection region will contain 0.05/2 = 0.025 = 2.5% of the area under the distribution. Because we split the rejection region, a two-tailed test has two critical values.
Critical Values for One-Tailed Tests
A one-tailed test has one rejection region (either in the right tail or the left tail of the distribution) and one critical value. In a lower tail (or left-tailed) test, the critical value and rejection region will be in the left tail of the distribution. In an upper tail (or right-tailed) test, the critical value and rejection region will be in the right tail of the distribution.

Two-tailed test

One-tailed lower tail test

One-tailed upper tail test
The tables below provide a list of critical values that are commonly used in hypothesis testing.
Z-Test Statistics (Using a Normal Distribution)
T-test statistics (using a t distribution), degrees of freedom (df), finding a critical value for a two-tailed z-test.
Suppose you don’t remember what the critical values for a two-sided Z-test are. How would you go about finding them?
To find the critical value, you start with the significance level of your hypothesis test. Your significance level is equal to the total area of the rejection region. For example, with a 0.05 significance level, the entire rejection region will be equal to 5% of the area under the normal distribution.
In a two-tailed test Z-test, we split equally the rejection region into two parts. One rejection region is in the distribution’s right tail, and the other is in the left tail of the distribution. Each of these two parts will contain half of the total area of the rejection region. For a two-tailed Z-test with a significance level of ɑ=0.05, each rejection region will contain ɑ/2 = 0.025 or 2.5% of the distribution. This leaves a confidence interval of 0.95 (or 95%) between the two rejection regions.

To find the critical values, you need to find the corresponding values (or Z-scores ) in the Z-distribution. Make sure the percentage lying to the left of the first critical value is equal to ɑ/2. Also, check that the percentage of the distribution lying to the right of the second critical value is equal to ɑ/2. You can use a Z-table to look up these figures.
Solved Example: Two-Tailed Z-Test
For a two-tailed Z-test with a significance level of ɑ=0.05, we are looking for two critical values such that ɑ/2 or 2.5% of the normal distribution lies to the left of the first critical value and ɑ/2 or 0.025 of the normal distribution lies to the right of the second critical value.
Z-tables will either show you probabilities to the LEFT or to the RIGHT of a particular value. We’ll stick to Z-tables showing probabilities to the LEFT.
For the first critical value, if the area to the left of the critical value is 0.025, we use the Z-table to find the number 0.025 in the table (we’ve shown this figure highlighted in an orange box). We then trace that value to the left to find the first two digits of the critical value (-1.9) and then up to the top to find the last digit (-0.06). If we put these together, we have the critical value -1.96. Z-tables provide Z-scores that are usually rounded to two decimal places.

For the second critical value, 2.5% of the distribution will lie to the right, meaning 97.5% of the distribution will lie to the left of the critical value (1-0.025=0.0975). To find this critical value, we look for the number 0.0975 in the Z-table (we’ve shown this figure highlighted in a green box). We trace that value to the left to find the first two digits of the critical value (1.9) and then up to the top to find the last digit (0.06). Our second critical value is 1.96.

Following similar steps, see if you can find the critical values for a Z-test with a significance level of ɑ=0.10. The critical values you find should be equal to -1.64 and 1.64.
Finding a Critical Value for a One-Tailed Z-Test
In a one-tailed test, there is just one rejection region, and the area of the rejection region is equal to the significance level.
For a one-tailed lower tail test, use the z-table to find a critical value where the total area to the left of the critical value is equal to alpha.
For a one-tailed upper tail test, use the z-table to find a critical value where the total area to the left of the critical value is equal to 1- alpha.
Solved Example: One-Tailed Z-Test
Let’s see if we can use the Z-table to find the critical value for a lower tail Z-test with a significance level of 0.01.
Since alpha equals 0.01, we are looking for this number in the Z-table. If you can’t find the exact number, you look for the closest number, which in this case is 0.0090. Once we’ve found this number, we trace the value to the first column to find the first two digits of the critical value and then up to the first row to find the last digit. The critical value is -2.33.

Now let’s see if we can use the Z-table to find the critical value for an upper tail Z-test with a significance level of 0.10.
Since this is an upper tail test, we need to use the Z-table to look for a critical value corresponding to 0.90 (1-ɑ = 1-0.10 = 0.90). The closest number to 0.90 we can find in the table is 0.89973. We trace this number to the left and then up to the top of the table to find a critical value of 1.28.

To find a critical value in R, you can use the qnorm() function for a Z-test or the qt() function for a T-test.
Here are some examples of how you could use these functions in your critical value approach.
Z-Critical Values Using R
For a two-tailed Z-test with a 0.05 significance level, you would type:
qnorm(p=0.05/2, lower.tail=FALSE)
This will give you one of your critical values. The second critical value is just the negative value of the first.
For a one-tailed lower tail Z-test with a 0.01 significance level, you would type:
qnorm(p=0.01, lower.tail=TRUE)
For a one-tailed upper tail Z-test with a 0.01 significance level, you would type:
qnorm(p=0.01, lower.tail=FALSE)
T-Critical Values Using R
For a two-tailed T-test with 15 degrees of freedom and a 0.1 significance level, you would type:
qt(p=0.1/2, df=15, lower.tail=FALSE)
For a one-tailed lower tail T-test with 10 degrees of freedom and a 0.05 significance level, you would type:
qt(p=0.05, df=10, lower.tail=TRUE)
For a one-tailed upper tail T-test with 20 degrees of freedom and a 0.01 significance level, you would type:
qt(p=0.01, df=20, lower.tail=FALSE)
Now that you know the ins and outs of critical values, you’re one step closer to conducting hypothesis tests with ease!
Explore Outlier's Award-Winning For-Credit Courses
Outlier (from the co-founder of MasterClass) has brought together some of the world's best instructors, game designers, and filmmakers to create the future of online college.
Check out these related courses:

Intro to Statistics
How data describes our world.

Intro to Microeconomics
Why small choices have big impact.

Intro to Macroeconomics
How money moves our world.

Intro to Psychology
The science of the mind.
Related Articles

Binomial Distribution: Meaning & Formula
Learn what binomial distribution is in probability. Read a list of the criteria that must be present to apply the formula and learn how to calculate it.

Understanding Math Probability - Definition, Formula & How To Find It
This article is about what probability is, its definition, and the formula. You’ll also learn how to calculate it.

What Is a Residual in Stats?
This article gives a quick definition of what’s a residual equation, the best way to read it, and how to use it with proper statistical models.
Further Reading
Set operations: formulas, properties, examples & exercises, what is set notation [+ bonus practice], how to make a box plot, a guide to understand negative correlation, calculating p-value in hypothesis testing.
Critical Value Calculator
Use this calculator for critical values to easily convert a significance level to its corresponding Z value, T score, F-score, or Chi-square value. Outputs the critical region as well. The tool supports one-tailed and two-tailed significance tests / probability values.
Related calculators
- Using the critical value calculator
- What is a critical value?
- T critical value calculation
- Z critical value calculation
- F critical value calculation
Using the critical value calculator
If you want to perform a statistical test of significance (a.k.a. significance test, statistical significance test), determining the value of the test statistic corresponding to the desired significance level is necessary. You need to know the desired error probability ( p-value threshold , common values are 0.05, 0.01, 0.001) corresponding to the significance level of the test. If you know the significance level in percentages, simply subtract it from 100%. For example, 95% significance results in a probability of 100%-95% = 5% = 0.05 .
Then you need to know the shape of the error distribution of the statistic of interest (not to be mistaken with the distribution of the underlying data!) . Our critical value calculator supports statistics which are either:
- Z -distributed (normally distributed, e.g. absolute difference of means)
- T -distributed (Student's T distribution, usually appropriate for small sample sizes, equivalent to the normal for sample sizes over 30)
- X 2 -distributed ( Chi square distribution, often used in goodness-of-fit tests, but also for tests of homogeneity or independence)
- F -distributed (Fisher-Snedecor distribution), usually used in analysis of variance (ANOVA)
Then, for distributions other than the normal one (Z), you need to know the degrees of freedom . For the F statistic there are two separate degrees of freedom - one for the numerator and one for the denominator.
Finally, to determine a critical region, one needs to know whether they are testing a point null versus a composite alternative (on both sides) or a composite null versus (covering one side of the distribution) a composite alternative (covering the other). Basically, it comes down to whether the inference is going to contain claims regarding the direction of the effect or not. Should one want to claim anything about the direction of the effect, the corresponding null hypothesis is direction as well (one-sided hypothesis).
Depending on the type of test - one-tailed or two-tailed, the calculator will output the critical value or values and the corresponding critical region. For one-sided tests it will output both possible regions, whereas for a two-sided test it will output the union of the two critical regions on the opposite sides of the distribution.
What is a critical value?
A critical value (or values) is a point on the support of an error distribution which bounds a critical region from above or below. If the statistics falls below or above a critical value (depending on the type of hypothesis, but it has to fall inside the critical region) then a test is declared statistically significant at the corresponding significance level. For example, in a two-tailed Z test with critical values -1.96 and 1.96 (corresponding to 0.05 significance level) the critical regions are from -∞ to -1.96 and from 1.96 to +∞. Therefore, if the statistic falls below -1.96 or above 1.96, the null hypothesis test is statistically significant.
You can think of the critical value as a cutoff point beyond which events are considered rare enough to count as evidence against the specified null hypothesis. It is a value achieved by a distance function with probability equal to or greater than the significance level under the specified null hypothesis. In an error-probabilistic framework, a proper distance function based on a test statistic takes the generic form [1] :

X (read "X bar") is the arithmetic mean of the population baseline or the control, μ 0 is the observed mean / treatment group mean, while σ x is the standard error of the mean (SEM, or standard deviation of the error of the mean).
Here is how it looks in practice when the error is normally distributed (Z distribution) with a one-tailed null and alternative hypotheses and a significance level α set to 0.05:

And here is the same significance level when applied to a point null and a two-tailed alternative hypothesis:

The distance function would vary depending on the distribution of the error: Z, T, F, or Chi-square (X 2 ). The calculation of a particular critical value based on a supplied probability and error distribution is simply a matter of calculating the inverse cumulative probability density function (inverse CPDF) of the respective distribution. This can be a difficult task, most notably for the T distribution [2] .
T critical value calculation
The T-distribution is often preferred in the social sciences, psychiatry, economics, and other sciences where low sample sizes are a common occurrence. Certain clinical studies also fall under this umbrella. This stems from the fact that for sample sizes over 30 it is practically equivalent to the normal distribution which is easier to work with. It was proposed by William Gosset, a.k.a. Student, in 1908 [3] , which is why it is also referred to as "Student's T distribution".
To find the critical t value, one needs to compute the inverse cumulative PDF of the T distribution. To do that, the significance level and the degrees of freedom need to be known. The degrees of freedom represent the number of values in the final calculation of a statistic that are free to vary whilst the statistic remains fixed at a certain value.
It should be noted that there is not, in fact, a single T-distribution, but there are infinitely many T-distributions, each with a different level of degrees of freedom. Below are some key values of the T-distribution with 1 degree of freedom, assuming a one-tailed T test is to be performed. These are often used as critical values to define rejection regions in hypothesis testing.
Z critical value calculation
The Z-score is a statistic showing how many standard deviations away from the normal, usually the mean, a given observation is. It is often called just a standard score, z-value, normal score, and standardized variable. A Z critical value is just a particular cutoff in the error distribution of a normally-distributed statistic.
Z critical values are computed by using the inverse cumulative probability density function of the standard normal distribution with a mean (μ) of zero and standard deviation (σ) of one. Below are some commonly encountered probability values (significance levels) and their corresponding Z values for the critical region, assuming a one-tailed hypothesis .
The critical region defined by each of these would span from the Z value to plus infinity for the right-tailed case, and from minus infinity to minus the Z critical value in the left-tailed case. Our calculator for critical value will both find the critical z value(s) and output the corresponding critical regions for you.
Chi Square (Χ 2 ) critical value calculation
Chi square distributed errors are commonly encountered in goodness-of-fit tests and homogeneity tests, but also in tests for independence in contingency tables. Since the distribution is based on the squares of scores, it only contains positive values. Calculating the inverse cumulative PDF of the distribution is required in order to convert a desired probability (significance) to a chi square critical value.
Just like the T and F distributions, there is a different chi square distribution corresponding to different degrees of freedom. Hence, to calculate a Χ 2 critical value one needs to supply the degrees of freedom for the statistic of interest.
F critical value calculation
F distributed errors are commonly encountered in analysis of variance (ANOVA), which is very common in the social sciences. The distribution, also referred to as the Fisher-Snedecor distribution, only contains positive values, similar to the Χ 2 one. Similar to the T distribution, there is no single F-distribution to speak of. A different F distribution is defined for each pair of degrees of freedom - one for the numerator and one for the denominator.
Calculating the inverse cumulative PDF of the F distribution specified by the two degrees of freedom is required in order to convert a desired probability (significance) to a critical value. There is no simple solution to find a critical value of f and while there are tables, using a calculator is the preferred approach nowadays.
References
1 Mayo D.G., Spanos A. (2010) – "Error Statistics", in P. S. Bandyopadhyay & M. R. Forster (Eds.), Philosophy of Statistics, (7, 152–198). Handbook of the Philosophy of Science . The Netherlands: Elsevier.
2 Shaw T.W. (2006) – "Sampling Student's T distribution – use of the inverse cumulative distribution function", Journal of Computational Finance 9(4):37-73, DOI:10.21314/JCF.2006.150
3 "Student" [William Sealy Gosset] (1908) - "The probable error of a mean", Biometrika 6(1):1–25. DOI:10.1093/biomet/6.1.1
Cite this calculator & page
If you'd like to cite this online calculator resource and information as provided on the page, you can use the following citation: Georgiev G.Z., "Critical Value Calculator" , [online] Available at: https://www.gigacalculator.com/calculators/critical-value-calculator.php URL [Accessed Date: 09 Apr, 2024].
Our statistical calculators have been featured in scientific papers and articles published in high-profile science journals by:

The author of this tool

Statistical calculators

Hypothesis Testing for Means & Proportions
- 1
- | 2
- | 3
- | 4
- | 5
- | 6
- | 7
- | 8
- | 9
- | 10

Hypothesis Testing: Upper-, Lower, and Two Tailed Tests
Type i and type ii errors.

All Modules

Z score Table
t score Table
The procedure for hypothesis testing is based on the ideas described above. Specifically, we set up competing hypotheses, select a random sample from the population of interest and compute summary statistics. We then determine whether the sample data supports the null or alternative hypotheses. The procedure can be broken down into the following five steps.
- Step 1. Set up hypotheses and select the level of significance α.
H 0 : Null hypothesis (no change, no difference);
H 1 : Research hypothesis (investigator's belief); α =0.05
- Step 2. Select the appropriate test statistic.
The test statistic is a single number that summarizes the sample information. An example of a test statistic is the Z statistic computed as follows:
When the sample size is small, we will use t statistics (just as we did when constructing confidence intervals for small samples). As we present each scenario, alternative test statistics are provided along with conditions for their appropriate use.
- Step 3. Set up decision rule.
The decision rule is a statement that tells under what circumstances to reject the null hypothesis. The decision rule is based on specific values of the test statistic (e.g., reject H 0 if Z > 1.645). The decision rule for a specific test depends on 3 factors: the research or alternative hypothesis, the test statistic and the level of significance. Each is discussed below.
- The decision rule depends on whether an upper-tailed, lower-tailed, or two-tailed test is proposed. In an upper-tailed test the decision rule has investigators reject H 0 if the test statistic is larger than the critical value. In a lower-tailed test the decision rule has investigators reject H 0 if the test statistic is smaller than the critical value. In a two-tailed test the decision rule has investigators reject H 0 if the test statistic is extreme, either larger than an upper critical value or smaller than a lower critical value.
- The exact form of the test statistic is also important in determining the decision rule. If the test statistic follows the standard normal distribution (Z), then the decision rule will be based on the standard normal distribution. If the test statistic follows the t distribution, then the decision rule will be based on the t distribution. The appropriate critical value will be selected from the t distribution again depending on the specific alternative hypothesis and the level of significance.
- The third factor is the level of significance. The level of significance which is selected in Step 1 (e.g., α =0.05) dictates the critical value. For example, in an upper tailed Z test, if α =0.05 then the critical value is Z=1.645.
The following figures illustrate the rejection regions defined by the decision rule for upper-, lower- and two-tailed Z tests with α=0.05. Notice that the rejection regions are in the upper, lower and both tails of the curves, respectively. The decision rules are written below each figure.

Rejection Region for Lower-Tailed Z Test (H 1 : μ < μ 0 ) with α =0.05
The decision rule is: Reject H 0 if Z < 1.645.

Rejection Region for Two-Tailed Z Test (H 1 : μ ≠ μ 0 ) with α =0.05
The decision rule is: Reject H 0 if Z < -1.960 or if Z > 1.960.
The complete table of critical values of Z for upper, lower and two-tailed tests can be found in the table of Z values to the right in "Other Resources."
Critical values of t for upper, lower and two-tailed tests can be found in the table of t values in "Other Resources."
- Step 4. Compute the test statistic.
Here we compute the test statistic by substituting the observed sample data into the test statistic identified in Step 2.
- Step 5. Conclusion.
The final conclusion is made by comparing the test statistic (which is a summary of the information observed in the sample) to the decision rule. The final conclusion will be either to reject the null hypothesis (because the sample data are very unlikely if the null hypothesis is true) or not to reject the null hypothesis (because the sample data are not very unlikely).
If the null hypothesis is rejected, then an exact significance level is computed to describe the likelihood of observing the sample data assuming that the null hypothesis is true. The exact level of significance is called the p-value and it will be less than the chosen level of significance if we reject H 0 .
Statistical computing packages provide exact p-values as part of their standard output for hypothesis tests. In fact, when using a statistical computing package, the steps outlined about can be abbreviated. The hypotheses (step 1) should always be set up in advance of any analysis and the significance criterion should also be determined (e.g., α =0.05). Statistical computing packages will produce the test statistic (usually reporting the test statistic as t) and a p-value. The investigator can then determine statistical significance using the following: If p < α then reject H 0 .
- Step 1. Set up hypotheses and determine level of significance
H 0 : μ = 191 H 1 : μ > 191 α =0.05
The research hypothesis is that weights have increased, and therefore an upper tailed test is used.
- Step 2. Select the appropriate test statistic.
Because the sample size is large (n > 30) the appropriate test statistic is
- Step 3. Set up decision rule.
In this example, we are performing an upper tailed test (H 1 : μ> 191), with a Z test statistic and selected α =0.05. Reject H 0 if Z > 1.645.
We now substitute the sample data into the formula for the test statistic identified in Step 2.
We reject H 0 because 2.38 > 1.645. We have statistically significant evidence at a =0.05, to show that the mean weight in men in 2006 is more than 191 pounds. Because we rejected the null hypothesis, we now approximate the p-value which is the likelihood of observing the sample data if the null hypothesis is true. An alternative definition of the p-value is the smallest level of significance where we can still reject H 0 . In this example, we observed Z=2.38 and for α=0.05, the critical value was 1.645. Because 2.38 exceeded 1.645 we rejected H 0 . In our conclusion we reported a statistically significant increase in mean weight at a 5% level of significance. Using the table of critical values for upper tailed tests, we can approximate the p-value. If we select α=0.025, the critical value is 1.96, and we still reject H 0 because 2.38 > 1.960. If we select α=0.010 the critical value is 2.326, and we still reject H 0 because 2.38 > 2.326. However, if we select α=0.005, the critical value is 2.576, and we cannot reject H 0 because 2.38 < 2.576. Therefore, the smallest α where we still reject H 0 is 0.010. This is the p-value. A statistical computing package would produce a more precise p-value which would be in between 0.005 and 0.010. Here we are approximating the p-value and would report p < 0.010.
In all tests of hypothesis, there are two types of errors that can be committed. The first is called a Type I error and refers to the situation where we incorrectly reject H 0 when in fact it is true. This is also called a false positive result (as we incorrectly conclude that the research hypothesis is true when in fact it is not). When we run a test of hypothesis and decide to reject H 0 (e.g., because the test statistic exceeds the critical value in an upper tailed test) then either we make a correct decision because the research hypothesis is true or we commit a Type I error. The different conclusions are summarized in the table below. Note that we will never know whether the null hypothesis is really true or false (i.e., we will never know which row of the following table reflects reality).
Table - Conclusions in Test of Hypothesis
In the first step of the hypothesis test, we select a level of significance, α, and α= P(Type I error). Because we purposely select a small value for α, we control the probability of committing a Type I error. For example, if we select α=0.05, and our test tells us to reject H 0 , then there is a 5% probability that we commit a Type I error. Most investigators are very comfortable with this and are confident when rejecting H 0 that the research hypothesis is true (as it is the more likely scenario when we reject H 0 ).
When we run a test of hypothesis and decide not to reject H 0 (e.g., because the test statistic is below the critical value in an upper tailed test) then either we make a correct decision because the null hypothesis is true or we commit a Type II error. Beta (β) represents the probability of a Type II error and is defined as follows: β=P(Type II error) = P(Do not Reject H 0 | H 0 is false). Unfortunately, we cannot choose β to be small (e.g., 0.05) to control the probability of committing a Type II error because β depends on several factors including the sample size, α, and the research hypothesis. When we do not reject H 0 , it may be very likely that we are committing a Type II error (i.e., failing to reject H 0 when in fact it is false). Therefore, when tests are run and the null hypothesis is not rejected we often make a weak concluding statement allowing for the possibility that we might be committing a Type II error. If we do not reject H 0 , we conclude that we do not have significant evidence to show that H 1 is true. We do not conclude that H 0 is true.

The most common reason for a Type II error is a small sample size.
return to top | previous page | next page
Content ©2017. All Rights Reserved. Date last modified: November 6, 2017. Wayne W. LaMorte, MD, PhD, MPH

Statistics Made Easy
Critical Z Value Calculator
z critical value (right-tailed): 1.645
z critical value (two-tailed): +/- 1.960

Published by Zach
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *

Critical Z-Values: Gatekeepers in Hypothesis Testing
The world of statistics is full of tools, techniques, and terminologies that help us navigate the vast seas of data and draw meaningful conclusions. Among the plethora of statistical terms, ‘critical Z-values’ stands out, especially when venturing into the domain of hypothesis testing. To comprehend the importance and application of critical Z-values, let’s dive deeper into its essence and workings.
Z-Values: A Brief Refresher
At its foundation, a Z-value, or Z-score, indicates how many standard deviations a data point is away from the mean in a given dataset. This score can be both positive and negative, denoting values above or below the mean, respectively.
Discover how to calculate the z-score
What Are Critical Z-Values?
Critical Z-values, often termed critical values, are threshold values set on a standard normal distribution curve. These values, usually one on the left (negative) and one on the right (positive), effectively create a boundary or region. When testing hypotheses, if your test statistic falls within this region, you would reject the null hypothesis in favor of the alternative hypothesis.
The selection of these critical values is directly linked to the significance level (often denoted as α) that the researcher or analyst has chosen. Commonly used significance levels include 0.05, 0.01, and 0.10.

The Mechanics of Critical Z-Values
To understand this concept better, let’s take the commonly used significance level of 0.05. If you’re conducting a two-tailed test (which means you’re considering extreme values on both ends of the distribution), you’d split this α into two, placing 0.025 in each tail. Using a Z-table or statistical software, you’d then identify the Z-values that correspond to these tail areas. For a significance level of 0.05, the critical Z-values are typically -1.96 and +1.96.
Critical Z-Values in Hypothesis Testing
Hypothesis testing is a methodological process where statisticians make an initial assumption (the null hypothesis) and test the validity of this assumption based on sample data.
The process typically follows these steps:
- State the Hypotheses: Formulate the null (Ho) and alternative hypotheses (Ha).
- Choose the Significance Level (α): Decide the threshold for rejecting the null hypothesis.
- Select the Test and Find the Critical Value(s): For a Z-test, this would be the critical Z-value.
- Compute the Test Statistic: Calculate the Z-score for your sample data.
- Make a Decision: If your test statistic falls within the critical region (beyond the critical Z-values), you’d reject the null hypothesis.
Examples and Applications
Example 1: Imagine a shoe manufacturer claims their shoes last an average of 365 days before showing significant wear. A competitor believes these shoes wear out faster and conducts a study with a sample of shoes. Using a significance level of 0.05 for a two-tailed test, the critical Z-values are -1.96 and +1.96. If the Z-score calculated from the sample data is -2.1 (indicating the shoes wore out faster than claimed), the null hypothesis would be rejected since -2.1 falls outside the critical values.
Example 2: A beverage company claims its juice box contains 250 ml of juice. A consumer group, suspecting the company overstates the quantity, tests a sample. Using a one-tailed test at α = 0.05 (because they only care if the juice box contains less than claimed), the critical Z-value for this test would be -1.645. If their sample calculation results in a Z-score of -1.8, the null hypothesis would be rejected, suggesting the juice boxes contain less than the stated amount.
Why Are Critical Z-Values Important?
Critical Z-values serve as gatekeepers. They provide the boundary beyond which the observed data is considered rare or unusual under the assumption that the null hypothesis is true. By setting these boundaries, statisticians have a clear framework to determine whether to reject the null hypothesis or fail to reject it.
Find out everything you need to know about standard deviation
Critical Z-values, while just numbers on the surface, are pivotal in hypothesis testing, guiding decisions and providing clarity. They act as the yardstick against which observed data is measured, helping determine the validity of initial assumptions. In a world drowning in data, tools like critical Z-values help sieve through the noise, enabling researchers, analysts, and professionals to draw significant, actionable insights. As the backbone of hypothesis testing, understanding and applying critical Z-values is indispensable for anyone seeking to make informed decisions based on data.
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
Critical Value
Critical value is a cut-off value that is used to mark the start of a region where the test statistic, obtained in hypothesis testing, is unlikely to fall in. In hypothesis testing, the critical value is compared with the obtained test statistic to determine whether the null hypothesis has to be rejected or not.
Graphically, the critical value splits the graph into the acceptance region and the rejection region for hypothesis testing. It helps to check the statistical significance of a test statistic. In this article, we will learn more about the critical value, its formula, types, and how to calculate its value.
What is Critical Value?
A critical value can be calculated for different types of hypothesis tests. The critical value of a particular test can be interpreted from the distribution of the test statistic and the significance level. A one-tailed hypothesis test will have one critical value while a two-tailed test will have two critical values.
Critical Value Definition
Critical value can be defined as a value that is compared to a test statistic in hypothesis testing to determine whether the null hypothesis is to be rejected or not. If the value of the test statistic is less extreme than the critical value, then the null hypothesis cannot be rejected. However, if the test statistic is more extreme than the critical value, the null hypothesis is rejected and the alternative hypothesis is accepted. In other words, the critical value divides the distribution graph into the acceptance and the rejection region. If the value of the test statistic falls in the rejection region, then the null hypothesis is rejected otherwise it cannot be rejected.
Critical Value Formula
Depending upon the type of distribution the test statistic belongs to, there are different formulas to compute the critical value. The confidence interval or the significance level can be used to determine a critical value. Given below are the different critical value formulas.
Critical Value Confidence Interval
The critical value for a one-tailed or two-tailed test can be computed using the confidence interval . Suppose a confidence interval of 95% has been specified for conducting a hypothesis test. The critical value can be determined as follows:
- Step 1: Subtract the confidence level from 100%. 100% - 95% = 5%.
- Step 2: Convert this value to decimals to get \(\alpha\). Thus, \(\alpha\) = 5%.
- Step 3: If it is a one-tailed test then the alpha level will be the same value in step 2. However, if it is a two-tailed test, the alpha level will be divided by 2.
- Step 4: Depending on the type of test conducted the critical value can be looked up from the corresponding distribution table using the alpha value.
The process used in step 4 will be elaborated in the upcoming sections.
T Critical Value
A t-test is used when the population standard deviation is not known and the sample size is lesser than 30. A t-test is conducted when the population data follows a Student t distribution . The t critical value can be calculated as follows:
- Determine the alpha level.
- Subtract 1 from the sample size. This gives the degrees of freedom (df).
- If the hypothesis test is one-tailed then use the one-tailed t distribution table. Otherwise, use the two-tailed t distribution table for a two-tailed test.
- Match the corresponding df value (left side) and the alpha value (top row) of the table. Find the intersection of this row and column to give the t critical value.
Test Statistic for one sample t test: t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\). \(\overline{x}\) is the sample mean, \(\mu\) is the population mean, s is the sample standard deviation and n is the size of the sample.
Test Statistic for two samples t test: \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{s_{1}^{2}}{n_{1}}+\frac{s_{2}^{2}}{n_{2}}}}\).
Decision Criteria:
- Reject the null hypothesis if test statistic > t critical value (right-tailed hypothesis test).
- Reject the null hypothesis if test statistic < t critical value (left-tailed hypothesis test).
- Reject the null hypothesis if the test statistic does not lie in the acceptance region (two-tailed hypothesis test).

This decision criterion is used for all tests. Only the test statistic and critical value change.
Z Critical Value
A z test is conducted on a normal distribution when the population standard deviation is known and the sample size is greater than or equal to 30. The z critical value can be calculated as follows:
- Find the alpha level.
- Subtract the alpha level from 1 for a two-tailed test. For a one-tailed test subtract the alpha level from 0.5.
- Look up the area from the z distribution table to obtain the z critical value. For a left-tailed test, a negative sign needs to be added to the critical value at the end of the calculation.
Test statistic for one sample z test: z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\). \(\sigma\) is the population standard deviation.
Test statistic for two samples z test: z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
F Critical Value
The F test is largely used to compare the variances of two samples. The test statistic so obtained is also used for regression analysis. The f critical value is given as follows:
- Subtract 1 from the size of the first sample. This gives the first degree of freedom. Say, x
- Similarly, subtract 1 from the second sample size to get the second df. Say, y.
- Using the f distribution table, the intersection of the x column and y row will give the f critical value.
Test Statistic for large samples: f = \(\frac{\sigma_{1}^{2}}{\sigma_{2}^{2}}\). \(\sigma_{1}^{2}\) variance of the first sample and \(\sigma_{2}^{2}\) variance of the second sample.
Test Statistic for small samples: f = \(\frac{s_{1}^{2}}{s_{2}^{2}}\). \(s_{1}^{1}\) variance of the first sample and \(s_{2}^{2}\) variance of the second sample.
Chi-Square Critical Value
The chi-square test is used to check if the sample data matches the population data. It can also be used to compare two variables to see if they are related. The chi-square critical value is given as follows:
- Identify the alpha level.
- Subtract 1 from the sample size to determine the degrees of freedom (df).
- Using the chi-square distribution table, the intersection of the row of the df and the column of the alpha value yields the chi-square critical value.
Test statistic for chi-squared test statistic: \(\chi ^{2} = \sum \frac{(O_{i}-E_{i})^{2}}{E_{i}}\).
Critical Value Calculation
Suppose a right-tailed z test is being conducted. The critical value needs to be calculated for a 0.0079 alpha level. Then the steps are as follows:
- Subtract the alpha level from 0.5. Thus, 0.5 - 0.0079 = 0.4921
- Using the z distribution table find the area closest to 0.4921. The closest area is 0.4922. As this value is at the intersection of 2.4 and 0.02 thus, the z critical value = 2.42.

Related Articles:
- Probability and Statistics
- Data Handling
Important Notes on Critical Value
- Critical value can be defined as a value that is useful in checking whether the null hypothesis can be rejected or not by comparing it with the test statistic.
- It is the point that divides the distribution graph into the acceptance and the rejection region.
- There are 4 types of critical values - z, f, chi-square, and t.
Examples on Critical Value
Example 1: Find the critical value for a left tailed z test where \(\alpha\) = 0.012.
Solution: First subtract \(\alpha\) from 0.5. Thus, 0.5 - 0.012 = 0.488.
Using the z distribution table, z = 2.26.
However, as this is a left-tailed z test thus, z = -2.26
Answer: Critical value = -2.26
Example 2: Find the critical value for a two-tailed f test conducted on the following samples at a \(\alpha\) = 0.025
Variance = 110, Sample size = 41
Variance = 70, Sample size = 21
Solution: \(n_{1}\) = 41, \(n_{2}\) = 21,
\(n_{1}\) - 1= 40, \(n_{2}\) - 1 = 20,
Sample 1 df = 40, Sample 2 df = 20
Using the F distribution table for \(\alpha\) = 0.025, the value at the intersection of the 40 th column and 20 th row is
F(40, 20) = 2.287
Answer: Critical Value = 2.287
Example 3: Suppose a one-tailed t-test is being conducted on data with a sample size of 8 at \(\alpha\) = 0.05. Then find the critical value.
Solution: n = 8
df = 8 - 1 = 7
Using the one tailed t distribution table t(7, 0.05) = 1.895.
Answer: Crititcal Value = 1.895
go to slide go to slide go to slide

Book a Free Trial Class
FAQs on Critical Value
What is the critical value in statistics.
Critical value in statistics is a cut-off value that is compared with a test statistic in hypothesis testing to check whether the null hypothesis should be rejected or not.
What are the Different Types of Critical Value?
There are 4 types of critical values depending upon the type of distributions they are obtained from. These distributions are given as follows:
- Normal distribution (z critical value).
- Student t distribution (t).
- Chi-squared distribution (chi-squared).
- F distribution (f).
What is the Critical Value Formula for an F test?
To find the critical value for an f test the steps are as follows:
- Determine the degrees of freedom for both samples by subtracting 1 from each sample size.
- Find the corresponding value from a one-tailed or two-tailed f distribution at the given alpha level.
- This will give the critical value.
What is the T Critical Value?
The t critical value is obtained when the population follows a t distribution. The steps to find the t critical value are as follows:
- Subtract the sample size number by 1 to get the df.
- Use the t distribution table for the alpha value to get the required critical value.
How to Find the Critical Value Using a Confidence Interval for a Two-Tailed Z Test?
The steps to find the critical value using a confidence interval are as follows:
- Subtract the confident interval from 100% and convert the resultant into a decimal value to get the alpha level.
- Subtract this value from 1.
- Find the z value for the corresponding area using the normal distribution table to get the critical value.
Can a Critical Value be Negative?
If a left-tailed test is being conducted then the critical value will be negative. This is because the critical value will be to the left of the mean thus, making it negative.
How to Reject Null Hypothesis Based on Critical Value?
The rejection criteria for the null hypothesis is given as follows:
- Right-tailed test: Test statistic > critical value.
- Left-tailed test: Test statistic < critical value.
- Two-tailed test: Reject if the test statistic does not lie in the acceptance region.
Critical Value Approach in Hypothesis Testing
by Nathan Sebhastian
Posted on Jun 05, 2023
Reading time: 5 minutes

The critical value is the cut-off point to determine whether to accept or reject the null hypothesis for your sample distribution.
The critical value approach provides a standardized method for hypothesis testing, enabling you to make informed decisions based on the evidence obtained from sample data.
After calculating the test statistic using the sample data, you compare it to the critical value(s) corresponding to the chosen significance level ( α ).
The critical value(s) represent the boundary beyond which you reject the null hypothesis. You will have rejection regions and non-rejection region as follows:
Two-sided test
A two-sided hypothesis test has 2 rejection regions, so you need 2 critical values on each side. Because there are 2 rejection regions, you must split the significance level in half.
Each rejection region has a probability of α / 2 , making the total likelihood for both areas equal the significance level.

In this test, the null hypothesis H0 gets rejected when the test statistic is too small or too large.
Left-tailed test
The left-tailed test has 1 rejection region, and the null hypothesis only gets rejected when the test statistic is too small.

Right-tailed test
The right-tailed test is similar to the left-tailed test, only the null hypothesis gets rejected when the test statistic is too large.

Now that you understand the definition of critical values, let’s look at how to use critical values to construct a confidence interval.
Using Critical Values to Construct Confidence Intervals
Confidence Intervals use the same Critical values as the test you’re running.
If you’re running a z-test with a 95% confidence interval, then:
- For a two-sided test, The CVs are -1.96 and 1.96
- For a one-tailed test, the critical value is -1.65 (left) or 1.65 (right)
To calculate the upper and lower bounds of the confidence interval, you need to calculate the sample mean and then add or subtract the margin of error from it.
To get the Margin of Error, multiply the critical value by the standard error:
Let’s see an example. Suppose you are estimating the population mean with a 95% confidence level.
You have a sample mean of 50, a sample size of 100, and a standard deviation of 10. Using a z-table, the critical value for a 95% confidence level is approximately 1.96.
Calculate the standard error:
Determine the margin of error:
Compute the lower bound and upper bound:
The 95% confidence interval is (48.04, 51.96). This means that we are 95% confident that the true population mean falls within this interval.
Finding the Critical Value
The formula to find critical values depends on the specific distribution associated with the hypothesis test or confidence interval you’re using.
Here are the formulas for some commonly used distributions.
Standard Normal Distribution (Z-distribution):
The critical value for a given significance level ( α ) in the standard normal distribution is found using the cumulative distribution function (CDF) or a standard normal table.
z(α) represents the z-score corresponding to the desired significance level α .
Student’s t-Distribution (t-distribution):
The critical value for a given significance level (α) and degrees of freedom (df) in the t-distribution is found using the inverse cumulative distribution function (CDF) or a t-distribution table.
t(α, df) represents the t-score corresponding to the desired significance level α and degrees of freedom df .
Chi-Square Distribution (χ²-distribution):
The critical value for a given significance level (α) and degrees of freedom (df) in the chi-square distribution is found using the inverse cumulative distribution function (CDF) or a chi-square distribution table.
where χ²(α, df) represents the chi-square value corresponding to the desired significance level α and degrees of freedom df .
F-Distribution:
The critical value for a given significance level (α), degrees of freedom for the numerator (df₁), and degrees of freedom for the denominator (df₂) in the F-distribution is found using the inverse cumulative distribution function (CDF) or an F-distribution table.
F(α, df₁, df₂) represents the F-value corresponding to the desired significance level α , df₁ , and df₂ .
As you can see, the specific formula to find critical values depends on the distribution and the parameters associated with the problem at hand.
Usually, you don’t calculate the critical values manually as you can use statistical tables or statistical software to determine the critical values.
I will update this tutorial with statistical tables that you can use later.
The critical value is as a threshold where you make a decision based on the observed test statistic and its relation to the significance level.
It provides a predetermined point of reference to objectively evaluate the strength of the evidence against the null hypothesis and guide the acceptance or rejection of the hypothesis.
If the test statistic falls in the critical region (beyond the critical value), it means the observed data provide strong evidence against the null hypothesis.
In this case, you reject the null hypothesis in favor of the alternative hypothesis, indicating that there is sufficient evidence to support the claim or relationship stated in the alternative hypothesis.
On the other hand, if the test statistic falls in the non-critical region (within the critical value), it means the observed data do not provide enough evidence to reject the null hypothesis.
In this case, you fail to reject the null hypothesis, indicating that there is insufficient evidence to support the alternative hypothesis.
Take your skills to the next level ⚡️
I'm sending out an occasional email with the latest tutorials on programming, web development, and statistics. Drop your email in the box below and I'll send new stuff straight into your inbox!
Hello! This website is dedicated to help you learn tech and data science skills with its step-by-step, beginner-friendly tutorials. Learn statistics, JavaScript and other programming languages using clear examples written for people.
Learn more about this website
Connect with me on Twitter
Or LinkedIn
Type the keyword below and hit enter
Click to see all tutorials tagged with:
Data Science Society
Data.Platform

Statistical Hypothesis Testing: How to Calculate Critical Values

Testing statistical hypotheses is one of the most important parts of data analysis. It lets the researcher and analyst conclude the whole community from a small sample. In this case, critical values are useful because they help figure out if the results are worthy of attention.
The goal of this article is to define a critical value calculator, talk about why it’s important in statistical hypothesis testing, and show how to use one.
What is statistical hypothesis testing?

Statistical hypothesis testing is a methodical way to draw conclusions about a whole community from a small group of samples. In this step, observed data is compared to an expected or null hypothesis to see if there is a difference that is caused by an effect, chance, or just a human mistake. Hypotheses are put to the test in economics, social studies, and science in order to come to reasonable conclusions.
What are critical values?
In this case, critical values are limits or borders that are used during hypothesis testing to see how important a test statistic is. In hypothesis testing, the critical value is compared to a test statistic that measures the difference between the data that was noticed and the value that was thought to be true. A critical value calculator is used to evaluate if there is sufficient information in the observed results that would make it possible to invalidate the zero hypothesis.
How to calculate critical values
Step 1: identify the test statistic.
Before you can figure out the key values, you need to choose the right test statistic for your hypothesis test. The “test statistic” is a number that shows that the data are different from the “null value.” This is a list of test statistics. Which one to use depends on the data or hypothesis being tested.
Examples of these statistics are the Z-score, T-statistics, F-statistics, and Chi-squared statistics. Here’s a brief overview of when each test statistic is typically used:
Z-score: If you have data that has a normal distribution, you can find out what the group mean and standard deviation are.
T-statistic: The t-statistic is used to test hypotheses when the sample size is small, or the community standard deviation is unknown.
F-statistic: In ANOVA tests, F-statistics are used to find changes between the variances of different groups or treatments.
The chi-squared measure is used for tests that use categorical data, such as the goodness of fit test or the test for independence in a contingency table.
Once you’ve found the best statistic for a hypothesis test, move on to the next step.
Step 2: Determine the degrees of freedom
Degrees of freedom (df) are one of the important things that are used to figure out critical numbers. Freedom of degrees refers to the number of separate factors that are linked to your dataset. The number of degrees of freedom changes based on the test measure that is used.
For example, to find the critical numbers for a T-statistic, one is usually taken away from n to get an idea of the degrees of freedom. An F-statistic in ANOVA, on the other hand, has two sets of degrees of freedom: one for the numerator (which is the difference between groups) and one for the denominator (which is the difference within groups).
Because of this, you need to figure out the right number of degrees of freedom for your analysis and not use the wrong numbers because they lead to wrong results. If you need to find the right degree of freedom values for your test statistic, look at the appropriate statistical tables or sources.
Step 3: One needs to find the critical value in a critical value table
A critical value table is an important part of any hypothesis test. For each degree of freedom and significant level, the table shows the test statistic values that go with them. This critical number sets a limit on how often the null should be rejected.
One example is a two-tailed Z-test with a significance level of 0.05 (alpha = 0.05). If you know the number of degrees of freedom, you can find the critical value that is equal to alpha/2 (0.025) in the
Also, the T-table shows the important number for alpha/2 and your degrees of freedom for the T-distribution with degrees of freedom.
Step 4: Do you believe that the test statistic is bigger than the critical value?
After that, we will compare this test statistic with the critical number we chose from the table. So, you will reject the null hypothesis if your test result is more extreme than what is needed for a significance level (the tail of the distribution above the critical value). This shows that the data that was seen is very different, which means it probably wasn’t just a matter of chance. On the other hand, you can’t reject the null hypothesis if your test statistic doesn’t fall in the rejection area. In this case, the data that was noticed is not enough to show that the value that was hypothesized might be wrong.
In the field of statistical hypothesis testing, researchers and other analysts need to know what key values are and how to find them. So, critical values are a common way to figure out how important the results of tests are. When researchers check to see if the test statistic is greater than or similar to the critical value, they can tell if their data supports the null hypothesis or not.
Always use the right critical value tables, and keep in mind that degrees of freedom are a big part of making sure that statistical analysis is correct and thorough. Using statistical software can also help cut down on mistakes and make the math part of this process easier.
Hypothesis testing is built on important values that help people come to conclusions, make decisions, make progress in science, and learn more. Critical value calculation is a skill that everyone who works with statistics needs to have.
Leave a Reply Cancel reply
You must be logged in to post a comment.
IMAGES
VIDEO
COMMENTS
To find a Z critical value for a given confidence level α: Check if you perform a one- or two-tailed test. For a one-tailed test: Left-tailed: critical value is the α-th quantile of the standard normal distribution N(0,1). Right-tailed: critical value is the (1-α)-th quantile. Two-tailed test: critical value equals ±(1-α/2)-th quantile of ...
A critical value defines regions in the sampling distribution of a test statistic. These values play a role in both hypothesis tests and confidence intervals. In hypothesis tests, critical values determine whether the results are statistically significant. For confidence intervals, they help calculate the upper and lower limits.
The critical value for conducting the left-tailed test H0 : μ = 3 versus HA : μ < 3 is the t -value, denoted -t( α, n - 1), such that the probability to the left of it is α. It can be shown using either statistical software or a t -table that the critical value -t0.05,14 is -1.7613. That is, we would reject the null hypothesis H0 : μ = 3 ...
A critical value often represents a rejection region cut-off value for a hypothesis test - also called a zc value for a confidence interval. For confidence intervals and two-tailed z-tests, you can use the zTable to determine the critical values (zc). Example. Find the critical values for a 90% Confidence Interval.
Related posts: Null Hypothesis: Definition, Rejecting & Examples and Understanding Significance Levels. Two-Sample Z Test Hypotheses. Null hypothesis (H 0): Two population means are equal (µ 1 = µ 2).; Alternative hypothesis (H A): Two population means are not equal (µ 1 ≠ µ 2).; Again, when the p-value is less than or equal to your significance level, reject the null hypothesis.
Step 2: Find the Critical Values. We have seen the critical values for z-tests at α = 0.05 levels of significance several times. To find the values for α = 0.01, we will go to the standard normal table and find the z-score cutting of 0.005 (0.01 divided by 2 for a two-tailed test) of the area in the tail, which is z crit * = ±2.575. Notice ...
Using Z-Tables to Find Critical Z-values. Z-tables can help you find the critical z-values for a z-test. To find these values, you need to know the significance level and whether you're performing a one- or two-tailed test. In a hypothesis test, the results are statistically significant when the test statistic exceeds a critical value. Z ...
When we use z z -scores in this way, the obtained value of z z (sometimes called z z -obtained) is something known as a test statistic, which is simply an inferential statistic used to test a null hypothesis. The formula for our z z -statistic has not changed: z = X¯¯¯¯ − μ σ¯/ n−−√ (7.5.1) (7.5.1) z = X ¯ − μ σ ¯ / n.
Equation 1. Processing alpha for a two-tailed test. Since we have calculated the alpha value for a two-tailed test, then we can determine the critical values, that is, those values that determine the rejection zone in the standard normal distribution.. To find the critical values, we look at z-table the value of z that approximates an area under the curve similar to 0.0250.
Example question: Find a critical value in the z-table for an alpha level of 0.0079. Step 1: Draw a diagram, like the one above. Shade in the area in the right tail. ... You can tell with hypothesis testing. 5. Types of Critical Values. Various types of critical values are used to calculate significance, including: t scores from student's t ...
For a one-tailed upper tail test, use the z-table to find a critical value where the total area to the left of the critical value is equal to 1- alpha. Solved Example: One-Tailed Z-Test Let's see if we can use the Z-table to find the critical value for a lower tail Z-test with a significance level of 0.01.
Test Statistic <= Critical Value: Fail to reject the null hypothesis of the statistical test. Test Statistic > Critical Value: Reject the null hypothesis of the statistical test. Two-Tailed Test. A two-tailed test has two critical values, one on each side of the distribution, which is often assumed to be symmetrical (e.g. Gaussian and Student-t ...
Z, T, Chi-Square, and F critical values and regions. Easy to use critical value calculator for converting a probability value (alpha threshold, a.k.a. significance level) to a Z value, T value, Chi-Square value, or F value using the inverse cumulative probability density function (inverse cumulative PDF) of the respective distribution. Calculate the score corresponding to a given significance ...
The level of significance which is selected in Step 1 (e.g., α =0.05) dictates the critical value. For example, in an upper tailed Z test, if α =0.05 then the critical value is Z=1.645. The following figures illustrate the rejection regions defined by the decision rule for upper-, lower- and two-tailed Z tests with α=0.05.
This calculator finds the z critical value associated with a given significance level. Simply fill in the significance level below, then click the "Calculate" button. Significance level. z critical value (right-tailed): 1.645. z critical value (two-tailed): +/- 1.960.
Find the critical value of z in a z table. Calculate the z test statistic (see below). Compare the test statistic to the critical z value and decide if you should support or reject the null hypothesis. You could perform all these steps by hand. For example, you could find a critical value by hand, or calculate a z value by hand.
Make a Decision: If your test statistic falls within the critical region (beyond the critical Z-values), you'd reject the null hypothesis. Examples and Applications. Example 1: Imagine a shoe manufacturer claims their shoes last an average of 365 days before showing significant wear. A competitor believes these shoes wear out faster and conducts a study with a sample of shoes.
The critical value for a one-tailed or two-tailed test can be computed using the confidence interval. Suppose a confidence interval of 95% has been specified for conducting a hypothesis test. The critical value can be determined as follows: Step 1: Subtract the confidence level from 100%. 100% - 95% = 5%. Step 2: Convert this value to decimals ...
In this video, we demonstrate how to find critical values for a large sample hypothesis test using a t and/or z table.
The critical value approach provides a standardized method for hypothesis testing, enabling you to make informed decisions based on the evidence obtained from sample data. After calculating the test statistic using the sample data, you compare it to the critical value (s) corresponding to the chosen significance level ( α ). The critical value ...
In this hypothesis testing video we discuss how to find rejection regions and critical values using a z test, when the standard deviation is known. We cover...
A critical value calculator is used to evaluate if there is sufficient information in the observed results that would make it possible to invalidate the zero hypothesis. How to calculate critical values Step 1: Identify the test statistic. Before you can figure out the key values, you need to choose the right test statistic for your hypothesis ...