Quantitative Data Analysis: A Comprehensive Guide
By: Ofem Eteng Published: May 18, 2022

Related Articles
A healthcare giant successfully introduces the most effective drug dosage through rigorous statistical modeling, saving countless lives. A marketing team predicts consumer trends with uncanny accuracy, tailoring campaigns for maximum impact.
Table of Contents
These trends and dosages are not just any numbers but are a result of meticulous quantitative data analysis. Quantitative data analysis offers a robust framework for understanding complex phenomena, evaluating hypotheses, and predicting future outcomes.
In this blog, we’ll walk through the concept of quantitative data analysis, the steps required, its advantages, and the methods and techniques that are used in this analysis. Read on!
What is Quantitative Data Analysis?
Quantitative data analysis is a systematic process of examining, interpreting, and drawing meaningful conclusions from numerical data. It involves the application of statistical methods, mathematical models, and computational techniques to understand patterns, relationships, and trends within datasets.
Quantitative data analysis methods typically work with algorithms, mathematical analysis tools, and software to gain insights from the data, answering questions such as how many, how often, and how much. Data for quantitative data analysis is usually collected from close-ended surveys, questionnaires, polls, etc. The data can also be obtained from sales figures, email click-through rates, number of website visitors, and percentage revenue increase.
Quantitative Data Analysis vs Qualitative Data Analysis
When we talk about data, we directly think about the pattern, the relationship, and the connection between the datasets – analyzing the data in short. Therefore when it comes to data analysis, there are broadly two types – Quantitative Data Analysis and Qualitative Data Analysis.
Quantitative data analysis revolves around numerical data and statistics, which are suitable for functions that can be counted or measured. In contrast, qualitative data analysis includes description and subjective information – for things that can be observed but not measured.
Let us differentiate between Quantitative Data Analysis and Quantitative Data Analysis for a better understanding.
Data Preparation Steps for Quantitative Data Analysis
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis:
- Step 1: Data Collection
Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as interviews, focus groups, surveys, and questionnaires.
- Step 2: Data Cleaning
Once the data is collected, begin the data cleaning process by scanning through the entire data for duplicates, errors, and omissions. Keep a close eye for outliers (data points that are significantly different from the majority of the dataset) because they can skew your analysis results if they are not removed.
This data-cleaning process ensures data accuracy, consistency and relevancy before analysis.
- Step 3: Data Analysis and Interpretation
Now that you have collected and cleaned your data, it is now time to carry out the quantitative analysis. There are two methods of quantitative data analysis, which we will discuss in the next section.
However, if you have data from multiple sources, collecting and cleaning it can be a cumbersome task. This is where Hevo Data steps in. With Hevo, extracting, transforming, and loading data from source to destination becomes a seamless task, eliminating the need for manual coding. This not only saves valuable time but also enhances the overall efficiency of data analysis and visualization, empowering users to derive insights quickly and with precision
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources (40+ free sources), we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Start for free now!
Now that you are familiar with what quantitative data analysis is and how to prepare your data for analysis, the focus will shift to the purpose of this article, which is to describe the methods and techniques of quantitative data analysis.
Methods and Techniques of Quantitative Data Analysis
Quantitative data analysis employs two techniques to extract meaningful insights from datasets, broadly. The first method is descriptive statistics, which summarizes and portrays essential features of a dataset, such as mean, median, and standard deviation.
Inferential statistics, the second method, extrapolates insights and predictions from a sample dataset to make broader inferences about an entire population, such as hypothesis testing and regression analysis.
An in-depth explanation of both the methods is provided below:
- Descriptive Statistics
- Inferential Statistics
1) Descriptive Statistics
Descriptive statistics as the name implies is used to describe a dataset. It helps understand the details of your data by summarizing it and finding patterns from the specific data sample. They provide absolute numbers obtained from a sample but do not necessarily explain the rationale behind the numbers and are mostly used for analyzing single variables. The methods used in descriptive statistics include:
- Mean: This calculates the numerical average of a set of values.
- Median: This is used to get the midpoint of a set of values when the numbers are arranged in numerical order.
- Mode: This is used to find the most commonly occurring value in a dataset.
- Percentage: This is used to express how a value or group of respondents within the data relates to a larger group of respondents.
- Frequency: This indicates the number of times a value is found.
- Range: This shows the highest and lowest values in a dataset.
- Standard Deviation: This is used to indicate how dispersed a range of numbers is, meaning, it shows how close all the numbers are to the mean.
- Skewness: It indicates how symmetrical a range of numbers is, showing if they cluster into a smooth bell curve shape in the middle of the graph or if they skew towards the left or right.
2) Inferential Statistics
In quantitative analysis, the expectation is to turn raw numbers into meaningful insight using numerical values, and descriptive statistics is all about explaining details of a specific dataset using numbers, but it does not explain the motives behind the numbers; hence, a need for further analysis using inferential statistics.
Inferential statistics aim to make predictions or highlight possible outcomes from the analyzed data obtained from descriptive statistics. They are used to generalize results and make predictions between groups, show relationships that exist between multiple variables, and are used for hypothesis testing that predicts changes or differences.
There are various statistical analysis methods used within inferential statistics; a few are discussed below.
- Cross Tabulations: Cross tabulation or crosstab is used to show the relationship that exists between two variables and is often used to compare results by demographic groups. It uses a basic tabular form to draw inferences between different data sets and contains data that is mutually exclusive or has some connection with each other. Crosstabs help understand the nuances of a dataset and factors that may influence a data point.
- Regression Analysis: Regression analysis estimates the relationship between a set of variables. It shows the correlation between a dependent variable (the variable or outcome you want to measure or predict) and any number of independent variables (factors that may impact the dependent variable). Therefore, the purpose of the regression analysis is to estimate how one or more variables might affect a dependent variable to identify trends and patterns to make predictions and forecast possible future trends. There are many types of regression analysis, and the model you choose will be determined by the type of data you have for the dependent variable. The types of regression analysis include linear regression, non-linear regression, binary logistic regression, etc.
- Monte Carlo Simulation: Monte Carlo simulation, also known as the Monte Carlo method, is a computerized technique of generating models of possible outcomes and showing their probability distributions. It considers a range of possible outcomes and then tries to calculate how likely each outcome will occur. Data analysts use it to perform advanced risk analyses to help forecast future events and make decisions accordingly.
- Analysis of Variance (ANOVA): This is used to test the extent to which two or more groups differ from each other. It compares the mean of various groups and allows the analysis of multiple groups.
- Factor Analysis: A large number of variables can be reduced into a smaller number of factors using the factor analysis technique. It works on the principle that multiple separate observable variables correlate with each other because they are all associated with an underlying construct. It helps in reducing large datasets into smaller, more manageable samples.
- Cohort Analysis: Cohort analysis can be defined as a subset of behavioral analytics that operates from data taken from a given dataset. Rather than looking at all users as one unit, cohort analysis breaks down data into related groups for analysis, where these groups or cohorts usually have common characteristics or similarities within a defined period.
- MaxDiff Analysis: This is a quantitative data analysis method that is used to gauge customers’ preferences for purchase and what parameters rank higher than the others in the process.
- Cluster Analysis: Cluster analysis is a technique used to identify structures within a dataset. Cluster analysis aims to be able to sort different data points into groups that are internally similar and externally different; that is, data points within a cluster will look like each other and different from data points in other clusters.
- Time Series Analysis: This is a statistical analytic technique used to identify trends and cycles over time. It is simply the measurement of the same variables at different times, like weekly and monthly email sign-ups, to uncover trends, seasonality, and cyclic patterns. By doing this, the data analyst can forecast how variables of interest may fluctuate in the future.
- SWOT analysis: This is a quantitative data analysis method that assigns numerical values to indicate strengths, weaknesses, opportunities, and threats of an organization, product, or service to show a clearer picture of competition to foster better business strategies
How to Choose the Right Method for your Analysis?
Choosing between Descriptive Statistics or Inferential Statistics can be often confusing. You should consider the following factors before choosing the right method for your quantitative data analysis:
1. Type of Data
The first consideration in data analysis is understanding the type of data you have. Different statistical methods have specific requirements based on these data types, and using the wrong method can render results meaningless. The choice of statistical method should align with the nature and distribution of your data to ensure meaningful and accurate analysis.
2. Your Research Questions
When deciding on statistical methods, it’s crucial to align them with your specific research questions and hypotheses. The nature of your questions will influence whether descriptive statistics alone, which reveal sample attributes, are sufficient or if you need both descriptive and inferential statistics to understand group differences or relationships between variables and make population inferences.
Pros and Cons of Quantitative Data Analysis
1. Objectivity and Generalizability:
- Quantitative data analysis offers objective, numerical measurements, minimizing bias and personal interpretation.
- Results can often be generalized to larger populations, making them applicable to broader contexts.
Example: A study using quantitative data analysis to measure student test scores can objectively compare performance across different schools and demographics, leading to generalizable insights about educational strategies.
2. Precision and Efficiency:
- Statistical methods provide precise numerical results, allowing for accurate comparisons and prediction.
- Large datasets can be analyzed efficiently with the help of computer software, saving time and resources.
Example: A marketing team can use quantitative data analysis to precisely track click-through rates and conversion rates on different ad campaigns, quickly identifying the most effective strategies for maximizing customer engagement.
3. Identification of Patterns and Relationships:
- Statistical techniques reveal hidden patterns and relationships between variables that might not be apparent through observation alone.
- This can lead to new insights and understanding of complex phenomena.
Example: A medical researcher can use quantitative analysis to pinpoint correlations between lifestyle factors and disease risk, aiding in the development of prevention strategies.
1. Limited Scope:
- Quantitative analysis focuses on quantifiable aspects of a phenomenon , potentially overlooking important qualitative nuances, such as emotions, motivations, or cultural contexts.
Example: A survey measuring customer satisfaction with numerical ratings might miss key insights about the underlying reasons for their satisfaction or dissatisfaction, which could be better captured through open-ended feedback.
2. Oversimplification:
- Reducing complex phenomena to numerical data can lead to oversimplification and a loss of richness in understanding.
Example: Analyzing employee productivity solely through quantitative metrics like hours worked or tasks completed might not account for factors like creativity, collaboration, or problem-solving skills, which are crucial for overall performance.
3. Potential for Misinterpretation:
- Statistical results can be misinterpreted if not analyzed carefully and with appropriate expertise.
- The choice of statistical methods and assumptions can significantly influence results.
This blog discusses the steps, methods, and techniques of quantitative data analysis. It also gives insights into the methods of data collection, the type of data one should work with, and the pros and cons of such analysis.
Gain a better understanding of data analysis with these essential reads:
- Data Analysis and Modeling: 4 Critical Differences
- Exploratory Data Analysis Simplified 101
- 25 Best Data Analysis Tools in 2024
Carrying out successful data analysis requires prepping the data and making it analysis-ready. That is where Hevo steps in.
Want to give Hevo a try? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing Hevo price , which will assist you in selecting the best plan for your requirements.
Share your experience of understanding Quantitative Data Analysis in the comment section below! We would love to hear your thoughts.

Ofem is a freelance writer specializing in data-related topics, who has expertise in translating complex concepts. With a focus on data science, analytics, and emerging technologies.
No-code Data Pipeline for your Data Warehouse
- Data Analysis
- Data Warehouse
- Quantitative Data Analysis
Continue Reading
Saloni Agarwal
Enterprise Data Lake: A Simplified Guide
Riya Bothra
An Expert Guide To Enterprise Data Analysis
Gcp storage buckets list: efficient data organizing strategy, i want to read this e-book.
Quantitative Data Analysis 101
The lingo, methods and techniques, explained simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020
Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo , like medians, modes, correlation and regression. Suddenly we’re all wishing we’d paid a little more attention in math class…
The good news is that while quantitative data analysis is a mammoth topic, gaining a working understanding of the basics isn’t that hard , even for those of us who avoid numbers and math . In this post, we’ll break quantitative analysis down into simple , bite-sized chunks so you can approach your research with confidence.

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones.
But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.
Don’t be a sucker – give your descriptive statistics the love and attention they deserve!

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

Of course, when you’re working with inferential statistics, the composition of your sample is really important. In other words, if your sample doesn’t accurately represent the population you’re researching, then your findings won’t necessarily be very useful.
For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post .
What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other.
Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.
Here’s a scatter plot demonstrating the correlation (relationship) between weight and height. Intuitively, we’d expect there to be some relationship between these two variables, which is what we see in this scatter plot. In other words, the results tend to cluster together in a diagonal line from bottom left to top right.

As I mentioned, these are are just a handful of inferential techniques – there are many, many more. Importantly, each statistical method has its own assumptions and limitations.
For example, some methods only work with normally distributed (parametric) data, while other methods are designed specifically for non-parametric data. And that’s exactly why descriptive statistics are so important – they’re the first step to knowing which inferential techniques you can and can’t use.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Why does this matter?
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
This is another reminder of why descriptive statistics are so important – they tell you all about the shape of your data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
74 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Anaesth
- v.60(9); 2016 Sep
Basic statistical tools in research and data analysis
Zulfiqar ali.
Department of Anaesthesiology, Division of Neuroanaesthesiology, Sheri Kashmir Institute of Medical Sciences, Soura, Srinagar, Jammu and Kashmir, India
S Bala Bhaskar
1 Department of Anaesthesiology and Critical Care, Vijayanagar Institute of Medical Sciences, Bellary, Karnataka, India
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if proper statistical tests are used. This article will try to acquaint the reader with the basic research tools that are utilised while conducting various studies. The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
INTRODUCTION
Statistics is a branch of science that deals with the collection, organisation, analysis of data and drawing of inferences from the samples to the whole population.[ 1 ] This requires a proper design of the study, an appropriate selection of the study sample and choice of a suitable statistical test. An adequate knowledge of statistics is necessary for proper designing of an epidemiological study or a clinical trial. Improper statistical methods may result in erroneous conclusions which may lead to unethical practice.[ 2 ]
Variable is a characteristic that varies from one individual member of population to another individual.[ 3 ] Variables such as height and weight are measured by some type of scale, convey quantitative information and are called as quantitative variables. Sex and eye colour give qualitative information and are called as qualitative variables[ 3 ] [ Figure 1 ].

Classification of variables
Quantitative variables
Quantitative or numerical data are subdivided into discrete and continuous measurements. Discrete numerical data are recorded as a whole number such as 0, 1, 2, 3,… (integer), whereas continuous data can assume any value. Observations that can be counted constitute the discrete data and observations that can be measured constitute the continuous data. Examples of discrete data are number of episodes of respiratory arrests or the number of re-intubations in an intensive care unit. Similarly, examples of continuous data are the serial serum glucose levels, partial pressure of oxygen in arterial blood and the oesophageal temperature.
A hierarchical scale of increasing precision can be used for observing and recording the data which is based on categorical, ordinal, interval and ratio scales [ Figure 1 ].
Categorical or nominal variables are unordered. The data are merely classified into categories and cannot be arranged in any particular order. If only two categories exist (as in gender male and female), it is called as a dichotomous (or binary) data. The various causes of re-intubation in an intensive care unit due to upper airway obstruction, impaired clearance of secretions, hypoxemia, hypercapnia, pulmonary oedema and neurological impairment are examples of categorical variables.
Ordinal variables have a clear ordering between the variables. However, the ordered data may not have equal intervals. Examples are the American Society of Anesthesiologists status or Richmond agitation-sedation scale.
Interval variables are similar to an ordinal variable, except that the intervals between the values of the interval variable are equally spaced. A good example of an interval scale is the Fahrenheit degree scale used to measure temperature. With the Fahrenheit scale, the difference between 70° and 75° is equal to the difference between 80° and 85°: The units of measurement are equal throughout the full range of the scale.
Ratio scales are similar to interval scales, in that equal differences between scale values have equal quantitative meaning. However, ratio scales also have a true zero point, which gives them an additional property. For example, the system of centimetres is an example of a ratio scale. There is a true zero point and the value of 0 cm means a complete absence of length. The thyromental distance of 6 cm in an adult may be twice that of a child in whom it may be 3 cm.
STATISTICS: DESCRIPTIVE AND INFERENTIAL STATISTICS
Descriptive statistics[ 4 ] try to describe the relationship between variables in a sample or population. Descriptive statistics provide a summary of data in the form of mean, median and mode. Inferential statistics[ 4 ] use a random sample of data taken from a population to describe and make inferences about the whole population. It is valuable when it is not possible to examine each member of an entire population. The examples if descriptive and inferential statistics are illustrated in Table 1 .
Example of descriptive and inferential statistics

Descriptive statistics
The extent to which the observations cluster around a central location is described by the central tendency and the spread towards the extremes is described by the degree of dispersion.
Measures of central tendency
The measures of central tendency are mean, median and mode.[ 6 ] Mean (or the arithmetic average) is the sum of all the scores divided by the number of scores. Mean may be influenced profoundly by the extreme variables. For example, the average stay of organophosphorus poisoning patients in ICU may be influenced by a single patient who stays in ICU for around 5 months because of septicaemia. The extreme values are called outliers. The formula for the mean is

where x = each observation and n = number of observations. Median[ 6 ] is defined as the middle of a distribution in a ranked data (with half of the variables in the sample above and half below the median value) while mode is the most frequently occurring variable in a distribution. Range defines the spread, or variability, of a sample.[ 7 ] It is described by the minimum and maximum values of the variables. If we rank the data and after ranking, group the observations into percentiles, we can get better information of the pattern of spread of the variables. In percentiles, we rank the observations into 100 equal parts. We can then describe 25%, 50%, 75% or any other percentile amount. The median is the 50 th percentile. The interquartile range will be the observations in the middle 50% of the observations about the median (25 th -75 th percentile). Variance[ 7 ] is a measure of how spread out is the distribution. It gives an indication of how close an individual observation clusters about the mean value. The variance of a population is defined by the following formula:

where σ 2 is the population variance, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The variance of a sample is defined by slightly different formula:

where s 2 is the sample variance, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. The formula for the variance of a population has the value ‘ n ’ as the denominator. The expression ‘ n −1’ is known as the degrees of freedom and is one less than the number of parameters. Each observation is free to vary, except the last one which must be a defined value. The variance is measured in squared units. To make the interpretation of the data simple and to retain the basic unit of observation, the square root of variance is used. The square root of the variance is the standard deviation (SD).[ 8 ] The SD of a population is defined by the following formula:

where σ is the population SD, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The SD of a sample is defined by slightly different formula:

where s is the sample SD, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. An example for calculation of variation and SD is illustrated in Table 2 .
Example of mean, variance, standard deviation

Normal distribution or Gaussian distribution
Most of the biological variables usually cluster around a central value, with symmetrical positive and negative deviations about this point.[ 1 ] The standard normal distribution curve is a symmetrical bell-shaped. In a normal distribution curve, about 68% of the scores are within 1 SD of the mean. Around 95% of the scores are within 2 SDs of the mean and 99% within 3 SDs of the mean [ Figure 2 ].

Normal distribution curve
Skewed distribution
It is a distribution with an asymmetry of the variables about its mean. In a negatively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the right of Figure 1 . In a positively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the left of the figure leading to a longer right tail.

Curves showing negatively skewed and positively skewed distribution
Inferential statistics
In inferential statistics, data are analysed from a sample to make inferences in the larger collection of the population. The purpose is to answer or test the hypotheses. A hypothesis (plural hypotheses) is a proposed explanation for a phenomenon. Hypothesis tests are thus procedures for making rational decisions about the reality of observed effects.
Probability is the measure of the likelihood that an event will occur. Probability is quantified as a number between 0 and 1 (where 0 indicates impossibility and 1 indicates certainty).
In inferential statistics, the term ‘null hypothesis’ ( H 0 ‘ H-naught ,’ ‘ H-null ’) denotes that there is no relationship (difference) between the population variables in question.[ 9 ]
Alternative hypothesis ( H 1 and H a ) denotes that a statement between the variables is expected to be true.[ 9 ]
The P value (or the calculated probability) is the probability of the event occurring by chance if the null hypothesis is true. The P value is a numerical between 0 and 1 and is interpreted by researchers in deciding whether to reject or retain the null hypothesis [ Table 3 ].
P values with interpretation

If P value is less than the arbitrarily chosen value (known as α or the significance level), the null hypothesis (H0) is rejected [ Table 4 ]. However, if null hypotheses (H0) is incorrectly rejected, this is known as a Type I error.[ 11 ] Further details regarding alpha error, beta error and sample size calculation and factors influencing them are dealt with in another section of this issue by Das S et al .[ 12 ]
Illustration for null hypothesis

PARAMETRIC AND NON-PARAMETRIC TESTS
Numerical data (quantitative variables) that are normally distributed are analysed with parametric tests.[ 13 ]
Two most basic prerequisites for parametric statistical analysis are:
- The assumption of normality which specifies that the means of the sample group are normally distributed
- The assumption of equal variance which specifies that the variances of the samples and of their corresponding population are equal.
However, if the distribution of the sample is skewed towards one side or the distribution is unknown due to the small sample size, non-parametric[ 14 ] statistical techniques are used. Non-parametric tests are used to analyse ordinal and categorical data.
Parametric tests
The parametric tests assume that the data are on a quantitative (numerical) scale, with a normal distribution of the underlying population. The samples have the same variance (homogeneity of variances). The samples are randomly drawn from the population, and the observations within a group are independent of each other. The commonly used parametric tests are the Student's t -test, analysis of variance (ANOVA) and repeated measures ANOVA.
Student's t -test
Student's t -test is used to test the null hypothesis that there is no difference between the means of the two groups. It is used in three circumstances:

where X = sample mean, u = population mean and SE = standard error of mean

where X 1 − X 2 is the difference between the means of the two groups and SE denotes the standard error of the difference.
- To test if the population means estimated by two dependent samples differ significantly (the paired t -test). A usual setting for paired t -test is when measurements are made on the same subjects before and after a treatment.
The formula for paired t -test is:

where d is the mean difference and SE denotes the standard error of this difference.
The group variances can be compared using the F -test. The F -test is the ratio of variances (var l/var 2). If F differs significantly from 1.0, then it is concluded that the group variances differ significantly.
Analysis of variance
The Student's t -test cannot be used for comparison of three or more groups. The purpose of ANOVA is to test if there is any significant difference between the means of two or more groups.
In ANOVA, we study two variances – (a) between-group variability and (b) within-group variability. The within-group variability (error variance) is the variation that cannot be accounted for in the study design. It is based on random differences present in our samples.
However, the between-group (or effect variance) is the result of our treatment. These two estimates of variances are compared using the F-test.
A simplified formula for the F statistic is:

where MS b is the mean squares between the groups and MS w is the mean squares within groups.
Repeated measures analysis of variance
As with ANOVA, repeated measures ANOVA analyses the equality of means of three or more groups. However, a repeated measure ANOVA is used when all variables of a sample are measured under different conditions or at different points in time.
As the variables are measured from a sample at different points of time, the measurement of the dependent variable is repeated. Using a standard ANOVA in this case is not appropriate because it fails to model the correlation between the repeated measures: The data violate the ANOVA assumption of independence. Hence, in the measurement of repeated dependent variables, repeated measures ANOVA should be used.
Non-parametric tests
When the assumptions of normality are not met, and the sample means are not normally, distributed parametric tests can lead to erroneous results. Non-parametric tests (distribution-free test) are used in such situation as they do not require the normality assumption.[ 15 ] Non-parametric tests may fail to detect a significant difference when compared with a parametric test. That is, they usually have less power.
As is done for the parametric tests, the test statistic is compared with known values for the sampling distribution of that statistic and the null hypothesis is accepted or rejected. The types of non-parametric analysis techniques and the corresponding parametric analysis techniques are delineated in Table 5 .
Analogue of parametric and non-parametric tests

Median test for one sample: The sign test and Wilcoxon's signed rank test
The sign test and Wilcoxon's signed rank test are used for median tests of one sample. These tests examine whether one instance of sample data is greater or smaller than the median reference value.
This test examines the hypothesis about the median θ0 of a population. It tests the null hypothesis H0 = θ0. When the observed value (Xi) is greater than the reference value (θ0), it is marked as+. If the observed value is smaller than the reference value, it is marked as − sign. If the observed value is equal to the reference value (θ0), it is eliminated from the sample.
If the null hypothesis is true, there will be an equal number of + signs and − signs.
The sign test ignores the actual values of the data and only uses + or − signs. Therefore, it is useful when it is difficult to measure the values.
Wilcoxon's signed rank test
There is a major limitation of sign test as we lose the quantitative information of the given data and merely use the + or – signs. Wilcoxon's signed rank test not only examines the observed values in comparison with θ0 but also takes into consideration the relative sizes, adding more statistical power to the test. As in the sign test, if there is an observed value that is equal to the reference value θ0, this observed value is eliminated from the sample.
Wilcoxon's rank sum test ranks all data points in order, calculates the rank sum of each sample and compares the difference in the rank sums.
Mann-Whitney test
It is used to test the null hypothesis that two samples have the same median or, alternatively, whether observations in one sample tend to be larger than observations in the other.
Mann–Whitney test compares all data (xi) belonging to the X group and all data (yi) belonging to the Y group and calculates the probability of xi being greater than yi: P (xi > yi). The null hypothesis states that P (xi > yi) = P (xi < yi) =1/2 while the alternative hypothesis states that P (xi > yi) ≠1/2.
Kolmogorov-Smirnov test
The two-sample Kolmogorov-Smirnov (KS) test was designed as a generic method to test whether two random samples are drawn from the same distribution. The null hypothesis of the KS test is that both distributions are identical. The statistic of the KS test is a distance between the two empirical distributions, computed as the maximum absolute difference between their cumulative curves.
Kruskal-Wallis test
The Kruskal–Wallis test is a non-parametric test to analyse the variance.[ 14 ] It analyses if there is any difference in the median values of three or more independent samples. The data values are ranked in an increasing order, and the rank sums calculated followed by calculation of the test statistic.
Jonckheere test
In contrast to Kruskal–Wallis test, in Jonckheere test, there is an a priori ordering that gives it a more statistical power than the Kruskal–Wallis test.[ 14 ]
Friedman test
The Friedman test is a non-parametric test for testing the difference between several related samples. The Friedman test is an alternative for repeated measures ANOVAs which is used when the same parameter has been measured under different conditions on the same subjects.[ 13 ]
Tests to analyse the categorical data
Chi-square test, Fischer's exact test and McNemar's test are used to analyse the categorical or nominal variables. The Chi-square test compares the frequencies and tests whether the observed data differ significantly from that of the expected data if there were no differences between groups (i.e., the null hypothesis). It is calculated by the sum of the squared difference between observed ( O ) and the expected ( E ) data (or the deviation, d ) divided by the expected data by the following formula:

A Yates correction factor is used when the sample size is small. Fischer's exact test is used to determine if there are non-random associations between two categorical variables. It does not assume random sampling, and instead of referring a calculated statistic to a sampling distribution, it calculates an exact probability. McNemar's test is used for paired nominal data. It is applied to 2 × 2 table with paired-dependent samples. It is used to determine whether the row and column frequencies are equal (that is, whether there is ‘marginal homogeneity’). The null hypothesis is that the paired proportions are equal. The Mantel-Haenszel Chi-square test is a multivariate test as it analyses multiple grouping variables. It stratifies according to the nominated confounding variables and identifies any that affects the primary outcome variable. If the outcome variable is dichotomous, then logistic regression is used.
SOFTWARES AVAILABLE FOR STATISTICS, SAMPLE SIZE CALCULATION AND POWER ANALYSIS
Numerous statistical software systems are available currently. The commonly used software systems are Statistical Package for the Social Sciences (SPSS – manufactured by IBM corporation), Statistical Analysis System ((SAS – developed by SAS Institute North Carolina, United States of America), R (designed by Ross Ihaka and Robert Gentleman from R core team), Minitab (developed by Minitab Inc), Stata (developed by StataCorp) and the MS Excel (developed by Microsoft).
There are a number of web resources which are related to statistical power analyses. A few are:
- StatPages.net – provides links to a number of online power calculators
- G-Power – provides a downloadable power analysis program that runs under DOS
- Power analysis for ANOVA designs an interactive site that calculates power or sample size needed to attain a given power for one effect in a factorial ANOVA design
- SPSS makes a program called SamplePower. It gives an output of a complete report on the computer screen which can be cut and paste into another document.
It is important that a researcher knows the concepts of the basic statistical methods used for conduct of a research study. This will help to conduct an appropriately well-designed study leading to valid and reliable results. Inappropriate use of statistical techniques may lead to faulty conclusions, inducing errors and undermining the significance of the article. Bad statistics may lead to bad research, and bad research may lead to unethical practice. Hence, an adequate knowledge of statistics and the appropriate use of statistical tests are important. An appropriate knowledge about the basic statistical methods will go a long way in improving the research designs and producing quality medical research which can be utilised for formulating the evidence-based guidelines.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
Learn / Guides / Quantitative data analysis guide
Back to guides
8 quantitative data analysis methods to turn numbers into insights
Setting up a few new customer surveys or creating a fresh Google Analytics dashboard feels exciting…until the numbers start rolling in. You want to turn responses into a plan to present to your team and leaders—but which quantitative data analysis method do you use to make sense of the facts and figures?
Last updated
Reading time.

This guide lists eight quantitative research data analysis techniques to help you turn numeric feedback into actionable insights to share with your team and make customer-centric decisions.
To pick the right technique that helps you bridge the gap between data and decision-making, you first need to collect quantitative data from sources like:
Google Analytics
Survey results
On-page feedback scores
Fuel your quantitative analysis with real-time data
Use Hotjar’s tools to collect quantitative data that helps you stay close to customers.
Then, choose an analysis method based on the type of data and how you want to use it.
Descriptive data analysis summarizes results—like measuring website traffic—that help you learn about a problem or opportunity. The descriptive analysis methods we’ll review are:
Multiple choice response rates
Response volume over time
Net Promoter Score®
Inferential data analyzes the relationship between data—like which customer segment has the highest average order value—to help you make hypotheses about product decisions. Inferential analysis methods include:
Cross-tabulation
Weighted customer feedback
You don’t need to worry too much about these specific terms since each quantitative data analysis method listed below explains when and how to use them. Let’s dive in!
1. Compare multiple-choice response rates
The simplest way to analyze survey data is by comparing the percentage of your users who chose each response, which summarizes opinions within your audience.
To do this, divide the number of people who chose a specific response by the total respondents for your multiple-choice survey. Imagine 100 customers respond to a survey about what product category they want to see. If 25 people said ‘snacks’, 25% of your audience favors that category, so you know that adding a snacks category to your list of filters or drop-down menu will make the purchasing process easier for them.
💡Pro tip: ask open-ended survey questions to dig deeper into customer motivations.
A multiple-choice survey measures your audience’s opinions, but numbers don’t tell you why they think the way they do—you need to combine quantitative and qualitative data to learn that.
One research method to learn about customer motivations is through an open-ended survey question. Giving customers space to express their thoughts in their own words—unrestricted by your pre-written multiple-choice questions—prevents you from making assumptions.
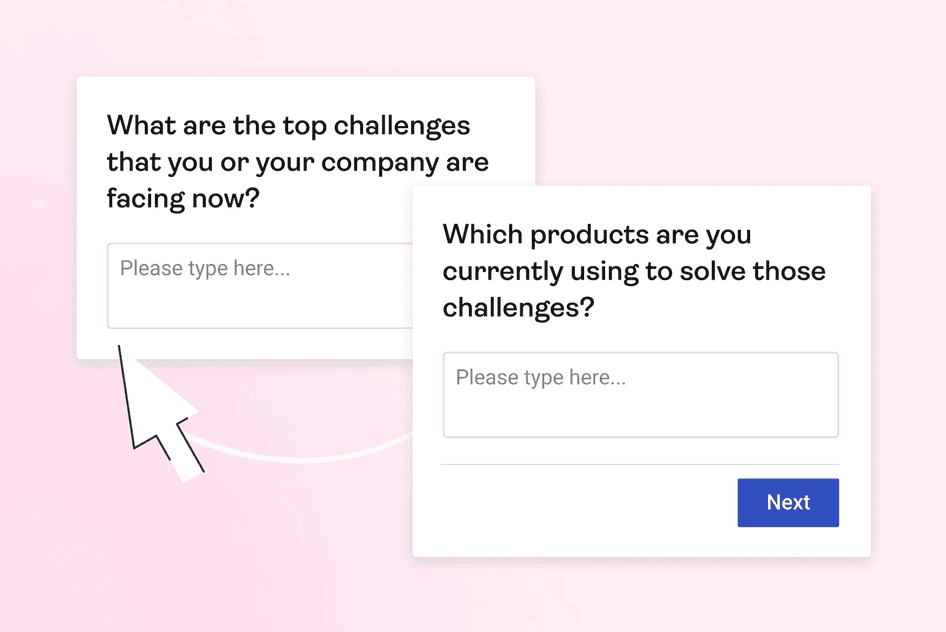
Hotjar’s open-ended surveys have a text box for customers to type a response
2. Cross-tabulate to compare responses between groups
To understand how responses and behavior vary within your audience, compare your quantitative data by group. Use raw numbers, like the number of website visitors, or percentages, like questionnaire responses, across categories like traffic sources or customer segments.

Let’s say you ask your audience what their most-used feature is because you want to know what to highlight on your pricing page. Comparing the most common response for free trial users vs. established customers lets you strategically introduce features at the right point in the customer journey .
💡Pro tip: get some face-to-face time to discover nuances in customer feedback.
Rather than treating your customers as a monolith, use Hotjar to conduct interviews to learn about individuals and subgroups. If you aren’t sure what to ask, start with your quantitative data results. If you notice competing trends between customer segments, have a few conversations with individuals from each group to dig into their unique motivations.
Hotjar Engage lets you identify specific customer segments you want to talk to
Mode is the most common answer in a data set, which means you use it to discover the most popular response for questions with numeric answer options. Mode and median (that's next on the list) are useful to compare to the average in case responses on extreme ends of the scale (outliers) skew the outcome.
Let’s say you want to know how most customers feel about your website, so you use an on-page feedback widget to collect ratings on a scale of one to five.

If the mode, or most common response, is a three, you can assume most people feel somewhat positive. But suppose the second-most common response is a one (which would bring the average down). In that case, you need to investigate why so many customers are unhappy.
💡Pro tip: watch recordings to understand how customers interact with your website.
So you used on-page feedback to learn how customers feel about your website, and the mode was two out of five. Ouch. Use Hotjar Recordings to see how customers move around on and interact with your pages to find the source of frustration.
Hotjar Recordings lets you watch individual visitors interact with your site, like how they scroll, hover, and click
Median reveals the middle of the road of your quantitative data by lining up all numeric values in ascending order and then looking at the data point in the middle. Use the median method when you notice a few outliers that bring the average up or down and compare the analysis outcomes.
For example, if your price sensitivity survey has outlandish responses and you want to identify a reasonable middle ground of what customers are willing to pay—calculate the median.
💡Pro-tip: review and clean your data before analysis.
Take a few minutes to familiarize yourself with quantitative data results before you push them through analysis methods. Inaccurate or missing information can complicate your calculations, and it’s less frustrating to resolve issues at the start instead of problem-solving later.
Here are a few data-cleaning tips to keep in mind:
Remove or separate irrelevant data, like responses from a customer segment or time frame you aren’t reviewing right now
Standardize data from multiple sources, like a survey that let customers indicate they use your product ‘daily’ vs. on-page feedback that used the phrasing ‘more than once a week’
Acknowledge missing data, like some customers not answering every question. Just note that your totals between research questions might not match.
Ensure you have enough responses to have a statistically significant result
Decide if you want to keep or remove outlying data. For example, maybe there’s evidence to support a high-price tier, and you shouldn’t dismiss less price-sensitive respondents. Other times, you might want to get rid of obviously trolling responses.
5. Mean (AKA average)
Finding the average of a dataset is an essential quantitative data analysis method and an easy task. First, add all your quantitative data points, like numeric survey responses or daily sales revenue. Then, divide the sum of your data points by the number of responses to get a single number representing the entire dataset.
Use the average of your quant data when you want a summary, like the average order value of your transactions between different sales pages. Then, use your average to benchmark performance, compare over time, or uncover winners across segments—like which sales page design produces the most value.
💡Pro tip: use heatmaps to find attention-catching details numbers can’t give you.
Calculating the average of your quant data set reveals the outcome of customer interactions. However, you need qualitative data like a heatmap to learn about everything that led to that moment. A heatmap uses colors to illustrate where most customers look and click on a page to reveal what drives (or drops) momentum.
Hotjar Heatmaps uses color to visualize what most visitors see, ignore, and click on
6. Measure the volume of responses over time
Some quantitative data analysis methods are an ongoing project, like comparing top website referral sources by month to gauge the effectiveness of new channels. Analyzing the same metric at regular intervals lets you compare trends and changes.
Look at quantitative survey results, website sessions, sales, cart abandons, or clicks regularly to spot trouble early or monitor the impact of a new initiative.
Here are a few areas you can measure over time (and how to use qualitative research methods listed above to add context to your results):
7. Net Promoter Score®
Net Promoter Score® ( NPS ®) is a popular customer loyalty and satisfaction measurement that also serves as a quantitative data analysis method.
NPS surveys ask customers to rate how likely they are to recommend you on a scale of zero to ten. Calculate it by subtracting the percentage of customers who answer the NPS question with a six or lower (known as ‘detractors’) from those who respond with a nine or ten (known as ‘promoters’). Your NPS score will fall between -100 and 100, and you want a positive number indicating more promoters than detractors.

💡Pro tip : like other quantitative data analysis methods, you can review NPS scores over time as a satisfaction benchmark. You can also use it to understand which customer segment is most satisfied or which customers may be willing to share their stories for promotional materials.
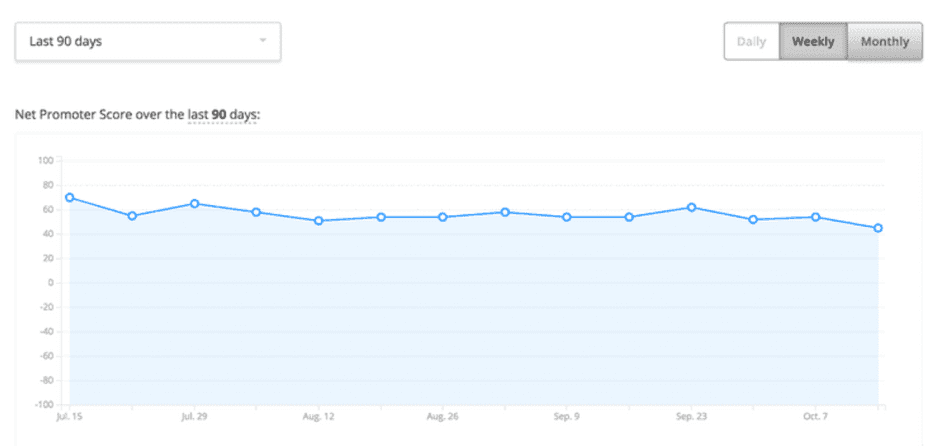
Review NPS score trends with Hotjar to spot any sudden spikes and benchmark performance over time
8. Weight customer feedback
So far, the quantitative data analysis methods on this list have leveraged numeric data only. However, there are ways to turn qualitative data into quantifiable feedback and to mix and match data sources. For example, you might need to analyze user feedback from multiple surveys.
To leverage multiple data points, create a prioritization matrix that assigns ‘weight’ to customer feedback data and company priorities and then multiply them to reveal the highest-scoring option.
Let’s say you identify the top four responses to your churn survey . Rate the most common issue as a four and work down the list until one—these are your customer priorities. Then, rate the ease of fixing each problem with a maximum score of four for the easy wins down to one for difficult tasks—these are your company priorities. Finally, multiply the score of each customer priority with its coordinating company priority scores and lead with the highest scoring idea.
💡Pro-tip: use a product prioritization framework to make decisions.
Try a product prioritization framework when the pressure is on to make high-impact decisions with limited time and budget. These repeatable decision-making tools take the guesswork out of balancing goals, customer priorities, and team resources. Four popular frameworks are:
RICE: weighs four factors—reach, impact, confidence, and effort—to weigh initiatives differently
MoSCoW: considers stakeholder opinions on 'must-have', 'should-have', 'could-have', and 'won't-have' criteria
Kano: ranks ideas based on how likely they are to satisfy customer needs
Cost of delay analysis: determines potential revenue loss by not working on a product or initiative
Share what you learn with data visuals
Data visualization through charts and graphs gives you a new perspective on your results. Plus, removing the clutter of the analysis process helps you and stakeholders focus on the insight over the method.
Data visualization helps you:
Get buy-in with impactful charts that summarize your results
Increase customer empathy and awareness across your company with digestible insights
Use these four data visualization types to illustrate what you learned from your quantitative data analysis:
Bar charts reveal response distribution across multiple options
Line graphs compare data points over time
Scatter plots showcase how two variables interact
Matrices contrast data between categories like customer segments, product types, or traffic source

Use a variety of customer feedback types to get the whole picture
Quantitative data analysis pulls the story out of raw numbers—but you shouldn’t take a single result from your data collection and run with it. Instead, combine numbers-based quantitative data with descriptive qualitative research to learn the what, why, and how of customer experiences.
Looking at an opportunity from multiple angles helps you make more customer-centric decisions with less guesswork.
Stay close to customers with Hotjar
Hotjar’s tools offer quantitative and qualitative insights you can use to make customer-centric decisions, get buy-in, and highlight your team’s impact.
Frequently asked questions about quantitative data analysis
What is quantitative data.
Quantitative data is numeric feedback and information that you can count and measure. For example, you can calculate multiple-choice response rates, but you can’t tally a customer’s open-ended product feedback response. You have to use qualitative data analysis methods for non-numeric feedback.
What are quantitative data analysis methods?
Quantitative data analysis either summarizes or finds connections between numerical data feedback. Here are eight ways to analyze your online business’s quantitative data:
Compare multiple-choice response rates
Cross-tabulate to compare responses between groups
Measure the volume of response over time
Net Promoter Score
Weight customer feedback
How do you visualize quantitative data?
Data visualization makes it easier to spot trends and share your analysis with stakeholders. Bar charts, line graphs, scatter plots, and matrices are ways to visualize quantitative data.
What are the two types of statistical analysis for online businesses?
Quantitative data analysis is broken down into two analysis technique types:
Descriptive statistics summarize your collected data, like the number of website visitors this month
Inferential statistics compare relationships between multiple types of quantitative data, like survey responses between different customer segments
Quantitative data analysis process
Previous chapter
Quantitative data analysis software
Next chapter
- Full funnel reporting
- Customized white label dashboards
- Custom connectors
- Bad data detection
- Solutions By Role PPC SEO Social Media CMO BI-IT Sales Vertical marketing Web analytics By Industry Marketing Agencies SaaS eCommerce
- Case Studies
- CEO Dashboard
- Sales Dashboard
- Schedule Demo
- 101 Guide to Quantitative Data Analysis [Methods + Techniques]
- March 8, 2023

Quantitative data analysis comes with the challenge of analyzing large datasets consisting of numeric variables and statistics. Researchers often get overwhelmed by various techniques, methods, and data sources.
At the same time, the importance of data collection and analysis drastically increases. It helps improve current products/services, identify the potential for a new product, understand target market psychology, and plan upcoming campaigns.
We have compiled this in-depth guide to ensure you get over the complexities of quantitative data analysis. Let’s begin with the basic meaning and importance of quantitative data analysis.
Quantitative data analysis meaning
Quantitative data analysis evaluates quantifiable and structured data to obtain simplified results. Analysts aim to interpret and draw conclusions from numeric variables and statistics. The entire analytical process works on algorithms and data analytics software, helping gain valuable insights. Continuous values are broken into parts for easy understanding using various tools and software. Such data is extracted through surveys and questionnaires.
However, data analytics software also helps extract quantitative data through email campaigns, websites, and social media.
Qualitative Vs. Quantitative research: major differences
Qualitative research aims at extracting valuable insights through non-numerical data like the psychology of customers . The research aims at obtaining solid results and confirming assumptions on general ideas. Furthermore, the collected data presentation remains descriptive instead of numerical-centric.
On the other hand, quantitative research focuses on numbers and statistics to identify gaps in current marketing and operational methods. It successfully answers questions like how many leads are converted in a specific email campaign.
Collecting quantitative data includes surveys, polls, questionnaires, etc. It remains efficient in identifying trends and patterns in the collected data. However, the obtained results aren’t always accurate as there are chances of numerical errors.
Note: both quantitative and qualitative data can be obtained with surveys. However, qualitative data collection focuses on asking open-ended questions.
In contrast, quantitative research focuses on close-ended ones.
4-Step Process of Quantitative data analysis
Now that we understand the meaning of quantitative data analysis, let’s proceed with four simple steps for conducting it.
Step 1: Identifying your goals and objectives.
Start by analyzing current business problems and the ones you plan to address with your analysis.
For example , your customer churn rate significantly increased in the last month.
Do you want to identify the reasons behind it? Being clear with the objective helps in collecting and analyzing relevant data.
Step 2: Data collection
Now you are clear with the issue you plan to address. Let’s identify and collect data from all relevant sources.
For example , conducting a survey of MCQs targeting all possible reasons behind the increase in the churn rate. Identify all relevant data sources and collect data for further analysis.
Step 3: Data cleaning
As discussed earlier, quantitative data doesn’t remain highly accurate as they are always chances of errors. Due to this, quantitative data analysis goes through many stages of cleaning.
Firstly, analysts start with data validation to identify if the data was collected based on defined procedures. Secondly, large datasets require a lot of editing to identify errors like empty fields or wrongly inserted digits.
Remember that the collected data consists of many duplications, unwanted data points, a lack of structure, and major gaps you must eliminate. Lastly, the collected data is presented in structured formats like tables for easy analysis.
Step 4: Data Analysis and interpretation
Now, you are equipped with fairly accurate data sets required for analysis. Using tools and software, data analysts interpret the collected data to draw valuable conclusions. Many techniques are used for quantitative data analysis, including time-series analysis, regression analysis, etc. However, applying the techniques correctly play a greater role than the type of technique used.
What are the methods for Quantitative research data collection?
Now that we know the meaning of quantitative data collection, let’s look at some methods of collecting it:
Surveys: close-ended questions
Surveys remain one of the most common methods of quantitative research data collection. These surveys include super-specific questions where respondents answer yes/no or multiple-choice questions. Most companies are going with rating questions or checklist-type survey questions.
Conducting interviews
Interviews remain another commonly used method for quantitative data collection. The interviews remain structured with specific questions. Telephone interviews were generally preferred until the introduction of video interviews using Skype, Zoom, etc. Some researchers also go with face-to-face interviews to collect quality data.
Analytical tools
Manually collecting and analyzing large datasets remain inconvenient. Many different analytical tools are available to collect, analyze, interpret, and visualize a large amount of data. For instance, tools like GrowthNirvana remain effective in efficient marketing analytics and provide relevant data without delays. All valuable insights required for business growth are easily extracted to make quicker decisions.
Document review: analyzing primary data
Researchers often analyze the available primary data like public records. The findings support the results generated from other quantitative data collection methods.
Methods and techniques of quantitative data analysis
The two common methods used for quantitative data analysis are descriptive and inferential statistics. Analysts use both methods to generate valuable insights. Here’s how:
Descriptive statistics
This method describes a dataset and provides an initial idea to help researchers identify potential trends or patterns. It generally focuses on analyzing single variables and explains the details of specific datasets. There are two ways of analyzing data using the descriptive statistics technique- numerical and graphical representation. Let’s start with the numerical method of quantitative data analysis.
- Numerical Method
The numerical method organizes and evaluates data arithmetically to obtain simpler answers to complex problems. Describing data remains the easiest using the measure of central tendency and dispersion.
The measures of central tendency like mean, median, and mode help identify the collected data’s central position. On the flip side, the measures of dispersion, like range, standard deviation, variance, etc., help understand the extent of data distribution concerning the central point.
- Graphical method
The graphical method provides a better understanding of data through visual representation. Evaluating large data sets becomes easier if presented using a bar chart, pie chart, histogram, boxplot, etc.
Inferential statistics
Conducting only descriptive analytics isn’t enough to draw valuable conclusions from the collected data. It only provides limited information on the datasets, emphasizing inferential statistics’ importance.
Inferential statistics make predictions using the data generated through descriptive statistics. It helps establish relationships between different variables to make relevant predictions. The technique remains suitable for large datasets.
Certain samples of the data are taken to represent the entire set as evaluating large data remains hectic. Therefore, the summarized samples generated with descriptive statistics are used to draw valuable conclusions.
Let’s now focus on some commonly used methods in inferential statistics:
- Regression analysis
The method establishes a relationship between a dependent and independent variable(s). It assesses their current strength and predicts future possibilities to devise enhanced strategies. The most commonly used regression models are simple linear and multiple linear.
- Cross tabulations
Cross tabulation or contingency table method is one of the most used methods for market research. It assists in the easy analysis of two or more variables through systematic rows and columns. Furthermore, the major goal of cross tabs remains intact in showing the changes in a dependent variable based on different subgroups.
- Monte Carlo method
The method focuses on weighing all possible outcomes of specific scenarios. Analyzing the pros and cons helps in predicting advanced risks before taking action. Therefore, forecasting future risks based on changing scenarios improves decision-making.
- SWOT analysis
A SWOT analysis identifies an organization’s strengths, weaknesses, opportunities, and threats. It takes into consideration internal and external factors to make better business plans. Companies often conduct a SWOT analysis to improve their products and services or while initiating a new project.
- Time Series analysis
Time series or trend analysis evaluates data sets recorded within specific intervals. Instead of taking random samples, the data is recorded in given time frames. Companies often use time series analysis for forecasting demand and supply.
What are examples of Quantitative data?
Let’s now look at some examples of quantitative data:
- Total number of app downloads in a month
- The total number of people who loved a newly introduced product feature
- Number of users converted with a marketing campaign
- Total number of website conversions in six months
- Number of customers residing in a specific location
What does a data analyst do?
A data analyst collects and interprets data to answer key questions like the potential of new product development, changes in customer purchase behavior, gaps in current marketing campaigns, etc. Many data analysts conduct exploratory analysis to identify trends and patterns during the data cleaning process.
The job also includes communicating the findings to team members to create better strategies. One can thrive in this position with the right technical and leadership skills. Therefore, a data analyst’s two key roles include knowing how to collect and use the collected data for business growth.
What is the typical process that a data analyst follows?
The process followed by a data analyst includes the following steps:
- Setting objectives
Understanding the goals behind collecting data help target the right areas for data collection. Next, identify the type of data you need to collect to conduct a specific analysis.
- Collecting data
Now you are clear with the goals and data requirements. Focus on collecting data from identified sources using different methods of data collection. Some of the top sources include surveys, polls, interviews, etc.
- Data cleaning
The data collection process includes collecting a large amount of data which requires further cleaning for analysis. This step removes duplicate records and identifies omissions and other numerical errors.
- Data analytics and interpretation
Now, data analysts focus on analyzing the collected data using various tools and software. Based on the analysis, they draw relevant conclusions to make the most of their findings.
- Data visualization
Data analysts must also convey the acquired information to relevant team members. Data visualization refers to the graphical interpretation of collected data for easy understanding. The process also helps analysts identify hidden insights for detailed reporting.
What techniques and tools do data analytics use?
Data analysts use various techniques, including regression analysis, the Monte Carlo method, factor analysis, cohort analysis, etc. The right blend of techniques to suit specific situations helps achieve the required results.
The tools used for data analysis reduce the manual burden of analysts and improve overall decision-making. There are varied categories of tools in data analysis, including business intelligence, ETL tools, automation tools, data mining, data visualization tools, etc.
Some popular choices for data analysis include Google Analytics, Growth Nirvana (marketing analytics), Improvado , Datapine , etc.
What are the skills required to become a data analyst?
A data analyst requires the following skills to thrive in the field:
- Complete knowledge of python programming
- Mathematical and statistical understanding
- Data decluttering, organizing, and analyzing
- SQL knowledge
- Problem-solving
- Logical reasoning and critical thinking
- Sharp communication skills
- Collaboration
What are some of the best data analytics course?
Let’s now look at some of the best data analytics courses in 2022 to help you gain all relevant skills:
- Detailed learning: Data Analyst Nanodegree program by Udacity
A 4-month program helping people develop advanced programming skills to handle complex data-related issues. It covers everything from data analysis, and visualization, to exploration.

Source
- Best data analytics course for beginners: Become A Data Analyst by LinkedIn.
The course consists of beginner-friendly lessons suitable for people with no prior understanding of data analysis. The experts in the industry take all sessions. Furthermore, you can easily complete the course within the free 30 days LinkedIn Learning period.

- Bite-sized learning: Data Analyst with R by Datacamp
The entire learning experience breaks down into multiple courses to help you keep up the pace. Industry experts curate about 19 different courses with a duration of 4 hours for every course. Furthermore, it also helps students gain practical exposure by working with real-life datasets.

Source
What does the future hold for data analytics?
Data analytics remains a constantly evolving area that will become increasingly important for businesses in the coming future. Extracting real-time insights will help enhance business operations for continuous growth. Furthermore, the increasing growth of business analytics tools makes it easier for businesses to analyze data and draw conclusions without complex coding knowledge.
Key Takeaways
- Analysts must use quantitative (number-oriented) and qualitative (non-numeric) data to devise and modify business strategies.
- Surveys are used for obtaining both quantitative and qualitative research data. However, quantitative surveys include only close-ended questions.
- Data cleaning remains one of the most crucial steps of data analysis. It ensures the collected data doesn’t contain duplications, omissions, unwanted data points, etc.
- The top skills possessed by data analysts include python programming, statistical knowledge, data decluttering, SQL knowledge, collaboration, and communication skills.
The top two data analytics techniques — descriptive and inferential statistics- are complementary.
Related Resources
- 101 Guide to Quantitative Data Analysis
- Marketing Automation In Your Marketing Strategy in 2023
- How to use Analytics Data to Reach New and Existing Customers
- How to Leverage Email Marketing with Advanced Analytics?
- The Best 7 Domo Alternatives in 2023
- 5 Best Improvado Alternatives for Marketers in 2023
- supermetrics alternatives
- marketing agency reporting tools
Related Guide Resources:
- Connect Google Analytics with Google Data Studio: 101 [New Guide]
- An Ultimate Guide To Omnichannel Analytics: Meaning, Benefits, Setup Process
- What is Marketing Analytics? Examples and Its Importance
You may also like...

Top 20 data connectors in 2023

How To Make Custom Reports In Google Analytics 4 (2023)

How To Get More Leads With PPC: Top 12 PPC Lead Generation St...
Growth Nirvana Inc. 145 Cedar Way #14 Laguna Beach, CA 92651
Copyright © 2024 Growth Nirvana. All rights reserved.
Give us a few details & get your automated custom dashboard in no time
No worries before you go explore how growth nirvana helped growing brands scale up to new heights., is your current reporting process taking up valuable time.
Tools for Analyzing Quantitative Data
- First Online: 01 January 2013
Cite this chapter

- Gerald A. Knezek Ph.D. 5 &
- Rhonda Christensen Ph.D. 5
30k Accesses
2 Citations
Data analysis tools for quantitative studies are addressed in the areas of: (a) enhancements for data acquisition, (b) simple to sophisticated analysis techniques, and (c) extended exploration of relationships in data, often with visualization of results. Examples that are interwoven with data and findings from published research studies are used to illustrate the use of the tools in the service of established research goals and objectives. The authors contend that capabilities have greatly expanded in all three areas over the past 30 years, and especially during the past two decades.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Note that multilevel analysis could also be used for detailed examination of this type of research question, and for separating out effects at different levels of a multilevel design. However, other issues such as having sufficient degrees of freedom to develop robust solutions also enter with multilevel designs. One practical consideration is the lack of broad-scale researcher access to multilevel analysis software, as of 2011. Multilevel approaches such as Hierarchical Linear Modeling (HLM) (Roberts & Herrington, 2005 ) are destined to gain in popularity in the coming years.
American Psychological Association. (2001). Publication manual of the American Psychological Association (5th ed.). Washington, DC: Author.
Google Scholar
Anderson, R., & O’Connor, B. (2009). Reconstructing bellour: Automating the semiotic analysis of film. Bulletin of the American Society for Information Science and Technology. Special Issue on Visual Representation, Search and Retrieval: Ways of Seeing, 35 (5), pp. 31–40, June/July 2009. Retrieved from http://www.asis.org/Bulletin/Jun-09/JunJul09_Anderson_OConnor.html .
Becker, L. A. (1999). Calculate d and r using means and standard deviations . Online calculator. Retrieved from http://www.uccs.edu/~faculty/lbecker/ .
Bialo, E. R., & Sivin-Kachala, J. (1996). The effectiveness of technology in schools: A summary of recent research. School Library Media Quarterly, 25 (1), 51–57.
Campbell, D. T., & Stanley, J. C. (1963). Experimental and quasi-experimental designs for research . Dallas, TX: Houghton Mifflin.
Cartwright, D. (2005). MySQL 5.0 open source database . Techworld, November 11, 2005. Retrieved from http://review.techworld.com/software/346/mysql-50-open-source-database/ .
Cattell, R. B. (1950). Personality. A systematic theoretical and factual study . New York, NY: McGraw-Hill.
Book Google Scholar
*Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Erlbaum Associates.
Cumming, G. (2003, February). Confidence intervals: Understanding, picturing, and using interval estimates . Keynote at the Educational Research Exchange 2003. College of Education, University of North Texas.
DeVellis, R. (2003). Scale development: Theory and applications (2nd ed.). Thousand Oaks, CA: Sage.
*Dunn - Rankin, P. (1978). The visual characteristics of words. Scientific American , 238 (1), 122–130.
Dunn-Rankin, P. (1983). Scaling methods . Mahwah, NJ: Lawrence Erlbaum.
Dunn-Rankin, P., Knezek, G., Wallace, S., & Zhang, S. (2004). Scaling methods (2nd ed.). Mahwah, NJ: Lawrence Erlbaum.
Frawley, W., Piatetsky-Shapiro, G., & Matheus, C. (1992). Knowledge discovery in databases: An overview. AI Magazine, 13 , 213–228.
*Gibbons, J. D. (1976). Nonparametric methods for quantitative analysis . New York, NY: Holt, Rinehart and Winston.
Gibson, D. (2009). Designing a computational model of learning. In R. Ferdig (Ed.), Handbook of research on effective electronic gaming in education (Vol. 2, pp. 671–701). Hershey, PA: Information Science Reference.
Gonzalez-Sanchez, J., Christopherson, R., Chavez-Echeagaray, M., Gibson, D., Atkinson, R., & Burleson, W. (2011). How to Do Multimodal Detection of Affective States? Proceedings from the 2011 IEEE International Conference on Advanced Learning Technologies. Athens, GA.
GraphPad Software. (2005). QuickCalcs Online Calculators for Scientists: sign and binomial test calculator . Retrieved from http://www.graphpad.com/quickcalcs/binomial1.cfm .
Ihaka, R., & Gentleman, R. (1996). R: A language for data analysis and graphics. Journal of Computational and Graphical Statistics, 5 , 299–314.
*Joreskog, K. G., & Van Thillo, M. (1972). LISREL: A general computer program for estimating a linear structural equation system involving multiple indicators of unmeasured variables (RB-72-56) . Princeton, NJ: Educational Testing Service. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/17478411 .
Knezek, G., & Christensen, R. (2001). Evolution of an online data acquisition system. In J. Price, D. A. Willis, N. Davis, & J. Willis (Eds.), Proceedings of the Society for Information Technology in Teacher Education (SITE) 12th International Conference 2001, Orlando, FL (pp. 1999–2001). Norfolk, VA: Association for the Advancement of Computing in Education.
Knezek, G., & Christensen, R. (2002). Technology, pedagogy, professional development and reading achievement: KIDS project findings 2001–2002 . Denton, TX: Institute for the Integration of Technology into Teaching and Learning (IITTL).
Knezek, G., & Christensen, R. (2008a). Effect of technology-based reading programs on first and second grade achievement. Computers in the Schools, 24 (3), 23–41.
Article Google Scholar
Knezek, G., & Christensen, R. (2008b). The importance of information technology attitudes and competencies in primary and secondary education. International Handbook of Information Technology in Primary and Secondary Education (Springer International Handbooks of Education), 20 , 321–328.
Knezek, G., & Miyashita, K. (1991). Computer-related attitudes of primary school students in Japan and the U.S.A. Educational Technology Research (Japan), 14 , 17–23.
Kulik, C. C., & Kulik, J. A. (1991). Effectiveness of computer-based instruction: An updated analysis. Computers in Human Behavior, 7 , 75–94.
Microsoft Research. (2010). WorldWide Telescope . Retrieved from http://www.worldwidetelescope.org/Home.aspx .
Morales, C. (2007). Testing predictive models of technology integration in Mexico and the United States. Computers in the Schools, 24 (3/4), 153, 157.
Naik, P., Wedel, M., Bacon, L., Bodapati, A., Bradlow, E., Kamakura, W., Kreulen, J., Lenk, P., Madigan, D. M., & Montgomery, A. (2008). Challenges and opportunities in high-dimensional choice data analyses. Marketing Letters, 19 , pp. 201–213. doi 10.1007/s11002-008-9036-3 . Retrieved from https://faculty.fuqua.duke.edu/~kamakura/bio/WagnerKamakuraResearch.htm .
*Onwuegbuzie, A. J., & Teddlie, C. (2003). A framework for analyzing data in mixed methods research. In A. Tashakkori, & C. Teddlie (Eds.), Handbook of mixed methods in social and behavioral research (pp. 351–383). Thousand Oaks, CA: Sage.
Physics Forums. (2007). Matlab vs. mathematica . (November 7, 2007 posting). Retrieved from http://www.physicsforums.com/showthread.php?t=196740 .
QI Macros. (n.d). Box Plots Show Variation . Retrieved from http://www.qimacros.com/spc-charts/box plot2.php?gclid = CP2qpbOKgqgCFcZw5QodD12WrA.
Roberts, J. K., & Herrington, R. (2005). Demonstration of software programs for estimating multilevel measurement models. Journal of Applied Measurement, 6 (3), 255–272.
SAS. (2011). About SAS . Retrieved from http://www.sas.com/company/about/index.html .
Schmidt, M., & Lipson, H. (2009). Cornell Creative Machines Lab: Eureqa . Retrieved from http://ccsl.mae.cornell.edu/eureqa .
Schulz-Zander, R., Pfeifer, M., & Voss, A. (2008). Observation measures for determining attitudes and competencies toward technology. International Handbook of Information Technology in Primary and Secondary Education (Springer International Handbooks of Education), 20 (4), 367–379.
Scientific Software International, Inc. (2011). Retrieved April 4, 2013, from http://www.ssicentral.com/ .
*Shumacker, R., & Lomax, R. (2004). A Beginner’s guide to structural equation modeling . Mahwah, NJ: Lawrence Erlbaum Associates, Inc.
SPSS. (2010). IBM SPSS statistics family . Retrieved from http://www.spss.com/ .
Tashakkori, A., & Teddlie, C. (2010). Handbook of mixed methods in social and behavioral research (2nd ed.). Thousand Oaks, CA: Sage.
The MathWorks, Inc. (2011). MATLAB . Retrieved from http://www.mathworks.com/products/matlab/description1.html .
The R Project for Statistical Computing. (2011). About R . Retrieved from http://www.r-project.org/ .
*Thompson, B. (1998). Statistical significance and effect size reporting: Portrait of a possible future. Research in the Schools, 5 (2), 33–38.
*Trochim, W. M. K. (2006). General issues in scaling. In: Research methods knowledge base . Retrieved from http://www.socialresearchmethods.net/kb/scalgen.php .
Tyler-Wood, T. L., Ellison, A., Lim, O., & Periathiruvadi, S. (2011). Bringing up girls in science (BUGS): The effectiveness of an afterschool environmental science program for increasing female student’s interest in science careers. Journal of Science Education and Technology, 21 (1), 46–55.
Tyler-Wood, T., Knezek, G., Christensen, R., Morales, C., & Dunn-Rankin, P. (2005, April 13). Scaling three versions of the Stanford-Binet Intelligence Test: Examining ceiling effects for identifying giftedness. Distinguished Paper Award for the Hawaii Educational Research Association. Presented at HERA in Hawaii in January 2005 and in the distinguished papers at the American Educational Research Association in Montreal, Canada.
Vallejo, M. A., Jordan, C. M., Diaz, M. I., Comeche, M. I., & Ortega, J. (2007). Psychological assessment via the Internet: A reliability and validity study of online (vs paper-and-pencil) versions of the General Health Questionnaire-28 (GHQ-28) and the Symptoms Check-List-90-Revised (SCL-90-R). Journal of Medical Internet Research, 9 (1), e2.
Wang, G., & Wang, Y. (2009). 3DM: Domain-oriented data-driven data mining. Fundamenta Informaticae 90 (2009), pp. 395–426, 395. doi 10.3233/FI-2009-0026 .
Wolfram Alpha. (2011). Wolfram Alpha computational knowledge engine . Retrieved from http://www.wolframalpha.com/ .
Zwilliger, D. (2003). CRC standard mathematical tables and formulae (31st ed.). Boca Raton, FL: Chapman & Hall.
Download references
Author information
Authors and affiliations.
University of North Texas, 3940 Elm St. #G150, Denton, TX, 76207-7102, USA
Gerald A. Knezek Ph.D. & Rhonda Christensen Ph.D.
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Gerald A. Knezek Ph.D. .
Editor information
Editors and affiliations.
, Department of Learning Technologies, C, University of North Texas, North Elm 3940, Denton, 76207-7102, Texas, USA
J. Michael Spector
W. Sunset Blvd. 1812, St. George, 84770, Utah, USA
M. David Merrill
, Centr. Instructiepsychol.&-technologie, K.U. Leuven, Andreas Vesaliusstraat 2, Leuven, 3000, Belgium
Research Drive, Iacocca A109 111, Bethlehem, 18015, Pennsylvania, USA
M. J. Bishop
Rights and permissions
Reprints and permissions
Copyright information
© 2014 Springer Science+Business Media New York
About this chapter
Knezek, G.A., Christensen, R. (2014). Tools for Analyzing Quantitative Data. In: Spector, J., Merrill, M., Elen, J., Bishop, M. (eds) Handbook of Research on Educational Communications and Technology. Springer, New York, NY. https://doi.org/10.1007/978-1-4614-3185-5_17
Download citation
DOI : https://doi.org/10.1007/978-1-4614-3185-5_17
Published : 22 May 2013
Publisher Name : Springer, New York, NY
Print ISBN : 978-1-4614-3184-8
Online ISBN : 978-1-4614-3185-5
eBook Packages : Humanities, Social Sciences and Law Education (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Quantitative Analysis Guide: Which Statistical Software to Use?
- Finding Data
- Which Statistical Software to Use?
- Merging Data Sets
- Reshaping Data Sets
- Choose Statistical Test for 1 Dependent Variable
- Choose Statistical Test for 2 or More Dependent Variables
- Data Services Home Page
Statistical Software Comparison
- What statistical test to use?
- Data Visualization Resources
- Data Analysis Examples External (UCLA) examples of regression and power analysis
- Supported software
- Request a consultation
- Making your code reproducible
Software Access
- The first version of SPSS was developed by Norman H. Nie, Dale H. Bent and C. Hadlai Hull in and released in 1968 as the Statistical Package for Social Sciences.
- In July 2009, IBM acquired SPSS.
- Social sciences
- Health sciences
Data Format and Compatibility
- .sav file to save data
- Optional syntax files (.sps)
- Easily export .sav file from Qualtrics
- Import Excel files (.xls, .xlsx), Text files (.csv, .txt, .dat), SAS (.sas7bdat), Stata (.dta)
- Export Excel files (.xls, .xlsx), Text files (.csv, .dat), SAS (.sas7bdat), Stata (.dta)
- SPSS Chart Types
- Chart Builder: Drag and drop graphics
- Easy and intuitive user interface; menus and dialog boxes
- Similar feel to Excel
- SEMs through SPSS Amos
- Easily exclude data and handle missing data
Limitations
- Absence of robust methods (e.g...Least Absolute Deviation Regression, Quantile Regression, ...)
- Unable to perform complex many to many merge
Sample Data
- Developed by SAS
- Created in the 1980s by John Sall to take advantage of the graphical user interface introduced by Macintosh
- Orginally stood for 'John's Macintosh Program'
- Five products: JMP, JMP Pro, JMP Clinical, JMP Genomics, JMP Graph Builder App
- Engineering: Six Sigma, Quality Control, Scientific Research, Design of Experiments
- Healthcare/Pharmaceutical
- .jmp file to save data
- Optional syntax files (.jsl)
- Import Excel files (.xls, .xlsx), Text files (.csv, .txt, .dat), SAS (.sas7bdat), Stata (.dta), SPSS (.sav)
- Export Excel files (.xls, .xlsx), Text files (.csv, .dat), SAS (.sas7bdat)
- Gallery of JMP Graphs
- Drag and Drop Graph Editor will try to guess what chart is correct for your data
- Dynamic interface can be used to zoom and change view
- Ability to lasso outliers on a graph and regraph without the outliers
- Interactive Graphics
- Scripting Language (JSL)
- SAS, R and MATLAB can be executed using JSL
- Interface for using R from within and add-in for Excel
- Great interface for easily managing output
- Graphs and data tables are dynamically linked
- Great set of online resources!
- Absence of some robust methods (regression: 2SLS, LAD, Quantile)
- Stata was first released in January 1985 as a regression and data management package with 44 commands, written by Bill Gould and Sean Becketti.
- The name Stata is a syllabic abbreviation of the words statistics and data.
- The graphical user interface (menus and dialog boxes) was released in 2003.
- Political Science
- Public Health
- Data Science
- Who uses Stata?
Data Format and Compatibility
- .dta file to save dataset
- .do syntax file, where commands can be written and saved
- Import Excel files (.xls, .xlsx), Text files (.txt, .csv, .dat), SAS (.XPT), Other (.XML), and various ODBC data sources
- Export Excel files (.xls, . xlsx ), Text files (.txt, .csv, .dat), SAS (.XPT), Other (.XML), and various ODBC data sources
- Newer versions of Stata can read datasets, commands, graphs, etc., from older versions, and in doing so, reproduce results
- Older versions of Stata cannot read newer versions of Stata datasets, but newer versions can save in the format of older versions
- Stata Graph Gallery
- UCLA - Stata Graph Gallery
- Syntax mainly used, but menus are an option as well
- Some user written programs are available to install
- Offers matrix programming in Mata
- Works well with panel, survey, and time-series data
- Data management
- Can only hold one dataset in memory at a time
- The specific Stata package ( Stata/IC, Stata/SE, and Stata/MP ) limits the size of usable datasets. One may have to sacrifice the number of variables for the number of observations, or vice versa, depending on the package.
- Overall, graphs have limited flexibility. Stata schemes , however, provide some flexibility in changing the style of the graphs.
- Sample Syntax
* First enter the data manually; input str10 sex test1 test2 "Male" 86 83 "Male" 93 79 "Male" 85 81 "Male" 83 80 "Male" 91 76 "Female" 94 79 "Fem ale" 91 94 "Fem ale" 83 84 "Fem ale" 96 81 "Fem ale" 95 75 end
* Next run a paired t-test; ttest test1 == test2
* Create a scatterplot; twoway ( scatter test2 test1 if sex == "Male" ) ( scatter test2 test1 if sex == "Fem ale" ), legend (lab(1 "Male" ) lab(2 "Fem ale" ))
- The development of SAS (Statistical Analysis System) began in 1966 by Anthony Bar of North Carolina State University and later joined by James Goodnight.
- The National Institute of Health funded this project with a goal of analyzing agricultural data to improve crop yields.
- The first release of SAS was in 1972. In 2012, SAS held 36.2% of the market making it the largest market-share holder in 'advanced analytics.'
- Financial Services
- Manufacturing
- Health and Life Sciences
- Available for Windows only
- Import Excel files (.xls, .xlsx), Text files (.txt, .dat, .csv), SPSS (.sav), Stata (.dta), JMP (.jmp), Other (.xml)
- Export Excel files (.xls, . xlsx ), Text files (.txt, .dat, .csv), SPSS (.sav), Stata (.dta), JMP (.jmp), Other (.xml)
- SAS Graphics Samples Output Gallery
- Can be cumbersome at times to create perfect graphics with syntax
- ODS Graphics Designer provides a more interactive interface
- BASE SAS contains the data management facility, programming language, data analysis and reporting tools
- SAS Libraries collect the SAS datasets you create
- Multitude of additional components are available to complement Base SAS which include SAS/GRAPH, SAS/PH (Clinical Trial Analysis), SAS/ETS (Econometrics and Time Series), SAS/Insight (Data Mining) etc...
- SAS Certification exams
- Handles extremely large datasets
- Predominantly used for data management and statistical procedures
- SAS has two main types of code; DATA steps and PROC steps
- With one procedure, test results, post estimation and plots can be produced
- Size of datasets analyzed is only limited by the machine
Limitations
- Graphics can be cumbersome to manipulate
- Since SAS is a proprietary software, there may be an extensive lag time for the implementation of new methods
- Documentation and books tend to be very technical and not necessarily new user friendly
* First enter the data manually; data example; input sex $ test1 test2; datalines ; M 86 83 M 93 79 M 85 81 M 83 80 M 91 76 F 94 79 F 91 94 F 83 84 F 96 81 F 95 75 ; run ;
* Next run a paired t-test; proc ttest data = example; paired test1*test2; run ;
* Create a scatterplot; proc sgplot data = example; scatter y = test1 x = test2 / group = sex; run ;
- R first appeared in 1993 and was created by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand.
- R is an implementation of the S programming language which was developed at Bell Labs.
- It is named partly after its first authors and partly as a play on the name of S.
- R is currently developed by the R Development Core Team.
- RStudio, an integrated development environment (IDE) was first released in 2011.
- Companies Using R
- Finance and Economics
- Bioinformatics
- Import Excel files (.xls, .xlsx), Text files (.txt, .dat, .csv), SPSS (.sav), Stata (.dta), SAS(.sas7bdat), Other (.xml, .json)
- Export Excel files (.xlsx), Text files (.txt, .csv), SPSS (.sav), Stata (.dta), Other (.json)
- ggplot2 package, grammar of graphics
- Graphs available through ggplot2
- The R Graph Gallery
- Network analysis (igraph)
- Flexible esthetics and options
- Interactive graphics with Shiny
- Many available packages to create field specific graphics
- R is a free and open source
- Over 6000 user contributed packages available through CRAN
- Large online community
- Network Analysis, Text Analysis, Data Mining, Web Scraping
- Interacts with other software such as, Python, Bioconductor, WinBUGS, JAGS etc...
- Scope of functions, flexible, versatile etc..
Limitations
- Large online help community but no 'formal' tech support
- Have to have a good understanding of different data types before real ease of use begins
- Many user written packages may be hard to sift through
# Manually enter the data into a dataframe dataset <- data.frame(sex = c("Male", "Male", "Male", "Male", "Male", "Female", "Female", "Female", "Female", "Female"), test1 = c( 86 , 93 , 85 , 83 , 91 , 94 , 91 , 83 , 96 , 95 ), test2 = c( 83 , 79 , 81 , 80 , 76 , 79 , 94 , 84 , 81 , 75 ))
# Now we will run a paired t-test t.test(dataset$test1, dataset$test2, paired = TRUE )
# Last let's simply plot these two test variables plot(dataset$test1, dataset$test2, col = c("red","blue")[dataset$sex]) legend("topright", fill = c("blue", "red"), c("Male", "Female"))
# Making the same graph using ggplot2 install.packages('ggplot2') library(ggplot2) mygraph <- ggplot(data = dataset, aes(x = test1, y = test2, color = sex)) mygraph + geom_point(size = 5) + ggtitle('Test1 versus Test2 Scores')
- Cleave Moler of the University of New Mexico began development in the late 1970s.
- With the help of Jack Little, they cofounded MathWorks and released MATLAB (matrix laboratory) in 1984.
- Education (linear algebra and numerical analysis)
- Popular among scientists involved in image processing
- Engineering
- .m Syntax file
- Import Excel files (.xls, .xlsx), Text files (.txt, .dat, .csv), Other (.xml, .json)
- Export Excel files (.xls, .xlsx), Text files (.txt, .dat, .csv), Other (.xml, .json)
- MATLAB Plot Gallery
- Customizable but not point-and-click visualization
- Optimized for data analysis, matrix manipulation in particular
- Basic unit is a matrix
- Vectorized operations are quick
- Diverse set of available toolboxes (apps) [Statistics, Optimization, Image Processing, Signal Processing, Parallel Computing etc..]
- Large online community (MATLAB Exchange)
- Image processing
- Vast number of pre-defined functions and implemented algorithms
- Lacks implementation of some advanced statistical methods
- Integrates easily with some languages such as C, but not others, such as Python
- Limited GIS capabilities
sex = { 'Male' , 'Male' , 'Male' , 'Male' , 'Male' , 'Female' , 'Female' , 'Female' , 'Female' , 'Female' }; t1 = [86,93,85,83,91,94,91,83,96,95]; t2 = [83,79,81,80,76,79,94,84,81,75];
% paired t-test [h,p,ci,stats] = ttest(t1,t2)
% independent samples t-test sex = categorical(sex); [h,p,ci,stats] = ttest2(t1(sex== 'Male' ),t1(sex== 'Female' ))
plot(t1,t2, 'o' ) g = sex== 'Male' ; plot(t1(g),t2(g), 'bx' ); hold on; plot(t1(~g),t2(~g), 'ro' )
Software Features and Capabilities
*The primary interface is bolded in the case of multiple interface types available.
Learning Curve

Further Reading
- The Popularity of Data Analysis Software
- Statistical Software Capability Table
- The SAS versus R Debate in Industry and Academia
- Why R has a Steep Learning Curve
- Comparison of Data Analysis Packages
- Comparison of Statistical Packages
- MATLAB commands in Python and R
- MATLAB and R Side by Side
- Stata and R Side by Side

- << Previous: Statistical Guidance
- Next: Merging Data Sets >>
- Last Updated: Apr 18, 2024 4:36 AM
- URL: https://guides.nyu.edu/quant
Part II: Data Analysis Methods in Quantitative Research
Data analysis methods in quantitative research.
We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim). Now, we are going to delve into two main statistical analyses to describe our data and make inferences about our data:
Descriptive Statistics and Inferential Statistics.
Descriptive Statistics:
Before you panic, we will not be going into statistical analyses very deeply. We want to simply get a good overview of some of the types of general statistical analyses so that it makes some sense to us when we read results in published research articles.
Descriptive statistics summarize or describe the characteristics of a data set. This is a method of simply organizing and describing our data. Why? Because data that are not organized in some fashion are super difficult to interpret.
Let’s say our sample is golden retrievers (population “canines”). Our descriptive statistics tell us more about the same.
- 37% of our sample is male, 43% female
- The mean age is 4 years
- Mode is 6 years
- Median age is 5.5 years

Let’s explore some of the types of descriptive statistics.
Frequency Distributions : A frequency distribution describes the number of observations for each possible value of a measured variable. The numbers are arranged from lowest to highest and features a count of how many times each value occurred.
For example, if 18 students have pet dogs, dog ownership has a frequency of 18.
We might see what other types of pets that students have. Maybe cats, fish, and hamsters. We find that 2 students have hamsters, 9 have fish, 1 has a cat.
You can see that it is very difficult to interpret the various pets into any meaningful interpretation, yes?
Now, let’s take those same pets and place them in a frequency distribution table.
As we can now see, this is much easier to interpret.
Let’s say that we want to know how many books our sample population of students have read in the last year. We collect our data and find this:
We can then take that table and plot it out on a frequency distribution graph. This makes it much easier to see how the numbers are disbursed. Easier on the eyes, yes?

Here’s another example of symmetrical, positive skew, and negative skew:

Correlation : Relationships between two research variables are called correlations . Remember, correlation is not cause-and-effect. Correlations simply measure the extent of relationship between two variables. To measure correlation in descriptive statistics, the statistical analysis called Pearson’s correlation coefficient I is often used. You do not need to know how to calculate this for this course. But, do remember that analysis test because you will often see this in published research articles. There really are no set guidelines on what measurement constitutes a “strong” or “weak” correlation, as it really depends on the variables being measured.
However, possible values for correlation coefficients range from -1.00 through .00 to +1.00. A value of +1 means that the two variables are positively correlated, as one variable goes up, the other goes up. A value of r = 0 means that the two variables are not linearly related.
Often, the data will be presented on a scatter plot. Here, we can view the data and there appears to be a straight line (linear) trend between height and weight. The association (or correlation) is positive. That means, that there is a weight increase with height. The Pearson correlation coefficient in this case was r = 0.56.

A type I error is made by rejecting a null hypothesis that is true. This means that there was no difference but the researcher concluded that the hypothesis was true.
A type II error is made by accepting that the null hypothesis is true when, in fact, it was false. Meaning there was actually a difference but the researcher did not think their hypothesis was supported.
Hypothesis Testing Procedures : In a general sense, the overall testing of a hypothesis has a systematic methodology. Remember, a hypothesis is an educated guess about the outcome. If we guess wrong, we might set up the tests incorrectly and might get results that are invalid. Sometimes, this is super difficult to get right. The main purpose of statistics is to test a hypothesis.
- Selecting a statistical test. Lots of factors go into this, including levels of measurement of the variables.
- Specifying the level of significance. Usually 0.05 is chosen.
- Computing a test statistic. Lots of software programs to help with this.
- Determining degrees of freedom ( df ). This refers to the number of observations free to vary about a parameter. Computing this is easy (but you don’t need to know how for this course).
- Comparing the test statistic to a theoretical value. Theoretical values exist for all test statistics, which is compared to the study statistics to help establish significance.
Some of the common inferential statistics you will see include:
Comparison tests: Comparison tests look for differences among group means. They can be used to test the effect of a categorical variable on the mean value of some other characteristic.
T-tests are used when comparing the means of precisely two groups (e.g., the average heights of men and women). ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults).
- t -tests (compares differences in two groups) – either paired t-test (example: What is the effect of two different test prep programs on the average exam scores for students from the same class?) or independent t-test (example: What is the difference in average exam scores for students from two different schools?)
- analysis of variance (ANOVA, which compares differences in three or more groups) (example: What is the difference in average pain levels among post-surgical patients given three different painkillers?) or MANOVA (compares differences in three or more groups, and 2 or more outcomes) (example: What is the effect of flower species on petal length, petal width, and stem length?)
Correlation tests: Correlation tests check whether variables are related without hypothesizing a cause-and-effect relationship.
- Pearson r (measures the strength and direction of the relationship between two variables) (example: How are latitude and temperature related?)
Nonparametric tests: Non-parametric tests don’t make as many assumptions about the data, and are useful when one or more of the common statistical assumptions are violated. However, the inferences they make aren’t as strong as with parametric tests.
- chi-squared ( X 2 ) test (measures differences in proportions). Chi-square tests are often used to test hypotheses. The chi-square statistic compares the size of any discrepancies between the expected results and the actual results, given the size of the sample and the number of variables in the relationship. For example, the results of tossing a fair coin meet these criteria. We can apply a chi-square test to determine which type of candy is most popular and make sure that our shelves are well stocked. Or maybe you’re a scientist studying the offspring of cats to determine the likelihood of certain genetic traits being passed to a litter of kittens.
Inferential Versus Descriptive Statistics Summary Table
Statistical Significance Versus Clinical Significance
Finally, when it comes to statistical significance in hypothesis testing, the normal probability value in nursing is <0.05. A p=value (probability) is a statistical measurement used to validate a hypothesis against measured data in the study. Meaning, it measures the likelihood that the results were actually observed due to the intervention, or if the results were just due by chance. The p-value, in measuring the probability of obtaining the observed results, assumes the null hypothesis is true.
The lower the p-value, the greater the statistical significance of the observed difference.
In the example earlier about our diabetic patients receiving online diet education, let’s say we had p = 0.05. Would that be a statistically significant result?
If you answered yes, you are correct!
What if our result was p = 0.8?
Not significant. Good job!
That’s pretty straightforward, right? Below 0.05, significant. Over 0.05 not significant.
Could we have significance clinically even if we do not have statistically significant results? Yes. Let’s explore this a bit.
Statistical hypothesis testing provides little information for interpretation purposes. It’s pretty mathematical and we can still get it wrong. Additionally, attaining statistical significance does not really state whether a finding is clinically meaningful. With a large enough sample, even a small very tiny relationship may be statistically significant. But, clinical significance is the practical importance of research. Meaning, we need to ask what the palpable effects may be on the lives of patients or healthcare decisions.
Remember, hypothesis testing cannot prove. It also cannot tell us much other than “yeah, it’s probably likely that there would be some change with this intervention”. Hypothesis testing tells us the likelihood that the outcome was due to an intervention or influence and not just by chance. Also, as nurses and clinicians, we are not concerned with a group of people – we are concerned at the individual, holistic level. The goal of evidence-based practice is to use best evidence for decisions about specific individual needs.
Additionally, begin your Discussion section. What are the implications to practice? Is there little evidence or a lot? Would you recommend additional studies? If so, what type of study would you recommend, and why?
- Were all the important results discussed?
- Did the researchers discuss any study limitations and their possible effects on the credibility of the findings? In discussing limitations, were key threats to the study’s validity and possible biases reviewed? Did the interpretations take limitations into account?
- What types of evidence were offered in support of the interpretation, and was that evidence persuasive? Were results interpreted in light of findings from other studies?
- Did the researchers make any unjustifiable causal inferences? Were alternative explanations for the findings considered? Were the rationales for rejecting these alternatives convincing?
- Did the interpretation consider the precision of the results and/or the magnitude of effects?
- Did the researchers draw any unwarranted conclusions about the generalizability of the results?
- Did the researchers discuss the study’s implications for clinical practice or future nursing research? Did they make specific recommendations?
- If yes, are the stated implications appropriate, given the study’s limitations and the magnitude of the effects as well as evidence from other studies? Are there important implications that the report neglected to include?
- Did the researchers mention or assess clinical significance? Did they make a distinction between statistical and clinical significance?
- If clinical significance was examined, was it assessed in terms of group-level information (e.g., effect sizes) or individual-level results? How was clinical significance operationalized?
References & Attribution
“ Green check mark ” by rawpixel licensed CC0 .
“ Magnifying glass ” by rawpixel licensed CC0
“ Orange flame ” by rawpixel licensed CC0 .
Polit, D. & Beck, C. (2021). Lippincott CoursePoint Enhanced for Polit’s Essentials of Nursing Research (10th ed.). Wolters Kluwer Health
Vaid, N. K. (2019) Statistical performance measures. Medium. https://neeraj-kumar-vaid.medium.com/statistical-performance-measures-12bad66694b7
Evidence-Based Practice & Research Methodologies Copyright © by Tracy Fawns is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Your Modern Business Guide To Data Analysis Methods And Techniques

Table of Contents
1) What Is Data Analysis?
2) Why Is Data Analysis Important?
3) What Is The Data Analysis Process?
4) Types Of Data Analysis Methods
5) Top Data Analysis Techniques To Apply
6) Quality Criteria For Data Analysis
7) Data Analysis Limitations & Barriers
8) Data Analysis Skills
9) Data Analysis In The Big Data Environment
In our data-rich age, understanding how to analyze and extract true meaning from our business’s digital insights is one of the primary drivers of success.
Despite the colossal volume of data we create every day, a mere 0.5% is actually analyzed and used for data discovery , improvement, and intelligence. While that may not seem like much, considering the amount of digital information we have at our fingertips, half a percent still accounts for a vast amount of data.
With so much data and so little time, knowing how to collect, curate, organize, and make sense of all of this potentially business-boosting information can be a minefield – but online data analysis is the solution.
In science, data analysis uses a more complex approach with advanced techniques to explore and experiment with data. On the other hand, in a business context, data is used to make data-driven decisions that will enable the company to improve its overall performance. In this post, we will cover the analysis of data from an organizational point of view while still going through the scientific and statistical foundations that are fundamental to understanding the basics of data analysis.
To put all of that into perspective, we will answer a host of important analytical questions, explore analytical methods and techniques, while demonstrating how to perform analysis in the real world with a 17-step blueprint for success.
What Is Data Analysis?
Data analysis is the process of collecting, modeling, and analyzing data using various statistical and logical methods and techniques. Businesses rely on analytics processes and tools to extract insights that support strategic and operational decision-making.
All these various methods are largely based on two core areas: quantitative and qualitative research.
To explain the key differences between qualitative and quantitative research, here’s a video for your viewing pleasure:
Gaining a better understanding of different techniques and methods in quantitative research as well as qualitative insights will give your analyzing efforts a more clearly defined direction, so it’s worth taking the time to allow this particular knowledge to sink in. Additionally, you will be able to create a comprehensive analytical report that will skyrocket your analysis.
Apart from qualitative and quantitative categories, there are also other types of data that you should be aware of before dividing into complex data analysis processes. These categories include:
- Big data: Refers to massive data sets that need to be analyzed using advanced software to reveal patterns and trends. It is considered to be one of the best analytical assets as it provides larger volumes of data at a faster rate.
- Metadata: Putting it simply, metadata is data that provides insights about other data. It summarizes key information about specific data that makes it easier to find and reuse for later purposes.
- Real time data: As its name suggests, real time data is presented as soon as it is acquired. From an organizational perspective, this is the most valuable data as it can help you make important decisions based on the latest developments. Our guide on real time analytics will tell you more about the topic.
- Machine data: This is more complex data that is generated solely by a machine such as phones, computers, or even websites and embedded systems, without previous human interaction.
Why Is Data Analysis Important?
Before we go into detail about the categories of analysis along with its methods and techniques, you must understand the potential that analyzing data can bring to your organization.
- Informed decision-making : From a management perspective, you can benefit from analyzing your data as it helps you make decisions based on facts and not simple intuition. For instance, you can understand where to invest your capital, detect growth opportunities, predict your income, or tackle uncommon situations before they become problems. Through this, you can extract relevant insights from all areas in your organization, and with the help of dashboard software , present the data in a professional and interactive way to different stakeholders.
- Reduce costs : Another great benefit is to reduce costs. With the help of advanced technologies such as predictive analytics, businesses can spot improvement opportunities, trends, and patterns in their data and plan their strategies accordingly. In time, this will help you save money and resources on implementing the wrong strategies. And not just that, by predicting different scenarios such as sales and demand you can also anticipate production and supply.
- Target customers better : Customers are arguably the most crucial element in any business. By using analytics to get a 360° vision of all aspects related to your customers, you can understand which channels they use to communicate with you, their demographics, interests, habits, purchasing behaviors, and more. In the long run, it will drive success to your marketing strategies, allow you to identify new potential customers, and avoid wasting resources on targeting the wrong people or sending the wrong message. You can also track customer satisfaction by analyzing your client’s reviews or your customer service department’s performance.
What Is The Data Analysis Process?

When we talk about analyzing data there is an order to follow in order to extract the needed conclusions. The analysis process consists of 5 key stages. We will cover each of them more in detail later in the post, but to start providing the needed context to understand what is coming next, here is a rundown of the 5 essential steps of data analysis.
- Identify: Before you get your hands dirty with data, you first need to identify why you need it in the first place. The identification is the stage in which you establish the questions you will need to answer. For example, what is the customer's perception of our brand? Or what type of packaging is more engaging to our potential customers? Once the questions are outlined you are ready for the next step.
- Collect: As its name suggests, this is the stage where you start collecting the needed data. Here, you define which sources of data you will use and how you will use them. The collection of data can come in different forms such as internal or external sources, surveys, interviews, questionnaires, and focus groups, among others. An important note here is that the way you collect the data will be different in a quantitative and qualitative scenario.
- Clean: Once you have the necessary data it is time to clean it and leave it ready for analysis. Not all the data you collect will be useful, when collecting big amounts of data in different formats it is very likely that you will find yourself with duplicate or badly formatted data. To avoid this, before you start working with your data you need to make sure to erase any white spaces, duplicate records, or formatting errors. This way you avoid hurting your analysis with bad-quality data.
- Analyze : With the help of various techniques such as statistical analysis, regressions, neural networks, text analysis, and more, you can start analyzing and manipulating your data to extract relevant conclusions. At this stage, you find trends, correlations, variations, and patterns that can help you answer the questions you first thought of in the identify stage. Various technologies in the market assist researchers and average users with the management of their data. Some of them include business intelligence and visualization software, predictive analytics, and data mining, among others.
- Interpret: Last but not least you have one of the most important steps: it is time to interpret your results. This stage is where the researcher comes up with courses of action based on the findings. For example, here you would understand if your clients prefer packaging that is red or green, plastic or paper, etc. Additionally, at this stage, you can also find some limitations and work on them.
Now that you have a basic understanding of the key data analysis steps, let’s look at the top 17 essential methods.
17 Essential Types Of Data Analysis Methods
Before diving into the 17 essential types of methods, it is important that we go over really fast through the main analysis categories. Starting with the category of descriptive up to prescriptive analysis, the complexity and effort of data evaluation increases, but also the added value for the company.
a) Descriptive analysis - What happened.
The descriptive analysis method is the starting point for any analytic reflection, and it aims to answer the question of what happened? It does this by ordering, manipulating, and interpreting raw data from various sources to turn it into valuable insights for your organization.
Performing descriptive analysis is essential, as it enables us to present our insights in a meaningful way. Although it is relevant to mention that this analysis on its own will not allow you to predict future outcomes or tell you the answer to questions like why something happened, it will leave your data organized and ready to conduct further investigations.
b) Exploratory analysis - How to explore data relationships.
As its name suggests, the main aim of the exploratory analysis is to explore. Prior to it, there is still no notion of the relationship between the data and the variables. Once the data is investigated, exploratory analysis helps you to find connections and generate hypotheses and solutions for specific problems. A typical area of application for it is data mining.
c) Diagnostic analysis - Why it happened.
Diagnostic data analytics empowers analysts and executives by helping them gain a firm contextual understanding of why something happened. If you know why something happened as well as how it happened, you will be able to pinpoint the exact ways of tackling the issue or challenge.
Designed to provide direct and actionable answers to specific questions, this is one of the world’s most important methods in research, among its other key organizational functions such as retail analytics , e.g.
c) Predictive analysis - What will happen.
The predictive method allows you to look into the future to answer the question: what will happen? In order to do this, it uses the results of the previously mentioned descriptive, exploratory, and diagnostic analysis, in addition to machine learning (ML) and artificial intelligence (AI). Through this, you can uncover future trends, potential problems or inefficiencies, connections, and casualties in your data.
With predictive analysis, you can unfold and develop initiatives that will not only enhance your various operational processes but also help you gain an all-important edge over the competition. If you understand why a trend, pattern, or event happened through data, you will be able to develop an informed projection of how things may unfold in particular areas of the business.
e) Prescriptive analysis - How will it happen.
Another of the most effective types of analysis methods in research. Prescriptive data techniques cross over from predictive analysis in the way that it revolves around using patterns or trends to develop responsive, practical business strategies.
By drilling down into prescriptive analysis, you will play an active role in the data consumption process by taking well-arranged sets of visual data and using it as a powerful fix to emerging issues in a number of key areas, including marketing, sales, customer experience, HR, fulfillment, finance, logistics analytics , and others.

As mentioned at the beginning of the post, data analysis methods can be divided into two big categories: quantitative and qualitative. Each of these categories holds a powerful analytical value that changes depending on the scenario and type of data you are working with. Below, we will discuss 17 methods that are divided into qualitative and quantitative approaches.
Without further ado, here are the 17 essential types of data analysis methods with some use cases in the business world:
A. Quantitative Methods
To put it simply, quantitative analysis refers to all methods that use numerical data or data that can be turned into numbers (e.g. category variables like gender, age, etc.) to extract valuable insights. It is used to extract valuable conclusions about relationships, differences, and test hypotheses. Below we discuss some of the key quantitative methods.
1. Cluster analysis
The action of grouping a set of data elements in a way that said elements are more similar (in a particular sense) to each other than to those in other groups – hence the term ‘cluster.’ Since there is no target variable when clustering, the method is often used to find hidden patterns in the data. The approach is also used to provide additional context to a trend or dataset.
Let's look at it from an organizational perspective. In a perfect world, marketers would be able to analyze each customer separately and give them the best-personalized service, but let's face it, with a large customer base, it is timely impossible to do that. That's where clustering comes in. By grouping customers into clusters based on demographics, purchasing behaviors, monetary value, or any other factor that might be relevant for your company, you will be able to immediately optimize your efforts and give your customers the best experience based on their needs.
2. Cohort analysis
This type of data analysis approach uses historical data to examine and compare a determined segment of users' behavior, which can then be grouped with others with similar characteristics. By using this methodology, it's possible to gain a wealth of insight into consumer needs or a firm understanding of a broader target group.
Cohort analysis can be really useful for performing analysis in marketing as it will allow you to understand the impact of your campaigns on specific groups of customers. To exemplify, imagine you send an email campaign encouraging customers to sign up for your site. For this, you create two versions of the campaign with different designs, CTAs, and ad content. Later on, you can use cohort analysis to track the performance of the campaign for a longer period of time and understand which type of content is driving your customers to sign up, repurchase, or engage in other ways.
A useful tool to start performing cohort analysis method is Google Analytics. You can learn more about the benefits and limitations of using cohorts in GA in this useful guide . In the bottom image, you see an example of how you visualize a cohort in this tool. The segments (devices traffic) are divided into date cohorts (usage of devices) and then analyzed week by week to extract insights into performance.

3. Regression analysis
Regression uses historical data to understand how a dependent variable's value is affected when one (linear regression) or more independent variables (multiple regression) change or stay the same. By understanding each variable's relationship and how it developed in the past, you can anticipate possible outcomes and make better decisions in the future.
Let's bring it down with an example. Imagine you did a regression analysis of your sales in 2019 and discovered that variables like product quality, store design, customer service, marketing campaigns, and sales channels affected the overall result. Now you want to use regression to analyze which of these variables changed or if any new ones appeared during 2020. For example, you couldn’t sell as much in your physical store due to COVID lockdowns. Therefore, your sales could’ve either dropped in general or increased in your online channels. Through this, you can understand which independent variables affected the overall performance of your dependent variable, annual sales.
If you want to go deeper into this type of analysis, check out this article and learn more about how you can benefit from regression.
4. Neural networks
The neural network forms the basis for the intelligent algorithms of machine learning. It is a form of analytics that attempts, with minimal intervention, to understand how the human brain would generate insights and predict values. Neural networks learn from each and every data transaction, meaning that they evolve and advance over time.
A typical area of application for neural networks is predictive analytics. There are BI reporting tools that have this feature implemented within them, such as the Predictive Analytics Tool from datapine. This tool enables users to quickly and easily generate all kinds of predictions. All you have to do is select the data to be processed based on your KPIs, and the software automatically calculates forecasts based on historical and current data. Thanks to its user-friendly interface, anyone in your organization can manage it; there’s no need to be an advanced scientist.
Here is an example of how you can use the predictive analysis tool from datapine:

**click to enlarge**
5. Factor analysis
The factor analysis also called “dimension reduction” is a type of data analysis used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. The aim here is to uncover independent latent variables, an ideal method for streamlining specific segments.
A good way to understand this data analysis method is a customer evaluation of a product. The initial assessment is based on different variables like color, shape, wearability, current trends, materials, comfort, the place where they bought the product, and frequency of usage. Like this, the list can be endless, depending on what you want to track. In this case, factor analysis comes into the picture by summarizing all of these variables into homogenous groups, for example, by grouping the variables color, materials, quality, and trends into a brother latent variable of design.
If you want to start analyzing data using factor analysis we recommend you take a look at this practical guide from UCLA.
6. Data mining
A method of data analysis that is the umbrella term for engineering metrics and insights for additional value, direction, and context. By using exploratory statistical evaluation, data mining aims to identify dependencies, relations, patterns, and trends to generate advanced knowledge. When considering how to analyze data, adopting a data mining mindset is essential to success - as such, it’s an area that is worth exploring in greater detail.
An excellent use case of data mining is datapine intelligent data alerts . With the help of artificial intelligence and machine learning, they provide automated signals based on particular commands or occurrences within a dataset. For example, if you’re monitoring supply chain KPIs , you could set an intelligent alarm to trigger when invalid or low-quality data appears. By doing so, you will be able to drill down deep into the issue and fix it swiftly and effectively.
In the following picture, you can see how the intelligent alarms from datapine work. By setting up ranges on daily orders, sessions, and revenues, the alarms will notify you if the goal was not completed or if it exceeded expectations.

7. Time series analysis
As its name suggests, time series analysis is used to analyze a set of data points collected over a specified period of time. Although analysts use this method to monitor the data points in a specific interval of time rather than just monitoring them intermittently, the time series analysis is not uniquely used for the purpose of collecting data over time. Instead, it allows researchers to understand if variables changed during the duration of the study, how the different variables are dependent, and how did it reach the end result.
In a business context, this method is used to understand the causes of different trends and patterns to extract valuable insights. Another way of using this method is with the help of time series forecasting. Powered by predictive technologies, businesses can analyze various data sets over a period of time and forecast different future events.
A great use case to put time series analysis into perspective is seasonality effects on sales. By using time series forecasting to analyze sales data of a specific product over time, you can understand if sales rise over a specific period of time (e.g. swimwear during summertime, or candy during Halloween). These insights allow you to predict demand and prepare production accordingly.
8. Decision Trees
The decision tree analysis aims to act as a support tool to make smart and strategic decisions. By visually displaying potential outcomes, consequences, and costs in a tree-like model, researchers and company users can easily evaluate all factors involved and choose the best course of action. Decision trees are helpful to analyze quantitative data and they allow for an improved decision-making process by helping you spot improvement opportunities, reduce costs, and enhance operational efficiency and production.
But how does a decision tree actually works? This method works like a flowchart that starts with the main decision that you need to make and branches out based on the different outcomes and consequences of each decision. Each outcome will outline its own consequences, costs, and gains and, at the end of the analysis, you can compare each of them and make the smartest decision.
Businesses can use them to understand which project is more cost-effective and will bring more earnings in the long run. For example, imagine you need to decide if you want to update your software app or build a new app entirely. Here you would compare the total costs, the time needed to be invested, potential revenue, and any other factor that might affect your decision. In the end, you would be able to see which of these two options is more realistic and attainable for your company or research.
9. Conjoint analysis
Last but not least, we have the conjoint analysis. This approach is usually used in surveys to understand how individuals value different attributes of a product or service and it is one of the most effective methods to extract consumer preferences. When it comes to purchasing, some clients might be more price-focused, others more features-focused, and others might have a sustainable focus. Whatever your customer's preferences are, you can find them with conjoint analysis. Through this, companies can define pricing strategies, packaging options, subscription packages, and more.
A great example of conjoint analysis is in marketing and sales. For instance, a cupcake brand might use conjoint analysis and find that its clients prefer gluten-free options and cupcakes with healthier toppings over super sugary ones. Thus, the cupcake brand can turn these insights into advertisements and promotions to increase sales of this particular type of product. And not just that, conjoint analysis can also help businesses segment their customers based on their interests. This allows them to send different messaging that will bring value to each of the segments.
10. Correspondence Analysis
Also known as reciprocal averaging, correspondence analysis is a method used to analyze the relationship between categorical variables presented within a contingency table. A contingency table is a table that displays two (simple correspondence analysis) or more (multiple correspondence analysis) categorical variables across rows and columns that show the distribution of the data, which is usually answers to a survey or questionnaire on a specific topic.
This method starts by calculating an “expected value” which is done by multiplying row and column averages and dividing it by the overall original value of the specific table cell. The “expected value” is then subtracted from the original value resulting in a “residual number” which is what allows you to extract conclusions about relationships and distribution. The results of this analysis are later displayed using a map that represents the relationship between the different values. The closest two values are in the map, the bigger the relationship. Let’s put it into perspective with an example.
Imagine you are carrying out a market research analysis about outdoor clothing brands and how they are perceived by the public. For this analysis, you ask a group of people to match each brand with a certain attribute which can be durability, innovation, quality materials, etc. When calculating the residual numbers, you can see that brand A has a positive residual for innovation but a negative one for durability. This means that brand A is not positioned as a durable brand in the market, something that competitors could take advantage of.
11. Multidimensional Scaling (MDS)
MDS is a method used to observe the similarities or disparities between objects which can be colors, brands, people, geographical coordinates, and more. The objects are plotted using an “MDS map” that positions similar objects together and disparate ones far apart. The (dis) similarities between objects are represented using one or more dimensions that can be observed using a numerical scale. For example, if you want to know how people feel about the COVID-19 vaccine, you can use 1 for “don’t believe in the vaccine at all” and 10 for “firmly believe in the vaccine” and a scale of 2 to 9 for in between responses. When analyzing an MDS map the only thing that matters is the distance between the objects, the orientation of the dimensions is arbitrary and has no meaning at all.
Multidimensional scaling is a valuable technique for market research, especially when it comes to evaluating product or brand positioning. For instance, if a cupcake brand wants to know how they are positioned compared to competitors, it can define 2-3 dimensions such as taste, ingredients, shopping experience, or more, and do a multidimensional scaling analysis to find improvement opportunities as well as areas in which competitors are currently leading.
Another business example is in procurement when deciding on different suppliers. Decision makers can generate an MDS map to see how the different prices, delivery times, technical services, and more of the different suppliers differ and pick the one that suits their needs the best.
A final example proposed by a research paper on "An Improved Study of Multilevel Semantic Network Visualization for Analyzing Sentiment Word of Movie Review Data". Researchers picked a two-dimensional MDS map to display the distances and relationships between different sentiments in movie reviews. They used 36 sentiment words and distributed them based on their emotional distance as we can see in the image below where the words "outraged" and "sweet" are on opposite sides of the map, marking the distance between the two emotions very clearly.

Aside from being a valuable technique to analyze dissimilarities, MDS also serves as a dimension-reduction technique for large dimensional data.
B. Qualitative Methods
Qualitative data analysis methods are defined as the observation of non-numerical data that is gathered and produced using methods of observation such as interviews, focus groups, questionnaires, and more. As opposed to quantitative methods, qualitative data is more subjective and highly valuable in analyzing customer retention and product development.
12. Text analysis
Text analysis, also known in the industry as text mining, works by taking large sets of textual data and arranging them in a way that makes it easier to manage. By working through this cleansing process in stringent detail, you will be able to extract the data that is truly relevant to your organization and use it to develop actionable insights that will propel you forward.
Modern software accelerate the application of text analytics. Thanks to the combination of machine learning and intelligent algorithms, you can perform advanced analytical processes such as sentiment analysis. This technique allows you to understand the intentions and emotions of a text, for example, if it's positive, negative, or neutral, and then give it a score depending on certain factors and categories that are relevant to your brand. Sentiment analysis is often used to monitor brand and product reputation and to understand how successful your customer experience is. To learn more about the topic check out this insightful article .
By analyzing data from various word-based sources, including product reviews, articles, social media communications, and survey responses, you will gain invaluable insights into your audience, as well as their needs, preferences, and pain points. This will allow you to create campaigns, services, and communications that meet your prospects’ needs on a personal level, growing your audience while boosting customer retention. There are various other “sub-methods” that are an extension of text analysis. Each of them serves a more specific purpose and we will look at them in detail next.
13. Content Analysis
This is a straightforward and very popular method that examines the presence and frequency of certain words, concepts, and subjects in different content formats such as text, image, audio, or video. For example, the number of times the name of a celebrity is mentioned on social media or online tabloids. It does this by coding text data that is later categorized and tabulated in a way that can provide valuable insights, making it the perfect mix of quantitative and qualitative analysis.
There are two types of content analysis. The first one is the conceptual analysis which focuses on explicit data, for instance, the number of times a concept or word is mentioned in a piece of content. The second one is relational analysis, which focuses on the relationship between different concepts or words and how they are connected within a specific context.
Content analysis is often used by marketers to measure brand reputation and customer behavior. For example, by analyzing customer reviews. It can also be used to analyze customer interviews and find directions for new product development. It is also important to note, that in order to extract the maximum potential out of this analysis method, it is necessary to have a clearly defined research question.
14. Thematic Analysis
Very similar to content analysis, thematic analysis also helps in identifying and interpreting patterns in qualitative data with the main difference being that the first one can also be applied to quantitative analysis. The thematic method analyzes large pieces of text data such as focus group transcripts or interviews and groups them into themes or categories that come up frequently within the text. It is a great method when trying to figure out peoples view’s and opinions about a certain topic. For example, if you are a brand that cares about sustainability, you can do a survey of your customers to analyze their views and opinions about sustainability and how they apply it to their lives. You can also analyze customer service calls transcripts to find common issues and improve your service.
Thematic analysis is a very subjective technique that relies on the researcher’s judgment. Therefore, to avoid biases, it has 6 steps that include familiarization, coding, generating themes, reviewing themes, defining and naming themes, and writing up. It is also important to note that, because it is a flexible approach, the data can be interpreted in multiple ways and it can be hard to select what data is more important to emphasize.
15. Narrative Analysis
A bit more complex in nature than the two previous ones, narrative analysis is used to explore the meaning behind the stories that people tell and most importantly, how they tell them. By looking into the words that people use to describe a situation you can extract valuable conclusions about their perspective on a specific topic. Common sources for narrative data include autobiographies, family stories, opinion pieces, and testimonials, among others.
From a business perspective, narrative analysis can be useful to analyze customer behaviors and feelings towards a specific product, service, feature, or others. It provides unique and deep insights that can be extremely valuable. However, it has some drawbacks.
The biggest weakness of this method is that the sample sizes are usually very small due to the complexity and time-consuming nature of the collection of narrative data. Plus, the way a subject tells a story will be significantly influenced by his or her specific experiences, making it very hard to replicate in a subsequent study.
16. Discourse Analysis
Discourse analysis is used to understand the meaning behind any type of written, verbal, or symbolic discourse based on its political, social, or cultural context. It mixes the analysis of languages and situations together. This means that the way the content is constructed and the meaning behind it is significantly influenced by the culture and society it takes place in. For example, if you are analyzing political speeches you need to consider different context elements such as the politician's background, the current political context of the country, the audience to which the speech is directed, and so on.
From a business point of view, discourse analysis is a great market research tool. It allows marketers to understand how the norms and ideas of the specific market work and how their customers relate to those ideas. It can be very useful to build a brand mission or develop a unique tone of voice.
17. Grounded Theory Analysis
Traditionally, researchers decide on a method and hypothesis and start to collect the data to prove that hypothesis. The grounded theory is the only method that doesn’t require an initial research question or hypothesis as its value lies in the generation of new theories. With the grounded theory method, you can go into the analysis process with an open mind and explore the data to generate new theories through tests and revisions. In fact, it is not necessary to collect the data and then start to analyze it. Researchers usually start to find valuable insights as they are gathering the data.
All of these elements make grounded theory a very valuable method as theories are fully backed by data instead of initial assumptions. It is a great technique to analyze poorly researched topics or find the causes behind specific company outcomes. For example, product managers and marketers might use the grounded theory to find the causes of high levels of customer churn and look into customer surveys and reviews to develop new theories about the causes.
How To Analyze Data? Top 17 Data Analysis Techniques To Apply

Now that we’ve answered the questions “what is data analysis’”, why is it important, and covered the different data analysis types, it’s time to dig deeper into how to perform your analysis by working through these 17 essential techniques.
1. Collaborate your needs
Before you begin analyzing or drilling down into any techniques, it’s crucial to sit down collaboratively with all key stakeholders within your organization, decide on your primary campaign or strategic goals, and gain a fundamental understanding of the types of insights that will best benefit your progress or provide you with the level of vision you need to evolve your organization.
2. Establish your questions
Once you’ve outlined your core objectives, you should consider which questions will need answering to help you achieve your mission. This is one of the most important techniques as it will shape the very foundations of your success.
To help you ask the right things and ensure your data works for you, you have to ask the right data analysis questions .
3. Data democratization
After giving your data analytics methodology some real direction, and knowing which questions need answering to extract optimum value from the information available to your organization, you should continue with democratization.
Data democratization is an action that aims to connect data from various sources efficiently and quickly so that anyone in your organization can access it at any given moment. You can extract data in text, images, videos, numbers, or any other format. And then perform cross-database analysis to achieve more advanced insights to share with the rest of the company interactively.
Once you have decided on your most valuable sources, you need to take all of this into a structured format to start collecting your insights. For this purpose, datapine offers an easy all-in-one data connectors feature to integrate all your internal and external sources and manage them at your will. Additionally, datapine’s end-to-end solution automatically updates your data, allowing you to save time and focus on performing the right analysis to grow your company.

4. Think of governance
When collecting data in a business or research context you always need to think about security and privacy. With data breaches becoming a topic of concern for businesses, the need to protect your client's or subject’s sensitive information becomes critical.
To ensure that all this is taken care of, you need to think of a data governance strategy. According to Gartner , this concept refers to “ the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption, and control of data and analytics .” In simpler words, data governance is a collection of processes, roles, and policies, that ensure the efficient use of data while still achieving the main company goals. It ensures that clear roles are in place for who can access the information and how they can access it. In time, this not only ensures that sensitive information is protected but also allows for an efficient analysis as a whole.
5. Clean your data
After harvesting from so many sources you will be left with a vast amount of information that can be overwhelming to deal with. At the same time, you can be faced with incorrect data that can be misleading to your analysis. The smartest thing you can do to avoid dealing with this in the future is to clean the data. This is fundamental before visualizing it, as it will ensure that the insights you extract from it are correct.
There are many things that you need to look for in the cleaning process. The most important one is to eliminate any duplicate observations; this usually appears when using multiple internal and external sources of information. You can also add any missing codes, fix empty fields, and eliminate incorrectly formatted data.
Another usual form of cleaning is done with text data. As we mentioned earlier, most companies today analyze customer reviews, social media comments, questionnaires, and several other text inputs. In order for algorithms to detect patterns, text data needs to be revised to avoid invalid characters or any syntax or spelling errors.
Most importantly, the aim of cleaning is to prevent you from arriving at false conclusions that can damage your company in the long run. By using clean data, you will also help BI solutions to interact better with your information and create better reports for your organization.
6. Set your KPIs
Once you’ve set your sources, cleaned your data, and established clear-cut questions you want your insights to answer, you need to set a host of key performance indicators (KPIs) that will help you track, measure, and shape your progress in a number of key areas.
KPIs are critical to both qualitative and quantitative analysis research. This is one of the primary methods of data analysis you certainly shouldn’t overlook.
To help you set the best possible KPIs for your initiatives and activities, here is an example of a relevant logistics KPI : transportation-related costs. If you want to see more go explore our collection of key performance indicator examples .

7. Omit useless data
Having bestowed your data analysis tools and techniques with true purpose and defined your mission, you should explore the raw data you’ve collected from all sources and use your KPIs as a reference for chopping out any information you deem to be useless.
Trimming the informational fat is one of the most crucial methods of analysis as it will allow you to focus your analytical efforts and squeeze every drop of value from the remaining ‘lean’ information.
Any stats, facts, figures, or metrics that don’t align with your business goals or fit with your KPI management strategies should be eliminated from the equation.
8. Build a data management roadmap
While, at this point, this particular step is optional (you will have already gained a wealth of insight and formed a fairly sound strategy by now), creating a data governance roadmap will help your data analysis methods and techniques become successful on a more sustainable basis. These roadmaps, if developed properly, are also built so they can be tweaked and scaled over time.
Invest ample time in developing a roadmap that will help you store, manage, and handle your data internally, and you will make your analysis techniques all the more fluid and functional – one of the most powerful types of data analysis methods available today.
9. Integrate technology
There are many ways to analyze data, but one of the most vital aspects of analytical success in a business context is integrating the right decision support software and technology.
Robust analysis platforms will not only allow you to pull critical data from your most valuable sources while working with dynamic KPIs that will offer you actionable insights; it will also present them in a digestible, visual, interactive format from one central, live dashboard . A data methodology you can count on.
By integrating the right technology within your data analysis methodology, you’ll avoid fragmenting your insights, saving you time and effort while allowing you to enjoy the maximum value from your business’s most valuable insights.
For a look at the power of software for the purpose of analysis and to enhance your methods of analyzing, glance over our selection of dashboard examples .
10. Answer your questions
By considering each of the above efforts, working with the right technology, and fostering a cohesive internal culture where everyone buys into the different ways to analyze data as well as the power of digital intelligence, you will swiftly start to answer your most burning business questions. Arguably, the best way to make your data concepts accessible across the organization is through data visualization.
11. Visualize your data
Online data visualization is a powerful tool as it lets you tell a story with your metrics, allowing users across the organization to extract meaningful insights that aid business evolution – and it covers all the different ways to analyze data.
The purpose of analyzing is to make your entire organization more informed and intelligent, and with the right platform or dashboard, this is simpler than you think, as demonstrated by our marketing dashboard .

This visual, dynamic, and interactive online dashboard is a data analysis example designed to give Chief Marketing Officers (CMO) an overview of relevant metrics to help them understand if they achieved their monthly goals.
In detail, this example generated with a modern dashboard creator displays interactive charts for monthly revenues, costs, net income, and net income per customer; all of them are compared with the previous month so that you can understand how the data fluctuated. In addition, it shows a detailed summary of the number of users, customers, SQLs, and MQLs per month to visualize the whole picture and extract relevant insights or trends for your marketing reports .
The CMO dashboard is perfect for c-level management as it can help them monitor the strategic outcome of their marketing efforts and make data-driven decisions that can benefit the company exponentially.
12. Be careful with the interpretation
We already dedicated an entire post to data interpretation as it is a fundamental part of the process of data analysis. It gives meaning to the analytical information and aims to drive a concise conclusion from the analysis results. Since most of the time companies are dealing with data from many different sources, the interpretation stage needs to be done carefully and properly in order to avoid misinterpretations.
To help you through the process, here we list three common practices that you need to avoid at all costs when looking at your data:
- Correlation vs. causation: The human brain is formatted to find patterns. This behavior leads to one of the most common mistakes when performing interpretation: confusing correlation with causation. Although these two aspects can exist simultaneously, it is not correct to assume that because two things happened together, one provoked the other. A piece of advice to avoid falling into this mistake is never to trust just intuition, trust the data. If there is no objective evidence of causation, then always stick to correlation.
- Confirmation bias: This phenomenon describes the tendency to select and interpret only the data necessary to prove one hypothesis, often ignoring the elements that might disprove it. Even if it's not done on purpose, confirmation bias can represent a real problem, as excluding relevant information can lead to false conclusions and, therefore, bad business decisions. To avoid it, always try to disprove your hypothesis instead of proving it, share your analysis with other team members, and avoid drawing any conclusions before the entire analytical project is finalized.
- Statistical significance: To put it in short words, statistical significance helps analysts understand if a result is actually accurate or if it happened because of a sampling error or pure chance. The level of statistical significance needed might depend on the sample size and the industry being analyzed. In any case, ignoring the significance of a result when it might influence decision-making can be a huge mistake.
13. Build a narrative
Now, we’re going to look at how you can bring all of these elements together in a way that will benefit your business - starting with a little something called data storytelling.
The human brain responds incredibly well to strong stories or narratives. Once you’ve cleansed, shaped, and visualized your most invaluable data using various BI dashboard tools , you should strive to tell a story - one with a clear-cut beginning, middle, and end.
By doing so, you will make your analytical efforts more accessible, digestible, and universal, empowering more people within your organization to use your discoveries to their actionable advantage.
14. Consider autonomous technology
Autonomous technologies, such as artificial intelligence (AI) and machine learning (ML), play a significant role in the advancement of understanding how to analyze data more effectively.
Gartner predicts that by the end of this year, 80% of emerging technologies will be developed with AI foundations. This is a testament to the ever-growing power and value of autonomous technologies.
At the moment, these technologies are revolutionizing the analysis industry. Some examples that we mentioned earlier are neural networks, intelligent alarms, and sentiment analysis.
15. Share the load
If you work with the right tools and dashboards, you will be able to present your metrics in a digestible, value-driven format, allowing almost everyone in the organization to connect with and use relevant data to their advantage.
Modern dashboards consolidate data from various sources, providing access to a wealth of insights in one centralized location, no matter if you need to monitor recruitment metrics or generate reports that need to be sent across numerous departments. Moreover, these cutting-edge tools offer access to dashboards from a multitude of devices, meaning that everyone within the business can connect with practical insights remotely - and share the load.
Once everyone is able to work with a data-driven mindset, you will catalyze the success of your business in ways you never thought possible. And when it comes to knowing how to analyze data, this kind of collaborative approach is essential.
16. Data analysis tools
In order to perform high-quality analysis of data, it is fundamental to use tools and software that will ensure the best results. Here we leave you a small summary of four fundamental categories of data analysis tools for your organization.
- Business Intelligence: BI tools allow you to process significant amounts of data from several sources in any format. Through this, you can not only analyze and monitor your data to extract relevant insights but also create interactive reports and dashboards to visualize your KPIs and use them for your company's good. datapine is an amazing online BI software that is focused on delivering powerful online analysis features that are accessible to beginner and advanced users. Like this, it offers a full-service solution that includes cutting-edge analysis of data, KPIs visualization, live dashboards, reporting, and artificial intelligence technologies to predict trends and minimize risk.
- Statistical analysis: These tools are usually designed for scientists, statisticians, market researchers, and mathematicians, as they allow them to perform complex statistical analyses with methods like regression analysis, predictive analysis, and statistical modeling. A good tool to perform this type of analysis is R-Studio as it offers a powerful data modeling and hypothesis testing feature that can cover both academic and general data analysis. This tool is one of the favorite ones in the industry, due to its capability for data cleaning, data reduction, and performing advanced analysis with several statistical methods. Another relevant tool to mention is SPSS from IBM. The software offers advanced statistical analysis for users of all skill levels. Thanks to a vast library of machine learning algorithms, text analysis, and a hypothesis testing approach it can help your company find relevant insights to drive better decisions. SPSS also works as a cloud service that enables you to run it anywhere.
- SQL Consoles: SQL is a programming language often used to handle structured data in relational databases. Tools like these are popular among data scientists as they are extremely effective in unlocking these databases' value. Undoubtedly, one of the most used SQL software in the market is MySQL Workbench . This tool offers several features such as a visual tool for database modeling and monitoring, complete SQL optimization, administration tools, and visual performance dashboards to keep track of KPIs.
- Data Visualization: These tools are used to represent your data through charts, graphs, and maps that allow you to find patterns and trends in the data. datapine's already mentioned BI platform also offers a wealth of powerful online data visualization tools with several benefits. Some of them include: delivering compelling data-driven presentations to share with your entire company, the ability to see your data online with any device wherever you are, an interactive dashboard design feature that enables you to showcase your results in an interactive and understandable way, and to perform online self-service reports that can be used simultaneously with several other people to enhance team productivity.
17. Refine your process constantly
Last is a step that might seem obvious to some people, but it can be easily ignored if you think you are done. Once you have extracted the needed results, you should always take a retrospective look at your project and think about what you can improve. As you saw throughout this long list of techniques, data analysis is a complex process that requires constant refinement. For this reason, you should always go one step further and keep improving.
Quality Criteria For Data Analysis
So far we’ve covered a list of methods and techniques that should help you perform efficient data analysis. But how do you measure the quality and validity of your results? This is done with the help of some science quality criteria. Here we will go into a more theoretical area that is critical to understanding the fundamentals of statistical analysis in science. However, you should also be aware of these steps in a business context, as they will allow you to assess the quality of your results in the correct way. Let’s dig in.
- Internal validity: The results of a survey are internally valid if they measure what they are supposed to measure and thus provide credible results. In other words , internal validity measures the trustworthiness of the results and how they can be affected by factors such as the research design, operational definitions, how the variables are measured, and more. For instance, imagine you are doing an interview to ask people if they brush their teeth two times a day. While most of them will answer yes, you can still notice that their answers correspond to what is socially acceptable, which is to brush your teeth at least twice a day. In this case, you can’t be 100% sure if respondents actually brush their teeth twice a day or if they just say that they do, therefore, the internal validity of this interview is very low.
- External validity: Essentially, external validity refers to the extent to which the results of your research can be applied to a broader context. It basically aims to prove that the findings of a study can be applied in the real world. If the research can be applied to other settings, individuals, and times, then the external validity is high.
- Reliability : If your research is reliable, it means that it can be reproduced. If your measurement were repeated under the same conditions, it would produce similar results. This means that your measuring instrument consistently produces reliable results. For example, imagine a doctor building a symptoms questionnaire to detect a specific disease in a patient. Then, various other doctors use this questionnaire but end up diagnosing the same patient with a different condition. This means the questionnaire is not reliable in detecting the initial disease. Another important note here is that in order for your research to be reliable, it also needs to be objective. If the results of a study are the same, independent of who assesses them or interprets them, the study can be considered reliable. Let’s see the objectivity criteria in more detail now.
- Objectivity: In data science, objectivity means that the researcher needs to stay fully objective when it comes to its analysis. The results of a study need to be affected by objective criteria and not by the beliefs, personality, or values of the researcher. Objectivity needs to be ensured when you are gathering the data, for example, when interviewing individuals, the questions need to be asked in a way that doesn't influence the results. Paired with this, objectivity also needs to be thought of when interpreting the data. If different researchers reach the same conclusions, then the study is objective. For this last point, you can set predefined criteria to interpret the results to ensure all researchers follow the same steps.
The discussed quality criteria cover mostly potential influences in a quantitative context. Analysis in qualitative research has by default additional subjective influences that must be controlled in a different way. Therefore, there are other quality criteria for this kind of research such as credibility, transferability, dependability, and confirmability. You can see each of them more in detail on this resource .
Data Analysis Limitations & Barriers
Analyzing data is not an easy task. As you’ve seen throughout this post, there are many steps and techniques that you need to apply in order to extract useful information from your research. While a well-performed analysis can bring various benefits to your organization it doesn't come without limitations. In this section, we will discuss some of the main barriers you might encounter when conducting an analysis. Let’s see them more in detail.
- Lack of clear goals: No matter how good your data or analysis might be if you don’t have clear goals or a hypothesis the process might be worthless. While we mentioned some methods that don’t require a predefined hypothesis, it is always better to enter the analytical process with some clear guidelines of what you are expecting to get out of it, especially in a business context in which data is utilized to support important strategic decisions.
- Objectivity: Arguably one of the biggest barriers when it comes to data analysis in research is to stay objective. When trying to prove a hypothesis, researchers might find themselves, intentionally or unintentionally, directing the results toward an outcome that they want. To avoid this, always question your assumptions and avoid confusing facts with opinions. You can also show your findings to a research partner or external person to confirm that your results are objective.
- Data representation: A fundamental part of the analytical procedure is the way you represent your data. You can use various graphs and charts to represent your findings, but not all of them will work for all purposes. Choosing the wrong visual can not only damage your analysis but can mislead your audience, therefore, it is important to understand when to use each type of data depending on your analytical goals. Our complete guide on the types of graphs and charts lists 20 different visuals with examples of when to use them.
- Flawed correlation : Misleading statistics can significantly damage your research. We’ve already pointed out a few interpretation issues previously in the post, but it is an important barrier that we can't avoid addressing here as well. Flawed correlations occur when two variables appear related to each other but they are not. Confusing correlations with causation can lead to a wrong interpretation of results which can lead to building wrong strategies and loss of resources, therefore, it is very important to identify the different interpretation mistakes and avoid them.
- Sample size: A very common barrier to a reliable and efficient analysis process is the sample size. In order for the results to be trustworthy, the sample size should be representative of what you are analyzing. For example, imagine you have a company of 1000 employees and you ask the question “do you like working here?” to 50 employees of which 49 say yes, which means 95%. Now, imagine you ask the same question to the 1000 employees and 950 say yes, which also means 95%. Saying that 95% of employees like working in the company when the sample size was only 50 is not a representative or trustworthy conclusion. The significance of the results is way more accurate when surveying a bigger sample size.
- Privacy concerns: In some cases, data collection can be subjected to privacy regulations. Businesses gather all kinds of information from their customers from purchasing behaviors to addresses and phone numbers. If this falls into the wrong hands due to a breach, it can affect the security and confidentiality of your clients. To avoid this issue, you need to collect only the data that is needed for your research and, if you are using sensitive facts, make it anonymous so customers are protected. The misuse of customer data can severely damage a business's reputation, so it is important to keep an eye on privacy.
- Lack of communication between teams : When it comes to performing data analysis on a business level, it is very likely that each department and team will have different goals and strategies. However, they are all working for the same common goal of helping the business run smoothly and keep growing. When teams are not connected and communicating with each other, it can directly affect the way general strategies are built. To avoid these issues, tools such as data dashboards enable teams to stay connected through data in a visually appealing way.
- Innumeracy : Businesses are working with data more and more every day. While there are many BI tools available to perform effective analysis, data literacy is still a constant barrier. Not all employees know how to apply analysis techniques or extract insights from them. To prevent this from happening, you can implement different training opportunities that will prepare every relevant user to deal with data.
Key Data Analysis Skills
As you've learned throughout this lengthy guide, analyzing data is a complex task that requires a lot of knowledge and skills. That said, thanks to the rise of self-service tools the process is way more accessible and agile than it once was. Regardless, there are still some key skills that are valuable to have when working with data, we list the most important ones below.
- Critical and statistical thinking: To successfully analyze data you need to be creative and think out of the box. Yes, that might sound like a weird statement considering that data is often tight to facts. However, a great level of critical thinking is required to uncover connections, come up with a valuable hypothesis, and extract conclusions that go a step further from the surface. This, of course, needs to be complemented by statistical thinking and an understanding of numbers.
- Data cleaning: Anyone who has ever worked with data before will tell you that the cleaning and preparation process accounts for 80% of a data analyst's work, therefore, the skill is fundamental. But not just that, not cleaning the data adequately can also significantly damage the analysis which can lead to poor decision-making in a business scenario. While there are multiple tools that automate the cleaning process and eliminate the possibility of human error, it is still a valuable skill to dominate.
- Data visualization: Visuals make the information easier to understand and analyze, not only for professional users but especially for non-technical ones. Having the necessary skills to not only choose the right chart type but know when to apply it correctly is key. This also means being able to design visually compelling charts that make the data exploration process more efficient.
- SQL: The Structured Query Language or SQL is a programming language used to communicate with databases. It is fundamental knowledge as it enables you to update, manipulate, and organize data from relational databases which are the most common databases used by companies. It is fairly easy to learn and one of the most valuable skills when it comes to data analysis.
- Communication skills: This is a skill that is especially valuable in a business environment. Being able to clearly communicate analytical outcomes to colleagues is incredibly important, especially when the information you are trying to convey is complex for non-technical people. This applies to in-person communication as well as written format, for example, when generating a dashboard or report. While this might be considered a “soft” skill compared to the other ones we mentioned, it should not be ignored as you most likely will need to share analytical findings with others no matter the context.
Data Analysis In The Big Data Environment
Big data is invaluable to today’s businesses, and by using different methods for data analysis, it’s possible to view your data in a way that can help you turn insight into positive action.
To inspire your efforts and put the importance of big data into context, here are some insights that you should know:
- By 2026 the industry of big data is expected to be worth approximately $273.4 billion.
- 94% of enterprises say that analyzing data is important for their growth and digital transformation.
- Companies that exploit the full potential of their data can increase their operating margins by 60% .
- We already told you the benefits of Artificial Intelligence through this article. This industry's financial impact is expected to grow up to $40 billion by 2025.
Data analysis concepts may come in many forms, but fundamentally, any solid methodology will help to make your business more streamlined, cohesive, insightful, and successful than ever before.
Key Takeaways From Data Analysis
As we reach the end of our data analysis journey, we leave a small summary of the main methods and techniques to perform excellent analysis and grow your business.
17 Essential Types of Data Analysis Methods:
- Cluster analysis
- Cohort analysis
- Regression analysis
- Factor analysis
- Neural Networks
- Data Mining
- Text analysis
- Time series analysis
- Decision trees
- Conjoint analysis
- Correspondence Analysis
- Multidimensional Scaling
- Content analysis
- Thematic analysis
- Narrative analysis
- Grounded theory analysis
- Discourse analysis
Top 17 Data Analysis Techniques:
- Collaborate your needs
- Establish your questions
- Data democratization
- Think of data governance
- Clean your data
- Set your KPIs
- Omit useless data
- Build a data management roadmap
- Integrate technology
- Answer your questions
- Visualize your data
- Interpretation of data
- Consider autonomous technology
- Build a narrative
- Share the load
- Data Analysis tools
- Refine your process constantly
We’ve pondered the data analysis definition and drilled down into the practical applications of data-centric analytics, and one thing is clear: by taking measures to arrange your data and making your metrics work for you, it’s possible to transform raw information into action - the kind of that will push your business to the next level.
Yes, good data analytics techniques result in enhanced business intelligence (BI). To help you understand this notion in more detail, read our exploration of business intelligence reporting .
And, if you’re ready to perform your own analysis, drill down into your facts and figures while interacting with your data on astonishing visuals, you can try our software for a free, 14-day trial .

*RESEARCH DATA SERVICES (RDS) @ Georgia State University Library: WORKSHOPs ~ Data Analysis Tools ~ Quantitative (Stata, SPSS, SAS, R, Python) & Qualitative (NVivo)
- RDS@GSU ~ iCollege/Syllabus Language
- RDS@GSU ~ Scope of Services
- WORKSHOPs ~ Calendar (Live - Online or In-Person) This link opens in a new window
- WORKSHOPs ~ Recordings
- WORKSHOPs ~ Data Analysis Tools ~ Quantitative (Stata, SPSS, SAS, R, Python) & Qualitative (NVivo)
- WORKSHOPs ~ Methods for Data Analysis & Collection ~ Survey Design, Qualitative Methods, Data Discovery
- WORKSHOPs ~ Mapping & Data Visualization (Tableau, ArcGIS, Power BI, Social Explorer)
- WORKSHOPs ~ Etiquette & Policies
- WORKSHOPs ~ College-To-Career Competencies & Skills
- GSU Data Ready! Badges
- TEACHING with Data & Statistics
- Data Events This link opens in a new window
- PIDLit Public Interest Data Literacy This link opens in a new window
- CAREERS in Data Services
WORKSHOPs ~ DATA ANALYSIS TOOLS
Coding: r | python | python for machine learning | text data analysis w/ r & python, software: spss | sas | stata | nvivo | nvivo for team coding , r workshop series.
Get GSU Data Ready! Badge Micro-Credentials for completing these workshops to show others your commitment to learning data skills! Learn more at lib.gsu.edu/data-read y
- LIVE workshops currently not offered.
- For RECORDED workshops: Click here .
- For ONLINE GUIDE: Click here .
The R workshop series will introduce participants to the fundamentals of using the R programming language and associated tools for the purposes of performing common data analysis tasks. The R programming language is 100% free to use and is extremely popular amongst researchers in both academia, business, and non-profits. It is especially useful for conducting statistical analysis.
This series consists of four workshops. For individuals who are new to R, coding, or data analysis, it is highly recommended that the workshops be attended in sequential order. Additionally, while these workshops are taught exclusively using code (i.e. there are no point-and-click methods), attendees do not need to have any prior experience with programming, coding, or scripting. All are welcome.
Skill Requirements: None.
Software Requirements for Hands-on Participation:
For participants wishing to follow along with the “hands-on” portion of the workshop, please see the directions at the following url: https://research.library.gsu.edu/R/workshop
R 1: Getting Started with R and RStudio
Workshop Topics:
- Using RStudio to work with R
- R syntax, commands, functions, and packages
- Opening, viewing, and exploring data
- Generating basic descriptive statistics from data
R 2: Tidyverse and Manipulating Data
- Introduction to Tidyverse packages (emphasis on dplyr)
- Transforming and generating variables
- Handling data with missing values
- “Piping” data and data processes
R 3: Data Visualization and Mapping
- Creating statistical plots using ggplot2
- Customizing plot colors, themes, labels, etc…
- Working with GIS data to create maps
- Modifying maps with overlays, custom aesthetics, and additional data
R 4: Statistical Modelling
- Basic analysis, descriptive statistics, t-tests
- Creating linear models (multiple linear regression & logistic regression)
- Evaluating linear models and generating predictions
- Creating simple machine learning models (Time permitting)
Python & Data Workshop Series
Get a GSU Data Ready! Badge Micro-Credential for completing these workshops to show others your commitment to learning data skills! Learn more at lib.gsu.edu/data-read y
The Python & Data workshop series will introduce participants to the fundamentals of using the Python programming language and associated tools for the purposes of performing common data analysis tasks. Python is an extremely popular programming language used by analysts, researchers, and scientists in many different disciplines.
This series consists of three workshops. For individuals who are new to Python, coding, or data analysis, it is highly recommended that the workshops be attended in sequential order. Additionally, while these workshops are taught exclusively using code (i.e. there are no point-and-click methods), attendees do not need to have any prior experience with programming, coding, or scripting. All are welcome.
- Participants will need a Google / Gmail account in order to access Google Colab
- No software installation is required.
Python & Data 0: Google Colab
This video-only recorded workshop provides a short, high-level overview of Google Colab and how it relates to the other Python workshops. There is no live version of this workshop; it is solely available as a recorded version on our recorded workshops page linked above.
- Brief overview of Google Colab
- Uploading, managing, and saving data in Google Colab environment
Python & Data 1: Getting Started with Python
- Using Google Colab and Jupyter to work with Python
- Python syntax, commands, functions, and packages/modules
Python & Data 2: Manipulating & Transforming Data
- Selecting, sub-setting, and manipulating data
- Generating crosstabs / contingency tables
Python & Data 3: Visualizing Data & Creating Models
- Plotting and visualizing data using Matplotlib and Seaborn
- Defining statistical models using both formulas and matrices
- Fitting and inspecting statistical models (e.g. anova, linear regression)
Python for Machine Learning (ML) Workshop Series
This applied Machine Learning (ML) series introduces participants to the fundamentals of supervised learning and provides experience in applying several ML algorithms in Python. Participants will gain experience in regression modeling; assessing model adequacy, prediction precision, and computational performance; and learn several tools for visualizing each step of the process.
This series consists of three (3) workshops. For individuals who are new to Python and/or Google Colab, it is highly recommended that you first complete the prerequisite Python & Data Workshop Series 0-3 workshops . For those who are new to Machine Learning, it is highly recommended that the workshops in this series be attended in sequential order. While these workshops are taught exclusively using code (i.e., there are no point-and-click methods), attendees do not need to have any prior experience with programming, coding, or scripting. All are welcome.
For participants wishing to follow along with the “hands-on” portion of the workshop, please see the directions here .
Python for Machine Learning (ML) 1: Univariate Linear Regression
Fundamentals of supervised learning in Python; applying a rudimentary ML model using univariate linear regression (i.e., one feature).
- Overview: “What is Machine Learning?”
- Univariate Linear Regression Model
- Mean-Squared Error Cost Function
- Gradient Descent Algorithm for Linear Regression
Prerequisites: Python & Data Workshop Series 0-3: https://lib.gsu.edu/rds-recordings
Python for Machine Learning (ML) 2: Multivariate Linear Regression
Fundamentals of supervised learning in Python; applying an ML model using multivariate regression (i.e., multiple features).
- Multivariate Regression Model
- Vectorization
- Feature Scaling
- Feature Engineering
Prerequisites: Python & Data Workshop Series 0-3: https://lib.gsu.edu/rds-recordings and Python for Machine Learning (ML) 1: Univariate Linear Regression Workshop.
Python for Machine Learning (ML) 3: Logistic Regression
Fundamentals of supervised learning in Python; applying an ML model using logistic regression (e.g., classification prediction).
- Logistic Regression Model
- Cost Function for Logistic Regression
- Gradient Descent for Logistic Regression
- Overfitting & Model Adequacy
Prerequisites: Python & Data Workshop Series 0-3: https://lib.gsu.edu/rds-recordings , Python for Machine Learning (ML) 1: Univariate Linear Regression Workshop, and Python for Machine Learning (ML) 2: Multivariate Linear Regression Workshop.
Text Data Analysis Workshop

Text Data: Basics of Text Processing and Regular Expressions
The size and volume of textual data available to academic researchers is absolutely immense. Consequently, for some researchers, having the skills to process, transform, and analyze text data using computational tools is increasingly necessary for certain types of research. This workshop will introduce the fundamentals of working with and manipulating text data using scripting languages (e.g. Python, R). This includes loading, processing, and preparing text data for use with quantitative models. Although advanced natural language processing (NLP) models are not included in this workshop, some possible applications may be demonstrated if time permits. No special background knowledge or skills are required to attend. All are welcome.
Skill Requirements: Basic familiarity with Python, R, or any scripting language preferred.
- Common text and string operations
- Tokenization, transformations, and processing
- Regular Expressions
- N-grams and term frequencies
SPSS Workshop Series
Spss workshop series.

- For LIVE workshops dates/times: Click here .
The SPSS 1 and SPSS 2 workshops in this two-part series focus on using the point-and-click method for using SPSS; the syntax/code method is introduced briefly.
SPSS 1: Getting Started
This workshop is the first of a two-part series on SPSS , a statistical software package that is widely used by scientists throughout the social sciences for analysis of quantitative data.
Please note: This workshop focuses on using the point-and-click method for using SPSS; the syntax/code method is introduced briefly.
Workshop Topics
- Navigating SPSS
- Entering and importing data from different formats (such as text and Excel files)
- Defining variables (defining and labeling codes, selecting appropriate levels of measurement)
- Manipulating and transforming data (selecting cases and splitting files; recoding and computing variables)
- Running descriptive statistics
- Generating simple graphs
Prerequisites: None.
SPSS 2: Analyzing Data
This workshop is the second of a two-part series on SPSS , a statistical software package that is widely used by scientists throughout the social sciences for analysis of quantitative data.
- Cross-tabulation and Chi-Square tests
- Analysis of Variance (ANOVA)
- Correlation analysis
- Multiple regression analysis
Prerequisites: Attendance at SPSS 1 preferred, or completion of Parts 1-6 of the Lynda.com "SPSS Statistics Essential Training" tutorial .
SAS Workshop Series
Sas workshop series.

This workshop series completes all analysis using code. No previous knowledge of coding is required. This series is for the Windows version of SAS.
SAS 1: SAS Basics
This is the first SAS workshop in a two-part series. This interactive workshop will introduce users to the SAS system. Applied, hands on, examples using real data will be used. NOTE: This workshop is aimed at people who do not have experience using the SAS system. Those who have used SAS in the past may find this workshop too foundational and are encouraged to attend our forthcoming advanced SAS sessions.
- Reading data into SAS
- Conducting basic data cleaning and recoding
- Using basic SAS procedures (e.g., PROC CONTENTS, PROC PRINT, PROC FREQ) to view and understand data.
- PROC FREQ, PROC UNIVARIATE, and PROC MEANS will be demonstrated to complete basic descriptive statistics.
- An introduction to bivariate statistics in SAS.
Prerequisites: No prior experience with SAS is required. Basic understanding of univariate and bivariate statistics is helpful but not required.
SAS 2: Data Analysis
This is the second SAS workshop in a two-part series. In this interactive workshop, SAS users will go beyond the basics to develop comfort with more advanced statistical analyses using the SAS system. Applied, hands on, examples using real data will be used. NOTE: Basic knowledge of the SAS system will be helpful for those who want to participate in the applied portion of the workshop.
- Conducting bivariate and multivariable analyses using SAS procedures like PROC FREQ, PROC TTEST, PROC ANOVA, PROC GLM, PROC LOGISTIC, and PROC REG.
- Best practices for checking statistical assumptions, selecting appropriate statistical procedures, and reporting and visualizing results will be discussed.
Prerequisites: Basic knowledge of the SAS system will be helpful for those who want to participate in the applied portion of the workshop. Basic understanding of bivariate and multivariable statistics is helpful.
Stata Workshop Series
Stata workshop series.

- For RECORDED workshops: Click here .
This workshop series completes all analysis using code. No previous knowledge of coding is required. This series is for the Windows version of Stata. See the Stata research guide here.
Stata 1: Introduction to Stata
This workshop is the first of a three-part series on Stata . Stata is a statistical software package. Stata is widely used by scientists throughout the social sciences for analysis of quantitative data ranging from simple descriptive analysis to complex statistical modeling.
Please note: This workshop completes all analysis using code. No previous knowledge of coding is required.
- Opening data
- Generating variables (basic)
- Frequency distributions
- Analysis: summary statistics
Prerequisites: None.
Stata 2: Basic Data Analysis
This workshop is the second in a three-part series on Stata . Stata is a statistical software package. Stata is widely used by scientists throughout the social sciences for analysis of quantitative data ranging from simple descriptive analysis to complex statistical modeling.
- Generating variables (advanced)
- Analysis: Chi-square, ANOVA, regression
- Navigating help features
Prerequisites: Stata 1 or basic knowledge of Stata.
Stata 3: Advanced Data Analysis
This workshop is the third in a three-part series on Stata . Stata is a statistical software package. Stata is widely used by scientists throughout the social sciences for analysis of quantitative data ranging from simple descriptive analysis to complex statistical modeling.
- Troubleshooting code
- Generating scales
- 3, 4, and 5 way cross tabulations
Prerequisites: Stata 1 and Stata 2 or moderate knowledge of Stata.
NVivo Workshop Series
Nvivo workshop series.
This workshop is for the *WINDOWS* version of NVivo. The Mac version differs significantly from the Windows; consequently, attending the Windows workshop if you will be using the Mac version is not recommended. We do not offer workshops on the Mac version due to having no Mac labs to do so. If you need one-on-one training for the Mac version of NVivo, please directly contact Mandy Swygart-Hobaugh, Ph.D. See the NVivo research guide here.
NVivo 1 for Windows: Getting Started
This is the first workshop in a two-part series on NVivo qualitative data analysis software.
- Getting to know the NVivo workspace
- Exploring different types of data types/files that can be analyzed
- Basic coding of text-based files
- Using Queries and Automated features to explore and code your data
- Recording comments and ideas
Prerequisites: Basic understanding of qualitative research methods is suggested, but not required. Watching this short tutorial on coding qualitative data before attending the workshop is recommended.
NVivo 2 for Windows: Exploring Your Data
This is the second workshop in a two-part series on NVivo qualitative data analysis software.
- Creating Classifications with Attribute Values to facilitate comparative analyses
- Crosstab and Matrix Coding queries
- Data visualizations
- Sharing findings with Reports and exporting Codebooks
Prerequisites: NVivo 1
NVivo for Team Coding Workshop
Nvivo for team coding.
Get a GSU Data Ready! Badge Micro-Credential for completing this workshop plus the NVivo 1 workshop to show others your commitment to learning data skills! Learn more at lib.gsu.edu/data-read y
This workshop is on using NVivo qualitative data analysis software to do team work / team coding in NVivo involving 2 or more people . It will cover various strategies for tracking team members’ work in NVivo and comparing coding, including generating inter-rater reliability measures.
- Creating and organizing NVivo project files for independent coding
- Merging / importing individual team member's project files into a master copy file.
- Comparing coding between team members, including generating inter-rater reliability measures
- Challenges of having team members working across Windows and Mac versions
Prerequisites: Attendance at minimally the NVivo 1 workshop (live or recorded) and optionally the NVivo 2 workshop (live or recorded).
- << Previous: WORKSHOPs ~ Recordings
- Next: WORKSHOPs ~ Methods for Data Analysis & Collection ~ Survey Design, Qualitative Methods, Data Discovery >>
- Last Updated: Apr 24, 2024 4:40 PM
- URL: https://research.library.gsu.edu/dataservices
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Quantitative Data Collection: Best 5 methods

In contrast to qualitative data , quantitative data collection is everything about figures and numbers. Researchers often rely on quantitative data when they intend to quantify attributes, attitudes, behaviors, and other defined variables with a motive to either back or oppose the hypothesis of a specific phenomenon by contextualizing the data obtained via surveying or interviewing the study sample.
Content Index
What is Quantitative Data Collection?
Importance of quantitative data collection, probability sampling, surveys/questionnaires, observations, document review in quantitative data collection.
Quantitative data collection refers to the collection of numerical data that can be analyzed using statistical methods. This type of data collection is often used in surveys, experiments, and other research methods. It measure variables and establish relationships between variables. The data collected through quantitative methods is typically in the form of numbers, such as response frequencies, means, and standard deviations, and can be analyzed using statistical software.
LEARN ABOUT: Research Process Steps
As a researcher, you do have the option to opt either for data collection online or use traditional data collection methods via appropriate research. Quantitative data collection is important for several reasons:
- Objectivity: Quantitative data collection provides objective and verifiable information, as the data is collected in a systematic and standardized manner.
- Generalizability: The results from quantitative data collection can be generalized to a larger population, making it an effective way to study large groups of people.
- Precision: Numerical data allows for precise measurement and unit of analysis , providing more accurate results than other data collection forms.
- Hypothesis testing: Quantitative data collection allows for testing hypotheses and theories, leading to a better understanding of the relationships between variables.
- Comparison: Quantitative data collection allows for data comparison and analysis. It can be useful in making decisions and identifying trends or patterns.
- Replicability: The numerical nature of quantitative data makes it easier to replicate research results. It is essential for building knowledge in a particular field.
LEARN ABOUT: Level of Analysis
Overall, quantitative data collection provides valuable information for understanding complex phenomena and making informed decisions based on empirical evidence.
LEARN ABOUT: Best Data Collection Tools
Methods used for Quantitative Data Collection
A data that can be counted or expressed in numerical’s constitute the quantitative data. It is commonly used to study the events or levels of concurrence. And is collected through a Structured Question & structured questionnaire asking questions starting with “how much” or “how many.” As the quantitative data is numerical, it represents both definitive and objective data. Furthermore, quantitative information is much sorted for statistical analysis and mathematical analysis, making it possible to illustrate it in the form of charts and graphs.
Discrete and continuous are the two major categories of quantitative data where discreet data have finite numbers and the constant data values falling on a continuum possessing the possibility to have fractions or decimals. If research is conducted to find out the number of vehicles owned by the American household, then we get a whole number, which is an excellent example of discrete data. When research is limited to the study of physical measurements of the population like height, weight, age, or distance, then the result is an excellent example of continuous data.
Any traditional or online data collection method that helps in gathering numerical data is a proven method of collecting quantitative data.
LEARN ABOUT: Survey Sampling

There are four significant types of probability sampling:
- Simple random sampling : More often, the targeted demographic is chosen for inclusion in the sample.
- Cluster sampling : Cluster sampling is a technique in which a population is divided into smaller groups or clusters, and a random sample of these clusters is selected. This method is used when it is impractical or expensive to obtain a random sample from the entire population .
- Systematic sampling : Any of the targeted demographic would be included in the sample, but only the first unit for inclusion in the sample is selected randomly, rest are selected in the ordered fashion as if one out of every ten people on the list .
- Stratified sampling : It allows selecting each unit from a particular group of the targeted audience while creating a sample. It is useful when the researchers are selective about including a specific set of people in the sample, i.e., only males or females, managers or executives, people working within a particular industry.
Interviewing people is a standard method used for data collection . However, the interviews conducted to collect quantitative data are more structured, wherein the researchers ask only a standard set of online questionnaires and nothing more than that.
There are three major types of interviews conducted for data collection
- Telephone interviews: For years, telephone interviews ruled the charts of data collection methods. Nowadays, there is a significant rise in conducting video interviews using the internet, Skype, or similar online video calling platforms.
- Face-to-face interviews: It is a proven technique to collect data directly from the participants. It helps in acquiring quality data as it provides a scope to ask detailed questions and probing further to collect rich and informative data. Literacy requirements of the participant are irrelevant as F2F surveys offer ample opportunities to collect non-verbal data through observation or to explore complex and unknown issues. Although it can be an expensive and time-consuming method, the response rates for F2F interviews are often higher.
- Computer-Assisted Personal Interviewing (CAPI): It is nothing but a similar setup of the face-to-face interview where the interviewer carries a desktop or laptop along with him at the time of interview to upload the data obtained from the interview directly into the database. CAPI saves a lot of time in updating and processing the data and also makes the entire process paperless as the interviewer does not carry a bunch of papers and questionnaires.

There are two significant types of survey questionnaires used to collect online data for quantitative market research.
- Web-based questionnaire : This is one of the ruling and most trusted methods for internet-based research or online research. In a web-based questionnaire, the receive an email containing the survey link, clicking on which takes the respondent to a secure online survey tool from where he/she can take the survey or fill in the survey questionnaire. Being a cost-efficient, quicker, and having a wider reach, web-based surveys are more preferred by the researchers. The primary benefit of a web-based questionnaire is flexibility. Respondents are free to take the survey in their free time using either a desktop, laptop, tablet, or mobile.
- Mail Questionnaire : In a mail questionnaire, the survey is mailed out to a host of the sample population, enabling the researcher to connect with a wide range of audiences. The mail questionnaire typically consists of a packet containing a cover sheet that introduces the audience about the type of research and reason why it is being conducted along with a prepaid return to collect data online. Although the mail questionnaire has a higher churn rate compared to other quantitative data collection methods, adding certain perks such as reminders and incentives to complete the survey help in drastically improving the churn rate. One of the major benefits of the mail questionnaire is all the responses are anonymous, and respondents are allowed to take as much time as they want to complete the survey and be completely honest about the answer without the fear of prejudice.
LEARN ABOUT: Steps in Qualitative Research
As the name suggests, it is a pretty simple and straightforward method of collecting quantitative data. In this method, researchers collect quantitative data through systematic observations by using techniques like counting the number of people present at the specific event at a particular time and a particular venue or number of people attending the event in a designated place. More often, for quantitative data collection, the researchers have a naturalistic observation approach. It needs keen observation skills and senses for getting the numerical data about the “what” and not about “why” and ”how.”
Naturalistic observation is used to collect both types of data; qualitative and quantitative. However, structured observation is more used to collect quantitative rather than qualitative data collection .
- Structured observation: In this type of observation method, the researcher has to make careful observations of one or more specific behaviors in a more comprehensive or structured setting compared to naturalistic or participant observation . In a structured observation, the researchers, rather than observing everything, focus only on very specific behaviors of interest. It allows them to quantify the behaviors they are observing. When the qualitative observations require a judgment on the part of the observers – it is often described as coding, which requires a clearly defining a set of target behaviors.
Document review is a process used to collect data after reviewing the existing documents. It is an efficient and effective way of gathering data as documents are manageable. Those are the practical resource to get qualified data from the past. Apart from strengthening and supporting the research by providing supplementary research data document review has emerged as one of the beneficial methods to gather quantitative research data.
Three primary document types are being analyzed for collecting supporting quantitative research data.
- Public Records: Under this document review, official, ongoing records of an organization are analyzed for further research. For example, annual reports policy manuals, student activities, game activities in the university, etc.
- Personal Documents: In contrast to public documents, this type of document review deals with individual personal accounts of individuals’ actions, behavior, health, physique, etc. For example, the height and weight of the students, distance students are traveling to attend the school, etc.
- Physical Evidence: Physical evidence or physical documents deal with previous achievements of an individual or of an organization in terms of monetary and scalable growth.
LEARN ABOUT: 12 Best Tools for Researchers
Quantitative data is not about convergent reasoning, but it is about divergent thinking. It deals with the numerical, logic, and an objective stance, by focusing on numeric and unchanging data. More often, data collection methods are used to collect quantitative research data, and the results are dependent on the larger sample sizes that are commonly representing the population researcher intend to study.
Although there are many other methods to collect quantitative data. Those mentioned above probability sampling, interviews, questionnaire observation, and document review are the most common and widely used methods for data collection.
With QuestionPro, you can precise results, and data analysis . QuestionPro provides the opportunity to collect data from a large number of participants. It increases the representativeness of the sample and providing more accurate results.
FREE TRIAL LEARN MORE
MORE LIKE THIS

Customer Communication Tool: Types, Methods, Uses, & Tools
Apr 23, 2024

Top 12 Sentiment Analysis Tools for Understanding Emotions

QuestionPro BI: From research data to actionable dashboards within minutes
Apr 22, 2024

21 Best Customer Experience Management Software in 2024
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
- Privacy Policy
Home » Quantitative Data – Types, Methods and Examples
Quantitative Data – Types, Methods and Examples
Table of Contents

Quantitative Data
Definition:
Quantitative data refers to numerical data that can be measured or counted. This type of data is often used in scientific research and is typically collected through methods such as surveys, experiments, and statistical analysis.
Quantitative Data Types
There are two main types of quantitative data: discrete and continuous.
- Discrete data: Discrete data refers to numerical values that can only take on specific, distinct values. This type of data is typically represented as whole numbers and cannot be broken down into smaller units. Examples of discrete data include the number of students in a class, the number of cars in a parking lot, and the number of children in a family.
- Continuous data: Continuous data refers to numerical values that can take on any value within a certain range or interval. This type of data is typically represented as decimal or fractional values and can be broken down into smaller units. Examples of continuous data include measurements of height, weight, temperature, and time.
Quantitative Data Collection Methods
There are several common methods for collecting quantitative data. Some of these methods include:
- Surveys : Surveys involve asking a set of standardized questions to a large number of people. Surveys can be conducted in person, over the phone, via email or online, and can be used to collect data on a wide range of topics.
- Experiments : Experiments involve manipulating one or more variables and observing the effects on a specific outcome. Experiments can be conducted in a controlled laboratory setting or in the real world.
- Observational studies : Observational studies involve observing and collecting data on a specific phenomenon without intervening or manipulating any variables. Observational studies can be conducted in a natural setting or in a laboratory.
- Secondary data analysis : Secondary data analysis involves using existing data that was collected for a different purpose to answer a new research question. This method can be cost-effective and efficient, but it is important to ensure that the data is appropriate for the research question being studied.
- Physiological measures: Physiological measures involve collecting data on biological or physiological processes, such as heart rate, blood pressure, or brain activity.
- Computerized tracking: Computerized tracking involves collecting data automatically from electronic sources, such as social media, online purchases, or website analytics.
Quantitative Data Analysis Methods
There are several methods for analyzing quantitative data, including:
- Descriptive statistics: Descriptive statistics are used to summarize and describe the basic features of the data, such as the mean, median, mode, standard deviation, and range.
- Inferential statistics : Inferential statistics are used to make generalizations about a population based on a sample of data. These methods include hypothesis testing, confidence intervals, and regression analysis.
- Data visualization: Data visualization involves creating charts, graphs, and other visual representations of the data to help identify patterns and trends. Common types of data visualization include histograms, scatterplots, and bar charts.
- Time series analysis: Time series analysis involves analyzing data that is collected over time to identify patterns and trends in the data.
- Multivariate analysis : Multivariate analysis involves analyzing data with multiple variables to identify relationships between the variables.
- Factor analysis : Factor analysis involves identifying underlying factors or dimensions that explain the variation in the data.
- Cluster analysis: Cluster analysis involves identifying groups or clusters of observations that are similar to each other based on multiple variables.
Quantitative Data Formats
Quantitative data can be represented in different formats, depending on the nature of the data and the purpose of the analysis. Here are some common formats:
- Tables : Tables are a common way to present quantitative data, particularly when the data involves multiple variables. Tables can be used to show the frequency or percentage of data in different categories or to display summary statistics.
- Charts and graphs: Charts and graphs are useful for visualizing quantitative data and can be used to highlight patterns and trends in the data. Some common types of charts and graphs include line charts, bar charts, scatterplots, and pie charts.
- Databases : Quantitative data can be stored in databases, which allow for easy sorting, filtering, and analysis of large amounts of data.
- Spreadsheets : Spreadsheets can be used to organize and analyze quantitative data, particularly when the data is relatively small in size. Spreadsheets allow for calculations and data manipulation, as well as the creation of charts and graphs.
- Statistical software : Statistical software, such as SPSS, R, and SAS, can be used to analyze quantitative data. These programs allow for more advanced statistical analyses and data modeling, as well as the creation of charts and graphs.
Quantitative Data Gathering Guide
Here is a basic guide for gathering quantitative data:
- Define the research question: The first step in gathering quantitative data is to clearly define the research question. This will help determine the type of data to be collected, the sample size, and the methods of data analysis.
- Choose the data collection method: Select the appropriate method for collecting data based on the research question and available resources. This could include surveys, experiments, observational studies, or other methods.
- Determine the sample size: Determine the appropriate sample size for the research question. This will depend on the level of precision needed and the variability of the population being studied.
- Develop the data collection instrument: Develop a questionnaire or survey instrument that will be used to collect the data. The instrument should be designed to gather the specific information needed to answer the research question.
- Pilot test the data collection instrument : Before collecting data from the entire sample, pilot test the instrument on a small group to identify any potential problems or issues.
- Collect the data: Collect the data from the selected sample using the chosen data collection method.
- Clean and organize the data : Organize the data into a format that can be easily analyzed. This may involve checking for missing data, outliers, or errors.
- Analyze the data: Analyze the data using appropriate statistical methods. This may involve descriptive statistics, inferential statistics, or other types of analysis.
- Interpret the results: Interpret the results of the analysis in the context of the research question. Identify any patterns, trends, or relationships in the data and draw conclusions based on the findings.
- Communicate the findings: Communicate the findings of the analysis in a clear and concise manner, using appropriate tables, graphs, and other visual aids as necessary. The results should be presented in a way that is accessible to the intended audience.
Examples of Quantitative Data
Here are some examples of quantitative data:
- Height of a person (measured in inches or centimeters)
- Weight of a person (measured in pounds or kilograms)
- Temperature (measured in Fahrenheit or Celsius)
- Age of a person (measured in years)
- Number of cars sold in a month
- Amount of rainfall in a specific area (measured in inches or millimeters)
- Number of hours worked in a week
- GPA (grade point average) of a student
- Sales figures for a product
- Time taken to complete a task.
- Distance traveled (measured in miles or kilometers)
- Speed of an object (measured in miles per hour or kilometers per hour)
- Number of people attending an event
- Price of a product (measured in dollars or other currency)
- Blood pressure (measured in millimeters of mercury)
- Amount of sugar in a food item (measured in grams)
- Test scores (measured on a numerical scale)
- Number of website visitors per day
- Stock prices (measured in dollars)
- Crime rates (measured by the number of crimes per 100,000 people)
Applications of Quantitative Data
Quantitative data has a wide range of applications across various fields, including:
- Scientific research: Quantitative data is used extensively in scientific research to test hypotheses and draw conclusions. For example, in biology, researchers might use quantitative data to measure the growth rate of cells or the effectiveness of a drug treatment.
- Business and economics: Quantitative data is used to analyze business and economic trends, forecast future performance, and make data-driven decisions. For example, a company might use quantitative data to analyze sales figures and customer demographics to determine which products are most popular among which segments of their customer base.
- Education: Quantitative data is used in education to measure student performance, evaluate teaching methods, and identify areas where improvement is needed. For example, a teacher might use quantitative data to track the progress of their students over the course of a semester and adjust their teaching methods accordingly.
- Public policy: Quantitative data is used in public policy to evaluate the effectiveness of policies and programs, identify areas where improvement is needed, and develop evidence-based solutions. For example, a government agency might use quantitative data to evaluate the impact of a social welfare program on poverty rates.
- Healthcare : Quantitative data is used in healthcare to evaluate the effectiveness of medical treatments, track the spread of diseases, and identify risk factors for various health conditions. For example, a doctor might use quantitative data to monitor the blood pressure levels of their patients over time and adjust their treatment plan accordingly.
Purpose of Quantitative Data
The purpose of quantitative data is to provide a numerical representation of a phenomenon or observation. Quantitative data is used to measure and describe the characteristics of a population or sample, and to test hypotheses and draw conclusions based on statistical analysis. Some of the key purposes of quantitative data include:
- Measuring and describing : Quantitative data is used to measure and describe the characteristics of a population or sample, such as age, income, or education level. This allows researchers to better understand the population they are studying.
- Testing hypotheses: Quantitative data is often used to test hypotheses and theories by collecting numerical data and analyzing it using statistical methods. This can help researchers determine whether there is a statistically significant relationship between variables or whether there is support for a particular theory.
- Making predictions : Quantitative data can be used to make predictions about future events or trends based on past data. This is often done through statistical modeling or time series analysis.
- Evaluating programs and policies: Quantitative data is often used to evaluate the effectiveness of programs and policies. This can help policymakers and program managers identify areas where improvements can be made and make evidence-based decisions about future programs and policies.
When to use Quantitative Data
Quantitative data is appropriate to use when you want to collect and analyze numerical data that can be measured and analyzed using statistical methods. Here are some situations where quantitative data is typically used:
- When you want to measure a characteristic or behavior : If you want to measure something like the height or weight of a population or the number of people who smoke, you would use quantitative data to collect this information.
- When you want to compare groups: If you want to compare two or more groups, such as comparing the effectiveness of two different medical treatments, you would use quantitative data to collect and analyze the data.
- When you want to test a hypothesis : If you have a hypothesis or theory that you want to test, you would use quantitative data to collect data that can be analyzed statistically to determine whether your hypothesis is supported by the data.
- When you want to make predictions: If you want to make predictions about future trends or events, such as predicting sales for a new product, you would use quantitative data to collect and analyze data from past trends to make your prediction.
- When you want to evaluate a program or policy : If you want to evaluate the effectiveness of a program or policy, you would use quantitative data to collect data about the program or policy and analyze it statistically to determine whether it has had the intended effect.
Characteristics of Quantitative Data
Quantitative data is characterized by several key features, including:
- Numerical values : Quantitative data consists of numerical values that can be measured and counted. These values are often expressed in terms of units, such as dollars, centimeters, or kilograms.
- Continuous or discrete : Quantitative data can be either continuous or discrete. Continuous data can take on any value within a certain range, while discrete data can only take on certain values.
- Objective: Quantitative data is objective, meaning that it is not influenced by personal biases or opinions. It is based on empirical evidence that can be measured and analyzed using statistical methods.
- Large sample size: Quantitative data is often collected from a large sample size in order to ensure that the results are statistically significant and representative of the population being studied.
- Statistical analysis: Quantitative data is typically analyzed using statistical methods to determine patterns, relationships, and other characteristics of the data. This allows researchers to make more objective conclusions based on empirical evidence.
- Precision : Quantitative data is often very precise, with measurements taken to multiple decimal points or significant figures. This precision allows for more accurate analysis and interpretation of the data.
Advantages of Quantitative Data
Some advantages of quantitative data are:
- Objectivity : Quantitative data is usually objective because it is based on measurable and observable variables. This means that different people who collect the same data will generally get the same results.
- Precision : Quantitative data provides precise measurements of variables. This means that it is easier to make comparisons and draw conclusions from quantitative data.
- Replicability : Since quantitative data is based on objective measurements, it is often easier to replicate research studies using the same or similar data.
- Generalizability : Quantitative data allows researchers to generalize findings to a larger population. This is because quantitative data is often collected using random sampling methods, which help to ensure that the data is representative of the population being studied.
- Statistical analysis : Quantitative data can be analyzed using statistical methods, which allows researchers to test hypotheses and draw conclusions about the relationships between variables.
- Efficiency : Quantitative data can often be collected quickly and efficiently using surveys or other standardized instruments, which makes it a cost-effective way to gather large amounts of data.
Limitations of Quantitative Data
Some Limitations of Quantitative Data are as follows:
- Limited context: Quantitative data does not provide information about the context in which the data was collected. This can make it difficult to understand the meaning behind the numbers.
- Limited depth: Quantitative data is often limited to predetermined variables and questions, which may not capture the complexity of the phenomenon being studied.
- Difficulty in capturing qualitative aspects: Quantitative data is unable to capture the subjective experiences and qualitative aspects of human behavior, such as emotions, attitudes, and motivations.
- Possibility of bias: The collection and interpretation of quantitative data can be influenced by biases, such as sampling bias, measurement bias, or researcher bias.
- Simplification of complex phenomena: Quantitative data may oversimplify complex phenomena by reducing them to numerical measurements and statistical analyses.
- Lack of flexibility: Quantitative data collection methods may not allow for changes or adaptations in the research process, which can limit the ability to respond to unexpected findings or new insights.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Primary Data – Types, Methods and Examples

Qualitative Data – Types, Methods and Examples

Research Data – Types Methods and Examples

Secondary Data – Types, Methods and Examples

Information in Research – Types and Examples
- Open access
- Published: 19 April 2024
A scoping review of continuous quality improvement in healthcare system: conceptualization, models and tools, barriers and facilitators, and impact
- Aklilu Endalamaw 1 , 2 ,
- Resham B Khatri 1 , 3 ,
- Tesfaye Setegn Mengistu 1 , 2 ,
- Daniel Erku 1 , 4 , 5 ,
- Eskinder Wolka 6 ,
- Anteneh Zewdie 6 &
- Yibeltal Assefa 1
BMC Health Services Research volume 24 , Article number: 487 ( 2024 ) Cite this article
598 Accesses
Metrics details
The growing adoption of continuous quality improvement (CQI) initiatives in healthcare has generated a surge in research interest to gain a deeper understanding of CQI. However, comprehensive evidence regarding the diverse facets of CQI in healthcare has been limited. Our review sought to comprehensively grasp the conceptualization and principles of CQI, explore existing models and tools, analyze barriers and facilitators, and investigate its overall impacts.
This qualitative scoping review was conducted using Arksey and O’Malley’s methodological framework. We searched articles in PubMed, Web of Science, Scopus, and EMBASE databases. In addition, we accessed articles from Google Scholar. We used mixed-method analysis, including qualitative content analysis and quantitative descriptive for quantitative findings to summarize findings and PRISMA extension for scoping reviews (PRISMA-ScR) framework to report the overall works.
A total of 87 articles, which covered 14 CQI models, were included in the review. While 19 tools were used for CQI models and initiatives, Plan-Do-Study/Check-Act cycle was the commonly employed model to understand the CQI implementation process. The main reported purposes of using CQI, as its positive impact, are to improve the structure of the health system (e.g., leadership, health workforce, health technology use, supplies, and costs), enhance healthcare delivery processes and outputs (e.g., care coordination and linkages, satisfaction, accessibility, continuity of care, safety, and efficiency), and improve treatment outcome (reduce morbidity and mortality). The implementation of CQI is not without challenges. There are cultural (i.e., resistance/reluctance to quality-focused culture and fear of blame or punishment), technical, structural (related to organizational structure, processes, and systems), and strategic (inadequate planning and inappropriate goals) related barriers that were commonly reported during the implementation of CQI.
Conclusions
Implementing CQI initiatives necessitates thoroughly comprehending key principles such as teamwork and timeline. To effectively address challenges, it’s crucial to identify obstacles and implement optimal interventions proactively. Healthcare professionals and leaders need to be mentally equipped and cognizant of the significant role CQI initiatives play in achieving purposes for quality of care.
Peer Review reports
Continuous quality improvement (CQI) initiative is a crucial initiative aimed at enhancing quality in the health system that has gradually been adopted in the healthcare industry. In the early 20th century, Shewhart laid the foundation for quality improvement by describing three essential steps for process improvement: specification, production, and inspection [ 1 , 2 ]. Then, Deming expanded Shewhart’s three-step model into ‘plan, do, study/check, and act’ (PDSA or PDCA) cycle, which was applied to management practices in Japan in the 1950s [ 3 ] and was gradually translated into the health system. In 1991, Kuperman applied a CQI approach to healthcare, comprising selecting a process to be improved, assembling a team of expert clinicians that understands the process and the outcomes, determining key steps in the process and expected outcomes, collecting data that measure the key process steps and outcomes, and providing data feedback to the practitioners [ 4 ]. These philosophies have served as the baseline for the foundation of principles for continuous improvement [ 5 ].
Continuous quality improvement fosters a culture of continuous learning, innovation, and improvement. It encourages proactive identification and resolution of problems, promotes employee engagement and empowerment, encourages trust and respect, and aims for better quality of care [ 6 , 7 ]. These characteristics drive the interaction of CQI with other quality improvement projects, such as quality assurance and total quality management [ 8 ]. Quality assurance primarily focuses on identifying deviations or errors through inspections, audits, and formal reviews, often settling for what is considered ‘good enough’, rather than pursuing the highest possible standards [ 9 , 10 ], while total quality management is implemented as the management philosophy and system to improve all aspects of an organization continuously [ 11 ].
Continuous quality improvement has been implemented to provide quality care. However, providing effective healthcare is a complicated and complex task in achieving the desired health outcomes and the overall well-being of individuals and populations. It necessitates tackling issues, including access, patient safety, medical advances, care coordination, patient-centered care, and quality monitoring [ 12 , 13 ], rooted long ago. It is assumed that the history of quality improvement in healthcare started in 1854 when Florence Nightingale introduced quality improvement documentation [ 14 ]. Over the passing decades, Donabedian introduced structure, processes, and outcomes as quality of care components in 1966 [ 15 ]. More comprehensively, the Institute of Medicine in the United States of America (USA) has identified effectiveness, efficiency, equity, patient-centredness, safety, and timeliness as the components of quality of care [ 16 ]. Moreover, quality of care has recently been considered an integral part of universal health coverage (UHC) [ 17 ], which requires initiatives to mobilise essential inputs [ 18 ].
While the overall objective of CQI in health system is to enhance the quality of care, it is important to note that the purposes and principles of CQI can vary across different contexts [ 19 , 20 ]. This variation has sparked growing research interest. For instance, a review of CQI approaches for capacity building addressed its role in health workforce development [ 21 ]. Another systematic review, based on random-controlled design studies, assessed the effectiveness of CQI using training as an intervention and the PDSA model [ 22 ]. As a research gap, the former review was not directly related to the comprehensive elements of quality of care, while the latter focused solely on the impact of training using the PDSA model, among other potential models. Additionally, a review conducted in 2015 aimed to identify barriers and facilitators of CQI in Canadian contexts [ 23 ]. However, all these reviews presented different perspectives and investigated distinct outcomes. This suggests that there is still much to explore in terms of comprehensively understanding the various aspects of CQI initiatives in healthcare.
As a result, we conducted a scoping review to address several aspects of CQI. Scoping reviews serve as a valuable tool for systematically mapping the existing literature on a specific topic. They are instrumental when dealing with heterogeneous or complex bodies of research. Scoping reviews provide a comprehensive overview by summarizing and disseminating findings across multiple studies, even when evidence varies significantly [ 24 ]. In our specific scoping review, we included various types of literature, including systematic reviews, to enhance our understanding of CQI.
This scoping review examined how CQI is conceptualized and measured and investigated models and tools for its application while identifying implementation challenges and facilitators. It also analyzed the purposes and impact of CQI on the health systems, providing valuable insights for enhancing healthcare quality.
Protocol registration and results reporting
Protocol registration for this scoping review was not conducted. Arksey and O’Malley’s methodological framework was utilized to conduct this scoping review [ 25 ]. The scoping review procedures start by defining the research questions, identifying relevant literature, selecting articles, extracting data, and summarizing the results. The review findings are reported using the PRISMA extension for a scoping review (PRISMA-ScR) [ 26 ]. McGowan and colleagues also advised researchers to report findings from scoping reviews using PRISMA-ScR [ 27 ].
Defining the research problems
This review aims to comprehensively explore the conceptualization, models, tools, barriers, facilitators, and impacts of CQI within the healthcare system worldwide. Specifically, we address the following research questions: (1) How has CQI been defined across various contexts? (2) What are the diverse approaches to implementing CQI in healthcare settings? (3) Which tools are commonly employed for CQI implementation ? (4) What barriers hinder and facilitators support successful CQI initiatives? and (5) What effects CQI initiatives have on the overall care quality?
Information source and search strategy
We conducted the search in PubMed, Web of Science, Scopus, and EMBASE databases, and the Google Scholar search engine. The search terms were selected based on three main distinct concepts. One group was CQI-related terms. The second group included terms related to the purpose for which CQI has been implemented, and the third group included processes and impact. These terms were selected based on the Donabedian framework of structure, process, and outcome [ 28 ]. Additionally, the detailed keywords were recruited from the primary health framework, which has described lists of dimensions under process, output, outcome, and health system goals of any intervention for health [ 29 ]. The detailed search strategy is presented in the Supplementary file 1 (Search strategy). The search for articles was initiated on August 12, 2023, and the last search was conducted on September 01, 2023.
Eligibility criteria and article selection
Based on the scoping review’s population, concept, and context frameworks [ 30 ], the population included any patients or clients. Additionally, the concepts explored in the review encompassed definitions, implementation, models, tools, barriers, facilitators, and impacts of CQI. Furthermore, the review considered contexts at any level of health systems. We included articles if they reported results of qualitative or quantitative empirical study, case studies, analytic or descriptive synthesis, any review, and other written documents, were published in peer-reviewed journals, and were designed to address at least one of the identified research questions or one of the identified implementation outcomes or their synonymous taxonomy as described in the search strategy. Based on additional contexts, we included articles published in English without geographic and time limitations. We excluded articles with abstracts only, conference abstracts, letters to editors, commentators, and corrections.
We exported all citations to EndNote x20 to remove duplicates and screen relevant articles. The article selection process includes automatic duplicate removal by using EndNote x20, unmatched title and abstract removal, citation and abstract-only materials removal, and full-text assessment. The article selection process was mainly conducted by the first author (AE) and reported to the team during the weekly meetings. The first author encountered papers that caused confusion regarding whether to include or exclude them and discussed them with the last author (YA). Then, decisions were ultimately made. Whenever disagreements happened, they were resolved by discussion and reconsideration of the review questions in relation to the written documents of the article. Further statistical analysis, such as calculating Kappa, was not performed to determine article inclusion or exclusion.
Data extraction and data items
We extracted first author, publication year, country, settings, health problem, the purpose of the study, study design, types of intervention if applicable, CQI approaches/steps if applicable, CQI tools and procedures if applicable, and main findings using a customized Microsoft Excel form.
Summarizing and reporting the results
The main findings were summarized and described based on the main themes, including concepts under conceptualizing, principles, teams, timelines, models, tools, barriers, facilitators, and impacts of CQI. Results-based convergent synthesis, achieved through mixed-method analysis, involved content analysis to identify the thematic presentation of findings. Additionally, a narrative description was used for quantitative findings, aligning them with the appropriate theme. The authors meticulously reviewed the primary findings from each included material and contextualized these findings concerning the main themes1. This approach provides a comprehensive understanding of complex interventions and health systems, acknowledging quantitative and qualitative evidence.
Search results
A total of 11,251 documents were identified from various databases: SCOPUS ( n = 4,339), PubMed ( n = 2,893), Web of Science ( n = 225), EMBASE ( n = 3,651), and Google Scholar ( n = 143). After removing duplicates ( n = 5,061), 6,190 articles were evaluated by title and abstract. Subsequently, 208 articles were assessed for full-text eligibility. Following the eligibility criteria, 121 articles were excluded, leaving 87 included in the current review (Fig. 1 ).

Article selection process
Operationalizing continuous quality improvement
Continuous Quality Improvement (CQI) is operationalized as a cyclic process that requires commitment to implementation, teamwork, time allocation, and celebrating successes and failures.
CQI is a cyclic ongoing process that is followed reflexive, analytical and iterative steps, including identifying gaps, generating data, developing and implementing action plans, evaluating performance, providing feedback to implementers and leaders, and proposing necessary adjustments [ 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 ].
CQI requires committing to the philosophy, involving continuous improvement [ 19 , 38 ], establishing a mission statement [ 37 ], and understanding quality definition [ 19 ].
CQI involves a wide range of patient-oriented measures and performance indicators, specifically satisfying internal and external customers, developing quality assurance, adopting common quality measures, and selecting process measures [ 8 , 19 , 35 , 36 , 37 , 39 , 40 ].
CQI requires celebrating success and failure without personalization, leading each team member to develop error-free attitudes [ 19 ]. Success and failure are related to underlying organizational processes and systems as causes of failure rather than blaming individuals [ 8 ] because CQI is process-focused based on collaborative, data-driven, responsive, rigorous and problem-solving statistical analysis [ 8 , 19 , 38 ]. Furthermore, a gap or failure opens another opportunity for establishing a data-driven learning organization [ 41 ].
CQI cannot be implemented without a CQI team [ 8 , 19 , 37 , 39 , 42 , 43 , 44 , 45 , 46 ]. A CQI team comprises individuals from various disciplines, often comprising a team leader, a subject matter expert (physician or other healthcare provider), a data analyst, a facilitator, frontline staff, and stakeholders [ 39 , 43 , 47 , 48 , 49 ]. It is also important to note that inviting stakeholders or partners as part of the CQI support intervention is crucial [ 19 , 38 , 48 ].
The timeline is another distinct feature of CQI because the results of CQI vary based on the implementation duration of each cycle [ 35 ]. There is no specific time limit for CQI implementation, although there is a general consensus that a cycle of CQI should be relatively short [ 35 ]. For instance, a CQI implementation took 2 months [ 42 ], 4 months [ 50 ], 9 months [ 51 , 52 ], 12 months [ 53 , 54 , 55 ], and one year and 5 months [ 49 ] duration to achieve the desired positive outcome, while bi-weekly [ 47 ] and monthly data reviews and analyses [ 44 , 48 , 56 ], and activities over 3 months [ 57 ] have also resulted in a positive outcome.
Continuous quality improvement models and tools
There have been several models are utilized. The Plan-Do-Study/Check-Act cycle is a stepwise process involving project initiation, situation analysis, root cause identification, solution generation and selection, implementation, result evaluation, standardization, and future planning [ 7 , 36 , 37 , 45 , 47 , 48 , 49 , 50 , 51 , 53 , 56 , 57 , 58 , 59 , 60 , 61 , 62 , 63 , 64 , 65 , 66 , 67 , 68 , 69 , 70 ]. The FOCUS-PDCA cycle enhances the PDCA process by adding steps to find and improve a process (F), organize a knowledgeable team (O), clarify the process (C), understand variations (U), and select improvements (S) [ 55 , 71 , 72 , 73 ]. The FADE cycle involves identifying a problem (Focus), understanding it through data analysis (Analyze), devising solutions (Develop), and implementing the plan (Execute) [ 74 ]. The Logic Framework involves brainstorming to identify improvement areas, conducting root cause analysis to develop a problem tree, logically reasoning to create an objective tree, formulating the framework, and executing improvement projects [ 75 ]. Breakthrough series approach requires CQI teams to meet in quarterly collaborative learning sessions, share learning experiences, and continue discussion by telephone and cross-site visits to strengthen learning and idea exchange [ 47 ]. Another CQI model is the Lean approach, which has been conducted with Kaizen principles [ 52 ], 5 S principles, and the Six Sigma model. The 5 S (Sort, Set/Straighten, Shine, Standardize, Sustain) systematically organises and improves the workplace, focusing on sorting, setting order, shining, standardizing, and sustaining the improvement [ 54 , 76 ]. Kaizen principles guide CQI by advocating for continuous improvement, valuing all ideas, solving problems, focusing on practical, low-cost improvements, using data to drive change, acknowledging process defects, reducing variability and waste, recognizing every interaction as a customer-supplier relationship, empowering workers, responding to all ideas, and maintaining a disciplined workplace [ 77 ]. Lean Six Sigma, a CQI model, applies the DMAIC methodology, which involves defining (D) and measuring the problem (M), analyzing root causes (A), improving by finding solutions (I), and controlling by assessing process stability (C) [ 78 , 79 ]. The 5 C-cyclic model (consultation, collection, consideration, collaboration, and celebration), the first CQI framework for volunteer dental services in Aboriginal communities, ensures quality care based on community needs [ 80 ]. One study used meetings involving activities such as reviewing objectives, assigning roles, discussing the agenda, completing tasks, retaining key outputs, planning future steps, and evaluating the meeting’s effectiveness [ 81 ].
Various tools are involved in the implementation or evaluation of CQI initiatives: checklists [ 53 , 82 ], flowcharts [ 81 , 82 , 83 ], cause-and-effect diagrams (fishbone or Ishikawa diagrams) [ 60 , 62 , 79 , 81 , 82 ], fuzzy Pareto diagram [ 82 ], process maps [ 60 ], time series charts [ 48 ], why-why analysis [ 79 ], affinity diagrams and multivoting [ 81 ], and run chart [ 47 , 48 , 51 , 60 , 84 ], and others mentioned in the table (Table 1 ).
Barriers and facilitators of continuous quality improvement implementation
Implementing CQI initiatives is determined by various barriers and facilitators, which can be thematized into four dimensions. These dimensions are cultural, technical, structural, and strategic dimensions.
Continuous quality improvement initiatives face various cultural, strategic, technical, and structural barriers. Cultural dimension barriers involve resistance to change (e.g., not accepting online technology), lack of quality-focused culture, staff reporting apprehensiveness, and fear of blame or punishment [ 36 , 41 , 85 , 86 ]. The technical dimension barriers of CQI can include various factors that hinder the effective implementation and execution of CQI processes [ 36 , 86 , 87 , 88 , 89 ]. Structural dimension barriers of CQI arise from the organization structure, process, and systems that can impede the effective implementation and sustainability of CQI [ 36 , 85 , 86 , 87 , 88 ]. Strategic dimension barriers are, for example, the inability to select proper CQI goals and failure to integrate CQI into organizational planning and goals [ 36 , 85 , 86 , 87 , 88 , 90 ].
Facilitators are also grouped to cultural, structural, technical, and strategic dimensions to provide solutions to CQI barriers. Cultural challenges were addressed by developing a group culture to CQI and other rewards [ 39 , 41 , 80 , 85 , 86 , 87 , 90 , 91 , 92 ]. Technical facilitators are pivotal to improving technical barriers [ 39 , 42 , 53 , 69 , 86 , 90 , 91 ]. Structural-related facilitators are related to improving communication, infrastructure, and systems [ 86 , 92 , 93 ]. Strategic dimension facilitators include strengthening leadership and improving decision-making skills [ 43 , 53 , 67 , 86 , 87 , 92 , 94 , 95 ] (Table 2 ).
Impact of continuous quality improvement
Continuous quality improvement initiatives can significantly impact the quality of healthcare in a wide range of health areas, focusing on improving structure, the health service delivery process and improving client wellbeing and reducing mortality.
Structure components
These are health leadership, financing, workforce, technology, and equipment and supplies. CQI has improved planning, monitoring and evaluation [ 48 , 53 ], and leadership and planning [ 48 ], indicating improvement in leadership perspectives. Implementing CQI in primary health care (PHC) settings has shown potential for maintaining or reducing operation costs [ 67 ]. Findings from another study indicate that the costs associated with implementing CQI interventions per facility ranged from approximately $2,000 to $10,500 per year, with an average cost of approximately $10 to $60 per admitted client [ 57 ]. However, based on model predictions, the average cost savings after implementing CQI were estimated to be $5430 [ 31 ]. CQI can also be applied to health workforce development [ 32 ]. CQI in the institutional system improved medical education [ 66 , 96 , 97 ], human resources management [ 53 ], motivated staffs [ 76 ], and increased staff health awareness [ 69 ], while concerns raised about CQI impartiality, independence, and public accountability [ 96 ]. Regarding health technology, CQI also improved registration and documentation [ 48 , 53 , 98 ]. Furthermore, the CQI initiatives increased cleanliness [ 54 ] and improved logistics, supplies, and equipment [ 48 , 53 , 68 ].
Process and output components
The process component focuses on the activities and actions involved in delivering healthcare services.
Service delivery
CQI interventions improved service delivery [ 53 , 56 , 99 ], particularly a significant 18% increase in the overall quality of service performance [ 48 ], improved patient counselling, adherence to appropriate procedures, and infection prevention [ 48 , 68 ], and optimised workflow [ 52 ].
Coordination and collaboration
CQI initiatives improved coordination and collaboration through collecting and analysing data, onsite technical support, training, supportive supervision [ 53 ] and facilitating linkages between work processes and a quality control group [ 65 ].
Patient satisfaction
The CQI initiatives increased patient satisfaction and improved quality of life by optimizing care quality management, improving the quality of clinical nursing, reducing nursing defects and enhancing the wellbeing of clients [ 54 , 76 , 100 ], although CQI was not associated with changes in adolescent and young adults’ satisfaction [ 51 ].
CQI initiatives reduced medication error reports from 16 to 6 [ 101 ], and it significantly reduced the administration of inappropriate prophylactic antibiotics [ 44 ], decreased errors in inpatient care [ 52 ], decreased the overall episiotomy rate from 44.5 to 33.3% [ 83 ], reduced the overall incidence of unplanned endotracheal extubation [ 102 ], improving appropriate use of computed tomography angiography [ 103 ], and appropriate diagnosis and treatment selection [ 47 ].
Continuity of care
CQI initiatives effectively improve continuity of care by improving client and physician interaction. For instance, provider continuity levels showed a 64% increase [ 55 ]. Modifying electronic medical record templates, scheduling, staff and parental education, standardization of work processes, and birth to 1-year age-specific incentives in post-natal follow-up care increased continuity of care to 74% in 2018 compared to baseline 13% in 2012 [ 84 ].
The CQI initiative yielded enhanced efficiency in the cardiac catheterization laboratory, as evidenced by improved punctuality in procedure starts and increased efficiency in manual sheath-pulls inside [ 78 ].
Accessibility
CQI initiatives were effective in improving accessibility in terms of increasing service coverage and utilization rate. For instance, screening for cigarettes, nutrition counselling, folate prescription, maternal care, immunization coverage [ 53 , 81 , 104 , 105 ], reducing the percentage of non-attending patients to surgery to 0.9% from the baseline 3.9% [ 43 ], increasing Chlamydia screening rates from 29 to 60% [ 45 ], increasing HIV care continuum coverage [ 51 , 59 , 60 ], increasing in the uptake of postpartum long-acting reversible contraceptive use from 6.9% at the baseline to 25.4% [ 42 ], increasing post-caesarean section prophylaxis from 36 to 89% [ 62 ], a 31% increase of kangaroo care practice [ 50 ], and increased follow-up [ 65 ]. Similarly, the QI intervention increased the quality of antenatal care by 29.3%, correct partograph use by 51.7%, and correct active third-stage labour management, a 19.6% improvement from the baseline, but not significantly associated with improvement in contraceptive service uptake [ 61 ].
Timely access
CQI interventions improved the time care provision [ 52 ], and reduced waiting time [ 62 , 74 , 76 , 106 ]. For instance, the discharge process waiting time in the emergency department decreased from 76 min to 22 min [ 79 ]. It also reduced mean postprocedural length of stay from 2.8 days to 2.0 days [ 31 ].
Acceptability
Acceptability of CQI by healthcare providers was satisfactory. For instance, 88% of the faculty, 64% of the residents, and 82% of the staff believed CQI to be useful in the healthcare clinic [ 107 ].
Outcome components
Morbidity and mortality.
CQI efforts have demonstrated better management outcomes among diabetic patients [ 40 ], patients with oral mucositis [ 71 ], and anaemic patients [ 72 ]. It has also reduced infection rate in post-caesarean Sect. [ 62 ], reduced post-peritoneal dialysis peritonitis [ 49 , 108 ], and prevented pressure ulcers [ 70 ]. It is explained by peritonitis incidence from once every 40.1 patient months at baseline to once every 70.8 patient months after CQI [ 49 ] and a 63% reduction in pressure ulcer prevalence within 2 years from 2008 to 2010 [ 70 ]. Furthermore, CQI initiatives significantly reduced in-hospital deaths [ 31 ] and increased patient survival rates [ 108 ]. Figure 2 displays the overall process of the CQI implementations.

The overall mechanisms of continuous quality improvement implementation
In this review, we examined the fundamental concepts and principles underlying CQI, the factors that either hinder or assist in its successful application and implementation, and the purpose of CQI in enhancing quality of care across various health issues.
Our findings have brought attention to the application and implementation of CQI, emphasizing its underlying concepts and principles, as evident in the existing literature [ 31 , 32 , 33 , 34 , 35 , 36 , 39 , 40 , 43 , 45 , 46 ]. Continuous quality improvement has shared with the principles of continuous improvement, such as a customer-driven focus, effective leadership, active participation of individuals, a process-oriented approach, systematic implementation, emphasis on design improvement and prevention, evidence-based decision-making, and fostering partnership [ 5 ]. Moreover, Deming’s 14 principles laid the foundation for CQI principles [ 109 ]. These principles have been adapted and put into practice in various ways: ten [ 19 ] and five [ 38 ] principles in hospitals, five principles for capacity building [ 38 ], and two principles for medication error prevention [ 41 ]. As a principle, the application of CQI can be process-focused [ 8 , 19 ] or impact-focused [ 38 ]. Impact-focused CQI focuses on achieving specific outcomes or impacts, whereas process-focused CQI prioritizes and improves the underlying processes and systems. These principles complement each other and can be utilized based on the objectives of quality improvement initiatives in healthcare settings. Overall, CQI is an ongoing educational process that requires top management’s involvement, demands coordination across departments, encourages the incorporation of views beyond clinical area, and provides non-judgemental evidence based on objective data [ 110 ].
The current review recognized that it was not easy to implement CQI. It requires reasonable utilization of various models and tools. The application of each tool can be varied based on the studied health problem and the purpose of CQI initiative [ 111 ], varied in context, content, structure, and usability [ 112 ]. Additionally, overcoming the cultural, technical, structural, and strategic-related barriers. These barriers have emerged from clinical staff, managers, and health systems perspectives. Of the cultural obstacles, staff non-involvement, resistance to change, and reluctance to report error were staff-related. In contrast, others, such as the absence of celebration for success and hierarchical and rational culture, may require staff and manager involvement. Staff members may exhibit reluctance in reporting errors due to various cultural factors, including lack of trust, hierarchical structures, fear of retribution, and a blame-oriented culture. These challenges pose obstacles to implementing standardized CQI practices, as observed, for instance, in community pharmacy settings [ 85 ]. The hierarchical culture, characterized by clearly defined levels of power, authority, and decision-making, posed challenges to implementing CQI initiatives in public health [ 41 , 86 ]. Although rational culture, a type of organizational culture, emphasizes logical thinking and rational decision-making, it can also create challenges for CQI implementation [ 41 , 86 ] because hierarchical and rational cultures, which emphasize bureaucratic norms and narrow definitions of achievement, were found to act as barriers to the implementation of CQI [ 86 ]. These could be solved by developing a shared mindset and collective commitment, establishing a shared purpose, developing group norms, and cultivating psychological preparedness among staff, managers, and clients to implement and sustain CQI initiatives. Furthermore, reversing cultural-related barriers necessitates cultural-related solutions: development of a culture and group culture to CQI [ 41 , 86 ], positive comprehensive perception [ 91 ], commitment [ 85 ], involving patients, families, leaders, and staff [ 39 , 92 ], collaborating for a common goal [ 80 , 86 ], effective teamwork [ 86 , 87 ], and rewarding and celebrating successes [ 80 , 90 ].
The technical dimension barriers of CQI can include inadequate capitalization of a project and insufficient support for CQI facilitators and data entry managers [ 36 ], immature electronic medical records or poor information systems [ 36 , 86 ], and the lack of training and skills [ 86 , 87 , 88 ]. These challenges may cause the CQI team to rely on outdated information and technologies. The presence of barriers on the technical dimension may challenge the solid foundation of CQI expertise among staff, the ability to recognize opportunities for improvement, a comprehensive understanding of how services are produced and delivered, and routine use of expertise in daily work. Addressing these technical barriers requires knowledge creation activities (training, seminar, and education) [ 39 , 42 , 53 , 69 , 86 , 90 , 91 ], availability of quality data [ 86 ], reliable information [ 92 ], and a manual-online hybrid reporting system [ 85 ].
Structural dimension barriers of CQI include inadequate communication channels and lack of standardized process, specifically weak physician-to-physician synergies [ 36 ], lack of mechanisms for disseminating knowledge and limited use of communication mechanisms [ 86 ]. Lack of communication mechanism endangers sharing ideas and feedback among CQI teams, leading to misunderstandings, limited participation and misinterpretations, and a lack of learning [ 113 ]. Knowledge translation facilitates the co-production of research, subsequent diffusion of knowledge, and the developing stakeholder’s capacity and skills [ 114 ]. Thus, the absence of a knowledge translation mechanism may cause missed opportunities for learning, inefficient problem-solving, and limited creativity. To overcome these challenges, organizations should establish effective communication and information systems [ 86 , 93 ] and learning systems [ 92 ]. Though CQI and knowledge translation have interacted with each other, it is essential to recognize that they are distinct. CQI focuses on process improvement within health care systems, aiming to optimize existing processes, reduce errors, and enhance efficiency.
In contrast, knowledge translation bridges the gap between research evidence and clinical practice, translating research findings into actionable knowledge for practitioners. While both CQI and knowledge translation aim to enhance health care quality and patient outcomes, they employ different strategies: CQI utilizes tools like Plan-Do-Study-Act cycles and statistical process control, while knowledge translation involves knowledge synthesis and dissemination. Additionally, knowledge translation can also serve as a strategy to enhance CQI. Both concepts share the same principle: continuous improvement is essential for both. Therefore, effective strategies on the structural dimension may build efficient and effective steering councils, information systems, and structures to diffuse learning throughout the organization.
Strategic factors, such as goals, planning, funds, and resources, determine the overall purpose of CQI initiatives. Specific barriers were improper goals and poor planning [ 36 , 86 , 88 ], fragmentation of quality assurance policies [ 87 ], inadequate reinforcement to staff [ 36 , 90 ], time constraints [ 85 , 86 ], resource inadequacy [ 86 ], and work overload [ 86 ]. These barriers can be addressed through strengthening leadership [ 86 , 87 ], CQI-based mentoring [ 94 ], periodic monitoring, supportive supervision and coaching [ 43 , 53 , 87 , 92 , 95 ], participation, empowerment, and accountability [ 67 ], involving all stakeholders in decision-making [ 86 , 87 ], a provider-payer partnership [ 64 ], and compensating staff for after-hours meetings on CQI [ 85 ]. The strategic dimension, characterized by a strategic plan and integrated CQI efforts, is devoted to processes that are central to achieving strategic priorities. Roles and responsibilities are defined in terms of integrated strategic and quality-related goals [ 115 ].
The utmost goal of CQI has been to improve the quality of care, which is usually revealed by structure, process, and outcome. After resolving challenges and effectively using tools and running models, the goal of CQI reflects the ultimate reason and purpose of its implementation. First, effectively implemented CQI initiatives can improve leadership, health financing, health workforce development, health information technology, and availability of supplies as the building blocks of a health system [ 31 , 48 , 53 , 68 , 98 ]. Second, effectively implemented CQI initiatives improved care delivery process (counselling, adherence with standards, coordination, collaboration, and linkages) [ 48 , 53 , 65 , 68 ]. Third, the CQI can improve outputs of healthcare delivery, such as satisfaction, accessibility (timely access, utilization), continuity of care, safety, efficiency, and acceptability [ 52 , 54 , 55 , 76 , 78 ]. Finally, the effectiveness of the CQI initiatives has been tested in enhancing responses related to key aspects of the HIV response, maternal and child health, non-communicable disease control, and others (e.g., surgery and peritonitis). However, it is worth noting that CQI initiative has not always been effective. For instance, CQI using a two- to nine-times audit cycle model through systems assessment tools did not bring significant change to increase syphilis testing performance [ 116 ]. This study was conducted within the context of Aboriginal and Torres Strait Islander people’s primary health care settings. Notably, ‘the clinics may not have consistently prioritized syphilis testing performance in their improvement strategies, as facilitated by the CQI program’ [ 116 ]. Additionally, by applying CQI-based mentoring, uptake of facility-based interventions was not significantly improved, though it was effective in increasing community health worker visits during pregnancy and the postnatal period, knowledge about maternal and child health and exclusive breastfeeding practice, and HIV disclosure status [ 117 ]. The study conducted in South Africa revealed no significant association between the coverage of facility-based interventions and Continuous Quality Improvement (CQI) implementation. This lack of association was attributed to the already high antenatal and postnatal attendance rates in both control and intervention groups at baseline, leaving little room for improvement. Additionally, the coverage of HIV interventions remained consistently high throughout the study period [ 117 ].
Regarding health care and policy implications, CQI has played a vital role in advancing PHC and fostering the realization of UHC goals worldwide. The indicators found in Donabedian’s framework that are positively influenced by CQI efforts are comparable to those included in the PHC performance initiative’s conceptual framework [ 29 , 118 , 119 ]. It is clearly explained that PHC serves as the roadmap to realizing the vision of UHC [ 120 , 121 ]. Given these circumstances, implementing CQI can contribute to the achievement of PHC principles and the objectives of UHC. For instance, by implementing CQI methods, countries have enhanced the accessibility, affordability, and quality of PHC services, leading to better health outcomes for their populations. CQI has facilitated identifying and resolving healthcare gaps and inefficiencies, enabling countries to optimize resource allocation and deliver more effective and patient-centered care. However, it is crucial to recognize that the successful implementation of Continuous Quality Improvement (CQI) necessitates optimizing the duration of each cycle, understanding challenges and barriers that extend beyond the health system and settings, and acknowledging that its effectiveness may be compromised if these challenges are not adequately addressed.
Despite abundant literature, there are still gaps regarding the relationship between CQI and other dimensions within the healthcare system. No studies have examined the impact of CQI initiatives on catastrophic health expenditure, effective service coverage, patient-centredness, comprehensiveness, equity, health security, and responsiveness.
Limitations
In conducting this review, it has some limitations to consider. Firstly, only articles published in English were included, which may introduce the exclusion of relevant non-English articles. Additionally, as this review follows a scoping methodology, the focus is on synthesising available evidence rather than critically evaluating or scoring the quality of the included articles.
Continuous quality improvement is investigated as a continuous and ongoing intervention, where the implementation time can vary across different cycles. The CQI team and implementation timelines were critical elements of CQI in different models. Among the commonly used approaches, the PDSA or PDCA is frequently employed. In most CQI models, a wide range of tools, nineteen tools, are commonly utilized to support the improvement process. Cultural, technical, structural, and strategic barriers and facilitators are significant in implementing CQI initiatives. Implementing the CQI initiative aims to improve health system blocks, enhance health service delivery process and output, and ultimately prevent morbidity and reduce mortality. For future researchers, considering that CQI is context-dependent approach, conducting scale-up implementation research about catastrophic health expenditure, effective service coverage, patient-centredness, comprehensiveness, equity, health security, and responsiveness across various settings and health issues would be valuable.
Availability of data and materials
The data used and/or analyzed during the current study are available in this manuscript and/or the supplementary file.
Shewhart WA, Deming WE. Memoriam: Walter A. Shewhart, 1891–1967. Am Stat. 1967;21(2):39–40.
Article Google Scholar
Shewhart WA. Statistical method from the viewpoint of quality control. New York: Dover; 1986. ISBN 978-0486652320. OCLC 13822053. Reprint. Originally published: Washington, DC: Graduate School of the Department of Agriculture, 1939.
Moen R, editor Foundation and History of the PDSA Cycle. Asian network for quality conference Tokyo. https://www.deming.org/sites/default/files/pdf/2015/PDSA_History_Ron_MoenPdf . 2009.
Kuperman G, James B, Jacobsen J, Gardner RM. Continuous quality improvement applied to medical care: experiences at LDS hospital. Med Decis Making. 1991;11(4suppl):S60–65.
Article CAS PubMed Google Scholar
Singh J, Singh H. Continuous improvement philosophy–literature review and directions. Benchmarking: An International Journal. 2015;22(1):75–119.
Goldstone J. Presidential address: Sony, Porsche, and vascular surgery in the 21st century. J Vasc Surg. 1997;25(2):201–10.
Radawski D. Continuous quality improvement: origins, concepts, problems, and applications. J Physician Assistant Educ. 1999;10(1):12–6.
Shortell SM, O’Brien JL, Carman JM, Foster RW, Hughes E, Boerstler H, et al. Assessing the impact of continuous quality improvement/total quality management: concept versus implementation. Health Serv Res. 1995;30(2):377.
CAS PubMed PubMed Central Google Scholar
Lohr K. Quality of health care: an introduction to critical definitions, concepts, principles, and practicalities. Striving for quality in health care. 1991.
Berwick DM. The clinical process and the quality process. Qual Manage Healthc. 1992;1(1):1–8.
Article CAS Google Scholar
Gift B. On the road to TQM. Food Manage. 1992;27(4):88–9.
CAS PubMed Google Scholar
Greiner A, Knebel E. The core competencies needed for health care professionals. health professions education: A bridge to quality. 2003:45–73.
McCalman J, Bailie R, Bainbridge R, McPhail-Bell K, Percival N, Askew D et al. Continuous quality improvement and comprehensive primary health care: a systems framework to improve service quality and health outcomes. Front Public Health. 2018:6 (76):1–6.
Sheingold BH, Hahn JA. The history of healthcare quality: the first 100 years 1860–1960. Int J Afr Nurs Sci. 2014;1:18–22.
Google Scholar
Donabedian A. Evaluating the quality of medical care. Milbank Q. 1966;44(3):166–206.
Institute of Medicine (US) Committee on Quality of Health Care in America. Crossing the Quality Chasm: A New Health System for the 21st Century. Washington (DC): National Academies Press (US). 2001. 2, Improving the 21st-century Health Care System. Available from: https://www.ncbi.nlm.nih.gov/books/NBK222265/ .
Rubinstein A, Barani M, Lopez AS. Quality first for effective universal health coverage in low-income and middle-income countries. Lancet Global Health. 2018;6(11):e1142–1143.
Article PubMed Google Scholar
Agency for Healthcare Reserach and Quality. Quality Improvement and monitoring at your fingertips USA,: Agency for Healthcare Reserach and Quality. 2022. Available from: https://qualityindicators.ahrq.gov/ .
Anderson CA, Cassidy B, Rivenburgh P. Implementing continuous quality improvement (CQI) in hospitals: lessons learned from the International Quality Study. Qual Assur Health Care. 1991;3(3):141–6.
Gardner K, Mazza D. Quality in general practice - definitions and frameworks. Aust Fam Physician. 2012;41(3):151–4.
PubMed Google Scholar
Loper AC, Jensen TM, Farley AB, Morgan JD, Metz AJ. A systematic review of approaches for continuous quality improvement capacity-building. J Public Health Manage Pract. 2022;28(2):E354.
Hill JE, Stephani A-M, Sapple P, Clegg AJ. The effectiveness of continuous quality improvement for developing professional practice and improving health care outcomes: a systematic review. Implement Sci. 2020;15(1):1–14.
Candas B, Jobin G, Dubé C, Tousignant M, Abdeljelil AB, Grenier S, et al. Barriers and facilitators to implementing continuous quality improvement programs in colonoscopy services: a mixed methods systematic review. Endoscopy Int Open. 2016;4(02):E118–133.
Peters MD, Marnie C, Colquhoun H, Garritty CM, Hempel S, Horsley T, et al. Scoping reviews: reinforcing and advancing the methodology and application. Syst Reviews. 2021;10(1):1–6.
Arksey H, O’Malley L. Scoping studies: towards a methodological framework. Int J Soc Res Methodol. 2005;8(1):19–32.
Tricco AC, Lillie E, Zarin W, O’Brien KK, Colquhoun H, Levac D, et al. PRISMA extension for scoping reviews (PRISMA-ScR): checklist and explanation. Ann Intern Med. 2018;169(7):467–73.
McGowan J, Straus S, Moher D, Langlois EV, O’Brien KK, Horsley T, et al. Reporting scoping reviews—PRISMA ScR extension. J Clin Epidemiol. 2020;123:177–9.
Donabedian A. Explorations in quality assessment and monitoring: the definition of quality and approaches to its assessment. Health Administration Press, Ann Arbor. 1980;1.
World Health Organization. Operational framework for primary health care: transforming vision into action. Geneva: World Health Organization and the United Nations Children’s Fund (UNICEF); 2020 [updated 14 December 2020; cited 2023 Nov Oct 17]. Available from: https://www.who.int/publications/i/item/9789240017832 .
The Joanna Briggs Institute. The Joanna Briggs Institute Reviewers’ Manual :2014 edition. Australia: The Joanna Briggs Institute. 2014:88–91.
Rihal CS, Kamath CC, Holmes DR Jr, Reller MK, Anderson SS, McMurtry EK, et al. Economic and clinical outcomes of a physician-led continuous quality improvement intervention in the delivery of percutaneous coronary intervention. Am J Manag Care. 2006;12(8):445–52.
Ade-Oshifogun JB, Dufelmeier T. Prevention and Management of Do not return notices: a quality improvement process for Supplemental staffing nursing agencies. Nurs Forum. 2012;47(2):106–12.
Rubenstein L, Khodyakov D, Hempel S, Danz M, Salem-Schatz S, Foy R, et al. How can we recognize continuous quality improvement? Int J Qual Health Care. 2014;26(1):6–15.
O’Neill SM, Hempel S, Lim YW, Danz MS, Foy R, Suttorp MJ, et al. Identifying continuous quality improvement publications: what makes an improvement intervention ‘CQI’? BMJ Qual Saf. 2011;20(12):1011–9.
Article PubMed PubMed Central Google Scholar
Sibthorpe B, Gardner K, McAullay D. Furthering the quality agenda in Aboriginal community controlled health services: understanding the relationship between accreditation, continuous quality improvement and national key performance indicator reporting. Aust J Prim Health. 2016;22(4):270–5.
Bennett CL, Crane JM. Quality improvement efforts in oncology: are we ready to begin? Cancer Invest. 2001;19(1):86–95.
VanValkenburgh DA. Implementing continuous quality improvement at the facility level. Adv Ren Replace Ther. 2001;8(2):104–13.
Loper AC, Jensen TM, Farley AB, Morgan JD, Metz AJ. A systematic review of approaches for continuous quality improvement capacity-building. J Public Health Manage Practice. 2022;28(2):E354–361.
Ryan M. Achieving and sustaining quality in healthcare. Front Health Serv Manag. 2004;20(3):3–11.
Nicolucci A, Allotta G, Allegra G, Cordaro G, D’Agati F, Di Benedetto A, et al. Five-year impact of a continuous quality improvement effort implemented by a network of diabetes outpatient clinics. Diabetes Care. 2008;31(1):57–62.
Wakefield BJ, Blegen MA, Uden-Holman T, Vaughn T, Chrischilles E, Wakefield DS. Organizational culture, continuous quality improvement, and medication administration error reporting. Am J Med Qual. 2001;16(4):128–34.
Sori DA, Debelew GT, Degefa LS, Asefa Z. Continuous quality improvement strategy for increasing immediate postpartum long-acting reversible contraceptive use at Jimma University Medical Center, Jimma, Ethiopia. BMJ Open Qual. 2023;12(1):e002051.
Roche B, Robin C, Deleaval PJ, Marti MC. Continuous quality improvement in ambulatory surgery: the non-attending patient. Ambul Surg. 1998;6(2):97–100.
O’Connor JB, Sondhi SS, Mullen KD, McCullough AJ. A continuous quality improvement initiative reduces inappropriate prescribing of prophylactic antibiotics for endoscopic procedures. Am J Gastroenterol. 1999;94(8):2115–21.
Ursu A, Greenberg G, McKee M. Continuous quality improvement methodology: a case study on multidisciplinary collaboration to improve chlamydia screening. Fam Med Community Health. 2019;7(2):e000085.
Quick B, Nordstrom S, Johnson K. Using continuous quality improvement to implement evidence-based medicine. Lippincotts Case Manag. 2006;11(6):305–15 ( quiz 16 – 7 ).
Oyeledun B, Phillips A, Oronsaye F, Alo OD, Shaffer N, Osibo B, et al. The effect of a continuous quality improvement intervention on retention-in-care at 6 months postpartum in a PMTCT Program in Northern Nigeria: results of a cluster randomized controlled study. J Acquir Immune Defic Syndr. 2017;75(Suppl 2):S156–164.
Nyengerai T, Phohole M, Iqaba N, Kinge CW, Gori E, Moyo K, et al. Quality of service and continuous quality improvement in voluntary medical male circumcision programme across four provinces in South Africa: longitudinal and cross-sectional programme data. PLoS ONE. 2021;16(8):e0254850.
Article CAS PubMed PubMed Central Google Scholar
Wang J, Zhang H, Liu J, Zhang K, Yi B, Liu Y, et al. Implementation of a continuous quality improvement program reduces the occurrence of peritonitis in PD. Ren Fail. 2014;36(7):1029–32.
Stikes R, Barbier D. Applying the plan-do-study-act model to increase the use of kangaroo care. J Nurs Manag. 2013;21(1):70–8.
Wagner AD, Mugo C, Bluemer-Miroite S, Mutiti PM, Wamalwa DC, Bukusi D, et al. Continuous quality improvement intervention for adolescent and young adult HIV testing services in Kenya improves HIV knowledge. AIDS. 2017;31(Suppl 3):S243–252.
Le RD, Melanson SE, Santos KS, Paredes JD, Baum JM, Goonan EM, et al. Using lean principles to optimise inpatient phlebotomy services. J Clin Pathol. 2014;67(8):724–30.
Manyazewal T, Mekonnen A, Demelew T, Mengestu S, Abdu Y, Mammo D, et al. Improving immunization capacity in Ethiopia through continuous quality improvement interventions: a prospective quasi-experimental study. Infect Dis Poverty. 2018;7:7.
Kamiya Y, Ishijma H, Hagiwara A, Takahashi S, Ngonyani HAM, Samky E. Evaluating the impact of continuous quality improvement methods at hospitals in Tanzania: a cluster-randomized trial. Int J Qual Health Care. 2017;29(1):32–9.
Kibbe DC, Bentz E, McLaughlin CP. Continuous quality improvement for continuity of care. J Fam Pract. 1993;36(3):304–8.
Adrawa N, Ongiro S, Lotee K, Seret J, Adeke M, Izudi J. Use of a context-specific package to increase sputum smear monitoring among people with pulmonary tuberculosis in Uganda: a quality improvement study. BMJ Open Qual. 2023;12(3):1–6.
Hunt P, Hunter SB, Levan D. Continuous quality improvement in substance abuse treatment facilities: how much does it cost? J Subst Abuse Treat. 2017;77:133–40.
Azadeh A, Ameli M, Alisoltani N, Motevali Haghighi S. A unique fuzzy multi-control approach for continuous quality improvement in a radio therapy department. Qual Quantity. 2016;50(6):2469–93.
Memiah P, Tlale J, Shimabale M, Nzyoka S, Komba P, Sebeza J, et al. Continuous quality improvement (CQI) institutionalization to reach 95:95:95 HIV targets: a multicountry experience from the Global South. BMC Health Serv Res. 2021;21(1):711.
Yapa HM, De Neve JW, Chetty T, Herbst C, Post FA, Jiamsakul A, et al. The impact of continuous quality improvement on coverage of antenatal HIV care tests in rural South Africa: results of a stepped-wedge cluster-randomised controlled implementation trial. PLoS Med. 2020;17(10):e1003150.
Dadi TL, Abebo TA, Yeshitla A, Abera Y, Tadesse D, Tsegaye S, et al. Impact of quality improvement interventions on facility readiness, quality and uptake of maternal and child health services in developing regions of Ethiopia: a secondary analysis of programme data. BMJ Open Qual. 2023;12(4):e002140.
Weinberg M, Fuentes JM, Ruiz AI, Lozano FW, Angel E, Gaitan H, et al. Reducing infections among women undergoing cesarean section in Colombia by means of continuous quality improvement methods. Arch Intern Med. 2001;161(19):2357–65.
Andreoni V, Bilak Y, Bukumira M, Halfer D, Lynch-Stapleton P, Perez C. Project management: putting continuous quality improvement theory into practice. J Nurs Care Qual. 1995;9(3):29–37.
Balfour ME, Zinn TE, Cason K, Fox J, Morales M, Berdeja C, et al. Provider-payer partnerships as an engine for continuous quality improvement. Psychiatric Serv. 2018;69(6):623–5.
Agurto I, Sandoval J, De La Rosa M, Guardado ME. Improving cervical cancer prevention in a developing country. Int J Qual Health Care. 2006;18(2):81–6.
Anderson CI, Basson MD, Ali M, Davis AT, Osmer RL, McLeod MK, et al. Comprehensive multicenter graduate surgical education initiative incorporating entrustable professional activities, continuous quality improvement cycles, and a web-based platform to enhance teaching and learning. J Am Coll Surg. 2018;227(1):64–76.
Benjamin S, Seaman M. Applying continuous quality improvement and human performance technology to primary health care in Bahrain. Health Care Superv. 1998;17(1):62–71.
Byabagambi J, Marks P, Megere H, Karamagi E, Byakika S, Opio A, et al. Improving the quality of voluntary medical male circumcision through use of the continuous quality improvement approach: a pilot in 30 PEPFAR-Supported sites in Uganda. PLoS ONE. 2015;10(7):e0133369.
Hogg S, Roe Y, Mills R. Implementing evidence-based continuous quality improvement strategies in an urban Aboriginal Community Controlled Health Service in South East Queensland: a best practice implementation pilot. JBI Database Syst Rev Implement Rep. 2017;15(1):178–87.
Hopper MB, Morgan S. Continuous quality improvement initiative for pressure ulcer prevention. J Wound Ostomy Cont Nurs. 2014;41(2):178–80.
Ji J, Jiang DD, Xu Z, Yang YQ, Qian KY, Zhang MX. Continuous quality improvement of nutrition management during radiotherapy in patients with nasopharyngeal carcinoma. Nurs Open. 2021;8(6):3261–70.
Chen M, Deng JH, Zhou FD, Wang M, Wang HY. Improving the management of anemia in hemodialysis patients by implementing the continuous quality improvement program. Blood Purif. 2006;24(3):282–6.
Reeves S, Matney K, Crane V. Continuous quality improvement as an ideal in hospital practice. Health Care Superv. 1995;13(4):1–12.
Barton AJ, Danek G, Johns P, Coons M. Improving patient outcomes through CQI: vascular access planning. J Nurs Care Qual. 1998;13(2):77–85.
Buttigieg SC, Gauci D, Dey P. Continuous quality improvement in a Maltese hospital using logical framework analysis. J Health Organ Manag. 2016;30(7):1026–46.
Take N, Byakika S, Tasei H, Yoshikawa T. The effect of 5S-continuous quality improvement-total quality management approach on staff motivation, patients’ waiting time and patient satisfaction with services at hospitals in Uganda. J Public Health Afr. 2015;6(1):486.
PubMed PubMed Central Google Scholar
Jacobson GH, McCoin NS, Lescallette R, Russ S, Slovis CM. Kaizen: a method of process improvement in the emergency department. Acad Emerg Med. 2009;16(12):1341–9.
Agarwal S, Gallo J, Parashar A, Agarwal K, Ellis S, Khot U, et al. Impact of lean six sigma process improvement methodology on cardiac catheterization laboratory efficiency. Catheter Cardiovasc Interv. 2015;85:S119.
Rahul G, Samanta AK, Varaprasad G A Lean Six Sigma approach to reduce overcrowding of patients and improving the discharge process in a super-specialty hospital. In 2020 International Conference on System, Computation, Automation and Networking (ICSCAN) 2020 July 3 (pp. 1-6). IEEE
Patel J, Nattabi B, Long R, Durey A, Naoum S, Kruger E, et al. The 5 C model: A proposed continuous quality improvement framework for volunteer dental services in remote Australian Aboriginal communities. Community Dent Oral Epidemiol. 2023;51(6):1150–8.
Van Acker B, McIntosh G, Gudes M. Continuous quality improvement techniques enhance HMO members’ immunization rates. J Healthc Qual. 1998;20(2):36–41.
Horine PD, Pohjala ED, Luecke RW. Healthcare financial managers and CQI. Healthc Financ Manage. 1993;47(9):34.
Reynolds JL. Reducing the frequency of episiotomies through a continuous quality improvement program. CMAJ. 1995;153(3):275–82.
Bunik M, Galloway K, Maughlin M, Hyman D. First five quality improvement program increases adherence and continuity with well-child care. Pediatr Qual Saf. 2021;6(6):e484.
Boyle TA, MacKinnon NJ, Mahaffey T, Duggan K, Dow N. Challenges of standardized continuous quality improvement programs in community pharmacies: the case of SafetyNET-Rx. Res Social Adm Pharm. 2012;8(6):499–508.
Price A, Schwartz R, Cohen J, Manson H, Scott F. Assessing continuous quality improvement in public health: adapting lessons from healthcare. Healthc Policy. 2017;12(3):34–49.
Gage AD, Gotsadze T, Seid E, Mutasa R, Friedman J. The influence of continuous quality improvement on healthcare quality: a mixed-methods study from Zimbabwe. Soc Sci Med. 2022;298:114831.
Chan YC, Ho SJ. Continuous quality improvement: a survey of American and Canadian healthcare executives. Hosp Health Serv Adm. 1997;42(4):525–44.
Balas EA, Puryear J, Mitchell JA, Barter B. How to structure clinical practice guidelines for continuous quality improvement? J Med Syst. 1994;18(5):289–97.
ElChamaa R, Seely AJE, Jeong D, Kitto S. Barriers and facilitators to the implementation and adoption of a continuous quality improvement program in surgery: a case study. J Contin Educ Health Prof. 2022;42(4):227–35.
Candas B, Jobin G, Dubé C, Tousignant M, Abdeljelil A, Grenier S, et al. Barriers and facilitators to implementing continuous quality improvement programs in colonoscopy services: a mixed methods systematic review. Endoscopy Int Open. 2016;4(2):E118–133.
Brandrud AS, Schreiner A, Hjortdahl P, Helljesen GS, Nyen B, Nelson EC. Three success factors for continual improvement in healthcare: an analysis of the reports of improvement team members. BMJ Qual Saf. 2011;20(3):251–9.
Lee S, Choi KS, Kang HY, Cho W, Chae YM. Assessing the factors influencing continuous quality improvement implementation: experience in Korean hospitals. Int J Qual Health Care. 2002;14(5):383–91.
Horwood C, Butler L, Barker P, Phakathi S, Haskins L, Grant M, et al. A continuous quality improvement intervention to improve the effectiveness of community health workers providing care to mothers and children: a cluster randomised controlled trial in South Africa. Hum Resour Health. 2017;15(1):39.
Hyrkäs K, Lehti K. Continuous quality improvement through team supervision supported by continuous self-monitoring of work and systematic patient feedback. J Nurs Manag. 2003;11(3):177–88.
Akdemir N, Peterson LN, Campbell CM, Scheele F. Evaluation of continuous quality improvement in accreditation for medical education. BMC Med Educ. 2020;20(Suppl 1):308.
Barzansky B, Hunt D, Moineau G, Ahn D, Lai CW, Humphrey H, et al. Continuous quality improvement in an accreditation system for undergraduate medical education: benefits and challenges. Med Teach. 2015;37(11):1032–8.
Gaylis F, Nasseri R, Salmasi A, Anderson C, Mohedin S, Prime R, et al. Implementing continuous quality improvement in an integrated community urology practice: lessons learned. Urology. 2021;153:139–46.
Gaga S, Mqoqi N, Chimatira R, Moko S, Igumbor JO. Continuous quality improvement in HIV and TB services at selected healthcare facilities in South Africa. South Afr J HIV Med. 2021;22(1):1202.
Wang F, Yao D. Application effect of continuous quality improvement measures on patient satisfaction and quality of life in gynecological nursing. Am J Transl Res. 2021;13(6):6391–8.
Lee SB, Lee LL, Yeung RS, Chan J. A continuous quality improvement project to reduce medication error in the emergency department. World J Emerg Med. 2013;4(3):179–82.
Chiang AA, Lee KC, Lee JC, Wei CH. Effectiveness of a continuous quality improvement program aiming to reduce unplanned extubation: a prospective study. Intensive Care Med. 1996;22(11):1269–71.
Chinnaiyan K, Al-Mallah M, Goraya T, Patel S, Kazerooni E, Poopat C, et al. Impact of a continuous quality improvement initiative on appropriate use of coronary CT angiography: results from a multicenter, statewide registry, the advanced cardiovascular imaging consortium (ACIC). J Cardiovasc Comput Tomogr. 2011;5(4):S29–30.
Gibson-Helm M, Rumbold A, Teede H, Ranasinha S, Bailie R, Boyle J. A continuous quality improvement initiative: improving the provision of pregnancy care for Aboriginal and Torres Strait Islander women. BJOG: Int J Obstet Gynecol. 2015;122:400–1.
Bennett IM, Coco A, Anderson J, Horst M, Gambler AS, Barr WB, et al. Improving maternal care with a continuous quality improvement strategy: a report from the interventions to minimize preterm and low birth weight infants through continuous improvement techniques (IMPLICIT) network. J Am Board Fam Med. 2009;22(4):380–6.
Krall SP, Iv CLR, Donahue L. Effect of continuous quality improvement methods on reducing triage to thrombolytic interval for Acute myocardial infarction. Acad Emerg Med. 1995;2(7):603–9.
Swanson TK, Eilers GM. Physician and staff acceptance of continuous quality improvement. Fam Med. 1994;26(9):583–6.
Yu Y, Zhou Y, Wang H, Zhou T, Li Q, Li T, et al. Impact of continuous quality improvement initiatives on clinical outcomes in peritoneal dialysis. Perit Dial Int. 2014;34(Suppl 2):S43–48.
Schiff GD, Goldfield NI. Deming meets Braverman: toward a progressive analysis of the continuous quality improvement paradigm. Int J Health Serv. 1994;24(4):655–73.
American Hospital Association Division of Quality Resources Chicago, IL: The role of hospital leadership in the continuous improvement of patient care quality. American Hospital Association. J Healthc Qual. 1992;14(5):8–14,22.
Scriven M. The Logic and Methodology of checklists [dissertation]. Western Michigan University; 2000.
Hales B, Terblanche M, Fowler R, Sibbald W. Development of medical checklists for improved quality of patient care. Int J Qual Health Care. 2008;20(1):22–30.
Vermeir P, Vandijck D, Degroote S, Peleman R, Verhaeghe R, Mortier E, et al. Communication in healthcare: a narrative review of the literature and practical recommendations. Int J Clin Pract. 2015;69(11):1257–67.
Eljiz K, Greenfield D, Hogden A, Taylor R, Siddiqui N, Agaliotis M, et al. Improving knowledge translation for increased engagement and impact in healthcare. BMJ open Qual. 2020;9(3):e000983.
O’Brien JL, Shortell SM, Hughes EF, Foster RW, Carman JM, Boerstler H, et al. An integrative model for organization-wide quality improvement: lessons from the field. Qual Manage Healthc. 1995;3(4):19–30.
Adily A, Girgis S, D’Este C, Matthews V, Ward JE. Syphilis testing performance in Aboriginal primary health care: exploring impact of continuous quality improvement over time. Aust J Prim Health. 2020;26(2):178–83.
Horwood C, Butler L, Barker P, Phakathi S, Haskins L, Grant M, et al. A continuous quality improvement intervention to improve the effectiveness of community health workers providing care to mothers and children: a cluster randomised controlled trial in South Africa. Hum Resour Health. 2017;15:1–11.
Veillard J, Cowling K, Bitton A, Ratcliffe H, Kimball M, Barkley S, et al. Better measurement for performance improvement in low- and middle-income countries: the primary Health Care Performance Initiative (PHCPI) experience of conceptual framework development and indicator selection. Milbank Q. 2017;95(4):836–83.
Barbazza E, Kringos D, Kruse I, Klazinga NS, Tello JE. Creating performance intelligence for primary health care strengthening in Europe. BMC Health Serv Res. 2019;19(1):1006.
Assefa Y, Hill PS, Gilks CF, Admassu M, Tesfaye D, Van Damme W. Primary health care contributions to universal health coverage. Ethiopia Bull World Health Organ. 2020;98(12):894.
Van Weel C, Kidd MR. Why strengthening primary health care is essential to achieving universal health coverage. CMAJ. 2018;190(15):E463–466.
Download references
Acknowledgements
Not applicable.
The authors received no fund.
Author information
Authors and affiliations.
School of Public Health, The University of Queensland, Brisbane, Australia
Aklilu Endalamaw, Resham B Khatri, Tesfaye Setegn Mengistu, Daniel Erku & Yibeltal Assefa
College of Medicine and Health Sciences, Bahir Dar University, Bahir Dar, Ethiopia
Aklilu Endalamaw & Tesfaye Setegn Mengistu
Health Social Science and Development Research Institute, Kathmandu, Nepal
Resham B Khatri
Centre for Applied Health Economics, School of Medicine, Grifth University, Brisbane, Australia
Daniel Erku
Menzies Health Institute Queensland, Grifth University, Brisbane, Australia
International Institute for Primary Health Care in Ethiopia, Addis Ababa, Ethiopia
Eskinder Wolka & Anteneh Zewdie
You can also search for this author in PubMed Google Scholar
Contributions
AE conceptualized the study, developed the first draft of the manuscript, and managing feedbacks from co-authors. YA conceptualized the study, provided feedback, and supervised the whole processes. RBK provided feedback throughout. TSM provided feedback throughout. DE provided feedback throughout. EW provided feedback throughout. AZ provided feedback throughout. All authors read and approved the final manuscript.
Corresponding author
Correspondence to Aklilu Endalamaw .
Ethics declarations
Ethics approval and consent to participate.
Not applicable because this research is based on publicly available articles.
Consent for publication
Competing interests.
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., supplementary material 2., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Endalamaw, A., Khatri, R.B., Mengistu, T.S. et al. A scoping review of continuous quality improvement in healthcare system: conceptualization, models and tools, barriers and facilitators, and impact. BMC Health Serv Res 24 , 487 (2024). https://doi.org/10.1186/s12913-024-10828-0
Download citation
Received : 27 December 2023
Accepted : 05 March 2024
Published : 19 April 2024
DOI : https://doi.org/10.1186/s12913-024-10828-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Continuous quality improvement
- Quality of Care
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
IMAGES
VIDEO
COMMENTS
Quantitative data has to be gathered and cleaned before proceeding to the stage of analyzing it. Below are the steps to prepare a data before quantitative research analysis: Step 1: Data Collection. Before beginning the analysis process, you need data. Data can be collected through rigorous quantitative research, which includes methods such as ...
Quantitative data analysis is one of those things that often strikes fear in students. It's totally understandable - quantitative analysis is a complex topic, full of daunting lingo, like medians, modes, correlation and regression.Suddenly we're all wishing we'd paid a little more attention in math class…. The good news is that while quantitative data analysis is a mammoth topic ...
6. Kissmetrics. Kissmetrics is a software for quantitative data analysis that focuses on customer analytics and helps businesses understand user behavior and customer journeys. Kissmetrics lets you track user actions, create funnels to analyze conversion rates, segment your user base, and measure customer lifetime value.
Whether you are part of a small or large organization, learning how to effectively utilize data analytics can help you take advantage of the wide range of data-driven benefits. 1. RapidMiner. Primary use: Data mining. RapidMiner is a comprehensive package for data mining and model development.
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
Statistical analysis means investigating trends, patterns, and relationships using quantitative data. It is an important research tool used by scientists, governments, businesses, and other organizations. To draw valid conclusions, statistical analysis requires careful planning from the very start of the research process. You need to specify ...
Best 10 Quantitative Data Analysis Software. 1. QuestionPro. Known for its robust survey and research capabilities, QuestionPro is a versatile platform that offers powerful data analysis tools tailored for market research, customer feedback, and academic studies.
The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
Abstract. Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility.
8. Weight customer feedback. So far, the quantitative data analysis methods on this list have leveraged numeric data only. However, there are ways to turn qualitative data into quantifiable feedback and to mix and match data sources. For example, you might need to analyze user feedback from multiple surveys.
Step 3: Data cleaning. As discussed earlier, quantitative data doesn't remain highly accurate as they are always chances of errors. Due to this, quantitative data analysis goes through many stages of cleaning. Firstly, analysts start with data validation to identify if the data was collected based on defined procedures.
Two commonly used statistical analysis packages described later in this chapter (SPSS and SAS) offer comprehensive data analysis tools for hypothesis testing. Spreadsheet and Relational Database Packages. Many application tools not created for quantitative data research have become sufficiently powerful to be used for that today.
Quantitative Research: Focus: Quantitative research focuses on numerical data, seeking to quantify variables and examine relationships between them. It aims to provide statistical evidence and generalize findings to a larger population. Measurement: Quantitative research involves standardized measurement instruments, such as surveys or questionnaires, to collect data.
Stata was first released in January 1985 as a regression and data management package with 44 commands, written by Bill Gould and Sean Becketti. The name Stata is a syllabic abbreviation of the words statistics and data. The graphical user interface (menus and dialog boxes) was released in 2003. Users. Economics; Sociology; Political Science ...
Part II: Data Analysis Methods in Quantitative Research Data Analysis Methods in Quantitative Research. We started this module with levels of measurement as a way to categorize our data. Data analysis is directed toward answering the original research question and achieving the study purpose (or aim).
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
KPIs are critical to both qualitative and quantitative analysis research. This is one of the primary methods of data analysis you certainly shouldn't overlook. ... Data analysis tools. In order to perform high-quality analysis of data, it is fundamental to use tools and software that will ensure the best results.
Stata 3: Advanced Data Analysis. This workshop is the third in a three-part series on Stata. Stata is a statistical software package. Stata is widely used by scientists throughout the social sciences for analysis of quantitative data ranging from simple descriptive analysis to complex statistical modeling.
Although there are many other methods to collect quantitative data. Those mentioned above probability sampling, interviews, questionnaire observation, and document review are the most common and widely used methods for data collection. With QuestionPro, you can precise results, and data analysis.
Replicable: Quantitative research aims to be replicable, meaning that other researchers should be able to conduct similar studies and obtain similar results using the same methods. Statistical analysis: Quantitative research involves using statistical tools and techniques to analyze the numerical data collected during the research process ...
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge. Quantitative research. Quantitative research is expressed in numbers and graphs. It is used to test or confirm theories and assumptions.
The purpose of quantitative data is to provide a numerical representation of a phenomenon or observation. Quantitative data is used to measure and describe the characteristics of a population or sample, and to test hypotheses and draw conclusions based on statistical analysis. Some of the key purposes of quantitative data include:
Quantitative Research Tools: Quantitative research tools consist of different types of questionnaires, surveys, struct ured. interviews, and behavioural observation which are based upon explicit ...
Data analysis is crucial in today's businesses and organizations. With the increasing amount of data being created at 328.77 million terabytes of data per day, and them being readily available to most businesses, having efficient tools that can help analyze and interpret this data effectively is essential.. In this article, we will discuss the top 9 best data analysis tools currently used in ...
The growing adoption of continuous quality improvement (CQI) initiatives in healthcare has generated a surge in research interest to gain a deeper understanding of CQI. However, comprehensive evidence regarding the diverse facets of CQI in healthcare has been limited. Our review sought to comprehensively grasp the conceptualization and principles of CQI, explore existing models and tools ...