Understanding Speech to Text in Depth

Have you ever transcribed an interview before? Or seen an individual with disabilities use voice recognition software to control their devices and create text using their voice commands?
If yes, then you have directly experienced the impact of speech to text technology . Better known as STT, these tools help convert audio into written text. It works with a combination of artificial intelligence, deep learning, and computational linguistics.
To give you another real-life example of speech to text, YouTube features a ‘Closed Captions’ option that enables the live transcription of the dialogue happening on the video in real-time.
There are several use cases where voice to text comes in handy, including the dictation processes during meetings, transcribing important interviews, and much more.
In this blog, we’ll go through the evolution of speech to text, benefits, applications, and what the future of the technology looks like.

Table of Contents
Need for speech to text, 1. enhanced accessibility through speech recognition, 2. improved productivity, 3. hands-free operation through spoken words, 4. multitasking through voice commands, 5. language support through google speech recognition, 1. multilingual and cross-language capabilities, 2. enhanced customization and personalization, 2. integration with virtual and augmented reality, 3. expanded use in healthcare, 4. incorporation into smart assistants and iot devices, does murf have a speech to text, evolution of speech to text.

Speech recognition has always been under constant improvement since the 1950s. In fact, Bell Laboratories pioneered the world’s first speech recognition setup called AUDREY, which could recognize spoken numbers with almost 99% accuracy. However, the system was too bulky and consumed copious amounts of power.
In 1962, IBM innovated the niche with Shoebox, a speech recognition system that was able to recognize both numbers and simple mathematical terms. On a parallel timeline, the Japanese scientists were hard at work creating phoneme -based speech recognition technologies and speech segmenters.
This was when Kyoto University achieved a breakthrough in speech segmentation, allowing computers to ‘Segment' one sentence into a new line of speech for the subsequent tech to work on sound identification.
It wasn’t until HARPY from Carnegie Mellon came around in the 1970s that computers could recognize sentences from just over a 1,000-word vocabulary. The system was the first to use Hidden Markov Models, a probabilistic method that laid the foundation for the modern-day ASR.
The 1980s saw the first speech to text tool that leveraged IBM’s transcription system, Tangora. These tools were viable and usable and would then be polished to become the modern-day speech recognition software.
The fact that people around the world needed to generate transcripts at scale and fast led to the development of speech to text software.
Today, their use has expanded into other utilities as well, serving to provide live translations of language and aiding people with disabilities to participate in the online world equitably.
The speech to text process can be explained in five simple steps:
Vibration analysis: When a person speaks, the voice vibrations are first analyzed by STT software.
Phoneme identification: The software then identifies the phonemes in the input sound.
Phoneme-sentence correlation: The identified phonemes are then run through a mathematical algorithm to create sentences.
Linguistic algorithmic conversions: The phonemes are put together to form words and put into coherent sentences.
Output in the form of Unicode characters: The words are now displayed as Unicode characters.
Benefits of Speech to Text
Speech to text provides tremendous advantages to users:
Speech to text is an exemplary accessibility tool for people with mobility or visual disabilities to express themselves. Spoken language can be converted into text automatically, allowing them to take part in threads and discussions on, say, social media platforms.
Speech to text is also an excellent tool to use for enhancing productivity at work that involves exhaustive transcribing processes. The entire workflow can be automated to convert audio to text, clean the text, and then push it further for translation or proofreading.
Hands-free keyboard operation is another productivity enhancement that speech to text provides to users. Professionals can leave their desks and dictate meeting notes or instructions or type a letter using speech to text on popular software like MS Word.
Speech to text allows users to tackle multiple tasks at the same time. For example, while using STT tools for dictating onboarding instructions for a new hire, a professional can continue to read through the files that have been closed or need to be handed over.
Speech to text enables professionals to type in another language using speech. There are tools that take input speech recognition in one language and output the text in a different language selected by the user. It helps prevent errors in sensitive documents for international businesses.
Future of Speech to Text
In the near future, innovations in speech to text would unravel the improved potential of the technology across a variety of use cases:
Polyglot capabilities are set to emerge with speech to text tools promptly converting one language into written text in a second language. In the next step, the typed text in L2 can be converted into spoken audio again, achieving cross-language capabilities.
Currently, speech to text technologies feature a wide range of voice and language selections. In the future, there is potential to offer better voice modulation, auto punctuation, and customization capabilities to users for enhanced branding and user experience.
Speech to text can be extensively employed in VR and AR modules for simulating conversations with AI assistants or agents. It can prove to be a highly effective tool for corporate training , skill-building, and scenario simulations.
Speech to text has the potential to provide enhanced functionality to administrative tasking in the healthcare sector. It can help doctors quickly and efficiently provide prescriptions to patients and also help medical researchers take notes on a subject as they continue to study.
Speech to text is already finding expanded utility in voice assistants that work by recognizing speech and following through with voice commands. This capability can be further expanded into IoT beyond domestic use into specialized operations as well (like industrial operations).
Murf Studio is primarily a versatile platform that provides high-quality AI voices for text to speech conversions. While the platform doesn’t offer a standalone speech to text module, users can still convert audio to script using Murf’s AI voice changer feature through the following steps:
Login to the Murf Studio dashboard and select AI voice changer from the left sidebar.
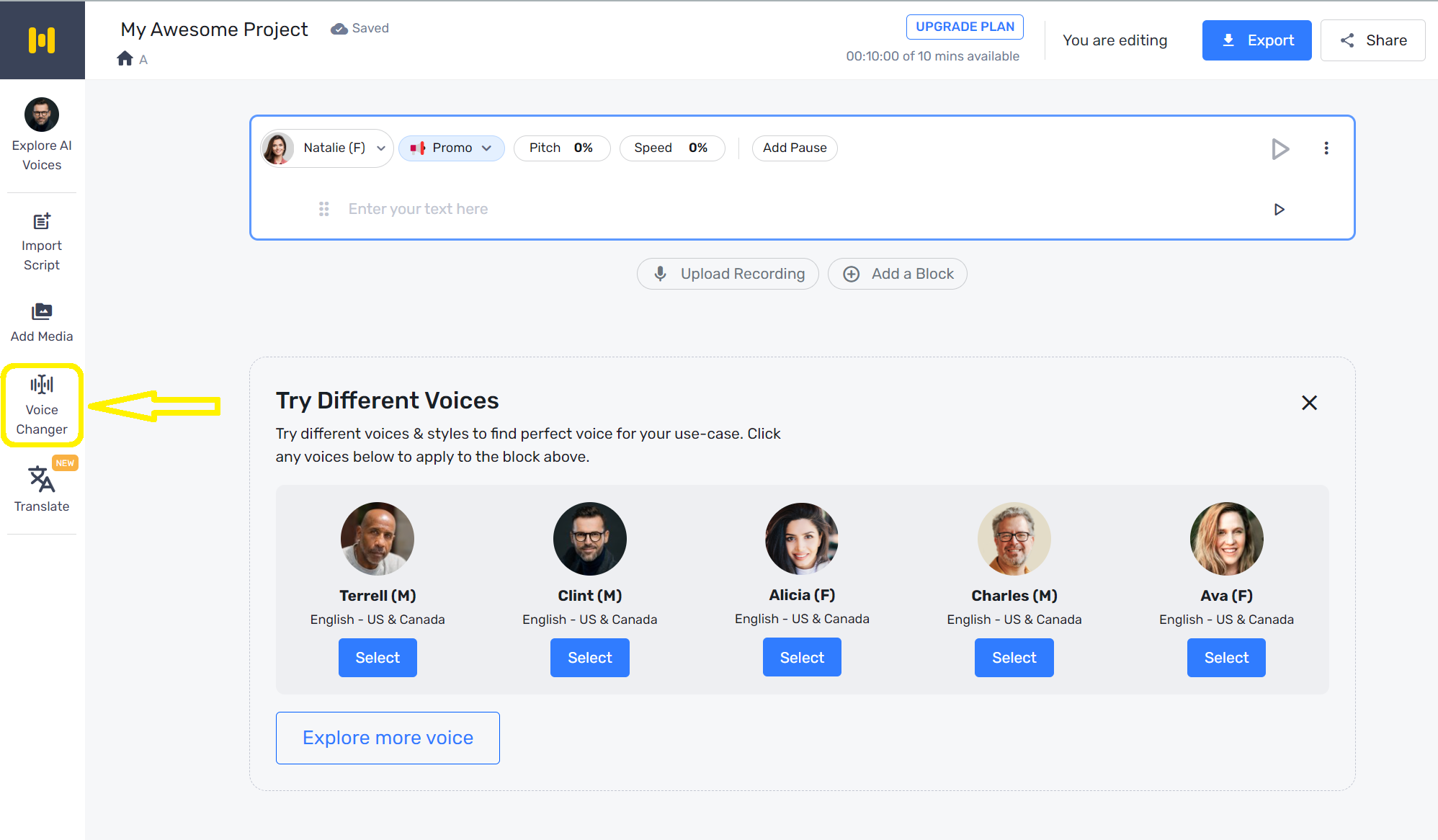
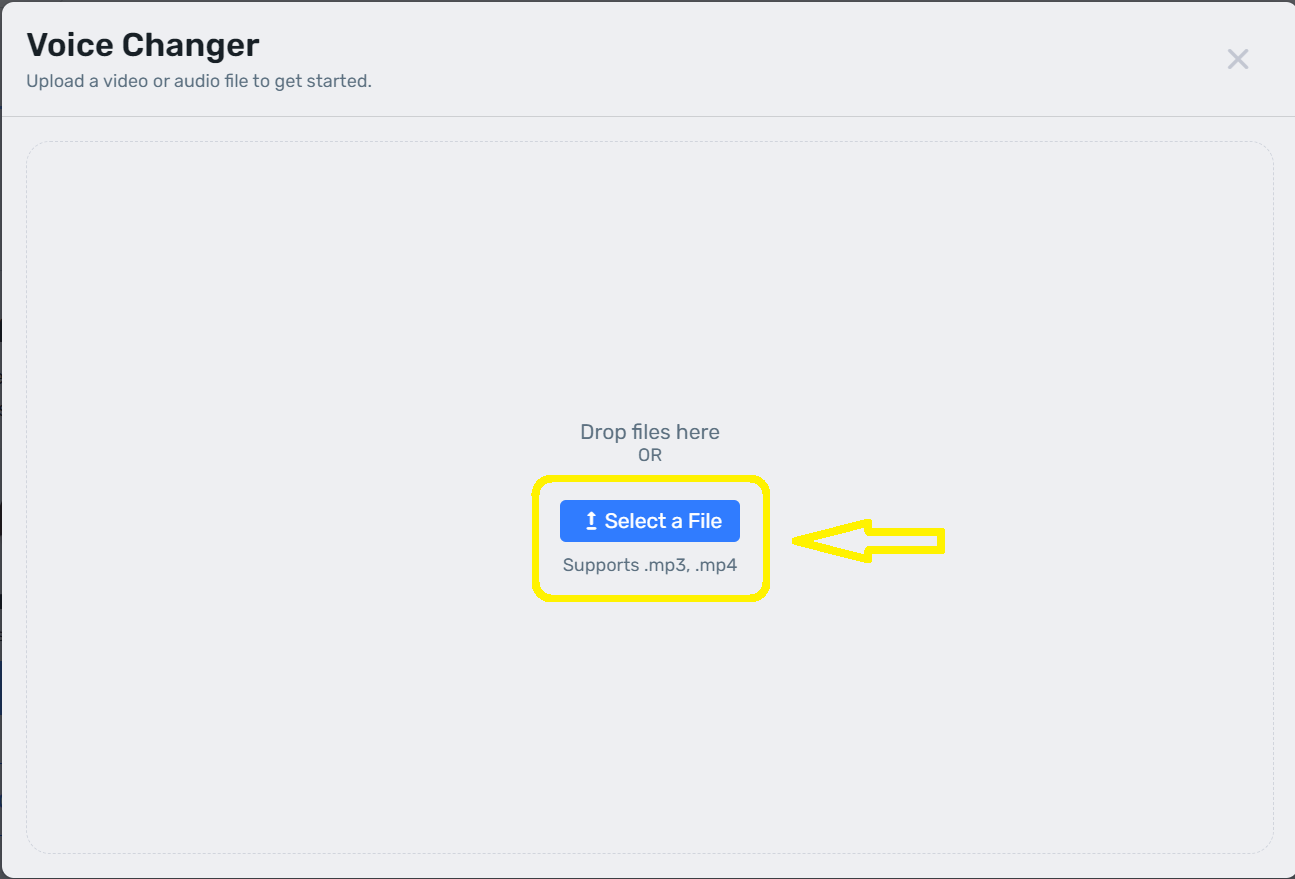
Select a recorded audio or video to upload to the platform.
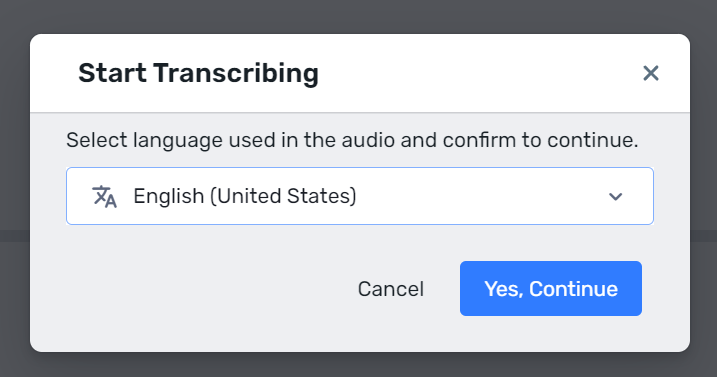
Select the language that your audio file is recorded in.
Once you see the transcribed text appear on the dashboard from your audio, you can proceed to download the text script from the interface. If required, you can apply customizations to the text here as well.
Click on the context menu option beside the text script and select “Download Script.”
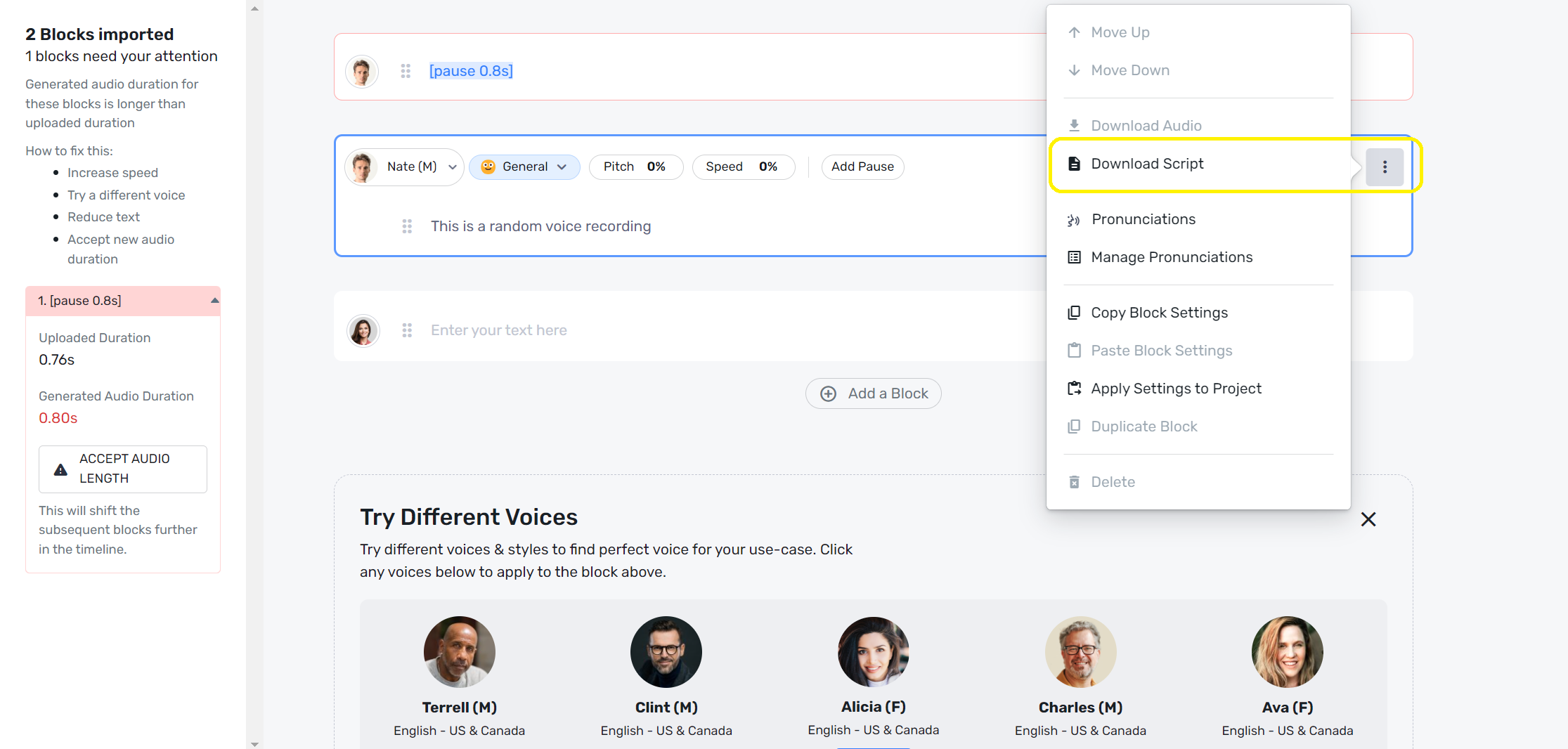
Murf Studio allows you to download the text script in a variety of formats. You can also translate the script into 20+ languages available on the platform.

Speech to Text: More Than Just an Accessibility Enhancer
Speech to text tools are a boon for people who require tasking assistance. However, these tools can do more than just assistive tasks. Professionals actively employ STT to achieve higher levels of productivity at work; people also use it in their daily lives to interact with voice assistants.
Speech to text tools have become extremely accessible today, with advanced online platforms available aplenty. The simplicity in ease of use and quick transcriptions they provide have made it more inclusive for the populace.
What is STT technology, and how does it work?
Speech to text tools convert spoken words into text. They work by identifying sounds in a recording and converting them into corresponding text.
How accurate is speech to text?
Modern-day speech to text tools are extremely accurate as they work with expanded voice databases that allow for accurate transcriptions.
What are the objectives of speech to text?
Speech to text is purposed to convert spoken words and phrases into typed text with a view to enhance accessibility and productivity.
How is AI used in speech to text?
AI enables predictive and voice typing when using dictation methods on software like MS Word.
What applications use speech to text technology?
Daily-use electronics like Amazon’s Alexa or the voice assistants on your phone use speech to text technology.
Can speech to text handle multiple languages?
Yes, speech to text software can convert between languages once a text transcript is available.
How secure is speech to text technology?
Depending on the software you select, the degree of security varies in STT.
Can speech to text technology be used for real-time transcription?
Yes, YouTube and other video platforms leverage STT for real-time caption generation.
You should also read:

Top 10 Speech to Text Software in 2024

How Speech Recognition is Changing Language Learning

Future of AI in Speech Recognition
- Bahasa Indonesia
- Sign out of AWS Builder ID
- AWS Management Console
- Account Settings
- Billing & Cost Management
- Security Credentials
- AWS Personal Health Dashboard
- Support Center
- Expert Help
- Knowledge Center
- AWS Support Overview
- AWS re:Post
- What is Cloud Computing?
- Cloud Computing Concepts Hub
- Machine Learning & AI
What is Speech To Text?

What is speech to text?
Speech to text is a speech recognition software that enables the recognition and translation of spoken language into text through computational linguistics. It is also known as speech recognition or computer speech recognition. Specific applications, tools, and devices can transcribe audio streams in real-time to display text and act on it.
How does speech to text work?
Speech to text is software that works by listening to audio and delivering an editable, verbatim transcript on a given device. The software does this through voice recognition. A computer program draws on linguistic algorithms to sort auditory signals from spoken words and transfer those signals into text using characters called Unicode. Converting speech to text works through a complex machine learning model that involves several steps. Let's take a closer look at how this works:
- When sounds come out of someone's mouth to create words, it also makes a series of vibrations. Speech to text technology works by picking up on these vibrations and translating them into a digital language through an analog to digital converter.
- The analog-to-digital-converter takes sounds from an audio file, measures the waves in great detail, and filters them to distinguish the relevant sounds.
- The sounds are then segmented into hundredths or thousandths of seconds and are then matched to phonemes. A phoneme is a unit of sound that distinguishes one word from another in any given language. For example, there are approximately 40 phonemes in the English language.
- The phonemes are then run through a network via a mathematical model that compares them to well-known sentences, words, and phrases.
- The text is then presented as text or a computer-based demand based on the audio’s most likely version.
What are the types of speech to text technology?
There are two main types of speech to text technology:
- Speaker-dependent : Mainly used for dictation software.
- Speaker-independent : Often used for phone applications.
These two speech recognition systems rely on software and services to function adequately, with the main type being built-in dictation technology. Many devices now have built-in dictation tools, such as laptops, smartphones, and tablets
What are the applications of speech to text?
Speech to text has quickly transcended from everyday use on phones in homes to applications in industries like marketing, banking, and medical. Speech recognition applications reveal how voice to text technology can increase the efficiency of simple tasks and extend to tasks that humans have traditionally performed.
Call analytics and agent assist
Using a tool like Transcribe Call Analytics allows you to extract actionable insights from customer conversations quickly, enabling improvements in customer engagement and increasing agent productivity.
Media content search
Amazon transcribe converts audio and video assets into searchable archives. It also allows users to improve the reach and accessibility of content by generating localized subtitles in combination with Amazon Translate .
Marketing is one of the leading industries to draw on speech to text through media content search. The introduction of voice-search allows for information about trends in data and consumer behavior for marketers.
For example, speech recognition provides information on people's accents and vocabulary, interpreting age, location, and other important demographics. Speaking is also a much more conversational search mode, allowing marketers to incorporate conversational keywords to stay ahead of trends.
Media subtitling
Amazon transcribe can also capture meetings and conversations through the digital scribe function, improving productivity, accessibility, and streamlining important notes.
Clinical documentation
Amazon Transcribe Medical is a tool for medical professionals to quickly and efficiently record clinical conversations into electronic health record systems for analysis. For example, in banking, speech to text is used through voice-activated customer service. In the healthcare sector, speech to text helps improve efficiency by providing immediate access to information and inputting data.
Why should you use speech to text?
Like all forms of technology, speech to text has many benefits that help us improve daily processes. These are some of the main advantages of using speech to text:
- Save time : Automatic speech recognition technology saves time by delivering accurate transcripts in real-time.
- Cost-efficient : Most speech to text software has a subscription fee, and a few services are free. However, the cost of the subscription is far more cost-efficient than hiring human transcription services.
- Enhance audio and video content : Speech to text capabilities mean that audio and video data can be converted in real-time for subtitling and fast video transcription.
- Streamline the customer experience : By drawing on natural language processing, the customer experience is transformed through ease, accessibility, and seamlessness.
What are the limitations of speech to text?
New technologies like speech to text don't come without imperfection, and these are some of the main limitations of speech to text:
- It isn't perfect : While dictation technology is a powerful tool, it is still in its early days,which means there are some gaps in its overall performance. Because it produces verbatim text only, you can end up with an inaccurate or awkward transcript or missing specific quotations.
- Requires human input : Because speech to text lacks complete accuracy, some human edits to the speech data are required for optimal usage.
- Requires clean recordings : To get a quality transcript from voice recognition software, you need to ensure the recorded audio is clear and intelligible. This means there needs to be no background noise, adequate pronunciation, no accents, and one person speaking at a time. You also need to provide voice commands for punctuation.
How to choose free speech to text software vs. paid?
Free speech to text software is helpful if you are on a limited budget. However, if you want to transcribe a large volume of audio to text you will need more robust software. Paid speech to text software is often more accurate, faster, and has added features and support.
Most free speech to text software:
- Do not offer quality technical support.
- Do not offer the greatest speed or accuracy.
- Have a limited capacity.
- Require a lot of extra editing on your part.
How to choose the best speech to text software?
With so many options available, choosing the best speech to text software can be challenging. Use the checklist below to assess the different speech to text software and make the best choice for you:
- No additional software is required - The most accessible speech to text software relies on an internet connection rather than additional software.
- Accuracy level is guaranteed - All speech to text services offer a degree of certainty. Some services have a greater focus on transcription, which ensures extra accuracy.
- Multi-language support - If you need multi-language support, you will need to choose a speech to text software that meets your language needs.
- App compatibility - Some speech to text services can be added to apps, which is important if you wish to use the software across multiple platforms.
How to use Amazon Transcribe for speech to text?
Using automatic speech recognition (ASR), Amazon Transcribe converts speech to text quickly and accurately. Amazon Transcribe offers a range of accessible tools for various uses including call analytics, medical transcriptions, subtitling, and generating metadata for media assets. To get started, simply sign up for a free AWS account and start transcribing with the free speech to text option today.
.ac6d31570dd8ee05e169f1568582927b56fd727c.png "speech to text dictation meaning")
Ending Support for Internet Explorer
How to use speech-to-text on a Windows computer to quickly dictate text without typing
- You can use the speech-to-text feature on Windows to dictate text in any window, document, or field that you could ordinarily type in.
- To get started with speech-to-text, you need to enable your microphone and turn on speech recognition in "Settings."
- Once configured, you can press Win + H to open the speech recognition control and start dictating.
- Visit Business Insider's Tech Reference library for more stories.
One of the lesser known major features in Windows 10 is the ability to use speech-to-text technology to dictate text rather than type. If you have a microphone connected to your computer, you can have your speech quickly converted into text, which is handy if you suffer from repetitive strain injuries or are simply an inefficient typist.
Check out the products mentioned in this article:
Windows 10 (from $139.99 at best buy), acer chromebook 15 (from $179.99 at walmart), how to turn on the speech-to-text feature on windows.
It's likely that speech-to-text is not turned on by default, so you need to enable it before you start dictating to Windows.
1. Click the "Start" button and then click "Settings," designated by a gear icon.
2. Click "Time & Language."
3. In the navigation pane on the left, click "Speech."
4. If you've never set up your microphone, do it now by clicking "Get started" in the Microphone section. Follow the instructions to speak into the microphone, which calibrates it for dictation.
5. Scroll down and click "Speech, inking, & typing privacy settings" in the "Related settings" section. Then slide the switch to "On" in the "Online speech recognition" section. If you don't have the sliding switch, this may appear as a button called "Turn on speech services and typing suggestions."
How to use speech-to-text on Windows
Once you've turned speech-to-text on, you can start using it to dictate into any window or field that accepts text. You can dictate into word processing apps, Notepad, search boxes, and more.
1. Open the app or window you want to dictate into.
2. Press Win + H. This keyboard shortcut opens the speech recognition control at the top of the screen.
3. Now just start speaking normally, and you should see text appear.
If you pause for more than a few moments, Windows will pause speech recognition. It will also pause if you use the mouse to click in a different window. To start again, click the microphone in the control at the top of the screen. You can stop voice recognition for now by closing the control at the top of the screen.
Common commands you should know for speech-to-text on Windows
In general, Windows will convert anything you say into text and place it in the selected window. But there are many commands that, rather than being translated into text, will tell Windows to take a specific action. Most of these commands are related to editing text, and you can discover many of them on your own – in fact, there are dozens of these commands. Here are the most important ones to get you started:
- Punctuation . You can speak punctuation out loud during dictation. For example, you can say "Dear Steve comma how are you question mark."
- New line . Saying "new line" has the same effect as pressing the Enter key on the keyboard.
- Stop dictation . At any time, you can say "stop dictation," which has the same effect as pausing or clicking another window.
- Go to the [start/end] of [document/paragraph] . Windows can move the cursor to various places in your document based on a voice command. You can say "go to the start of the document," or "go to the end of the paragraph," for example, to quickly start dictating text from there.
- Undo that . This is the same as clicking "Undo" and undoes the last thing you dictated.
- Select [word/paragraph] . You can give commands to select a word or paragraph. It's actually a lot more powerful than that – you can say things like "select the previous three paragraphs."
Related coverage from Tech Reference :
How to use your ipad as a second monitor for your windows computer, you can use text-to-speech in the kindle app on an ipad using an accessibility feature— here's how to turn it on, how to use text-to-speech on discord, and have the desktop app read your messages aloud, how to use google text-to-speech on your android phone to hear text instead of reading it, 2 ways to lock a windows computer from your keyboard and quickly secure your data.
Insider Inc. receives a commission when you buy through our links.
Watch: A diehard Mac user switches to PC
- Main content
- Contact Sales Log In

What is speech-to-text?

Speech-to-text, or automatic speech recognition (ASR), technology has been around for a while, but it is only recently that it has gained widespread adoption. ASR allows users to speak commands and control their devices using their voice, making it a popular choice for virtual assistants, captioning and transcription, customer service, education, medical documentation, and legal documentation. According to Forrester's survey , many information workers in North America and Europe use voice commands on their smartphones at least occasionally, with the most common use being texting (56%), searching (46%), and navigation/directions (40%). However, there are still challenges that need to be addressed in order for this technology to reach its full potential.
In this article, we will explore the different methods of speech-to-text and how it is used in various applications, including transcription services, voice recognition software, and accessibility tools. We'll also take a look at the future of speech-to-text and see how this technology is likely to continue to improve and expand in the coming years. So, let's dive in and see what makes speech-to-text such a powerful tool for businesses and individuals alike.
How speech-to-text technology works
Speech-to-text technology is a type of natural language processing (NLP) that converts spoken words into written text. It is used in a variety of applications, including voice assistants, transcription services, and accessibility tools. Here is a more detailed explanation of how speech-to-text technology works:
Sound conversion
The first challenge in speech-to-text technology is that sound is analog, while computers can only understand digital inputs. To convert sound into a digital format that computers can understand, a microphone is used. The microphone converts sound waves into an electrical current, which is then converted into voltage and read by a computer.
Frequency isolation
The next step in the process is to isolate individual frequencies from the sound input. This is done using a technique called Fast Fourier Transform (FFT), which converts the sound input into a spectrogram. A spectrogram is a visual representation of sound, with time on the X-axis, frequencies on the Y-axis, and intensity represented by brightness.

Phoneme recognition
It’s the process of identifying the basic building blocks of speech, known as phonemes. This is a crucial step in speech-to-text technology because phonemes are the foundation upon which words are built. There are several different approaches to phoneme recognition, including statistical models like the hidden Markov model and machine learning systems like neural networks.
Neural networks are a type of machine learning system that is made up of interconnected nodes that can adjust their weights based on feedback. A neural network consists of layers of nodes that are organized into an input layer, an output layer, and one or more hidden layers. The input layer receives data, the hidden layers perform transformations on the data, and the output layer produces the final result. Every time the neural network receives feedback, it adjusts the weights of the connections between the nodes to improve its performance.
One advantage of neural networks is that they can adapt to large variations in speech, such as different accents and mispronunciations. However, they do require a large amount of data to be set up and trained, which may be a limitation for some applications. In contrast, statistical models like the hidden Markov model are less data-hungry, but they are unable to adapt to large variations in speech. As a result, it is common to use both types of models in speech-to-text technology, with the hidden Markov model being used to handle basic phoneme recognition and the neural network handling more complex tasks.
Word analysis
It’s the process of analyzing the sequence of phonemes that make up a word in order to identify the intended meaning. This is done using either a language or an acoustic model.
The language model takes into account the context of the word, as well as the frequency of different phoneme combinations in the language being used. For example, in English, the phoneme "m" is never followed by an "s." Therefore, if the language model encounters the sequence "ms," it will consider it to be an error and attempt to correct it based on the context and the likelihood of different phoneme combinations.
The language model is an important part of speech-to-text technology because it allows the system to understand the meaning of words and sentences. By analyzing the sequence of phonemes and taking into account the context, the language model can determine the intended meaning of spoken words and produce the corresponding written text.
The acoustic model is a statistical model that maps the acoustic features of speech to the corresponding words or phonemes. The acoustic model is trained on a large dataset of audio recordings and the corresponding transcriptions, and it uses this data to learn the patterns and features that are characteristic of the language being used.
During the STT process, the audio input is analyzed by the acoustic model, which produces a sequence of probability scores for each possible word or phoneme. The sequence of scores is then fed into a language model, which takes into account the context and the likelihood of different word combinations to produce the final transcription.
There are several different types of acoustic models, including hidden Markov models (HMMs) and deep neural networks (DNNs). HMMs are statistical model that consists of states and corresponding evidence, and they are commonly used for speech recognition because they are computationally efficient and relatively easy to train. DNNs are a type of machine learning model that consists of layers of interconnected nodes, and they are able to adapt to large variations in speech. DNNs are more data-hungry and require more computational resources to train, but they tend to perform better than HMMs on many speech recognition tasks.
Which model is better or more common for a given language depends on a variety of factors, including the complexity of the language, the amount of data available for training, and the resources available for training and running the model. In general, DNNs tend to perform better on a wide range of tasks, but they may not be the best choice for all languages or situations.
Final transcript
Text output is the final step in converting spoken words or text from one language to another using speech-to-text technology. It involves displaying the translated text on a screen or saving it to a file.
What are STT APIs and their advantages?
API (Application Programming Interface) is a set of rules and protocols that allows different software systems to communicate with each other. In the context of speech-to-text applications, an API is a set of programming instructions that allows developers to access and use the STT capabilities of a service or platform in their own applications.
There are several different types of voice recognition APIs available, including cloud-based APIs and on-premises APIs. Cloud-based APIs are hosted by a third-party provider and accessed over the internet, while on-premises APIs are installed on a local server and accessed within an organization's network.
Speech-to-text APIs offer plenty of advantages for individuals and businesses:
Increased productivity : Allows users to input text quickly and efficiently using their voice, rather than typing on a keyboard or touchpad. This can save time and increase productivity, especially for tasks that involve a lot of text input.
Improved accessibility : Can be used to provide accessibility features such as live captions and subtitles, which can be helpful for individuals with hearing impairments or learning disabilities.
Enhanced customer experience : Speech-to-text applications can provide various manipulations with recognized and transcribed text, for example, summarization . By getting a quick summary of customer feedback businesses can identify common issues, for example.
Greater flexibility : STT APIs can be accessed from any device with an internet connection, allowing users to input text using their voice from anywhere.
Cost savings : One of the major benefits for businesses is cost savings. By automating text input tasks, businesses can reduce or eliminate the need for manual transcription services, which can be costly and time-consuming. Additionally, it can help businesses streamline their processes and increase efficiency.
Improved accuracy : Advanced natural language processing algorithms have a high level of accuracy in transcribing spoken words, which can help reduce errors and improve the quality of the resulting text.
Best speech-to-text API applications
There are many speech-to-text (STT) application programming interfaces (APIs) available on the market, and the best one for you will depend on your specific needs and preferences. Here are some popular STT APIs that are widely used and well-regarded by experts:
- Google Cloud Speech-to-Text API : Use a powerful API to convert speeches into texts accurately with the help of Google Cloud’s Speech-to-Text solution known for its high accuracy and wide range of customization options. It offers an excellent user experience by transcribing your speech with accurate captions.
- IBM Watson Speech to Text API : IBM Watson Speech to Text offers AI-powered transcription and speech recognition solutions. It enables accurate and fast speech recognition in different languages for various use cases, such as customer self-service, speech analytics, agent assistance, and more.
- Microsoft Azure Speech Services : Use a powerful API to convert speeches into texts accurately with the help of Google Cloud’s Speech-to-Text solution. It offers an excellent user experience by transcribing your speech with accurate captions. It also helps improve your services through the insights taken and transcribed from your customer interactions.
- Amazon Transcribe : Amazon Transcribe is a big cloud-based automatic speech recognition platform developed specifically to convert audio to text for apps. It is available for use on a variety of platforms, including Windows, Mac, and mobile devices.
- OneAI is a language AI service that offers product-ready APIs and pre-trained models for developers. It allows developers to access speech-to-text and audio-intelligence capabilities in a single API call, enabling them to process audio and video into structured data for various purposes such as generating summaries and transcripts, and detecting sentiments and topics.
Use cases of speech-to-text applications
There are many potential use cases for speech-to-text technology. Some of the most common use cases include:
Automated dictation
If you're a content creator, writer, or anyone who needs to type long-form text, STT APIs can be a huge help. You can dictate your words and produce written text, saving time and effort.
Voice control
Speech-to-text can be used to enable voice control of various applications, such as virtual assistants or smart home devices. By issuing voice commands, users can easily interact with these devices and perform a wide range of tasks without having to type or use other input methods.
Medical transcription
In the medical field, this technology can be used to transcribe medical reports, notes, and other documents. This can help to reduce the workload for medical professionals and improve the accuracy of patient records
Translation
You can translate spoken words into different languages, which can be particularly useful for people who are traveling or working with people who speak different languages.
Voice biometrics
It’s the process of verifying the identity of a user based on their voice and also can be a task for voice recognition applications. This can be used to enable secure authentication for applications such as banking or online services.
Students with learning disabilities or language barriers can use the benefits of STT applications by getting real-time transcriptions of lectures or other educational materials. This can make learning more accessible and inclusive for all students.
Emotion recognition
Speech-to-text can also be used to analyze certain vocal characteristics to determine what emotion the speaker is feeling. Paired with sentiment analysis, this can reveal how someone feels about a product or service.
Limitations and future of speech-to-text
Like all technology, speech-to-text technology has its limitations. Some of the main limitations include:
Accurate transcription relies on clear speech : voice recognition systems are more likely to produce accurate transcriptions when the spoken words are clear and easily understood. If the speech is distorted or difficult to understand, the accuracy of the transcription may suffer.
Accents and dialects : Voice recognition systems are typically trained on a particular accent or dialect of a language. If the speaker has a different accent or dialect, the accuracy of the transcription may be lower.
Problems with context understanding : STT systems may struggle to understand the context in which words are being used, which can lead to incorrect transcriptions or translations.
Significant computing resources are required : Developing and maintaining voice recognition systems can be resource-intensive, as they require large amounts of data and computing power to train and operate.
Despite these limitations, the future of this technology looks bright. The speech-to-text industry has seen significant growth in recent years, with the global market value expected to reach $28.1 billion by 2027. The increased demand for this technology has led to the development of advanced capabilities such as punctuation, speaker diarization, global language packs, and entity formatting. One major breakthrough in the industry is the introduction of self-supervised learning, which allows STT engines to learn from unstructured data on the internet, giving them access to a wider range of voices and dialects and reducing the need for human supervision.
Universal availability will make ASR accessible to everyone, while the collaboration between humans and machines will allow for the organic learning of new words and speech styles. Finally, responsible AI principles will ensure that ASR operates without bias.
Speech-to-text technology has come a long way in recent years, and its capabilities continue to expand with the development of self-supervised learning and the integration of natural language understanding (NLU) . These advancements have enabled speech-to-text systems to learn from a wide range of unstructured data and improve their accuracy in a variety of languages and accents. As a result, STT technology is being utilized in an increasingly diverse range of industries, from healthcare and finance to communications and customer service.
OneAI creates 93% accurate speech-to-text transcriptions and suggests a wide range of Language Skills (use-case ready, vertically pre-trained models) like summarization , proofreading , sentiment analysis , and many more. Just check our Language Studio and pick those which will increase the efficiency of your business.
TURN YOUR C o NTENT INTO A GPT AGENT

Understanding Transcription: The Meaning of Dictating for Text Conversion

Understanding Transcribe Dictation in the Medical Field
In today’s fast-paced medical environment, transcribe dictation has emerged as a critical component of healthcare documentation. This process involves the conversion of spoken language into a written text by a healthcare provider. Traditionally, doctors would dictate their findings into a recorder after a patient visit, which would subsequently be transcribed either by an in-house transcriptionist or an outsourced service. However, the integration of AI-powered digital scribe services like ScribeMD is revolutionizing this practice by providing real-time transcription with a high degree of accuracy and efficiency.
One of the fundamental aspects of understanding transcribe dictation in the medical field is recognizing its impact on workflow optimization . The practice of dictation itself allows healthcare professionals to verbalize patient encounters and treatment plans without the need for typing or writing, saving valuable time. The subsequent transcription is then incorporated into patient records, which is essential for continuity of care, insurance processes, and legal documentation. Leveraging high-tech solutions to automate this process reduces the turnaround time from spoken word to electronic health records and minimizes potential for human error.
Welcome to the medical revolution, where words become your most powerful ally
Here at ScribeMD.AI, we’ve unlocked the secret to freeing medical professionals to focus on what truly matters: their patients. Can you imagine a world where the mountain of paperwork is reduced to a whisper in the wind? That’s ScribeMD.AI. An AI-powered digital assistant, meticulously designed to liberate you from the chains of the tedious medical note-taking process. It’s like having a second pair of eyes and ears but with the precision of a surgeon and the speed of lightning. Our service isn’t just a software program; it’s an intelligent companion that listens, understands, and transcribes your medical consultations with astounding accuracy. Think of it as a transcription maestro, a virtuoso of spoken words, trained to capture every crucial detail with expert precision. With ScribeMD.AI, say goodbye to endless hours of reviewing and correcting notes. Our advanced AI technology and language learning models ensure an accuracy rate that makes errors seem like a thing of the past. And best of all, it responds faster than you can blink. The true beauty of ScribeMD.AI lies in its ability to lighten your administrative burden, allowing you to return to the essence of your calling: caring for your patients. It’s more than a service; it’s a statement that in the world of medicine, patient care should always come first. So, are you ready to make the leap and join the healthcare revolution? ScribeMD.AI isn’t just a change; it’s the future. A future where doctors can be doctors, and patients receive all the attention they deserve.
- Conversion of spoken language into text
- Traditionally performed by human transcriptionists
- AI-powered services enhance speed and accuracy
- Dictation saves practitioners’ time during patient visits
- Essential for thorough patient records and documentation
Medical dictation isn’t just about capturing words; it’s a complex system that must recognize and adapt to various medical terminologies, accents, and dictation styles. Healthcare providers often use highly specialized language, and an effective transcription service must be equipped with medical-specific linguistic databases to accurately interpret and document these terms. The advent of advanced AI language learning models, as implemented by ScribeMD, means that modern dictation systems can continually learn and improve, offering increasingly precise transcriptions over time.
Furthermore, the value of transcribe dictation extends into the realm of medical billing and coding. Detailed and accurate documentation is paramount for correct billing codes, which not only ensures proper reimbursement but also aids in maintaining compliance with healthcare regulations. Here, the introduction of AI digital scribe technology simplifies this intricate process, reducing the likelihood of coding errors and enhancing the financial integrity of healthcare practices.
- Necessity for understanding specialized medical terms
- AI models provide contextual understanding
- Continuous improvement in speech recognition accuracy
- Accurate documentation aids in medical billing and compliance
The Role of AI in Enhancing Dictation Transcription
In the swiftly evolving medical industry, the integration of Artificial Intelligence (AI) in dictation transcription is transforming the landscape of patient record-keeping. AI-driven platforms, such as those provided by ScribeMD , are revolutionizing the way medical professionals document consultations and procedures. By harnessing the power of sophisticated algorithms and natural language processing (NLP) techniques, these systems are able to interpret and transcribe spoken language with remarkable accuracy . Such technology not only captures the nuances of medical terminology but also adapts to the distinct speech patterns of individual clinicians.
Hospitals and clinics embracing AI transcription tools are observing a significant uptick in efficiency. Traditional methods of transcribing dictated notes often involve a time-consuming process that can lead to delays in updating patient records. With AI, the transition from oral dictation to textual documentation occurs almost instantaneously, implying that health records are kept current with very little lag. The benefits of this advancement are multifold:
- Reduced Turnaround Time : Automated transcription delivers documentation expeditiously, thus streamlining patient care.
- Enhanced Accuracy : AI programs continually learn and improve, reducing the likelihood of errors associated with human transcription.
- Decreased Administrative Burden : By automating the transcription process, medical staff can redirect their focus toward patient-centric tasks, enhancing the overall quality of care.
Moreover, the role of AI extends beyond just the transcription of words. It entails an understanding of context and intent, distinguishing it from rudimentary voice recognition tools of the past. AI transcription services deploy highly advanced NLP engines that recognize jargon, abbreviations, and even slang pertinent to the medical field. Furthermore, these systems are capable of discerning relevant information for different sections of medical notes, including symptoms, diagnoses, and treatment plans. Thus, the adoption of an AI-powered digital scribe promises a more cohesive and reliable method for maintaining patient narratives, which are instrumental in delivering high-quality healthcare.
What Does Transcribe Dictation Mean for Patient Care?
Transcribing dictation in the medical field means converting the spoken word of healthcare professionals into accurate, accessible written records. At its core, this process is designed to capture the intricate details of patient encounters, ensuring that every symptom, diagnosis, and treatment plan is meticulously documented. The precision of medical transcription holds immense significance for patient care—it ensures continuity by creating a reliable, comprehensive narrative that can be referenced by practitioners now and in the future. This written account allows doctors to revisit patient information quickly, aiding in recalling specific case particulars, which is essential for ongoing care and treatment adjustments when necessary.
Moreover, the integration of an AI-powered digital scribe, such as ScribeMD , enhances the quality and efficiency of transcribing dictation. By leveraging advanced language models and speech recognition, the service minimizes the risk of human error often found in manual transcription. The outcomes are noteworthy:
– Higher accuracy rate : Ensuring that records reflect the correct terminology and details of the patient’s visit. – Quicker turnaround time : Rapid documentation means that patient records are updated almost in real-time, promoting better follow-up care. – Increased availability for patient interaction : When medical professionals are freed from the burdens of note-taking, they can refocus their attention on direct patient care, fostering a more personal and comprehensive healthcare experience.
These innovations fundamentally elevate the standard of care provided to patients by streamlining the processes behind the scenes.
Importantly, accurate transcribed notes act as a legal safeguard for both patients and healthcare providers. Quality documentation is a critical component of patient care, serving as evidence of the treatments provided and the healthcare professional’s adherence to the standard of care. Inaccurate or incomplete documentation can lead to misdiagnoses, inappropriate treatments, and even legal ramifications. Thus, the significance of transcribe dictation extends beyond administrative utility—it embodies a commitment to excellence in patient care. The adoption of technology like ScribeMD in the process optimizes this commitment by offering:
– Compliance with healthcare regulations : Automated transcriptions made to meet the stringent standards of medical documentation. – Enhanced security and confidentiality : Digitally securing patient information to comply with privacy laws such as the Health Insurance Portability and Accountability Act (HIPAA). – Interoperability : Seamless integration with Electronic Health Record (EHR) systems, ensuring that transcribed data enhances the healthcare ecosystem.
By encapsulating and preserving the integrity of the patient’s medical journey, transcribe dictation, when executed with technological finesse, becomes a cornerstone of exceptional patient-centered healthcare.
How Transcribe Dictation Saves Time for Healthcare Professionals
In today’s high-paced healthcare environment, time is a critical resource, and finding ways to save it is at the forefront of operational efficiency. Transcribe dictation has emerged as a transformative solution for healthcare professionals by streamlining one of the most time-consuming tasks— medical documentation . By enabling clinicians to speak their notes, observations, and patient interactions directly into a digital repository, the need for manual typing or writing is notably reduced. This not only accelerates the process of note-taking but also captures the nuances of verbal communication that might be lost in translation to written text.
Another facet where transcribe dictation shines is in its ability to allow healthcare professionals to multi-task effectively. As physicians engage with patients, they can dictate the relevant medical information in real-time. This immediacy greatly decreases the chances of omitting important patient data, which might be the case when notes are transcribed well after the patient encounter. Furthermore, when utilizing an AI-powered digital scribe, like ScribeMD , the integration of advanced language processing models ensures that the transcribed notes are not just fast, but also accurate and contextually coherent.
- Reduction in manual typing : Decreases the physical task of note-taking, saving time.
- Immediate documentation : Captures patient data in real-time, avoiding data loss.
- Advanced language processing : Ensures accuracy and contextual integrity of notes.
Moreover, the time saved by transcribing dictations translates into more direct patient care and improved clinical outcomes. Healthcare providers can allocate the hours gained from reduced administrative burdens to patient consultations, crafting more personalized care plans, or simply to increase patient throughput. This optimization of time is not only synonymous with financial prudence for healthcare establishments, but it also elevates patient satisfaction by fostering a healthcare experience where the focus visibly shifts from paperwork to patient interaction.
Lastly, the long-term benefits of transcribe dictation on time management echo through the overall healthcare system. With digital transcriptions readily available, information sharing between departments, specialists, and even across different healthcare facilities becomes significantly swifter and more efficient. The accumulation of these incremental time savings has the potential to make a substantial impact on healthcare delivery, setting the groundwork for a more agile and responsive medical practice.
- Enhanced patient care : Providers spend less time on documentation and more time with patients.
- Increased patient throughput : More efficient processes can lead to seeing more patients daily.
- Improved information sharing : Easier access to digital records streamlines communication between healthcare entities.
The Future of Dictation Transcription in Healthcare
As the landscape of healthcare continuously evolves, so does the necessity to streamline the documentation process. Dictation transcription, long a staple in the medical field, is poised for a transformative leap thanks to advancements in artificial intelligence (AI) and natural language processing (NLP). In the future, healthcare professionals can expect a seamless integration of AI-powered systems like ScribeMD.ai into their workflow, offering unprecedented accuracy and efficiency in transcribing medical dictations. This digital scribe technology not only understands the nuances of medical jargon but also contextualizes patient encounters, improving the quality of clinical documentation significantly.
Key drivers for this revolutionary change stem from the need to reduce administrative burdens and the growing emphasis on patient-centered care. With AI-enhanced dictation services, the speed at which spoken words are translated into written text vastly outstrips that of traditional methods. Healthcare providers can dictate medical notes in real-time, and the AI system promptly captures and converts this data with remarkable precision. This means less time spent on paperwork and more on direct patient interaction, aligning with modern healthcare’s ethos of personalized care.
- Improved accuracy in capturing complex medical terminology
- Reduced time spent on documentation
- Faster turnaround times for medical record completion
Moving beyond mere voice-to-text conversion, the future of dictation transcription will incorporate context-aware AI that can adapt to different accents, dialects, and the unique speech patterns of individual providers. The technology is expected to enhance with continuous learning capabilities, meaning it gets better over time with increased exposure to diverse linguistic data. Furthermore, AI-driven transcription services can be integrated with Electronic Health Record (EHR) systems, streamlining data entry and minimizing errors. This integration point allows healthcare practitioners to maintain comprehensive and accurate patient records without the tedium of manual input.
When considering data security and patient privacy, future dictation transcription tools will feature state-of-the-art encryption and compliance protocols aligned with Health Insurance Portability and Accountability Act (HIPAA) guidelines. Developers and healthcare institutions are keenly aware of the sensitivity of medical information; thus, the security aspect of transcription tools is a top priority. These hardened measures ensure that the confidential patient data physicians dictate is safeguarded throughout the documentation process.
Related Posts

Medical Transcriptionist: The Essential Guide to Launching Your Career

Master Medical Abbreviations: The Ultimate Guide for Healthcare Professionals

Become a Pro at Charting: The Ultimate Guide to Medical Scribe Mastery
Leave a comment cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
How-To Geek
Voice dictation works great, but should you use it.
Look who's (not) talking now.
Quick Links
We don't write the way we speak, formatting and editing is still a pain, voice dictation doesn't work in shared spaces, talking too much can be bad for you, it's a great hands-free and mobile typing technology, transcription is the real star.
For years we were promised voice dictation that was accurate, real-time, and easy. Today that promise has (largely) come true, but should you write your next work report, dissertation, or novel using your voice? Maybe not, as it turns out.
The biggest problem with dictating any serious writing is that, unlike reading, writing isn't a linear process. We don't think out whole paragraphs and sentences on the fly, so speaking the written word is rarely efficient.
Instead, writing goes back and forth. We stop and think. Then type out a torrent of words once those thoughts are in order. With the way current dictation systems work, it's hard to have this natural writing cadence work smoothly. The alternative is to adapt how we write to dictation. This author has certainly tried, but it doesn't seems conducive to the writing process, regardless of what you write.
Related: How to Use Voice Dictation on Windows 10
A significant amount of writing is simply formatting and editing text. No dictation system has really nailed perfect punctuation and formatting. Some of them infer where commas and periods should go and often do a great job. However, the most reliable method is still explicitly telling the system verbally where to put punctuation or when to, for example, create bold or italicized text.
Using your voice to format text is practically a no-go from the outset. It's simply faster and more efficient to use tactile controls. Even touch controls work better than formatting by voice. So inevitably, you'll have to go back and do manual typing no matter how well your initial voice draft came out.
While lots of people are working from home , open-plan offices and other communal workspaces are still common. This makes it a problem to produce text in a way that makes noise. Mechanical keyboards are already annoying when someone's mashing out an article on one, but could you imagine a room full of people talking at their computers?
It also makes it impossible to, for example, listen to music or other audio content while writing, unless you're willing to wear headphones . Overall, the noise pollution caused by voice dictation narrows down the types of environments and situations where you can use it comfortably.
Another potential reason voice dictation hasn't become the mainstream writing mode, is that talking for hours on end isn't great for anyone's voice. That's not to say that excessive typing isn't going to put some strain on your hands, but we've had decades to figure out better typing ergonomics . We don't have "ergonomic" microphones, after all.
Where voice dictation really shines is in writing small sections of text hands-free. Such as dictating a text message for use with your favorite app while driving. Even when you're not working hands-free, voice typing is generally less frustrating than typing on a tiny touch-screen keyboard. At least for anyone with human-sized thumbs.
So if you haven't tried voice typing on your smartphone , it's actually one of the best use cases for the technology, if you tend to mistype things on your phone regularly, voice typing is definitely worth a try.
So far, it may seem like voice dictation has turned out to be less useful than it seems, but that's only when you try to use this technology in real-time. What's far more practical is taking voice recordings and then transcribing them to editable text .
Voice dictation and transcription are essentially the same technology, except in the case of transcription the software has more time to get it right, has the context of the whole recording to work with, and does have to be interrupted for editing.
Related: Are Online Transcription Services Safe and Private?
By using a dedicated voice recorder, or a recording app on your phone, or even a smart watch , you can put down your thoughts over a period of time and then feed all of that audio into your transcription software. Then it's a matter of editing the end result, which is must faster than the stop-and-start nature of dictation.
So voice recognition technology is definitely something you should use, but perhaps live dictation isn't the best way to benefit from it.

Dictate your documents in Word
Dictation lets you use speech-to-text to author content in Microsoft 365 with a microphone and reliable internet connection. It's a quick and easy way to get your thoughts out, create drafts or outlines, and capture notes.

Start speaking to see text appear on the screen.
How to use dictation

Tip: You can also start dictation with the keyboard shortcut: ⌥ (Option) + F1.

Learn more about using dictation in Word on the web and mobile
Dictate your documents in Word for the web
Dictate your documents in Word Mobile
What can I say?
In addition to dictating your content, you can speak commands to add punctuation, navigate around the page, and enter special characters.
You can see the commands in any supported language by going to Available languages . These are the commands for English.
Punctuation
Navigation and selection, creating lists, adding comments, dictation commands, mathematics, emoji/faces, available languages.
Select from the list below to see commands available in each of the supported languages.
- Select your language
Arabic (Bahrain)
Arabic (Egypt)
Arabic (Saudi Arabia)
Croatian (Croatia)
Gujarati (India)
- Hebrew (Israel)
- Hungarian (Hungary)
- Irish (Ireland)
Marathi (India)
- Polish (Poland)
- Romanian (Romania)
- Russian (Russia)
- Slovenian (Slovenia)
Tamil (India)
Telugu (India)
- Thai (Thailand)
- Vietnamese (Vietnam)
More Information
Spoken languages supported.
By default, Dictation is set to your document language in Microsoft 365.
We are actively working to improve these languages and add more locales and languages.
Supported Languages
Chinese (China)
English (Australia)
English (Canada)
English (India)
English (United Kingdom)
English (United States)
French (Canada)
French (France)
German (Germany)
Italian (Italy)
Portuguese (Brazil)
Spanish (Spain)
Spanish (Mexico)
Preview languages *
Chinese (Traditional, Hong Kong)
Chinese (Taiwan)
Dutch (Netherlands)
English (New Zealand)
Norwegian (Bokmål)
Portuguese (Portugal)
Swedish (Sweden)
Turkish (Turkey)
* Preview Languages may have lower accuracy or limited punctuation support.
Dictation settings
Click on the gear icon to see the available settings.

Spoken Language: View and change languages in the drop-down
Microphone: View and change your microphone
Auto Punctuation: Toggle the checkmark on or off, if it's available for the language chosen
Profanity filter: Mask potentially sensitive phrases with ***
Tips for using Dictation
Saying “ delete ” by itself removes the last word or punctuation before the cursor.
Saying “ delete that ” removes the last spoken utterance.
You can bold, italicize, underline, or strikethrough a word or phrase. An example would be dictating “review by tomorrow at 5PM”, then saying “ bold tomorrow ” which would leave you with "review by tomorrow at 5PM"
Try phrases like “ bold last word ” or “ underline last sentence .”
Saying “ add comment look at this tomorrow ” will insert a new comment with the text “Look at this tomorrow” inside it.
Saying “ add comment ” by itself will create a blank comment box you where you can type a comment.
To resume dictation, please use the keyboard shortcut ALT + ` or press the Mic icon in the floating dictation menu.
Markings may appear under words with alternates we may have misheard.
If the marked word is already correct, you can select Ignore .

This service does not store your audio data or transcribed text.
Your speech utterances will be sent to Microsoft and used only to provide you with text results.
For more information about experiences that analyze your content, see Connected Experiences in Microsoft 365 .
Troubleshooting
Can't find the dictate button.
If you can't see the button to start dictation:
Make sure you're signed in with an active Microsoft 365 subscription
Dictate is not available in Office 2016 or 2019 for Windows without Microsoft 365
Make sure you have Windows 10 or above
Dictate button is grayed out
If you see the dictate button is grayed out
Make sure the note is not in a Read-Only state.
Microphone doesn't have access
If you see "We don’t have access to your microphone":
Make sure no other application or web page is using the microphone and try again
Refresh, click on Dictate, and give permission for the browser to access the microphone
Microphone isn't working
If you see "There is a problem with your microphone" or "We can’t detect your microphone":
Make sure the microphone is plugged in
Test the microphone to make sure it's working
Check the microphone settings in Control Panel
Also see How to set up and test microphones in Windows
On a Surface running Windows 10: Adjust microphone settings
Dictation can't hear you
If you see "Dictation can't hear you" or if nothing appears on the screen as you dictate:
Make sure your microphone is not muted
Adjust the input level of your microphone
Move to a quieter location
If using a built-in mic, consider trying again with a headset or external mic
Accuracy issues or missed words
If you see a lot of incorrect words being output or missed words:
Make sure you're on a fast and reliable internet connection
Avoid or eliminate background noise that may interfere with your voice
Try speaking more deliberately
Check to see if the microphone you are using needs to be upgraded

Need more help?
Want more options.
Explore subscription benefits, browse training courses, learn how to secure your device, and more.

Microsoft 365 subscription benefits

Microsoft 365 training

Microsoft security

Accessibility center
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.

Ask the Microsoft Community

Microsoft Tech Community

Windows Insiders
Microsoft 365 Insiders
Was this information helpful?
Thank you for your feedback.
- Law Enforcement
- Ditto Difference/About
- Case Studies
- Work for Us
- Upload A File
Dictation Speech-to-Text Apps Vs. Transcription

By Ben Walker
Dictation and transcription are commonly mistaken for the same thing. However, that is far from the truth. Dictation is the process of speaking or dictating information, often to a device. Transcription involves listening to an audio recording and accurately transcribing the spoken words into a written document. Dictation and transcription services have different purposes in professional settings, and knowing which to use when can be greatly beneficial for businesses.
In this article, you’ll learn how:
- Transcription means converting speech to text through either automated or manual means. Dictation is speaking into a recording device or app to be listened to or transcribed in the future.
- Speech recognition software is often incorporated into dictation apps for real-time transcription.
- Professional, human-powered transcription is the best choice for transcribing audio files and other recordings into immediately usable transcripts.
Difference Between Dictation And Transcription
Dictation is the process of speaking or dictating information, while transcription is the process of converting spoken language into written form. To illustrate the point, here are their key factors and differences.
Key differences:
- Timing: Dictation happens in real-time, while transcription occurs after a recording.
- Accuracy: Transcription often requires greater accuracy and attention to detail due to its potential use as a legal or medical record.
- Formatting: Transcription often involves adding timestamps, speaker labels, and formatting for readability and referencing.
- Software: The best dictation software often has voice recognition and editing features, while transcription software focuses on playback control and accuracy.
Disadvantages of Dictation Apps
Dictation and transcription software that use speech recognition have their uses. However, to be sure they are right for your application, you must be aware of their limitations.
Transcription Vs. Dictation Software: When To Use And Why
Here’s a quick summary to figure out if dictation or transcription is appropriate for your needs:
Transcription is preferable when looking for accurate, permanent records accessible to everyone who needs them. Dictation is excellent for note-taking and reminders to be transcribed later.
For example, doctors can save time dictating their patients’ notes instead of taking them in real-time. Real estate agents can dictate as they survey a house instead of scribbling notes. However, voice dictations must still be converted into physical or digital medical documentation.
So, let’s talk about your options for getting transcription work done.
Can I Assign Transcription Work To My Employees?
You can assign transcription tasks to your clerks, admins, or clinic assistants for different businesses. Everyone can use a keyboard—it’s practically a life skill these days. Many people can even be called typists. You can transcribe your own dictations, and your employees can do the work you originally hired them to do.
Here’s the question, though: is transcription the real reason why you hired them in the first place?
You remove key human resources from your core business functions by assigning dictated recordings to your employees for transcription. Transcription is essential—there is no question about that. However, assigning your people to that task might not be the most cost-efficient way.
How About Hiring In-House To Transcribe Dictations And Recordings?
Another option is to hire a transcriptionist or a whole team to work on your audio recordings. However, there might be better options.
In-house transcription is time-consuming and costly. The business needs to spend money finding and hiring competent transcriptionists (which can take up to 24 days and cost upwards of $10,000 for the search), provide a decent salary and benefits package (which can cost up to $60,000 a year for salary alone), supply them with the necessary equipment (which may cost up to $2,000 each, depending on the quality of the equipment), and provide continuous training and development so that their skills do not stagnate.
How About Voice Recognition Software or Speech-To-Text Transcription Software?
Artificial intelligence can transcribe audio files; the best speech-to-text dictation apps often include the feature. With some apps, it’s often as simple as pressing the microphone icon and watching the words get written on your screen. So why don’t the best transcription services use them?
The issue lies with accuracy. Transcription services that use AI software suffer from transcription errors because automated transcription can only reach 86% accuracy without human intervention.
Applications that transform spoken words into documents are popular dictation transcription options. They’re pretty good, but you’ll quickly realize how frustrating they can be once you’ve dictated a critical letter into a dictation transcription application. While some software might recognize most of your words, the app can still surprise you with punctuation in odd places, butchered professional jargon, and unusable formats.
Simply put, you cannot use AI to transcribe everything.
Medical transcription services must offer near-perfect transcripts every time. Medical terminology can make it hard for automated transcription to produce accurate transcripts. That’s why certified medical transcriptionists are preferred.
Legal transcription is often used in court cases. Walking up to the judge and presenting error-filled transcripts and legal documents is a great way to lose cases and potentially send your client to jail.
Why Outsource To Human Transcription Services
Professional dictation transcription services that employ human transcriptionists are your best option when the correspondence and documents you produce are crucial to your reputation. Your documents are often your first line of interaction with the public. They tell people who and what you are and what you do. You want them to be accurate, attractive, and just as professional as you are.
A human transcriber might not recognize your words the first time you say them, but unlike a program or application, they can replay them and ensure they get them right. You can spell out complicated words; a transcriber will spell them exactly as you ask.
You can tell a professional dictation transcription service provider the punctuation and formatting you need—period, quotation marks, paragraph breaks, and everything in between.
Stop Yelling At Your Phone And Get Ditto’s Best Transcription Services Instead
Transcription services rely on accuracy, making automated typing software not the best choice.
Dictation apps are free, easy to use, and they’re everywhere. And sure, convenience is important— but it’s no substitute for quality and accuracy.
Get accurate, quality, and professional transcription services when you work with Ditto Transcripts. We’ll take dictations, audio recordings, and video content and create accurate, crystal-clear transcripts that can be used in any professional or business setting. Additionally, we offer flexible and affordable pricing options, customizable formats, fast turnaround times, and excellent customer service.
So what are you waiting for? Call us, or sign up for our free trial and experience the Ditto difference.
Ditto Transcripts is a HIPAA-compliant and CJIS-compliant Denver, Colorado-based transcription services company that provides fast, accurate, and affordable transcripts for individuals and companies of all sizes. Call (720) 287-3710 today for a free quote, and ask about our free five-day trial.
Looking For A Transcription Service?
Ditto Transcripts is a U.S.-based HIPAA and CJIS compliant company with experienced U.S. transcriptionists. Learn how we can help with your next project!
The SpeakWrite Blog
Transcription vs dictation: learn the difference.
- January 31, 2023
No, they’re not the same. But they’re both great time-saving options that allow you to get more done in less time—here’s what you should know.
Are you using the terms dictation and transcription interchangeably? Is there a discernible difference between dictation vs transcription?
The short answer is yes.
Whether it’s transcribing audio or notes from meetings or simply speeding up document creation efforts all around, understanding these terms is essential for any busy professional.
In this article, we’ll break down the difference between transcription vs dictation so you can optimize your workflow with the best document creation tools around, including the best transcription services and dictation software.
What is the difference between transcription vs dictation?
Dictation is the process of speaking aloud to produce a document or other type of output, while transcription is the process of converting a wav file into written text. It’s common to write a transcription from a dictation, and many modern pieces of software are capable of transcribing a dictation in real time.
No matter what your use case, dictation and transcription can be a great time-saving option that allows you to get more done in less time. Transcription services are usually provided by professional typists, while dictation services rely on AI software and speech recognition technology to transcribe audio into text.
What is Dictation?
Simply put, dictation is when you record your speaking, usually by speaking into a recording device. From there, you can either replay your dictation out loud and type it or have it professionally transcribed into written notes.
Dictation is useful because you can dictate in real-time, a nifty ability when:
- Typing is difficult or impossible due to injury or disability
- You need to take meeting or lecture notes
- You need to record patient information
- Recording thoughts or ideas while walking or driving
- Looking for ways to spend more time on billable hours
- You need documents transcribed into a different language
Types of Dictation Software
With smartphones, dictation has never been easier. Here are a few of the best dictation apps for recording raw audio with your phone.
Voice Memos (Apple)
Apple users can use their Voice Memos app for dictation. Simply hit the “record” button and begin speaking. Voice Memos also allows you to trim, re-record, and improve recording’s quality with ease.
Sound Recording (Android)
Android users can dictate using the Sound Recording app. Hit the “record” button and boom—you’re started. You can trim, re-record, and improve the audio quality within the app.
AudioNote is a fantastic dictation app that allows you to record audio while taking notes at the same time. It’s an excellent option for those who use dictation in an academic or commercial setting.
What Is Transcription?
Transcription is the process of converting spoken words into written text. Transcription can be achieved by using a human typist (still the most accurate form of transcription) or transcription software.
Transcription software—also called speech-to-text—uses artificial intelligence (AI) to automatically convert speech into written text. If you’ve ever used your phone’s voice-to-text feature, you’ve used transcription.
However, AI transcription isn’t perfect . It often has trouble transcribing language spoken quickly or with an accent.
For that reason, many people still prefer manual dictation. With manual transcription, you can simply upload an audio file and–voila!—a few hours later, you’ll have a super-accurate transcription of your dictation.
Transcription is used in a variety of settings, including:
- Sending texts on-the-go
- Note-taking during meetings or lectures
- Converting recorded interviews to text documents
- Making audio more accessible for those with disabilities
Types of Transcription
Different use cases require different types of transcription. Police interviews, for example, typically include every utterance spoken. Meeting notes, on the other hand, may not require the same level of detail. There are three types of transcription:
Verbatim transcription includes all features of speech, including laughing, sighing, and filler words like “um” and
Intelligent verbatim
Intelligent verbatim transcription is a type of transcription that accurately captures all spoken words, including filler words and false starts, while also providing context and meaning through the use of punctuation, formatting, and other techniques.
Edited transcription is a type of transcription that includes only the essential spoken words, omits filler words and false starts, and may also include additional context, meaning and punctuation for better readability and understanding.
This example of a legal letter transcription uses the edited style of transcription. However, there are some confusing formatting mistakes causing quality issues throughout the transcription document.
- There is no date included
- Dictation instructions are not omitted and have been incorrectly followed
- Missing punctuation
- Distracting misspellings
- Numerical formatting is incorrect
Check out this much more professional, correctly formatted example.
Dictation and transcription software & services
Human transcriptionists or transcription software can quickly convert audio or video recordings into written text. Here are a few of the best services and programs for getting faster transcriptions .
SpeakWrite uses 100% human transcription, employing professional transcriptionists trained in legal document formatting. SpeakWrite is also HIPAA compliant. It’s an excellent choice for medical, legal, and corporate professionals.
Scribie offers A.I. transcription that is manually reviewed by humans. It may be a good choice for basic transcription in non-commercial or non-official settings. However, you may incur extra costs if the audio quality is poor, if the speakers have accents, or if you need timestamps.
GoTranscript
GoTranscript is a transcription service that uses a combination of AI and manual processing. They offer a range of prices based on turnaround time, and there is no statement on their website about HIPAA compliance.
Rev offers fast, affordable A.I. transcription service. Though it will likely require a manual review, it may be a good option if you have the time to review and format the rough draft of your transcription.
Check out our transcription services case study to see what makes us the best transcription service available today!
What are the benefits of human transcription?
While there are many transcription services that use AI and speech recognition technology, good old fashioned professional typists are still considered the gold standard for accuracy and quality.
Here are a few reasons why.
Human transcriptionists follow formatting instructions.
A typist will listen to your formatting directions and follow them accurately. So you can communicate your specific formatting needs and have them carried out with precision.
For example, if you need specific formatting for a legal document, a human typist can ensure that your document is formatted correctly and meets the necessary legal standards.
Professional typists offer better value.
Another key benefit of human transcription is that it offers better value than automated transcription services. While automated transcription services can be faster and more cost-effective in some cases, the quality and accuracy of the transcription may not be up to par.
Typists, on the other hand, guarantee a high level of accuracy and quality, which is critical in legal, medical, and academic settings.
You can count on the pros to consider the context for better accuracy.
Human transcription is typically much more accurate than automated speech-to-text software. It makes sense—humans are able to understand the unique features of speech, such as accents, dialects, and idiomatic expressions. It may be difficult for a machine to interpret such nuances.
Additionally, humans can check for errors and make corrections, whereas automated transcription often produces errors that are difficult to detect and fix.
Human transcription services can handle background noise.
Human transcription services are able to handle background noise to a certain extent, whereas speech-to-text software often has trouble in such situations.
However, it is important to note that excessive background noise can make the speech difficult for the human transcribers to understand, which may lead to errors in the transcription. In such cases, it may be necessary to clean up the audio or use noise reduction techniques before sending it for transcription.
Frequently Asked Questions
Can a voice recording be transcribed.
Yes, a voice recording can be transcribed. Transcription services employ human typists to convert spoken audio into written text. You can also use AI transcription software but beware—it’s not as accurate.
What are some common problems with dictation and transcription?
- Accents and dialects: Speech-to-text software and human transcribers may have difficulty understanding and transcribing speech with heavy accents or dialects.
- Background noise: Excessive background noise can make the speech difficult to transcribe and can lead to errors.
- Idiomatic expressions and colloquial language: These can also be difficult for software to understand and transcribe accurately.
- Homophones: Words that sound the same but are spelled differently (e.g. “flower” and “flour”) can cause confusion for transcription software. However, human transcriptionists can use context to differentiate between the two.
- Technical terms and proper nouns: These can be difficult for AI to transcribe accurately, particularly if it has to do with advanced subject matter.
- Errors: Transcription software may make errors in transcription, particularly if the audio quality is poor or the speech is difficult to understand.
What can you use dictation and transcription services for?
Both dictation and transcription software have a number of use cases, including:
- Writing – Dictation software allows users to dictate their writing, which can be useful for those who struggle with typing or have mobility issues.
- Note-taking – Users can dictate notes during meetings, lectures, interviews , or patient consultations, and have them instantly transcribed into written form.
- Transcribing audio or video – Transcription software can be used to transcribe audio or video recordings, such as interviews, podcasts , or speeches, into written text.
- Captioning – Transcription software makes captioning and subtitling easy, which is helpful if you want to make your video or audio project accessible to all.
- Searchable text – Transcription software can help you create searchable text from audio or video recordings, making it easier to find specific information within the recording.
- Language translation – Some dictation and transcription software can be used to transcribe speech from one language to another.
- Medical and legal documentation – Medical and legal professionals often transcribe their dictated notes into patient charts, legal documents, and other official records.
- Everyday communication – Some users prefer to dictate text for social media, text messages, and email. Dictation makes a great hands-free option if you’re on the go or want to find ways to save time during the work day.
- Research and data analysis – Transcription software and services can be used to transcribe qualitative research data such as interviews or focus groups. You can search for keywords or phrases and break down the data for further analysis.
Ready for a Free Trial?
If you think transcription is the way to go, a professional transcription service such as Speakwrite can help. Speakwrite offers properly formatted transcriptions in as little as three hours.
It’s a super simple process that takes the headache out of transcription.
Our transcriptionists are trained in formatting and will listen carefully to your directions, so you can use your transcription however you need to. Get started with a free trial today and see how straightforward transcription can be!

Explore FAQs
Discover blogs, get support.

- Daily Crossword
- Word Puzzle
- Word Finder
- Word of the Day
- Synonym of the Day
- Word of the Year
- Language stories
- All featured
- Gender and sexuality
- All pop culture
- Grammar Coach ™
- Writing hub
- Grammar essentials
- Commonly confused
- All writing tips
- Pop culture
- Writing tips
- speech-to-text
or speech to text
a computerized, algorithmic process that transcribes a user’s spoken input into digital text, such as a video transcript rendered by auto caption (often used attributively): Speech-to-text is a great way to send a text when you are driving and can’t pick up your phone. Speech-to-text technology showed a bias toward certain mainstream accents and dialects in its speech recognition. Abbreviation : STT
Origin of speech-to-text
Words nearby speech-to-text.
- speechreading
- speech recognition
- speech sound
- speech synthesis
- speech therapy
- speechwriter
Dictionary.com Unabridged Based on the Random House Unabridged Dictionary, © Random House, Inc. 2024
- For Developers
Introduction to speech-to-text AI

Speech-to-text (STT), also known as Automatic Speech Recognition (ASR), is an AI technology that transcribes spoken language into written text. Previously reserved for the privileged few, STT is becoming increasingly leveraged by companies worldwide to embed new audio features in existing apps and create smart assistants for a range of use cases.
If you’re a CTO, CPO, data scientist, or developer interested in getting started with ASR for your business, you’ve come to the right place.
In this article, we’ll introduce you to the main models and types of STT, explain the basic mechanics and features involved, and give you an overview of the existing open-source and API solutions to try. With a comprehensive NLP glossary at the end!
A brief history of speech-to-text models
First, some context. Speech-to-text is part of the natural language processing (NLP) branch in AI. Its goal is to make machines able to understand and transcribe human speech into a written format.
How hard can it be to transcribe speech, you may wonder. The short answer is: very. Unlike images, which can be put into a matrix in a relatively straightforward way, audio data is influenced by background noise, audio quality, accents, and industry jargon, which makes it notoriously difficult for machines to grasp.
Researchers have been grappling with these challenges for several decades now. It all began with Weaver’s memorandum in 1949, which sparked the idea of using computers to process language. Early natural language processing (NLP) models used statistical methods like Hidden Markov Models (HMM) to transcribe speech, but they were limited in their ability to accurately recognize different accents, dialects, and speech styles.
The following decades saw many important developments — from grammar theories to symbolic NLP to statistical models — all of which paved the way for the ASR systems we know today. But the real step change in the field occurred in the 2010s with the rise of machine learning (ML) and deep learning .
Statistical models were replaced by ML algorithms, such as deep neural networks (DNN) and recurrent neural networks (RNNs) capable of capturing idiomatic expressions and other nuances that were previously difficult to detect. There was still an issue of context though: the models couldn’t infer meanings of specific words based on the overall sentence, which inevitably led to mistakes.
The biggest invention of the decade, however, was the invention of transformers in 2017. Transformers revolutionized ASR with their self-attention mechanism. Unlike all previous models, transformers succeeded at capturing long-range dependencies between different parts of speech, allowing them to take into account the broader context of each transcribed sentence.

The advent of transformer-based ASR models has reshaped the field of speech recognition. Their superior performance and efficiency have empowered various applications, from voice assistants to advanced transcription and translation services.
Many consider that it was at that point that we passed from mere ‘‘speech recognition” to a more holistic domain of “language understanding”.

We’re at the stage where Speech AI providers are relying on an increasingly more diverse and hybrid AI-based system, with each new generation of tools moving closer to mimicking the way the human brain captures, processes, and analyses, speech.
As a result of the latest breakthrough, the overall performance of ASR systems – in terms of both speed and quality – has improved significantly over the years, propelled by the availability of open-source repositories, large training datasets from the web, and more accessible GPU/CPU hardware costs.
How speech-to-text works
Today, cutting-edge ASR solutions rely on a variety of models and algorithms to produce quick and accurate results. But how exactly does AI transform speech into written form?
Transcription is a complex process that involves multiple stages and AI models working together. Here's an overview of key steps in speech-to-text:
- Pre-processing. Before the input audio can be transcribed, it often undergoes some pre-processing steps. This can include noise reduction, echo cancellation, and other techniques to enhance the quality of the audio signal.
- Feature extraction. The audio waveform is then converted into a more suitable representation for analysis. This usually involves extracting features from the audio signal that capture important characteristics of the sound, such as frequency, amplitude, and duration. Mel-frequency cepstral coefficients (MFCCs) are commonly used features in speech processing.
- Acoustic modeling. Involves training a statistical model that maps the extracted features to phonemes , the smallest units of sound in a language.
- Language modeling. Language modeling focuses on the linguistic aspect of speech. It involves creating a probabilistic model of how words and phrases are likely to appear in a particular language. This helps the system make informed decisions about which words are more likely to occur, given the previous words in the sentence.
- Decoding. In the decoding phase, the system uses the acoustic and language models to transcribe the audio into a sequence of words or tokens. This process involves searching for the most likely sequence of words that correspond to the given audio features.
- Post-processing. The decoded transcription may still contain errors, such as misrecognitions or homophones (words that sound the same but have different meanings). Post-processing techniques, including language constraints, grammar rules, and contextual analysis, are applied to improve the accuracy and coherence of the transcription before producing the final output.
Key types of STT models
The exact way in which transcription occurs depends on the AI models used. Generally speaking, we can distinguish between the acoustic legacy systems and those based on the end-to-end deep learning models.
Acoustic systems rely on a combination of traditional models like the Hidden Markov models (HMM) and deep neural networks (DNN) to conduct a series of sub-processes to perform the steps describe above.
Transcription process here is done via traditional acoustic-phonetic matching, i.e. the system attempts to guess the word based on the sound. Because each step is executed by a separate model, this method is prone to errors and can be rather costly and inefficient due to the need to train each model involved independently.
In contrast, end-to-end systems , powered by CNNs, RNNs, and/or transformers, operate as a single neural network, with all key steps merged into a single interconnected process. A notable example of this is Whisper ASR by OpenAI .

Designed to address the limitations of legacy systems, this approach allows for greater accuracy thanks to a more elaborate embeddings-based mechanism, enabling contextual understanding of language based on the semantic proximity of each given word.
All in all, end-to-end systems are easier to train and more flexible. They also enable more advanced functionalities, such as translation, and generative AI tasks, such as summarization and semantic search.
If you want to learn about the best ASR engines on the market and models that power them, see this dedicated blog post .
Note on fine-tuning
As accurate as last-generation transcription models are, thanks to new techniques and Large Language Models (LLMs) that power them, they still need a little help before they can be applied to specific use cases without compromising the output accuracy. More specifically, the models may need additional work before they can be used for specific transcription or audio intelligence tasks.
Fine-tuning consists of adapting a pre-trained neural network to a new application by training it on task-specific data. It is key to making high-quality STT commercially viable.
In audio, fine-tuning is used to adapt models to technical professional domains (i.e. medical vocabulary, legal jargon), accents, languages, levels of noise, specific speakers, and more. In our guide to fine-tuning ASR models , we dive into the mechanics, use cases and application of this technique in a lot more details.
Thanks to fine-tuning, a one-size-fits-all model can become tailored to a wide variety of specific and niche use cases – without the need to retain it from scratch.
Key features and parameters
All of the above-mentioned models and methodologies unlock an array of value-generating features for business. To learn more about the benefits it presents across various industries, check this article .
Beyond core transcription technology, most providers today offer a range of additional features —from speaker diarization , to summarization, to sentiment analysis – collectively referred to as “audio intelligence.”

With APIs, the foundational transcription output is not always executed by the same model as the one(s) responsible for the “intelligence” layer. In fact, the combination of several models is usually used by commercial speech-t-text providers to create high-quality and versatile enterprise-grade STT APIs.
Transcription: key notions
There are a number of parameters that affect the transcription process and can influence one’s choice of an STT solution or provider. Here are the key ones to consider.
- Format: Most transcription models deliver different levels of quality depending on the audio file format (m4a, mp3, mp4, mpeg), and some of them will only accept specific formats. Formats will apply differently depending on whether the transcription is asynchronous or live.
- Audio encoding : Audio encoding is the process of changing audio files from one format to another, for example, to reduce the number of bits needed to transmit the audio information.
- Frequency: There are minimal frequencies under which the sound is intelligible for speech-to-text models. Most audio files being produced today are at a minimum of 40 kHz, but some types of audio – such as phone recordings from call centers – are at lower frequencies, resulting in recordings at 16 kHz or even 8kHz. Higher frequencies, such as mp3 files at 128Khz, need to be resampled.
- Bit depth : Bit depth indicates how much of an audio sample’s amplitude was recorded. It is a little like image resolution but for sound. A file with a higher bit depth will represent a wider range of sound, from very soft to very loud. For example, most DVDs have audio at 24 bits, while most telephony happens at 8 bits.
- Channels: Input audio can come in several channels: mono (single channel), stereo (dual-channel); multi-channel (several tracks). For optimal results, many speech-to-text providers need to know how many channels are in your recording, but some of them will automatically detect the number of channels and use that information to improve transcription quality.
Any transcription output should have a few basic components and will generally come in the form of a series of transcribed text with associated IDs and timestamps.
Beyond that, it’s important to consider the format of the transcription output. Most providers will provide, at the very least, a JSON file of the transcript containing at least the data points mentioned above. Some will also provide a plain text version of the transcript, such as a .txt file, or a format that lends itself to subtitling, such as SRT or VTT.
Performance
Latency refers to the delay between the moment a model receives an input (i.e., the speech or audio signal) and when it starts producing the output (i.e., the transcribed text). In STT systems, latency is a crucial factor as it directly affects the user experience. Lower latency indicates a faster response time and a more real-time transcription experience.
In AI, inference refers to the action of ‘inferring’ outputs based on data and previous learning. In STT, during the inference stage, the model leverages its learned knowledge of speech patterns and language to produce accurate transcriptions.
The efficiency and speed of inference can impact the latency of an STT system.
The performance of an STT model combines many factors, such as:
- End-to-end latency (during uploads, encoding, etc.)
- Robustness in adverse environments (e.g. background noise or static).
- Coverage of complex vocabulary and languages.
- Model architecture, training data quantity and quality.
Word Error Rate (WER) is the industry-wide metric used to evaluate the accuracy of a speech recognition system or machine translation system. It measures the percentage of words in the system's output that differ from the words in the reference or ground truth text.

Additional metrics used to benchmark accuracy are Diarization Error Rate (DER) , which assesses speaker diarization and Mean Absolute Alignment Error (MAE) for word-level timestamps.
Even state-of-the-art multilingual models like OpenAI’s Whisper skew heavily towards some languages, like English, French, and Spanish. This happens either because of the data used to train them or because of the way the model weighs different parameters in the transcription process.
Additional fine-tuning and optimization techniques are necessary to extend the scope of languages and dialects, especially where open-source models are concerned.
Audio Intelligence
For an increasing number of use cases, transcription alone is not enough. Most commercial STT providers today offer at least some additional features, also known as add-ons, aimed at making transcripts easier to digest and informative, as well as to get speaker insights. Here are some examples:

A full list of features available with our own API can be found here .
When it comes to data security, hosting architecture plays a significant role. Companies that want to integrate Language AI into their existing tech stack need to decide where they want the underlying network infrastructure to be located and who they want to own it: cloud multi-tenant (SaaS), cloud single-tenant, on-premise, air-gap.
And don’t forget to inquire about data handling policies and add-ons. After all, you don’t always wish for your confidential enterprise data to be used for training models. At Gladia , we comply with the latest EU regulations to ensure the full protection of user data.
What can you build with speech-to-text
AI speech-to-text is a highly versatile technology, unlocking a range of use cases across industries. With the help of a specialized API, you can embed Language AI capabilities into existing applications and platforms, allowing your users to enjoy transcriptions, subtitling, keyword search, and analytics. You can also build entirely new voice-enabled applications, such as virtual assistants and bots.
Some more specific examples:
- Transcription services : Written transcripts of interviews, lectures, meetings, etc.
- Call center automation : Converting audio recordings of customer interactions into text for analysis and processing.
- Voice notes and dictation : Allow users to dictate notes, messages, or emails and convert them into written text.
- Real-time captioning: Provide real-time captions and dubbing for live events, conferences, webinars, or videos.
- Translation: Real-time translation services for multilingual communication.
- Voice and keyword search : Search for information using voice commands or semantic search.
- Speech analytics: Analyze recorded audio for sentiment analysis, customer feedback, or market research.
- Accessibility : Develop apps that assist people with disabilities by converting spoken language into text for easier communication and understanding.
Current market for speech-to-text software
If you want to build speech recognition software, you’re essentially confronted with two options — build it in-house on top of an open-source model, or pick a specialized speech-to-text API provider.
Here’s an overview of what we consider to be the best alternatives in both categories.

The best option ultimately depends on your needs and use case. Of all the open-source models, Whisper ASR is generally considered the most performant and versatile model of data, trained on 680,000 hours of data. It has been selected by many indie developers and companies alike as a go-to foundation for their ASR efforts.
Open source vs API
Here are some factors to consider when deploying Whisper or other open-source alternatives in-house:
- Do we possess the necessary AI expertise in-house to deploy a model in-house and make the necessary improvement to adapt it at scale?
- Do we need just batch transcription? Or also live one? Do we need additional features, like summarization?
- Are we dealing with multilingual clients?
- Is our case-specific and requires a dedicated industry-specific vocabulary?
- How much time can we afford to postpone going-to-market with the in-house solution in production? Do we have the necessary hardware (CAPEX) for it, too?
Based on first-hand experience with open-source models in speech-to-text, here are some of our key conclusions on the topic.
- In exchange for full control and adaptability afforded by open source, you have to assume the full burden of hosting, optimizing, and maintaining the model . In contrast, speech-to-text APIs come as pre-packaged deal with optimized models (usually hybrid architectures and specialized language models), custom options, regular maintenance updates, and client support to deal with downtime or other emergencies.
- Open-source models can be rough around the edges (i.e. slow, limited in features, and prone to errors), meaning that you need to have at least some AI expertise to make them work well for you. To be fully production-ready and function reliably at scale, it would more realistically require a dedicated team to guarantee top performance.
- Whenever you pick the open-source route and build from scratch, your time-to-market increases . It’s important to conduct a proper risk-benefit analysis, knowing that your competitors may pick a production-ready option in the meantime and move ahead.
Commercial STT providers
Commercial STT players in the space provide a range of advantages via plug-and-play API, such as flexible pricing formulas, extended functionalities, optimized models to accommodate niche use cases, and a dedicated support team.
Beyond that, you’ll find a lot of differences between the various providers on the market.
Ever since the market for STT opened up to the general public, solutions provided by Big Tech providers such as AWS, Google, or Microsoft as part of their wider suite of services have stayed relatively expensive and poor in overall performance compared to specialized providers.
Moreover, they tend to underperform on the five key factors used to assess the quality of ASR transcription: speed, accuracy, supported languages, and extra features. Anyone looking for a provider in the space should take careful consideration of the following:
- When it comes to the speed of transcription, there is a significant discrepancy between providers, ranging from as little as 10 seconds to 30 minutes or more. The latter is usually the case for the Big Tech players listed above.
- Speed and accuracy are inversely proportional in STT, with some providers striking a significantly better balance than others between the two. Whereas Big Tech providers have a WER of 10%-18%, many startups and specialized providers are within the 1-10% WER range. That means, for every 100 words of transcription with a Big Tech provider, you’ll get at least 10 erroneous words.
- Number of supported languages is another differentiator to consider. Commercial offers range from 12 to 99+ supported languages. It is important to distinguish between APIs that enable multilingual transcription and/or translation and those that extend this support to other features as well.
- Availability of audio intelligence features and optimizations, like speaker diarization, smart formatting, custom vocabulary, word-level timestamps, and real-time transcription, is not to be overlooked when estimating your cost-benefit ratio. These can come as part of the core offer, as in the case of Gladia API, or be sold as a separate unit or bundle.
- Finally, how does this all come together to affect the price ? Once again, the market offers are as varied as you’d expect. On the high end, Big Tech providers charge up to $1.44 per hour of transcription. In contrast, some startup providers charge as little as $0.26. Some will charge per minute, while others have hourly rates or tokens, and others still only offer custom quotes.
Some additional resources to help you navigate the commercial market:
- Main red flags to look out for when picking an STT provider;
- Open source vs API , which compares Whisper ASR to STT APIs in terms of benefits, limitations, and total cost of ownership .
And that’s a wrap! If you enjoyed our content, feel free to subscribe to our newsletter for more actionable tips and insights on Language AI.
Ultimate Glossary of Speech-to-Text AI
Speech-to-Text - also known as automatic speech recognition (ASR), it is the technology that converts spoken language into written text.
Natural Language Processing (NLP) - a subfield of AI that focuses on the interactions between computers and human language.
Machine Learning - a field of artificial intelligence that involves developing algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed for specific tasks.
Neural Network - a machine learning algorithm that is modelled after the structure of the human brain.
Deep Learning - a subset of machine learning that involves the use of deep neural networks.
Acoustic Model - a model used in speech recognition that maps acoustic features to phonetic units.
Language Model - a statistical model used in NLP to determine the probability of a sequence of words.
Large Language Model (LLM) - advanced AI systems like GPT-3 that are trained on massive amounts of text data to generate human-like text and perform various natural language processing tasks.
Phoneme - the smallest unit of sound in a language, which is represented by a specific symbol.
Transformers - a neural network architecture that relies on a multi-head self-attention mechanism -among other things- which allows the model to attend to different parts of the input sequence to capture its relationships and dependencies.
Encoder - in the context of neural networks, a component that transforms input data into a compressed or abstract representation, often used in tasks like feature extraction or creating embeddings.
Decoder - a neural network component that takes a compressed representation (often from an encoder) and reconstructs or generates meaningful output data, frequently used in tasks like language generation or image synthesis.
Embedding - a numerical representation of an object, such as a word or an image, in a lower-dimensional space where relationships between objects are preserved. Embeddings are commonly used to convert categorical data into a format suitable for ML algorithms and to capture semantic similarities between words.
Dependencies - a relationships between words and sentences in a given text. Can be related to grammar and syntax or can be related to the content’s meaning.
Speaker Diarization - the process of separating and identifying who is speaking in a recording or audio stream. You can learn more here .
Speaker Adaptation - the process of adjusting a speech recognition model to better recognize the voice of a specific speaker.
Language Identification - the process of automatically identifying the language being spoken in an audio recording.
Keyword Spotting - the process of detecting specific words or phrases within an audio recording.
Automatic Captioning - the process of generating captions or subtitles for a video or audio recording.
Speaker Verification - the process of verifying the identity of a speaker, often used for security or authentication purposes.
Speech Synthesis - the process of generating spoken language from written text, also known as text-to-speech (TTS) technology.
Word Error Rate (WER) - a metric used to measure the accuracy of speech recognition systems.
Recurrent Neural Network (RNN) - a type of neural network that is particularly well-suited for sequential data, such as speech.
Fine-Tuning vs. Optimization - fine-tuning involves training a pre-existing model on a specific dataset or domain to adapt it for better performance, while optimization focuses on fine-tuning the hyperparameters and training settings to maximize the model's overall effectiveness. Both processes contribute to improving the accuracy and suitability of speech-to-text models for specific applications or domains.
Model Parallelism - enables different parts of a large model to be spread across multiple GPUs, allowing the model to be trained in a distributed manner with AI chips. By dividing the model into smaller parts, each part can be trained in parallel, resulting in a faster training process compared to training the entire model on a single GPU or processor.
About Gladia
At Gladia, we built an optimized version of Whisper in the form of an API, adapted to real-life business use cases and distinguished by exceptional accuracy, speed, extended multilingual capabilities, and state-of-the-art features, including speaker diarization and word-level timestamps.

Speech-To-Text
How do speech recognition models work?
Automatic speech recognition (ASR) is a cornerstone of many business applications in domains ranging from call centers to smart device engineering. At their core, ASR models, also referred to as Speech-to-Text (STT), intelligently recognize human speech and convert it into a written format.

Fine-tuning ASR models: Key definitions, mechanics, and use cases
Many modern AI models are built for general-purpose applications and require fine-tuning for domain-specific tasks. The fine-tuning process involves taking an existing model and training it further on domain-specific data. The additional training allows the model to understand the new data and improve its performance in a particular field.

Building a song transcription system with profanity filter using Whisper, GPT 3.5 and Spleeter
The inception of music streaming gained initial popularity in 1999 with the founding of Napster, one of the pioneering streaming platforms. Millions of songs were available to listen to and download for free through the platform using the internet. One no longer needed to buy pre-recorded tapes, go to live shows, or tune into radio stations to listen to music.
Become the Speech AI expert in your organization with content from Gladia right in your inbox, no more than twice a month.
- Talkatoo Dictation + Dictation Assistant
- Human Verified Records
- Download Talkatoo Desktop
- Download Talkatoo Mobile
- Customer Stories
- Desktop Dictation Onboarding
- Auto-SOAP Onboarding
- Help Center
- Book a Demo
- Download Now
- Instagram icon
- Twitter icon
Dictation, Speech-to-text, Transcription – What’s the Difference?

In today’s digital age, we are lucky to have so many different kinds of software that help make our lives a little bit easier. Dictation software is one that is particularly helpful to the medical field both human and veterinarian. By definition , dictation is “the action of saying words aloud to be typed, written down, or recorded on tape.” You may have also heard this definition applied to speech-to-text and transcription software, as well.
While dictation software, speech-to-text software, and transcription software all perform the same essential function (turning the spoken word into something that can be read), they each have their own definitions that are a bit nuanced. Let’s discuss their differences and how they can help you at work!
Dictation Software
When we talk about dictation software, we’re really talking about dictation technology. It can be considered as the umbrella term for the different types of software that help turn words you can hear into words you can read.
There are a few different types of methods of using dictation technology:
- Built-in dictation software – Most smart phones and computers are built with dictation software that works with the device’s built-in microphone. This is what allows users to use “speech-to-text” features.
- Dictation apps – Even if a decide has built-in dictation software, it may not be compatible with certain programs or be suitable for your specific needs. Dictation apps can be downloaded on computers, tablets, and smartphones to be used on their own or in conjunction with other apps.
- Dictation software programs – Typically, these will have more features than dictation apps or built-in dictation software. These programs work with users to learn their vernacular and style of speaking to provide a more personalized and accurate experience.
Let’s take a deeper dive into how dictation software can be used.
Speech-to-text
Speech-to-text software is exactly what it sounds like: it turns your speech into readable content. This can be incredibly helpful in situations where you need to take accurate notes (like SOAP notes) but want to make sure you’re really listening to the speaker.
Speech-to-text is much more efficient than using a voice recording device because you don’t have to listen to an entire conversation just to recall a certain detail! With speech-to-text software, you can skim the words on the page until you find what you’re looking for.
Transcription Software
Transcription software helps turn spoken word into readable text, but most will only turn pre-recorded audio files into text – they cannot be used in real-time. There are also transcription services that you can utilize in which a human being transforms your recordings into text files. However, this method can be time-consuming and pricey!
If you have a collection of audio notes that you need turned into readable content, transcription software can be very helpful.
Save Time & Money with Talkatoo Dictation Software
Talkatoo Dictation software is built with artificial intelligence that does so much more than turn your words into readable text – it learns your specific style of speaking so it just gets better and better every time you use it!
Talkatoo dictation software includes speech-to-text and transcription services so you’ll never have to miss a word again. Save time writing your notes and improve your accuracy with Talkatoo!
Stay up to date.
Join our mailing list for product updates, client success stories, and the occasional cat video.

Comparing Dictation and Transcription: Key Differences and Benefits

Transkriptor 2024-01-17
Dictation is the act of expressing verbally what is said about a subject in order to put it into writing. Transcription is the conversion of spoken words or audio content into writing. Dictation is a process used in different fields such as journalism, medicine, law, and business environment. Dictation and transcription enable the spoken words to be converted into writing.
Thus, what is said is translated into text by a dictation machine without the need for any manual operation. Dictating involves the speaker articulating their thoughts, ideas, or information in a clear and structured manner, facilitating accurate conversion into written text during the transcription process. The most important difference between dictation and transcription is the transmission process. Dictation is the conversion of what is spoken into writing, whereas transcription involves converting an audio recording into written form.
Dictation and transcription are able to be used for many different purposes. Transcription plays a crucial role in the medical field, particularly during the process of obtaining patient histories, as well as in the legal domain, where it is employed to accurately record statements and court hearings. Journalists have the ability to expediently transcribe their interviews through the utilization of a dictation machine.
What is Dictation?
Dictation is the recording of spoken words by transcribing them into writing. Dictation is a method used in teaching reading and writing in education. People also use speech recognition software in everyday tasks such as sending text messages, setting reminders, or searching the web using voice commands.
Dictation is related to the writing system called shorthand. Dictation and transcription system is one of the most used shorthand writing systems. Speech recognition technology made major strides in the 1970s, thanks to interest and funding from the U.S. Department of Defense.
The vocabulary of voice recognition increased from a few hundred to several thousand words. Computers with faster processors developed and voice dictation software became available to the public in the 1990S.
How Does Dictation Work?
Dictation works by transcribing spoken expressions into text using voice recognition technology. Voice recognition technology performs dictation by incorporating various technologies. Machine Learning and Deep Learning are some of the most used technologies. First, the sound is recorded with a microphone, and machine learning separates its sound into words and sentences with language models. Thus, the transfer of the expressions in the speech is completed. Lastly, the transmitted text is divided into sentences by artificial intelligence and the transcription of the speech is prepared.
Medical dictation is the method used in medicine when taking anamnesis from the patient. It has been used by doctors for a long time to detect the disease. Smartphones stand out as the best dictation and transcription equipment today. Dictations are conveniently performed through the utilization of transcription programs that are available to download onto both iPhone and Android phones.

What are the Uses of Dictation?
The use of dictations are listed below.
- Medical Transcription: Doctors and healthcare professionals provide evidence for treatment by recording patients' disease history and information.
- Note Taking: Dictation is used by students to record lectures, study for exams, and prepare study notes.
- Interviews and Research: Researchers and recruiters record their interviews.
- Business Communication: Notes are taken on what is said in business meetings, what will be done in the next meeting, and handover procedures.
- Legal Process: In court cases, during the examination of witnesses and the taking of their statements, what is recorded through dictation is documented. Recording legal statements with a transcription application saves time.
- Subtitles: Dictation is used to convert speech in movies into subtitles.
What Industry Uses Dictation?
The industries that use dictation are music, media, business, and education. Journalists and reporters use dictation to transcribe interviews, capture field notes, and draft news stories. Dictation is important for transferring notes of business meetings.
Dictation transcribes meeting records and puts them into writing. Transcribing meeting notes and working plans makes things easier. Education, like the business and media sectors, is one of the areas. Students are able to quickly transcribe lecture recordings and conferences into notes.
What is the Purpose of Dictation?
The purpose of dictation is converting spoken words into written text efficiently and accurately. Modern dictation software and technologies have advanced speech recognition capabilities, enhancing the accuracy of transcribed text and reducing errors associated with manual data entry. Voice recorders, smartphones, and computers are used as dictation and transcription equipment. The purpose of dictation is to transcribe spoken expressions accurately and effectively. With transcription dictation, real-time conversations are quickly transferred to writing.
What is the Best Dictation software?
The 3 best dictation software is listed below.
Transkriptor
- Google Speech API

Transkriptor is available in Android, Apple, and Web versions. It quickly converts audio files of different formats into text.
Google Speech API recognizes multiple languages and accents and converts them into text.
Otter.ai is an application for automatically creating transcripts and taking notes. Transcribing dictation is also available in the free version.
Google Speech API, Transkriptor, and Otter.ai are the best dictation software . Users are able to choose between them based on their needs.
What Situations Favor Dictation over Transcription?
Dictation is preferred over transcription to transcribe words that are difficult to say or in environments where voice recording is not possible. The recording of audio becomes difficult in situations necessitating the protection of personal data. The use of dictation facilitates the process of manual transcribing in some instances. Dictation is additionally used in education to teach reading and writing. Dictation is a tool employed in the context of speech problems, word spelling, and learning a new language. Dictation is preferred over transcription in customer service when delivering names and addresses.

Is Dictation the Same as Speech Recognition?
No, speech recognition, unlike dictation, includes features such as voice-controlled systems and acoustic analysis of the voice. Dictation is essential in converting voice to text. Speech recognition is used in mobile applications, navigation, and security systems.
What is Transcription?
Transcription is the recording of voice-transmitted expressions in writing. Transcription allows for the writing down and recording of conversations, meetings, course material, and court minutes. It is possible to convert voice to text with transcription software developed with artificial intelligence.
Dictation definition has similar meanings to transcription. Dictation and transcription services perform identical tasks. Transcription begins after recording the audio.
How Does Transcription Work?
Transcription works with voice recognition and artificial intelligence technologies. Transcription consists of 3 stages: audio recording, analysis of the audio file, proofreading, and formatting.
First, the sound is recorded with a digital voice recorder for dictation and transcription. The recorded audio is then converted to an audio file format. The audio file is converted into words using artificial intelligence and language processing models through dictation services.
Second, the sound is transformed into text by taking into account the rules of spelling and punctuation. Third, the transcription text is reviewed manually. Lastly, the proofreading stages come to the stage.
What are the Uses of Transcription?
The uses of transcription are listed below.
- Business: It makes it easier to implement the outcomes of the meetings and planning.
- Education: Dictation and transcription for converting audio into text from lecture recordings and videos effortlessly create quick notes.
- Media: People use transcription in the media industry for editing interviews, creating news texts, and creating subtitles from audio recordings.
- Research: Word analysis and transcription for emotion detection are very helpful in studies or research. It becomes easier to detect the emotion in the audio file and analyze the words used with language processing models.
- Medical Records: Transcription is helpful in taking patients' anamnesis and disease history and turning them into an index.
- Podcasting: Dictation and transcription turn podcasts into subtitles on YouTube or to transcribe.
- Language Learning: People use dictation in language learning for correct pronunciation and vocabulary learning.
- Accessibility: It is easy for deaf and hard of hearing individuals to listen to audio files by converting them into text through transcription.
What Industry Uses Transcription?
The industries that use transcription are media, reporters, journalists, legal, lawyers and so on.
Transcription is frequently used in the preparation of case reports in law. What is said must be transcribed and recorded. For this reason, case officers record what is said in the case. Nowadays, transcription is frequently used in fields such as business and research. While conducting market research in businesses, interviews are held with customers. Business strategy is determined according to the outputs of this research. Researchers use transcription for analysis when conducting qualitative research. It can take a long time to put what is said into writing. With transcription software, it has now become easier to transcribe what is said within seconds.
What is the Purpose of Transcription?
The purpose of transcription is to convert audio into text. It makes it easier to transcribe speech into text in cases, interviews, and qualitative research.
Some software companies, such as Transkriptor, use voice recognition technology to distinguish who speaks in conversations. It makes transcribing audio recordings involving multiple speakers, such as meetings and conferences, into notes easier.
What Situations Favor Transcription over Dictation?
Transcription software is used when fast transcription is required instead of dictation. Transcription is more effective than dictation in converting online meetings, video recordings, and digital audio files into text.
Many of the best transcription software have integration with different applications. Machine transcription uses many technologies provided by artificial intelligence, such as natural language processing models.
What is the best transcription software?
The best transcription software is Transkriptor. Transkriptor as a best transcription software converts audio content from meetings and movies into written text. Translating the transcription output obtained from Transkriptor into many languages is also easy.
What are the Key Differences between Dictation and Transcription?
The key differences between dictation and transcription are listed below.
- Live vs. Pre-recorded: Dictation is a live process where the speaker speaks.
- Applications: Dictation is often used for creating documents, emails, or text messages quickly and efficiently.
- Input Source: The input source for dictation is live speech, typically involving a person speaking directly to a transcription tool. The input source for transcription is pre-recorded audio, such as interviews, meetings, or audio files.

Is Dictation more Accurate than Transcription?
No, dictation is no more accurate than transcription. Errors occur even in authentic human dictations. Most stenographers use the "Gregg Shorthand Dictation" method when dictating. Transcription converts audio into text more quickly and clearly.
What is the Cost Difference between Dictation and Transcription?
The difference in cost between dictation and transcription is that digital transcription is cheaper than dictation. It is also possible to transcribe for free with the trial version of most transcription software. Additionally, using transcription and dictation software will provide faster results.
Dictation and transcription software companies have different subscription packages. The subscription packages offer different pricing depending on usage needs. Thus, customers can receive transcription services at an affordable price by choosing a subscription that suits their requirements.
What is the Difference in Dictation and Transcription Turnaround Times?
The difference between dictation and transcription turnaround times is in favor of transcription. Transcription also uses voice recognition technologies, it is faster than dictation. It also helps to get results quickly by saving time.
In addition, transcription and dictation software that provides transcription services also includes different services with artificial intelligence integrations. Users use artificial intelligence to ask questions and create bullet points with the text results after the transcription process. The dictation process takes place manually, so there is a need for more time for the recording and editing stages.
Frequently Asked Questions
Speech recognition plays a crucial role in both dictation and transcription by converting spoken language into text. In dictation, it facilitates real-time speech-to-text conversion, while in transcription, it processes recorded audio to generate a written transcript.
Yes, there are dictation tools available that also offer transcription features. These tools combine the functionality of converting real-time speech into text with the ability to transcribe pre-recorded audio files.
Yes, advanced transcription software can accurately capture complex technical terms, especially if it has been trained or customized for specific jargon or industries.
Speech to Text
Convert your audio and video files to text
Audio to Text
Video Transcription
Transcription Service
Privacy Policy
Terms of Service
Contact Information
© 2024 Transkriptor
- Features for Creative Writers
- Features for Work
- Features for Higher Education
- Features for Teachers
- Features for Non-Native Speakers
- Learn Blog Grammar Guide Community Events FAQ
- Grammar Guide
The Dictation Sensation: A Beginner's Guide to Speech-to-Text Writing

Kyle A. Massa

I’m not writing this article. I’m speaking it.
Dictation is a popular trend in the writing community of late. It’s a method of writing where you speak words rather than write or type them, then have an app transcribe those words for you.
Like any new method of doing anything, there are pros and cons to dictation. In this article, we’ll explore both.
Dictation Apps
Closing thoughts.
You say it, the app writes it. That’s dictation in a nutshell. Popular dictation apps include:
- Apple Dictation
- Dragon Anywhere
- Dictation – Speech to Text
- Amazon Transcribe
Some of these apps are free, some are paid. They’re all similar, so I’d recommend trying several to find your favorite.
Now, let’s examine the pros and cons of dictating your work.
What’s the primary advantage of dictation? Speed (not to be confused with the Keanu Reeves movie)! Dictation is far faster than typing, and certainly faster than writing by hand.
I’ll give you a personal example. Every weekday morning, I write 2,000 words. Depending on how inspired I’m feeling, this can take anywhere from two to three hours. Sometimes I still don’t finish, so I need to tack on another hour in the evening.
This all might go faster if I was a better typist. Unfortunately, I never took those Mavis Beacon computer lessons, so I type with about half as many fingers as I probably should. Even if I typed at 60 words per minute (which is about 10 words faster than the average ), it would take me about 33 minutes just to type my words. And handwriting is even slower, with most 9th graders writing about 24 words per minute .
Dictation is generally the most efficient way to work, since the average person talks faster than they type or write. To illustrate, I challenged myself to a little test. Using a one-minute typing exercise on TypingTest.com , I typed 50 words per minute. Not great, but slightly above average. I then took the same test, only this time I said the words rather than typing them. I dictated 117 words in a minute. With speed like that, I'm lucky I didn't get a ticket!

Furthermore, dictation is perfect for our multitasking age. On busy days, sometimes I complete my daily word count by dictating during my drive to work. Better yet, when inspiration strikes, I can write a piece no matter where I am, so long as I have my phone (and it's appropriate to talk). Dictation is far easier than finding a notebook and pen or booting up a laptop.
Finally, you might find that dictation actually changes the way you write. For example, when I write on my computer, my writing feels more literary. I’m much more likely to use figurative language or elaborate imagery. When dictating, on the other hand, my writing feels much more conversational and spontaneous, since I’m actually saying it aloud. Therefore, I’ve found I have more success typing short stories and novels, especially those with an omniscient narrator. Dictation works best for me when I’m writing articles with a first person, conversational tone. (Like the articles I write here at ProWritingAid!)
Though I love dictation, I must admit, it can get sloppy. Even superior dictation software occasionally misunderstands words. For instance, in the paragraph above, my phone mistook the word “ProWritingAid” for “prorating eight.”
It’s inevitable, but still annoying. Occasionally I’ll return to a dictated piece and find a word jumble I can’t interpret. Sometimes I can figure it out, but sometimes I need to scrap the sentence entirely. That can be discouraging.
Also, I do feel dictation lacks the refinement of pen and paper or keys. Since you’re freewheel ramblin’, your prose tends to meander, and therefore requires more editing time post-creation. Yes, you save time upfront in the actual computation stage. But be warned: you’ll probably give some of that time back in editing.
That said, editing doesn’t have to be too painful. With tools like ProWritingAid , you can cut down on editing time by having software highlight potential errors for you. It includes a grammar checker but also goes way beyond grammar checking to help you improve the style and clarity of your writing. The editor analyses your text and highlights a variety of key writing issues by running reports. My favorites for dictated writing are the overused words, sentence structure, and readability reports. These help me work out where I strayed from the point when dictating, and stop long sentences that sound short when spoken from sneaking into my writing.
Writing via dictation is a skill, and therefore requires practice. Don’t expect great results on the first few tries. And, like some skills, you might discover you don’t have the patience to improve at it. If your writing always comes out better through traditional means, stick with them. Dictation might not be right for you.
I hope this article helped inform you about dictation. But it’s just like they say—there’s no substitute for experience. Try dictation and see if it helps your writing. Take advantage of those free app trials or, if you have a smartphone, try the built-in microphone capabilities. See what works for you!
Have you dictated your writing recently? Try ProWritingAid's editor for yourself.

Be confident about grammar
Check every email, essay, or story for grammar mistakes. Fix them before you press send.
Kyle A. Massa is the author of the short fiction collection Monsters at Dusk and and the novel Gerald Barkley Rocks. He lives in upstate New York with his wife and their two cats. Learn more about Kyle and his work at his website, kyleamassa.com.
Get started with ProWritingAid
Drop us a line or let's stay in touch via :
Winscribe end of life : Special migration offers available!
Which device to use for speech to text and dictation?
Speech recognition

When it comes to speech to text or digital dictation, it all comes down to recognition quality. Only a high speech recognition rate can ensure a user-friendly interface, which is key to long term adoption at any organization.

The recognition accuracy depends on many factors, such as the environment. A noisy environment by itself, or even some background noise, can have a negative effect on the recognition quality. This means that not only human typists, but also automatic speech recognition systems, can reach their limits. Mumbling, unclear speech, dialect, a missing structure - a good recognition rate also depends on the speaker.
What is often forgotten is the hardware, meaning the input device for speech recognition (or speech to text) and digital dictation.
Smartphone apps are not suitable for heavy users
Many people use dictation and speech-to-text with smartphone apps, such as Philips SpeechLive or apps from other manufacturers. The advantages are obvious: working on the go from anywhere, following up on meetings straight away, quickly sending another email from home or jotting down thoughts after work? With a smartphone, innovative voice technology is always at hand.
However, there are a few shortcomings that can get in the way of heavy users in particular. For example, recordings get interrupted when a call comes in, which can become annoying when you are in the middle of a recording. The microphones of a smartphone are not designed for dictation and speech recognition, and the storage space quickly reaches its limits as well. Last but not least, the ergonomics (handling of the device) are not ideal either, since you have to keep the record button pressed all the time.
This is why using special devices for speech recognition and digital dictation is so important.
Best microphones for speech to text
Specialized microphones for speech recognition and dictation, for example the SpeechMike series from market leader Philips, have been specifically developed for this purpose. The microphone is decoupled from the device housing, which means that background or operating noises get suppressed. A built-in motion sensor mutes the microphone when not in use, to avoid unnecessary recording and speech recognition that would then need to be manually edited out of a transcript.
The Philips SpeechMike microphones are natively integrated into Philips SpeechLive, allowing them to work seamlessly without any additional configuration. So if you want to use speech recognition with SpeechLive, for example, directly in different applications or in the web browser, Philips SpeechMike is the ideal tool.
Dictation and transcription devices
As described above, smartphone apps are not ideal for high-volume dictation or speech to text. However, if you still want to use speech recognition and digital dictation remotely and on the go, Philips Digital PocketMemos can come in handy. These robust, portable dictation devices come with microphones that are designed to accurately recognize recordings from multiple sound sources, such as conferences, but also from individual speakers, for example, for speech recognition purposes. A particularly popular feature is the slide switch, which allows you to control recordings in a convenient way. Recordings can be encrypted in real time using Advanced Encryption Standard and the device can be protected from unauthorized access using a PIN code.
For transcription staff who already have a dictation workflow in place, there are also foot pedals and headphones available that work seamlessly with Philips SpeechLive.
Philips SpeechLive is vendor independent
Overall, a speech-to-text solution like Philips SpeechLive, combined with streamlined speech recognition, dictation and transcription hardware, gives you the perfect tools to efficiently turn speech into text.
Although we would recommend our customers to use hardware from the market leader Philips, SpeechLive is also compatible with dictation and transcription hardware from other manufacturers. So, if you are already using other devices and want to switch to Philips SpeechLive, you will be able to use your existing devices as usual.
Professional speech to text, digital dictation and transcription devices significantly improve the user experience and help organizations achieve increased productivity.
Learn more about our speech to text service
These articles might also interest you

Speech Recognition and Dictation on iPhone, Mac and Apple Watch

Cybersecurity threats in 2024 – what do they mean for your business?

What is digital dictation?

Using speech to text solutions to address common business challenges

How are law firms adapting to the new hybrid working opportunities?

How is cloud computing enabling law firms to address cybersecurity concerns?
Accommodations Toolkit
Speech-to-text: research.
Share this page
- Share this page on Facebook.
- Share this page on Twitter.
- Share this page on LinkedIn.
- Share this page via email.
- Print this page.
This fact sheet on speech-to-text is part of the Accommodations Toolkit published by the National Center on Educational Outcomes (NCEO). It summarizes information and research findings on speech-to-text as an accommodation. This toolkit also contains a summary of states’ accessibility policies for speech-to-text .
What is speech-to-text? Speech-to-text, sometimes called speech recognition, is the use of a software program to accommodate students when writing. A person dictates words through a microphone connected to a computer that converts the spoken words into written digital text, while providing visual feedback on a monitor (Lee, 2011; MacArthur & Cavalier, 2004; McCollum et al., 2014; Noakes, 2017; Noakes et al., 2019; Quinlan, 2004).
What are the research findings on who should use this accommodation? Speech-to-text has been shown to improve writing performance in elementary students with specific learning disabilities and emotional disturbance (McCollum, 2014), secondary students with learning disabilities (MacArthur & Cavalier, 2004) and intellectual disabilities (McCollum, 2014), and elementary and secondary students with traumatic brain injuries (Noakes, 2017; Noakes et al., 2019). Overall, the research reviewed showed that speech-to-text can be useful for some students with disabilities.
What are the research findings on implementation of speech-to-text? Six studies were located that addressed speech-to-text as an accommodation in writing assessments.
- Five studies compared use of speech-to-text and handwriting for students with a specific disability. In general, all five studies found that written text was longer and had fewer mechanics errors, such as spelling, when speech-to-text was used. The results from a study of elementary and secondary students with traumatic brain injury, including those whose disabilities affected fine motor handwriting skills, found that students who used speech-to text had a significant increase in the total words written, a higher percentage of words correctly spelled, and correct writing sequences compared to handwritten text (Noakes, 2017, 2019). Another study compared the written essays of secondary students with and without learning disabilities (LD) (MacArthur and Cavalier, 2004). Secondary students with LD had better writing quality with fewer word errors when using speech-to-text when compared to the handwritten essays. There were no differences in quality for students without LD. Similarly, another study of secondary students with LD (which also included other students with lower writing fluency), found that the students produced significantly more words and had fewer errors than when with handwritten narratives (Quinlan, 2004). A study that investigated the use of speech-to-text with elementary students with LD, found that the use of speech-to-text increased students’ writing fluency as measured by more words, longer sentences, and improved mechanics (i.e., spelling, punctuation) (Lee, 2011). The same study (Lee,2011) found that for secondary students with LD, there was a greater improvement in writing quality as measured by sentence structure complexity and story structure level development with either writing mode than for the elementary students.
- Speech-to-text used by elementary and secondary students with various disabilities, which included emotional disturbance, intellectual disabilities, and LD had a positive effect. All students used more words, more multisyllabic words, and followed an appropriate writing sequence with improved spelling and punctuation, but the effect was greatest for students with specific learning disabilities (McCollum et al., 2014).
What perceptions do students and teachers have about speech-to-text? There were no studies identified that examined teachers' perspectives. Two studies examined students’ perceptions regarding the use of speech-to-text.
- In one study most high school students with LD had a positive view of speech-to-text (MacArthur & Cavalier, 2004). Students preferred to write using speech-to-text as compared to using a scribe or handwriting their essays. Students’ reasons for their preferences included increased speed, helped with spelling, enjoyable to use, and helped to get their thoughts down. Students did not like that speech-to-text sometimes made mistakes in word recognition, the time it took to correct errors, and the difficulty to initially learn the program. Overall, most said they would recommend it to friends.
- In a second study, a survey of elementary and secondary students with various disabilities, found that the students had positive to neutral attitudes toward writing using speech-to-text (McCollum, 2014). The results suggested that students’ use of speech-to-text software may reduce the cognitive load in writing for students with disabilities.
What have we learned overall? Speech-to-text is beneficial for some students with disabilities, including those with fine motor impairments that affect handwriting, across grade levels. Overall, students produced longer written text with fewer errors. However, speech-to-text is more effective for improving writing quality for secondary students compared to elementary students because they do more in-depth writing using more complex sentences, advanced vocabulary, and greater narrative development. Students generally have positive perceptions of speech-to-text and believe that it that facilitates greater independence from their reliance on a human scribe. The increasing use of technology and the availability of speech-to-text software programs make implementation of speech-to-text a more feasible option for students than in the past.
Lee, I. X. C. (2011). The application of speech recognition technology for remediating the writing difficulties of students with learning disabilities (Publication No. 3501541) [Doctoral dissertation, University of Washington]. ProQuest Dissertations and Theses Global.
MacArthur, C. A., & Cavalier, A. R. (2004). Dictation and speech recognition technology as test accommodations . Exceptional Children , 71 (1), 43–58. https://doi.org/10.1177/001440290407100103
McCollum, D., Nation, S., & Gunn, S. (2014). The effects of a speech-to-text software application on written expression for students with various disabilities . National Forum of Special Education Journal , 25 (1), 1–13. http://www.nationalforum.com/Journals/NFSEJ/NFSEJ.htm
Noakes, M. A. (2017). Does speech-to-text assistive technology improve the written expression of students with traumatic brain injury ? (Publication No. 10602238)) [Doctoral dissertation, Duquesne University]. ProQuest Dissertations and Theses Global.
Noakes, M. A., Schmitt, A. J., McCallum, E., & Schutte, K. (2019). Speech-to-text assistive technology for the written expression of students with traumatic brain injuries: A single case experimental study . School Psychology , 34 (6), 656–664. https://doi.org/10.1037/spq0000316
Attribution
All rights reserved. Any or all portions of this document may be reproduced and distributed without prior permission, provided the source is cited as:
Goldstone, L., Lazarus, S. S., Olson, R., Hinkle, A. R., & Ressa, V. A. (2021). Speech-to-text: Research (NCEO Accommodations Toolkit #16a) . National Center on Educational Outcomes.
NCEO is supported through a Cooperative Agreement (#H326G160001) with the Research to Practice Division, Office of Special Education Programs, U.S. Department of Education. The Center is affiliated with the Institute on Community Integration at the College of Education and Human Development, University of Minnesota. NCEO does not endorse any of the commercial products used in the studies. The contents of this report were developed under the Cooperative Agreement from the U.S. Department of Education, but does not necessarily represent the policy or opinions of the U.S. Department of Education or Offices within it. Readers should not assume endorsement by the federal government. Project Officer: David Egnor
Icon(s) used on this page:
Speech to Text - Voice Typing & Transcription
Take notes with your voice for free, or automatically transcribe audio & video recordings. secure, accurate & blazing fast..
~ Proudly serving millions of users since 2015 ~
I need to >
Dictate Notes
Start taking notes, on our online voice-enabled notepad right away, for free.
Transcribe Recordings
Automatically transcribe audios & videos - upload files from your device or link to an online resource (Drive, YouTube, TikTok and more).
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export options, Speechnotes provides an efficient and user-friendly dictation and transcription experience. Proudly serving millions of users since 2015, Speechnotes is the go-to tool for anyone who needs fast, accurate & private transcription. Our Portfolio of Complementary Speech-To-Text Tools Includes:
Voice typing - Chrome extension
Dictate instead of typing on any form & text-box across the web. Including on Gmail, and more.
Transcription API & webhooks
Speechnotes' API enables you to send us files via standard POST requests, and get the transcription results sent directly to your server.
Zapier integration
Combine the power of automatic transcriptions with Zapier's automatic processes. Serverless & codeless automation! Connect with your CRM, phone calls, Docs, email & more.
Android Speechnotes app
Speechnotes' notepad for Android, for notes taking on your mobile, battle tested with more than 5Million downloads. Rated 4.3+ ⭐
iOS TextHear app
TextHear for iOS, works great on iPhones, iPads & Macs. Designed specifically to help people with hearing impairment participate in conversations. Please note, this is a sister app - so it has its own pricing plan.
Audio & video converting tools
Tools developed for fast - batch conversions of audio files from one type to another and extracting audio only from videos for minimizing uploads.
Our Sister Apps for Text-To-Speech & Live Captioning
Complementary to Speechnotes
Reads out loud texts, files & web pages
Reads out loud texts, PDFs, e-books & websites for free
Speechlogger
Live Captioning & Translation
Live captions & translations for online meetings, webinars, and conferences.
Need Human Transcription? We Can Offer a 10% Discount Coupon
We do not provide human transcription services ourselves, but, we partnered with a UK company that does. Learn more on human transcription and the 10% discount .
Dictation Notepad
Start taking notes with your voice for free
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing.
Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts. We strive to provide the best online dictation tool by engaging cutting-edge speech-recognition technology for the most accurate results technology can achieve today, together with incorporating built-in tools (automatic or manual) to increase users' efficiency, productivity and comfort. Works entirely online in your Chrome browser. No download, no install and even no registration needed, so you can start working right away.
Speechnotes is especially designed to provide you a distraction-free environment. Every note, starts with a new clear white paper, so to stimulate your mind with a clean fresh start. All other elements but the text itself are out of sight by fading out, so you can concentrate on the most important part - your own creativity. In addition to that, speaking instead of typing, enables you to think and speak it out fluently, uninterrupted, which again encourages creative, clear thinking. Fonts and colors all over the app were designed to be sharp and have excellent legibility characteristics.
Example use cases
- Voice typing
- Writing notes, thoughts
- Medical forms - dictate
- Transcribers (listen and dictate)
Transcription Service
Start transcribing
Fast turnaround - results within minutes. Includes timestamps, auto punctuation and subtitles at unbeatable price. Protects your privacy: no human in the loop, and (unlike many other vendors) we do NOT keep your audio. Pay per use, no recurring payments. Upload your files or transcribe directly from Google Drive, YouTube or any other online source. Simple. No download or install. Just send us the file and get the results in minutes.
- Transcribe interviews
- Captions for Youtubes & movies
- Auto-transcribe phone calls or voice messages
- Students - transcribe lectures
- Podcasters - enlarge your audience by turning your podcasts into textual content
- Text-index entire audio archives
Key Advantages
Speechnotes is powered by the leading most accurate speech recognition AI engines by Google & Microsoft. We always check - and make sure we still use the best. Accuracy in English is very good and can easily reach 95% accuracy for good quality dictation or recording.
Lightweight & fast
Both Speechnotes dictation & transcription are lightweight-online no install, work out of the box anywhere you are. Dictation works in real time. Transcription will get you results in a matter of minutes.
Super Private & Secure!
Super private - no human handles, sees or listens to your recordings! In addition, we take great measures to protect your privacy. For example, for transcribing your recordings - we pay Google's speech to text engines extra - just so they do not keep your audio for their own research purposes.
Health advantages
Typing may result in different types of Computer Related Repetitive Strain Injuries (RSI). Voice typing is one of the main recommended ways to minimize these risks, as it enables you to sit back comfortably, freeing your arms, hands, shoulders and back altogether.
Saves you time
Need to transcribe a recording? If it's an hour long, transcribing it yourself will take you about 6! hours of work. If you send it to a transcriber - you will get it back in days! Upload it to Speechnotes - it will take you less than a minute, and you will get the results in about 20 minutes to your email.
Saves you money
Speechnotes dictation notepad is completely free - with ads - or a small fee to get it ad-free. Speechnotes transcription is only $0.1/minute, which is X10 times cheaper than a human transcriber! We offer the best deal on the market - whether it's the free dictation notepad ot the pay-as-you-go transcription service.
Dictation - Free
- Online dictation notepad
- Voice typing Chrome extension
Dictation - Premium
- Premium online dictation notepad
- Premium voice typing Chrome extension
- Support from the development team
Transcription
$0.1 /minute.
- Pay as you go - no subscription
- Audio & video recordings
- Speaker diarization in English
- Generate captions .srt files
- REST API, webhooks & Zapier integration
Compare plans
Privacy policy.
We at Speechnotes, Speechlogger, TextHear, Speechkeys value your privacy, and that's why we do not store anything you say or type or in fact any other data about you - unless it is solely needed for the purpose of your operation. We don't share it with 3rd parties, other than Google / Microsoft for the speech-to-text engine.
Privacy - how are the recordings and results handled?
- transcription service.
Our transcription service is probably the most private and secure transcription service available.
- HIPAA compliant.
- No human in the loop. No passing your recording between PCs, emails, employees, etc.
- Secure encrypted communications (https) with and between our servers.
- Recordings are automatically deleted from our servers as soon as the transcription is done.
- Our contract with Google / Microsoft (our speech engines providers) prohibits them from keeping any audio or results.
- Transcription results are securely kept on our secure database. Only you have access to them - only if you sign in (or provide your secret credentials through the API)
- You may choose to delete the transcription results - once you do - no copy remains on our servers.
- Dictation notepad & extension
For dictation, the recording & recognition - is delegated to and done by the browser (Chrome / Edge) or operating system (Android). So, we never even have access to the recorded audio, and Edge's / Chrome's / Android's (depending the one you use) privacy policy apply here.
The results of the dictation are saved locally on your machine - via the browser's / app's local storage. It never gets to our servers. So, as long as your device is private - your notes are private.
Payments method privacy
The whole payments process is delegated to PayPal / Stripe / Google Pay / Play Store / App Store and secured by these providers. We never receive any of your credit card information.
More generic notes regarding our site, cookies, analytics, ads, etc.
- We may use Google Analytics on our site - which is a generic tool to track usage statistics.
- We use cookies - which means we save data on your browser to send to our servers when needed. This is used for instance to sign you in, and then keep you signed in.
- For the dictation tool - we use your browser's local storage to store your notes, so you can access them later.
- Non premium dictation tool serves ads by Google. Users may opt out of personalized advertising by visiting Ads Settings . Alternatively, users can opt out of a third-party vendor's use of cookies for personalized advertising by visiting https://youradchoices.com/
- In case you would like to upload files to Google Drive directly from Speechnotes - we'll ask for your permission to do so. We will use that permission for that purpose only - syncing your speech-notes to your Google Drive, per your request.
- Cambridge Dictionary +Plus
Meaning of text-to-speech in English
Your browser doesn't support HTML5 audio
- text-to-speech
Examples of text-to-speech

Word of the Day
your bread and butter
a job or activity that provides you with the money you need to live

Shoots, blooms and blossom: talking about plants

Learn more with +Plus
- Recent and Recommended {{#preferredDictionaries}} {{name}} {{/preferredDictionaries}}
- Definitions Clear explanations of natural written and spoken English English Learner’s Dictionary Essential British English Essential American English
- Grammar and thesaurus Usage explanations of natural written and spoken English Grammar Thesaurus
- Pronunciation British and American pronunciations with audio English Pronunciation
- English–Chinese (Simplified) Chinese (Simplified)–English
- English–Chinese (Traditional) Chinese (Traditional)–English
- English–Dutch Dutch–English
- English–French French–English
- English–German German–English
- English–Indonesian Indonesian–English
- English–Italian Italian–English
- English–Japanese Japanese–English
- English–Norwegian Norwegian–English
- English–Polish Polish–English
- English–Portuguese Portuguese–English
- English–Spanish Spanish–English
- English–Swedish Swedish–English
- Dictionary +Plus Word Lists
- All translations
Add text-to-speech to one of your lists below, or create a new one.
{{message}}
Something went wrong.
There was a problem sending your report.
- Dictionaries home
- American English
- Collocations
- German-English
- Grammar home
- Practical English Usage
- Learn & Practise Grammar (Beta)
- Word Lists home
- My Word Lists
- Recent additions
- Resources home
- Text Checker

NEW words and meanings added: March 2024
Game on or game over ?
With the Summer Olympics coming up, the main focus for our latest release is on the world of sport.
Worrying about your team’s back four in the relegation six-pointer ? Did one of your team’s blueliners just score an empty-netter ? Or maybe you prefer T20™ , with the drama of one-dayers and super overs , or just like to pay your green fee and get started on the front nine ?
We’ve added over 170 new words and meanings from sport and other topics.

Our word lists are designed to help learners at any level focus on the most important words to learn.
Explore our general English and academic English lists.

Spread the Word
A recent addition to our online dictionary is the term culture war , which is used to describe the conflict between groups of people with different ideals and beliefs.

Topic Dictionaries
Our Topic Dictionaries are lists of topic-related words, like Animals and Health , that can help you expand your vocabulary. Each topic is divided into smaller subtopics and every word has a CEFR level.

Learn & Practise Grammar
Our grammar pages combine clear explanations with interactive exercises to test your understanding.
Learn more with these dictionary and grammar resources
We offer a number of premium products on this website to help you improve your english..

JOIN our community of language learners!
Connect with us TODAY to start receiving the language learning and assessment resources you need directly to your newsfeed and inbox.

IMAGES
VIDEO
COMMENTS
With dictation technology, people can write sentences by speaking them. Dictation is sometimes called "speech-to-text," "voice-to-text," or "speech recognition" technology. Dictation is an assistive technology (AT) tool that can help people who struggle with writing. You may hear it referred to as "speech-to-text," "voice-to ...
Kids can use dictation to write with their voices, instead of writing by hand or with a keyboard — helpful for kids with dysgraphia, dyslexia and other learning and attention issues that impact writing. Dictation is an assistive technology (AT) tool that can help kids who struggle with writing. You may hear it referred to as "speech-to-text ...
Dragon Professional. $699.00 at Nuance. See It. Dragon is one of the most sophisticated speech-to-text tools. You use it not only to type using your voice but also to operate your computer with ...
With voice typing, you can enter text on your PC by speaking. Voice typing uses online speech recognition, which is powered by Azure Speech services. ... Pause dictation . Stop voice typing . Stop dictation . Stop listening . Stop dictating . Stop voice mode . Pause voice mode . Delete last spoken word or phrase. Delete that .
4. Multitasking Through Voice Commands. Speech to text allows users to tackle multiple tasks at the same time. For example, while using STT tools for dictating onboarding instructions for a new hire, a professional can continue to read through the files that have been closed or need to be handed over. 5.
Speech to text is a speech recognition software that enables the recognition and translation of spoken language into text through computational linguistics. It is also known as speech recognition or computer speech recognition. Specific applications, tools, and devices can transcribe audio streams in real-time to display text and act on it.
Open the app or window you want to dictate into. 2. Press Win + H. This keyboard shortcut opens the speech recognition control at the top of the screen. 3. Now just start speaking normally, and ...
Speech-to-text technology is a type of natural language processing (NLP) that converts spoken words into written text. It is used in a variety of applications, including voice assistants, transcription services, and accessibility tools. Here is a more detailed explanation of how speech-to-text technology works:
Moving beyond mere voice-to-text conversion, the future of dictation transcription will incorporate context-aware AI that can adapt to different accents, dialects, and the unique speech patterns of individual providers. The technology is expected to enhance with continuous learning capabilities, meaning it gets better over time with increased ...
It's a Great Hands-Free and Mobile Typing Technology. Where voice dictation really shines is in writing small sections of text hands-free. Such as dictating a text message for use with your favorite app while driving. Even when you're not working hands-free, voice typing is generally less frustrating than typing on a tiny touch-screen keyboard.
It's a quick and easy way to get your thoughts out, create drafts or outlines, and capture notes. Windows Mac. Open a new or existing document and go to Home > Dictate while signed into Microsoft 365 on a mic-enabled device. Wait for the Dictate button to turn on and start listening. Start speaking to see text appear on the screen.
Voice to text is a broader term, encompassing automated processes that convert spoken language into text, while dictation specifically involves verbally delivering content for transcription. Voice-to-text technology is traced back to the introduction of IBM's "Shoebox" device in 1961. What Does Speech to Text Mean?
Dictation and transcription are commonly mistaken for the same thing. However, that is far from the truth. Dictation is the process of speaking or dictating information, often to a device. Transcription involves listening to an audio recording and accurately transcribing the spoken words into a written document.
Dictation is the process of speaking aloud to produce a document or other type of output, while transcription is the process of converting a wav file into written text. It's common to write a transcription from a dictation, and many modern pieces of software are capable of transcribing a dictation in real time.. No matter what your use case, dictation and transcription can be a great time ...
Speech-to-text definition: a computerized, algorithmic process that transcribes a user's spoken input into digital text, such as a video transcript rendered by auto caption (often used attributively): Speech-to-text is a great way to send a text when you are driving and can't pick up your phone.Speech-to-text technology showed a bias toward certain mainstream accents and dialects in its ...
A brief history of speech-to-text models First, some context. Speech-to-text is part of the natural language processing (NLP) branch in AI. Its goal is to make machines able to understand and transcribe human speech into a written format. How hard can it be to transcribe speech, you may wonder. The short answer is: very.
Dictation software is one that is particularly helpful to the medical field both human and veterinarian. By definition, dictation is "the action of saying words aloud to be typed, written down, or recorded on tape." You may have also heard this definition applied to speech-to-text and transcription software, as well.
Dictation is the act of expressing verbally what is said about a subject in order to put it into writing. Transcription is the conversion of spoken words or audio content into writing. Dictation is a process used in different fields such as journalism, medicine, law, and business environment. Dictation and transcription enable the spoken words ...
Popular dictation apps include: Apple Dictation. Dragon Anywhere. Dictation - Speech to Text. Verbit. Amazon Transcribe. Some of these apps are free, some are paid. They're all similar, so I'd recommend trying several to find your favorite. Now, let's examine the pros and cons of dictating your work.
What is often forgotten is the hardware, meaning the input device for speech recognition (or speech to text) and digital dictation. Smartphone apps are not suitable for heavy users. Many people use dictation and speech-to-text with smartphone apps, such as Philips SpeechLive or apps from other manufacturers.
Speech-to-Text: Research. This fact sheet on speech-to-text is part of the Accommodations Toolkit published by the National Center on Educational Outcomes (NCEO). It summarizes information and research findings on speech-to-text as an accommodation. This toolkit also contains a summary of states' accessibility policies for speech-to-text.
Speech to Text online notepad. Professional, accurate & free speech recognizing text editor. Distraction-free, fast, easy to use web app for dictation & typing. Speechnotes is a powerful speech-enabled online notepad, designed to empower your ideas by implementing a clean & efficient design, so you can focus on your thoughts.
TEXT-TO-SPEECH meaning: relating to computer technology that is used to change data into spoken words: . Learn more.
The largest and most trusted free online dictionary for learners of British and American English with definitions, pictures, example sentences, synonyms, antonyms, word origins, audio pronunciation, and more. Look up the meanings of words, abbreviations, phrases, and idioms in our free English Dictionary.