Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Quantitative Data Analysis

5 Hypothesis Testing in Quantitative Research
Mikaila Mariel Lemonik Arthur
Statistical reasoning is built on the assumption that data are normally distributed , meaning that they will be distributed in the shape of a bell curve as discussed in the chapter on Univariate Analysis . While real life often—perhaps even usually—does not resemble a bell curve, basic statistical analysis assumes that if all possible random samples from a population were drawn and the mean taken from each sample, the distribution of sample means, when plotted on a graph, would be normally distributed (this assumption is called the Central Limit Theorem ). Given this assumption, we can use the mathematical techniques developed for the study of probability to determine the likelihood that the relationships or patterns we observe in our data occurred due to random chance rather than due some actual real-world connection, which we call statistical significance.
Statistical significance is not the same as practical significance. The fact that we have determined that a given result is unlikely to have occurred due to random chance does not mean that this given result is important, that it matters, or that it is useful. Similarly, we might observe a relationship or result that is very important in practical terms, but that we cannot claim is statistically significant—perhaps because our sample size is too small, for instance. Such a result might have occurred by chance, but ignoring it might still be a mistake. Let’s consider some examples to make this a bit clearer. Assume we were interested in the impacts of diet on health outcomes and found the statistically significant result that people who eat a lot of citrus fruit end up having pinky fingernails that are, on average, 1.5 millimeters longer than those who tend not to eat any citrus fruit. Should anyone change their diet due to this finding? Probably not, even those it is statistically significant. On the other hand, if we found that the people who ate the diets highest in processed sugar died on average five years sooner than those who ate the least processed sugar, even in the absence of a statistically significant result we might want to advise that people consider limiting sugar in their diet. This latter result has more practical significance (lifespan matters more than the length of your pinky fingernail) as well as a larger effect size or association (5 years of life as opposed to 1.5 millimeters of length), a factor that will be discussed in the chapter on association .
While people generally use the shorthand of “the likelihood that the results occurred by chance” when talking about statistical significance, it is actually a bit more complicated than that. What statistical significance is really telling us is the likelihood (or probability ) that a result equal to or more “extreme [1] ” is true in the real world, rather than our results having occurred due to random chance or sampling error . Testing for statistical significance, then, requires us to understand something about probability.
A Brief Review of Probability
You might remember having studied probability in a math class, with questions about coin flips or drawing marbles out of a jar. Such exercises can make probability seem very abstract. But in reality, computations of probability are deeply important for a wide variety of activities, ranging from gambling and stock trading to weather forecasts and, yes, statistical significance.
Probability is represented as a proportion (or decimal number) somewhere between 0 and 1. At 0, there is absolutely no likelihood that the event or pattern of interest would occur; at 1, it is absolutely certain that the event or pattern of interest will occur. We indicate that we are talking about probability by using the symbol [latex]p[/latex]. For example, if something has a 50% chance of occurring, we would write [latex]p=0.5[/latex] or [latex]\frac {1}{2}[/latex]. If we want to represent the likelihood of something not occurring, we can write [latex]1-p[/latex].
Check your thinking: Assume you were flipping coins, and you called heads. The probability of getting heads on a coin flip using a fair coin (in other words, a normal coin that has not been weighted to bias the result) is 0.5. Thus, in 50% of coin flips you should get heads. Consider the following probability questions and write down your answers so you can check them against the discussion below.
- Imagine you have flipped the coin 29 times and you have gotten heads each time. What is the probability you will get heads on flip 30?
- What is the probability that you will get heads on all of the first five coin flips?
- What is the probability that you will get heads on at least one of the first five coin flips?
There are a few basic concepts from the mathematical study of probability that are important for beginner data analysts to know, and we will review them here.
Probability over Repeated Trials : The probability of the outcome of interest is the same in each trial or test, regardless of the results of the prior test. So, if we flip a coin 29 times and get heads each time, what happens when we flip it the 29th time? The probability of heads is still 0.5! The belief that “this time it must be tails because it has been heads so many times” or “this coin just wants to come up heads” is simply superstition, and—assuming a fair coin—the results of prior trials do not influence the results of this one.
Probability of Multiple Events : The probability that the outcome of interest will occur repeatedly across multiple trials is the product [2] of the probability of the outcome on each individual trial. This is called the multiplication theorem . Thinking about the multiplication theorem requires that we keep in mind the fact that when we multiply decimal numbers together, those numbers get smaller— thus, the probability that a series of outcomes will occur is smaller than the probability of any one of those outcomes occurring on its own. So, what is the probability that we will get heads on all five of our coin flips? Well, to figure that out, we need to multiply the probability of getting heads on each of our coin flips together. The math looks like this (and produces a very small probability indeed):
[latex]\frac {1}{2} \cdot \frac {1}{2} \cdot \frac {1}{2} \cdot \frac {1}{2} \cdot \frac {1}{2} = 0.03125[/latex]
Probability of One of Many Events : Determining the probability that the outcome of interest will occur on at least one out of a series of events or repeated trials is a little bit more complicated. Mathematicians use the addition theorem to refer to this, because the basic way to calculate it is to calculate the probability of each sequence of events (say, heads-heads-heads, heads-heads-tails, heads-tails-heads, and so on) and add them together. But the greater the number of repeated trials, the more complicated that gets, so there is a simpler way to do it. Consider that the probability of getting no heads is the same as the probability of getting all tails (which would be the same as the probability of getting all heads that we calculated above). And the only circumstance in which we would not have at least one flip resulting in heads would be a circumstance in which all flips had resulted in tails. Therefore, what we need to do in order to calculate the probability that we get at least one heads is to subtract the probability that we get no heads from 1—and as you can imagine, this procedure shows us that the probability of the outcome of interest occurring at least once over repeated trials is higher than the probability of the occurrence on any given trial. The math would look like this:
[latex]1- (\frac{1}{2})^5=0.9688[/latex]
So why is this digression into the math of probability important? Well, when we test for statistical significance, what we are really doing is determining the probability that the outcome we observed—or one that is more extreme than that which we observed—occurred by chance. We perform this analysis via a procedure called Null Hypothesis Significance Testing.
Null Hypothesis Significance Testing
Null hypothesis significance testing , or NHST , is a method of testing for statistical significance by comparing observed data to the data we would expect to see if there were no relationship between the variables or phenomena in question. NHST can take a little while to wrap one’s head around, especially because it relies on a logic of double negatives: first, we state a hypothesis we believe not to be true (there is no relationship between the variables in question) and then, we look for evidence that disconfirms this hypothesis. In other words, we are assuming that there is no relationship between the variables—even though our research hypothesis states that we think there is a relationship—and then looking to see if there is any evidence to suggest there is not no relationship. Confusing, right?
So why do we use the null hypothesis significance testing approach?
- The null hypothesis—that there is no relationship between the variables we are exploring—would be what we would generally accept as true in the absence of other information,
- It means we are assuming that differences or patterns occur due to chance unless there is strong evidence to suggest otherwise,
- It provides a benchmark for comparing observed outcomes, and
- It means we are searching for evidence that disconforms our hypothesis, making it less likely that we will accept a conclusion that turns out to be untrue.
Thus, NHST helps us avoid making errors in our interpretation of the result. In particular, it helps us avoid Type 2 error , as discussed in the chapter on Bivariate Analyses . As a reminder, Type 2 error is error where you accept a hypothesis as true when in fact it was false (while Type 1 error is error where you reject the hypothesis when in fact it was true). For example, you are making a Type 1 error if you decide not to study for a test because you assume you are so bad at the subject that studying simply cannot help you, when in fact we know from research that studying does lead to higher grades. And you are making a Type 2 error if your boss tells you that she is going to promote you if you do enough overtime and you then work lots of overtime in response, when actually your boss is just trying to make you work more hours and already had someone else in mind to promote.
We can never remove all sources of error from our analyses, though larger sample sizes help reduce error. Looking at the formula for computing standard error , we can see that the standard error ([latex]SE[/latex]) would get smaller as the sample size ([latex]N[/latex]) gets larger. Note: σ is the symbol we use to represent standard deviation.
[latex]SE = \frac{\sigma}{\sqrt N}[/latex]
Besides making our samples larger, another thing that we can do is that we can choose whether we are more willing to accept Type 1 error or Type 2 error and adjust our strategies accordingly. In most research, we would prefer to accept more Type 1 error, because we are more willing to miss out on a finding than we are to make a finding that turns out later to be inaccurate (though, of course, lots of research does eventually turn out to be inaccurate).
Performing NHST
Performing NHST requires that our data meet several assumptions:
- Our sample must be a random sample—statistical significance testing and other inferential and explanatory statistical methods are generally not appropriate for non-random samples [3] —as well as representative and of a sufficient size (see the Central Limit Theorem above).
- Observations must be independent of other observations, or else additional statistical manipulation must be performed. For instance, a dataset of data about siblings would need to be handled differently due to the fact that siblings affect one another, so data on each person in the dataset is not truly independent.
- You must determine the rules for your significance test, including the level of uncertainty you are willing to accept (significance level) and whether or not you are interested in the direction of the result (one-tailed versus two-tailed tests, to be discussed below), in advance of performing any analysis.
- The number of significance tests you run should be limited, because the more tests you run, the greater the likelihood that one of your tests will result in an error. To make this more clear, if you are willing to accept a 5% probability that you will make the error of accepting a hypothesis as true when it is really false, and you run 20 tests, one of those tests (5% of them!) is pretty likely to have produced an incorrect result.
If our data has met these assumptions, we can move forward with the process of conducting an NHST. This requires us to make three decisions: determining our null hypothesis , our confidence level (or acceptable significance level), and whether we will conduct a one-tailed or a two-tailed test. In keeping with Assumption 3 above, we must make these decisions before performing our analysis. The null hypothesis is the hypothesis that there is no relationship between the variables in question. So, for example, if our research hypothesis was that people who spend more time with their friends are happier, our null hypothesis would be that there is no relationship between how much time people spend with their friends and their happiness.
Our confidence level is the level of risk we are willing to accept that our results could have occurred by chance. Typically, in social science research, researchers use p<0.05 (we are willing to accept up to a 5% risk that our results occurred by chance), p<0.01 (we are willing to accept up to a 1% risk that our results occurred by chance), and/or p<0.001 (we are willing to accept up to a 0.1% risk that our results occurred by chance). P, as was noted above, is the mathematical notation for probability, and that’s why we use a p-value to indicate the probability that our results may have occurred by chance. A higher p-value increases the likelihood that we will accept as accurate a result that really occurred by chance; a lower p-value increases the likelihood that we will assume a result occurred by chance when actually it was real. Remember, what the p-value tells us is not the probability that our own research hypothesis is true, but rather this: assuming that the null hypothesis is correct, what is the probability that the data we observed—or data more extreme than the data we observed—would have occurred by chance.
Whether we choose a one-tailed or a two-tailed test tells us what we mean when we say “data more extreme than.” Remember that normal curve? A two-tailed test is agnostic as to the direction of our results—and many of the most common tests for statistical significance that we perform, like the Chi square, are two-tailed by default. However, if you are only interested in a result that occurs in a particular direction, you might choose a one-tailed test. For instance, if you were testing a new blood pressure medication, you might only care if the blood pressure of those taking the medication is significantly lower than those not taking the medication—having blood pressure significantly higher would not be a good or helpful result, so you might not want to test for that.
Having determined the parameters for our analysis, we then compute our test of statistical significance. There are different tests of statistical significance for different variables (for example, the Chi square discussed in the chapter on bivariate analyses ), as you will see in other chapters of this text, but all of them produce results in a similar format. We then compare this result to the p value we already selected. If the p value produced by our analysis is lower than the confidence level we selected, we can reject the null hypothesis, as the probability that our result occurred by chance is very low. If, on the other hand, the p value produced by our analysis is higher than the confidence level we selected, we fail to reject the null hypothesis, as the probability that our result occurred by chance is too high to accept. Keep in mind this is what we do even when the p value produced by our analysis is quite close to the threshold we have selected. So, for instance, if we have selected the confidence level of p<0.05 and the p value produced by our analysis is p=0.0501, we still fail to reject the null hypothesis and proceed as if there is not any support for our research hypothesis.
Thus, the process of null hypothesis significance testing proceeds according to the following steps:
- Determine the null hypothesis
- Set the confidence level and whether this will be a one-tailed or two-tailed test
- Compute the test value for the appropriate significance test
- Compare the test value to the critical value of that test statistic for the confidence level you selected
- Determine whether or not to reject the null hypothesis
Your statistical analysis software will perform steps 3 and 4 for you (before there was computer software to do this, researchers had to do the calculations by hand and compare their results to figures on published tables of critical values). But you as the researcher must perform steps 1, 2, and 5 yourself.
Confidence Intervals & Margins of Error
When talking about statistical significance, some researchers also use the terms confidence intervals and margins of error . Confidence intervals are ranges of probabilities within which we can assume the true population parameter lies. Most typically, analysts aim for 95% confidence intervals, meaning that in 95 out of 100 cases, the population parameter will lie within the upper and lower levels specified by your confidence interval. These are calculated by your statistics software as well. The margin of error, then, is the range of values within the confidence interval. So, for instance, a 2021 survey of Americans conducted by the Robert Wood Johnson Foundation and the Harvard T.H. Chan School of Public Health found that 71% of respondents favor substantially increasing federal spending on public health programs. This poll had a 95% confidence interval with a +/- 3.6 margin of error. What this tells us is that there is a 95% probability (19 in 20) that between 67.4% (71-3.6) and 74.6% (71+3.6) of Americans favored increasing federal public health spending at the time the poll was conducted. When a figure reflects an overwhelming majority, such as this one, the margin of error may seem of little relevance. But consider a similar poll with the same margin of error that sought to predict support for a political candidate and found that 51.5% of people said they would vote for that candidate. In that case, we would have found that there was a 95% probability that between 47.9% and 55.1% of people intended to vote for the candidate—which means the race is total tossup and we really would have no idea what to expect. For some people, thinking in terms of confidence intervals and margins of error is easier to understand than thinking in terms of p values; confidence intervals and margins of error are more frequently used in analyses of polls while p values are found more often in academic research. But basically, both approaches are doing the same fundamental analysis—they are determining the likelihood that the results we observed or a similarly-meaningful result would have occurred by chance.
What Does Significance Testing Tell Us?
One of the most important things to remember about significance testing is that, while the word “significance” is used in ordinary speech to mean importance, significance testing does not tell us whether our results are important—or even whether they are interesting. A full understanding of the relationship between a given set of variables requires looking at statistical significance as well as association and the theoretical importance of the findings. Table 1 provides a perspective on using the combination of significance and association to determine how important the results of statistical analysis are—but even using Table 1 as a guide, evaluating findings based on theoretical importance remains key. So: make sure that when you are conducting analyses, you avoid being misled into assuming that significant results are sufficient for making broad claims about the importance and meaning of results. And remember as well that significance only tells us the likelihood that the pattern of relationships we observe occurred by chance—not whether that pattern is causal. For, after all, quantitative research can never eliminate all plausible alternative explanations for the phenomenon in question (one of the three elements of causation, along with association and temporal order).
- Getting 7 heads on 7 coin flips
- Getting 5 heads on 7 coin flips
- Getting 1 head on 10 coin flips
Then check your work using the Coin Flip Probability Calculator .
- As the advertised hourly pay for a job goes up, the number of job applicants increases.
- Teenagers who watch more hours of makeup tutorial videos on TikTok have, on average, lower self-esteem.
- Couples who share hobbies in common are less likely to get divorced.
- Assume a research conducted a study that found that people wearing green socks type on average one word per minute faster than people who are not wearing green socks, and that this study found a p value of p<0.01. Is this result statistically significant? Is this result practically significant? Explain your answers.
- If we conduct a political poll and have a 95% confidence interval and a margin of error of +/- 2.3%, what can we conclude about support for Candidate X if 49.3% of respondents tell us they will vote for Candidate X? If 24.7% do? If 52.1% do? If 83.7% do?
- One way to think about this is to imagine that your result has been plotted on a bell curve. Statistical significance tells us the probability that the "real" result—the thing that is true in the real world and not due to random chance—is at the same point as or further along the skinny tails of the bell curve than the result we have plotted. ↵
- In other words, what you get when you multiply. ↵
- They also are not appropriate for censuses—but you do not need inferential statistics in a census because you are looking at the entire population rather than a sample, so you can simply describe the relationships that do exist. ↵
A distribution of values that is symmetrical and bell-shaped.
A graph showing a normal distribution—one that is symmetrical with a rounded top that then falls away towards the extremes in the shape of a bell
The sum of all the values in a list divided by the number of such values.
The theorem that states that if you take a series of sufficiently large random samples from the population (replacing people back into the population so they can be reselected each time you draw a new sample), the distribution of the sample means will be approximately normally distributed.
A statistical measure that suggests that sample results can be generalized to the larger population, based on a low probability of having made a Type 1 error.
How likely something is to happen; also, a branch of mathematics concerned with investigating the likelihood of occurrences.
Measurement error created due to the fact that even properly-constructed random samples are do not have precisely the same characteristics as the larger population from which they were drawn.
The theorem in probability about the likelihood of a given outcome occurring repeatedly over multiple trials; this is determined by multiplying the probabilities together.
The theorem addressing the determination of the probability of a given outcome occurring at least once across a series of trials; it is determined by adding the probability of each possible series of outcomes together.
A method of testing for statistical significance in which an observed relationship, pattern, or figure is tested against a hypothesis that there is no relationship or pattern among the variables being tested
Null hypothesis significance testing.
The error you make when you do not infer a relationship exists in the larger population when it actually does exist; in other words, a false negative conclusion.
The error made if one infers that a relationship exists in a larger population when it does not really exist; in other words, a false positive error.
A measure of accuracy of sample statistics computed using the standard deviation of the sampling distribution.
The hypothesis that there is no relationship between the variables in question.
The probability that the sample statistics we observe holds true for the larger population.
A measure of statistical significance used in crosstabulation to determine the generalizability of results.
A range of estimates into which it is highly probable that an unknown population parameter falls.
A suggestion of how far away from the actual population parameter a sample statistic is likely to be.
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.

- Teesside University Student & Library Services
- Learning Hub Group
Quantitative data collection and analysis
- Testing hypotheses
- Quantitative data collection
- Averages and percentiles
- Measures of Spread or Dispersion
- Samples and population
- Statistical tests - parametric
- Statistical tests - non-parametric
- Probability
- Reliability and Validity
- Analysing relationships
- Useful Books
Testing Hypotheses
- What is a hypothesis?
- Significance testing
- One-tailed or two-tailed?
- Degrees of freedom
A hypothesis is a statement that we are trying to prove or disprove. It is used to express the relationship between variables and whether this relationship is significant. It is specific and offers a prediction on the results of your research question.
Your research question will lead you to developing a hypothesis, this is why your research question needs to be specific and clear.
The hypothesis will then guide you to the most appropriate techniques you should use to answer the question. They reflect the literature and theories on which you basing them. They need to be testable (i.e. measurable and practical).
Null hypothesis (H 0 ) is the proposition that there will not be a relationship between the variables you are looking at. i.e. any differences are due to chance). They always refer to the population. (Usually we don't believe this to be true.)
e.g. There is no difference in instances of illegal drug use by teenagers who are members of a gang and those who are not..
Alternative hypothesis (H A ) or ( H 1 ): this is sometimes called the research hypothesis or experimental hypothesis. It is the proposition that there will be a relationship. It is a statement of inequality between the variables you are interested in. They always refer to the sample. It is usually a declaration rather than a question and is clear, to the point and specific.
e.g. The instances of illegal drug use of teenagers who are members of a gang is different than the instances of illegal drug use of teenagers who are not gang members.
A non-directional research hypothesis - reflects an expected difference between groups but does not specify the direction of this difference (see two-tailed test).
A directional research hypothesis - reflects an expected difference between groups but does specify the direction of this difference. (see one-tailed test)
e.g. The instances of illegal drug use by teenagers who are members of a gang will be higher t han the instances of illegal drug use of teenagers who are not gang members.
Then the process of testing is to ascertain which hypothesis to believe.
It is usually easier to prove something as untrue rather than true, so looking at the null hypothesis is the usual starting point.
The process of examining the null hypothesis in light of evidence from the sample is called significance testing . It is a way of establishing a range of values in which we can establish whether the null hypothesis is true or false.
The debate over hypothesis testing
There has been discussion over whether the scientific method employed in traditional hypothesis testing is appropriate.
See below for some articles that discuss this:
- Gill, J. (1999) 'The insignificance of null hypothesis testing', Politics Research Quarterly , 52(3), pp. 647-674 .
- Wainer, H. and Robinson, D.H. (2003) 'Shaping up the practice of null hypothesis significance testing', Educational Researcher, 32(7), pp.22-30 .
- Ferguson, C.J. and Heener, M. (2012) ' A vast graveyard of undead theories: publication bias and psychological science's aversion to the null' , Perspectives on Psychological Science, 7(6), pp.555-561 .
Taken from: Salkind, N.J. (2017) Statistics for people who (think they) hate statistics. 6th edn. London: SAGE pp. 144-145.
- Null hypothesis - a simple introduction (SPSS)
A significance level defines the level when your sample evidence contradicts your null hypothesis so that your can then reject it. It is the probability of rejecting the null hypothesis when it is really true.
e.g. a significance level of 0.05 indicates that there is a 5% (or 1 in 20) risk of deciding that there is an effect when in fact there is none.
The lower the significance level that you set, then the evidence from the sample has to be stronger to be able to reject the null hypothesis.
N.B. - it is important that you set the significance level before you carry out your study and analysis.
Using Confidence Intervals
I t is possible to test the significance of your null hypothesis using Confidence Interval (see under samples and populations tab).
- if the range lies outside our predicted null hypothesis value we can reject it and accept the alternative hypothesis
The test statistic
This is another commonly used statistic
- Write down your null and alternative hypothesis
- Find the sample statistic (e.g.the mean of your sample)
- Calculate the test statistic Z score (see under Measures of spread or dispersion and Statistical tests - parametric). In this case the sample mean is compared to the population mean (assumed from the null hypothesis) and the standard error (see under Samples and population) is used rather than the standard deviation.
- Compare the test statistic with the critical values (e.g. plus or minus 1.96 for 5% significance)
- Draw a conclusion about the hypotheses - does the calculated z value lies in this critical range i.e. above 1.96 or below -1.96? If it does we can reject the null hypothesis. This would indicate that the results are significant (or an effect has been detected) - which means that if there were no difference in the population then getting a result that you have observed would be highly unlikely therefore you can reject the null hypothesis.

Type I error - this is the chance of wrongly rejecting the null hypothesis even though it is actually true, e.g. by using a 5% p level you would expect the null hypothesis to be rejected about 5% of the time when the null hypothesis is true. You could set a more stringent p level such as 1% (or 1 in 100) to be more certain of not seeing a Type I error. This, however, makes more likely another type of error (Type II) occurring.
Type II error - this is where there is an effect, but the p value you obtain is non-significant hence you don’t detect this effect.
- Statistical significance - what does it really mean?
- Statistical tables
One-tailed tests - where we know in which direction (e.g. larger or smaller) the difference between sample and population will be. It is a directional hypothesis.
Two-tailed tests - where we are looking at whether there is a difference between sample and population. This difference could be larger or smaller. This is a non-directional hypothesis.
If the difference is in the direction you have predicted (i.e. a one-tailed test) it is easier to get a significant result. Though there are arguments against using a one-tailed test (Wright and London, 2009, p. 98-99)*
*Wright, D. B. & London, K. (2009) First (and second) steps in statistics . 2nd edn. London: SAGE.
N.B. - think of the ‘tails’ as the regions at the far-end of a normal distribution. For a two-tailed test with significance level of 0.05% then 0.025% of the values would be at one end of the distribution and the other 0.025% would be at the other end of the distribution. It is the values in these ‘critical’ extreme regions where we can think about rejecting the null hypothesis and claim that there has been an effect.
Degrees of freedom ( df) is a rather difficult mathematical concept, but is needed to calculate the signifcance of certain statistical tests, such as the t-test, ANOVA and Chi-squared test.
It is broadly defined as the number of "observations" (pieces of information) in the data that are free to vary when estimating statistical parameters. (Taken from Minitab Blog ).
The higher the degrees of freedom are the more powerful and precise your estimates of the parameter (population) will be.
Typically, for a 1-sample t-test it is considered as the number of values in your sample minus 1.
For chi-squared tests with a table of rows and columns the rule is:
(Number of rows minus 1) times (number of columns minus 1)
Any accessible example to illustrate the principle of degrees of freedom using chocolates.
- You have seven chocolates in a box, each being a different type, e.g. truffle, coffee cream, caramel cluster, fudge, strawberry dream, hazelnut whirl, toffee.
- You are being good and intend to eat only one chocolate each day of the week.
- On the first day, you can choose to eat any one of the 7 chocolate types - you have a choice from all 7.
- On the second day, you can choose from the 6 remaining chocolates, on day 3 you can choose from 5 chocolates, and so on.
- On the sixth day you have a choice of the remaining 2 chocolates you haven't ate that week.
- However on the seventh day - you haven't really got any choice of chocolate - it has got to be the one you have left in your box.
- You had 7-1 = 6 days of “chocolate” freedom—in which the chocolate you ate could vary!
- << Previous: Samples and population
- Next: Statistical tests - parametric >>
- Last Updated: Jan 9, 2024 11:01 AM
- URL: https://libguides.tees.ac.uk/quantitative
- Privacy Policy
Buy Me a Coffee
Home » Quantitative Research – Methods, Types and Analysis
Quantitative Research – Methods, Types and Analysis
Table of Contents

Quantitative Research
Quantitative research is a type of research that collects and analyzes numerical data to test hypotheses and answer research questions . This research typically involves a large sample size and uses statistical analysis to make inferences about a population based on the data collected. It often involves the use of surveys, experiments, or other structured data collection methods to gather quantitative data.
Quantitative Research Methods

Quantitative Research Methods are as follows:
Descriptive Research Design
Descriptive research design is used to describe the characteristics of a population or phenomenon being studied. This research method is used to answer the questions of what, where, when, and how. Descriptive research designs use a variety of methods such as observation, case studies, and surveys to collect data. The data is then analyzed using statistical tools to identify patterns and relationships.
Correlational Research Design
Correlational research design is used to investigate the relationship between two or more variables. Researchers use correlational research to determine whether a relationship exists between variables and to what extent they are related. This research method involves collecting data from a sample and analyzing it using statistical tools such as correlation coefficients.
Quasi-experimental Research Design
Quasi-experimental research design is used to investigate cause-and-effect relationships between variables. This research method is similar to experimental research design, but it lacks full control over the independent variable. Researchers use quasi-experimental research designs when it is not feasible or ethical to manipulate the independent variable.
Experimental Research Design
Experimental research design is used to investigate cause-and-effect relationships between variables. This research method involves manipulating the independent variable and observing the effects on the dependent variable. Researchers use experimental research designs to test hypotheses and establish cause-and-effect relationships.
Survey Research
Survey research involves collecting data from a sample of individuals using a standardized questionnaire. This research method is used to gather information on attitudes, beliefs, and behaviors of individuals. Researchers use survey research to collect data quickly and efficiently from a large sample size. Survey research can be conducted through various methods such as online, phone, mail, or in-person interviews.
Quantitative Research Analysis Methods
Here are some commonly used quantitative research analysis methods:
Statistical Analysis
Statistical analysis is the most common quantitative research analysis method. It involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis can be used to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
Regression Analysis
Regression analysis is a statistical technique used to analyze the relationship between one dependent variable and one or more independent variables. Researchers use regression analysis to identify and quantify the impact of independent variables on the dependent variable.
Factor Analysis
Factor analysis is a statistical technique used to identify underlying factors that explain the correlations among a set of variables. Researchers use factor analysis to reduce a large number of variables to a smaller set of factors that capture the most important information.
Structural Equation Modeling
Structural equation modeling is a statistical technique used to test complex relationships between variables. It involves specifying a model that includes both observed and unobserved variables, and then using statistical methods to test the fit of the model to the data.
Time Series Analysis
Time series analysis is a statistical technique used to analyze data that is collected over time. It involves identifying patterns and trends in the data, as well as any seasonal or cyclical variations.
Multilevel Modeling
Multilevel modeling is a statistical technique used to analyze data that is nested within multiple levels. For example, researchers might use multilevel modeling to analyze data that is collected from individuals who are nested within groups, such as students nested within schools.
Applications of Quantitative Research
Quantitative research has many applications across a wide range of fields. Here are some common examples:
- Market Research : Quantitative research is used extensively in market research to understand consumer behavior, preferences, and trends. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform marketing strategies, product development, and pricing decisions.
- Health Research: Quantitative research is used in health research to study the effectiveness of medical treatments, identify risk factors for diseases, and track health outcomes over time. Researchers use statistical methods to analyze data from clinical trials, surveys, and other sources to inform medical practice and policy.
- Social Science Research: Quantitative research is used in social science research to study human behavior, attitudes, and social structures. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform social policies, educational programs, and community interventions.
- Education Research: Quantitative research is used in education research to study the effectiveness of teaching methods, assess student learning outcomes, and identify factors that influence student success. Researchers use experimental and quasi-experimental designs, as well as surveys and other quantitative methods, to collect and analyze data.
- Environmental Research: Quantitative research is used in environmental research to study the impact of human activities on the environment, assess the effectiveness of conservation strategies, and identify ways to reduce environmental risks. Researchers use statistical methods to analyze data from field studies, experiments, and other sources.
Characteristics of Quantitative Research
Here are some key characteristics of quantitative research:
- Numerical data : Quantitative research involves collecting numerical data through standardized methods such as surveys, experiments, and observational studies. This data is analyzed using statistical methods to identify patterns and relationships.
- Large sample size: Quantitative research often involves collecting data from a large sample of individuals or groups in order to increase the reliability and generalizability of the findings.
- Objective approach: Quantitative research aims to be objective and impartial in its approach, focusing on the collection and analysis of data rather than personal beliefs, opinions, or experiences.
- Control over variables: Quantitative research often involves manipulating variables to test hypotheses and establish cause-and-effect relationships. Researchers aim to control for extraneous variables that may impact the results.
- Replicable : Quantitative research aims to be replicable, meaning that other researchers should be able to conduct similar studies and obtain similar results using the same methods.
- Statistical analysis: Quantitative research involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis allows researchers to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
- Generalizability: Quantitative research aims to produce findings that can be generalized to larger populations beyond the specific sample studied. This is achieved through the use of random sampling methods and statistical inference.
Examples of Quantitative Research
Here are some examples of quantitative research in different fields:
- Market Research: A company conducts a survey of 1000 consumers to determine their brand awareness and preferences. The data is analyzed using statistical methods to identify trends and patterns that can inform marketing strategies.
- Health Research : A researcher conducts a randomized controlled trial to test the effectiveness of a new drug for treating a particular medical condition. The study involves collecting data from a large sample of patients and analyzing the results using statistical methods.
- Social Science Research : A sociologist conducts a survey of 500 people to study attitudes toward immigration in a particular country. The data is analyzed using statistical methods to identify factors that influence these attitudes.
- Education Research: A researcher conducts an experiment to compare the effectiveness of two different teaching methods for improving student learning outcomes. The study involves randomly assigning students to different groups and collecting data on their performance on standardized tests.
- Environmental Research : A team of researchers conduct a study to investigate the impact of climate change on the distribution and abundance of a particular species of plant or animal. The study involves collecting data on environmental factors and population sizes over time and analyzing the results using statistical methods.
- Psychology : A researcher conducts a survey of 500 college students to investigate the relationship between social media use and mental health. The data is analyzed using statistical methods to identify correlations and potential causal relationships.
- Political Science: A team of researchers conducts a study to investigate voter behavior during an election. They use survey methods to collect data on voting patterns, demographics, and political attitudes, and analyze the results using statistical methods.
How to Conduct Quantitative Research
Here is a general overview of how to conduct quantitative research:
- Develop a research question: The first step in conducting quantitative research is to develop a clear and specific research question. This question should be based on a gap in existing knowledge, and should be answerable using quantitative methods.
- Develop a research design: Once you have a research question, you will need to develop a research design. This involves deciding on the appropriate methods to collect data, such as surveys, experiments, or observational studies. You will also need to determine the appropriate sample size, data collection instruments, and data analysis techniques.
- Collect data: The next step is to collect data. This may involve administering surveys or questionnaires, conducting experiments, or gathering data from existing sources. It is important to use standardized methods to ensure that the data is reliable and valid.
- Analyze data : Once the data has been collected, it is time to analyze it. This involves using statistical methods to identify patterns, trends, and relationships between variables. Common statistical techniques include correlation analysis, regression analysis, and hypothesis testing.
- Interpret results: After analyzing the data, you will need to interpret the results. This involves identifying the key findings, determining their significance, and drawing conclusions based on the data.
- Communicate findings: Finally, you will need to communicate your findings. This may involve writing a research report, presenting at a conference, or publishing in a peer-reviewed journal. It is important to clearly communicate the research question, methods, results, and conclusions to ensure that others can understand and replicate your research.
When to use Quantitative Research
Here are some situations when quantitative research can be appropriate:
- To test a hypothesis: Quantitative research is often used to test a hypothesis or a theory. It involves collecting numerical data and using statistical analysis to determine if the data supports or refutes the hypothesis.
- To generalize findings: If you want to generalize the findings of your study to a larger population, quantitative research can be useful. This is because it allows you to collect numerical data from a representative sample of the population and use statistical analysis to make inferences about the population as a whole.
- To measure relationships between variables: If you want to measure the relationship between two or more variables, such as the relationship between age and income, or between education level and job satisfaction, quantitative research can be useful. It allows you to collect numerical data on both variables and use statistical analysis to determine the strength and direction of the relationship.
- To identify patterns or trends: Quantitative research can be useful for identifying patterns or trends in data. For example, you can use quantitative research to identify trends in consumer behavior or to identify patterns in stock market data.
- To quantify attitudes or opinions : If you want to measure attitudes or opinions on a particular topic, quantitative research can be useful. It allows you to collect numerical data using surveys or questionnaires and analyze the data using statistical methods to determine the prevalence of certain attitudes or opinions.
Purpose of Quantitative Research
The purpose of quantitative research is to systematically investigate and measure the relationships between variables or phenomena using numerical data and statistical analysis. The main objectives of quantitative research include:
- Description : To provide a detailed and accurate description of a particular phenomenon or population.
- Explanation : To explain the reasons for the occurrence of a particular phenomenon, such as identifying the factors that influence a behavior or attitude.
- Prediction : To predict future trends or behaviors based on past patterns and relationships between variables.
- Control : To identify the best strategies for controlling or influencing a particular outcome or behavior.
Quantitative research is used in many different fields, including social sciences, business, engineering, and health sciences. It can be used to investigate a wide range of phenomena, from human behavior and attitudes to physical and biological processes. The purpose of quantitative research is to provide reliable and valid data that can be used to inform decision-making and improve understanding of the world around us.
Advantages of Quantitative Research
There are several advantages of quantitative research, including:
- Objectivity : Quantitative research is based on objective data and statistical analysis, which reduces the potential for bias or subjectivity in the research process.
- Reproducibility : Because quantitative research involves standardized methods and measurements, it is more likely to be reproducible and reliable.
- Generalizability : Quantitative research allows for generalizations to be made about a population based on a representative sample, which can inform decision-making and policy development.
- Precision : Quantitative research allows for precise measurement and analysis of data, which can provide a more accurate understanding of phenomena and relationships between variables.
- Efficiency : Quantitative research can be conducted relatively quickly and efficiently, especially when compared to qualitative research, which may involve lengthy data collection and analysis.
- Large sample sizes : Quantitative research can accommodate large sample sizes, which can increase the representativeness and generalizability of the results.
Limitations of Quantitative Research
There are several limitations of quantitative research, including:
- Limited understanding of context: Quantitative research typically focuses on numerical data and statistical analysis, which may not provide a comprehensive understanding of the context or underlying factors that influence a phenomenon.
- Simplification of complex phenomena: Quantitative research often involves simplifying complex phenomena into measurable variables, which may not capture the full complexity of the phenomenon being studied.
- Potential for researcher bias: Although quantitative research aims to be objective, there is still the potential for researcher bias in areas such as sampling, data collection, and data analysis.
- Limited ability to explore new ideas: Quantitative research is often based on pre-determined research questions and hypotheses, which may limit the ability to explore new ideas or unexpected findings.
- Limited ability to capture subjective experiences : Quantitative research is typically focused on objective data and may not capture the subjective experiences of individuals or groups being studied.
- Ethical concerns : Quantitative research may raise ethical concerns, such as invasion of privacy or the potential for harm to participants.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Case Study – Methods, Examples and Guide

Qualitative Research – Methods, Analysis Types...

Descriptive Research Design – Types, Methods and...

Qualitative Research Methods

Basic Research – Types, Methods and Examples

Exploratory Research – Types, Methods and...
Hypothesis Testing
When you conduct a piece of quantitative research, you are inevitably attempting to answer a research question or hypothesis that you have set. One method of evaluating this research question is via a process called hypothesis testing , which is sometimes also referred to as significance testing . Since there are many facets to hypothesis testing, we start with the example we refer to throughout this guide.
An example of a lecturer's dilemma
Two statistics lecturers, Sarah and Mike, think that they use the best method to teach their students. Each lecturer has 50 statistics students who are studying a graduate degree in management. In Sarah's class, students have to attend one lecture and one seminar class every week, whilst in Mike's class students only have to attend one lecture. Sarah thinks that seminars, in addition to lectures, are an important teaching method in statistics, whilst Mike believes that lectures are sufficient by themselves and thinks that students are better off solving problems by themselves in their own time. This is the first year that Sarah has given seminars, but since they take up a lot of her time, she wants to make sure that she is not wasting her time and that seminars improve her students' performance.
The research hypothesis
The first step in hypothesis testing is to set a research hypothesis. In Sarah and Mike's study, the aim is to examine the effect that two different teaching methods – providing both lectures and seminar classes (Sarah), and providing lectures by themselves (Mike) – had on the performance of Sarah's 50 students and Mike's 50 students. More specifically, they want to determine whether performance is different between the two different teaching methods. Whilst Mike is skeptical about the effectiveness of seminars, Sarah clearly believes that giving seminars in addition to lectures helps her students do better than those in Mike's class. This leads to the following research hypothesis:
Before moving onto the second step of the hypothesis testing process, we need to take you on a brief detour to explain why you need to run hypothesis testing at all. This is explained next.
Sample to population
If you have measured individuals (or any other type of "object") in a study and want to understand differences (or any other type of effect), you can simply summarize the data you have collected. For example, if Sarah and Mike wanted to know which teaching method was the best, they could simply compare the performance achieved by the two groups of students – the group of students that took lectures and seminar classes, and the group of students that took lectures by themselves – and conclude that the best method was the teaching method which resulted in the highest performance. However, this is generally of only limited appeal because the conclusions could only apply to students in this study. However, if those students were representative of all statistics students on a graduate management degree, the study would have wider appeal.
In statistics terminology, the students in the study are the sample and the larger group they represent (i.e., all statistics students on a graduate management degree) is called the population . Given that the sample of statistics students in the study are representative of a larger population of statistics students, you can use hypothesis testing to understand whether any differences or effects discovered in the study exist in the population. In layman's terms, hypothesis testing is used to establish whether a research hypothesis extends beyond those individuals examined in a single study.
Another example could be taking a sample of 200 breast cancer sufferers in order to test a new drug that is designed to eradicate this type of cancer. As much as you are interested in helping these specific 200 cancer sufferers, your real goal is to establish that the drug works in the population (i.e., all breast cancer sufferers).
As such, by taking a hypothesis testing approach, Sarah and Mike want to generalize their results to a population rather than just the students in their sample. However, in order to use hypothesis testing, you need to re-state your research hypothesis as a null and alternative hypothesis. Before you can do this, it is best to consider the process/structure involved in hypothesis testing and what you are measuring. This structure is presented on the next page .
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Research Questions & Hypotheses
Generally, in quantitative studies, reviewers expect hypotheses rather than research questions. However, both research questions and hypotheses serve different purposes and can be beneficial when used together.
Research Questions
Clarify the research’s aim (farrugia et al., 2010).
- Research often begins with an interest in a topic, but a deep understanding of the subject is crucial to formulate an appropriate research question.
- Descriptive: “What factors most influence the academic achievement of senior high school students?”
- Comparative: “What is the performance difference between teaching methods A and B?”
- Relationship-based: “What is the relationship between self-efficacy and academic achievement?”
- Increasing knowledge about a subject can be achieved through systematic literature reviews, in-depth interviews with patients (and proxies), focus groups, and consultations with field experts.
- Some funding bodies, like the Canadian Institute for Health Research, recommend conducting a systematic review or a pilot study before seeking grants for full trials.
- The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility.
- It’s advisable to focus on a single primary research question for the study.
- The primary question, clearly stated at the end of a grant proposal’s introduction, usually specifies the study population, intervention, and other relevant factors.
- The FINER criteria underscore aspects that can enhance the chances of a successful research project, including specifying the population of interest, aligning with scientific and public interest, clinical relevance, and contribution to the field, while complying with ethical and national research standards.
- The P ICOT approach is crucial in developing the study’s framework and protocol, influencing inclusion and exclusion criteria and identifying patient groups for inclusion.
- Defining the specific population, intervention, comparator, and outcome helps in selecting the right outcome measurement tool.
- The more precise the population definition and stricter the inclusion and exclusion criteria, the more significant the impact on the interpretation, applicability, and generalizability of the research findings.
- A restricted study population enhances internal validity but may limit the study’s external validity and generalizability to clinical practice.
- A broadly defined study population may better reflect clinical practice but could increase bias and reduce internal validity.
- An inadequately formulated research question can negatively impact study design, potentially leading to ineffective outcomes and affecting publication prospects.
Checklist: Good research questions for social science projects (Panke, 2018)
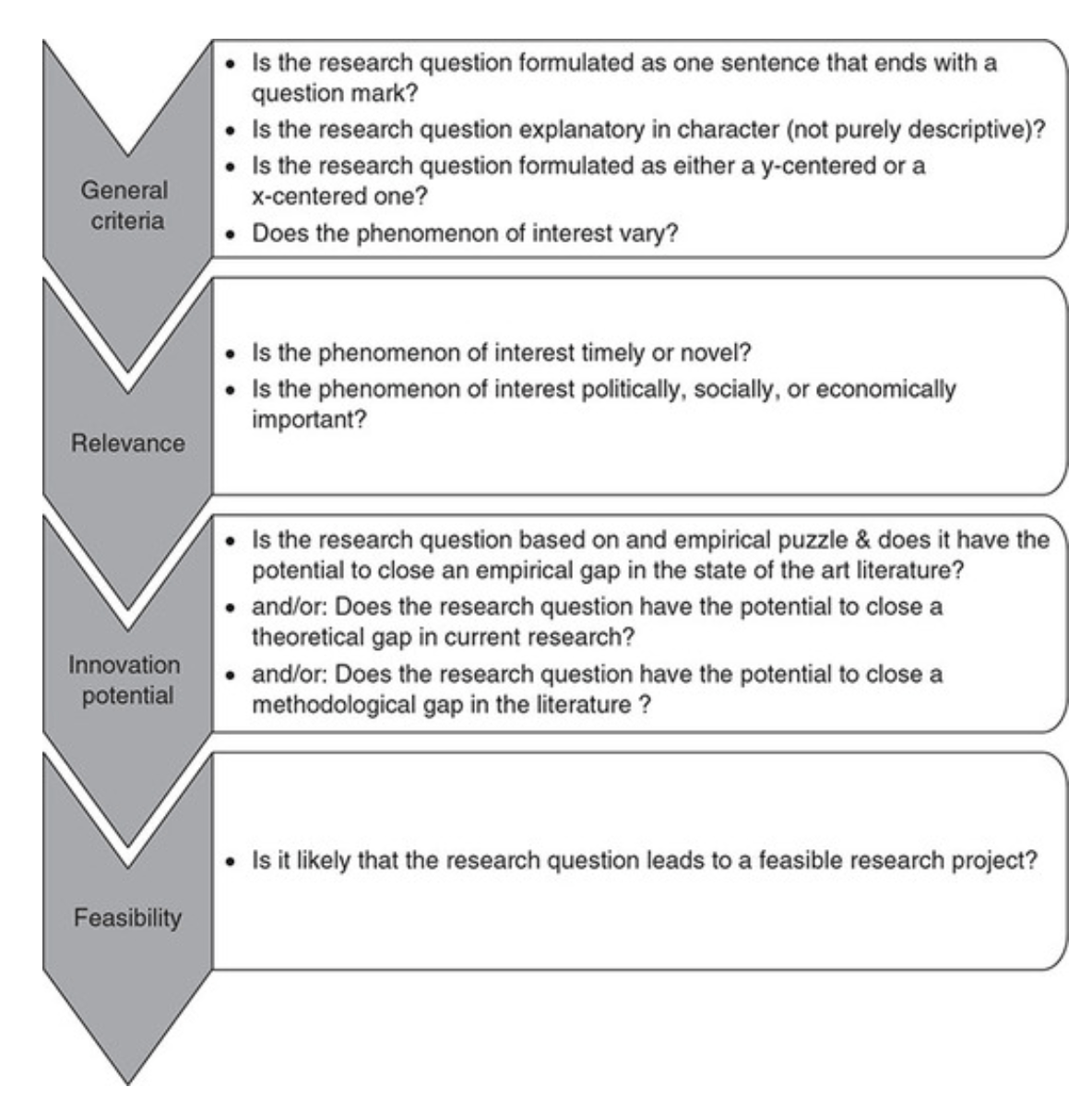
Research Hypotheses
Present the researcher’s predictions based on specific statements.
- These statements define the research problem or issue and indicate the direction of the researcher’s predictions.
- Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
- The research or clinical hypothesis, derived from the research question, shapes the study’s key elements: sampling strategy, intervention, comparison, and outcome variables.
- Hypotheses can express a single outcome or multiple outcomes.
- After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant.
- Hypothesis testing helps determine if observed findings are due to true differences and not chance.
- Hypotheses can be 1-sided (specific direction of difference) or 2-sided (presence of a difference without specifying direction).
- 2-sided hypotheses are generally preferred unless there’s a strong justification for a 1-sided hypothesis.
- A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives.
Types of Research Hypothesis
- In a Y-centered research design, the focus is on the dependent variable (DV) which is specified in the research question. Theories are then used to identify independent variables (IV) and explain their causal relationship with the DV.
- Example: “An increase in teacher-led instructional time (IV) is likely to improve student reading comprehension scores (DV), because extensive guided practice under expert supervision enhances learning retention and skill mastery.”
- Hypothesis Explanation: The dependent variable (student reading comprehension scores) is the focus, and the hypothesis explores how changes in the independent variable (teacher-led instructional time) affect it.
- In X-centered research designs, the independent variable is specified in the research question. Theories are used to determine potential dependent variables and the causal mechanisms at play.
- Example: “Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student interest and participation.”
- Hypothesis Explanation: The independent variable (technology-based learning tools) is the focus, with the hypothesis exploring its impact on a potential dependent variable (student engagement).
- Probabilistic hypotheses suggest that changes in the independent variable are likely to lead to changes in the dependent variable in a predictable manner, but not with absolute certainty.
- Example: “The more teachers engage in professional development programs (IV), the more their teaching effectiveness (DV) is likely to improve, because continuous training updates pedagogical skills and knowledge.”
- Hypothesis Explanation: This hypothesis implies a probable relationship between the extent of professional development (IV) and teaching effectiveness (DV).
- Deterministic hypotheses state that a specific change in the independent variable will lead to a specific change in the dependent variable, implying a more direct and certain relationship.
- Example: “If the school curriculum changes from traditional lecture-based methods to project-based learning (IV), then student collaboration skills (DV) are expected to improve because project-based learning inherently requires teamwork and peer interaction.”
- Hypothesis Explanation: This hypothesis presumes a direct and definite outcome (improvement in collaboration skills) resulting from a specific change in the teaching method.
- Example : “Students who identify as visual learners will score higher on tests that are presented in a visually rich format compared to tests presented in a text-only format.”
- Explanation : This hypothesis aims to describe the potential difference in test scores between visual learners taking visually rich tests and text-only tests, without implying a direct cause-and-effect relationship.
- Example : “Teaching method A will improve student performance more than method B.”
- Explanation : This hypothesis compares the effectiveness of two different teaching methods, suggesting that one will lead to better student performance than the other. It implies a direct comparison but does not necessarily establish a causal mechanism.
- Example : “Students with higher self-efficacy will show higher levels of academic achievement.”
- Explanation : This hypothesis predicts a relationship between the variable of self-efficacy and academic achievement. Unlike a causal hypothesis, it does not necessarily suggest that one variable causes changes in the other, but rather that they are related in some way.
Tips for developing research questions and hypotheses for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues, and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Ensure that the research question and objectives are answerable, feasible, and clinically relevant.
If your research hypotheses are derived from your research questions, particularly when multiple hypotheses address a single question, it’s recommended to use both research questions and hypotheses. However, if this isn’t the case, using hypotheses over research questions is advised. It’s important to note these are general guidelines, not strict rules. If you opt not to use hypotheses, consult with your supervisor for the best approach.
Farrugia, P., Petrisor, B. A., Farrokhyar, F., & Bhandari, M. (2010). Practical tips for surgical research: Research questions, hypotheses and objectives. Canadian journal of surgery. Journal canadien de chirurgie , 53 (4), 278–281.
Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D., & Newman, T. B. (2007). Designing clinical research. Philadelphia.
Panke, D. (2018). Research design & method selection: Making good choices in the social sciences. Research Design & Method Selection , 1-368.
Quantitative Research Methods
- Introduction
- Descriptive and Inferential Statistics
- Hypothesis Testing
- Regression and Correlation
- Time Series
- Meta-Analysis
- Mixed Methods
- Additional Resources
- Get Research Help
Hypothesis Tests
A hypothesis test is exactly what it sounds like: You make a hypothesis about the parameters of a population, and the test determines whether your hypothesis is consistent with your sample data.
- Hypothesis Testing Penn State University tutorial
- Hypothesis Testing Wolfram MathWorld overview
- Hypothesis Testing Minitab Blog entry
- List of Statistical Tests A list of commonly used hypothesis tests and the circumstances under which they're used.
The p-value of a hypothesis test is the probability that your sample data would have occurred if you hypothesis were not correct. Traditionally, researchers have used a p-value of 0.05 (a 5% probability that your sample data would have occurred if your hypothesis was wrong) as the threshold for declaring that a hypothesis is true. But there is a long history of debate and controversy over p-values and significance levels.
Nonparametric Tests
Many of the most commonly used hypothesis tests rely on assumptions about your sample data—for instance, that it is continuous, and that its parameters follow a Normal distribution. Nonparametric hypothesis tests don't make any assumptions about the distribution of the data, and many can be used on categorical data.
- Nonparametric Tests at Boston University A lesson covering four common nonparametric tests.
- Nonparametric Tests at Penn State Tutorial covering the theory behind nonparametric tests as well as several commonly used tests.
- << Previous: Descriptive and Inferential Statistics
- Next: Regression and Correlation >>
- Last Updated: Aug 18, 2023 11:55 AM
- URL: https://guides.library.duq.edu/quant-methods
- Getting Started
- GLG Institute
- Expert Witness
- Integrated Insights
- Qualitative
- Featured Content
- Medical Devices & Diagnostics
- Pharmaceuticals & Biotechnology
- Industrials
- Consumer Goods
- Payments & Insurance
- Hedge Funds
- Private Equity
- Private Credit
- Investment Managers & Mutual Funds
- Investment Banks & Research
- Consulting Firms
- Advertising & Public Relations
- Law Firm Resources
- Network Members
- Social Impact
- Clients - MyGLG
Qualitative vs. Quantitative Research — Here’s What You Need to Know
Will Mellor, Director of Surveys, GLG
Read Time: 0 Minutes
Qualitative vs. Quantitative — you’ve heard the terms before, but what do they mean? Here’s what you need to know on when to use them and how to apply them in your research projects.
Most research projects you undertake will likely require some combination of qualitative and quantitative data. The magnitude of each will depend on what you need to accomplish. They are opposite in their approach, which makes them balanced in their outcomes.

When Are They Applied?
Qualitative
Qualitative research is used to formulate a hypothesis . If you need deeper information about a topic you know little about, qualitative research can help you uncover themes. For this reason, qualitative research often comes prior to quantitative. It allows you to get a baseline understanding of the topic and start to formulate hypotheses around correlation and causation.
Quantitative
Quantitative research is used to test or confirm a hypothesis . Qualitative research usually informs quantitative. You need to have enough understanding about a topic in order to develop a hypothesis you can test. Since quantitative research is highly structured, you first need to understand what the parameters are and how variable they are in practice. This allows you to create a research outline that is controlled in all the ways that will produce high-quality data.
In practice, the parameters are the factors you want to test against your hypothesis. If your hypothesis is that COVID is going to transform the way companies think about office space, some of your parameters might include the percent of your workforce working from home pre- and post-COVID, total square footage of office space held, and/or real-estate spend expectations by executive leadership. You would also want to know the variability of those parameters. In the COVID example, you will need to know standard ranges of square footage and real-estate expenditures so that you can create answer options that will capture relevant, high-quality, and easily actionable data.
Methods of Research
Often, qualitative research is conducted with a small sample size and includes many open-ended questions . The goal is to understand “Why?” and the thinking behind the decisions. The best way to facilitate this type of research is through one-on-one interviews, focus groups, and sometimes surveys. A major benefit of the interview and focus group formats is the ability to ask follow-up questions and dig deeper on answers that are particularly insightful.
Conversely, quantitative research is designed for larger sample sizes, which can garner perspectives across a wide spectrum of respondents. While not always necessary, sample sizes can sometimes be large enough to be statistically significant . The best way to facilitate this type of research is through surveys or large-scale experiments.
Unsurprisingly, the two different approaches will generate different types of data that will need to be analyzed differently.
For qualitative data, you’ll end up with data that will be highly textual in nature. You’ll be reading through the data and looking for key themes that emerge over and over. This type of research is also great at producing quotes that can be used in presentations or reports. Quotes are a powerful tool for conveying sentiment and making a poignant point.
For quantitative data, you’ll end up with a data set that can be analyzed, often with statistical software such as Excel, R, or SPSS. You can ask many different types of questions that produce this quantitative data, including rating/ranking questions, single-select, multiselect, and matrix table questions. These question types will produce data that can be analyzed to find averages, ranges, growth rates, percentage changes, minimums/maximums, and even time-series data for longer-term trend analysis.
Mixed Methods Approach
You aren’t limited to just one approach. If you need both quantitative and qualitative data, then collect both. You can even collect both quantitative and qualitative data within one type of research instrument. In a survey, you can ask both open-ended questions about “Why?” as well as closed-ended, data-related questions. Even in an unstructured format, like an interview or focus group, you can ask numerical questions to capture analyzable data.
Just be careful. While qualitative themes can be generalized, it can be dangerous to generalize on such a small sample size of quantitative data. For instance, why companies like a certain software platform may fall into three to five key themes. How much they spend on that platform can be highly variable.
The Takeaway
If you are unfamiliar with the topic you are researching, qualitative research is the best first approach. As you get deeper in your research, certain themes will emerge, and you’ll start to form hypotheses. From there, quantitative research can provide larger-scale data sets that can be analyzed to either confirm or deny the hypotheses you formulated earlier in your research. Most importantly, the two approaches are not mutually exclusive. You can have an eye for both themes and data throughout the research process. You’ll just be leaning more heavily to one or the other depending on where you are in your understanding of the topic.
Ready to get started? Get the actionable insights you need with the help of GLG’s qualitative and quantitative research methods.
About Will Mellor
Will Mellor leads a team of accomplished project managers who serve financial service firms across North America. His team manages end-to-end survey delivery from first draft to final deliverable. Will is an expert on GLG’s internal membership and consumer populations, as well as survey design and research. Before coming to GLG, he was the vice president of an economic consulting group, where he was responsible for designing economic impact models for clients in both the public sector and the private sector. Will has bachelor’s degrees in international business and finance and a master’s degree in applied economics.
For more information, read our articles: Three Ways to Apply Qualitative Research , Focusing on Focus Groups: Best Practices, What Type of Survey Do You Need?, or The 6 Pillars of Successful Survey Design
You can also download our eBooks: GLG’s Guide to Effective Qualitative Research or Strategies for Successful Surveys
Enter your contact information below and a member of our team will reach out to you shortly.
Thank you for contacting GLG, someone will respond to your inquiry as soon as possible.
Subscribe to Insights 360
Enter your email below and receive our monthly newsletter, featuring insights from GLG’s network of approximately 1 million professionals with first-hand expertise in every industry.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.36(50); 2021 Dec 27
Formulating Hypotheses for Different Study Designs
Durga prasanna misra.
1 Department of Clinical Immunology and Rheumatology, Sanjay Gandhi Postgraduate Institute of Medical Sciences, Lucknow, India.
Armen Yuri Gasparyan
2 Departments of Rheumatology and Research and Development, Dudley Group NHS Foundation Trust (Teaching Trust of the University of Birmingham, UK), Russells Hall Hospital, Dudley, UK.
Olena Zimba
3 Department of Internal Medicine #2, Danylo Halytsky Lviv National Medical University, Lviv, Ukraine.
Marlen Yessirkepov
4 Department of Biology and Biochemistry, South Kazakhstan Medical Academy, Shymkent, Kazakhstan.
Vikas Agarwal
George d. kitas.
5 Centre for Epidemiology versus Arthritis, University of Manchester, Manchester, UK.
Generating a testable working hypothesis is the first step towards conducting original research. Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate hypotheses. Observational and interventional studies help to test hypotheses. A good hypothesis is usually based on previous evidence-based reports. Hypotheses without evidence-based justification and a priori ideas are not received favourably by the scientific community. Original research to test a hypothesis should be carefully planned to ensure appropriate methodology and adequate statistical power. While hypotheses can challenge conventional thinking and may be controversial, they should not be destructive. A hypothesis should be tested by ethically sound experiments with meaningful ethical and clinical implications. The coronavirus disease 2019 pandemic has brought into sharp focus numerous hypotheses, some of which were proven (e.g. effectiveness of corticosteroids in those with hypoxia) while others were disproven (e.g. ineffectiveness of hydroxychloroquine and ivermectin).
Graphical Abstract

DEFINING WORKING AND STANDALONE SCIENTIFIC HYPOTHESES
Science is the systematized description of natural truths and facts. Routine observations of existing life phenomena lead to the creative thinking and generation of ideas about mechanisms of such phenomena and related human interventions. Such ideas presented in a structured format can be viewed as hypotheses. After generating a hypothesis, it is necessary to test it to prove its validity. Thus, hypothesis can be defined as a proposed mechanism of a naturally occurring event or a proposed outcome of an intervention. 1 , 2
Hypothesis testing requires choosing the most appropriate methodology and adequately powering statistically the study to be able to “prove” or “disprove” it within predetermined and widely accepted levels of certainty. This entails sample size calculation that often takes into account previously published observations and pilot studies. 2 , 3 In the era of digitization, hypothesis generation and testing may benefit from the availability of numerous platforms for data dissemination, social networking, and expert validation. Related expert evaluations may reveal strengths and limitations of proposed ideas at early stages of post-publication promotion, preventing the implementation of unsupported controversial points. 4
Thus, hypothesis generation is an important initial step in the research workflow, reflecting accumulating evidence and experts' stance. In this article, we overview the genesis and importance of scientific hypotheses and their relevance in the era of the coronavirus disease 2019 (COVID-19) pandemic.
DO WE NEED HYPOTHESES FOR ALL STUDY DESIGNS?
Broadly, research can be categorized as primary or secondary. In the context of medicine, primary research may include real-life observations of disease presentations and outcomes. Single case descriptions, which often lead to new ideas and hypotheses, serve as important starting points or justifications for case series and cohort studies. The importance of case descriptions is particularly evident in the context of the COVID-19 pandemic when unique, educational case reports have heralded a new era in clinical medicine. 5
Case series serve similar purpose to single case reports, but are based on a slightly larger quantum of information. Observational studies, including online surveys, describe the existing phenomena at a larger scale, often involving various control groups. Observational studies include variable-scale epidemiological investigations at different time points. Interventional studies detail the results of therapeutic interventions.
Secondary research is based on already published literature and does not directly involve human or animal subjects. Review articles are generated by secondary research. These could be systematic reviews which follow methods akin to primary research but with the unit of study being published papers rather than humans or animals. Systematic reviews have a rigid structure with a mandatory search strategy encompassing multiple databases, systematic screening of search results against pre-defined inclusion and exclusion criteria, critical appraisal of study quality and an optional component of collating results across studies quantitatively to derive summary estimates (meta-analysis). 6 Narrative reviews, on the other hand, have a more flexible structure. Systematic literature searches to minimise bias in selection of articles are highly recommended but not mandatory. 7 Narrative reviews are influenced by the authors' viewpoint who may preferentially analyse selected sets of articles. 8
In relation to primary research, case studies and case series are generally not driven by a working hypothesis. Rather, they serve as a basis to generate a hypothesis. Observational or interventional studies should have a hypothesis for choosing research design and sample size. The results of observational and interventional studies further lead to the generation of new hypotheses, testing of which forms the basis of future studies. Review articles, on the other hand, may not be hypothesis-driven, but form fertile ground to generate future hypotheses for evaluation. Fig. 1 summarizes which type of studies are hypothesis-driven and which lead on to hypothesis generation.

STANDARDS OF WORKING AND SCIENTIFIC HYPOTHESES
A review of the published literature did not enable the identification of clearly defined standards for working and scientific hypotheses. It is essential to distinguish influential versus not influential hypotheses, evidence-based hypotheses versus a priori statements and ideas, ethical versus unethical, or potentially harmful ideas. The following points are proposed for consideration while generating working and scientific hypotheses. 1 , 2 Table 1 summarizes these points.
Evidence-based data
A scientific hypothesis should have a sound basis on previously published literature as well as the scientist's observations. Randomly generated (a priori) hypotheses are unlikely to be proven. A thorough literature search should form the basis of a hypothesis based on published evidence. 7
Unless a scientific hypothesis can be tested, it can neither be proven nor be disproven. Therefore, a scientific hypothesis should be amenable to testing with the available technologies and the present understanding of science.
Supported by pilot studies
If a hypothesis is based purely on a novel observation by the scientist in question, it should be grounded on some preliminary studies to support it. For example, if a drug that targets a specific cell population is hypothesized to be useful in a particular disease setting, then there must be some preliminary evidence that the specific cell population plays a role in driving that disease process.
Testable by ethical studies
The hypothesis should be testable by experiments that are ethically acceptable. 9 For example, a hypothesis that parachutes reduce mortality from falls from an airplane cannot be tested using a randomized controlled trial. 10 This is because it is obvious that all those jumping from a flying plane without a parachute would likely die. Similarly, the hypothesis that smoking tobacco causes lung cancer cannot be tested by a clinical trial that makes people take up smoking (since there is considerable evidence for the health hazards associated with smoking). Instead, long-term observational studies comparing outcomes in those who smoke and those who do not, as was performed in the landmark epidemiological case control study by Doll and Hill, 11 are more ethical and practical.
Balance between scientific temper and controversy
Novel findings, including novel hypotheses, particularly those that challenge established norms, are bound to face resistance for their wider acceptance. Such resistance is inevitable until the time such findings are proven with appropriate scientific rigor. However, hypotheses that generate controversy are generally unwelcome. For example, at the time the pandemic of human immunodeficiency virus (HIV) and AIDS was taking foot, there were numerous deniers that refused to believe that HIV caused AIDS. 12 , 13 Similarly, at a time when climate change is causing catastrophic changes to weather patterns worldwide, denial that climate change is occurring and consequent attempts to block climate change are certainly unwelcome. 14 The denialism and misinformation during the COVID-19 pandemic, including unfortunate examples of vaccine hesitancy, are more recent examples of controversial hypotheses not backed by science. 15 , 16 An example of a controversial hypothesis that was a revolutionary scientific breakthrough was the hypothesis put forth by Warren and Marshall that Helicobacter pylori causes peptic ulcers. Initially, the hypothesis that a microorganism could cause gastritis and gastric ulcers faced immense resistance. When the scientists that proposed the hypothesis themselves ingested H. pylori to induce gastritis in themselves, only then could they convince the wider world about their hypothesis. Such was the impact of the hypothesis was that Barry Marshall and Robin Warren were awarded the Nobel Prize in Physiology or Medicine in 2005 for this discovery. 17 , 18
DISTINGUISHING THE MOST INFLUENTIAL HYPOTHESES
Influential hypotheses are those that have stood the test of time. An archetype of an influential hypothesis is that proposed by Edward Jenner in the eighteenth century that cowpox infection protects against smallpox. While this observation had been reported for nearly a century before this time, it had not been suitably tested and publicised until Jenner conducted his experiments on a young boy by demonstrating protection against smallpox after inoculation with cowpox. 19 These experiments were the basis for widespread smallpox immunization strategies worldwide in the 20th century which resulted in the elimination of smallpox as a human disease today. 20
Other influential hypotheses are those which have been read and cited widely. An example of this is the hygiene hypothesis proposing an inverse relationship between infections in early life and allergies or autoimmunity in adulthood. An analysis reported that this hypothesis had been cited more than 3,000 times on Scopus. 1
LESSONS LEARNED FROM HYPOTHESES AMIDST THE COVID-19 PANDEMIC
The COVID-19 pandemic devastated the world like no other in recent memory. During this period, various hypotheses emerged, understandably so considering the public health emergency situation with innumerable deaths and suffering for humanity. Within weeks of the first reports of COVID-19, aberrant immune system activation was identified as a key driver of organ dysfunction and mortality in this disease. 21 Consequently, numerous drugs that suppress the immune system or abrogate the activation of the immune system were hypothesized to have a role in COVID-19. 22 One of the earliest drugs hypothesized to have a benefit was hydroxychloroquine. Hydroxychloroquine was proposed to interfere with Toll-like receptor activation and consequently ameliorate the aberrant immune system activation leading to pathology in COVID-19. 22 The drug was also hypothesized to have a prophylactic role in preventing infection or disease severity in COVID-19. It was also touted as a wonder drug for the disease by many prominent international figures. However, later studies which were well-designed randomized controlled trials failed to demonstrate any benefit of hydroxychloroquine in COVID-19. 23 , 24 , 25 , 26 Subsequently, azithromycin 27 , 28 and ivermectin 29 were hypothesized as potential therapies for COVID-19, but were not supported by evidence from randomized controlled trials. The role of vitamin D in preventing disease severity was also proposed, but has not been proven definitively until now. 30 , 31 On the other hand, randomized controlled trials identified the evidence supporting dexamethasone 32 and interleukin-6 pathway blockade with tocilizumab as effective therapies for COVID-19 in specific situations such as at the onset of hypoxia. 33 , 34 Clues towards the apparent effectiveness of various drugs against severe acute respiratory syndrome coronavirus 2 in vitro but their ineffectiveness in vivo have recently been identified. Many of these drugs are weak, lipophilic bases and some others induce phospholipidosis which results in apparent in vitro effectiveness due to non-specific off-target effects that are not replicated inside living systems. 35 , 36
Another hypothesis proposed was the association of the routine policy of vaccination with Bacillus Calmette-Guerin (BCG) with lower deaths due to COVID-19. This hypothesis emerged in the middle of 2020 when COVID-19 was still taking foot in many parts of the world. 37 , 38 Subsequently, many countries which had lower deaths at that time point went on to have higher numbers of mortality, comparable to other areas of the world. Furthermore, the hypothesis that BCG vaccination reduced COVID-19 mortality was a classic example of ecological fallacy. Associations between population level events (ecological studies; in this case, BCG vaccination and COVID-19 mortality) cannot be directly extrapolated to the individual level. Furthermore, such associations cannot per se be attributed as causal in nature, and can only serve to generate hypotheses that need to be tested at the individual level. 39
IS TRADITIONAL PEER REVIEW EFFICIENT FOR EVALUATION OF WORKING AND SCIENTIFIC HYPOTHESES?
Traditionally, publication after peer review has been considered the gold standard before any new idea finds acceptability amongst the scientific community. Getting a work (including a working or scientific hypothesis) reviewed by experts in the field before experiments are conducted to prove or disprove it helps to refine the idea further as well as improve the experiments planned to test the hypothesis. 40 A route towards this has been the emergence of journals dedicated to publishing hypotheses such as the Central Asian Journal of Medical Hypotheses and Ethics. 41 Another means of publishing hypotheses is through registered research protocols detailing the background, hypothesis, and methodology of a particular study. If such protocols are published after peer review, then the journal commits to publishing the completed study irrespective of whether the study hypothesis is proven or disproven. 42 In the post-pandemic world, online research methods such as online surveys powered via social media channels such as Twitter and Instagram might serve as critical tools to generate as well as to preliminarily test the appropriateness of hypotheses for further evaluation. 43 , 44
Some radical hypotheses might be difficult to publish after traditional peer review. These hypotheses might only be acceptable by the scientific community after they are tested in research studies. Preprints might be a way to disseminate such controversial and ground-breaking hypotheses. 45 However, scientists might prefer to keep their hypotheses confidential for the fear of plagiarism of ideas, avoiding online posting and publishing until they have tested the hypotheses.
SUGGESTIONS ON GENERATING AND PUBLISHING HYPOTHESES
Publication of hypotheses is important, however, a balance is required between scientific temper and controversy. Journal editors and reviewers might keep in mind these specific points, summarized in Table 2 and detailed hereafter, while judging the merit of hypotheses for publication. Keeping in mind the ethical principle of primum non nocere, a hypothesis should be published only if it is testable in a manner that is ethically appropriate. 46 Such hypotheses should be grounded in reality and lend themselves to further testing to either prove or disprove them. It must be considered that subsequent experiments to prove or disprove a hypothesis have an equal chance of failing or succeeding, akin to tossing a coin. A pre-conceived belief that a hypothesis is unlikely to be proven correct should not form the basis of rejection of such a hypothesis for publication. In this context, hypotheses generated after a thorough literature search to identify knowledge gaps or based on concrete clinical observations on a considerable number of patients (as opposed to random observations on a few patients) are more likely to be acceptable for publication by peer-reviewed journals. Also, hypotheses should be considered for publication or rejection based on their implications for science at large rather than whether the subsequent experiments to test them end up with results in favour of or against the original hypothesis.
Hypotheses form an important part of the scientific literature. The COVID-19 pandemic has reiterated the importance and relevance of hypotheses for dealing with public health emergencies and highlighted the need for evidence-based and ethical hypotheses. A good hypothesis is testable in a relevant study design, backed by preliminary evidence, and has positive ethical and clinical implications. General medical journals might consider publishing hypotheses as a specific article type to enable more rapid advancement of science.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Data curation: Gasparyan AY, Misra DP, Zimba O, Yessirkepov M, Agarwal V, Kitas GD.
- Resources Home 🏠
- Try SciSpace Copilot
- Search research papers
- Add Copilot Extension
- Try AI Detector
- Try Paraphraser
- Try Citation Generator
- April Papers
- June Papers
- July Papers

The Craft of Writing a Strong Hypothesis

Table of Contents
Writing a hypothesis is one of the essential elements of a scientific research paper. It needs to be to the point, clearly communicating what your research is trying to accomplish. A blurry, drawn-out, or complexly-structured hypothesis can confuse your readers. Or worse, the editor and peer reviewers.
A captivating hypothesis is not too intricate. This blog will take you through the process so that, by the end of it, you have a better idea of how to convey your research paper's intent in just one sentence.
What is a Hypothesis?
The first step in your scientific endeavor, a hypothesis, is a strong, concise statement that forms the basis of your research. It is not the same as a thesis statement , which is a brief summary of your research paper .
The sole purpose of a hypothesis is to predict your paper's findings, data, and conclusion. It comes from a place of curiosity and intuition . When you write a hypothesis, you're essentially making an educated guess based on scientific prejudices and evidence, which is further proven or disproven through the scientific method.
The reason for undertaking research is to observe a specific phenomenon. A hypothesis, therefore, lays out what the said phenomenon is. And it does so through two variables, an independent and dependent variable.
The independent variable is the cause behind the observation, while the dependent variable is the effect of the cause. A good example of this is “mixing red and blue forms purple.” In this hypothesis, mixing red and blue is the independent variable as you're combining the two colors at your own will. The formation of purple is the dependent variable as, in this case, it is conditional to the independent variable.
Different Types of Hypotheses

Types of hypotheses
Some would stand by the notion that there are only two types of hypotheses: a Null hypothesis and an Alternative hypothesis. While that may have some truth to it, it would be better to fully distinguish the most common forms as these terms come up so often, which might leave you out of context.
Apart from Null and Alternative, there are Complex, Simple, Directional, Non-Directional, Statistical, and Associative and casual hypotheses. They don't necessarily have to be exclusive, as one hypothesis can tick many boxes, but knowing the distinctions between them will make it easier for you to construct your own.
1. Null hypothesis
A null hypothesis proposes no relationship between two variables. Denoted by H 0 , it is a negative statement like “Attending physiotherapy sessions does not affect athletes' on-field performance.” Here, the author claims physiotherapy sessions have no effect on on-field performances. Even if there is, it's only a coincidence.
2. Alternative hypothesis
Considered to be the opposite of a null hypothesis, an alternative hypothesis is donated as H1 or Ha. It explicitly states that the dependent variable affects the independent variable. A good alternative hypothesis example is “Attending physiotherapy sessions improves athletes' on-field performance.” or “Water evaporates at 100 °C. ” The alternative hypothesis further branches into directional and non-directional.
- Directional hypothesis: A hypothesis that states the result would be either positive or negative is called directional hypothesis. It accompanies H1 with either the ‘<' or ‘>' sign.
- Non-directional hypothesis: A non-directional hypothesis only claims an effect on the dependent variable. It does not clarify whether the result would be positive or negative. The sign for a non-directional hypothesis is ‘≠.'
3. Simple hypothesis
A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, “Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking.
4. Complex hypothesis
In contrast to a simple hypothesis, a complex hypothesis implies the relationship between multiple independent and dependent variables. For instance, “Individuals who eat more fruits tend to have higher immunity, lesser cholesterol, and high metabolism.” The independent variable is eating more fruits, while the dependent variables are higher immunity, lesser cholesterol, and high metabolism.
5. Associative and casual hypothesis
Associative and casual hypotheses don't exhibit how many variables there will be. They define the relationship between the variables. In an associative hypothesis, changing any one variable, dependent or independent, affects others. In a casual hypothesis, the independent variable directly affects the dependent.
6. Empirical hypothesis
Also referred to as the working hypothesis, an empirical hypothesis claims a theory's validation via experiments and observation. This way, the statement appears justifiable and different from a wild guess.
Say, the hypothesis is “Women who take iron tablets face a lesser risk of anemia than those who take vitamin B12.” This is an example of an empirical hypothesis where the researcher the statement after assessing a group of women who take iron tablets and charting the findings.
7. Statistical hypothesis
The point of a statistical hypothesis is to test an already existing hypothesis by studying a population sample. Hypothesis like “44% of the Indian population belong in the age group of 22-27.” leverage evidence to prove or disprove a particular statement.
Characteristics of a Good Hypothesis
Writing a hypothesis is essential as it can make or break your research for you. That includes your chances of getting published in a journal. So when you're designing one, keep an eye out for these pointers:
- A research hypothesis has to be simple yet clear to look justifiable enough.
- It has to be testable — your research would be rendered pointless if too far-fetched into reality or limited by technology.
- It has to be precise about the results —what you are trying to do and achieve through it should come out in your hypothesis.
- A research hypothesis should be self-explanatory, leaving no doubt in the reader's mind.
- If you are developing a relational hypothesis, you need to include the variables and establish an appropriate relationship among them.
- A hypothesis must keep and reflect the scope for further investigations and experiments.
Separating a Hypothesis from a Prediction
Outside of academia, hypothesis and prediction are often used interchangeably. In research writing, this is not only confusing but also incorrect. And although a hypothesis and prediction are guesses at their core, there are many differences between them.
A hypothesis is an educated guess or even a testable prediction validated through research. It aims to analyze the gathered evidence and facts to define a relationship between variables and put forth a logical explanation behind the nature of events.
Predictions are assumptions or expected outcomes made without any backing evidence. They are more fictionally inclined regardless of where they originate from.
For this reason, a hypothesis holds much more weight than a prediction. It sticks to the scientific method rather than pure guesswork. "Planets revolve around the Sun." is an example of a hypothesis as it is previous knowledge and observed trends. Additionally, we can test it through the scientific method.
Whereas "COVID-19 will be eradicated by 2030." is a prediction. Even though it results from past trends, we can't prove or disprove it. So, the only way this gets validated is to wait and watch if COVID-19 cases end by 2030.
Finally, How to Write a Hypothesis

Quick tips on writing a hypothesis
1. Be clear about your research question
A hypothesis should instantly address the research question or the problem statement. To do so, you need to ask a question. Understand the constraints of your undertaken research topic and then formulate a simple and topic-centric problem. Only after that can you develop a hypothesis and further test for evidence.
2. Carry out a recce
Once you have your research's foundation laid out, it would be best to conduct preliminary research. Go through previous theories, academic papers, data, and experiments before you start curating your research hypothesis. It will give you an idea of your hypothesis's viability or originality.
Making use of references from relevant research papers helps draft a good research hypothesis. SciSpace Discover offers a repository of over 270 million research papers to browse through and gain a deeper understanding of related studies on a particular topic. Additionally, you can use SciSpace Copilot , your AI research assistant, for reading any lengthy research paper and getting a more summarized context of it. A hypothesis can be formed after evaluating many such summarized research papers. Copilot also offers explanations for theories and equations, explains paper in simplified version, allows you to highlight any text in the paper or clip math equations and tables and provides a deeper, clear understanding of what is being said. This can improve the hypothesis by helping you identify potential research gaps.
3. Create a 3-dimensional hypothesis
Variables are an essential part of any reasonable hypothesis. So, identify your independent and dependent variable(s) and form a correlation between them. The ideal way to do this is to write the hypothetical assumption in the ‘if-then' form. If you use this form, make sure that you state the predefined relationship between the variables.
In another way, you can choose to present your hypothesis as a comparison between two variables. Here, you must specify the difference you expect to observe in the results.
4. Write the first draft
Now that everything is in place, it's time to write your hypothesis. For starters, create the first draft. In this version, write what you expect to find from your research.
Clearly separate your independent and dependent variables and the link between them. Don't fixate on syntax at this stage. The goal is to ensure your hypothesis addresses the issue.
5. Proof your hypothesis
After preparing the first draft of your hypothesis, you need to inspect it thoroughly. It should tick all the boxes, like being concise, straightforward, relevant, and accurate. Your final hypothesis has to be well-structured as well.
Research projects are an exciting and crucial part of being a scholar. And once you have your research question, you need a great hypothesis to begin conducting research. Thus, knowing how to write a hypothesis is very important.
Now that you have a firmer grasp on what a good hypothesis constitutes, the different kinds there are, and what process to follow, you will find it much easier to write your hypothesis, which ultimately helps your research.
Now it's easier than ever to streamline your research workflow with SciSpace Discover . Its integrated, comprehensive end-to-end platform for research allows scholars to easily discover, write and publish their research and fosters collaboration.
It includes everything you need, including a repository of over 270 million research papers across disciplines, SEO-optimized summaries and public profiles to show your expertise and experience.
If you found these tips on writing a research hypothesis useful, head over to our blog on Statistical Hypothesis Testing to learn about the top researchers, papers, and institutions in this domain.
Frequently Asked Questions (FAQs)
1. what is the definition of hypothesis.
According to the Oxford dictionary, a hypothesis is defined as “An idea or explanation of something that is based on a few known facts, but that has not yet been proved to be true or correct”.
2. What is an example of hypothesis?
The hypothesis is a statement that proposes a relationship between two or more variables. An example: "If we increase the number of new users who join our platform by 25%, then we will see an increase in revenue."
3. What is an example of null hypothesis?
A null hypothesis is a statement that there is no relationship between two variables. The null hypothesis is written as H0. The null hypothesis states that there is no effect. For example, if you're studying whether or not a particular type of exercise increases strength, your null hypothesis will be "there is no difference in strength between people who exercise and people who don't."
4. What are the types of research?
• Fundamental research
• Applied research
• Qualitative research
• Quantitative research
• Mixed research
• Exploratory research
• Longitudinal research
• Cross-sectional research
• Field research
• Laboratory research
• Fixed research
• Flexible research
• Action research
• Policy research
• Classification research
• Comparative research
• Causal research
• Inductive research
• Deductive research
5. How to write a hypothesis?
• Your hypothesis should be able to predict the relationship and outcome.
• Avoid wordiness by keeping it simple and brief.
• Your hypothesis should contain observable and testable outcomes.
• Your hypothesis should be relevant to the research question.
6. What are the 2 types of hypothesis?
• Null hypotheses are used to test the claim that "there is no difference between two groups of data".
• Alternative hypotheses test the claim that "there is a difference between two data groups".
7. Difference between research question and research hypothesis?
A research question is a broad, open-ended question you will try to answer through your research. A hypothesis is a statement based on prior research or theory that you expect to be true due to your study. Example - Research question: What are the factors that influence the adoption of the new technology? Research hypothesis: There is a positive relationship between age, education and income level with the adoption of the new technology.
8. What is plural for hypothesis?
The plural of hypothesis is hypotheses. Here's an example of how it would be used in a statement, "Numerous well-considered hypotheses are presented in this part, and they are supported by tables and figures that are well-illustrated."
9. What is the red queen hypothesis?
The red queen hypothesis in evolutionary biology states that species must constantly evolve to avoid extinction because if they don't, they will be outcompeted by other species that are evolving. Leigh Van Valen first proposed it in 1973; since then, it has been tested and substantiated many times.
10. Who is known as the father of null hypothesis?
The father of the null hypothesis is Sir Ronald Fisher. He published a paper in 1925 that introduced the concept of null hypothesis testing, and he was also the first to use the term itself.
11. When to reject null hypothesis?
You need to find a significant difference between your two populations to reject the null hypothesis. You can determine that by running statistical tests such as an independent sample t-test or a dependent sample t-test. You should reject the null hypothesis if the p-value is less than 0.05.
You might also like

Consensus GPT vs. SciSpace GPT: Choose the Best GPT for Research

Literature Review and Theoretical Framework: Understanding the Differences

Types of Essays in Academic Writing
Introduction to Quantitative Methods in R
9 hypothesis testing.
In this chaper we’ll start to use the central limit theorem to its full potential.
Let’s quickly remind ourselves. The central limit theorem states that for any population, the means of repeatedly taken samples will approximate the population mean. Because of that, we could tell a bus of lost individuals was very very unlikely to be headed to a marathon. But we can do more, or at least we can answer quetions that come up in the real world.
Most importantely, what we can do with a knowledge of probabilities and the central limit theorem is test hypotheses. I believe this is one of the most difficult sections to understand in an intro to statistics or research methods class. It’s where we make a leap from doing math on known things (how many inches is this loaf of bread?) to the unknown (Is the baker cheating customers?)
9.1 Building Hypotheses
A hypothesis is a statement of a potential relationship, that has not yet been proven. Hypothesis testing, the topic of this chapter, is a more formalied version of testing hypotheses using statistical tests. There are other ways of testing hypothesis (if you think a squirrel is stealing food from a bird feeder, you might watch it to test that hypothesis), but we’ll focus just on the methods statistics gives us.
We use hypothesis testing as a structure in order to analyze whether relationships exist between different pheonomena or varaibles. Is there a relationship between eating breakfast as a child and height? Is there a relationship between driving and dementia? Is there a relationship between misspellings of the word pterodactyl and the release of new Jurassic Park movies? Those are all relationships we can test with the structure of hypothesis testing.
Hypothesis testing is a lot like detective work in a way (or at least the way criminal justics is supposed to be managed). What is the presumption we begin with in the legal system? Everyone is presumed innocent, until they are proven beyond a reasonable doubt to be guilty. In the context of statistics, we would call the presumption of innocence the null hypothesis. That term will be important, the null hypothesis states what our begining state of knowledge is, which is that there is no relationship between two things. Until we know a person is un-innocent,they are innocent. Untill we know there is a relationship, there is no relationship. It is generally written as H0, H for hypothesis and 0 as the starting point.
H0: The defendent is innocent.
Should our tests and evidence not disprove the null hypothesis, it will stand. We must provide evidence to disprove it. Thus, it is the prosecutors or researchers job to prove the alternative hypothesis they have proposed. We can have multiple alternative hypothesis, and we generally write them as H1, H2, and so on.
H1: The defendent committed the crime.
I should say something more about null hypotheses. Because it is the starting point of the tests, we generally aren’t concerned with proving it to be correct. As Ronald Fisher, one of the people that developed this line of statistics said, a null hypothesis, is “never proved or established, but is possibly disproved, in the course of experimentation”. It doesn’t matter if the defense attorney proves that the defendent is innocent. It can help, but that isn’t what’s important. What matters is whether the prosecutor proves the guilt. The jury can walk away with questions and be uncertain, they may even think there’s a better than 50-50 chance the accused commited the crime, but unless guilt is proven beyond a resonable doubt they are supposed to find them innocent. Our hypothesis tests works the same way.
Unless we prove that our alternative hypothesis (H1) is correct beyond a reasonable doubt, we can not reject the null hypothesis (H0). That phrase may sound slightly clunky, but it’s specific to the context of what we’re doing. We are attempting with our statistical tests to reject the null hypothesis of no relationship. If we don’t, we say that we have failed to reject the null.
One more time, because this point that will come up on a test at some point. We are attempting to disprove the null hypothesis, in order to confirm the alternative that we have proposed. If we do not, we have failed to reject the null - not proven the null, failed to reject the null.
9.1.1 An Example
What might that look like in a social science context?
Let’s say your statistics professor is always looking for ways to boost their students learning. They hypothesize that listening to classical music during lectures will help students retain the information. How could they measure that? For one thing, they could compare the grades of students that sit in class with classical music playing, against those that don’t. So to be more specific, the hypothesis would be that listening to classical music increases grades in intro to stats classes.
So what is the null hypothesis in that case, or stated differently, what is the equivalence of innocence, in the case of classical music and grades? The null hypothesis that needs to be disproven is that there is no effect of classical music.
H0: CLassical music has no effect on student grades.
And what we want to test with our hypothesis is that classical music does have an effect.
H1: Classical music improves student grades.
The professor could collect data on tests taken by one class where they played classical music and another where they didn’t If they compared the grades, they may be able to reject the null hypothesis, or they may fail. In the next section we’ll describe a bit more about what that looks like.
9.2 Rock The Hypothesis
In 2004, researchers wanted to test the impact of tv commercials that would encourage young voters to go to cast votes. In order to test the impact of tv commercials, they chose 43 tv markets (similar to cities, but slightly larger) that would see the commercials several times a day, and selected other similar tv markets that wouldn’t see the commercial. That way, they could observe whether watching the commercial had any impact on the number of 18 and 19 year olds that actually voted in the 2004 Presidential Election.
H0: TV commercials had no impact on voting rates by 18 an 19 year olds H1: TV commercials increased voting rates by 18 an 19 year olds
The data from their test is avaliable in R with the pscl package and the dataset RockTheVote.
Before we start, we should make sure we understand the data we are using. We can us nrow() to see how many observations are in the data.
THere are 85 tv markets that are studied. Next we can look at the summary statistics to get an idea of the varaibles available.
Treated is a dichotomous numerical varaible, that is 1 if the tv market watched the commercials, and is 0 if not. The mean here indicates that 49.41% of the tv markets were treated, and the remainders were untreated. In an experiment, researchers create a treatment group (those that saw the commercials) and a control group, in order to test for a difference.
r is the number of 18 and 19 year olds that voted in the 2004 election. The average tv market had 151 young registered voters that cast votes in the election.
n is the number of registered voters between the ages of 18 and 19 in each tv market.
p is the percentage of registered voters between the ages of 18 and 19 that voted in the election, meaning it could be calcualted by dividing r by n.
Strata and treatedIndex aren’t important for this exercise. The different tv markets were chosen because they were similar, so there is one market that saw the commercaisl and another similar market that didn’t. The varaible strata indicates which markets are matched together. treatedIndex indicates how many treated tv markets are above each observation. Full confession, I don’t totally understand what treatedIndex is supposed to be used for.
So to restate our hypotheses, we intend to test whether being in a tv market that saw commercails encouraging young adults to vote (treated) incaresed the voting rates among 18 and 19 year olds (p). The null hypothesis which we are attempting to reject is that there is no relationship between treated and p.
So what do we need to do to test the hypothesis that these tv commercials increased voting rates?
Last chapter we saw how similar the mean of the tour bus we found was to mean of the population of marathoners. Here, we don’t know what the population of 18 and 19 year old voters is. But we do have a control group, which we assume stands in for all 18 and 19 year olds. We’re assuming that the treated group is a random sample of the population of 18 and 19 year olds, so they should have the same exact voting rates as all other 18 and 19 year olds. However, they saw the commercials, so if there is a difference between the two groups, we can ascribe it to the commercials. Thus, we can test whether the mean voting rate among the tv markets that were treated with the commercials differs sigificantly.
Let’s start then by calculating the mean voting rate for the two groups, the treated tv markets and the control group. We can do that by using the subset() command to split RockTheVote into two data frames, based on whether the tv market was in the treated group or not.
The average voting rate among 18 and 19 year olds for the tv markets that saw the commercials is .545 or 54.5%, and the averge for the tv markets that were not treated is .516 or 51.6%. Interesting, the mean differs between the two samples.
However, as we learned last chapter, we should expet some variation between the means as we’re taking diferent samples. The means of samples will conform to a normal distribution over time, but we should expect varaiation for each individual mean. The question then is whether the mean of the treatment group differs significantly from the mean of the control group.
9.2.1 Statistical Significance
Statistical significance is important. Much of social science is driven by statistical significance. We’ll talk about the limitations later, for now though we can describe what we mean by that term. As we’ve discussed, the means of samples will differ from the mean of the population somewhat, and those means will differ by some number of standard deviations. We expect the majority of the data to fall within two standard deviations above or below the mean, and that very few will fall further away.

credit: Wikipedia
34.1 percent of the data falls within 1 standard deviation above and below the mean. That’s on both sides, so a total of 68.2 percent of the data falls between 1 standard deviation below the mean and one standard deviation above the mean. 13.6 percent of the data is between 1 and 2 standard deviations. In total, we expect 95.4 percent of the data to be within two standard deviations, either above or below the mean. - The Professor, one chapter earlier
That means, to state it a different way, that the probability that the mean of a sample taken from a population being within 2 standard deviations is .954, and the probability that it will fall further from the mean is only .046. That is fairly unlikely. So if the mean of the treatment group falls more than 2 standard deviations from the mean of the control group, that indicates it’s either a weird sample OR it isn’t from the same population. That’s what we concluded about the tour bus we found, it wasn’t drawn from the population of marathoners. And if the tv markets that saw the commercaials are that different from the markets that didn’t watch, we can conclued that they are different because of the commercials. The commercials had such a large effect on voting rates, they have changed voters.
So we know the means for the two groups, and we know they differ somewhat How do we test them to see if they come from the same poplation?
The easiest way is with what’s called a t-test, which quickly analyzes the means of two groups and determines how many standard deviations they are apart. A t-test can be used to test whether a sample comes from a certain population (marathoners, buses) or if two samples differ significantly. More often than not, you will use them to test whether two samples are different, generally with the goal of understanding whether some policy or intervention or trait makes two samples different - and the hope is to ascribe that difference to what we’re testing.
Essentially, a t-test does the work for us. Interpretting it correctly then becomes all the more important, but implementing it is straight forward with the command t.test(). Within the parentheses, we enter the two data frames and the varaible of interest. Here our two data frames are named treatment and control and the variable of interest is p
We can slowely look over the output, and discuss each term that’s produced. These will help to clarify the nuts and bolts of a t-test further.
Let’s start with the headline takeaway. We want to test whether tv commercials encouraging young adults to vote would actually make them vote in higher numbers. We see the two means that we calucalted above. 54.5% of registered 18 and 19 year olds in communities where the commercials were shown vote, while in other tv markets only 51.6% did so. Is that significant?
The answer to that quesiton is shown below P value, and the result is no. We aren’t very sure that these two groups are different, even though there is a gap between the means. We think that difference might have just been produced by chance, or the luck of the draw in creating different samples. The p value indicates the chances that we could have generated the difference between the means by chance: .1794, or roughly .18 (18%), and we aren’t willing to declare something different if we’re only 18% sure they’re different.
Why are we that uncertain? Because the test statistic isn’t very big, which helps to indicate the distance betwene our two means. The formula for calculating a test statistic is complicated, but we will discuss it. It’s a bit like your mother letting you see everything she has to do to put together thanksgiving dinner, so that you learn not to complain. We’ll see what R just did for us, so that we can more fully apprecaite how nice the software is to us.

x1 and x2 our the means for the two groups we are comparing. In this case, we’ll call everyhing with a 1 the treatment group, and 2 the control group.
s1 and s2 are the standard deviations for the treatment and control group.
And n1 and n2 are the number of observations or the sample size of both groups.
That wasn’t so bad. Then we just throw it all together!
That matches. What was all of that we just did? Essentially, we look at how far the distance between the means is, relative to the variance in the data of both.
One way to intuatively undestand what all that means is to think about what would make the test statistic larger or smaller. A larger difference in means, would produce a larger statistic. Less variance, meaning data that was more tightly clustered, would produce a larger t statistic. And a larger sample size would produce a larger t statistic. Once more, a larger difference, less variation in the data, and more data all make us more certain that differnces are real.
df stands for degrees of freedom, which is the number of independent data values in our sample.
Finally, we have the alternative hypothesis. Here it says “two.sided”. That means we were testing whether the commericals either increased the share of voting, or decreased it - we were looking at both ends or two sides of the distribution. We can specify whether we want to only look at the area above the mean, below the mean, or at both ends as we have done.
Assuming we’re seeking a difference in the means that would only be predicted by chance with a probability of .05, which test is tougher? A two-tailed test. For a two tailed test we seek a p value of .05 at both tails, splitting it with .025 above the mean and .025 below the mean. A one-tailed test places all .05 above or below the mean. Below, the green lines show the cut off at both ends if we only look for the difference in one tail, whereas the red line shows what happens when we look in both tails. This is all to explain why the default option is two.sided, and to generally tell you to let the default stand.

That, was a lot. It might help to walk through another example a bit quicker where we just lay out the basics of a t-test. We can use some polling data for the 1992 election, that asked people who they voted for along with a few demographic questions.
The vote varaible shows who they voters voted for. dem and rep indicate the registered party of voters and females records their gender. The questions persfinance and natlecon indicate whether the respondont thought their personl finances had improved over the previous 4 years (Bush’s first term) and whether the national economy was improving. The other three varaibles require more math than we need right now, but they generally record how distant the voters views are from the candidates.
Let’s see whether personal finances drove people to vote for Bush’s relection.
H0: Personal finance made no difference in the election H1: Voters that felt their personal fiances improved voted more for George Bush
the vote variable has three levels.
We need to create a new variable that indicates just whether people voted for or against Bush, because for a T-test to operate we need two groups. Earlier our two groups were the treatment and the control for whether people watched the tv commercials. Here the two groups are wether people voted for Bush or not.
Rather than splitting the vote92 data set into two halves using subset (like we did earlier) we can just use the ~ operator. ~ is a t1lde mark. ~ can be used to define indicate the varaible being tested (persfinance) and the two groups for our analysis (Bush). This is a little quicker than using subset, and we’ll use the tilde mark in future work in the course.
The answer is yes, those who viewed their personal finances as improving were more likely to vote for Bush. The pvalue indicates that the difference in means between the two groups was highly unlikely to have occured by chance. It is not impossible, but it is highly unlikely so we can declare there is a significant difference.
9.4 Populations and samples
Let’s think more about the example we just did. With the the 1992 eletion data, we declared that people with improving personal finances were more likely to vote for Bush. Why do we need test anything about them, we know who they voted for? It’s beause we have a sample of respondents, similar to an exit poll, but what we’re concnered about is all voters. We want to know if people outside the 909 we have data for were more likly to vote for Bush if their personal finances improved. That’s what the test is telling us, that there is a difference in the population (all voters). Just looking at the means between the two groups tells us that there is a difference in our sample. But we rarely care about the sample, what concerns us is projecting or inferring the qualities of others we haven’t asked.
9.5 The problem with .05
That brings us to discuss the .05 test more directly. What would it have meant if the P value had been .06. Well, we would have failed to reject the null. We wouldn’t feel confident enough to say there is a difference in the population. But there would still be a difference in the sample.
Is there a large difference between a P value of .04 and .05 and .06? No, not really. and .05 is a fairly arbitrary standard. Probabilities exist as a continuoum without clear cut offs. A P value of .05 means we’re much more confident than a P value of .6 and a little more confident than a P value of .15. The standard for such a test has to be set somewhere, but we shouldn’t hold .05 as a golden standard.
What does a probability of .05 mean? Let’s think back to the chapter on probability’ it’s equivalent to 1/20. When we set .05 as a standard for hypothesis testing, we’re saying we want to know that there is only a 1 in 20 chance that the difference in voting rates created by the Rock The Vote commercials is by random luck, and to know that 19 out of 20 times it’ll be a true difference between the groups.
So when we get a P value of .05 and reject the null hypothesis, we’re doing so because we think a difference between the two groups is most likely explained by the commercials (or whatever we’re testing). But implicit in a .05 P value is that random chance isn’t impossible, just unlikely. But there is still a 1/20 chance that the difference in voting rates seen after the commercials just occured by random chance and had nothing to do with the commercial. And similarly to flipping a coin, if we do 20 seperate tests in one of them we’ll get a significant value that is generated by random chance. That is a false positive, and we can never identify it.
One approach then is to set a higher standard. We could only reject a null hypothesis if we get a P value of .01 or lower. That would mean only 1 in 100 significant results would be from chance along. Or we could use a standard of .001. That would help to reduce false positives, but not eliminate them still.
.05 has been described as the standard for rejecting the null hypothesis here, but it’s really more of a minimum. Scholars prefer their P values to be .01 or lower when possible, but generally accept .05 as indicative of a significant difference.
9.6 One more problem
Let’s go back to how we calculated P values.
How can we get a larger t-statistic and be more likely to get a significant result? Having a larger difference in the means is one way. That would mean the numerator would get larger. The other way is to make the denomenator smaller, so that whatever the difference in the means is comparatively larger.
If we grow the size of our sample, the n1 and n2, that would shrink the denomenator. That makes intuative sense too. We shouldn’t be very confident if we talk to 10 people and find out that the democrats in the group like cookies more than the republicans. But if we talked to 10 million people, that would be a lot of evidence to disregard if there was a difference in our mean. As we grow our sample size, it becomes more likely that any difference in our means will create a significant finding with a P value of .05 or smaller.
That’s good right? It means we get more precise results, but it creates another concern. When we use larger quantitives of data it becomes necessary to ask whether the differences are significant, as well as large. If I surveyed 10 million voters and found that 72.1 percent of democrats like cookies and only 72.05 republicans like cookies, would the difference be significant?
Yes, that finding is very very significant. Is it meaningful? Not really. There is a statistical difference between the two groups, but that difference is so small it doesn’t help someone to plan a party or pick out deserts. With large enough samples the color of your shirt might impact pay by .13 cents or putting your left shoe on first might add 79 minutes to your life. But those differences lack magnitude to be valuable. Thus, as data sets grow in size it becomes important to test for significance, but also the magnitude of the differences to find what’s meaningfull. Unfortunately, evaluating whether a difference is large is a matter of opinion, and can’t be tested for with certainty.
Those are the basics of hypothesis tests with t-tests. We’ll continue to expand on the tests we can run in the following chapters. Next we’ll talk about a specific instance where we use the tools we’ve discussed: polling.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Choosing the Right Statistical Test | Types & Examples
Choosing the Right Statistical Test | Types & Examples
Published on January 28, 2020 by Rebecca Bevans . Revised on June 22, 2023.
Statistical tests are used in hypothesis testing . They can be used to:
- determine whether a predictor variable has a statistically significant relationship with an outcome variable.
- estimate the difference between two or more groups.
Statistical tests assume a null hypothesis of no relationship or no difference between groups. Then they determine whether the observed data fall outside of the range of values predicted by the null hypothesis.
If you already know what types of variables you’re dealing with, you can use the flowchart to choose the right statistical test for your data.
Statistical tests flowchart
Table of contents
What does a statistical test do, when to perform a statistical test, choosing a parametric test: regression, comparison, or correlation, choosing a nonparametric test, flowchart: choosing a statistical test, other interesting articles, frequently asked questions about statistical tests.
Statistical tests work by calculating a test statistic – a number that describes how much the relationship between variables in your test differs from the null hypothesis of no relationship.
It then calculates a p value (probability value). The p -value estimates how likely it is that you would see the difference described by the test statistic if the null hypothesis of no relationship were true.
If the value of the test statistic is more extreme than the statistic calculated from the null hypothesis, then you can infer a statistically significant relationship between the predictor and outcome variables.
If the value of the test statistic is less extreme than the one calculated from the null hypothesis, then you can infer no statistically significant relationship between the predictor and outcome variables.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

You can perform statistical tests on data that have been collected in a statistically valid manner – either through an experiment , or through observations made using probability sampling methods .
For a statistical test to be valid , your sample size needs to be large enough to approximate the true distribution of the population being studied.
To determine which statistical test to use, you need to know:
- whether your data meets certain assumptions.
- the types of variables that you’re dealing with.
Statistical assumptions
Statistical tests make some common assumptions about the data they are testing:
- Independence of observations (a.k.a. no autocorrelation): The observations/variables you include in your test are not related (for example, multiple measurements of a single test subject are not independent, while measurements of multiple different test subjects are independent).
- Homogeneity of variance : the variance within each group being compared is similar among all groups. If one group has much more variation than others, it will limit the test’s effectiveness.
- Normality of data : the data follows a normal distribution (a.k.a. a bell curve). This assumption applies only to quantitative data .
If your data do not meet the assumptions of normality or homogeneity of variance, you may be able to perform a nonparametric statistical test , which allows you to make comparisons without any assumptions about the data distribution.
If your data do not meet the assumption of independence of observations, you may be able to use a test that accounts for structure in your data (repeated-measures tests or tests that include blocking variables).
Types of variables
The types of variables you have usually determine what type of statistical test you can use.
Quantitative variables represent amounts of things (e.g. the number of trees in a forest). Types of quantitative variables include:
- Continuous (aka ratio variables): represent measures and can usually be divided into units smaller than one (e.g. 0.75 grams).
- Discrete (aka integer variables): represent counts and usually can’t be divided into units smaller than one (e.g. 1 tree).
Categorical variables represent groupings of things (e.g. the different tree species in a forest). Types of categorical variables include:
- Ordinal : represent data with an order (e.g. rankings).
- Nominal : represent group names (e.g. brands or species names).
- Binary : represent data with a yes/no or 1/0 outcome (e.g. win or lose).
Choose the test that fits the types of predictor and outcome variables you have collected (if you are doing an experiment , these are the independent and dependent variables ). Consult the tables below to see which test best matches your variables.
Parametric tests usually have stricter requirements than nonparametric tests, and are able to make stronger inferences from the data. They can only be conducted with data that adheres to the common assumptions of statistical tests.
The most common types of parametric test include regression tests, comparison tests, and correlation tests.
Regression tests
Regression tests look for cause-and-effect relationships . They can be used to estimate the effect of one or more continuous variables on another variable.
Comparison tests
Comparison tests look for differences among group means . They can be used to test the effect of a categorical variable on the mean value of some other characteristic.
T-tests are used when comparing the means of precisely two groups (e.g., the average heights of men and women). ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults).
Correlation tests
Correlation tests check whether variables are related without hypothesizing a cause-and-effect relationship.
These can be used to test whether two variables you want to use in (for example) a multiple regression test are autocorrelated.
Non-parametric tests don’t make as many assumptions about the data, and are useful when one or more of the common statistical assumptions are violated. However, the inferences they make aren’t as strong as with parametric tests.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
This flowchart helps you choose among parametric tests. For nonparametric alternatives, check the table above.

If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
- Null hypothesis
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Statistical tests commonly assume that:
- the data are normally distributed
- the groups that are being compared have similar variance
- the data are independent
If your data does not meet these assumptions you might still be able to use a nonparametric statistical test , which have fewer requirements but also make weaker inferences.
A test statistic is a number calculated by a statistical test . It describes how far your observed data is from the null hypothesis of no relationship between variables or no difference among sample groups.
The test statistic tells you how different two or more groups are from the overall population mean , or how different a linear slope is from the slope predicted by a null hypothesis . Different test statistics are used in different statistical tests.
Statistical significance is a term used by researchers to state that it is unlikely their observations could have occurred under the null hypothesis of a statistical test . Significance is usually denoted by a p -value , or probability value.
Statistical significance is arbitrary – it depends on the threshold, or alpha value, chosen by the researcher. The most common threshold is p < 0.05, which means that the data is likely to occur less than 5% of the time under the null hypothesis .
When the p -value falls below the chosen alpha value, then we say the result of the test is statistically significant.
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Choosing the Right Statistical Test | Types & Examples. Scribbr. Retrieved March 22, 2024, from https://www.scribbr.com/statistics/statistical-tests/
Is this article helpful?

Rebecca Bevans
Other students also liked, hypothesis testing | a step-by-step guide with easy examples, test statistics | definition, interpretation, and examples, normal distribution | examples, formulas, & uses.
No internet connection.
All search filters on the page have been cleared., your search has been saved..
- All content
- Dictionaries
- Encyclopedias
- Expert Insights
- Foundations
- How-to Guides
- Journal Articles
- Little Blue Books
- Little Green Books
- Project Planner
- Tools Directory
- Sign in to my profile My Profile
- Sign in Signed in
- My profile My Profile
- Offline Playback link

Have you created a personal profile? sign in or create a profile so that you can create alerts, save clips, playlists and searches.
Hypothesis Test for a Proportion
- Watching now: Chapter 1: .Hypothesis Test for Proportion Start time: 00:00:00 End time: 00:09:27
Video Type: Tutorial
(Academic). (2016). Hypothesis test for a proportion [Video]. Sage Research Methods. https:// doi. org/10.4135/9781529695021
"Hypothesis Test for a Proportion." In Sage Video . : Duke Learning Innovation, 2016. Video, 00:09:27. https:// doi. org/10.4135/9781529695021.
, 2016. Hypothesis Test for a Proportion , Sage Video. [Streaming Video] London: Sage Publications Ltd. Available at: <https:// doi. org/10.4135/9781529695021 & gt; [Accessed 23 Mar 2024].
Hypothesis Test for a Proportion . Online video clip. SAGE Video. London: SAGE Publications, Ltd., 30 Jan 2024. doi: https:// doi. org/10.4135/9781529695021. 23 Mar 2024.
Hypothesis Test for a Proportion [Streaming video]. 2016. doi:10.4135/9781529695021. Accessed 03/23/2024
Please log in from an authenticated institution or log into your member profile to access the email feature.
- Sign in/register
Add this content to your learning management system or webpage by copying the code below into the HTML editor on the page. Look for the words HTML or </>. Learn More about Embedding Video icon link (opens in new window)
Sample View:

- Download PDF opens in new window
- icon/tools/download-video icon/tools/video-downloaded Download video Downloading... Video downloaded
Dr. Mine Cetinkaya-Rundel explains the steps for doing a hypothesis test for a proportion.
Chapter 1: .Hypothesis Test for Proportion
- Start time: 00:00:00
- End time: 00:09:27
- Product: Sage Research Methods Video: Quantitative and Mixed Methods
- Type of Content: Tutorial
- Title: Hypothesis Test for a Proportion
- Publisher: Duke Learning Innovation
- Series: Inferential Statistics
- Publication year: 2016
- Online pub date: January 30, 2024
- Discipline: Sociology , Nursing , Economics , Criminology and Criminal Justice , Marketing , Business and Management , Science , Technology , Education , Computer Science , Engineering , Mathematics , History , Dentistry , Public Health , Psychology , Health , Anthropology , Social Policy and Public Policy , Social Work , Political Science and International Relations , Counseling and Psychotherapy , Geography , Medicine , Communication and Media Studies
- Methods: Quantitative data analysis , Hypothesis testing , Statistical inference
- Duration: 00:09:27
- DOI: https:// doi. org/10.4135/9781529695021
- Keywords: hypothesis testing , null hypothesis , p value , proportion , Sample size , Skewness Show all Show less
Sign in to access this content
Get a 30 day free trial, more like this, sage recommends.
We found other relevant content for you on other Sage platforms.
Have you created a personal profile? Login or create a profile so that you can save clips, playlists and searches
Navigating away from this page will delete your results
Please save your results to "My Self-Assessments" in your profile before navigating away from this page.
Sign in to my profile
Sign up for a free trial and experience all Sage Learning Resources have to offer.
You must have a valid academic email address to sign up.
Get off-campus access
- View or download all content my institution has access to.
Sign up for a free trial and experience all Sage Research Methods has to offer.
- view my profile
- view my lists
IMAGES
VIDEO
COMMENTS
Hypothesis-testing (Quantitative hypothesis-testing research) - Quantitative research uses deductive reasoning. - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses.
Step 5: Present your findings. The results of hypothesis testing will be presented in the results and discussion sections of your research paper, dissertation or thesis.. In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p-value).
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
5 Hypothesis Testing in Quantitative Research . Mikaila Mariel Lemonik Arthur. Statistical reasoning is built on the assumption that data are normally distributed, meaning that they will be distributed in the shape of a bell curve as discussed in the chapter on Univariate Analysis.While real life often—perhaps even usually—does not resemble a bell curve, basic statistical analysis assumes ...
Alternative hypothesis (HA) or (H1): this is sometimes called the research hypothesis or experimental hypothesis. It is the proposition that there will be a relationship. It is a statement of inequality between the variables you are interested in. They always refer to the sample. It is usually a declaration rather than a question and is clear ...
Hypotheses are the testable statements linked to your research question. Hypotheses bridge the gap from the general question you intend to investigate (i.e., the research question) to concise statements of what you hypothesize the connection between your variables to be. For example, if we were studying the influence of mentoring relationships ...
To test a hypothesis: Quantitative research is often used to test a hypothesis or a theory. It involves collecting numerical data and using statistical analysis to determine if the data supports or refutes the hypothesis. To generalize findings: ...
The most rigorous form of quantitative research follows from a test of a theory (see Chapter 3) and the specification of research questions or hypotheses that are included in the theory. The independent and dependent variables must be measured sepa-rately. This procedure reinforces the cause-and-effect logic of quantitative research.
6. Write a null hypothesis. If your research involves statistical hypothesis testing, you will also have to write a null hypothesis. The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0, while the alternative hypothesis is H 1 or H a.
Hypothesis Testing. When you conduct a piece of quantitative research, you are inevitably attempting to answer a research question or hypothesis that you have set. One method of evaluating this research question is via a process called hypothesis testing, which is sometimes also referred to as significance testing. Since there are many facets ...
The primary research question should originate from the hypothesis, not the data, and be established before starting the study. Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
P-Values. The p-value of a hypothesis test is the probability that your sample data would have occurred if you hypothesis were not correct. Traditionally, researchers have used a p-value of 0.05 (a 5% probability that your sample data would have occurred if your hypothesis was wrong) as the threshold for declaring that a hypothesis is true.
Quantitative. Quantitative research is used to test or confirm a hypothesis. Qualitative research usually informs quantitative. You need to have enough understanding about a topic in order to develop a hypothesis you can test. Since quantitative research is highly structured, you first need to understand what the parameters are and how variable ...
What they need at the start of their research is to formulate a scientific hypothesis that revisits conventional theories, real-world processes, and related evidence to propose new studies and test ideas in an ethical way.3 Such a hypothesis can be of most benefit if published in an ethical journal with wide visibility and exposure to relevant ...
Steps in Hypothesis Testing for Quantitative Research Designs Hypothesis testing is a four phase procedure. Phase I: Research hypotheses, design, and variables. 1. State your research hypotheses. 2. Decide on a research design based on your research problem, your hypotheses, and what you really want to be able to say about your
Such research may prove or disprove the proposed hypothesis. Case reports, case series, online surveys and other observational studies, clinical trials, and narrative reviews help to generate hypotheses. Observational and interventional studies help to test hypotheses. A good hypothesis is usually based on previous evidence-based reports.
3. Simple hypothesis. A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, "Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking. 4.
9. Hypothesis Testing. In this chaper we'll start to use the central limit theorem to its full potential. Let's quickly remind ourselves. The central limit theorem states that for any population, the means of repeatedly taken samples will approximate the population mean. Because of that, we could tell a bus of lost individuals was very very ...
ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults). Predictor variable. Outcome variable. Research question example. Paired t-test. Categorical. 1 predictor. Quantitative. groups come from the same population.
Essentially, a hypothesis is a tentative statement that predicts the relationship between two or more variables in a research study. It is usually derived from a theoretical framework or previous ...
Popular answers (1) Muayyad Ahmad. University of Jordan. Hi, No, it is not a must to have hypotheses in all quantitative research. Descriptive studies dont need hypotheses. however, RCT and ...
Yes, both qualitative and quantitative studies need hypothesis, a research question you answer. Cite. 1 Recommendation. Madelaine Lawrence. RnCeus Interactive. Generally speaking, hypotheses are ...
Find step-by-step guidance to complete your research project. Which Stats Test. ... Dr. Mine Cetinkaya-Rundel explains the steps for doing a hypothesis test for a proportion. Chapter 1:.Hypothesis Test ... Product: Sage Research Methods Video: Quantitative and Mixed Methods; Type of Content: Tutorial Title: Hypothesis Test for a ...
Testing in qualitative research may mean different things to researchers in quantitative research. The term "test" has never been about quantities or numerical calculations in science. ... In the context of social-sciences, hypothesis testing does not always mean quantitative calculations to prove or nullify (disprove) hypothetical ...