
The world’s most powerful AI-based qualitative data analysis solution.
QualAI utilizes advanced AI technology to increase researcher efficiency, enhance data reliability, and mitigate bias.


researchers
QualAI aids researchers with data codification, thematic analyses, and content summaries to increase data reliability and mitigate bias.
organizations
QualAI helps organizations with market research, consumer analysis, business development, data aggregation and interpretation.
See how QualAI helps students analyze large-scale qualitative data sets, codify transcripts, and generate themes to reduce bias and increase efficiency.

ERIK ALANSON, Ph.d.
Co-Founder, QualAI
Academic Researcher
University Professor

tonkia bridges, ed.d.
Powered by WordPress.com .
- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Try Thematic
Welcome to the community

Coding Qualitative Data: How to Code Qualitative Research
Authored by Alyona Medelyan, PhD – Natural Language Processing & Machine Learning
How many hours have you spent sitting in front of Excel spreadsheets trying to find new insights from customer feedback?
You know that asking open-ended survey questions gives you more actionable insights than asking your customers for just a numerical Net Promoter Score (NPS) . But when you ask open-ended, free-text questions, you end up with hundreds (or even thousands) of free-text responses.
How can you turn all of that text into quantifiable, applicable information about your customers’ needs and expectations? By coding qualitative data.
Keep reading to learn:
- What coding qualitative data means (and why it’s important)
- Different methods of coding qualitative data
- How to manually code qualitative data to find significant themes in your data
What is coding in qualitative research?
Coding is the process of labeling and organizing your qualitative data to identify different themes and the relationships between them.
When coding customer feedback , you assign labels to words or phrases that represent important (and recurring) themes in each response. These labels can be words, phrases, or numbers; we recommend using words or short phrases, since they’re easier to remember, skim, and organize.
Coding qualitative research to find common themes and concepts is part of thematic analysis . Thematic analysis extracts themes from text by analyzing the word and sentence structure.
Within the context of customer feedback, it's important to understand the many different types of qualitative feedback a business can collect, such as open-ended surveys, social media comments, reviews & more.
What is qualitative data analysis?
Qualitative data analysis is the process of examining and interpreting qualitative data to understand what it represents.
Qualitative data is defined as any non-numerical and unstructured data; when looking at customer feedback, qualitative data usually refers to any verbatim or text-based feedback such as reviews, open-ended responses in surveys , complaints, chat messages, customer interviews, case notes or social media posts
For example, NPS metric can be strictly quantitative, but when you ask customers why they gave you a rating a score, you will need qualitative data analysis methods in place to understand the comments that customers leave alongside numerical responses.
Methods of qualitative data analysis
- Content analysis: This refers to the categorization, tagging and thematic analysis of qualitative data. This can include combining the results of the analysis with behavioural data for deeper insights.
- Narrative analysis: Some qualitative data, such as interviews or field notes may contain a story. For example, the process of choosing a product, using it, evaluating its quality and decision to buy or not buy this product next time. Narrative analysis helps understand the underlying events and their effect on the overall outcome.
- Discourse analysis: This refers to analysis of what people say in social and cultural context. It’s particularly useful when your focus is on building or strengthening a brand.
- Framework analysis: When performing qualitative data analysis, it is useful to have a framework. A code frame (a hierarchical set of themes used in coding qualitative data) is an example of such framework.
- Grounded theory: This method of analysis starts by formulating a theory around a single data case. Therefore the theory is “grounded’ in actual data. Then additional cases can be examined to see if they are relevant and can add to the original theory.
Automatic coding software
Advances in natural language processing & machine learning have made it possible to automate the analysis of qualitative data, in particular content and framework analysis
While manual human analysis is still popular due to its perceived high accuracy, automating the analysis is quickly becoming the preferred choice. Unlike manual analysis, which is prone to bias and doesn’t scale to the amount of qualitative data that is generated today, automating analysis is not only more consistent and therefore can be more accurate, but can also save a ton of time, and therefore money.
The most commonly used software for automated coding of qualitative data is text analytics software such as Thematic .
Why is it important to code qualitative data?
Coding qualitative data makes it easier to interpret customer feedback. Assigning codes to words and phrases in each response helps capture what the response is about which, in turn, helps you better analyze and summarize the results of the entire survey.
Researchers use coding and other qualitative data analysis processes to help them make data-driven decisions based on customer feedback. When you use coding to analyze your customer feedback, you can quantify the common themes in customer language. This makes it easier to accurately interpret and analyze customer satisfaction.
Automated vs. Manual coding of qualitative data
Methods of coding qualitative data fall into two categories: automated coding and manual coding.
You can automate the coding of your qualitative data with thematic analysis software . Thematic analysis and qualitative data analysis software use machine learning, artificial intelligence (AI) , and natural language processing (NLP) to code your qualitative data and break text up into themes.
Thematic analysis software is autonomous, which means…
- You don’t need to set up themes or categories in advance.
- You don’t need to train the algorithm — it learns on its own.
- You can easily capture the “unknown unknowns” to identify themes you may not have spotted on your own.
…all of which will save you time (and lots of unnecessary headaches) when analyzing your customer feedback.
Businesses are also seeing the benefit of using thematic analysis softwares that have the capacity to act as a single data source, helping to break down data silos, unifying data across an organization. This is now being referred to as Unified Data Analytics.
What is thematic coding?
Thematic coding, also called thematic analysis, is a type of qualitative data analysis that finds themes in text by analyzing the meaning of words and sentence structure.
When you use thematic coding to analyze customer feedback for example, you can learn which themes are most frequent in feedback. This helps you understand what drives customer satisfaction in an accurate, actionable way.
To learn more about how thematic analysis software helps you automate the data coding process, check out this article .
How to manually code qualitative data
For the rest of this post, we’ll focus on manual coding. Different researchers have different processes, but manual coding usually looks something like this:
- Choose whether you’ll use deductive or inductive coding.
- Read through your data to get a sense of what it looks like. Assign your first set of codes.
- Go through your data line-by-line to code as much as possible. Your codes should become more detailed at this step.
- Categorize your codes and figure out how they fit into your coding frame.
- Identify which themes come up the most — and act on them.
Let’s break it down a little further…
Deductive coding vs. inductive coding
Before you start qualitative data coding, you need to decide which codes you’ll use.
What is Deductive Coding?
Deductive coding means you start with a predefined set of codes, then assign those codes to the new qualitative data. These codes might come from previous research, or you might already know what themes you’re interested in analyzing. Deductive coding is also called concept-driven coding.
For example, let’s say you’re conducting a survey on customer experience . You want to understand the problems that arise from long call wait times, so you choose to make “wait time” one of your codes before you start looking at the data.
The deductive approach can save time and help guarantee that your areas of interest are coded. But you also need to be careful of bias; when you start with predefined codes, you have a bias as to what the answers will be. Make sure you don’t miss other important themes by focusing too hard on proving your own hypothesis.
What is Inductive Coding?
Inductive coding , also called open coding, starts from scratch and creates codes based on the qualitative data itself. You don’t have a set codebook; all codes arise directly from the survey responses.
Here’s how inductive coding works:
- Break your qualitative dataset into smaller samples.
- Read a sample of the data.
- Create codes that will cover the sample.
- Reread the sample and apply the codes.
- Read a new sample of data, applying the codes you created for the first sample.
- Note where codes don’t match or where you need additional codes.
- Create new codes based on the second sample.
- Go back and recode all responses again.
- Repeat from step 5 until you’ve coded all of your data.
If you add a new code, split an existing code into two, or change the description of a code, make sure to review how this change will affect the coding of all responses. Otherwise, the same responses at different points in the survey could end up with different codes.
Sounds like a lot of work, right? Inductive coding is an iterative process, which means it takes longer and is more thorough than deductive coding. But it also gives you a more complete, unbiased look at the themes throughout your data.
Categorize your codes with coding frames
Once you create your codes, you need to put them into a coding frame. A coding frame represents the organizational structure of the themes in your research. There are two types of coding frames: flat and hierarchical.
Flat Coding Frame
A flat coding frame assigns the same level of specificity and importance to each code. While this might feel like an easier and faster method for manual coding, it can be difficult to organize and navigate the themes and concepts as you create more and more codes. It also makes it hard to figure out which themes are most important, which can slow down decision making.
Hierarchical Coding Frame
Hierarchical frames help you organize codes based on how they relate to one another. For example, you can organize the codes based on your customers’ feelings on a certain topic:

In this example:
- The top-level code describes the topic (customer service)
- The mid-level code specifies whether the sentiment is positive or negative
- The third level details the attribute or specific theme associated with the topic
Hierarchical framing supports a larger code frame and lets you organize codes based on organizational structure. It also allows for different levels of granularity in your coding.
Whether your code frames are hierarchical or flat, your code frames should be flexible. Manually analyzing survey data takes a lot of time and effort; make sure you can use your results in different contexts.
For example, if your survey asks customers about customer service, you might only use codes that capture answers about customer service. Then you realize that the same survey responses have a lot of comments about your company’s products. To learn more about what people say about your products, you may have to code all of the responses from scratch! A flexible coding frame covers different topics and insights, which lets you reuse the results later on.
Tips for coding qualitative data
Now that you know the basics of coding your qualitative data, here are some tips on making the most of your qualitative research.
Use a codebook to keep track of your codes
As you code more and more data, it can be hard to remember all of your codes off the top of your head. Tracking your codes in a codebook helps keep you organized throughout the data analysis process. Your codebook can be as simple as an Excel spreadsheet or word processor document. As you code new data, add new codes to your codebook and reorganize categories and themes as needed.
Make sure to track:
- The label used for each code
- A description of the concept or theme the code refers to
- Who originally coded it
- The date that it was originally coded or updated
- Any notes on how the code relates to other codes in your analysis
How to create high-quality codes - 4 tips
1. cover as many survey responses as possible..
The code should be generic enough to apply to multiple comments, but specific enough to be useful in your analysis. For example, “Product” is a broad code that will cover a variety of responses — but it’s also pretty vague. What about the product? On the other hand, “Product stops working after using it for 3 hours” is very specific and probably won’t apply to many responses. “Poor product quality” or “short product lifespan” might be a happy medium.
2. Avoid commonalities.
Having similar codes is okay as long as they serve different purposes. “Customer service” and “Product” are different enough from one another, while “Customer service” and “Customer support” may have subtle differences but should likely be combined into one code.
3. Capture the positive and the negative.
Try to create codes that contrast with each other to track both the positive and negative elements of a topic separately. For example, “Useful product features” and “Unnecessary product features” would be two different codes to capture two different themes.
4. Reduce data — to a point.
Let’s look at the two extremes: There are as many codes as there are responses, or each code applies to every single response. In both cases, the coding exercise is pointless; you don’t learn anything new about your data or your customers. To make your analysis as useful as possible, try to find a balance between having too many and too few codes.
Group responses based on themes, not wording
Make sure to group responses with the same themes under the same code, even if they don’t use the same exact wording. For example, a code such as “cleanliness” could cover responses including words and phrases like:
- Looked like a dump
- Could eat off the floor
Having only a few codes and hierarchical framing makes it easier to group different words and phrases under one code. If you have too many codes, especially in a flat frame, your results can become ambiguous and themes can overlap. Manual coding also requires the coder to remember or be able to find all of the relevant codes; the more codes you have, the harder it is to find the ones you need, no matter how organized your codebook is.
Make accuracy a priority
Manually coding qualitative data means that the coder’s cognitive biases can influence the coding process. For each study, make sure you have coding guidelines and training in place to keep coding reliable, consistent, and accurate .
One thing to watch out for is definitional drift, which occurs when the data at the beginning of the data set is coded differently than the material coded later. Check for definitional drift across the entire dataset and keep notes with descriptions of how the codes vary across the results.
If you have multiple coders working on one team, have them check one another’s coding to help eliminate cognitive biases.
Conclusion: 6 main takeaways for coding qualitative data
Here are 6 final takeaways for manually coding your qualitative data:
- Coding is the process of labeling and organizing your qualitative data to identify themes. After you code your qualitative data, you can analyze it just like numerical data.
- Inductive coding (without a predefined code frame) is more difficult, but less prone to bias, than deductive coding.
- Code frames can be flat (easier and faster to use) or hierarchical (more powerful and organized).
- Your code frames need to be flexible enough that you can make the most of your results and use them in different contexts.
- When creating codes, make sure they cover several responses, contrast one another, and strike a balance between too much and too little information.
- Consistent coding = accuracy. Establish coding procedures and guidelines and keep an eye out for definitional drift in your qualitative data analysis.
Some more detail in our downloadable guide
If you’ve made it this far, you’ll likely be interested in our free guide: Best practises for analyzing open-ended questions.
The guide includes some of the topics covered in this article, and goes into some more niche details.
If your company is looking to automate your qualitative coding process, try Thematic !
If you're looking to trial multiple solutions, check out our free buyer's guide . It covers what to look for when trialing different feedback analytics solutions to ensure you get the depth of insights you need.
Happy coding!

CEO and Co-Founder
Alyona has a PhD in NLP and Machine Learning. Her peer-reviewed articles have been cited by over 2600 academics. Her love of writing comes from years of PhD research.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
Watercare, New Zealand's largest water and wastewater utility, are responsible for bringing clean water to people and managing the waste water systems that safeguard the Auckland environment and citizen health. On a typical day, Aucklanders don’t say much to Watercare. Water as a sector gets taken for granted, with
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Qualtrics is one of the most well-known and powerful Customer Feedback Management platforms. But even so, it has limitations. We recently hosted a live panel where data analysts from two well-known brands shared their experiences with Qualtrics, and how they extended this platform’s capabilities. Below, we’ll share the
HTML conversions sometimes display errors due to content that did not convert correctly from the source. This paper uses the following packages that are not yet supported by the HTML conversion tool. Feedback on these issues are not necessary; they are known and are being worked on.
- failed: stackengine
Authors: achieve the best HTML results from your LaTeX submissions by following these best practices .
Decoding Complexity: Exploring Human-AI Concordance in Qualitative Coding
Qualitative data analysis provides insight into the underlying perceptions and experiences within unstructured data. However, the time-consuming nature of the coding process, especially for larger datasets, calls for innovative approaches, such as the integration of Large Language Models (LLMs). This short paper presents initial findings from a study investigating the integration of LLMs for coding tasks of varying complexity in a real-world dataset. Our results highlight the challenges inherent in coding with extensive codebooks and contexts, both for human coders and LLMs, and suggest that the integration of LLMs into the coding process requires a task-by-task evaluation. We examine factors influencing the complexity of coding tasks and initiate a discussion on the usefulness and limitations of incorporating LLMs in qualitative research.
1. Introduction
Qualitative Data Analysis ( QDA ) is an approach used in Human-Computer Interaction ( HCI ) research to analyze unstructured data, such as interview data or responses to open-ended survey questions. A fundamental step in QDA is coding, the systematic process of identifying, annotating, and categorizing data segments based on recurring themes and patterns, and assigning according categories or “codes” (Braun and Clarke, 2006 ; Flick, 2022 ; Bergin, 2018 ; Kuckartz, 2019 ; Adams et al . , 2008 ) . Coding data can be a time-consuming process, particularly when analyzing large volumes of data (e. g., tens of thousands of open-ended survey responses). The emergence of Generative Artificial Intelligence, and in particular Large Language Models ( LLMs ) (e. g., GPT-4 (Achiam et al . , 2023 ) , Gemini (Team et al . , 2023 ) , or Llama 2 (Touvron et al . , 2023 ) ) could significantly speed up the coding process, yet their value and validity needs to be evaluated. Large Language Models have demonstrated remarkable performance in annotation tasks in zero-shot or few-shot learning scenarios where no or little labeled data is given (Törnberg, 2023 ; Gilardi et al . , 2023 ; Ziems et al . , 2023 ) . As these models become integral to HCI research, it is imperative to critically evaluate their potential benefits and risks, as well as methodological challenges associated with the integration of LLMs . In this workshop submission, we present the preliminary results of a study scrutinizing how LLMs perform at applying tags for QDA in coding tasks of different complexity. Specifically, we explore LLM -assisted QDA of a real-world dataset to understand how LLMs perform, how they compare to human coders, and how their performance is affected by the type of coding (e. g., semantic vs. latent themes (Braun and Clarke, 2006 ) ). First, we develop a strategy for prompting LLMs to apply tags for QDA . We then implement this strategy with GPT-3.5 (Brown et al . , 2020 ) and GPT-4 (Achiam et al . , 2023 ) on interview data and compare the models’ performance with human coding in three tasks that require different levels of interpretation.
2. Research Method
To evaluate the performance of LLMs in QDA , we provide the model with segments of qualitative data from interview transcripts 1 1 1 The data for our experiments is drawn from a separate interview study (n=47) focused on users’ perceptions of digital security and privacy. The interview data is in German, and we conduct all experiments using German data segments and prompts. , a human-generated codebook, and the instruction to assign zero, one, or more tags to each data segment using codes from the codebook. We then calculate the Inter-Rater Reliability ( IRR ) to evaluate the agreement of the resulting coded datasets between LLMs and human coders. We analyze three distinct themes in the data, each of which presents unique challenges and considerations for coding.
Coding Tasks
The models and two human coders annotate the dataset using the same human-generated codebook per task 2 2 2 To facilitate the coding process and adhere to the models’ token length limits, two researchers extracted relevant segments from the interview transcripts for all three coding tasks. . We hypothesize that the difficulty of assigning tags to interview segments is influenced by several factors, such as the length of the segments, the codebook and its length, and the background knowledge and judgment required to assign appropriate categories. In this context, Braun and Clarke ( 2006 ) classify possible themes as semantic/latent or a combination of both. Semantic themes can be identified from the surface meanings of the data by simply looking at what a participant has said. Latent themes go beyond the surface meaning of the data and require interpretation of the underlying ideas and assumptions. To analyze how the similarity of results between human coders and LLMs is affected by coding for semantic versus latent themes, we perform coding for three different coding tasks:
Task A (Internet-connected devices): This coding task involves identifying the Internet-connected devices that participants use. We expect that the assignment of semantic codes for Internet-connected devices is straightforward for both humans and LLMs , and requires only the identification of the entities as communicated by the interviewees. (average segment length: 118 words; codebook length: 18 codes)
Task B (Apps, programs, services, and use cases): This coding task focuses on apps, programs, and services participants use on their Internet-connected devices and for what purpose. This introduces a layer of complexity, as participants may articulate their interactions in different ways, e. g., by enumerating individual apps, grouping applications, or explicitly describing their use cases. This variability introduces a hierarchy in the data that demands both semantic and latent coding. (average segment length: 274 words; codebook length: 24 codes)
Task C (Trusted sources): This coding task explores participants’ practices and sources when seeking guidance on digital security and privacy. This task goes beyond capturing the semantic content of the data, as it requires examining underlying ideas and assumptions. (average segment length: 469 words; codebook length: 32 codes)
Experimental Design
For our experiments, we use OpenAI’s GPT-3.5 (Brown et al . , 2020 ) and GPT-4 (Achiam et al . , 2023 ) models via the API service. To achieve more consistent and less random completions, we set the temperature parameter to 0 0 . To enable performance comparisons between humans and LLMs , we implement both coding approaches in an annotation task, where the models and human coders code all data segments using a human-generated codebook as a common benchmark for evaluation. We design a prompt for each coding task to instruct the models to perform the coding given an interview segment and the codebook, following the scheme in Figure 1 . We experiment with two different models and prompt engineering techniques, including few-shot learning (OpenAI, 2023 ; White et al . , 2023 ; Brown et al . , 2020 ) :
GPT-3.5 Turbo vs. GPT-4: We compare the performance of OpenAI’s GPT-3.5 and GPT-4 models. While GPT-4 offers broader general knowledge via a larger context window and can follow complex instructions, GPT-3.5 is offered at a lower price, and versions of this model are also accessible via OpenAI’s free AI system ChatGPT.
Zero-shot vs. One-shot vs. Few-shot: Providing the model with expected inputs and outputs can increase performance, and teach the model to adopt a specific style (Brown et al . , 2020 ) . In the zero-shot setting, we do not include examples in the prompt. In the one-shot setting, we provide the model with one exemplary data segment and expected output. In the few-shot setting, we provide three examples 3 3 3 As examples, we use synthetic interview data generated with GPT-4 and annotated by human coders. .
Evaluation of Agreement
For each coding task, we calculate the Inter-Rater Reliability ( IRR ) between the two human coders as well as between the final, unified human annotations and both models via Cohen’s Kappa (Cohen, 1960 ; McHugh, 2012 ) . While the IRR between human coders is based on the 80% of annotations that were not used to generate the codebook, we compute the IRR between models and humans based on all annotations.
3. Results: Agreement between Humans and LLMs
Table 1 presents the IRR between human coders’ and models’ annotations. For tasks A and B, human coders achieved almost perfect agreement and for Task C they reached substantial agreement. GPT-4 consistently outperforms its predecessor in all three tasks. It achieves almost perfect agreement with human annotations on Task A in all settings – comparable to inter-human agreement. In contrast, with zero or one example, GPT-3.5 only achieves substantial agreement in Task A, which can be raised to almost perfect agreement when three examples are provided. In Task B, both models show moderate to substantial agreement. However, in Task C, the agreement for GPT-3.5 is only fair for the one-shot and few-shot settings, while GPT-4 achieves moderate agreement across all settings. As the complexity of the coding tasks increases from Task A to Task C, there is both a notable decrease in inter-human agreement and a widening gap between inter-human and model-human scores.
Providing the model with examples did not significantly improve IRR . However, it played a critical role in mitigating certain challenges, particularly for GPT-3.5, given its inherent limitations, such as restricted input and output sizes. In particular, few-shot learning helped reduce the number of formatting errors that required manual correction. It also played a key role in reducing the number of codes introduced by the model that did not exist in the given codebook, commonly referred to as hallucinations (Ji et al . , 2023 ) . Notably, GPT-3.5 introduced as many as 47 47 47 47 new, incorrect codes for Task B – an amount that could be reduced by more than half with the provision of examples. In contrast, GPT-4 generated only two incorrect codes in the same setting.
4. Discussion
Inter-human vs. model-human performance.
Although inter-human agreement is in one case equivalent to, and generally higher than model-human agreement, our research highlights the shared challenges faced by human coders and LLMs when confronted with increasingly complex QDA tasks. Our quantitative findings underscore the inherent difficulty in coding with longer codebooks and contexts, which necessitates capturing nuanced signals and latent themes. Thus, we advocate for the evaluation of LLMs on a task-specific basis, recognizing that not all tasks are uniformly compatible with LLMs . Various factors, including data collection methods (e. g., survey data, interview data) and segmentation techniques, contribute to the complexity of QDA . Our ongoing work delves into these dimensions to gain a comprehensive understanding of the challenges and nuances associated with using LLMs for qualitative coding.
Model choice and few-shot learning
GPT-4 outperformed GPT 3.5 on all tasks, indicating an improved ability to understand and encode qualitative data. While GPT-4 shows higher agreement with human coders, GPT-3.5 offers a considerably lower cost, with input tokens priced 60 times less in our experiments (OpenAI, 2024 ) . This makes GPT-3.5 particularly suitable for rapid prototyping, e. g., when engineering prompts for QDA . While few-shot learning did not improve the models’ performance, it could play a crucial role in mitigating hallucinations and formatting errors, especially for less capable models such as GPT-3.5. However, researchers will need to consider whether to use synthetic examples or to manually annotate a subset of data to provide examples. This decision may impact performance, calling for a careful analysis of the choice of examples for few-shot learning.
Methodological challenges
While IRR provides a quantitative measure of agreement, it falls short of capturing the depth and subtleties of qualitative analysis (McDonald et al . , 2019 ) . In our future work, we aim to conduct a qualitative assessment of our results, along with a detailed error analysis. It is critical to recognize that the human benchmark is not infallible, as human coders are susceptible to subjectivity and potential bias (Seaman, 1999 ; Ortloff et al . , 2023 ) . This raises the normative question of whether to hold LLMs to the standard of human coding or to explore alternative scales and benchmarks that might better capture the strengths and limitations of these models.
Risks and limitations
While LLMs exhibit remarkable performance in processing and generating language (Brown et al . , 2020 ; Ziems et al . , 2023 ) , there are inherent limitations in their ability to understand and encode complex contexts, especially in tasks that require a deeper understanding, potentially leading to oversights and misinterpretations. Moreover, the role and integration of LLMs in QDA requires a normative discussion. For some, the researcher’s subjectivity is integral to QDA (Wa-Mbaleka, 2020 ) , where they essentially serve as the measurement instrument (Merriam and Tisdell, 2015 ) . In this view, coding involves becoming familiar with the data, and its meaning is derived through human interpretation. Using LLMs for coding could disrupt this process, removing human involvement in text interpretation. Thus, aside from determining the suitability of LLMs for specific coding tasks, it is crucial to reconsider the fundamental purpose of QDA . In addition, the current lack of transparency in LLMs makes it difficult to track the reasoning behind the results generated. Small changes in prompt phrasing can result in completely different outputs (Jones and Steinhardt, 2022 ) . Memory issues and limited context windows raise concerns about the consistency and reproducibility of model outputs, as the model does not retain information about its coding decisions between segments. In addition, the use of LLMs involves the processing of significant amounts of data, raising questions about the confidentiality and protection of sensitive information of participants, especially when using ChatGPT as a non-API consumer application. As LLMs become more integrated into qualitative research, ethical considerations regarding these challenges and their potential impact on research findings become paramount. Continued attention to ethical guidelines and responsible use of LLMs is essential to maintaining the integrity and reliability of qualitative research.
- Achiam et al . (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774 (2023).
- Adams et al . (2008) Anne Adams, Peter Lunt, and Paul Cairns. 2008. A qualitative approach to HCI research. (2008).
- Bergin (2018) Tiffany Bergin. 2018. An Introduction to Data Analysis: Quantitative, Qualitative and Mixed Methods. An Introduction to Data Analysis (2018), 1–296.
- Braun and Clarke (2006) Virginia Braun and Victoria Clarke. 2006. Using Thematic Analysis in Psychology. Qualitative research in psychology 3, 2 (2006), 77–101.
- Brown et al . (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al . 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Cohen (1960) Jacob Cohen. 1960. A Coefficient of Agreement for Nominal Scales. Educational and psychological measurement 20, 1 (1960), 37–46.
- Flick (2022) Uwe Flick. 2022. An Introduction to Qualitative Research. An introduction to qualitative research (2022), 1–100.
- Gilardi et al . (2023) Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks. arXiv preprint arXiv:2303.15056 (2023).
- Ji et al . (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of Hallucination in Natural Language Generation. Comput. Surveys 55, 12 (2023), 1–38.
- Jones and Steinhardt (2022) Erik Jones and Jacob Steinhardt. 2022. Capturing Failures of Large Language Models via Human Cognitive Biases. Advances in Neural Information Processing Systems 35 (2022), 11785–11799.
- Kuckartz (2019) Udo Kuckartz. 2019. Qualitative Text Analysis: A Systematic Approach. Compendium for early career researchers in mathematics education (2019), 181–197.
- Landis and Koch (1977) J Richard Landis and Gary G Koch. 1977. The Measurement of Observer Agreement for Categorical Data. biometrics (1977), 159–174.
- McDonald et al . (2019) Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and Inter-Rater Reliability in Qualitative Research: Norms and Guidelines for CSCW and HCI Practice. Proc. ACM Hum.-Comput. Interact. (CSCW) (2019).
- McHugh (2012) Mary L McHugh. 2012. Interrater reliability: the kappa statistic. Biochemia medica 22, 3 (2012), 276–282.
- Merriam and Tisdell (2015) Sharan B Merriam and Elizabeth J Tisdell. 2015. Qualitative Research: A Guide to Design and Implementation . John Wiley & Sons.
- OpenAI (2023) OpenAI. 2023. Prompt Engineering Guide . Retrieved 2024-02-02 from https://platform.openai.com/docs/guides/prompt-engineering
- OpenAI (2024) OpenAI. 2024. Pricing . Retrieved 2024-02-23 from https://openai.com/pricing
- Ortloff et al . (2023) Anna-Marie Ortloff, Matthias Fassl, Alexander Ponticello, Florin Martius, Anne Mertens, Katharina Krombholz, and Matthew Smith. 2023. Different Researchers, Different Results? Analyzing the Influence of Researcher Experience and Data Type During Qualitative Analysis of an Interview and Survey Study on Security Advice. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems . 1–21.
- Seaman (1999) C.B. Seaman. 1999. Qualitative methods in empirical studies of software engineering. IEEE Transactions on Software Engineering 25, 4 (1999), 557–572. https://doi.org/10.1109/32.799955
- Team et al . (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al . 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv preprint arXiv:2312.11805 (2023).
- Törnberg (2023) Petter Törnberg. 2023. ChatGPT-4 Outperforms Experts and Crowd Workers in Annotating Political Twitter Messages with Zero-Shot Learning. arXiv preprint arXiv:2304.06588 (2023).
- Touvron et al . (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al . 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288 (2023).
- Wa-Mbaleka (2020) Safary Wa-Mbaleka. 2020. The Researcher as an Instrument. In Computer Supported Qualitative Research , António Pedro Costa, Luís Paulo Reis, and António Moreira (Eds.). Springer International Publishing, Cham, 33–41.
- White et al . (2023) Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C Schmidt. 2023. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv preprint arXiv:2302.11382 (2023).
- Ziems et al . (2023) Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. 2023. Can Large Language Models Transform Computational Social Science? arXiv preprint arXiv:2305.03514 (2023).
Appendix A PROMPT DESIGN

The Ultimate Guide to Qualitative Research - Part 2: Handling Qualitative Data

- Handling qualitative data
- Transcripts
- Field notes
- Survey data and responses
- Visual and audio data
- Data organization
- Introduction
Qualitative data
Coding qualitative data, coding methods, using atlas.ti for qualitative data coding, automated coding tools in atlas.ti.
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative analysis software
Coding qualitative data for valuable insights
Qualitative researchers, at one point or another, will inevitably find themselves involved in coding their data. The coding process can be arduous and time-consuming, so it's essential to understand how coding contributes to the understanding of knowledge in qualitative research .

Qualitative research tends to work with unstructured data that requires some systematic organization to facilitate insights relevant to your research inquiry. Suppose you need to determine the most critical aspects for deciding what hotel to stay in when you go on vacation. The decision process that goes into choosing the "best" hotel can be located in various and separate places (e.g., travel websites, blogs, personal conversations) and scattered among pieces of information that may not be relevant to you. In qualitative research, one of the goals prior to data analysis is to identify what information is important, find that information, and sort that information in a way that makes it easy for you to come to a decision.

Qualitative coding is almost always a necessary part of the qualitative data analysis process . Coding provides a way to make the meaning of the data clear to you and to your research audience.
What is a code?
A code in the context of qualitative data analysis is a summary of a larger segment of text. Imagine applying a couple of sticky notes to a collection of recipes, marking each section with short labels like "ingredients," "directions," and "advice." Afterward, someone can page through those recipes and easily locate the section they are looking for, thanks to those sticky notes.
Now, suppose you have different colors of sticky notes, where each color denotes a particular cuisine (e.g., Italian, Chinese, vegetarian). Now, with two ways to organize the data in front of you, you can look at all of the ingredient sections of all the recipes belonging to a cuisine to get a sense of the items that are commonly used for such recipes.
As illustrated in this example, one reason someone might apply sticky notes to a recipe is to help the reader save time in getting the desired information from that text, which is essentially the goal of qualitative coding. Coding allows a reader to get the information they are looking for to facilitate the analysis process. Moreover, this process of categorizing the different pieces of data helps researchers see what is going on in their data and identify emerging dimensions and patterns.
The use of codes also has a purpose beyond simply establishing a convenient means to draw meaning from the data . When presenting qualitative research to an audience, researchers could rely on a narrative summary of the data, but such narratives might be too lengthy to grasp or difficult to convey to others.
As a result, researchers in all fields tend to rely on data visualizations to illustrate their data analysis . Naturally, suppose such visualizations rely on tables and figures like bar charts and diagrams to convey meaning. In that case, researchers need to find ways to "count" the data along established data points, which is a role that coding can fulfill. While a strictly numerical understanding of qualitative research may overlook the finer aspects of social phenomena, researchers ultimately benefit from an analysis of the frequency of codes, combinations of codes, and patterns of codes that can contribute to theory generation. In addition, codes can be visualized in numerous ways to present qualitative insights. From flow charts to semantic networks, codes provide researchers with almost limitless possibilities in choosing how to present their rich qualitative data to different audiences.
Applying codes
To engage in coding, a researcher looks at the data line-by-line and develops a codebook by identifying data segments that can be represented by words or short phrases.
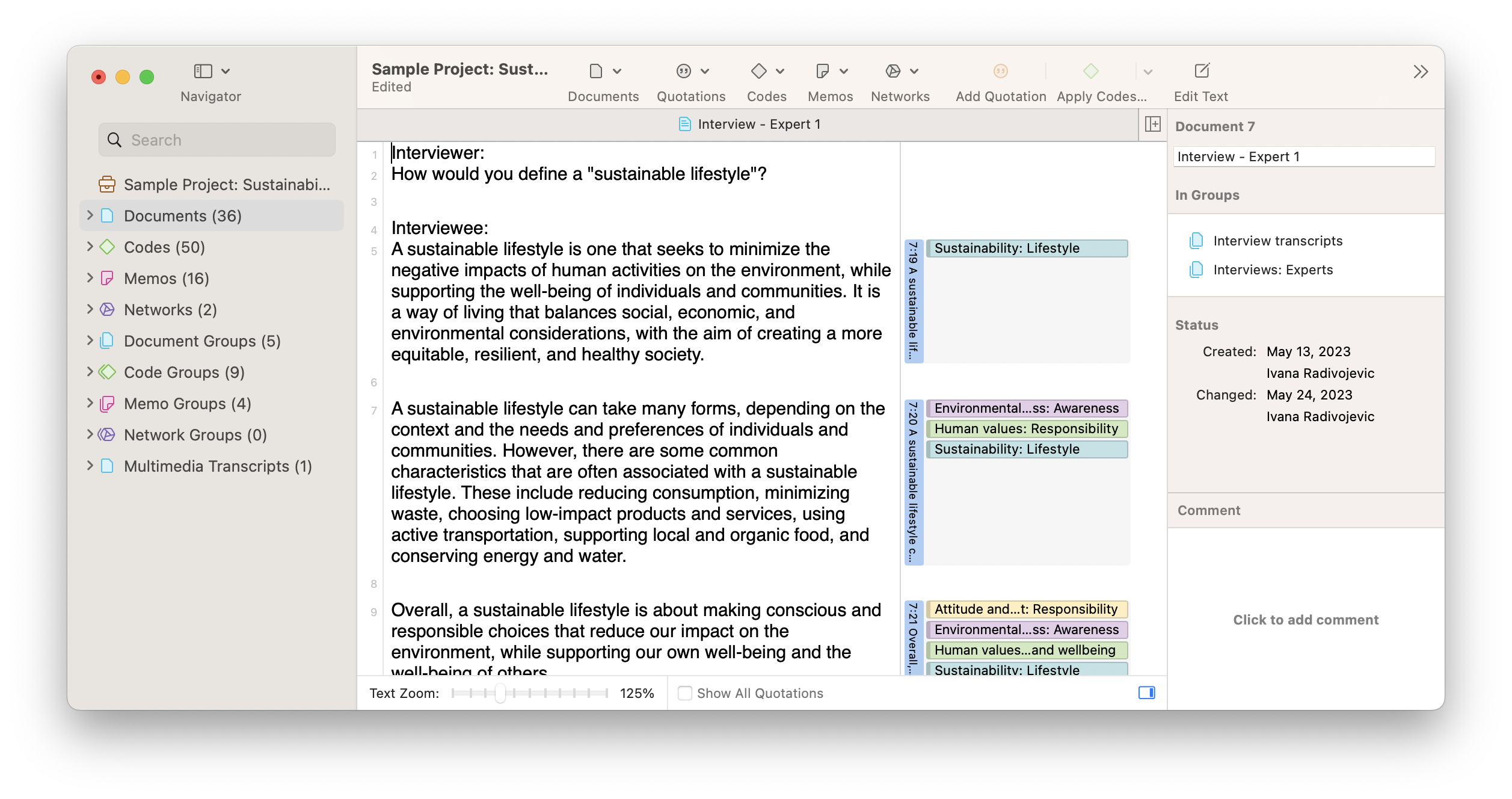
In the example above, a set of three paragraphs is represented by one code displayed in green in the right margin. Without codes, the researcher might have to re-read all of the text to remind themselves what the data is about. Indeed, any researcher who examines the codebook of a project can glean a sense of the data and analysis.
Analyzing codes
Think of a simple example to illustrate the importance of analyzing codes. Suppose you are analyzing survey responses for people's preferences for shopping in brick-and-mortar stores and shopping online. In that case, you might think about marking each survey response as either "prefers shopping in-person" or "prefers shopping online." Once you have applied the relevant codes to each survey response, you can compare the frequencies of both codes to determine where the population as a whole stands on the subject.
Among other things, codes can be analyzed by their frequency or their connection to other codes (or co-occurrence with other codes). In the example above, you may also decide to code the data for the reasons that inform people's shopping habits, applying labels such as "convenience," "value," and "service." Then, the analysis process is simply a matter of determining how often each reason co-occurs with preferences for in-person shopping and online shopping by analyzing the codes applied to the data.
As a result, qualitative coding transforms raw data into a form that facilitates the generation of deeper insights through empirical analysis.
That said, coding is a time-consuming, albeit necessary, task in qualitative research and one that researchers have developed into an array of established methods that are worth briefly looking at.
Years of development of qualitative research methods have yielded multiple methods for assigning codes to data. While all qualitative coding approaches essentially seek to summarize large amounts of information succinctly, there are various approaches you can apply to your coding process.
Inductive coding
Probably the most basic form of coding is to look at the data and reduce it to its salient points of information through coding. Any inductive approach to research involves generating knowledge from the ground up. Inductive coding, as a result, looks to generate insights from the qualitative data itself.
Inductive coding benefits researchers who need to look at the data primarily for its inherent meaning rather than for how external frameworks of knowledge might look at it. Inductive coding can also provide a new perspective that established theory has yet to consider, which would make a theory-driven approach inappropriate.
Deductive coding
A deductive approach to coding is also useful in qualitative research . In contrast with inductive coding, a deductive coding approach applies an existing research framework or previous research study to new data. This means that the researcher applies a set of predefined codes based on established research to the new data.
Researchers can benefit from using both approaches in tandem if their research questions call for a synthesized analysis . Returning to the example of a cookbook, a person may mark the different sections of each recipe because they have prior knowledge about what a typical recipe might look like. On the other hand, if they come across a non-typical recipe (e.g., a recipe that may not have an ingredients section), they might need to create new codes to identify parts of the recipe that seem unusual or novel.
Employing both inductive coding and deductive coding , as a result, can help you achieve a more holistic analysis of your data by building on existing knowledge of a phenomenon while generating new knowledge about the less familiar aspects.
Thematic analysis coding
Whether you decide to apply an inductive coding or deductive coding approach to qualitative data, the coding should also be relevant to your research inquiry in order to be useful and avoid a cumbersome amount of coding that might defeat the purpose of summarizing your data. Let's look at a series of more specific approaches to qualitative coding to get a wider sense of how coding has been applied to qualitative research.
The goal of a thematic analysis arising from coding, as the name suggests, is to identify themes revolving around a particular concept or phenomenon. While concepts in the natural sciences, such as temperature and atomic weight, can be measured with numerical data, concepts in the social sciences often escape easy numerical analysis. Rather than reduce the beauty of a work of art or proficiency in a foreign language down to a number, thematic analysis coding looks to describe these phenomena by various aspects that can be grouped together within common themes.
Looking at the recipe again, we can describe a typical recipe by the sections that appear the most often. The same is true for describing a sport (e.g., rules, strategies, equipment) or a car (e.g., type, price, fuel efficiency, safety rating). While later analysis might be able to numerically measure these themes if they are particular enough, the role of coding along the lines of themes provides a good starting point for recognizing and analyzing relevant concepts.
Process coding
Processes are phenomena that are characterized by action. Think about the act of driving a car rather than describing the car itself. In this case, process coding can be thought of as an extension of thematic coding, except that the major aspects of a process can also be identified by sequences and patterns, on the assumption that some actions may follow other actions. After all, drivers typically turn the key in the ignition before releasing the parking brake or shifting to drive. Capturing the specific phases and sequences is a key objective in process coding.
Structural coding
The "structure" of a recipe in a cookbook is different from that of an essay or a newspaper article. Also, think about how an interview for research might be structured differently from an interview for a TV news program. Researchers can employ structural coding to organize the data according to its distinct structural elements, such as specific elements, the ordering of information, or the purpose behind different structures. This kind of analysis could help, for instance, to achieve a greater understanding of how cultures shape a particular piece of writing or social practice.
Longitudinal coding
Studies that observe people or practices over time do so to capture and understand changes in dynamic environments. The role of longitudinal coding is to also code for relevant contextual or temporal aspects. These can then be analyzed together with other codes to assess how frequencies and patterns change from one observation or interview to the next. This will help researchers empirically illustrate differences or changes over time.

Whatever your approach, code your data with ATLAS.ti
Powerful tools for manual coding and automated coding. Check them out with a free trial.
Qualitative data analysis software should effectively facilitate qualitative coding. Researchers can choose between manual coding and automated coding , where tools can be employed to suggest and apply codes to save time. ATLAS.ti is ideal for both approaches to suit researchers of all needs and backgrounds.
Manual coding
At the core of any qualitative data analysis software is the interface that allows researchers the freedom of assigning codes to qualitative data . ATLAS.ti's interface for viewing data makes it easy to highlight data segments and apply new codes or existing codes quickly and efficiently.
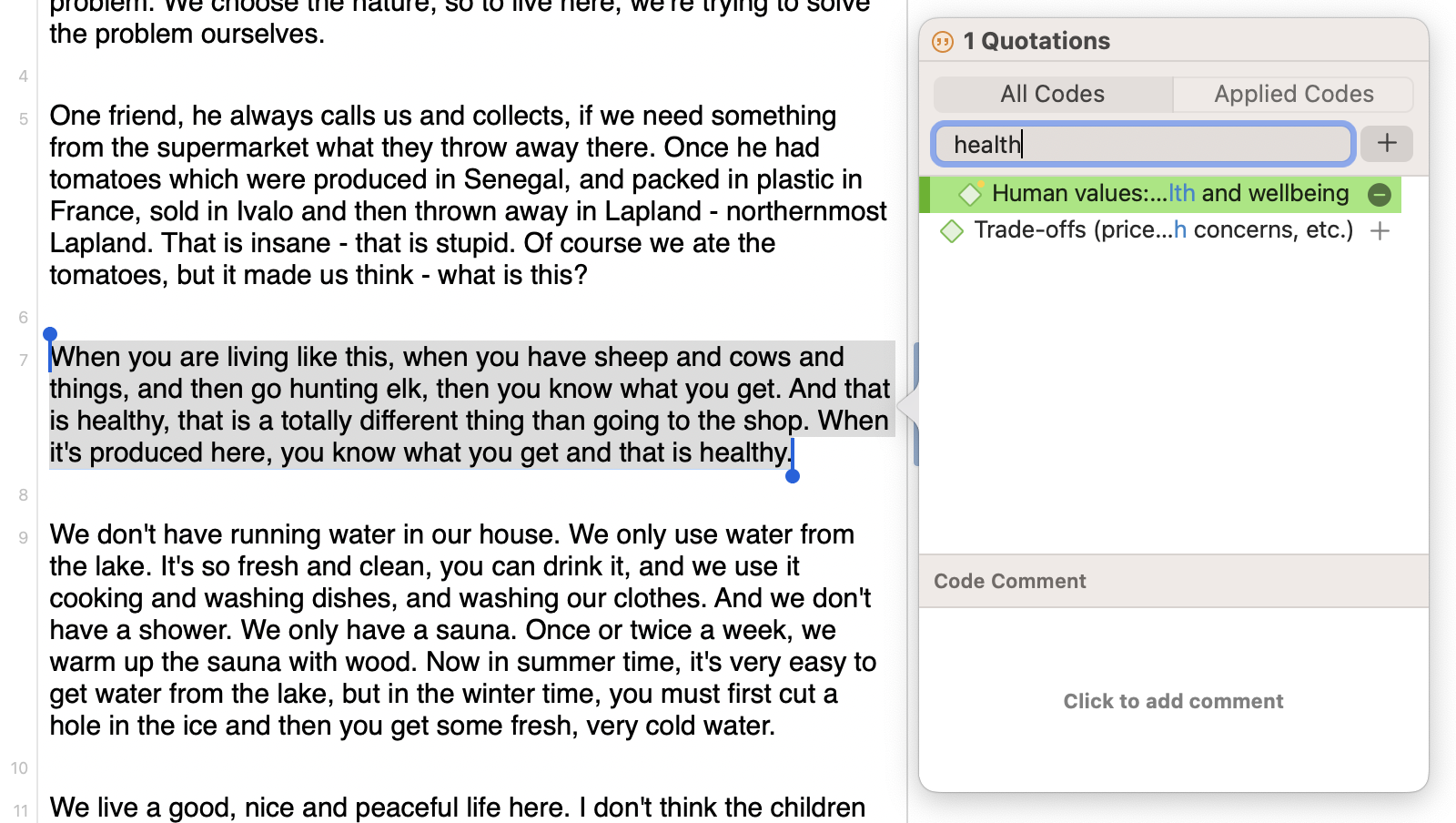
In vivo coding
Interpreting qualitative data to create codes is often a part of the coding process. This can mean that the names of codes may differ from the actual text of the data itself.
However, the best names for codes sometimes come from the textual data itself, as opposed to some interpretation of the text. As a result, there may be a particular word or short phrase that stands out to you in your data set, compelling you to incorporate that word or phrase into your qualitative codes. Think about how social media has slang or acronyms like "YOLO" or "YMMV" which condense a lot of meaning or convey something of importance in the context of the research. Rather than obscuring participants’ meanings or experiences within another layer of interpretation, researchers can build meaningful and rich insights by using participants’ own words to create in vivo codes .

In vivo coding is a handy feature in ATLAS.ti for when you come across a key term or phrase that you want to create a code out of. Simply highlight the desired text and click on "Code in Vivo" to create a new code instantly.
Code Manager
One of the biggest challenges of coding qualitative data is keeping track of dozens or even hundreds of codes, because a lack of organization may hinder researchers in the main objective of succinctly summarizing qualitative data.
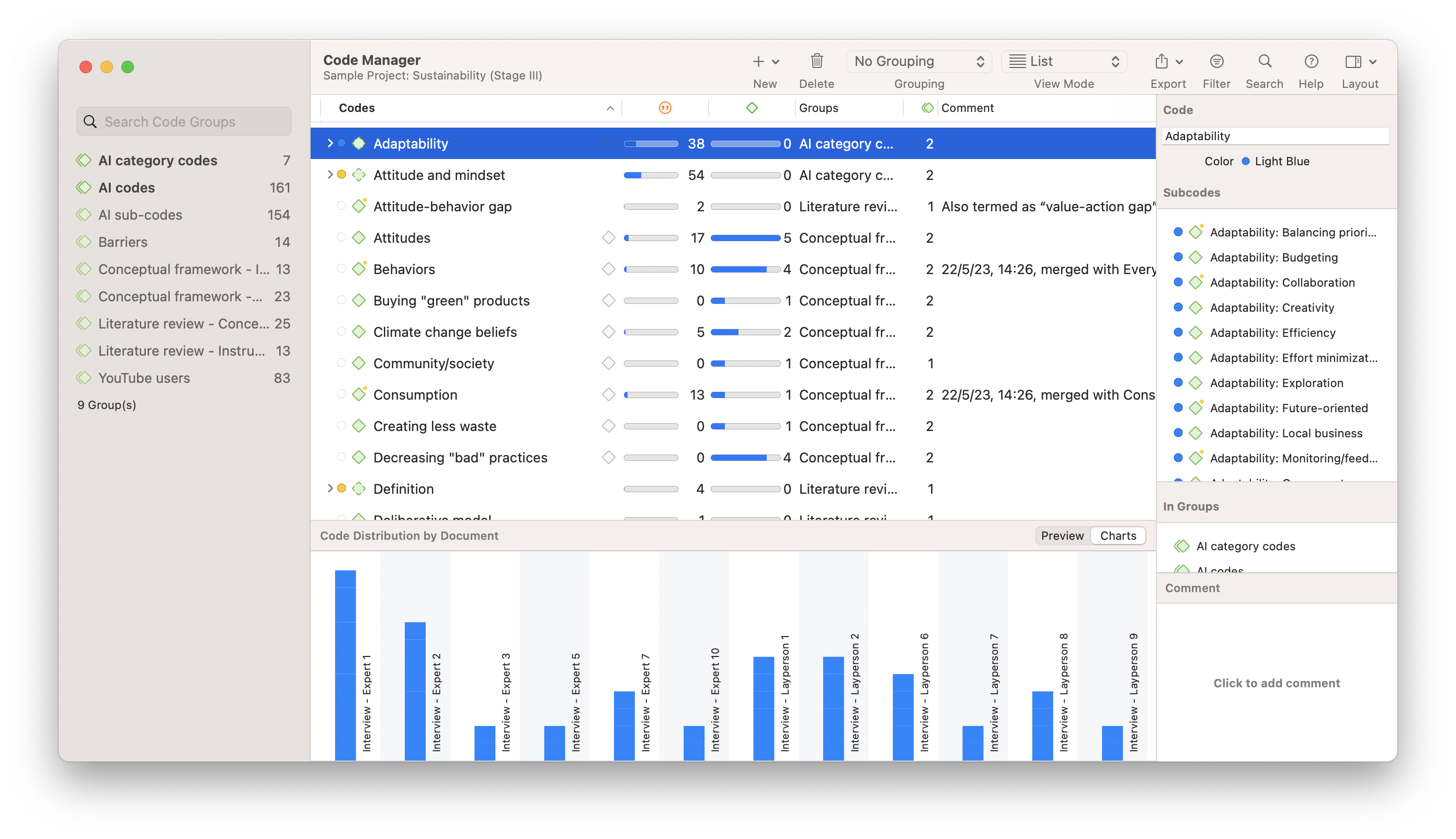
Once you have developed and applied a set of codes to your project data, you can open the Code Manager to gain a bird's eye view of all of your codes so you can develop and reorganize them, into hierarchies, groups, or however you prefer. Your list of codes can also be exported to share with others or use in other qualitative or quantitative analysis software .
Use ATLAS.ti for efficient and insightful coding
Intuitive tools to help you code and analyze your data, available starting with a free trial.
Traditionally, qualitative researchers would perform this coding on their data manually by hand, which involves carefully reading each piece of data and attaching codes. For qualitative researchers using pen and paper, they can use highlighters or bookmark flags to mark the key points in their data for later reference. Qualitative researchers also have powerful qualitative data analysis software they can rely on to facilitate all aspects of the coding process.

Although researchers can use qualitative data analysis software to engage in manual coding, there is also now a range of software tools that can even automate the coding process . A number of automated coding tools in ATLAS.ti such as AI Coding, Sentiment Analysis, and Opinion Mining use machine learning and natural language processing to apply useful codes for later analysis. Moreover, other tools in ATLAS.ti rely on pattern recognition to facilitate the creation of descriptive codes throughout your project.
One of the most exciting implications of recent advances in artificial intelligence is its potential for facilitating the research process, especially in qualitative research. The use of machine learning to understand the salient points in data can be especially useful to researchers in all fields.
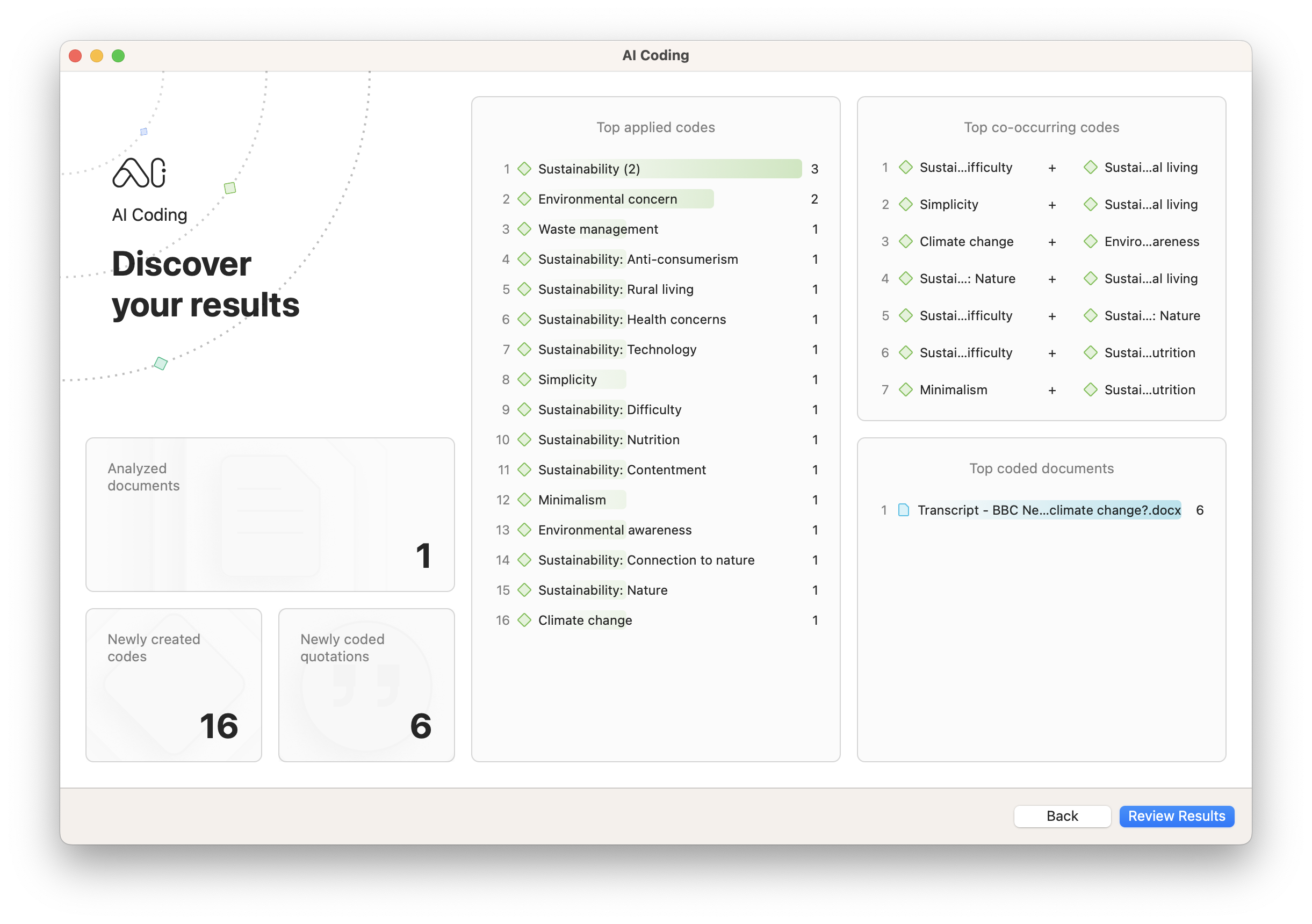
AI Coding , available in both the Desktop platforms and Web version of ATLAS.ti, performs comprehensive descriptive coding on your qualitative data . It processes data through OpenAI's language models to suggest and apply codes to your project in a fraction of the time that it would take to do manually.
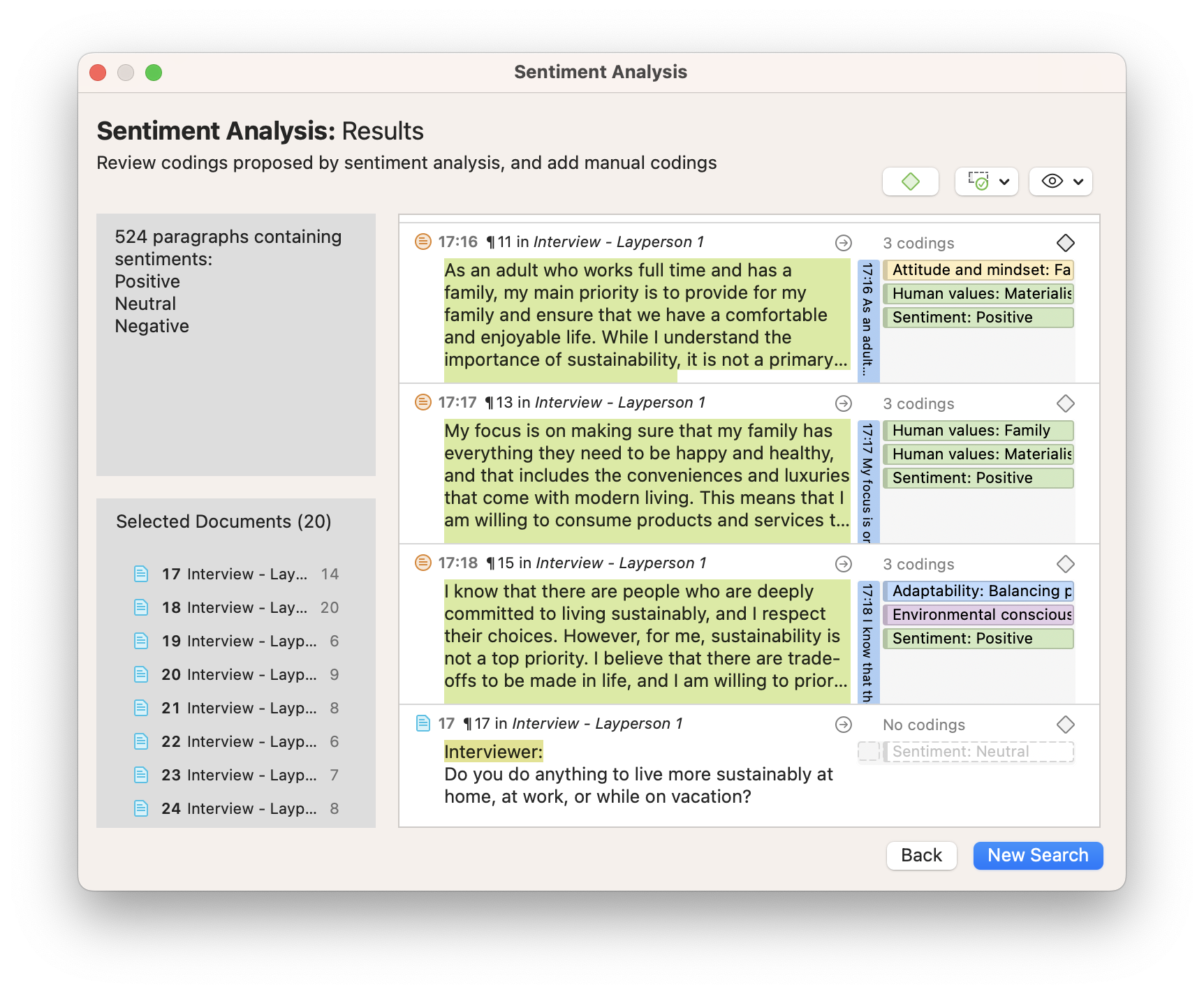
Sentiment Analysis
Participants may often express sentiments that are positive or negative in nature. If you are interested in analyzing the feelings expressed in your data, you can analyze these sentiments . To conduct automated coding for these sentiments, ATLAS.ti employs machine learning to process your data quickly and suggest codes to be applied to relevant data segments.
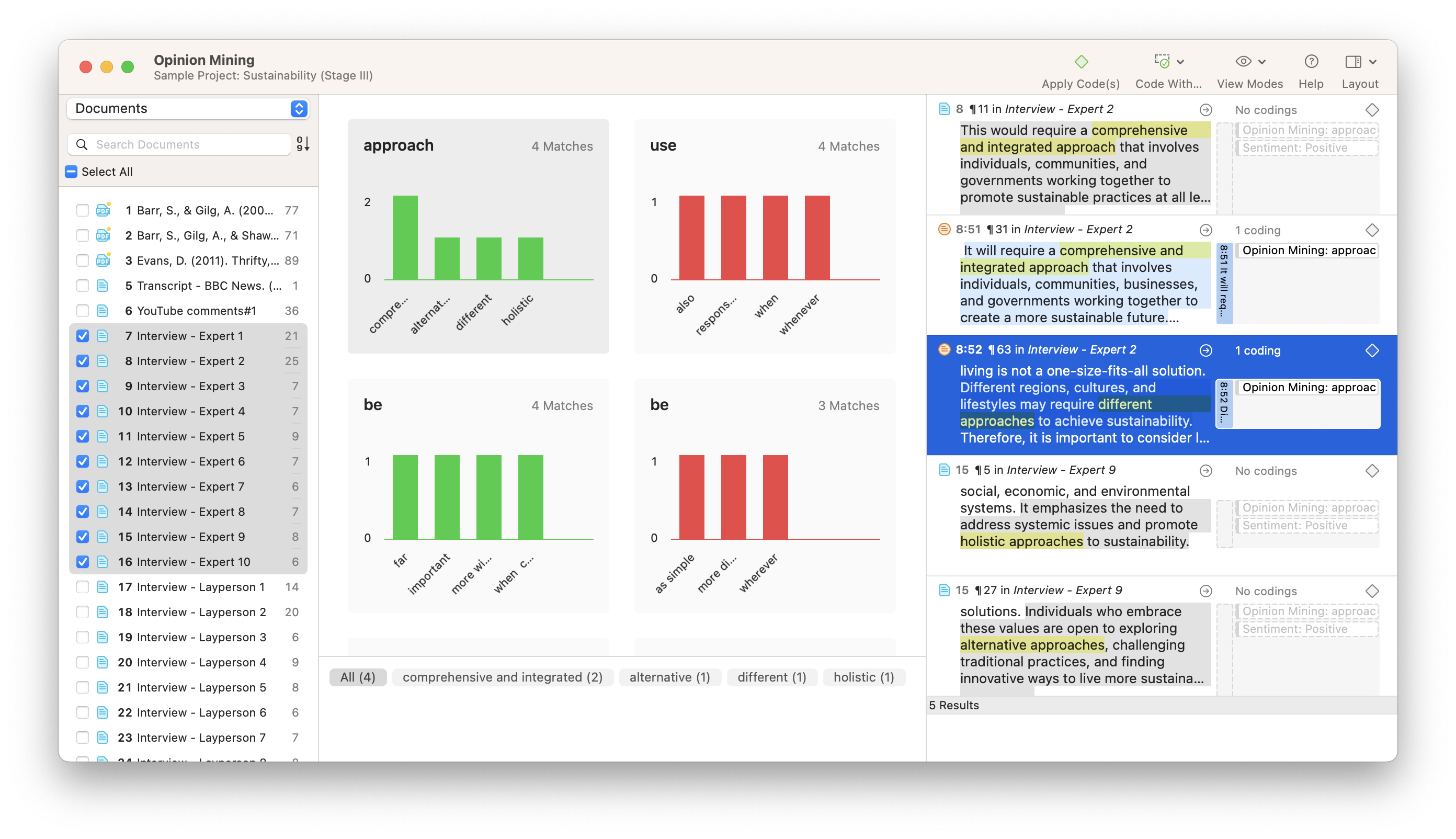
Opinion Mining
If you want to understand both what participants talked about and how they felt about it, you can conduct Opinion Mining. This tool synthesizes key phrases in your textual data according to whether they are being talked about in a positive or negative manner. The codes generated from Opinion Mining can provide a useful illustration of how language in interviews, focus groups, and surveys is used when discussing certain topics or phenomena.
Code qualitative data with ATLAS.ti
Download a free trial of ATLAS.ti and code your data with ease.
Qualitative Data Coding 101
How to code qualitative data, the smart way (with examples).
By: Jenna Crosley (PhD) | Reviewed by:Dr Eunice Rautenbach | December 2020
As we’ve discussed previously , qualitative research makes use of non-numerical data – for example, words, phrases or even images and video. To analyse this kind of data, the first dragon you’ll need to slay is qualitative data coding (or just “coding” if you want to sound cool). But what exactly is coding and how do you do it?
Overview: Qualitative Data Coding
In this post, we’ll explain qualitative data coding in simple terms. Specifically, we’ll dig into:
- What exactly qualitative data coding is
- What different types of coding exist
- How to code qualitative data (the process)
- Moving from coding to qualitative analysis
- Tips and tricks for quality data coding

What is qualitative data coding?
Let’s start by understanding what a code is. At the simplest level, a code is a label that describes the content of a piece of text. For example, in the sentence:
“Pigeons attacked me and stole my sandwich.”
You could use “pigeons” as a code. This code simply describes that the sentence involves pigeons.
So, building onto this, qualitative data coding is the process of creating and assigning codes to categorise data extracts. You’ll then use these codes later down the road to derive themes and patterns for your qualitative analysis (for example, thematic analysis ). Coding and analysis can take place simultaneously, but it’s important to note that coding does not necessarily involve identifying themes (depending on which textbook you’re reading, of course). Instead, it generally refers to the process of labelling and grouping similar types of data to make generating themes and analysing the data more manageable.
Makes sense? Great. But why should you bother with coding at all? Why not just look for themes from the outset? Well, coding is a way of making sure your data is valid . In other words, it helps ensure that your analysis is undertaken systematically and that other researchers can review it (in the world of research, we call this transparency). In other words, good coding is the foundation of high-quality analysis.

What are the different types of coding?
Now that we’ve got a plain-language definition of coding on the table, the next step is to understand what types of coding exist. Let’s start with the two main approaches, deductive and inductive coding.
Deductive coding 101
With deductive coding, we make use of pre-established codes, which are developed before you interact with the present data. This usually involves drawing up a set of codes based on a research question or previous research . You could also use a code set from the codebook of a previous study.
For example, if you were studying the eating habits of college students, you might have a research question along the lines of
“What foods do college students eat the most?”
As a result of this research question, you might develop a code set that includes codes such as “sushi”, “pizza”, and “burgers”.
Deductive coding allows you to approach your analysis with a very tightly focused lens and quickly identify relevant data . Of course, the downside is that you could miss out on some very valuable insights as a result of this tight, predetermined focus.

Inductive coding 101
But what about inductive coding? As we touched on earlier, this type of coding involves jumping right into the data and then developing the codes based on what you find within the data.
For example, if you were to analyse a set of open-ended interviews , you wouldn’t necessarily know which direction the conversation would flow. If a conversation begins with a discussion of cats, it may go on to include other animals too, and so you’d add these codes as you progress with your analysis. Simply put, with inductive coding, you “go with the flow” of the data.
Inductive coding is great when you’re researching something that isn’t yet well understood because the coding derived from the data helps you explore the subject. Therefore, this type of coding is usually used when researchers want to investigate new ideas or concepts , or when they want to create new theories.

A little bit of both… hybrid coding approaches
If you’ve got a set of codes you’ve derived from a research topic, literature review or a previous study (i.e. a deductive approach), but you still don’t have a rich enough set to capture the depth of your qualitative data, you can combine deductive and inductive methods – this is called a hybrid coding approach.
To adopt a hybrid approach, you’ll begin your analysis with a set of a priori codes (deductive) and then add new codes (inductive) as you work your way through the data. Essentially, the hybrid coding approach provides the best of both worlds, which is why it’s pretty common to see this in research.
Need a helping hand?
How to code qualitative data
Now that we’ve looked at the main approaches to coding, the next question you’re probably asking is “how do I actually do it?”. Let’s take a look at the coding process , step by step.
Both inductive and deductive methods of coding typically occur in two stages: initial coding and line by line coding .
In the initial coding stage, the objective is to get a general overview of the data by reading through and understanding it. If you’re using an inductive approach, this is also where you’ll develop an initial set of codes. Then, in the second stage (line by line coding), you’ll delve deeper into the data and (re)organise it according to (potentially new) codes.
Step 1 – Initial coding
The first step of the coding process is to identify the essence of the text and code it accordingly. While there are various qualitative analysis software packages available, you can just as easily code textual data using Microsoft Word’s “comments” feature.
Let’s take a look at a practical example of coding. Assume you had the following interview data from two interviewees:
What pets do you have?
I have an alpaca and three dogs.
Only one alpaca? They can die of loneliness if they don’t have a friend.
I didn’t know that! I’ll just have to get five more.
I have twenty-three bunnies. I initially only had two, I’m not sure what happened.
In the initial stage of coding, you could assign the code of “pets” or “animals”. These are just initial, fairly broad codes that you can (and will) develop and refine later. In the initial stage, broad, rough codes are fine – they’re just a starting point which you will build onto in the second stage.

How to decide which codes to use
But how exactly do you decide what codes to use when there are many ways to read and interpret any given sentence? Well, there are a few different approaches you can adopt. The main approaches to initial coding include:
- In vivo coding
Process coding
- Open coding
Descriptive coding
Structural coding.
- Value coding
Let’s take a look at each of these:
In vivo coding
When you use in vivo coding, you make use of a participants’ own words , rather than your interpretation of the data. In other words, you use direct quotes from participants as your codes. By doing this, you’ll avoid trying to infer meaning, rather staying as close to the original phrases and words as possible.
In vivo coding is particularly useful when your data are derived from participants who speak different languages or come from different cultures. In these cases, it’s often difficult to accurately infer meaning due to linguistic or cultural differences.
For example, English speakers typically view the future as in front of them and the past as behind them. However, this isn’t the same in all cultures. Speakers of Aymara view the past as in front of them and the future as behind them. Why? Because the future is unknown, so it must be out of sight (or behind us). They know what happened in the past, so their perspective is that it’s positioned in front of them, where they can “see” it.
In a scenario like this one, it’s not possible to derive the reason for viewing the past as in front and the future as behind without knowing the Aymara culture’s perception of time. Therefore, in vivo coding is particularly useful, as it avoids interpretation errors.
Next up, there’s process coding, which makes use of action-based codes . Action-based codes are codes that indicate a movement or procedure. These actions are often indicated by gerunds (words ending in “-ing”) – for example, running, jumping or singing.
Process coding is useful as it allows you to code parts of data that aren’t necessarily spoken, but that are still imperative to understanding the meaning of the texts.
An example here would be if a participant were to say something like, “I have no idea where she is”. A sentence like this can be interpreted in many different ways depending on the context and movements of the participant. The participant could shrug their shoulders, which would indicate that they genuinely don’t know where the girl is; however, they could also wink, showing that they do actually know where the girl is.
Simply put, process coding is useful as it allows you to, in a concise manner, identify the main occurrences in a set of data and provide a dynamic account of events. For example, you may have action codes such as, “describing a panda”, “singing a song about bananas”, or “arguing with a relative”.

Descriptive coding aims to summarise extracts by using a single word or noun that encapsulates the general idea of the data. These words will typically describe the data in a highly condensed manner, which allows the researcher to quickly refer to the content.
Descriptive coding is very useful when dealing with data that appear in forms other than traditional text – i.e. video clips, sound recordings or images. For example, a descriptive code could be “food” when coding a video clip that involves a group of people discussing what they ate throughout the day, or “cooking” when coding an image showing the steps of a recipe.
Structural coding involves labelling and describing specific structural attributes of the data. Generally, it includes coding according to answers to the questions of “ who ”, “ what ”, “ where ”, and “ how ”, rather than the actual topics expressed in the data. This type of coding is useful when you want to access segments of data quickly, and it can help tremendously when you’re dealing with large data sets.
For example, if you were coding a collection of theses or dissertations (which would be quite a large data set), structural coding could be useful as you could code according to different sections within each of these documents – i.e. according to the standard dissertation structure . What-centric labels such as “hypothesis”, “literature review”, and “methodology” would help you to efficiently refer to sections and navigate without having to work through sections of data all over again.
Structural coding is also useful for data from open-ended surveys. This data may initially be difficult to code as they lack the set structure of other forms of data (such as an interview with a strict set of questions to be answered). In this case, it would useful to code sections of data that answer certain questions such as “who?”, “what?”, “where?” and “how?”.
Let’s take a look at a practical example. If we were to send out a survey asking people about their dogs, we may end up with a (highly condensed) response such as the following:
Bella is my best friend. When I’m at home I like to sit on the floor with her and roll her ball across the carpet for her to fetch and bring back to me. I love my dog.
In this set, we could code Bella as “who”, dog as “what”, home and floor as “where”, and roll her ball as “how”.
Values coding
Finally, values coding involves coding that relates to the participant’s worldviews . Typically, this type of coding focuses on excerpts that reflect the values, attitudes, and beliefs of the participants. Values coding is therefore very useful for research exploring cultural values and intrapersonal and experiences and actions.
To recap, the aim of initial coding is to understand and familiarise yourself with your data , to develop an initial code set (if you’re taking an inductive approach) and to take the first shot at coding your data . The coding approaches above allow you to arrange your data so that it’s easier to navigate during the next stage, line by line coding (we’ll get to this soon).
While these approaches can all be used individually, it’s important to remember that it’s possible, and potentially beneficial, to combine them . For example, when conducting initial coding with interviews, you could begin by using structural coding to indicate who speaks when. Then, as a next step, you could apply descriptive coding so that you can navigate to, and between, conversation topics easily.
Step 2 – Line by line coding
Once you’ve got an overall idea of our data, are comfortable navigating it and have applied some initial codes, you can move on to line by line coding. Line by line coding is pretty much exactly what it sounds like – reviewing your data, line by line, digging deeper and assigning additional codes to each line.
With line-by-line coding, the objective is to pay close attention to your data to add detail to your codes. For example, if you have a discussion of beverages and you previously just coded this as “beverages”, you could now go deeper and code more specifically, such as “coffee”, “tea”, and “orange juice”. The aim here is to scratch below the surface. This is the time to get detailed and specific so as to capture as much richness from the data as possible.
In the line-by-line coding process, it’s useful to code everything in your data, even if you don’t think you’re going to use it (you may just end up needing it!). As you go through this process, your coding will become more thorough and detailed, and you’ll have a much better understanding of your data as a result of this, which will be incredibly valuable in the analysis phase.

Moving from coding to analysis
Once you’ve completed your initial coding and line by line coding, the next step is to start your analysis . Of course, the coding process itself will get you in “analysis mode” and you’ll probably already have some insights and ideas as a result of it, so you should always keep notes of your thoughts as you work through the coding.
When it comes to qualitative data analysis, there are many different types of analyses (we discuss some of the most popular ones here ) and the type of analysis you adopt will depend heavily on your research aims, objectives and questions . Therefore, we’re not going to go down that rabbit hole here, but we’ll cover the important first steps that build the bridge from qualitative data coding to qualitative analysis.
When starting to think about your analysis, it’s useful to ask yourself the following questions to get the wheels turning:
- What actions are shown in the data?
- What are the aims of these interactions and excerpts? What are the participants potentially trying to achieve?
- How do participants interpret what is happening, and how do they speak about it? What does their language reveal?
- What are the assumptions made by the participants?
- What are the participants doing? What is going on?
- Why do I want to learn about this? What am I trying to find out?
- Why did I include this particular excerpt? What does it represent and how?

Code categorisation
Categorisation is simply the process of reviewing everything you’ve coded and then creating code categories that can be used to guide your future analysis. In other words, it’s about creating categories for your code set. Let’s take a look at a practical example.
If you were discussing different types of animals, your initial codes may be “dogs”, “llamas”, and “lions”. In the process of categorisation, you could label (categorise) these three animals as “mammals”, whereas you could categorise “flies”, “crickets”, and “beetles” as “insects”. By creating these code categories, you will be making your data more organised, as well as enriching it so that you can see new connections between different groups of codes.
Theme identification
From the coding and categorisation processes, you’ll naturally start noticing themes. Therefore, the logical next step is to identify and clearly articulate the themes in your data set. When you determine themes, you’ll take what you’ve learned from the coding and categorisation and group it all together to develop themes. This is the part of the coding process where you’ll try to draw meaning from your data, and start to produce a narrative . The nature of this narrative depends on your research aims and objectives, as well as your research questions (sounds familiar?) and the qualitative data analysis method you’ve chosen, so keep these factors front of mind as you scan for themes.

Tips & tricks for quality coding
Before we wrap up, let’s quickly look at some general advice, tips and suggestions to ensure your qualitative data coding is top-notch.
- Before you begin coding, plan out the steps you will take and the coding approach and technique(s) you will follow to avoid inconsistencies.
- When adopting deductive coding, it’s useful to use a codebook from the start of the coding process. This will keep your work organised and will ensure that you don’t forget any of your codes.
- Whether you’re adopting an inductive or deductive approach, keep track of the meanings of your codes and remember to revisit these as you go along.
- Avoid using synonyms for codes that are similar, if not the same. This will allow you to have a more uniform and accurate coded dataset and will also help you to not get overwhelmed by your data.
- While coding, make sure that you remind yourself of your aims and coding method. This will help you to avoid directional drift , which happens when coding is not kept consistent.
- If you are working in a team, make sure that everyone has been trained and understands how codes need to be assigned.

Psst… there’s more (for free)
This post is part of our dissertation mini-course, which covers everything you need to get started with your dissertation, thesis or research project.
You Might Also Like:

28 Comments

I appreciated the valuable information provided to accomplish the various stages of the inductive and inductive coding process. However, I would have been extremely satisfied to be appraised of the SPECIFIC STEPS to follow for: 1. Deductive coding related to the phenomenon and its features to generate the codes, categories, and themes. 2. Inductive coding related to using (a) Initial (b) Axial, and (c) Thematic procedures using transcribe data from the research questions

Thank you so much for this. Very clear and simplified discussion about qualitative data coding.

This is what I want and the way I wanted it. Thank you very much.

All of the information’s are valuable and helpful. Thank for you giving helpful information’s. Can do some article about alternative methods for continue researches during the pandemics. It is more beneficial for those struggling to continue their researchers.

Thank you for your information on coding qualitative data, this is a very important point to be known, really thank you very much.

Very useful article. Clear, articulate and easy to understand. Thanks

This is very useful. You have simplified it the way I wanted it to be! Thanks

Thank you so very much for explaining, this is quite helpful!

hello, great article! well written and easy to understand. Can you provide some of the sources in this article used for further reading purposes?

You guys are doing a great job out there . I will not realize how many students you help through your articles and post on a daily basis. I have benefited a lot from your work. this is remarkable.

Wonderful one thank you so much.

Hello, I am doing qualitative research, please assist with example of coding format.

This is an invaluable website! Thank you so very much!

Well explained and easy to follow the presentation. A big thumbs up to you. Greatly appreciate the effort 👏👏👏👏

Thank you for this clear article with examples

Thank you for the detailed explanation. I appreciate your great effort. Congrats!

Ahhhhhhhhhh! You just killed me with your explanation. Crystal clear. Two Cheers!

D0 you have primary references that was used when creating this? If so, can you share them?

Being a complete novice to the field of qualitative data analysis, your indepth analysis of the process of thematic analysis has given me better insight. Thank you so much.

Excellent summary

Thank you so much for your precise and very helpful information about coding in qualitative data.

Thanks a lot to this helpful information. You cleared the fog in my brain.

Glad to hear that!

This has been very helpful. I am excited and grateful.

I still don’t understand the coding and categorizing of qualitative research, please give an example on my research base on the state of government education infrastructure environment in PNG

Wahho, this is amazing and very educational to have come across this site.. from a little search to a wide discovery of knowledge.
Thanks I really appreciate this.

Thank you so much! Very grateful.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Fam Med Community Health
- v.9(Suppl 1); 2021
Developing and testing an automated qualitative assistant (AQUA) to support qualitative analysis
Robert p lennon.
1 Family and Community Medicine, Penn State Health Milton S. Hershey Medical Center, Hershey, Pennsylvania, USA
Robbie Fraleigh
2 Applied Research Laboratory, Pennsylvania State University, University Park, Pennsylvania, USA
Lauren J Van Scoy
3 Internal Medicine, Penn State Health Milton S. Hershey Medical Center, Hershey, Pennsylvania, USA
Aparna Keshaviah
4 Mathematica Policy Research Inc, Princeton, New Jersey, USA
Bethany L Snyder
5 Center for Community Health Integration, Case Western Reserve University, Cleveland, Ohio, USA
Erin L Miller
William a calo.
6 Public Health Services, Penn State Health Milton S. Hershey Medical Center, Hershey, Pennsylvania, USA
Aleksandra E Zgierska
Christopher griffin, associated data.
fmch-2021-001287supp001.pdf
Data are available in a public, open access repository.
Qualitative research remains underused, in part due to the time and cost of annotating qualitative data (coding). Artificial intelligence (AI) has been suggested as a means to reduce those burdens, and has been used in exploratory studies to reduce the burden of coding. However, methods to date use AI analytical techniques that lack transparency, potentially limiting acceptance of results. We developed an automated qu alitative assistant (AQUA) using a semiclassical approach, replacing Latent Semantic Indexing/Latent Dirichlet Allocation with a more transparent graph-theoretic topic extraction and clustering method. Applied to a large dataset of free-text survey responses, AQUA generated unsupervised topic categories and circle hierarchical representations of free-text responses, enabling rapid interpretation of data. When tasked with coding a subset of free-text data into user-defined qualitative categories, AQUA demonstrated intercoder reliability in several multicategory combinations with a Cohen’s kappa comparable to human coders (0.62–0.72), enabling researchers to automate coding on those categories for the entire dataset. The aim of this manuscript is to describe pertinent components of best practices of AI/machine learning (ML)-assisted qualitative methods, illustrating how primary care researchers may use AQUA to rapidly and accurately code large text datasets. The contribution of this article is providing guidance that should increase AI/ML transparency and reproducibility.
Introduction
Despite its value in studying complex public health issues, qualitative research remains underused. 1 In part this stems from the time and cost of annotating data in a qualitative study, a process known as coding. 2 There may also be a desire to publish quantitative data when it is available instead of waiting for the qualitative component to be completed, 3 and, for time-sensitive research questions like those related to COVID-19 behaviours, the time delay to complete traditional qualitative research may circumvent meaningful contributions to public health crises.
Computer-Assisted Qualitative Data Analysis Software (CAQDAS) is commonly used to assist researchers with the management, organisation, and analysis of qualitative data. 4 These software programs began as mechanisms to better organise and code data, and now include analytic tools such as word frequencies, word clustering, sentiment analysis and thematic analysis. All of these features help researchers construct themes from large datasets, but still require manual coding of data within the software package. The process of coding itself remains a time consuming, labour intense process.
Natural language processing (NLP) has been used to code qualitative data in exploratory mixed methods research. 5 6 Guetterman et al found NLP coding to be time-efficient and comparable to human coders in identifying major themes, but lacking in the ability to identify nuances. 5 NLP using latent Dirichlet allocation (LDA) as an initial modelling technique was able to generate topic categories from which the researcher identified overall theme sets similar to traditional methods. 7 Modern unsupervised NLP (especially for topic extraction or document classification) has extended beyond the linear algebraic techniques like Latent Semantic Indexing (LSI) 8 or probabilistic techniques like LDA. 9 More recently, Chang et al used human thematic analysis to inform NLP algorithms to evaluate clinical records to identify meta-inferences about barriers related to rapid adoption of virtual medicine visits during COVID-19, and separately to evaluate short text survey responses. 6
These approaches have been extended for time-varying topic analysis of text corpi, including the use of Tensor decomposition methods by Lowe and Berry. 10 Current ‘best in class’ approaches use Transformer approaches, 11 that is, a deep neural network approach to language analysis. These techniques can be extended for use in time-varying topic analysis, for example, for Twitter analysis. 12 Techniques using Topic Modelling and Word2Vec produced similar outcomes to traditional qualitative methods in a proof-of-concept application in public health research. 13 However, the challenge with transformer methods is that, even more than LDA, the approach is fundamentally opaque (as is the case with most deep learning techniques) and consequently may be subject to slow uptake by the qualitative science community. Indeed, the lack of transparency and poor reproducibility of artificial intelligence (AI)/machine learning (ML) results have led to calls for best practice guidance in AI/ML research. 14
We developed an AI/ML platform to augment qualitative analysis by automating components of qualitative coding—the time-intensive process of matching specific qualitative input into response categories developed by the research team—that avoids the opacity of LDA and Transformer approaches. We further integrated visual analytics into the platform to generate useful, visually appealing data displays to facilitate rapid data exploration and knowledge discovery when analysing large datasets by reducing dimensionality 15 and showing hierarchies within data. 16–18 The objective of this paper is to describe a model methodology for primary care researchers to use our automated qu alitative assistant (AQUA) to augment qualitative coding of large datasets in an effort to broaden the feasibility of large-scale qualitative research.
Qualitative methods for AQUA application
A detailed review of qualitative analytic methods is beyond the scope of this paper. AQUA may be integrated into qualitative design at two stages of analysis. In early analysis, AQUA enables researchers to conduct rapid thematic analysis of large free-text datasets and generate visually interpretable outputs. After human coders analyse a subset of a large qualitative dataset, AQUA may be used to code some thematic categories across the remaining dataset, markedly increasing the scope of analysis a given team may complete. AQUA is designed to analyse free-text answers to survey questions. Careful question design and data collection methods will improve AQUA’s accuracy. An a priori interpretive framework is necessary to maintain the integrity of the qualitative analysis, and care is needed when reporting AQUA-generated results to avoid over-reach and improve generalisability.
Question design and data collection
AQUA capitalises on the epistemological compatibility between text mining and qualitative research. 19 Human-generated text is rife with idiom, non-standard expressions and jargon. AI/ML that works beautifully in a sterile environment may not work when confronted with the gritty reality of human experience. 20 Researchers must, therefore, carefully construct qualitative questions to minimise idiosyncrasies without compromising the goal of open-ended responses. We recommend that draft survey questions be refined using at least 2 rounds of cognitive interviewing procedures using the think-aloud technique, 21 22 followed by pilot testing on a sample of participants from the desired study populations. Throughout this iterative improvement process, questions should be refined to improve answers’ qualitative sensibility and linguistic harmony. Qualitative sensibility ensures that the responses are indeed answering your questions. Linguistic harmony improves AQUA’s ability to properly categorise responses. For population samples markedly different from the researchers, we recommend employing population sample focus groups, which have been used with success in cross-cultural and cross-linguistic analysis. 23
Results interpretation and reporting
We compared coding between a human coding team and AI/ML algorithms by comparing the AI/ML-human intercoder reliability (ICR) to the intrateam ICR of human coders. AI/ML-human ICRs which are substantially lower than the human intra-team ICR indicate that the given data is not easily matched to given categories, and is thus not amenable to automated analysis. ICR is commonly measured using Cohen’s kappa or Krippendorff’s alpha. 24 For simplicity, where it applies we recommend Cohen’s kappa. While there is not universal agreement on a minimum acceptable ICR to indicate clinical utility, it is reasonable to use the interpretation rubric developed by Landis and Koch 25 : values <0 = disagreement, between 0 and 0.20=slight, 0.21–0.40=fair, 0.41–0.60=moderate, 0.61–0.80=substantial and 0.81–1=nearly perfect agreement. Researchers should select a minimum ICR based on the intended use of anticipated results. For example, if using AQUA to code data in a grounded theory study to develop a theory with immediate clinical implications (ie, vaccine distribution), researchers might require ICRs indicating near perfect agreement and set an acceptable ICR cut-off of ≥0.81. Researchers looking to better understand a given populations’ lived experience using a phenomenology design might not wish to miss potential areas of exploration, and therefore include ICRs that indicate substantial, or even moderate agreement, with acceptable ICR cutoffs set at ≥0.61 or ≥0.41, respectively.
Because AI/ML techniques are able to analyse very large sets of data, including dozens of analytic categories, the AI/ML output can include not only single category comparisons, but dozens of topic clusters, all with a wide range of ICRs. To maximise generalisability and reproducibility, it is incumbent on researchers to clearly identify a priori ICR cut-offs and category selection requirements, and when interpreting results avoid any temptation to select category topics simply to increase ICR, or include desired topics by lowering ICR targets post hoc. 26
Researchers must clearly report their a priori interpretation frameworks. If unanticipated results are found that suggest a new direction for study that fall outside this framework, it is reasonable to report these results, with the caveat that they must be identified as a post hoc result, which may be less generalisable. For example, suppose the researchers using the grounded theory design above, with an acceptable ICR cut-off of 0.70, found an interesting coding outcome with an ICR of 0.60. Because that falls outside their a priori framework, they must reject that outcome in their primary results. It would be appropriate, however, to comment that while rejected for this work, the moderate agreement found indicates an area that warrants further study.
Illustrating the application of AQUA
To illustrate the utility of AQUA to primary care researchers analysing large text datasets, we present an exemplar study in which AQUA was used to code free-text responses to a survey about public health recommendations related to COVID-19. 27 28 Figure 1 provides an overview of how AQUA was integrated into qualitative analysis to provide immediate, usable outputs and then enable researchers to code elements from the entire dataset.

Procedural diagram for the application of AQUA to free-text data used in the Illustration. AQUA, automated qualitative assistant.
Data source
The data source was 3148 free-text responses from 538 participants (stratified from 5948 total respondents) who completed a survey to explore the role of trust within information sources related to COVID-19. 27 Six human coders analysed the data using traditional inductive thematic analysis, 29 generating a codebook which identified 11 qualitative categories and 72 subcategories (categories).
Data analysis
Early unsupervised analysis.
AQUA uses two methods to code the raw data using this codebook: a semiclassical approach that replaces LSI/LDA with a graphtheoretic topic extraction and clustering method 12 30 and a more modern transformer method based on BERT-based solutions and top2vec. 31 The graph theoretic method is developed in the spirit of Miller’s parsimonious topic models 32 but with the Bayesian Information Criterion for determining optimal topic clustering replaced by a maximum modularity (ie, spectral 33 ) clustering. 34 We choose these two methods because (i) BERT and top2vec based methods have already been shown to outperform LDA in information theoretic terms while (2) graph theoretic methods lend themselves to visualisation, which is an important element of interpreting data.
The unsupervised clustering approach used is a variation on both LSI 8 and Spectral Clustering, 34 using a maximum modularity subroutine that eliminates the requirement that users choose the number of free-form text response clusters a priori. Responses are clustered into groups with similar linguistic features by creating a response similarity graph and then using maximum modularity clustering to find ‘response communities’ within the graph. Bags of words for each automatically generated response cluster are computed using a word assignment model that minimises mutual information between the bags of words (subject to some constraints). The dimension of vocabulary space is first reduced using a non-linear dimensional reduction method. Specifically, a trimmed term-response matrix is formed by removing common and non-key words. A term-graph is then formed and maximum modularity clustering is used to find an orthogonal topic basis. Graph edges are words comentioned in a response. This process is similar to principal components analysis 35 (or LSI 8 ) but the projection is mediated by the graph clustering step, which handles non-linearity in a similar manner to manifold learning. 36 Hierarchical clustering is then performed by iteratively executing the unsupervised clustering procedure for each individual response community so that the linguistic diversity of each subtopic can be preserved.
Analysis of AQUA’s coding accuracy
Supervised word/phrase assignment of words to response clusters (eg, human or machine-created code categories) is accomplished by solving a linear assignment problem 37 of words/phrases to preclustered response groups. The assignment problem minimises a linearised version of the mutual information between text clusters (in word/phrase space) resulting in a parsimonious weighted assignment of words/phrases to responses. These words/phrases characterise the underlying language within the response groups (code categories). The weighted bag of words were then used to assign new text to one of the pre-existing categories.
Unlike traditional machine-learning processes where the algorithm trains on 90% of the dataset and tests on 10% of the dataset, we trained on much smaller dataset subsets. This is because human coding is time-expensive and we sought to develop algorithmic robustness to perform well using small training datasets. AQUA was tasked with coding the raw data. Item codes were assigned using cosine-similarity on text in the response and the weighted bag of words identified during the supervised learning process. In using this approach, we relied on the fact that text is highly separable 38 and adapted the graph-theoretic methods that underlie our initial methods as a graph-based manifold regularisation approach 39 (in a semisupervised context).
Summary of analysis
Unsupervised clustering and topic selection were used to identify areas of importance to survey respondents and relationships between responses. Highly accurate coding categories by AQUA were identified for further automated analysis. To evaluate the accuracy of AQUA’s coding, a human coding team first coded the same data using the same codebook. The human team had an intrateam ICR using Cohen’s kappa of ≥0.65 among six human coders (two coders per response). For an AQUA-coded topic to be accepted, we set the AQUA-human ICR cut-off at ≥0.65 (at least as good as the intrahuman team ICR). Categories and clusters of categories with AQUA-human ICRs ≥0.65 were deemed suitable for AQUA coding of the entire dataset (over 35 000 free-text responses from 5948 respondents 28 ).
AQUA generated a circle hierarchy of free-text responses and also seven unsupervised topics ( figure 2 ). This enabled rapid assessments of key issues important to survey participants, and also identified relationships between responses in an easy-to-read circle hierarchy.

Unsupervised clustering (circle hierarchy) of survey responses. (A) Circles represent a linguistic community or topic. Nested circles represent hierarchical organisation. The smallest circles are individual survey responses. The seven parent unsupervised topics are labeled. (B) Parent unsupervised topics.
AQUA’s kappa for coding all categories was low (kappa ~0.45), reflecting the challenge of automated analysis of diverse language. However, for several three-category combinations (with less linguistic diversity), AQUA performed comparably to human coders, with an ICR kappa range of 0.66 to 0.72 based on test-train split ( table 1 ; see online supplemental material for all three-category results.) AQUA may appropriately be applied to the entire dataset for categories and groups of categories with AQUA-human ICRs ≥0.65. Figure 3 shows the relationship between automatically generated message clusters (topics) and manually coded categories.
Kappa values evaluating the inter-rater reliability (agreement) between human coders and supervised training of three-topic training models
Topic labels are: (1) distrust, (2) media messaging, (3) trusted sources of information, (4) personal medical concerns, (5) family concerns, (6) societal concerns, (7) barriers to recommendations, (8) no worries, (9) other Broad.

Human-coded topics (rows) are compared with unsupervised topic communities (columns). Each row depicts the distribution of responses for each humancoded topic across unsupervised topic communities. The heat chart to the right shows the gradient color scheme for percent-agreement (darker is better agreement).
Supplementary data
A secondary result was the time spent by AQUA (including human interpretation of AQUA’s results) compared with the time spent by human coders. The human coding team spent approximately 30 person-hours to complete their traditional coding. All results generated by AQUA (including human interpretation) took approximately 5 hours.
This study demonstrates the feasibility of using AI methods to augment certain kinds of qualitative research. Like current exploratory NLP applications, AQUA offers coding capability beyond was is available in current CAQDAS applications. The primary benefit of the AQUA platform over current exploratory NLP applications 5 6 is the transparency of the graph theoretic approach, which avoids the opacity inherent to NLP based on LDA or Transformer methods. 11 Results of our study suggest that graph-theoretic methods are well suited to augment qualitative researchers during coding, and when integrated into a data visualisation and statistical comparison programme offers qualitative researchers a powerful assistant to enable rapid, rigorous, analysis of large, qualitative datasets.
Unsupervised applications of AQUA offer immediate topic generation and a circle hierarchy of responses which enables rapid analysis without time-intensive human coding. If human coding is completed on a subset of data, for coding categories or clusters of categories in which AQUA’s ICR meets a priori ICR cutoffs, AQUA may then be applied to those categories across the entire dataset. In the illustration, human coding time to code 3148 free-text responses from a stratified samples of 538 respondents enabled AQUA to code over 35 000 free-text responses from the entire pool of 5948 respondents for certain categories and category clusters—a 10-fold increase in coding power.
Train-test splits of 20%–80% appear adequate to achieve ICR >0.7 for certain combinations of topics. Variance of kappas by subtopic is not unexpected; categories of inquiry that themselves use complex linguistic patterns, or whose associated raw text to be coded to that category use complex linguistic patterns, will be more challenging for AI/ML algorithms to match human ability. Our kappa range of 0.66–0.72 represents ‘substantial agreement’ under Landis and Koch’s rubric. 25 For particularly challenging datasets or discovery applications, lower ICRs may be acceptable. For example, a combination of topics with an ICR of 0.45 (moderate agreement) might not suggest changes to clinical practice, but might serve as a valuable indicator of where to direct future research or conduct additional human analysis. While the generalisability of results may vary with the ‘acceptable’ ICR, as noted above, the integrity of qualitative analysis may be maintained by reliance on systematic application of an a priori interpretive framework. 26
We also caution against researchers modifying their category selection to boost kappas using AQUA (or any other AI/ML technique). While it is certainly appropriate to be precise in category descriptions, it is incumbent on the researcher to match the technique to the data, and not vice versa. Some categories or their answers may simply not be amenable to augmentation using this technique. Further, it is important to appreciate that coding accuracy is necessary but insufficient for interpretation. While qualitative models will continue to evolve, incorporating increasingly sophisticated AI/ML algorithms, the heart of interpretation and sensibility lies in human interpretation.
Contribution to family medicine and community health research and future directions
AQUA’s use of a graph-theoretic approach advances the theory of AI/ML in clinical research. Our methods advance researchers’ approach to AI/ML applications in qualitative research, and are particularly useful for very large datasets on which some level of qualitative analysis is already completed. Once a set of category coding is validated on a sample, AQUA enables researchers to rapidly conduct mixed methods analysis on the entirety of the dataset.
In addition to facilitating greater analysis of other existing survey data, the platform and methods may be applied to any set of text data, such as social media posts. This offers researchers a method of rapid and in-depth assessment of any subject of interest and moment, which may improve scientific recommendations, in turn improving policy decisions. The next steps in advancing the AQUA platform are to verify its accuracy across other existing free-text surveys and social media platforms.
Limitations
Limitations of AQUA include that its augmentation focuses on supporting free-text analysis, which may not translate to other areas of qualitative research. Our testing of the AQUA approach is limited to a single dataset, which has unique features that may not be present in other large qualitative datasets. Another limitation is that qualitative analysis is still required on a sample of a larger dataset in order to calibrate AQUA and confirm its kappa, and is also required to generate the categories for coding in order to compare the AQUA-human ICR with the human team’s ICR. Finally, AQUA is not able to match human ICRs for some categories; to analyse those categories across the entire dataset, human teams must still do the coding.
Partial automation of qualitative research studies enables researchers to conduct rigorous, rapid studies that more easily incorporate the many benefits of qualitative research. Further research is needed to determine the extent to which AQUA may be applied to other qualitative data, and the extent to which the algorithms used to augment coding may also be used to augment category development.
Acknowledgments
Without the assistance of the following individuals and groups, the scope and scale of this project would not have been possible. We thank Cletis Earle, Susan Chobanoff, Neal Thomas, Leslie Parent, Sarah Bronson, Heather Stuckey-Peyrot and the rest of the Penn State Qualitative Mixed Methods Core team at Penn State.
Contributors: RPL (guarantor): conceptualisation, funding acquisition, methodology, visualisation, supervision, project administration, writing-review and editing. LJVS: conceptualisation, methodology, visualisation, supervision, writing-review and editing. RF: conceptualisation, methodology, investigation, formal analysis, software, visualisation, writing-review and editing. AK: visualisation, software, writing-review and editing. XCH: visualisation, software, writing-review and editing. BLS: methodology, writing-review and editing. ELM: methodology, data curation, writing-review and editing. WAC: formal analysis, writing-review and editing. AEZ: supervision, writing-review and editing. CG: conceptualisation, methodology, investigation, formal analysis, software, supervision, visualisation, writing-review and editing.
Funding: The dataset used in this work was developed with the support of the Huck Institutes of the Life Sciences (grant number 7601); the Social Science Research Institute at Penn State University (grant number 7601); and the Department of Family and Community Medicine at Penn State College of Medicine (grant number 7601-M). CG’s and RF’s work were supported by the Huck Institute of Life Sciences. Portions of CG’s work were supported by the Defense Advanced Research Project’s Agency SCORE programme (Cooperative Agreement W911NF-19-0272).
Competing interests: None declared.
Provenance and peer review: Not commissioned; externally peer reviewed.
Supplemental material: This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.
Data availability statement
Ethics statements, patient consent for publication.
Not applicable.
SenseMate: an AI-based platform to support qualitative coding
Creative Commons
Attribution-ShareAlike 4.0 International
MIT Center for Constructive Communication
Project Contact:
- Cassandra Overney
- [email protected]
- Other Press Inquiries
- Media Lab Research Theme: Life with AI
Many community organizations want to engage in conversations with their constituents but lack the support they need to analyze feedback. Most of the time, these organizations either outsource the analysis, which is expensive and distances decision-making from community members, complete a superficial reading of the data, or let the data collect dust and never uplift the stories that people shared.
We first became aware of this problem while collaborating with Charlotte-Mecklenburg Schools (CMS), a school district in North Carolina, to gather people’s stories and feedback around two new magnet schools. One of the major challenges we faced was when we tried to analyze all of the data. Our partners in CMS were passionate about creating magnet programs grounded in community voices but had no experience in qualitative data analysis (QDA), or sensemaking . With help from expert sensemakers, we were able to examine the data, which involved creating a codebook, or a list of themes, from a subset of our data and then applying the codebook to the rest of our data through a process called qualitative coding.
Not all organizations can work closely with expert sensemakers for every community engagement initiative they launch. As a result, we aim to create accessible entry points into sensemaking for people with no prior experience. We plan to apply machine learning and human-centered design methods to create, and then evaluate, a platform that helps non-expert sensemakers conduct qualitative coding, or apply a codebook to their entire dataset. We focus on this phase of sensemaking because it is one of the most time-consuming and tedious parts of the analysis process. Our goal is to reduce the amount of time it takes to code a sample of community conversations while improving the overall coding reliability.

Research Topics
How AI can revolutionise the way we analyse student surveys
Student surveys provide a potential goldmine of data. Kirsty Bryant suggests deploying AI to maximise your insight

Kirsty Bryant

Created in partnership with

You may also like

Popular resources
.css-1txxx8u{overflow:hidden;max-height:81px;text-indent:0px;} Emotions and learning: what role do emotions play in how and why students learn?
A diy guide to starting your own journal, universities, ai and the common good, artificial intelligence and academic integrity: striking a balance, create an onboarding programme for neurodivergent students.
At the University of Westminster, we have been thematically analysing open comments from student surveys for several years. This academic year marks a change for us as we employ AI to help us in analysing student and staff qualitative feedback.
In previous years, we have manually conducted a thematic analysis of about 3,000 students per year, developing themes and uncovering patterns in the open comments response. This was a long and laborious task – especially in comparison with quantitative data, which is often received very rapidly by decision-makers.
- Can academics tell the difference between AI-generated and human-authored content?
- How hard can it be? Testing the dependability of AI detection tools
- Go head-to-head with ChatGPT to enhance your students’ personal learning
This year, we have implemented cutting-edge machine learning software that enables us to process open comments responses and provide insights much faster. We are one of the first UK universities to analyse the results of the National Student Survey (NSS) using AI software ( MLY provided by Explorance ), leading to better insights into enhancing student experience.
We’re still early on in our journey with AI, but here is what we’ve learned so far.
Good output relies on good input
AI models available on the market have been trained on relevant data and feedback. If you are seeking to build your own model, or to purchase a model, be mindful that AI systems rely on large amounts of data to learn and perform well – but not all existing data is reliable, valid or representative. For example, student feedback surveys may have low response rates, missing values or leading question wording that affect the accuracy and usefulness of an AI model. Question wording that is leading can also impact the usefulness of an AI model.
To make the most of your input, consider the phrasing of your questions and how they might influence the answers. For instance, “Could you tell us one thing you liked and one thing you didn’t like?” Possible responses might be:
⦁ “Classrooms, quality of teaching”
⦁ “I enjoyed the teaching but didn’t like the classroom.”
Based on the above responses, an AI model may identify themes for the first response (but not likes or dislikes) and sentiments for the second response. You will likely get a more accurate sentiment and theme analysis by ensuring that one question is asked at a time. Changing the wording to “Tell us about your experience” ensures the respondent is providing the sentiment and meaning behind their response (ie, “I enjoyed X, but didn’t like Y”) which the AI can code.
Additionally, your survey data may require a process of cleaning to remove jargon or non-responses (such as “N/A”) in your text. This will help you to ensure accuracy and reliability in your analysis. The output can only be as good as the input.
Combine your AI analysis with human input and validation
While AI can provide you with many insights from your students’ comments, it cannot replace the human judgement and expertise needed to interpret and act on them.
We decided to purchase AI because we wanted to build on our qualitative analysis capabilities and knowledge. Our institutional research teams’ skill set in thematic analysis, prior knowledge of datasets and experience in inductive and deductive thematic analysis provides our source of human input, interrogation and validation of the AI analysis.
We can spot discrepancies between human interpretation and AI interpretation and feed back into the AI model. For example, a human can read into sarcasm in texts whereas AI cannot. The AI model currently only understands what it has already seen (eg, deductive coding) and relies on being taught themes, but humans are capable of inductive coding and can spot new themes.
You should always review your AI results with a critical eye. Consult with other stakeholders to make sure that your new insight can be actioned in line with your institution’s key priorities. Be careful to identify which department can action what insight, and whether that might be an academic or non-academic concern – responses about heating, cafeteria options or accommodation would fall into the latter, for example.
Also, think about whether these action points are quick wins for a team or important to the institution as a whole. If talks with stakeholders confirm they are neither, then move on to the actions that are.
Make the most of AI’s capabilities
The AI gives us a greater capacity. We can run all our major surveys (student surveys and colleague surveys) through this system, enabling us to be more responsive, where we can identify in-year issues and react quickly.
Bringing in the qualitative data from all our major surveys means we will have the capacity to map different levels of study or different time periods, allowing us to identify patterns and trends. We can segment the data to better understand different student user journeys and develop measures to create a successful experience for all our students. For example, separating out the experiences of those who have been on placements versus those who haven’t, or pre- and post-placement groupings, can show us how they each self-report on their student experience, education and learning gains, and any differences between their responses.
We can now share high-level analysis of the open comments almost as quickly as we currently deliver the quantitative counterparts of our surveys.
However, without action and accountability, the development of this analysis will not realise its potential. A culture shift in listening to qualitative insight and actioning the insight is required. Stakeholders must buy in to make the most of the use of AI and its outcomes. If this is achieved, we might expect to see a change in future survey results as the impact of these changes is realised.
Kirsty Bryant is senior institutional research analyst at the University of Westminster.
If you would like advice and insight from academics and university staff delivered direct to your inbox each week, sign up for the Campus newsletter .
Emotions and learning: what role do emotions play in how and why students learn?
Global perspectives: navigating challenges in higher education across borders, how to help young women see themselves as coders, contextual learning: linking learning to the real world, authentic assessment in higher education and the role of digital creative technologies, how hard can it be testing ai detection tools.
Register for free
and unlock a host of features on the THE site
IMAGES
VIDEO
COMMENTS
AI-Powered Qualitative Data Analysis Solutions. ABOUT; RESEARCHERS; ORGANIZATIONS; students; CODE Code your qualitative data based on the in vivo coding technique. THEMATIC ANALYSIS Conduct a thematic analysis of your qualitative data. DEMO; ... QualAI helps organizations with market research, consumer analysis, business development, data ...
AI is Transforming Qualitative Research Coding. Discover the significance of coding in qualitative research, explore traditional methods, and witness the transformative impact of AI. Coding transforms raw data into meaningful insights, the cornerstone of any research endeavor. As the research field progresses, we find ourselves at the cusp of a ...
A smarter way to betterresearch findings. Analyze what you want, the way you want. ATLAS.ti removes the headache from qualitative data analysis and lets the software do the heavy lifting. Generate deep insights automatically, leveraging the latest AI and machine learning algorithms for faster results.
Jiang et al., studied human-AI interaction in qualitative research. They pointed out another possible limitation: researchers might be reluctant to have AI to eliminate the "uncertainty" from their research efforts. ... Semi-automated coding for qualitative research: A user-centered inquiry and initial prototypes. In Proceedings of the 2018 CHI ...
Prior to ChatGPT, the most extensive use of AI in qualitative data analysis was the implementation of Natural Language Processing in various versions of software packages (see overview in Silver, 2023).For example, two common features in these packages are sentiment analysis (the ability to detect positive or negative content in text segments) and semantic coding (a form of content analysis).
Prior to the widespread availability of AI platforms, Lennon et al. (2021) developed and tested an automated qualitative assistant (AQUA) software tool based on NLP to automate coding and analysis of qualitative data. The data was derived from open free text responses to a survey and use the software to undertake a rapid descriptive thematic analysis, an approach that presents a thematic ...
You can automate the coding of your qualitative data with thematic analysis software. Thematic analysis and qualitative data analysis software use machine learning, artificial intelligence (AI), and natural language processing (NLP) to code your qualitative data and break text up into themes. Thematic analysis software is autonomous, which ...
The first CAQDAS-package to include real assistance - i.e. beyond searching for words/phrases and auto-coding the hits - came around 15 years into the CAQDAS-history, ... CoLoop is an "AI Copilot" for qualitative research that allows the user to ask questions of the data using AI prompts using a "chat" function. This can be used to ...
Think of it as your personal research assistant: AI Coding Beta generates fully automated code proposals while allowing you to review and refine results quickly - ensuring 100% transparency and human supervision. Your key benefits: Reduce your overall data analysis time by up to 90% ⏱️.
Human-only coding of 9,673 paragraphs achieved an ICA of α = 0.80. The "hybrid" strategy, which involved coding 2,418 paragraphs for BERT training and human review of an additional 1,471 paragraphs that the machine coded with less confidence, achieved the highest reliability (F-1 = 0.88) with a total of 3,889 paragraphs coded.
Each of these AI systems showcases the capability of AI to aid qualitative researchers in expediting the coding process and minimizing human effort [18,24,28,45], but only on specific phases of ...
Further, little is known about the interaction of researchers with AI-based coding assistance. We introduce Cody, an AI-based system that semi-automates coding through code rules and supervised ML. ... Semi-automated coding for Qualitative research: A user-centered inquiry and initial prototypes. In Proceedings of the Conference on Human ...
Qualitative Data Analysis (QDA) is an approach used in Human-Computer Interaction (HCI) research to analyze unstructured data, such as interview data or responses to open-ended survey questions.A fundamental step in QDA is coding, the systematic process of identifying, annotating, and categorizing data segments based on recurring themes and patterns, and assigning according categories or ...
CRISbot ( Conversational Research Insight System, no less) is a virtual moderator that uses AI to conduct text-based interviews through a chat interface. It collects both qualitative and quantitative data through a web-based messaging platform. Results are reported automatically in an online dashboard that includes a full summary report, survey ...
AI Coding. One of the most exciting implications of recent advances in artificial intelligence is its potential for facilitating the research process, especially in qualitative research. The use of machine learning to understand the salient points in data can be especially useful to researchers in all fields.
Intellectus Qualitative empowers researchers to seamlessly conduct qualitative research with ease. We keep things simple by providing step-by-step guidance in coding data, creating themes, and generating a comprehensive summary document. Going beyond the basics, our advanced AI components assist users in naming and describing themes and ...
Step 1 - Initial coding. The first step of the coding process is to identify the essence of the text and code it accordingly. While there are various qualitative analysis software packages available, you can just as easily code textual data using Microsoft Word's "comments" feature.
Qualitative research remains underused, in part due to the time and cost of annotating qualitative data (coding). Artificial intelligence (AI) has been suggested as a means to reduce those burdens, and has been used in exploratory studies to reduce the burden of coding.
SenseMate: an AI-based platform to support qualitative coding was active from September 2022 to May 2023. Many community organizations want to engage in conversations with their constituents but lack the support they need to analyze feedback. Most of the time, these organizations either outsource the analysis, which is expensive and distances ...
We highlight two intertwined concerns about interpretive sufficiency in qualitative analysis. Software for qualitative data analysis has been in use since at least the early 1980s.5 For instance, both ATLAS.ti and NVivo (among others) allow automated coding by structure, style or existing coding patterns. However, the incorporation of GAI into ...
This can be achieved by adding a predefined pseudo code say, "failure cases" in the original coding scheme. Once the AI is run on the data, ... While use of AI can make qualitative research more efficient, explicatory, and equitable, there are two pitfalls that need to be underscored. First, AI is a tool to enhance researcher's ...
between AI and theory development, and presents key considerations for the. use of AI in the creation of new theories or the advancement of existing ones. Though the necessity of AI tools in ...
We decided to purchase AI because we wanted to build on our qualitative analysis capabilities and knowledge. Our institutional research teams' skill set in thematic analysis, prior knowledge of datasets and experience in inductive and deductive thematic analysis provides our source of human input, interrogation and validation of the AI analysis.
Larry Ellison, chairman and CTO of Oracle: "Oracle's close collaboration with NVIDIA will enable qualitative and quantitative breakthroughs in AI, machine learning and data analytics. In order for customers to uncover more actionable insights, an even more powerful engine like Blackwell is needed, which is purpose-built for accelerated ...
Released in November of 2022, ChatGPT is an artificial intelligence (AI) chatbot that can understand and generate human-like language. The responses are generated using data collected using Reinforcement Learning with Human Feedback (RLHF), which utilizes human feedback to distinguish which response would be most preferable according to the conversation.
Johnny Saldaña - Methods of Coding Qualitative Data (August 29-30, 2024) - 2 Day Workshop Johnny Saldaña - An Introduction to Thematic Analysis (October 1, 2024) Autoethnographic Storytelling in Qualitative Research - Carolyn Ellis and Arthur Bochner - January 15, 2025