
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25

A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- What Is Quantitative Research? | Definition & Methods
What Is Quantitative Research? | Definition & Methods
Published on 4 April 2022 by Pritha Bhandari . Revised on 10 October 2022.
Quantitative research is the process of collecting and analysing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalise results to wider populations.
Quantitative research is the opposite of qualitative research , which involves collecting and analysing non-numerical data (e.g. text, video, or audio).
Quantitative research is widely used in the natural and social sciences: biology, chemistry, psychology, economics, sociology, marketing, etc.
- What is the demographic makeup of Singapore in 2020?
- How has the average temperature changed globally over the last century?
- Does environmental pollution affect the prevalence of honey bees?
- Does working from home increase productivity for people with long commutes?
Table of contents
Quantitative research methods, quantitative data analysis, advantages of quantitative research, disadvantages of quantitative research, frequently asked questions about quantitative research.
You can use quantitative research methods for descriptive, correlational or experimental research.
- In descriptive research , you simply seek an overall summary of your study variables.
- In correlational research , you investigate relationships between your study variables.
- In experimental research , you systematically examine whether there is a cause-and-effect relationship between variables.
Correlational and experimental research can both be used to formally test hypotheses , or predictions, using statistics. The results may be generalised to broader populations based on the sampling method used.
To collect quantitative data, you will often need to use operational definitions that translate abstract concepts (e.g., mood) into observable and quantifiable measures (e.g., self-ratings of feelings and energy levels).
Prevent plagiarism, run a free check.
Once data is collected, you may need to process it before it can be analysed. For example, survey and test data may need to be transformed from words to numbers. Then, you can use statistical analysis to answer your research questions .
Descriptive statistics will give you a summary of your data and include measures of averages and variability. You can also use graphs, scatter plots and frequency tables to visualise your data and check for any trends or outliers.
Using inferential statistics , you can make predictions or generalisations based on your data. You can test your hypothesis or use your sample data to estimate the population parameter .
You can also assess the reliability and validity of your data collection methods to indicate how consistently and accurately your methods actually measured what you wanted them to.
Quantitative research is often used to standardise data collection and generalise findings . Strengths of this approach include:
- Replication
Repeating the study is possible because of standardised data collection protocols and tangible definitions of abstract concepts.
- Direct comparisons of results
The study can be reproduced in other cultural settings, times or with different groups of participants. Results can be compared statistically.
- Large samples
Data from large samples can be processed and analysed using reliable and consistent procedures through quantitative data analysis.
- Hypothesis testing
Using formalised and established hypothesis testing procedures means that you have to carefully consider and report your research variables, predictions, data collection and testing methods before coming to a conclusion.
Despite the benefits of quantitative research, it is sometimes inadequate in explaining complex research topics. Its limitations include:
- Superficiality
Using precise and restrictive operational definitions may inadequately represent complex concepts. For example, the concept of mood may be represented with just a number in quantitative research, but explained with elaboration in qualitative research.
- Narrow focus
Predetermined variables and measurement procedures can mean that you ignore other relevant observations.
- Structural bias
Despite standardised procedures, structural biases can still affect quantitative research. Missing data , imprecise measurements or inappropriate sampling methods are biases that can lead to the wrong conclusions.
- Lack of context
Quantitative research often uses unnatural settings like laboratories or fails to consider historical and cultural contexts that may affect data collection and results.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to test a hypothesis by systematically collecting and analysing data, while qualitative methods allow you to explore ideas and experiences in depth.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organisations.
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research , you also have to consider the internal and external validity of your experiment.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, October 10). What Is Quantitative Research? | Definition & Methods. Scribbr. Retrieved 2 April 2024, from https://www.scribbr.co.uk/research-methods/introduction-to-quantitative-research/
Is this article helpful?

Pritha Bhandari
Quantitative Data Analysis 101
The lingo, methods and techniques, explained simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020
Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo , like medians, modes, correlation and regression. Suddenly we’re all wishing we’d paid a little more attention in math class…
The good news is that while quantitative data analysis is a mammoth topic, gaining a working understanding of the basics isn’t that hard , even for those of us who avoid numbers and math . In this post, we’ll break quantitative analysis down into simple , bite-sized chunks so you can approach your research with confidence.

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones.
But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.
Don’t be a sucker – give your descriptive statistics the love and attention they deserve!

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

Of course, when you’re working with inferential statistics, the composition of your sample is really important. In other words, if your sample doesn’t accurately represent the population you’re researching, then your findings won’t necessarily be very useful.
For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post .
What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other.
Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.
Here’s a scatter plot demonstrating the correlation (relationship) between weight and height. Intuitively, we’d expect there to be some relationship between these two variables, which is what we see in this scatter plot. In other words, the results tend to cluster together in a diagonal line from bottom left to top right.

As I mentioned, these are are just a handful of inferential techniques – there are many, many more. Importantly, each statistical method has its own assumptions and limitations.
For example, some methods only work with normally distributed (parametric) data, while other methods are designed specifically for non-parametric data. And that’s exactly why descriptive statistics are so important – they’re the first step to knowing which inferential techniques you can and can’t use.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Why does this matter?
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
This is another reminder of why descriptive statistics are so important – they tell you all about the shape of your data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Psst… there’s more (for free)
This post is part of our dissertation mini-course, which covers everything you need to get started with your dissertation, thesis or research project.
You Might Also Like:
")
74 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Research Questions & Hypotheses
Generally, in quantitative studies, reviewers expect hypotheses rather than research questions. However, both research questions and hypotheses serve different purposes and can be beneficial when used together.
Research Questions
Clarify the research’s aim (farrugia et al., 2010).
- Research often begins with an interest in a topic, but a deep understanding of the subject is crucial to formulate an appropriate research question.
- Descriptive: “What factors most influence the academic achievement of senior high school students?”
- Comparative: “What is the performance difference between teaching methods A and B?”
- Relationship-based: “What is the relationship between self-efficacy and academic achievement?”
- Increasing knowledge about a subject can be achieved through systematic literature reviews, in-depth interviews with patients (and proxies), focus groups, and consultations with field experts.
- Some funding bodies, like the Canadian Institute for Health Research, recommend conducting a systematic review or a pilot study before seeking grants for full trials.
- The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility.
- It’s advisable to focus on a single primary research question for the study.
- The primary question, clearly stated at the end of a grant proposal’s introduction, usually specifies the study population, intervention, and other relevant factors.
- The FINER criteria underscore aspects that can enhance the chances of a successful research project, including specifying the population of interest, aligning with scientific and public interest, clinical relevance, and contribution to the field, while complying with ethical and national research standards.
- The P ICOT approach is crucial in developing the study’s framework and protocol, influencing inclusion and exclusion criteria and identifying patient groups for inclusion.
- Defining the specific population, intervention, comparator, and outcome helps in selecting the right outcome measurement tool.
- The more precise the population definition and stricter the inclusion and exclusion criteria, the more significant the impact on the interpretation, applicability, and generalizability of the research findings.
- A restricted study population enhances internal validity but may limit the study’s external validity and generalizability to clinical practice.
- A broadly defined study population may better reflect clinical practice but could increase bias and reduce internal validity.
- An inadequately formulated research question can negatively impact study design, potentially leading to ineffective outcomes and affecting publication prospects.
Checklist: Good research questions for social science projects (Panke, 2018)
Research Hypotheses
Present the researcher’s predictions based on specific statements.
- These statements define the research problem or issue and indicate the direction of the researcher’s predictions.
- Formulating the research question and hypothesis from existing data (e.g., a database) can lead to multiple statistical comparisons and potentially spurious findings due to chance.
- The research or clinical hypothesis, derived from the research question, shapes the study’s key elements: sampling strategy, intervention, comparison, and outcome variables.
- Hypotheses can express a single outcome or multiple outcomes.
- After statistical testing, the null hypothesis is either rejected or not rejected based on whether the study’s findings are statistically significant.
- Hypothesis testing helps determine if observed findings are due to true differences and not chance.
- Hypotheses can be 1-sided (specific direction of difference) or 2-sided (presence of a difference without specifying direction).
- 2-sided hypotheses are generally preferred unless there’s a strong justification for a 1-sided hypothesis.
- A solid research hypothesis, informed by a good research question, influences the research design and paves the way for defining clear research objectives.
Types of Research Hypothesis
- In a Y-centered research design, the focus is on the dependent variable (DV) which is specified in the research question. Theories are then used to identify independent variables (IV) and explain their causal relationship with the DV.
- Example: “An increase in teacher-led instructional time (IV) is likely to improve student reading comprehension scores (DV), because extensive guided practice under expert supervision enhances learning retention and skill mastery.”
- Hypothesis Explanation: The dependent variable (student reading comprehension scores) is the focus, and the hypothesis explores how changes in the independent variable (teacher-led instructional time) affect it.
- In X-centered research designs, the independent variable is specified in the research question. Theories are used to determine potential dependent variables and the causal mechanisms at play.
- Example: “Implementing technology-based learning tools (IV) is likely to enhance student engagement in the classroom (DV), because interactive and multimedia content increases student interest and participation.”
- Hypothesis Explanation: The independent variable (technology-based learning tools) is the focus, with the hypothesis exploring its impact on a potential dependent variable (student engagement).
- Probabilistic hypotheses suggest that changes in the independent variable are likely to lead to changes in the dependent variable in a predictable manner, but not with absolute certainty.
- Example: “The more teachers engage in professional development programs (IV), the more their teaching effectiveness (DV) is likely to improve, because continuous training updates pedagogical skills and knowledge.”
- Hypothesis Explanation: This hypothesis implies a probable relationship between the extent of professional development (IV) and teaching effectiveness (DV).
- Deterministic hypotheses state that a specific change in the independent variable will lead to a specific change in the dependent variable, implying a more direct and certain relationship.
- Example: “If the school curriculum changes from traditional lecture-based methods to project-based learning (IV), then student collaboration skills (DV) are expected to improve because project-based learning inherently requires teamwork and peer interaction.”
- Hypothesis Explanation: This hypothesis presumes a direct and definite outcome (improvement in collaboration skills) resulting from a specific change in the teaching method.
- Example : “Students who identify as visual learners will score higher on tests that are presented in a visually rich format compared to tests presented in a text-only format.”
- Explanation : This hypothesis aims to describe the potential difference in test scores between visual learners taking visually rich tests and text-only tests, without implying a direct cause-and-effect relationship.
- Example : “Teaching method A will improve student performance more than method B.”
- Explanation : This hypothesis compares the effectiveness of two different teaching methods, suggesting that one will lead to better student performance than the other. It implies a direct comparison but does not necessarily establish a causal mechanism.
- Example : “Students with higher self-efficacy will show higher levels of academic achievement.”
- Explanation : This hypothesis predicts a relationship between the variable of self-efficacy and academic achievement. Unlike a causal hypothesis, it does not necessarily suggest that one variable causes changes in the other, but rather that they are related in some way.
Tips for developing research questions and hypotheses for research studies
- Perform a systematic literature review (if one has not been done) to increase knowledge and familiarity with the topic and to assist with research development.
- Learn about current trends and technological advances on the topic.
- Seek careful input from experts, mentors, colleagues, and collaborators to refine your research question as this will aid in developing the research question and guide the research study.
- Use the FINER criteria in the development of the research question.
- Ensure that the research question follows PICOT format.
- Develop a research hypothesis from the research question.
- Ensure that the research question and objectives are answerable, feasible, and clinically relevant.
If your research hypotheses are derived from your research questions, particularly when multiple hypotheses address a single question, it’s recommended to use both research questions and hypotheses. However, if this isn’t the case, using hypotheses over research questions is advised. It’s important to note these are general guidelines, not strict rules. If you opt not to use hypotheses, consult with your supervisor for the best approach.
Farrugia, P., Petrisor, B. A., Farrokhyar, F., & Bhandari, M. (2010). Practical tips for surgical research: Research questions, hypotheses and objectives. Canadian journal of surgery. Journal canadien de chirurgie , 53 (4), 278–281.
Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D., & Newman, T. B. (2007). Designing clinical research. Philadelphia.
Panke, D. (2018). Research design & method selection: Making good choices in the social sciences. Research Design & Method Selection , 1-368.

- Teesside University Student & Library Services
- Learning Hub Group
Quantitative data collection and analysis
- Testing hypotheses
- Quantitative data collection
- Averages and percentiles
- Measures of Spread or Dispersion
- Samples and population
- Statistical tests - parametric
- Statistical tests - non-parametric
- Probability
- Reliability and Validity
- Analysing relationships
- Useful Books
Testing Hypotheses
- What is a hypothesis?
- Significance testing
- One-tailed or two-tailed?
- Degrees of freedom
A hypothesis is a statement that we are trying to prove or disprove. It is used to express the relationship between variables and whether this relationship is significant. It is specific and offers a prediction on the results of your research question.
Your research question will lead you to developing a hypothesis, this is why your research question needs to be specific and clear.
The hypothesis will then guide you to the most appropriate techniques you should use to answer the question. They reflect the literature and theories on which you basing them. They need to be testable (i.e. measurable and practical).
Null hypothesis (H 0 ) is the proposition that there will not be a relationship between the variables you are looking at. i.e. any differences are due to chance). They always refer to the population. (Usually we don't believe this to be true.)
e.g. There is no difference in instances of illegal drug use by teenagers who are members of a gang and those who are not..
Alternative hypothesis (H A ) or ( H 1 ): this is sometimes called the research hypothesis or experimental hypothesis. It is the proposition that there will be a relationship. It is a statement of inequality between the variables you are interested in. They always refer to the sample. It is usually a declaration rather than a question and is clear, to the point and specific.
e.g. The instances of illegal drug use of teenagers who are members of a gang is different than the instances of illegal drug use of teenagers who are not gang members.
A non-directional research hypothesis - reflects an expected difference between groups but does not specify the direction of this difference (see two-tailed test).
A directional research hypothesis - reflects an expected difference between groups but does specify the direction of this difference. (see one-tailed test)
e.g. The instances of illegal drug use by teenagers who are members of a gang will be higher t han the instances of illegal drug use of teenagers who are not gang members.
Then the process of testing is to ascertain which hypothesis to believe.
It is usually easier to prove something as untrue rather than true, so looking at the null hypothesis is the usual starting point.
The process of examining the null hypothesis in light of evidence from the sample is called significance testing . It is a way of establishing a range of values in which we can establish whether the null hypothesis is true or false.
The debate over hypothesis testing
There has been discussion over whether the scientific method employed in traditional hypothesis testing is appropriate.
See below for some articles that discuss this:
- Gill, J. (1999) 'The insignificance of null hypothesis testing', Politics Research Quarterly , 52(3), pp. 647-674 .
- Wainer, H. and Robinson, D.H. (2003) 'Shaping up the practice of null hypothesis significance testing', Educational Researcher, 32(7), pp.22-30 .
- Ferguson, C.J. and Heener, M. (2012) ' A vast graveyard of undead theories: publication bias and psychological science's aversion to the null' , Perspectives on Psychological Science, 7(6), pp.555-561 .
Taken from: Salkind, N.J. (2017) Statistics for people who (think they) hate statistics. 6th edn. London: SAGE pp. 144-145.
- Null hypothesis - a simple introduction (SPSS)
A significance level defines the level when your sample evidence contradicts your null hypothesis so that your can then reject it. It is the probability of rejecting the null hypothesis when it is really true.
e.g. a significance level of 0.05 indicates that there is a 5% (or 1 in 20) risk of deciding that there is an effect when in fact there is none.
The lower the significance level that you set, then the evidence from the sample has to be stronger to be able to reject the null hypothesis.
N.B. - it is important that you set the significance level before you carry out your study and analysis.
Using Confidence Intervals
I t is possible to test the significance of your null hypothesis using Confidence Interval (see under samples and populations tab).
- if the range lies outside our predicted null hypothesis value we can reject it and accept the alternative hypothesis
The test statistic
This is another commonly used statistic
- Write down your null and alternative hypothesis
- Find the sample statistic (e.g.the mean of your sample)
- Calculate the test statistic Z score (see under Measures of spread or dispersion and Statistical tests - parametric). In this case the sample mean is compared to the population mean (assumed from the null hypothesis) and the standard error (see under Samples and population) is used rather than the standard deviation.
- Compare the test statistic with the critical values (e.g. plus or minus 1.96 for 5% significance)
- Draw a conclusion about the hypotheses - does the calculated z value lies in this critical range i.e. above 1.96 or below -1.96? If it does we can reject the null hypothesis. This would indicate that the results are significant (or an effect has been detected) - which means that if there were no difference in the population then getting a result that you have observed would be highly unlikely therefore you can reject the null hypothesis.

Type I error - this is the chance of wrongly rejecting the null hypothesis even though it is actually true, e.g. by using a 5% p level you would expect the null hypothesis to be rejected about 5% of the time when the null hypothesis is true. You could set a more stringent p level such as 1% (or 1 in 100) to be more certain of not seeing a Type I error. This, however, makes more likely another type of error (Type II) occurring.
Type II error - this is where there is an effect, but the p value you obtain is non-significant hence you don’t detect this effect.
- Statistical significance - what does it really mean?
- Statistical tables
One-tailed tests - where we know in which direction (e.g. larger or smaller) the difference between sample and population will be. It is a directional hypothesis.
Two-tailed tests - where we are looking at whether there is a difference between sample and population. This difference could be larger or smaller. This is a non-directional hypothesis.
If the difference is in the direction you have predicted (i.e. a one-tailed test) it is easier to get a significant result. Though there are arguments against using a one-tailed test (Wright and London, 2009, p. 98-99)*
*Wright, D. B. & London, K. (2009) First (and second) steps in statistics . 2nd edn. London: SAGE.
N.B. - think of the ‘tails’ as the regions at the far-end of a normal distribution. For a two-tailed test with significance level of 0.05% then 0.025% of the values would be at one end of the distribution and the other 0.025% would be at the other end of the distribution. It is the values in these ‘critical’ extreme regions where we can think about rejecting the null hypothesis and claim that there has been an effect.
Degrees of freedom ( df) is a rather difficult mathematical concept, but is needed to calculate the signifcance of certain statistical tests, such as the t-test, ANOVA and Chi-squared test.
It is broadly defined as the number of "observations" (pieces of information) in the data that are free to vary when estimating statistical parameters. (Taken from Minitab Blog ).
The higher the degrees of freedom are the more powerful and precise your estimates of the parameter (population) will be.
Typically, for a 1-sample t-test it is considered as the number of values in your sample minus 1.
For chi-squared tests with a table of rows and columns the rule is:
(Number of rows minus 1) times (number of columns minus 1)
Any accessible example to illustrate the principle of degrees of freedom using chocolates.
- You have seven chocolates in a box, each being a different type, e.g. truffle, coffee cream, caramel cluster, fudge, strawberry dream, hazelnut whirl, toffee.
- You are being good and intend to eat only one chocolate each day of the week.
- On the first day, you can choose to eat any one of the 7 chocolate types - you have a choice from all 7.
- On the second day, you can choose from the 6 remaining chocolates, on day 3 you can choose from 5 chocolates, and so on.
- On the sixth day you have a choice of the remaining 2 chocolates you haven't ate that week.
- However on the seventh day - you haven't really got any choice of chocolate - it has got to be the one you have left in your box.
- You had 7-1 = 6 days of “chocolate” freedom—in which the chocolate you ate could vary!
- << Previous: Samples and population
- Next: Statistical tests - parametric >>
- Last Updated: Jan 9, 2024 11:01 AM
- URL: https://libguides.tees.ac.uk/quantitative
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Quantitative Data Analysis
9 Presenting the Results of Quantitative Analysis
Mikaila Mariel Lemonik Arthur
This chapter provides an overview of how to present the results of quantitative analysis, in particular how to create effective tables for displaying quantitative results and how to write quantitative research papers that effectively communicate the methods used and findings of quantitative analysis.
Writing the Quantitative Paper
Standard quantitative social science papers follow a specific format. They begin with a title page that includes a descriptive title, the author(s)’ name(s), and a 100 to 200 word abstract that summarizes the paper. Next is an introduction that makes clear the paper’s research question, details why this question is important, and previews what the paper will do. After that comes a literature review, which ends with a summary of the research question(s) and/or hypotheses. A methods section, which explains the source of data, sample, and variables and quantitative techniques used, follows. Many analysts will include a short discussion of their descriptive statistics in the methods section. A findings section details the findings of the analysis, supported by a variety of tables, and in some cases graphs, all of which are explained in the text. Some quantitative papers, especially those using more complex techniques, will include equations. Many papers follow the findings section with a discussion section, which provides an interpretation of the results in light of both the prior literature and theory presented in the literature review and the research questions/hypotheses. A conclusion ends the body of the paper. This conclusion should summarize the findings, answering the research questions and stating whether any hypotheses were supported, partially supported, or not supported. Limitations of the research are detailed. Papers typically include suggestions for future research, and where relevant, some papers include policy implications. After the body of the paper comes the works cited; some papers also have an Appendix that includes additional tables and figures that did not fit into the body of the paper or additional methodological details. While this basic format is similar for papers regardless of the type of data they utilize, there are specific concerns relating to quantitative research in terms of the methods and findings that will be discussed here.
In the methods section, researchers clearly describe the methods they used to obtain and analyze the data for their research. When relying on data collected specifically for a given paper, researchers will need to discuss the sample and data collection; in most cases, though, quantitative research relies on pre-existing datasets. In these cases, researchers need to provide information about the dataset, including the source of the data, the time it was collected, the population, and the sample size. Regardless of the source of the data, researchers need to be clear about which variables they are using in their research and any transformations or manipulations of those variables. They also need to explain the specific quantitative techniques that they are using in their analysis; if different techniques are used to test different hypotheses, this should be made clear. In some cases, publications will require that papers be submitted along with any code that was used to produce the analysis (in SPSS terms, the syntax files), which more advanced researchers will usually have on hand. In many cases, basic descriptive statistics are presented in tabular form and explained within the methods section.
The findings sections of quantitative papers are organized around explaining the results as shown in tables and figures. Not all results are depicted in tables and figures—some minor or null findings will simply be referenced—but tables and figures should be produced for all findings to be discussed at any length. If there are too many tables and figures, some can be moved to an appendix after the body of the text and referred to in the text (e.g. “See Table 12 in Appendix A”).
Discussions of the findings should not simply restate the contents of the table. Rather, they should explain and interpret it for readers, and they should do so in light of the hypothesis or hypotheses that are being tested. Conclusions—discussions of whether the hypothesis or hypotheses are supported or not supported—should wait for the conclusion of the paper.
Creating Effective Tables
When creating tables to display the results of quantitative analysis, the most important goals are to create tables that are clear and concise but that also meet standard conventions in the field. This means, first of all, paring down the volume of information produced in the statistical output to just include the information most necessary for interpreting the results, but doing so in keeping with standard table conventions. It also means making tables that are well-formatted and designed, so that readers can understand what the tables are saying without struggling to find information. For example, tables (as well as figures such as graphs) need clear captions; they are typically numbered and referred to by number in the text. Columns and rows should have clear headings. Depending on the content of the table, formatting tools may need to be used to set off header rows/columns and/or total rows/columns; cell-merging tools may be necessary; and shading may be important in tables with many rows or columns.
Here, you will find some instructions for creating tables of results from descriptive, crosstabulation, correlation, and regression analysis that are clear, concise, and meet normal standards for data display in social science. In addition, after the instructions for creating tables, you will find an example of how a paper incorporating each table might describe that table in the text.
Descriptive Statistics
When presenting the results of descriptive statistics, we create one table with columns for each type of descriptive statistic and rows for each variable. Note, of course, that depending on level of measurement only certain descriptive statistics are appropriate for a given variable, so there may be many cells in the table marked with an — to show that this statistic is not calculated for this variable. So, consider the set of descriptive statistics below, for occupational prestige, age, highest degree earned, and whether the respondent was born in this country.
To display these descriptive statistics in a paper, one might create a table like Table 2. Note that for discrete variables, we use the value label in the table, not the value.
If we were then to discuss our descriptive statistics in a quantitative paper, we might write something like this (note that we do not need to repeat every single detail from the table, as readers can peruse the table themselves):
This analysis relies on four variables from the 2021 General Social Survey: occupational prestige score, age, highest degree earned, and whether the respondent was born in the United States. Descriptive statistics for all four variables are shown in Table 2. The median occupational prestige score is 47, with a range from 16 to 80. 50% of respondents had occupational prestige scores scores between 35 and 59. The median age of respondents is 53, with a range from 18 to 89. 50% of respondents are between ages 37 and 66. Both variables have little skew. Highest degree earned ranges from less than high school to a graduate degree; the median respondent has earned an associate’s degree, while the modal response (given by 39.8% of the respondents) is a high school degree. 88.8% of respondents were born in the United States.
Crosstabulation
When presenting the results of a crosstabulation, we simplify the table so that it highlights the most important information—the column percentages—and include the significance and association below the table. Consider the SPSS output below.
Table 4 shows how a table suitable for include in a paper might look if created from the SPSS output in Table 3. Note that we use asterisks to indicate the significance level of the results: * means p < 0.05; ** means p < 0.01; *** means p < 0.001; and no stars mean p > 0.05 (and thus that the result is not significant). Also note than N is the abbreviation for the number of respondents.
If we were going to discuss the results of this crosstabulation in a quantitative research paper, the discussion might look like this:
A crosstabulation of respondent’s class identification and their highest degree earned, with class identification as the independent variable, is significant, with a Spearman correlation of 0.419, as shown in Table 4. Among lower class and working class respondents, more than 50% had earned a high school degree. Less than 20% of poor respondents and less than 40% of working-class respondents had earned more than a high school degree. In contrast, the majority of middle class and upper class respondents had earned at least a bachelor’s degree. In fact, 50% of upper class respondents had earned a graduate degree.
Correlation
When presenting a correlating matrix, one of the most important things to note is that we only present half the table so as not to include duplicated results. Think of the line through the table where empty cells exist to represent the correlation between a variable and itself, and include only the triangle of data either above or below that line of cells. Consider the output in Table 5.
Table 6 shows what the contents of Table 5 might look like when a table is constructed in a fashion suitable for publication.
If we were to discuss the results of this bivariate correlation analysis in a quantitative paper, the discussion might look like this:
Bivariate correlations were run among variables measuring age, occupational prestige, the highest year of school respondents completed, and family income in constant 1986 dollars, as shown in Table 6. Correlations between age and highest year of school completed and between age and family income are not significant. All other correlations are positive and significant at the p<0.001 level. The correlation between age and occupational prestige is weak; the correlations between income and occupational prestige and between income and educational attainment are moderate, and the correlation between education and occupational prestige is strong.
To present the results of a regression, we create one table that includes all of the key information from the multiple tables of SPSS output. This includes the R 2 and significance of the regression, either the B or the beta values (different analysts have different preferences here) for each variable, and the standard error and significance of each variable. Consider the SPSS output in Table 7.
The regression output in shown in Table 7 contains a lot of information. We do not include all of this information when making tables suitable for publication. As can be seen in Table 8, we include the Beta (or the B), the standard error, and the significance asterisk for each variable; the R 2 and significance for the overall regression; the degrees of freedom (which tells readers the sample size or N); and the constant; along with the key to p/significance values.
If we were to discuss the results of this regression in a quantitative paper, the results might look like this:
Table 8 shows the results of a regression in which age, occupational prestige, and highest year of school completed are the independent variables and family income is the dependent variable. The regression results are significant, and all of the independent variables taken together explain 15.6% of the variance in family income. Age is not a significant predictor of income, while occupational prestige and educational attainment are. Educational attainment has a larger effect on family income than does occupational prestige. For every year of additional education attained, family income goes up on average by $3,988.545; for every one-unit increase in occupational prestige score, family income goes up on average by $522.887. [1]
- Choose two discrete variables and three continuous variables from a dataset of your choice. Produce appropriate descriptive statistics on all five of the variables and create a table of the results suitable for inclusion in a paper.
- Using the two discrete variables you have chosen, produce an appropriate crosstabulation, with significance and measure of association. Create a table of the results suitable for inclusion in a paper.
- Using the three continuous variables you have chosen, produce a correlation matrix. Create a table of the results suitable for inclusion in a paper.
- Using the three continuous variables you have chosen, produce a multivariate linear regression. Create a table of the results suitable for inclusion in a paper.
- Write a methods section describing the dataset, analytical methods, and variables you utilized in questions 1, 2, 3, and 4 and explaining the results of your descriptive analysis.
- Write a findings section explaining the results of the analyses you performed in questions 2, 3, and 4.
- Note that the actual numberical increase comes from the B values, which are shown in the SPSS output in Table 7 but not in the reformatted Table 8. ↵
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
- Privacy Policy
Buy Me a Coffee
Home » Quantitative Research – Methods, Types and Analysis
Quantitative Research – Methods, Types and Analysis
Table of Contents

Quantitative Research
Quantitative research is a type of research that collects and analyzes numerical data to test hypotheses and answer research questions . This research typically involves a large sample size and uses statistical analysis to make inferences about a population based on the data collected. It often involves the use of surveys, experiments, or other structured data collection methods to gather quantitative data.
Quantitative Research Methods

Quantitative Research Methods are as follows:
Descriptive Research Design
Descriptive research design is used to describe the characteristics of a population or phenomenon being studied. This research method is used to answer the questions of what, where, when, and how. Descriptive research designs use a variety of methods such as observation, case studies, and surveys to collect data. The data is then analyzed using statistical tools to identify patterns and relationships.
Correlational Research Design
Correlational research design is used to investigate the relationship between two or more variables. Researchers use correlational research to determine whether a relationship exists between variables and to what extent they are related. This research method involves collecting data from a sample and analyzing it using statistical tools such as correlation coefficients.
Quasi-experimental Research Design
Quasi-experimental research design is used to investigate cause-and-effect relationships between variables. This research method is similar to experimental research design, but it lacks full control over the independent variable. Researchers use quasi-experimental research designs when it is not feasible or ethical to manipulate the independent variable.
Experimental Research Design
Experimental research design is used to investigate cause-and-effect relationships between variables. This research method involves manipulating the independent variable and observing the effects on the dependent variable. Researchers use experimental research designs to test hypotheses and establish cause-and-effect relationships.
Survey Research
Survey research involves collecting data from a sample of individuals using a standardized questionnaire. This research method is used to gather information on attitudes, beliefs, and behaviors of individuals. Researchers use survey research to collect data quickly and efficiently from a large sample size. Survey research can be conducted through various methods such as online, phone, mail, or in-person interviews.
Quantitative Research Analysis Methods
Here are some commonly used quantitative research analysis methods:
Statistical Analysis
Statistical analysis is the most common quantitative research analysis method. It involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis can be used to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
Regression Analysis
Regression analysis is a statistical technique used to analyze the relationship between one dependent variable and one or more independent variables. Researchers use regression analysis to identify and quantify the impact of independent variables on the dependent variable.
Factor Analysis
Factor analysis is a statistical technique used to identify underlying factors that explain the correlations among a set of variables. Researchers use factor analysis to reduce a large number of variables to a smaller set of factors that capture the most important information.
Structural Equation Modeling
Structural equation modeling is a statistical technique used to test complex relationships between variables. It involves specifying a model that includes both observed and unobserved variables, and then using statistical methods to test the fit of the model to the data.
Time Series Analysis
Time series analysis is a statistical technique used to analyze data that is collected over time. It involves identifying patterns and trends in the data, as well as any seasonal or cyclical variations.
Multilevel Modeling
Multilevel modeling is a statistical technique used to analyze data that is nested within multiple levels. For example, researchers might use multilevel modeling to analyze data that is collected from individuals who are nested within groups, such as students nested within schools.
Applications of Quantitative Research
Quantitative research has many applications across a wide range of fields. Here are some common examples:
- Market Research : Quantitative research is used extensively in market research to understand consumer behavior, preferences, and trends. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform marketing strategies, product development, and pricing decisions.
- Health Research: Quantitative research is used in health research to study the effectiveness of medical treatments, identify risk factors for diseases, and track health outcomes over time. Researchers use statistical methods to analyze data from clinical trials, surveys, and other sources to inform medical practice and policy.
- Social Science Research: Quantitative research is used in social science research to study human behavior, attitudes, and social structures. Researchers use surveys, experiments, and other quantitative methods to collect data that can inform social policies, educational programs, and community interventions.
- Education Research: Quantitative research is used in education research to study the effectiveness of teaching methods, assess student learning outcomes, and identify factors that influence student success. Researchers use experimental and quasi-experimental designs, as well as surveys and other quantitative methods, to collect and analyze data.
- Environmental Research: Quantitative research is used in environmental research to study the impact of human activities on the environment, assess the effectiveness of conservation strategies, and identify ways to reduce environmental risks. Researchers use statistical methods to analyze data from field studies, experiments, and other sources.
Characteristics of Quantitative Research
Here are some key characteristics of quantitative research:
- Numerical data : Quantitative research involves collecting numerical data through standardized methods such as surveys, experiments, and observational studies. This data is analyzed using statistical methods to identify patterns and relationships.
- Large sample size: Quantitative research often involves collecting data from a large sample of individuals or groups in order to increase the reliability and generalizability of the findings.
- Objective approach: Quantitative research aims to be objective and impartial in its approach, focusing on the collection and analysis of data rather than personal beliefs, opinions, or experiences.
- Control over variables: Quantitative research often involves manipulating variables to test hypotheses and establish cause-and-effect relationships. Researchers aim to control for extraneous variables that may impact the results.
- Replicable : Quantitative research aims to be replicable, meaning that other researchers should be able to conduct similar studies and obtain similar results using the same methods.
- Statistical analysis: Quantitative research involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis allows researchers to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
- Generalizability: Quantitative research aims to produce findings that can be generalized to larger populations beyond the specific sample studied. This is achieved through the use of random sampling methods and statistical inference.
Examples of Quantitative Research
Here are some examples of quantitative research in different fields:
- Market Research: A company conducts a survey of 1000 consumers to determine their brand awareness and preferences. The data is analyzed using statistical methods to identify trends and patterns that can inform marketing strategies.
- Health Research : A researcher conducts a randomized controlled trial to test the effectiveness of a new drug for treating a particular medical condition. The study involves collecting data from a large sample of patients and analyzing the results using statistical methods.
- Social Science Research : A sociologist conducts a survey of 500 people to study attitudes toward immigration in a particular country. The data is analyzed using statistical methods to identify factors that influence these attitudes.
- Education Research: A researcher conducts an experiment to compare the effectiveness of two different teaching methods for improving student learning outcomes. The study involves randomly assigning students to different groups and collecting data on their performance on standardized tests.
- Environmental Research : A team of researchers conduct a study to investigate the impact of climate change on the distribution and abundance of a particular species of plant or animal. The study involves collecting data on environmental factors and population sizes over time and analyzing the results using statistical methods.
- Psychology : A researcher conducts a survey of 500 college students to investigate the relationship between social media use and mental health. The data is analyzed using statistical methods to identify correlations and potential causal relationships.
- Political Science: A team of researchers conducts a study to investigate voter behavior during an election. They use survey methods to collect data on voting patterns, demographics, and political attitudes, and analyze the results using statistical methods.
How to Conduct Quantitative Research
Here is a general overview of how to conduct quantitative research:
- Develop a research question: The first step in conducting quantitative research is to develop a clear and specific research question. This question should be based on a gap in existing knowledge, and should be answerable using quantitative methods.
- Develop a research design: Once you have a research question, you will need to develop a research design. This involves deciding on the appropriate methods to collect data, such as surveys, experiments, or observational studies. You will also need to determine the appropriate sample size, data collection instruments, and data analysis techniques.
- Collect data: The next step is to collect data. This may involve administering surveys or questionnaires, conducting experiments, or gathering data from existing sources. It is important to use standardized methods to ensure that the data is reliable and valid.
- Analyze data : Once the data has been collected, it is time to analyze it. This involves using statistical methods to identify patterns, trends, and relationships between variables. Common statistical techniques include correlation analysis, regression analysis, and hypothesis testing.
- Interpret results: After analyzing the data, you will need to interpret the results. This involves identifying the key findings, determining their significance, and drawing conclusions based on the data.
- Communicate findings: Finally, you will need to communicate your findings. This may involve writing a research report, presenting at a conference, or publishing in a peer-reviewed journal. It is important to clearly communicate the research question, methods, results, and conclusions to ensure that others can understand and replicate your research.
When to use Quantitative Research
Here are some situations when quantitative research can be appropriate:
- To test a hypothesis: Quantitative research is often used to test a hypothesis or a theory. It involves collecting numerical data and using statistical analysis to determine if the data supports or refutes the hypothesis.
- To generalize findings: If you want to generalize the findings of your study to a larger population, quantitative research can be useful. This is because it allows you to collect numerical data from a representative sample of the population and use statistical analysis to make inferences about the population as a whole.
- To measure relationships between variables: If you want to measure the relationship between two or more variables, such as the relationship between age and income, or between education level and job satisfaction, quantitative research can be useful. It allows you to collect numerical data on both variables and use statistical analysis to determine the strength and direction of the relationship.
- To identify patterns or trends: Quantitative research can be useful for identifying patterns or trends in data. For example, you can use quantitative research to identify trends in consumer behavior or to identify patterns in stock market data.
- To quantify attitudes or opinions : If you want to measure attitudes or opinions on a particular topic, quantitative research can be useful. It allows you to collect numerical data using surveys or questionnaires and analyze the data using statistical methods to determine the prevalence of certain attitudes or opinions.
Purpose of Quantitative Research
The purpose of quantitative research is to systematically investigate and measure the relationships between variables or phenomena using numerical data and statistical analysis. The main objectives of quantitative research include:
- Description : To provide a detailed and accurate description of a particular phenomenon or population.
- Explanation : To explain the reasons for the occurrence of a particular phenomenon, such as identifying the factors that influence a behavior or attitude.
- Prediction : To predict future trends or behaviors based on past patterns and relationships between variables.
- Control : To identify the best strategies for controlling or influencing a particular outcome or behavior.
Quantitative research is used in many different fields, including social sciences, business, engineering, and health sciences. It can be used to investigate a wide range of phenomena, from human behavior and attitudes to physical and biological processes. The purpose of quantitative research is to provide reliable and valid data that can be used to inform decision-making and improve understanding of the world around us.
Advantages of Quantitative Research
There are several advantages of quantitative research, including:
- Objectivity : Quantitative research is based on objective data and statistical analysis, which reduces the potential for bias or subjectivity in the research process.
- Reproducibility : Because quantitative research involves standardized methods and measurements, it is more likely to be reproducible and reliable.
- Generalizability : Quantitative research allows for generalizations to be made about a population based on a representative sample, which can inform decision-making and policy development.
- Precision : Quantitative research allows for precise measurement and analysis of data, which can provide a more accurate understanding of phenomena and relationships between variables.
- Efficiency : Quantitative research can be conducted relatively quickly and efficiently, especially when compared to qualitative research, which may involve lengthy data collection and analysis.
- Large sample sizes : Quantitative research can accommodate large sample sizes, which can increase the representativeness and generalizability of the results.
Limitations of Quantitative Research
There are several limitations of quantitative research, including:
- Limited understanding of context: Quantitative research typically focuses on numerical data and statistical analysis, which may not provide a comprehensive understanding of the context or underlying factors that influence a phenomenon.
- Simplification of complex phenomena: Quantitative research often involves simplifying complex phenomena into measurable variables, which may not capture the full complexity of the phenomenon being studied.
- Potential for researcher bias: Although quantitative research aims to be objective, there is still the potential for researcher bias in areas such as sampling, data collection, and data analysis.
- Limited ability to explore new ideas: Quantitative research is often based on pre-determined research questions and hypotheses, which may limit the ability to explore new ideas or unexpected findings.
- Limited ability to capture subjective experiences : Quantitative research is typically focused on objective data and may not capture the subjective experiences of individuals or groups being studied.
- Ethical concerns : Quantitative research may raise ethical concerns, such as invasion of privacy or the potential for harm to participants.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide

Survey Research – Types, Methods, Examples

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
11 Hypothesis Testing with One Sample
Student learning outcomes.
By the end of this chapter, the student should be able to:
- Be able to identify and develop the null and alternative hypothesis
- Identify the consequences of Type I and Type II error.
- Be able to perform an one-tailed and two-tailed hypothesis test using the critical value method
- Be able to perform a hypothesis test using the p-value method
- Be able to write conclusions based on hypothesis tests.
Introduction
Now we are down to the bread and butter work of the statistician: developing and testing hypotheses. It is important to put this material in a broader context so that the method by which a hypothesis is formed is understood completely. Using textbook examples often clouds the real source of statistical hypotheses.
Statistical testing is part of a much larger process known as the scientific method. This method was developed more than two centuries ago as the accepted way that new knowledge could be created. Until then, and unfortunately even today, among some, “knowledge” could be created simply by some authority saying something was so, ipso dicta . Superstition and conspiracy theories were (are?) accepted uncritically.
The scientific method, briefly, states that only by following a careful and specific process can some assertion be included in the accepted body of knowledge. This process begins with a set of assumptions upon which a theory, sometimes called a model, is built. This theory, if it has any validity, will lead to predictions; what we call hypotheses.
As an example, in Microeconomics the theory of consumer choice begins with certain assumption concerning human behavior. From these assumptions a theory of how consumers make choices using indifference curves and the budget line. This theory gave rise to a very important prediction, namely, that there was an inverse relationship between price and quantity demanded. This relationship was known as the demand curve. The negative slope of the demand curve is really just a prediction, or a hypothesis, that can be tested with statistical tools.
Unless hundreds and hundreds of statistical tests of this hypothesis had not confirmed this relationship, the so-called Law of Demand would have been discarded years ago. This is the role of statistics, to test the hypotheses of various theories to determine if they should be admitted into the accepted body of knowledge; how we understand our world. Once admitted, however, they may be later discarded if new theories come along that make better predictions.
Not long ago two scientists claimed that they could get more energy out of a process than was put in. This caused a tremendous stir for obvious reasons. They were on the cover of Time and were offered extravagant sums to bring their research work to private industry and any number of universities. It was not long until their work was subjected to the rigorous tests of the scientific method and found to be a failure. No other lab could replicate their findings. Consequently they have sunk into obscurity and their theory discarded. It may surface again when someone can pass the tests of the hypotheses required by the scientific method, but until then it is just a curiosity. Many pure frauds have been attempted over time, but most have been found out by applying the process of the scientific method.
This discussion is meant to show just where in this process statistics falls. Statistics and statisticians are not necessarily in the business of developing theories, but in the business of testing others’ theories. Hypotheses come from these theories based upon an explicit set of assumptions and sound logic. The hypothesis comes first, before any data are gathered. Data do not create hypotheses; they are used to test them. If we bear this in mind as we study this section the process of forming and testing hypotheses will make more sense.
One job of a statistician is to make statistical inferences about populations based on samples taken from the population. Confidence intervals are one way to estimate a population parameter. Another way to make a statistical inference is to make a decision about the value of a specific parameter. For instance, a car dealer advertises that its new small truck gets 35 miles per gallon, on average. A tutoring service claims that its method of tutoring helps 90% of its students get an A or a B. A company says that women managers in their company earn an average of $60,000 per year.
A statistician will make a decision about these claims. This process is called ” hypothesis testing .” A hypothesis test involves collecting data from a sample and evaluating the data. Then, the statistician makes a decision as to whether or not there is sufficient evidence, based upon analyses of the data, to reject the null hypothesis.
In this chapter, you will conduct hypothesis tests on single means and single proportions. You will also learn about the errors associated with these tests.
Null and Alternative Hypotheses
The actual test begins by considering two hypotheses . They are called the null hypothesis and the alternative hypothesis . These hypotheses contain opposing viewpoints.

Since the null and alternative hypotheses are contradictory, you must examine evidence to decide if you have enough evidence to reject the null hypothesis or not. The evidence is in the form of sample data.
Table 1 presents the various hypotheses in the relevant pairs. For example, if the null hypothesis is equal to some value, the alternative has to be not equal to that value.
NOTE
We want to test whether the mean GPA of students in American colleges is different from 2.0 (out of 4.0). The null and alternative hypotheses are:

We want to test if college students take less than five years to graduate from college, on the average. The null and alternative hypotheses are:
Outcomes and the Type I and Type II Errors
The four possible outcomes in the table are:
Each of the errors occurs with a particular probability. The Greek letters α and β represent the probabilities.

By way of example, the American judicial system begins with the concept that a defendant is “presumed innocent”. This is the status quo and is the null hypothesis. The judge will tell the jury that they can not find the defendant guilty unless the evidence indicates guilt beyond a “reasonable doubt” which is usually defined in criminal cases as 95% certainty of guilt. If the jury cannot accept the null, innocent, then action will be taken, jail time. The burden of proof always lies with the alternative hypothesis. (In civil cases, the jury needs only to be more than 50% certain of wrongdoing to find culpability, called “a preponderance of the evidence”).
The example above was for a test of a mean, but the same logic applies to tests of hypotheses for all statistical parameters one may wish to test.
The following are examples of Type I and Type II errors.
Type I error : Frank thinks that his rock climbing equipment may not be safe when, in fact, it really is safe.
Type II error : Frank thinks that his rock climbing equipment may be safe when, in fact, it is not safe.
Notice that, in this case, the error with the greater consequence is the Type II error. (If Frank thinks his rock climbing equipment is safe, he will go ahead and use it.)
This is a situation described as “accepting a false null”.
Type I error : The emergency crew thinks that the victim is dead when, in fact, the victim is alive. Type II error : The emergency crew does not know if the victim is alive when, in fact, the victim is dead.
The error with the greater consequence is the Type I error. (If the emergency crew thinks the victim is dead, they will not treat him.)
Distribution Needed for Hypothesis Testing
Particular distributions are associated with hypothesis testing.We will perform hypotheses tests of a population mean using a normal distribution or a Student’s t -distribution. (Remember, use a Student’s t -distribution when the population standard deviation is unknown and the sample size is small, where small is considered to be less than 30 observations.) We perform tests of a population proportion using a normal distribution when we can assume that the distribution is normally distributed. We consider this to be true if the sample proportion, p ‘ , times the sample size is greater than 5 and 1- p ‘ times the sample size is also greater then 5. This is the same rule of thumb we used when developing the formula for the confidence interval for a population proportion.
Hypothesis Test for the Mean
Going back to the standardizing formula we can derive the test statistic for testing hypotheses concerning means.

This gives us the decision rule for testing a hypothesis for a two-tailed test:
P-Value Approach
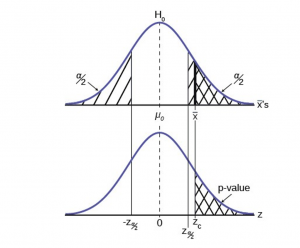
Both decision rules will result in the same decision and it is a matter of preference which one is used.
One and Two-tailed Tests

The claim would be in the alternative hypothesis. The burden of proof in hypothesis testing is carried in the alternative. This is because failing to reject the null, the status quo, must be accomplished with 90 or 95 percent significance that it cannot be maintained. Said another way, we want to have only a 5 or 10 percent probability of making a Type I error, rejecting a good null; overthrowing the status quo.
Figure 5 shows the two possible cases and the form of the null and alternative hypothesis that give rise to them.
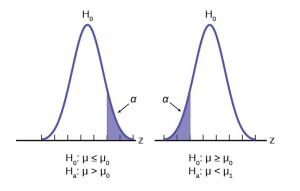
Effects of Sample Size on Test Statistic

Table 3 summarizes test statistics for varying sample sizes and population standard deviation known and unknown.
A Systematic Approach for Testing A Hypothesis
A systematic approach to hypothesis testing follows the following steps and in this order. This template will work for all hypotheses that you will ever test.
- Set up the null and alternative hypothesis. This is typically the hardest part of the process. Here the question being asked is reviewed. What parameter is being tested, a mean, a proportion, differences in means, etc. Is this a one-tailed test or two-tailed test? Remember, if someone is making a claim it will always be a one-tailed test.
- Decide the level of significance required for this particular case and determine the critical value. These can be found in the appropriate statistical table. The levels of confidence typical for the social sciences are 90, 95 and 99. However, the level of significance is a policy decision and should be based upon the risk of making a Type I error, rejecting a good null. Consider the consequences of making a Type I error.
- Take a sample(s) and calculate the relevant parameters: sample mean, standard deviation, or proportion. Using the formula for the test statistic from above in step 2, now calculate the test statistic for this particular case using the parameters you have just calculated.
- Compare the calculated test statistic and the critical value. Marking these on the graph will give a good visual picture of the situation. There are now only two situations:
a. The test statistic is in the tail: Cannot Accept the null, the probability that this sample mean (proportion) came from the hypothesized distribution is too small to believe that it is the real home of these sample data.
b. The test statistic is not in the tail: Cannot Reject the null, the sample data are compatible with the hypothesized population parameter.
- Reach a conclusion. It is best to articulate the conclusion two different ways. First a formal statistical conclusion such as “With a 95 % level of significance we cannot accept the null hypotheses that the population mean is equal to XX (units of measurement)”. The second statement of the conclusion is less formal and states the action, or lack of action, required. If the formal conclusion was that above, then the informal one might be, “The machine is broken and we need to shut it down and call for repairs”.
All hypotheses tested will go through this same process. The only changes are the relevant formulas and those are determined by the hypothesis required to answer the original question.
Full Hypothesis Test Examples
Tests on means.
Jeffrey, as an eight-year old, established a mean time of 16.43 seconds for swimming the 25-yard freestyle, with a standard deviation of 0.8 seconds . His dad, Frank, thought that Jeffrey could swim the 25-yard freestyle faster using goggles. Frank bought Jeffrey a new pair of expensive goggles and timed Jeffrey for 15 25-yard freestyle swims . For the 15 swims, Jeffrey’s mean time was 16 seconds. Frank thought that the goggles helped Jeffrey to swim faster than the 16.43 seconds. Conduct a hypothesis test using a preset α = 0.05.
Solution – Example 6
Set up the Hypothesis Test:
Since the problem is about a mean, this is a test of a single population mean . Set the null and alternative hypothesis:
In this case there is an implied challenge or claim. This is that the goggles will reduce the swimming time. The effect of this is to set the hypothesis as a one-tailed test. The claim will always be in the alternative hypothesis because the burden of proof always lies with the alternative. Remember that the status quo must be defeated with a high degree of confidence, in this case 95 % confidence. The null and alternative hypotheses are thus:
For Jeffrey to swim faster, his time will be less than 16.43 seconds. The “<” tells you this is left-tailed. Determine the distribution needed:
Distribution for the test statistic:
The sample size is less than 30 and we do not know the population standard deviation so this is a t-test and the proper formula is:

Our step 2, setting the level of significance, has already been determined by the problem, .05 for a 95 % significance level. It is worth thinking about the meaning of this choice. The Type I error is to conclude that Jeffrey swims the 25-yard freestyle, on average, in less than 16.43 seconds when, in fact, he actually swims the 25-yard freestyle, on average, in 16.43 seconds. (Reject the null hypothesis when the null hypothesis is true.) For this case the only concern with a Type I error would seem to be that Jeffery’s dad may fail to bet on his son’s victory because he does not have appropriate confidence in the effect of the goggles.
To find the critical value we need to select the appropriate test statistic. We have concluded that this is a t-test on the basis of the sample size and that we are interested in a population mean. We can now draw the graph of the t-distribution and mark the critical value (Figure 6). For this problem the degrees of freedom are n-1, or 14. Looking up 14 degrees of freedom at the 0.05 column of the t-table we find 1.761. This is the critical value and we can put this on our graph.
Step 3 is the calculation of the test statistic using the formula we have selected.

We find that the calculated test statistic is 2.08, meaning that the sample mean is 2.08 standard deviations away from the hypothesized mean of 16.43.
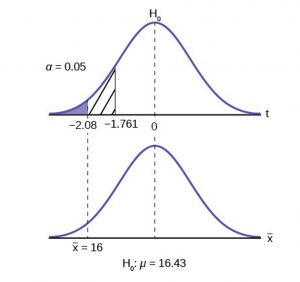
Step 4 has us compare the test statistic and the critical value and mark these on the graph. We see that the test statistic is in the tail and thus we move to step 4 and reach a conclusion. The probability that an average time of 16 minutes could come from a distribution with a population mean of 16.43 minutes is too unlikely for us to accept the null hypothesis. We cannot accept the null.
Step 5 has us state our conclusions first formally and then less formally. A formal conclusion would be stated as: “With a 95% level of significance we cannot accept the null hypothesis that the swimming time with goggles comes from a distribution with a population mean time of 16.43 minutes.” Less formally, “With 95% significance we believe that the goggles improves swimming speed”
If we wished to use the p-value system of reaching a conclusion we would calculate the statistic and take the additional step to find the probability of being 2.08 standard deviations from the mean on a t-distribution. This value is .0187. Comparing this to the α-level of .05 we see that we cannot accept the null. The p-value has been put on the graph as the shaded area beyond -2.08 and it shows that it is smaller than the hatched area which is the alpha level of 0.05. Both methods reach the same conclusion that we cannot accept the null hypothesis.
Jane has just begun her new job as on the sales force of a very competitive company. In a sample of 16 sales calls it was found that she closed the contract for an average value of $108 with a standard deviation of 12 dollars. Test at 5% significance that the population mean is at least $100 against the alternative that it is less than 100 dollars. Company policy requires that new members of the sales force must exceed an average of $100 per contract during the trial employment period. Can we conclude that Jane has met this requirement at the significance level of 95%?
Solution – Example 7
STEP 1 : Set the Null and Alternative Hypothesis.
STEP 2 : Decide the level of significance and draw the graph (Figure 7) showing the critical value.

STEP 3 : Calculate sample parameters and the test statistic.

STEP 4 : Compare test statistic and the critical values
STEP 5 : Reach a Conclusion
The test statistic is a Student’s t because the sample size is below 30; therefore, we cannot use the normal distribution. Comparing the calculated value of the test statistic and the critical value of t ( t a ) at a 5% significance level, we see that the calculated value is in the tail of the distribution. Thus, we conclude that 108 dollars per contract is significantly larger than the hypothesized value of 100 and thus we cannot accept the null hypothesis. There is evidence that supports Jane’s performance meets company standards.

Again we will follow the steps in our analysis of this problem.
Solution – Example 8
STEP 1 : Set the Null and Alternative Hypothesis. The random variable is the quantity of fluid placed in the bottles. This is a continuous random variable and the parameter we are interested in is the mean. Our hypothesis therefore is about the mean. In this case we are concerned that the machine is not filling properly. From what we are told it does not matter if the machine is over-filling or under-filling, both seem to be an equally bad error. This tells us that this is a two-tailed test: if the machine is malfunctioning it will be shutdown regardless if it is from over-filling or under-filling. The null and alternative hypotheses are thus:
STEP 2 : Decide the level of significance and draw the graph showing the critical value.
This problem has already set the level of significance at 99%. The decision seems an appropriate one and shows the thought process when setting the significance level. Management wants to be very certain, as certain as probability will allow, that they are not shutting down a machine that is not in need of repair. To draw the distribution and the critical value, we need to know which distribution to use. Because this is a continuous random variable and we are interested in the mean, and the sample size is greater than 30, the appropriate distribution is the normal distribution and the relevant critical value is 2.575 from the normal table or the t-table at 0.005 column and infinite degrees of freedom. We draw the graph and mark these points (Figure 8).
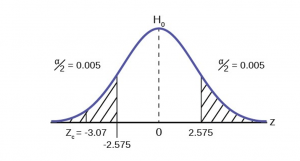
STEP 3 : Calculate sample parameters and the test statistic. The sample parameters are provided, the sample mean is 7.91 and the sample variance is .03 and the sample size is 35. We need to note that the sample variance was provided not the sample standard deviation, which is what we need for the formula. Remembering that the standard deviation is simply the square root of the variance, we therefore know the sample standard deviation, s, is 0.173. With this information we calculate the test statistic as -3.07, and mark it on the graph.

STEP 4 : Compare test statistic and the critical values Now we compare the test statistic and the critical value by placing the test statistic on the graph. We see that the test statistic is in the tail, decidedly greater than the critical value of 2.575. We note that even the very small difference between the hypothesized value and the sample value is still a large number of standard deviations. The sample mean is only 0.08 ounces different from the required level of 8 ounces, but it is 3 plus standard deviations away and thus we cannot accept the null hypothesis.
Three standard deviations of a test statistic will guarantee that the test will fail. The probability that anything is within three standard deviations is almost zero. Actually it is 0.0026 on the normal distribution, which is certainly almost zero in a practical sense. Our formal conclusion would be “ At a 99% level of significance we cannot accept the hypothesis that the sample mean came from a distribution with a mean of 8 ounces” Or less formally, and getting to the point, “At a 99% level of significance we conclude that the machine is under filling the bottles and is in need of repair”.
Media Attributions
- Type1Type2Error
- HypTestFig2
- HypTestFig3
- HypTestPValue
- OneTailTestFig5
- HypTestExam7
- HypTestExam8
Quantitative Analysis for Business Copyright © by Margo Bergman is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

Data Mining and Market Intelligence pp 39–49 Cite as
Hypothesis Testing and Regression Analysis
- Mustapha Akinkunmi 2
44 Accesses
Part of the book series: Synthesis Lectures on Engineering ((SLE))
In this chapter, we look at the different stages of data preparation involved in quantitative analysis. Understanding these processes will help us gather reliable data and reach a valid conclusion. We will discuss types of hypotheses and how they are stated mathematically. Furthermore, we shall discuss hypothesis testing with worked examples.
This is a preview of subscription content, log in via an institution .
Buying options
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Unable to display preview. Download preview PDF.
Author information
Authors and affiliations.
American University of Nigeria, Nigeria
Mustapha Akinkunmi
You can also search for this author in PubMed Google Scholar
Rights and permissions
Reprints and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this chapter
Cite this chapter.
Akinkunmi, M. (2018). Hypothesis Testing and Regression Analysis. In: Data Mining and Market Intelligence. Synthesis Lectures on Engineering. Springer, Cham. https://doi.org/10.1007/978-3-031-79390-5_5
Download citation
DOI : https://doi.org/10.1007/978-3-031-79390-5_5
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-79389-9
Online ISBN : 978-3-031-79390-5
eBook Packages : Synthesis Collection of Technology (R0) eBColl Synthesis Collection 8
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.14: Chapter 14 Quantitative Analysis Descriptive Statistics
- Last updated
- Save as PDF
- Page ID 84790

- William Pelz
- Herkimer College via Lumen Learning
Numeric data collected in a research project can be analyzed quantitatively using statistical tools in two different ways. Descriptive analysis refers to statistically describing, aggregating, and presenting the constructs of interest or associations between these constructs. Inferential analysis refers to the statistical testing of hypotheses (theory testing). In this chapter, we will examine statistical techniques used for descriptive analysis, and the next chapter will examine statistical techniques for inferential analysis. Much of today’s quantitative data analysis is conducted using software programs such as SPSS or SAS. Readers are advised to familiarize themselves with one of these programs for understanding the concepts described in this chapter.
Data Preparation
In research projects, data may be collected from a variety of sources: mail-in surveys, interviews, pretest or posttest experimental data, observational data, and so forth. This data must be converted into a machine -readable, numeric format, such as in a spreadsheet or a text file, so that they can be analyzed by computer programs like SPSS or SAS. Data preparation usually follows the following steps.
Data coding. Coding is the process of converting data into numeric format. A codebook should be created to guide the coding process. A codebook is a comprehensive document containing detailed description of each variable in a research study, items or measures for that variable, the format of each item (numeric, text, etc.), the response scale for each item (i.e., whether it is measured on a nominal, ordinal, interval, or ratio scale; whether such scale is a five-point, seven-point, or some other type of scale), and how to code each value into a numeric format. For instance, if we have a measurement item on a seven-point Likert scale with anchors ranging from “strongly disagree” to “strongly agree”, we may code that item as 1 for strongly disagree, 4 for neutral, and 7 for strongly agree, with the intermediate anchors in between. Nominal data such as industry type can be coded in numeric form using a coding scheme such as: 1 for manufacturing, 2 for retailing, 3 for financial, 4 for healthcare, and so forth (of course, nominal data cannot be analyzed statistically). Ratio scale data such as age, income, or test scores can be coded as entered by the respondent. Sometimes, data may need to be aggregated into a different form than the format used for data collection. For instance, for measuring a construct such as “benefits of computers,” if a survey provided respondents with a checklist of b enefits that they could select from (i.e., they could choose as many of those benefits as they wanted), then the total number of checked items can be used as an aggregate measure of benefits. Note that many other forms of data, such as interview transcripts, cannot be converted into a numeric format for statistical analysis. Coding is especially important for large complex studies involving many variables and measurement items, where the coding process is conducted by different people, to help the coding team code data in a consistent manner, and also to help others understand and interpret the coded data.
Data entry. Coded data can be entered into a spreadsheet, database, text file, or directly into a statistical program like SPSS. Most statistical programs provide a data editor for entering data. However, these programs store data in their own native format (e.g., SPSS stores data as .sav files), which makes it difficult to share that data with other statistical programs. Hence, it is often better to enter data into a spreadsheet or database, where they can be reorganized as needed, shared across programs, and subsets of data can be extracted for analysis. Smaller data sets with less than 65,000 observations and 256 items can be stored in a spreadsheet such as Microsoft Excel, while larger dataset with millions of observations will require a database. Each observation can be entered as one row in the spreadsheet and each measurement item can be represented as one column. The entered data should be frequently checked for accuracy, via occasional spot checks on a set of items or observations, during and after entry. Furthermore, while entering data, the coder should watch out for obvious evidence of bad data, such as the respondent selecting the “strongly agree” response to all items irrespective of content, including reverse-coded items. If so, such data can be entered but should be excluded from subsequent analysis.
Missing values. Missing data is an inevitable part of any empirical data set. Respondents may not answer certain questions if they are ambiguously worded or too sensitive. Such problems should be detected earlier during pretests and corrected before the main data collection process begins. During data entry, some statistical programs automatically treat blank entries as missing values, while others require a specific numeric value such as -1 or 999 to be entered to denote a missing value. During data analysis, the default mode of handling missing values in most software programs is to simply drop the entire observation containing even a single missing value, in a technique called listwise deletion . Such deletion can significantly shrink the sample size and make it extremely difficult to detect small effects. Hence, some software programs allow the option of replacing missing values with an estimated value via a process called imputation . For instance, if the missing value is one item in a multi-item scale, the imputed value may be the average of the respondent’s responses to remaining items on that scale. If the missing value belongs to a single-item scale, many researchers use the average of other respondent’s responses to that item as the imputed value. Such imputation may be biased if the missing value is of a systematic nature rather than a random nature. Two methods that can produce relatively unbiased estimates for imputation are the maximum likelihood procedures and multiple imputation methods, both of which are supported in popular software programs such as SPSS and SAS.
Data transformation. Sometimes, it is necessary to transform data values before they can be meaningfully interpreted. For instance, reverse coded items, where items convey the opposite meaning of that of their underlying construct, should be reversed (e.g., in a 1-7 interval scale, 8 minus the observed value will reverse the value) before they can be compared or combined with items that are not reverse coded. Other kinds of transformations may include creating scale measures by adding individual scale items, creating a weighted index from a set of observed measures, and collapsing multiple values into fewer categories (e.g., collapsing incomes into income ranges).
Univariate Analysis
Univariate analysis, or analysis of a single variable, refers to a set of statistical techniques that can describe the general properties of one variable. Univariate statistics include: (1) frequency distribution, (2) central tendency, and (3) dispersion. The frequency distribution of a variable is a summary of the frequency (or percentages) of individual values or ranges of values for that variable. For instance, we can measure how many times a sample of respondents attend religious services (as a measure of their “religiosity”) using a categorical scale: never, once per year, several times per year, about once a month, several times per month, several times per week, and an optional category for “did not answer.” If we count the number (or percentage) of observations within each category (except “did not answer” which is really a missing value rather than a category), and display it in the form of a table as shown in Figure 14.1, what we have is a frequency distribution. This distribution can also be depicted in the form of a bar chart, as shown on the right panel of Figure 14.1, with the horizontal axis representing each category of that variable and the vertical axis representing the frequency or percentage of observations within each category.

Quantitative and qualitative research use different research methods to collect and analyze data, and they allow you to answer different kinds of research questions.

Quantitative and qualitative data can be collected using various methods. It is important to use a data collection method that will help answer your research question(s).
Many data collection methods can be either qualitative or quantitative. For example, in surveys, observational studies or case studies , your data can be represented as numbers (e.g., using rating scales or counting frequencies) or as words (e.g., with open-ended questions or descriptions of what you observe).
However, some methods are more commonly used in one type or the other.
Quantitative data collection methods
- Surveys : List of closed or multiple choice questions that is distributed to a sample (online, in person, or over the phone).
- Experiments : Situation in which different types of variables are controlled and manipulated to establish cause-and-effect relationships.
- Observations : Observing subjects in a natural environment where variables can’t be controlled.
Qualitative data collection methods
- Interviews : Asking open-ended questions verbally to respondents.
- Focus groups : Discussion among a group of people about a topic to gather opinions that can be used for further research.
- Ethnography : Participating in a community or organization for an extended period of time to closely observe culture and behavior.
- Literature review : Survey of published works by other authors.
A rule of thumb for deciding whether to use qualitative or quantitative data is:
- Use quantitative research if you want to confirm or test something (a theory or hypothesis )
- Use qualitative research if you want to understand something (concepts, thoughts, experiences)
For most research topics you can choose a qualitative, quantitative or mixed methods approach . Which type you choose depends on, among other things, whether you’re taking an inductive vs. deductive research approach ; your research question(s) ; whether you’re doing experimental , correlational , or descriptive research ; and practical considerations such as time, money, availability of data, and access to respondents.
Quantitative research approach
You survey 300 students at your university and ask them questions such as: “on a scale from 1-5, how satisfied are your with your professors?”
You can perform statistical analysis on the data and draw conclusions such as: “on average students rated their professors 4.4”.
Qualitative research approach
You conduct in-depth interviews with 15 students and ask them open-ended questions such as: “How satisfied are you with your studies?”, “What is the most positive aspect of your study program?” and “What can be done to improve the study program?”
Based on the answers you get you can ask follow-up questions to clarify things. You transcribe all interviews using transcription software and try to find commonalities and patterns.
Mixed methods approach
You conduct interviews to find out how satisfied students are with their studies. Through open-ended questions you learn things you never thought about before and gain new insights. Later, you use a survey to test these insights on a larger scale.
It’s also possible to start with a survey to find out the overall trends, followed by interviews to better understand the reasons behind the trends.
Qualitative or quantitative data by itself can’t prove or demonstrate anything, but has to be analyzed to show its meaning in relation to the research questions. The method of analysis differs for each type of data.
Analyzing quantitative data
Quantitative data is based on numbers. Simple math or more advanced statistical analysis is used to discover commonalities or patterns in the data. The results are often reported in graphs and tables.
Applications such as Excel, SPSS, or R can be used to calculate things like:
- Average scores ( means )
- The number of times a particular answer was given
- The correlation or causation between two or more variables
- The reliability and validity of the results
Analyzing qualitative data
Qualitative data is more difficult to analyze than quantitative data. It consists of text, images or videos instead of numbers.
Some common approaches to analyzing qualitative data include:
- Qualitative content analysis : Tracking the occurrence, position and meaning of words or phrases
- Thematic analysis : Closely examining the data to identify the main themes and patterns
- Discourse analysis : Studying how communication works in social contexts
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
A research project is an academic, scientific, or professional undertaking to answer a research question . Research projects can take many forms, such as qualitative or quantitative , descriptive , longitudinal , experimental , or correlational . What kind of research approach you choose will depend on your topic.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Streefkerk, R. (2023, June 22). Qualitative vs. Quantitative Research | Differences, Examples & Methods. Scribbr. Retrieved April 2, 2024, from https://www.scribbr.com/methodology/qualitative-quantitative-research/
Is this article helpful?

Raimo Streefkerk
Other students also liked, what is quantitative research | definition, uses & methods, what is qualitative research | methods & examples, mixed methods research | definition, guide & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
14 Quantitative analysis: Descriptive statistics
Numeric data collected in a research project can be analysed quantitatively using statistical tools in two different ways. Descriptive analysis refers to statistically describing, aggregating, and presenting the constructs of interest or associations between these constructs. Inferential analysis refers to the statistical testing of hypotheses (theory testing). In this chapter, we will examine statistical techniques used for descriptive analysis, and the next chapter will examine statistical techniques for inferential analysis. Much of today’s quantitative data analysis is conducted using software programs such as SPSS or SAS. Readers are advised to familiarise themselves with one of these programs for understanding the concepts described in this chapter.
Data preparation
In research projects, data may be collected from a variety of sources: postal surveys, interviews, pretest or posttest experimental data, observational data, and so forth. This data must be converted into a machine-readable, numeric format, such as in a spreadsheet or a text file, so that they can be analysed by computer programs like SPSS or SAS. Data preparation usually follows the following steps:
Data coding. Coding is the process of converting data into numeric format. A codebook should be created to guide the coding process. A codebook is a comprehensive document containing a detailed description of each variable in a research study, items or measures for that variable, the format of each item (numeric, text, etc.), the response scale for each item (i.e., whether it is measured on a nominal, ordinal, interval, or ratio scale, and whether this scale is a five-point, seven-point scale, etc.), and how to code each value into a numeric format. For instance, if we have a measurement item on a seven-point Likert scale with anchors ranging from ‘strongly disagree’ to ‘strongly agree’, we may code that item as 1 for strongly disagree, 4 for neutral, and 7 for strongly agree, with the intermediate anchors in between. Nominal data such as industry type can be coded in numeric form using a coding scheme such as: 1 for manufacturing, 2 for retailing, 3 for financial, 4 for healthcare, and so forth (of course, nominal data cannot be analysed statistically). Ratio scale data such as age, income, or test scores can be coded as entered by the respondent. Sometimes, data may need to be aggregated into a different form than the format used for data collection. For instance, if a survey measuring a construct such as ‘benefits of computers’ provided respondents with a checklist of benefits that they could select from, and respondents were encouraged to choose as many of those benefits as they wanted, then the total number of checked items could be used as an aggregate measure of benefits. Note that many other forms of data—such as interview transcripts—cannot be converted into a numeric format for statistical analysis. Codebooks are especially important for large complex studies involving many variables and measurement items, where the coding process is conducted by different people, to help the coding team code data in a consistent manner, and also to help others understand and interpret the coded data.
Data entry. Coded data can be entered into a spreadsheet, database, text file, or directly into a statistical program like SPSS. Most statistical programs provide a data editor for entering data. However, these programs store data in their own native format—e.g., SPSS stores data as .sav files—which makes it difficult to share that data with other statistical programs. Hence, it is often better to enter data into a spreadsheet or database where it can be reorganised as needed, shared across programs, and subsets of data can be extracted for analysis. Smaller data sets with less than 65,000 observations and 256 items can be stored in a spreadsheet created using a program such as Microsoft Excel, while larger datasets with millions of observations will require a database. Each observation can be entered as one row in the spreadsheet, and each measurement item can be represented as one column. Data should be checked for accuracy during and after entry via occasional spot checks on a set of items or observations. Furthermore, while entering data, the coder should watch out for obvious evidence of bad data, such as the respondent selecting the ‘strongly agree’ response to all items irrespective of content, including reverse-coded items. If so, such data can be entered but should be excluded from subsequent analysis.

Data transformation. Sometimes, it is necessary to transform data values before they can be meaningfully interpreted. For instance, reverse coded items—where items convey the opposite meaning of that of their underlying construct—should be reversed (e.g., in a 1-7 interval scale, 8 minus the observed value will reverse the value) before they can be compared or combined with items that are not reverse coded. Other kinds of transformations may include creating scale measures by adding individual scale items, creating a weighted index from a set of observed measures, and collapsing multiple values into fewer categories (e.g., collapsing incomes into income ranges).
Univariate analysis
Univariate analysis—or analysis of a single variable—refers to a set of statistical techniques that can describe the general properties of one variable. Univariate statistics include: frequency distribution, central tendency, and dispersion. The frequency distribution of a variable is a summary of the frequency—or percentages—of individual values or ranges of values for that variable. For instance, we can measure how many times a sample of respondents attend religious services—as a gauge of their ‘religiosity’—using a categorical scale: never, once per year, several times per year, about once a month, several times per month, several times per week, and an optional category for ‘did not answer’. If we count the number or percentage of observations within each category—except ‘did not answer’ which is really a missing value rather than a category—and display it in the form of a table, as shown in Figure 14.1, what we have is a frequency distribution. This distribution can also be depicted in the form of a bar chart, as shown on the right panel of Figure 14.1, with the horizontal axis representing each category of that variable and the vertical axis representing the frequency or percentage of observations within each category.

With very large samples, where observations are independent and random, the frequency distribution tends to follow a plot that looks like a bell-shaped curve—a smoothed bar chart of the frequency distribution—similar to that shown in Figure 14.2. Here most observations are clustered toward the centre of the range of values, with fewer and fewer observations clustered toward the extreme ends of the range. Such a curve is called a normal distribution .

Lastly, the mode is the most frequently occurring value in a distribution of values. In the previous example, the most frequently occurring value is 15, which is the mode of the above set of test scores. Note that any value that is estimated from a sample, such as mean, median, mode, or any of the later estimates are called a statistic .

Bivariate analysis
Bivariate analysis examines how two variables are related to one another. The most common bivariate statistic is the bivariate correlation —often, simply called ‘correlation’—which is a number between -1 and +1 denoting the strength of the relationship between two variables. Say that we wish to study how age is related to self-esteem in a sample of 20 respondents—i.e., as age increases, does self-esteem increase, decrease, or remain unchanged?. If self-esteem increases, then we have a positive correlation between the two variables, if self-esteem decreases, then we have a negative correlation, and if it remains the same, we have a zero correlation. To calculate the value of this correlation, consider the hypothetical dataset shown in Table 14.1.

After computing bivariate correlation, researchers are often interested in knowing whether the correlation is significant (i.e., a real one) or caused by mere chance. Answering such a question would require testing the following hypothesis:
![\[H_0:\quad r = 0 \]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-74bb8e9e674477ba33a9eb751bfd254d_l3.png "Rendered by QuickLaTeX.com")
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
At AllTheScience, we're committed to delivering accurate, trustworthy information. Our expert-authored content is rigorously fact-checked and sourced from credible authorities. Discover how we uphold the highest standards in providing you with reliable knowledge.
Learn more...
What Is a Quantitative Hypothesis?
A quantitative hypothesis contains a null and an alternative proposition that is either proved or disproved through statistical analysis. The process speculates that an independent variable affects a dependent variable and an experiment is conducted to see if there is a relationship between the two. This type of hypothesis is stated in numerical terms and has specific rules and limits. The null hypothesis is either rejected or accepted as a result of statistical data gathered during a set of experiments.
One of the main differences between a qualitative and a quantitative hypothesis is that it has very specific limits. An example of a null hypothesis might be "five additional hours of study time per week lead to a higher grade point average in college students." The alternative hypothesis would probably state "five additional hours of study time per week does not increase the grade point average of college students." In order to reject or accept the null hypothesis, experimental data would need to be recorded over a specified period of time.
Most studies that set out to test a quantitative hypothesis measure data based on statistical significance , which means there is a low possibility of error. In the case of proving or disproving the effect of study time on the grade point averages of college students, a control group would most likely be tested. The behaviors and environments of these groups are usually controlled by the researchers. Data would also be obtained from a group of students whose behaviors and environments were not controlled.
Since a quantitative hypothesis and research study rely on numerical data, the results of an experiment or surveys are translated into mathematical values. For example, many market research studies use scales that assign a numerical value to each response. A reply of "agree" may correspond to the number "4," while a response of "disagree" may correspond to the number "2." When all of the survey feedback is recorded and analyzed, a percentage based on the total amount of responses is then assigned to each number.
Statistical analysis is often used to examine the results of survey and experimental data. Whether the quantitative hypothesis is rejected or accepted is dependent on the numerical result of the analysis. For example, if the average grade point average must be at least 3.5 in order to prove that the amount of study time has a direct effect, an average of 3.45 would result in a rejection of the quantitative hypothesis.
AS FEATURED ON:
Related Articles
- What Are the Different Types of Quantitative Analysis Tools?
- What Is a Qualitative Experiment?
- What Is Quantitative Statistical Analysis?
- What Are the Different Types of Quantitative Research?
- What is Qualitative Research?
Discussion Comments
Post your comments.
- By: Andres Rodriguez Statistical analysis is often used to examine the results of survey and experimental data.
- Search Search Please fill out this field.
- Understanding QA
- Quantitative vs. Qualitative Analysis
Example of Quantitative Analysis in Finance
Drawbacks and limitations of quantitative analaysis, using quantitative finance outside of finance, the bottom line.
- Quantitative Analysis
Quantitative Analysis (QA): What It Is and How It's Used in Finance
:max_bytes(150000):strip_icc():format(webp)/wk_headshot_aug_2018_02__william_kenton-5bfc261446e0fb005118afc9.jpg "quantitative analysis hypothesis")
Ariel Courage is an experienced editor, researcher, and former fact-checker. She has performed editing and fact-checking work for several leading finance publications, including The Motley Fool and Passport to Wall Street.
:max_bytes(150000):strip_icc():format(webp)/ArielCourage-50e270c152b046738d83fb7355117d67.jpg "quantitative analysis hypothesis")
Investopedia / Hilary Allison
Quantitative analysis (QA) refers to methods used to understand the behavior of financial markets and make more informed investment or trading decisions. It involves the use of mathematical and statistical techniques to analyze financial data. For instance, by examining past stock prices, earnings reports, and other information, quantitative analysts, often called “ quants ,” aim to forecast where the market is headed.
Unlike fundamental analysis that might focus on a company's management team or industry conditions, quantitative analysis relies chiefly on crunching numbers and complex computations to derive actionable insights.
Quantitative analysis can be a powerful tool, especially in modern markets where data is abundant and computational tools are advanced, enabling a more precise examination of the financial landscape. However, many also believe that the raw numbers produced by quantitative analysis should be combined with the more in-depth understanding and nuance afforded by qualitative analysis .
Key Takeaways
- Quantitative analysis (QA) is a set of techniques that use mathematical and statistical modeling, measurement, and research to understand behavior.
- Quantitative analysis presents financial information in terms of a numerical value.
- It's used for the evaluation of financial instruments and for predicting real-world events such as changes in GDP.
- While powerful, quantitative analysis has some drawbacks that can be supplemented with qualitative analysis.
Understanding Quantitative Analysis
Quantitative analysis (QA) in finance refers to the use of mathematical and statistical techniques to analyze financial & economic data and make trading, investing, and risk management decisions.
QA starts with data collection, where quants gather a vast amount of financial data that might affect the market. This data can include anything from stock prices and company earnings to economic indicators like inflation or unemployment rates. They then use various mathematical models and statistical techniques to analyze this data, looking for trends, patterns, and potential investment opportunities. The outcome of this analysis can help investors decide where to allocate their resources to maximize returns or minimize risks.
Some key aspects of quantitative analysis in finance include:
- Statistical analysis - this aspect of quantitative analysis involves examining data to identify trends and relationships, build predictive models, and make forecasts. Techniques used can include regression analysis , which helps in understanding relationships between variables; time series analysis , which looks at data points collected or recorded at a specific time; and Monte Carlo simulations , a mathematical technique that allows you to account for uncertainty in your analyses and forecasts. Through statistical analysis, quants can uncover insights that may not be immediately apparent, helping investors and financial analysts make more informed decisions.
- Algorithmic trading - this entails using computer algorithms to automate the trading process. Algorithms can be programmed to carry out trades based on a variety of factors such as timing, price movements, liquidity changes, and other market signals. High-frequency trading (HFT), a type of algorithmic trading, involves making a large number of trades within fractions of a second to capitalize on small price movements. This automated approach to trading can lead to more efficient and often profitable trading strategies.
- Risk modeling - risk is an inherent part of financial markets. Risk modeling involves creating mathematical models to measure and quantify various risk exposures within a portfolio. Methods used in risk modeling include Value-at-Risk (VaR) models, scenario analysis , and stress testing . These tools help in understanding the potential downside and uncertainties associated with different investment scenarios, aiding in better risk management and mitigation strategies.
- Derivatives pricing - derivatives are financial contracts whose value is derived from other underlying assets like stocks or bonds. Derivatives pricing involves creating mathematical models to evaluate these contracts and determine their fair prices and risk profiles. A well-known model used in this domain is the Black-Scholes model , which helps in pricing options contracts . Accurate derivatives pricing is crucial for investors and traders to make sound financial decisions regarding buying, selling, or hedging with derivatives.
- Portfolio optimization - This is about constructing a portfolio in such a way that it yields the highest possible expected return for a given level of risk. Techniques like Modern Portfolio Theory (MPT) are employed to find the optimal allocation of assets within a portfolio. By analyzing various asset classes and their expected returns, risks, and correlations, quants can suggest the best mix of investments to achieve specific financial goals while minimizing risk.
The overall goal is to use data, math, statistics, and software to make more informed financial decisions, automate processes, and ultimately generate greater risk-adjusted returns.
Quantitative analysis is widely used in central banking, algorithmic trading, hedge fund management, and investment banking activities. Quantitative analysts, employ advanced skills in programming, statistics, calculus, linear algebra etc. to execute quantitative analysis.
Quantitative Analysis vs. Qualitative Analysis
Quantitative analysis relies heavily on numerical data and mathematical models to make decisions regarding investments and financial strategies. It focuses on the measurable, objective data that can be gathered about a company or a financial instrument.
But analysts also evaluate information that is not easily quantifiable or reduced to numeric values to get a better picture of a company's performance. This important qualitative data can include reputation, regulatory insights, or employee morale. Qualitative analysis thus focuses more on understanding the underlying qualities of a company or a financial instrument, which may not be immediately quantifiable.
Quantitative isn't the opposite of qualitative analysis. They're different and often complementary philosophies. They each provide useful information for informed decisions. When used together. better decisions can be made than using either one in isolation.
Some common uses of qualitative analysis include:
- Management Evaluation: Qualitative analysis is often better at evaluating a company's management team, their experience, and their ability to lead the company toward growth. While quantifiable metrics are useful, they often cannot capture the full picture of management's ability and potential. For example, the leadership skills, vision, and corporate culture instilled by management are intangible factors that can significantly impact a company's success, yet are difficult to measure with numbers alone.
- Industry Analysis: It also includes an analysis of the industry in which the company operates, the competition, and market conditions. For instance, it can explore how changes in technology or societal behaviors could impact the industry. Qualitative approaches can also better identify barriers to entry or exit, which can affect the level of competition and profitability within the industry.
- Brand Value and Company Reputation: The reputation of a company, its brand value, and customer loyalty are also significant factors considered in qualitative analysis. Understanding how consumers perceive the brand, their level of trust, and satisfaction can provide insights into customer loyalty and the potential for sustained revenue. This can be done through focus groups, surveys, or interviews.
- Regulatory Environment: The regulatory environment, potential legal issues, and other external factors that could impact a company are also analyzed qualitatively. Evaluating a company's compliance with relevant laws, regulations, and industry standards to ascertain its legal standing and the potential risk of legal issues. In addition, understanding a company's ethical practices and social responsibility initiatives, that can influence its relationship with stakeholders and the community at large.
Suppose you are interested in investing in a particular company, XYZ Inc. One way to evaluate its potential as an investment is by analyzing its past financial performance using quantitative analysis. Let's say, over the past five years, XYZ Inc. has been growing its revenue at an average rate of 8% per year. You decide to use regression analysis to forecast its future revenue growth. Regression analysis is a statistical method used to examine the relationship between variables.
After collecting the necessary data, you run a simple linear regression with the year as the independent variable and the revenue as the dependent variable. The output gives you a regression equation, let's say, R e v e n u e = 100 + 8 ( Y e a r ) Revenue=100+8(Year) R e v e n u e = 100 + 8 ( Y e a r ) . This equation suggests that for every year, the revenue of XYZ Inc. increases by $8 million, starting from a base of $100 million. This quantitative insight could be instrumental in helping you decide whether XYZ Inc. represents a good investment opportunity based on its historical revenue growth trend.
However, while you can quantify revenue growth for the firm and make predictions, the reasons for why may not be apparent from quantitative number crunching.
Augmenting with Qualitative Analysis
Qualitative analysis can provide a more nuanced understanding of XYZ Inc.'s potential. You decide to delve into the company's management and industry reputation. Through interviews, reviews, and industry reports, you find that the management team at XYZ Inc. is highly regarded with a track record of successful ventures. Moreover, the company has a strong brand value and a loyal customer base.
Additionally, you assess the industry in which XYZ Inc. operates and find it to be stable with a steady demand for the products that XYZ Inc. offers. The regulatory environment is also favorable, and the company has a good relationship with the local communities in which it operates.
By analyzing these qualitative factors, you obtain a more comprehensive understanding of the company's operational environment, the competence of its management team, and its reputation in the market. This qualitative insight complements the quantitative analysis, providing you with a well-rounded view of XYZ Inc.'s investment potential.
Combining both quantitative and qualitative analyses could therefore lead to a more informed investment decision regarding XYZ Inc.
Quantitative analysis, while powerful, comes with certain limitations:
- Data Dependency: Quantitative analysis is heavily dependent on the quality and availability of numerical data. If the data is inaccurate, outdated, or incomplete, the analysis and the subsequent conclusions drawn will be flawed. As they say, 'garbage-in, garbage-out'.
- Complexity: The methods and models used in quantitative analysis can be very complex, requiring a high level of expertise to develop, interpret, and act upon. This complexity can also make it difficult to communicate findings to individuals who lack a quantitative background.
- Lack of Subjectivity: Quantitative analysis often overlooks qualitative factors like management quality, brand reputation, and other subjective factors that can significantly affect a company's performance or a financial instrument's value. In other words, you may have the 'what' without the 'why' or 'how.' Qualitative analysis can augment this blind spot.
- Assumption-based Modeling: Many quantitative models are built on assumptions that may not hold true in real-world situations. For example, assumptions about normal distribution of returns or constant volatility may not reflect actual market conditions.
- Over-reliance on Historical Data: Quantitative analysis often relies heavily on historical data to make predictions about the future. However, past performance is not always indicative of future results, especially in rapidly changing markets or unforeseen situations like economic crises.
- Inability to Capture Human Emotion and Behavior: Markets are often influenced by human emotions and behaviors which can be erratic and hard to predict. Quantitative analysis, being number-driven, struggles to properly account for these human factors.
- Cost and Time Intensive: Developing accurate and reliable quantitative models can be time-consuming and expensive. It requires skilled personnel, sophisticated software tools, and often, extensive computational resources.
- Overfitting: There's a risk of overfitting , where a model might perform exceedingly well on past data but fails to predict future outcomes accurately because it's too tailored to past events.
- Lack of Flexibility: Quantitative models may lack the flexibility to adapt to new information or changing market conditions quickly, which can lead to outdated or incorrect analysis.
- Model Risk: There's inherent model risk involved where the model itself may have flaws or errors that can lead to incorrect analysis and potentially significant financial losses.
Understanding these drawbacks is crucial for analysts and decision-makers to interpret quantitative analysis results accurately and to balance them with qualitative insights for more holistic decision-making.
Quantitative analysis is a versatile tool that extends beyond the realm of finance into a variety of fields. In the domain of social sciences, for instance, it's used to analyze behavioral patterns, social trends, and the impact of policies on different demographics. Researchers employ statistical models to examine large datasets, enabling them to identify correlations, causations, and trends that can provide a deeper understanding of human behaviors and societal dynamics. Similarly, in the field of public policy, quantitative analysis plays a crucial role in evaluating the effectiveness of different policies, analyzing economic indicators, and forecasting the potential impacts of policy changes. By providing a method to measure and analyze data, it aids policymakers in making informed decisions based on empirical evidence.
In the arena of healthcare, quantitative analysis is employed for clinical trials, genetic research, and epidemiological studies to name a few areas. It assists in analyzing patient data, evaluating treatment outcomes, and understanding disease spread and its determinants. Meanwhile, in engineering and manufacturing, it's used to optimize processes, improve quality control, and enhance operational efficiency. By analyzing data related to production processes, material properties, and operational performance, engineers can identify bottlenecks, optimize workflows, and ensure the reliability and quality of products. Additionally, in the field of marketing, quantitative analysis is fundamental for market segmentation, advertising effectiveness, and consumer satisfaction studies. It helps marketers understand consumer preferences, the impact of advertising campaigns, and the market potential for new products. Through these diverse applications, quantitative analysis serves as a bedrock for data-driven decision-making, enabling professionals across different fields to derive actionable insights from complex data.
What Is Quantitative Analysis Used for in Finance?
Quantitative analysis is used by governments, investors, and businesses (in areas such as finance, project management, production planning, and marketing) to study a certain situation or event, measure it, predict outcomes, and thus help in decision-making. In finance, it's widely used for assessing investment opportunities and risks. For instance, before venturing into investments, analysts rely on quantitative analysis to understand the performance metrics of different financial instruments such as stocks, bonds, and derivatives. By delving into historical data and employing mathematical and statistical models, they can forecast potential future performance and evaluate the underlying risks. This practice isn't just confined to individual assets; it's also essential for portfolio management. By examining the relationships between different assets and assessing their risk and return profiles, investors can construct portfolios that are optimized for the highest possible returns for a given level of risk.
What Kind of Education Do You Need to Be a Quant?
Individuals pursuing a career in quantitative analysis usually have a strong educational background in quantitative fields like mathematics, statistics, computer science, finance, economics, or engineering. Advanced degrees (Master’s or Ph.D.) in quantitative disciplines are often preferred, and additional coursework or certifications in finance and programming can also be beneficial.
What Is the Difference Between Quantitative Analysis and Fundamental Analysis?
While both rely on the use of math and numbers, fundamental analysis takes a broader approach by examining the intrinsic value of a security. It dives into a company's financial statements, industry position, the competence of the management team, and the economic environment in which it operates. By evaluating factors like earnings, dividends, and the financial health of a company, fundamental analysts aim to ascertain the true value of a security and whether it is undervalued or overvalued in the market. This form of analysis is more holistic and requires a deep understanding of the company and the industry in which it operates.
How Does Artificial Intelligence (AI) Influence Quantitative Analysis?
Quantitative analysis often intersects with machine learning (ML) and other forms of artificial intelligence (AI). ML and AI can be employed to develop predictive models and algorithms based on the quantitative data. These technologies can automate the analysis process, handle large datasets, and uncover complex patterns or trends that might be difficult to detect through traditional quantitative methods.
Quantitative analysis is a mathematical approach that collects and evaluates measurable and verifiable data in order to evaluate performance, make better decisions, and predict trends. Unlike qualitative analysis, quantitative analysis uses numerical data to provide an explanation of "what" happened, but not "why" those events occurred.
DeFusco, R. A., McLeavey, D. W., Pinto, J. E., Runkle, D. E., & Anson, M. J. (2015). Quantitative investment analysis . John Wiley & Sons.
University of Sydney. " On Becoming a Quant ," Page 1
Linsmeier, Thomas J., and Neil D. Pearson. " Value at risk ." Financial analysts journal 56, no. 2 (2000): 47-67.
Fischer, Black, and Myron Scholes, " The Pricing of Options and Corporate Liabilities ." Journal of Political Economy, vol. 81, no. 3, 1974, pp. 637-654.
Francis, J. C., & Kim, D. (2013). Modern portfolio theory: Foundations, analysis, and new developments . John Wiley & Sons.
Kaczynski, D., Salmona, M., & Smith, T. (2014). " Qualitative research in finance ." Australian Journal of Management , 39 (1), 127-135.
:max_bytes(150000):strip_icc():format(webp)/Primary-Image-how-to-invest-in-commodities-7480946-604a7bbb3a9a4273af6b8db20586981a.jpg "quantitative analysis hypothesis")
- Terms of Service
- Editorial Policy
- Privacy Policy
- Your Privacy Choices
IMAGES
VIDEO
COMMENTS
Hypothesis-testing (Quantitative hypothesis-testing research) - Quantitative research uses deductive reasoning. - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses.
5 Hypothesis Testing in Quantitative Research . Mikaila Mariel Lemonik Arthur. Statistical reasoning is built on the assumption that data are normally distributed, meaning that they will be distributed in the shape of a bell curve as discussed in the chapter on Univariate Analysis.While real life often—perhaps even usually—does not resemble a bell curve, basic statistical analysis assumes ...
There are 5 main steps in hypothesis testing: State your research hypothesis as a null hypothesis and alternate hypothesis (H o) and (H a or H 1 ). Collect data in a way designed to test the hypothesis. Perform an appropriate statistical test. Decide whether to reject or fail to reject your null hypothesis. Present the findings in your results ...
5. Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable. If a first-year student starts attending more lectures, then their exam scores will improve.
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
Hypotheses are the testable statements linked to your research question. Hypotheses bridge the gap from the general question you intend to investigate (i.e., the research question) to concise statements of what you hypothesize the connection between your variables to be. For example, if we were studying the influence of mentoring relationships ...
Data analysis should be straightforward if researchers have taken the time to clearly articulate their research hypothesis(ses). If a research hypothesis is clearly stated at the time the study is designed, the hypothesis itself directs the researcher to the appropriate analysis (or at least category of analyses).
Hypothesis testing can be confusing because the researcher must assume no difference or relationship between variables until proven to the contrary. This process involves creating two hypotheses: a null hypothesis and an alternative hypothesis. ... Pugliese A, Recker J (2018) Quantitative data analysis, research methods: information, systems ...
Revised on 10 October 2022. Quantitative research is the process of collecting and analysing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalise results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and ...
Hypothesis testing (sometimes called significance testing) in quantitative research is conducted on either the "null" or the "alternative" hypothesis. 8.1 The Null Hypothesis. The null hypothesis is a statement that assumes the problem being investigated is absent or has no effect (i.e., the difference between means equals zero).
Quantitative data analysis is one of those things that often strikes fear in students. It's totally understandable - quantitative analysis is a complex topic, full of daunting lingo, like medians, modes, correlation and regression.Suddenly we're all wishing we'd paid a little more attention in math class…. The good news is that while quantitative data analysis is a mammoth topic ...
The presence of multiple research questions in a study can complicate the design, statistical analysis, and feasibility. It's advisable to focus on a single primary research question for the study. The primary question, clearly stated at the end of a grant proposal's introduction, usually specifies the study population, intervention, and ...
Alternative hypothesis (HA) or (H1): this is sometimes called the research hypothesis or experimental hypothesis. It is the proposition that there will be a relationship. It is a statement of inequality between the variables you are interested in. They always refer to the sample. It is usually a declaration rather than a question and is clear ...
When creating tables to display the results of quantitative analysis, the most important goals are to create tables that are clear and concise but that also meet standard conventions in the field. This means, first of all, paring down the volume of information produced in the statistical output to just include the information most necessary for ...
Statistical analysis is the most common quantitative research analysis method. It involves using statistical tools and techniques to analyze the numerical data collected during the research process. Statistical analysis can be used to identify patterns, trends, and relationships between variables, and to test hypotheses and theories.
STEP 3: Calculate sample parameters and the test statistic. The sample parameters are provided, the sample mean is 7.91 and the sample variance is .03 and the sample size is 35. We need to note that the sample variance was provided not the sample standard deviation, which is what we need for the formula.
In this chapter, we look at the different stages of data preparation involved in quantitative analysis. Understanding these processes will help us gather reliable data and reach a valid conclusion. We will discuss types of hypotheses and how they are stated mathematically. Furthermore, we shall discuss hypothesis testing with worked examples.
For most statistical analysis, α is set to 0.05. A p-value less than α=0.05 indicates that we have enough statistical evidence to reject the null hypothesis, and thereby, indirectly accept the alternative hypothesis. If p>0.05, then we do not have adequate statistical evidence to reject the null hypothesis or accept the alternative hypothesis.
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge. Quantitative research. Quantitative research is expressed in numbers and graphs. It is used to test or confirm theories and assumptions.
For most statistical analysis, is set to 0.05. A -value less than indicates that we have enough statistical evidence to reject the null hypothesis, and thereby, indirectly accept the alternative hypothesis. If , then we do not have adequate statistical evidence to reject the null hypothesis or accept the alternative hypothesis.
A quantitative hypothesis contains a null and an alternative proposition that is either proved or disproved through statistical analysis. The process speculates that an independent variable affects a dependent variable and an experiment is conducted to see if there is a relationship between the two. This type of hypothesis is stated in numerical terms and has specific rules and limits.
Quantitative analysis refers to economic, business or financial analysis that aims to understand or predict behavior or events through the use of mathematical measurements and calculations ...
The applicability of remote sensing enables the prediction of nutritional value, phytosanitary conditions, and productivity of crops in a non-destructive manner, with greater efficiency than conventional techniques. By identifying problems early and providing specific management recommendations in bean cultivation, farmers can reduce crop losses, provide more accurate and adequate diagnoses ...