Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.

2.1 How Humans Produce Speech
Phonetics studies human speech. Speech is produced by bringing air from the lungs to the larynx (respiration), where the vocal folds may be held open to allow the air to pass through or may vibrate to make a sound (phonation). The airflow from the lungs is then shaped by the articulators in the mouth and nose (articulation).
Check Yourself
Video script.
The field of phonetics studies the sounds of human speech. When we study speech sounds we can consider them from two angles. Acoustic phonetics , in addition to being part of linguistics, is also a branch of physics. It’s concerned with the physical, acoustic properties of the sound waves that we produce. We’ll talk some about the acoustics of speech sounds, but we’re primarily interested in articulatory phonetics , that is, how we humans use our bodies to produce speech sounds. Producing speech needs three mechanisms.
The first is a source of energy. Anything that makes a sound needs a source of energy. For human speech sounds, the air flowing from our lungs provides energy.
The second is a source of the sound: air flowing from the lungs arrives at the larynx. Put your hand on the front of your throat and gently feel the bony part under your skin. That’s the front of your larynx . It’s not actually made of bone; it’s cartilage and muscle. This picture shows what the larynx looks like from the front.

This next picture is a view down a person’s throat.

What you see here is that the opening of the larynx can be covered by two triangle-shaped pieces of skin. These are often called “vocal cords” but they’re not really like cords or strings. A better name for them is vocal folds .
The opening between the vocal folds is called the glottis .
We can control our vocal folds to make a sound. I want you to try this out so take a moment and close your door or make sure there’s no one around that you might disturb.
First I want you to say the word “uh-oh”. Now say it again, but stop half-way through, “Uh-”. When you do that, you’ve closed your vocal folds by bringing them together. This stops the air flowing through your vocal tract. That little silence in the middle of “uh-oh” is called a glottal stop because the air is stopped completely when the vocal folds close off the glottis.
Now I want you to open your mouth and breathe out quietly, “haaaaaaah”. When you do this, your vocal folds are open and the air is passing freely through the glottis.
Now breathe out again and say “aaah”, as if the doctor is looking down your throat. To make that “aaaah” sound, you’re holding your vocal folds close together and vibrating them rapidly.
When we speak, we make some sounds with vocal folds open, and some with vocal folds vibrating. Put your hand on the front of your larynx again and make a long “SSSSS” sound. Now switch and make a “ZZZZZ” sound. You can feel your larynx vibrate on “ZZZZZ” but not on “SSSSS”. That’s because [s] is a voiceless sound, made with the vocal folds held open, and [z] is a voiced sound, where we vibrate the vocal folds. Do it again and feel the difference between voiced and voiceless.
Now take your hand off your larynx and plug your ears and make the two sounds again with your ears plugged. You can hear the difference between voiceless and voiced sounds inside your head.
I said at the beginning that there are three crucial mechanisms involved in producing speech, and so far we’ve looked at only two:
- Energy comes from the air supplied by the lungs.
- The vocal folds produce sound at the larynx.
- The sound is then filtered, or shaped, by the articulators .
The oral cavity is the space in your mouth. The nasal cavity, obviously, is the space inside and behind your nose. And of course, we use our tongues, lips, teeth and jaws to articulate speech as well. In the next unit, we’ll look in more detail at how we use our articulators.
So to sum up, the three mechanisms that we use to produce speech are:
- respiration at the lungs,
- phonation at the larynx, and
- articulation in the mouth.
Essentials of Linguistics Copyright © 2018 by Catherine Anderson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Speech Production
- Reference work entry
- First Online: 01 January 2015
- pp 1493–1498
- Cite this reference work entry

- Laura Docio-Fernandez 3 &
- Carmen García Mateo 4
1213 Accesses
3 Altmetric
Sound generation; Speech system
Speech production is the process of uttering articulated sounds or words, i.e., how humans generate meaningful speech. It is a complex feedback process in which hearing, perception, and information processing in the nervous system and the brain are also involved.
Speaking is in essence the by-product of a necessary bodily process, the expulsion from the lungs of air charged with carbon dioxide after it has fulfilled its function in respiration. Most of the time, one breathes out silently; but it is possible, by contracting and relaxing the vocal tract, to change the characteristics of the air expelled from the lungs.
Introduction
Speech is one of the most natural forms of communication for human beings. Researchers in speech technology are working on developing systems with the ability to understand speech and speak with a human being.
Human-computer interaction is a discipline concerned with the design, evaluation, and implementation...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
T. Hewett, R. Baecker, S. Card, T. Carey, J. Gasen, M. Mantei, G. Perlman, G. Strong, W. Verplank, Chapter 2: Human-computer interaction, in ACM SIGCHI Curricula for Human-Computer Interaction ed. by B. Hefley (ACM, 2007)
Google Scholar
G. Fant, Acoustic Theory of Speech Production , 1st edn. (Mouton, The Hague, 1960)
G. Fant, Glottal flow: models and interaction. J. Phon. 14 , 393–399 (1986)
R.D. Kent, S.G. Adams, G.S. Turner, Models of speech production, in Principles of Experimental Phonetics , ed. by N.J. Lass (Mosby, St. Louis, 1996), pp. 2–45
T.L. Burrows, Speech Processing with Linear and Neural Network Models (1996)
J.R. Deller, J.G. Proakis, J.H.L. Hansen, Discrete-Time Processing of Speech Signals , 1st edn. (Macmillan, New York, 1993)
Download references
Author information
Authors and affiliations.
Department of Signal Theory and Communications, University of Vigo, Vigo, Spain
Laura Docio-Fernandez
Atlantic Research Center for Information and Communication Technologies, University of Vigo, Pontevedra, Spain
Carmen García Mateo
You can also search for this author in PubMed Google Scholar
Editor information
Editors and affiliations.
Center for Biometrics and Security, Research & National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing, China
Departments of Computer Science and Engineering, Michigan State University, East Lansing, MI, USA
Anil K. Jain
Rights and permissions
Reprints and permissions
Copyright information
© 2015 Springer Science+Business Media New York
About this entry
Cite this entry.
Docio-Fernandez, L., García Mateo, C. (2015). Speech Production. In: Li, S.Z., Jain, A.K. (eds) Encyclopedia of Biometrics. Springer, Boston, MA. https://doi.org/10.1007/978-1-4899-7488-4_199
Download citation
DOI : https://doi.org/10.1007/978-1-4899-7488-4_199
Published : 03 July 2015
Publisher Name : Springer, Boston, MA
Print ISBN : 978-1-4899-7487-7
Online ISBN : 978-1-4899-7488-4
eBook Packages : Computer Science Reference Module Computer Science and Engineering
Share this entry
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Subject List
- Take a Tour
- For Authors
- Subscriber Services
- Publications
- African American Studies
- African Studies
- American Literature
- Anthropology
- Architecture Planning and Preservation
- Art History
- Atlantic History
- Biblical Studies
- British and Irish Literature
- Childhood Studies
- Chinese Studies
- Cinema and Media Studies
- Communication
- Criminology
- Environmental Science
- Evolutionary Biology
- International Law
- International Relations
- Islamic Studies
- Jewish Studies
- Latin American Studies
- Latino Studies
Linguistics
- Literary and Critical Theory
- Medieval Studies
- Military History
- Political Science
- Public Health
- Renaissance and Reformation
- Social Work
- Urban Studies
- Victorian Literature
- Browse All Subjects
How to Subscribe
- Free Trials
In This Article Expand or collapse the "in this article" section Speech Production
Introduction.
- Historical Studies
- Animal Studies
- Evolution and Development
- Functional Magnetic Resonance and Positron Emission Tomography
- Electroencephalography and Other Approaches
- Theoretical Models
- Speech Apparatus
- Speech Disorders
Related Articles Expand or collapse the "related articles" section about
About related articles close popup.
Lorem Ipsum Sit Dolor Amet
Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Aliquam ligula odio, euismod ut aliquam et, vestibulum nec risus. Nulla viverra, arcu et iaculis consequat, justo diam ornare tellus, semper ultrices tellus nunc eu tellus.
- Acoustic Phonetics
- Animal Communication
- Articulatory Phonetics
- Biology of Language
- Clinical Linguistics
- Cognitive Mechanisms for Lexical Access
- Cross-Language Speech Perception and Production
- Dementia and Language
- Early Child Phonology
- Interface Between Phonology and Phonetics
- Khoisan Languages
- Language Acquisition
- Speech Perception
- Speech Synthesis
- Voice and Voice Quality
Other Subject Areas
Forthcoming articles expand or collapse the "forthcoming articles" section.
- Cognitive Grammar
- Edward Sapir
- Find more forthcoming articles...
- Export Citations
- Share This Facebook LinkedIn Twitter
Speech Production by Eryk Walczak LAST REVIEWED: 22 February 2018 LAST MODIFIED: 22 February 2018 DOI: 10.1093/obo/9780199772810-0217
Speech production is one of the most complex human activities. It involves coordinating numerous muscles and complex cognitive processes. The area of speech production is related to Articulatory Phonetics , Acoustic Phonetics and Speech Perception , which are all studying various elements of language and are part of a broader field of Linguistics . Because of the interdisciplinary nature of the current topic, it is usually studied on several levels: neurological, acoustic, motor, evolutionary, and developmental. Each of these levels has its own literature but in the vast majority of speech production literature, each of these elements will be present. The large body of relevant literature is covered in the speech perception entry on which this bibliography builds upon. This entry covers general speech production mechanisms and speech disorders. However, speech production in second language learners or bilinguals has special features which were described in separate bibliography on Cross-Language Speech Perception and Production . Speech produces sounds, and sounds are a topic of study for Phonology .
As mentioned in the introduction, speech production tends to be described in relation to acoustics, speech perception, neuroscience, and linguistics. Because of this interdisciplinarity, there are not many published textbooks focusing exclusively on speech production. Guenther 2016 and Levelt 1993 are the exceptions. The former has a stronger focus on the neuroscientific underpinnings of speech. Auditory neuroscience is also extensively covered by Schnupp, et al. 2011 and in the extensive textbook Hickok and Small 2015 . Rosen and Howell 2011 is a textbook focusing on signal processing and acoustics which are necessary to understand by any speech scientist. A historical approach to psycholinguistics which also covers speech research is Levelt 2013 .
Guenther, F. H. 2016. Neural control of speech . Cambridge, MA: MIT.
This textbook provides an overview of neural processes responsible for speech production. Large sections describe speech motor control, especially the DIVA model (co-authored by Guenther). It includes extensive coverage of behavioral and neuroimaging studies of speech as well as speech disorders and ties them together with a unifying theoretical framework.
Hickok, G., and S. L. Small. 2015. Neurobiology of language . London: Academic Press.
This voluminous textbook edited by Hickok and Small covers a wide range of topics related to neurobiology of language. It includes a section devoted to speaking which covers neurobiology of speech production, motor control perspective, neuroimaging studies, and aphasia.
Levelt, W. J. M. 1993. Speaking: From intention to articulation . Cambridge, MA: MIT.
A seminal textbook Speaking is worth reading particularly for its detailed explanation of the author’s speech model, which is part of the author’s language model. The book is slightly dated, as it was released in 1993, but chapters 8–12 are especially relevant to readers interested in phonetic plans, articulating, and self-monitoring.
Levelt, W. J. M. 2013. A history of psycholinguistics: The pre-Chomskyan era . Oxford: Oxford University Press.
Levelt published another important book detailing the development of psycholinguistics. As its title suggests, it focuses on the early history of discipline, so readers interested in historical research on speech can find an abundance of speech-related research in that book. It covers a wide range of psycholinguistic specializations.
Rosen, S., and P. Howell. 2011. Signals and Systems for Speech and Hearing . 2d ed. Bingley, UK: Emerald.
Rosen and Howell provide a low-level explanation of speech signals and systems. The book includes informative charts explaining the basic acoustic and signal processing concepts useful for understanding speech science.
Schnupp, J., I. Nelken, and A. King. 2011. Auditory neuroscience: Making sense of sound . Cambridge, MA: MIT.
A general introduction to speech concepts with main focus on neuroscience. The textbook is linked with a website which provides a demonstration of described phenomena.
back to top
Users without a subscription are not able to see the full content on this page. Please subscribe or login .
Oxford Bibliographies Online is available by subscription and perpetual access to institutions. For more information or to contact an Oxford Sales Representative click here .
- About Linguistics »
- Meet the Editorial Board »
- Acceptability Judgments
- Accessibility Theory in Linguistics
- Acquisition, Second Language, and Bilingualism, Psycholin...
- Adpositions
- African Linguistics
- Afroasiatic Languages
- Algonquian Linguistics
- Altaic Languages
- Ambiguity, Lexical
- Analogy in Language and Linguistics
- Applicatives
- Applied Linguistics, Critical
- Arawak Languages
- Argument Structure
- Artificial Languages
- Australian Languages
- Austronesian Linguistics
- Auxiliaries
- Balkans, The Languages of the
- Baudouin de Courtenay, Jan
- Berber Languages and Linguistics
- Bilingualism and Multilingualism
- Borrowing, Structural
- Caddoan Languages
- Caucasian Languages
- Celtic Languages
- Celtic Mutations
- Chomsky, Noam
- Chumashan Languages
- Classifiers
- Clauses, Relative
- Cognitive Linguistics
- Colonial Place Names
- Comparative Reconstruction in Linguistics
- Comparative-Historical Linguistics
- Complementation
- Complexity, Linguistic
- Compositionality
- Compounding
- Computational Linguistics
- Conditionals
- Conjunctions
- Connectionism
- Consonant Epenthesis
- Constructions, Verb-Particle
- Contrastive Analysis in Linguistics
- Conversation Analysis
- Conversation, Maxims of
- Conversational Implicature
- Cooperative Principle
- Coordination
- Creoles, Grammatical Categories in
- Critical Periods
- Cyberpragmatics
- Default Semantics
- Definiteness
- Dene (Athabaskan) Languages
- Dené-Yeniseian Hypothesis, The
- Dependencies
- Dependencies, Long Distance
- Derivational Morphology
- Determiners
- Dialectology
- Distinctive Features
- Dravidian Languages
- Endangered Languages
- English as a Lingua Franca
- English, Early Modern
- English, Old
- Eskimo-Aleut
- Euphemisms and Dysphemisms
- Evidentials
- Exemplar-Based Models in Linguistics
- Existential
- Existential Wh-Constructions
- Experimental Linguistics
- Fieldwork, Sociolinguistic
- Finite State Languages
- First Language Attrition
- Formulaic Language
- Francoprovençal
- French Grammars
- Gabelentz, Georg von der
- Genealogical Classification
- Generative Syntax
- Genetics and Language
- Grammar, Categorial
- Grammar, Construction
- Grammar, Descriptive
- Grammar, Functional Discourse
- Grammars, Phrase Structure
- Grammaticalization
- Harris, Zellig
- Heritage Languages
- History of Linguistics
- History of the English Language
- Hmong-Mien Languages
- Hokan Languages
- Humor in Language
- Hungarian Vowel Harmony
- Idiom and Phraseology
- Imperatives
- Indefiniteness
- Indo-European Etymology
- Inflected Infinitives
- Information Structure
- Interjections
- Iroquoian Languages
- Isolates, Language
- Jakobson, Roman
- Japanese Word Accent
- Jones, Daniel
- Juncture and Boundary
- Kiowa-Tanoan Languages
- Kra-Dai Languages
- Labov, William
- Language and Law
- Language Contact
- Language Documentation
- Language, Embodiment and
- Language for Specific Purposes/Specialized Communication
- Language, Gender, and Sexuality
- Language Geography
- Language Ideologies and Language Attitudes
- Language in Autism Spectrum Disorders
- Language Nests
- Language Revitalization
- Language Shift
- Language Standardization
- Language, Synesthesia and
- Languages of Africa
- Languages of the Americas, Indigenous
- Languages of the World
- Learnability
- Lexical Access, Cognitive Mechanisms for
- Lexical Semantics
- Lexical-Functional Grammar
- Lexicography
- Lexicography, Bilingual
- Linguistic Accommodation
- Linguistic Anthropology
- Linguistic Areas
- Linguistic Landscapes
- Linguistic Prescriptivism
- Linguistic Profiling and Language-Based Discrimination
- Linguistic Relativity
- Linguistics, Educational
- Listening, Second Language
- Literature and Linguistics
- Machine Translation
- Maintenance, Language
- Mande Languages
- Mass-Count Distinction
- Mathematical Linguistics
- Mayan Languages
- Mental Health Disorders, Language in
- Mental Lexicon, The
- Mesoamerican Languages
- Minority Languages
- Mixed Languages
- Mixe-Zoquean Languages
- Modification
- Mon-Khmer Languages
- Morphological Change
- Morphology, Blending in
- Morphology, Subtractive
- Munda Languages
- Muskogean Languages
- Nasals and Nasalization
- Niger-Congo Languages
- Non-Pama-Nyungan Languages
- Northeast Caucasian Languages
- Oceanic Languages
- Papuan Languages
- Penutian Languages
- Philosophy of Language
- Phonetics, Acoustic
- Phonetics, Articulatory
- Phonological Research, Psycholinguistic Methodology in
- Phonology, Computational
- Phonology, Early Child
- Policy and Planning, Language
- Politeness in Language
- Positive Discourse Analysis
- Possessives, Acquisition of
- Pragmatics, Acquisition of
- Pragmatics, Cognitive
- Pragmatics, Computational
- Pragmatics, Cross-Cultural
- Pragmatics, Developmental
- Pragmatics, Experimental
- Pragmatics, Game Theory in
- Pragmatics, Historical
- Pragmatics, Institutional
- Pragmatics, Second Language
- Pragmatics, Teaching
- Prague Linguistic Circle, The
- Presupposition
- Psycholinguistics
- Quechuan and Aymaran Languages
- Reading, Second-Language
- Reciprocals
- Reduplication
- Reflexives and Reflexivity
- Register and Register Variation
- Relevance Theory
- Representation and Processing of Multi-Word Expressions in...
- Salish Languages
- Sapir, Edward
- Saussure, Ferdinand de
- Second Language Acquisition, Anaphora Resolution in
- Semantic Maps
- Semantic Roles
- Semantic-Pragmatic Change
- Semantics, Cognitive
- Sentence Processing in Monolingual and Bilingual Speakers
- Sign Language Linguistics
- Sociolinguistics
- Sociolinguistics, Variationist
- Sociopragmatics
- Sound Change
- South American Indian Languages
- Specific Language Impairment
- Speech, Deceptive
- Speech Production
- Switch-Reference
- Syntactic Change
- Syntactic Knowledge, Children’s Acquisition of
- Tense, Aspect, and Mood
- Text Mining
- Tone Sandhi
- Transcription
- Transitivity and Voice
- Translanguaging
- Translation
- Trubetzkoy, Nikolai
- Tucanoan Languages
- Tupian Languages
- Usage-Based Linguistics
- Uto-Aztecan Languages
- Valency Theory
- Verbs, Serial
- Vocabulary, Second Language
- Vowel Harmony
- Whitney, William Dwight
- Word Classes
- Word Formation in Japanese
- Word Recognition, Spoken
- Word Recognition, Visual
- Word Stress
- Writing, Second Language
- Writing Systems
- Zapotecan Languages
- Privacy Policy
- Cookie Policy
- Legal Notice
- Accessibility
Powered by:
- [66.249.64.20|45.133.227.243]
- 45.133.227.243
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 31 January 2024
Single-neuronal elements of speech production in humans
- Arjun R. Khanna ORCID: orcid.org/0000-0003-0677-5598 1 na1 ,
- William Muñoz ORCID: orcid.org/0000-0002-1354-3472 1 na1 ,
- Young Joon Kim 2 na1 ,
- Yoav Kfir 1 ,
- Angelique C. Paulk ORCID: orcid.org/0000-0002-4413-3417 3 ,
- Mohsen Jamali ORCID: orcid.org/0000-0002-1750-7591 1 ,
- Jing Cai ORCID: orcid.org/0000-0002-2970-0567 1 ,
- Martina L. Mustroph 1 ,
- Irene Caprara 1 ,
- Richard Hardstone ORCID: orcid.org/0000-0002-7502-9145 3 ,
- Mackenna Mejdell 1 ,
- Domokos Meszéna ORCID: orcid.org/0000-0003-4042-2542 3 ,
- Abigail Zuckerman 2 ,
- Jeffrey Schweitzer ORCID: orcid.org/0000-0003-4079-0791 1 ,
- Sydney Cash ORCID: orcid.org/0000-0002-4557-6391 3 na2 &
- Ziv M. Williams ORCID: orcid.org/0000-0002-0017-0048 1 , 4 , 5 na2
Nature volume 626 , pages 603–610 ( 2024 ) Cite this article
24k Accesses
4 Citations
476 Altmetric
Metrics details
- Extracellular recording
Humans are capable of generating extraordinarily diverse articulatory movement combinations to produce meaningful speech. This ability to orchestrate specific phonetic sequences, and their syllabification and inflection over subsecond timescales allows us to produce thousands of word sounds and is a core component of language 1 , 2 . The fundamental cellular units and constructs by which we plan and produce words during speech, however, remain largely unknown. Here, using acute ultrahigh-density Neuropixels recordings capable of sampling across the cortical column in humans, we discover neurons in the language-dominant prefrontal cortex that encoded detailed information about the phonetic arrangement and composition of planned words during the production of natural speech. These neurons represented the specific order and structure of articulatory events before utterance and reflected the segmentation of phonetic sequences into distinct syllables. They also accurately predicted the phonetic, syllabic and morphological components of upcoming words and showed a temporally ordered dynamic. Collectively, we show how these mixtures of cells are broadly organized along the cortical column and how their activity patterns transition from articulation planning to production. We also demonstrate how these cells reliably track the detailed composition of consonant and vowel sounds during perception and how they distinguish processes specifically related to speaking from those related to listening. Together, these findings reveal a remarkably structured organization and encoding cascade of phonetic representations by prefrontal neurons in humans and demonstrate a cellular process that can support the production of speech.
Similar content being viewed by others

Large-scale single-neuron speech sound encoding across the depth of human cortex

Neural dynamics of phoneme sequences reveal position-invariant code for content and order

Phonemic segmentation of narrative speech in human cerebral cortex
Humans can produce a remarkably wide array of word sounds to convey specific meanings. To produce fluent speech, linguistic analyses suggest a structured succession of processes involved in planning the arrangement and structure of phonemes in individual words 1 , 2 . These processes are thought to occur rapidly during natural speech and to recruit prefrontal regions in parts of the broader language network known to be involved in word planning 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 and sentence construction 13 , 14 , 15 , 16 and which widely connect with downstream areas that play a role in their motor production 17 , 18 , 19 . Cortical surface recordings have also demonstrated that phonetic features may be regionally organized 20 and that they can be decoded from local-field activities across posterior prefrontal and premotor areas 21 , 22 , 23 , suggesting an underlying cortical structure. Understanding the basic cellular elements by which we plan and produce words during speech, however, has remained a significant challenge.
Although previous studies in animal models 24 , 25 , 26 and more recent investigation in humans 27 , 28 have offered an important understanding of how cells in primary motor areas relate to vocalization movements and the production of sound sequences such as song, they do not reveal the neuronal process by which humans construct individual words and by which we produce natural speech 29 . Further, although linguistic theory based on behavioural observations has suggested tightly coupled sublexical processes necessary for the coordination of articulators during word planning 30 , how specific phonetic sequences, their syllabification or inflection are precisely coded for by individual neurons remains undefined. Finally, whereas previous studies have revealed a large regional overlap in areas involved in articulation planning and production 31 , 32 , 33 , 34 , 35 , little is known about whether and how these linguistic process may be uniquely represented at a cellular scale 36 , what their cortical organization may be or how mechanisms specifically related to speech production and perception may differ.
Single-neuronal recordings have the potential to begin revealing some of the basic functional building blocks by which humans plan and produce words during speech and study these processes at spatiotemporal scales that have largely remained inaccessible 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 , 45 . Here, we used an opportunity to combine recently developed ultrahigh-density microelectrode arrays for acute intraoperative neuronal recordings, speech tracking and modelling approaches to begin addressing these questions.
Neuronal recordings during natural speech
Single-neuronal recordings were obtained from the language-dominant (left) prefrontal cortex in participants undergoing planned intraoperative neurophysiology (Fig. 1a ; section on ‘Acute intraoperative single-neuronal recordings’). These recordings were obtained from the posterior middle frontal gyrus 10 , 46 , 47 , 48 , 49 , 50 in a region known to be broadly involved in word planning 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 and sentence construction 13 , 14 , 15 , 16 and to connect with neighbouring motor areas shown to play a role in articulation 17 , 18 , 19 and lexical processing 51 , 52 , 53 (Extended Data Fig. 1a ). This region was traversed during recordings as part of planned neurosurgical care and roughly ranged in distribution from alongside anterior area 55b to 8a, with sites varying by approximately 10 mm (s.d.) across subjects (Extended Data Fig. 1b ; section on ‘Anatomical localization of recordings’). Moreover, the participants undergoing recordings were awake and thus able to perform language-based tasks (section on ‘Study participants’), together providing an extraordinarily rare opportunity to study the action potential (AP) dynamics of neurons during the production of natural speech.

a , Left, single-neuronal recordings were confirmed to localize to the posterior middle frontal gyrus of language-dominant prefrontal cortex in a region known to be involved in word planning and production (Extended Data Fig. 1a,b ); right, acute single-neuronal recordings were made using Neuropixels arrays (Extended Data Fig. 1c,d ); bottom, speech production task and controls (Extended Data Fig. 2a ). b , Example of phonetic groupings based on the planned places of articulation (Extended Data Table 1 ). c , A ten-dimensional feature space was constructed to provide a compositional representation of all phonemes per word. d , Peri-event time histograms were constructed by aligning the APs of each neuron to word onset at millisecond resolution. Data are presented as mean (line) values ± s.e.m. (shade). Inset, spike waveform morphology and scale bar (0.5 ms). e , Left, proportions of modulated neurons that selectively changed their activities to specific planned phonemes; right, tuning curve for a cell that was preferentially tuned to velar consonants. f , Average z -scored firing rates as a function of the Hamming distance between the preferred phonetic composition of the neuron (that producing largest change in activity) and all other phonetic combinations. Here, a Hamming distance of 0 indicates that the words had the same phonetic compositions, whereas a Hamming distance of 1 indicates that they differed by a single phoneme. Data are presented as mean (line) values ± s.e.m. (shade). g , Decoding performance for planned phonemes. The orange points provide the sampled distribution for the classifier’s ROC-AUC; n = 50 random test/train splits; P = 7.1 × 10 −18 , two-sided Mann–Whitney U -test. Data are presented as mean ± s.d.
Source Data
To obtain acute recordings from individual cortical neurons and to reliably track their AP activities across the cortical column, we used ultrahigh-density, fully integrated linear silicon Neuropixels arrays that allowed for high throughput recordings from single cortical units 54 , 55 . To further obtain stable recordings, we developed custom-made software that registered and motion-corrected the AP activity of each unit and kept track of their position across the cortical column (Fig. 1a , right) 56 . Only well-isolated single units, with low relative neighbour noise and stable waveform morphologies consistent with that of neocortical neurons were used (Extended Data Fig. 1c,d ; section on ‘Acute intraoperative single-neuronal recordings’). Altogether, we obtained recordings from 272 putative neurons across five participants for an average of 54 ± 34 (s.d.) single units per participant (range 16–115 units).
Next, to study neuronal activities during the production of natural speech and to track their per word modulation, the participants performed a naturalistic speech production task that required them to articulate broadly varied words in a replicable manner (Extended Data Fig. 2a ) 57 . Here, the task required the participants to produce words that varied in phonetic, syllabic and morphosyntactic content and to provide them in a structured and reproducible format. It also required them to articulate the words independently of explicit phonetic cues (for example, from simply hearing and then repeating the same words) and to construct them de novo during natural speech. Extra controls were further used to evaluate for preceding word-related responses, sensory–perceptual effects and phonetic–acoustic properties as well as to evaluate the robustness and generalizability of neuronal activities (section on ‘Speech production task’).
Together, the participants produced 4,263 words for an average of 852.6 ± 273.5 (s.d.) words per participant (range 406–1,252 words). The words were transcribed using a semi-automated platform and aligned to AP activity at millisecond resolution (section on ‘Audio recordings and task synchronization’) 51 . All participants were English speakers and showed comparable word-production performances (Extended Data Fig. 2b ).
Representations of phonemes by neurons
To first examine the relation between single-neuronal activities and the specific speech organs involved 58 , 59 , we focused our initial analyses on the primary places of articulation 60 . The places of articulation describe the points where constrictions are made between an active and a passive articulator and are what largely give consonants their distinctive sounds. Thus, for example, whereas bilabial consonants (/p/ and /b/) involve the obstruction of airflow at the lips, velar consonants are articulated with the dorsum of the tongue placed against the soft palate (/k/ and /g/; Fig. 1b ). To further examine sounds produced without constriction, we also focused our initial analyses on vowels in relation to the relative height of the tongue (mid-low and high vowels). More phonetic groupings based on the manners of articulation (configuration and interaction of articulators) and primary cardinal vowels (combined positions of the tongue and lips) are described in Extended Data Table 1 .
Next, to provide a compositional phonetic representation of each word, we constructed a feature space on the basis of the constituent phonemes of each word (Fig. 1c , left). For instance, the words ‘like’ and ‘bike’ would be represented uniquely in vector space because they differ by a single phoneme (‘like’ contains alveolar /l/ whereas ‘bike’ contains bilabial /b/; Fig. 1c , right). The presence of a particular phoneme was therefore represented by a unitary value for its respective vector component, together yielding a vectoral representation of the constituent phonemes of each word (section on ‘Constructing a word feature space’). Generalized linear models (GLMs) were then used to quantify the degree to which variations in neuronal activity during planning could be explained by individual phonemes across all possible combinations of phonemes per word (section on ‘Single-neuronal analysis’).
Overall, we find that the firing activities of many of the neurons (46.7%, n = 127 of 272 units) were explained by the constituent phonemes of the word before utterance (−500 to 0 ms); GLM likelihood ratio test, P < 0.01); meaning that their activity patterns were informative of the phonetic content of the word. Among these, the activities of 56 neurons (20.6% of the 272 units recorded) were further selectively tuned to the planned production of specific phonemes (two-sided Wald test for each GLM coefficient, P < 0.01, Bonferroni-corrected across all phoneme categories; Fig. 1d,e and Extended Data Figs. 2 and 3 ). Thus, for example, whereas certain neurons changed their firing rate when the upcoming words contained bilabial consonants (for example, /p/ or /b/), others changed their firing rate when they contained velar consonants. Of these neurons, most encoded information both about the planned places and manners of articulation ( n = 37 or 66% overlap, two-sided hypergeometric test, P < 0.0001) or planned places of articulation and vowels ( n = 27 or 48% overlap, two-sided hypergeometric test, P < 0.0001; Extended Data Fig. 4 ). Most also reflected the spectral properties of the articulated words on a phoneme-by-phoneme basis (64%, n = 36 of 56; two-sided hypergeometric test, P = 1.1 × 10 −10 ; Extended Data Fig. 5a,b ); together providing detailed information about the upcoming phonemes before utterance.
Because we had a complete representation of the upcoming phonemes for each word, we could also quantify the degree to which neuronal activities reflected their specific combinations. For example, we could ask whether the activities of certain neurons not only reflected planned words with velar consonants but also words that contained the specific combination of both velar and labial consonants. By aligning the activity of each neuron to its preferred phonetic composition (that is, the specific combination of phonemes to which the neuron most strongly responded) and by calculating the Hamming distance between this and all other possible phonetic compositions across words (Fig. 1c , right; section on ‘Single-neuronal analysis’), we find that the relation between the vectoral distances across words and neuronal activity was significant (two-sided Spearman’s ρ = −0.97, P = 5.14 × 10 −7 ; Fig. 1f ). These neurons therefore seemed not only to encode specific planned phonemes but also their specific composition with upcoming words.
Finally, we asked whether the constituent phonemes of the word could be robustly decoded from the activity patterns of the neuronal population. Using multilabel decoders to classify the upcoming phonemes of words not used for model training (section on ‘Population modelling’), we find that the composition of phonemes could be predicted from neuronal activity with significant accuracy (receiver operating characteristic area under the curve; ROC-AUC = 0.75 ± 0.03 mean ± s.d. observed versus 0.48 ± 0.02 chance, P < 0.001, two-sided Mann–Whitney U -test; Fig. 1g ). Similar findings were also made when examining the planned manners of articulation (AUC = 0.77 ± 0.03, P < 0.001, two-sided Mann–Whitney U -test), primary cardinal vowels (AUC = 0.79 ± 0.04, P < 0.001, two-sided Mann–Whitney U -test) and their spectral properties (AUC = 0.75 ± 0.03, P < 0.001, two-sided Mann–Whitney U -test; Extended Data Fig. 5a , right). Taken together, these neurons therefore seemed to reliably predict the phonetic composition of the upcoming words before utterance.
Motoric and perceptual processes
Neurons that reflected the phonetic composition of the words during planning were largely distinct from those that reflected their composition during perception. It is possible, for instance, that similar response patterns could have been observed when simply hearing the words. Therefore, to test for this, we performed an extra ‘perception’ control in three of the participants whereby they listened to, rather than produced, the words ( n = 126 recorded units; section on ‘Speech production task’). Here, we find that 29.3% ( n = 37) of the neurons showed phonetic selectively during listening (Extended Data Fig. 6a ) and that their activities could be used to accurately predict the phonemes being heard (AUC = 0.70 ± 0.03 observed versus 0.48 ± 0.02 chance, P < 0.001, two-sided Mann–Whitney U -test; Extended Data Fig. 6b ). We also find, however, that these cells were largely distinct from those that showed phonetic selectivity during planning ( n = 10; 7.9% overlap) and that their activities were uninformative of phonemic content of the words being planned (AUC = 0.48 ± 0.01, P = 0.99, two-sided Mann–Whitney U -test; Extended Data Fig. 6b ). Similar findings were also made when replaying the participant’s own voices to them (‘playback’ control; 0% overlap in neurons); together suggesting that speaking and listening engaged largely distinct but complementary sets of cells in the neural population.
Given the above observations, we also examined whether the activities of the neurons could have been explained by the acoustic–phonetic properties of the preceding spoken words. For example, it is possible that the activities of the neuron may have partly reflected the phonetic composition of the previous articulated word or their motoric components. Thus, to test for this, we repeated our analyses but now excluded words in which the preceding articulated word contained the phoneme being decoded (section on ‘Single-neuronal analysis’) and find that decoding performance remained significant (AUC = 0.72 ± 0.1, P < 0.001, two-sided Mann–Whitney U -test). We also find that decoding performance remained significant when constricting (−400 to 0 ms window instead of −500:0 ms; AUC = 0.72 ± 0.1, P < 0.001, two-sided Mann–Whitney U -test) or shifting the analysis window closer to utterance (−300 to +200 ms window results in AUC = 0.76 ± 0.1, P < 0.001, two-sided Mann–Whitney U -test); indicating that these neurons coded for the phonetic composition of the upcoming words.
Syllabic and morphological features
To transform sets of consonants and vowels into words, the planned phonemes must also be arranged and segmented into distinct syllables 61 . For example, even though the words ‘casting’ and ‘stacking’ possess the same constituent phonemes, they are distinguished by their specific syllabic structure and order. Therefore, to examine whether neurons in the population may further reflect these sublexical features, we created an extra vector space based on the specific order and segmentation of phonemes (section on ‘Constructing a word feature space’). Here, focusing on the most common syllables to allow for tractable neuronal analysis (Extended Data Table 1 ), we find that the activities of 25.0% ( n = 68 of 272) of the neurons reflected the presence of specific planned syllables (two-sided Wald test for each GLM coefficient, P < 0.01, Bonferroni-corrected across all syllable categories; Fig. 2a,b ). Thus, whereas certain neurons may respond selectively to a velar-low-alveolar syllable, other neurons may respond selectively to an alveolar-low-velar syllable. Together, the neurons responded preferentially to specific syllables when tested across words (two-sided Spearman’s ρ = −0.96, P = 1.85 × 10 −6 ; Fig. 2c ) and accurately predicted their content (AUC = 0.67 ± 0.03 observed versus 0.50 ± 0.02 chance, P < 0.001, two-sided Mann–Whitney U -test; Fig. 2d ); suggesting that these subsets of neurons encoded information about the syllables.

a , Peri-event time histograms were constructed by aligning the APs of each neuron to word onset. Data are presented as mean (line) values ± s.e.m. (shade). Examples of two representative neurons which selectively changed their activity to specific planned syllables. Inset, spike waveform morphology and scale bar (0.5 ms). b , Scatter plots of D 2 values (the degree to which specific features explained neuronal response, n = 272 units) in relation to planned phonemes, syllables and morphemes. c , Average z -scored firing rates as a function of the Hamming distance between the preferred syllabic composition and all other compositions of the neuron. Data are presented as mean (line) values ± s.e.m. (shade). d , Decoding performance for planned syllables. The orange points provide the sampled distribution for the classifier’s ROC-AUC values ( n = 50 random test/train splits; P = 7.1 × 10 −18 two-sided Mann–Whitney U -test). Data are presented as mean ± s.d. e , To evaluate the selectivity of neurons to specific syllables, their activities were further compared for words that contained the preferred syllable of each neuron (that is, the syllable to which they responded most strongly; green) to (i) words that contained one or more of same individual phonemes but not necessarily their preferred syllable, (ii) words that contained different phonemes and syllables, (iii) words that contained the same phonemes but divided across different syllables and (iv) words that contained the same phonemes in a syllable but in different order (grey). Neuronal activities across all comparisons (to green points) were significant ( n = 113; P = 6.2 × 10 −20 , 8.8 × 10 −20 , 4.2 × 10 −20 and 1.4 × 10 −20 , for the comparisons above, respectively; two-sided Wilcoxon signed-rank test). Data are presented as mean (dot) values ± s.e.m.
Next, to confirm that these neurons were selectively tuned to specific syllables, we compared their activities for words that contained the preferred syllable of each neuron (for example, /d-iy/) to words that simply contained their constituent phonemes (for example, d or iy). Thus, for example, if these neurons reflected individual phonemes irrespective of their specific order, then we would observe no difference in response. On the basis of these comparisons, however, we find that the responses of the neurons to their preferred syllables was significantly greater than to that of their individual constituent phonemes ( z -score difference 0.92 ± 0.04; two-sided Wilcoxon signed-rank test, P < 0.0001; Fig. 2e ). We also tested words containing syllables with the same constituent phonemes but in which the phonemes were simply in a different order (for example, /g-ah-d/ versus /d-ah-g/) but again find that the neurons were preferentially tuned to specific syllables ( z -score difference 0.99 ± 0.06; two-sided Wilcoxon signed-rank test, P < 1.0 × 10 −6 ; Fig. 2e ). Then, we examined words that contained the same arrangements of phonemes but in which the phonemes themselves belonged to different syllables (for example, /r-oh-b/ versus r-oh/b-; accounting prosodic emphasis) and similarly find that the neurons were preferentially tuned to specific syllables ( z -score difference 1.01 ± 0.06; two-sided Wilcoxon signed-rank test, P < 0.0001; Fig. 2e ). Therefore, rather than simply reflecting the phonetic composition of the upcoming words, these subsets of neurons encoded their specific segmentation and order in individual syllables.
Finally, we asked whether certain neurons may code for the inclusion of morphemes. Unlike phonemes, bound morphemes such as ‘–ed’ in ‘directed’ or ‘re–’ in ‘retry’ are capable of carrying specific meanings and are thus thought to be subserved by distinct neural mechanisms 62 , 63 . Therefore, to test for this, we also parsed each word on the basis of whether it contained a suffix or prefix (controlling for word length) and find that the activities of 11.4% ( n = 31 of 272) of the neurons selectively changed for words that contained morphemes compared to those that did not (two-sided Wald test for each GLM coefficient, P < 0.01, Bonferroni-corrected across morpheme categories; Extended Data Fig. 5c ). Moreover, neural activity across the population could be used to reliably predict the inclusion of morphemes before utterance (AUC = 0.76 ± 0.05 observed versus 0.52 ± 0.01 for shuffled data, P < 0.001, two-sided Mann–Whitney U -test; Extended Data Fig. 5c ), together suggesting that the neurons coded for this sublexical feature.
Spatial distribution of neurons
Neurons that encoded information about the sublexical components of the upcoming words were broadly distributed across the cortex and cortical column depth. By tracking the location of each neuron in relation to the Neuropixels arrays, we find that there was a slightly higher preponderance of neurons that were tuned to phonemes (one-sided χ 2 test (2) = 0.7 and 5.2, P > 0.05, for places and manners of articulation, respectively), syllables (one-sided χ 2 test (2) = 3.6, P > 0.05) and morphemes (one-sided χ 2 test (2) = 4.9, P > 0.05) at lower cortical depths, but that this difference was non-significant, suggesting a broad distribution (Extended Data Fig. 7 ). We also find, however, that the proportion of neurons that showed selectivity for phonemes increased as recordings were acquired more posteriorly along the rostral–caudal axis of the cortex (one-sided χ 2 test (4) = 45.9 and 52.2, P < 0.01, for places and manners of articulation, respectively). Similar findings were also made for syllables and morphemes (one-sided χ 2 test (4) = 31.4 and 49.8, P < 0.01, respectively; Extended Data Fig. 7 ); together suggesting a gradation of cellular representations, with caudal areas showing progressively higher proportions of selective neurons.
Collectively, the activities of these cell ensembles provided richly detailed information about the phonetic, syllabic and morphological components of upcoming words. Of the neurons that showed selectivity to any sublexical feature, 51% ( n = 46 of 90 units) were significantly informative of more than one feature. Moreover, the selectivity of these neurons lay along a continuum and were closely correlated (two-sided test of Pearson’s correlation in D 2 across all sublexical feature comparisons, r = 0.80, 0.51 and 0.37 for phonemes versus syllables, phonemes versus morphemes and syllables versus morphemes, respectively, all P < 0.001; Fig. 2b ), with most cells exhibiting a mixture of representations for specific phonetic, syllabic or morphological features (two-sided Wilcoxon signed-rank test, P < 0.0001). Figure 3a further illustrates this mixture of representations (Fig. 3a , left; t -distributed stochastic neighbour embedding (tSNE)) and their hierarchical structure (Fig. 3a , right; D 2 distribution), together revealing a detailed characterization of the phonetic, syllabic and morphological components of upcoming words at the level of the cell population.

a , Left, response selectivity of neurons to specific word features (phonemes, syllables and morphemes) is visualized across the population using a tSNE procedure (that is, neurons with similar response characteristics were plotted in closer proximity). The hue of each point reflects the degree of selectivity to a particular sublexical feature whereas the size of each point reflects the degree to which those features explained neuronal response. Inset, the relative proportions of neurons showing selectivity and their overlap. Right, the D 2 metric (the degree to which specific features explained neuronal response) for each cell shown individually per feature. b , The relative degree to which the activities of the neurons were explained by the phonetic, syllabic and morphological features of the words ( D 2 metric) and their hierarchical structure (agglomerative hierarchical clustering). c , Distribution of peak decoding performances for phonemes, syllables and morphemes aligned to word utterance onset. Significant differences in peak decoding timings across sample distribution are labelled in brackets above ( n = 50 random test/train splits; P = 0.024, 0.002 and 0.002; pairwise, two-sided permutation tests of differences in medians for phonemes versus syllables, syllables versus morphemes and phonemes versus morphemes, respectively; Methods ). Data are presented as median (dot) values ± bootstrapped standard error of the median.
Temporal organization of representations
Given the above observations, we examined the temporal dynamic of neuronal activities during the production of speech. By tracking peak decoding in the period leading up to utterance onset (peak AUC; 50 model testing/training splits) 64 , we find these neural populations showed a consistent morphological–phonetic–syllabic dynamic in which decoding performance first peaked for morphemes. Peak decoding then followed for phonemes and syllables (Fig. 3b and Extended Data Fig. 8a,b ; section on ‘Population modelling’). Overall, decoding performance peaked for the morphological properties of words at −405 ± 67 ms before utterance, followed by peak decoding for phonemes at −195 ± 16 ms and syllables at −70 ± 62 ms (s.e.m.; Fig. 3b ). This temporal dynamic was highly unlikely to have been observed by chance (two-sided Kruskal–Wallis test, H = 13.28, P < 0.01) and was largely distinct from that observed during listening (two-sided Kruskal–Wallis test, H = 14.75, P < 0.001; Extended Data Fig. 6c ). The activities of these neurons therefore seemed to follow a consistent, temporally ordered morphological–phonetic–syllabic dynamic before utterance.
The activities of these neurons also followed a temporally structured transition from articulation planning to production. When comparing their activities before utterance onset (−500:0 ms) to those after (0:500 ms), we find that neurons which encoded information about the upcoming phonemes during planning encoded similar information during production ( P < 0.001, Mann–Whitney U -test for phonemes and syllables; Fig. 4a ). Moreover, when using models that were originally trained on words before utterance onset to decode the properties of the articulated words during production (model-switch approach), we find that decoding accuracy for the phonetic, syllabic and morphological properties of the words all remained significant (AUC = 0.76 ± 0.02 versus 0.48 ± 0.03 chance, 0.65 ± 0.03 versus 0.51 ± 0.04 chance, 0.74 ± 0.06 versus 0.44 ± 0.07 chance, for phonemes, syllables and morphemes, respectively; P < 0.001 for all, two-sided Mann–Whitney U -tests; Extended Data Fig. 8c ). Information about the sublexical features of words was therefore reliably represented during articulation planning and execution by the neuronal population.

a , Top, the D 2 value of neuronal activity (the degree to which specific features explained neuronal response, n = 272 units) during word planning (green) and production (orange) sorted across all population neurons. Middle, relationship between explanatory power ( D 2 ) of neuronal activity ( n = 272 units) for phonemes (Spearman’s ρ = 0.69), syllables (Spearman’s ρ = 0.40) and morphemes (Spearman’s ρ = 0.08) during planning and production ( P = 1.3 × 10 −39 , P = 6.6 × 10 −12 , P = 0.18, respectively, two-sided test of Spearman rank-order correlation). Bottom, the D 2 metric for each cell during production per feature ( n = 272 units). b , Top left, schematic illustration of speech planning (blue plane) and production (red plane) subspaces as traversed by a neuron for different phonemes (yellow arrows; Extended Data Fig. 9 ). Top right, subspace misalignment quantified by an alignment index (red) or Grassmannian chordal distance (red) compared to that expected from chance (grey), demonstrating that the subspaces occupied by the neural population ( n = 272 units) during planning and production were distinct. Bottom, projection of neural population activity ( n = 272 units) during word planning (blue) and production (red) onto the first three PCs for the planning (upper row) and production (lower row) subspaces.
Utilizing a dynamical systems approach to further allow for the unsupervised identification of functional subspaces (that is, wherein neural activity is embedded into a high-dimensional vector space; Fig. 4b , left; section on ‘Dynamical system and subspace analysis’) 31 , 34 , 65 , 66 , we find that the activities of the population were mostly low-dimensional, with more than 90% of the variance in neuronal activity being captured by its first four principal components (Fig. 4b , right). However, when tracking how the dimensions in which neural populations evolved over time, we also find that the subspaces which defined neural activity during articulation planning and production were largely distinct. In particular, whereas the first five subspaces captured 98.4% of variance in the trajectory of the population during planning, they captured only 11.9% of variance in the trajectory during articulation (two-sided permutation test, P < 0.0001; Fig. 4b , bottom and Extended Data Fig. 9 ). Together, these cell ensembles therefore seemed to occupy largely separate preparatory and motoric subspaces while also allowing for information about the phonetic, syllabic and morphological contents of the words to be stably represented during the production of speech.
Using Neuropixels probes to obtain acute, fine-scaled recordings from single neurons in the language-dominant prefrontal cortex 3 , 4 , 5 , 6 —in a region proposed to be involved in word planning 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 and production 13 , 14 , 15 , 16 —we find a strikingly detailed organization of phonetic representations at a cellular level. In particular, we find that the activities of many of the neurons closely mirrored the way in which the word sounds were produced, meaning that they reflected how individual planned phonemes were generated through specific articulators 58 , 59 . Moreover, rather than simply representing phonemes independently of their order or structure, many of the neurons coded for their composition in the upcoming words. They also reliably predicted the arrangement and segmentation of phonemes into distinct syllables, together suggesting a process that could allow the structure and order of articulatory events to be encoded at a cellular level.
Collectively, this putative mechanism supports the existence of context-general representations of classes of speech sounds that speakers use to construct different word forms. In contrast, coding of sequences of phonemes as syllables may represent a context-specific representation of these speech sounds in a particular segmental context. This combination of context-general and context-specific representation of speech sound classes, in turn, is supportive of many speech production models which suggest that speakers hold abstract representations of discrete phonological units in a context-general way and that, as part of speech planning, these units are organized into prosodic structures that are context-specific 1 , 30 . Although the present study does not reveal whether these representations may be stored in and retrieved from a mental syllabary 1 or are constructed from abstract phonology ad hoc, it lays a groundwork from which to begin exploring these possibilities at a cellular scale. It also expands on previous observations in animal models such as marmosets 67 , 68 , singing mice 69 and canaries 70 on the syllabic structure and sequence of vocalization processes, providing us with some of the earliest lines of evidence for the neuronal coding of vocal-motor plans.
Another interesting finding from these studies is the diversity of phonetic feature representations and their organization across cortical depth. Although our recordings sampled locally from relatively small columnar populations, most phonetic features could be reliably decoded from their collective activities. Such findings suggest that phonetic information necessary for constructing words may be potentially fully represented in certain regions along the cortical column 10 , 46 , 47 , 48 , 49 , 50 . They also place these populations at a putative intersection for the shared coding of places and manners of articulation and demonstrate how these representations may be locally distributed. Such redundancy and accessibility of information in local cortical populations is consistent with that observed from animal models 31 , 32 , 33 , 34 , 35 and could serve to allow for the rapid orchestration of neuronal processes necessary for the real-time construction of words; especially during the production of natural speech. Our findings are also supportive of a putative ‘mirror’ system that could allow for the shared representation of phonetic features within the population when speaking and listening and for the real-time feedback of phonetic information by neurons during perception 23 , 71 .
A final notable observation from these studies is the temporal succession of neuronal encoding events. In particular, our findings are supportive of previous neurolinguistic theories suggesting closely coupled processes for coordination planned articulatory events that ultimately produces words. These models, for example, suggest that the morphology of a word is probably retrieved before its phonologic code, as the exact phonology depends on the morphemes in the word form 1 . They also suggest the later syllabification of planned phonemes which would enable them to be sequentially arranged in specific order (although different temporal orders have been suggested as well) 72 . Here, our findings provide tentative support for a structured sublexical coding succession that could allow for the discretization of such information during articulation. Our findings also suggest (through dynamical systems modelling) a mechanism that, consistent with previous observations on motor planning and execution 31 , 34 , 65 , 66 , could enable information to occupy distinct functional subspaces 34 , 73 and therefore allow for the rapid separation of neural processes necessary for the construction and articulation of words.
Taken together, these findings reveal a set of processes and framework in the language-dominant prefrontal cortex by which to begin understanding how words may be constructed during natural speech at a single-neuronal level through which to start defining their fine-scale spatial and temporal dynamics. Given their robust decoding performances (especially in the absence of natural language processing-based predictions), it is interesting to speculate whether such prefrontal recordings could also be used for synthetic speech prostheses or for the augmentation of other emerging approaches 21 , 22 , 74 used in brain–machine interfaces. It is important to note, however, that the production of words also involves more complex processes, including semantic retrieval, the arrangement of words in sentences, and prosody, which were not tested here. Moreover, future experiments will be required to investigate eloquent areas such as ventral premotor and superior posterior temporal areas not accessible with our present techniques. Here, this study provides a prospective platform by which to begin addressing these questions using a combination of ultrahigh-density microelectrode recordings, naturalistic speech tracking and acute real-time intraoperative neurophysiology to study human language at cellular scale.
Study participants
All aspects of the study were carried out in strict accordance with and were approved by the Massachusetts General Brigham Institutional Review Board. Right-handed native English speakers undergoing awake microelectrode recording-guided deep brain stimulator implantation were screened for enrolment. Clinical consideration for surgery was made by a multidisciplinary team of neurosurgeons, neurologists and neuropsychologists. Operative planning was made independently by the surgical team and without consideration of study participation. Participants were only enroled if: (1) the surgical plan was for awake microelectrode recording-guided placement, (2) the patient was at least 18 years of age, (3) they had intact language function with English fluency and (4) were able to provide informed consent for study participation. Participation in the study was voluntary and all participants were informed that they were free to withdraw from the study at any time.
Acute intraoperative single-neuronal recordings
Single-neuronal prefrontal recordings using neuropixels probes.
As part of deep brain stimulator implantation at our institution, participants are often awake and microelectrode recordings are used to optimize anatomical targeting of the deep brain structures 46 . During these cases, the electrodes often traverse part of the posterior language-dominant prefrontal cortex 3 , 4 , 5 , 6 in an area previously shown be involved in word planning 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 and sentence construction 13 , 14 , 15 , 16 and which broadly connects with premotor areas involved in their articulation 51 , 52 , 53 and lexical processing 17 , 18 , 19 by imaging studies (Extended Data Fig. 1a,b ). All microelectrode entry points and placements were based purely on planned clinical targeting and were made independently of any study consideration.
Sterile Neuropixels probes (v.1.0-S, IMEC, ethylene oxide sterilized by BioSeal 54 ) together with a 3B2 IMEC headstage were attached to cannula and a manipulator connected to a ROSA ONE Brain (Zimmer Biomet) robotic arm. Here, the probes were inserted into the cortical ribbon under direct robot navigational guidance through the implanted burr hole (Fig. 1a ). The probes (width 70 µm; length 10 mm; thickness 100 µm) consisted of a total of 960 contact sites (384 preselected recording channels) laid out in a chequerboard pattern with approximately 25 µm centre-to-centre nearest-neighbour site spacing. The IMEC headstage was connected through a multiplexed cable to a PXIe acquisition module card (IMEC), installed into a PXIe Chassis (PXIe-1071 chassis, National Instruments). Neuropixels recordings were performed using SpikeGLX (v.20201103 and v.20221012-phase30; http://billkarsh.github.io/SpikeGLX/ ) or OpenEphys (v.0.5.3.1 and v.0.6.0; https://open-ephys.org/ ) on a computer connected to the PXIe acquisition module recording the action potential band (AP, band-pass filtered from 0.3 to 10 kHz) sampled at 30 kHz and a local-field potential band (LFP, band-pass filtered from 0.5 to 500 Hz), sampled at 2,500 Hz. Once putative units were identified, the Neuropixels probe was briefly held in position to confirm signal stability (we did not screen putative neurons for speech responsiveness). Further description of this recording approach can be found in refs. 54 , 55 . After single-neural recordings from the cortex were completed, the Neuropixels probe was removed and subcortical neuronal recordings and deep brain stimulator placement proceeded as planned.
Single-unit isolation
Single-neuronal recordings were performed in two main steps. First, to track the activities of putative neurons at high spatiotemporal resolution and to account for intraoperative cortical motion, we use a Decentralized Registration of Electrophysiology Data software (DREDge; https://github.com/evarol/DREDge ) and interpolation approach ( https://github.com/williamunoz/InterpolationAfterDREDge ). Briefly, and as previously described 54 , 55 , 56 , an automated protocol was used to track LFP voltages using a decentralized correlation technique that re-aligned the recording channels in relation to brain movements (Fig. 1a , right). Following this step, we then interpolated the AP band continuous voltage data using the DREDge motion estimate to allow the activities of the putative neurons to be stably tracked over time. Next, single units were isolated from the motion-corrected interpolated signal using Kilosort (v.1.0; https://github.com/cortex-lab/KiloSort ) followed by Phy for cluster curation (v.2.0a1; https://github.com/cortex-lab/phy ; Extended Data Fig. 1c,d ). Here, units were selected on the basis of their waveform morphologies and separability in principal component space, their interspike interval profiles and similarity of waveforms across contacts. Only well-isolated single units with mean firing rates ≥0.1 Hz were included. The range of units obtained from these recordings was 16–115 units per participant.
Audio recordings and task synchronization
For task synchronization, we used the TTL output and audio output to send the synchronization trigger through the SMA input to the IMEC PXIe acquisition module card. To allow for added synchronizing, triggers were also recorded on an extra breakout analogue and digital input/output board (BNC2110, National Instruments) connected through a PXIe board (PXIe-6341 module, National Instruments).
Audio recordings were obtained at 44 kHz sampling frequency (TASCAM DR-40×4-Channel/ 4-Track Portable Audio Recorder and USB Interface with Adjustable Microphone) which had an audio input. These recordings were then sent to a NIDAQ board analogue input in the same PXIe acquisition module containing the IMEC PXIe board for high-fidelity temporal alignment with neuronal data. Synchronization of neuronal activity with behavioural events was performed through TTL triggers through a parallel port sent to both the IMEC PXIe board (the sync channel) and the analogue NIDAQ input as well as the parallel audio input into the analogue input channels on the NIDAQ board.
Audio recordings were annotated in semi-automated fashion (Audacity; v.2.3). Recorded audio for each word and sentence by the participants was analysed in Praat 75 and Audacity (v.2.3). Exact word and phoneme onsets and offsets were identified using the Montreal Forced Aligner (v.2.2; https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner ) 76 and confirmed with manual review of all annotated recordings. Together, these measures allowed for the millisecond-level alignment of neuronal activity with each produced word and phoneme.
Anatomical localization of recordings
Pre-operative high-resolution magnetic resonance imaging and postoperative head computerized tomography scans were coregistered by combination of ROSA software (Zimmer Biomet; v.3.1.6.276), Mango (v.4.1; https://mangoviewer.com/download.html ) and FreeSurfer (v.7.4.1; https://surfer.nmr.mgh.harvard.edu/fswiki/DownloadAndInstall ) to reconstruct the cortical surface and identify the cortical location from which Neuropixels recordings were obtained 77 , 78 , 79 , 80 , 81 . This registration allowed localization of the surgical areas that underlaid the cortical sites of recording (Fig. 1a and Extended Data Fig. 1a ) 54 , 55 , 56 . The MNI transformation of these coordinates was then carried out to register the locations in MNI space with Fieldtrip toolbox (v.20230602; https://www.fieldtriptoolbox.org/ ; Extended Data Fig. 1b ) 82 .
For depth calculation, we estimated the pial boundary of recordings according to the observed sharp signal change in signal from channels that were implanted in the brain parenchyma versus those outside the brain. We then referenced our single-unit recording depth (based on their maximum waveform amplitude channel) in relation to this estimated pial boundary. Here, all units were assessed on the basis of their relative depths in relation to the pial boundary as superficial, middle and deep (Extended Data Fig. 7 ).
Speech production task
The participants performed a priming-based naturalistic speech production task 57 in which they were given a scene on a screen that consisted of a scenario that had to be described in specific order and format. Thus, for example, the participant may be given a scene of a boy and a girl playing with a balloon or they may be given a scene of a dog chasing a cat. These scenes, together, required the participants to produce words that varied in phonetic, syllabic and morphosyntactic content. They were also highlighted in a way that required them to produce the words in a structured format. Thus, for example, a scene may be highlighted in a way that required the participants to produce the sentence “The mouse was being chased by the cat” or in a way that required them to produce the sentence “The cat was chasing the mouse” (Extended Data Fig. 2a ). Because the sentences had to be constructed de novo, it also required the participants to produce the words without providing explicit phonetic cues (for example, from hearing and then repeating the word ‘cat’). Taken together, this task therefore allowed neuronal activity to be examined whereby words (for example, ‘cat’), rather than independent phonetic sounds (for example, /k/), were articulated and in which the words were produced during natural speech (for example, constructing the sentence “the dog chased the cat”) rather than simply repeated (for example, hearing and then repeating the word ‘cat’).
Finally, to account for the potential contribution of sensory–perceptual responses, three of the participants also performed a ‘perception’ control in which they listened to words spoken to them. One of these participants further performed an auditory ‘playback’ control in which they listened to their own recorded voice. For this control, all words spoken by the participant were recorded using a high-fidelity microphone (Zoom ZUM-2 USM microphone) and then played back to them on a word-by-word level in randomized separate blocks.
Constructing a word feature space
To allow for single-neuronal analysis and to provide a compositional representation for each word, we grouped the constituent phonemes on the basis of the relative positions of articulatory organs associated with their production 60 . Here, for our primary analyses, we selected the places of articulation for consonants (for example, bilabial consonants) on the basis of established IPA categories defining the primary articulators involved in speech production. For consonants, phonemes were grouped on the basis of their places of articulation into glottal, velar, palatal, postalveolar, alveolar, dental, labiodental and bilabial. For vowels, we grouped phonemes on the basis of the relative height of the tongue with high vowels being produced with the tongue in a relatively high position and mid-low (that is, mid+low) vowels being produced with it in a lower position. Here, this grouping of phonemes is broadly referred to as ‘places of articulation’ together reflecting the main positions of articulatory organs and their combinations used to produce the words 58 , 59 . Finally, to allow for comparison and to test their generalizability, we examined the manners of articulation stop, fricative, affricate, nasal, liquid and glide for consonants which describe the nature of airflow restriction by various parts of the mouth and tongue. For vowels, we also evaluated the primary cardinal vowels i, e, ɛ, a, α, ɔ, o and u which are described, in combination, by the position of the tongue relative to the roof of the mouth, how far forward or back it lies and the relative positions of the lips 83 , 84 . A detailed summary of these phonetic groupings can be found in Extended Data Table 1 .
Phoneme feature space
To further evaluate the relationship between neuronal activity and the presence of specific constituent phonemes per word, the phonemes in each word were parsed according to their precise pronunciation provided by the English Lexicon Project (or the Longman Pronunciation Dictionary for American English where necessary) as described previously 85 . Thus, for example, the word ‘like’ (l-aɪ-k) would be parsed into a sequence of alveolar-mid-low-velar phonemes, whereas the word ‘bike’ (b-aɪ-k) would be parsed into a sequence of bilabial-mid-low-velar phonemes.
These constituent phonemes were then used to represent each word as a ten-dimensional vector in which the value in each position reflected the presence of each type of phoneme (Fig. 1c ). For example, the word ‘like’, containing a sequence of alveolar-mid-low-velar phonemes, was represented by the vector [0 0 0 1 0 0 1 0 0 1], with each entry representing the number of the respective type of phoneme in the word. Together, such vectors representing all words defined a phonetic ‘vector space’. Further analyses to evaluate the precise arrangement of phonemes per word are described further below. Goodness-of-fit and selectivity metrics used to evaluate single-neuronal responses to these phonemes and their specific combination in words are described further below.
Syllabic feature space
Next, to evaluate the relationship between neuronal activity and the specific arrangement of phonemes in syllables, we parsed the constituent syllables for each word using American pronunciations provided in ref. 85 . Thus, for example, ‘back’ would be defined as a labial-low-velar sequence. Here, to allow for neuronal analysis and to limit the combination of all possible syllables, we selected the ten most common syllable types. High and mid-low vowels were considered as syllables here only if they reflected syllables in themselves and were unbound from a consonant (for example, /ih/ in ‘hesitate’ or /ah-/ in ‘adore’). Similar to the phoneme space, the syllables were then transformed into an n -dimensional binary vector in which the value in each dimension reflected the presence of specific syllables (similar to construction of the phoneme space). Thus, for the n -dimensional representation of each word in this syllabic feature space, the value in each dimension could be also interpreted in relation to neuronal activity.
To account for the functional distinction between phonemes and morphemes 62 , 63 , we also parsed words into those that contained bound morphemes which were either prefixed (for example, ‘re–’) or suffixed (for example, ‘–ed’). Unlike phonemes, morphemes such as ‘–ed’ in ‘directed’ or ‘re–’ in ‘retry’ are the smallest linguistic units capable of carrying meaning and, therefore, accounting for their presence allowed their effect on neuronal responses to be further examined. To allow for neuronal analysis and to control for potential differences in neuronal activity due to word lengths, models also took into account the total number of phonemes per word.
Spectral features
To evaluate the time-varying spectral features of the articulated phonemes on a phoneme-by-phoneme basis, we identified the occurrence of each phoneme using a Montreal Forced Aligner (v.2.2; https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner ). For pitch, we calculated the spectral power in ten log-spaced frequency bins from 200 to 5,000 Hz for each phoneme per word. For amplitude, we took the root-mean-square of the recorded waveform of each phoneme.
Single-neuronal analysis
Evaluating the selectivity of single-neuronal responses.
To investigate the relationship between single-neuronal activity and specific word features, we used a regression analysis to determine the degree to which variation in neural activity could be explained by phonetic, syllabic or morphologic properties of spoken words 86 , 87 , 88 , 89 . For all analyses, neuronal activity was considered in relation to word utterance onset ( t = 0) and taken as the mean spike count in the analysis window of interest (that is, −500 to 0 ms from word onset for word planning and 0 to +500 ms for word production). To limit the potential effects of preceding words on neuronal activity, words with planning periods that overlapped temporally were excluded from regression and selectivity analyses. For each neuron, we constructed a GLM that modelled the spike count rate as the realization of a Poisson process whose rate varied as a function of the linguistic (for example, phonetic, syllabic and morphologic) or acoustic features (for example, spectral power and root-mean-square amplitude) of the planned words.
Models were fit using the Python (v.3.9.17) library statsmodels (v.0.13.5) by iterative least-squares minimization of the Poisson negative log-likelihood function 86 . To assess the goodness-of-fit of the models, we used both the Akaike information criterion ( \({\rm{AIC}}=2k-2{\rm{ln}}(L)\) where k is the number of estimated parameters and L is the maximized value of the likelihood function) and a generalization of the R 2 score for the exponential family of regression models that we refer to as D 2 whereby 87 :
y is a vector of realized outcomes, μ is a vector of estimated means from a full (including all regressors) or restricted (without regressors of interest) model and \({K}({\bf{y}}\,,{\boldsymbol{\mu }})=2\bullet {\rm{llf}}({\bf{y}}\,;{\bf{y}})-2\bullet {\rm{llf}}({\boldsymbol{\mu }}\,;{\bf{y}})\) where \({\rm{llf}}({\boldsymbol{\mu }}\,;{\bf{y}})\) is the log-likelihood of the model and \({\rm{llf}}({\bf{y}}\,;{\bf{y}})\) is the log-likelihood of the saturated model. The D 2 value represents the proportion of reduction in uncertainty (measured by the Kullback–Leibler divergence) due to the inclusion of regressors. The statistical significance of model fit was evaluated using the likelihood ratio test compared with a model with all covariates except the regressors of interest (the task variables).
We characterized a neuron as selectively ‘tuned’ to a given word feature if the GLM of neuronal firing rates as a function of task variables for that feature exhibited a statistically significant model fit (likelihood ratio test with α set at 0.01). For neurons meeting this criterion, we also examined the point estimates and confidence intervals for each coefficient in the model. A vector of these coefficients (or, in our feature space, a vector of the sign of these coefficients) indicates a word with the combination of constituent elements expected to produce a maximal neuronal response. The multidimensional feature spaces also allowed us to define metrics that quantified the phonemic, syllabic or morphologic similarity between words. Here, we calculated the Hamming distance between the vector describing each word u and the vector of the sign of regression coefficients that defines each neuron’s maximal predicted response v , which is equal to the number of positions at which the corresponding values are different:
For each ‘tuned’ neuron, we compared the Z -scored firing rate elicited by each word as a function of the Hamming distance between the word and the ‘preferred word’ of the neuron to examine the ‘tuning’ characteristics of these neurons (Figs. 1f and 2c ). A Hamming distance of zero would therefore indicate that the words have phonetically identical compositions. Finally, to examine the relationship between neuronal activity and spectral features of each phoneme, we extracted the acoustic waveform for each phoneme and calculated the power in ten log-spaced spectral bands. We then constructed a ‘spectral vector’ representation for each word based on these ten values and fit a Poisson GLM of neuronal firing rates against these values. For amplitude analysis, we regressed neuronal firing rates against the root-mean-square amplitude of the waveform for each word.
Controlling for interdependency between phonetic and syllabic features
Three more word variations were used to examine the interdependency between phonetic and syllabic features. First, we compared firing rates for words containing specific syllables with words containing individual phonemes in that syllable but not the syllable itself (for example, simply /d/ in ‘god’ or ‘dog’). Second, we examined words containing syllables with the same constituent phonemes but in a different order (for example, /g-ah-d/ for ‘god’ versus /d-ah-g/ for ‘dog’). Thus, if neurons responded preferentially to specific syllables, then they should continue to respond to them preferentially even when comparing words that had the same arrangements of phonemes but in different or reverse order. Third, we examined words containing the same sequence of syllables but spanning a syllable boundary such that the cluster of phonemes did not constitute a syllable (that is, in the same syllable versus spanning across syllable boundaries).
Visualization of neuronal responses within the population
To allow for visualization of groupings of neurons with shared representational characteristics, we calculated the AIC and D 2 for phoneme, syllable and morpheme models for each neuron and conducted tSNE procedure which transformed these data into two dimensions such that neurons with similar feature representations are spatially closer together than those with dissimilar representations 90 . We used the tSNE implantation in the scikit-learn Python module (v.1.3.0). In Fig. 3a left, a tSNE was fit on the AIC values for phoneme, syllable and morpheme models for each neuron during the planning period with the following parameters: perplexity = 35, early exaggeration = 2 and using Euclidean distance as the metric. In Fig. 3a right and Fig. 4a bottom, a different tSNE was fit on the D 2 values for all planning and production models using the following parameters: perplexity = 10, early exaggeration = 10 and using a cosine distance metric. The resulting embeddings were mapped onto a grid of points according to a linear sum assignment algorithm between embeddings and grid points.
Population modelling
Modelling population activity.
To quantify the degree to which the neural population coded information about the planned phonemes, syllables and morphemes, we modelled the activity of the entire pseudopopulation of recorded neurons. To match trials across the different participants, we first labelled each word according to whether it contained the feature of interest and then matched words across subjects based on the features that were shared. Using this procedure, no trials or neural data were duplicated or upsampled, ensuring strict separation between training and testing sets during classifier training and subsequent evaluation.
For decoding, words were randomly split into training (75%) and testing (25%) trials across 50 iterations. A support vector machine (SVM) as implemented in the scikit-learn Python package (v.1.3.0) 91 was used to construct a hyperplane in n -dimensional space that optimally separates samples of different word features by solving the following minimization problem:
subject to \({y}_{i}({w}^{T}\phi ({x}_{i})+b)\ge 1-{\zeta }_{i}\) and \({\zeta }_{i}\ge 0\) for all \(i\in \left\{1,\ldots ,n\right\}\) , where w is the margin in feature space, C is the regularization strength, ζ i is the distance of each point from the margin, y i is the predicted class for each sample and ϕ ( x i ) is the image of each datapoint in transformed feature space. A radial basis function kernel with coefficient γ = 1/272 was applied. The penalty term C was optimized for each classifier using a cross-validation procedure nested in the training set.
A separate classifier was trained for each dimension in a task space (for example, separate classifiers for bilabial, dental and alveolar consonants) and scores for each of these classifiers were averaged to calculate an overall decoding score for that feature type. Each decoder was trained to predict whether the upcoming word contained an instance of a specific phoneme, syllable or morpheme arrangement. For phonemes, we used nine of the ten phoneme groups (there were insufficient instances of palatal consonants to train a classifier; Extended Data Table 1 ). For syllables, we used ten syllables taken from the most common syllables across the study vocabulary (Extended Data Table 1 ). For morpheme analysis, a single classifier was trained to predict the presence or absence of any bound morpheme in the upcoming word.
Finally, to assess performance, we scored classifiers using the area under the curve of the receiver operating characteristic (AUC-ROC) model. With this scoring metric, a classifier that always guesses the most common class (that is, an uninformative classifier) results in a score of 0.5 whereas a perfect classification results in a score of 1. The overall decoding score for a particular feature space was the mean score of the classifier for each dimension in the space. The entire procedure was repeated 50 times with random train/test splits. Summary statistics for these 50 iterations are presented in the main text.
Model switching
Assessing decoder generalization across different experimental conditions provides a powerful method to evaluate the similarity of neuronal representations of information in different contexts 64 . To determine how neurons encoded the same word features but under different conditions, we trained SVM decoders using neuronal data during one condition (for example, word production) but tested the decoder using data from another (for example, no word production). Before decoder training or testing, trials were split into disjoint training and testing sets, from which the neuronal data were extracted in the epoch of interest. Thus, trials used to train the model were never used to test the model while testing either native decoder performance or decoder generalizability.
Modelling temporal dynamic
To further study the temporal dynamic of neuronal response, we trained decoders to predict the phonemes, syllables and morpheme arrangement for each word across successive time points before utterance 64 . For each neuron, we aligned all spikes to utterance onset, binned spikes into 5 ms windows and convolved with a Gaussian kernel with standard deviation of 25 ms to generate an estimated instantaneous firing rate at each point in time during word planning. For each time point, we evaluated the performance of decoders of phonemes, syllables and morphemes trained on these data over 50 random splits of training and testing trials. The distribution of times of peak decoding performance across the planning or perception period revealed the dynamic of information encoding by these neurons during word planning or perception and we then calculated the median peak decoding times for phonemes, syllables or morphemes.
Dynamical system and subspace analysis
To study the dimensionality of neuronal activity and to evaluate the functional subspaces occupied by the neuronal population, we used dynamical systems approach that quantified the time-dependent changes in neural activity patterns 31 . For the dynamical system analysis, activity for all words were averaged for each neuron to come up with a single peri-event time projection (aligned to word onset) which allowed all neurons to be analysed together as a pseudopopulation. First, we calculated the instantaneous firing rates of the neuron which showed selectivity to any word feature (phonemes, syllables or morpheme arrangement) into 5 ms bins convolved with a Gaussian filter with standard deviation of 50 ms. We used equal 500 ms windows set at −500 to 0 ms before utterance onset for the planning phase and 0 to 500 ms following utterance onset for the production phase to allow for comparison. These data were then standardized to zero mean and unit variance. Finally, the neural data were concatenated into a T × N matrix of sampled instantaneous firing rates for each of the N neurons at every time T .
Together, these matrices represented the evolution of the system in N -dimensional space over time. A principal component analysis revealed a small set of five principal components (PC) embedded in the full N -dimensional space that captured most of the variance in the data for each epoch (Fig. 4b ). Projection of the data into this space yields a T × 5 matrix representing the evolution of the system in five-dimensional space over time. The columns of the N × 5 principal components form an orthonormal basis for the five-dimensional subspace occupied by the system during each epoch.
Next, to quantify the relationship between these subspaces during planning and production, we took two approaches. First, we calculated the alignment index from ref. 66 :
where D A is the matrix defined by the orthonormal basis of subspace A, C B is the covariance of the neuronal data as it evolves in space B, \({\sigma }_{{\rm{B}}}(i)\) is the i th singular value of the covariance matrix C B and Tr(∙) is the matrix trace. The alignment index A ranges from 0 to 1 and quantifies the fraction of variance in space B recovered when the data are projected into space A. Higher values indicate that variance in the data is adequately captured by either subspace.
As discussed in ref. 66 , subspace misalignment in the form of low alignment index A can arise by chance when considering high-dimensional neuronal data because of the probability that two randomly selected sets of dimensions in high-dimensional space may not align well. Therefore, to further explore the degree to which our subspace misalignment was attributable to chance, we used the Monte Carlo analysis to generate random subspaces from data with the same covariance structure as the true (observed) data:
where V is a random subspace, U and S are the eigenvectors and eigenvalues of the covariance matrix of the observed data across all epochs being compared, v is a matrix of white noise and orth(∙) orthogonalizes the matrix. The alignment index A of the subspaces defined by the resulting basis vectors V was recalculated 1,000 times to generate a distribution of alignment index values A attributable to chance alone (compare Fig. 4b ).
Finally, we calculated the projection error between each pair of subspaces on the basis of relationships between the three orthonormal bases (rather than a projection of the data into each of these subspaces). The set of all (linear) subspaces of dimension k < n embedded in an n -dimensional vector space V forms a manifold known as the Grassmannian, endowed with several metrics which can be used to quantify distances between two subspaces on the manifold. Thus, the subspaces (defined by the columns of a T × N ′ matrix, where N ′ is the number of selected principal components; five in our case) explored by the system during planning and production are points on the Grassmannian manifold of the full N -neuron dimensional vector space. Here, we used the Grassmannian chordal distance 92 :
where A and B are matrices whose columns are the orthonormal basis for their respective subspaces and \({\parallel \cdot \parallel }_{F}\) is the Frobenius norm. By normalizing this distance by the Frobenius norm of subspace A , we scale the distance metric from 0 to 1, where 0 indicates a subspace identical to A (that is, completely overlapping) and increasing values indicate greater misalignment from A . Random sampling of subspaces under the null hypothesis was repeated using the same procedure outlined above.
Participant demographics
Across the participants, there was no statistically significant difference in word length based on sex (three-way analysis of variance, F (1,4257) = 1.78, P = 0.18) or underlying diagnosis (essential tremor versus Parkinson’s disease; F (1,4257) = 0.45, P = 0.50). Among subjects with Parkinson’s disease, there was a significant difference based on disease severity (both ON score and OFF score) with more advanced disease (higher scores) correlating with longer word lengths ( F (1,3295) = 145.8, P = 7.1 × 10 −33 for ON score and F (1,3295) = 1,006.0, P = 6.7 × 10 −193 for OFF score, P < 0.001) and interword intervals ( F (1,3291) = 14.9, P = 1.1 × 10 −4 for ON score and F (1,3291) = 31.8, P = 1.9 × 10 −8 for OFF score). Modelling neuronal activities in relation to these interword intervals (bottom versus top quartile), decoding performances were slightly higher for longer compared to shorter delays (0.76 ± 0.01 versus 0.68 ± 0.01, P < 0.001, two-sided Mann–Whitney U -test).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All the primary data supporting the main findings of this study are available online at https://doi.org/10.6084/m9.figshare.24720501 . Source data are provided with this paper.
Code availability
All codes necessary for reproducing the main findings of this study are available online at https://doi.org/10.6084/m9.figshare.24720501 .
Levelt, W. J. M., Roelofs, A. & Meyer, A. S. A Theory of Lexical Access in Speech Production Vol. 22 (Cambridge Univ. Press, 1999).
Kazanina, N., Bowers, J. S. & Idsardi, W. Phonemes: lexical access and beyond. Psychon. Bull. Rev. 25 , 560–585 (2018).
Article PubMed Google Scholar
Bohland, J. W. & Guenther, F. H. An fMRI investigation of syllable sequence production. NeuroImage 32 , 821–841 (2006).
Basilakos, A., Smith, K. G., Fillmore, P., Fridriksson, J. & Fedorenko, E. Functional characterization of the human speech articulation network. Cereb. Cortex 28 , 1816–1830 (2017).
Article PubMed Central Google Scholar
Tourville, J. A., Nieto-Castañón, A., Heyne, M. & Guenther, F. H. Functional parcellation of the speech production cortex. J. Speech Lang. Hear. Res. 62 , 3055–3070 (2019).
Article PubMed PubMed Central Google Scholar
Lee, D. K. et al. Neural encoding and production of functional morphemes in the posterior temporal lobe. Nat. Commun. 9 , 1877 (2018).
Article ADS PubMed PubMed Central Google Scholar
Glanz, O., Hader, M., Schulze-Bonhage, A., Auer, P. & Ball, T. A study of word complexity under conditions of non-experimental, natural overt speech production using ECoG. Front. Hum. Neurosci. 15 , 711886 (2021).
Yellapantula, S., Forseth, K., Tandon, N. & Aazhang, B. NetDI: methodology elucidating the role of power and dynamical brain network features that underpin word production. eNeuro 8 , ENEURO.0177-20.2020 (2020).
Hoffman, P. Reductions in prefrontal activation predict off-topic utterances during speech production. Nat. Commun. 10 , 515 (2019).
Article ADS CAS PubMed PubMed Central Google Scholar
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536 , 171–178 (2016).
Chang, E. F. et al. Pure apraxia of speech after resection based in the posterior middle frontal gyrus. Neurosurgery 87 , E383–E389 (2020).
Hazem, S. R. et al. Middle frontal gyrus and area 55b: perioperative mapping and language outcomes. Front. Neurol. 12 , 646075 (2021).
Fedorenko, E. et al. Neural correlate of the construction of sentence meaning. Proc. Natl Acad. Sci. USA 113 , E6256–E6262 (2016).
Article CAS PubMed PubMed Central Google Scholar
Nelson, M. J. et al. Neurophysiological dynamics of phrase-structure building during sentence processing. Proc. Natl Acad. Sci. USA 114 , E3669–E3678 (2017).
Walenski, M., Europa, E., Caplan, D. & Thompson, C. K. Neural networks for sentence comprehension and production: an ALE-based meta-analysis of neuroimaging studies. Hum. Brain Mapp. 40 , 2275–2304 (2019).
Elin, K. et al. A new functional magnetic resonance imaging localizer for preoperative language mapping using a sentence completion task: validity, choice of baseline condition and test–retest reliability. Front. Hum. Neurosci. 16 , 791577 (2022).
Duffau, H. et al. The role of dominant premotor cortex in language: a study using intraoperative functional mapping in awake patients. Neuroimage 20 , 1903–1914 (2003).
Ikeda, S. et al. Neural decoding of single vowels during covert articulation using electrocorticography. Front. Hum. Neurosci. 8 , 125 (2014).
Ghosh, S. S., Tourville, J. A. & Guenther, F. H. A neuroimaging study of premotor lateralization and cerebellar involvement in the production of phonemes and syllables. J. Speech Lang. Hear. Res. 51 , 1183–1202 (2008).
Bouchard, K. E., Mesgarani, N., Johnson, K. & Chang, E. F. Functional organization of human sensorimotor cortex for speech articulation. Nature 495 , 327–332 (2013).
Anumanchipalli, G. K., Chartier, J. & Chang, E. F. Speech synthesis from neural decoding of spoken sentences. Nature 568 , 493–498 (2019).
Moses, D. A. et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. N. Engl. J. Med. 385 , 217–227 (2021).
Wang, R. et al. Distributed feedforward and feedback cortical processing supports human speech production. Proc. Natl Acad. Sci. USA 120 , e2300255120 (2023).
Coudé, G. et al. Neurons controlling voluntary vocalization in the Macaque ventral premotor cortex. PLoS ONE 6 , e26822 (2011).
Hahnloser, R. H. R., Kozhevnikov, A. A. & Fee, M. S. An ultra-sparse code underlies the generation of neural sequences in a songbird. Nature 419 , 65–70 (2002).
Aronov, D., Andalman, A. S. & Fee, M. S. A specialized forebrain circuit for vocal babbling in the juvenile songbird. Science 320 , 630–634 (2008).
Article ADS CAS PubMed Google Scholar
Stavisky, S. D. et al. Neural ensemble dynamics in dorsal motor cortex during speech in people with paralysis. eLife 8 , e46015 (2019).
Tankus, A., Fried, I. & Shoham, S. Structured neuronal encoding and decoding of human speech features. Nat. Commun. 3 , 1015 (2012).
Article ADS PubMed Google Scholar
Basilakos, A., Smith, K. G., Fillmore, P., Fridriksson, J. & Fedorenko, E. Functional characterization of the human speech articulation network. Cereb. Cortex 28 , 1816–1830 (2018).
Keating, P. & Shattuck-Hufnagel, S. A prosodic view of word form encoding for speech production. UCLA Work. Pap. Phon. 101 , 112–156 (1989).
Google Scholar
Vyas, S., Golub, M. D., Sussillo, D. & Shenoy, K. V. Computation through neural population dynamics. Ann. Rev. Neurosci. 43 , 249–275 (2020).
Article CAS PubMed Google Scholar
Churchland, M. M., Cunningham, J. P., Kaufman, M. T., Ryu, S. I. & Shenoy, K. V. Cortical preparatory activity: representation of movement or first cog in a dynamical machine? Neuron 68 , 387–400 (2010).
Shenoy, K. V., Sahani, M. & Churchland, M. M. Cortical control of arm movements: a dynamical systems perspective. Ann. Rev. Neurosci. 36 , 337–359 (2013).
Kaufman, M. T., Churchland, M. M., Ryu, S. I. & Shenoy, K. V. Cortical activity in the null space: permitting preparation without movement. Nat. Neurosci. 17 , 440–448 (2014).
Mante, V., Sussillo, D., Shenoy, K. V. & Newsome, W. T. Context-dependent computation by recurrent dynamics in prefrontal cortex. Nature 503 , 78–84 (2013).
Vitevitch, M. S. & Luce, P. A. Phonological neighborhood effects in spoken word perception and production. Ann. Rev. Linguist. 2 , 75–94 (2016).
Jamali, M. et al. Dorsolateral prefrontal neurons mediate subjective decisions and their variation in humans. Nat. Neurosci. 22 , 1010–1020 (2019).
Mian, M. K. et al. Encoding of rules by neurons in the human dorsolateral prefrontal cortex. Cereb. Cortex 24 , 807–816 (2014).
Patel, S. R. et al. Studying task-related activity of individual neurons in the human brain. Nat. Protoc. 8 , 949–957 (2013).
Sheth, S. A. et al. Human dorsal anterior cingulate cortex neurons mediate ongoing behavioural adaptation. Nature 488 , 218–221 (2012).
Williams, Z. M., Bush, G., Rauch, S. L., Cosgrove, G. R. & Eskandar, E. N. Human anterior cingulate neurons and the integration of monetary reward with motor responses. Nat. Neurosci. 7 , 1370–1375 (2004).
Jang, A. I., Wittig, J. H. Jr., Inati, S. K. & Zaghloul, K. A. Human cortical neurons in the anterior temporal lobe reinstate spiking activity during verbal memory retrieval. Curr. Biol. 27 , 1700–1705 (2017).
Ponce, C. R. et al. Evolving images for visual neurons using a deep generative network reveals coding principles and neuronal preferences. Cell 177 , 999–1009 (2019).
Yoshor, D., Ghose, G. M., Bosking, W. H., Sun, P. & Maunsell, J. H. Spatial attention does not strongly modulate neuronal responses in early human visual cortex. J. Neurosci. 27 , 13205–13209 (2007).
Jamali, M. et al. Single-neuronal predictions of others’ beliefs in humans. Nature 591 , 610–614 (2021).
Hickok, G. & Poeppel, D. Dorsal and ventral streams: a framework for understanding aspects of the functional anatomy of language. Cognition 92 , 67–99 (2004).
Poologaindran, A., Lowe, S. R. & Sughrue, M. E. The cortical organization of language: distilling human connectome insights for supratentorial neurosurgery. J. Neurosurg. 134 , 1959–1966 (2020).
Genon, S. et al. The heterogeneity of the left dorsal premotor cortex evidenced by multimodal connectivity-based parcellation and functional characterization. Neuroimage 170 , 400–411 (2018).
Milton, C. K. et al. Parcellation-based anatomic model of the semantic network. Brain Behav. 11 , e02065 (2021).
Sun, H. et al. Functional segregation in the left premotor cortex in language processing: evidence from fMRI. J. Integr. Neurosci. 12 , 221–233 (2013).
Peeva, M. G. et al. Distinct representations of phonemes, syllables and supra-syllabic sequences in the speech production network. Neuroimage 50 , 626–638 (2010).
Paulk, A. C. et al. Large-scale neural recordings with single neuron resolution using Neuropixels probes in human cortex. Nat. Neurosci. 25 , 252–263 (2022).
Coughlin, B. et al. Modified Neuropixels probes for recording human neurophysiology in the operating room. Nat. Protoc. 18 , 2927–2953 (2023).
Windolf, C. et al. Robust online multiband drift estimation in electrophysiology data.In Proc. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 1–5 (IEEE, Rhodes Island, 2023).
Mehri, A. & Jalaie, S. A systematic review on methods of evaluate sentence production deficits in agrammatic aphasia patients: validity and reliability issues. J. Res. Med. Sci. 19 , 885–898 (2014).
PubMed PubMed Central Google Scholar
Abbott, L. F. & Sejnowski, T. J. Neural Codes and Distributed Representations: Foundations of Neural Computation (MIT, 1999).
Green, D. M. & Swets, J. A. Signal Detection Theory and Psychophysics (Wiley, 1966).
Association, I. P. & Staff, I. P. A. Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet (Cambridge Univ. Press, 1999).
Indefrey, P. & Levelt, W. J. M. in The New Cognitive Neurosciences 2nd edn (ed. Gazzaniga, M. S.) 845–865 (MIT, 2000).
Slobin, D. I. Thinking for speaking. In Proc. 13th Annual Meeting of the Berkeley Linguistics Society (eds Aske, J. et al.) 435–445 (Berkeley Linguistics Society, 1987).
Pillon, A. Morpheme units in speech production: evidence from laboratory-induced verbal slips. Lang. Cogn. Proc. 13 , 465–498 (1998).
Article Google Scholar
King, J. R. & Dehaene, S. Characterizing the dynamics of mental representations: the temporal generalization method. Trends Cogn. Sci. 18 , 203–210 (2014).
Machens, C. K., Romo, R. & Brody, C. D. Functional, but not anatomical, separation of “what” and “when” in prefrontal cortex. J. Neurosci. 30 , 350–360 (2010).
Elsayed, G. F., Lara, A. H., Kaufman, M. T., Churchland, M. M. & Cunningham, J. P. Reorganization between preparatory and movement population responses in motor cortex. Nat. Commun. 7 , 13239 (2016).
Roy, S., Zhao, L. & Wang, X. Distinct neural activities in premotor cortex during natural vocal behaviors in a New World primate, the Common Marmoset ( Callithrix jacchus ). J. Neurosci. 36 , 12168–12179 (2016).
Eliades, S. J. & Miller, C. T. Marmoset vocal communication: behavior and neurobiology. Dev. Neurobiol. 77 , 286–299 (2017).
Okobi, D. E. Jr, Banerjee, A., Matheson, A. M. M., Phelps, S. M. & Long, M. A. Motor cortical control of vocal interaction in neotropical singing mice. Science 363 , 983–988 (2019).
Cohen, Y. et al. Hidden neural states underlie canary song syntax. Nature 582 , 539–544 (2020).
Hickok, G. Computational neuroanatomy of speech production. Nat. Rev. Neurosci. 13 , 135–145 (2012).
Sahin, N. T., Pinker, S., Cash, S. S., Schomer, D. & Halgren, E. Sequential processing of lexical, grammatical and phonological information within Broca’s area. Science 326 , 445–449 (2009).
Russo, A. A. et al. Neural trajectories in the supplementary motor area and motor cortex exhibit distinct geometries, compatible with different classes of computation. Neuron 107 , 745–758 (2020).
Willett, F. R. et al. A high-performance speech neuroprosthesis. Nature 620 , 1031–1036 (2023).
Boersma, P. & Weenink, D. Praat: Doing Phonetics by Computer (2020); www.fon.hum.uva.nl/praat/ .
McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M. & Sonderegger, M. Montreal forced aligner: trainable text-speech alignment using kaldi. In Proc. Annual Conference of the International Speech Communication Association 498–502 (ISCA, 2017).
Lancaster, J. L. et al. Automated regional behavioral analysis for human brain images. Front. Neuroinform. 6 , 23 (2012).
Lancaster, J. L. et al. Automated analysis of fundamental features of brain structures. Neuroinformatics 9 , 371–380 (2011).
Fischl, B. & Dale, A. M. Measuring the thickness of the human cerebral cortex from magnetic resonance images. Proc. Natl Acad. Sci. USA 97 , 11050–11055 (2000).
Fischl, B., Liu, A. & Dale, A. M. Automated manifold surgery: constructing geometrically accurate and topologically correct models of the human cerebral cortex. IEEE Trans. Med. Imaging 20 , 70–80 (2001).
Reuter, M., Schmansky, N. J., Rosas, H. D. & Fischl, B. Within-subject template estimation for unbiased longitudinal image analysis. Neuroimage 61 , 1402–1418 (2012).
Oostenveld, R., Fries, P., Maris, E. & Schoffelen, J. M. FieldTrip: open source software for advanced analysis of MEG, EEG and invasive electrophysiological data. Comput. Intell. Neurosci. 2011 , 156869 (2011).
Noiray, A., Iskarous, K., Bolanos, L. & Whalen, D. Tongue–jaw synergy in vowel height production: evidence from American English. In 8th International Seminar on Speech Production (eds Sock, R. et al.) 81–84 (ISSP, 2008).
Flege, J. E., Fletcher, S. G., McCutcheon, M. J. & Smith, S. C. The physiological specification of American English vowels. Lang. Speech 29 , 361–388 (1986).
Wells, J. Longman Pronunciation Dictionary (Pearson, 2008).
Seabold, S. & Perktold, J. Statsmodels: econometric and statistical modeling with Python. In Proc. 9th Python in Science Conference (eds van der Walt, S. & Millman, J.) 92–96 (SCIPY, 2010).
Cameron, A. C. & Windmeijer, F. A. G. An R -squared measure of goodness of fit for some common nonlinear regression models. J. Econometr. 77 , 329–342 (1997).
Article MathSciNet Google Scholar
Hamilton, L. S. & Huth, A. G. The revolution will not be controlled: natural stimuli in speech neuroscience. Lang. Cogn. Neurosci. 35 , 573–582 (2020).
Hamilton, L. S., Oganian, Y., Hall, J. & Chang, E. F. Parallel and distributed encoding of speech across human auditory cortex. Cell 184 , 4626–4639 (2021).
Van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9 , 2579–2605 (2008).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12 , 2825–2830 (2011).
MathSciNet Google Scholar
Ye, K. & Lim, L.-H. Schubert varieties and distances between subspaces of different dimensions. SIAM J. Matrix Anal. Appl. 37 , 1176–1197 (2016).
Download references
Acknowledgements
We thank all the participants for their generosity and willingness to take part in the research. We also thank A. Turk and S. Hufnagel for their insightful comments and suggestions as well as D. J. Kellar, Y. Chou, A. Zhang, A. O’Donnell and B. Mash for their assistance and contributions to the intraoperative setup and feedback. Finally, we thank B. Coughlin, E. Trautmann, C. Windolf, E. Varol, D. Soper, S. Stavisky and K. Shenoy for their assistance in developing the data processing pipeline. A.R.K. and W.M. are supported by the NIH Neuroscience Resident Research Program R25NS065743, M.J. is supported by CIHR and Foundations of Human Behavior Initiative, A.C.P. is supported by UG3NS123723, Tiny Blue Dot Foundation and P50MH119467. J.C. is supported by American Association of University Women, S.S.C. is supported by R44MH125700 and Tiny Blue Dot Foundation and Z.M.W. is supported by R01DC019653 and U01NS121616.
Author information
These authors contributed equally: Arjun R. Khanna, William Muñoz, Young Joon Kim
These authors jointly supervised this work: Sydney Cash, Ziv M. Williams
Authors and Affiliations
Department of Neurosurgery, Massachusetts General Hospital, Harvard Medical School, Boston, MA, USA
Arjun R. Khanna, William Muñoz, Yoav Kfir, Mohsen Jamali, Jing Cai, Martina L. Mustroph, Irene Caprara, Mackenna Mejdell, Jeffrey Schweitzer & Ziv M. Williams
Harvard Medical School, Boston, MA, USA
Young Joon Kim & Abigail Zuckerman
Department of Neurology, Massachusetts General Hospital, Harvard Medical School, Boston, MA, USA
Angelique C. Paulk, Richard Hardstone, Domokos Meszéna & Sydney Cash
Harvard-MIT Division of Health Sciences and Technology, Boston, MA, USA
Ziv M. Williams
Harvard Medical School, Program in Neuroscience, Boston, MA, USA
You can also search for this author in PubMed Google Scholar
Contributions
A.R.K. and Y.J.K. performed the analyses. Z.M.W., J.S. and W.M. performed the intraoperative neuronal recordings. W.M., Y.J.K., A.C.P., R.H. and D.M. performed the data processing and neuronal alignments. W.M. performed the spike sorting. A.C.P. and W.M. reconstructed the recording locations. A.R.K., W.M., Y.J.K., Y.K., A.C.P., M.J., J.C., M.L.M., I.C. and D.M. performed the experiments. Y.K. and M.J. implemented the task. M.M. and A.Z. transcribed the speech signals. A.C.P., S.C. and Z.M.W. devised the intraoperative Neuropixels recording approach. A.R.K., W.M., Y.J.K., A.C.P., M.J., J.S. and S.C. edited the manuscript and Z.M.W. conceived and designed the study, wrote the manuscript and directed and supervised all aspects of the research.
Corresponding author
Correspondence to Ziv M. Williams .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature thanks Eyiyemisi Damisah, Yves Boubenec and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended data fig. 1 single-unit isolations from the human prefrontal cortex using neuropixels recordings..
a . Individual recording sites on a standardized 3D brain model (FreeSurfer), on side ( top ), zoomed-in oblique ( inset ) and top ( bottom ) views. Recordings lay across the posterior middle frontal gyrus of the language-dominant prefrontal cortex and roughly ranged in distribution from alongside anterior area 55b to 8a. b . Recording coordinates for the five participants are given in MNI space. c . Left , representative example of raw, motion-corrected action potential traces recorded across neighbouring channels over time. Right , an example of overlayed spike waveform morphologies and their distribution across neighbouring channels recorded from a Neuropixels array. d . Isolation metrics for the recorded population (n = 272 units) together with an example of spikes from four concomitantly recorded units (labelled red, blue, cyan and yellow) in principal component space.
Extended Data Fig. 2 Naturalistic speech production task performance and phonetic selectivity across neurons and participants.
a . A priming-based speech production task that provided participants with pictorial representations of naturalistic events and that had to be verbally described in specific order. The task trial example is given here for illustrative purposes (created with BioRender.com). b . Mean word production times across participants and their standard deviation of the mean. The blue bars and dots represent performances for the five participants in which recordings were acquired (n = 964, 1252, 406, 836, 805 words, respectively). The grey bar and dots represent healthy control (n = 1534 words). c . Percentage of modulated neurons that responded selectively to specific planned phonemes across participants. All participants possessed neurons that responded to various phonetic features (one-sided χ 2 = 10.7, 6.9, 7.4, 0.5 and 1.3, p = 0.22, 0.44, 0.49, 0.97, 0.86, for participants 1–5, respectively).
Extended Data Fig. 3 Examples of single-neuronal activities and their temporal dynamics.
a . Peri-event time histograms were constructed by aligning the action potentials of each neuron to word onset. Data are presented as mean (line) values ± standard error of the mean (shade). Examples of three representative neurons that selectively changed their activity to specific planned phonemes. Inset , spike waveform morphology and scale bar (0.5 ms). b . Peri-event time histogram and action potential raster for the same neurons above but now aligned to the onset of the articulated phonemes themselves. Data are presented as mean (line) values ± standard error of the mean (shade). c . Sankey diagram displaying the proportions of neurons (n = 56) that displayed a change in activity polarity (increases in orange and decreases in purple) from planning to production.
Extended Data Fig. 4 Generalizability of explanatory power across phonetic groupings for consonants and vowels.
a . Scatter plots of the model explanatory power (D 2 ) for different phonetic groupings across the cell population (n = 272 units). Phonetic groupings were based on the planned (i) places of articulation of consonants and/or vowels (ii) manners of articulation of consonants and (iii) primary cardinal vowels (Extended Data Table 1 ). Model D 2 explanatory power across all phonetic groupings were significantly correlated (from top left to bottom right, p = 1.6×10 −146 , p = 2.8×10 −70 , p = 6.1×10 −54 , p = 1.4×10 −57 , p = 2.3×10 −43 and p = 5.9×10 −43 , two-sided tests of Spearman rank-order correlations). Spearman’s ρ are 0.96, 0.83, 0.77, respectively for left to right top panels and 0.78, 0.71, 0.71, respectively for left to right bottom panels (dashed regression lines). Among phoneme-selective neurons, the planned places of articulation provided the highest explanatory power (two-sided Wilcoxon signed-rank test of model D 2 values, W = 716, p = 7.9×10 −16 ) and the best model fits (two-sided Wilcoxon signed-rank test of AIC, W = 2255, p = 1.3×10 −5 ) compared to manners of articulation. They also provided the highest explanatory power (two-sided Wilcoxon signed-rank test of model D 2 values, W = 846, p = 9.7×10 −15 ) and fits (two-sided Wilcoxon signed-rank test of AIC, W = 2088, p = 2.0×10 −6 ) compared to vowels. b . Multidimensional scaling (MDS) representation of all neurons across phonetic groupings. Neurons with similar response characteristics are plotted closer together. The hue of each point reflects the degree of selectivity to specific phonetic features. Here, the colour scale for places of articulation is provided in red, manners of articulation in green and vowels in blue. The size of each point reflects the magnitude of the maximum explanatory power in relation to each cell’s phonetic selectivity (maximum D 2 for places of articulation of consonants and/or vowels, manners of articulation of consonants and primary cardinal vowels).
Extended Data Fig. 5 Explanatory power for the acoustic–phonetic properties of phonemes and neuronal tuning to morphemes.
a . Left , scatter plot of the D 2 explanatory power of neurons for planned phonemes and their observed spectral frequencies during articulation (n = 272 units; Spearman’s ρ = 0.75, p = 9.3×10 −50 , two-sided test of Spearman rank-order correlation). Right , decoding performances for the spectral frequency of phonemes (n = 50 random test/train splits; p = 7.1×10 −18 , two-sided Mann–Whitney U-test). Data are presented as mean values ± standard error of the mean. b . Venn diagrams of neurons that were modulated by phonemes during planning and those that were modulated by the spectral frequency (left) and amplitude (right) of the phonemes during articulation. c . Left , peri-event time histogram and raster for a representative neuron exhibiting selectivity to words that contained bound morphemes (for example, –ing , –ed ) compared to words that did not. Data are presented as mean (line) values ± standard error of the mean (shade). Inset , spike waveform morphology and scale bar (0.5 ms). Right , decoding performance distribution for morphemes (n = 50 random test/train splits; p = 1.0×10 −17 , two-sided Mann–Whitney U-test). Data are presented as mean values ± standard deviation.
Extended Data Fig. 6 Phonetic representations of words during speech perception and the comparison of speaking to listening.
a . Left , Venn diagrams of neurons that selectively changed their activity to specific phonemes during word planning (−500:0 ms from word utterance onset) and perception (0:500 ms from word utterance onset). Right , average z-scored firing rate for selective neurons during word planning (black) and perception (grey) as a function of the Hamming distance. Here, the Hamming distance was based on the neurons’ preferred phonetic compositions during production and compared for the same neurons during perception. Data are presented as mean (line) values ± standard error of the mean (shade). b . Left , classifier decoding performances for selective neurons during word planning. The points provide the sampled distribution for the classifier’s ROC-AUC values (black) compared to random chance (grey; n = 50 random test/train splits; p = 7.1×10 −18 , two-sided Mann–Whitney U-test). Middle , decoding performance for selective neurons during perception (n = 50 random test/train splits; 7.1×10 −18 , two-sided Mann–Whitney U-test). Right , word planning-perception model-switch decoding performances for selective neurons. Here, models were trained on neural data for specific phonemes during planning and then used to decode those same phonemes during perception (n = 50 random test/train splits; p > 0.05, two-sided Mann–Whitney U-test; Methods ). The boundaries and midline of the boxplots represent the 25 th and 75 th percentiles and the median, respectively. c . Peak decoding performance for phonemes, syllables and morphemes as a function of time from perceived word onset. Peak decoding for morphemes was observed significantly later than for phonemes and syllables during perception (n = 50 random test/train splits; two-sided Kruskal–Wallis, H = 14.8, p = 0.00062). Data are presented here as median (dot) values ± bootstrapped standard error of the median.
Extended Data Fig. 7 Spatial distribution of representations based on cortical location and depth.
a . Relationship between recording location along the rostral–caudal axis of the prefrontal cortex and the proportion of neurons that displayed selectivity to specific phonemes, syllables and morphemes. Neurons that displayed selectivity were more likely to be found posteriorly (one-sided χ 2 test, p = 2.6×10 −9 , 3.0×10 −11 , 2.5×10 −6 , 3.9×10 −10 , for places of articulation, manners of articulation, syllables and morpheme, respectively). b . Relationship between recording depth along the cortical column and the proportion of neurons that display selectivity to specific phonemes, syllables and morphemes. Neurons that displayed selectivity were broadly distributed along the cortical column (one-sided χ 2 test, p > 0.05). Here, S indicates superficial, M middle and D deep.
Extended Data Fig. 8 Receiver operating characteristic curves across planned phonetic representations and decoding model-switching performances for word planning and production.
a . ROC-AUC curves for neurons across different phonemes, grouped by placed of articulation, during planning (there were insufficient palatal consonants to allow for classification and are therefore not displayed here). b . Average (solid line) and shuffled (dotted line) data across all phonemes. Data are presented as mean (line) values ± standard error of the mean (shade). c . Planning-production model-switch decoding performance sample distribution (n = 50 random test/train splits) for all selective neurons. Here, models were trained on neuronal data recorded during planning and then used to decode those same phoneme ( left ), syllable ( middle ), or morpheme ( right ) on neuronal data recorded during production. Slightly lower decoding performances were noted for syllables and morphemes when comparing word planning to production (p = 0.020 for syllable comparison and p = 0.032 for morpheme comparison, two-sided Mann–Whitney U-test). Data are presented as mean values ± standard deviation.
Extended Data Fig. 9 Example of phonetic representations in planning and production subspaces.
Modelled depiction of the neuronal population trajectory (bootstrap resampled) across averaged trials with (green) and without (grey) mid-low phonemes, projected into a plane within the “planning” subspace (y-axis) and a plane within the “production” subspace (z-axis). Projection planes within planning and production subspaces were chosen to enable visualization of trajectory divergence. Zero indicates word onset on the x-axis. Separation between the population trajectory during trials with and without mid-low phonemes is apparent in the planning subspace (y-axis) independently of the projection subspace (z-axis) because these subspaces are orthogonal. The orange plane indicates a hypothetical decision boundary learned by a classifier to separate neuronal activities between mid-low and non-mid-low trials. Because the classifier decision boundary is not constrained to lie within a particular subspace, classifier performance may therefore generalize across planning and production epochs, despite the near-orthogonality of these respective subspaces.
Supplementary information
Reporting summary, source data, source data fig. 1, source data fig. 2, source data fig. 3, source data fig. 4, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Khanna, A.R., Muñoz, W., Kim, Y.J. et al. Single-neuronal elements of speech production in humans. Nature 626 , 603–610 (2024). https://doi.org/10.1038/s41586-023-06982-w
Download citation
Received : 22 June 2023
Accepted : 14 December 2023
Published : 31 January 2024
Issue Date : 15 February 2024
DOI : https://doi.org/10.1038/s41586-023-06982-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
How speech is produced and perceived in the human cortex.
- Yves Boubenec
Nature (2024)
Mind-reading devices are revealing the brain’s secrets
- Miryam Naddaf
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

- Search Menu
- Browse content in Arts and Humanities
- Browse content in Archaeology
- Anglo-Saxon and Medieval Archaeology
- Archaeological Methodology and Techniques
- Archaeology by Region
- Archaeology of Religion
- Archaeology of Trade and Exchange
- Biblical Archaeology
- Contemporary and Public Archaeology
- Environmental Archaeology
- Historical Archaeology
- History and Theory of Archaeology
- Industrial Archaeology
- Landscape Archaeology
- Mortuary Archaeology
- Prehistoric Archaeology
- Underwater Archaeology
- Urban Archaeology
- Zooarchaeology
- Browse content in Architecture
- Architectural Structure and Design
- History of Architecture
- Residential and Domestic Buildings
- Theory of Architecture
- Browse content in Art
- Art Subjects and Themes
- History of Art
- Industrial and Commercial Art
- Theory of Art
- Biographical Studies
- Byzantine Studies
- Browse content in Classical Studies
- Classical History
- Classical Philosophy
- Classical Mythology
- Classical Literature
- Classical Reception
- Classical Art and Architecture
- Classical Oratory and Rhetoric
- Greek and Roman Papyrology
- Greek and Roman Epigraphy
- Greek and Roman Law
- Greek and Roman Archaeology
- Late Antiquity
- Religion in the Ancient World
- Digital Humanities
- Browse content in History
- Colonialism and Imperialism
- Diplomatic History
- Environmental History
- Genealogy, Heraldry, Names, and Honours
- Genocide and Ethnic Cleansing
- Historical Geography
- History by Period
- History of Emotions
- History of Agriculture
- History of Education
- History of Gender and Sexuality
- Industrial History
- Intellectual History
- International History
- Labour History
- Legal and Constitutional History
- Local and Family History
- Maritime History
- Military History
- National Liberation and Post-Colonialism
- Oral History
- Political History
- Public History
- Regional and National History
- Revolutions and Rebellions
- Slavery and Abolition of Slavery
- Social and Cultural History
- Theory, Methods, and Historiography
- Urban History
- World History
- Browse content in Language Teaching and Learning
- Language Learning (Specific Skills)
- Language Teaching Theory and Methods
- Browse content in Linguistics
- Applied Linguistics
- Cognitive Linguistics
- Computational Linguistics
- Forensic Linguistics
- Grammar, Syntax and Morphology
- Historical and Diachronic Linguistics
- History of English
- Language Evolution
- Language Reference
- Language Acquisition
- Language Variation
- Language Families
- Lexicography
- Linguistic Anthropology
- Linguistic Theories
- Linguistic Typology
- Phonetics and Phonology
- Psycholinguistics
- Sociolinguistics
- Translation and Interpretation
- Writing Systems
- Browse content in Literature
- Bibliography
- Children's Literature Studies
- Literary Studies (Romanticism)
- Literary Studies (American)
- Literary Studies (Asian)
- Literary Studies (European)
- Literary Studies (Eco-criticism)
- Literary Studies (Modernism)
- Literary Studies - World
- Literary Studies (1500 to 1800)
- Literary Studies (19th Century)
- Literary Studies (20th Century onwards)
- Literary Studies (African American Literature)
- Literary Studies (British and Irish)
- Literary Studies (Early and Medieval)
- Literary Studies (Fiction, Novelists, and Prose Writers)
- Literary Studies (Gender Studies)
- Literary Studies (Graphic Novels)
- Literary Studies (History of the Book)
- Literary Studies (Plays and Playwrights)
- Literary Studies (Poetry and Poets)
- Literary Studies (Postcolonial Literature)
- Literary Studies (Queer Studies)
- Literary Studies (Science Fiction)
- Literary Studies (Travel Literature)
- Literary Studies (War Literature)
- Literary Studies (Women's Writing)
- Literary Theory and Cultural Studies
- Mythology and Folklore
- Shakespeare Studies and Criticism
- Browse content in Media Studies
- Browse content in Music
- Applied Music
- Dance and Music
- Ethics in Music
- Ethnomusicology
- Gender and Sexuality in Music
- Medicine and Music
- Music Cultures
- Music and Media
- Music and Religion
- Music and Culture
- Music Education and Pedagogy
- Music Theory and Analysis
- Musical Scores, Lyrics, and Libretti
- Musical Structures, Styles, and Techniques
- Musicology and Music History
- Performance Practice and Studies
- Race and Ethnicity in Music
- Sound Studies
- Browse content in Performing Arts
- Browse content in Philosophy
- Aesthetics and Philosophy of Art
- Epistemology
- Feminist Philosophy
- History of Western Philosophy
- Metaphysics
- Moral Philosophy
- Non-Western Philosophy
- Philosophy of Language
- Philosophy of Mind
- Philosophy of Perception
- Philosophy of Science
- Philosophy of Action
- Philosophy of Law
- Philosophy of Religion
- Philosophy of Mathematics and Logic
- Practical Ethics
- Social and Political Philosophy
- Browse content in Religion
- Biblical Studies
- Christianity
- East Asian Religions
- History of Religion
- Judaism and Jewish Studies
- Qumran Studies
- Religion and Education
- Religion and Health
- Religion and Politics
- Religion and Science
- Religion and Law
- Religion and Art, Literature, and Music
- Religious Studies
- Browse content in Society and Culture
- Cookery, Food, and Drink
- Cultural Studies
- Customs and Traditions
- Ethical Issues and Debates
- Hobbies, Games, Arts and Crafts
- Lifestyle, Home, and Garden
- Natural world, Country Life, and Pets
- Popular Beliefs and Controversial Knowledge
- Sports and Outdoor Recreation
- Technology and Society
- Travel and Holiday
- Visual Culture
- Browse content in Law
- Arbitration
- Browse content in Company and Commercial Law
- Commercial Law
- Company Law
- Browse content in Comparative Law
- Systems of Law
- Competition Law
- Browse content in Constitutional and Administrative Law
- Government Powers
- Judicial Review
- Local Government Law
- Military and Defence Law
- Parliamentary and Legislative Practice
- Construction Law
- Contract Law
- Browse content in Criminal Law
- Criminal Procedure
- Criminal Evidence Law
- Sentencing and Punishment
- Employment and Labour Law
- Environment and Energy Law
- Browse content in Financial Law
- Banking Law
- Insolvency Law
- History of Law
- Human Rights and Immigration
- Intellectual Property Law
- Browse content in International Law
- Private International Law and Conflict of Laws
- Public International Law
- IT and Communications Law
- Jurisprudence and Philosophy of Law
- Law and Politics
- Law and Society
- Browse content in Legal System and Practice
- Courts and Procedure
- Legal Skills and Practice
- Primary Sources of Law
- Regulation of Legal Profession
- Medical and Healthcare Law
- Browse content in Policing
- Criminal Investigation and Detection
- Police and Security Services
- Police Procedure and Law
- Police Regional Planning
- Browse content in Property Law
- Personal Property Law
- Study and Revision
- Terrorism and National Security Law
- Browse content in Trusts Law
- Wills and Probate or Succession
- Browse content in Medicine and Health
- Browse content in Allied Health Professions
- Arts Therapies
- Clinical Science
- Dietetics and Nutrition
- Occupational Therapy
- Operating Department Practice
- Physiotherapy
- Radiography
- Speech and Language Therapy
- Browse content in Anaesthetics
- General Anaesthesia
- Neuroanaesthesia
- Clinical Neuroscience
- Browse content in Clinical Medicine
- Acute Medicine
- Cardiovascular Medicine
- Clinical Genetics
- Clinical Pharmacology and Therapeutics
- Dermatology
- Endocrinology and Diabetes
- Gastroenterology
- Genito-urinary Medicine
- Geriatric Medicine
- Infectious Diseases
- Medical Toxicology
- Medical Oncology
- Pain Medicine
- Palliative Medicine
- Rehabilitation Medicine
- Respiratory Medicine and Pulmonology
- Rheumatology
- Sleep Medicine
- Sports and Exercise Medicine
- Community Medical Services
- Critical Care
- Emergency Medicine
- Forensic Medicine
- Haematology
- History of Medicine
- Browse content in Medical Skills
- Clinical Skills
- Communication Skills
- Nursing Skills
- Surgical Skills
- Browse content in Medical Dentistry
- Oral and Maxillofacial Surgery
- Paediatric Dentistry
- Restorative Dentistry and Orthodontics
- Surgical Dentistry
- Medical Ethics
- Medical Statistics and Methodology
- Browse content in Neurology
- Clinical Neurophysiology
- Neuropathology
- Nursing Studies
- Browse content in Obstetrics and Gynaecology
- Gynaecology
- Occupational Medicine
- Ophthalmology
- Otolaryngology (ENT)
- Browse content in Paediatrics
- Neonatology
- Browse content in Pathology
- Chemical Pathology
- Clinical Cytogenetics and Molecular Genetics
- Histopathology
- Medical Microbiology and Virology
- Patient Education and Information
- Browse content in Pharmacology
- Psychopharmacology
- Browse content in Popular Health
- Caring for Others
- Complementary and Alternative Medicine
- Self-help and Personal Development
- Browse content in Preclinical Medicine
- Cell Biology
- Molecular Biology and Genetics
- Reproduction, Growth and Development
- Primary Care
- Professional Development in Medicine
- Browse content in Psychiatry
- Addiction Medicine
- Child and Adolescent Psychiatry
- Forensic Psychiatry
- Learning Disabilities
- Old Age Psychiatry
- Psychotherapy
- Browse content in Public Health and Epidemiology
- Epidemiology
- Public Health
- Browse content in Radiology
- Clinical Radiology
- Interventional Radiology
- Nuclear Medicine
- Radiation Oncology
- Reproductive Medicine
- Browse content in Surgery
- Cardiothoracic Surgery
- Gastro-intestinal and Colorectal Surgery
- General Surgery
- Neurosurgery
- Paediatric Surgery
- Peri-operative Care
- Plastic and Reconstructive Surgery
- Surgical Oncology
- Transplant Surgery
- Trauma and Orthopaedic Surgery
- Vascular Surgery
- Browse content in Science and Mathematics
- Browse content in Biological Sciences
- Aquatic Biology
- Biochemistry
- Bioinformatics and Computational Biology
- Developmental Biology
- Ecology and Conservation
- Evolutionary Biology
- Genetics and Genomics
- Microbiology
- Molecular and Cell Biology
- Natural History
- Plant Sciences and Forestry
- Research Methods in Life Sciences
- Structural Biology
- Systems Biology
- Zoology and Animal Sciences
- Browse content in Chemistry
- Analytical Chemistry
- Computational Chemistry
- Crystallography
- Environmental Chemistry
- Industrial Chemistry
- Inorganic Chemistry
- Materials Chemistry
- Medicinal Chemistry
- Mineralogy and Gems
- Organic Chemistry
- Physical Chemistry
- Polymer Chemistry
- Study and Communication Skills in Chemistry
- Theoretical Chemistry
- Browse content in Computer Science
- Artificial Intelligence
- Computer Architecture and Logic Design
- Game Studies
- Human-Computer Interaction
- Mathematical Theory of Computation
- Programming Languages
- Software Engineering
- Systems Analysis and Design
- Virtual Reality
- Browse content in Computing
- Business Applications
- Computer Security
- Computer Games
- Computer Networking and Communications
- Digital Lifestyle
- Graphical and Digital Media Applications
- Operating Systems
- Browse content in Earth Sciences and Geography
- Atmospheric Sciences
- Environmental Geography
- Geology and the Lithosphere
- Maps and Map-making
- Meteorology and Climatology
- Oceanography and Hydrology
- Palaeontology
- Physical Geography and Topography
- Regional Geography
- Soil Science
- Urban Geography
- Browse content in Engineering and Technology
- Agriculture and Farming
- Biological Engineering
- Civil Engineering, Surveying, and Building
- Electronics and Communications Engineering
- Energy Technology
- Engineering (General)
- Environmental Science, Engineering, and Technology
- History of Engineering and Technology
- Mechanical Engineering and Materials
- Technology of Industrial Chemistry
- Transport Technology and Trades
- Browse content in Environmental Science
- Applied Ecology (Environmental Science)
- Conservation of the Environment (Environmental Science)
- Environmental Sustainability
- Environmentalist Thought and Ideology (Environmental Science)
- Management of Land and Natural Resources (Environmental Science)
- Natural Disasters (Environmental Science)
- Nuclear Issues (Environmental Science)
- Pollution and Threats to the Environment (Environmental Science)
- Social Impact of Environmental Issues (Environmental Science)
- History of Science and Technology
- Browse content in Materials Science
- Ceramics and Glasses
- Composite Materials
- Metals, Alloying, and Corrosion
- Nanotechnology
- Browse content in Mathematics
- Applied Mathematics
- Biomathematics and Statistics
- History of Mathematics
- Mathematical Education
- Mathematical Finance
- Mathematical Analysis
- Numerical and Computational Mathematics
- Probability and Statistics
- Pure Mathematics
- Browse content in Neuroscience
- Cognition and Behavioural Neuroscience
- Development of the Nervous System
- Disorders of the Nervous System
- History of Neuroscience
- Invertebrate Neurobiology
- Molecular and Cellular Systems
- Neuroendocrinology and Autonomic Nervous System
- Neuroscientific Techniques
- Sensory and Motor Systems
- Browse content in Physics
- Astronomy and Astrophysics
- Atomic, Molecular, and Optical Physics
- Biological and Medical Physics
- Classical Mechanics
- Computational Physics
- Condensed Matter Physics
- Electromagnetism, Optics, and Acoustics
- History of Physics
- Mathematical and Statistical Physics
- Measurement Science
- Nuclear Physics
- Particles and Fields
- Plasma Physics
- Quantum Physics
- Relativity and Gravitation
- Semiconductor and Mesoscopic Physics
- Browse content in Psychology
- Affective Sciences
- Clinical Psychology
- Cognitive Psychology
- Cognitive Neuroscience
- Criminal and Forensic Psychology
- Developmental Psychology
- Educational Psychology
- Evolutionary Psychology
- Health Psychology
- History and Systems in Psychology
- Music Psychology
- Neuropsychology
- Organizational Psychology
- Psychological Assessment and Testing
- Psychology of Human-Technology Interaction
- Psychology Professional Development and Training
- Research Methods in Psychology
- Social Psychology
- Browse content in Social Sciences
- Browse content in Anthropology
- Anthropology of Religion
- Human Evolution
- Medical Anthropology
- Physical Anthropology
- Regional Anthropology
- Social and Cultural Anthropology
- Theory and Practice of Anthropology
- Browse content in Business and Management
- Business Ethics
- Business Strategy
- Business History
- Business and Technology
- Business and Government
- Business and the Environment
- Comparative Management
- Corporate Governance
- Corporate Social Responsibility
- Entrepreneurship
- Health Management
- Human Resource Management
- Industrial and Employment Relations
- Industry Studies
- Information and Communication Technologies
- International Business
- Knowledge Management
- Management and Management Techniques
- Operations Management
- Organizational Theory and Behaviour
- Pensions and Pension Management
- Public and Nonprofit Management
- Strategic Management
- Supply Chain Management
- Browse content in Criminology and Criminal Justice
- Criminal Justice
- Criminology
- Forms of Crime
- International and Comparative Criminology
- Youth Violence and Juvenile Justice
- Development Studies
- Browse content in Economics
- Agricultural, Environmental, and Natural Resource Economics
- Asian Economics
- Behavioural Finance
- Behavioural Economics and Neuroeconomics
- Econometrics and Mathematical Economics
- Economic History
- Economic Systems
- Economic Methodology
- Economic Development and Growth
- Financial Markets
- Financial Institutions and Services
- General Economics and Teaching
- Health, Education, and Welfare
- History of Economic Thought
- International Economics
- Labour and Demographic Economics
- Law and Economics
- Macroeconomics and Monetary Economics
- Microeconomics
- Public Economics
- Urban, Rural, and Regional Economics
- Welfare Economics
- Browse content in Education
- Adult Education and Continuous Learning
- Care and Counselling of Students
- Early Childhood and Elementary Education
- Educational Equipment and Technology
- Educational Strategies and Policy
- Higher and Further Education
- Organization and Management of Education
- Philosophy and Theory of Education
- Schools Studies
- Secondary Education
- Teaching of a Specific Subject
- Teaching of Specific Groups and Special Educational Needs
- Teaching Skills and Techniques
- Browse content in Environment
- Applied Ecology (Social Science)
- Climate Change
- Conservation of the Environment (Social Science)
- Environmentalist Thought and Ideology (Social Science)
- Natural Disasters (Environment)
- Social Impact of Environmental Issues (Social Science)
- Browse content in Human Geography
- Cultural Geography
- Economic Geography
- Political Geography
- Browse content in Interdisciplinary Studies
- Communication Studies
- Museums, Libraries, and Information Sciences
- Browse content in Politics
- African Politics
- Asian Politics
- Chinese Politics
- Comparative Politics
- Conflict Politics
- Elections and Electoral Studies
- Environmental Politics
- European Union
- Foreign Policy
- Gender and Politics
- Human Rights and Politics
- Indian Politics
- International Relations
- International Organization (Politics)
- International Political Economy
- Irish Politics
- Latin American Politics
- Middle Eastern Politics
- Political Behaviour
- Political Economy
- Political Institutions
- Political Methodology
- Political Communication
- Political Philosophy
- Political Sociology
- Political Theory
- Politics and Law
- Public Policy
- Public Administration
- Quantitative Political Methodology
- Regional Political Studies
- Russian Politics
- Security Studies
- State and Local Government
- UK Politics
- US Politics
- Browse content in Regional and Area Studies
- African Studies
- Asian Studies
- East Asian Studies
- Japanese Studies
- Latin American Studies
- Middle Eastern Studies
- Native American Studies
- Scottish Studies
- Browse content in Research and Information
- Research Methods
- Browse content in Social Work
- Addictions and Substance Misuse
- Adoption and Fostering
- Care of the Elderly
- Child and Adolescent Social Work
- Couple and Family Social Work
- Developmental and Physical Disabilities Social Work
- Direct Practice and Clinical Social Work
- Emergency Services
- Human Behaviour and the Social Environment
- International and Global Issues in Social Work
- Mental and Behavioural Health
- Social Justice and Human Rights
- Social Policy and Advocacy
- Social Work and Crime and Justice
- Social Work Macro Practice
- Social Work Practice Settings
- Social Work Research and Evidence-based Practice
- Welfare and Benefit Systems
- Browse content in Sociology
- Childhood Studies
- Community Development
- Comparative and Historical Sociology
- Economic Sociology
- Gender and Sexuality
- Gerontology and Ageing
- Health, Illness, and Medicine
- Marriage and the Family
- Migration Studies
- Occupations, Professions, and Work
- Organizations
- Population and Demography
- Race and Ethnicity
- Social Theory
- Social Movements and Social Change
- Social Research and Statistics
- Social Stratification, Inequality, and Mobility
- Sociology of Religion
- Sociology of Education
- Sport and Leisure
- Urban and Rural Studies
- Browse content in Warfare and Defence
- Defence Strategy, Planning, and Research
- Land Forces and Warfare
- Military Administration
- Military Life and Institutions
- Naval Forces and Warfare
- Other Warfare and Defence Issues
- Peace Studies and Conflict Resolution
- Weapons and Equipment

- < Previous chapter
- Next chapter >

15 Phonetic Processing
Adam Buchwald, Department of Communicative Sciences and Disorders, New York University
- Published: 16 December 2013
- Cite Icon Cite
- Permissions Icon Permissions
Successful speech production requires a speaker to map from an encoded phonological representation of linguistic form to a more detailed representation of sound structure that may interface with the motor planning and implementation system. This chapter describes phonetic processing as this component of language production. Although the mapping from context-independent sound representations to context-specific sound representations may be largely predictable, there are a variety of factors that affect the outcome of these processes still being explored. This chapter reviews the recent literature addressing phonetic and articulatory processing, and considers the implications of an interactive language production system by exploring research that focuses on the interaction of phonetic processing with “earlier” and later processing systems. It also reviews data from normal and impaired speaker populations using both traditional psycholinguistic methods and articulatory and acoustic analysis.
Introduction
As is evident from the variety of contributions to this volume, conveying messages through language production is a remarkably complex aspect of human cognition and behavior. This chapter focuses on a part of language production that links the more abstract representations of linguistic form with the more detailed aspects of speech production: phonetic processing. Here, phonetic processing is viewed as the process (or set of processes) involved in mapping from an encoded phonological representation (see the chapter by Goldrick in this volume) to a more detailed representation of sound structure that may interface with the motor planning and implementation system. Although this is a relatively predictable mapping (i.e., from context-independent representations to context-specific representations), a variety of factors that affect the outcome of these processes are still being explored. As has been widely noted (e.g., Goldstein, Pouplier, Chen, Saltzman, & Byrd, 2007 ), this topic has typically been glossed over in psycholinguistics, because many of the seminal papers described models of the spoken production system that essentially collapsed the entire set of cognitive processes following phonological encoding (e.g., Shattuck-Hufnagel & Klatt, 1979 ; Garrett, 1980 ; Dell, 1986 ). Thus, this chapter largely focuses on the literature that has emerged over the past decade addressing these issues.
With respect to psycholinguistic accounts of speech production, the discussion of phonetic processing in this chapter is most closely related to the notions of postlexical phonological processing (as in Goldrick & Rapp, 2007 ) and phonetic encoding ( Levelt, Roelofs, & Meyer, 1999 ). The goal of this chapter is to identify the type of information that is encoded at this level and to explore the nature of the processing mechanisms underlying phonetic processing. Given that these systems have been examined more directly in recent years, the focus here is on research from the past decade that has been particularly influential in moving this field forward.
The remainder of this introductory section presents a more detailed definition of the topic by exploring proposals that have been put forth, and relating this processing system to accounts in other domains. The chapter then reviews research that has directly explored articulatory processing and research that focuses on the interaction of articulatory processing with “earlier” processing systems (e.g., phonological encoding and lexical processing) and later processing systems (e.g., motor processing).
From Phonological Encoding to Articulatory Representations
Phonological encoding (see the chapter by Goldrick in this volume) is typically described as the process of retrieving a phonological representation from long-term memory into a code that can be used to generate more detailed forms for production ( Butterworth, 1992 ; Stemberger, 1985, 1990 ; Levelt, 1989 ; Levelt et al., 1999 ). With respect to psycholinguistic accounts of language production, Goldrick and Rapp (2007) referred to this system as lexical phonological processing . As discussed in Goldrick (this volume), the factors that affect the likelihood of successful processing at this level are lexical-level factors (e.g., word frequency; neighborhood density). The output of these processes is then acted on by the postlexical phonological processes, resulting in a more detailed phonetic representation. This processing system is referred to here as phonetic processing (as in Levelt et al., 1999 ; also “post-lexical phonological processing” in Goldrick and Rapp, 2007 ).
Input to Phonetic Processing
Phonetic processing takes the output of phonological encoding and transforms it into a more detailed, context-specific representation that can interface with motor planning and execution processes. Traditional descriptions of the output of phonological encoding are as a sequence of phoneme-sized sound structure units ( Levelt, 1989 ; Shattuck-Hufnagel, 1987 ; Fromkin, 1971 ; Stemberger, 1990 ), which may or may not be organized into syllables (see Goldrick, this volume). For example, the word cat is represented with its constituent phonemes /k/, /æ/, and /t/ represented as the sequence /kæt/. Accounts of spoken production differ in whether these representations are already specified for their subphonemic detail (i.e., their underlying feature structure, such that /k/ is [–voice ], [+dorsal],[–continuant]; Wheeler & Touretzky, 1997 ) or not ( Garrett, 1980 ; Stemberger, 1985 ; Dell, 1986 , 1988 ; Shattuck-Hufnagel, 1987 ; Butterworth, 1992 ; Levelt et al., 1999 ; Goldrick & Rapp, 2007 ). Although debate remains regarding the content of these representations, most accounts hold that these representations are not yet context-specific; in other words, they are not yet specified for coarticulatory or allophonic detail. Thus, one critical function of phonetic processing is to specify the detail associated with these forms (e.g., that the /k/ in cat is aspirated, as in [k h ]). In this way, phonetic processing is the system that generates the predictable details associated with a particular context, typically defined with respect to syllable position.
The most influential proposal offering an alternative to phonemic representations comes from the framework of articulatory phonology ( Browman & Goldstein, 1986 , 1988 et seq.; see the chapter by Goldstein & Pouplier in this volume). In this account, the primitive units of phonological representations are articulatory gestures , which are dynamic action units reflecting the structure of the vocal tract. A gesture consists of an active articulator having a particular degree of constriction and location of constriction. For example, the primary gesture associated with the voiceless velar stop /k/ is the tongue body having the constriction degree of “close” at the “velar” constriction location. These gestural representations are coordinated with one another in a gestural score , which specifies the target temporal coordination and spatial locations of adjacent gestures. Although this framework has not been directly integrated with a full processing account of spoken production, the processes involved in the generation of the gestural score from the component gestures (by the coupling graph; see the chapter by Goldstein & Pouplier in this volume and references within) are largely commensurate with the phonetic encoding processing system under discussion in this chapter. Thus, in this framework, the input to phonetic processing consists of articulatory gestures that are not yet specified for their context-specific temporal and spatial coordination patterns.
Generating Context-Specific Detail
The role of phonetic processing is to generate more detailed representations of these input representations that can be used to drive the motor planning, programming, and execution processes required for speech production. Linguists have long described the mapping from context-independent representations of sounds to context-sensitive representations as a language-specific mapping based on systematic principles ( Chomsky & Halle, 1968 ; Prince & Smolensky, 1993/2004 ). Although there has been much debate about the nature of these mappings (e.g., inviolable rules vs. violable, ordered constraints), they are the core of phonological grammar (see the chapter by Baković in this volume).
In describing this mapping within the context of cognitive and neural processing, there are some issues that arise that have been and continue to be active areas of interest. First, what is the nature of the representations that are generated? There is a range of descriptions of the output of phonetic processing, including a string of phonetic representations incorporating (syllable-) position-specific allophonic detail ( Dell, 1986 , 1988 ), a string of syllables retrieved from the mental syllabary ( Levelt et al., 1999 ; Cholin, 2008 ), and a gestural score specified for spatial targets and temporal coordination among elements ( Browman & Goldstein, 1988 , 1989 ).
A second critical issue in understanding phonetic processing is to determine the factors that affect the success of these processes. That is, given the mapping from one relatively abstract representation of sound structure (e.g., segments, gestures) to another relatively concrete level of sound structure (e.g., encoding context-specific spatiotemporal detail), one can ask whether the success of this process is determined by complexity at the former level, the latter level, or both. The third critical issue we will address is how these processes are affected by the interfaces with related processing systems, including both “higher” lexical processes and “lower” motor output processes.
This part of the language production system is critically affected by and defined by its interfaces with other parts of the production system. The remainder of this chapter focuses on the generation of context-specific detail and the factors that influence that detail. The next section reviews findings that directly examine phonetic processing by looking at normal and impaired speech production, and provides evidence supporting a variety of claims about the units in phonetic processing. Recent research indicating that information from higher-level processing (e.g., lexical and phonological processing) affects phonetic processing and articulatory detail is then explored. Finally, the relationship between phonetic processing and more peripheral motor speech systems is addressed.
Examining Phonetic Processing
As noted above, phonetic and articulatory processing has not typically been a focus of processing accounts of spoken language production. Although details of articulation and acoustics have been active areas of research both in phonetics (see Hardcastle & Laver, 1997 and papers within) and the motor speech literature (see McNeil, 2009 and papers within), this work has not typically been approached from an information processing view of spoken production. The next sections consider four sources of evidence regarding the structure of phonetic processes. These consider error patterns in impaired and unimpaired speakers, chronometric data, and phonetic data concerning context-specific variation.
A critical source of evidence in this domain has been instrumental analyses of speech. This contrasts with traditional analyses of sound structure processing within psycholinguistics that involved transcribing speech (both with and without errors) and analyzing the transcriptions, an approach that has been shown to be difficult to use in order to gain an accurate reflection of spoken production output. In particular, instrumental research has demonstrated that examining the articulation and acoustic output of speech allows us to obtain a more complete understanding of spoken production. This section explores some results from articulatory and acoustic analyses that have been influential in showing the need for this type of research.
Nature of Phonetic Representations: Evidence from Speech Errors
Given that most psycholinguistic research on the production of speech has focused on transcription, the use of acoustic and articulatory data to address issues related to spoken language processing has been relatively recent. One primary source of evidence has been speech errors, notably those that are elicited in the laboratory with a variety of tasks. Such errors from laboratory tasks ( Dell, 1988 , 1990 ) and naturally occurring speech errors ( Fromkin, 1971 ; Nooteboom, 1969 ; Stemberger, 1983 ) have long been used to understand the nature of the spoken production system. Using transcription as the primary source of examining speech errors led to the widespread belief that naturally occurring or task-induced errors consist of well-formed canonical phonemic productions. The use of instrumental methods (both articulatory and acoustic) to address the nature of speech errors has been critical in debunking this notion. In contrast, a variety of evidence has indicated that speech errors often incorporate components of more than one production simultaneously. That is, these errors appear to reflect the competition among two competing sound structure targets ( Mowrey & MacKay, 1990 ; Frisch & Wright, 2002 ; Pouplier, 2003 ; Pouplier & Hardcastle, 2005 ; Goldrick & Blumstein, 2006 ; Goldstein et al., 2007 ; McMillan, Corley, & Lickley, 2009 ; McMillan & Corley, 2010 ; Goldrick, Baker, Murphy, & Baese-Berk, 2011 ).
Goldrick and Blumstein (2006) reported on acoustic analyses of speech errors in a tongue twister task. Specifically, they analyzed errors in which a target voiceless sound (e.g., /k/) was erroneously produced as its voiceless cognate (e.g., [g]). The data indicated that the production of [g] when /k/ was the target had a longer voice onset times (VOT; i.e., was more [k]-like) than correctly produced [g] targets. They used this pattern to argue that the spoken output reflects partial activation of both the target production and the error production. Thus, the combination of these elements active in phonological and phonetic processing leads to a production that incorporates components of both the target and the error.
Goldstein et al. (2007) reported on electromagnetic articulography studies of a tongue twister task in which participants were asked to quickly keep repeating the phrase top cop . They found a specific type of error in which participants produced the articulatory gestures associated with /t/ and /k/ simultaneously, clearly indicating that not all errors result in the production of well-formed phonemic productions. This result mirrored findings from electropalatography research in individuals with apraxia of speech (AOS; Hardcastle & Edwards, 1992 ; Wood & Hardcastle, 2000 ) who made similar errors in their stop productions (see later). Pouplier and Goldstein (2010) examined these “coproduction” errors from unimpaired participants and determined that the coproduced closures begin simultaneously, but that the target sound that was intended in any particular context is released later and has a longer duration, reflecting the relative differences of activation of the two gestures.
McMillan and Corley (2010) examined performance in a tongue twister task using both acoustic and articulatory methods and found that articulatory variability can be predicted by feature-based competition. Over two experiments, their participants read groups of four ABBA nonsense syllables where A and B differed by a single place feature (e.g., kif tif tif kif ); a single voice feature (e.g., kif gif gif kif ); both place and voice features (e.g., kif dif dif kif ); or were identical (e.g., kef kef kef kef ). The results indicated that, relative to the baseline (no change) condition, there was more variability in the VOT production (the main determinant of voicing in English) when A and B differed in voice only (e.g., kif gif gif kif ), revealing competition at the level of the voice feature. Similarly, there was more variability in lingual contact with the palate (measured with electropalatography) when the competing syllables differed only in place of articulation (e.g., kif tif tif kif ). In addition, variability of both VOT and of location of palate contact was significantly smaller when the onsets of the two syllables differed in both place and voice (e.g., kif dif dif kif ), indicating that similarity among segments contributes to competition effects.
These findings from instrumental studies examining speech production clearly suggest that production processes can generate gradient errors that are described more accurately in terms of articulatory detail rather than phonemic representations. Given that the results discussed previously measure the result of the final motor speech output, it is not immediately clear that these results address the cognitive system that is the focus of this chapter. Thus, to verify that these findings inform us about phonetic processes, we must also establish that the output being measured reflects variation that arises during phonetic processing as opposed to during later motor processes or earlier lexical processes. One distinction that suggests many of these results do not arise in lexical processing is that many of the tongue twister tasks used focus either on nonwords or on CVC syllables that may be treated as nonwords in the context of the experiment. Furthermore, the gradient distortions of the type discussed here have been reported to be stronger for nonwords ( Goldrick, 2006 ; McMillan et al., 2009 ). However, it remains somewhat less clear how we can distinguish effects arising in phonetic processing from those arising in motor planning.
Nature of Phonetic Processes: Evidence from Cognitive Neuropsychology
Goldrick and Rapp (2007) posited the distinction between lexical phonological processing and postlexical phonological processing (the system of interest here). They contended that we can use task dissociation logic to determine the level of the deficit of an individual with acquired impairment. Individuals with a lexical phonological processing impairment should be impaired at picture-naming tasks that require lexical items to be retrieved from long-term memory, but not necessarily at word and nonword repetition tasks in which the phonological representation of the word is provided to the individual. In contrast, impairment to postlexical phonological processing affects the ability to perform all tasks involving spoken output because this system is central in spoken production regardless of the task being produced.
Goldrick and Rapp (2007) used this task dissociation logic to explore the factors that influenced error rates in two individuals, CSS and BON. CSS fit the pattern of lexical phonological processing by exhibiting a more severe impairment in naming tasks than repetition tasks, and showed clear effects of lexical frequency and neighborhood density on his spoken production accuracy. In contrast, BON exhibited impairment in both naming and repetition, and displayed sensitivity to several sublexical linguistic factors, such as syllable position (onset > coda); place of articulation (coronal > velar); and phoneme frequency. The comparison between these two individuals showed a clear distinction between impairment affected by word-level properties (lexical phonological impairment) and impairment affected by factors involved in specifying the details of articulation (postlexical phonological impairment). It is worth noting, however, that each property that affected BON’s production (phoneme frequency, place of articulation, and syllable position) have both phonological and articulatory correlates. For example, although onset consonants are described as unmarked relative to codas, they are also produced differently in that they are directly coupled with the following vowel that is produced. Thus, we are not able to determine whether BON’s sensitivity to these sublexical properties followed from their phonological complexity or their articulatory complexity.
Romani, Olson, Semenza, and Granà (2002) compared the performance of two individuals (DB and MM) who made similar proportions of errors in speech production. DB’s production was considered dysfluent and MM’s speech was characterized as fluent. Although MM’s production errors occurred at similar rates as DB’s, the errors showed a different set of characteristics. In contrast to DB ( Romani & Calabrese, 1998 ), MM’s production errors did not improve the sonority profile of the target. Additionally, although DB’s performance was affected by the sound structure complexity of the target word (he displayed a tendency to simplify consonant clusters, even at syllable boundaries), MM’s were not. Romani et al. argued that MM’s performance was indicative of a deficit to phonological encoding, whereas DB’s performance reflects an “articulatory planning” deficit. This contrast appears similar to that presented by Goldrick and Rapp (2007) ; however, it is unclear whether DB’s deficit may actually impair the process of generating motor plans from the articulatory plan, rather than the generation of the articulatory plan itself.
Romani and Galluzzi (2005) performed a case-series study examining individuals with and without some articulatory deficit (defined through perceptions of speech) and reported that individuals with articulatory impairment were likely to be sensitive to effects of sound structure complexity (e.g., consonant clusters), whereas individuals who make phonological errors in the absence of articulatory errors were more likely to be sensitive to overall length of words regardless of the structural complexity (also see Nickels & Howard, 2004 ). If we assume that the individuals with articulatory impairment are impaired at the postlexical level, these findings may be relevant to the issue of what types of complexity affect error rate in individuals with impairment at this level. However, it is not possible to determine whether the individuals in Romani and Galluzzi’s (2005) study have additional motor planning and implementation disorders leading to these patterns.
Distinguishing Impairment to Phonetic Processes from Impairment to Motor Processes
Although many psycholinguistic models of spoken production identify differences between lexical phonological processing and phonetic processing, these distinctions are not always clear in the literature on impaired speakers. AOS is a type of impairment associated with impairment to the speech motor planning system. Although the history of the description of this disorder includes defining it as a disorder affecting phonological processing ( Wertz, Lapointe, & Rosenbek, 1984 ), it is now widely agreed that AOS is by definition a disorder affecting motor processing, leading to slowed, distorted, and prosodically abnormal speech ( McNeil, Pratt, & Fossett, 2004 ; McNeil, Robin, & Schmidt, 2009 ). Given that this disorder affects a motoric level of processing, we may assume that the motor plans are generated based on the already existing context-specific detail. However, it has also been argued to be a deficit in phonetic processing ( Aichert & Ziegler, 2004 ; Staiger & Ziegler, 2008 ; Ziegler, 2002 ). It remains possible that there is a terminological impasse here. In psycholinguistic models and in linguistics, phonetic processing typically refers to something that is still linguistic in nature, providing the interface between abstract representations of sound structure and the motor production of that structure by computing the language-specific context-specific detail associated with an utterance. We will return to a more detailed discussion of the relationship among these systems later in the chapter.
One type of error that has often been taken as an indication of speech motor planning impairment is intrusive schwa produced in legal consonant clusters of an individual with an acquired deficit (e.g., clone → [kəlon]). These errors are typically assumed to arise in this population as a function of mistiming the articulatory gestures, and similar mistimings have been observed for unimpaired English speakers producing consonant clusters that are not legal in English (e.g., /zgomu/; Davidson, 2006 ). Buchwald, Rapp, and Stone (2007) examined VBR, a native English speaker with both AOS and aphasia who regularly made these intrusive schwa errors on words with consonant clusters in all output tasks (i.e., the errors arose because of impairment after lexical phonological processing), and found that not all errors involving intrusive schwa are attributable to articulatory mistiming.
Using ultrasound imaging to track the movements of the tongue, Buchwald et al. (2007) compared VBR’s articulation of words beginning with consonant clusters with words beginning with the same consonants with a lexical schwa between them (e.g., clone vs. cologne ). If the error arose because of impairment in speech motor planning as opposed to phonetic processing, then there should have been a difference between the mistimed production and the production with a lexical schwa (as seen in Davidson’s 2006 data), and this should have been reflected in the articulations associated with the two word types. However, this was not the case. VBR’s productions of words with lexical schwa (e.g., cologne ) and words with consonant clusters (e.g., clone ) did not differ on a variety of articulatory and acoustic dimensions, and the schwa in the cluster words was produced with its own articulatory target, distinct from that of the neighboring consonants. Buchwald et al.’s data revealed that individuals with acquired deficits to phonetic processing may make true schwa insertion errors that are distinct from errors resulting from mistiming the planning and execution of the motor processes. This suggests the possibility of a distinction between errors arising during phonetic processing and errors arising during motor planning. It is worth noting that to observe this difference, it was critical to use instrumental measures (ultrasound and acoustics) to address the nature of the errors.
To further distinguish errors at these two levels, Buchwald and Miozzo (2011) directly examined the nature of the errors in two individuals with acquired impairment to phonetic processing who deleted /s/ from words that begin with /s/-stop clusters (e.g., spill ). The question they addressed was whether the /s/ was deleted before (or while) generating the context-specific detail of the words or after the detail is generated. If /s/ is deleted before the completion of phonetic processes, then the errors should reflect a context without the /s/ (i.e., the /p/ should be produced with aspiration, as it is produced in pill ). In contrast, if /s/ is deleted after the context-specific mapping takes place, then the resulting form should surface with an unaspirated /p/, as in spill . Buchwald and Miozzo (2011) examined two speakers and determined that one speaker (DLE) produced aspirated stops in the forms with /s/-deletion, and another (HFL) produced unaspirated stops in these contexts. This indicated that DLE’s deletion occurred before specifying the output of phonetic processing, whereas HFL’s deletion occurred as part of the motor planning or implementation processes. Taken together, these patterns indicate a distinction between individuals with phonetic processing impairment and motor impairment among those with deficits affecting postlexical processing.
The Role of Speaking Rate in Generating Phonetic Representations
An additional source of context-dependent variation comes from changes in speaking rate. Although speaking rate can be manipulated in experimental settings, these changes have also been reported to be extremely widespread in spontaneous speech ( Miller, Grosjean, & Lomanto, 1984 ). In particular, changes in speaking rate have been reported to affect articulation of both vowel ( Gay, 1968 ) and consonant ( Miller, Green, & Reeves, 1986 ) segments, and consonant clusters ( Byrd & Tan, 1996 ) and CV transitions ( Agwuele, Sussman, & Lindblom, 2008 ). Additionally, the articulatory composition of sounds may alter rate effects ( Byrd & Tan, 1996 ), and interspeaker variation has been reported in how speaking rate affects at least certain sounds ( Theodore, Miller, & DeSteno, 2009 ).
Many of the effects of speaking rate that occur both within words and across words appear to result from changes in duration and temporal overlap of the gestures that compose the articulation. The articulatory phonology framework ( Browman & Goldstein, 1986 , 1988 ; Saltzman & Munhall, 1989 ) provides a clear and straightforward explanation of how and why speaking rate-induced context-dependent variation affects the production of particular sequences, and the variation that may exist can be explored with TADA, the task dynamic application developed at Haskins Laboratories ( Saltzman & Munhall, 1989 ; Nam, Goldstein, Saltzman, & Byrd, 2004 ) that includes a rate parameter that can be changed to determine how the articulatory output of a particular sequence is altered by variation in speaking rate. The issue with respect to the gestural scores of individual words is addressed more in “ The Temporal Organization of Speech ” by Goldstein and Pouplier, and “ Phrase-level Phonological and Phonetic Phenomena ” by Shattuck-Hufnagel addresses this issue with respect to multiword utterances.
The Role of the Syllable in Phonetic Processing
Rather than simply focusing on context-specific variation of phonetic units, other research has looked at larger units of sound structure with respect to phonetic processing. In Levelt et al.’s (1999) influential account of spoken production, phonetic encoding consists of retrieving and encoding stored abstract syllable plans from the mental syllabary (also see Levelt, 1992 ). The mental syllabary contains context-dependent syllable-sized representations, and it is argued that retrieving syllables as holistic elements relieves the burden of generating syllables segment-by-segment during production ( Schiller, Meyer, Baayen, & Levelt, 1996 ). In addition to the economy argument, there is ample evidence that syllable-sized units play an important role in word production. Most descriptions of the mental syllabary hold that syllable frequency influences ease of retrieval with high-frequency syllables, and that high-frequency syllables are retrieved faster than low-frequency syllables (the latter of which may not even be stored). Differences based on syllable frequency have been found in speech production tasks from a variety of languages in both unimpaired (Spanish, Carreiras & Perea, 2004 ; French, Laganaro & Alario, 2006 ; Dutch, Cholin, Levelt, & Schiller, 2006 ; Levelt & Wheeldon, 1994 ) and impaired speakers (German, Aichert & Ziegler, 2004 ; Staiger & Ziegler, 2008 ; French, Laganaro, 2005 ; Laganaro, 2008 ).
Although there is clear evidence that syllable frequency affects speech production, it remains less clear whether these effects arise during phonological encoding, phonetic processing, motor processing, or more than one of these levels. There is evidence that at least some syllable effects arise after lexical processing and phonological encoding. For example, Laganaro and Alario (2006) varied syllable frequency in a delayed naming task performed with and without articulatory suppression (i.e., participants repeating a syllable during the delay). Syllable frequency effects were obtained only with articulatory suppression, when the phonetic and motor processing systems were active during the delay. The authors concluded that this indicated that syllable frequency effects arise during those processes that were engaged during the delay that was filled by articulatory suppression—in other words, after phonological encoding (also see Cholin & Levelt, 2009 ). However, although some effects of syllable frequency have been reported to arise after phonological encoding, it remains difficult to pinpoint the level of these effects within phonetic and motor processing systems.
Interim Summary
This section explored a variety of findings regarding the nature of phonetic processing. It has been shown that a system incorporating only discrete, context-independent sound structure representations (e.g., segments) cannot account for the patterns seen in phonetic processing. These findings are seen in data from both unimpaired and impaired speakers. It is also likely that syllables are one type of unit of sound structure in phonetic processing, although it remains unclear whether they are the only units relevant at this level. Finally, the success of the processes at this level appear to relate to complexity at a variety of levels including sound structure sequences; frequency of sound structure sequences (e.g., syllable frequency); and the rate of speech production. These factors are all argued to be intrinsic to phonetic processing. The next section reviews research indicating that a variety of lexical variables that are extrinsic to phonetic processing can systematically affect the phonetic details of word production.
Interactions with Lexical Processing and Phonological Encoding
Many current descriptions of phonetic processing consider the interactions between articulatory detail and higher-level representations that are activated earlier in spoken production. In particular, the notion of lexical influences on articulatory detail has received a great deal of attention in recent years and several phenomena suggest that phonetic variation directly reflects differences in the activation dynamics of lexical entries. The details of how a word is articulated has been shown to be affected by a variety of properties (e.g., lexical frequency, neighborhood density, syntactic predictability) that are part of lexical processing, suggesting that lexical processing dynamics affect postlexical articulatory processing. This section explores results demonstrating this type of lexically conditioned phonetic variation, and reviews some of the prominent accounts of why this variation exists.
Lexical Frequency
It has long been reported that high-frequency words are more reduced than low-frequency words ( Zipf, 1929 ), and a variety of studies have demonstrated effects of frequency on different aspects of speech production, ranging from durational differences to the degree to which a phonological process is applied (e.g., Bybee, 2001 ; Pierrehumbert, 2001 ; Munson, 2007 ; see Bell, Brenier, Gregory, Girand, & Jurafsky, 2009 for a recent review). To determine whether lexical frequency affects acoustic duration in word production, it is critical to ensure that the sound structure sequences being compared are matched on other properties relevant to sound structure processing (e.g., phonemic identity, word length). Several recent lines of research have shown clear effects of word frequency on articulatory detail when these other factors are controlled. Pluymaekers, Ernestus, and Baayen (2005) examined the production of the same affixes appearing in different words that varied in frequency, with the data coming from a spoken corpus of spontaneous speech in Dutch. They reported that frequency can affect the degree of reduction in the production the suffixes, with more reduction being obtained in higher-frequency words. These effects were seen over a variety of affixes, and interacted with other variables, such as speech rate.
Although the Pluymaekers et al. (2005) study used natural speech tokens that share sound structure sequences, one of the more compelling tests of the effect of lexical frequency on articulatory detail comes from Gahl (2008) , who examined the production of English homophones that vary in frequency (e.g., time ~ thyme ) from the Switchboard corpus of American English telephone conversations. Gahl reported that high-frequency homophones (e.g., time ) were produced with shorter durations than their low-frequency counterparts (e.g., thyme ), and a multiple regression analysis indicated that frequency significantly predicted performance above the effects of several other relevant variables (e.g., measures of contextual predictability, likelihood of being phrase-final). Taken together, these findings indicate that lexical frequency affects the low-level articulation (e.g., duration) even when two words share the same phonemic content, indicating an effect of lexical frequency on articulatory detail (also see Goldrick et al., 2011 ).
Although these studies show that lexical frequency affects articulation even when other lexical effects are controlled, there is some evidence that frequency may alter production differently in different parts of the lexicon. In particular, Bell et al. (2009) reported that frequency effects on articulation affected content words (with more frequent words produced more quickly) but did not affect function words, where no frequency effect on production was observed. However, despite the lack of a frequency effect on the articulation of function words, Bell et al. reported that these words are produced with shorter durations than content words.
Neighborhood Structure
An additional type of lexical processing effect on phonetic detail comes from effects of phonological neighborhood structure. Phonological neighbors refer to the other words in the lexicon that are phonologically similar to a target word, and a large number of neighbors has been shown to inhibit word recognition in perception (through slower and less accurate word recognition; see Luce & Pisoni, 1998 ), but facilitate word production ( Dell & Gordon, 2003 ; Vitevitch & Sommers, 2003 ). With respect to effects of phonological neighborhood structure on word production, one area that has been explored is that the production of the vowel space is expanded in the production of words from high-density neighborhoods compared with low-density neighborhoods ( Munson, 2007 ; Munson & Solomon, 2004 ; Wright, 2004 ). Each of these studies shows that vowels in words from dense neighborhoods (i.e., words with several other words containing overlapping sound structure, see the chapter by Goldrick in this volume) are produced closer to the periphery of the vowel space (i.e., with more extreme articulation), whereas vowels in words from sparse neighborhoods are produced closer to the center of the vowel space. The effect of this difference is that there is an enhancement of distinctiveness in the vowels in words from high-density neighborhoods relative to vowels in words from low-density neighborhoods.
Vowel space expansion such as this is typical of what speakers do when they are producing “clear” speech ( Bradlow, 2002 ), and has been associated with more intelligible speakers ( Bradlow, Torretta, & Pisoni, 1996 ). Thus, when speakers are producing words from dense phonological neighborhoods, they adopt the strategies used in clear speech, referred to as “hyperarticulation” in Lindblom’s hyperspeech and hypospeech theory ( Lindblom, 1990 ). Additionally, Scarborough (2004) found that vowels in low-frequency words from high-density neighborhoods exhibit more coarticulation (e.g. V-to-V coarticulation) than vowels in high-frequency words from low-density neighborhoods. This pattern indicates that speakers produce more coarticulation among vowels for words that are harder for listeners to accurately recognize (low-frequency words in high-density neighborhoods; see Luce & Pisoni, 1998 ). Scarborough (2004) argued (contra Lindblom, 1990 ) it is helpful to the process of lexical access for the listener.
In recent work, Baese-Berk and Goldrick (2009) address a specific type of neighborhood effect: the presence or absence of a specific minimal pair lexical item. They examined the productions of words beginning with a voiceless consonant that have a voiced consonant-initial cognate (e.g. cod ~ god ) and compared them with voiceless-initial words without a voiced cognate (e.g. cop ~ * gop ). Their data revealed that participants produce more extreme VOT when producing words with the minimal pair neighbor than when producing words without a minimal pair neighbor. Because VOT is a key indicator of the voicing contrast ( Lisker & Abramson, 1964 ), the enhanced VOT in the presence of a minimal pair neighbor can be viewed as another type of hyperarticulation due to a lexical item being from a lexical neighborhood with a particular neighborhood structure.
As can be inferred from this limited review of phonetic consequences of neighborhood density and structure, there have been relatively few attempts to understand how density can affect the acoustic details of speech production. Nevertheless, this remains a fruitful area of research and will likely lead to further insights regarding the relationship between lexical representations in the lexicon and the processing systems that allow those representations to be articulated in speech production.
Predictability Effects
In addition to effects from lexical properties of individual words, such as frequency and neighborhood density, an additional factor affecting articulatory detail is predictability within an utterance. Lieberman (1963) compared the production of words when they were predictable (as part of a formulaic expression) or unpredictable within an utterance. Acoustic measures indicated that unpredictable words are longer and exhibit clearer correlates of stress, such as increased amplitude. Additional investigations have shown that redundancy within a discourse ( Aylett & Turk, 2004 ) and probability of producing a particular syntactic construction ( Tily et al., 2009 ; Gahl & Garnsey, 2004 , 2006 ) also affect articulatory detail, with less probable (and less redundant) forms produced with increased duration relative to more probable forms (also see Bell et al., 2009 ). Thus, the literature on articulatory detail shows that speakers are sensitive to a large number of factors (e.g., lexical, syntactic, discourse), which all affect the variation in how words are produced.
Relating Phonetic Processing to Speech Motor Planning
Throughout this chapter we have discussed phonetic processing as a part of spoken language production involved in mapping from a relatively abstract phonological representation (the output of phonological encoding) to a more detailed level of representation that may interface with the speech motor planning system. In this section we will discuss how the output of phonetic processing relates to speech motor planning, drawing on the literature from both unimpaired and impaired speech planning.
Speech Motor Planning: Targets of Production
One prominent debate in the literature on speech motor planning is whether the targets of speech sound production are articulatory targets (e.g., moving the tongue to a certain location; Saltzman & Munhall, 1989 ) or acoustic targets (e.g., achieving a particular formant structure; Guenther, Hampson, & Johnson, 1998 ). The main motor planning accounts focusing on articulatory targets are part of the articulatory phonology framework based on a coupled-oscillator model ( Browman & Goldstein, 1986 ; Saltzman & Munhall, 1989 ). Given a description of phonetic planning that yields a representation akin to the coordinated gestural scores, the speech motor planning system can be viewed as a system that specifies these abstract gestural representations into specific vocal tract variables and yields a description of inter-articulator coordination that serve as plans to drive motor execution. The discussion of this speech planning mapping from gestural coordination to articulator coordination is couched in the dynamical systems framework (see Port & van Gelder, 1995 and papers within). A review of this literature is outside the scope of this chapter, and the reader is referred to Goldstein and Pouplier (this volume) for further discussion.
There exists some evidence that acoustic targets play a role in speech motor planning. This type of account is formalized in the DIVA model of speech production put forth by Frank Guenther and colleagues ( Guenther, 1994 ; Guenther et al., 1998 ; Guenther & Perkell, 2004 ; Tourville & Guenther, 2011 ). Several lines of research have indicated that speakers make online adjustments to their productions to achieve an acoustic (not an articulatory) target when their production is disturbed with a bite block ( Lane et al., 2005 ) or when the auditory feedback they receive from their own voice (over headphones) is modified to alter the acoustic details of their productions (see Guenther & Perkell, 2004 ). In addition, recent research suggests that even during covert syllable production, speakers generate an internal representation of the production of a word that generates activity in the auditory cortex that is consistent with hearing the syllable ( Tian & Poeppel, 2010 ). The work of Guenther and others suggests the possibility that motor information is used to generate auditory representations and that those representations are assessed and then used to potentially modify motor production.
Relating Phonetic Processing to Motor Speech Impairment
Descriptions of impairment to speech motor control differentiate between the clinical categories of AOS (speech motor planning impairment) and dysarthria, typically viewed as impairment to speech motor production ( McNeil et al., 2004 ; McNeil et al., 2009 ; Duffy, 2005 ). In relating acquired impairment to psycholinguistic models of speech production, there has been some debate as to whether AOS refers to phonetic encoding impairment ( Ziegler, 2002 ; Varley & Whiteside, 2001 ) or whether a framework that accounts for the range of needs to distinguish phonetic encoding impairment (as a type of aphasia) from speech planning (AOS), programming, and execution ( van der Merwe, 2009 ). Although most work relating AOS to psycholinguistic models holds the view that AOS is impairment to phonetic encoding ( Ziegler, Staiger, & Aichert, 2010 ), and this assumption has guided the interpretation of empirical findings, it has not been tested directly as a hypothesis other than to show that these individuals show a clear syllable frequency effect (e.g., Aichert & Ziegler, 2004 ). As mentioned earlier, the assumption may be based in part on the limited number of possible levels that could relate to AOS in the Levelt et al. (1999) framework, although some have proposed further refinement of the mechanisms involved in speech planning and production ( van der Merwe, 2009 ; Maas, Robin, Wright, & Ballard, 2008 ).
Critically, psycholinguistic and linguistic accounts of phonetic processing typically hold that the phonetic processing level is linguistic in nature. In particular, phonetic processing acts as an interface between abstract representations of sound structure and the motor production of that structure by computing language-specific and context-specific detail associated with an utterance. To the extent that AOS is a disorder that is separate from linguistic processing (as argued by McNeil et al., 2009 ), it remains possible that the descriptions of these processing systems require additional elaboration. Although some have specifically argued for a distinction between phonetically driven impairment and motorically driven impairment among individuals with acquired sound production deficits ( Buchwald et al., 2007 ; Buchwald & Miozzo, 2011 ), there is as yet no clear study that distinguishes between these two levels and verifies that AOS refers to a population distinct from individuals with phonetic impairment.
It is clear that determining whether there is a distinction to be made among individuals with AOS and individuals with phonetic processing impairment will help to further understand the unique roles of these cognitive systems. At present, it is important to note that much of the difficulty of clearly distinguishing these impairments arises from their frequent co-occurrence, with only a small number of influential papers helping to build a description of AOS based solely on individuals without comorbid aphasia or dysarthrias ( McNeil, Odell, Miller, & Hunter, 1995 ; Odell, McNeil, Rosenbek, & Hunter, 1990 ; Odell, McNeil, Rosenbek, & Hunter, 1991 ). This type of work looking at additional psycholinguistic variables is necessary to integrate the research on AOS with psycholinguistic accounts of spoken language production.
This chapter has focused on a variety of issues with respect to phonetic processing, and has addressed a number of ongoing debates and challenges in research on this component of spoken language production. In particular, two critical issues that need to be addressed include the nature of the representations at this level and the degree of interaction between this processing system and related processing systems involved in language production. With respect to the nature of the representations, the gestural representations posited in Articulatory Phonology ( Browman & Goldstein, 1986 , 1988 ; 1989 et seq.) provide a clear means for discussing a variety of types of phonetic detail, including context-dependent effects of syllable position ( Byrd, 1995 ), speaking rate ( Byrd & Tan, 1996 ), and temporal overlap ( Goldstein et al., 2007 ), although it is unclear how these representations may be integrated with the type of acoustic targets posited in the DIVA model (e.g., Tourville & Guenther, 2011 ).
One of the main obstacles to learning more about this system is to determine what data we can use to learn about phonetic processing. As we discussed, speech error data using instrumental measures of articulation and acoustics have been quite helpful in this regard, but there is still no means for forming a clear distinction between changes arising at the phonetic level and others arising at more peripheral stages of motor speech production. One attempt to understand processing systems that has been beneficial in cognitive science has been to examine individuals with selective impairment to that system. With respect to phonetic processing, these attempts have largely been based on the assumption that AOS reflects an impairment to phonetic processing and then to explore the nature of the errors in AOS ( Varley & Whiteside, 2001 ; Ziegler, 2002 ). However, this strategy relies on the assumption that the clinical category of AOS reflects a selective deficit to phonetic processing; this assumption has not been verified, and the frequent co-occurrence of AOS with both aphasic impairments and dysarthria complicates these analyses unless these analyses are restricted to cases where there is a single level of impairment. Additional attempts to distinguish errors that occur in phonological processing from those arising in phonetic processing are necessary to make use of data from neurologically impaired populations in addressing these issues (see Buchwald et al., 2007 ; Buchwald & Miozzo, 2011 for examples).
Agwuele, A. , Sussman, H. , & Lindblom, B. ( 2008 ). The effect of speaking rate on consonant vowel coarticulation. Phonetica , 65 , 194–209.
Google Scholar
Aichert, I. , & Ziegler, W. ( 2004 ). Syllable frequency and syllable structure in apraxia of speech. Brain and Language , 88 , 148–159.
Aylett, M. , & Turk, A. ( 2004 ). The smooth signal redundancy hypothesis: A functional explanation for relationships between redundancy, prosodic prominence, and duration in spontaneous speech. Language and Speech , 47 (1), 31–56.
Baese-Berk, M. , & Goldrick, M. ( 2009 ). Mechanisms of interaction in speech production. Language and Cognitive Processes , 24 (4), 527–554.
Bell, A. , Brenier, J. M. , Gregory, M. , Girand, C. , & Jurafsky, D. ( 2009 ). Predictability effects on durations of content and function words in conversational English. Journal of Memory and Language , 60 , 92–111.
Bradlow, A. R. ( 2002 ). Confluent talker- and listener-related forces in clear speech production. In C. Gussenhoven & N. Warner (Eds.), Papers in laboratory phonology (Vol. 7, pp. 241–273). New York: Mouton de Gruyter.
Google Preview
Bradlow, A. R. , Torretta, G. , & Pisoni, D. B. ( 1996 ). Intelligibility of normal speech I: Global and fine-grained acoustic-phonetic talker characteristics. Speech Communication , 20 , 255–272.
Browman, C. P. , & Goldstein, L. M. ( 1986 ). Towards an articulatory phonology. Phonology , 6 , 219–252.
Browman, C. P. , & Goldstein, L. M. ( 1988 ). Some notes on syllable structure in articulatory phonology. Phonetica , 45 , 140–155.
Browman, C. P. , & Goldstein, L. M. ( 1989 ). Articulatory gestures as phonological units. Phonology , 6 , 201–251.
Buchwald, A. , & Miozzo, M. ( 2011 ). Finding levels of abstraction in speech production: Evidence from sound production impairment. Psychological Science , 22 , 1113–1119.
Buchwald, A. , Rapp, B. , & Stone, M. ( 2007 ). Insertion of discrete phonological units: An ultrasound investigation of aphasic speech. Language and Cognitive Processes , 22 (6), 910–948.
Butterworth, B. ( 1992 ). Disorders of phonological encoding. Cognition , 42 , 261–286.
Bybee, J. ( 2001 ). Frequency and language use . Cambridge: Cambridge University Press.
Byrd, D. ( 1995 ). C-centers revisited. Phonetica , 52 , 285–306.
Byrd, D. , & Tan, C. C. ( 1996 ). Saying consonant clusters quickly. Journal of Phonetics , 24 , 263–282.
Carreiras, M. , & Perea, M. ( 2004 ). Naming pseudowords in Spanish: Effects of syllable frequency. Brain and Language , 90 , 393–400.
Cholin, J. ( 2008 ). The mental syllabary in speech production: An integration of different approaches and domains. Aphasiology , 22 , 1–15.
Cholin, J. , & Levelt, W. J. M. ( 2009 ). Effects of syllable preparation and syllable frequency in speech production: Further evidence for the retrieval of stored syllables at a post-lexical level. Language and Cognitive Processes , 24 , 662–684.
Cholin, J. , Levelt, W. J. M. , & Schiller, N. O. ( 2006 ). Effects of syllable frequency in speech production. Cognition , 99 , 205–235.
Chomsky, N. , & Halle, M. ( 1968 ). The sound pattern of English . New York, NY: Harper and Row.
Davidson, L. ( 2006 ). Phonotactics and articulatory coordination interact in phonology: Evidence from non-native production. Cognitive Science , 30 (5), 837–862.
Dell, G. ( 1986 ). A spreading activation theory of retrieval in sentence processing. Psychological Review , 93 , 283–321.
Dell, G. ( 1988 ). The retrieval of phonological forms in production: Tests of predictions from a connectionist model. Journal of Memory and Language , 27 , 124–142.
Dell, G. ( 1990 ). Effects of frequency and vocabulary type on phonological speech errors. Language and Cognitive Processes , 4 , 313–349.
Dell, G. , & Gordon, J. K. ( 2003 ). Neighbors in the lexicon: Friends or foes. In N. O. Schiller & A. S. Meyer (Eds.), Phonetics and phonology in language comprehension and production: Differences and similarities (pp. 9–38). New York: Mouton de Gruyter.
Duffy, J. R. ( 2005 ). Motor speech disorders: Substrates, differential diagnosis, and management . St. Louis: Elsevier Mosby.
Frisch, S. , & Wright, R. ( 2002 ). The phonetics of phonological speech errors: An acoustic analysis of slips of the tongue. Journal of Phonetics , 30 , 139–162.
Fromkin, V. ( 1971 ). The non-anomalous nature of anomalous utterances. Language , 47 , 27–52.
Gahl, S. ( 2008 ). “Thyme” and “Time” are not homophones. Word durations in spontaneous speech. Language , 84 (3), 474–496.
Gahl, S. , & Garnsey, S. M. ( 2004 ). Knowledge of grammar, knowledge of usage: Syntactic probabilities affect pronunciation variation. Language , 80 (4), 748–775.
Gahl, S. , & Garnsey, S. M. ( 2006 ). Syntactic probabilities affect pronunciation variation. Language , 82 (2), 405–410.
Garrett, M. F. ( 1980 ). Levels of processing in sentence production. In B. Butterworth (Ed.), Language production . New York: Academic Press.
Gay, T. ( 1968 ). Effect of speaking rate on diphthong formant movements. Journal of the Acoustical Society of America , 44 (6), 1570–1573.
Goldrick, M. ( 2006 ). Limited interaction in speech production: Chronometric, speech error, and neuropsychological evidence. Language and Cognitive Processes , 21 , 817–855.
Goldrick, M. , Baker, H. R. , Murphy, A. , & Baese-Berk, M. ( 2011 ). Interaction and representational integration: Evidence from speech errors. Cognition , 121 , 58–72.
Goldrick, M. , & Blumstein, S. E. ( 2006 ). Cascading activation from phonological planning to articulatory processes: Evidence from tongue twisters. Language and Cognitive Processes , 21 , 649–683.
Goldrick, M. , & Rapp, B. ( 2007 ). Lexical and post-lexical phonological representations in spoken production. Cognition , 102 (2), 219–260.
Goldstein, L. , Pouplier, M. , Chen, L. , Saltzman, E. , & Byrd, D. ( 2007 ). Dynamic action units slip in speech production errors. Cognition , 103 , 386–412.
Guenther, F. ( 1994 ). A neural network model of speech acquisition and motor equivalent speech production. Biological Cybernetics , 72 , 43–53.
Guenther, F. H. , Hampson, M. , & Johnson, D. ( 1998 ). A theoretical investigation of reference frames for the planning of speech movements. Psychological Review , 105 , 611–633.
Guenther, F. H. , & Perkell, J. H. ( 2004 ). A neural model of speech production and its application to studies of the role of auditory feedback in speech. In B. Maassen , R. D. Kent , H. Peters , P. H. H. M. Van Lieshout , & W. Hulstijn (Eds.), Speech motor control in normal and disordered speech (pp. 29–49). Oxford: Oxford University Press.
Hardcastle, W. J. , & Edwards, S. ( 1992 ). EPG-based description of apraxic speech errors. In R. D. Kent (Ed.), Intelligibility in speech disorders (pp. 287–328). Amsterdam: John Benjamins Publishing Company.
Hardcastle, W. J. , & Laver, J. (Eds.). ( 1997 ). The Handbook of phonetic sciences . Oxford: Blackwell.
Laganaro, M. ( 2005 ). Syllable frequency effect in speech production: evidence from aphasia. Journal of Neurolinguistics , 18 , 221–235.
Laganaro, M. ( 2008 ). Is there a syllable frequency effect in aphasia or in apraxia of speech or both? Aphasiology , 22 (11), 1191–1200.
Laganaro, M. , & Alario, F.-X. ( 2006 ). On the locus of the syllable frequency effect in speech production. Journal of Memory and Language , 55 , 178–196.
Lane, H. , Denny, M. , Guenther, F. , Matthies, M. L. , Menard, L. , Perkell, J. S. ,...& Zandipour, M. ( 2005 ). Effects of bite blocks and hearing status on vowel production. Journal of the Acoustical Society of America , 118 , 1636–1646.
Levelt, W. J. M. ( 1989 ). Speaking: From intention to articulation . Cambridge, MA: MIT Press.
Levelt, W. J. M. ( 1992 ). Accessing words in speech production: Stages, processes and representations. Cognition , 42 , 1–22.
Levelt, W. J. M. , Roelofs, A. , & Meyer, A. S. ( 1999 ). A theory of lexical access in speech production. Behavioral and Brain Sciences , 22 , 1–75.
Levelt, W. J. M. , & Wheeldon, L. ( 1994 ). Do speakers have access to a mental syllabary? Cognition , 50 , 239–269.
Lieberman, P. ( 1963 ). Some effects of semantic and grammatical context on the production and perception of speech. Language and Speech , 6 , 172–187.
Lindblom, B. ( 1990 ). Explaining phonetic variation: A sketch of the H&H theory. In W. J. Hardcastle & A. Marchal (Eds.), Speech production and speech modeling (pp. 403–439). Dordrecht: Kluwer.
Lisker, L. , & Abramson, A. S. ( 1964 ). A cross-language study of voicing in initial stops: Acoustical measurements. Word , 20 , 384–422.
Luce, P. A. , & Pisoni, D. B. ( 1998 ). Recognizing spoken words: The neighborhood activation model. Ear and Hearing , 19 , 1–36.
Maas, E. , Robin, D. A. , Wright, D. L. , & Ballard, K. J. ( 2008 ). Motor programming in apraxia of speech. Brain and Language , 106 (2), 107–118.
McMillan, C. T. , & Corley, M. ( 2010 ). Cascading influences on the production of speech: Evidence from articulation. Cognition , 117 (3), 243–260.
McMillan, C. T. , Corley, M. , & Lickley, R. ( 2009 ). Articulation evidence for feedback and competition in speech production. Language and Cognitive Processes , 24 , 44–66.
McNeil, M. R. (Ed.). ( 2009 ). Clinical management of sensorimotor speech disorders (2nd. ed.). New York: Thieme.
McNeil, M. R. , Odell, K. , Miller, S. B. , & Hunter, L. ( 1995 ). Consistency, variability, and target approximation for successive speech repetitions among apraxic, conduction aphasic, and ataxic dysarthria speakers. Clinical Aphasiology , 23 , 39–55.
McNeil, M. R. , Pratt, S. R. , & Fossett, T. R. D. ( 2004 ). The differential diagnosis of apraxia of speech. In B. Maassen , R. D. Kent , H. Peters , P. H. H. M. Van Lieshout , & W. Hulstijn (Eds.), Speech motor control in normal and disordered speech (pp. 389–414). Oxford: Oxford University Press.
McNeil, M. R. , Robin, D. A. , & Schmidt, R. A. ( 2009 ). Apraxia of speech: Definition and differential diagnosis. In M. R. McNeil (Ed.), Clinical management of sensorimotor speech disorders (pp. 249–268). New York: Thieme.
Miller, J. L. , Green, K. P. , & Reeves, A. ( 1986 ). Speaking rate and segments: A look at the relation between speech production and perception for the voicing contrast. Phonetica , 43 , 106–115.
Miller, J. L. , Grosjean, F. , & Lomanto, C. ( 1984 ). Articulation rate and its variability in spontaneous speech: A reanalysis and some implications. Phonetica , 41 , 215–255.
Mowrey, R. A. , & MacKay, I. R. A. ( 1990 ). Phonological primitives: Electromyographic speech error evidence. Journal of the Acoustical Society of America , 88 , 1299–1312.
Munson, B. ( 2007 ). Lexical access, lexical representation, and vowel articulation. In J. Cole & J. Hualde (Eds.), Laboratory phonology (Vol. 9, pp. 201–228). New York: Mouton de Gruyter.
Munson, B. , & Solomon, N. P. ( 2004 ). The effect of phonological neighborhood density on vowel articulation. Journal of Speech, Language, and Hearing Research , 47 , 1048–1058.
Nam, H. , Goldstein, L. , Saltzman, E. , & Byrd, D. ( 2004 ). TADA: An enhanced, portable task dynamics model in MATLAB. Journal of the Acoustical Society of America , 115 (5), 2430.
Nickels, L. , & Howard, D. ( 2004 ). Dissociating effects of number of phonemes, number of syllables, and syllabic complexity on word production in aphasia: It’s the number of phonemes that counts. Cognitive Neuropsychology , 21 , 57–78.
Nooteboom, S. G. ( 1969 ). The tongue slips into patterns. In A. G. Sciarone , A. J. van Essen , & A. A. van Raad (Eds.), Leyden studies in linguistics and phonetics (pp. 114–132). The Hague: Mouton.
Odell, K. , McNeil, M. R. , Rosenbek, J. C. , & Hunter, L. ( 1990 ). Perceptual characteristics of consonant production by apraxic speakers. Journal of Speech and Hearing Disorders , 55 , 345–359.
Odell, K. , McNeil, M. R. , Rosenbek, J. C. , & Hunter, L. ( 1991 ). Perceptual characteristics of vowel and prosody production in apraxic, aphasic and dysarthric speakers. Journal of Speech and Hearing Research , 34 , 67–80.
Pierrehumbert, J. ( 2001 ). Exemplar dynamics: Word frequency, lenition, and contrast. In J. Bybee & P. Hopper (Eds.), Frequency effects and the emergence of lexical structure (pp. 137–157). Amsterdam: John Benjamins.
Pluymaekers, M. , Ernestus, M. , & Baayen, R. H. ( 2005 ). Lexical frequency and acoustic reduction in spoken Dutch. Journal of the Acoustical Society of America , 118 , 2561–2569.
Port, R. F. , & van Gelder, T. J. (Eds.). ( 1995 ). Mind as motion: Explorations in the dynamics of cognition . Cambridge, MA: MIT Press.
Pouplier, M. (2003). Units of phonological encoding: Empirical evidence (Unpublished doctoral dissertation). Yale University, New Haven, CT.
Pouplier, M. , & Goldstein, L. ( 2010 ). Intention in articulation: Articulatory timing in alternating consonant sequences and its implications for models of speech production. Language and Cognitive Processes , 25 (5), 616–649.
Pouplier, M. , & Hardcastle, W. J. ( 2005 ). A re-evaluation of the nature of speech errors in normal and disordered speakers. Phonetica , 62 , 227–243.
Prince, A. , & Smolensky, P. (1993/2004). Optimality theory: Constraint interaction in generative grammar (Technical report). Rutgers University, New Brunswick and University of Colorado, Boulder.
Romani, C. , & Calabrese, A. ( 1998 ). Syllabic constraints on the phonological errors of an aphasic patient. Brain and Language , 64 , 83–121.
Romani, C. , & Galluzzi, C. ( 2005 ). Effects of syllabic complexity in predicting accuracy of repetition and direction of errors in patients with articulatory and phonological difficulties. Cognitive Neuropsychology , 22 (7), 817–850.
Romani, C. , Olson, A. , Semenza, C. , & Granà, A. ( 2002 ). Patterns of phonological errors as a function of a phonological versus articulatory locus of impairment. Cortex , 38 , 541–567.
Saltzman, E. L. , & Munhall, K. G. ( 1989 ). A dynamical approach to gestural patterning in speech production. Ecological Psychology , 1 , 333–382.
Scarborough, R. A. (2004). Coarticulation and the structure of the lexicon (Unpublished doctoral dissertation). UCLA, Los Angeles, CA.
Schiller, N. O. , Meyer, A. S. , Baayen, R. H. , & Levelt, W. J. M. ( 1996 ). A comparison of lexeme and speech syllables in Dutch. Journal of Quantitative Linguistics , 3 , 8–28.
Shattuck-Hufnagel, S. ( 1987 ). The role of word-onset consonants in speech production planning: New evidence from speech error patterns. In E. Keller & M. Gopnik (Eds.), Motor and sensory processes of language (pp. 17–51). Hillsdale, NJ: Lawrence Erlbaum Associates.
Shattuck-Hufnagel, S. , & Klatt, D. H. ( 1979 ). The limited use of distinctive features and markedness in speech production: Evidence from speech error data. Journal of Verbal Learning and Verbal Behavior , 18 , 41–55.
Staiger, A. , & Ziegler, W. ( 2008 ). Syllable frequency and syllable structure in the spontaneous speech production of patients with apraxia of speech. Aphasiology , 22 (11), 1201–1215.
Stemberger, J. P. (1983). Speech errors and theoretical phonology: A review (Unpublished manuscript). Distributed by the Indiana University Linguistics Club, Bloomington, IN.
Stemberger, J. P. ( 1985 ). An interactive activation model of language production. In A. W. Ellis (Ed.), Progress in the psychology of language (Vol. 1, pp. 143–186). Hillsdale, NJ: Lawrence Erlbaum Associates.
Stemberger, J. P. ( 1990 ). Wordshape errors in language production. Cognition , 35 , 123–157.
Theodore, R. M. , Miller, J. L. , & DeSteno, D. ( 2009 ). Individual talker differences in voice-onset-time: Contextual influences. Journal of the Acoustical Society of America , 125 , 3974–3982.
Tian, X. , & Poeppel, D. ( 2010 ). Mental imagery of speech and movement implicates the dynamics of internal forward models. [Original Research]. Frontiers in Psychology , 1 , 12.
Tily, H. , Gahl, S. , Arnon, I. , Snider, N. , Kothari, A. , & Bresnan, J. ( 2009 ). Syntactic probabilities affect pronunciation variation in spontaneous speech. Language and Cognition , 1–2 , 147–165.
Tourville, J. A. , & Guenther, F. ( 2011 ). The DIVA model: A neural theory of speech acquisition and production. Language and Cognitive Processes , 26 , 952–981.
van der Merwe, A. ( 2009 ). A theoretical framework for the characterization of pathological speech motor control. In M. R. McNeil (Ed.), Clinical management of sensorimotor speech disorders (2nd ed., pp. 3–18). New York: Thieme.
Varley, R. A. , & Whiteside, S. P. ( 2001 ). What is the underlying impairment in acquired apraxia of speech? Aphasiology , 15 , 39–49.
Vitevitch, M. S. , & Sommers, M. S. ( 2003 ). The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Memory and Cognition , 31 , 491–504.
Wertz, R. T. , Lapointe, L. L. , & Rosenbek, J. C. ( 1984 ). Apraxia of speech in adults: The disorder and its management . Orlando, FL: Grune and Stratton.
Wheeler, D. W. , & Touretzky, D. S. ( 1997 ). A parallel licensing model of normal slips and phonemic paraphasias. Brain and Language , 59 , 147–201.
Wood, S. , & Hardcastle, W. J. ( 2000 ). Instrumentation in the assessment and therapy of motor speech disorders: A survey of techniques and case studies with EPG. In I. Papathanasiou (Ed.), Acquired neurogenic communication disorders: A clinical perspective (pp. 203–248). London: Whurr.
Wright, R. A. ( 2004 ). Factors of lexical competition in vowel articulation. In J. J. Local , R. Ogden , & R. Temple (Eds.), Laboratory phonology (Vol. 6, pp. 26–50). Cambridge: Cambridge University Press.
Ziegler, W. ( 2002 ). Psycholinguistic and motor theories of apraxia of speech. Seminars in Speech and Language , 23 , 231–243.
Ziegler, W. , Staiger, A. , & Aichert, I. ( 2010 ). Apraxia of speech: What the deconstruction of phonetic plans tells us about the construction of articulate language. In B. Maassen , & P. H. H. M. Van Lieshout (Eds.), Speech motor control (pp. 3–21). Oxford: Oxford University Press.
Zipf, G. K. ( 1929 ). Relative frequency as a determinant of phonetic change. Harvard Studies in Classical Philology , 15 , 1–95.
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
9.1 Evidence for Speech Production
Dinesh Ramoo
The evidence used by psycholinguistics in understanding speech production can be varied and interesting. These include speech errors, reaction time experiments, neuroimaging, computational modelling, and analysis of patients with language disorders. Until recently, the most prominent set of evidence for understanding how we speak came from speech errors . These are spontaneous mistakes we sometimes make in casual speech. Ordinary speech is far from perfect and we often notice how we slip up. These slips of the tongue can be transcribed and analyzed for broad patterns. The most common method is to collect a large corpus of speech errors by recording all the errors one comes across in daily life.
Perhaps the most famous example of this type of analysis are what are termed ‘ Freudian slips .’ Freud (1901-1975) proposed that slips of the tongue were a way to understand repressed thoughts. According to his theories about the subconscious, certain thoughts may be too uncomfortable to be processed by the conscious mind and can be repressed. However, sometimes these unconscious thoughts may surface in dreams and slips of the tongue. Even before Freud, Meringer and Mayer (1895) analysed slips of the tongue (although not in terms of psychoanalysis).
Speech errors can be categorized into a number of subsets in terms of the linguistic units or mechanisms involved. Linguistic units involved in speech errors could be phonemes, syllables, morphemes, words or phrases. The mechanisms of the errors can involve the deletion, substitution, insertion, or blending of these units in some way. Fromkin (1971; 1973) argued that the fact that these errors involve some definable linguistic unit established their mental existence at some level in speech production. We will consider these in more detail in discussing the various stages of speech production.
An error in the production of speech.
An unintentional speech error hypothesized by Sigmund Freud as indicating subconscious feelings.
9.1 Evidence for Speech Production Copyright © 2021 by Dinesh Ramoo is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Tools and Resources
- Customer Services
- Applied Linguistics
- Biology of Language
- Cognitive Science
- Computational Linguistics
- Historical Linguistics
- History of Linguistics
- Language Families/Areas/Contact
- Linguistic Theories
- Neurolinguistics
- Phonetics/Phonology
- Psycholinguistics
- Sign Languages
- Sociolinguistics
- Share This Facebook LinkedIn Twitter
Article contents
Psycholinguistic approaches to morphology: production.
- Benjamin V. Tucker Benjamin V. Tucker Department of Linguistics, University of Alberta
- https://doi.org/10.1093/acrefore/9780199384655.013.597
- Published online: 30 September 2019
Speech production is an important aspect of linguistic competence. An attempt to understand linguistic morphology without speech production would be incomplete. A central research question develops from this perspective: what is the role of morphology in speech production. Speech production researchers collect many different types of data and much of that data has informed how linguists and psycholinguists characterize the role of linguistic morphology in speech production. Models of speech production play an important role in the investigation of linguistic morphology. These models provide a framework, which allows researchers to explore the role of morphology in speech production. However, models of speech production generally focus on different aspects of the production process. These models are split between phonetic models (which attempt to understand how the brain creates motor commands for uttering and articulating speech) and psycholinguistic models (which attempt to understand the cognitive processes and representation of the production process). Models that merge these two model types, phonetic and psycholinguistic models, have the potential to allow researchers the possibility to make specific predictions about the effects of morphology on speech production. Many studies have explored models of speech production, but the investigation of the role of morphology and how morphological properties may be represented in merged speech production models is limited.
- psycholinguistics
- speech production
- mental lexicon
You do not currently have access to this article
Please login to access the full content.
Access to the full content requires a subscription
Printed from Oxford Research Encyclopedias, Linguistics. Under the terms of the licence agreement, an individual user may print out a single article for personal use (for details see Privacy Policy and Legal Notice).
date: 28 April 2024
- Cookie Policy
- Privacy Policy
- Legal Notice
- [66.249.64.20|45.133.227.243]
- 45.133.227.243
Character limit 500 /500
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
9.3 Speech Production Models
The dell model.
Speech error analysis has been used as the basis for the model developed by Dell (1986, 1988). Dell’s spreading activation model (as seen in Figure 9.3) has features that are informed by the nature of speech errors that respect syllable position constraints. This is based on the observation that when segmental speech errors occur, they usually involve exchanges between onsets, peaks or codas but rarely between different syllable positions. Dell (1986) states that word-forms are represented in a lexical network composed on nodes that represent morphemes, segments and features. These nodes are connected by weighted bidirectional vertices.

As seen in Figure 9.3, when the morpheme node is activated, it spreads through the lexical network with each node transmitting a proportion of its activation to its direct neighbour(s). The morpheme is mapped onto its associated segments with the highest level of activation. The selected segments are encoded for particular syllable positions which can then be slotted into a syllable frame. This means that the /p/ phoneme that is encoded for syllable onset is stored separately from the /p/ phonemes encoded for syllable coda position. This also accounts for the phonetic level in that instead of having two separate levels for segments (phonological and phonetic levels), there is only one segmental level. In this level, the onset /p/ is stored with its characteristic aspiration as [ph] and the coda /p/ is stored in its unaspirated form [p]. Although this means that segments need to be stored twice for onset and coda positions, it simplified the syllabification process as the segments automatically slot into their respective position. Dell’s model ensures the preservation of syllable constraints in that onset phonemes can only fit into onset syllable slots in the syllable template (the same being true for peaks and codas). The model also has an implicit competition between phonemes that belong to the same syllable position and this explains tongue-twisters such as the following:
- “She sells sea shells by the seashore” ʃiː sɛlz siːʃɛlz baɪ ðiː siːʃɔː
- “Betty Botter bought a bit of butter” bɛtiː bɒtə bɔːt ə bɪt ɒv bʌtə
In these examples, speakers are assumed to make errors because of competition between segments that share the same syllable position. As seen in Figure 9.3, Dell (1988) proposes a word-shape header node that contains the CV specifications for the word-form. This node activates the segment nodes one after the other. This is supported by the serial effects seen in implicit priming studies (Meyer, 1990; 1991) as well as some findings on the influence of phonological similarity on semantic substitution errors (Dell & Reich, 1981). For example, the model assumes that semantic errors (errors based on shared meaning) arise in lemma nodes. The word cat shares more segments with a target such as mat ((/æ/nu and /t/cd) than with sap (only /æ/nu). Therefore, the lemma node of mat will have a higher activation level than the one for sap creating the opportunity for a substitution error. In addition, the feedback from morpheme nodes leads to a bias towards producing words rather then nonword error. The model also takes into account the effect of speech rate on error probability (Dell, 1986) and the frequency distribution of anticipation-, perseveration- and transposition- errors (Nooteboom, 1969). The model accounts for differences between various error types by having an in-built bias for anticipation. Activation spreads through time. Therefore, upcoming words receive activation (at a lower level than the current target). Speech rate also has an influence on errors because higher speech rates may lead to nodes not having enough time to reach a specified level of activation (leading to more errors).
While the Dell model has a lot of support for it’s architecture, there have been criticisms. The main evidence used for the model, speech errors, have themselves been questioned as a useful piece of evidence for informing speech production models (Cutler, 1981). For instance, the listener might misinterpret the units involved in the error and may have a bias towards locating errors at the beginning of words (accounting for the large number of word-onset errors). Evidence for the CV header node is limited as segment insertions usually create clusters when the target word also had a cluster and CV similarities are not found for peaks.
The model also has an issue with storage and retrieval as segments need to be stored for each syllable position. For example, the /l/ in English needs to be stored as [l] for syllable onset, [ɫ] for coda and [ḷ] when it appears as a syllabic consonant in the peak (as in bottle ). However, while this may seem redundant and inefficient, recent calculations of storage costs based on information theory by Ramoo and Olson (2021) suggest that the Dell model may actually be more storage efficient than previously thought. They suggest that one of the main inefficiencies of the model are during syllabification across word and morpheme boundaries. During the production of connected speech or polymorphic words, segments from one morpheme or word will move to another (Chomsky & Halle, 1968; Selkirk, 1984; Levelt, 1989). For example, when we say “walk away” /wɔk.ə.weɪ/, we produce [wɔ.kə.weɪ] where the /k/ moves from coda to onset in the next syllable. As the Dell model codes segments for syllable position, it may not be possible for such segments to move from coda to onset position during resyllabification . These and other limitations have led researchers such as Levelt (1989) and his colleagues (Meyer, 1992; Roelofs, 2000) to propose a new model based on reaction time experiments.
The Levelt, Roelofs, and Meyer (LRM) Model
The Levelt, Roelofs, and Meyer or LRM model is one of the most popular models for speech production in psycholinguistics. It is also one of the most comprehensive in that it takes into account all stages from conceptualization to articulation (Levelt et al., 1999). The model is based on reaction time data from naming experiments and is a top-down model where information flows from more abstract levels to more concrete stages. The Word-form Encoding by Activation and VERification (WEAVER) is the computational implementation of the LRM model developed by Roelof (1992, 1996, 1997a, 1997b, 1998, 1999). It is a spreading activation model inspired by Dell’s (1986) ideas about word-form encoding. It accounts for the syllable frequency effect and ambiguous syllable priming data (although the computational implementation has been more successful in illustrating syllable frequency effects rather than priming effects).

As we can see in Figure 9.4, the lemma node is connected to segment nodes. These vertices are specified for serial position and the segments are not coded for syllable position. Indeed, the only syllabic information that is stored in this model are syllable templates that indicate the stress patterns of each word (which syllable in the word is stressed and which is not). These syllabic templates are used during speech production to syllabify the segments using the principle of onset-maximization (all segments that can legally go into a syllable onset in a language are put into the onset and the leftover segments go into the coda). This kind of syllabification during production accounts for resyllabification (which is a problem for the Dell model). The model also has a mental syllabary which is hypothesized to contain the articulatory programs that are used to plan articulation.
The model is interesting in that syllabification is only relevant at the time of production. Phonemes are defined within the lexicon with regard to their serial position in the word or lemma. This allows for resyllabification across morpheme and word boundaries without any difficulties. Roelofs and Meyer (1998) investigated whether syllable structures are stored in the mental frame. They employed an implicit priming paradigm where participants produced one word out of a set of words in rapid succession. The words were either homogenous (all words had the same word onsets) or heterogeneous. They found that priming depended on the targets having the same number of syllable and stress patterns but not the same syllable structure. This led them to conclude that syllable structure was not a stored component of speech production but computed during speech (Choline et al., 2004). Costa and Sebastian-Galles (1998) employed a picture-word interference paradigm to investigate this further. They asked participants to name a picture while a word was presented after 150 ms. They found that participants were faster to name a picture when they shared the same syllable structure with the word. These results challenge the view that syllable structure is absent as an abstract encoding within the lexicon. A new model has challenged the LRM model’s assumptions on this with a Lexicon with Syllable Structure (LEWISS) model.
The Lexicon with Syllable Structure (LEWISS) Model
Proposed by Romani et al. (2011), the Lexicon with Syllable Structure (LEWISS) model explores the possibility of stored syllable structure in phonological encoding. As seen in Figure 9.5 the organisation of segments in this model is based on a syllable structure framework (similar to proposals by Selkirk, 1982; Cairns & Feinstein, 1982). However, unlike the Dell model, the segments are not coded for syllable position. The syllable structural hierarchy is composed of syllable constituent nodes (onset, peak and coda) with the vertices having different weights based on their relative positions. This means that the peak (the most important part of a syllable) has a very strongly weighted vertex compared to onsets and codas. Within onsets and codas, the core positions are more strongly weighted compared to satellite position. This is based on the fact that there are positional variations in speech errors. For example, onsets and codas are more vulnerable to errors compared to vowels or peaks. Within onsets and codas, the satellite positions are more vulnerable compared to core positions. For example, in a word like print , the /r/ and /n/ in onset and coda satellite positions are more likely to be the subjects of errors than the /p/ and /t/ which are core positions. The main evidence for the LEWISS model comes from the speech errors of aphasic patients (Romani et al., 2011). It was observed that not only did they produce errors that weighted syllable positions differently, they also preserved the syllable structure of their targets even when making speech errors.

In terms of syllabification, the LEWISS model syllabifies at morpheme and word edges instead of having to syllabify the entire utterance each time it is produced. The evidence from speech errors supports the idea of having syllable position constraints. While Romani et al. (2011) have presented data from Italian, speech error analysis in Spanish also supports this view (Garcia-Albea et al., 1989). The evidence from Spanish is also interesting in that the errors are mostly word-medial rather than word-initial as is the case for English (Shattuck-Hufnagel, 1987, 1992). Stemberger (1990) hypothesised that structural frames for CV structure encoding may be compatible with phonological systems proposed by Clements and Keyser (1983) as well as Goldsmith (1990). This was supported by speech errors from German and Swedish (Stemberger, 1984). However, such patterns were not observed in English. Costa and Sebastian-Gallés (1998) found primed picture-naming was facilitated by primes that shared CV structure with the targets. Sevald, Dell and Cole (1995) found similar effects in repeated pronunciation tasks in English. Romani et al. (2011) brought these ideas to the fore with their analysis of speech errors made by Italian aphasic and apraxic patients. The patients did repetition, reading, and picture-naming tasks. Both groups of patients produced errors that targeted vulnerable syllable positions such as onset- and coda- satellites consistent with previous findings (Den Ouden, 2002). They also found that a large proportion of the errors preserved syllable structure even in the errors. This is noted by previous findings as well (Wilshire, 2002). Previous findings by Romani and Calabrese (1996) found that Italian patients replaced geminates with heterosyllabic clusters rather than homosyllabic clusters. For example, /ʤi.raf.fa/ became /ʤi.rar.fa/ rather than /ʤi.ra.fra/ preserving the original syllable structure of the target. While the Dell model’s segments coded for syllable position can also explain such errors, it cannot account for errors that moved from one syllable position to another. More recent computational calculations by Ramoo and Olson (2021) found that the resyllabification rates in English and Hindi as well as storage costs predicted by information theory do not discount LEWISS based on storage and computational costs.
Language Production Models
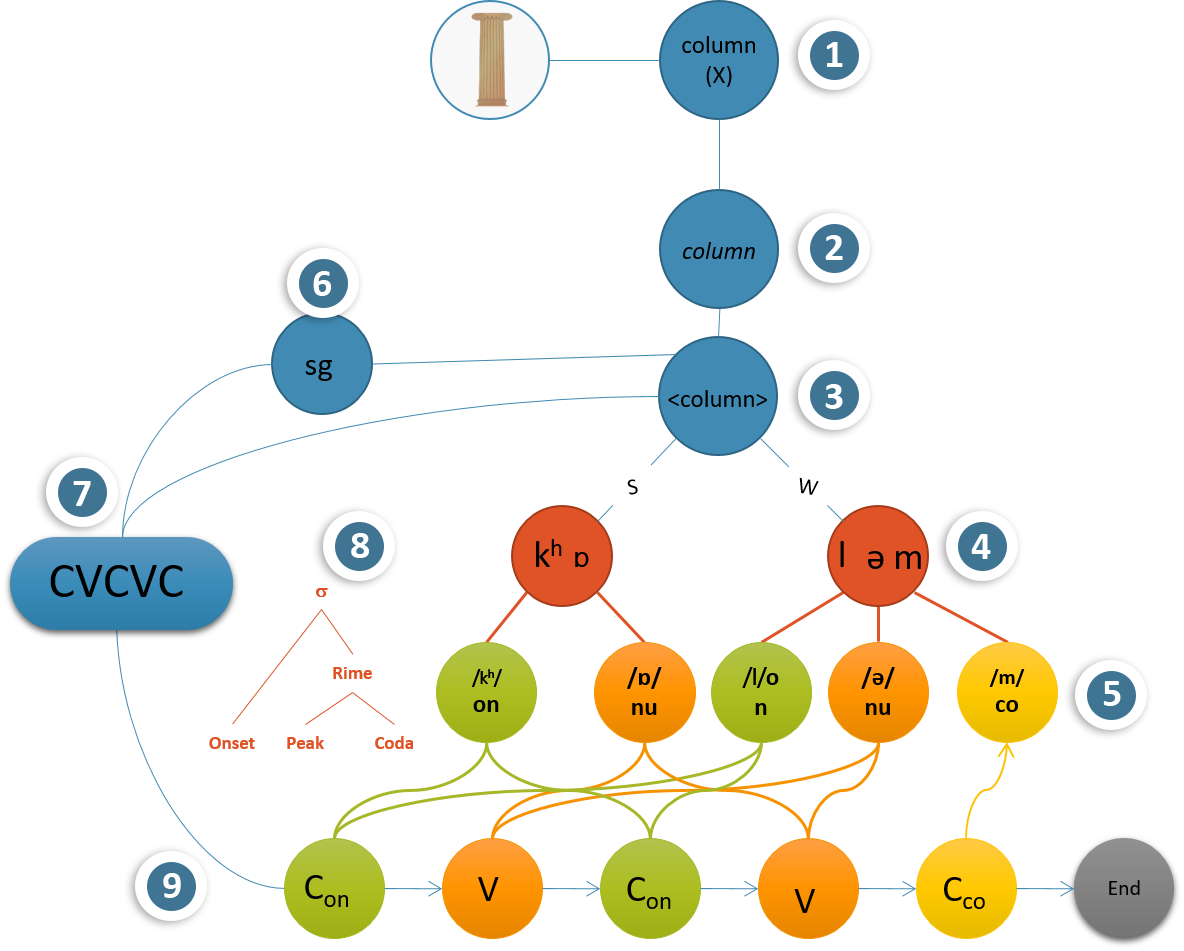
- This is the non-verbal concept of the object that is elicited when we see a picture, read the word or hear it.
- An abstract conceptual form of a word that has been mentally selected for utterance.
- The meaningful unit (or units) of the lemma attached to specific segments.
- Syllable nodes are created using the syllable template.
- Segment nodes are specified for syllable position. So, [p onset] will be a separate segment from [p coda].
- This node indicates that the word is singular.
- This node specifies the CV structure and order of the word.
- A syllable template is used in the syllabification process to indicate which segments can go where.
- The segment category nodes are specified for syllable position. So, they only activate segments that are for onset, peak or coda syllable positions. Activation will be higher for the appropriate segment.
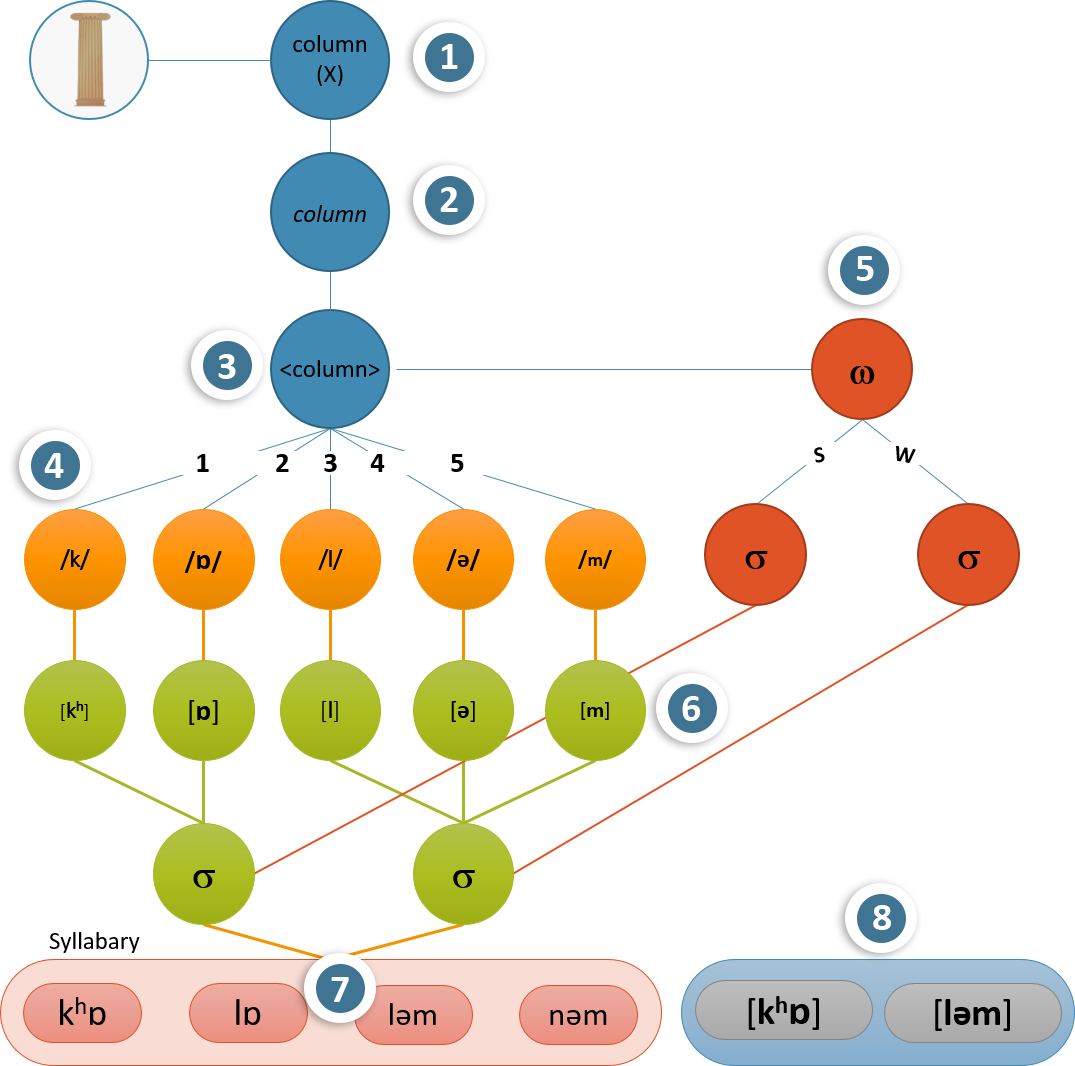
- Segment nodes are connected to the morpheme node specified for serial position.
- The morpheme is connected to a syllable template that indicates how many syllable are contained within the phonological word. It also indicates which syllables are stressed and unstressed.
- Post-lexical syllabification uses the syllable template to syllabify the phonemes. This is also the place where phonological rules can be implimented. For example, in English, unvoiced stops will be aspirated in output.
- Syllabified representations are used to access a Mental Syllabary of articulatory motor programs.
- The final output.
LEWISS Model
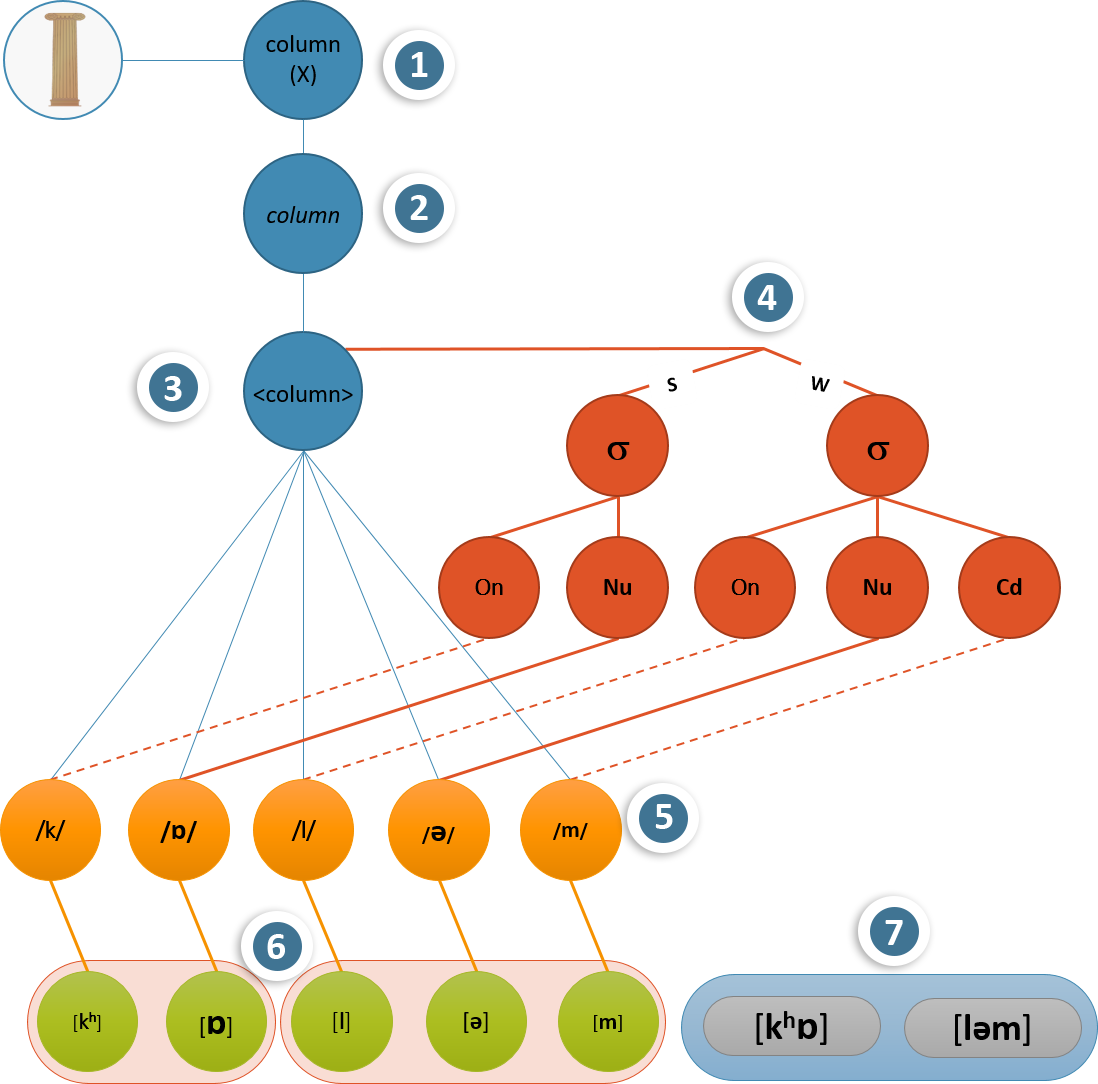
- The syllable structure nodes indicate the structure of the word’s syllable structure. They also specify syllable stress or tone. In addition, the connections are weighted. So, core positions and peak positions are strongly weighted compared to satellite positions.
- Segment nodes are connected to the morpheme node. They are also connected to a syllable structure that keeps them in place.
- Post-lexical syllabification syllabify the phonemes at morpheme and word boundaries. This is also the place where phonological rules can be implimented. For example, in English, unvoiced stops will be aspirated in output.
Navigate to the above link to view the interactive version of these models.
Media Attributions
- Figure 9.3 The Dell Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence .
- Figure 9.4 The LRM Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence .
- Figure 9.5 The LEWIS Model by Dinesh Ramoo, the author, is licensed under a CC BY 4.0 licence .
The process of putting individual segments into syllables based on language-specific rules.
The process by which segments that belong to one syllable move to another syllable during morphological changes and connected speech.
The structure of the syllable in terms of onset, peak (or nucleus) and coda.
Psychology of Language Copyright © 2021 by Dinesh Ramoo is licensed under a Creative Commons Attribution 4.0 International License , except where otherwise noted.
Share This Book

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Acoust Soc Am
Mechanics of human voice production and control
As the primary means of communication, voice plays an important role in daily life. Voice also conveys personal information such as social status, personal traits, and the emotional state of the speaker. Mechanically, voice production involves complex fluid-structure interaction within the glottis and its control by laryngeal muscle activation. An important goal of voice research is to establish a causal theory linking voice physiology and biomechanics to how speakers use and control voice to communicate meaning and personal information. Establishing such a causal theory has important implications for clinical voice management, voice training, and many speech technology applications. This paper provides a review of voice physiology and biomechanics, the physics of vocal fold vibration and sound production, and laryngeal muscular control of the fundamental frequency of voice, vocal intensity, and voice quality. Current efforts to develop mechanical and computational models of voice production are also critically reviewed. Finally, issues and future challenges in developing a causal theory of voice production and perception are discussed.
I. INTRODUCTION
In the broad sense, voice refers to the sound we produce to communicate meaning, ideas, opinions, etc. In the narrow sense, voice, as in this review, refers to sounds produced by vocal fold vibration, or voiced sounds. This is in contrast to unvoiced sounds which are produced without vocal fold vibration, e.g., fricatives which are produced by airflow through constrictions in the vocal tract, plosives produced by sudden release of a complete closure of the vocal tract, or other sound producing mechanisms such as whispering. For voiced sound production, vocal fold vibration modulates airflow through the glottis and produces sound (the voice source), which propagates through the vocal tract and is selectively amplified or attenuated at different frequencies. This selective modification of the voice source spectrum produces perceptible contrasts, which are used to convey different linguistic sounds and meaning. Although this selective modification is an important component of voice production, this review focuses on the voice source and its control within the larynx.
For effective communication of meaning, the voice source, as a carrier for the selective spectral modification by the vocal tract, contains harmonic energy across a large range of frequencies that spans at least the first few acoustic resonances of the vocal tract. In order to be heard over noise, such harmonic energy also has to be reasonably above the noise level within this frequency range, unless a breathy voice quality is desired. The voice source also contains important information of the pitch, loudness, prosody, and voice quality, which convey meaning (see Kreiman and Sidtis, 2011 , Chap. 8 for a review), biological information (e.g., size), and paralinguistic information (e.g., the speaker's social status, personal traits, and emotional state; Sundberg, 1987 ; Kreiman and Sidtis, 2011 ). For example, the same vowel may sound different when spoken by different people. Sometimes a simple “hello” is all it takes to recognize a familiar voice on the phone. People tend to use different voices to different speakers on different occasions, and it is often possible to tell if someone is happy or sad from the tone of their voice.
One of the important goals of voice research is to understand how the vocal system produces voice of different source characteristics and how people associate percepts to these characteristics. Establishing a cause-effect relationship between voice physiology and voice acoustics and perception will allow us to answer two essential questions in voice science and effective clinical care ( Kreiman et al. , 2014 ): when the output voice changes, what physiological alteration caused this change; if a change to voice physiology occurs, what change in perceived voice quality can be expected? Clinically, such knowledge would lead to the development of a physically based theory of voice production that is capable of better predicting voice outcomes of clinical management of voice disorders, thus improving both diagnosis and treatment. More generally, an understanding of this relationship could lead to a better understanding of the laryngeal adjustments that we use to change voice quality, adopt different speaking or singing styles, or convey personal information such as social status and emotion. Such understanding may also lead to the development of improved computer programs for synthesis of naturally sounding, speaker-specific speech of varying emotional percepts.
Understanding such cause-effect relationship between voice physiology and production necessarily requires a multi-disciplinary effort. While voice production results from a complex fluid-structure-acoustic interaction process, which again depends on the geometry and material properties of the lungs, larynx, and the vocal tract, the end interest of voice is its acoustics and perception. Changes in voice physiology or physics that cannot be heard are not that interesting. On the other hand, the physiology and physics may impose constraints on the co-variations among fundamental frequency (F0), vocal intensity, and voice quality, and thus the way we use and control our voice. Thus, understanding voice production and voice control requires an integrated approach, in which physiology, vocal fold vibration, and acoustics are considered as a whole instead of disconnected components. Traditionally, the multi-disciplinary nature of voice production has led to a clear divide between research activities in voice production, voice perception, and their clinical or speech applications, with few studies attempting to link them together. Although much advancement has been made in understanding the physics of phonation, some misconceptions still exist in textbooks in otolaryngology and speech pathology. For example, the Bernoulli effect, which has been shown to play a minor role in phonation, is still considered an important factor in initiating and sustaining phonation in many textbooks and reviews. Tension and stiffness are often used interchangeably despite that they have different physical meanings. The role of the thyroarytenoid muscle in regulating medial compression of the membranous vocal folds is often understated. On the other hand, research on voice production often focuses on the glottal flow and vocal fold vibration, but can benefit from a broader consideration of the acoustics of the produced voice and their implications for voice communication.
This paper provides a review on our current understanding of the cause-effect relation between voice physiology, voice production, and voice perception, with the hope that it will help better bridge research efforts in different aspects of voice studies. An overview of vocal fold physiology is presented in Sec. II , with an emphasis on laryngeal regulation of the geometry, mechanical properties, and position of the vocal folds. The physical mechanisms of self-sustained vocal fold vibration and sound generation are discussed in Sec. III , with a focus on the roles of various physical components and features in initiating phonation and affecting the produced acoustics. Some misconceptions of the voice production physics are also clarified. Section IV discusses the physiologic control of F0, vocal intensity, and voice quality. Section V reviews past and current efforts in developing mechanical and computational models of voice production. Issues and future challenges in establishing a causal theory of voice production and perception are discussed in Sec. VI .
II. VOCAL FOLD PHYSIOLOGY AND BIOMECHANICS
A. vocal fold anatomy and biomechanics.
The human vocal system includes the lungs and the lower airway that function to supply air pressure and airflow (a review of the mechanics of the subglottal system can be found in Hixon, 1987 ), the vocal folds whose vibration modulates the airflow and produces voice source, and the vocal tract that modifies the voice source and thus creates specific output sounds. The vocal folds are located in the larynx and form a constriction to the airway [Fig. 1(a) ]. Each vocal fold is about 11–15 mm long in adult women and 17–21 mm in men, and stretches across the larynx along the anterior-posterior direction, attaching anteriorly to the thyroid cartilage and posteriorly to the anterolateral surface of the arytenoid cartilages [Fig. 1(c) ]. Both the arytenoid [Fig. 1(d) ] and thyroid [Fig. 1(e) ] cartilages sit on top of the cricoid cartilage and interact with it through the cricoarytenoid joint and cricothyroid joint, respectively. The relative movement of these cartilages thus provides a means to adjust the geometry, mechanical properties, and position of the vocal folds, as further discussed below. The three-dimensional airspace between the two opposing vocal folds is the glottis. The glottis can be divided into a membranous portion, which includes the anterior portion of the glottis and extends from the anterior commissure to the vocal process of the arytenoid, and a cartilaginous portion, which is the posterior space between the arytenoid cartilages.

(Color online) (a) Coronal view of the vocal folds and the airway; (b) histological structure of the vocal fold lamina propria in the coronal plane (image provided by Dr. Jennifer Long of UCLA); (c) superior view of the vocal folds, cartilaginous framework, and laryngeal muscles; (d) medial view of the cricoarytenoid joint formed between the arytenoid and cricoid cartilages; (e) posterolateral view of the cricothyroid joint formed by the thyroid and the cricoid cartilages. The arrows in (d) and (e) indicate direction of possible motions of the arytenoid and cricoid cartilages due to LCA and CT muscle activation, respectively.
The vocal folds are layered structures, consisting of an inner muscular layer (the thyroarytenoid muscle) with muscle fibers aligned primarily along the anterior-posterior direction, a soft tissue layer of the lamina propria, and an outmost epithelium layer [Figs. 1(a) and 1(b) ]. The thyroarytenoid (TA) muscle is sometimes divided into a medial and a lateral bundle, with each bundle responsible for a certain vocal fold posturing function. However, such functional division is still a topic of debate ( Zemlin, 1997 ). The lamina propria consists of the extracellular matrix (ECM) and interstitial substances. The two primary ECM proteins are the collagen and elastin fibers, which are aligned mostly along the length of the vocal folds in the anterior-posterior direction ( Gray et al. , 2000 ). Based on the density of the collagen and elastin fibers [Fig. 1(b) ], the lamina propria can be divided into a superficial layer with limited and loose elastin and collagen fibers, an intermediate layer of dominantly elastin fibers, and a deep layer of mostly dense collagen fibers ( Hirano and Kakita, 1985 ; Kutty and Webb, 2009 ). In comparison, the lamina propria (about 1 mm thick) is much thinner than the TA muscle.
Conceptually, the vocal fold is often simplified into a two-layer body-cover structure ( Hirano, 1974 ; Hirano and Kakita, 1985 ). The body layer includes the muscular layer and the deep layer of the lamina propria, and the cover layer includes the intermediate and superficial lamina propria and the epithelium layer. This body-cover concept of vocal fold structure will be adopted in the discussions below. Another grouping scheme divides the vocal fold into three layers. In addition to a body and a cover layer, the intermediate and deep layers of the lamina propria are grouped into a vocal ligament layer ( Hirano, 1975 ). It is hypothesized that this layered structure plays a functional role in phonation, with different combinations of mechanical properties in different layers leading to production of different voice source characteristics ( Hirano, 1974 ). However, because of lack of data of the mechanical properties in each vocal fold layer and how they vary at different conditions of laryngeal muscle activation, a definite understanding of the functional roles of each vocal fold layer is still missing.
The mechanical properties of the vocal folds have been quantified using various methods, including tensile tests ( Hirano and Kakita, 1985 ; Zhang et al. , 2006b ; Kelleher et al. , 2013a ), shear rheometry ( Chan and Titze, 1999 ; Chan and Rodriguez, 2008 ; Miri et al. , 2012 ), indentation ( Haji et al. , 1992a , b ; Tran et al. , 1993 ; Chhetri et al. , 2011 ), and a surface wave method ( Kazemirad et al. , 2014 ). These studies showed that the vocal folds exhibit a nonlinear, anisotropic, viscoelastic behavior. A typical stress-strain curve of the vocal folds under anterior-posterior tensile test is shown in Fig. Fig.2. 2 . The slope of the curve, or stiffness, quantifies the extent to which the vocal folds resist deformation in response to an applied force. In general, after an initial linear range, the slope of the stress-strain curve (stiffness) increases gradually with further increase in the strain (Fig. (Fig.2), 2 ), presumably due to the gradual engagement of the collagen fibers. Such nonlinear mechanical behavior provides a means to regulate vocal fold stiffness and tension through vocal fold elongation or shortening, which plays an important role in the control of the F0 or pitch of voice production. Typically, the stress is higher during loading than unloading, indicating a viscous behavior of the vocal folds. Due to the presence of the AP-aligned collagen, elastin, and muscle fibers, the vocal folds also exhibit anisotropic mechanical properties, stiffer along the AP direction than in the transverse plane. Experiments ( Hirano and Kakita, 1985 ; Alipour and Vigmostad, 2012 ; Miri et al. , 2012 ; Kelleher et al. , 2013a ) showed that the Young's modulus along the AP direction in the cover layer is more than 10 times (as high as 80 times in Kelleher et al. , 2013a ) larger than in the transverse plane. Stiffness anisotropy has been shown to facilitate medial-lateral motion of the vocal folds ( Zhang, 2014 ) and complete glottal closure during phonation ( Xuan and Zhang, 2014 ).

Typical tensile stress-strain curve of the vocal fold along the anterior-posterior direction during loading and unloading at 1 Hz. The slope of the tangent line (dashed lines) to the stress-strain curve quantifies the tangent stiffness. The stress is typically higher during loading than unloading due to the viscous behavior of the vocal folds. The curve was obtained by averaging data over 30 cycles after a 10-cycle preconditioning.
Accurate measurement of vocal fold mechanical properties at typical phonation conditions is challenging, due to both the small size of the vocal folds and the relatively high frequency of phonation. Although tensile tests and shear rheometry allow direct measurement of material modules, the small sample size often leads to difficulties in mounting tissue samples to the testing equipment, thus creating concerns of accuracy. These two methods also require dissecting tissue samples from the vocal folds and the laryngeal framework, making it impossible for in vivo measurement. The indentation method is ideal for in vivo measurement and, because of the small size of indenters used, allows characterization of the spatial variation of mechanical properties of the vocal folds. However, it is limited for measurement of mechanical properties at conditions of small deformation. Although large indentation depths can be used, data interpretation becomes difficult and thus it is not suitable for assessment of the nonlinear mechanical properties of the vocal folds.
There has been some recent work toward understanding the contribution of individual ECM components to the macro-mechanical properties of the vocal folds and developing a structurally based constitutive model of the vocal folds (e.g., Chan et al. , 2001 ; Kelleher et al. , 2013b ; Miri et al. , 2013 ). The contribution of interstitial fluid to the viscoelastic properties of the vocal folds and vocal fold stress during vocal fold vibration and collision has also been investigated using a biphasic model of the vocal folds in which the vocal fold was modeled as a solid phase interacting with an interstitial fluid phase ( Zhang et al. , 2008 ; Tao et al. , 2009 , Tao et al. , 2010 ; Bhattacharya and Siegmund, 2013 ). This structurally based approach has the potential to predict vocal fold mechanical properties from the distribution of collagen and elastin fibers and interstitial fluids, which may provide new insights toward the differential mechanical properties between different vocal fold layers at different physiologic conditions.
B. Vocal fold posturing
Voice communication requires fine control and adjustment of pitch, loudness, and voice quality. Physiologically, such adjustments are made through laryngeal muscle activation, which stiffens, deforms, or repositions the vocal folds, thus controlling the geometry and mechanical properties of the vocal folds and glottal configuration.
One important posturing is adduction/abduction of the vocal folds, which is primarily achieved through motion of the arytenoid cartilages. Anatomical analysis and numerical simulations have shown that the cricoarytenoid joint allows the arytenoid cartilages to slide along and rotate about the long axis of the cricoid cartilage, but constrains arytenoid rotation about the short axis of the cricoid cartilage ( Selbie et al. , 1998 ; Hunter et al. , 2004 ; Yin and Zhang, 2014 ). Activation of the lateral cricoarytenoid (LCA) muscles, which attach anteriorly to the cricoid cartilage and posteriorly to the arytenoid cartilages, induce mainly an inward rotation motion of the arytenoid about the cricoid cartilages in the coronal plane, and moves the posterior portion of the vocal folds toward the glottal midline. Activation of the interarytenoid (IA) muscles, which connect the posterior surfaces of the two arytenoids, slides and approximates the arytenoid cartilages [Fig. 1(c) ], thus closing the cartilaginous glottis. Because both muscles act on the posterior portion of the vocal folds, combined action of the two muscles is able to completely close the posterior portion of the glottis, but is less effective in closing the mid-membranous glottis (Fig. (Fig.3; 3 ; Choi et al. , 1993 ; Chhetri et al. , 2012 ; Yin and Zhang, 2014 ). Because of this inefficiency in mid-membranous approximation, LCA/IA muscle activation is unable to produce medial compression between the two vocal folds in the membranous portion, contrary to current understandings ( Klatt and Klatt, 1990 ; Hixon et al. , 2008 ). Complete closure and medial compression of the mid-membranous glottis requires the activation of the TA muscle ( Choi et al. , 1993 ; Chhetri et al. , 2012 ). The TA muscle forms the bulk of the vocal folds and stretches from the thyroid prominence to the anterolateral surface of the arytenoid cartilages (Fig. (Fig.1). 1 ). Activation of the TA muscle produces a whole-body rotation of the vocal folds in the horizontal plane about the point of its anterior attachment to the thyroid cartilage toward the glottal midline ( Yin and Zhang, 2014 ). This rotational motion is able to completely close the membranous glottis but often leaves a gap posteriorly (Fig. (Fig.3). 3 ). Complete closure of both the membranous and cartilaginous glottis thus requires combined activation of the LCA/IA and TA muscles. The posterior cricoarytenoid (PCA) muscles are primarily responsible for opening the glottis but may also play a role in voice production of very high pitches, as discussed below.

Activation of the LCA/IA muscles completely closes the posterior glottis but leaves a small gap in the membranous glottis, whereas TA activation completely closes the anterior glottis but leaves a gap at the posterior glottis. From unpublished stroboscopic recordings from the in vivo canine larynx experiments in Choi et al. (1993) .
Vocal fold tension is regulated by elongating or shortening the vocal folds. Because of the nonlinear material properties of the vocal folds, changing vocal fold length also leads to changes in vocal fold stiffness, which otherwise would stay constant for linear materials. The two laryngeal muscles involved in regulating vocal fold length are the cricothyroid (CT) muscle and the TA muscle. The CT muscle consists of two bundles. The vertically oriented bundle, the pars recta, connects the anterior surface of the cricoid cartilage and the lower border of the thyroid lamina. Its contraction approximates the thyroid and cricoid cartilages anteriorly through a rotation about the cricothyroid joint. The other bundle, the pars oblique, is oriented upward and backward, connecting the anterior surface of the cricoid cartilage to the inferior cornu of the thyroid cartilage. Its contraction displaces the cricoid and arytenoid cartilages backwards ( Stone and Nuttall, 1974 ), although the thyroid cartilage may also move forward slightly. Contraction of both bundles thus elongates the vocal folds and increases the stiffness and tension in both the body and cover layers of the vocal folds. In contrast, activation of the TA muscle, which forms the body layer of the vocal folds, increase the stiffness and tension in the body layer. Activation of the TA muscle, in addition to an initial effect of mid-membranous vocal fold approximation, also shortens the vocal folds, which decreases both the stiffness and tension in the cover layer ( Hirano and Kakita, 1985 ; Yin and Zhang, 2013 ). One exception is when the tension in the vocal fold cover is already negative (i.e., under compression), in which case shortening the vocal folds further through TA activation decreases tension (i.e., increased compression force) but may increase stiffness in the cover layer. Activation of the LCA/IA muscles generally does not change the vocal fold length much and thus has only a slight effect on vocal fold stiffness and tension ( Chhetri et al. , 2009 ; Yin and Zhang, 2014 ). However, activation of the LCA/IA muscles (and also the PCA muscles) does stabilize the arytenoid cartilage and prevent it from moving forward when the cricoid cartilage is pulled backward due to the effect of CT muscle activation, thus facilitating extreme vocal fold elongation, particularly for high-pitch voice production. As noted above, due to the lack of reliable measurement methods, our understanding of how vocal fold stiffness and tension vary at different muscular activation conditions is limited.
Activation of the CT and TA muscles also changes the medial surface shape of the vocal folds and the glottal channel geometry. Specifically, TA muscle activation causes the inferior part of the medial surface to bulge out toward the glottal midline ( Hirano and Kakita, 1985 ; Hirano, 1988 ; Vahabzadeh-Hagh et al. , 2016 ), thus increasing the vertical thickness of the medial surface. In contrast, CT activation reduces this vertical thickness of the medial surface. Although many studies have investigated the prephonatory glottal shape (convergent, straight, or divergent) on phonation ( Titze, 1988a ; Titze et al. , 1995 ), a recent study showed that the glottal channel geometry remains largely straight under most conditions of laryngeal muscle activation ( Vahabzadeh-Hagh et al. , 2016 ).
III. PHYSICS OF VOICE PRODUCTION
A. sound sources of voice production.
The phonation process starts from the adduction of the vocal folds, which approximates the vocal folds to reduce or close the glottis. Contraction of the lungs initiates airflow and establishes pressure buildup below the glottis. When the subglottal pressure exceeds a certain threshold pressure, the vocal folds are excited into a self-sustained vibration. Vocal fold vibration in turn modulates the glottal airflow into a pulsating jet flow, which eventually develops into turbulent flow into the vocal tract.
In general, three major sound production mechanisms are involved in this process ( McGowan, 1988 ; Hofmans, 1998 ; Zhao et al. , 2002 ; Zhang et al. , 2002a ), including a monopole sound source due to volume of air displaced by vocal fold vibration, a dipole sound source due to the fluctuating force applied by the vocal folds to the airflow, and a quadrupole sound source due to turbulence developed immediately downstream of the glottal exit. When the false vocal folds are tightly adducted, an additional dipole source may arise as the glottal jet impinges onto the false vocal folds ( Zhang et al. , 2002b ). The monopole sound source is generally small considering that the vocal folds are nearly incompressible and thus the net volume flow displacement is small. The dipole source is generally considered as the dominant sound source and is responsible for the harmonic component of the produced sound. The quadrupole sound source is generally much weaker than the dipole source in magnitude, but it is responsible for broadband sound production at high frequencies.
For the harmonic component of the voice source, an equivalent monopole sound source can be defined at a plane just downstream of the region of major sound sources, with the source strength equal to the instantaneous pulsating glottal volume flow rate. In the source-filter theory of phonation ( Fant, 1970 ), this monopole sound source is the input signal to the vocal tract, which acts as a filter and shapes the sound source spectrum into different sounds before they are radiated from the mouth to the open as the voice we hear. Because of radiation from the mouth, the sound source is proportional to the time derivative of the glottal flow. Thus, in the voice literature, the time derivate of the glottal flow, instead of the glottal flow, is considered as the voice source.
The phonation cycle is often divided into an open phase, in which the glottis opens (the opening phase) and closes (the closing phase), and a closed phase, in which the glottis is closed or remains a minimum opening area when the glottal closure is incomplete. The glottal flow increases and decreases in the open phase, and remains zero during the closed phase or minimum for incomplete glottal closure (Fig. (Fig.4). 4 ). Compared to the glottal area waveform, the glottal flow waveform reaches its peak at a later time in the cycle so that the glottal flow waveform is more skewed to the right. This skewing in the glottal flow waveform to the right is due to the acoustic mass in the glottis and the vocal tract (when the F0 is lower than a nearby vocal tract resonance frequency), which causes a delay in the increase in the glottal flow during the opening phase, and a faster decay in the glottal flow during the closing phase ( Rothenberg, 1981 ; Fant, 1982 ). Because of this waveform skewing to the right, the negative peak of the time derivative of the glottal flow in the closing phase is often much more dominant than the positive peak in the opening phase. The instant of the most negative peak is thus considered the point of main excitation of the vocal tract and the corresponding negative peak, also referred to as the maximum flow declination rate (MFDR), is a major determinant of the peak amplitude of the produced voice. After the negative peak, the time derivative of the glottal flow waveform returns to zero as phonation enters the closed phase.

(Color online) Typical glottal flow waveform and its time derivative (left) and their correspondence to the spectral slopes of the low-frequency and high-frequency portions of the voice source spectrum (right).
Much work has been done to directly link features of the glottal flow waveform to voice acoustics and potentially voice quality (e.g., Fant, 1979 , 1982 ; Fant et al. , 1985 ; Gobl and Chasaide, 2010 ). These studies showed that the low-frequency spectral shape (the first few harmonics) of the voice source is primarily determined by the relative duration of the open phase with respect to the oscillation period (To/T in Fig. Fig.4, 4 , also referred to as the open quotient). A longer open phase often leads to a more dominant first harmonic (H1) in the low-frequency portion of the resulting voice source spectrum. For a given oscillation period, shortening the open phrase causes most of the glottal flow change to occur within a duration (To) that is increasingly shorter than the period T. This leads to an energy boost in the low-frequency portion of the source spectrum that peaks around a frequency of 1/To. For a glottal flow waveform of a very short open phase, the second harmonic (H2) or even the fourth harmonic (H4) may become the most dominant harmonic. Voice source with a weak H1 relative to H2 or H4 is often associated with a pressed voice quality.
The spectral slope in the high-frequency range is primarily related to the degree of discontinuity in the time derivative of the glottal flow waveform. Due to the waveform skewing discussed earlier, the most dominant source of discontinuity often occurs around the instant of main excitation when the time derivative of the glottal flow waveform returns from the negative peak to zero within a time scale of Ta (Fig. (Fig.4). 4 ). For an abrupt glottal flow cutoff ( Ta = 0), the time derivative of the glottal flow waveform has a strong discontinuity at the point of main excitation, which causes the voice source spectrum to decay asymptotically at a roll-off rate of −6 dB per octave toward high frequencies. Increasing Ta from zero leads to a gradual return from the negative peak to zero. When approximated by an exponential function, this gradual return functions as a lower-pass filter, with a cutoff frequency around 1/ Ta , and reduces the excitation of harmonics above the cutoff frequency 1/ Ta . Thus, in the frequency range concerning voice perception, increasing Ta often leads to reduced higher-order harmonic excitation. In the extreme case when there is minimal vocal fold contact, the time derivative of the glottal flow waveform is so smooth that the voice source spectrum only has a few lower-order harmonics. Perceptually, strong excitation of higher-order harmonics is often associated with a bright output sound quality, whereas voice source with limited excitation of higher-order harmonics is often perceived to be weak.
Also of perceptual importance is the turbulence noise produced immediately downstream of the glottis. Although small in amplitude, the noise component plays an important role in voice quality perception, particularly for female voice in which aspiration noise is more persistent than in male voice. While the noise component of voice is often modeled as white noise, its spectrum often is not flat and may exhibit different spectral shapes, depending on the glottal opening and flow rate as well as the vocal tract shape. Interaction between the spectral shape and relative levels of harmonic and noise energy in the voice source has been shown to influence the perception of voice quality ( Kreiman and Gerratt, 2012 ).
It is worth noting that many of the source parameters are not independent from each other and often co-vary. How they co-vary at different voicing conditions, which is essential to natural speech synthesis, remains to be the focus of many studies (e.g., Sundberg and Hogset, 2001 ; Gobl and Chasaide, 2003 ; Patel et al. , 2011 ).
B. Mechanisms of self-sustained vocal fold vibration
That vocal fold vibration results from a complex airflow-vocal fold interaction within the glottis rather than repetitive nerve stimulation of the larynx was first recognized by van den Berg (1958) . According to his myoelastic-aerodynamic theory of voice production, phonation starts from complete adduction of the vocal folds to close the glottis, which allows a buildup of the subglottal pressure. The vocal folds remain closed until the subglottal pressure is sufficiently high to push them apart, allowing air to escape and producing a negative (with respect to atmospheric pressure) intraglottal pressure due to the Bernoulli effect. This negative Bernoulli pressure and the elastic recoil pull the vocal folds back and close the glottis. The cycle then repeats, which leads to sustained vibration of the vocal folds.
While the myoelastic-aerodynamic theory correctly identifies the interaction between the vocal folds and airflow as the underlying mechanism of self-sustained vocal fold vibration, it does not explain how energy is transferred from airflow into the vocal folds to sustain this vibration. Traditionally, the negative intraglottal pressure is considered to play an important role in closing the glottis and sustaining vocal fold vibration. However, it is now understood that a negative intraglottal pressure is not a critical requirement for achieving self-sustained vocal fold vibration. Similarly, an alternatingly convergent-divergent glottal channel geometry during phonation has been considered a necessary condition that leads to net energy transfer from airflow into the vocal folds. We will show below that an alternatingly convergent-divergent glottal channel geometry does not always guarantee energy transfer or self-sustained vocal fold vibration.
For flow conditions typical of human phonation, the glottal flow can be reasonably described by Bernoulli's equation up to the point when airflow separates from the glottal wall, often at the glottal exit at which the airway suddenly expands. According to Bernoulli's equation, the flow pressure p at a location within the glottal channel with a time-varying cross-sectional area A is
where P sub and P sup are the subglottal and supraglottal pressure, respectively, and A sep is the time-varying glottal area at the flow separation location. For simplicity, we assume that the flow separates at the upper margin of the medial surface. To achieve a net energy transfer from airflow to the vocal folds over one cycle, the air pressure on the vocal fold surface has to be at least partially in-phase with vocal fold velocity. Specifically, the intraglottal pressure needs to be higher in the opening phase than in the closing phase of vocal fold vibration so that the airflow does more work on the vocal folds in the opening phase than the work the vocal folds do back to the airflow in the closing phase.
Theoretical analysis of the energy transfer between airflow and vocal folds ( Ishizaka and Matsudaira, 1972 ; Titze, 1988a ) showed that this pressure asymmetry can be achieved by a vertical phase difference in vocal fold surface motion (also referred to as a mucosal wave), i.e., different portions of the vocal fold surface do not necessarily move inward and outward together as a whole. This mechanism is illustrated in Fig. Fig.5, 5 , the upper left of which shows vocal fold surface shape in the coronal plane for six consecutive, equally spaced instants during one vibration cycle in the presence of a vertical phase difference. Instants 2 and 3 in solid lines are in the closing phase whereas 5 and 6 in dashed lines are in the opening phase. Consider for an example energy transfer at the lower margin of the medial surface. Because of the vertical phase difference, the glottal channel has a different shape in the opening phase (dashed lines 5 and 6) from that in the closing (solid lines 3 and 2) when the lower margin of the medial surface crosses the same locations. Particularly, when the lower margin of the medial surface leads the upper margin in phase, the glottal channel during opening (e.g., instant 6) is always more convergent [thus a smaller A sep / A in Eq. (1) ] or less divergent than that in the closing (e.g., instant 2) for the same location of the lower margin, resulting in an air pressure [Eq. (1) ] that is higher in the opening phase than the closing phase (Fig. (Fig.5, 5 , top row). As a result, energy is transferred from airflow into the vocal folds over one cycle, as indicated by a non-zero area enclosed by the aerodynamic force-vocal fold displacement curve in Fig. Fig.5 5 (top right). The existence of a vertical phase difference in vocal fold surface motion is generally considered as the primary mechanism of phonation onset.

Two energy transfer mechanisms. Top row: the presence of a vertical phase difference leads to different medial surface shapes between glottal opening (dashed lines 5 and 6; upper left panel) and closing (solid lines 2 and 3) when the lower margin of the medial surface crosses the same locations, which leads to higher air pressure during glottal opening than closing and net energy transfer from airflow into vocal folds at the lower margin of the medial surface. Middle row: without a vertical phase difference, vocal fold vibration produces an alternatingly convergent-divergent but identical glottal channel geometry between glottal opening and closing (bottom left panel), thus zero energy transfer (middle row). Bottom row: without a vertical phase difference, air pressure asymmetry can be imposed by a negative damping mechanism.
In contrast, without a vertical phase difference, the vocal fold surface during opening (Fig. (Fig.5, 5 , bottom left; dashed lines 5 and 6) and closing (solid lines 3 and 2) would be identical when the lower margin crosses the same positions, for which Bernoulli's equation would predict symmetric flow pressure between the opening and closing phases, and zero net energy transfer over one cycle (Fig. (Fig.5, 5 , middle row). Under this condition, the pressure asymmetry between the opening and closing phases has to be provided by an external mechanism that directly imposes a phase difference between the intraglottal pressure and vocal fold movement. In the presence of such an external mechanism, the intraglottal pressure is no longer the same between opening and closing even when the glottal channel has the same shape as the vocal fold crosses the same locations, resulting in a net energy transfer over one cycle from airflow to the vocal folds (Fig. (Fig.5, 5 , bottom row). This energy transfer mechanism is often referred to as negative damping, because the intraglottal pressure depends on vocal fold velocity and appears in the system equations of vocal fold motion in a form similar to a damping force, except that energy is transferred to the vocal folds instead of being dissipated. Negative damping is the only energy transfer mechanism in a single degree-of-freedom system or when the entire medial surface moves in phase as a whole.
In humans, a negative damping can be provided by an inertive vocal tract ( Flanagan and Landgraf, 1968 ; Ishizaka and Matsudaira, 1972 ; Ishizaka and Flanagan, 1972 ) or a compliant subglottal system ( Zhang et al. , 2006a ). Because the negative damping associated with acoustic loading is significant only for frequencies close to an acoustic resonance, phonation sustained by such negative damping alone always occurs at a frequency close to that acoustic resonance ( Flanagan and Landgraf, 1968 ; Zhang et al. , 2006a ). Although there is no direct evidence of phonation sustained dominantly by acoustic loading in humans, instabilities in voice production (or voice breaks) have been reported when the fundamental frequency of vocal fold vibration approaches one of the vocal tract resonances (e.g., Titze et al. , 2008 ). On the other hand, this entrainment of phonation frequency to the acoustic resonance limits the degree of independent control of the voice source and the spectral modification by the vocal tract, and is less desirable for effective speech communication. Considering that humans are capable of producing a large variety of voice types independent of vocal tract shapes, negative damping due to acoustic coupling to the sub- or supra-glottal acoustics is unlikely the primary mechanism of energy transfer in voice production. Indeed, excised larynges are able to vibrate without a vocal tract. On the other hand, experiments have shown that in humans the vocal folds vibrate at a frequency close to an in vacuo vocal fold resonance ( Kaneko et al. , 1986 ; Ishizaka, 1988 ; Svec et al. , 2000 ) instead of the acoustic resonances of the sub- and supra-glottal tracts, suggesting that phonation is essentially a resonance phenomenon of the vocal folds.
A negative damping can be also provided by glottal aerodynamics. For example, glottal flow acceleration and deceleration may cause the flow to separate at different locations between opening and closing even when the glottis has identical geometry. This is particularly the case for a divergent glottal channel geometry, which often results in asymmetric flow separation and pressure asymmetry between the glottal opening and closing phases ( Park and Mongeau, 2007 ; Alipour and Scherer, 2004 ). The effect of this negative damping mechanism is expected to be small at phonation onset at which the vocal fold vibration amplitude and thus flow unsteadiness is small and the glottal channel is less likely to be divergent. However, its contribution to energy transfer may increase with increasing vocal fold vibration amplitude and flow unsteadiness ( Howe and McGowan, 2010 ). It is important to differentiate this asymmetric flow separation between glottal opening and closing due to unsteady flow effects from a quasi-steady asymmetric flow separation that is caused by asymmetry in the glottal channel geometry between opening and closing. In the latter case, because flow separation may occur at a more upstream location for a divergent glottal channel than a convergent glottal channel, an asymmetric glottal channel geometry (e.g., a glottis opening convergent and closing divergent) may lead to asymmetric flow separation between glottal opening and closing. Compared to conditions of a fixed flow separation (i.e., flow separates at the same location during the entire cycle, as in Fig. Fig.5), 5 ), such geometry-induced asymmetric flow separation actually reduces pressure asymmetry between glottal opening and closing [this can be shown using Eq. (1) ] and thus weakens net energy transfer. In reality, these two types of asymmetric flow separation mechanisms (due to unsteady effects or changes in glottal channel geometry) interact and can result in very complex flow separation patterns ( Alipour and Scherer, 2004 ; Sciamarella and Le Quere, 2008 ; Sidlof et al. , 2011 ), which may or may not enhance energy transfer.
From the discussion above it is clear that a negative Bernoulli pressure is not a critical requirement in either one of the two mechanisms. Being proportional to vocal fold displacement, the negative Bernoulli pressure is not a negative damping and does not directly provide the required pressure asymmetry between glottal opening and closing. On the other hand, the existence of a vertical phase difference in vocal fold vibration is determined primarily by vocal fold properties (as discussed below), rather than whether the intraglottal pressure is positive or negative during a certain phase of the oscillation cycle.
Although a vertical phase difference in vocal fold vibration leads to a time-varying glottal channel geometry, an alternatingly convergent-divergent glottal channel geometry does not guarantee self-sustained vocal fold vibration. For example, although the in-phase vocal fold motion in the bottom left of Fig. Fig.5 5 (the entire medial surface moves in and out together) leads to an alternatingly convergent-divergent glottal geometry, the glottal geometry is identical between glottal opening and closing and thus this motion is unable to produce net energy transfer into the vocal folds without a negative damping mechanism (Fig. (Fig.5, 5 , middle row). In other words, an alternatingly convergent-divergent glottal geometry is an effect, not cause, of self-sustained vocal fold vibration. Theoretically, the glottis can maintain a convergent or divergent shape during the entire oscillation cycle and yet still self-oscillate, as observed in experiments using physical vocal fold models which had a divergent shape during most portions of the oscillation cycle ( Zhang et al. , 2006a ).
C. Eigenmode synchronization and nonlinear dynamics
The above shows that net energy transfer from airflow into the vocal folds is possible in the presence of a vertical phase difference. But how is this vertical phase difference established, and what determines the vertical phase difference and the vocal fold vibration pattern? In voice production, vocal fold vibration with a vertical phase difference results from a process of eigenmode synchronization, in which two or more in vacuo eigenmodes of the vocal folds are synchronized to vibrate at the same frequency but with a phase difference ( Ishizaka and Matsudaira, 1972 ; Ishizaka, 1981 ; Horacek and Svec, 2002 ; Zhang et al. , 2007 ), in the same way as a travelling wave formed by superposition of two standing waves. An eigenmode or resonance is a pattern of motion of the system that is allowed by physical laws and boundary constraints to the system. In general, for each mode, the vibration pattern is such that all parts of the system move either in-phase or 180° out of phase, similar to a standing wave. Each eigenmode has an inherently distinct eigenfrequency (or resonance frequency) at which the eigenmode can be maximally excited. An example of eigenmodes that is often encountered in speech science is formants, which are peaks in the output voice spectra due to excitation of acoustic resonances of the vocal tract, with the formant frequency dependent on vocal tract geometry. Figure Figure6 6 shows three typical eigenmodes of the vocal fold in the coronal plane. In Fig. Fig.6, 6 , the thin line indicates the resting vocal fold surface shape, whereas the solid and dashed lines indicate extreme positions of the vocal fold when vibrating at the corresponding eigenmode, spaced 180° apart in a vibratory cycle. The first eigenmode shows an up and down motion in the vertical direction, which does not modulate glottal airflow much. The second eigenmode has a dominantly in-phase medial-lateral motion along the medial surface, which does modulate airflow. The third eigenmode also exhibits dominantly medial-lateral motion, but the upper portion of the medial surface vibrates 180° out of phase with the lower portion of the medial surface. Such out-of-phase motion as in the third eigenmode is essential to achieving vocal fold vibration with a large vertical phase difference, e.g., when synchronized with an in-phase eigenmode as in Fig. 6(b) .

Typical vocal fold eigenmodes exhibiting (a) a dominantly superior-inferior motion, (b) a medial-lateral in-phase motion, and (c) a medial-lateral out-of-phase motion along the medial surface.
In the absence of airflow, the vocal fold in vacuo eigenmodes are generally neutral or damped, meaning that when excited they will gradually decay in amplitude with time. When the vocal folds are subject to airflow, however, the vocal fold-airflow coupling modifies the eigenmodes and, in some conditions, synchronizes two eigenmodes to the same frequency (Fig. (Fig.7). 7 ). Although vibration in each eigenmode by itself does not produce net energy transfer (Fig. (Fig.5, 5 , middle row), when two modes are synchronized at the same frequency but with a phase difference in time, the vibration velocity associated with one eigenmode [e.g., the eigenmode in Fig. 6(b) ] will be at least partially in-phase with the pressure induced by the other eigenmode [e.g., the eigenmode in Fig. 6(c) ], and this cross-model pressure-velocity interaction will produce net energy transfer into the vocal folds ( Ishizaka and Matsudaira, 1972 ; Zhang et al. , 2007 ).

A typical eigenmode synchronization pattern. The evolution of the first three eigenmodes is shown as a function of the subglottal pressure. As the subglottal pressure increases, the frequencies (top) of the second and third vocal fold eigenmodes gradually approach each other and, at a threshold subglottal pressure, synchronize to the same frequency. At the same time, the growth rate (bottom) of the second mode becomes positive, indicating the coupled airflow-vocal fold system becomes linearly unstable and phonation starts.
The minimum subglottal pressure required to synchronize two eigenmodes and initiate net energy transfer, or the phonation threshold pressure, is proportional to the frequency spacing between the two eigenmodes being synchronized and the coupling strength between the two eigenmodes ( Zhang, 2010 ):
where ω 0,1 and ω 0,2 are the eigenfrequencies of the two in vacuo eigenmodes participating in the synchronization process and β is the coupling strength between the two eigenmodes. Thus, the closer the two eigenmodes are to each other in frequency or the more strongly they are coupled, the less pressure is required to synchronize them. This is particularly the case in an anisotropic material such as the vocal folds in which the AP stiffness is much larger than the stiffness in the transverse plane. Under such anisotropic stiffness conditions, the first few in vacuo vocal fold eigenfrequencies tend to cluster together and are much closer to each other compared to isotropic stiffness conditions ( Titze and Strong, 1975 ; Berry, 2001 ). Such clustering of eigenmodes makes it possible to initiate vocal fold vibration at very low subglottal pressures.
The coupling strength β between the two eigenmodes in Eq. (2) depends on the prephonatory glottal opening, with the coupling strength increasing with decreasing glottal opening (thus lowered phonation threshold pressure). In addition, the coupling strength also depends on the spatial similarity between the air pressure distribution over the vocal fold surface induced by one eigenmode and vocal fold surface velocity of the other eigenmode ( Zhang, 2010 ). In other words, the coupling strength β quantifies the cross-mode energy transfer efficiency between the eigenmodes that are being synchronized. The higher the degree of cross-mode pressure-velocity similarity, the better the two eigenmodes are coupled, and the less subglottal pressure is required to synchronize them.
In reality, the vocal folds have an infinite number of eigenmodes. Which eigenmodes are synchronized and eventually excited depends on the frequency spacing and relative coupling strength among different eigenmodes. Because vocal fold vibration depends on the eigenmodes that are eventually excited, changes in the eigenmode synchronization pattern often lead to changes in the F0, vocal fold vibration pattern, and the resulting voice quality. Previous studies have shown that a slight change in vocal fold properties such as stiffness or medial surface shape may cause phonation to occur at a different eigenmode, leading to a qualitatively different vocal fold vibration pattern and abrupt changes in F0 ( Tokuda et al. , 2007 ; Zhang, 2009 ). Eigenmode synchronization is not limited to two vocal fold eigenmodes, either. It may also occur between a vocal fold eigenmode and an eigenmode of the subglottal or supraglottal system. In this sense, the negative damping due to subglottal or supraglottal acoustic loading can be viewed as the result of synchronization between one of the vocal fold modes and one of the acoustic resonances.
Eigenmode synchronization discussed above corresponds to a 1:1 temporal synchronization of two eigenmodes. For a certain range of vocal fold conditions, e.g., when asymmetry (left-right or anterior-posterior) exists in the vocal system or when the vocal folds are strongly coupled with the sub- or supra-glottal acoustics, synchronization may occur so that the two eigenmodes are synchronized not toward the same frequency, but at a frequency ratio of 1:2, 1:3, etc., leading to subharmonics or biphonation ( Ishizaka and Isshiki, 1976 ; Herzel, 1993 ; Herzel et al. , 1994 ; Neubauer et al. , 2001 ; Berry et al. , 1994 ; Berry et al. , 2006 ; Titze, 2008 ; Lucero et al. , 2015 ). Temporal desynchronization of eigenmodes often leads to irregular or chaotic vocal fold vibration ( Herzel et al. , 1991 ; Berry et al. , 1994 ; Berry et al. , 2006 ; Steinecke and Herzel, 1995 ). Transition between different synchronization patterns, or bifurcation, often leads to a sudden change in the vocal fold vibration pattern and voice quality.
These studies show that the nonlinear interaction between vocal fold eigenmodes is a central feature of the phonation process, with different synchronization or desynchronization patterns producing a large variety of voice types. Thus, by changing the geometrical and biomechanical properties of the vocal folds, either through laryngeal muscle activation or mechanical modification as in phonosurgery, we can select eigenmodes and eigenmode synchronization pattern to control or modify our voice, in the same way as we control speech formants by moving articulators in the vocal tract to modify vocal tract acoustic resonances.
The concept of eigenmode and eigenmode synchronization is also useful for phonation modeling, because eigenmodes can be used as building blocks to construct more complex motion of the system. Often, only the first few eigenmodes are required for adequate reconstruction of complex vocal fold vibrations (both regular and irregular; Herzel et al. , 1994 ; Berry et al. , 1994 ; Berry et al. , 2006 ), which would significantly reduce the degrees of freedom required in computational models of phonation.
D. Biomechanical requirements of glottal closure during phonation
An important feature of normal phonation is the complete closure of the membranous glottis during vibration, which is essential to the production of high-frequency harmonics. Incomplete closure of the membranous glottis, as often observed in pathological conditions, often leads to voice production of a weak and/or breathy quality.
It is generally assumed that approximation of the vocal folds through arytenoid adduction is sufficient to achieve glottal closure during phonation, with the duration of glottal closure or the closed quotient increasing with increasing degree of vocal fold approximation. While a certain degree of vocal fold approximation is obviously required for glottal closure, there is evidence suggesting that other factors also are in play. For example, excised larynx experiments have shown that some larynges would vibrate with incomplete glottal closure despite that the arytenoids are tightly sutured together ( Isshiki, 1989 ; Zhang, 2011 ). Similar incomplete glottal closure is also observed in experiments using physical vocal fold models with isotropic material properties ( Thomson et al. , 2005 ; Zhang et al. , 2006a ). In these experiments, increasing the subglottal pressure increased the vocal fold vibration amplitude but often did not lead to improvement in the glottal closure pattern ( Xuan and Zhang, 2014 ). These studies show that addition stiffness or geometry conditions are required to achieve complete membranous glottal closure.
Recent studies have started to provide some insight toward these additional biomechanical conditions. Xuan and Zhang (2014) showed that embedding fibers along the anterior-posterior direction in otherwise isotropic models is able to improve glottal closure ( Xuan and Zhang, 2014 ). With an additional thin stiffer outmost layer simulating the epithelium, these physical models are able to vibrate with a considerably long closed period. It is interesting that this improvement in the glottal closure pattern occurred only when the fibers were embedded to a location close to the vocal fold surface in the cover layer. Embedding fibers in the body layer did not improve the closure pattern at all. This suggests a possible functional role of collagen and elastin fibers in the intermediate and deep layers of the lamina propria in facilitating glottal closure during vibration.
The difference in the glottal closure pattern between isotropic and anisotropic vocal folds could be due to many reasons. Compared to isotropic vocal folds, anisotropic vocal folds (or fiber-embedded models) are better able to maintain their adductory position against the subglottal pressure and are less likely to be pushed apart by air pressure ( Zhang, 2011 ). In addition, embedding fibers along the AP direction may also enhance the medial-lateral motion, further facilitating glottal closure. Zhang (2014) showed that the first few in vacuo eigenmodes of isotropic vocal folds exhibit similar in-phase, up-and-down swing-like motion, with the medial-lateral and superior-inferior motions locked in a similar phase relationship. Synchronization of modes of similar vibration patterns necessarily leads to qualitatively the same vibration patterns, in this case an up-and-down swing-like motion, with vocal fold vibration dominantly along the superior-inferior direction, as observed in recent physical model experiments ( Thomson et al. , 2005 ; Zhang et al. , 2006a ). In contrast, for vocal folds with the AP stiffness much higher than the transverse stiffness, the first few in vacuo modes exhibit qualitatively distinct vibration patterns, and the medial-lateral motion and the superior-inferior motion are no longer locked in a similar phase in the first few in vacuo eigenmodes. This makes it possible to strongly excite large medial-lateral motion without proportional excitation of the superior-inferior motion. As a result, anisotropic models exhibit large medial-lateral motion with a vertical phase difference along the medial surface. The improved capability to maintain adductory position against the subglottal pressure and to vibrate with large medial-lateral motion may contribute to the improved glottal closure pattern observed in the experiment of Xuan and Zhang (2014) .
Geometrically, a thin vocal fold has been shown to be easily pushed apart by the subglottal pressure ( Zhang, 2016a ). Although a thin anisotropic vocal fold vibrates with a dominantly medial-lateral motion, this is insufficient to overcome its inability to maintain position against the subglottal pressure. As a result, the glottis never completely closes during vibration, which leads to a relatively smooth glottal flow waveform and weak excitation of higher-order harmonics in the radiated output voice spectrum ( van den Berg, 1968 ; Zhang, 2016a ). Increasing vertical thickness of the medial surface allows the vocal fold to better resist the glottis-opening effect of the subglottal pressure, thus maintaining the adductory position and achieving complete glottal closure.
Once these additional stiffness and geometric conditions (i.e., certain degree of stiffness anisotropy and not-too-small vertical vocal fold thickness) are met, the duration of glottal closure can be regulated by varying the vertical phase difference in vocal fold motion along the medial surface. A non-zero vertical phase difference means that, when the lower margins of the medial surfaces start to open, the glottis would continue to remain closed until the upper margins start to open. One important parameter affecting the vertical phase difference is the vertical thickness of the medial surface or the degree of medial bulging in the inferior portion of the medial surface. Given the same condition of vocal fold stiffness and vocal fold approximation, the vertical phase difference during vocal fold vibration increases with increasing vertical medial surface thickness (Fig. (Fig.8). 8 ). Thus, the thicker the medial surface, the larger the vertical phase difference, and the longer the closed phase (Fig. (Fig.8; 8 ; van den Berg, 1968 ; Alipour and Scherer, 2000 ; Zhang, 2016a ). Similarly, the vertical phase difference and thus the duration of glottal closure can be also increased by reducing the elastic surface wave speed in the superior-inferior direction ( Ishizaka and Flanagan, 1972 ; Story and Titze, 1995 ), which depends primarily on the stiffness in the transverse plane and to a lesser degree on the AP stiffness, or increasing the body-cover stiffness ratio ( Story and Titze, 1995 ; Zhang, 2009 ).

(Color online) The closed quotient CQ and vertical phase difference VPD as a function of the medial surface thickness, the AP stiffness (G ap ), and the resting glottal angle ( α ). Reprinted with permission of ASA from Zhang (2016a) .
Theoretically, the duration of glottal closure can be controlled by changing the ratio between the vocal fold equilibrium position (or the mean glottal opening) and the vocal fold vibration amplitude. Both stiffening the vocal folds and tightening vocal fold approximation are able to move the vocal fold equilibrium position toward glottal midline. However, such manipulations often simultaneously reduce the vibration amplitude. As a result, the overall effect on the duration of glottal closure is unclear. Zhang (2016a) showed that stiffening the vocal folds or increasing vocal fold approximation did not have much effect on the duration of glottal closure except around onset when these manipulations led to significant improvement in vocal fold contact.
E. Role of flow instabilities
Although a Bernoulli-based flow description is often used for phonation models, the realistic glottal flow is highly three-dimensional and much more complex. The intraglottal pressure distribution is shown to be affected by the three-dimensionality of the glottal channel geometry ( Scherer et al. , 2001 ; Scherer et al. , 2010 ; Mihaescu et al. , 2010 ; Li et al. , 2012 ). As the airflow separates from the glottal wall as it exits the glottis, a jet forms downstream of the flow separation point, which leads to the development of shear layer instabilities, vortex roll-up, and eventually vortex shedding from the jet and transition into turbulence. The vortical structures would in turn induce disturbances upstream, which may lead to oscillating flow separation point, jet attachment to one side of the glottal wall instead of going straight, and possibly alternating jet flapping ( Pelorson et al. , 1994 ; Shinwari et al. , 2003 ; Triep et al. , 2005 ; Kucinschi et al. , 2006 ; Erath and Plesniak, 2006 ; Neubauer et al. , 2007 ; Zheng et al. , 2009 ). Recent experiments and simulations also showed that for a highly divergent glottis, airflow may separate inside the glottis, which leads to the formation and convection of intraglottal vortices ( Mihaescu et al. , 2010 ; Khosla et al. , 2014 ; Oren et al. , 2014 ).
Some of these flow features have been incorporated in phonation models (e.g., Liljencrants, 1991 ; Pelorson et al. , 1994 ; Kaburagi and Tanabe, 2009 ; Erath et al. , 2011 ; Howe and McGowan, 2013 ). Resolving other features, particularly the jet instability, vortices, and turbulence downstream of the glottis, demands significantly increased computational costs so that simulation of a few cycles of vocal fold vibration often takes days or months. On the other hand, the acoustic and perceptual relevance of these intraglottal and supraglottal flow structures has not been established. From the sound production point of view, these complex flow structures in the downstream glottal flow field are sound sources of quadrupole type (dipole type when obstacles are present in the pathway of airflow, e.g., tightly adducted false vocal folds). Due to the small length scales associated with the flow structures, these sound sources are broadband in nature and mostly at high frequencies (generally above 2 kHz), with an amplitude much smaller than the harmonic component of the voice source. Therefore, if the high-frequency component of voice is of interest, these flow features have to be accurately modeled, although the degree of accuracy required to achieve perceptual sufficiency has yet to be determined.
It has been postulated that the vortical structures may directly affect the near-field glottal fluid-structure interaction and thus vocal fold vibration and the harmonic component of the voice source. Once separated from the vocal fold walls, the glottal jet starts to develop jet instabilities and is therefore susceptible to downstream disturbances, especially when the glottis takes on a divergent shape. In this way, the unsteady supraglottal flow structures may interact with the boundary layer at the glottal exit and affect the flow separation point within the glottal channel ( Hirschberg et al. , 1996 ). Similarly, it has been hypothesized that intraglottal vortices can induce a local negative pressure on the medial surface of the vocal folds as the intraglottal vortices are convected downstream and thus may facilitate rapid glottal closure during voice production ( Khosla et al. , 2014 ; Oren et al. , 2014 ).
While there is no doubt that these complex flow features affect vocal fold vibration, the question remains concerning how large an influence these vortical structures have on vocal fold vibration and the produced acoustics. For the flow conditions typical of voice production, many of the flow features or instabilities have time scales much different from that of vocal fold vibration. For example, vortex shedding at typical voice conditions occurs generally at frequencies above 1000 Hz ( Zhang et al. , 2004 ; Kucinschi et al. , 2006 ). Considering that phonation is essentially a resonance phenomenon of the vocal folds (Sec. III B ) and the mismatch between vocal fold resonance and typical frequency scales of the vortical structures, it is questionable that compared to vocal fold inertia and elastic recoil, the pressure perturbations on vocal fold surface due to intraglottal or supraglottal vortical structures are strong enough or last for a long enough period to have a significant effect on voice production. Given a longitudinal shear modulus of the vocal fold of about 10 kPa and a shear strain of 0.2, the elastic recoil stress of the vocal fold is approximately 2000 Pa. The pressure perturbations induced by intraglottal or supraglottal vortices are expected to be much smaller than the subglottal pressure. Assuming an upper limit of about 20% of the subglottal pressure for the pressure perturbations (as induced by intraglottal vortices, Oren et al. , 2014 ; in reality this number is expected to be much smaller at normal loudness conditions and even smaller for supraglottal vortices) and a subglottal pressure of 800 Pa (typical of normal speech production), the pressure perturbation on vocal fold surface is about 160 Pa, which is much smaller than the elastic recoil stress. Specifically to the intraglottal vortices, while a highly divergent glottal geometry is required to create intraglottal vortices, the presence of intraglottal vortices induces a negative suction force applied mainly on the superior portion of the medial surface and, if the vortices are strong enough, would reduce the divergence of the glottal channel. In other words, while intraglottal vortices are unable to create the necessary divergence conditions required for their creation, their existence tends to eliminate such conditions.
There have been some recent studies toward quantifying the degree of the influence of the vortical structures on phonation. In an excised larynx experiment without a vocal tract, it has been observed that the produced sound does not change much when sticking a finger very close to the glottal exit, which presumably would have significantly disturbed the supraglottal flow field. A more rigorous experiment was designed in Zhang and Neubauer (2010) in which they placed an anterior-posteriorly aligned cylinder in the supraglottal flow field and traversed it in the flow direction at different left-right locations and observed the acoustics consequences. The hypothesis was that, if these supraglottal flow structures had a significant effect on vocal fold vibration and acoustics, disturbing these flow structures would lead to noticeable changes in the produced sound. However, their experiment found no significant changes in the sound except when the cylinder was positioned within the glottal channel.
The potential impact of intraglottal vortices on phonation has also been numerically investigated ( Farahani and Zhang, 2014 ; Kettlewell, 2015 ). Because of the difficulty in removing intraglottal vortices without affecting other aspects of the glottal flow, the effect of the intraglottal vortices was modeled as a negative pressure superimposed on the flow pressure predicted by a base glottal flow model. In this way, the effect of the intraglottal vortices can be selectively activated or deactivated independently of the base flow so that its contribution to phonation can be investigated. These studies showed that intraglottal vortices only have small effects on vocal fold vibration and the glottal flow. Kettlewell (2015) further showed that the vortices are either not strong enough to induce significant pressure perturbation on vocal fold surfaces or, if they are strong enough, the vortices advect rapidly into the supraglottal region and the induced pressure perturbations would be too brief to have any impact to overcome the inertia of the vocal fold tissue.
Although phonation models using simplified flow models neglecting flow vortical structures are widely used and appear to qualitatively compare well with experiments ( Pelorson et al. , 1994 ; Zhang et al. , 2002a ; Ruty et al. , 2007 ; Kaburagi and Tanabe, 2009 ), more systematic investigations are required to reach a definite conclusion regarding the relative importance of these flow structures to phonation and voice perception. This may be achieved by conducting parametric studies in a large range of conditions over which the relative strength of these vortical structures are known to vary significantly and observing their consequences on voice production. Such an improved understanding would facilitate the development of computationally efficient reduced-order models of phonation.
IV. BIOMECHANICS OF VOICE CONTROL
A. fundamental frequency.
In the discussion of F0 control, an analogy is often made between phonation and vibration in strings in the voice literature (e.g., Colton et al. , 2011 ). The vibration frequency of a string is determined by its length, tension, and mass. By analogy, the F0 of voice production is also determined by its length, tension, and mass, with the mass interpreted as the mass of the vocal folds that is set into vibration. Specifically, F0 increases with increasing tension, decreasing mass, and decreasing vocal fold length. While the string analogy is conceptually simple and heuristically useful, some important features of the vocal folds are missing. Other than the vague definition of an effective mass, the string model, which implicitly assumes cross-section dimension much smaller than length, completely neglects the contribution of vocal fold stiffness in F0 control. Although stiffness and tension are often not differentiated in the voice literature, they have different physical meanings and represent two different mechanisms that resist deformation (Fig. (Fig.2). 2 ). Stiffness is a property of the vocal fold and represents the elastic restoring force in response to deformation, whereas tension or stress describes the mechanical state of the vocal folds. The string analogy also neglects the effect of vocal fold contact, which introduces additional stiffening effect.
Because phonation is essentially a resonance phenomenon of the vocal folds, the F0 is primarily determined by the frequency of the vocal fold eigenmodes that are excited. In general, vocal fold eigenfrequencies depend on both vocal fold geometry, including length, depth, and thickness, and the stiffness and stress conditions of the vocal folds. Shorter vocal folds tend to have high eigenfrequencies. Thus, because of the small vocal fold size, children tend to have the highest F0, followed by female and then male. Vocal fold eigenfrequencies also increase with increasing stiffness or stress (tension), both of which provide a restoring force to resist vocal fold deformation. Thus, stiffening or tensioning the vocal folds would increase the F0 of the voice. In general, the effect of stiffness on vocal fold eigenfrequencies is more dominant than tension when the vocal fold is slightly elongated or shortened, at which the tension is small or even negative and the string model would underestimate F0 or fail to provide a prediction. As the vocal fold gets further elongated and tension increases, the stiffness and tension become equally important in affecting vocal fold eigenfrequencies ( Titze and Hunter, 2004 ; Yin and Zhang, 2013 ).
When vocal fold contact occurs during vibration, the vocal fold collision force appears as an additional restoring force ( Ishizaka and Flanagan, 1972 ). Depending on the extent, depth of influence, and duration of vocal fold collision, this additional force can significantly increase the effective stiffness of the vocal folds and thus F0. Because the vocal fold contact pattern depends on the degree of vocal fold approximation, subglottal pressure, and vocal fold stiffness and geometry, changes in any of these parameters may have an effect on F0 by affecting vocal fold contact ( van den Berg and Tran, 1959 ; Zhang, 2016a ).
In humans, F0 can be increased by increasing either vocal fold eigenfrequencies or the extent and duration of vocal fold contact. Control of vocal fold eigenfrequencies is largely achieved by varying the stiffness and tension along the AP direction. Due to the nonlinear material properties of the vocal folds, both the AP stiffness and tension can be controlled by elongating or shortening the vocal folds, through activation of the CT muscle. Although elongation also increases vocal fold length which lowers F0, the effect of the increase in stiffness and tension on F0 appears to dominate that of increasing length.
The effect of TA muscle activation on F0 control is a little more complex. In addition to shortening vocal fold length, TA activation tensions and stiffens the body layer, decreases tension in the cover layer, but may decrease or increase the cover stiffness ( Yin and Zhang, 2013 ). Titze et al. (1988) showed that depending on the depth of the body layer involved in vibration, increasing TA activation can either increase or decrease vocal fold eigenfrequencies. On the other hand, Yin and Zhang (2013) showed that for an elongated vocal fold, as is often the case in phonation, the overall effect of TA activation is to reduce vocal fold eigenfrequencies. Only for conditions of a slightly elongated or shortened vocal folds, TA activation may increase vocal fold eigenfrequencies. In addition to the effect on vocal fold eigenfrequencies, TA activation increases vertical thickness of the vocal folds and produces medial compression between the two folds, both of which increase the extent and duration of vocal tract contact and would lead to an increased F0 ( Hirano et al. , 1969 ). Because of these opposite effects on vocal fold eigenfrequencies and vocal fold contact, the overall effect of TA activation on F0 would vary depending on the specific vocal fold conditions.
Increasing subglottal pressure or activation of the LCA/IA muscles by themselves do not have much effect on vocal fold eigenfrequencies ( Hirano and Kakita, 1985 ; Chhetri et al. , 2009 ; Yin and Zhang, 2014 ). However, they often increase the extent and duration of vocal fold contact during vibration, particularly with increasing subglottal pressure, and thus lead to increased F0 ( Hirano et al. , 1969 ; Ishizaka and Flanagan, 1972 ; Zhang, 2016a ). Due to nonlinearity in vocal fold material properties, increased vibration amplitude at high subglottal pressures may lead to increased effective stiffness and tension, which may also increase F0 ( van den Berg and Tan, 1959 ; Ishizaka and Flanagan, 1972 ; Titze, 1989 ). Ishizaka and Flanagan (1972) showed in their two-mass model that vocal fold contact and material nonlinearity combined can lead to an increase of about 40 Hz in F0 when the subglottal pressure is increased from about 200 to 800 Pa. In the continuum model of Zhang (2016a) , which includes the effect of vocal fold contact but not vocal fold material nonlinearity, increasing subglottal pressure alone can increase the F0 by as large as 20 Hz/kPa.
B. Vocal intensity
Because voice is produced at the glottis, filtered by the vocal tract, and radiated from the mouth, an increase in vocal intensity can be achieved by either increasing the source intensity or enhancing the radiation efficiency. The source intensity is controlled primarily by the subglottal pressure, which increases the vibration amplitude and the negative peak or MFDR of the time derivative of the glottal flow. The subglottal pressure depends primarily on the alveolar pressure in the lungs, which is controlled by the respiratory muscles and the lung volume. In general, conditions of the laryngeal system have little effect on the establishment of the alveolar pressure and subglottal pressure ( Hixon, 1987 ; Finnegan et al. , 2000 ). However, an open glottis often results in a small glottal resistance and thus a considerable pressure drop in the lower airway and a reduced subglottal pressure. An open glottis also leads to a large glottal flow rate and a rapid decline in the lung volume, thus reducing the duration of speech between breaths and increasing the respiratory effort required in order to maintain a target subglottal pressure ( Zhang, 2016b ).
In the absence of a vocal tract, laryngeal adjustments, which control vocal fold stiffness, geometry, and position, do not have much effect on the source intensity, as shown in many studies using laryngeal, physical, or computational models of phonation ( Tanaka and Tanabe, 1986 ; Titze, 1988b ; Zhang, 2016a ). In the experiment by Tanaka and Tanabe (1986) , for a constant subglottal pressure, stimulation of the CT and LCA muscles had almost no effects on vocal intensity whereas stimulation of the TA muscle slightly decreased vocal intensity. In an excised larynx experiment, Titze (1988b) found no dependence of vocal intensity on the glottal width. Similar secondary effects of laryngeal adjustments have also been observed in a recent computational study ( Zhang, 2016a ). Zhang (2016a) also showed that the effect of laryngeal adjustments may be important at subglottal pressures slightly above onset, in which case an increase in either AP stiffness or vocal fold approximation may lead to improved vocal fold contact and glottal closure, which significantly increased the MFDR and thus vocal intensity. However, these effects became less efficient with increasing vocal intensity.
The effect of laryngeal adjustments on vocal intensity becomes a little more complicated in the presence of the vocal tract. Changing vocal tract shape by itself does not amplify the produced sound intensity because sound propagation in the vocal tract is a passive process. However, changes in vocal tract shape may provide a better impedance match between the glottis and the free space outside the mouth and thus improve efficiency of sound radiation from the mouth ( Titze and Sundberg, 1992 ). This is particularly the case for harmonics close to a formant, which are often amplified more than the first harmonic and may become the most energetic harmonic in the spectrum of the output voice. Thus, vocal intensity can be increased through laryngeal adjustments that increase excitation of harmonics close to the first formant of the vocal tract ( Fant, 1982 ; Sundberg, 1987 ) or by adjusting vocal tract shape to match one of the formants with one of the dominant harmonics in the source spectrum.
In humans, all three strategies (respiratory, laryngeal, and articulatory) are used to increase vocal intensity. When asked to produce an intensity sweep from soft to loud voice, one generally starts with a slightly breathy voice with a relatively open glottis, which requires the least laryngeal effort but is inefficient in voice production. From this starting position, vocal intensity can be increased by increasing either the subglottal pressure, which increases vibration amplitude, or vocal fold adduction (approximation and/or thickening). For a soft voice with minimal vocal fold contact and minimal higher-order harmonic excitation, increasing vocal fold adduction is particularly efficient because it may significantly improve vocal fold contact, in both spatial extent and duration, thus significantly boosting the excitation of harmonics close to the first formant. In humans, for low to medium vocal intensity conditions, vocal intensity increase is often accompanied by simultaneous increases in the subglottal pressure and the glottal resistance ( Isshiki, 1964 ; Holmberg et al. , 1988 ; Stathopoulos and Sapienza, 1993 ). Because the pitch level did not change much in these experiments, the increase in glottal resistance was most likely due to tighter vocal fold approximation through LCA/IA activation. The duration of the closed phase is often observed to increase with increasing vocal intensity ( Henrich et al. , 2005 ), indicating increased vocal fold thickening or medial compression, which are primarily controlled by the TA muscle. Thus, it seems that both the LCA/IA/TA muscles and subglottal pressure increase play a role in vocal intensity increase at low to medium intensity conditions. For high vocal intensity conditions, when further increase in vocal fold adduction becomes less effective ( Hirano et al. , 1969 ), vocal intensity increase appears to rely dominantly on the subglottal pressure increase.
On the vocal tract side, Titze (2002) showed that the vocal intensity can be increased by matching a wide epilarynx with lower glottal resistance or a narrow epilarynx with higher glottal resistance. Tuning the first formant (e.g., by opening mouth wider) to match the F0 is often used in soprano singing to maximize vocal output ( Joliveau et al. , 2004 ). Because radiation efficiency can be improved through adjustments in either the vocal folds or the vocal tract, this makes it possible to improve radiation efficiency yet still maintain desired pitch or articulation, whichever one wishes to achieve.
C. Voice quality
Voice quality generally refers to aspects of the voice other than pitch and loudness. Due to the subjective nature of voice quality perception, many different descriptions are used and authors often disagree with the meanings of these descriptions ( Gerratt and Kreiman, 2001 ; Kreiman and Sidtis, 2011 ). This lack of a clear and consistent definition of voice quality makes it difficult for studies of voice quality and identifying its physiological correlates and controls. Acoustically, voice quality is associated with the spectral amplitude and shape of the harmonic and noise components of the voice source, and their temporal variations. In the following we focus on physiological factors that are known to have an impact on the voice spectra and thus are potentially perceptually important.
One of the first systematic investigations of the physiological controls of voice quality was conducted by Isshiki (1989 , 1998) using excised larynges, in which regions of normal, breathy, and rough voice qualities were mapped out in the three-dimensional parameter space of the subglottal pressure, vocal fold stiffness, and prephonatory glottal opening area (Fig. (Fig.9). 9 ). He showed that for a given vocal fold stiffness and prephonatory glottal opening area, increasing subglottal pressure led to voice production of a rough quality. This effect of the subglottal pressure can be counterbalanced by increasing vocal fold stiffness, which increased the region of normal voice in the parameter space of Fig. Fig.9. 9 . Unfortunately, the details of this study, including the definition and manipulation of vocal fold stiffness and perceptual evaluation of different voice qualities, are not fully available. The importance of the coordination between the subglottal pressure and laryngeal conditions was also demonstrated in van den Berg and Tan (1959) , which showed that although different vocal registers were observed, each register occurred in a certain range of laryngeal conditions and subglottal pressures. For example, for conditions of low longitudinal tension, a chest-like phonation was possible only for small airflow rates. At large values of the subglottal pressure, “it was impossible to obtain good sound production. The vocal folds were blown too wide apart…. The shape of the glottis became irregularly curved and this curving was propagated along the glottis.” Good voice production at large flow rates was possible only with thyroid cartilage compression which imitates the effect of TA muscle activation. Irregular vocal fold vibration at high subglottal pressures has also been observed in physical model experiments (e.g., Xuan and Zhang, 2014 ). Irregular or chaotic vocal fold vibration at conditions of pressure-stiffness mismatch has also been reported in the numerical simulation of Berry et al. (1994) , which showed that while regular vocal fold vibration was observed for typical vocal fold stiffness conditions, irregular vocal fold vibration (e.g., subharmonic or chaotic vibration) was observed when the cover layer stiffness was significantly reduced while maintaining the same subglottal pressure.

A three-dimensional map of normal (N), breathy (B), and rough (R) phonation in the parameter space of the prephonatory glottal area (Ag0), subglottal pressure (Ps), vocal fold stiffness (k). Reprinted with permission of Springer from Isshiki (1989) .
The experiments of van den Berg and Tan (1959) and Isshiki (1989) also showed that weakly adducted vocal folds (weak LCA/IA/TA activation) often lead to vocal fold vibration with incomplete glottal closure during phonation. When the airflow is sufficiently high, the persistent glottal gap would lead to increased turbulent noise production and thus phonation of a breathy quality (Fig. (Fig.9). 9 ). The incomplete glottal closure may occur in the membranous or the cartilaginous portion of the glottis. When the incomplete glottal closure is limited to the cartilaginous glottis, the resulting voice is breathy but may still have strong harmonics at high frequencies. When the incomplete glottal closure occurs in the membranous glottis, the reduced or slowed vocal fold contact would also reduce excitation of higher-order harmonics, resulting in a breathy and weak quality of the produced voice. When the vocal folds are sufficiently separated, the coupling between the two vocal folds may be weakened enough so that each vocal fold can vibrate at a different F0. This would lead to biphonation or voice containing two distinct fundamental frequencies, resulting in a perception similar to that of the beat frequency phenomenon.
Compared to a breathy voice, a pressed voice is presumably produced with tight vocal fold approximation or even some degree of medial compression in the membranous portion between the two folds. A pressed voice is often characterized by a second harmonic that is stronger than the first harmonic, or a negative H1-H2, with a long period of glottal closure during vibration. Although a certain degree of vocal fold approximation and stiffness anisotropy is required to achieve vocal fold contact during phonation, the duration of glottal closure has been shown to be primarily determined by the vertical thickness of the vocal fold medial surface ( van den Berg, 1968 ; Zhang, 2016a ). Thus, although it is generally assumed that a pressed voice can be produced with tight arytenoid adduction through LCA/IA muscle activation, activation of the LCA/IA muscles alone is unable to achieve prephonatory medial compression in the membranous glottis or change the vertical thickness of the medial surface. Activation of the TA muscle appears to be essential in producing a voice change from a breathy to a pressed voice quality. A weakened TA muscle, as in aging or muscle atrophy, would lead to difficulties in producing a pressed voice or even sufficient glottal closure during phonation. On the other hand, strong TA muscle activation, as in for example, spasmodic dysphonia, may lead to too tight a closure of the glottis and a rough voice quality ( Isshiki, 1989 ).
In humans, vocal fold stiffness, vocal fold approximation, and geometry are regulated by the same set of laryngeal muscles and thus often co-vary, which has long been considered as one possible origin of vocal registers and their transitions ( van den Berg, 1968 ). Specifically, it has been hypothesized that changes in F0 are often accompanied by changes in the vertical thickness of the vocal fold medial surface, which lead to changes in the spectral characteristics of the produced voice. The medial surface thickness is primarily controlled by the CT and TA muscles, which also regulate vocal fold stiffness and vocal fold approximation. Activation of the CT muscle reduces the medial surface thickness, but also increases vocal fold stiffness and tension, and in some conditions increases the resting glottal opening ( van den Berg and Tan, 1959 ; van den Berg, 1968 ; Hirano and Kakita, 1985 ). Because the LCA/IA/TA muscles are innervated by the same nerve and often activated together, an increase in the medial surface thickness through TA muscle activation is often accompanied by increased vocal fold approximation ( Hirano and Kakita, 1985 ) and contact. Thus, if one attempts to increase F0 primarily by activation of the LCA/IA/TA muscles, the vocal folds are likely to have a large medial surface thickness and probably low AP stiffness, which will lead to a chest-like voice production, with large vertical phase difference along the medial surface, long closure of the glottis, small flow rate, and strong harmonic excitation. In the extreme case of strong TA activation and minimum CT activation and very low subglottal pressure, the glottis can remain closed for most of the cycle, leading to a vocal fry-like voice production. In contrast, if one attempts to increase F0 by increasing CT activation alone, the vocal folds, with a small medial surface thickness, are likely to produce a falsetto-like voice production, with incomplete glottal closure and a nearly sinusoidal flow waveform, very high F0, and a limited number of harmonics.
V. MECHANICAL AND COMPUTER MODELS FOR VOICE APPLICATIONS
Voice applications generally fall into two major categories. In the clinic, simulation of voice production has the potential to predict outcomes of clinical management of voice disorders, including surgery and voice therapy. For such applications, accurate representation of vocal fold geometry and material properties to the degree that matches actual clinical treatment is desired, and for this reason continuum models of the vocal folds are preferred over lumped-element models. Computational cost is not necessarily a concern in such applications but still has to be practical. In contrast, for some other applications, particularly in speech technology applications, the primary goal is to reproduce speech acoustics or at least perceptually relevant features of speech acoustics. Real-time capability is desired in these applications, whereas realistic representation of the underlying physics involved is often not necessary. In fact, most of the current speech synthesis systems consider speech purely as an acoustic signal and do not model the physics of speech production at all. However, models that take into consideration the underlying physics, at least to some degree, may hold the most promise in speech synthesis of natural-sounding, speaker-specific quality.
A. Mechanical vocal fold models
Early efforts on artificial speech production, dating back to as early as the 18th century, focused on mechanically reproducing the speech production system. A detailed review can be found in Flanagan (1972) . The focus of these early efforts was generally on articulation in the vocal tract rather than the voice source, which is understandable considering that meaning is primarily conveyed through changes in articulation and the lack of understanding of the voice production process. The vibrating element in these mechanical models, either a vibrating reed or a slotted rubber sheet stretched over an opening, is only a rough approximation of the human vocal folds.
More sophisticated mechanical models have been developed more recently to better reproduce the three-dimensional layered structure of the vocal folds. A membrane (cover)-cushion (body) two-layer rubber vocal fold model was first developed by Smith (1956) . Similar mechanical models were later developed and used in voice production research (e.g., Isogai et al. , 1988 ; Kakita, 1988 ; Titze et al. , 1995 ; Thomson et al. , 2005 ; Ruty et al. , 2007 ; Drechsel and Thomson, 2008 ), using silicone or rubber materials or liquid-filled membranes. Recent studies ( Murray and Thomson, 2012 ; Xuan and Zhang, 2014 ) have also started to embed fibers into these models to simulate the anisotropic material properties due to the presence of collagen and elastin fibers in the vocal folds. A similar layered vocal fold model has been incorporated into a mechanical talking robot system ( Fukui et al. , 2005 ; Fukui et al. , 2007 ; Fukui et al. , 2008 ). The most recent version of the talking robot, Waseda Talker, includes mechanisms for the control of pitch and resting glottal opening, and is able to produce voice of modal, creaky, or breathy quality. Nevertheless, although a mechanical voice production system may find application in voice prosthesis or humanoid robotic systems in the future, current mechanical models are still a long way from reproducing or even approaching humans' capability and flexibility in producing and controlling voice.
B. Formant synthesis and parametric voice source models
Compared to mechanically reproducing the physical process involved in speech production, it is easier to reproduce speech as an acoustic signal. This is particularly the case for speech synthesis. One approach adopted in most of the current speech synthesis systems is to concatenate segments of pre-recorded natural voice into new speech phrases or sentences. While relatively easy to implement, in order to achieve natural-sounding speech, this approach requires a large database of words spoken in different contexts, which makes it difficult to apply to personalized speech synthesis of varying emotional percepts.
Another approach is to reproduce only perceptually relevant acoustic features of speech, as in formant synthesis. The target acoustic features to be reproduced generally include the F0, sound amplitude, and formant frequencies and bandwidths. This approach gained popularity with the development of electrical synthesizers and later computer simulations which allow flexible and accurate control of these acoustic features. Early formant-based synthesizers used simple sound sources, often a filtered impulse train as the sound source for voiced sounds and white noise for unvoiced sounds. Research on the voice sources (e.g., Fant, 1979 ; Fant et al. , 1985 ; Rothenberg et al. , 1971 ; Titze and Talkin, 1979 ) has led to the development of parametric voice source models in the time domain, which are capable of producing voice source waveforms of varying F0, amplitude, open quotient, and degree of abruptness of the glottal flow shutoff, and thus synthesis of different voice qualities.
While parametric voice source models provide flexibility in source variations, synthetic speech generated by the formant synthesis still suffers limited naturalness. This limited naturalness may result from the primitive rules used in specifying dynamic controls of the voice source models ( Klatt, 1987 ). Also, the source model control parameters are not independent from each other and often co-vary during phonation. A challenge in formant synthesis is thus to specify voice source parameter combinations and their time variation patterns that may occur in realistic voice production of different voice qualities by different speakers. It is also possible that some perceptually important features are missing from time-domain voice source models ( Klatt, 1987 ). Human perception of voice characteristics is better described in the frequency domain as the auditory system performs an approximation to Fourier analysis of the voice and sound in general. While time-domain models have better correspondence to the physical events occurring during phonation (e.g., glottal opening and closing, and the closed phase), it is possible some spectral details of perceptual importance are not captured in the simple time-domain voice source models. For example, spectral details in the low and middle frequencies have been shown to be of considerable importance to naturalness judgment, but are difficult to be represented in a time-domain source model ( Klatt, 1987 ). A recent study ( Kreiman et al. , 2015 ) showed that spectral-domain voice source models are able to create significantly better matches to natural voices than time-domain voice source models. Furthermore, because of the independence between the voice source and the sub- and supra-glottal systems in formant synthesis, interactions and co-variations between vocal folds and the sub- and supra-glottal systems are by design not accounted for. All these factors may contribute to the limited naturalness of the formant synthesized speech.
C. Physically based computer models
An alternative approach to natural speech synthesis is to computationally model the voice production process based on physical principles. The control parameters would be geometry and material properties of the vocal system or, in a more realistic way, respiratory and laryngeal muscle activation. This approach avoids the need to specify consistent characteristics of either the voice source or the formants, thus allowing synthesis and modification of natural voice in a way intuitively similar to human voice production and control.
The first such computer model of voice production is the one-mass model by Flanagan and Landgraf (1968) , in which the vocal fold is modeled as a horizontally moving single-degree of freedom mass-spring-damper system. This model is able to vibrate in a restricted range of conditions when the natural frequency of the mass-spring system is close to one of the acoustic resonances of the subglottal or supraglottal tracts. Ishizaka and Flanagan (1972) extended this model to a two-mass model in which the upper and lower parts of the vocal fold are modeled as two separate masses connected by an additional spring along the vertical direction. The two-mass model is able to vibrate with a vertical phase difference between the two masses, and thus able to vibrate independently of the acoustics of the sub- and supra-glottal tracts. Many variants of the two-mass model have since been developed. Titze (1973) developed a 16-mass model to better represent vocal fold motion along the anterior-posterior direction. To better represent the body-cover layered structure of the vocal folds, Story and Titze (1995) extended the two-mass model to a three-mass model, adding an additional lateral mass representing the inner muscular layer. Empirical rules have also been developed to relate control parameters of the three-mass model to laryngeal muscle activation levels ( Titze and Story, 2002 ) so that voice production can be simulated with laryngeal muscle activity as input. Designed originally for speech synthesis purpose, these lumped-element models of voice production are generally fast in computational time and ideal for real-time speech synthesis.
A drawback of the lumped-element models of phonation is that the model control parameters cannot be directly measured or easily related to the anatomical structure or material properties of the vocal folds. Thus, these models are not as useful in applications in which a realistic representation of voice physiology is required, as, for example, in the clinical management of voice disorders. To better understand the voice source and its control under different voicing conditions, more sophisticated computational models of the vocal folds based on continuum mechanics have been developed to understand laryngeal muscle control of vocal fold geometry, stiffness, and tension, and how changes in these vocal fold properties affect the glottal fluid-structure interaction and the produced voice. One of the first such models is the finite-difference model by Titze and Talkin (1979) , which coupled a three-dimensional vocal fold model of linear elasticity with the one-dimensional glottal flow model of Ishizaka and Flanagan (1972) . In the past two decades more refined phonation models using a two-dimensional or three-dimensional Navier-Stokes description of the glottal flow have been developed (e.g., Alipour et al. , 2000 ; Zhao et al. , 2002 ; Tao et al. , 2007 ; Luo et al. , 2009 ; Zheng et al. , 2009 ; Bhattacharya and Siegmund, 2013 ; Xue et al. , 2012 , 2014 ). Continuum models of laryngeal muscle activation have also been developed to model vocal fold posturing ( Hunter et al. , 2004 ; Gommel et al. , 2007 ; Yin and Zhang, 2013 , 2014 ). By directly modeling the voice production process, continuum models with realistic geometry and material properties ideally hold the most promise in reproducing natural human voice production. However, because the phonation process is highly nonlinear and involves large displacement and deformation of the vocal folds and complex glottal flow patterns, modeling this process in three dimensions is computationally very challenging and time-consuming. As a result, these computational studies are often limited to one or two specific aspects instead of the entire voice production process, and the acoustics of the produced voice, other than F0 and vocal intensity, are often not investigated. For practical applications, real-time or not, reduced-order models with significantly improved computational efficiency are required. Some reduced-order continuum models, with simplifications in both the glottal flow and vocal fold dynamics, have been developed and used in large-scale parametric studies of voice production (e.g., Titze and Talkin, 1979 ; Zhang, 2016a ), which appear to produce qualitatively reasonable predictions. However, these simplifications have yet to be rigorously validated by experiment.
VI. FUTURE CHALLENGES
We currently have a general understanding of the physical principles of voice production. Toward establishing a cause-effect theory of voice production, much is to be learned about voice physiology and biomechanics. This includes the geometry and mechanical properties of the vocal folds and their variability across subject, sex, and age, and how they vary across different voicing conditions under laryngeal muscle activation. Even less is known about changes in vocal fold geometry and material properties in pathologic conditions. The surface conditions of the vocal folds and their mechanical properties have been shown to affect vocal fold vibration ( Dollinger et al. , 2014 ; Bhattacharya and Siegmund, 2015 ; Tse et al. , 2015 ), and thus need to be better quantified. While in vivo animal or human larynx models ( Moore and Berke, 1988 ; Chhetri et al. , 2012 ; Berke et al. , 2013 ) could provide such information, more reliable measurement methods are required to better quantify the viscoelastic properties of the vocal fold, vocal fold tension, and the geometry and movement of the inner vocal fold layers. While macro-mechanical properties are of interest, development of vocal fold constitutive laws based on ECM distribution and interstitial fluids within the vocal folds would allow us to better understand how vocal fold mechanical properties change with prolonged vocal use, vocal fold injury, and wound healing, which otherwise is difficult to quantify.
While oversimplification of the vocal folds to mass and tension is of limited practical use, the other extreme is not appealing, either. With improved characterization and understanding of vocal fold properties, establishing a cause-effect relationship between voice physiology and production thus requires identifying which of these physiologic features are actually perceptually relevant and under what conditions, through systematic parametric investigations. Such investigations will also facilitate the development of reduced-order computational models of phonation in which perceptually relevant physiologic features are sufficiently represented and features of minimum perceptual relevance are simplified. We discussed earlier that many of the complex supraglottal flow phenomena have questionable perceptual relevance. Similar relevance questions can be asked with regard to the geometry and mechanical properties of the vocal folds. For example, while the vocal folds exhibit complex viscoelastic properties, what are the main material properties that are definitely required in order to reasonably predict vocal fold vibration and voice quality? Does each of the vocal fold layers, in particular, the different layers of the lamina propria, have a functional role in determining the voice output or preventing vocal injury? Current vocal fold models often use a simplified vocal fold geometry. Could some geometric features of a realistic vocal fold that are not included in current models have an important role in affecting voice efficiency and voice quality? Because voice communication spans a large range of voice conditions (e.g., pitch, loudness, and voice quality), the perceptual relevance and adequacy of specific features (i.e., do changes in specific features lead to perceivable changes in voice?) should be investigated across a large number of voice conditions rather than a few selected conditions. While physiologic models of phonation allow better reproduction of realistic vocal fold conditions, computational models are more suitable for such systematic parametric investigations. Unfortunately, due to the high computational cost, current studies using continuum models are often limited to a few conditions. Thus, the establishment of cause-effect relationship and the development of reduced-order models are likely to be iterative processes, in which the models are gradually refined to include more physiologic details to be considered in the cause-effect relationship.
A causal theory of voice production would allow us to map out regions in the physiological parameter space that produce distinct vocal fold vibration patterns and voice qualities of interest (e.g., normal, breathy, rough voices for clinical applications; different vocal registers for singing training), similar to that described by Isshiki (1989 ; also Fig. Fig.9). 9 ). Although the voice production system is quite complex, control of voice should be both stable and simple, which is required for voice to be a robust and easily controlled means of communication. Understanding voice production in the framework of nonlinear dynamics and eigenmode interactions and relating it to voice quality may facilitate toward this goal. Toward practical clinical applications, such a voice map would help us understand what physiologic alteration caused a given voice change (the inverse problem), and what can be done to restore the voice to normal. Development of efficient and reliable tools addressing the inverse problem has important applications in the clinical diagnosis of voice disorders. Some methods already exist that solve the inverse problem in lumped-element models (e.g., Dollinger et al. , 2002 ; Hadwin et al. , 2016 ), and these can be extended to physiologically more realistic continuum models.
Solving the inverse problem would also provide an indirect approach toward understanding the physiologic states that lead to percepts of different emotional states or communication of other personal traits, which are otherwise difficult to measure directly in live human beings. When extended to continuous speech production, this approach may also provide insights into the dynamic physiologic control of voice in running speech (e.g., time contours of the respiratory and laryngeal adjustments). Such information would facilitate the development of computer programs capable of natural-sounding, conversational speech synthesis, in which the time contours of control parameters may change with context, speaking style, or emotional state of the speaker.
ACKNOWLEDGMENTS
This study was supported by research Grant Nos. R01 DC011299 and R01 DC009229 from the National Institute on Deafness and Other Communication Disorders, the National Institutes of Health. The author would like to thank Dr. Liang Wu for assistance in preparing the MRI images in Fig. Fig.1, 1 , Dr. Jennifer Long for providing the image in Fig. 1(b) , Dr. Gerald Berke for providing the stroboscopic recording from which Fig. Fig.3 3 was generated, and Dr. Jody Kreiman, Dr. Bruce Gerratt, Dr. Ronald Scherer, and an anonymous reviewer for the helpful comments on an earlier version of this paper.
Acoustic Effects of Speaker Sex, Speech Sample, and Mandarin Tone on Vowel Production of Poststroke Spastic Dysarthria
- Article contents
- Figures & tables
- Supplementary Data
- Peer Review
- Get Permissions
- Cite Icon Cite
- Search Site
Shengnan Ge , Qin Wan , Yongli Wang , Zhaoming Huang; Acoustic Effects of Speaker Sex, Speech Sample, and Mandarin Tone on Vowel Production of Poststroke Spastic Dysarthria. Folia Phoniatr Logop 2024; https://doi.org/10.1159/000538554
Download citation file:
- Ris (Zotero)
- Reference Manager
Introduction: Vowel production in dysarthria tends to be centralized, which is affected by many factors. This study examined the acoustic effects of speaker sex, tones, and speech samples (including sustained vowels, syllables, and sentences) and their interactions on vowel production in Mandarin speakers with poststroke spastic dysarthria. Methods: Twenty-eight patients with poststroke spastic dysarthria (18 males, 10 females) and 21 healthy speakers (11 males, 10 females) with no significant difference in sex and age with dysarthria were recruited. They were asked to read sustained vowels /a, i, u/, 12 syllables, and 12 sentences containing three vowels in four tones (bā, bá, bǎ, bà, bī, bí, bǐ, bì, pū, pú, pǔ, pù). Multiple spectral and temporal acoustic metrics were analyzed. Results: Results showed that regardless of the speech samples or tones, vowel production was more centralized in dysarthria than healthy controls, manifested as the decrease in F1 range, F2 range, vowel space area (VSA), and vowel articulation index (VAI). A similar performance was observed for male speakers compared to females, and vowel duration in males was shorter than females. F1 range, F2 range, VSA, VAI, and vowel duration were significantly different across speech samples and tones, decreasing in the order of vowel-syllable-sentence and T3-T2-T1-T4, respectively. Interactions of group, speaker sex, speech sample, and tone were more sensitive in VAI and vowel duration. Conclusion: VAI and vowel duration were recommended as the prior metrics to the assessment of vowel production. Specific influencing factors (speaker sex, speech sample, and tone) of vowel production need to be considered by speech and language pathologists in the assessment and rehabilitation.
Plain Language Summary
Mandarin speakers with poststroke spastic dysarthria often have vowel production deficits that affect articulation and speech intelligibility. Vowel production is influenced by many factors. This study explored the acoustic effects of speaker sex, tones, and speech samples and their interactions on vowel production in Mandarin speakers with poststroke spastic dysarthria and confirmed the existence of these effects. We found that regardless of the speech samples or tones, there were the reduced range of articulatory movements, centralized vowel production, and prolonged vowel duration in dysarthria compared to healthy people. The most sensitive and useful analysis measures were the vowel articulation index and vowel duration. Specific influencing factors (speaker sex, speech sample, and tone) of vowel production need to be taken seriously by speech and language pathologists and considered in the assessment and rehabilitation.
Individual Login
Institutional login.
- Access via Shibboleth and OpenAthens
- Access via username and password
Digital Version
Email alerts, citing articles via, suggested reading.
- Online ISSN 1421-9972
- Print ISSN 1021-7762
INFORMATION
- Contact & Support
- Information & Downloads
- Rights & Permissions
- Terms & Conditions
- Catalogue & Pricing
- Policies & Information
- People & Organization
- Stay Up-to-Date
- Regional Offices
- Community Voice
SERVICES FOR
- Researchers
- Healthcare Professionals
- Patients & Supporters
- Health Sciences Industry
- Medical Societies
- Agents & Booksellers
Karger International
- S. Karger AG
- P.O Box, CH-4009 Basel (Switzerland)
- Allschwilerstrasse 10, CH-4055 Basel
- Tel: +41 61 306 11 11
- Fax: +41 61 306 12 34
- Contact: Front Office
- Experience Blog
- Privacy Policy
- Terms of Use
This Feature Is Available To Subscribers Only
Sign In or Create an Account
- Election 2024
- Entertainment
- Newsletters
- Photography
- Personal Finance
- AP Investigations
- AP Buyline Personal Finance
- AP Buyline Shopping
- Press Releases
- Israel-Hamas War
- Russia-Ukraine War
- Global elections
- Asia Pacific
- Latin America
- Middle East
- Election Results
- Delegate Tracker
- AP & Elections
- Auto Racing
- 2024 Paris Olympic Games
- Movie reviews
- Book reviews
- Personal finance
- Financial Markets
- Business Highlights
- Financial wellness
- Artificial Intelligence
- Social Media
Macron outlines his vision for Europe to become an assertive global power as war in Ukraine rages on
French President Emmanuel Macron delivers a speech on Europe in the amphitheater of the Sorbonne University, Thursday, April 25 in Paris. 2024. French President Emmanuel Macron will outline his vision for Europe as a more assertive global power at the backdrop of war in Ukraine, security, and economic challenges in a speech ahead of pivotal election for the European Parliament in June. (Christophe Petit Tesson, Pool via AP)
French President Emmanuel Macron arrives to deliver a speech on Europe in the amphitheater of the Sorbonne University, Thursday, April 25 in Paris. 2024. French President Emmanuel Macron will outline his vision for Europe as a more assertive global power at the backdrop of war in Ukraine, security, and economic challenges in a speech ahead of pivotal election for the European Parliament in June. (Christophe Petit Tesson, Pool via AP)
- Copy Link copied
PARIS (AP) — French President Emmanuel Macron warned Thursday that Europe could “die” if it fails to build its own robust defense as Russia’s war in Ukraine rages on, or if it fails to undertake major trade and economic reforms to compete with China and the U.S.
Macron urged Europeans to become more ambitious in a fast-changing world to face the challenges of war, fierce trade competition, energy scarcity, climate change and increasing authoritarianism.
In a nearly two-hour speech at Sorbonne University in Paris, Macron said that the continent is divided and “too slow and lacks ambition” at a time when the 27-member European Union needs to become a superpower, defend its own borders and speak with one voice if it wants to survive and thrive.
“Our Europe today is mortal,” Macron said. “It can die and that depends solely on our choices,” he added. He called on people to make those choices now because, “it’s today that Europe is between war and peace.”
Russia’s full-scale invasion of Ukraine, now in its third year, is an existential threat and Europe isn’t armed enough to defend itself when “confronted by a power like Russia that has no inhibitions, no limits,” Macron said.
‘Our ability to ensure our security is at stake,” Macron said. “Russia mustn’t be allowed to win.”
Europe now has the “good fortune” of having the Biden administration’s commitment to supporting Ukraine, Macron said. But, in a year of key elections around Europe, in the U.S. and elsewhere, support may fragment or disappear entirely, he added.
“Europe must become capable of defending its interests, with its allies by our side whenever they are willing, and alone if necessary,” Macron said.
Strong armies, a European rapid intervention program and force, tanks, a missile shield and other weapons, produced in Europe, will need the support of “a joint diplomatic force that will speak with one voice and build bridges with Africa and Latin America,” the French leader said.
“Only then will Europe show that it’s not a United States’ lap dog, and that it also knows how to talk to other regions of the world,” he said.
France has been a firm supporter of Ukraine in its fight against Russian aggression, and Macron has often clashed with other Western leaders as he has insisted that Europe must stand by the country at any cost. The French president alarmed European leaders by saying recently that sending Western troops into Ukraine to shore up its defenses shouldn’t be ruled out.
Referring to trade practices of China and the U.S., Macron said “the two world powers have decided not to respect the rules of global trade” by shoring up protections and subsides while Europe’s industry remains open and is stuck in overregulation.
“Let’s do the same, we are in competition,” Macron said.
“We must buy faster, we must produce more and we must buy more that is made in Europe. That is key,” Macron said.
Thursday’s speech came less than two months before a pivotal European Parliament election.
Macron, an avid advocate of a united and assertive Europe, also rallied support for his centrist Renaissance party before the June 6-9 vote as far-right parties lead the moderate coalitions in the polls. He called for safeguarding democratic values as the “authoritarian model” was becoming “more popular” across the continent.
The war in Ukraine and immigration are top priorities for European Union voters, according to polls. Far-right parties have gained support by criticizing Macron’s government policies on both issues. Macron acknowledged divisions on immigration policies, including on asylum and deportation rules for those who have arrived to Europe illegally.
He emphasized the need for an effective response and Europe-wide coordination for curbing illegal immigration, closer cooperation with immigrants’ countries of origin and a unified, relentless fight against human traffickers.
Macron criticized the idea of striking an agreement, as Britain as done, with countries in Africa and elsewhere to transfer immigrants there.
“This is a betrayal of our values that ultimately leads us to dependency on other counties,” Macron said.
The British government earlier this week approved a law allowing the deportation of some migrants who enter the country illegally to Rwanda.
Macron lost his majority in France’s most influential house of parliament, the National Assembly, after the 2022 election to the far-left coalition and the far-right National Rally party.
The social situation in France remains tense as Paris prepares to host the Olympic Games this summer, amid protests from teachers and police officers, and farmer demonstrations in recent weeks. The protests follow huge rallies last year against Macron’s ultimately successful proposal to increase the retirement age from 62 to 64.
Barbara Surk reported from Nice, France. Lorne Cook contributed to this report from Brussels.

'Europe could die': Macron urges stronger defences, economic reforms
- Medium Text
- Macron in landmark speech stresses need for strong defences
- Says Europe must support firms in AI, green energy
- Hopes to repeat success of 2017 Sorbonne speech
- Speech comes against troubled global backdrop
- Macron keen to energise his base ahead of EU election

ECONOMIC CHALLENGES
Sign up here.
Additional reporting by Dominique Vidalon, Benoit Van Overstraeten, Gabriel Stargardter, Writing by Michel Rose and Ingrid Melander, Editing by Gareth Jones and Angus MacSwan
Our Standards: The Thomson Reuters Trust Principles. New Tab , opens new tab
Russia's air defence systems destroyed 17 drones launched by Ukraine over its territory, Russia's defence ministry said on Sunday, with a regional official saying the attack targeted an oil storage facility in the Kaluga region.
A Russian drone attack heavily damaged a hotel in Ukraine's southern city of Mykolaiv, the governor of the broader Mykolaiv region said, with Russia's RIA news agency reporting the hotel housed English-speaking mercenaries fighting in Ukraine.

World Chevron

IMAGES
VIDEO
COMMENTS
Speech is produced by bringing air from the lungs to the larynx (respiration), where the vocal folds may be held open to allow the air to pass through or may vibrate to make a sound (phonation). The airflow from the lungs is then shaped by the articulators in the mouth and nose (articulation). The field of phonetics studies the sounds of human ...
Speech production is the process of uttering articulated sounds or words, i.e., how humans generate meaningful speech. It is a complex feedback process in which hearing, perception, and information processing in the nervous system and the brain are also involved. Speaking is in essence the by-product of a necessary bodily process, the expulsion ...
Speech production is a complex process that includes the articulation of sounds and words, relying on the intricate interplay of hearing, perception, and information processing by the brain and ...
Speech production is one of the most complex human activities. It involves coordinating numerous muscles and complex cognitive processes. The area of speech production is related to Articulatory Phonetics, Acoustic Phonetics and Speech Perception, which are all studying various elements of language and are part of a broader field of Linguistics.
Speech production is the process by which thoughts are translated into speech. This includes the selection of words, the organization of relevant grammatical forms, and then the articulation of the resulting sounds by the motor system using the vocal apparatus.Speech production can be spontaneous such as when a person creates the words of a conversation, reactive such as when they name a ...
By. Yves Boubenec. In the human brain, the perception and production of speech requires the tightly coordinated activity of neurons across diverse regions of the cerebral cortex. Writing in Nature ...
To systematically understand the mechanism of speech production, the source-filter theory divides such process into two stages (Chiba & Kajiyama, 1941; Fant, 1960) (see figure 1): (a) The air flow coming from the lungs induces tissue vibration of the vocal folds that generates the "source" sound.Turbulent noise sources are also created at constricted parts of the glottis or the vocal tract.
Figure 9.2 The Standard Model of Speech Production. The Standard Model of Word-form Encoding as described by Meyer (2000), illustrating five level of summation of conceptualization, lemma, morphemes, phonemes, and phonetic levels, using the example word "tiger". From top to bottom, the levels are:
Next, to study neuronal activities during the production of natural speech and to track their per word modulation, the participants performed a naturalistic speech production task that required ...
Speech is the faculty of producing articulated sounds, which, when blended together, form language. Human speech is served by a bellows-like respiratory activator, which furnishes the driving energy in the form of an airstream; a phonating sound generator in the larynx (low in the throat) to transform the energy; a sound-molding resonator in ...
Summary of Auditory Speech Comprehension In summary, auditory speech comprehension requires: (1) the continuous analysis of rapidly changing sound frequencies and their amplitudes, (2) recognition of phonetic cues and features, SPEECH PRODUCTION and (3) access to the semantic system. The lesion studies suggest that the early acoustic processing ...
The Handbook of Speech Production is the first reference work to provide an overview of this burgeoning area of study. Twenty-four chapters written by an international team of authors examine issues in speech planning, motor control, the physical aspects of speech production, and external factors that impact speech production. Contributions bring together behavioral, clinical, computational ...
2. Models and Theories of Speech Production. In summarizing his review of the models and theories of speech production, Levelt (1989, p. 452) notes that "There is no lack of theories, but there is a great need of convergence."This section first briefly reviews a number of the theoretical proposals that led to this conclusion, culminating with the influential task dynamic model of speech ...
9.1 Evidence for Speech Production. The evidence used by psycholinguistics in understanding speech production can be varied and interesting. These include speech errors, reaction time experiments, neuroimaging, computational modelling, and analysis of patients with language disorders. Until recently, the most prominent set of evidence for ...
The production of a speech sound may be divided into four separate but interrelated processes: the initiation of the air stream, normally in the lungs; its phonation in the larynx through the operation of the vocal folds; its direction by the velum into either the oral cavity or the nasal cavity (the oro-nasal process); and finally its ...
Abstract. Successful speech production requires a speaker to map from an encoded phonological representation of linguistic form to a more detailed representation of sound structure that may interface with the motor planning and implementation system. This chapter describes phonetic processing as this component of language production.
The evidence used by psycholinguistics in understanding speech production can be varied and interesting. These include speech errors, reaction time experiments, neuroimaging, computational modelling, and analysis of patients with language disorders. Until recently, the most prominent set of evidence for understanding how we speak came from.
Summary. Speech production is an important aspect of linguistic competence. An attempt to understand linguistic morphology without speech production would be incomplete. A central research question develops from this perspective: what is the role of morphology in speech production. Speech production researchers collect many different types of ...
Finally, they cited Menn's (1983) analysis of consonant harmony in her son's first words to make a point about the existence of "articulatory routines" for word production. In summary, children's speech patterns are more compatible with the hypothesis of whole-word production than with the hypothesis of phonemic, or segmental, production.
Summary. Speech perception is often described in reference to production. Classic accounts of speech perception favored features of production because instrumental means for describing speech sound did not yet exist. With the advent of the sound spectrograph, accounts moved to describe linguistic types as sounds, but the theoretical momentum of ...
Dell's spreading activation model (as seen in Figure 9.3) has features that are informed by the nature of speech errors that respect syllable position constraints. This is based on the observation that when segmental speech errors occur, they usually involve exchanges between onsets, peaks or codas but rarely between different syllable positions.
Summary: A new study utilizes advanced Neuropixels probes to unravel the complexities of how the human brain plans and produces speech.The team identified specific neurons in the prefrontal cortex involved in the language production process, including the separate neural pathways for speaking and listening.
Designed originally for speech synthesis purpose, these lumped-element models of voice production are generally fast in computational time and ideal for real-time speech synthesis. A drawback of the lumped-element models of phonation is that the model control parameters cannot be directly measured or easily related to the anatomical structure ...
Exploring speech production. The researchers have unveiled new insights into the organization of speech within the brain. They found that the delays before speech disruption, known as latencies ...
Abstract. Introduction: Vowel production in dysarthria tends to be centralized, which is affected by many factors. This study examined the acoustic effects of speaker sex, tones, and speech samples (including sustained vowels, syllables, and sentences) and their interactions on vowel production in Mandarin speakers with poststroke spastic dysarthria. Methods: Twenty-eight patients with ...
This extremely up-to-date book, Speech Production and Second Language Acquisition, is the first volume in the exciting new series, Cognitive Science and Second Language Acquisition. This new volume provides a thorough overview of the field and proposes a new integrative model of how L2 speech is produced. The study of speech production is its ...
French President Emmanuel Macron delivers a speech on Europe in the amphitheater of the Sorbonne University, Thursday, April 25 in Paris. 2024. French President Emmanuel Macron will outline his vision for Europe as a more assertive global power at the backdrop of war in Ukraine, security, and economic challenges in a speech ahead of pivotal ...
The speech won a positive response from Macron's main EU partner, German Chancellor Olaf Scholz, with whom he has often clashed on defence and trade issues. "France and Germany want Europe to be ...
'Send in the army' say Italian ham producers as prosciutto pigs face wild boar fever threat Italy mulls military intervention to combat swine fever threatening production of iconic meat
The Biden administration finalized on Monday the first-ever minimum staffing rule at nursing homes, Vice President Kamala Harris announced. The controversial mandate requires that all nursing ...