
The Wobble Hypothesis: Importance and Examples
The “wobble hypothesis” refers to a concept in molecular biology that explains the degeneracy of codons.
So, what are codons? Codons are sets of three nucleotides in mRNA (messenger RNA) that correspond to specific amino acids. 64 possible codons codes for the 20 standard amino acids used in protein synthesis.
Since there are only 20 amino acids and 64 possible codons, multiple codons may code for a single amino acid during protein synthesis. In molecular biology, this redundancy or multiplicity of codons is termed degeneracy.
The wobble hypothesis or wobble theory, proposed by Francis Crick in 1966, suggests that the third base of a codon can sometimes be flexible or “wobble.” The wobbling or flexibility allows for non-standard base pairing between the mRNA codon and the tRNA (t RNA) anticodon during translation.
The first two nucleotides of the codon typically adhere to strict base-pairing rules. Still, the third position may tolerate mismatches, allowing for variations such as G-U (guanine-uracil) pairing or other non-standard interactions.
This hypothesis helps explain how a relatively limited number of tRNA molecules can recognize and bind to multiple codons for the same amino acid, facilitating efficient and accurate protein synthesis. Experimental evidence has supported the wobble hypothesis, a fundamental concept in understanding the genetic code and translation machinery.\

Table of Contents
Crick’s wobble hypothesis states that the base at the 5′ end of the anticodon does not confine spatially as the other two bases, which allows the development of hydrogen bonds with other bases present at the 3′ end of a codon. The wobble hypothesis outlines several key points:
- Degeneracy of the Genetic Code: The genetic code degenerates, meaning multiple codons can code for the same amino acid. For example, six codons, UUA, UUG, CUU, CUC, CUA, and CUG, code the amino acid leucine.
- Flexibility in Codon-Anticodon Interactions: The wobble hypothesis suggests that the base pairing between the mRNA codon’s third nucleotide and the tRNA anticodon’s corresponding nucleotide is flexible. Instead, it allows for some flexibility or “wobble” in the pairing.
- Non-Standard Base Pairing: The third position of the codon-anticodon interaction can tolerate non-standard base pairs, such as G-U (guanine-uracil) pairing or other non-Watson-Crick interactions. For example, a tRNA with the anticodon 3′-CCU-5′ can recognize the codons CGU, CGC, and CGA, where the third position allows for wobble pairing.
Importance of Wobble Hypothesis
The wobble hypothesis is essential in molecular biology for several reasons:
- Efficient Translation : The wobble hypothesis explains how fewer tRNA molecules can recognize multiple codons coding for the same amino acid. This reduces the number of tRNA species required for protein synthesis, streamlining the translation process and making it more efficient.
- Error Reduction : By allowing for flexibility in base pairing at the third position of the codon-anticodon interaction, the wobble hypothesis helps reduce the impact of errors or mutations in the genetic code. Even if a mutation occurs in the third position of a codon, it may not necessarily result in a change in the protein’s amino acid sequence, thereby minimizing errors in protein synthesis.
- Evolutionary Conservation : The wobble hypothesis is evolutionarily conserved across species, indicating its fundamental importance in translation. This conservation suggests that the wobble base pairing mechanism provides an evolutionary advantage by allowing for greater adaptability and efficiency in protein synthesis.
- Understanding Genetic Code Variability : The wobble hypothesis helps us understand the variability in the genetic code, where multiple codons can code for the same amino acid. This variability provides flexibility and redundancy in the genetic code. This allows for robustness and adaptability in the face of genetic mutations and environmental changes.
- Biotechnological Applications : Understanding the wobble hypothesis is crucial in biotechnology and genetic engineering applications. For example, it informs the design of synthetic genes and optimization of codon usage to enhance protein expression in heterologous expression systems.
Overall, the wobble hypothesis plays a fundamental role in understanding protein synthesis and the genetic code, with implications for various aspects of molecular biology, genetics, and biotechnology.
Examples of Wobble Hypothesis
Here are some examples of the wobble hypothesis in action:
- Arginine: The amino acid arginine is coded by six different codons: CGU, CGC, CGA, CGG, AGA, and AGG. However, no six different tRNA molecules correspond to each of these codons. Instead, one tRNA molecule with the anticodon 3′-CCU-5′ can recognize the codons CGU, CGC, and CGA (where the third nucleotide is flexible), thanks to wobble base pairing.
- Leucine: Leucine is another example of wobble base pairing. The codons UUA, UUG, CUU, CUC, CUA, and CUG are all codes for leucine. However, the tRNA molecule with the anticodon 3′-AAG-5′ can recognize UUA and UUG codons due to wobble base pairing at the third position.
- Serine: Serine is encoded by six codons: UCU, UCC, UCA, UCG, AGU, and AGC. Due to wobble base pairing, the tRNA molecule with the anticodon 3′-AGU-5′ can recognize both AGU and AGC codons.
- Isoleucine: The codons AUU, AUC, and AUA all code for isoleucine. The tRNA molecule with the anticodon 3′-IAU-5′ (where “I” represents inosine, a modified nucleotide capable of wobble base pairing) can recognize all three codons through wobble interactions.
These examples illustrate how the wobble hypothesis allows for flexibility in the genetic code, enabling fewer tRNA molecules to recognize multiple codons and facilitating efficient protein synthesis.
Limitation of Wobble Hypothesis
While the wobble hypothesis provides a valuable framework for understanding how the genetic code is flexible and the efficiency of translation, it also has some limitations and considerations:
- Context-dependence : The wobble hypothesis primarily applies to the standard codon-anticodon interactions during translation. However, non-standard base pairing beyond the wobble hypothesis may occur in certain contexts or under specific conditions. For example, modified nucleotides in tRNA or mRNA can influence base pairing interactions in ways that go beyond traditional wobble pairing rules.
- Accuracy and Specificity : While wobble base pairing can contribute to the recognition of multiple codons by a single tRNA molecule, it may also lead to potential errors during translation. The flexibility in the third position of the codon-anticodon interaction could allow non-standard base pairs to form. This can potentially lead to misinterpretation of the genetic code and errors in protein synthesis.
- Influence of Structural Constraints : The wobble hypothesis primarily focuses on the base pairing interactions between codons and anticodons. However, other factors such as tRNA structure, modifications, and interactions with the ribosome also influence the accuracy and efficiency of translation. These factors may impose additional constraints or considerations beyond the wobble hypothesis.
- Evolutionary Variability : While the wobble hypothesis explains a general trend in codon-anticodon recognition, there can be variations in wobble base pairing preferences across species or even within different tissues or cellular conditions. Evolutionary pressures, genetic variations, and differences in tRNA modifications can influence the extent and specificity of wobble interactions.
- Complexity of Codon Usage : The relationship between codon usage bias, tRNA abundance, and wobble interactions is complex and can vary between organisms and genes. While wobble base pairing contributes to codon redundancy and efficient translation, other factors such as codon optimality, mRNA secondary structure, and ribosome kinetics influence translation efficiency and protein expression levels.
- Crick F. H. (1966). Codon–anticodon pairing: the wobble hypothesis. Journal of molecular biology , 19 (2), 548–555. https://doi.org/10.1016/s0022-2836(66)80022-0
- Mangang, S. U., & Lyngdoh, R. H. (2001). Wobble base-pairing in codon-anticodon interactions: a theoretical modelling study. Indian journal of biochemistry & biophysics , 38 (1-2), 115–119.
- Verma, P. S., & Agarwal, V. K. (2019). Cell Biology, genetics, Molecular Biology, evolution and ecology (25th ed.). S. Chand and Company Limited.
Ashma Shrestha
Hello, I am Ashma Shrestha. I had recently completed my Masters degree in Medical Microbiology. Passionate about writing and blogging. Key interest in virology and molecular biology.
We love to get your feedback. Share your queries or comments Cancel reply
This site uses Akismet to reduce spam. Learn how your comment data is processed .
Recent Posts
DNA Polymerase: Structure, Types, and Functions
An enzyme, DNA polymerase, catalyzes the synthesis of new DNA molecules from deoxyribonucleotides (the building blocks of DNA). It is crucial in living organisms' DNA replication, repair, and...
Topoisomerase: Structure, Types, and Functions
Topoisomerases are a class of enzymes that play a crucial role in DNA metabolism. Their primary function is to regulate the topological state of DNA by introducing temporary breaks in the DNA...

- Collections
Wobble Hypothesis

Wobble Base Pair
- A wobble base pair is type of non-canonical base pairing that occurs between two nucleotides in RNA molecules, the codon and the anticodon of mRNA and tRNA, respectively that does not follow Watson-Crick base pair rules.
- The four main wobble base pairs are guanine-uracil ( G-U ), hypoxanthine-uracil ( I-U ), hypoxanthine-adenine ( I-A ), and hypoxanthine-cytosine ( I-C )
- Wobble base pairs are fundamental in RNA secondary structure and are critical for the proper translation of the genetic code
- The term “wobble” refers to the flexibility or deviation from the standard Watson-Crick base pairing rules at the third position of the codon, which allows a single tRNA to recognize more than one codon for the same amino acid.
- This phenomenon explains the degeneracy of the genetic code and reduces the number of tRNA molecules required for protein synthesis.
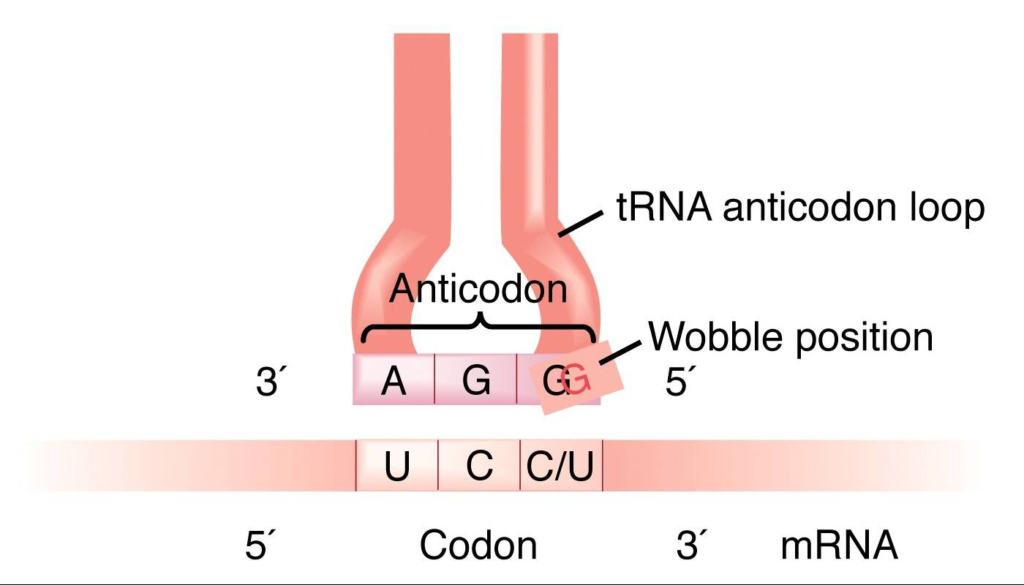
The Wobble Hypothesis
Genetic Code Study Notes:
- There are 64 possible codons in the genetic code, each consisting of a 3-nucleotide sequence. Translation requires tRNA molecules, each with an anticodon that complements a specific mRNA codon. Canonical Watson-Crick base pairing is used for stable tRNA-mRNA binding during translation.
- In the standard genetic code, 3 mRNA codons (UAA, UAG, UGA) act as stop codons, terminating translation. This leaves 61 mRNA codons that require tRNA molecules, suggesting a need for 61 types of tRNA.
- Due to the limited number of tRNA species in organisms (usually fewer than 45), some tRNA types can pair with multiple synonymous codons.
- Francis Crick proposed the Wobble Hypothesis in 1966, suggesting that the 5′ base on the anticodon has non-standard base pairing due to spatial flexibility. The “wobble” at the third codon position allows for small conformational adjustments, influencing the overall pairing geometry of tRNA anticodons.
- Crick suggested that the first two bases of the codon form strong and specific Watson-Crick base pairs with the second and third bases of the anticodon, while the third base of the codon can form weaker and less specific base pairs with the first base of the anticodon.
- The first two bases of each codon are primary determinants of specificity. The third base pairing is not very stable and wobbles. For example, CUU, CUG, CUC, CUA codons, which differ only at the third base represent the same amino acid leucine. The first two bases of the codon form strong base pairs with the corresponding bases of the anticodon but the third base forms weak hydrogen bond.
- This allows some tRNA molecules to bind to more than one codon, as long as they differ only at the third position. For example, a tRNA with the anticodon 5′-GmAA-3′ can recognize both UUC and UUU codons for phenylalanine.
The Wobble Rules
Crick also proposed a set of rules that govern the possible wobble base pairs, based on the geometry and hydrogen bonding patterns of the nucleotides involved. The rules are as follows:
- G can pair with U or C (in addition to the canonical C)
- U can pair with A or G (in addition to the canonical A)
- I (inosine, a deaminated form of A) can pair with A, U, or C
- A can pair only with U (the canonical pair)
- C can pair only with G (the canonical pair)
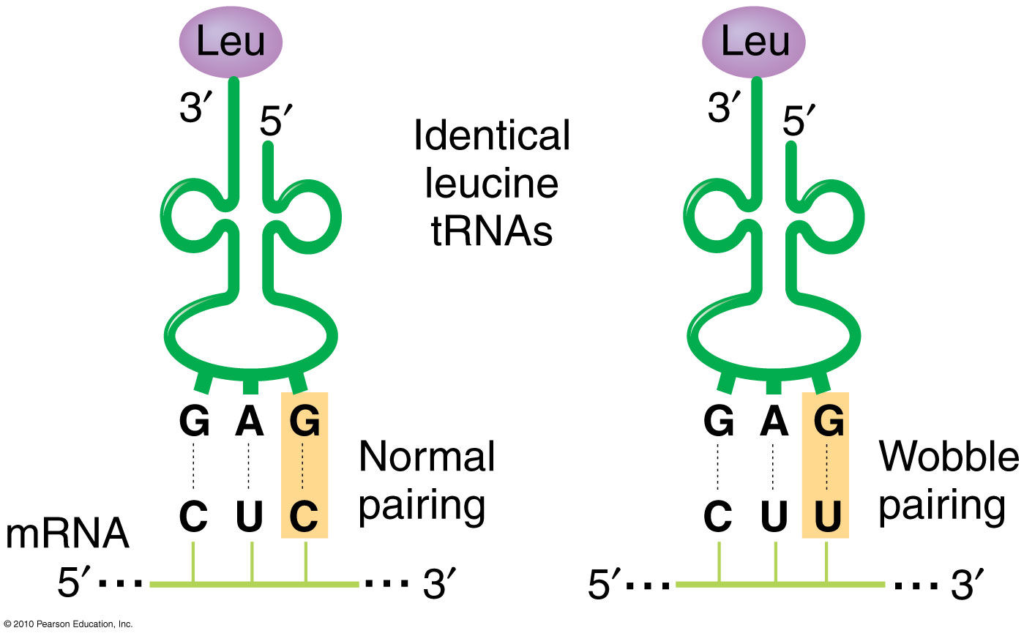
These rules imply that some codons for the same amino acid are more versatile than others in terms of wobble pairing. For instance, codons ending with A or C can be recognized by only one specific tRNA, while codons ending with U or G can be recognized by one or two tRNAs, depending on whether the first base of the anticodon is U, G, or I.
The Significance of Wobble Base Pairing
Wobble base pairing has several advantages for the cell:
- It reduces the number of tRNA genes and tRNA molecules needed to translate all 61 sense codons, which saves genetic space and energy.
- It allows for some mutations or errors at the third position of the codon without affecting the protein sequence, which increases the genetic robustness and diversity.
- It enables some tRNA molecules to act as suppressors of nonsense mutations by recognizing stop codons and inserting amino acids instead, which may rescue some defective proteins.
Wobble base pairing is a common feature of RNA secondary structure and is essential for the accurate and efficient translation of the genetic code.
Sign Up For Daily Newsletter
Be keep up get the latest articles delivered straight to your inbox..
I have read and agree to the terms & conditions
Leave a review Cancel reply
Your email address will not be published. Required fields are marked *
Your comment *
Your name *
Your Email *
Biotechtutorials
Share knowledge..
- Quick Links
Username or Email Address
Remember Me
- Register / Log in
Wobble hypothesis tRNA wobble, Wobble position
A property of the genetic code in which codons that differ in the third position (wobble position) can specify the same tRNA/amino acid.
- Subscriber Services
- For Authors
- Publications
- Archaeology
- Art & Architecture
- Bilingual dictionaries
- Classical studies
- Encyclopedias
- English Dictionaries and Thesauri
- Language reference
- Linguistics
- Media studies
- Medicine and health
- Names studies
- Performing arts
- Science and technology
- Social sciences
- Society and culture
- Overview Pages
- Subject Reference
- English Dictionaries
- Bilingual Dictionaries
Recently viewed (0)
- Save Search
- Share This Facebook LinkedIn Twitter
Related Content
Related overviews.
transfer RNA
genetic code
translation
See all related overviews in Oxford Reference »
More Like This
Show all results sharing these subjects:
- Life Sciences
wobble hypothesis
Quick reference.
A theory to explain the partial degeneracy of the genetic code due to the fact that some t-RNA molecules can recognize more than one codon. The theory proposes that the first two bases in the codon and anticodon will form complementary pairs in the normal antiparallel fashion. However, a degree of steric freedom or ‘wobble’ is allowed in the base-pairing at the third position. Thus, for serine, six m-RNA codons may be paired with only three t-RNA anticodons.
From: wobble hypothesis in A Dictionary of Zoology »
Subjects: Science and technology — Life Sciences
Related content in Oxford Reference
Reference entries.
View all reference entries »
View all related items in Oxford Reference »
Search for: 'wobble hypothesis' in Oxford Reference »
- Oxford University Press
PRINTED FROM OXFORD REFERENCE (www.oxfordreference.com). (c) Copyright Oxford University Press, 2023. All Rights Reserved. Under the terms of the licence agreement, an individual user may print out a PDF of a single entry from a reference work in OR for personal use (for details see Privacy Policy and Legal Notice ).
date: 02 April 2024
- Cookie Policy
- Privacy Policy
- Legal Notice
- Accessibility
- [66.249.64.20|185.80.149.115]
- 185.80.149.115
Character limit 500 /500

Microbiology Notes
Genetic Code – Definition, Characteristics, Wobble Hypothesis
Table of Contents
What is a Genetic Code?
The genetic code is a set of rules that living cells use to decipher the information encoded in genetic material (DNA or mRNA sequences). The ribosomes are responsible for carrying out the translation process. Using tRNA (transfer RNA) molecules to carry amino acids and to read the mRNA three nucleotides at a time, they link the amino acids in an mRNA-specified (messenger RNA) order.
- As DNA is a genetic substance, it transmits genetic information from one cell to the next and from one generation to the next.
- At this point, it will be attempted to determine how genetic information is stored within the DNA molecule. On the DNA molecule, are they written in an articulated or encoded language? In the language of codes, what is the genetic code’s nature?
- A DNA molecule contains three types of moieties: phosphoric acid, deoxyribose sugar, and nitrogen bases.
- The genetic information may be encoded in any of the three DNA molecules. However, because the poly-sugarphosphate backbone is always the same, it is doubtful that these DNA molecules convey genetic information.
- However, the nitrogen bases vary from one DNA segment to the next, therefore the information may depend on their sequences.
- In fact, the sequences of nitrogen bases in a specific section of DNA are similar to the linear sequence of amino acids in a protein molecule.
- An investigation of mutations of the head protein of bacteriophage T4 and the A protein of tryptophan synthetase from Escherichia coli provided the initial evidence for the colinearity between DNA nitrogen base sequence and amino acid sequence in protein molecules.
- Colinearity between protein molecules and DNA polynucleotides provides evidence that the arrangement of four nitrogen bases (e.g., A, T, C, and G) in DNA polynucleotide chains dictates the sequence of amino acids in protein molecules.
- These four DNA bases can therefore be viewed as the four alphabets of the DNA molecule. Therefore, all genetic information should be encoded using these four DNA alphabets.
- The question that now emerges is whether genetic information is written in articulated or coded language. If genetic information could have been communicated in an articulated language, the DNA molecule would have required multiple alphabets, a complicated grammar system, and adequate space.
- All of these could be practically difficult and also problematic for the DNA. Therefore, it was reasonable for molecular biologists to assume that genetic information resided in the DNA molecule as a specific language of code words that utilised the four nitrogen bases of DNA as their symbols. Any encoded message is referred to as a cryptogram.

Basis of Cryptoanalysis
- How information written in a four-letter language (four nucleotides or nitrogen bases of DNA) may be transformed into a twenty-letter language is the fundamental challenge of such a genetic code (twenty amino acids of proteins).
- A code word or codon is the set of nucleotides that specifies one amino acid. By genetic code, one refers to the collection of sequences of bases (codons) that correspond to each amino acid and translation signals.
- Regarding the possible size of a codon, we can consider George Gamov’s (1954) traditional yet rational explanation.
- The simplest conceivable code is a singlet code (a code of a single letter) that specifies a single nucleotide amino acid.
- A doublet code (consisting of two letters) is similarly insufficient, as it can only define sixteen (4×4) amino acids, but a triplet code (consisting of three letters) can specify sixty-four (4x4x4) amino acids.
- Therefore, it is probable that 64 triplet codes exist for 20 amino acids. The conceivable singlet, doublet, and triplet codes, which are conventionally described in terms of “mRNA language” [mRNA is a complementary molecule that copies the genetic information (cryptogram of DNA) during its transcription] are depicted in Table.
- In 1961, Crick and his colleagues present the first experimental evidence supporting the hypothesis of triplet coding.
- During their experiment, when they inserted or deleted single or double base pairs in a specific region of the DNA of E.coli T4 bacteriophages, they discovered that these bacteriophages ceased to execute their regular tasks.
- Nevertheless, bacteriophages with the addition or deletion of three base pairs in the DNA molecule had normal functionality.
- In this experiment, the addition of one or two nucleotides caused the message to be read incorrectly, however the addition of a third nucleotide resulted in the message being read correctly again.

Codon Assignment (Cracking the Code or Deciphering the Code)
The genetic code has been broken or deciphered using the following methods:
A. Theoretical Approach
- George Gamow, a physicist, proposed the diamond code (1954) and the triangle code (1955), as well as a comprehensive theoretical framework for the various aspects of the genetic code.
- A triplet codon that corresponds to a single polypeptide chain amino acid.
- Direct template translation by linking codons with amino acids.
- The code is translated in an overlapping fashion.
- Degeneration of the code, or the coding of an amino acid by more than one codon.
- The colinearity of nucleic acid and the produced main protein.
- Universality of the code, i.e., the code being fundamentally identical throughout organisms.
- Molecular biologists have refuted a number of these statements by Gamow. Brenner (1957) demonstrated that the overlapping triplet code is impossible, and further research has demonstrated that the code is non-overlapping.
- Crick’s adopter hypothesis similarly contested Gamow’s assumption of a direct template relationship between nucleic acid and polypeptide chain.
- Adaptor molecules, according to this concept, intervene between nucleic acid and amino acids during translation.
- In actuality, it is now understood that tRNA molecules serve as adaptors between the codons of mRNA and the amino acids of the resultant polypeptide chain.
B. The in vitro codon Assignment
1. discovery and use of polynucleotide phosphorylase enzyme.
Marianne Grunberg Manago and Severo Ochoa identified an enzyme from bacteria (e.g., Azobacter vinelandii or Micrococcus lysodeikticus) that catalyses RNA degradation in bacterial cells. The name of this enzyme is polynucleotide phosphorylase. Outside of the cell (in vitro), with high amounts of ribonucleotides, Manago and Ochoa discovered that the reaction could be driven in reverse and an RNA molecule could be produced (see Burns and Bottino, 1989). The random incorporation of nucleotides into the molecule is independent of a DNA template. Thus, in 1955, Manago and Ochoa made possible the artificial synthesis of polynucleotides (=mRNA) comprising only a single type of nucleotides (U, A, C, or G, respectively, repeated several times).

Consequently, the action of polynucleotide phosphorylase can be depicted as follows:

The polynucleotide phosphorylase enzyme differs from RNA polymerase used to transcribe mRNA and DNA polymerase used to transcribe mRNA from DNA in the following ways: I it does not require a template or primer; (ii) the activated substrates are ribonucleoside diphosphates (e.g., UDP, ADP, CDP, and GDP) and not triphosphates; and (iii (PPi). The introduction of synthetic (or artificial) polynucleotides and trinucleotides made the deciphering of the genetic code possible.
Use of polymers containing a single type of nucleotide (called homopolymers), mixed polymers (copolymers) containing multiple types of nucleotides (heteropolymers) in random or defined sequences, and trinucleotides (or “minimessengers”) in ribosome-binding or filter-binding are among the various techniques employed.
2. Codon assignment with unknown sequence
(i) codon assignment by homopolymer..
- Marshall Nirenberg and Heinrich Matthaei (1961) supplied the first indication to codon assignment when they utilised an in vitro technique for the creation of a polypeptide utilising an artificially produced mRNA molecule containing only one type of nucleotide (i.e., homopolymer).
- Before doing the actual tests, they evaluated the capacity of a cell-free protein synthesis system to integrate radioactive amino acids into newly produced proteins.
- Their E.coli cell-free extracts comprised ribosomes, tRNAs, aminoacyl-tRNA synthetase enzymes, DNA, and messenger RNA.
- This extract’s DNA was eliminated by the deoxyribonuclease enzyme, so destroying the template for the synthesis of new mRNA.
- When twenty amino acids together with ATP, GTP, K+, and MG2+ were introduced to this mixture, they were integrated into proteins.
- As long as mRNA was present in the cell-free suspension, incorporation persisted. It also continued in the presence of synthetic polynucleotides (mRNAs) that might be synthesised using the polynucleotide phosphorylase enzyme.
- Nirenberg and Matthaei made the first successful application of this approach when they created a chain of uracil molecules (poly U) as their synthetic mRNA (homopolymer).
- A message consisting of a single base could not contain ambiguity, hence Poly (U) looked to be the best option. It binds well to ribosomes and, as it turned out, the resultant protein was insoluble and simple to isolate.
- When poly (U) was supplied as the message to the cell-free system containing all the amino acids, polyphenylalanine was picked solely from the mixture for incorporation into the polypeptide.
- This amino acid was phenylalanine, hence it was deduced that a sequence of UUU encoded for phenylalanine. Other homogeneous nucleotide chains (Poly A, Poly C, and Poly G) were inert for incorporation of phenylalanine. The phenlalanine mRNA code was consequently determined to be UUU.
- AAA is derived to be the equivalent DNA code word for phenylalanine. Thus, UUU was the first code word to be decrypted. In the laboratories of Nirenberg and Ochoa, this finding was developed.
- Using synthetic poly (A) and poly (C) chains, the experiment was repeated, yielding polylysine and polyproline, respectively.
- Thus, AAA was determined to be the code for lysine and CCC was determined to be the code for proline. A poly (G) message was discovered to be nonfunctional in vitro due to its secondary structure, which prevented it from attaching to ribosomes. Thus, three of the sixty-four codons were simply explained.
(ii) Codon assignment by heteropolymers (Copolymers with random sequences)
- Using synthetic messenger RNAs containing two different types of nucleotides, the genetic code was elucidated further.
- This approach was utilised in the laboratories of Ochoa and Nirenberg to deduce the codon composition for the 20 amino acids.
- The bases in the synthetic messengers were chosen at random (called random copolymers). In a random copolymer composed of U and A nucleotides, for instance, eight triplets are feasible, including UUU, UUA, UAA, UAU, AAA, AAU, AUU, and AUA.
- Theoretically, these eight codons may code for eight amino acids. However, actual experiments produced only six amino acids: phenylalanine, leucine, tyrosine, lysine, asparagine, and isoleucine.
- It was feasible to derive the composition of the code for different amino acids by altering the relative proportions of U and A in the random copolymer and determining the fraction of the different amino acids in the proteins generated.
3. Assignment of codons with known sequences.
- I The application of trinucleotides or minimessengers in filter binding (Ribosome-binding technique). Nirenberg and Leder’s (1964) ribosome binding technique takes use of the observation that aminoacyl-tRNA molecules attach selectively to the ribosomemRNA complex.
- The connection of a trinucleotide or minimessenger with the ribosome is necessary for aminoacyltRNA binding to occur.
- When a mixture of such small mRNA molecules-ribosomes and amino acid-tRNA complexes is incubated for a brief period and then filtered over a nitrocellulose membrane, the mRNA-ribosome-tRNA-amino acid complex is kept and the remainder of the mixture is discarded.
- Using a series of 20 different amino acid mixtures, each containing one radioactive amino acid, it is possible to determine the amino acid corresponding to each triplet by analysing the radioactivity absorbed by the membrane; for instance, the triplet GCC and GUU retain only alanyl-tRNA and valyl-tRNA, respectively.
- In this manner, all 64 potential triplets have been synthesised and evaluated. 45 of them have produced conclusive results. Later on, with the use of lengthier synthetic messages, 61 of the 64 potential codons have been deciphered.

C. The in vivo Codon Assignment
- Despite the fact that cell-free protein synthesis systems have played a significant role in the decipherment of the genetic code, they cannot tell us whether the deciphered genetic code is likewise utilised in the living systems of all organisms.
- Different molecular biologists use three techniques to determine if the same code is used in vivo: (a) amino acid replacement studies (e.g., tryptophan synthetase synthesis in E.coli and haemoglobin synthesis in man), (b) frameshift mutations (e.g., Terzaghi et al. 1966, on lysozyme enzyme of T4 bacteriophages), and (c) comparison of a DNA (e.g., comparison of amino acid sequence of the R17 bacteriophage coat protein with the nucleotide sequence of the R17 mRNA in the region of the molecule that dictates coat-protein synthesis by S. Cory et al., 1970).
- Thus, the previously mentioned in vitro and in vivo experiments allowed for the formulation of a code table for twenty amino acids.
Characteristics of Genetic Code
The genetic code has the following general properties :
1. The code is a triplet codon
- The nucleotides of messenger RNA (mRNA) are organised as a linear sequence of codons, with each codon consisting of three consecutive nitrogenous bases, i.e., the code is a triplet codon.
- Two types of point mutations, frameshift mutations and base substitution, provide support for the concept of triplet codon.
(i) Frameshift mutations
- Evidently, the genetic communication, once launched at a particular place, is decoded into a series of three-letter phrases within a specific time frame.
- As soon as one or more bases are removed or added, the structure would be disrupted. When such frameshift mutations were intercrossed, they produced wild-type normal genes in certain combinations.
- It was determined that one was a deletion and the other was an insertion, so that the disordered frame order caused by the mutation will be corrected by the other.
(ii) Base substitution
- If, at a specific location in an mRNA molecule, one base pair is replaced by another without deletion or insertion, the meaning of a codon containing the altered base will be altered.
- As a result, another amino acid will be inserted in place of a particular amino acid at a particular location in a polypeptide.
- Due to a substitution mutation in the gene for the tryptophan synthetase enzyme in E. coli, the glycine-coding GGA codon becomes the arginine-coding AGA.
- A missense codon is a codon that has been altered to specify a different amino acid. The discovery that a fragment of mRNA comprising 90 nucleotides corresponded to a polypeptide chain having 30 amino acids of a developing haemoglobin molecule provided more direct proof for the existence of a triplet code.
- Similarly, 1200 nucleotides of the “satellite” tobacco necrosis virus direct the creation of 372 amino acid-containing coat protein molecules.
2. The code is non-overlapping
- In the translation of mRNA molecules, codons are “read” sequentially and do not overlap.
- Therefore, a non-overlapping coding indicates that a nucleotide in an mRNA is not utilised for multiple codons.
- In practise, however, six bases code for no more than two amino acids. In the event of an overlapping code, for instance, a single change (of replacement type) in the base sequence will result in several amino acid substitutions in the associated protein.
- In insulin, tryptophan synthetase, TMV coat protein, alkaline phosphatase, haemoglobin, etc., a single base substitution leads in a single amino acid change. Since 1956, a large number of examples have accumulated in which a single base substitution results in a single amino acid change.
- Recently, however, it has been demonstrated that overlapping genes and codons are possible in bacteriophage φ × 174.
3. The code is commaless
- The genetic code is punctuation-free, thus no codons are reserved for punctuation.
- It means that when one amino acid is coded, the next three characters will automatically code the second amino acid and no letters will be wasted as punctuation marks.
4. The code is non-ambiguous
- A codon always codes for the same amino acid when it is non-ambiguous.
- In the situation of ambiguous code, the same codon may have many meanings; in other words, the same codon may code for two or more amino acids. As a general rule, a single codon should never code for two distinct amino acids.
- There are, however, documented exceptions to this rule: the codons AUG and GUG may both code for methionine as beginning or starting codons, despite the fact that GUG is intended for valine. Similarly, the GGA codon represents the amino acids glycine and glutamic acid.
5. The code has polarity
The direction in which the code is always read is 5’→3′. Thus, the codon possesses a polarity. Clearly, if the code is read in opposing directions, it would specify two distinct proteins, as the codon’s base sequence would be reversed:

6. The code is degenerate
- Multiple codons might define the same amino acid; this phenomenon is known as degeneracy of the code. Except for tryptophan and methionine, which each contain a single codon, the remaining 18 amino acids have several codons.
- Consequently, each of the nine amino acids phenylalanine, tyrosine, histidine, glutamine, asparagine, lysine, aspartic acid, glutamic acid, and cysteine has two codons. Isoleucine consists of three codons.
- Each of the five amino acids valine, proline, threonine, alanine, and glycine has four codons. Each of the three amino acids leucine, arginine, and serine has six codons.
- There are essentially two types of code degeneration: partial and total. Partial degeneracy occurs when the first two nucleotides of degenerate codons are identical, but the third (3′ base) nucleotide differs, e.g., CUU and CUC code for leucine.
- Complete degeneracy happens when any of the four bases can code for the same amino acid in the third position (e.g., UCU,UCC, UCA and UCG code for serine).
- Degeneration of genetic coding has several biological benefits. It enables, for instance, bacteria with vastly different DNA base compositions to specify virtually the same complement of enzymes and other proteins.
- Degeneration also provides a technique for decreasing the lethality of mutations.
7. Some codes act as start codons
- In the majority of organisms, the AUG codon is the start or initiation codon, meaning that the polypeptide chain begins with methionine (eukaryotes) or N-formylmethionine (prokaryotes) (prokaryotes).
- Methionyl or N-formylmethionyl-tRNA binds particularly to the start site of mRNA with an AUG initiation codon.
- In rare instances, GUG functions as an initiating codon, such as in bacterial protein production. GUG normally codes for valine; however, when the regular AUG codon is deleted, only GUG is used as an initiation codon.
8. Some codes act as stop codons
- Triple codons UAG, UAA, and UGA are the stop or termination codons for the chain. They do not code for any of the amino acids.
- These codons are not read by any tRNA molecules (via their anticodons), but are read by some specialised proteins, called release factors (e.g., RF-1, RF-2, RF-3 in prokaryotes and RF in eukaryotes) (e.g., RF-1, RF-2, RF-3 in prokaryotes and RF in eukaryotes).
- These codons are also called nonsense codons, since they do not designate any amino acid. The UAG was the first termination codon to be found by Sidney Brenner (1965). (1965).
- It was named amber in honour of a doctoral student named Bernstein (= the German term for ‘amber,’ and amber signifies brownish yellow) who helped identify a class of mutations.
- Apparently, the other two termination codons were also named after colours, such as ochre for UAA and opal or umber for UGA, in order to maintain consistency. (ochre indicates pale yellow or golden red, opal means milky white, and umber signifies brown)
- The presence of multiple stop codons may be a precautionary mechanism in case the first stop codon fails to work.
9. The code is universal
- The same genetic code is valid for all creatures, from bacteria to humans. Marshall, Caskey, and Nirenberg (1967) showed the universality of the code by showing that E.coli (bacterial), Xenopus laevis (amphibian), and guinea pig (mammal) amino acyl-tRNA utilise nearly the same code.
- Nirenberg has also suggested that the genetic code may have originated with the first bacteria three billion years ago, and that it has altered very little over the history of living species.
- Recently, inconsistencies between the universal genetic code and the mitochondrial genetic code have been revealed.

Codon and Anticodon
- The codon words of DNA are complementary to the mRNA code words (i.e., DNA codes run in the 3’→5′ direction whereas mRNA code words run in the 5’→3′ direction), as are the three bases composing the anticodon of tRNA (i.e., anticodon bases run in the 3’→5′ direction).
- Three bases of the anticodon pair with the mRNA on the ribosomes during the alignment of amino acids during protein synthesis (i.e., the translation of mRNA into proteins in the N2→COOH direction).
- For instance, one of the two mRNA and DNA code words for the amino acid phenylalanine is UUC, while the equivalent anticodon of tRNA is CAA.
- This suggests that the pairing of codons and anticodons is antiparallel. C pairs with G and U pairs with A in this instance.
Wobble Hypothesis
- Crick (1966) presented the wobble hypothesis to explain the potential origin of codon degeneracy (wobble means to sway or move unsteadily).
- Given that there are 61 codons that specify amino acids, the cell must possess 61 tRNA molecules, each with a unique anticodon.
- The actual number of tRNA molecule types discovered is far fewer than 61. This suggests that tRNA anticodons read many codons on mRNA.
- For instance, yeast tRNAala with anticodon bases 5′ IGC 3′ (where I stands for inosine, a derivative of adenine or A) may bind to three codons in mRNA, including 5′ GCU 3′, 5’GCC3′, and 5′ GCA3′.
- Inosine is usually found as the 5′ base of the anticodon; when pairing with the base of the codons, it wobbles and can pair with U, C, or A of three different codons.
- Therefore, according to Crick’s wobble hypothesis, the base at the 5′ end of the anticodon is not as spatially constrained as the other two bases, allowing it to establish hydrogen bonds with any of the bases positioned at the 3′ end of a codon.

Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.

Adblocker detected! Please consider reading this notice.
We've detected that you are using AdBlock Plus or some other adblocking software which is preventing the page from fully loading.
We don't have any banner, Flash, animation, obnoxious sound, or popup ad. We do not implement these annoying types of ads!
We need money to operate the site, and almost all of it comes from our online advertising.
Please add Microbiologynote.com to your ad blocking whitelist or disable your adblocking software.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
11.5: Key Words and Terms
- Last updated
- Save as PDF
- Page ID 16482

- Gerald Bergtrom
- University of Wisconsin-Milwaukee
Wobble Pair
- Living reference work entry
- Latest version View entry history
- First Online: 25 December 2022
- Cite this living reference work entry

- Henderson James Cleaves 11 , 12 , 13
23 Accesses
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Author information
Authors and affiliations.
Earth-Life Science Institute (ELSI), Tokyo Institute of Technology, Tokyo, Japan
Henderson James Cleaves
Blue Marble Space Institute of Science, Washington, DC, USA
Center for Chemical Evolution, Georgia Institute of Technology, Atlanta, GA, USA
You can also search for this author in PubMed Google Scholar
Editor information
Editors and affiliations.
Laboratoire d'Astrophysique de Bordeaux, University of Bordeaux, Pessac CX, France
Muriel Gargaud
Department of Astronomy, University of Massachusetts, Amherst, MA, USA
William M. Irvine
Centro Biología Molecular Severo Ochoa, Univ. Autónoma de Madrid Cantoblanco, Madrid, Spain
Ricardo Amils
Analytical-, Environm., Geo-Chemistry, Vrije Universiteit Brussel, VUB, Brussels, Belgium
Philippe Claeys
Earth-Life Science Institute, Tokyo Institute of Technology, WASHINGTON, DC, USA
Radio Astronomy, Paris Observatory, Paris, France
Maryvonne Gerin
Observatoire de Paris-Meudon, Meudon, France
Daniel Rouan
International Space Science Institute, Bern, Bern, Switzerland
Tilman Spohn
Centre Francois Viète, Universite de Nantes, Nantes, France
Stéphane Tirard
Innovaxiom, Paris CX, France
Michel Viso
Rights and permissions
Reprints and permissions
Copyright information
© 2022 Springer-Verlag GmbH Germany, part of Springer Nature
About this entry
Cite this entry.
Cleaves, H.J. (2022). Wobble Pair. In: Gargaud, M., et al. Encyclopedia of Astrobiology. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-27833-4_5248-2
Download citation
DOI : https://doi.org/10.1007/978-3-642-27833-4_5248-2
Received : 02 September 2021
Accepted : 23 September 2021
Published : 25 December 2022
Publisher Name : Springer, Berlin, Heidelberg
Print ISBN : 978-3-642-27833-4
Online ISBN : 978-3-642-27833-4
eBook Packages : Springer Reference Physics and Astronomy Reference Module Physical and Materials Science Reference Module Chemistry, Materials and Physics
- Publish with us
Policies and ethics
Chapter history
DOI: https://doi.org/10.1007/978-3-642-27833-4_5248-2
DOI: https://doi.org/10.1007/978-3-642-27833-4_5248-1
- Find a journal
- Track your research

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- v.13(12); Dec 2007
The wobble hypothesis revisited: Uridine-5-oxyacetic acid is critical for reading of G-ending codons
S. joakim näsvall.
Department of Molecular Biology, Umeå University, S-901 87 Umeå, Sweden
Glenn R. Björk
According to Crick's wobble hypothesis, tRNAs with uridine at the wobble position (position 34) recognize A- and G-, but not U- or C-ending codons. However, U in the wobble position is almost always modified, and Salmonella enterica tRNAs containing the modified nucleoside uridine-5-oxyacetic acid (cmo 5 U34) at this position are predicted to recognize U- (but not C-) ending codons, in addition to A- and G-ending codons. We have constructed a set of S. enterica mutants with only the cmo 5 U-containing tRNA left to read all four codons in the proline, alanine, valine, and threonine family codon boxes. From the phenotypes of these mutants, we deduce that the proline, alanine, and valine tRNAs containing cmo 5 U read all four codons including the C-ending codons, while the corresponding threonine tRNA does not. A cmoB mutation, leading to cmo 5 U deficiency in tRNA, was introduced. Monitoring A-site selection rates in vivo revealed that the presence of cmo 5 U34 stimulated the reading of CCU and CCC (Pro), GCU (Ala), and GUC (Val) codons. Unexpectedly, cmo 5 U is critical for efficient decoding of G-ending Pro, Ala, and Val codons. Apparently, whereas G34 pairs with U in mRNA, the reverse pairing (U34-G) requires a modification of U34.
INTRODUCTION
The genetic message is read by tRNAs that decode one triplet at a time. Of the 64 codons, 61 are sense codons and represent an amino acid in the final protein. Triplets with the same first two nucleosides constitute a codon box, and if all four codons represent one amino acid, such a box is called a family codon box. In all organisms there are eight family codon boxes ( Fig. 1 , shaded), and in Salmonella enterica serovar Typhimurium, six of them are decoded by tRNAs of which one has uridine-5-oxyacetic acid (cmo 5 U34) or its methylester (mcmo 5 U34) in position 34 (the wobble position) ( Fig. 2 ). These six family codon boxes are specific for leucine, valine, serine, proline, threonine, and alanine ( Fig. 1 , light shade). To read the four codons in such a family codon box, there are, besides the cmo 5 U34-containing tRNA, one (valine and alanine) or two (leucine, serine, threonine, and proline) additional isoacceptor tRNAs. One of these isoacceptors has G as the wobble nucleoside, and in four boxes (leucine, proline, threonine, and serine) the third isoacceptor has C as the wobble nucleoside ( Fig. 1 ). According to the wobble hypothesis ( Crick 1966 ), G34 base-pairs with C and U as the third nucleoside of the codon [denoted C(III) and U(III)], whereas C34 only base-pairs with G(III). Uridine as the wobble nucleoside cannot interact with a pyrimidine in the mRNA, since two pyrimidines are too “short” to form a base pair. Therefore, it was thought that the G34-containing tRNAs are essential for decoding the U- and C-ending codons. However, U as the wobble nucleoside is almost always modified, and the cmo 5 -modification and the related modification 5-methoxyuridine, mo 5 U, present in tRNA of Bacillus subtilis , is predicted to extend the wobble capacity to read not only A(III) and G(III), as predicted by the wobble hypothesis, but also U(III), but not C(III) ( Yokoyama et al. 1985 ). Thus, the G34-containing tRNAs seems to be required to decode the C-ending codons in these family codon boxes. Most in vitro experiments with Escherichia coli tRNAs or anticodon stem–loops (ASLs) support the theoretical considerations that a U reads A(III) and G(III) and that cmo 5 U enhances the wobble to include U(III), but not C(III) ( Oda et al. 1969 ; Ishikura et al. 1971 ; Mitra et al. 1979 ; Samuelsson et al. 1980 ; Takai et al. 1999 ; Phelps et al. 2004 ; Sørensen et al. 2005 ).

The genetic code. The eight codon boxes with shaded background are the family codon boxes, containing four codons encoding one amino acid (fourfold degenerate). The six lighter-shaded boxes contain tRNAs having cmo 5 U as wobble nucleoside. The boxes with white background are the mixed codon boxes. A circle corresponds to a codon read by a tRNA, and a line connecting two or more circles indicates that the same tRNA is able to read those codons. Filled circles indicate codon reading as predicted by the wobble hypothesis ( Crick 1966 ) or the revised wobble rules ( Yokoyama et al. 1985 ). Open circles indicate that those tRNAs are able to read also the C-ending codons (results presented in this study and in Näsvall et al. 2004 ). Next to the symbol for each tRNA is indicated which wobble nucleoside it contains. The letters within parentheses below the wobble nucleoside in the family boxes for proline, threonine, alanine, and valine indicate the last letter in the name of the genes encoding the corresponding tRNAs (e.g., tRNA Val cmo5UAC is encoded by the four genes val T , val U , val X , and val Y , and tRNA Pro GGG is encoded by the gene pro L ).

The proposed biosynthetic pathway for the synthesis of cmo 5 U and mcmo 5 U. (Gray arrows) Indicate the link between chorismic acid (or an unknown derivative of it) and different steps in the synthesis of cmo 5 U according to Näsvall et al. (2004) . (U) Uridine; (ho 5 U) 5-hydroxyuridine; (mo 5 U) 5-methoxyuridine; (cmo 5 U) uridine-5-oxyacetic acid; (mcmo 5 U) uridine-5-oxyacetic acid methyl ester. (Adapted from Näsvall et al. 2004 and reprinted with permission from the RNA Society ©2004.)
In contrast to the above-mentioned results obtained in vitro, there is evidence from in vivo experiments that cmo 5 U34-containing tRNAs base-pair also with C(III). A strain that lacks the G34-containing tRNA Pro GGG (the subscript indicates the sequence of the anticodon in the 5′→3′ direction) and the C34-containing tRNA Pro CGG and thus only has the cmo 5 U34-containing tRNA Pro cmo5UGG is viable, demonstrating that tRNA Pro cmo5UGG with cmo 5 U34 as the wobble nucleoside can read all four proline codons ( Näsvall et al. 2004 ). Based on a synergistic growth defect in mutants that lack tRNA Pro GGG and are hypo-modified in the wobble position of tRNA Pro cmo5UGG , the presence of cmo 5 U34 was suggested to promote an efficient reading of C- and U-ending proline codons ( Näsvall et al. 2004 ). Similarly, a strain having only tRNA Ala cmo5UGC with cmo 5 U34 as the wobble nucleoside is also viable ( Gabriel et al. 1996 ). It was recently shown that the binding of tRNA Ala cmo5UGC to GCC codons is only slightly weaker than binding to GCA, and that the kinetics of A-site binding at GCC is within the range for cognate interactions ( Kothe and Rodnina 2007 ). Thus, at least tRNA Pro cmo5UGG and tRNA Ala cmo5UGC are able to read codons ending with C(III), contrary to the theory and to most results obtained in vitro. However, the impact of cmo 5 U34 on decoding by tRNA Ala cmo5UGC was not addressed by Gabriel et al. (1996) or Kothe and Rodnina (2007) , since their analysis was performed with fully modified tRNA Ala cmo5UGC ( Gabriel et al. 1996 ; Kothe and Rodnina 2007 ). Here, we extend these studies to elucidate whether the cmo 5 U34-containing tRNAs specific for valine and threonine are also able to read the four codons in the corresponding family boxes and if the presence of cmo 5 U34 is required for such a reading in the family codon boxes specific for valine, alanine, and threonine.
To study the function of cmo 5 U34 in vivo, we need a way to manipulate the presence of cmo 5 U34 in tRNA. We have recently identified two genes ( cmoA and B ) whose products are required for the synthesis of cmo 5 U34 ( Näsvall et al. 2004 ). Deletion of the cmoB gene results in a complete absence of cmo 5 U34 in tRNA, and all of the cmo 5 U found in the wild type is present as the biosynthetic intermediate 5-hydroxyuridine (ho 5 U) ( Fig. 2 ; Näsvall et al. 2004 ). Therefore, we have changed the allelic state of the cmoB gene in our attempt to demonstrate the coding capacities of cmo 5 U versus ho 5 U in tRNAs specific for proline, alanine, and valine. Surprisingly, considering the wobble hypothesis and other predictions ( Crick 1966 ; Yokoyama et al. 1985 ), our results show that cmo 5 U is required for efficient decoding of G-ending codons by tRNA Ala cmo5UGC , tRNA Val cmo5UAC , and tRNA Pro cmo5UGG . Thus, whereas G as the wobble nucleoside can base-pair with U in mRNA, apparently the reverse pairing [U34-G(III)] requires a modification of uridine.
tRNA Thr cmo5UGU containing cmo 5 U34 cannot read all four threonine codons
S. enterica has three threonine isoacceptors (tRNA Thr cmo5UGU , tRNA Thr GGU , and tRNA Thr CGU ) (see Fig. 1 ). The G34-containing tRNA Thr GGU is encoded by the genes thrT and thrV and the C34-containing tRNA Thr CGU is encoded by the gene thrW ( Fig. 3A ). Strains lacking the genes encoding tRNA Thr GGU and tRNA Thr CGU were constructed by inserting a kanamycin resistance cassette flanked by FLP recombinase target sequences (FRTs) ( Datsenko and Wanner 2000 ) into the thrT , thrV , or thrW genes. The three resulting single mutants lacking either the C34-containing tRNA Thr CGU or one of the two genes encoding the G34-containing tRNA Thr GGU were all viable, with no apparent growth phenotype on solid rich medium at 37°C (data not shown).

Locations of tRNA genes in the S. enterica genome. ( A ) Threonine tRNAs. ( Upper line) The thrW gene, encoding tRNA Thr CGU . ( Middle line) The rrnD rRNA operon containing one of the two genes encoding tRNA Thr GGU . ( Lower line) The tufB operon, containing the gene encoding tRNA Thr cmo5UGC as well as the second gene encoding tRNA Thr GGU . ( B ) Valine tRNA genes. ( Upper and middle lines) The two tRNA operons containing the four genes encoding tRNA Val cmo5UAC . ( Lower line) The dicistronic valV , valW operon containing the two genes encoding tRNA Val GAC . ( C ) Alanine tRNAs. ( Upper line) The three rRNA operons rrnH , rrnA , and rrnB , containing the genes encoding tRNA Ala cmo5UGC , have the same basic organization except an additional tRNA gene ( aspU ) at the end of rrnH . ( Lower line) The alaW , alaX tRNA operon encoding tRNA Ala GGC . ( D ) Proline isoacceptors. ( Upper line) The monocistronic proL gene, encoding tRNA Pro GGG . ( Middle line) The proK gene, encoding tRNA Pro CGG . ( Lower line) The operon containing the gene encoding tRNA Pro cmo5UGG as well as three other tRNA genes. (Black arrows) tRNA genes encoding threonine, valine, alanine, or proline tRNAs; (dark gray arrows) other tRNA genes; (light gray arrows) other genes. The anticodons of the relevant tRNAs are written below the genes. The drawings are not to scale. The asterisk (*) after gltT (which encodes tRNA Glu mnm5s2UUC ) in A , middle line, indicates that the gene (STM3397) is not named in Salmonella . gltT is the name of an identical gene in the E. coli rrnB operon, which in Salmonella instead contains the genes ileU and alaU (asterisks in C ).
To test if tRNA Thr cmo5UGU is able to read all four threonine codons, we attempted to generate a mutant having tRNA Thr cmo5UGU as the only remaining threonine isoacceptor by deleting the two genes encoding the G34-containing tRNA Thr GGU ( thrT and V ) and the C34-containing tRNA Thr CGU (thrW ). Whereas construction of mutants with one remaining gene encoding the G34-containing tRNA Thr GGU was possible, combining mutations in both genes encoding this tRNA failed ( Table 1 ). These results suggest that a double mutant ( thrT thrV ) having only the cmo 5 U34- and C34-containing threonine isoacceptors is not viable and consequently indicates that tRNA Thr GGU is essential. Still, a few transductants appeared in the attempts to make the thrT thrV double mutant. Since it is known that in a growing culture of Salmonella , different loci can be transiently duplicated, the rare Km R transductants may have both the wild-type allele and the mutated allele of thrT or thrV . Indeed, all of the 37 tested transductants possessed both the wild-type and the thrT <> kan alleles. Moreover, purification of 10 different Km R transductants on nonselective plates revealed segregation of Km R and Km S clones as expected if the original transductant contains a duplication of the wild-type and the thrT <> kan alleles. We conclude that the G34-containing tRNA Thr GGU is essential, most likely because the cmo 5 U34-containing tRNA Thr cmo5UGU cannot recognize C-ending threonine codons.
The cmo 5 U-containing tRNA Thr cmo5UGU is unable to decode all four threonine codons

The cmo 5 U-containing tRNA Val cmo5UAC by itself can only support growth at an extremely reduced rate
The two genes valV and valW , encoding two slightly different tRNA Val GAC s, are present as a tandem repeat in a dicistronic operon with no other genes ( Fig. 3B ). A mutant (Δ valVW ) lacking tRNA Val GAC , and thus having only the cmo 5 U-containing tRNA Val cmo5UAC to read the four valine codons ( Fig. 1 ), was viable but showed a 70% reduction in growth rate ( Table 2 ). These results indicate that, similarly to tRNA Pro cmo5UGG ( Näsvall et al. 2004 ), tRNA Val cmo5UAC is also able to read all four valine codons, albeit with low efficiency.
tRNA Val cmo5UAC by itself supports growth at an extremely reduced rate

As earlier reported, cmoB mutants have ho 5 U34 instead of cmo 5 U34 in their tRNA ( Näsvall et al. 2004 ). To test the impact of such hypo-modification on the decoding capacity of tRNA Val cmo5UAC , we disrupted the cmoB gene in a strain lacking the G34-containing tRNA Val GAC . This strain is viable but showed a decrease in growth rate compared to the parent strain ( Table 2 ), and it also accumulated faster-growing suppressor mutants (data not shown). In addition to the slow-growth phenotype, cultures sometimes formed visible aggregates, which were caused by part of the population of cells forming long filaments (data not shown). Clearly, the presence of the cmo 5 -modification improves the decoding efficiency of tRNA Val cmo5UAC .
To test if increased levels of tRNA Val cmo5UAC would help mutants lacking tRNA Val GAC and cmo 5 U, we compared the growth of strains harboring either plasmid p815 ( O'Connor 2002 ) (carrying the E. coli valU operon, containing three genes encoding tRNA Val cmo5UAC and one gene encoding tRNA Lys mnm5s2UUU ) or plasmid pLG339 (vector control). Overexpression of tRNA Val cmo5UAC partially suppressed the growth phenotypes of the strains having only this tRNA ( Fig. 4 ). Also, overexpression of the hypo-modified tRNA Val ho5UAC improved the growth of the Δ valVW cmoB2 mutant, demonstrating that tRNA Val cmo5UAC at normal concentration is, indeed, dependent on the cmo 5 -modification.

Overexpression of tRNA Val cmo5UAC restores growth of a Δ valVW mutant. ( A ) Growth after 25 h of incubation at 37°C. (Sectors 1 – 4 ) Strains carrying pLG339 (vector control); (sectors 5 – 8 ) strains carrying p815 ( valU valX valY lysV ). The chromosomal genotypes are ( 1 , 8 ) LT2 (wt); ( 2 , 7 ) cmoB2<>cat ; ( 3 , 6 ) ΔvalVW ; ( 4 , 5 ) ΔvalVW cmoB2<>cat . ( B ) Sectors 3 and 4 of the same plate as in A , but after 44 h at 37°C. No suppressor mutants were apparent in this particular experiment. The relative colony sizes after 15 h of growth were (LT2/pLG339 and cmoB2 /pLG339) 1.0 ± 0.03; (LT2/p815) 1.0 ± 0.07; ( cmoB2 /p815) 1.0 ± 0.03; (Δ valVW /p815) 0.68 ± 0.04. Colonies of Δ valVW cmoB2 /p815 were visible but still too small to measure, and no colonies were visible of Δ valVW /pLG339 or Δ valVW cmoB2 /pLG339. After 25 h, colonies of ΔvalVW cmoB2 /p815 were ∼30% smaller than Δ valVW /p815, and after 44 h, ( B ) colonies of Δ valVW cmoB2 /pLG339 were approximately half the size compared to Δ valVW /pLG339.
In order to further study the efficiency of tRNA Val cmo5UAC in reading the four valine codons and the effect of having ho 5 U in place of cmo 5 U, we used the system described by Curran and Yarus (1989) to measure the in vivo A-site selection rates ( Fig. 5 ). The mutant lacking both tRNA Val GAC and cmo 5 U (Δ valVW cmoB2 <> frt ) was not included because of difficulties in keeping the culture suppressor free, but also because of the filamentous growth phenotype, which would produce unreliable OD values. As expected, the rate of A-site selection is severely reduced at all four codons in the strain lacking the G34-containing tRNA Val GAC ( Fig. 5 ). Most severely affected was the rate at the GUC codon. This is not surprising considering the fact that this strain lacks the tRNA (tRNA Val GAC ) that is the major tRNA recognizing GUC codons. The data show the relative efficiency of fully modified tRNA Val cmo5UAC at recognizing the different codons; it recognized GUA, GUU, and GUG with equal efficiency, while, as expected, it was quite poor at recognizing the GUC codon. Whereas the cmoB2 mutation did not influence the rate of valyl-tRNA Val selection to the GUU- and GUA-programmed ribosomal A-site ( Fig. 5 ), significant decreases in the rates at GUC and, unexpectedly, also at GUG codons were observed.

A-site selection rates at valine (GUN) codons. (*) Values in the cmoB2 mutant are significantly different from the control (LT2), as determined by a student's t -test (two sample, equal variance, p < 0.05). All values for the Δ valVW mutant are significantly different from LT2 ( p < 0.005). The values are averages of four experiments, with at least two independent cultures of each strain.
tRNA Ala cmo5UGC requires cmo 5 U34 for efficient wobble reading of GCG
The two identical genes alaX and alaW (sometimes referred to as alaW α and alaW β ) ( Fig. 3C ) encoding tRNA Ala GGC , are arranged as a tandem repeat in a single operon containing no other genes. A strain lacking tRNA Ala GGC (Δ alaXW ) is viable, as is also the case in E. coli ( Gabriel et al. 1996 ), but has a clear reduction in growth rate compared to the wild-type strain (LT2) ( Table 3 ), a phenotype that is further enhanced at higher temperature, seen as a decreased colony size on plates at 44°C (data not shown). These results indicate that, similarly to tRNA Pro cmo5UGG ( Näsvall et al. 2004 ), tRNA Ala cmo5UGC is able to read all four alanine codons, although not efficiently enough to support a maximum growth rate.
tRNA Ala cmo5UGC alone can support growth only at a reduced rate

When cmoB <> kan was transduced into a strain (Δ alaXW ) lacking tRNA Ala GGC , tiny colonies (barely visible without magnification) started to appear after 2 d of incubation at 37°C. A few larger colonies (∼0.2% of totally 409 transductants in one transduction) were also apparent, indicating the presence of suppressor mutants in some colonies. The “tiny” colonies were purified on selective medium and found to be viable but to accumulate suppressor mutations that partially restored growth ( Fig. 6 ). When we transduced a wild-type strain (LT2) with the same amount of the same phage lysate, we received about the same number of transductants as when strain GT7365 (Δ alaXW ) was used as recipient, but the obtained transductants showed a normal growth phenotype. These results show that a mutant lacking tRNA Ala GGC is viable even when it is hypo-modified at the wobble position in the only remaining alanine tRNA, but it has an extremely reduced growth rate, and mutations that partially restore growth are relatively frequent. If the growth phenotype would be caused by poor reading of one or more of the alanine codons, expression of more of the hypo-modified tRNA Ala cmo5UGC would allow the mutant to grow faster. To test this, we introduced the cmoB2 <> kan allele into strains harboring plasmid p70 ( Vila-Sanjurjo et al. 1999 ), carrying E. coli genes encoding tRNA Ala cmo5UGC and four other tRNAs (tRNA Asp QUC , tRNA Trp CCA , tRNA Ile GAU , and tRNA Thr GGU ) expressed from the tac promoter. The growth phenotypes (seen as relative colony sizes on plates) of these strains were compared to the corresponding plasmid-free strains ( Fig. 6 ). The relatively mild growth defect of the Δ alaXW strain, which has only the cmo 5 U34-containing alanine tRNA, seems to be fully suppressed, and the Δ alaXW cmoB2 <> kan mutant is partially suppressed by overexpression of tRNA Ala cmo5UGC . Thus tRNA Ala cmo5UGC , when expressed at normal levels, is very dependent on the presence of the modification for its ability to read some of the four codons, but less so if it is overexpressed. We also measured the A-site selection rate at the four alanine codons. The Δ alaXW cmoB2 mutant was considered too slow growing and unstable to be included in such an analysis. The cmoB2 mutant shows a large reduction in the rate of reading the GCG codon ( Fig. 7 ). The Δ alaXW mutant has a reduction in the rate of alanyl-tRNA entry on all four codons, and the most severe reduction is on the GCC codon. Taken together, these results show that fully modified tRNA Ala cmo5UGC reads GCA, GCG, and GCU efficiently and GCC poorly and that cmo 5 U improves reading of the G-ending codon.

Overexpression of hypo-modified tRNA Ala cmo5UGC from plasmid p70 can partially restore growth of a Δ alaXW cmoB2 mutant. ( A ) Growth of (sector 1 ) LT2/p70 (wild-type); (sector 2 ) cmoB2<>kan /p70; (sector 3 ) Δ alaXW /p70; and (sector 4 ) Δ alaXW cmoB2<>kan /p70 after 27 h at 37°C on an LA + tetracycline plate. The relative colony diameters (after 16 h) were (LT2/p70) 1.0 ± 0.05; ( cmoB2 /p70) 0.96 ± 0.04; and (Δ alaXW /p70) 0.92 ± 0.07. The colonies of Δ alaXW cmoB2 /p70 were visible but too small to measure. ( B ) Same as in A , but the strains do not contain any plasmid, and the plate is LA without any antibiotic. The relative colony diameters (after 16 h) were (LT2) 1.0 ± 0.07; ( cmoB2 ) 1.0 ± 0.01; and (Δ alaXW ) 0.71 ± 0.04. At the time of the size measurements, no single colonies of the Δ alaXW cmoB2 mutant had appeared, but after 27 h, very tiny colonies (<0.1 mm in diameter) as well as some faster-growing colonies (still too small to be clearly visible in the picture) could be seen. ( C ) Sector 4 of the plate in B , but after 75 h. The absolute majority of the colonies of the Δ alaXW cmoB2 mutant were still <0.4 mm in diameter, while a few larger colonies ranging in sizes between ∼0.5 and 2 mm were visible.

A-site selection rates at alanine (GCN) codons. The asterisks (*) indicate values from the cmoB2 mutant that are different from the control (LT2), as determined by a student's t -test [two sample, equal variance; (*) p < 0.05, (***) p < 0.0005]. All values from the Δ alaXW mutant are significantly different from LT2 ( p < 0.0005). The values are averages from four experiments.
cmo 5 U34 in tRNA Pro cmo5UGG mainly enhances wobble reading of G
A mutant having only the cmo 5 U-contatining tRNA Pro cmo5UGG is viable without any apparent phenotype, demonstrating that this tRNA reads efficiently all four proline codons. If this tRNA in such a mutant contains ho 5 U instead of cmo 5 U34, a clear reduction in growth rate caused by the hypo-modification is observed ( Näsvall et al. 2004 ). Furthermore, a mutant lacking the G34-containing tRNA Pro GGG and thus having the cmo 5 U34- and C34-containing tRNAs has a significant growth rate reduction in conjunction with hypo-modification of the wobble nucleoside in tRNA Pro cmo5UGG ( Näsvall et al. 2004 ). Based on these data and the theoretical prediction that cmo 5 U34 reads U-ending codons (but not C-ending codons) ( Yokoyama et al. 1985 ), we suggested that the reason for the observed phenotypes of the various mutants being deficient in tRNA Pro and cmo 5 U was the slower reading of mainly the U- and C- ending proline codons ( Näsvall et al. 2004 ). To verify this suggestion, we measured the A-site selection rates on each of the four proline codons. Lack of tRNA Pro CGG and tRNA Pro GGG leads to a large reduction in the rate of reading all four proline codons ( Fig. 8 , cf. LT2 and Δ proKL ). This is not surprising, since the two missing tRNAs together make up about two-thirds of the total proline tRNA pool ( Dong et al. 1996 ) and should normally read most of the CCC, CCU, and CCG codons. Similarly to the alanine tRNA ( Fig. 7 ), the largest effect of hypo-modification of tRNA Pro cmo5UGG ( Fig. 8 , cf. LT2 and cmoB2 and Δ proKL and cmoB2 Δ proKL ) seems to be a reduced rate of reading CCG. We also measured the effect of not having cmo 5 U on the A-site selection rates in mutants only lacking the C34-containing tRNA Pro CGG ( proK <> frt ). In two separate experiments, the rate of reading the CCG codon in the cmoB2 mutant was reduced by 42% and 39%, respectively (data not shown), further strengthening our observations that cmo 5 U34 is important for recognizing the G-ending proline codon.

A-site selection rates at proline (CCN) codons. The asterisks (*) indicate values from the cmoB2 mutant that are different from the control (LT2), as determined by a student's t -test [two sample, equal variance; (*) p < 0.05]. All values for the Δ proL proK <> frt and Δ proL proK <> frt cmoB2 <> frt mutants are significantly different from LT2 ( p < 0.01). The values are averages from at least three experiments. For simplicity, Δ proL proK <> frt is written Δ proKL .
In this study, we show that the function of the modified nucleoside cmo 5 U34 is different from what has previously been hypothesized and that the impact on hypo-modification of the wobble position is different in different cmo 5 U34-containing tRNAs. According to a theoretical model, cmo 5 U is predicted to allow reading of U-ending codons ( Yokoyama et al. 1985 ). This model was based on how the modification (cmo 5 or mo 5 ), by interacting with the 5′-phosphate, affects the equilibrium between two different conformations (C2′-endo and C3′-endo) of the ribose moiety of synthetic nucleotides in solution. 5-Hydroxy uridine would not be able to make this interaction and would thus have decoding properties similar to uridine, which should only read A- and G-ending codons according to the wobble hypothesis ( Crick 1966 ). The model did not explain why some cmo 5 U-containing tRNAs can read C-ending codons, and, in fact, it was predicted that a cmo 5 U-C pair would be impossible due to steric repulsion between ribose 34 and ribose 35 ( Yokoyama et al. 1985 ). Moreover, this model would predict that a tRNA having ho 5 U in place of cmo 5 U would have a dramatically reduced rate of reading U-ending (and probably also C-ending in the cases where it does happen) codons, while the rates of reading the A- and G-ending codons should not be too much affected. However, our results do not support such a hypothesis, since the largest effect of hypo-modification of three tested tRNAs is on the rate of reading G-ending codons, while the effects (if any) on C- and U-ending codons are minor. This leads us to question the validity of the above model and suggests an alternative molecular mechanism for the decoding by cmo 5 U.
Interestingly, the effects on the growth rates or viability when removing all other tRNA isoacceptors for the different amino acids are quite different. One extreme is the cmo 5 U-containing threonine tRNA, which cannot at all support growth of a mutant lacking the G34-containing threonine isoacceptor ( Table 1 ). This is similar to previously reported data for codon recognition by cmo 5 U-containing (or mo 5 U-containing) leucine ( Nishiyama and Tokuda 2005 ; Sørensen et al. 2005 ) and serine ( Takai et al. 1999 ) tRNAs. The cmo 5 U-containing valine and alanine tRNAs can support growth of mutants lacking the corresponding G34-containing isoacceptors ( Tables 2 , ,3), 3 ), although the growth rates of such mutants are reduced compared to a wild-type strain. At the other extreme is the cmo 5 U34-containing proline isoacceptor, which supports growth at a rate indistinguishable from a wild-type strain even when both the G34- and C34-containing proline isoacceptors are missing ( Näsvall et al. 2004 ). These dramatic differences between the different tRNAs could be the result of tRNAs having different relative efficiencies of recognizing one or more of their specific codons. Alternatively, the expression of the cmo 5 U34-containing tRNA Pro cmo5UGG could be high enough relative to the codon usage to allow efficient decoding even in the absence of the other proline tRNAs. However, among the cmo 5 U-containing alanine, valine, and proline tRNAs, the proline tRNA is the least abundant relative to the codon usage ( Table 4 ). Thus, codon usage and tRNA levels alone cannot explain the differences in phenotypes we observe.
Codon usage and tRNA availability

Comparing the relative rates of A-site selection for the different cmo 5 U34-containing proline, valine, and alanine tRNAs when they are the only isoacceptors present ( Fig. 5 , Δ valVW ; Fig. 7 , Δ alaXW ; Fig. 8 , Δ proKL ) the A-, G-, and U-ending codons were recognized at similar rates, while the rates of recognizing the C-ending alanine and valine codons are much lower (about fourfold lower than the other codons). In all cases, the rates at the A-ending codons were lower in the strains lacking the other isoacceptors than in the wild type. This was expected, as the remaining tRNAs have to read more of the codons that are normally also read by the other isoacceptors, leading to fewer tRNAs available to read the A-ending codon. In vitro a slightly lower rate of recognition was also observed toward the GCC (Ala) codon compared to the GCA (Ala) codon ( Kothe and Rodnina 2007 ). However, tRNA Pro cmo5UGG recognized the C-ending codon almost as efficiently as the other proline codons ( Fig. 8 ), which could partly explain why the mutant (Δ proL proK <> frt ) lacking the G34- and C34-containing proline isoacceptors has no apparent growth phenotype. One feature differentiating the anticodon loop in the cmo 5 U-containing proline tRNA from the anticodon loops in the other tested tRNAs is the presence of four consecutive purines (G35-G36-m 1 G37-A38). As purine–purine stacking is the most stable stacking interaction ( Saenger 1984 ), this may lead to an exceptionally stable anticodon loop through extensive stacking of these bases, perhaps contributing to the efficiency of decoding the CCC codon by tRNA Pro cmo5UGG .
Combining the lack of the G34-containing (and C34-containing) isoacceptors with hypo-modification (ho 5 U34 instead of cmo 5 U34) of the wobble nucleoside in the remaining isoacceptors also has different effects on the growth rates of the different mutants. All three mutants with only the cmo 5 U-containing isoacceptors left in the respective family codon boxes (Δ proL proK <> frt , Δ alaXW , and Δ valVW ) have significantly reduced growth rates when combined with a cmoB mutation ( Tables 1 , ,3; 3 ; Näsvall et al. 2004 ), but the severity of the synergistic phenotypes is very different. The Δ alaXW cmoB2 mutant is virtually impossible to keep as a pure culture without accumulation of faster-growing suppressors ( Fig. 6 ). The nature of the suppressors that accumulated in the Δ alaXW cmoB2 and Δ valVW mutants was not examined in detail, but at least some of them segregated into small and large colonies, indicating that they may be amplifications of the tRNA genes (data not shown). As both mutants were suppressed by expressing more of the remaining tRNA ( Figs. 4 and and6), 6 ), it is likely that amplification of the genes encoding these tRNAs would account for some of the suppressors. The effects of hypo-modification on the Δ proL proK <> frt and the Δ valVW mutants seem to be similar (although the Δ valVW mutant is very slow growing even in the presence of cmo 5 U34) ( Fig. 4 ). Comparing the effects of having ho 5 U in place of cmo 5 U on the A-site selection rate for the different tRNAs ( Figs. 5 , ,7, 7 , ,8, 8 , cf. LT2 and cmoB2 ; Fig. 8 , cf. Δ proKL and Δ proKL cmoB2 ), the only codons where we observed significant differences in all three family boxes are at the G-ending codons. The largest effect is at the G-ending alanine codon. Taken together, the data from the A-site selection assays indicate that the extreme phenotype of the cmoB2 Δ alaXW mutant probably is a combination of very poor recognition of the GCC codon due to the lack of the G34-containing alanine isoacceptor and the reduced efficiency of recognizing the GCG codon caused by the modification deficiency. In addition to the decreases in the selection rates at the G-ending codons, we also observed decreased rates on the C-ending valine and proline codons and the U-ending alanine and proline codons. The effect of cmo 5 U deficiency on the ability of the Δ proL proK <> frt and Δ valVW mutants to recognize their corresponding G-ending codons is not as large as for the Δ alaXW mutant, which could be an explanation of why the different mutants have such different growth phenotypes. There may be several reasons why cmo 5 U apparently is more important for the function of tRNA Ala cmo5UGC than it seems to be for the functions of tRNA Pro cmo5UGG and tRNA Val cmo5UAC . One might be that other features present in tRNA Pro cmo5UGG and tRNA Val cmo5UAC but absent in tRNA Ala cmo5UGC contribute to their efficient decoding. One candidate for such a feature would be the modification of position 37 (immediately 3′ of the anticodon). tRNA Pro has m 1 G37 ( Kuchino et al. 1984 ), and tRNA Val has m 6 A37 ( Kimura et al. 1971 ), while tRNA Ala has an unmodified adenosine at position 37 ( Lund and Dahlberg 1977 ). m 1 G37 has previously been demonstrated to be important for the A-site selection rate at all four proline codons ( Li et al. 1997 ). As the effects on growth rates of some of the mutants appear to be larger than one would expect from the changes in the A-site selection rates, it is possible that part of the growth phenotypes are due to defects in a stage of the translation elongation cycle other than the A-site selection. We have previously shown that having ho 5 U instead of cmo 5 U in tRNA Pro cmo5UGG actually leads to decreased +1 frameshifting at CCC codons ( Qian et al. 1998 ; Näsvall et al. 2004 ), which is why we do not think frameshifting in such a mutant reaches high enough levels to cause the observed growth-rate reduction.
It should be noted that there are organisms that have only a U34-containing tRNAs to read all four codons in some or all of the family codon boxes encoding Ser, Pro, Thr, Ala, Val, and Leu. Bacillus subtilis have only one proline tRNA (containing mo 5 U34) ( Yamada et al. 2005 ), while it has two (mo 5 U34 and G34) or three (mo 5 U34, G34, and C34) tRNAs in the other five boxes ( Sprinzl and Vassilenko 2005 ). Certain intracellular parasites, like the Mollicutes (to which the Mycoplasmas belong), have very small, A/T-rich genomes with a reduced number of tRNA genes compared to free-living bacteria. Some of these use only U34-containing tRNAs in all these boxes, while the others have additional G34-, C34-, or A34-containing tRNAs in some of the serine, threonine, alanine, valine, or leucine boxes (for review, see De Crécy-Lagard et al. 2007 ). The codon usages of these organisms are very strongly biased toward A- and U-ending codons. The modification status of tRNAs from most of these organisms are unknown, but at least Mycoplasma capricolum and Mycoplasma mycoides have unmodified uridines at the wobble position. This may indicate that during their reductive evolution, the Mollicutes (distantly related to Bacillus ) have lost the genes required to synthesize mo 5 U, and have unmodified U34. As these bacteria use U34-containing tRNAs to read primarily A- and U-ending codons, while they use C- and G-ending codons very rarely, this suggests that U34-containing tRNAs in the family codon boxes are unexpectedly efficient at reading U-ending codons, while this requirement may not be relevant for the rarely used G- and C-ending codons. This may be an exception enabled by special features of the ribosomes and/or tRNAs from these highly specialized organisms, but it may also be a general rule for U34-containing tRNAs in other organisms as well. In fact, completely unmodified E. coli tRNA Ser UGA (which normally has cmo 5 U34) is capable of reading UCA and UCU in an in vitro translation system, but UCG is very poorly translated unless the wobble nucleoside is modified to mo 5 U ( Takai et al. 1999 ). With this in mind, perhaps the unknown gene(s) encoding the enzyme(s) responsible for making ho 5 U34 from U34 in tRNA is essential for Salmonella and E. coli even in strains with the full complement of tRNAs, as the U34-containing alanine and valine tRNAs may require at least ho 5 U in order to recognize their G-ending codons efficiently enough to support growth.
Relevant to the coding capacities in Mollicutes is the “two out of three” decoding model, which states that the third position of the codon–anticodon interaction can be disregarded, as long as the interactions in the first two positions are strong ( Lagerkvist 1978 ). This would apply to codons where the first two positions form G-C pairs (Pro, Ala, Arg, and Gly) but not to codons forming only A-U pairs (such as the Phe/Leu, Ile/Met, Tyr/Stop, and Asn/Lys mixed codon boxes). The two out of three model is supported by in vitro translation experiments in which the E. coli cmo 5 U-containing alanine and valine tRNAs could incorporate the respective cognate amino acids at all four of their codons even in the presence of a competing cognate tRNA ( Mitra et al. 1979 ; Samuelsson et al. 1980 ). The relative efficiency of the cmo 5 U-containing tRNA in reading the four alanine and valine codons in the presence of the cognate tRNA is similar to our results obtained using the A-site selection assay in cells with only the fully modified cmo 5 U-containing tRNA present to read all four codons ( Figs. 5 , ,7). 7 ). Lagerkvist assumed that the efficient reading of U-ending codons was caused by the presence of cmo 5 U, while the less efficient reading of C-ending codons was regarded as two-out-of-three reading that did not involve an interaction at the third position. However, in vivo ( Figs. 5 , ,7, 7 , ,8) 8 ) the hypo-modified derivatives were less efficient to read the G-ending and sometimes the U- or C-ending codons, although the extent of the reductions at the C- and U-ending codons may be masked by the presence of the competing G34-containing tRNAs. Thus, the modification of the wobble base may contribute to the decoding efficiency even at C-ending codons and cannot be disregarded as suggested by the two out of three model. However, as we have no mutant that has unmodified U34, we cannot conclusively say if alanine, valine, or proline tRNA in such a mutant would still read U- or C-ending codons. Moreover, the fact that the Leu and Thr family boxes cannot be decoded by a single tRNA ( Table 1 ; Nishiyama and Tokuda 2005 ; Sørensen et al. 2005 ) is not consistent with the two out of three decoding model. Why the cmo 5 U-containing Ala and Pro tRNAs can read C-ending codons but the Leu, Thr, and Ser tRNAs cannot may be related to the stability of the first two base pairs in the codon–anticodon complex (Ala and Pro make two G-C pairs, whereas Leu, Thr, and Ser make only one G-C pair). Still, it is unclear why tRNA Val cmo5UAC can read all four codons (although not efficiently enough to support normal growth) when it also makes only one G-C pair ( Fig. 5 ; Table 2 ).
In his wobble hypothesis, Crick predicted that U34 in tRNA would be able to form a wobble pair with G(III) in the mRNA ( Crick 1966 ), with two hydrogen bonds between U34 and G(III). In order to allow formation of such a base pair, either U34 has to be displaced toward the major groove or G(III) has to be displaced toward the minor groove of the codon–anticodon mini-helix (a move of ∼2.5 Å for one of the glycosidic bonds compared to a Watson–Crick base pair) ( Fig. 9B ; Crick 1966 ). It is unlikely that G(III) would be allowed to move, since its movement is restricted by its interactions with residues in the ribosomal 30S subunit ( Ogle et al. 2001 ; Murphy et al. 2004 ). If U34 would move the entire distance required to form a U-G wobble pair, it would be unable to make a stacking interaction with the base in position 35 of the tRNA ( Murphy et al. 2004 ), which could perhaps lead to poor recognition of G-ending codons by tRNAs with unmodified U34. Weixlbaumer et al. (2007) have recently solved the crystal structures of Thermus thermophilus 70S ribosomes containing an ASL Val cmo5UAC (with the modifications cmo 5 U34 and m 6 A37) bound to the four Val codons in the A-site. One interesting feature of the cmo 5 U-G base pair is that it has standard Watson–Crick geometry rather than the expected wobble geometry ( Fig. 9 ). This means that the 4-carbonyl group of cmo 5 U34 has to be in the rare enol form rather than the normal keto form and that the base pair makes three hydrogen bonds ( Fig. 9B ). Hillen et al. (1978) showed that mo 5 U has a shifted keto–enol equilibrium compared to uridine and ho 5 U. Our data showing that tRNAs with cmo 5 U34 are significantly more efficient than tRNAs with ho 5 U at reading G-ending codons are consistent with the observed crystal structure and predict that cmo 5 U34 is, indeed, in the enol form. In all four of these structures, the ether oxygen (O5) of the modification forms a hydrogen bond to the 2′-OH of U33 ( Fig. 9A ). This leads to a more constrained anticodon than if the wobble uridine would have been unmodified ( Weixlbaumer et al. 2007 ), with the wobble nucleoside “locked” in position close to where it would be in a Watson–Crick base pair. The cmo 5 U-U and cmo 5 U-C pairs in the structures only form one hydrogen bond between the codon and anticodon bases ( Weixlbaumer et al. 2007 ). Part of the stabilization needed to allow these pairs may come from the observed hydrogen bond between the O5 of cmo 5 U34 and the 2′-OH of U33. The cmo 5 U-U pair may be further stabilized by interactions with 16S rRNA, whereas the cmo 5 U-C pair may be slightly destabilized by poor stacking between C(III) and its 5′-base ( Weixlbaumer et al. 2007 ). These differences between the cmo 5 U-U and cmo 5 U-C pairs may explain why the C-ending codons are poorly recognized by the cmo 5 U-containing alanine and valine tRNAs, while the U-ending codons are recognized efficiently ( Figs. 5 , ,7). 7 ). Weixlbaumer et al. also point out that the carboxyl group of cmo 5 U34 is close enough to the oxygen of the 4-carbonyl group of U(III) to be able to form a hydrogen bond if the carboxyl group is protonated ( Weixlbaumer et al. 2007 ). This would provide even further stability to the cmo 5 U-U pair but not to the cmo 5 U-C pair. In such a case, the hypo-modified ho 5 U34-containing tRNAs in a cmoB mutant (lacking the carboxyl group) would be affected in their reading of U-ending codons. Since we see no large effect on the rates of reading U-ending codons, our data do not support this suggestion. Another important observation in these structures is that in all four pairs, the ribose of cmo 5 U34 adopts the 3′-endo conformation, and the modification does not interact with its 5′-phosphate as predicted by Yokoyama et al. (1985) .

( A ) The cmo 5 U34-G(III) base pair seen in the crystal structure solved by Weixlbaumer et al. (2007) (Protein Databank accession code 2UU9). The hydrogen bond between the 2′-OH of U33 and the O5 ether oxygen of cmo 5 U34 is indicated. ( B ) Keto-enol tautomerization of cmo 5 U. ( Left ) The keto tautomer of cmo 5 U (black), forming a wobble pair with G (gray) as predicted by Crick. ( Right ) The enol tautomer of cmo 5 U (black), engaged in a base pair with G (gray). The geometry of the cmo 5 U-G pair is the same as for a Watson–Crick (A-U or G-C) base pair.
Based on the structures discussed above ( Fig. 9 ; Weixlbaumer et al. 2007 ) and our in vivo data, we suggest that the function of cmo 5 U34 (and mo 5 U34) may be dual: Firstly, the ether oxygen (or the hydroxyl of ho 5 U) stabilizes the anticodon loop in a conformation where the wobble uridine is locked in position to form a base pair with Watson–Crick geometry. This leads to sufficient stabilization to compensate for the poor interactions between cmo 5 U34 and U(III) or C(III). Secondly, the rest of the modification (–CH 3 in mo 5 U or –CH 3 COOH in cmo 5 U) stabilizes the enol form of the wobble nucleoside, promoting a nonstandard U34-G(III) base pair.
MATERIALS AND METHODS
Bacteria and growth conditions.
The strains and plasmids used are listed in Table 5 . All Salmonella strains are derivatives of Salmonella enterica serovar Typhimurium strain LT2. As solid rich medium, TYS (10 g of Trypticase peptone, 5 g of yeast extract, 5 g of NaCl, and 15 g of agar per liter) was used. As solid minimal medium, medium E ( Vogel and Bonner 1956 ) containing 15 g of agar per liter and 0.2% glucose was used. As rich liquid medium, either LB or NAA (0.8% Difco nutrient broth; Difco Laboratories) supplemented with the aromatic amino acids, aromatic vitamins, and adenine at concentrations as described previously ( Davis et al. 1980 ) was used. For growth rate determination and assay of β-galactosidase activities, Rich MOPS ( Neidhardt et al. 1977 ) was used. All growth was done at 37°C. Antibiotics were used at the following concentrations: Carbenicillin (Cb): 50 mg/L; Kanamycin (Km): 100 mg/L; Chloramphenicol (Cm): 12.5 mg/L; Tetracycline (Tet): 15 mg/L.
Salmonella enterica serovar Typhimurium and Escherichia coli strains and plasmids

Genetic procedures
To transfer chromosomal markers or plasmids between Salmonella strains, transductions were performed as described previously ( Davis et al. 1980 ) with a derivative of phage P22 containing the mutations HT105/I ( Schmieger 1972 ) and int-201 ( Scott et al. 1975 ). Green indicator plates ( Chan et al. 1972 ) were used for testing that the clones were phage free and phage sensitive.
Molecular cloning procedures
PCR fragments were purified from agarose gels using Wizard DNA clean-up resin (Promega) or directly using PCR kleen-spin (Bio-Rad). DNA sequencing was done using the DYEnamic ET terminator cycle sequencing kit (Amersham Pharmacia Biotech Inc.) or the BigDye Terminator v3.1 cycle sequencing kit (Applied Biosystems).
A 1.8-kb crossover PCR product containing the deletion of the alaXW operon (from 101 nt upstream to 55 nt downstream of alaXW ) was generated as described by Link et al. (1997) and cloned into the suicide vector pDM4 ( Milton et al. 1996 ). The plasmid (pUST300) was transformed into E. coli strain GRB1371, and the resulting strain (GRB1748) was used as donor in conjugation with the Salmonella strain GT1796 as recipient. Cointegrates were segregated by nonselective growth in LB supplemented with 5% sucrose. Sucrose-resistant segregants were screened by PCR to find clones carrying the alaXW deletion. To generate the valVW deletion, a 1.2-kb crossover fragment containing a deletion of the valV and valW genes (from 6 nt upstream of valV to 28 nt downstream of valW ) was cloned into the temperature-sensitive suicide vector pMAK705 ( Hamilton et al. 1989 ), generating pUST301. Cointegrates were obtained by growing at 44°C in the presence of chloramphenicol and segregated by growing nonselectively at 30°C. Chloramphenicol-sensitive segregants were screened by PCR to find clones carrying the valVW deletion on the chromosome.
We used the method described by Datsenko and Wanner (2000) to replace thrT , thrV , or thrW in strain GT6315 (an LT2 derivative with the λ-red recombinase plasmid pKD46) with the kanamycin resistance cassette amplified from plasmid pKD4 ( Datsenko and Wanner 2000 ). The <> kan alleles were transferred by P22 transductions into strain LT2 before the FLP-recombinase helper plasmid pCP20 ( Datsenko and Wanner 2000 ) was introduced to convert the <> kan alleles into <> frt alleles. To combine the different mutations, we used P22 lysates grown on strains containing the different thr <> kan alleles as donors and cultures of strains containing the different thr <> frt alleles as recipients in transductions, selecting Km R transductants ( Table 1 ). To examine the presence of duplications in the rare transductants that appeared when trying to construct a thrT , thrV double mutant, 37 transductants (from transductions using thrT <> kan as donor and thrV <> frt as recipient), including clones that appeared after up to 72 h of incubation, were checked by PCR reactions designed to distinguish between the wild-type and thrT <> kan alleles.
The cmoB2 <> cat allele was constructed to be identical to the cmoB2 <> kan allele ( Näsvall et al. 2004 ), except the chloramphenicol resistance cassette from plasmid pKD3 was used instead of the kanamycin resistance cassette from pKD4.
Nomenclature of mutants
An allele number followed by <> and “ kan ” or “ cat ” indicates that the gene is replaced by the kanamycin or chloramphenicol resistance cassettes from plasmid pKD4 or pKD3, respectively (e.g., cmoB2 <> kan or cmoB2 <> cat ). After FLP-recombinase-mediated removal of the cassette, the mutation is referred to with the same allele number, but with “ frt ” as description of the resulting scar sequence (e.g., cmoB2 <> frt ). The same allele number is also used for replacements where removal of two different FRT (Flp Recombinase Target sequence) flanked antibiotic resistance cassettes would produce an identical end result; hence cmoB2 <> kan , cmoB2 <> cat , and cmoB2 <> frt have the same allele number. A “Δ” before a gene name refers to a precise deletion rather than a replacement (e.g., “Δ proL ”).
Nomenclature of tRNAs
In most cases, tRNAs are referred to with their cognate amino acid in three-letter code in superscript and with their anticodon sequence (5′→3′) in subscript, i.e., tRNA Thr cmo5UGC refers to a threonine tRNA with the anticodon cmo 5 U34-G35-U36. In some cases, the names of tRNA genes are followed by the wobble nucleoside of the corresponding tRNA within parentheses.
Determination of growth rates
Overnight cultures of the different strains were diluted to ∼0.05–0.1 OD 420 units in pre-warmed medium and were pre-grown to OD 420 ≈1.0. The cultures were then diluted to OD 420 ≈0.02–0.06, and growth was monitored with a Shimadzu UV-1601 spectrophotometer at 420 nm. When the OD of the cultures reached OD 420 ≈1.0, they were again diluted into fresh pre-warmed medium. The cultures were judged to be in balanced growth when the growth rate determined after a dilution did not change more than 5% from what it was before dilution. We did not wait for the slow-growing Δ valVW (GT6300) or Δ valVW , cmoB2 (GT6972) mutants ( Table 2 ) to reach balanced growth; instead, they were treated as follows: Overnight cultures of GT6300 or still growing cultures (with an OD 420 below 1.0) of GT6972 were diluted once to OD 420 ≈0.05, and growth was monitored until the OD again reached 1.0. Cultures of GT6300 were diluted once more, and monitoring continued until OD 420 ≈1.0. Samples were withdrawn from the cultures and plated to estimate the proportion of faster-growing suppressor mutants. The data in Table 2 were calculated from cultures that contained <5% suppressors at the end of the experiments. The specific growth rate is expressed as k (h −1 ), where k =ln 2/ g (where g is the generation time in hours). Strain LT2 (wild-type) was always grown in parallel with the mutants to get a reference value for each experiment. Because of this, the values for LT2 in Tables 2 and and3 3 differ slightly from each other. To estimate the colony diameters reported in the legends for Figure 4 and Figure 6 , the plates were photographed with a ChemiDoc XRS (Bio-Rad). Quantity One software (Bio-Rad) was used to measure the approximate width and height of square boxes manually fitted to surround each colony. The values are averages of five representative colonies (except the cmoB2 <> kan mutant in Fig. 6B , sector 2, where only two colonies were sufficiently separated from other colonies). The average diameter of strain LT2 (containing the relevant plasmids) growing on the same plate was set to 1.0.
Determination of A-site selection rates
Strains were grown overnight at 37°C in Rich MOPS medium supplemented with 12.5 μg/mL chloramphenicol, subcultured and grown to mid-log phase (OD 600 ≈0.5 using a Shimadzu UV-1201 spectrophotometer, corresponding to ∼2 × 10 8 CFU/mL). β-Galactosidase activity was measured as described by Miller (1972) (using the alternative method with chloroform and SDS instead of toluene to open the cells). ONPG was from Sigma. For each strain to be tested, at least two independent cultures were grown, and each strain was tested in at least three separate experiments. The plasmids for testing the alanine and valine codons were constructed by mutagenizing previously constructed plasmids ( Curran and Yarus 1989 ) according to the protocol for the QuikChange Site-Directed Mutagenesis kit (Stratagene). The numbers presented in Figures 5 , ,7, 7 , and and8 8 are the A-site selection rates expressed as

where F is the frequency of frameshifting, determined by dividing the β-galactosidase activity of the test codon constructs with that of the pseudo-wild-type plasmid pJC27.
ACKNOWLEDGMENTS
This work was supported by grants from the Swedish Cancer Foundation (Project 680) and the Swedish Science Research Council (Project BU-2930). We are grateful to Drs. V. Ramakrishnan and A. Weixlbaumer (Cambridge, UK) for making their manuscript available prior to its publication and for the kind gift of the unpublished Figure 9A . We thank Gunilla Jäger for performing β-galactosidase assays and Tord Hagervall, Anders Byström, and Anders Esberg for critical reading of the manuscript.
Article published online ahead of print. Article and publication date are at http://www.rnajournal.org/cgi/doi/10.1261/rna.731007 .
- Chan, R.K., Botstein, D., Watanabe, T., Ogata, Y. Specialized transduction of tetracycline resistance by phage P22 in Salmonella typhimurium . II. Properties of a high-frequency-transducing lysate. Virology. 1972; 50 :883–898. [ PubMed ] [ Google Scholar ]
- Crick, F.H.C. Codon–anticodon pairing. The wobble hypothesis. J. Mol. Biol. 1966; 19 :548–555. [ PubMed ] [ Google Scholar ]
- Curran, J.F., Yarus, M. Rates of aminoacyl-tRNA selection at 29 sense codons in vivo. J. Mol. Biol. 1989; 209 :65–77. [ PubMed ] [ Google Scholar ]
- Datsenko, K.A., Wanner, B.L. One-step inactivation of chromosomal genes in Escherichia coli K-12 using PCR products. Proc. Natl. Acad. Sci. 2000; 97 :6640–6645. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Davis, W., Botstein, D., Roth, J.R. A manual for genetic engineering: Advanced bacterial genetics. Cold Spring Harbor Laboratory; Cold Spring Harbor, New York: 1980. [ Google Scholar ]
- De Crécy-Lagard, V., Marck, C., Brochier-Armanet, C., Grosjean, H. Comparative RNomics and Modomics in mollicutes: Prediction of gene function and evolutionary implications. IUBMB Life. 2007; 59 :634–658. [ PubMed ] [ Google Scholar ]
- Dong, H.J., Nilsson, L., Kurland, C.G. Covariation of tRNA abundance and codon usage in Escherichia coli at different growth rates. J. Mol. Biol. 1996; 260 :649–663. [ PubMed ] [ Google Scholar ]
- Gabriel, K., Schneider, J., McClain, W.H. Functional evidence for indirect recognition of G•U in tRNA Ala by alanyl-tRNA synthetase. Science. 1996; 271 :195–197. [ PubMed ] [ Google Scholar ]
- Hamilton, C.M., Aldea, M., Washburn, B.K., Babitzke, P., Kushner, S.R. New method for generating deletions and gene replacements in Escherichia coli . J. Bacteriol. 1989; 171 :4617–4622. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Hillen, W., Egert, E., Lindner, H.J., Gassen, H.G., Vorbruggen, H. 5-Methoxyuridine: The influence of 5-substituents on the Keto-enol tautomerism of the 4-carbonyl group. J. Carbohydrates Nucleosides Nucleotides. 1978; 5 :23–32. [ Google Scholar ]
- Ishikura, H., Yamada, Y., Nishimura, S. Structure of serine tRNA from Escherichia coli . I. Purification of serine tRNA's with different codon responses. Biochim. Biophys. Acta. 1971; 228 :471–481. [ PubMed ] [ Google Scholar ]
- Kimura, F., Harada, F., Nishimura, S. Primary sequence of tRNA-Val-1 from Escherichia coli B. II. Isolation of large fragments by limited digestion with RNases, and overlapping of fragments to reduce the total primary sequence. Biochemistry. 1971; 10 :3277–3283. [ PubMed ] [ Google Scholar ]
- Kothe, U., Rodnina, M.V. Codon reading by tRNA Ala with modified uridine in the wobble position. Mol. Cell. 2007; 25 :167–174. [ PubMed ] [ Google Scholar ]
- Kuchino, Y., Yabusaki, Y., Mori, F., Nishimura, S. Nucleotide sequences of three proline tRNAs from Salmonella typhimurium . Nucleic Acids Res. 1984; 12 :1559–1562. doi: 10.1093/nar/12.3.1559. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Lagerkvist, U. “Two out of three”: An alternative method for codon reading. Proc. Natl. Acad. Sci. 1978; 75 :1759–1762. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Li, J.N., Esberg, B., Curran, J.F., Björk, G.R. Three modified nucleosides present in the anticodon stem and loop influence the in vivo aa-tRNA selection in a tRNA-dependent manner. J. Mol. Biol. 1997; 271 :209–221. [ PubMed ] [ Google Scholar ]
- Link, A.J., Phillips, D., Church, G.M. Methods for generating precise deletions and insertions in the genome of wild-type Escherichia coli : Application to open reading frame characterization. J. Bacteriol. 1997; 179 :6228–6237. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Lund, E., Dahlberg, J.E. Spacer transfer RNAs in ribosomal RNA transcripts of E. coli : Processing of 30S ribosomal RNA in vitro. Cell. 1977; 11 :247–262. [ PubMed ] [ Google Scholar ]
- Miller, J.H. Experiments in molecular genetics. Cold Spring Harbor Laboratory; Cold Spring Harbor, New York: 1972. [ Google Scholar ]
- Milton, D.L., O'Toole, R., Horstedt, P., Wolf-Watz, H. Flagellin A is essential for the virulence of Vibrio anguillarum . J. Bacteriol. 1996; 178 :1310–1319. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Mitra, S.K., Lustig, F., Akesson, B., Axberg, T., Elias, P., Lagerkvist, U. Relative efficiency of anticodons in reading the valine codons during protein synthesis in vitro. J. Biol. Chem. 1979; 254 :6397–6401. [ PubMed ] [ Google Scholar ]
- Murphy, F.V., Ramakrishnan, V., Malkiewicz, A., Agris, P.F. The role of modifications in codon discrimination by tRNA Lys UUU . Nat. Struct. Mol. Biol. 2004; 11 :1186–1192. [ PubMed ] [ Google Scholar ]
- Nakamura, Y., Gojobori, T., Ikemura, T. Codon usage tabulated from international DNA sequence databases: Status for the year 2000. Nucleic Acids Res. 2000; 28 :292. doi: 10.1093/nar/28.1.292. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Näsvall, S.J., Chen, P., Björk, G.R. The modified wobble nucleoside uridine-5-oxyacetic acid in tRNA Pro cmo5UGG promotes reading of all four proline codons in vivo. RNA. 2004; 10 :1662–1673. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Neidhardt, F.C., Bloch, P.L., Pedersen, S., Reeh, S. Chemical measurement of steady-state levels of ten aminoacyl-transfer ribonucleic acid synthetases in Escherichia coli . J. Bacteriol. 1977; 129 :378–387. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Nishiyama, K.I., Tokuda, H. Genes coding for SecG and Leu2-tRNA form an operon to give an unusual RNA comprising mRNA and a tRNA precursor. Biochim. Biophys. Acta. 2005; 1729 :166–173. [ PubMed ] [ Google Scholar ]
- O'Connor, M. Insertions in the anticodon loop of tRNA Gln 1 ( sufG ) and tRNA Lys promote quadruplet decoding of CAAA. Nucleic Acids Res. 2002; 30 :1985–1990. doi: 10.1093/nar/30.9.1985. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Oda, K., Kimura, F., Harada, F., Nishimura, S. Restoration of valine acceptor activity by combining oligonucleotide fragments derived from a Bacillus subtilis ribonuclease digest of Escherichia coli valine transfer RNA. Biochim. Biophys. Acta. 1969; 179 :97–105. [ PubMed ] [ Google Scholar ]
- Ogle, J.M., Brodersen, D.E., Clemons W.M., Jr, Tarry, M.J., Carter, A.P., Ramakrishnan, V. Recognition of cognate transfer RNA by the 30S ribosomal subunit. Science. 2001; 292 :897–902. [ PubMed ] [ Google Scholar ]
- Phelps, S.S., Malkiewicz, A., Agris, P.F., Joseph, S. Modified nucleotides in tRNA Lys and tRNA Val are important for translocation. J. Mol. Biol. 2004; 338 :439–444. [ PubMed ] [ Google Scholar ]
- Qian, Q., Li, J.N., Zhao, H., Hagervall, T.G., Farabaugh, P.J., Björk, G.R. A new model for phenotypic suppression of frameshift mutations by mutant tRNAs. Mol. Cell. 1998; 1 :471–482. [ PubMed ] [ Google Scholar ]
- Saenger, W. 6.6 Thermodynamic description of stacking interactions. Principles of nucleic acid structure. Springer-Verlag; New York: 1984. pp. 134–137. [ Google Scholar ]
- Samuelsson, T., Elias, P., Lustig, F., Axberg, T., Fölsch, G., Åkesson, B., Lagerkvist, U. Aberrations of the classic codon reading scheme during protein synthesis in vitro. J. Biol. Chem. 1980; 255 :4583–4588. [ PubMed ] [ Google Scholar ]
- Schmieger, H. Phage P22 -mutants with increased or decreased transduction abilities. Mol. Gen. Genet. 1972; 119 :75–88. [ PubMed ] [ Google Scholar ]
- Scott, J.F., Roth, J.R., Artz, S.W. Regulation of histidine operon does not require hisG enzyme. Proc. Natl. Acad. Sci. 1975; 72 :5021–5025. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Simon, R., Priefer, U., Pühler, A. A broad host range mobilization system for in vivo genetic engineering: transposon mutagenesis in Gram negative bacteria. Biotechnology (N. Y.) 1983; 1 :784–791. [ Google Scholar ]
- Sørensen, M.A., Elf, J., Bouakaz, E., Tenson, T., Sanyal, S., Björk, G.R., Ehrenberg, M. Overexpression of a tRNA Leu isoacceptor changes charging pattern of leucine tRNAs and reveals new codon reading. J. Mol. Biol. 2005; 354 :16–24. [ PubMed ] [ Google Scholar ]
- Sprinzl, M., Vassilenko, K.S. Compilation of tRNA sequences and sequences of tRNA genes. Nucleic Acids Res. 2005; 33 :D139–D140. doi: 10.1093/nar/gki012. [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Stoker, N.G., Fairweather, N.F., Spratt, B.G. Versatile low-copy-number plasmid vectors for cloning in Escherichia coli . Gene. 1982; 18 :335–341. [ PubMed ] [ Google Scholar ]
- Takai, K., Okumura, S., Hosono, K., Yokoyama, S., Takaku, H. A single uridine modification at the wobble position of an artificial tRNA enhances wobbling in an Escherichia coli cell-free translation system. FEBS Lett. 1999; 447 :1–4. [ PubMed ] [ Google Scholar ]
- Vila-Sanjurjo, A., Squires, C.L., Dahlberg, A.E. Isolation of kasugamycin resistant mutants in the 16 S ribosomal RNA of Escherichia coli . J. Mol. Biol. 1999; 293 :1–8. [ PubMed ] [ Google Scholar ]
- Vogel, H.J., Bonner, D.M. Acetylornithinase of Escherichia coli : Partial purification and some properties. J. Biol. Chem. 1956; 218 :97–106. [ PubMed ] [ Google Scholar ]
- Weixlbaumer, A., Murphy, F.V., Dziergowska, A., Malkiewicz, A., Vendeix, F.A., Agris, P.F., Ramakrishnan, V. Mechanism for expanding the decoding capacity of transfer RNAs by modification of uridines. Nat. Struct. Mol. Biol. 2007; 14 :498–502. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Yamada, Y., Matsugi, J., Ishikura, H., Murao, K. Bacillus subtilis tRNA Pro with the anticodon mo5UGG can recognize the codon CCC. Biochim. Biophys. Acta. 2005; 1728 :143–149. [ PubMed ] [ Google Scholar ]
- Yokoyama, S., Watanabe, T., Murao, K., Ishikura, H., Yamaizumi, Z., Nishimura, S., Miyazawa, T. Molecular mechanism of codon recognition by tRNA species with modified uridine in the first position of the anticodon. Proc. Natl. Acad. Sci. 1985; 82 :4905–4909. [ PMC free article ] [ PubMed ] [ Google Scholar ]
Update image
- Wobble hypothesis

Support our developers

More in this section
- The Genetic Code
- Properties of genetic code
- Chain initiation and chain termination codons
- Synonym codons and degeneracy
- Mutations and the genetic code
- New genetic codes in mitochondria and ciliate protozoa
- Suppressor mutations, base substitutions and suppressor tRNAs
- Second genetic code, and second half of the genetic code
- Recoding of the genetic code
© 2012 - 2024 Biocyclopedia
Disclaimer Privacy Policy Feedback
Login to your account
Login / signup with.

Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Letters to Editor
- Published: 08 August 1973
A Wobbly Double Helix
- AXEL G. LEZIUS 1 &
- ERIKA DOMIN 1
Nature New Biology volume 244 , pages 169–170 ( 1973 ) Cite this article
80 Accesses
14 Citations
Metrics details
CRICK 1 first considered in the “wobble hypothesis” the biological relevance of base pairs beyond the canonical ones A:T(U) and G(I):C. Podder 2 was able to estimate the stability of the G:U wobble pair from T jump relaxation spectra of the interacting tetranucleotides GpGpGpU:GpCpCpC. Paetkau et al. 3 concluded from poly rG synthesis on d(T-C) n ·d(G-A) n and d(T-C-C) by Escherichia coli RNA polymerase that under appropriate conditions thymine-guanine base pairing may occur during transcription.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
We are sorry, but there is no personal subscription option available for your country.
Buy this article
Purchase on Springer Link
Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Crick, F. H. C., J. Mol. Biol. , 19 , 548 (1966).
Article CAS Google Scholar
Podder, S. K., Nature new Biol. , 232 , 115 (1971).
Paetkau, V., Coulter, M. B., Flintoff, W. F., and Morgan, A. R., J. Mol. Biol. , 71 , 293 (1972).
Wells, R. D., Othsuka, E., Khorana, H. G., Doerfler, W., and Hogness, D. S., J. Mol. Biol. , 14 , 221 (1965).
Donohue, J., Proc. US Nat. Acad. Sci. , 42 , 60 (1956).
Lezius, A. G., Hoppe Seyler's Z. Physiol. Chem. , 352 , 491 (1971).
Bähr, W., Faerber, P., and Scheit, K., Eur. J. Biochem. , 33 , 535 (1973).
Article Google Scholar
Bugg, C. E., and Thewalt, U., J. Amer. Chem. Soc. , 92 , 7441 (1970).
Download references
Author information
Authors and affiliations.
Max-Planck-Institut für experimentelle Medizin, Abteilung Chemie, 34, Göttingen
AXEL G. LEZIUS & ERIKA DOMIN
You can also search for this author in PubMed Google Scholar
Rights and permissions
Reprints and permissions
About this article
Cite this article.
LEZIUS, A., DOMIN, E. A Wobbly Double Helix. Nature New Biology 244 , 169–170 (1973). https://doi.org/10.1038/newbio244169a0
Download citation
Received : 09 March 1973
Issue Date : 08 August 1973
DOI : https://doi.org/10.1038/newbio244169a0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Polydesoxynucleotide als dna-modelle.
Die Naturwissenschaften (1974)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.


Biology Notes Online
The Wobble Hypothesis – Definition, Exaplanation, Importance
Table of Contents
What is Wobble Hypothesis?
The Wobble Hypothesis, proposed by Francis Crick in 1966, provides an explanation for the degeneracy of the genetic code. Degeneracy refers to the fact that multiple codons can code for the same amino acid. According to the Wobble Hypothesis, the precise pairing between the bases of the codon and the anticodon of tRNA occurs only for the first two bases of the codon. However, the pairing between the third base of the codon and the anticodon can exhibit some flexibility or “wobble.”
In other words, the third base of the codon and the anticodon can sway or move unsteadily, allowing for non-standard base pairing. This phenomenon enables a single tRNA molecule to recognize and bind to multiple codons, despite differences in their third base. As a result, although there are 61 codons that code for amino acids, the number of tRNA molecules is significantly lower (around 40) due to wobbling.
Wobble base pairs play a crucial role in RNA secondary structure and are critical for accurate translation of the genetic code. The four main wobble base pairs are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C). These wobble base pairs exhibit thermodynamic stability comparable to that of Watson-Crick base pairs.
In the genetic code, there are 64 possible codons, out of which three are stop codons that terminate translation. If canonical Watson-Crick base pairing were required for each codon, it would necessitate 61 different types of tRNA molecules. However, most organisms have fewer than 45 types of tRNA. The Wobble Hypothesis explains how some tRNA molecules can recognize multiple synonymous codons, which encode the same amino acid.
Crick proposed that the 5′ base on the anticodon, which binds to the 3′ base on the mRNA codon, is more flexible spatially compared to the other two bases. This flexibility allows for non-standard base pairing and small conformational adjustments, resulting in the overall pairing geometry of tRNA anticodons.
Overall, the Wobble Hypothesis provides a mechanism to account for the degeneracy of the genetic code and the ability of a limited number of tRNA molecules to recognize and bind to multiple codons. The wobbling of the third base allows for greater flexibility in genetic coding while maintaining the accuracy of translation.
Definition of Wobble Hypothesis
The Wobble Hypothesis proposes that the third base of a codon and the anticodon of tRNA can exhibit flexibility or “wobble” in their base pairing, allowing a single tRNA molecule to recognize and bind to multiple codons, contributing to the degeneracy of the genetic code.
The Wobble Hypothesis
The Wobble Hypothesis proposes that the base at the 5′ end of the anticodon in tRNA is not as constrained spatially as the other two bases. This flexibility allows it to form hydrogen bonds with multiple bases located at the 3′ end of a codon in mRNA. The wobble hypothesis states that:
- The first two bases of the codon and the corresponding bases in the anticodon form normal Watson-Crick base pairs.
- The third position in the codon follows less strict base-pairing rules, leading to non-canonical pairing or “wobble.”
- The relaxed base-pairing requirement at the third position enables a single tRNA molecule to pair with more than one mRNA triplet.
- The specific rules for wobble pairing are: U in the first position of the anticodon can recognize A or G in the codon, G can recognize U or C, and I (inosine) can recognize U, C, or A.
- These characteristics led Francis Crick to propose the wobble hypothesis, which explains the flexible base-pairing interactions observed in the genetic code.
The coding specificity of the genetic code primarily depends on the first two bases of the codon, which form strong Watson-Crick base pairs with the anticodon of tRNA. The first nucleotide in the anticodon determines how many nucleotides the tRNA can distinguish when reading the codon in the 5′ to 3′ direction.
If the first nucleotide in the anticodon is C or A, the pairing is specific, and only one specific codon can be recognized by that tRNA. However, if the first nucleotide is U or G, the pairing is less specific, allowing interchangeability between two bases in the codon. In the case of inosine as the first nucleotide, it exhibits true wobble properties, enabling it to pair with any of three bases in the original codon.
Due to the specificity of the first two nucleotides in the codon, if an amino acid is coded for by multiple anticodons and those anticodons differ in the second or third position (first or second position in the codon), a different tRNA is required for each anticodon.
To satisfy all possible codons (61 excluding three stop codons), a minimum of 32 tRNA molecules is required. This includes 31 tRNAs for the amino acids and one for the initiation codon.
The Wobble Hypothesis provides a key understanding of the flexibility and degeneracy of the genetic code, allowing a limited number of tRNA molecules to recognize and bind to multiple codons while maintaining the accuracy of protein translation.

Wobble base pairs

Wobble base pairs are specific pairings between nucleotides in RNA molecules that deviate from the standard Watson-Crick base pair rules. They play a crucial role in RNA structure and translation. Here are some key points about wobble base pairs:
- Wobble base pairs involve non-standard pairings between nucleotides in specific positions.
- The four main wobble base pairs identified in RNA are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C).
- The use of “I” for hypoxanthine maintains consistency in nucleic acid nomenclature since hypoxanthine is the nucleobase of inosine.
- Among the wobble base pairs, inosine exhibits the most significant characteristics. If inosine is present as the first nucleotide in the anticodon of tRNA, it can pair with any of three bases (adenine, cytosine, or uracil) in the corresponding codon on mRNA.
- Inosine’s ability to wobble allows a single tRNA molecule with an inosine-containing anticodon to recognize multiple codons, expanding the flexibility of the genetic code.
Wobble base pairs introduce a level of versatility in RNA interactions, particularly during translation. They enable a reduced number of tRNA molecules to recognize multiple codons, compensating for the degeneracy of the genetic code. The wobble hypothesis, which explains these non-standard pairings, provides insights into the efficiency and accuracy of protein synthesis.

Short Exaplanation of The Wobble Hypothesis
Let’s dive into the Wobble Hypothesis step by step.
The Wobble Hypothesis is a concept that explains how the genetic code, stored in the form of nucleotides, is translated into proteins by the ribosome. To understand this hypothesis, we need to know a little bit about codons and anticodons.
Codons are sequences of three nucleotides in mRNA, and each codon corresponds to a specific amino acid or a stop signal. On the other hand, anticodons are sequences of three nucleotides in tRNA that bind to the codon during protein synthesis.
According to the Wobble Hypothesis, the base at the 5′ end of the anticodon is not as restricted in its pairing as the other two bases. This means that the first two bases of the codon and anticodon form normal hydrogen bond pairs, following the usual base-pairing rules (A with U, G with C). However, at the third position of the codon, the rules are more relaxed, and non-canonical pairing can occur.
In other words, the third base of the codon and the first base of the anticodon can form “wobble” pairs that do not strictly follow the A-U and G-C base-pairing rules. This flexibility allows the anticodon of a single tRNA molecule to recognize and bind to more than one codon with different nucleotide sequences at the third position.
To give you some examples of the wobble pairing rules:
- If the first base of the anticodon is U, it can recognize codons with A or G as the third base.
- If the first base of the anticodon is G, it can recognize codons with U or C as the third base.
- If the first base of the anticodon is I (Inosine), it can recognize codons with U, C, or A as the third base.
By allowing this “wobble” or relaxed base-pairing, the cell can minimize the number of tRNA molecules needed for protein synthesis. It provides flexibility and efficiency in translating the genetic code.
So, in summary, the Wobble Hypothesis proposes that the third base of the codon and the first base of the anticodon can form non-standard base pairs, leading to a more flexible set of base-pairing rules at the third position of the codon. This flexibility allows a single tRNA molecule to recognize and bind to multiple codons with different nucleotide sequences at the third position, optimizing protein synthesis.
Importance of the Wobble Hypothesis
The wobble hypothesis holds significant importance in understanding the efficiency and accuracy of protein synthesis. Here are key points highlighting the importance of the wobble hypothesis:
- Broad specificity with limited tRNAs: Our bodies possess a limited number of tRNA molecules. The wobble hypothesis allows a single tRNA to recognize multiple codons due to non-standard pairings at the wobble position. This broad specificity enables efficient translation with a smaller set of tRNAs.
- Facilitation of biological functions: Wobble base pairs have been extensively studied in organisms such as Escherichia coli ( E. coli ), demonstrating their role in various biological processes. They contribute to the accuracy of translation and protein synthesis.
- Comparable thermodynamic stability: Wobble base pairs exhibit thermodynamic stability similar to Watson-Crick base pairs. This stability ensures the integrity of RNA secondary structures and promotes reliable translation of the genetic code.
- Essential for RNA secondary structure: Wobble base pairs play a fundamental role in the formation of RNA secondary structures. They contribute to the stability and folding of RNA molecules, enabling the proper functioning of RNA in various cellular processes.
- Faster dissociation and protein synthesis: The wobble base pairing allows faster dissociation of tRNA from mRNA during the translation process. This rapid dissociation promotes efficient protein synthesis by facilitating the movement of ribosomes along the mRNA template.
- Minimizing errors in genetic code interpretation: The existence of wobble minimizes the impact of certain errors in the genetic code. If a codon is misread during transcription, wobble allows the tRNA to still recognize and correctly translate the codon, maintaining the appropriate amino acid sequence during protein synthesis. This reduces the potential damage that can arise from occasional errors in the reading of the genetic code.
Quiz on Wobble Hypothesis
What does the Wobble Hypothesis explain? a) The structure of DNA b) The replication of DNA c) The flexibility in the pairing of the third base of the codon d) The synthesis of proteins
Who proposed the Wobble Hypothesis? a) Rosalind Franklin b) James Watson c) Francis Crick d) Maurice Wilkins
According to the Wobble Hypothesis, which position of the codon shows flexibility in base pairing? a) First b) Second c) Third d) Fourth
Which base can pair with multiple bases according to the Wobble Hypothesis? a) Adenine b) Cytosine c) Guanine d) Thymine
The Wobble Hypothesis helps to explain why: a) There are more codons than amino acids b) There are more amino acids than codons c) Codons are always of fixed length d) DNA is double-stranded
Which of the following is NOT a valid wobble pairing? a) G-U b) A-U c) I-A d) C-G
The Wobble Hypothesis reduces the need for: a) Multiple DNA strands b) Multiple types of amino acids c) Multiple types of tRNAs d) Multiple types of ribosomes
Inosine (I) can pair with which of the following bases? a) Adenine b) Cytosine c) Both Adenine and Cytosine d) Neither Adenine nor Cytosine
The Wobble Hypothesis is primarily associated with: a) DNA replication b) Transcription c) Translation d) DNA repair
The flexibility in base pairing, as proposed by the Wobble Hypothesis, occurs between: a) mRNA codon and DNA template b) mRNA codon and tRNA anticodon c) tRNA anticodon and DNA template d) tRNA anticodon and ribosomal RNA
What is the wobble hypothesis?
The wobble hypothesis proposes that the base at the 5′ end of the anticodon in tRNA is not as strictly paired with the corresponding base in the mRNA codon, allowing for non-standard or wobble base pairings.
Why is it called the “wobble” hypothesis?
It is named the “wobble” hypothesis because the base at the wobble position is not spatially confined like the other two bases in the anticodon, allowing it to wobble or move unsteadily and form non-standard base pairs.
How does the wobble hypothesis explain degeneracy in the genetic code?
The wobble hypothesis suggests that the relaxed base-pairing rules at the third position of the codon allow a single tRNA molecule to recognize more than one codon. This accounts for the degeneracy or redundancy of the genetic code.
What are the main wobble base pairs?
The main wobble base pairs are guanine-uracil (G-U), hypoxanthine-uracil (I-U), hypoxanthine-adenine (I-A), and hypoxanthine-cytosine (I-C).
Why is hypoxanthine used in wobble base pairs?
Hypoxanthine is used to represent wobble base pairs because it is the nucleobase of inosine, which displays the true qualities of wobble by allowing for pairing with multiple bases in the original codon.
How does the wobble hypothesis impact protein synthesis?
The wobble base pairing allows for faster dissociation of tRNA from mRNA during protein synthesis, facilitating the movement of ribosomes and enhancing the efficiency of translation.
What role do wobble base pairs play in RNA secondary structure?
Wobble base pairs are fundamental in RNA secondary structure. They contribute to the stability and folding of RNA molecules, influencing their overall structure and function.
Does the wobble hypothesis affect the accuracy of the genetic code?
Yes, the wobble hypothesis helps to minimize errors in the interpretation of the genetic code. It ensures that even if there is a mismatch at the wobble position, the correct amino acid can still be incorporated during protein synthesis.
How does the wobble hypothesis impact the number of tRNA molecules needed?
The wobble hypothesis allows a single tRNA molecule to recognize multiple codons due to non-standard pairings. This broad specificity reduces the number of unique tRNA molecules required for translation.
How has the wobble hypothesis contributed to our understanding of molecular biology?
The wobble hypothesis has provided insights into the efficiency and accuracy of protein synthesis, RNA structure, and the functioning of the genetic code. It has enhanced our understanding of how cells optimize resources and maintain fidelity in the complex process of translating genetic information into functional proteins.
- https://microbenotes.com/the-wobble-hypothesis/
- https://en.wikipedia.org/wiki/Wobble_base_pair
- https://teaching.ncl.ac.uk/bms/wiki/index.php/Wobble_Hypothesis
- https://link.springer.com/referenceworkentry/10.1007%2F978-3-642-11274-4_1692
- https://www.biologydiscussion.com/genetics/wobble-hypothesis-with-diagram-genetics/65163
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
This site uses Akismet to reduce spam. Learn how your comment data is processed .

- __Crossword/Puzzle
- __Resources
- Difference Between
- Biology MCQ
- _Chemistry for Biologists
What is Wobble Hypothesis?
- The multiple codes for a given amino acid( degeneracy )
- Possible suppression of point mutations in the third base of the codon
- More easily removed deacylated tRNA during protein synthesis.
- Fewer tRNA molecules than expected.
Our website uses cookies to improve your experience. Learn more
Contact form
Explain 'Wobble hypothesis' with the help of a suitable diagram.
Wobble hypothesis states the degeneracy of the genetic code. the pairing of the third base varies according to the base at the third position, for example, g may pair with u. the conventional pairing (a = u, g = c) is called watson-crick pairing and the second abnormal pairing is called wobble pairing..

What is the wobble theory?
Wobble theory: the crick wobble hypothesis attributes the phenomenon of codon degeneracy to an imprecise pairing of the codon's third base and the anticodon's first base. the pairing features of several wobble bases, both seen and undiscovered, are investigated in this theoretical work. the genetic code is degenerate, which means that one amino acid is coded by several codons. to explain the degeneracy of codons in the third position of the codon. a wobble is defined as an unstable movement or a quiver in the voice..

What is the wobble effect?

IMAGES
VIDEO
COMMENTS
The Wobble Hypothesis: Definition, Statement, Significance. There are more than one codon for one amino acid. This is called degeneracy of genetic code. To explain the possible cause of degeneracy of codons, in 1966, Francis Crick proposed "the Wobble hypothesis". According to The Wobble Hypothesis, only the first two bases of the codon ...
Here are some examples of the wobble hypothesis in action: Arginine: The amino acid arginine is coded by six different codons: CGU, CGC, CGA, CGG, AGA, and AGG. However, no six different tRNA molecules correspond to each of these codons. Instead, one tRNA molecule with the anticodon 3′-CCU-5′ can recognize the codons CGU, CGC, and CGA ...
The Wobble Hypothesis, proposed by Francis Crick in 1966, provides an explanation for the degeneracy of the genetic code. Degeneracy refers to the fact that multiple codons can code for the same amino acid. According to the Wobble Hypothesis, the precise pairing between the bases of the codon and the anticodon of tRNA occurs only for the first ...
In this article we will discuss about the concept of wobble hypothesis. Crick (1966) proposed the 'wobble hypothesis' to explain the degeneracy of the genetic code. Except for tryptophan and methionine, more than one codons direct the synthesis of one amino acid. There are 61 codons that synthesise amino acids, therefore, there must be 61 ...
The Wobble Hypothesis. Genetic Code Study Notes: There are 64 possible codons in the genetic code, each consisting of a 3-nucleotide sequence. Translation requires tRNA molecules, each with an anticodon that complements a specific mRNA codon. Canonical Watson-Crick base pairing is used for stable tRNA-mRNA binding during translation.
Wobble hypothesis tRNA wobble, Wobble position. A property of the genetic code in which codons that differ in the third position (wobble position) can specify the same tRNA/amino acid.
Search for: 'wobble hypothesis' in Oxford Reference ». A theory to explain the partial degeneracy of the genetic code due to the fact that some t-RNA molecules can recognize more than one codon. The theory proposes that the first two bases in the codon and anticodon will form complementary pairs in the normal antiparallel fashion.
The Wobble Hypothesis states that position 34 inosine may base pair with uridine, cytidine, and adenosine. ... It is interesting to note that U 34 is primarily modified at C5 adjacent to the base-pairing face and hence the modifications do not interfere with its hydrogen bonding to the codon except in cases where the modifications introduce ...
wobble hypothesis A theory proposed to explain the partial degeneracy of the genetic code in that some t-RNA molecules can recognize more than one codon.It is proposed that the first 2 bases in the codon and anticodon will form complementary pairs in the normal antiparallel fashion. However, a degree of steric freedom or 'wobble' is allowed in the base pairing at the third position.
The rules governing this RNA:RNA interaction were originally summarised in Crick's 'wobble hypothesis'. Covalent modification of the first base of an anticodon of a transfer RNA can profoundly affect the degree of flexibility in its base-pairing potential by either extending or restricting such interactions. Recent studies suggest that the ...
A code word or codon is the set of nucleotides that specifies one amino acid. By genetic code, one refers to the collection of sequences of bases (codons) that correspond to each amino acid and translation signals. Regarding the possible size of a codon, we can consider George Gamov's (1954) traditional yet rational explanation.
elongation. polysome. Wobble Hypothesis. free v. bound ribosomes. reading phase. This page titled 11.5: Key Words and Terms is shared under a CC BY license and was authored, remixed, and/or curated by Gerald Bergtrom. 11.4: Translation. 12: Regulation of Transcription and Epigenetic Inheritance.
A wobble pair, or wobble-base pair, is a hydrogen-bonded pairing between two nucleotides generally occurring between two RNA molecules. These base pairs are geometrically distinct from the canonical Watson-Crick-type base-pairing. The main wobble base pairs are hypoxanthine-uracil (I-U, where I represents inosine, the nucleoside formed from ...
individual and combined effects on tRNA function in recognition of cognate and wobble codons. As forecast by the Modified Wobble Hypothesis 25 years ago, some individual modifications at tRNA's wobble position have evolved to restrict codon recognition whereas others expand the tRNA's ability to read as many as four synonymous codons.
According to the wobble hypothesis , G34 base-pairs with C and U as the third nucleoside of the codon [denoted C(III) and U(III)], whereas C34 only base-pairs with G(III). Uridine as the wobble nucleoside cannot interact with a pyrimidine in the mRNA, since two pyrimidines are too "short" to form a base pair.
F.H.C. Crick, in 1965 proposed a hypothesis called Wobble hypothesis to explain this phenomenon. He discovered that if U is present at first position of anticodon, it can pair with either A or G at the third position of codon. Similar is the case with G and I (I = inosine is a modified base in tRNA) found in anticodon. The pairing relationships ...
CRICK1 first considered in the "wobble hypothesis" the biological relevance of base pairs beyond the canonical ones A:T(U) and G(I):C. Podder2 was able to estimate the stability of the G:U ...
eg. Inosine (I) can pair with A, C, or U. This base is called a Wobble base or fluctuating base. Wobble occurs at position 1 of the anti-codon and position 3 of the codon. The wobble hypothesis states that the third position (3') of the codon on mRNA and the first position (5') of the anti-codon on tRNA are bound less tightly than the other ...
The wobble hypothesis holds significant importance in understanding the efficiency and accuracy of protein synthesis. Here are key points highlighting the importance of the wobble hypothesis: Broad specificity with limited tRNAs: Our bodies possess a limited number of tRNA molecules. The wobble hypothesis allows a single tRNA to recognize ...
The wobble hypothesis states that the third position (3') of the codon on mRNA and the first position (5') of the anticodon on tRNA are bound less tightly than the other pair and therefore, offer unusual base combinations. This phenomenon give rise to: The multiple codes for a given amino acid ( degeneracy) Possible suppression of point ...
Solution. Verified by Toppr. Wobble hypothesis states the degeneracy of the genetic code. The pairing of the third base varies according to the base at the third position, for example, G may pair with U. The conventional pairing (A = U, G = C) is called Watson-Crick pairing and the second abnormal pairing is called wobble pairing.
The pairing features of several wobble bases, both seen and undiscovered, are investigated in this theoretical work. The genetic code is degenerate, which means that one amino acid is coded by several codons. To explain the degeneracy of codons in the third position of the codon. A wobble is defined as an unstable movement or a quiver in the voice.