
An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.


StatPearls [Internet].
Case control studies.
Steven Tenny ; Connor C. Kerndt ; Mary R. Hoffman .
Affiliations
Last Update: March 27, 2023 .
- Introduction
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes. [1] The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to the case individuals but do not have the outcome of interest. The researcher then looks at historical factors to identify if some exposure(s) is/are found more commonly in the cases than the controls. If the exposure is found more commonly in the cases than in the controls, the researcher can hypothesize that the exposure may be linked to the outcome of interest.
For example, a researcher may want to look at the rare cancer Kaposi's sarcoma. The researcher would find a group of individuals with Kaposi's sarcoma (the cases) and compare them to a group of patients who are similar to the cases in most ways but do not have Kaposi's sarcoma (controls). The researcher could then ask about various exposures to see if any exposure is more common in those with Kaposi's sarcoma (the cases) than those without Kaposi's sarcoma (the controls). The researcher might find that those with Kaposi's sarcoma are more likely to have HIV, and thus conclude that HIV may be a risk factor for the development of Kaposi's sarcoma.
There are many advantages to case-control studies. First, the case-control approach allows for the study of rare diseases. If a disease occurs very infrequently, one would have to follow a large group of people for a long period of time to accrue enough incident cases to study. Such use of resources may be impractical, so a case-control study can be useful for identifying current cases and evaluating historical associated factors. For example, if a disease developed in 1 in 1000 people per year (0.001/year) then in ten years one would expect about 10 cases of a disease to exist in a group of 1000 people. If the disease is much rarer, say 1 in 1,000,0000 per year (0.0000001/year) this would require either having to follow 1,000,0000 people for ten years or 1000 people for 1000 years to accrue ten total cases. As it may be impractical to follow 1,000,000 for ten years or to wait 1000 years for recruitment, a case-control study allows for a more feasible approach.
Second, the case-control study design makes it possible to look at multiple risk factors at once. In the example above about Kaposi's sarcoma, the researcher could ask both the cases and controls about exposures to HIV, asbestos, smoking, lead, sunburns, aniline dye, alcohol, herpes, human papillomavirus, or any number of possible exposures to identify those most likely associated with Kaposi's sarcoma.
Case-control studies can also be very helpful when disease outbreaks occur, and potential links and exposures need to be identified. This study mechanism can be commonly seen in food-related disease outbreaks associated with contaminated products, or when rare diseases start to increase in frequency, as has been seen with measles in recent years.
Because of these advantages, case-control studies are commonly used as one of the first studies to build evidence of an association between exposure and an event or disease.
In a case-control study, the investigator can include unequal numbers of cases with controls such as 2:1 or 4:1 to increase the power of the study.
Disadvantages and Limitations
The most commonly cited disadvantage in case-control studies is the potential for recall bias. [2] Recall bias in a case-control study is the increased likelihood that those with the outcome will recall and report exposures compared to those without the outcome. In other words, even if both groups had exactly the same exposures, the participants in the cases group may report the exposure more often than the controls do. Recall bias may lead to concluding that there are associations between exposure and disease that do not, in fact, exist. It is due to subjects' imperfect memories of past exposures. If people with Kaposi's sarcoma are asked about exposure and history (e.g., HIV, asbestos, smoking, lead, sunburn, aniline dye, alcohol, herpes, human papillomavirus), the individuals with the disease are more likely to think harder about these exposures and recall having some of the exposures that the healthy controls.
Case-control studies, due to their typically retrospective nature, can be used to establish a correlation between exposures and outcomes, but cannot establish causation . These studies simply attempt to find correlations between past events and the current state.
When designing a case-control study, the researcher must find an appropriate control group. Ideally, the case group (those with the outcome) and the control group (those without the outcome) will have almost the same characteristics, such as age, gender, overall health status, and other factors. The two groups should have similar histories and live in similar environments. If, for example, our cases of Kaposi's sarcoma came from across the country but our controls were only chosen from a small community in northern latitudes where people rarely go outside or get sunburns, asking about sunburn may not be a valid exposure to investigate. Similarly, if all of the cases of Kaposi's sarcoma were found to come from a small community outside a battery factory with high levels of lead in the environment, then controls from across the country with minimal lead exposure would not provide an appropriate control group. The investigator must put a great deal of effort into creating a proper control group to bolster the strength of the case-control study as well as enhance their ability to find true and valid potential correlations between exposures and disease states.
Similarly, the researcher must recognize the potential for failing to identify confounding variables or exposures, introducing the possibility of confounding bias, which occurs when a variable that is not being accounted for that has a relationship with both the exposure and outcome. This can cause us to accidentally be studying something we are not accounting for but that may be systematically different between the groups.
The major method for analyzing results in case-control studies is the odds ratio (OR). The odds ratio is the odds of having a disease (or outcome) with the exposure versus the odds of having the disease without the exposure. The most straightforward way to calculate the odds ratio is with a 2 by 2 table divided by exposure and disease status (see below). Mathematically we can write the odds ratio as follows.
Odds ratio = [(Number exposed with disease)/(Number exposed without disease) ]/[(Number not exposed to disease)/(Number not exposed without disease) ]
This can be rewritten as:
Odds ratio = [ (Number exposed with disease) x (Number not exposed without disease) ] / [ (Number exposed without disease ) x (Number not exposed with disease) ]
The odds ratio tells us how strongly the exposure is related to the disease state. An odds ratio of greater than one implies the disease is more likely with exposure. An odds ratio of less than one implies the disease is less likely with exposure and thus the exposure may be protective. For example, a patient with a prior heart attack taking a daily aspirin has a decreased odds of having another heart attack (odds ratio less than one). An odds ratio of one implies there is no relation between the exposure and the disease process.
Odds ratios are often confused with Relative Risk (RR), which is a measure of the probability of the disease or outcome in the exposed vs unexposed groups. For very rare conditions, the OR and RR may be very similar, but they are measuring different aspects of the association between outcome and exposure. The OR is used in case-control studies because RR cannot be estimated; whereas in randomized clinical trials, a direct measurement of the development of events in the exposed and unexposed groups can be seen. RR is also used to compare risk in other prospective study designs.
- Issues of Concern
The main issues of concern with a case-control study are recall bias, its retrospective nature, the need for a careful collection of measured variables, and the selection of an appropriate control group. [3] These are discussed above in the disadvantages section.
- Clinical Significance
A case-control study is a good tool for exploring risk factors for rare diseases or when other study types are not feasible. Many times an investigator will hypothesize a list of possible risk factors for a disease process and will then use a case-control study to see if there are any possible associations between the risk factors and the disease process. The investigator can then use the data from the case-control study to focus on a few of the most likely causative factors and develop additional hypotheses or questions. Then through further exploration, often using other study types (such as cohort studies or randomized clinical studies) the researcher may be able to develop further support for the evidence of the possible association between the exposure and the outcome.
- Enhancing Healthcare Team Outcomes
Case-control studies are prevalent in all fields of medicine from nursing and pharmacy to use in public health and surgical patients. Case-control studies are important for each member of the health care team to not only understand their common occurrence in research but because each part of the health care team has parts to contribute to such studies. One of the most important things each party provides is helping identify correct controls for the cases. Matching the controls across a spectrum of factors outside of the elements of interest take input from nurses, pharmacists, social workers, physicians, demographers, and more. Failure for adequate selection of controls can lead to invalid study conclusions and invalidate the entire study.
- Review Questions
- Access free multiple choice questions on this topic.
- Comment on this article.
2x2 table with calculations for the odds ratio and 95% confidence interval for the odds ratio Contributed by Steven Tenny MD, MPH, MBA
Disclosure: Steven Tenny declares no relevant financial relationships with ineligible companies.
Disclosure: Connor Kerndt declares no relevant financial relationships with ineligible companies.
Disclosure: Mary Hoffman declares no relevant financial relationships with ineligible companies.
This book is distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) ( http://creativecommons.org/licenses/by-nc-nd/4.0/ ), which permits others to distribute the work, provided that the article is not altered or used commercially. You are not required to obtain permission to distribute this article, provided that you credit the author and journal.
- Cite this Page Tenny S, Kerndt CC, Hoffman MR. Case Control Studies. [Updated 2023 Mar 27]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.
In this Page
Bulk download.
- Bulk download StatPearls data from FTP
Related information
- PMC PubMed Central citations
- PubMed Links to PubMed
Similar articles in PubMed
- Suicidal Ideation. [StatPearls. 2024] Suicidal Ideation. Harmer B, Lee S, Duong TVH, Saadabadi A. StatPearls. 2024 Jan
- Qualitative Study. [StatPearls. 2024] Qualitative Study. Tenny S, Brannan JM, Brannan GD. StatPearls. 2024 Jan
- Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas. [Cochrane Database Syst Rev. 2022] Folic acid supplementation and malaria susceptibility and severity among people taking antifolate antimalarial drugs in endemic areas. Crider K, Williams J, Qi YP, Gutman J, Yeung L, Mai C, Finkelstain J, Mehta S, Pons-Duran C, Menéndez C, et al. Cochrane Database Syst Rev. 2022 Feb 1; 2(2022). Epub 2022 Feb 1.
- Review The epidemiology of classic, African, and immunosuppressed Kaposi's sarcoma. [Epidemiol Rev. 1991] Review The epidemiology of classic, African, and immunosuppressed Kaposi's sarcoma. Wahman A, Melnick SL, Rhame FS, Potter JD. Epidemiol Rev. 1991; 13:178-99.
- Review Epidemiology of Kaposi's sarcoma. [Cancer Surv. 1991] Review Epidemiology of Kaposi's sarcoma. Beral V. Cancer Surv. 1991; 10:5-22.
Recent Activity
- Case Control Studies - StatPearls Case Control Studies - StatPearls
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
- En español – ExME
- Em português – EME
Case-control and Cohort studies: A brief overview
Posted on 6th December 2017 by Saul Crandon

Introduction
Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence . These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as randomised controlled trials, they can provide strong evidence if designed appropriately.
Case-control studies
Case-control studies are retrospective. They clearly define two groups at the start: one with the outcome/disease and one without the outcome/disease. They look back to assess whether there is a statistically significant difference in the rates of exposure to a defined risk factor between the groups. See Figure 1 for a pictorial representation of a case-control study design. This can suggest associations between the risk factor and development of the disease in question, although no definitive causality can be drawn. The main outcome measure in case-control studies is odds ratio (OR) .
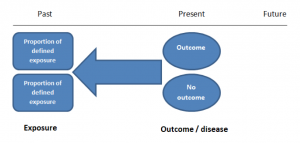
Figure 1. Case-control study design.
Cases should be selected based on objective inclusion and exclusion criteria from a reliable source such as a disease registry. An inherent issue with selecting cases is that a certain proportion of those with the disease would not have a formal diagnosis, may not present for medical care, may be misdiagnosed or may have died before getting a diagnosis. Regardless of how the cases are selected, they should be representative of the broader disease population that you are investigating to ensure generalisability.
Case-control studies should include two groups that are identical EXCEPT for their outcome / disease status.
As such, controls should also be selected carefully. It is possible to match controls to the cases selected on the basis of various factors (e.g. age, sex) to ensure these do not confound the study results. It may even increase statistical power and study precision by choosing up to three or four controls per case (2).
Case-controls can provide fast results and they are cheaper to perform than most other studies. The fact that the analysis is retrospective, allows rare diseases or diseases with long latency periods to be investigated. Furthermore, you can assess multiple exposures to get a better understanding of possible risk factors for the defined outcome / disease.
Nevertheless, as case-controls are retrospective, they are more prone to bias. One of the main examples is recall bias. Often case-control studies require the participants to self-report their exposure to a certain factor. Recall bias is the systematic difference in how the two groups may recall past events e.g. in a study investigating stillbirth, a mother who experienced this may recall the possible contributing factors a lot more vividly than a mother who had a healthy birth.
A summary of the pros and cons of case-control studies are provided in Table 1.
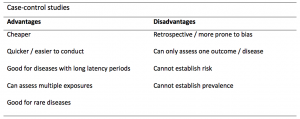
Table 1. Advantages and disadvantages of case-control studies.
Cohort studies
Cohort studies can be retrospective or prospective. Retrospective cohort studies are NOT the same as case-control studies.
In retrospective cohort studies, the exposure and outcomes have already happened. They are usually conducted on data that already exists (from prospective studies) and the exposures are defined before looking at the existing outcome data to see whether exposure to a risk factor is associated with a statistically significant difference in the outcome development rate.
Prospective cohort studies are more common. People are recruited into cohort studies regardless of their exposure or outcome status. This is one of their important strengths. People are often recruited because of their geographical area or occupation, for example, and researchers can then measure and analyse a range of exposures and outcomes.
The study then follows these participants for a defined period to assess the proportion that develop the outcome/disease of interest. See Figure 2 for a pictorial representation of a cohort study design. Therefore, cohort studies are good for assessing prognosis, risk factors and harm. The outcome measure in cohort studies is usually a risk ratio / relative risk (RR).
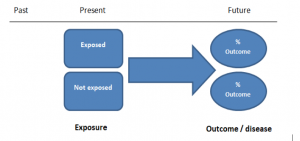
Figure 2. Cohort study design.
Cohort studies should include two groups that are identical EXCEPT for their exposure status.
As a result, both exposed and unexposed groups should be recruited from the same source population. Another important consideration is attrition. If a significant number of participants are not followed up (lost, death, dropped out) then this may impact the validity of the study. Not only does it decrease the study’s power, but there may be attrition bias – a significant difference between the groups of those that did not complete the study.
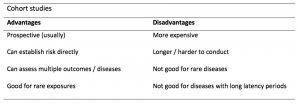
Cohort studies can assess a range of outcomes allowing an exposure to be rigorously assessed for its impact in developing disease. Additionally, they are good for rare exposures, e.g. contact with a chemical radiation blast.
Whilst cohort studies are useful, they can be expensive and time-consuming, especially if a long follow-up period is chosen or the disease itself is rare or has a long latency.
A summary of the pros and cons of cohort studies are provided in Table 2.
The Strengthening of Reporting of Observational Studies in Epidemiology Statement (STROBE)
STROBE provides a checklist of important steps for conducting these types of studies, as well as acting as best-practice reporting guidelines (3). Both case-control and cohort studies are observational, with varying advantages and disadvantages. However, the most important factor to the quality of evidence these studies provide, is their methodological quality.
- Song, J. and Chung, K. Observational Studies: Cohort and Case-Control Studies . Plastic and Reconstructive Surgery.  2010 Dec;126(6):2234-2242.
- Ury HK. Efficiency of case-control studies with multiple controls per case: Continuous or dichotomous data . Biometrics . 1975 Sep;31(3):643–649.
- von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP; STROBE Initiative. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies.  Lancet 2007 Oct;370(9596):1453-14577. PMID: 18064739.

Saul Crandon
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on Case-control and Cohort studies: A brief overview

Very well presented, excellent clarifications. Has put me right back into class, literally!

Very clear and informative! Thank you.

very informative article.

Thank you for the easy to understand blog in cohort studies. I want to follow a group of people with and without a disease to see what health outcomes occurs to them in future such as hospitalisations, diagnoses, procedures etc, as I have many health outcomes to consider, my questions is how to make sure these outcomes has not occurred before the “exposure disease”. As, in cohort studies we are looking at incidence (new) cases, so if an outcome have occurred before the exposure, I can leave them out of the analysis. But because I am not looking at a single outcome which can be checked easily and if happened before exposure can be left out. I have EHR data, so all the exposure and outcome have occurred. my aim is to check the rates of different health outcomes between the exposed)dementia) and unexposed(non-dementia) individuals.

Very helpful information

Thanks for making this subject student friendly and easier to understand. A great help.

Thanks a lot. It really helped me to understand the topic. I am taking epidemiology class this winter, and your paper really saved me.
Happy new year.

Wow its amazing n simple way of briefing ,which i was enjoyed to learn this.its very easy n quick to pick ideas .. Thanks n stay connected

Saul you absolute melt! Really good work man

am a student of public health. This information is simple and well presented to the point. Thank you so much.

very helpful information provided here

really thanks for wonderful information because i doing my bachelor degree research by survival model

Quite informative thank you so much for the info please continue posting. An mph student with Africa university Zimbabwe.

Thank you this was so helpful amazing

Apreciated the information provided above.

So clear and perfect. The language is simple and superb.I am recommending this to all budding epidemiology students. Thanks a lot.

Great to hear, thank you AJ!

I have recently completed an investigational study where evidence of phlebitis was determined in a control cohort by data mining from electronic medical records. We then introduced an intervention in an attempt to reduce incidence of phlebitis in a second cohort. Again, results were determined by data mining. This was an expedited study, so there subjects were enrolled in a specific cohort based on date(s) of the drug infused. How do I define this study? Thanks so much.

thanks for the information and knowledge about observational studies. am a masters student in public health/epidemilogy of the faculty of medicines and pharmaceutical sciences , University of Dschang. this information is very explicit and straight to the point

Very much helpful
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.

Expertise-based Randomized Controlled Trials
This blog summarizes the concepts of Expertise-based randomized controlled trials with a focus on the advantages and challenges associated with this type of study.

An introduction to different types of study design
Conducting successful research requires choosing the appropriate study design. This article describes the most common types of designs conducted by researchers.
Randomized Trials and Case–Control Matching Techniques
- First Online: 14 December 2022
Cite this chapter

- Emanuele Russo 34 ,
- Annalaura Montalti 35 ,
- Domenico Pietro Santonastaso 34 &
- Giuliano Bolondi 34
Part of the book series: Hot Topics in Acute Care Surgery and Trauma ((HTACST))
310 Accesses
Randomized control trials (RCTs) are deemed to be among the most powerful and rigorous clinical research instruments. The main application is to evaluate the effectiveness and safety of new treatment or clinical approach. Researchers employ several strategies to reduce bias and increase the strength of results such as “blinding,” multicenter enrollment, and different randomization designs. Finding’s interpretation needs meticulous reporting of each phase of the trial. RCTs are not appropriate for the validation of screening tests and for the study of rare outcomes.
Case–control studies are a sub-type of retrospective observational studies. The main goal of case–control studies is to investigate the risk factors that led to the development of the disease. This type of design allows relative risk to be estimated by means of odds ratios and it is deemed to be an efficient means of studying rare diseases with a long-term latency period.
In case–control studies, matching techniques are often employed. Pairing techniques allow to control some confounding factors and increase statistical power in studies with small populations. Patient matching is increasingly performed by complex techniques such as propensity score and inverse probability.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Holy Bible Book of Daniel (1; 1–21).
Google Scholar
Amberson JB, McMahon BT, Pinner M. A clinical trial of sanocrysin in pulmonary tuberculosis. Am Rev Tuberc. 1931;24:401–35.
Streptomycin treatment of pulmonary tuberculosis. Br Med J. 1948;2(4582):769–82.
Article Google Scholar
Stolberg HO, Norman G, Trop I. Randomized controlled trials. Fundamentals of clinical research for radiologists. Am J Roentgenol. 2004;183:1539–44. https://doi.org/10.2214/ajr.183.6.01831539 .
De Angelis C, Drazen JM, Frizelle FA, et al. Clinical trial registration: a statement from the International Committee of Medical Journal Editors. N Engl J Med. 2004;351(12):1250–1.
Pocock SJ, Assmann SE, Enos LE, Kasten LE. Subgroup analysis, covariate adjustment and baseline comparisons in clinical trial reporting: current practice and problems. Stat Med. 2002;21(19):2917–30. https://doi.org/10.1002/sim.1296 .
Horton R. From star signs to trial guidelines. Lancet. 2000;355(9209):1033–4. https://doi.org/10.1016/S0140-6736(00)02031-6 .
Article CAS Google Scholar
World Medical Association. World Medical Association Declaration of Helsinki: ethical principles for medical research involving human subjects. JAMA. 2013;310(20):2191–4. https://doi.org/10.1001/jama.2013.281053 .
Hannan EL. Randomized clinical trials and observational studies: guidelines for assessing respective strengths and limitations. JACC Cardiovasc Interv. 2008;1(3):211–7. https://doi.org/10.1016/j.jcin.2008.01.008 .
Benson K, Hartz AJ. A comparison of observational studies and randomized, controlled trials. N Engl J Med. 2000;342(25):1878–86. https://doi.org/10.1056/NEJM200006223422506 .
Feys F, et al. Do randomized clinical trials with inadequate blinding report enhanced placebo effects for intervention groups and nocebo effects for placebo groups? Syst Rev. 2014;3:14.
Lee CS, Lee AY. How artificial intelligence can transform randomized controlled trials. Transl Vis Sci Technol. 2020;9(2):9. https://doi.org/10.1167/tvst.9.2.9 .
Banerjee A, Chitnis UB, Jadhav SL, Bhawalkar JS, Chaudhury S. Hypothesis testing, type I and type II errors. Ind Psychiatry J. 2009;18(2):127–31. https://doi.org/10.4103/0972-6748.62274 .
Moher D, Schulz KF, Altman DG, CONSORT GROUP (Consolidated Standards of Reporting Trials). The CONSORT statement: revised recommendations for improving the quality of reports of parallel-group randomized trials. Ann Intern Med. 2001;134(8):657–62. https://doi.org/10.7326/0003-4819-134-8-200104170-00011 .
Begg C, Cho M, Eastwood S, Horton R, Moher D, Olkin I, et al. Improving the quality of reporting of randomized controlled trials. The CONSORT Statement. JAMA. 1996;276(8):637–9. https://doi.org/10.1001/jama.276.8.637 .
Piaggio G, Elbourne DR, Altman DG, Pocock SJ, SJW E, CONSORT Group FT. Reporting of noninferiority and equivalence randomized trials: an extension of the CONSORT Statement. JAMA. 2006;295(10):1152–60. https://doi.org/10.1001/jama.295.10.1152 .
Ioannidis JPA, Dixon DO, McIntosh M, Albert JM, Bozzette SA, Schnittman SN. Relationship between event rates and treatment effects in clinical site differences within multicenter trials: an example from primary Pneumocystis carinii Prophylaxi. Control Clin Trials. 1999;20:253–66.
CRASH-2 Collaborators, Roberts I, Shakur H, Afolabi A, Brohi K, Coats T, Dewan Y, Gando S, Guyatt G, Hunt BJ, Morales C, Perel P, Prieto-Merino D, Woolley T. The importance of early treatment with tranexamic acid in bleeding trauma patients: an exploratory analysis of the CRASH-2 randomised controlled trial. Lancet. 2011;377(9771):1096–101, 1101.e1–2. https://doi.org/10.1016/S0140-6736(11)60278-X .
Mitra B, Mazur S, Cameron PA, Bernard S, Burns B, Smith A, Rashford S, Fitzgerald M, Smith K, Gruen RL. Tranexamic acid for trauma: filling the GAP in evidence. Emerg Med Australas. 2014;26:194–7.
Hróbjartsson A, Boutron I. Blinding in randomized clinical trials: imposed impartiality. Clin Pharmacol Ther. 2011;90(5):732–6. https://doi.org/10.1038/clpt.2011.207 .
Karanicolas PJ, Farrokhyar F, Bhandari M. Practical tips for surgical research: blinding: who, what, when, why, how? Can J Surg. 2010;53(5):345–8.
Kao LS, Tyson JE, Blakely ML, Lally KP. Clinical research methodology I: introduction to randomized trials. J Am Coll Surg. 2008;206(2):361–9.
Suresh KP. An overview of randomization techniques: an unbiased assessment of outcome in clinical research. J Hum Reprod Sci. 2011;4:8–11.
Hopewell S, Dutton S, Yu LM, Chan AW, Altman DG. The quality of reports of randomised trials in 2000 and 2006: comparative study of articles indexed in PubMed. BMJ. 2010;340:c723. https://doi.org/10.1136/bmj.c723 .
Deaton A, Cartwright N. Understanding and misunderstanding randomized controlled trials. Soc Sci Med. 2018;210:2–21. https://doi.org/10.1016/j.socscimed.2017.12.005 .
Sibbald B, Roland M. Why are randomized controlled trials important? BMJ. 1998;316:201.
Hein S, Weeland J. Introduction to the special issue. Randomized control trials (RCTs) in clinical and community settings: challenges, alternatives and supplementary designs. New Dir Child Adolesc Dev. 2019;2019(167):7–15. https://doi.org/10.1002/cad.20312 .
Thompson D. Understanding financial conflicts of interest. N Engl J Med. 1993;329:573–6.
Bekelman JE, Li Y, Gross CP. Scope and impact of financial conflicts of interest in biomedical research: a systematic review. JAMA. 2003;289(4):454–65. https://doi.org/10.1001/jama.289.4.454 .
Bhandari M, Busse JW, Jackowski D, Montori VM, Schünemann H, Sprague S, Mears D, Schemitsch EH, Heels-Ansdell D, Devereaux PJ. Association between industry funding and statistically significant pro-industry findings in medical and surgical randomized trials. CMAJ. 2004;170(4):477–80.
Sason-Fisher RW, Bonevski B, Green LW, D’Este C. Limitations of the randomized controlled trial in evaluation population-based Health intervention. Am J Prev Med. 2007;33(2):155–61.
Kraemer HC, Robinson TN. Are certain multicenter randomized clinical trial structures misleading clinical and policy decisions? Contemp Clin Trials. 2005;26(5):518–29. https://doi.org/10.1016/j.cct.2005.05.002 .
Harris PNA, Tambyah PA, Lye DC, et al. MERINO Trial Investigators and the Australasian Society for Infectious Disease Clinical Research Network (ASID-CRN). Effect of Piperacillin-Tazobactam vs Meropenem on 30-day mortality for patients with E coli or Klebsiella pneumoniae bloodstream infection and ceftriaxone resistance: a randomized clinical trial. JAMA. 2018;320(10):984–94. [Erratum in: JAMA. 2019 Jun 18;321(23):2370]. https://doi.org/10.1001/jama.2018.12163 .
Rodríguez-Baño J, Gutiérrez-Gutiérrez B, Kahlmeter G. Antibiotics for ceftriaxone-resistant gram-negative bacterial bloodstream infections. JAMA. 2019;321(6):612–3. https://doi.org/10.1001/jama.2018.19345 .
Missing information on sample size. JAMA. 2019;321(23):2370. [Erratum for: JAMA. 2018;320(10):984–994]. https://doi.org/10.1001/jama.2019.6706 .
Pearce N. Analysis of matched case-control studies. BMJ. 2016;352:i969. https://doi.org/10.1136/bmj.i969 .
Wachoider S, Silverman DT, McLaughlin JK, Mandel JS. Selection of controls in case-control studies. Am J Epidemiol. 1992;135(9):1042–50.
Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70(1):41–55.
Chesnaye NC, Stel VS, Tripepi G, Dekker FW, Fu EL, Zoccali C, Jager KJ. An introduction to inverse probability of treatment weighting in observational research. Clin Kidney J. 2021;15(1):14–20. https://doi.org/10.1093/ckj/sfab158 .
Schulte PJ, Mascha EJ. Propensity score methods: theory and practice for anesthesia research. Anesth Analg. 2018;127(4):1074–84. https://doi.org/10.1213/ANE.0000000000002920 .
Rodríguez-Pardo J, Plaza Herráiz A, Lobato-Pérez L, Ramírez-Torres M, De Lorenzo I, Alonso de Leciñana M, Díez-Tejedor E, Fuentes B. Influence of oral anticoagulation on stroke severity and outcomes: a propensity score matching case-control study. J Neurol Sci. 2020;410:116685. https://doi.org/10.1016/j.jns.2020.116685 .
Austin PC, Stuart EA. Moving towards best practice when using inverse probability of treatment weighting (IPTW) using the propensity score to estimate causal treatment effects in observational studies. Stat Med. 2015;34(28):3661–79. https://doi.org/10.1002/sim.6607 .
Download references
Author information
Authors and affiliations.
Anesthesia and Intensive Care Unit, AUSL Romagna, Maurizio Bufalini Hospital, Cesena FC, Italy
Emanuele Russo, Domenico Pietro Santonastaso & Giuliano Bolondi
Risk and Compliance, Healthcare, KPMG Advisory S.p.A., Milan, Italy
Annalaura Montalti
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Emanuele Russo .
Editor information
Editors and affiliations.
General and Emergency Surgery Department, School of Medicine and Surgery, Milano-Bicocca University, Monza, Italy
Marco Ceresoli
Department of Surgery, College of Medicine and Health Science, United Arab Emirates University, Abu Dhabi, United Arab Emirates
Fikri M. Abu-Zidan
Department of Surgery, Stanford University, Stanford, CA, USA
Kristan L. Staudenmayer
General and Emergency Surgery Department, Bufalini Hospital, Cesena, Italy
Fausto Catena
Department of General, Emergency and Trauma Surgery, Pisa University Hospital, Pisa, Pisa, Italy
Federico Coccolini
Rights and permissions
Reprints and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Russo, E., Montalti, A., Santonastaso, D.P., Bolondi, G. (2022). Randomized Trials and Case–Control Matching Techniques. In: Ceresoli, M., Abu-Zidan, F.M., Staudenmayer, K.L., Catena, F., Coccolini, F. (eds) Statistics and Research Methods for Acute Care and General Surgeons. Hot Topics in Acute Care Surgery and Trauma. Springer, Cham. https://doi.org/10.1007/978-3-031-13818-8_10
Download citation
DOI : https://doi.org/10.1007/978-3-031-13818-8_10
Published : 14 December 2022
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-13817-1
Online ISBN : 978-3-031-13818-8
eBook Packages : Medicine Medicine (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Research article
- Open access
- Published: 12 May 2020
A mixed methods case study investigating how randomised controlled trials (RCTs) are reported, understood and interpreted in practice
- Ben E. Byrne ORCID: orcid.org/0000-0002-2183-8166 1 ,
- Leila Rooshenas 1 ,
- Helen S. Lambert 2 &
- Jane M. Blazeby 1 , 3 , 4
BMC Medical Research Methodology volume 20 , Article number: 112 ( 2020 ) Cite this article
3143 Accesses
2 Citations
10 Altmetric
Metrics details
While randomised controlled trials (RCTs) provide high-quality evidence to guide practice, much routine care is not based upon available RCTs. This disconnect between evidence and practice is not sufficiently well understood. This case study explores this relationship using a novel approach. Better understanding may improve trial design, conduct, reporting and implementation, helping patients benefit from the best available evidence.
We employed a case-study approach, comprising mixed methods to examine the case of interest: the primary outcome paper of a surgical RCT (the TIME trial). Letters and editorials citing the TIME trial’s primary report underwent qualitative thematic analysis, and the RCT was critically appraised using validated tools. These analyses were compared to provide insight into how the TIME trial findings were interpreted and appraised by the clinical community.
23 letters and editorials were studied. Most authorship included at least one academic (20/23) and one surgeon (21/23). Authors identified wide-ranging issues including confounding variables or outcome selection. Clear descriptions of bias or generalisability were lacking. Structured appraisal identified risks of bias. Non-RCT evidence was less critically appraised. Authors reached varying conclusions about the trial without consistent justification. Authors discussed aspects of internal and external validity covered by appraisal tools but did not use these methodological terms in their articles.
Conclusions
This novel method for examining interpretation of an RCT in the clinical community showed that published responses identified limited issues with trial design. Responses did not provide coherent rationales for accepting (or not) trial results. Findings may suggest that authors lacked skills in appraisal of RCT design and conduct. Multiple case studies with cross-case analysis of other trials are needed.
Peer Review reports
It is widely recognised that clinical practice is often not in line with the best available evidence. This is the so-called ‘gap’ between research and practice [ 1 , 2 ]. Best evidence predominantly comes from well designed and conducted randomised controlled trials (RCTs) [ 3 ]. However, RCTs are often complex and challenging. Surgical RCTs present specific issues with recruitment, blinding of patients and surgeons, and intervention standardisation [ 4 ]. Many of these issues have been clarified with methodological research [ 5 , 6 , 7 , 8 , 9 , 10 ]. Such work has led to improvements in trial quality over time [ 11 , 12 ]. However, the gap between trials and implementation of their results in practice persists [ 13 ], potentially compromising patient care and wasting resources. Reasons for the disconnect are myriad.
Trial findings that report putative evidence for a change in clinical practice may not be implemented because of poor conduct and reporting [ 14 ], limitations in generalisation and applicability [ 15 ], cost, and unacceptability of new interventions. Clinical culture may emphasise the importance of experience over evidence [ 16 ], and some clinicians may have limited numeracy skills required to understand and apply quantitative results from trials [ 17 ]. Appropriate understanding of RCTs is critical to implementation and of vital importance to clinicians, researchers and funders. We have previously described a novel approach to explore understanding and interpretation of RCT evidence, by examining writings about individual surgical trials [ 18 ]. The present study aims to apply this new method to a single case study: the TIME (Traditional Invasive versus Minimally invasive Esophagectomy) RCT [ 19 ]. The purpose is to better understand how this trial has been interpreted and to illustrate the potential of this novel approach.
The methodology used in this study has been described in detail elsewhere [ 18 ] and will be summarised here. The approach represents a form of case-study research, comprising mixed methods analysis of documentary evidence relating to a published RCT [ 20 ]. Case-study approaches have been defined in various ways and used across numerous disciplines. Their central tenet is to explore an event or phenomenon in depth and in its natural context [ 21 ]. The ‘real-world context’ in this study was the landscape of published articles that interpreted, appraised and discussed implementation of the TIME trial’s findings. Our approach aligned with Stake’s ‘instrumental case-study’ [ 22 ], using a particular case (the TIME RCT’s outcomes paper) to gain a broader appreciation of the issue or phenomenon of interest (in this case, interpretation and appraisal of RCTs in the clinical community, and implications for implementation). We conducted qualitative analysis of selected published articles citing this RCT’s primary report and compared this with structured critical appraisal of the RCT using established tools. We also sought to demonstrate the utility of this novel approach, which we intend to apply in future case studies.
Identify and analyse articles citing a trial
Purposefully select a major surgical rct.
An index RCT was identified and summarised as the case of interest. We sought a highly cited trial report, published in a high-impact journal within the last 10 years. The TIME trial [ 19 ], comparing open and minimally invasive surgical access for removal of oesophageal cancer, was selected as it met these criteria and was within our area of expertise.
Identify and systematically sample articles citing the RCT
All articles citing this RCT were identified using Web of Science and Scopus citation tracking tools. Letter, editorial and discussion article types were included. On-line comments were identified using the Altmetric.com bookmarklet. Non-English language articles were excluded. Searches were conducted in October 2017.
Undertake in-depth qualitative analysis and identify relevant themes
Included articles were thematically analysed using the constant comparison technique, adopted from grounded theory [ 23 , 24 ]. Articles were read in detail, with no a priori coding framework. Text was considered against the research topic, which focused on understanding how the authors interpreted, appraised and/or applied the findings of the trial. New findings or interpretations were continuously related to existing findings to develop the data set as a whole (i.e. the constant comparison technique). Coding was not constrained by pre-defined boundaries defining relevance. Rather, this was guided by the content of the articles being analysed. During analysis, it transpired that understanding authors’ interpretations of the RCT required examination of their discussion of evidence from other studies. Therefore, other articles cited by the authors were sought to determine the types of evidence being referenced. The designs of these additional studies were ascertained based on the descriptions in those articles (rather than our assessment).
Analysis was performed by BEB and LR. BEB is a senior surgical trainee and postdoctoral researcher with previous experience of qualitative research. LR is a Lecturer in Qualitative Health Science with an interest in trial recruitment issues, implementation of trial evidence, and experience of working on multiple surgical RCTs. Both researchers work within a department with expertise in trials methodology and have detailed knowledge in this field which is likely to have influenced their identification and coding of relevant themes.
Two rounds of double coding of five articles were performed by BEB and LR. Further coding was conducted by BEB and reviewed among the team to revise coded themes. Descriptive data on authorship and origins of the articles were collected.
Summarise validity and reporting of the RCT
The RCT was assessed by BEB using a range of critical appraisal tools commonly used to appraise RCTs. These included two of the most commonly used tools to assess RCTs: one examining trial reporting in a broad sense (Consolidated Standards of Reporting Trials for Non-Pharmacological Treatments (CONSORT-NPT) [ 5 ]), and another focusing on internal validity as commonly assessed in systematic reviews of trials (the updated Cochrane Risk of Bias Tool (ROBT 2.0) [ 7 ]). In addition, the Pragmatic Explanatory Continuum Indicator Scale (PRECIS-2) tool [ 8 ] was included, to examine domains associated with the broad applicability and utility of the trial, and the Context and Implementation of Complex Interventions (CICI) framework [ 25 ] was included on an exploratory basis to identify broader contextual factors that could be relevant. JMB contributed to assessment during piloting of the tools and in discussion with BEB where there was uncertainty.
Broad comparison of all results to develop deeper understanding of how trials are understood and relationship with trial quality
The results of both qualitative analysis and structured critical appraisal were considered side-by-side, with the overall aim of better understanding how other authors’ interpretations of the TIME trial compared with the critical appraisal guided by the above tools. The qualitative analysis of the authors’ interpretations was conducted before the structured critical appraisal to ensure the coding/themes were grounded in authors’ writings, rather than our experience of conducting the structured appraisals. The final step aimed to draw together both analyses, to see whether authors discussing the trial raised concerns across similar domains to the areas covered by the critical appraisal tools, or whether their topics of discussion addressed other considerations.
Ethical considerations
This study involved secondary use of publicly available written material and did not require ethical review.
Patient and public involvement
Patients and members of the public were not involved in any aspect of the design of this study.
Summary of index RCT
The TIME trial was a two-group, multicentre randomised trial comparing a minimally invasive approach to the surgical removal of oesophageal cancer with an open approach to the abdomen and chest. It was conducted in five centres across four European countries from 2009 to 2011 and is summarised in Table 1 .
Characteristics of articles
Searches identified 26 articles, and 23 were included (exclusions: an incorrectly classified case report and two articles in German). Summary characteristics are provided in Table 2 . Most articles (18/23, 78%) originated from Europe or the United States. The majority (20/23, 87%) included at least one author holding an academic position; 18/23 (78%) included at least one professor or associate professor (as defined within their own institution). Nearly all included at least one consultant or trainee surgeon (21/23, 91%).
Altmetric.com identified several references to the TIME trial, detailed in Table 3 . Only one, part of the British Medical Journal blog series, included text discussing the trial, rather than simply restating its results or directing readers to the study report.
Themes identified
Qualitative analysis resulted in description of three key themes: identification of wide-ranging issues with the RCT; limited appraisal of non-RCT studies; and variable recommendations for future practice and research. Codes linking quotes to articles and bibliographic data are provided in supplementary Table 1 .
Identification of wide-ranging issues with the RCT
Authors extensively discussed and critiqued several features of trial design and conduct. These included the population, intervention and outcomes of the trial.
If the author’s primary outcome was focused on pulmonary infection, perhaps other patient associated inclusion / exclusion criteria may have been of value. These would include patients with poor pulmonary function parameters … patients with major organ disease … and recent history of prior malignancy. (E2).
In the present [TIME] trial, the difference between minimally invasive and open oesophagectomy was maximised with a purely thoracoscopic (prone position) and laparoscopic technique. (E1).
The primary outcome … was pulmonary infection within the first 2 weeks after surgery and during the whole stay in hospital. This cannot be considered as the relevant primary outcome with reference to the decision problem outline by the authors … (E5).
Beyond these basic trial design parameters, authors of the citing articles also highlighted important confounding variables.
Many non-studied variables, including malnutrition, previous and current smoking, pulmonary comorbidities, functional status, and clinical TNM (tumour, node, metastasis) staging, have all been shown to strongly affect the primary endpoint of this trial – postoperative pulmonary infection. (L2).
Several correspondents suggest that lower rates of respiratory infection might have been achieved by use of alternative strategies for preoperative preparation, patient positioning, ventilator settings, anaesthetic agents, or postoperative care. (L6).
The articles also covered other potential problems with the trial, such as sample size and learning curve effects.
The sample size for sufficient statistical power for major morbidity, survival, total morbidity and other similarly important outcomes may actually be larger. (E2).
The inclusion criteria for participating surgeons appears to have the performance of a minimum of only 10 MIOs and this low level of experience may be reflected in relatively high conversion rate of 13%. (E4).
Only one article (E2) made clear statements praising aspects of the trial:
‘…The protocols for the RCT appear sound with randomization, intention to treat, PICO … and bias elimination.’
The next sentence of this article balanced these positive comments with discussion of limits due to the lack of blinding and other potential confounding variables.
Limited appraisal of non-RCT studies
Authors often cited other types of evidence in the same field to support their views without discussing their methodological limitations. Types of evidence included single-surgeon series, non-randomised comparative studies, systematic reviews (SRs) and meta-analyses (MAs).
Luketich et al. , one of the earlier pioneers of MIE, reported their extensive experience of 1033 consecutive patients undergoing MIE with acceptable lymph node resection, postoperative outcomes, and a 1.7% mortality rate. (L8).
In a population-based national study, … the incidence of pneumonia was 18.6% after open oesophagectomy and 19.9% after minimally invasive oesophagectomy … (L3).
Although systematic reviews and a large comparative study of minimally invasive oesophagectomy have not shown this technique to be beneficial as compared with open oesophagectomy, some meta-analyses have suggested specific advantages. (E1).
The existing SRs and MAs were discussed in relation to the intervention and its outcomes, without directly relating them to the TIME trial itself. The implications for authors’ impressions of the TIME trial findings were generally unclear.
There was limited appraisal of these SRs and MAs, especially when contrasted with discussion of the TIME trial. Several authors referred to the large, single-surgeon series of MIO by Luketich, but only one author described limits of this single-institution non-comparative study.
We must not rely on the limitation of single-institution studies and historical data. This procedure must be broadly applicable and not the domain of a few experts for it to become the new gold standard. (E12).
A few others highlighted the limits of other study designs, but there was a striking disparity in the level of critique, when compared with that of the TIME trial.
In their systematic review … Uttley et al. correctly conclude that due to factors such as selection bias, sufficient evidence does not exist to suggest the MIO is either equivalent to or superior to open surgery. (E6).
All these studies however, concede that due to a lack of feasible evidence by way of prospective randomized controlled trials (RCT), no definitive statement of MIE ‘superiority’ over standard open techniques can be made. (E2).
Although several authors referred to the existing SRs and MAs, none reported the design of the included primary studies, which were largely retrospective and non-randomised.
Variable recommendations for future practice and research
The authors had differing interpretations and recommendations for implementation based on the TIME trial. Some articles discussed issues with the trial and did not make recommendations for future practice, in some cases asking for additional information to better understand or interpret the trial.(L1, L3–5) For example, one simply wrote that the authors ‘have several concerns’, before reporting differences in outcomes between TIME and other studies, and describing practice in their own institution. (L1) Others reported that more work was required, such as further analysis of long-term results of patients included in TIME, or called for further trials in different patient populations.
However, the main issue which this study [TIME] does not address is that of long-term survival. … If the authors can indeed demonstrate at least equivalent long-term oncological outcome for MIO and open oesophagectomy, then this paper should provide an impetus for driving forward the widespread adoption of MIO. (E4).
Of interest will be whether similar results can be repeated in patients in Asia, with mainly squamous cell cancers that are proximally located. … The substantial benefit shown in this trial [TIME] … might encourage investigators to do further randomised studies at other centres. If these results can be confirmed in other settings, minimally invasive oesophagectomy could truly become the standard of care. (E1).
One article (E6) considered the evidence for MIO, discussed this against methodological aspects of a colorectal trial evaluating a minimally invasive approach, before restating the findings of TIME, opining that:
‘This study confirms that RCT [sic] for open versus MIO is indeed possible, but further larger trials are required.’
Later in that article, the authors suggested extensive control of wide-ranging aspects of perioperative care would be important for future trials.
Authors of three articles (E7, E9, E11) suggested that the available evidence was enough for increasing adoption of MIO.
…The available evidence increasingly favors a prominent role for minimally invasive approaches in the management of esophageal cancer. Endoscopic therapies and minimally invasive approaches offer at least equivalent oncologic outcomes, with reduced complications and improved quality of life compared with maximal surgery. (E11).
We are close to a situation in which one can argue that MIE is ready for prime time in the curative treatment of invasive esophageal cancer. If we critically analyse the level and grading of evidence, the current situation concerning MIE and hybrid MIE is far better than was the case when laparoscopic cholecystectomy, anti-reflux surgery, and bariatric surgery were introduced into clinical practice. (E9).
No authors called for the cessation of MIO, although one referred to some centres stopping ‘their MIE [minimally invasive esophagectomy] program due to safety reasons’. (E13).
Assessment of RCT using validated tools
The TIME trial results and protocol papers [ 19 , 26 ] were examined to assess the trial and its reporting. Assessment using CONSORT-NPT demonstrated reporting shortfalls in several areas (full notes in supplementary Table 2 ). These included: lack of information on adherence of care providers and patients to the treatment protocol; discrepancies between the primary outcomes proposed in the protocol (3 pulmonary outcomes) and the trial report (one pulmonary result); no information on interim analyses or stopping criteria; a lack of information regarding statistical analysis to allow for clustering of patients by centre; and absence of discussion of the trial limitations or generalisability.
Risk of bias was assessed as shown in Table 4 . Overall, the TIME trial was considered at high risk of bias.
Assessment using the PRECIS-2 tool is shown in Table 5 . Overall, TIME had features in keeping with a more pragmatic rather than explanatory trial. This suggested a reasonable degree of applicability and usefulness to wider clinical practice.
Application of the CICI framework highlighted several higher-level considerations relevant to the applicability of the TIME trial not described in the protocol or study report (see Table 6 ). These included lack of detail on the setting, as well as epidemiological and socio-economic information.
Overall, these tools suggested that TIME had several limitations. These included issues with standardisation and monitoring of intervention adherence, lack of blinding, failure to use hierarchical analysis and a lack of information on provider volume. The risk of bias was high, limiting confidence attributing outcomes to the allocated interventions. Broad applicability was considered reasonable, though study utility was compromised by a short-term clinical outcome, rather than longer term or patient-reported outcomes. While TIME may have provided early evidence for benefit of MIO to reduce pulmonary infection within 2 weeks of surgery, the appraisal suggested more evidence was needed before considering wider adoption of MIO.
Broad comparison of all results to develop deeper understanding
We considered the findings from the qualitative analysis in relation to those of the critical appraisal. In doing so, broad domains of internal and external validity seemed a useful system to bring together results of both analyses. While the ROBT was described by its creators as focused on internal validity, the PRECIS-2 and CICI tools were not described in terms of validity. Rather, their authors referred to applicability and reproducibility in other settings, which may also be described as external validity. CONSORT-NPT is a tool focused on reporting of trials, and its authors referred to both domains, with some duplication of factors covered in the other tools. However, authors of the articles included in the qualitative analysis did not adopt such methodological terminology when expressing concerns about these aspects of the index RCT’s conduct or reporting.
Robust internal validity allows confident attribution of treatment effects to the experimental intervention. The ROBT identified high risk of bias in the TIME trial. Qualitative analysis revealed discussion of various aspects relevant to internal validity. For example, several authors discussed differences in patient positioning and anaesthetic techniques. These confounding variables may have introduced systematic differences in care between groups, aside from the allocated intervention, resulting in bias. However, the article authors did not articulate the implications of their concerns in such terms and did not consider whether these problems rendered the trial fatally biased.
Sound external validity suggests similar treatment effects may be achieved by other clinicians in other settings for other patients. Pragmatic trials have broad applicability, with wide inclusion criteria, and patient-centred outcomes. The PRECIS-2 describes domains relevant to this applicability. TIME had several features of a pragmatic trial, suggesting relatively broad applicability. The qualitative analysis showed authors were concerned about these issues. For example, several discussed the appropriateness and utility of 2-week and in-hospital pulmonary infection rates as the primary outcome measure. However, authors did not directly relate such concerns to external validity or generalisability, to reach a conclusion about whether the trial should influence practice.
While many authors identified issues relevant to internal and external validity, the lack of clear explanation of their implications meant it was difficult to determine whether they thought the trial justified a change in practice. This contrasts with the structured assessments, which defined clear problems with the trial and limits to its usefulness.
This study presents the first application and results of a new method to generate insights into how evidence from a trial was understood, contextualised and related to practice. Qualitative analysis of letters and editorials, largely written by academic surgeons, documented extensive discussion of problems with the trial, but without clear formulation of the implications of these concerns for its internal or external validity and applicability. These authors reached a variety of conclusions about the implications of the trial for surgical practice. A separate assessment using structured tools defined specific weaknesses in trial methodology. Whilst this new approach yielded useful findings in this single case study, the method should be further tested using multiple trials and cross-case analyses. The initial findings based on this single case study suggest a need to clarify standards against which a trial may be assessed to guide decisions about its role in changing practice, and potentially also to guide efforts to influence practitioners to implement change if appropriate. Within this, our findings suggest a need to focus efforts on educating surgeons about trial design and quality, which may contribute to implementation science-based efforts to inform clinical decision-making and implementation of trial results.
This study contributes to the wider literature showing that evidence does not speak for itself. New evidence is often considered alongside competing bodies of existing evidence that may support different ideas, theories or interventions [ 27 , 28 ]. When a study is published, this new evidence is assimilated into the wider scientific context. Its strengths, weaknesses and overall contribution are debated and disputed. Through the lens of Latour’s actor-network theory [ 29 , 30 ], the new trial can be considered a novel actor within the wider network of actors that includes other trials and studies of the intervention, as well as the consumers of this evidence. Those commenting on the trial have an important role in how different features of the trial are identified, discussed and debated, and how its findings are framed. This agency may be influenced by their own clinical experience, education, skill set, work environment and colleagues, amongst other factors. Given these complexities, it is not surprising to find that different authors reached different conclusions about the TIME trial.
The way authors of the included articles used and appraised different types of study raises questions about how the hierarchy of evidence, and the primacy of the RCT, is applied to routine clinical practice. We found extensive criticism of the TIME trial. Article authors described several limitations relating to its population, intervention, associated co-interventions and confounding variables, as well as the outcomes selected. Certainly, the authors presented valid criticisms that limited the trial’s validity, as identified by structured critical appraisal. Over recent years, trials methodologists have worked to better understand and optimise many such aspects of trial conduct. The development of the CONSORT reporting standards promotes detailed description of key methods, such as random sequence generation and allocation concealment, that allow critical judgements about internal validity to be made [ 5 ]. The growth of pragmatic trials, featuring wide inclusion criteria, conducted across multiple sites, with clinically meaningful outcomes, reflects a concerted effort to improve applicability or external validity of RCTs [ 8 , 31 ]. It may never be possible to conduct a ‘perfect’ trial, but improvements in the rigor and transparency of design hopefully ensure that RCTs can provide sufficiently robust evidence that is useful to the broad population of patients and clinicians within a healthcare system. Whether these developments, designed to address valid criticisms of RCTs, are widely understood outside the sphere of trials methodologists is unclear.
Conversely, the authors of the included articles were far less critical of non-RCT evidence. For example, several authors referred to the single-surgeon case-series of Luketich [ 32 ]. Only one author discussed its limitations for generalisation. Surgical skill and performance vary [ 33 ]; what is possible for a single surgeon cannot be generalised to what is usual for most. Similarly, authors cited systematic reviews and meta-analyses without clear description of the original study designs. Evidence synthesis cannot eliminate biases in retrospective, non-randomised studies using statistical techniques. Failure to clearly articulate limitations of these different studies may support our contention that the authors lacked appropriate appraisal skills. Alternatively, it may suggest bias in favour of the intervention, such that the authors understood, but did not want to articulate its limitations.
While RCTs have not been toppled from their position at the top of the hierarchy of evidence about the efficacy of interventions, developments in other areas have seen increasingly sophisticated use of observational data to better understand the effects of treatments. Researchers have taken advantage of increasing availability of vast quantities of genetic data. In epidemiology, the concept of Mendelian randomisation has been used to try and unpick causal relationships from non-causative correlations [ 34 ]. At the patient level, genetic testing of different types of cancer has allowed targeting of treatments according to cellular sensitivities [ 35 ]. The development of such markers by which to tailor treatment have led to proposals of an idealised future whereby individual treatments are entirely personalised according to a panel of markers that accurately predict treatment response and prognosis. These different research approaches are inevitably competing for resources and intellectual priority. However, as has been argued by Backmann, for these other study types to take priority, “what needs to be shown is not only that RCTs might be problematic …, but that other methods such as cohort studies actually have better external validity.” [ 36 ]
Evidence-based medicine aims to apply the best available evidence to individual patients [ 37 ]. This aim, by its very nature, creates a disconnect between evidence from RCTs, which are aggregated studies of groups of patients to determine average effects, and clinical decision-making at the individual level [ 38 ]. This could be considered to represent an insurmountable ‘get-out’ clause, whereby a clinician may always justify deviation from ‘the evidence’ due to differences between the patient in front of them and those included in the relevant study. It may also prove very difficult to allow the theory-based weight of a journal article to over-ride an individual clinician’s personal lived experience of different interventions and their efficacy. This may be particularly problematic in surgical practice [ 16 ] where the practitioner is usually physically connected with the intervention. This may increase the importance attached to experience, even if that experience is at odds with large-scale studies. We do not disagree that clinicians must treat individual patients according to their specific condition and their wishes. However, it may be considered that aggregate practice, across a surgeon’s cases or across a department, should fall roughly in line with an appropriate body of suitably valid and relevant evidence.
Implementation science research has illuminated many factors affecting implementation beyond knowledge of the evidence. Damschroder et al. described the Consolidated Framework for Implementation Research (CFIR) to identify real-world constructs influencing implementation, relating to the intervention, individuals, organisations and systems [ 39 ]. These included ‘evidence strength and quality’ as well as ‘knowledge and beliefs about the intervention’, constructs readily identified within the present study. Their framework also highlights many other important factors such as cost, patient needs and resources, peer pressure, external policies and incentives, and organisational culture. Surgical research has demonstrated wide variation in practice, even in the presence of high quality evidence [ 40 ], and the broad range of factors affecting implementation of interventions, such as Enhanced Recovery After Surgery [ 41 ]. Our approach may contribute as another tool to understand barriers and facilitators to evidence implementation. It may prove particularly useful in conjunction with other methods such as interviews and observations, informed by a relevant framework, such as the Theoretical Domains Framework [ 42 , 43 ].
The early promise of our new method needs further work to conduct multiple case studies of different RCTs to allow cross-case analyses and a more thorough understanding of how RCTs are interpreted and appraised in the landscape of written commentaries. Examination of further case-studies may also inform refinements to the methods. For example, further analyses may indicate recurring themes across case-studies, which may in turn contribute towards a priori coding criteria and more efficient approaches to analyses (e.g. framework analysis [ 44 ]). It will also be important to include assessment of how each trial is situated in the wider context of relevant evidence, across study types. For individual trials, combined qualitative and structured analyses may determine the extent to which that RCT is flawed and requires further evaluation in a more methodologically sound study. Alternatively, it may demonstrate that the problem in bridging the gap between evidence and practice resides in the competition between different bodies of evidence, comprised of different types of study, and appropriate understanding of their strengths and weaknesses, as well as their applicability to practice. Work should also be undertaken to investigate how contemporary practice may have changed alongside publication of such articles, to investigate the relationship between what is written about the trial, and clinical practice as delivered.
While this study has shown the potential of this new method, its strengths and limitations must be considered. Rigorous analysis using robust qualitative methods and double coding by experienced researchers was undertaken. The articles examined were written without knowledge that they would be analysed in this manner, limiting bias this could introduce. The use of multiple tools to assess the index RCT created a broad overview of its strengths and weaknesses. The most important study limitation was that we did not directly explore authors’ understandings and interpretations, so underlying understanding of the key issues was inferred, rather than directly scrutinised. Failure to articulate is not the same as a lack of understanding. Further, we did not ask authors their motivations to publish their articles, an activity with its own significance. In addition, this study attempted to provide insights into the authors understanding and interpretation of the trial, and it does not purport to be an assessment of practice itself, which would benefit from other approaches to investigation (e.g. qualitative observations, interviews, quantitative procedure rate analyses). This study applied our new method to a single, surgical RCT. The issues identified may be particular to that intervention, specialty, or trial design; further case studies are required to determine broader relevance.
This study has successfully applied a new method to better understand how clinicians and academics understand evidence from a surgical RCT - the TIME trial. It identified discussion of many issues with the trial, but the authors who cited the trial did not specifically articulate the implications of these issues in terms of its internal and external validity. The authors reached a wide range of conclusions, ranging from further evaluation of the intervention, to widespread adoption. Structured appraisal of TIME suggested that the trial was at high risk of bias with limited generalisability. Further application of this method to multiple trials will allow cross-case analyses to determine whether the issues identified are similar across other trials and yield information to better understand how this type of evidence is interpreted and related to practice. This approach may be complemented by other data, such as in-depth interviews. This may reveal genuine flaws in trial design that limit application, or that other issues such as poor understanding or competing non-clinical factors impede the translation of evidence into practice. We hope that this work may help existing efforts to close the research-practice gap, and help ensure that patients receive the best care, based upon the highest level of evidence.
Availability of data and materials
The dataset upon which this work is based consists of articles already available within the published literature.
Abbreviations
- Randomised controlled trial
Traditional Invasive versus Minimally invasive Esophagectomy
CONsolidated Standards Of Reporting Trials for Non-Pharmacological Treatments
PRagmatic Explanatory Continuum Indicator Scale
Context and Implementation of Complex Interventions
Risk Of Bias Tool
Minimally Invasive Oesophagectomy
Systematic Review
Meta-Analysis
Bero LA, Grilli R, Grimshaw JM, Harvey E, Oxman AD, Thomson MA, et al. Closing the gap between research and practice: an overview of systematic reviews of interventions to promote the implementation of research findings. Br Med J. 1998;317:465–8 Available from: http://www.bmj.com/cgi/doi/10.1136/bmj.317.7156.465 .
Article CAS Google Scholar
Grol R, Grimshaw J. From best evidence to best practice: effective implementation of change in patients’ care. Lancet. 2003;362:1225–30.
Article Google Scholar
Oxford Centre for Evidence-Based Medicine. Levels of evidence. 2009 [cited 2018 Sep 25]. Available from: http://www.cebm.net/oxford-centre-evidence-based-medicine-levels-evidence-march-2009/ .
Google Scholar
Ergina PL, Cook JA, Blazeby JM, Boutron I, Clavien P-A, Reeves BC, et al. Challenges in evaluating surgical innovation. Lancet. 2009;374:1097–104. Available from. https://doi.org/10.1016/S0140-6736(09)61086-2 .
Article PubMed PubMed Central Google Scholar
Boutron I, Moher D, Altman DG, Schulz KF, Ravaud P. Methods and processes of the CONSORT group: example of an extension for trials assessing nonpharmacologic treatments. Ann Intern Med. 2008;148:295–309. Available from. https://doi.org/10.7326/0003-4819-148-4-200802190-00008 .
Article PubMed Google Scholar
Higgins JPT, Altman DG, Gøtzsche PC, Jüni P, Moher D, Oxman AD, et al. The Cochrane Collaboration’s tool for assessing risk of bias in randomised trials. Br Med J. 2011;343:d5928 Available from: http://www.bmj.com/cgi/doi/10.1136/bmj.d5928 .
Higgins JPT, Sterne JAC, Savović J, Page MJ, Hróbjartsson A, Boutron I, et al. A revised tool for assessing risk of bias in randomized trials. Cochrane Database Syst Rev. 2016;10:CD201601.
Loudon K, Treweek S, Sullivan F, Donnan P, Thorpe KE, Zwarenstein M. The PRECIS-2 tool: designing trials that are fit for purpose. Br Med J. 2015;350:h2147 Available from: http://www.bmj.com/cgi/doi/10.1136/bmj.h2147 .
McDonald AM, Knight RC, Campbell MK, Entwistle VA, Grant AM, Cook JA, et al. What influences recruitment to randomised controlled trials? A review of trials funded by two UK funding agencies. Trials. 2006;7:1–8.
Donovan JL, Rooshenas L, Jepson M, Elliott D, Wade J, Avery K, et al. Optimising recruitment and informed consent in randomised controlled trials: the development and implementation of the quintet recruitment intervention (QRI). Trials. 2016;17:1–11. Available from. https://doi.org/10.1186/s13063-016-1391-4 .
Antoniou SA, Andreou A, Antoniou GA, Koch OO, Köhler G, Luketina RR, et al. Volume and methodological quality of randomized controlled trials in laparoscopic surgery: assessment over a 10-year period. Am J Surg. 2015;210:922–9.
Ali UA, van der Sluis PC, Issa Y, Habaga IA, Gooszen HG, Flum DR, et al. Trends in worldwide volume and methodological quality of surgical randomized controlled trials. Ann Surg. 2013;258:199–207.
Kristensen N, Nymann C, Konradsen H. Implementing research results in clinical practice - the experiences of healthcare professionals. BMC Health Serv Res. 2016;16:48. Available from. https://doi.org/10.1186/s12913-016-1292-y .
Blencowe NS, Boddy AP, Harris A, Hanna T, Whiting P, Cook JA, et al. Systematic review of intervention design and delivery in pragmatic and explanatory surgical randomized clinical trials. Br J Surg. 2015;102:1037–47.
Rothwell PM. External validity of randomised controlled trials: “to whom do the results of this trial apply?”. Lancet. 2005;365:82–93.
Orri M, Farges O, Clavien P-A, Barkun J, Revah-Lévy A. Being a surgeon - the myth and the reality. A meta-synthesis of surgeons’ perspectives about factors affecting their practice and well-being. Ann Surg. 2014;260:721–9 Available from: http://content.wkhealth.com/linkback/openurl?sid=WKPTLP:landingpage&an=00000658-201411000-00002 .
Garcia-Retamero R, Cokely ET, Wicki B, Joeris A. Improving risk literacy in surgeons. Patient Educ Couns. 2016;99:1156–61. Available from. https://doi.org/10.1016/j.pec.2016.01.013 .
Byrne BE, Rooshenas L, Lambert H, Blazeby JM. Evidence into practice: protocol for a new mixed-methods approach to explore the relationship between trials evidence and clinical practice through systematic identification and analysis of articles citing randomised controlled trials. BMJ Open. 2018;8:e023215 Available from: http://bmjopen.bmj.com/lookup/doi/10.1136/bmjopen-2018-023215 .
Biere SSAY, van Berge Henegouwen MI, Maas KW, Bonavina L, Rosman C, Garcia JR, et al. Minimally invasive versus open oesophagectomy for patients with oesophageal cancer: a multicentre, open-label, randomised controlled trial. Lancet. 2012;379:1887–92.
Yin RK. Case study research and applications: design and methods. Sixth: SAGE Publications; 2018.
Crowe S, Cresswell K, Robertson A, Huby G, Avery A, Sheikh A. The case study approach. BMC Med Res Methodol. 2011;11:100.
Stake RE. The art of case study research. Thousand Oaks: SAGE Publications; 1995.
Glaser BG, Strauss AL. The discovery of grounded theory: strategies for qualitative research. Observations. Aldine Transaction; 1967. Available from: http://www.amazon.com/dp/0202302601 .
Braun V, Clarke V. Using thematic analysis in psychology. Qual Res Psychol. 2006;3:77–101 [cited 2014 May 25]. Available from: http://www.tandfonline.com/doi/abs/10.1191/1478088706qp063oa .
Pfadenhauer L, Rohwer A, Burns J, Booth A, Lysdahl KB, Hofmann B, et al. Guidance for the assessment of context and implementation in Health Technology Assessments (HTA) and systematic reviews of complex interventions: the Context and Implementation of Complex Interventions (CICI) framework. 2016. Available from: https://www.integrate-hta.eu/wp-content/uploads/2016/02/Guidance-for-the-Assessment-of-Context-and-Implementation-in-HTA-and-Systematic-Reviews-of-Complex-Interventions-The-Co.pdf .
Biere SSAY, Maas KW, Bonavina L, Garcia JR, van Berge Henegouwen MI, Rosman C, et al. Traditional invasive vs. minimally invasive esophagectomy: a multi-center, randomized trial (TIME-trial). BMC Surg. 2011;11:1–7. Available from: http://ovidsp.ovid.com/ovidweb.cgi?T=JS&CSC=Y&NEWS=N&PAGE=fulltext&D=emed10&AN=71483010%5Cnhttp://nt2yt7px7u.search.serialssolutions.com/?sid=OVID:Embase&genre=article&id=pmid:&id=doi:10.1007%2Fs00464-012-2198-3&issn=0930-2794&volume=26&issue=1&spage=S40&.
Fitzgerald L, Ferlie E, Wood M, Hawkins C. Interlocking interactions, the diffusion of innovations in health care. Hum Relat. 2002;55:1429–49.
Fitzgerald L, Ferlie E, Wood M, Hawkins C. Evidence into practice? An exploratory analysis of the interpretation of evidence. In: Mark AL, Dopson S, editors. Organisational Behaviour in Health Care: The Research Agenda. Palgrave Macmillan; 1999.
Latour B. Reassembling the social: an introduction to actor-network theory. Oxford: Oxford University Press; 2005..
Cresswell KM, Worth A, Sheikh A. Actor-network theory and its role in understanding the implementation of information technology developments in healthcare. BMC Med Inform Decis Mak. 2010;10:1–11.
Ford I, Norrie J. Pragmatic trials. N Engl J Med. 2016;375:454–63.
Luketich JD, Pennathur A, Awais O, Levy RM, Keeley R, Shende M, et al. Outcomes after minimally invasive esophagectomy: review of over 1000 patients. Ann Surg. 2012;256:95–103.
Birkmeyer JD, Finks JF, O’Reilly A, Oerline M, Carlin AM, Nunn AR, et al. Surgical skill and complication rates after bariatric surgery. N Engl J Med. 2013;369:1434–42 [cited 2014 Jul 23]. Available from: http://www.ncbi.nlm.nih.gov/pubmed/24106936 .
Ebrahim S, Ferrie JE, Smith GD. The future of epidemiology: methods or matter? Int J Epidemiol. 2016;45:1699–716.
Jackson SE, Chester JD. Personalised cancer medicine. Int J Cancer. 2015;137:262–6.
Backmann M. What’s in a gold standard? In defence of randomised controlled trials. Med Health Care Philos. 2017;20:513–23.
Evidence-based Medicine Working Group. Evidence-based medicine: a new approach to teaching the practice of medicine. J Am Med Assoc. 1992;268:2420–5 Available from: http://content.wkhealth.com/linkback/openurl?sid=WKPTLP:landingpage&an=00006534-201412000-00040 .
Kravitz RL, Duan N, Braslow J. Evidence-based medicine, heterogeneity of treatment effects, and the trouble with averages. Milbank Q. 2004;82:661–87.
Damschroder LJ, Aron DC, Keith RE, Kirsh SR, Alexander JA, Lowery JC. Fostering implementation of health services research findings into practice: a consolidated framework for advancing implementation science. Implement Sci. 2009;4:50.
Urbach DR, Baxter NN. Reducing variation in surgical care. Br Med J. 2005;330:1401–2.
Gramlich LM, Sheppard CE, Wasylak T, Gilmour LE, Ljungqvist O, Basualdo-Hammond C, et al. Implementation of Enhanced Recovery After Surgery: a strategy to transform surgical care across a health system. Implement Sci. 2017;12:67.
Michie S, Johnston M, Abraham C, Lawton R, Parker D, Walker A. Making psychological theory useful for implementing evidence based practice: a consensus approach. Qual Saf Heal Care. 2005;14:26–33.
Cane J, O’Connor D, Michie S. Validation of the theoretical domains framework for use in behaviour change and implementation research. Implement Sci. 2012;7:1–17.
Ritchie J, Spencer L. In: Bryman A, Burgess RG, editors. Qualitative data analysis for applied policy research. Routledge: Anal Qual data; 1994.
Chapter Google Scholar
Download references
Acknowledgements
We would like to thank Cath Borwick, Information Specialist at the University of Bristol for her help developing the literature search strategy, advising on the available tools and highlighting the full range of resources available for this study.
B E Byrne is supported by the National Institute for Health Research. Jane Blazeby is a NIHR Senior Investigator. This work was undertaken with the support of the MRC ConDuCT-II (Collaboration and innovation for Difficult and Complex randomised controlled Trials In Invasive procedures) Hub for Trials Methodology Research (MR/K025643/1) and the NIHR Bristol Biomedical Research Centre at the University Hospitals Bristol NHS Foundation Trust and the University of Bristol (BRC-1215-20011) and support from the Royal College of Surgeons of England Bristol Surgical Trials Centre. The views expressed are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health. The funders had no role in developing the protocol.
Author information
Authors and affiliations.
Centre for Surgical Research, Population Health Sciences, Bristol Medical School, University of Bristol, Canynge Hall, 39 Whatley Road, Clifton, Bristol, BS8 2PS, UK
Ben E. Byrne, Leila Rooshenas & Jane M. Blazeby
Population Health Sciences, Bristol Medical School, University of Bristol, Bristol, UK
Helen S. Lambert
MRC ConDuCT-II Hub, Bristol Medical School, University of Bristol, Bristol, UK
Jane M. Blazeby
NIHR Bristol Biomedical Research Centre, University Hospitals Bristol NHS Foundation Trust, Bristol, UK
You can also search for this author in PubMed Google Scholar
Contributions
BEB and JMB conceived the study. BEB, LR, HL and JMB developed the protocol and refined the study design. BEB and LR conducted the qualitative analysis. BEB prepared a preliminary draft manuscript. JMB, LR and HL extensively revised the manuscript. All authors have approved the final manuscript.
Corresponding author
Correspondence to Ben E. Byrne .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1 table s1..
Identifying codes and bibliographic information on all citing articles included in analysis. Table S2. CONSORT-NPT checklist with notes on TIME trial.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Byrne, B.E., Rooshenas, L., Lambert, H.S. et al. A mixed methods case study investigating how randomised controlled trials (RCTs) are reported, understood and interpreted in practice. BMC Med Res Methodol 20 , 112 (2020). https://doi.org/10.1186/s12874-020-01009-8
Download citation
Received : 26 November 2019
Accepted : 06 May 2020
Published : 12 May 2020
DOI : https://doi.org/10.1186/s12874-020-01009-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Translational medical research
- Health services research
- Evidence-based medicine
BMC Medical Research Methodology
ISSN: 1471-2288
- General enquiries: [email protected]
Why randomized controlled trials matter and the procedures that strengthen them
Randomized controlled trials are a key tool to study cause and effect. why do they matter and how do they work.
At Our World in Data, we bring attention to the world's largest problems. We explore what these problems are, why they matter and how large they are. Whenever possible, we try to explain why these problems exist, and how we might solve them.
To make progress, we need to be able to identify real solutions and evaluate them carefully. But doing this well is not simple. It's difficult for scientists to collect good evidence on the costs and benefits of a new idea, policy, or treatment. And it's challenging for decision-makers to scrutinize the evidence that exists, to make better decisions.
What we need are reliable ways to distinguish between ideas that work and those that don't.
In this post, I will explain a crucial tool that helps us do this – randomized controlled trials (RCTs). We will see that RCTs matter for three reasons: when we don't know about the effects of interventions, when we don't know how to study them, and when scientific research is affected by biases.
What are randomized controlled trials?
To begin with, what are RCTs? These are experiments where people are given, at random, either an intervention (such as a drug) or a control and then followed up to see how they fare on various outcomes.
RCTs are conducted by researchers around the world. In the map, you can see how many RCTs have ever been published in high-ranked medical journals, by the country where the first author was based. Over 18,000 of these were from the United States, but most countries have had fewer than a hundred. 1 RCTs have also become more common over time. 2
It's easy to take RCTs for granted, but these trials have transformed our understanding of cause and effect. They are a powerful tool to illuminate what is unknown or uncertain; to discern whether something works and how well it works.
But it's also important to recognize that these trials are not always perfect, and understand why.
The strengths of RCTs are subtle: they are powerful because of the set of procedures that they are expected to follow. This includes the use of controls, placebos, experimentation, randomization, concealment, blinding, intention-to-treat analysis, and pre-registration.
In this post, we will explore why these procedures matter – how each one adds a layer of protection against complications that scientists face when they do research.
The fundamental problem of causal inference
We make decisions based on our understanding of how things work – we try to predict the consequences of our actions.
But understanding cause and effect is not just crucial for personal decisions: our knowledge of what works can have large consequences for people around us.
An example is antiretroviral therapy (ART), which is used to treat HIV/AIDS . The benefits of these drugs were surprising. One of the first ART drugs discovered was azidothymidine, which had previously been abandoned as an ineffective treatment for cancer. 3 The discovery that azidothymidine and other antiretroviral therapies worked, and their use worldwide, has prevented millions of deaths from HIV/AIDS, as the chart shows.
Discovering what works can save lives. But discovering what doesn’t work can do the same. It means we can redirect our time and resources away from things that don't work, towards things that do.
Even when we already know that something works, understanding how well it works can help us make better decisions.
An example for this is the BCG vaccine , which reduces the risk of tuberculosis. The efficacy of this vaccine is different for different people around the world, and the reasons for this are unclear. 4 Still, knowing this is informative, because it tells us that more effort is needed to protect people against the disease in places where the benefit of the vaccine is low.
If there was a reliable way to know about the effects of the measures we took, we could prioritize solutions that are most effective.
So, how would we understand cause and effect without trials?
One way is through observation: we can observe what different people did and track their outcomes afterwards. But it's possible that the events that followed their actions were simply a coincidence, or that they would have happened anyway.
The biggest challenge in trying to understand causes and effects is that we are only able to see one version of history.
When someone makes a particular decision, we are able to see what follows, but we cannot see what would have happened if they had made a different decision. This is known as “the fundamental problem of causal inference." 5
What this means is that it is impossible to predict the effects that an action will have for an individual person, but we can try to predict the effects it would have on average.
Why randomized controlled trials matter
Sometimes we do not need an RCT to identify causes and effects. The effect of smoking on lung cancer is one example, where scientists could be confident as early as the 1960s that the large increase in lung cancer rates could not have been caused by other factors.
This was because there was already knowledge from many different lines of evidence. 6 Experiments, biopsies and population studies all showed that cigarette smoke was associated with specific changes in lung tissue and with the incidence of lung cancer. The association was so large and consistent that it could not be explained by other factors. 7
Even now, smoking is estimated to cause a large proportion of cancer deaths in many countries, as you can see in the chart.
But in other situations, RCTs have made a huge difference to our understanding of the world. Prioritizing the drugs that were shown to be effective in trials saved lives, as we saw with the example of antiretroviral therapy to treat HIV/AIDS.
People sometimes refer to RCTs as the "gold standard of evidence", but it's more useful to recognize that their strengths emerge from a set of procedures that they aim to follow.
Why do RCTs matter?
In my opinion, even though we do have lots of knowledge about various topics, these trials matter for three reasons. They matter because we may not know enough, because we can be wrong, and because we might see what we want to see.
First, they matter when we don't know .
Randomized controlled trials can illuminate our understanding of effects, especially when there is uncertainty around them. They can help resolve disagreements between experts.
In some cases, scientists can use other methods to investigate these topics. But when there is insufficient knowledge, other methods may not be enough.
This is because, in a typical study, scientists need to be able to account for the possibility that other factors are causing the outcome.
They need to have knowledge about why an effect usually occurs and whether it will happen anyway. They need to know about which other risk factors can cause the outcome and what makes it likely that someone will receive the treatment. They also need to know how to measure these factors properly, and how to account for them.
The second reason they matter is when we are wrong .
Even when scientists think they know which risk factors affect the outcome, they might be incorrect. They might not account for the right risk factors or they might account for the wrong ones.
In an RCT where scientists use randomization, blinding and concealment, they can minimize both of these problems. Despite people's risks before the trial, the reason that someone will receive the treatment is the random number they are given. The reason that participants in each group differ at the end of the study is the group they were randomized to.
Even if we don't know about other risk factors, or even if we are wrong about them, these procedures mean that we can still find out whether a treatment has an effect and how large the effect is.
The third reason is when we see what we want to see .
When participants expect to feel different after a treatment, they might report that they feel different, even if they didn't receive the treatment at all.
When scientists want to see people improve after a treatment, they might decide to allocate the treatment to healthier participants. They might measure their data differently or re-analyze their data until they can find an improvement. They might even decide against publishing their findings when they don't find a benefit.
If scientists use concealment, blinding, and pre-registration, they can reduce these biases. They can protect research against their own prejudices and the expectations of participants. They can also defend scientific knowledge from poor incentives, such as the desires of scientists to hype up their findings and the incentives for pharmaceutical companies to claim that their drugs work.
The layers of protection against bias
Previously, I described how the strengths of RCTs emerge from the set of procedures that they aim to follow.
In medicine, this commonly includes the use of controls, placebos, experimentation, randomization, concealment, blinding, intention-to-treat analysis, and pre-registration. 8 Each of these helps to protect the evidence against distortions, which can come from many sources. But they are not always enforced. Below, we will explore them in more detail.
The control group gives us a comparison to see what would have happened otherwise
The most crucial element to understand causes and effects is a control group.
Let's use antidepressants as an example to see why we need them.
If no one in the world received antidepressants, we wouldn’t know what their effects were. But the opposite is also true. If everyone received antidepressants, we wouldn't know how things would be without them.
In order to understand the effect of an antidepressant, we need to see which other outcomes are possible. The most important thing we need to understand effects is a comparison – we need some people who receive the treatment and some who don’t. The people who don’t could be our control group.
An ideal control group should allow us to control the biases and measurement errors in a study completely.
For example, different doctors may diagnose depression differently. If someone had symptoms of depression, then the chances they get diagnosed should be equal in the antidepressant group and the control group. If they weren't equal, we could mistake differences between the groups for an effect of antidepressants, even if they didn't have any effect.
In fact, an ideal control group should allow us to control the total effects of all of the other factors that could affect people's mood, not just control for the biases and errors in studies.
As an example, we know that the symptoms of depression tend to change over time, as I explained in this earlier post .
You can see this in the chart. This shows that the symptoms of depression tend to decline over time, among people who are diagnosed with depression but not treated for it. This is measured by seeing how many patients would still meet the threshold for a diagnosis of depression later on.

Almost a quarter of patients with depression (23%) would no longer meet the threshold for depression after three months, despite receiving no treatment. Just over half (53%) would no longer meet the threshold after one year. 9 This change is known as "regression to the mean."
If we didn’t have a control group in our study, we might misattribute such an improvement to the antidepressant. We need a control group to know how much their symptoms would improve anyway.
Placebos allow us to account for placebo effects
Some types of controls are special because they resemble the treatment without actually being it – these controls are called placebos. An ideal placebo has all the qualities above and also allows us to account for "placebo effects." In this case, the placebo effect refers to when people's moods improve from the mere procedure of receiving the antidepressant.
For example, taking a pill might improve people's mood because they believe that taking a pill will give them some benefit, even if the pill does not actually contain any active ingredient.
How large is the placebo effect?
Some clinical trials have tried to estimate this by comparing patients who received a placebo to patients who received no treatment at all. Overall, these studies have found that placebo effects are small in clinical trials for many conditions, but are larger for physical treatments, such as acupuncture to treat pain. 10
Placebo effects tend to be larger when scientists are recording symptoms reported by patients, rather than when they are measuring something that can be verified by others, such as results from a blood test or death.
For depression, the placebo effect is non-significant. Studies do not detect a difference in the moods of patients who receive a placebo and those who do not receive any treatment at all. 11 Instead, the placebo group serves as a typical control group, to show what would happen to these patients even if they did not receive treatment.
Randomization ensures that there are no differences between control and treatment group apart from whether they received the treatment
Before participants are enrolled in a trial, they might already have different levels of risk of developing the outcomes.
Let's look at an example to illustrate this point.
Statins are a type of drug commonly used to prevent stroke. But strokes are more common among people who use statins. Does that mean that statins caused an increase in the rates of stroke?
No – people who are prescribed statins are more likely to have cardiovascular problems to begin with, which increases the chances of having a stroke later on. When this is accounted for, researchers find that people who take statins are actually less likely to develop a stroke. 12
If researchers simply compared the rates of stroke in those who used statins with those who did not, they would miss the fact that there were other differences between the two groups, which could have caused differences in their rates of stroke.
Important differences such as these – which affect people's likelihood of receiving the treatment (using statins) and also affect the outcome (the risk of a stroke) – are called ‘confounders’.
But it can be difficult to know what all of these confounders might be. It can also be difficult to measure and account for them properly. In fact, scientists can actually worsen a study by accounting for the wrong factors. 13
What happens when participants are randomized in a trial?
Randomization is the procedure of allocating them into one of two groups at random.
With randomization, the problems above are minimized: everyone has the possibility of receiving the treatment. Whether people receive the treatment is not determined by the risks they have, but whether they are randomly selected to receive the treatment.
So, the overall risks of developing the outcome in one group become comparable to the risks in the other group.
Randomization means that it is not a problem when there are confounders that are not known or not measured. Researchers don't have to know about why or how the outcome usually occurs. 14
Concealment and blinding limit the biases of researchers and expectations of participants
In a clinical trial, participants or scientists might realize which groups they are assigned to. For example, the drug might smell, taste or look different from the placebo. Or it might have obvious benefits or different side effects compared to the placebo. 15
Concealment is a first step in preventing this: this is the procedure of preventing scientists from knowing which treatment people will be assigned to.
Blinding is a second step: this is the procedure of preventing participants and scientists from finding out which treatment group people have been assigned to. 16
When blinding is incomplete, it can partly reverse the benefits of randomization. For example, in clinical trials for oral health, the benefits of treatments appear larger when patients and the scientists who assess their health are not blinded sufficiently. 17
If randomization was maintained, the only reason that groups would differ on their outcomes was the treatment they received. However, if the treatments were not hidden from scientists and participants, other factors could cause differences between them.
Sometimes, blinding is not possible – there might not be something that is safe and closely resembles the treatment, which could be used as a placebo.
Fortunately, this does not necessarily mean that these trials cannot be useful. Researchers can measure verifiable outcomes (such as changes in blood levels or even deaths) to avoid some placebo effects.
But even when blinding occurs, participants and researchers might still make different decisions, because of the effects of the treatment or placebo.
For example, some participants might decide to withdraw from the trial or not follow the protocols of the trial closely. Similarly, scientists might guess which groups people are in and therefore treat them differently or measure their outcomes in a biased way.
It's difficult to predict how this might affect the results of a trial. It could cause us to overestimate or underestimate the benefit of a treatment. For example, in the clinical trials for Covid-19 vaccines , some participants may have guessed that they received the vaccine because they experienced side effects.
So, they may have believed that they were more protected and took fewer precautions. This means they may have increased their risk of catching Covid-19. This would make it appear as if the vaccines gave less protection than they actually did: it would result in an underestimate of their efficacy.
Preregistration allows us to hold researchers accountable to their original study plans
Some of the procedures we've explored so far are used to safeguard research against errors and biases that scientists can have. Pre-registration is another procedure that contributes to the same goal.
After the data in a study is analyzed, scientists have some choice in which results they present to their colleagues and the wider community. This opens up research to the possibility of cherry-picking.
This problem unfortunately often arises in studies that are sponsored by industry. If a pharmaceutical company is testing their new drugs in trials, disappointing results can lead to financial losses. So, they may decide not to publish them.
But this problem is not limited to trials conducted by pharmaceutical companies.
For many reasons, scientists may decide not to publish some of their studies. Or they might re-analyze their data in a different way to find more positive results. Even if scientists want to publish their findings, journals may decide not to publish them because they may be seen as disappointing, controversial or uninteresting.
To counter these incentives, scientists can follow the practice of "pre-registration." This is when they publicly declare which analyses they plan to do in advance of collecting the data.
In 2000, the United States Food and Drug Administration (FDA) established an online registry for the details of clinical trials. The FDA required that scientists who were studying therapies for serious diseases needed to provide some details of their study designs and the outcomes that they planned to investigate. 18
This requirement reduced the bias towards positive findings in published research. We see evidence of this in the chart, showing clinical trials funded by the National Heart, Lung and Blood Institute (NHLBI), which adopted this requirement.
Before 2000 – when pre-registration of studies was not required – most candidate drugs to treat or prevent cardiovascular disease showed large benefits. But most trials published after 2000 showed no benefit. 19

Over the last two decades, this practice was strengthened and expanded. In 2007, the FDA required that most approved trials must be registered when people are enrolled into the study. They introduced notices and civil penalties for not doing so. Now, similar requirements are in place in Europe, Canada and some other parts of the world. 20
Importantly, sponsors of clinical trials are required to share the results online after the trial is completed.
But unfortunately many still violate these requirements. For example, less than half (40%) of trials that were conducted in the US since 2017 actually reported their results on time. 21
Here, you can see patterns in reporting results in Europe. According to EU regulations, all clinical trials in the European Economic Area are required to report their results to the European Clinical Trials Register (EU-CTR) within a year of completing the trial. But reporting rates vary a lot by country. By January 2021, most clinical trials by non-commercial sponsors in the UK (94%) reported their results in time, while nearly none (4%) in France had. 22
Although a large share of clinical trials fail to report their results when they are due, this has improved recently: only half (50%) of clinical trials by non-commercial sponsors reported their results in time in 2018, while more than two-thirds (69%) did in 2021. 23
Pulling the layers together
Together, these procedures give us a far more reliable way to distinguish between what works and what doesn't – even when we don't know enough, when we're wrong and when we see what we want to see.
Unfortunately, we have seen that many clinical trials do not follow them. They tend not to report the details of their methods or test whether their participants were blinded to what they received. These standards cannot just be expected from scientists – they require cooperation from funders and journals, and they need to be actively enforced with penalties and incentives.
We've also seen that trials can still suffer from remaining problems: that participants may drop out of the study and not adhere to the treatment. And clinical trials tend to not share their data or the code that they used to analyze it.
So, despite all the benefits they provide, we shouldn't see these layers as a fixed checklist. Just as some of them were introduced recently, they may still evolve in the future – open data sharing, registered reports and procedures to reduce dropouts may be next on the list. 24
The procedures used in these trials are not a silver bullet. But when they are upheld, they can make these trials a more powerful source of evidence for understanding cause and effect.
To make progress, we need to be able to understand the problems that affect us, their causes and solutions. Randomized controlled trials can give scientists a reliable way to collect evidence on these important questions, and give us the ability to make better decisions. At Our World in Data, this is why they matter most of all.
Acknowledgements
I would like to thank Darren Dahly, Nathaniel Bechhofer, Hannah Ritchie and Max Roser for reading drafts of this post and their very helpful guidance and suggestions to improve it.
Additional information
Trials are useful to test new ideas or treatments, when people do not have enough knowledge to recommend them on a larger scale.
But people also have ethical concerns surrounding trials of treatments that are already used by doctors. For one, they might believe that it isn't justified to give patients a placebo when a drug is available, even if it is unclear how well the drug works.
How can we balance these concerns with the benefits of trials? When are trials important?
A leading view is that they are justified when there is disagreement or uncertainty about the benefits of an intervention. 25
Outside of a trial, some doctors might prescribe a particular treatment, while other doctors would not, because they believe that same treatment is ineffective. In this case, the options in a trial – an intervention or control – would not be so different from what people could already encounter.
When experts disagree on a topic, an RCT is useful because it can resolve these conflicts and inform us about which option is better.
So, to make the most of trials, they should be planned in line with the questions that people have. For example, if we wanted to understand whether vaccines gave less protection to people who were immunocompromised, then we should plan a trial with enough participants with these conditions.
Catalá-López, F., Aleixandre-Benavent, R., Caulley, L., Hutton, B., Tabarés-Seisdedos, R., Moher, D., & Alonso-Arroyo, A. (2020). Global mapping of randomised trials related articles published in high-impact-factor medical journals: a cross-sectional analysis. Trials , 21 (1), 1-24.
Vinkers, C. H., Lamberink, H. J., Tijdink, J. K., Heus, P., Bouter, L., Glasziou, P., Moher, D., Damen, J. A., Hooft, L., & Otte, W. M. (2021). The methodological quality of 176,620 randomized controlled trials published between 1966 and 2018 reveals a positive trend but also an urgent need for improvement. PLOS Biology , 19 (4), e3001162. https://doi.org/10.1371/journal.pbio.3001162
National Research Council (U.S.) (1993). The social impact of AIDS in the United States. 4. Clinical Research and Drug Regulation. National Academy Press.
Dockrell, H. M., & Smith, S. G. (2017). What Have We Learnt about BCG Vaccination in the Last 20 Years? Frontiers in Immunology , 8 , 1134. https://doi.org/10.3389/fimmu.2017.01134
Mangtani, P., Abubakar, I., Ariti, C., Beynon, R., Pimpin, L., Fine, P. E. M., Rodrigues, L. C., Smith, P. G., Lipman, M., Whiting, P. F., & Sterne, J. A. (2014). Protection by BCG Vaccine Against Tuberculosis: A Systematic Review of Randomized Controlled Trials. Clinical Infectious Diseases , 58 (4), 470–480. https://doi.org/10.1093/cid/cit790
Holland, P. W. (1986). Statistics and Causal Inference. Journal of the American Statistical Association , 81 (396), 945–960. https://doi.org/10.1080/01621459.1986.10478354
Imbens, G. W., & Rubin, D. B. (2010). Rubin causal model. In Microeconometrics (pp. 229–241). Springer.
Rubin, D. B. (1977). Assignment to Treatment Group on the Basis of a Covariate. Journal of Educational Statistics , 2 (1), 1–26. https://doi.org/10.3102/10769986002001001
Hill, G., Millar, W., & Connelly, J. (2003). “The Great Debate”: Smoking, Lung Cancer, and Cancer Epidemiology. Canadian Bulletin of Medical History , 20 (2), 367-386.
Cornfield, J., Haenszel, W., Hammond, E. C., Lilienfeld, A. M., Shimkin, M. B., & Wynder, E. L. (1959). Smoking and Lung Cancer: Recent Evidence and a Discussion of Some Questions. JNCI: Journal of the National Cancer Institute . https://doi.org/10.1093/jnci/22.1.173
Although these procedures are also used outside of medicine, it can be difficult to apply them elsewhere. For example, in a trial that tests the effectiveness of talking therapy, it would be known to the participants that they are receiving it; it may not be possible to find a placebo control version to disguise the procedure. Due to constraints in length and focus, I will not detail the advantages of intention-to-treat analysis or experimentation.
Whiteford, H. A., Harris, M. G., McKeon, G., Baxter, A., Pennell, C., Barendregt, J. J., & Wang, J. (2013). Estimating remission from untreated major depression: A systematic review and meta-analysis. Psychological Medicine , 43 (8), 1569–1585. https://doi.org/10.1017/S0033291712001717
Hróbjartsson, A., & Gøtzsche, P. C. (2010). Placebo interventions for all clinical conditions. Cochrane Database of Systematic Reviews . https://doi.org/10.1002/14651858.CD003974.pub3
Hróbjartsson, A., & Gøtzsche, P. C. (2001). Is the Placebo Powerless?: An Analysis of Clinical Trials Comparing Placebo with No Treatment. New England Journal of Medicine , 344 (21), 1594–1602. https://doi.org/10.1056/NEJM200105243442106
Orkaby, A. R., Gaziano, J. M., Djousse, L., & Driver, J. A. (2017). Statins for Primary Prevention of Cardiovascular Events and Mortality in Older Men. Journal of the American Geriatrics Society , 65 (11), 2362–2368. https://doi.org/10.1111/jgs.14993
Makihara, N., Kamouchi, M., Hata, J., Matsuo, R., Ago, T., Kuroda, J., Kuwashiro, T., Sugimori, H., & Kitazono, T. (2013). Statins and the risks of stroke recurrence and death after ischemic stroke: The Fukuoka Stroke Registry. Atherosclerosis , 231 (2), 211–215. https://doi.org/10.1016/j.atherosclerosis.2013.09.017
Ní Chróinín, D., Asplund, K., Åsberg, S., Callaly, E., Cuadrado-Godia, E., Díez-Tejedor, E., Di Napoli, M., Engelter, S. T., Furie, K. L., Giannopoulos, S., Gotto, A. M., Hannon, N., Jonsson, F., Kapral, M. K., Martí-Fàbregas, J., Martínez-Sánchez, P., Milionis, H. J., Montaner, J., Muscari, A., … Kelly, P. J. (2013). Statin Therapy and Outcome After Ischemic Stroke: Systematic Review and Meta-Analysis of Observational Studies and Randomized Trials. Stroke , 44 (2), 448–456. https://doi.org/10.1161/STROKEAHA.112.668277
Cinelli, C., Forney, A., & Pearl, J. (2020). A crash course in good and bad controls. Available at SSRN, 3689437: http://dx.doi.org/10.2139/ssrn.3689437
Aronow, P., Robins, J. M., Saarinen, T., Sävje, F., & Sekhon, J. (2021). Nonparametric identification is not enough, but randomized controlled trials are. ArXiv Preprint ArXiv:2108.11342 .
Higgins, J. P. T., Altman, D. G., Gotzsche, P. C., Juni, P., Moher, D., Oxman, A. D., Savovic, J., Schulz, K. F., Weeks, L., Sterne, J. A. C., Cochrane Bias Methods Group, & Cochrane Statistical Methods Group. (2011). The Cochrane Collaboration’s tool for assessing risk of bias in randomised trials. BMJ , 343 (oct18 2), d5928–d5928. https://doi.org/10.1136/bmj.d5928
Schulz, K. F., Chalmers, I., & Altman, D. G. (2002). The Landscape and Lexicon of Blinding in Randomized Trials. Annals of Internal Medicine , 136 (3), 254. https://doi.org/10.7326/0003-4819-136-3-200202050-00022
Saltaji, H. et al. Influence of blinding on treatment effect size estimate in randomized controlled trials of oral health interventions. BMC Med Res Methodol 18 , 42 (2018).
Dickersin, K., & Rennie, D. (2012). The evolution of trial registries and their use to assess the clinical trial enterprise. Jama , 307 (17), 1861–1864.
Kaplan, R. M., & Irvin, V. L. (2015). Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time. PLOS ONE , 10 (8), e0132382. https://doi.org/10.1371/journal.pone.0132382
Dickersin, K., & Rennie, D. (2012). The evolution of trial registries and their use to assess the clinical trial enterprise. Jama , 307 (17), 1861–1864. https://doi.org/10.1001/jama.2012.4230
DeVito, N. J., & Goldacre, B. (2021). Evaluation of Compliance With Legal Requirements Under the FDA Amendments Act of 2007 for Timely Registration of Clinical Trials, Data Verification, Delayed Reporting, and Trial Document Submission. JAMA Internal Medicine, 181(8), 1128. https://doi.org/10.1001/jamainternmed.2021.2036
Note: Data is shown until January 2021 for trials. After the UK left the European Union in January 2021, clinical trials in the UK were then no longer required to report their results to the EU-CTR. Only data from trials by non-commercial sponsors is shown. This includes trials sponsored by institutions such as universities, hospitals, research foundations and so on.
Dal-Ré, R., Goldacre, B., Mahillo-Fernández, I., & DeVito, N. J. (2021). European non-commercial sponsors showed substantial variation in results reporting to the EU trial registry. Journal of Clinical Epidemiology , S0895435621003577. https://doi.org/10.1016/j.jclinepi.2021.11.005
Chambers, C., & Tzavella, L. (2020). The past, present, and future of Registered Reports.
Wendler, D. The Ethics of Clinical Research. in The Stanford Encyclopedia of Philosophy (ed. Zalta, E. N.) (Metaphysics Research Lab, Stanford University, 2021).
London, A. J. Equipoise in Research: Integrating Ethics and Science in Human Research. JAMA 317, 525 (2017).
Cite this work
Our articles and data visualizations rely on work from many different people and organizations. When citing this article, please also cite the underlying data sources. This article can be cited as:
BibTeX citation
Reuse this work freely
All visualizations, data, and code produced by Our World in Data are completely open access under the Creative Commons BY license . You have the permission to use, distribute, and reproduce these in any medium, provided the source and authors are credited.
The data produced by third parties and made available by Our World in Data is subject to the license terms from the original third-party authors. We will always indicate the original source of the data in our documentation, so you should always check the license of any such third-party data before use and redistribution.
All of our charts can be embedded in any site.
Our World in Data is free and accessible for everyone.
Help us do this work by making a donation.
- Evidence-Based Medicine
- Finding the Evidence
- eJournals for EBM
Levels of Evidence
- JAMA Users' Guides
- Tutorials (Learning EBM)
- Web Resources
Resources That Rate The Evidence
- ACP Smart Medicine
- Agency for Healthcare Research and Quality
- Clinical Evidence
- Cochrane Library
- Health Services/Technology Assessment Texts (HSTAT)
- PDQ® Cancer Information Summaries from NCI
- Trip Database
Critically Appraised Individual Articles
- Evidence-Based Complementary and Alternative Medicine
- Evidence-Based Dentistry
- Evidence-Based Nursing
- Journal of Evidence-Based Dental Practice
Grades of Recommendation
Critically-appraised individual articles and synopses include:
Filtered evidence:
- Level I: Evidence from a systematic review of all relevant randomized controlled trials.
- Level II: Evidence from a meta-analysis of all relevant randomized controlled trials.
- Level III: Evidence from evidence summaries developed from systematic reviews
- Level IV: Evidence from guidelines developed from systematic reviews
- Level V: Evidence from meta-syntheses of a group of descriptive or qualitative studies
- Level VI: Evidence from evidence summaries of individual studies
- Level VII: Evidence from one properly designed randomized controlled trial
Unfiltered evidence:
- Level VIII: Evidence from nonrandomized controlled clinical trials, nonrandomized clinical trials, cohort studies, case series, case reports, and individual qualitative studies.
- Level IX: Evidence from opinion of authorities and/or reports of expert committee
Two things to remember:
1. Studies in which randomization occurs represent a higher level of evidence than those in which subject selection is not random.
2. Controlled studies carry a higher level of evidence than those in which control groups are not used.
Strength of Recommendation Taxonomy (SORT)
- SORT The American Academy of Family Physicians uses the Strength of Recommendation Taxonomy (SORT) to label key recommendations in clinical review articles. In general, only key recommendations are given a Strength-of-Recommendation grade. Grades are assigned on the basis of the quality and consistency of available evidence.
- << Previous: eJournals for EBM
- Next: JAMA Users' Guides >>
- Last Updated: Jan 25, 2024 4:15 PM
- URL: https://guides.library.stonybrook.edu/evidence-based-medicine
- Request a Class
- Hours & Locations
- Ask a Librarian
- Special Collections
- Library Faculty & Staff
Library Administration: 631.632.7100
- Stony Brook Home
- Campus Maps
- Web Accessibility Information
- Accessibility Barrier Report Form

Comments or Suggestions? | Library Webmaster

Except where otherwise noted, this work by SBU Libraries is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License .
What is a Randomized Control Trial (RCT)?
Julia Simkus
Editor at Simply Psychology
BA (Hons) Psychology, Princeton University
Julia Simkus is a graduate of Princeton University with a Bachelor of Arts in Psychology. She is currently studying for a Master's Degree in Counseling for Mental Health and Wellness in September 2023. Julia's research has been published in peer reviewed journals.
Learn about our Editorial Process
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
A randomized control trial (RCT) is a type of study design that involves randomly assigning participants to either an experimental group or a control group to measure the effectiveness of an intervention or treatment.
Randomized Controlled Trials (RCTs) are considered the “gold standard” in medical and health research due to their rigorous design.
? 1")
Control Group
A control group consists of participants who do not receive any treatment or intervention but a placebo or reference treatment. The control participants serve as a comparison group.
The control group is matched as closely as possible to the experimental group, including age, gender, social class, ethnicity, etc.
Because the participants are randomly assigned, the characteristics between the two groups should be balanced, enabling researchers to attribute any differences in outcome to the study intervention.
Since researchers can be confident that any differences between the control and treatment groups are due solely to the effects of the treatments, scientists view RCTs as the gold standard for clinical trials.
Random Allocation
Random allocation and random assignment are terms used interchangeably in the context of a randomized controlled trial (RCT).
Both refer to assigning participants to different groups in a study (such as a treatment group or a control group) in a way that is completely determined by chance.
The process of random assignment controls for confounding variables , ensuring differences between groups are due to chance alone.
Without randomization, researchers might consciously or subconsciously assign patients to a particular group for various reasons.
Several methods can be used for randomization in a Randomized Control Trial (RCT). Here are a few examples:
- Simple Randomization: This is the simplest method, like flipping a coin. Each participant has an equal chance of being assigned to any group. This can be achieved using random number tables, computerized random number generators, or drawing lots or envelopes.
- Block Randomization: In this method, participants are randomized within blocks, ensuring that each block has an equal number of participants in each group. This helps to balance the number of participants in each group at any given time during the study.
- Stratified Randomization: This method is used when researchers want to ensure that certain subgroups of participants are equally represented in each group. Participants are divided into strata, or subgroups, based on characteristics like age or disease severity, and then randomized within these strata.
- Cluster Randomization: In this method, groups of participants (like families or entire communities), rather than individuals, are randomized.
- Adaptive Randomization: In this method, the probability of being assigned to each group changes based on the participants already assigned to each group. For example, if more participants have been assigned to the control group, new participants will have a higher probability of being assigned to the experimental group.
Computer software can generate random numbers or sequences that can be used to assign participants to groups in a simple randomization process.
For more complex methods like block, stratified, or adaptive randomization, computer algorithms can be used to consider the additional parameters and ensure that participants are assigned to groups appropriately.
Using a computerized system can also help to maintain the integrity of the randomization process by preventing researchers from knowing in advance which group a participant will be assigned to (a principle known as allocation concealment). This can help to prevent selection bias and ensure the validity of the study results .
Allocation Concealment
Allocation concealment is a technique to ensure the random allocation process is truly random and unbiased.
RCTs use allocation concealment to decide which patients get the real medicine and which get a placebo (a fake medicine)
It involves keeping the sequence of group assignments (i.e., who gets assigned to the treatment group and who gets assigned to the control group next) hidden from the researchers before a participant has enrolled in the study.
This helps to prevent the researchers from consciously or unconsciously selecting certain participants for one group or the other based on their knowledge of which group is next in the sequence.
Allocation concealment ensures that the investigator does not know in advance which treatment the next person will get, thus maintaining the integrity of the randomization process.
Blinding (Masking)
Binding, or masking, refers to withholding information regarding the group assignments (who is in the treatment group and who is in the control group) from the participants, the researchers, or both during the study .
A blinded study prevents the participants from knowing about their treatment to avoid bias in the research. Any information that can influence the subjects is withheld until the completion of the research.
Blinding can be imposed on any participant in an experiment, including researchers, data collectors, evaluators, technicians, and data analysts.
Good blinding can eliminate experimental biases arising from the subjects’ expectations, observer bias, confirmation bias, researcher bias, observer’s effect on the participants, and other biases that may occur in a research test.
In a double-blind study , neither the participants nor the researchers know who is receiving the drug or the placebo. When a participant is enrolled, they are randomly assigned to one of the two groups. The medication they receive looks identical whether it’s the drug or the placebo.
? 2")
Figure 1 . Evidence-based medicine pyramid. The levels of evidence are appropriately represented by a pyramid as each level, from bottom to top, reflects the quality of research designs (increasing) and quantity (decreasing) of each study design in the body of published literature. For example, randomized control trials are higher quality and more labor intensive to conduct, so there is a lower quantity published.
Prevents bias
In randomized control trials, participants must be randomly assigned to either the intervention group or the control group, such that each individual has an equal chance of being placed in either group.
This is meant to prevent selection bias and allocation bias and achieve control over any confounding variables to provide an accurate comparison of the treatment being studied.
Because the distribution of characteristics of patients that could influence the outcome is randomly assigned between groups, any differences in outcome can be explained only by the treatment.
High statistical power
Because the participants are randomized and the characteristics between the two groups are balanced, researchers can assume that if there are significant differences in the primary outcome between the two groups, the differences are likely to be due to the intervention.
This warrants researchers to be confident that randomized control trials will have high statistical power compared to other types of study designs.
Since the focus of conducting a randomized control trial is eliminating bias, blinded RCTs can help minimize any unconscious information bias.
In a blinded RCT, the participants do not know which group they are assigned to or which intervention is received. This blinding procedure should also apply to researchers, health care professionals, assessors, and investigators when possible.
“Single-blind” refers to an RCT where participants do not know the details of the treatment, but the researchers do.
“ Double-blind ” refers to an RCT where both participants and data collectors are masked of the assigned treatment.
Limitations
Costly and timely.
Some interventions require years or even decades to evaluate, rendering them expensive and time-consuming.
It might take an extended period of time before researchers can identify a drug’s effects or discover significant results.
Requires large sample size
There must be enough participants in each group of a randomized control trial so researchers can detect any true differences or effects in outcomes between the groups.
Researchers cannot detect clinically important results if the sample size is too small.
Change in population over time
Because randomized control trials are longitudinal in nature, it is almost inevitable that some participants will not complete the study, whether due to death, migration, non-compliance, or loss of interest in the study.
This tendency is known as selective attrition and can threaten the statistical power of an experiment.
Randomized control trials are not always practical or ethical, and such limitations can prevent researchers from conducting their studies.
For example, a treatment could be too invasive, or administering a placebo instead of an actual drug during a trial for treating a serious illness could deny a participant’s normal course of treatment. Without ethical approval, a randomized control trial cannot proceed.
Fictitious Example
An example of an RCT would be a clinical trial comparing a drug’s effect or a new treatment on a select population.
The researchers would randomly assign participants to either the experimental group or the control group and compare the differences in outcomes between those who receive the drug or treatment and those who do not.
Real-life Examples
- Preventing illicit drug use in adolescents: Long-term follow-up data from a randomized control trial of a school population (Botvin et al., 2000).
- A prospective randomized control trial comparing medical and surgical treatment for early pregnancy failure (Demetroulis et al., 2001).
- A randomized control trial to evaluate a paging system for people with traumatic brain injury (Wilson et al., 2009).
- Prehabilitation versus Rehabilitation: A Randomized Control Trial in Patients Undergoing Colorectal Resection for Cancer (Gillis et al., 2014).
- A Randomized Control Trial of Right-Heart Catheterization in Critically Ill Patients (Guyatt, 1991).
- Berry, R. B., Kryger, M. H., & Massie, C. A. (2011). A novel nasal excitatory positive airway pressure (EPAP) device for the treatment of obstructive sleep apnea: A randomized controlled trial. Sleep , 34, 479–485.
- Gloy, V. L., Briel, M., Bhatt, D. L., Kashyap, S. R., Schauer, P. R., Mingrone, G., . . . Nordmann, A. J. (2013, October 22). Bariatric surgery versus non-surgical treatment for obesity: A systematic review and meta-analysis of randomized controlled trials. BMJ , 347.
- Streeton, C., & Whelan, G. (2001). Naltrexone, a relapse prevention maintenance treatment of alcohol dependence: A meta-analysis of randomized controlled trials. Alcohol and Alcoholism, 36 (6), 544–552.
How Should an RCT be Reported?
Reporting of a Randomized Controlled Trial (RCT) should be done in a clear, transparent, and comprehensive manner to allow readers to understand the design, conduct, analysis, and interpretation of the trial.
The Consolidated Standards of Reporting Trials ( CONSORT ) statement is a widely accepted guideline for reporting RCTs.
Further Information
- Cocks, K., & Torgerson, D. J. (2013). Sample size calculations for pilot randomized trials: a confidence interval approach. Journal of clinical epidemiology, 66(2), 197-201.
- Kendall, J. (2003). Designing a research project: randomised controlled trials and their principles. Emergency medicine journal: EMJ, 20(2), 164.
Akobeng, A.K., Understanding randomized controlled trials. Archives of Disease in Childhood , 2005; 90: 840-844.
Bell, C. C., Gibbons, R., & McKay, M. M. (2008). Building protective factors to offset sexually risky behaviors among black youths: a randomized control trial. Journal of the National Medical Association, 100 (8), 936-944.
Bhide, A., Shah, P. S., & Acharya, G. (2018). A simplified guide to randomized controlled trials. Acta obstetricia et gynecologica Scandinavica, 97 (4), 380-387.
Botvin, G. J., Griffin, K. W., Diaz, T., Scheier, L. M., Williams, C., & Epstein, J. A. (2000). Preventing illicit drug use in adolescents: Long-term follow-up data from a randomized control trial of a school population. Addictive Behaviors, 25 (5), 769-774.
Demetroulis, C., Saridogan, E., Kunde, D., & Naftalin, A. A. (2001). A prospective randomized control trial comparing medical and surgical treatment for early pregnancy failure. Human Reproduction, 16 (2), 365-369.
Gillis, C., Li, C., Lee, L., Awasthi, R., Augustin, B., Gamsa, A., … & Carli, F. (2014). Prehabilitation versus rehabilitation: a randomized control trial in patients undergoing colorectal resection for cancer. Anesthesiology, 121 (5), 937-947.
Globas, C., Becker, C., Cerny, J., Lam, J. M., Lindemann, U., Forrester, L. W., … & Luft, A. R. (2012). Chronic stroke survivors benefit from high-intensity aerobic treadmill exercise: a randomized control trial. Neurorehabilitation and Neural Repair, 26 (1), 85-95.
Guyatt, G. (1991). A randomized control trial of right-heart catheterization in critically ill patients. Journal of Intensive Care Medicine, 6 (2), 91-95.
MediLexicon International. (n.d.). Randomized controlled trials: Overview, benefits, and limitations. Medical News Today. Retrieved from https://www.medicalnewstoday.com/articles/280574#what-is-a-randomized-controlled-trial
Wilson, B. A., Emslie, H., Quirk, K., Evans, J., & Watson, P. (2005). A randomized control trial to evaluate a paging system for people with traumatic brain injury. Brain Injury, 19 (11), 891-894.
Study Design 101: Randomized Controlled Trial
- Case Report
- Case Control Study
- Cohort Study
- Randomized Controlled Trial
- Practice Guideline
- Systematic Review
- Meta-Analysis
- Helpful Formulas
- Finding Specific Study Types
A study design that randomly assigns participants into an experimental group or a control group. As the study is conducted, the only expected difference between the control and experimental groups in a randomized controlled trial (RCT) is the outcome variable being studied.
- Good randomization will "wash out" any population bias
- Easier to blind/mask than observational studies
- Results can be analyzed with well known statistical tools
- Populations of participating individuals are clearly identified
Disadvantages
- Expensive in terms of time and money
- Volunteer biases: the population that participates may not be representative of the whole
- Loss to follow-up attributed to treatment
Design pitfalls to look out for
An RCT should be a study of one population only.
Was the randomization actually "random", or are there really two populations being studied?
The variables being studied should be the only variables between the experimental group and the control group.
Are there any confounding variables between the groups?
Fictitious Example
To determine how a new type of short wave UVA-blocking sunscreen affects the general health of skin in comparison to a regular long wave UVA-blocking sunscreen, 40 trial participants were randomly separated into equal groups of 20: an experimental group and a control group. All participants' skin health was then initially evaluated. The experimental group wore the short wave UVA-blocking sunscreen daily, and the control group wore the long wave UVA-blocking sunscreen daily.
After one year, the general health of the skin was measured in both groups and statistically analyzed. In the control group, wearing long wave UVA-blocking sunscreen daily led to improvements in general skin health for 60% of the participants. In the experimental group, wearing short wave UVA-blocking sunscreen daily led to improvements in general skin health for 75% of the participants.
Real-life Examples
van Der Horst, N., Smits, D., Petersen, J., Goedhart, E., & Backx, F. (2015). The preventive effect of the nordic hamstring exercise on hamstring injuries in amateur soccer players: a randomized controlled trial. The American Journal of Sports Medicine, 43 (6), 1316-1323. https://doi.org/10.1177/0363546515574057
This article reports on the research investigating whether the Nordic Hamstring Exercise is effective in preventing both the incidence and severity of hamstring injuries in male amateur soccer players. Over the course of a year, there was a statistically significant reduction in the incidence of hamstring injuries in players performing the NHE, but for those injured, there was no difference in severity of injury. There was also a high level of compliance in performing the NHE in that group of players.
Natour, J., Cazotti, L., Ribeiro, L., Baptista, A., & Jones, A. (2015). Pilates improves pain, function and quality of life in patients with chronic low back pain: a randomized controlled trial. Clinical Rehabilitation, 29 (1), 59-68. https://doi.org/10.1177/0269215514538981
This study assessed the effect of adding pilates to a treatment regimen of NSAID use for individuals with chronic low back pain. Individuals who included the pilates method in their therapy took fewer NSAIDs and experienced statistically significant improvements in pain, function, and quality of life.
Related Formulas
- Relative Risk
Related Terms
Blinding/Masking
When the groups that have been randomly selected from a population do not know whether they are in the control group or the experimental group.
Being able to show that an independent variable directly causes the dependent variable. This is generally very difficult to demonstrate in most study designs.
Confounding Variables
Variables that cause/prevent an outcome from occurring outside of or along with the variable being studied. These variables render it difficult or impossible to distinguish the relationship between the variable and outcome being studied).
Correlation
A relationship between two variables, but not necessarily a causation relationship.
Double Blinding/Masking
When the researchers conducting a blinded study do not know which participants are in the control group of the experimental group.
Null Hypothesis
That the relationship between the independent and dependent variables the researchers believe they will prove through conducting a study does not exist. To "reject the null hypothesis" is to say that there is a relationship between the variables.
Population/Cohort
A group that shares the same characteristics among its members (population).
Population Bias/Volunteer Bias
A sample may be skewed by those who are selected or self-selected into a study. If only certain portions of a population are considered in the selection process, the results of a study may have poor validity.
Randomization
Any of a number of mechanisms used to assign participants into different groups with the expectation that these groups will not differ in any significant way other than treatment and outcome.
Research (alternative) Hypothesis
The relationship between the independent and dependent variables that researchers believe they will prove through conducting a study.
Sensitivity
The relationship between what is considered a symptom of an outcome and the outcome itself; or the percent chance of not getting a false positive (see formulas).
Specificity
The relationship between not having a symptom of an outcome and not having the outcome itself; or the percent chance of not getting a false negative (see formulas).
Type 1 error
Rejecting a null hypothesis when it is in fact true. This is also known as an error of commission.
Type 2 error
The failure to reject a null hypothesis when it is in fact false. This is also known as an error of omission.
Now test yourself!
1. Having a volunteer bias in the population group is a good thing because it means the study participants are eager and make the study even stronger.
a) True b) False
2. Why is randomization important to assignment in an RCT?
a) It enables blinding/masking b) So causation may be extrapolated from results c) It balances out individual characteristics between groups. d) a and c e) b and c
Evidence Pyramid - Navigation
- Meta- Analysis
- Case Reports
- << Previous: Cohort Study
- Next: Practice Guideline >>
- Last Updated: Sep 25, 2023 10:59 AM
- URL: https://guides.himmelfarb.gwu.edu/studydesign101

- Himmelfarb Intranet
- Privacy Notice
- Terms of Use
- GW is committed to digital accessibility. If you experience a barrier that affects your ability to access content on this page, let us know via the Accessibility Feedback Form .
- Himmelfarb Health Sciences Library
- 2300 Eye St., NW, Washington, DC 20037
- Phone: (202) 994-2850
- [email protected]
- https://himmelfarb.gwu.edu
Your Account
Manage your account, subscriptions and profile.
MyKomen Health
ShareForCures
In Your Community
In Your Community
View resources and events in your local community.
Change your location:
Susan G. Komen®
One moment can change everything.
Types of Research Studies
Epidemiology studies.
Epidemiology is the study of the patterns and causes of disease in people.
The goal of epidemiology studies is to give information that helps support or disprove an idea about a possible link between an exposure (such as alcohol use) and an outcome (such as breast cancer) in people.
The 2 main types of epidemiology studies are:
- Observational studies ( prospective cohort or case-control )
Randomized controlled trials
Though they have the same goal, observational studies and randomized controlled trials differ in:
- The way they are conducted
- The strengths of the conclusions they reach
Observational studies
In observational studies, the people in the study live their daily lives as they choose. They exercise when they want, eat what they like and take the medicines their doctors prescribe. They report these activities to researchers.
There are 2 types of observational studies:
Prospective cohort studies
Case-control studies.
A prospective cohort study follows a large group of people forward in time.
Some people will have a certain exposure (such as alcohol use) and others will not.
Researchers compare the different groups (for example, they might compare heavy drinkers, moderate drinkers, light drinkers and non-drinkers) to see which group is more likely to develop an outcome (such as breast cancer).
In a case-control study, researchers identify 2 groups: cases and controls.
- Cases are people who already have an outcome (such as breast cancer).
- Controls are people who do not have the outcome.
The researchers compare the 2 groups to see if any exposure (such as alcohol use) was more common in the history of one group compared to the other.
In randomized controlled trials (randomized clinical trials), researchers divide people into groups to compare different treatments or other interventions.
These studies are called randomized controlled trials because people are randomly assigned (as if by coin toss) to a certain treatment or behavior.
For example, in a randomized trial of a new drug therapy, half the people might be randomly assigned to a new drug and the other half to the standard treatment.
In a randomized controlled trial on exercise and breast cancer risk, half the participants might be randomly assigned to walk 10 minutes a day and the other half to walk 2 hours a day. The researchers would then see which group was more likely to develop breast cancer, those who walked 10 minutes a day or those who walked 2 hours a day.
Many behaviors, such as smoking or heavy alcohol drinking, can’t be tested in this way because it isn’t ethical to assign people to a behavior known to be harmful. In these cases, researchers must use observational studies.
Patient series
A patient series is a doctor’s observations of a group of patients who are given a certain treatment.
There is no comparison group in a patient series. All the patients are given a certain treatment and the outcomes of these patients are studied.
With no comparison group, it’s hard to draw firm conclusions about the effectiveness of a treatment.
For example, if 10 women with breast cancer are given a new treatment, and 2 of them respond, how do we know if the new treatment is better than standard treatment?
If we had a comparison group of 10 women with breast cancer who got standard treatment, we could compare their outcomes to those of the 10 women on the new treatment. If no women in the comparison group responded to standard treatment, then the 2 women who responded to the new treatment would represent a success of the new treatment. If, however, 2 of the 10 women in the standard treatment group also responded, then the new treatment is no better than the standard.
The lack of a comparison group makes it hard to draw conclusions from a patient series. However, data from a patient series can help form hypotheses that can be tested in other types of studies.
Strengths and weaknesses of different types of research studies
When reviewing scientific evidence, it’s helpful to understand the strengths and weaknesses of different types of research studies.
Case-control studies have some strengths:
- They are easy and fairly inexpensive to conduct.
- They are a good way for researchers to study rare diseases. If a disease is rare, you would need to follow a very large group of people forward in time to have many cases of the disease develop.
- They are a good way for researchers to study diseases that take a long time to develop. If a disease takes a long time to develop, you would have to follow a group of people for many years for cases of the disease to develop.
Case-control studies look at past exposures of people who already have a disease. This causes some concerns:
- It can be hard for people to remember details about the past, especially when it comes to things like diet.
- Memories can be biased (or influenced) because the information is gathered after an event, such as the diagnosis of breast cancer.
- When it comes to sensitive topics (such as abortion), the cases (the people with the disease) may be much more likely to give complete information about their history than the controls (the people without the disease). Such differences in reporting bias study results.
For these reasons, the accuracy of the results of case-control studies can be questionable.
Cohort studies
Prospective cohort studies avoid many of the problems of case-control studies because they gather information from people over time and before the events being studied happen.
However, compared to case-control studies, they are expensive to conduct.
Nested case-control studies
A nested case-control study is a case-control study within a prospective cohort study.
Nested case-control studies use the design of a case-control study. However, they use data gathered as part of a cohort study, so they are less prone to bias than standard case-control studies.
All things being equal, the strength of nested case-control data falls somewhere between that of standard case-control studies and cohort studies.
Randomized controlled trials are considered the gold standard for studying certain exposures, such as breast cancer treatment. Similar to cohort studies, they follow people over time and are expensive to do.
Because people in a randomized trial are randomly assigned to an intervention (such as a new chemotherapy drug) or standard treatment, these studies are more likely to show the true link between an intervention and a health outcome (such as survival).
Learn more about randomized clinical trials , including the types of clinical trials, benefits, and possible drawbacks.
Overall study quality
The overall quality of a study is important. For example, the results from a well-designed case-control study can be more reliable than those from a poorly-designed randomized trial.
Finding more information on research study design
If you’re interested in learning more about research study design, a basic epidemiology textbook from your local library may be a good place to start. The National Cancer Institute also has information on epidemiology studies and randomized controlled trials.
Animal studies
Animal studies add to our understanding of how and why some factors cause cancer in people.
However, there are many differences between animals and people, so it makes it hard to translate findings directly from one to the other.
Animal studies are also designed differently. They often look at exposures in larger doses and for shorter periods of time than are suitable for people.
While animal studies can lay the groundwork for research in people, we need human studies to draw conclusions for people.
All data presented within this section of the website come from studies done with people.
Joining a research study
Research is ongoing to improve all areas of breast cancer, from prevention to treatment.
Whether you’re newly diagnosed, finished breast cancer treatment many years ago, or even if you’ve never had breast cancer, there may be breast cancer research studies you can join.
If you have breast cancer, BreastCancerTrials.org in collaboration with Susan G. Komen® offers a custom matching service that can help find a studies that fit your needs. You can also visit the National Institutes of Health’s website to find a breast cancer treatment study.
If you’re interested in being part of other studies, talk with your health care provider. Your provider may know of studies in your area looking for volunteers.
Learn more about joining a research study .
Learn more about clinical trials .
Learn what Komen is doing to help people find and participate in clinical trials .
Updated 12/16/20
TOOLS & RESOURCES
In Your Own Words
How has having breast cancer changed your outlook?
Share Your Story or Read Others
- Open access
- Published: 26 April 2024
A randomized controlled trial comparison of PTEBL and traditional teaching methods in “Stop the Bleed” training
- Wanchen Zhao 1 , 2 , 4 ,
- Yangbo Cao 1 ,
- Liangrong Hu 2 ,
- Chenxiao Lu 1 , 2 , 4 ,
- Gaoming Liu 1 , 2 , 4 ,
- Matthew Gong 3 &
- Jinshen He ORCID: orcid.org/0000-0003-0277-3819 1
BMC Medical Education volume 24 , Article number: 462 ( 2024 ) Cite this article
146 Accesses
Metrics details
The Stop the Bleed (STB) training program was launched by the White House to minimize hemorrhagic deaths. Few studies focused on the STB were reported outside the United States. This study aimed to evaluate the effectiveness of a problem-, team- and evidence-based learning (PTEBL) approach to teaching, compared to traditional teaching methods currently employed in STB courses in China.
This study was a parallel group, unmasked, randomised controlled trial. We included third-year medical students of a five-year training program from the Xiangya School of Medicine, Central South University who voluntarily participated in the trial. One hundred fifty-three medical students were randomized (1:1) into the PTEBL group ( n = 77) or traditional group ( n = 76). Every group was led by a single instructor. The instructor in the PTEBL group has experienced in educational reform. However, the instructor in the traditional group follows a traditional teaching mode. The teaching courses for both student groups had the same duration of four hours. Questionnaires were conducted to assess teaching quality before and after the course. The trial was registered in the Central South University (No. 2021JY188).
In the PTEBL group, students reported mastery in three fundamental STB skills—Direct Finger Compression (61/77, 79.2%), Packing (72/77, 93.8%), and Tourniquet Placement (71/77, 92.2%) respectively, while 76.3% (58/76), 89.5% (68/76), and 88.2% (67/76) of students in the traditional group ( P > 0.05 for each pairwise comparison). 96.1% (74/77) of students in the PTEBL group felt prepared to help in an emergency, while 90.8% (69/76) of students in the traditional group ( P > 0.05). 94.8% (73/77) of students reported improved teamwork skills after the PTEBL course, in contrast with 81.6% (62/76) of students in the traditional course ( P = 0.011). Furthermore, a positive correlation was observed between improved clinical thinking skills and improved teamwork skills ( R = 0.82, 95% CI: 0.74–0.88; P < 0.001).
Conclusions
Compared with the traditional teaching method, the PTEBL method was superior in teaching teamwork skills, and has equally effectively taught hemostasis techniques in the emergency setting. The PTEBL method can be introduced to the STB training in China.
Peer Review reports
Introduction
According to the World Health Organization, mass traumatic injuries result in over five million deaths annually [ 1 ]. In the United States, increasing shooting incidents have contributed to this high mortality rate [ 2 ]. Due to rapid development in China, more than 700,000 motor vehicle accidents occur annually, leading to approximately 1.3 million injuries and 80,000 to 100,000 deaths [ 3 , 4 ]. Traumatic hemorrhage remains a significant cause of death for all ages regardless of the form of trauma [ 5 ]. It is estimated that 57% of deaths could be avoided with proper control of bleeding [ 6 , 7 , 8 ]. In 2015, the White House launched the Stop the Bleed (STB) training program to minimize preventable deaths from trauma [ 9 , 10 ]. Bleeding control techniques of both medical professionals and the general public have indeed improved through this campaign, with a 63% decrease in deaths from uncontrolled bleeding [ 11 , 12 ]. However, only one STB course with small sample size equipped with Caesar (a trauma patient simulator) has been reported in China [ 13 ]. But, the cost of the trauma simulator is relatively high and difficult to obtain. It is crucial to introduce STB skills courses utilizing proper teaching methods to general Chinese medical students without expensive equipment.
Medical students are the primary target population of STB training courses. Education in the course traditionally includes demonstrations, lectures, and hands-on teaching sessions [ 14 , 15 , 16 ]. Although students’ skills can be enhanced through these traditional teaching methods; training teamwork skills are often neglected. It can be difficult for medical students to manage complex clinical scenarios in a real-life trauma setting after completing a course that emphasizes single-skills training and de-emphasizes teamwork-based training. In a traumatic event, responding students are required to make comprehensive decisions in real time, including asking for help, diagnosing injuries, assigning tasks, transferring the patient, implementing clinical interventions, and more [ 17 ]. Furthermore, medical training is about acquiring clinical skills and cultivating a state of mind that will allow students to embrace the sacrifice and love for humanity embedded in the Hippocratic oath [ 18 ]. These comprehensive abilities should be enhanced through teamwork-based training. To facilitate this learning, a novel problem-, team- and evidence-based learning (PTEBL) approach to teaching may compensate for the weaknesses of traditional teaching methods [ 19 ]. We conducted a cluster randomised controlled trial to compare PTEBL teaching approach (intervention) to a traditional course (control) among medical students of a five-year training program from the Xiangya School of Medicine, Central South University.
This research aimed to evaluate the effectiveness of PTEBL, a novel teaching method, via comparison between an experimental PTEBL and control traditional teaching group. It was hypothesized that implementing a PTEBL teaching approach in the STB course could contribute to better teamwork skills and noninferior hemorrhage controlling skills compared with the traditional teaching method.
Study design
This is a parallel group, unmasked, randomized clinical trial (RCT) using online surveys completed before and after the STB course. STB was launched in the situation of increasing number of gunshot injuries in the United States, while there may be more traffic accident injuries in China. Traffic accident injuries usually involve complex injury processes. Therefore, the traffic accident injuries might need team work more. We applied the PTEBL teaching approach to fit the new situation..Students of this case study were randomized into either an experimental group utilizing the PTEBL teaching approach ( n = 77) or a control group utilizing the traditional teaching approach ( n = 76), using a 1:1 allocation ratio. Random grouping is mainly achieved through random numbers. Every group was led by a single instructor. The instructor in PTEBL group has experiences in educational reform, and has published related articles on the PTEBL teaching method [ 19 ] and STB training [ 13 ]. The instructor has also completed a “Stop the Bleed” training certificate. The instructor in the traditional group was trained in China and follows a traditional teaching mode. Both teachers were provided with scripts to follow. They prepared the lessons before each class. Each instructor also engaged students by asking questions to ensure students were learning the technique correctly. In addition, the teaching courses for both student groups had the same teaching duration of four hours on Jun 14, 2022. A 15-min break was provided for every 45 min of class. All courses were completed in the laboratory of the teaching building of Xiangya School of Medicine. Each instructor taught 16 to 17 students per class (teacher to student ratio: 1:16–17). In the questionnaire [ 20 ], students were queried about their mastery of STB skills and willingness to apply these skills during a traumatic medical emergency, etc. The questionnaires also included statistics to assess the students’ attitudes of willingness to provide aid to a bleeding patient. The outcomes of the questionnaire were analyzed to assess the effectiveness of the PTEBL teaching approach. (Appendices 1 and 2 ) The trial was registered in the Central South University (No. 2021JY188). No incentives / reimbursements were provided to participants.
The learner attendance, the materials and the educational strategies used in the educational intervention and the duration for the educational intervention were assessed by raters. Raters were two doctoral level students, trained by senior staff.
Participants
All participants were the third-year medical students of a five-year training program from the Xiangya School of Medicine, Central South University. STB is a course for all people regardless of medical background. However, considering that our medical students still have gaps in hemostatic skills, we intended to incorporate this advanced skill into our training program for medical students. We have released recruitment information on Apr 30, 2022 and included medical students who voluntarily participated in the trial. We excluded students who have received systematic hemostatic training due to certain opportunities. One hundred fifty-three participants were randomized into two study groups (Fig. 1 ). We generated random numbers using IBM SPSS Statistics v26.0 statistical software. The demographic data of participants in age and sex are shown in Table 1 . Informed consent was obtained from all participants enrolled in the study.

Enrollment, randomization, and protocol of participants
Study protocol
Prior to the course, participants completed both an anonymous pre-training questionnaire about their prior experiences with hemorrhage control techniques and a post-training questionnaire about their confidence levels with applying these techniques after completion of the course. (See Appendix 1 Pre-Questionnaire and Appendix 2 Post-Questionnaire [ 12 , 21 ]).
For the traditional teaching method, the instructor demonstrated three fundamental skills for obtaining hemostasis (Direct Finger Compression, Packing, and Tourniquet Placement) while describing each step and explaining techniques in detail according to the standard STB (two hours in this part). Students then practiced these three skills for stopping bleeding (two hours in this part). At the end of the course, instructors evaluated and scored each participant’s skill level (Fig. 1 ).
For the PTEBL teaching approach implemented in the experimental group, classes included three sessions: 1) problem-based learning (PBL) (1.5 h in this part), 2) team-based learning (TBL) (two hours in this part), and 3) evidence-based learning (EBL) (0.5 h in this part). The PTEBL teaching approach emphasized four steps in the EBM process a) developing an answerable question, b) finding the best available evidence, c) evaluation the evidence and d) applying the evidence to a patient care decision.
The first session presented theoretical knowledge and posed questions to students. Students read a scenario of traumatic bleeding adapted from a medical TV series. Instructors then posed four questions about the operation of pre-hospital emergency medical services: (Q1) How can bleeding be stopped effectively? (Q2) When should cardiopulmonary resuscitation be initiated? (Q3) Which actions were performed well? (Q4) Which actions were not performed well? After learning Direct Finger Compression, Packing, and Tourniquet Placement academic knowledge using interactive multimedia, students completed a 3-item knowledge quiz (see Appendix 3 Theoretical Test) to gauge the efficacy of theoretical teaching and the students’ comprehension.
In the second session, participants were divided into small groups to practice hands-on bleeding control skills and to provide critiques to their team members. After instruction with tourniquet placement, where each student had an opportunity to perform at least one placement, each team member played different roles in the scenario simulation: the injured victim, the injured victim's friend, the primary rescuer, and the rescuer’s colleague. The simulation involved a disabled individual sustaining an active brachial artery injury after a ground level fall. After direct finger compression, packing, and tourniquet placement were implemented by the team, bleeding control was achieved. During the simulation, team members made comprehensive decisions through collaboration, including assigning tasks, transferring patients, and implementing emergency medical services. After this scenario, participants described their experiences acting in different roles. Trained STB instructors observing the scenario evaluated their operation and provided participants with feedback on proper hemorrhage control techniques.
In the last session, instructors contributed to establishing competencies for medical students by adhering to expert consensus standards on emergency tourniquet application derived from current International Medical Association guidelines [ 22 , 23 , 24 , 25 ]. The consensus presented an outline of international guidelines and practices in emergency medicine [ 26 , 27 ].
Statistical analysis
Statistical analysis was performed using IBM SPSS Statistics v26.0 statistical software. Continuous variables were expressed as the mean with standard deviation. Categorical variables were defined as frequency and compared using a paired X 2 test. Wilcoxon signed-rank test was used for the ordered variables of the Likert scale data. Spearman's correlation coefficient (CC) was applied to analyze the correlation between the variables, and the results were presented as a correlation heatmap. The greater the absolute value of CC, the stronger the correlation. When the absolute value of CC is between 0.9 and 1, variables are highly correlated. When the absolute value of CC is between 0.7 and 0.9, variables are strongly correlated [ 21 ]. A P -value of < 0.05 was considered statistically significant. The "strongly agree" (5) and "agree" (4) components of the Likert scale were transferred into one, and the remaining three components were changed into zero, namely converting the variables into dichotomous variables for statistical analysis. To estimate the number of samples, an a priori power analysis was performed using G*power v3.1 (UCLA Statistical Consulting Group, Los Angeles, CA) based on repeated measures within X 2 tests, with a hypothesized effect size of 0.3, an α error of 0.05 and a power of 0.95, which resulted in a sample size of n = 145. Our total sample size is 153, which meet the requirements.
Characteristics of participants
A total of 153 participants participated in the study. All participants completed two questionnaires before and after the STB course independently. There were no statistically significant differences ( P > 0.05) in demographics for the experimental group ( n = 77) compared with the control group ( n = 76). Meanwhile, the characteristics of participants in prior basic knowledge of obtaining hemostasis are shown in Table 1 . 41.2% (63/153) of the participants had no experience in hemorrhage control techniques; 58.8% (90/153) of the participants only had minimal basic training in hemorrhage control techniques. No record of any specific adaptations made to the educational intervention was kept.
Mastery level of hemostasis skills
Proficiency of hemostasis skills in compression via direct finger compression, packing, and tourniquet placement before and after the PTEBL and the traditional methods are presented in Table 2 . Both the PTEBL method and the traditional method had statistically significant differences ( P < 0.001) in reported proficiency before and after the course. However, there were no statistically significant differences between the PTEBL method and the traditional method in proficiency of fundamental hemostatic skills ( P = 0.243, 0.645, and 0.280, respectively). No record of any modifications made during the course of the educational intervention was retained.
Rescue attitude
The number of participants who felt prepared to help and those who would refuse to provide assistance in a trauma even pre- and post-course were recorded and shown in Table 3 . Again, there were statistically significant differences ( P < 0.001) in the PTEBL group pre- course and post-course. There were also statistically significant differences ( P < 0.001) in the traditional group. But no statistically significant differences ( P > 0.05) between the PTEBL group and the traditional group.
Effectiveness evaluation of the PTEBL method and the traditional method.
Evaluation of the effectiveness of the PTEBL method and the traditional method based on five indicators are presented in Fig. 2 . 94.8% (73/77) of the PTEBL course participants believed their teamwork skills were improved, while 81.6% (62/76) of the traditional course participants believed their teamwork skills were improved, with a statistically significant difference ( P < 0.05) observed. There were no statistically significant differences in teaching effectiveness between the PTEBL method and the traditional method ( P > 0.05).

Effectiveness evaluation of the two groups
Performance assessment of the PTEBL method and the traditional method.
There was no statistically significant difference ( P > 0.05) between the assessment scores after the PTEBL method (92.9 ± 2.8) compared to those after the traditional method (92.9 ± 2.1).
Correlation heatmap of relevant independent variables.
The Spearman CC heatmap is shown in Fig. 3 . The highest positive correlation in specific skills was observed between pre-course confidence with compression via packing and pre-course confidence with compression via tourniquet placement ( R = 0.88; 95%CI: 0.81–0.93; P < 0.001). The second-highest positive correlation was observed between reported improved clinical thinking and reported improved teamwork skills on the post-course questionnaire ( R = 0.82; 95%CI: 0.74–0.88; P < 0.001). There were three groups of variables with positive correlations of R values greater than 0.7 and less than 0.8, which were the correlation between pre-course confidence with compression via direct finger pressure and pre-course confidence with compression via packing ( R = 0.76; 95%CI: 0.66–0.84; P < 0.001), pre-course confidence with compression via direct finger pressure and pre-course confidence with compression via tourniquet placement ( R = 0.75; 95%CI: 0.66–0.82; P < 0.001), and post-course confidence with compression via packing and post-course confidence with compression via tourniquet placement ( R = 0.74; 95%CI: 0.63–0.83; P < 0.001). Other correlations are indicated in Fig. 3 .

Correlation heatmap of relevant independent variables
In summary, our initial hypothesis was confirmed that the application of PTEBL in STB courses contributes to better teamwork. Furthermore, results of our pre-post evaluation demonstrated an increase in bleeding control knowledge, skills and willingness to be first responders regardless of the teaching methods, which indicates the PTEBL method could be applied in the STB courses in China.
These observations are consistent with the results of some prior studies. In a study by Goralnick et al., hemorrhage-control training consisting of a lecture followed by hands-on skills training (87.7% proven to be effective) was found to be the most effective method to enable laypersons to control hemorrhage using a tourniquet [ 10 ]. Kaori et al . also suggested that STB training lectures with a practical session improved tourniquet knowledge and prepared Japanese citizens for mass casualty events [ 28 ]. Generally, the teaching method of “demonstration-practice-examination”, a single skill operation with little teamwork-based teaching, does have remarkable effectiveness, proven by its high utilization in traditional hemostasis training and widespread use in different countries [ 14 , 15 ]. However, the best form of education for the STB course is still a source of debate [ 2 ]. Despite individual hemorrhage-control skills being enhanced through this training; it is also important to note that teamwork, cooperation and, comprehensive ability to respond to emergencies are also important in a trauma scenario.
The novel PTEBL teaching method was first applied in an STB course in China by our group [ 13 ]. In the present study without Caesar, students felt more inclined to express their opinions based on problems occurring during a trauma response, and a team-based approach encouraged collaborative thinking. Their abilities to analyze issues independently and think critically were also improved effectively. Furthermore, students worked in teams to practice and simulated clinical scenarios in which different emergency tasks were assigned to every individual. PTEBL achieved an overall improvement in personal and group development, improved the ability of students to integrate skills, especially in terms of communication skills, critical thinking, evidence-based thinking, and successfully prepared students for future clinical work [ 19 ]. Findings of Orlas et al . have previously supported that via STB course lectures and hands-on skills practice, 92.1% of all participants from different groups felt confident in being able to apply a tourniquet correctly [ 1 ]. Our study found that 92.2% of participants in the PTEBL course and 88.2% of participants in the traditional course could successfully apply a tourniquet after training. We suspect that this difference may be due to initial problem-based learning allowing for multiple practice opportunities and real-time feedback to correct mistakes or address overconfidence in some medical students [ 11 ].
Given that no statistically significant difference was seen in five other areas besides improved teamwork skills, including clinical thinking, problem analysis, learning effect, performance assessment, and pre-course guideline distribution, we cannot conclude that our new PTEBL teaching method performs better than the former traditional method remarkably. However, we observed that students' team cooperation ability was significantly improved in the PTEBL group compared with the traditional group due to team-based simulation scenarios. The mastery of bleeding control knowledge, skills and willingness to be first responders were also increased after PTEBL method on the basis of data from questionnaires, built on many references [ 21 ]. Although the quality control of data may be affected to some extent, students often assess relevant skills and have a more accurate grasp of their skill level and self-confidence, reducing the research error. The heatmap demonstrated improved problem analysis correlated with pre-course guideline distribution, improved learning effect, and improved teamwork skills. Improved clinical thinking is also associated with enhanced learning effects, improved problem analysis, and teamwork skills. Those comprehensive abilities may change reciprocally due to STB training, which suggests that these items influence mutually. In addition, the confidence of hemostasis skills to compress via direct finger pressure, packing, and tourniquet placement also correlate significantly with each other pre- or post-course, suggesting the same principles and techniques of hemostasis were conveyed. Based on our overall results, we believe that PTEBL would be beneficial for developing comprehensive emergency response competence and teamwork skills in particular, and would be superior to traditional methods of teaching STB courses.
A study by Dhillon et al . evaluated all participants of an American College of Surgeons STB course and reported a high likelihood of utilizing hemorrhage control skills upon completion of the class, between 95.5%-97.9% [ 29 ]. Moreover, the STB protocol has been well received in Italy and rendered good results among civilian health professionals and medical students [ 30 ]. In the Middle East, lay members of the public have contributed to a positive response to trauma emergencies after STB training [ 31 ]. However, such standardized bleeding control curriculum rely heavily on the acquisition and accessibility of specific equipment and materials, including tourniquets. Thus, the lack of cost and equipment, which would be readily accessible when required, contributed to only a few participants obtaining the necessary materials to mount an appropriate trauma response, as well as the practical education needed for long term use. This suggests that professional tourniquets should be readily available in a public area or commercially in stores, especially in China. Today, AEDs are designed to be simple enough to be used by any individual regardless of training [ 32 ]. If we wish for STB courses to have a significant impact on reducing risk of death in a trauma setting, we must create an environment where people can obtain hemostasis tools and materials in case of an emergency. Otherwise, the STB course would be a waste of time, cost, and usefulness.
This study has several limitations. Firstly, the hemorrhage-control ability was measured using self-report questionnaires, which may not accurately reflect practice competence [ 31 ]. Secondly, our study analyzed data from a small sample, making it difficult to generalize to other populations comprehensively [ 33 ]. The STB project is designed for public education, for which the effect should be evaluated in larger public groups, including all medical personnel and laypersons [ 5 ]. The third limitation is that our study only focused on the results of the current course and failed to demonstrate retention of STB skills. However, nearly all STB research has been limited by use of pre- and post-course assessment models [ 14 , 34 ]. The ideal outcomes measures would be both current and long-term retention after this educational intervention, which would allow improved ability to assess effectiveness of novel teaching methods. The fourth limitation is that the injured victim was all played by group participants rather than real traumatic bleeding patients in our trial, which may lead to a loss of accuracy and scientificity in evaluating student performance. Considering the lack of medical permission and suitable patients, we schedule to test them at the last year of those students (two years after the course) to reveal whether long-term retention after this educational intervention would allow improved ability to cure the real patients. Moreover, building a team in real life is quite difficult, single practice can’t reflect the effectiveness of the PTEBL teaching method and the improvement of teamwork may not necessarily benefit every STB action.
This study suggests that PTEBL approach increases teamwork during hemorrhage control and manifests superior effectiveness compared with the traditional teaching method. Therefore, the PTEBL deserves to be introduced in STB courses to prevent future deaths from life-threatening hemorrhages in China.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Orlas CP, Parra MW, Herrera-Escobar JP, et al. The challenge of implementing the “Stop the Bleed” campaign in Latin America. J Surg Res. 2020;246:591–8. https://doi.org/10.1016/j.jss.2019.09.042 .
Article Google Scholar
Zwislewski A, Nanassy AD, Meyer LK, et al. Practice makes perfect: the impact of Stop the Bleed training on hemorrhage control knowledge, wound packing, and tourniquet application in the workplace. Injury. 2019;50(4):864–8. https://doi.org/10.1016/j.injury.2019.03.025 .
Zhang LY, Zhang XZ, Bai XJ, et al. Current trauma care system and trauma care training in China. Chin J Traumatol. 2018;21(2):73–6. https://doi.org/10.1016/j.cjtee.2017.07.005 .
Fayard G. Road injury prevention in China: current state and future challenges. J Public Health Policy. 2019;40(3):292–307. https://doi.org/10.1057/s41271-019-00164-7 .
Smith LA, Caughey S, Liu S, et al. World trauma education: hemorrhage control training for healthcare providers in India. Trauma Surg Acute Care Open. 2019;4(1):2018–20. https://doi.org/10.1136/tsaco-2018-000263 .
Lei R, Swartz MD, Harvin JA, et al. Stop the Bleed Training empowers learners to act to prevent unnecessary hemorrhagic death. Am J Surg. 2019;217(2):368–72. https://doi.org/10.1016/j.amjsurg.2018.09.025 .
Scerbo MH, Holcomb JB, Taub E, et al. The trauma center is too late: major limb trauma without a pre-hospital tourniquet has increased death from hemorrhagic shock. J Trauma Acute Care Surg. 2017;83(6):1165–72. https://doi.org/10.1097/TA.0000000000001666 .
Dorlac WC, DeBakey ME, Holcomb JB, et al. Mortality from isolated civilian penetrating extremity injury. J Trauma. 2005;59(1):217–22. https://doi.org/10.1097/01.TA.0000173699.71652.BA .
Ali F, Petrone P, Berghorn E, et al. Teaching how to stop the bleed: does it work? A prospective evaluation of tourniquet application in law enforcement officers and private security personnel. Eur J Trauma Emerg Surg. 2021;47(1):79–83. https://doi.org/10.1007/s00068-019-01113-5 .
Goralnick E, Chaudhary MA, McCarty JC, et al. Effectiveness of instructional interventions for hemorrhage control readiness for laypersons in the public access and tourniquet training study (PATTS) a randomized clinical trial. JAMA Surg. 2018;153(9):791–9. https://doi.org/10.1001/jamasurg.2018.1099 .
Schroll R, Smith A, Martin MS, et al. Stop the Bleed Training: rescuer skills, knowledge, and attitudes of hemorrhage control techniques. J Surg Res. 2020;245:636–42. https://doi.org/10.1016/j.jss.2019.08.011 .
McCarty JC, Caterson EJ, Chaudhary MA, et al. Can they stop the bleed? Evaluation of tourniquet application by individuals with varying levels of prior self-reported training. Injury. 2019;50(1):10–5. https://doi.org/10.1016/j.injury.2018.09.041 .
Chen S, Li J, DiNenna MA, et al. Comparison of two teaching methods for stopping the bleed: a randomized controlled trial. BMC Med Educ. 2022;22(1):281. https://doi.org/10.1186/s12909-022-03360-4 .
Jafri FN, Dadario NB, Kumar A, et al. The addition of high-technology into the Stop the Bleed program among school personnel improves short-term skill application, not long-term retention. Simul Healthc. 2021;16(6):e159–67. https://doi.org/10.1097/sih.0000000000000546 .
Muret-Wagstaff SL, Faber DA, Gamboa AC, Lovasik BP. Increasing the effectiveness of “Stop the Bleed” training through stepwise mastery learning with deliberate practice. J Surg Educ. 2020;77(5):1146–53. https://doi.org/10.1016/j.jsurg.2020.03.001 .
Zhao KL, Herrenkohl M, Paulsen M, et al. Learners’ perspectives on Stop the Bleed: A course to improve survival during mass casualty events. Trauma Surg Acute Care Open. 2019;4(1):1–5. https://doi.org/10.1136/tsaco-2019-000331 .
Lau E, Wang HH, Qiao J, et al. Wakley–Wu Lien Teh Prize Essay 2020: passing the baton to the next generation of health workers. Lancet. 2021;397(10271):261–2. https://doi.org/10.1016/S0140-6736(21)00040-4 .
Zeng J, Zeng XX, Tu Q. A gloomy future for medical students in China. Lancet. 2013;382(9908):1878. https://doi.org/10.1016/S0140-6736(13)62624-0 .
He J, Tang Q, Dai R, et al. Problem-, team- and evidence-based learning. Med Educ. 2012;46(11):1102–3. https://doi.org/10.1111/medu.12033 .
Ross EM, Redman TT, Mapp JG, et al. Stop the Bleed: the effect of hemorrhage control education on laypersons’ willingness to respond during a traumatic medical emergency. Prehosp Disaster Med. 2018;33(2):127–32. https://doi.org/10.1017/S1049023X18000055 .
Gowen JT, Sexton KW, Thrush C, et al. Hemorrhage-Control training in medical education. J Med Educ Curric Dev. 2020;7:238212052097321. https://doi.org/10.1177/2382120520973214 .
Pellegrino JL, Charlton N, Goolsby C. “Stop the Bleed” Education Assessment Tool (SBEAT): development and validation. Cureus. 2020;12(9):e10567. https://doi.org/10.7759/cureus.10567 .
Spahn DR, Bouillon B, Cerny V, et al. The European guideline on management of major bleeding and coagulopathy following trauma fifth edition. Crit Care. 2019;23(1):98. https://doi.org/10.1186/s13054-019-2347-3 .
Bulger EM, Snyder D, Schoelles K, et al. An evidence-based prehospital guideline for external hemorrhage control: American college of surgeons committee on trauma. Prehospital Emerg Care. 2014;18(2):163–73. https://doi.org/10.3109/10903127.2014.896962 .
Levy MJ, Pasley J, Remick KN, et al. Removal of the prehospital tourniquet in the emergency department. J Emerg Med. 2021;60(1):98–102. https://doi.org/10.1016/j.jemermed.2020.10.018 .
Taylor DM, Coleman M, Parker PJ. The evaluation of an abdominal aortic tourniquet for the control of pelvic and lower limb hemorrhage. Mil Med. 2013;178(11):1196–201. https://doi.org/10.7205/MILMED-D-13-00223 .
Doyle GS, Taillac PP. Tourniquets a review of current use with proposals for expanded prehospital use. Prehosp Emerg Care. 2008;12(2):241–56. https://doi.org/10.1080/10903120801907570 .
Ito K, Morishita K, Tsunoyama T, et al. Prospective evaluation of the “stop the Bleed” program in Japanese participants. Trauma Surg Acute Care Open. 2020;5(1):1–4. https://doi.org/10.1136/tsaco-2020-000490 .
Dhillon NK, Dodd BA, Hotz H, et al. What happens after a Stop the Bleed class? The contrast between theory and practice. J Surg Educ. 2019;76(2):446–52. https://doi.org/10.1016/j.jsurg.2018.08.014 .
Valsecchi D, Sassi G, Tiraboschi L, et al. The rise of the Stop the Bleed campaign in Italy. J Spec Oper Med. 2019;19(4):95–9 ( http://europepmc.org/abstract/MED/31910480 ).
AlSabah S, AlHaddad E, AlSaleh F. Stop the bleed campaign: a qualitative study from our experience from the middle east. Ann Med Surg. 2018;36:67–70. https://doi.org/10.1016/j.amsu.2018.10.013 .
Dennis A, Bajani F, Schlanser V, et al. Missing expectations: windlass tourniquet use without formal training yields poor results. J Trauma Acute Care Surg. 2019;87(5):1096–103. https://doi.org/10.1097/TA.0000000000002431 .
Sainbayar E, Holt N, Jacobson A, et al. Efficacy of implementing intermittent STOP THE BLEED reviews on long term retention of hemorrhage control skills of first year medical students. J Osteopath Med. 2021;121(6):543–50. https://doi.org/10.1515/jom-2020-0231 .
Villegas CV, Gupta A, Liu S, et al. Stop the Bleed: Effective Training in Need of Improvement. J Surg Res. 2020;255:627–31. https://doi.org/10.1016/j.jss.2020.02.004 .
Download references
Acknowledgements
Not applicable.
The Education Reform Foundation of Central South University (No. 2021JY188) and the Education Reform Foundation of Hunan Province (No. HNJG-2021–0322) fund this study.
Author information
Authors and affiliations.
Department of Orthopaedic Surgery, The Third Xiangya Hospital of Central South University, Changsha, Hunan, 410013, China
Wanchen Zhao, Yangbo Cao, Chenxiao Lu, Gaoming Liu & Jinshen He
QingFang Orthopaedic Hospital of Wugang City, Shaoyang, Hunan, 422499, China
Wanchen Zhao, Liangrong Hu, Chenxiao Lu & Gaoming Liu
Department of Orthopaedic Surgery, University of Pittsburgh, Pittsburgh, PA, 15213, USA
Matthew Gong
Xiangya Scool of Medicine, Central South University, Changsha, Hunan, 410013, China
Wanchen Zhao, Chenxiao Lu & Gaoming Liu
You can also search for this author in PubMed Google Scholar
Contributions
WZ, YC and JH were responsible for the design and implementation of this study. LH and CL wrote most of the original manuscript. GL analyzed the results. MG revised the English writing and grammar. All authors participated in the design of the research, and revised the manuscript. WZ was the key person to revise this manuscript and to prepare the reply.
Corresponding author
Correspondence to Jinshen He .
Ethics declarations
Ethics approval and consent to participate.
The ethics committee of the third Xiangya Hospital of Central South University approved this study (ID: 2021-S078). Students were voluntary to enroll in the research. Informed consent was obtained from all participants in the randomized controlled trial.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., supplementary material 2., supplementary material 3., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Zhao, W., Cao, Y., Hu, L. et al. A randomized controlled trial comparison of PTEBL and traditional teaching methods in “Stop the Bleed” training. BMC Med Educ 24 , 462 (2024). https://doi.org/10.1186/s12909-024-05457-4
Download citation
Received : 01 August 2023
Accepted : 22 April 2024
Published : 26 April 2024
DOI : https://doi.org/10.1186/s12909-024-05457-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Stop the Bleed
- PTEBL teaching method
- Traditional method
- Hemostasis techniques
- Teamwork skills
BMC Medical Education
ISSN: 1472-6920
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- Open access
- Published: 27 April 2024
Assessing fragility of statistically significant findings from randomized controlled trials assessing pharmacological therapies for opioid use disorders: a systematic review
- Leen Naji ORCID: orcid.org/0000-0003-0994-1109 1 , 2 , 3 ,
- Brittany Dennis 4 , 5 ,
- Myanca Rodrigues 2 ,
- Monica Bawor 6 ,
- Alannah Hillmer 7 ,
- Caroul Chawar 8 ,
- Eve Deck 9 ,
- Andrew Worster 2 , 4 ,
- James Paul 10 ,
- Lehana Thabane 11 , 2 &
- Zainab Samaan 12 , 2
Trials volume 25 , Article number: 286 ( 2024 ) Cite this article
179 Accesses
1 Altmetric
Metrics details
The fragility index is a statistical measure of the robustness or “stability” of a statistically significant result. It has been adapted to assess the robustness of statistically significant outcomes from randomized controlled trials. By hypothetically switching some non-responders to responders, for instance, this metric measures how many individuals would need to have responded for a statistically significant finding to become non-statistically significant. The purpose of this study is to assess the fragility index of randomized controlled trials evaluating opioid substitution and antagonist therapies for opioid use disorder. This will provide an indication as to the robustness of trials in the field and the confidence that should be placed in the trials’ outcomes, potentially identifying ways to improve clinical research in the field. This is especially important as opioid use disorder has become a global epidemic, and the incidence of opioid related fatalities have climbed 500% in the past two decades.
Six databases were searched from inception to September 25, 2021, for randomized controlled trials evaluating opioid substitution and antagonist therapies for opioid use disorder, and meeting the necessary requirements for fragility index calculation. Specifically, we included all parallel arm or two-by-two factorial design RCTs that assessed the effectiveness of any opioid substitution and antagonist therapies using a binary primary outcome and reported a statistically significant result. The fragility index of each study was calculated using methods described by Walsh and colleagues. The risk of bias of included studies was assessed using the Revised Cochrane Risk of Bias tool for randomized trials.
Ten studies with a median sample size of 82.5 (interquartile range (IQR) 58, 179, range 52–226) were eligible for inclusion. Overall risk of bias was deemed to be low in seven studies, have some concerns in two studies, and be high in one study. The median fragility index was 7.5 (IQR 4, 12, range 1–26).
Conclusions
Our results suggest that approximately eight participants are needed to overturn the conclusions of the majority of trials in opioid use disorder. Future work should focus on maximizing transparency in reporting of study results, by reporting confidence intervals, fragility indexes, and emphasizing the clinical relevance of findings.
Trial registration
PROSPERO CRD42013006507. Registered on November 25, 2013.
Peer Review reports
Introduction
Opioid use disorder (OUD) has become a global epidemic, and the incidence of opioid related fatality is unparalleled to the rates observed in North America, having climbed 500% in the past two decades [ 1 , 2 ]. There is a dire need to identify the most effective treatment modality to maintain patient engagement in treatment, mitigate high risk consumption patterns, as well as eliminate overdose risk. Numerous studies have aimed to identify the most effective treatment modality for OUD [ 3 , 4 , 5 ]. Unfortunately, this multifaceted disease is complicated by the interplay between both neurobiological and social factors, impacting our current body of evidence and clinical decision making. Optimal treatment selection is further challenged by the rising number of pharmacological opioid substitution and antagonist therapies (OSAT) [ 6 ]. Despite this growing body of evidence and available therapies, we have yet to arrive to a consensus regarding the best treatment modality given the substantial variability in research findings and directly conflicting results [ 6 , 7 , 8 , 9 ]. More concerning, international clinical practice guidelines rely on out-of-date systematic review evidence to inform guideline development [ 10 ]. In fact, these guidelines make strong recommendations based on a fraction of the available evidence, employing trials with restrictive eligibility criteria which fail to reflect the common OUD patients seen in clinical practice [ 10 ].
A major factor hindering our ability to advance the field of addiction medicine is our failure to apply the necessary critical lens to the growing body of evidence used to inform clinical practice. While distinct concerns exist regarding the external validity of randomized trials in addiction medicine, the robustness of the universally recognized “well designed” trials remains unknown [ 10 ]. The reliability of the results of clinical trials rests on not only the sample size of the study but also the number of outcome events. In fact, a shift in the results of only a few events could in theory render the findings of the trial null, impacting the traditional hypothesis tests above the standard threshold accepted as “statistical significance.” A metric of this fragility was first introduced in 1990, known formally as the fragility index (FI) [ 11 ]. In 2014, it was adapted for use as a tool to assess the robustness of findings from randomized controlled trials (RCTs) [ 12 ]. Briefly, the FI determines the minimum number of participants whose outcome would have to change from non-event to event in order for a statistically significant result to become non-significant. Larger FIs indicate more robust findings [ 11 , 13 ]. Additionally, when the number of study participants lost to follow-up exceeds the FI of the trial, this implies that the outcome of these participants could have significantly altered the statistical significance and final conclusions of the study. The FI has been applied across multiple fields, often yielding similar results such that the change in a small number of outcome events has been powerful enough to overturn the statistical conclusions of many “well-designed” trials [ 13 ].
The concerning state of the OUD literature has left us with guidelines which neither acknowledge the lack of external validity and actually go so far as to rank the quality of the evidence as good, despite the concerning limitations we have raised [ 10 ]. Such alarming practices necessitate vigilance on behalf of methodologists and practitioners to be critical and open to a thorough review of the evidence in the field of addiction medicine [ 12 ]. Given the complex nature of OUD treatment and the increasing number of available therapies, concentrated efforts are needed to ensure the reliability and internal validity of the results of clinical trials used to inform guidelines. Application of the FI can serve to provide additional insight into the robustness of the evidence in addiction medicine. The purpose of this study is to assess the fragility of findings of RCTs assessing OSAT for OUD.
Systematic review protocol
We conducted a systematic review of the evidence surrounding OSATs for OUD [ 5 ]. The study protocol was registered with PROSPERO a priori (PROSPERO CRD42013006507). We searched Medline, EMBASE, PubMed, PsycINFO, Web of Science, and Cochrane Library for relevant studies from inception to September 25, 2021. We included all RCTs evaluating the effectiveness of any OSAT for OUD, which met the criteria required for FI calculation. Specifically, we included all parallel arm or two-by-two factorial design RCTs that allocated patients at a 1:1 ratio, assessed the effectiveness of any OSAT using a binary primary or co-primary outcome, and reported this outcome to be statistically significant ( p < 0.05).
All titles, abstracts, and full texts were screened for eligibility by two reviewers independently and in duplicate. Any discrepancies between the two reviewers were discussed for consensus, and a third reviewer was called upon when needed.
Data extraction and risk of bias assessment (ROB)
Two reviewers extracted the following data from the included studies in duplicate and independently using a pilot-tested excel data extraction sheet: sample size, whether a sample size calculation was conducted, statistical test used, primary outcome, number of responders and non-responders in each arm, number lost to follow-up, and the p -value. The 2021 Thomson Reuters Journal Impact Factor for each included study was also recorded. The ROB of included studies for the dichotomous outcome used in the FI calculation was assessed using the Revised Cochrane ROB tool for randomized trials [ 14 ]. Two reviewers independently assessed the included studies based on the following domains for potential ROB: randomization process, deviations from the intended interventions, missing outcome data, measurement of the outcome, and selection of the reported results.
Statistical analyses
Study characteristics were summarized using descriptive statistics. Means and standard deviations (SD), as well as medians and interquartile ranges (IQR: Q 25 , Q 75 ) were used as measures of central tendency for continuous outcomes with normal and skewed distributions, respectively. Frequencies and percentages were used to summarize categorical variables. The FI was calculated using a publicly available free online calculator, using the methods described by Walsh et al. [ 12 , 15 ] In summary, the number of events and non-events in each treatment arm were entered into a two-by-two contingency table for each trial. An event was added to the treatment arm with the smaller number of events, while subtracting a non-event from the same arm, thus keeping the overall sample size the same. Each time this was done, the two-sided p -value for Fisher’s exact test was recalculated. The FI was defined as the number of non-events that needed to be switched to events for the p -value to reach non-statistical significance (i.e., ≥0.05).
We intended to conduct a linear regression and Spearman’s rank correlations to assess the association between FI and journal impact factor, study sample size, and number events. However, we were not powered to do so given the limited number of eligible studies included in this review and thus refrained from conducting any inferential statistics.
We followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines for reporting (see Supplementary Material ) [ 16 ].
Study selection
Our search yielded 13,463 unique studies, of which 104 were RCTs evaluating OSAT for OUD. Among these, ten studies met the criteria required for FI calculation and were included in our analyses. Please refer to Fig. 1 for the search results, study inclusion flow diagram, and Table 1 for details on included studies.

PRISMA flow diagram delineating study selection
Characteristics of included studies
The included studies were published between 1980 and 2018, in eight different journals with a median impact factor of 8.48 (IQR 6.53–56.27, range 3.77–91.25). Four studies reported on a calculated sample size [ 17 , 18 , 19 , 20 ], and only one study specified that reporting guidelines were used [ 21 ]. Treatment retention was the most commonly reported primary outcome ( k = 8). The median sample size of included studies was 82.5 (IQR 58–179, range 52–226).
Overall ROB was deemed to be low in seven studies [ 17 , 19 , 20 , 21 , 22 , 23 , 24 ], have some concerns in two studies [ 18 , 25 ], and be high in one study [ 26 ] due to a high proportion of missing outcome data that was not accounted for in the analyses. We present a breakdown of the ROB assessment of the included studies for the dichotomous outcome of interest in Table 2 .
- Fragility index
The median FI of included studies was 7.5 (IQR 4–12; range 1–26). The FI of individual studies is reported in Table 1 . The number of participants lost to follow-up exceeded the FI in two studies [ 23 , 26 ]. We find that there is a relatively positive correlation between the FI and sample size. However, no clear correlation was appreciated between FI and journal impact factor or number of events.
This is the first study to evaluate the FI in the field of addiction medicine, and more specifically in OUD trials. Among the ten RCTs evaluating the OSAT for OUD, we found that, in some cases, changing the outcome of one or two participants could completely alter the study’s conclusions and render the results statistically non-significant.
We compare our findings to those of Holek et al. , wherein they examined the mean FI across all reviews published in PubMed between 2014 and 2019 that assessed the distribution of FI indices, irrespective of discipline (though none were in addiction medicine) [ 13 ]. Among 24 included reviews with a median sample size of 134 (IQR 82, 207), they found a mean FI of 4 (95% CI 3, 5) [ 13 ]. This is slightly lower than our calculated our median FI of 7.5 (IQR 4–12; range 1–26). It is important to note that half of the reviews included in the study by Holek et al. were conducted in surgical disciplines, which are generally subjected to more limitations to internal and external validity, as it is often not possible to conceal allocation, blind participants, or operators, and the intervention is operator dependent. [ 27 ] To date, no study has directly applied FI to the findings of trials in OUD. In the HIV/AIDS literature, however, a population which is commonly shared with addiction medicine due to the prevalence of the comorbidities coexisting, the median fragility across all trials assessing anti-retroviral therapies ( n = 39) was 6 (IQR = 1, 11) [ 28 ], which is more closely related to our calculated FI. Among the included studies, only 3 were deemed to be at high risk of bias, whereas 13 and 20 studies were deemed to be at low and some risk of bias, respectively.
Loss-to-follow-up plays an important role in the interpretation of the FI. For instance, when the number of study participants lost to follow-up exceeds the FI of the trial, this implies that the outcome of these participants could have significantly altered the statistical significance and final conclusions of the study. While only two of the included studies had an FI that was greater than the total number of participants lost to follow-up [ 23 , 26 ], this metric is less important in our case given the primary outcome assessed by the majority of trials was retention in treatment, rendering loss to follow-up an outcome itself. In our report, we considered participants to be lost to follow-up if they left the study for reasons that were known and not necessarily indicative of treatment failure, such as due to factors beyond the participants, control including incarceration or being transferred to another treatment location.
Findings from our analysis of the literature as well as the application of FI to the existing clinical trials in the field of addiction medicine demonstrates significant concerns regarding the robustness of the evidence. This, in conjunction with the large differences between the clinical population and trial participants of opioid-dependent patients inherent in addiction medicine trials, raises larger concerns as to a growing body of evidence with deficiencies in both internal and external validity. The findings from this study raise important clinical concerns regarding the applicability of the current evidence to treating patients in the context of the opioid epidemic. Are we recommending the appropriate treatments for patients with OUD based on robust and applicable evidence? Are we completing our due diligence and ensuring clinicians and researchers alike understand the critical issues rampant in the literature, including the fragility of the data and misconceptions of p -values? Are we possibly putting our patients at risk employing such treatment based on fragile data? These questions cannot be answered until the appropriate re-evaluation of the evidence takes place employing both the use pragmatic trial designs as well as transparent metrics to reflect the reliability and robustness of the findings.
Strengths and limitations
Our study is strengthened by a comprehensive search strategy, rigorous and systematic screening of studies, and the use of an objective measure to gauge the robustness of studies (i.e., FI). The limitations of this study are inherent in the limitations of the FI. Precisely, that it can only be calculated for RCTs with a 1:1 allocation ratio, a parallel arm or two-by-two factorial design, and a dichotomous primary outcome. As a result, 94 RCTs evaluating OSAT for OUD were excluded for not meeting these criteria (Fig. 1 ). Nonetheless, the FI provides a general sense of the robustness of the available studies, and our data reflect studies published across almost four decades in journals of varying impact factor.
Future direction
This study serves as further evidence for the need of a shift away from p -values [ 29 , 30 ]. Although there is increasingly a shift among statisticians to shift away from relying on statistical significance due to its inability to convey clinical importance [ 31 ], this remains the simplest way and most commonly reported metric in manuscripts. p -values provide a simple statistical measure to confirm or refute a null hypothesis, by providing a measure of how likely the observed result would be if the null hypothesis were true. An arbitrary cutoff of 5% is traditionally used as a threshold for rejecting the null hypothesis. However, a major drawback of the p -value is that it does not take into account the effect size of the outcome measure, such that a small incremental change that may not be clinically significant may still be statistically significant in a large enough trial. Contrastingly, a very large effect size that has biological plausibility, for instance, may not reach statistical significance if the trial size is not large enough [ 29 , 30 ]. This is highly problematic given the common misconceptions surrounding the p -value. Increasing emphasis is being placed on the importance of transparency in outcome reporting, and the reporting of confidence intervals to allow the reader to gauge the uncertainty in the evidence, and make a clinically informed decision about whether a finding is clinically significant or not. It has also been recommended that studies report FI where possible to provide readers with a comprehensible way of gauging the robustness of their findings [ 12 , 13 ]. There is a strive to make all data publicly available, allowing for replication of study findings as well as pooling of data among databases for generating more robust analyses using larger pragmatic samples [ 32 ]. Together, these efforts aim to increase transparency of research and facilitate data sharing to allow for stronger and more robust evidence to be produced, allowing for advancements in evidence-based medicine and improvements in the quality of care delivered to patients.
Our results suggest that approximately eight participants are needed to overturn the conclusions of the majority of trials in addiction medicine. Findings from our analysis of the literature and application of FI to the existing clinical trials in the field of addiction medicine demonstrates significant concerns regarding the overall quality and specifically robustness and stability of the evidence and the conclusions of the trials. Findings from this work raises larger concerns as to a growing body of evidence with deficiencies in both internal and external validity. In order to advance the field of addiction medicine, we must re-evaluate the quality of the evidence and consider employing pragmatic trial designs as well as transparent metrics to reflect the reliability and robustness of the findings. Placing emphasis on clinical relevance and reporting the FI along with confidence intervals may provide researchers, clinicians, and guideline developers with a transparent method to assess the outcomes from clinical trials, ensuring vigilance in decisions regarding management and treatment of patients with substance use disorders.
Availability of data and materials
All data generated or analyzed during this study are included in this published article (and its supplementary information files).
Abbreviations
Interquartile range
- Opioid use disorder
Opioid substitution and antagonist therapies
- Randomized controlled trials
Risk of bias
Standard deviation
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
Products - Vital Statistics Rapid Release - Provisional Drug Overdose Data. https://www.cdc.gov/nchs/nvss/vsrr/drug-overdose-data.htm . Accessed April 26, 2020.
Spencer MR, Miniño AM, Warner M. Drug overdose deaths in the United States, 2001–2021. NCHS Data Brief, no 457. Hyattsville, MD: National Center for Health Statistics. 2022. https://doi.org/10.15620/cdc:122556 .
Mattick RP, Breen C, Kimber J, Davoli M. Methadone maintenance therapy versus no opioid replacement therapy for opioid dependence. Cochrane Database Syst Rev. 2009;(3). https://doi.org/10.1002/14651858.CD002209.PUB2/FULL .
Hedrich D, Alves P, Farrell M, Stöver H, Møller L, Mayet S. The effectiveness of opioid maintenance treatment in prison settings: a systematic review. Addiction. 2012;107(3):501–17. https://doi.org/10.1111/J.1360-0443.2011.03676.X .
Article PubMed Google Scholar
Dennis BB, Naji L, Bawor M, et al. The effectiveness of opioid substitution treatments for patients with opioid dependence: a systematic review and multiple treatment comparison protocol. Syst Rev. 2014;3(1):105. https://doi.org/10.1186/2046-4053-3-105 .
Article PubMed PubMed Central Google Scholar
Dennis BB, Sanger N, Bawor M, et al. A call for consensus in defining efficacy in clinical trials for opioid addiction: combined results from a systematic review and qualitative study in patients receiving pharmacological assisted therapy for opioid use disorder. Trials. 2020;21(1). https://doi.org/10.1186/s13063-019-3995-y .
British Columbia Centre on Substance Use. (2017). A Guideline for the Clinical Management of Opioid Use Disorder . http://www.bccsu.ca/care-guidance-publications/ . Accessed December 4, 2020.
Kampman K, Jarvis M. American Society of Addiction Medicine (ASAM) national practice guideline for the use of medications in the treatment of addiction involving opioid use. J Addict Med. 2015;9(5):358–367.
Srivastava A, Wyman J, Fcfp MD, Mph D. Methadone treatment for people who use fentanyl: recommendations. 2021. www.metaphi.ca . Accessed November 14, 2023.
Dennis BB, Roshanov PS, Naji L, et al. Opioid substitution and antagonist therapy trials exclude the common addiction patient: a systematic review and analysis of eligibility criteria. Trials. 2015;16(1):1. https://doi.org/10.1186/s13063-015-0942-4 .
Article CAS Google Scholar
Feinstein AR. The unit fragility index: an additional appraisal of “statistical significance” for a contrast of two proportions. J Clin Epidemiol. 1990;43(2):201–9. https://doi.org/10.1016/0895-4356(90)90186-S .
Article CAS PubMed Google Scholar
Walsh M, Srinathan SK, McAuley DF, et al. The statistical significance of randomized controlled trial results is frequently fragile: a case for a fragility index. J Clin Epidemiol. 2014;67(6):622–8. https://doi.org/10.1016/j.jclinepi.2013.10.019 .
Holek M, Bdair F, Khan M, et al. Fragility of clinical trials across research fields: a synthesis of methodological reviews. Contemp Clin Trials. 2020;97. doi: https://doi.org/10.1016/j.cct.2020.106151
Sterne JAC, Savović J, Page MJ, et al. RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ. 2019;366. doi: https://doi.org/10.1136/bmj.l4898
Kane SP. Fragility Index Calculator. ClinCalc: https://clincalc.com/Stats/FragilityIndex.aspx . Updated July 19, 2018. Accessed October 17, 2023.
Page MJ, McKenzie JE, Bossuyt PM, The PRISMA, et al. statement: an updated guideline for reporting systematic reviews. BMJ. 2020;2021:372. https://doi.org/10.1136/bmj.n71 .
Article Google Scholar
Petitjean S, Stohler R, Déglon JJ, et al. Double-blind randomized trial of buprenorphine and methadone in opiate dependence. Drug Alcohol Depend. 2001;62(1):97–104. https://doi.org/10.1016/S0376-8716(00)00163-0 .
Sees KL, Delucchi KL, Masson C, et al. Methadone maintenance vs 180-day psychosocially enriched detoxification for treatment of opioid dependence: a randomized controlled trial. JAMA. 2000;283(10):1303–10. https://doi.org/10.1001/JAMA.283.10.1303 .
Kakko J, Dybrandt Svanborg K, Kreek MJ, Heilig M. 1-year retention and social function after buprenorphine-assisted relapse prevention treatment for heroin dependence in Sweden: a randomised, placebo-controlled trial. Lancet (London, England). 2003;361(9358):662–8. https://doi.org/10.1016/S0140-6736(03)12600-1 .
Oviedo-Joekes E, Brissette S, Marsh DC, et al. Diacetylmorphine versus methadone for the treatment of opioid addiction. N Engl J Med. 2009;361(8):777–86. https://doi.org/10.1056/NEJMoa0810635 .
Article CAS PubMed PubMed Central Google Scholar
Hulse GK, Morris N, Arnold-Reed D, Tait RJ. Improving clinical outcomes in treating heroin dependence: randomized, controlled trial of oral or implant naltrexone. Arch Gen Psychiatry. 2009;66(10):1108–15. https://doi.org/10.1001/ARCHGENPSYCHIATRY.2009.130 .
Krupitsky EM, Zvartau EE, Masalov DV, et al. Naltrexone for heroin dependence treatment in St. Petersburg, Russia. J Subst Abuse Treat. 2004;26(4):285–94. https://doi.org/10.1016/j.jsat.2004.02.002 .
Krook AL, Brørs O, Dahlberg J, et al. A placebo-controlled study of high dose buprenorphine in opiate dependents waiting for medication-assisted rehabilitation in Oslo. Norway Addiction. 2002;97(5):533–42. https://doi.org/10.1046/J.1360-0443.2002.00090.X .
Hartnoll RL, Mitcheson MC, Battersby A, et al. Evaluation of heroin maintenance in controlled trial. Arch Gen Psychiatry. 1980;37(8):877–84. https://doi.org/10.1001/ARCHPSYC.1980.01780210035003 .
Fischer G, Gombas W, Eder H, et al. Buprenorphine versus methadone maintenance for the treatment of opioid dependence. Addiction. 1999;94(9):1337–47. https://doi.org/10.1046/J.1360-0443.1999.94913376.X .
Yancovitz SR, Des Jarlais DC, Peyser NP, et al. A randomized trial of an interim methadone maintenance clinic. Am J Public Health. 1991;81(9):1185–91. https://doi.org/10.2105/AJPH.81.9.1185 .
Demange MK, Fregni F. Limits to clinical trials in surgical areas. Clinics (Sao Paulo). 2011;66(1):159–61. https://doi.org/10.1590/S1807-59322011000100027 .
Wayant C, Meyer C, Gupton R, Som M, Baker D, Vassar M. The fragility index in a cohort of HIV/AIDS randomized controlled trials. J Gen Intern Med. 2019;34(7):1236–43. https://doi.org/10.1007/S11606-019-04928-5 .
Amrhein V, Greenland S, McShane B. Scientists rise up against statistical significance. Nature. 2019;567(7748):305–7. https://doi.org/10.1038/D41586-019-00857-9 .
Ioannidis JPA. Why most published research findings are false. PLoS Med. 2005;2(8):e124. https://doi.org/10.1371/journal.pmed.0020124 .
Goodman SN. Toward evidence-based medical statistics. 1: the p value fallacy. Ann Intern Med. 1999;130(12):995–1004. https://doi.org/10.7326/0003-4819-130-12-199906150-00008 .
Allison DB, Shiffrin RM, Stodden V. Reproducibility of research: issues and proposed remedies. Proc Natl Acad Sci U S A. 2018;115(11):2561–2. https://doi.org/10.1073/PNAS.1802324115 .
Download references
Acknowledgements
The authors received no funding for this work.
Author information
Authors and affiliations.
Department of Family Medicine, David Braley Health Sciences Centre, McMaster University, 100 Main St W, 3rdFloor, Hamilton, ON, L8P 1H6, Canada
Department of Health Research Methods, Evidence, and Impact, McMaster University, Hamilton, ON, Canada
Leen Naji, Myanca Rodrigues, Andrew Worster, Lehana Thabane & Zainab Samaan
Department of Medicine, Montefiore Medical Center, New York, NY, USA
Department of Medicine, McMaster University, Hamilton, ON, Canada
Brittany Dennis & Andrew Worster
Department of Medicine, University of British Columbia, Vancouver, Canada
Brittany Dennis
Department of Medicine, Imperial College Healthcare NHS Trust, London, UK
Monica Bawor
Department of Psychiatry and Behavaioral Neurosciences, McMaster University, Hamilton, ON, Canada
Alannah Hillmer
Physician Assistant Program, University of Toronto, Toronto, ON, Canada
Caroul Chawar
Department of Family Medicine, Western University, London, ON, Canada
Department of Anesthesia, McMaster University, Hamilton, ON, Canada
Biostatistics Unit, Research Institute at St Joseph’s Healthcare, Hamilton, ON, Canada
Lehana Thabane
Department of Psychiatry and Behavioral Neurosciences, McMaster University, Hamilton, ON, Canada
Zainab Samaan
You can also search for this author in PubMed Google Scholar
Contributions
LN, BD, MB, LT, and ZS conceived the research question and protocol. LN, BD, MR, and AH designed the search strategy and ran the literature search. LN, BD, MR, AH, CC, and ED contributed to screening studies for eligibility and data extraction. LN and LT analyzed data. All authors contributed equally to the writing and revision of the manuscript. All authors approved the final version of the manuscript.
Corresponding author
Correspondence to Leen Naji .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Naji, L., Dennis, B., Rodrigues, M. et al. Assessing fragility of statistically significant findings from randomized controlled trials assessing pharmacological therapies for opioid use disorders: a systematic review. Trials 25 , 286 (2024). https://doi.org/10.1186/s13063-024-08104-x
Download citation
Received : 11 December 2022
Accepted : 10 April 2024
Published : 27 April 2024
DOI : https://doi.org/10.1186/s13063-024-08104-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Research methods
- Critical appraisal
- Systematic review
ISSN: 1745-6215
- Submission enquiries: Access here and click Contact Us
- General enquiries: [email protected]
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Research: More People Use Mental Health Benefits When They Hear That Colleagues Use Them Too
- Laura M. Giurge,
- Lauren C. Howe,
- Zsofia Belovai,
- Guusje Lindemann,
- Sharon O’Connor

A study of 2,400 Novartis employees around the world found that simply hearing about others’ struggles can normalize accessing support at work.
Novartis has trained more than 1,000 employees as Mental Health First Aiders to offer peer-to-peer support for their colleagues. While employees were eager for the training, uptake of the program remains low. To understand why, a team of researchers conducted a randomized controlled trial with 2,400 Novartis employees who worked in the UK, Ireland, India, and Malaysia. Employees were shown one of six framings that were designed to overcome two key barriers: privacy concerns and usage concerns. They found that employees who read a story about their colleague using the service were more likely to sign up to learn more about the program, and that emphasizing the anonymity of the program did not seem to have an impact. Their findings suggest that one way to encourage employees to make use of existing mental health resources is by creating a supportive culture that embraces sharing about mental health challenges at work.
“I almost scheduled an appointment about a dozen times. But no, in the end I never went. I just wasn’t sure if my problems were big enough to warrant help and I didn’t want to take up someone else’s time unnecessarily.”
- Laura M. Giurge is an assistant professor at the London School of Economics, and a faculty affiliate at London Business School. Her research focuses on time and boundaries in organizations, workplace well-being, and the future of work. She is also passionate about translating research to the broader public through interactive and creative keynote talks, workshops, and coaching. Follow her on LinkedIn here .
- Lauren C. Howe is an assistant professor in management at the University of Zurich. As head of research at the Center for Leadership in the Future of Work , she focuses on how human aspects, such as mindsets, socioemotional skills, and leadership, play a role in the changing world of work.
- Zsofia Belovai is a behavioral science lead for the organizational performance research practice at MoreThanNow, focusing on exploring how employee welfare can drive KPIs.
- Guusje Lindemann is a senior behavioral scientist at MoreThanNow, in the social impact and organizational performance practices, working on making the workplace better for all.
- Sharon O’Connor is the global employee wellbeing lead at Novartis. She is a founding member of the Wellbeing Executives Council of The Conference Board, and a guest lecturer on the Workplace Wellness postgraduate certificate at Trinity College Dublin.
Partner Center
Advertisement
Supported by
political memo
Trump’s Trial Challenge: Being Stripped of Control
The mundanity of the courtroom has all but swallowed Donald Trump, who for decades has sought to project an image of bigness and a sense of power.
- Share full article

By Maggie Haberman
“Sir, can you please have a seat.”
Donald J. Trump had stood up to leave the Manhattan criminal courtroom as Justice Juan M. Merchan was wrapping up a scheduling discussion on Tuesday.
But the judge had not yet adjourned the court or left the bench. Mr. Trump, the 45th president of the United States and the owner of his own company, is used to setting his own pace. Still, when Justice Merchan admonished him to sit back down, the former president did so without saying a word.
The moment underscored a central reality for the presumptive Republican presidential nominee. For the next six weeks, a man who values control and tries to shape environments and outcomes to his will is in control of very little.
Everything about the circumstances in which the former president comes to court every day to sit as the defendant in the People v. Donald J. Trump at 100 Centre Street is repellent to him. The trapped-in-amber surroundings that evoke New York City’s more crime-ridden past. The lack of control. The details of a case in which he is accused of falsifying business records to conceal a payoff to a porn star to keep her claims of an affair with him from emerging in the 2016 election.
Of the four criminal cases Mr. Trump is facing, this is the one that is the most acutely personal. And people close to him are blunt when privately discussing his reaction: He looks around each day and cannot believe he has to be there.
Asked about the former president’s aversion to the case, a campaign spokeswoman, Karoline Leavitt, said that Mr. Trump “proved he will remain defiant” and called the case “political lawfare.”
He is sitting in a decrepit courtroom that, for the second half of last week, was so cold his lead lawyer complained respectfully to the judge about it. Mr. Trump hugged his arms to his chest and told an aide, “It’s freezing.”
For the first few minutes of each day during jury selection, a small pool of still photographers was ushered into Part 59 on the 15th floor of the courthouse. Mr. Trump, obsessed with being seen as strong and being seen generally, prepared for them to rush in front of him by adjusting his suit jacket and contorting his face into a jut-jawed scowl. But, by day’s end on Friday, Mr. Trump appeared haggard and rumpled, his gait off-center, his eyes blank.

The Donald Trump Indictment, Annotated
The indictment unveiled in April 2023 centers on a hush-money deal with a porn star, but a related document alleges a broader scheme to protect Donald J. Trump’s 2016 campaign.
Mr. Trump has often seemed to fade into the background in a light wood-paneled room with harsh flourescent lighting and a perpetual smell of sour, coffee-laced breath wafting throughout.
His face has been visible to dozens of reporters watching in an overflow room on a large monitor with a closed-circuit camera trained on the defense table. He has whispered to his lawyer and poked him to get his attention, leafed through sheafs of paper and, at least twice, appeared to nod off during the morning session. (His aides have publicly denied he was dozing.) Nodding off is something that happens from time to time to various people in court proceedings, including jurors, but it conveys, for Mr. Trump, the kind of public vulnerability he has rigorously tried to avoid.
Trials are by nature mundane, with strict routines and long periods of inactivity. Mr. Trump has always steered clear of this type of officialism, whether by eschewing strict schedules or anyone else’s practices or structures, from the time he was in his 20s through his time in the Oval Office.
The mundanity of the courtroom has all but swallowed Mr. Trump, who for decades has sought to project an image of bigness, one he rode from a reality-television studio set to the White House.
When the first panel of 96 prospective jurors was brought into the room last Monday afternoon, Mr. Trump seemed to disappear among them, as they were seated in the jury box and throughout the rows in the well of the court. The judge has made clear that the jurors’ time is his highest priority, even when it comes at the former president’s expense.
Mr. Trump’s communications advisers or aides who provide him with a morale boost have been sitting at a remove. Natalie Harp, a former host on the right-wing OAN news network, who for years has carried a portable printer to supply Mr. Trump with a steady stream of uplifting articles or social media posts about him, is there. But she and others have been in the second row behind the defense table, or several rows back in the courtroom, unable to talk to Mr. Trump during the proceedings.
It is hard to recall any other time when Mr. Trump has had to sit and listen to insults without turning to social media or a news conference to punch back. And it is just as hard to recall any other time he has been forced to be bored for so long.
People close to him are anxious about how he will handle having so little to do as he sits there for weeks on end, with only a handful of days of testimony expected to be significant. It has been decades since he has had to spend so much time in the immediate vicinity of anyone who is not part of his family, his staff or his throng of admirers.

Who Are Key Players in the Trump Manhattan Criminal Trial?
The first criminal trial of former President Donald J. Trump is underway. Take a closer look at central figures related to the case.
Over the next six weeks or so, Mr. Trump will have to endure more, including listening as prosecutors ask witnesses uncomfortable questions about his personal life in open court. On Tuesday, he’ll face a hearing over whether the judge agrees with prosecutors that he has repeatedly violated the order prohibiting him from publicly criticizing witnesses and others.
Most of the time, Mr. Trump has been forced to sit at the table, unable to use his cellphone, and listen as prosecutors have described him as a criminal, as jurors have been asked their opinions of him. Some of those opinions have been negative, with one potential juror made to read aloud her old social media posts blasting him as a sociopath and an egomaniac. The only times he has smiled have been when prospective jurors have referred to work of his that they have liked.
The highly telegraphed plan was for Mr. Trump to behave as a candidate in spite of the trial, using the entire event as a set piece in his claims of a weaponized judicial system.
But last week, in New York, Mr. Trump’s only political event was a stop at an Upper Manhattan bodega to emphasize crime rates in the borough. The appearance seemed to breathe life into him, but it also felt more like a stop a mayoral candidate would make than a presumptive presidential nominee. Some advisers are conscious of Mr. Trump appearing diminished, and they are pressing for more — and larger — events around the New York area.
Many in Mr. Trump’s broader orbit are pessimistic about the case ending in a hung jury or a mistrial, and they see an outright acquittal as virtually impossible. They are bracing for him to be convicted, not because they cede the legal grounds, but because they think jurors in overwhelmingly Democratic Manhattan will be against the polarizing former president.
But the shared sense among many of his advisers is that the process may damage him as much as a guilty verdict. The process, they believe, is its own punishment.
Maggie Haberman is a senior political correspondent reporting on the 2024 presidential campaign, down ballot races across the country and the investigations into former President Donald J. Trump. More about Maggie Haberman
Our Coverage of the 2024 Election
Presidential Race
Protests and arrests on college campuses exploded into the forefront of the presidential race recently, opening up a new line of attack for Republicans and forcing President Biden to directly address an issue that has divided the liberal wing of his party.
In a stop in Wilmington, N.C., a possible swing state in the fall election, the president announced $3 billion in new spending to upgrade water systems around the country.
Biden has been under pressure to prove he can be tough at the border. But at a campaign reception, he also tried to voice his commitment to America’s long history of immigration, calling Japan and India “xenophobic” in the process.
A Key to 2024: As Democrats confront a presidential race against a resurgent and resilient Trump as well as a brutally challenging Senate map, they believe they have an increasingly powerful political weapon: ballot measures to protect abortion rights.
Presidential Medal of Freedom: With the election looming, Biden assembled a list of 19 people to honor that was heavy with major Democratic Party figures and others he has worked with over the years.
The Ultimate D.C. Veteran: In 30 years of Senate bids, Joe Biden was such a formidable incumbent that he did not face a serious threat to his return to office. But his last re-election is shaping up to be a fight.
Awash in Federal Money: Across Milwaukee, there is evidence of federal money from laws passed under the Biden administration. The president hopes voters will notice .
Fulton County officials say by law they don't control Fani Willis' spending in Trump case
Leaders of Georgia’s Fulton County say they had no legal power to control District Attorney Fani Willis’ spending or her hiring of former special prosecutor Nathan Wade
ATLANTA -- Leaders of Georgia's Fulton County testified Friday before a special state Senate committee that they had no legal power to control District Attorney Fani Willis' spending or her hiring of former special prosecutor Nathan Wade.
The Republican-led committee is probing Willis' hiring of Wade to lead a team to investigate and ultimately prosecute Donald Trump and 18 others accused illegally trying to overturn the 2020 presidential election in Georgia. Willis and Wade have acknowledged a romantic relationship with each other.
In one example of the kind of threats Willis has been receiving, federal officials announced that a California man was indicted on April 24 on charges of transmitting interstate threats against Willis. Ryan Buchanan, the U.S. attorney in Atlanta, said Marc Shultz, 66, of Chula Vista made threatening comments against Willis in the comment streams of two YouTube videos in October, pledging violence and murder including a statement that she “will be killed like a dog.”
Shultz's indictment wasn't available in online court records on Friday. Those records show Shultz appeared before a judge in San Diego on Thursday and was released on bail. A federal public defender representing Shultz didn't immediately return an email seeking comment Friday. Buchanan said Shultz would be formally arraigned in Atlanta in June.
Trump and some other defendants in the case have tried to get Willis and her office removed from the case, saying the relationship with Wade created a conflict of interest. Wade stepped down from the prosecution after Fulton County Superior Court Judge Scott McAfee in March found that no conflict of interest existed that should force Willis off the case. But he ruled that Willis could continue prosecuting Trump only if Wade left. Trump and others are appealing that ruling to a higher state court.
The allegations that Willis had improperly benefited from her romance with Wade resulted in a tumultuous months in the case as intimate details of Willis and Wade’s personal lives were aired in court in mid-February. The serious charges in one of four criminal cases against the Republican former president were largely overshadowed by the love lives of the prosecutors.
Willis told reporters Friday that she had done nothing wrong.
“They can look all they want," Willis said. "The DA’s office has done everything according to the books. We are following the law. I’m sorry that folks get mad when everybody in society can be prosecuted.”
Willis is running for reelection this year and faces a Democratic opponent, Christian Wise Smith in a May 21 primary. Early voting for that election is ongoing.
But the lawyer who initiated the effort to remove Willis, Ashleigh Merchant, has also claimed that Wade's firing violated a state law that required approval of the hiring of a special prosecutor by the county commission.
Fulton County Commission Chairman Rob Pitts, a Democrat, and Fulton County Attorney Soo Jo both told the committee that while the law appears to require county commission approval, judges decades ago interpreted the law in such a way to give Willis the freedom to hire who she wants without approval. Jo, who represents the commission, cited three separate Georgia Court of Appeals cases backing up that point
“What I have found is that the court has rejected the proposition that this particular statute requires a district attorney to obtain explicit permission from a county prior to appointing a special assistant district attorney,” Jo said.
State Sen. Bill Cowsert, the Athens Republican who chairs the committee, disputed that interpretation when questioned by reporters after the hearing.
“I think the clear language of the statute says that that requires county approval, and especially where it’s funded by the county,” Cowsert said.
He went on to suggest the committee, which doesn't directly have the power to sanction Willis, might change the law to give counties more control over spending by state officers funded by counties, including district attorneys and sheriffs. Fulton County officials said they don't believe they currently can control how Willis spends money once it's appropriated to her.
Cowsert said increased county oversight would be “extraordinarily complex" for district attorneys managing funds contributed by more than one county. While Willis and 15 other district attorneys in Georgia only prosecute cases from one county, others prosecute cases from as many as eight counties.
Senate Democratic Whip Harold Jones II of Augusta said the hours of questioning over details of how Fulton County budgets money shows the panel is “on its last legs," noting three of six Republicans didn't appear for a committee meeting called on short notice.
“They’re not even interested in this anymore,” Jones said. “There’s nothing else to talk about, quite frankly. And we found that out today.”
Top Stories

South Dakota Gov. Noem admits error of describing meeting Kim Jong Un in new book
- May 3, 1:37 PM

Arkansas governor says state won't comply with new federal rules on treatment of trans students
- May 2, 7:25 PM

Jurors hear recording of Trump and Cohen allegedly discussing hush money payment
- May 3, 11:00 PM

Noem backpedals on anecdote in book about meeting with Kim Jong Un
- May 3, 5:04 PM

Inside the 'Hungryland Homicide': How police found a Florida mom's killer
- May 3, 8:25 AM
ABC News Live
24/7 coverage of breaking news and live events
IMAGES
VIDEO
COMMENTS
A case-control study is a type of observational study commonly used to look at factors associated with diseases or outcomes.[1] The case-control study starts with a group of cases, which are the individuals who have the outcome of interest. The researcher then tries to construct a second group of individuals called the controls, who are similar to the case individuals but do not have the ...
Introduction. Case-control and cohort studies are observational studies that lie near the middle of the hierarchy of evidence. These types of studies, along with randomised controlled trials, constitute analytical studies, whereas case reports and case series define descriptive studies (1). Although these studies are not ranked as highly as ...
Revised on June 22, 2023. A case-control study is an experimental design that compares a group of participants possessing a condition of interest to a very similar group lacking that condition. Here, the participants possessing the attribute of study, such as a disease, are called the "case," and those without it are the "control.".
A case-control study (also known as case-referent study) is a type of observational study in which two existing groups differing in outcome are identified and compared on the basis of some supposed causal attribute. Case-control studies are often used to identify factors that may contribute to a medical condition by comparing subjects who have the condition with patients who do not have ...
Case-control studies are a sub-type of observational studies which often use matching factors. These research methodologies do not belong to the category of randomized trials; however, we consider appropriate to report a brief mention of them because this study design, diametrically opposed to RCTs, allows to answer questions to which trials ...
Background While randomised controlled trials (RCTs) provide high-quality evidence to guide practice, much routine care is not based upon available RCTs. This disconnect between evidence and practice is not sufficiently well understood. This case study explores this relationship using a novel approach. Better understanding may improve trial design, conduct, reporting and implementation ...
The highest grade is reserved for research involving "at least one properly randomized controlled trial," and the lowest grade is applied to descriptive studies (e.g., case series) and expert ...
The strengths of RCTs are subtle: they are powerful because of the set of procedures that they are expected to follow. This includes the use of controls, placebos, experimentation, randomization, concealment, blinding, intention-to-treat analysis, and pre-registration.
Individual cohort study / low-quality randomized control studies: B: 3a: Systematic review of (homogeneous) case-control studies: B: 3b: Individual case-control studies: C: 4: Case series, low-quality cohort or case-control studies: D : 5: Expert opinions based on non-systematic reviews of
A randomized controlled trial (or randomized control trial; [2] RCT) is a form of scientific experiment used to control factors not under direct experimental control. Examples of RCTs are clinical trials that compare the effects of drugs, surgical techniques, medical devices, diagnostic procedures, diets or other medical treatments.
A randomized control trial (RCT) is a type of study design that involves randomly assigning participants to either an experimental group or a control group to measure the effectiveness of an intervention or treatment. Randomized Controlled Trials (RCTs) are considered the "gold standard" in medical and health research due to their rigorous ...
A case-control study was conducted to investigate if exposure to zinc oxide is a more effective skin cancer prevention measure. The study involved comparing a group of former lifeguards that had developed cancer on their cheeks and noses (cases) to a group of lifeguards without this type of cancer (controls) and assess their prior exposure to ...
A study design that randomly assigns participants into an experimental group or a control group. As the study is conducted, the only expected difference between the control and experimental groups in a randomized controlled trial (RCT) is the outcome variable being studied. Advantages. Good randomization will "wash out" any population bias
It is noted that case study research is more than simply to data collection, analysis, and report writing differing from the traditional, randomized control trial in terms of issues such as rigour ...
The 2 main types of epidemiology studies are: Observational studies ( prospective cohort or case-control) Randomized controlled trials. Though they have the same goal, observational studies and randomized controlled trials differ in: The way they are conducted. The strengths of the conclusions they reach.
We applied the PTEBL teaching approach to fit the new situation..Students of this case study were randomized into either an experimental group utilizing the PTEBL teaching approach (n = 77) or a control group utilizing the traditional teaching approach (n = 76), using a 1:1 allocation ratio. Random grouping is mainly achieved through random ...
The fragility index is a statistical measure of the robustness or "stability" of a statistically significant result. It has been adapted to assess the robustness of statistically significant outcomes from randomized controlled trials. By hypothetically switching some non-responders to responders, for instance, this metric measures how many individuals would need to have responded for a ...
All Phase III procedures, including setting, participant eligibility and recruitment, randomization, and measures and assessments were identical for the Phase III Pilot Randomized Controlled Trial. The following additional analyses were included: acceptability and analysis of patient reported outcomes.
To understand why, a team of researchers conducted a randomized controlled trial with 2,400 Novartis employees who worked in the UK, Ireland, India, and Malaysia.
In a recent, small randomized trial of 43 patients with recent ST‐segment-elevation myocardial infarction and low trait anger control, anger management by cognitive behavioral therapy versus control condition led to a greater improvement in EDV at 3‐month follow‐up. 44 However, both groups had an improvement in trait anger control with ...
In 2019, Esther Duflo became the second woman to ever win a Nobel Prize in Economic Sciences for her groundbreaking contributions to development economics through the innovative application of randomized controlled trials (RCTs). Duflo's transformative approach involved adapting RCTs from the medical field to address complex social issues. As Duflo gained prominence, she endorsed a shift ...
Favipiravir has been used in the therapy of COVID-19, including patients with mild to moderate symptoms in certain countries. The aim of our systematic review and meta-analysis was to investigate its efficacy and safety in mild-to-moderate COVID-19 infections. The PubMed, Embase, Web of Science, and Cochrane databases were systematically reviewed for articles reporting the results of ...
The first criminal trial of former President Donald J. Trump is underway. Take a closer look at central figures related to the case. Over the next six weeks or so, Mr. Trump will have to endure ...
Fulton County officials say by law they don't control Fani Willis' spending in Trump case. Leaders of Georgia's Fulton County say they had no legal power to control District Attorney Fani Willis ...