

+91 9629863243
- Output Screenshots
- IEEE ANDROID PROJECTS
- IEEE Cloudsim Projects
- IEEE Communication Projects
- IEEE Computer Science Projects
- IEEE Dotnet Projects
- IEEE Hadoop Projects
- IEEE Java Projects
- IEEE Matlab Projects
- IEEE Networking Projects
- Ns2 Projects code
- IEEE PHD Projects
- IEEE ARM Projects
- IEEE GPS Projects
- IEEE GSM Projects
- IEEE LabView Projects
- IEEE RFID Projects
- IEEE Robotics Projects
- IEEE VLSI Projects
- IEEE Zigbee Projects
- IEEE MATLAB Simulink Projects
- IEEE Power Electronics Projects
- PhD Guidance
- Master Thesis Image Processing Projects
Master Thesis Image Processing Projects is our world’s utmost image processing research centre launch with our great motivation of give evergreen research zone for our students and research intellectuals. Recently, we guided 5000+ scholars in all over the world. Today, our students are widely-spread in world’s popular countries. We always welcome to connect with our record-breaking research systems to simulate your extraordinary ambition to move on your professional profile.
Latest List of Topics in Image Processing:
- Image compressive sensing using group sparse representation via truncated nuclear norm minimization
- Doppler measurement of liquid flow in pipe using decimation and parametric spectral estimation method
- SAR patch categorization using dual tree oriented wavelet transform and stacked auto encoder [ Master Thesis Image Processing Projects ]
- Non-contact signal detection and processing techniques for cardio-respiratory thoracic activity
- An effective consistency correction and blending method for camera-array-based microscopy imaging
- An analysis of the applicability of the TFD IP option for QoS assurance of multiple video streams in a congested network
- Signal analysis on the ball: Design of optimal basis functions with maximal multiplicative concentration in spatial and spectral domains
- Choice of optimal measurement conditions for calculating the correlation between EMA sensor and video marker position coordinates in electromagnetic articulography
- Improving matching performance of the keypoints in images of 3D scenes by using depth information
- Towards multi-scale personalized modeling of brain vasculature based on magnetic resonance image processing
- Surface-Height Determination of Crevassed Glaciers Mathematical Principles of an Autoadaptive Density-Dimension Algorithm and Validation Using ICESat-2 Simulator (SIMPL) Data
- Testing and integration of JPSS VIIRS aerosol EDR algorithms and evaluation of upstream/downstream effects using the Algorithm Development Library (ADL)
- Size-scalable content-based histopathological image retrieval from database that consists of WSIs [ Master Thesis Image Processing Projects ]
- Piecewise Linear Approximation of Vector-Valued Images and Curves via Second-Order Variational Model
- Modeling and parameter estimation of vehicle vibration inducing transmitter displacement in ITS image sensor communication
Related Pages
- Master Thesis Wireless Sensor Networks Projects
- Master Thesis Wireless Security Projects
- Master Thesis Wireless Networks Projects
- Master Thesis Wireless Network Projects
- Master Thesis Wireless Communication Projects
- Master Thesis Wireless Body Area Network Projects
- Master Thesis Wired Network Projects
- Master Thesis WiMax Projects
- Master Thesis WiFi Network Projects
- Master Thesis Web Service Projects
- Master Thesis Web Mining Projects
- Master Thesis VOIP Projects
- Master Thesis Visual Cryptography Projects
- Master Thesis Video Streaming Projects
- Master Thesis Video Processing Projects
- Master Thesis Vehicular Ad Hoc Network Projects
- Master Thesis UMTS Network Projects
- Master Thesis Ubiquitous Computing Projects
- Master Thesis Text Mining Projects
- Master Thesis Telecommunication Projects
- Master Thesis Telecommunication Engineering Projects
- Master Thesis Systems and Cybernetics Projects
- Master Thesis Swans Simulator Projects
- Master Thesis Software Re-Engineering Projects
- Master Thesis Software Engineering Projects
- Master Thesis Software Defined Radio Projects
- Master Thesis Software Defined Networking Projects
- Master Thesis Software Defined Network Projects
- Master Thesis Soft Computing Projects
- Master Thesis Social Sensor Networks Projects
- Master Thesis Simulink Projects
- Master Thesis Signals & Systems Projects
- Master Thesis Service Computing Projects
- Master Thesis Sensor Networks Projects
- Master Thesis Security Projects
- Master Thesis Scilab Projects
- Master Thesis Routing Protocol Projects
- Master Thesis Resource Allocation Projects
- Master Thesis Renewable Energy Projects
- Master Thesis Remote Sensing Projects
- Master Thesis Power Electronics Projects
- Master Thesis Pervasive Computing Projects
- Master Thesis Peer to Peer Network Projects
- Master Thesis Pattern Recognition Projects
- Master Thesis Parallel and Distributed Systems Projects
- Master Thesis P2P Live Streaming Projects
- Master Thesis OptiSystem Projects
- Master Thesis OPNET Projects
- Master Thesis OpenCV Projects
- Master Thesis Open Stack Projects
- Master Thesis NS3 Projects
- Master Thesis NLP Projects
- Master Thesis Neural Networks Projects
- Master Thesis Multimedia Projects
- Master Thesis Mobile Networking Projects
- Master Thesis Medical Image Processing Projects
- Master Thesis MATLAB Simulink Projects
- Master Thesis MATLAB Projects
- Master Thesis MapReduce Projects
- Master Thesis LTE Projects
- Master Thesis Java Projects
- Master Thesis IT Projects
- Master Thesis Information Technology Projects
- Master Thesis Hadoop Projects
- Master Thesis Electronics and Communication Projects
- Master Thesis Electrical Projects
- Master Thesis CloudSim Projects
- Master Thesis Big Data Projects
- Master Thesis Android Projects
- Master Thesis IEEE Projects
- IEEE Projects
- IEEE Projects CSE
- IEEE Projects ECE
- IEEE Projects EEE
Copyright IEEE Projects © 2005 - 2024 PHD Projects Experts © 2024. All Rights Reserved.
Interactive Media Systems, TU Wien
Simple Microservices for Image Processing
Master Thesis
About This Topic
Build a small collection of microservices to perform simple image processing tasks commonly required in modern web environments.
Additional Information
Image processing.
Simple image processing involves tasks such as:
- Image optimization [1].
- Crop an image to fit a given aspect ratio [2].
- Perform face detection on a photo and extract a person's portrait [3].
- Take a full-page screenshot of a web page [4].
- Analyze a web page and extract the most significant image [5].
Architecture
Clients talk to your services over HTTP via simple JSON APIs [6]. Services are containerized and run in a Docker Swarm [7] to provide redundancy and easy scaling. Services expose simple metrics [8] to assert their health. Time-consuming tasks (e.g., high-quality face detection) are queued up [9] and performed asynchronously. Images are stored on an object storage server [10]. Service orchestration is a core aspect of the project.
Ideally, your services are written in Go or Ruby.
Comparative Study
If executed as a diploma thesis, the project includes a comparative study of three different implementation approaches to the service layer:
- From scratch,
- based on a general-purpose microservices framework [11],
- in the context of a serverless environment [12].
Please note that only the service layer is relevant for the comparison. For the actual image processing, you can use any open-source third-party library you like (i.e., don't implement face detection from scratch in step one).
- jsonapi.org
- github.com/toy/image_optim
- github.com/esimov/caire
- github.com/muesli/smartcrop
- github.com/GoogleChrome/puppeteer
- github.com/advancedlogic/GoOse
- docs.docker.com/engine/swarm/
- prometheus.io
- github.com/contribsys/faktory
- github.com/go-kit/kit
- github.com/openfaas/faas
- Bibliography
- More Referencing guides Blog Automated transliteration Relevant bibliographies by topics
- Automated transliteration
- Relevant bibliographies by topics
- Referencing guides
What is Digital Image Processing?
Digital image processing is the process of using computer algorithms to perform image processing on digital images. Latest topics in digital image processing for research and thesis are based on these algorithms. Being a subcategory of digital signal processing, digital image processing is better and carries many advantages over analog image processing. It permits to apply multiple algorithms to the input data and does not cause the problems such as the build-up of noise and signal distortion while processing. As images are defined over two or more dimensions that make digital image processing “a model of multidimensional systems”. The history of digital image processing dates back to early 1920s when the first application of digital image processing came into news. Many students are going for this field for their m tech thesis as well as for Ph.D. thesis. There are various thesis topics in digital image processing for M.Tech, M.Phil and Ph.D. students. The list of thesis topics in image processing is listed here. Before going into topics in image processing , you should have some basic knowledge of image processing.

Latest research topics in image processing for research scholars:
- The hybrid classification scheme for plant disease detection in image processing
- The edge detection scheme in image processing using ant and bee colony optimization
- To improve PNLM filtering scheme to denoise MRI images
- The classification method for the brain tumor detection
- The CNN approach for the lung cancer detection in image processing
- The neural network method for the diabetic retinopathy detection
- The copy-move forgery detection approach using textual feature extraction method
- Design face spoof detection method based on eigen feature extraction and classification
- The classification and segmentation method for the number plate detection
- Find the link at the end to download the latest thesis and research topics in Digital Image Processing
Formation of Digital Images
Firstly, the image is captured by a camera using sunlight as the source of energy. For the acquisition of the image, a sensor array is used. These sensors sense the amount of light reflected by the object when light falls on that object. A continuous voltage signal is generated when the data is being sensed. The data collected is converted into a digital format to create digital images. For this process, sampling and quantization methods are applied. This will create a 2-dimensional array of numbers which will be a digital image.
Why is Image Processing Required?
- Image Processing serves the following main purpose:
- Visualization of the hidden objects in the image.
- Enhancement of the image through sharpening and restoration.
- Seek valuable information from the images.
- Measuring different patterns of objects in the image.
- Distinguishing different objects in the image.
Applications of Digital Image Processing
- There are various applications of digital image processing which can also be a good topic for the thesis in image processing. Following are the main applications of image processing:
- Image Processing is used to enhance the image quality through techniques like image sharpening and restoration. The images can be altered to achieve the desired results.
- Digital Image Processing finds its application in the medical field for gamma-ray imaging, PET Scan, X-ray imaging, UV imaging.
- It is used for transmission and encoding.
- It is used in color processing in which processing of colored images is done using different color spaces.
- Image Processing finds its application in machine learning for pattern recognition.
List of topics in image processing for thesis and research
- There are various in digital image processing for thesis and research. Here is the list of latest thesis and research topics in digital image processing:
- Image Acquisition
- Image Enhancement
- Image Restoration
- Color Image Processing
- Wavelets and Multi Resolution Processing
- Compression
- Morphological Processing
- Segmentation
- Representation and Description
- Object recognition
- Knowledge Base
1. Image Acquisition:
Image Acquisition is the first and important step of the digital image of processing . Its style is very simple just like being given an image which is already in digital form and it involves preprocessing such as scaling etc. It starts with the capturing of an image by the sensor (such as a monochrome or color TV camera) and digitized. In case, the output of the camera or sensor is not in digital form then an analog-to-digital converter (ADC) digitizes it. If the image is not properly acquired, then you will not be able to achieve tasks that you want to. Customized hardware is used for advanced image acquisition techniques and methods. 3D image acquisition is one such advanced method image acquisition method. Students can go for this method for their master’s thesis and research.
2. Image Enhancement:
Image enhancement is one of the easiest and the most important areas of digital image processing. The core idea behind image enhancement is to find out information that is obscured or to highlight specific features according to the requirements of an image. Such as changing brightness & contrast etc. Basically, it involves manipulation of an image to get the desired image than original for specific applications. Many algorithms have been designed for the purpose of image enhancement in image processing to change an image’s contrast, brightness, and various other such things. Image Enhancement aims to change the human perception of the images. Image Enhancement techniques are of two types: Spatial domain and Frequency domain.
3. Image Restoration:
Image restoration involves improving the appearance of an image. In comparison to image enhancement which is subjective, image restoration is completely objective which makes the sense that restoration techniques are based on probabilistic or mathematical models of image degradation. Image restoration removes any form of a blur, noise from images to produce a clean and original image. It can be a good choice for the M.Tech thesis on image processing. The image information lost during blurring is restored through a reversal process. This process is different from the image enhancement method. Deconvolution technique is used and is performed in the frequency domain. The main defects that degrade an image are restored here.
4. Color Image Processing:
Color image processing has been proved to be of great interest because of the significant increase in the use of digital images on the Internet. It includes color modeling and processing in a digital domain etc. There are various color models which are used to specify a color using a 3D coordinate system. These models are RGB Model, CMY Model, HSI Model, YIQ Model. The color image processing is done as humans can perceive thousands of colors. There are two areas of color image processing full-color processing and pseudo color processing. In full-color processing, the image is processed in full colors while in pseudo color processing the grayscale images are converted to colored images. It is an interesting topic in image processing.


- Hamprecht Lab
- Prof. Hamprecht
- Lab members
- Publications
- Prof. Ommer
- Digital Humanities
- Visual Search Tool
- Prof. Rother
- Prof. Köthe
- Dr. Savchynskyy
- Schnörr Lab
- Prof. Schnörr
- All Publications
- Hamprecht: Image Analysis and Learning Lab
- Ommer: Computer Vision
- Rother: Visual Learning Lab
- Schnörr: Image and Pattern Analysis
- Current Members
- Alumni (Former Members)
Master Thesis Projects
If you are interested, send an email to Fred Hamprecht or Ullrich Köthe . Our topics are particularly suitable for students of physics, mathematics, and computer science, but motivated people from other fields are also welcome!
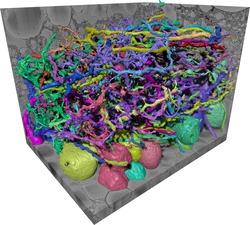
A major goal of neuro-science is the understanding of basic neural circuits. To this end, novel electron microscopic methods acquire 3-dimensional images of the brain at a resolution of 10-20 nm and a field of view of up to 0.1 mm. These huge data-sets can only be analyzed automatically, and our group is a major algorithm provider for this application . We continuously offer interesting master projects dealing with specific sub-problems, for example:
- Design and implementation of new features that capture important image properties such as the shape and layout of candidate regions.
- Detection methods for organelles such as mitochondria and vesicles.
- Novel optimization algorithms that efficiently find the best among many candidate segmentations.
- Development of semi-automatic tools that optimally combine automatic methods with interactive user guidance to arrive at high quality results as quickly as possible.
Biologist are making rapid progress towards the understanding of embryonic development. Thanks to novel light-sheet microscopes that can capture fully 3-dimensional volume data at a temporal resolution of under one minute over several days, they can now study how initially independent cells manage to group themselves into all the different organs of an organism. Our group addresses the algorithmic challenge to track all visible cells in such a data-set over time. We continuously offer interesting master projects dealing with specific sub-problems, for example:
- Design of a reliable detector for cell division events, where the track of a single cell splits up into two child tracks.
- Hierarchical segmentation algorithms that reliably find all visible cells even under high noise levels.
- Efficient methods to estimate the uncertainty of the results of our analysis.
- Algorithms for the intuitive visualization of 3D+time data on 2-dimensional displays.
Machine learning has become the method of choice to solve complex image analysis problems. It allows non-expert users to train a generic analysis algorithm by showing examples of desired outcomes. To extend the scope of this approach to more complex problems, we investigate new learning methods and novel ways to train them. Interesting master projects in this context include:
- Development of active learning methods that minimize training time by guiding the user towards particularly valuable examples.
- New image features that capture important aspects of the data for subsequent use by learning methods.
- Intuitive training strategies for non-standard types of training data such as object shape and layout.
- Design of novel ensemble methods that combine analysis results from several sources into an integrated result of much higher quality than any of the inputs.
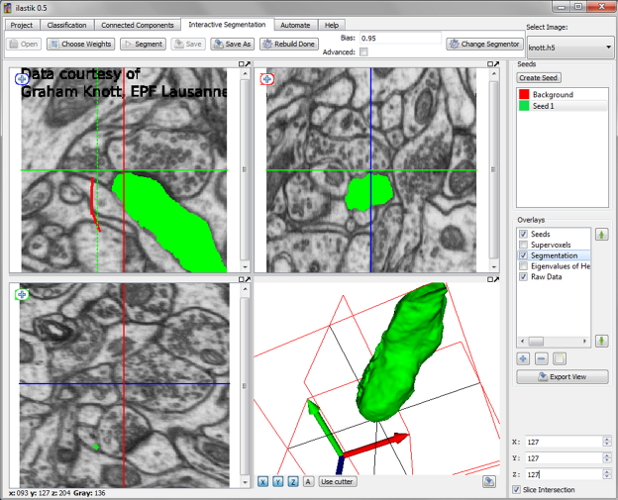
Our image analysis solutions apply complex algorithms to huge amounts of data and yet must be intuitively operable by non-experts. This poses great challenges on careful software design, and our group maintains a number of major open-source projects to address these challenges. Fast and flexible modules for fundamental image analysis and optimization algorithms are mainly implemented in the VIGRA and OpenGM C++ libraries, whereas the Python-based ilastik project takes care of the high-level organization, parallelization, and graphical user interface. Students who want to master advanced software development techniques can contribute to these projects in many ways, for example:
- Design of easy-to-use workflows for recurring tasks in the application fields we address.
- Reusable integration of novel algorithms developed by our group or elsewhere into these projects.
- Implementation of advanced parallelization strategies to fully utilize the power of modern multi-core CPUs and clusters.
- Powerful 3-dimensional visualization of analysis results for rapid user feedback and presentation.
- Datenschutzerklärung
- Data Privacy Policy
- Internal Information
- Haftungsausschluss (Disclaimer)
A list of completed theses and new thesis topics from the Computer Vision Group.
Are you about to start a BSc or MSc thesis? Please read our instructions for preparing and delivering your work.
Below we list possible thesis topics for Bachelor and Master students in the areas of Computer Vision, Machine Learning, Deep Learning and Pattern Recognition. The project descriptions leave plenty of room for your own ideas. If you would like to discuss a topic in detail, please contact the supervisor listed below and Prof. Paolo Favaro to schedule a meeting. Note that for MSc students in Computer Science it is required that the official advisor is a professor in CS.
AI deconvolution of light microscopy images
Level: master.
Background Light microscopy became an indispensable tool in life sciences research. Deconvolution is an important image processing step in improving the quality of microscopy images for removing out-of-focus light, higher resolution, and beter signal to noise ratio. Currently classical deconvolution methods, such as regularisation or blind deconvolution, are implemented in numerous commercial software packages and widely used in research. Recently AI deconvolution algorithms have been introduced and being currently actively developed, as they showed a high application potential.
Aim Adaptation of available AI algorithms for deconvolution of microscopy images. Validation of these methods against state-of-the -art commercially available deconvolution software.
Material and Methods Student will implement and further develop available AI deconvolution methods and acquire test microscopy images of different modalities. Performance of developed AI algorithms will be validated against available commercial deconvolution software.

- Al algorithm development and implementation: 50%.
- Data acquisition: 10%.
- Comparison of performance: 40 %.
Requirements
- Interest in imaging.
- Solid knowledge of AI.
- Good programming skills.
Supervisors Paolo Favaro, Guillaume Witz, Yury Belyaev.
Institutes Computer Vison Group, Digital Science Lab, Microscopy imaging Center.
Contact Yury Belyaev, Microscopy imaging Center, [email protected] , + 41 78 899 0110.
Instance segmentation of cryo-ET images
Level: bachelor/master.
In the 1600s, a pioneering Dutch scientist named Antonie van Leeuwenhoek embarked on a remarkable journey that would forever transform our understanding of the natural world. Armed with a simple yet ingenious invention, the light microscope, he delved into uncharted territory, peering through its lens to reveal the hidden wonders of microscopic structures. Fast forward to today, where cryo-electron tomography (cryo-ET) has emerged as a groundbreaking technique, allowing researchers to study proteins within their natural cellular environments. Proteins, functioning as vital nano-machines, play crucial roles in life and understanding their localization and interactions is key to both basic research and disease comprehension. However, cryo-ET images pose challenges due to inherent noise and a scarcity of annotated data for training deep learning models.

Credit: S. Albert et al./PNAS (CC BY 4.0)
To address these challenges, this project aims to develop a self-supervised pipeline utilizing diffusion models for instance segmentation in cryo-ET images. By leveraging the power of diffusion models, which iteratively diffuse information to capture underlying patterns, the pipeline aims to refine and accurately segment cryo-ET images. Self-supervised learning, which relies on unlabeled data, reduces the dependence on extensive manual annotations. Successful implementation of this pipeline could revolutionize the field of structural biology, facilitating the analysis of protein distribution and organization within cellular contexts. Moreover, it has the potential to alleviate the limitations posed by limited annotated data, enabling more efficient extraction of valuable information from cryo-ET images and advancing biomedical applications by enhancing our understanding of protein behavior.
Methods The segmentation pipeline for cryo-electron tomography (cryo-ET) images consists of two stages: training a diffusion model for image generation and training an instance segmentation U-Net using synthetic and real segmentation masks.
1. Diffusion Model Training: a. Data Collection: Collect and curate cryo-ET image datasets from the EMPIAR database (https://www.ebi.ac.uk/empiar/). b. Architecture Design: Select an appropriate architecture for the diffusion model. c. Model Evaluation: Cryo-ET experts will help assess image quality and fidelity through visual inspection and quantitative measures 2. Building the Segmentation dataset: a. Synthetic and real mask generation: Use the trained diffusion model to generate synthetic cryo-ET images. The diffusion process will be seeded from either a real or a synthetic segmentation mask. This will yield to pairs of cryo-ET images and segmentation masks. 3. Instance Segmentation U-Net Training: a. Architecture Design: Choose an appropriate instance segmentation U-Net architecture. b. Model Evaluation: Evaluate the trained U-Net using precision, recall, and F1 score metrics.
By combining the diffusion model for cryo-ET image generation and the instance segmentation U-Net, this pipeline provides an efficient and accurate approach to segment structures in cryo-ET images, facilitating further analysis and interpretation.
References 1. Kwon, Diana. "The secret lives of cells-as never seen before." Nature 598.7882 (2021): 558-560. 2. Moebel, Emmanuel, et al. "Deep learning improves macromolecule identification in 3D cellular cryo-electron tomograms." Nature methods 18.11 (2021): 1386-1394. 3. Rice, Gavin, et al. "TomoTwin: generalized 3D localization of macromolecules in cryo-electron tomograms with structural data mining." Nature Methods (2023): 1-10.
Contacts Prof. Thomas Lemmin Institute of Biochemistry and Molecular Medicine Bühlstrasse 28, 3012 Bern ( [email protected] )
Prof. Paolo Favaro Institute of Computer Science Neubrückstrasse 10 3012 Bern ( [email protected] )
Adding and removing multiple sclerosis lesions with to imaging with diffusion networks
Background multiple sclerosis lesions are the result of demyelination: they appear as dark spots on t1 weighted mri imaging and as bright spots on flair mri imaging. image analysis for ms patients requires both the accurate detection of new and enhancing lesions, and the assessment of atrophy via local thickness and/or volume changes in the cortex. detection of new and growing lesions is possible using deep learning, but made difficult by the relative lack of training data: meanwhile cortical morphometry can be affected by the presence of lesions, meaning that removing lesions prior to morphometry may be more robust. existing ‘lesion filling’ methods are rather crude, yielding unrealistic-appearing brains where the borders of the removed lesions are clearly visible., aim: denoising diffusion networks are the current gold standard in mri image generation [1]: we aim to leverage this technology to remove and add lesions to existing mri images. this will allow us to create realistic synthetic mri images for training and validating ms lesion segmentation algorithms, and for investigating the sensitivity of morphometry software to the presence of ms lesions at a variety of lesion load levels., materials and methods: a large, annotated, heterogeneous dataset of mri data from ms patients, as well as images of healthy controls without white matter lesions, will be available for developing the method. the student will work in a research group with a long track record in applying deep learning methods to neuroimaging data, as well as experience training denoising diffusion networks..
Nature of the Thesis:
Literature review: 10%
Replication of Blob Loss paper: 10%
Implementation of the sliding window metrics:10%
Training on MS lesion segmentation task: 30%
Extension to other datasets: 20%
Results analysis: 20%
Fig. Results of an existing lesion filling algorithm, showing inadequate performance
Requirements:
Interest/Experience with image processing
Python programming knowledge (Pytorch bonus)
Interest in neuroimaging
Supervisor(s):
PD. Dr. Richard McKinley
Institutes: Diagnostic and Interventional Neuroradiology
Center for Artificial Intelligence in Medicine (CAIM), University of Bern
References: [1] Brain Imaging Generation with Latent Diffusion Models , Pinaya et al, Accepted in the Deep Generative Models workshop @ MICCAI 2022 , https://arxiv.org/abs/2209.07162
Contact : PD Dr Richard McKinley, Support Centre for Advanced Neuroimaging ( [email protected] )
Improving metrics and loss functions for targets with imbalanced size: sliding window Dice coefficient and loss.
Background The Dice coefficient is the most commonly used metric for segmentation quality in medical imaging, and a differentiable version of the coefficient is often used as a loss function, in particular for small target classes such as multiple sclerosis lesions. Dice coefficient has the benefit that it is applicable in instances where the target class is in the minority (for example, in case of segmenting small lesions). However, if lesion sizes are mixed, the loss and metric is biased towards performance on large lesions, leading smaller lesions to be missed and harming overall lesion detection. A recently proposed loss function (blob loss[1]) aims to combat this by treating each connected component of a lesion mask separately, and claims improvements over Dice loss on lesion detection scores in a variety of tasks.
Aim: The aim of this thesisis twofold. First, to benchmark blob loss against a simple, potentially superior loss for instance detection: sliding window Dice loss, in which the Dice loss is calculated over a sliding window across the area/volume of the medical image. Second, we will investigate whether a sliding window Dice coefficient is better corellated with lesion-wise detection metrics than Dice coefficient and may serve as an alternative metric capturing both global and instance-wise detection.
Materials and Methods: A large, annotated, heterogeneous dataset of MRI data from MS patients will be available for benchmarking the method, as well as our existing codebases for MS lesion segmentation. Extension of the method to other diseases and datasets (such as covered in the blob loss paper) will make the method more plausible for publication. The student will work alongside clinicians and engineers carrying out research in multiple sclerosis lesion segmentation, in particular in the context of our running project supported by the CAIM grant.

Fig. An annotated MS lesion case, showing the variety of lesion sizes
References: [1] blob loss: instance imbalance aware loss functions for semantic segmentation, Kofler et al, https://arxiv.org/abs/2205.08209
Idempotent and partial skull-stripping in multispectral MRI imaging
Background Skull stripping (or brain extraction) refers to the masking of non-brain tissue from structural MRI imaging. Since 3D MRI sequences allow reconstruction of facial features, many data providers supply data only after skull-stripping, making this a vital tool in data sharing. Furthermore, skull-stripping is an important pre-processing step in many neuroimaging pipelines, even in the deep-learning era: while many methods could now operate on data with skull present, they have been trained only on skull-stripped data and therefore produce spurious results on data with the skull present.
High-quality skull-stripping algorithms based on deep learning are now widely available: the most prominent example is HD-BET [1]. A major downside of HD-BET is its behaviour on datasets to which skull-stripping has already been applied: in this case the algorithm falsely identifies brain tissue as skull and masks it. A skull-stripping algorithm F not exhibiting this behaviour would be idempotent: F(F(x)) = F(x) for any image x. Furthermore, legacy datasets from before the availability of high-quality skull-stripping algorithms may still contain images which have been inadequately skull-stripped: currently the only solution to improve the skull-stripping on this data is to go back to the original datasource or to manually correct the skull-stripping, which is time-consuming and prone to error.
Aim: In this project, the student will develop an idempotent skull-stripping network which can also handle partially skull-stripped inputs. In the best case, the network will operate well on a large subset of the data we work with (e.g. structural MRI, diffusion-weighted MRI, Perfusion-weighted MRI, susceptibility-weighted MRI, at a variety of field strengths) to maximize the future applicability of the network across the teams in our group.
Materials and Methods: Multiple datasets, both publicly available and internal (encompassing thousands of 3D volumes) will be available. Silver standard reference data for standard sequences at 1.5T and 3T can be generated using existing tools such as HD-BET: for other sequences and field strengths semi-supervised learning or methods improving robustness to domain shift may be employed. Robustness to partial skull-stripping may be induced by a combination of learning theory and model-based approaches.

Dataset curation: 10%
Idempotent skull-stripping model building: 30%
Modelling of partial skull-stripping:10%
Extension of model to handle partial skull: 30%
Results analysis: 10%
Fig. An example of failed skull-stripping requiring manual correction
References: [1] Isensee, F, Schell, M, Pflueger, I, et al. Automated brain extraction of multisequence MRI using artificial neural networks. Hum Brain Mapp . 2019; 40: 4952– 4964. https://doi.org/10.1002/hbm.24750
Automated leaf detection and leaf area estimation (for Arabidopsis thaliana)
Correlating plant phenotypes such as leaf area or number of leaves to the genotype (i.e. changes in DNA) is a common goal for plant breeders and molecular biologists. Such data can not only help to understand fundamental processes in nature, but also can help to improve ecotypes, e.g., to perform better under climate change, or reduce fertiliser input. However, collecting data for many plants is very time consuming and automated data acquisition is necessary.
The project aims at building a machine learning model to automatically detect plants in top-view images (see examples below), segment their leaves (see Fig C) and to estimate the leaf area. This information will then be used to determine the leaf area of different Arabidopsis ecotypes. The project will be carried out in collaboration with researchers of the Institute of Plant Sciences at the University of Bern. It will also involve the design and creation of a dataset of plant top-views with the corresponding annotation (provided by experts at the Institute of Plant Sciences).

Contact: Prof. Dr. Paolo Favaro ( [email protected] )
Master Projects at the ARTORG Center
The Gerontechnology and Rehabilitation group at the ARTORG Center for Biomedical Engineering is offering multiple MSc thesis projects to students, which are interested in working with real patient data, artificial intelligence and machine learning algorithms. The goal of these projects is to transfer the findings to the clinic in order to solve today’s healthcare problems and thus to improve the quality of life of patients. Assessment of Digital Biomarkers at Home by Radar. [PDF] Comparison of Radar, Seismograph and Ballistocardiography and to Monitor Sleep at Home. [PDF] Sentimental Analysis in Speech. [PDF] Contact: Dr. Stephan Gerber ( [email protected] )
Internship in Computational Imaging at Prophesee
A 6 month intership at Prophesee, Grenoble is offered to a talented Master Student.
The topic of the internship is working on burst imaging following the work of Sam Hasinoff , and exploring ways to improve it using event-based vision.
A compensation to cover the expenses of living in Grenoble is offered. Only students that have legal rights to work in France can apply.
Anyone interested can send an email with the CV to Daniele Perrone ( [email protected] ).
Using machine learning applied to wearables to predict mental health
This Master’s project lies at the intersection of psychiatry and computer science and aims to use machine learning techniques to improve health. Using sensors to detect sleep and waking behavior has as of yet unexplored potential to reveal insights into health. In this study, we make use of a watch-like device, called an actigraph, which tracks motion to quantify sleep behavior and waking activity. Participants in the study consist of healthy and depressed adolescents and wear actigraphs for a year during which time we query their mental health status monthly using online questionnaires. For this masters thesis we aim to make use of machine learning methods to predict mental health based on the data from the actigraph. The ability to predict mental health crises based on sleep and wake behavior would provide an opportunity for intervention, significantly impacting the lives of patients and their families. This Masters thesis is a collaboration between Professor Paolo Favaro at the Institute of Computer Science ( [email protected] ) and Dr Leila Tarokh at the Universitäre Psychiatrische Dienste (UPD) ( [email protected] ). We are looking for a highly motivated individual interested in bridging disciplines.
Bachelor or Master Projects at the ARTORG Center
The Gerontechnology and Rehabilitation group at the ARTORG Center for Biomedical Engineering is offering multiple BSc- and MSc thesis projects to students, which are interested in working with real patient data, artificial intelligence and machine learning algorithms. The goal of these projects is to transfer the findings to the clinic in order to solve today’s healthcare problems and thus to improve the quality of life of patients. Machine Learning Based Gait-Parameter Extraction by Using Simple Rangefinder Technology. [PDF] Detection of Motion in Video Recordings [PDF] Home-Monitoring of Elderly by Radar [PDF] Gait feature detection in Parkinson's Disease [PDF] Development of an arthroscopic training device using virtual reality [PDF] Contact: Dr. Stephan Gerber ( [email protected] ), Michael Single ( [email protected]. ch )
Dynamic Transformer
Level: bachelor.
Visual Transformers have obtained state of the art classification accuracies [ViT, DeiT, T2T, BoTNet]. Mixture of experts could be used to increase the capacity of a neural network by learning instance dependent execution pathways in a network [MoE]. In this research project we aim to push the transformers to their limit and combine their dynamic attention with MoEs, compared to Switch Transformer [Switch], we will use a much more efficient formulation of mixing [CondConv, DynamicConv] and we will use this idea in the attention part of the transformer, not the fully connected layer.
- Input dependent attention kernel generation for better transformer layers.
Publication Opportunity: Dynamic Neural Networks Meets Computer Vision (a CVPR 2021 Workshop)
Extensions:
- The same idea could be extended to other ViT/Transformer based models [DETR, SETR, LSTR, TrackFormer, BERT]
Related Papers:
- Visual Transformers: Token-based Image Representation and Processing for Computer Vision [ViT]
- DeiT: Data-efficient Image Transformers [DeiT]
- Bottleneck Transformers for Visual Recognition [BoTNet]
- Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet [T2TViT]
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer [MoE]
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity [Switch]
- CondConv: Conditionally Parameterized Convolutions for Efficient Inference [CondConv]
- Dynamic Convolution: Attention over Convolution Kernels [DynamicConv]
- End-to-End Object Detection with Transformers [DETR]
- Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers [SETR]
- End-to-end Lane Shape Prediction with Transformers [LSTR]
- TrackFormer: Multi-Object Tracking with Transformers [TrackFormer]
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [BERT]
Contact: Sepehr Sameni
Visual Transformers have obtained state of the art classification accuracies for 2d images[ViT, DeiT, T2T, BoTNet]. In this project, we aim to extend the same ideas to 3d data (videos), which requires a more efficient attention mechanism [Performer, Axial, Linformer]. In order to accelerate the training process, we could use [Multigrid] technique.
- Better video understanding by attention blocks.
Publication Opportunity: LOVEU (a CVPR workshop) , Holistic Video Understanding (a CVPR workshop) , ActivityNet (a CVPR workshop)
- Rethinking Attention with Performers [Performer]
- Axial Attention in Multidimensional Transformers [Axial]
- Linformer: Self-Attention with Linear Complexity [Linformer]
- A Multigrid Method for Efficiently Training Video Models [Multigrid]
GIRAFFE is a newly introduced GAN that can generate scenes via composition with minimal supervision [GIRAFFE]. Generative methods can implicitly learn interpretable representation as can be seen in GAN image interpretations [GANSpace, GanLatentDiscovery]. Decoding GIRAFFE could give us per-object interpretable representations that could be used for scene manipulation, data augmentation, scene understanding, semantic segmentation, pose estimation [iNeRF], and more.
In order to invert a GIRAFFE model, we will first train the generative model on Clevr and CompCars datasets, then we add a decoder to the pipeline and train this autoencoder. We can make the task easier by knowing the number of objects in the scene and/or knowing their positions.
Goals:
Scene Manipulation and Decomposition by Inverting the GIRAFFE
Publication Opportunity: DynaVis 2021 (a CVPR workshop on Dynamic Scene Reconstruction)
Related Papers:
- GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields [GIRAFFE]
- Neural Scene Graphs for Dynamic Scenes
- pixelNeRF: Neural Radiance Fields from One or Few Images [pixelNeRF]
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis [NeRF]
- Neural Volume Rendering: NeRF And Beyond
- GANSpace: Discovering Interpretable GAN Controls [GANSpace]
- Unsupervised Discovery of Interpretable Directions in the GAN Latent Space [GanLatentDiscovery]
- Inverting Neural Radiance Fields for Pose Estimation [iNeRF]
Quantized ViT
Visual Transformers have obtained state of the art classification accuracies [ViT, CLIP, DeiT], but the best ViT models are extremely compute heavy and running them even only for inference (not doing backpropagation) is expensive. Running transformers cheaply by quantization is not a new problem and it has been tackled before for BERT [BERT] in NLP [Q-BERT, Q8BERT, TernaryBERT, BinaryBERT]. In this project we will be trying to quantize pretrained ViT models.
Quantizing ViT models for faster inference and smaller models without losing accuracy
Publication Opportunity: Binary Networks for Computer Vision 2021 (a CVPR workshop)
Extensions:
- Having a fast pipeline for image inference with ViT will allow us to dig deep into the attention of ViT and analyze it, we might be able to prune some attention heads or replace them with static patterns (like local convolution or dilated patterns), We might be even able to replace the transformer with performer and increase the throughput even more [Performer].
- The same idea could be extended to other ViT based models [DETR, SETR, LSTR, TrackFormer, CPTR, BoTNet, T2TViT]
- Learning Transferable Visual Models From Natural Language Supervision [CLIP]
- Visual Transformers: Token-based Image Representation and Processing for Computer Vision [ViT]
- DeiT: Data-efficient Image Transformers [DeiT]
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [BERT]
- Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT [Q-BERT]
- Q8BERT: Quantized 8Bit BERT [Q8BERT]
- TernaryBERT: Distillation-aware Ultra-low Bit BERT [TernaryBERT]
- BinaryBERT: Pushing the Limit of BERT Quantization [BinaryBERT]
- Rethinking Attention with Performers [Performer]
- End-to-End Object Detection with Transformers [DETR]
- Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers [SETR]
- End-to-end Lane Shape Prediction with Transformers [LSTR]
- TrackFormer: Multi-Object Tracking with Transformers [TrackFormer]
- CPTR: Full Transformer Network for Image Captioning [CPTR]
- Bottleneck Transformers for Visual Recognition [BoTNet]
- Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet [T2TViT]
Multimodal Contrastive Learning
Recently contrastive learning has gained a lot of attention for self-supervised image representation learning [SimCLR, MoCo]. Contrastive learning could be extended to multimodal data, like videos (images and audio) [CMC, CoCLR]. Most contrastive methods require large batch sizes (or large memory pools) which makes them expensive for training. In this project we are going to use non batch size dependent contrastive methods [SwAV, BYOL, SimSiam] to train multimodal representation extractors.
Our main goal is to compare the proposed method with the CMC baseline, so we will be working with STL10, ImageNet, UCF101, HMDB51, and NYU Depth-V2 datasets.
Inspired by the recent works on smaller datasets [ConVIRT, CPD], to accelerate the training speed, we could start with two pretrained single-modal models and finetune them with the proposed method.
- Extending SwAV to multimodal datasets
- Grasping a better understanding of the BYOL
Publication Opportunity: MULA 2021 (a CVPR workshop on Multimodal Learning and Applications)
- Most knowledge distillation methods for contrastive learners also use large batch sizes (or memory pools) [CRD, SEED], the proposed method could be extended for knowledge distillation.
- One could easily extend this idea to multiview learning, for example one could have two different networks working on the same input and train them with contrastive learning, this may lead to better models [DeiT] by cross-model inductive biases communications.
- Self-supervised Co-training for Video Representation Learning [CoCLR]
- Learning Spatiotemporal Features via Video and Text Pair Discrimination [CPD]
- Audio-Visual Instance Discrimination with Cross-Modal Agreement [AVID-CMA]
- Self-Supervised Learning by Cross-Modal Audio-Video Clustering [XDC]
- Contrastive Multiview Coding [CPC]
- Contrastive Learning of Medical Visual Representations from Paired Images and Text [ConVIRT]
- A Simple Framework for Contrastive Learning of Visual Representations [SimCLR]
- Momentum Contrast for Unsupervised Visual Representation Learning [MoCo]
- Bootstrap your own latent: A new approach to self-supervised Learning [BYOL]
- Exploring Simple Siamese Representation Learning [SimSiam]
- Unsupervised Learning of Visual Features by Contrasting Cluster Assignments [SwAV]
- Contrastive Representation Distillation [CRD]
- SEED: Self-supervised Distillation For Visual Representation [SEED]
Robustness of Neural Networks
Neural Networks have been found to achieve surprising performance in several tasks such as classification, detection and segmentation. However, they are also very sensitive to small (controlled) changes to the input. It has been shown that some changes to an image that are not visible to the naked eye may lead the network to output an incorrect label. This thesis will focus on studying recent progress in this area and aim to build a procedure for a trained network to self-assess its reliability in classification or one of the popular computer vision tasks.
Contact: Paolo Favaro
Masters projects at sitem center
The Personalised Medicine Research Group at the sitem Center for Translational Medicine and Biomedical Entrepreneurship is offering multiple MSc thesis projects to the biomed eng MSc students that may also be of interest to the computer science students. Automated quantification of cartilage quality for hip treatment decision support. PDF Automated quantification of massive rotator cuff tears from MRI. PDF Deep learning-based segmentation and fat fraction analysis of the shoulder muscles using quantitative MRI. PDF Unsupervised Domain Adaption for Cross-Modality Hip Joint Segmentation. PDF Contact: Dr. Kate Gerber
Internships/Master thesis @ Chronocam
3-6 months internships on event-based computer vision. Chronocam is a rapidly growing startup developing event-based technology, with more than 15 PhDs working on problems like tracking, detection, classification, SLAM, etc. Event-based computer vision has the potential to solve many long-standing problems in traditional computer vision, and this is a super exciting time as this potential is becoming more and more tangible in many real-world applications. For next year we are looking for motivated Master and PhD students with good software engineering skills (C++ and/or python), and preferable good computer vision and deep learning background. PhD internships will be more research focused and possibly lead to a publication. For each intern we offer a compensation to cover the expenses of living in Paris. List of some of the topics we want to explore:
- Photo-realistic image synthesis and super-resolution from event-based data (PhD)
- Self-supervised representation learning (PhD)
- End-to-end Feature Learning for Event-based Data
- Bio-inspired Filtering using Spiking Networks
- On-the fly Compression of Event-based Streams for Low-Power IoT Cameras
- Tracking of Multiple Objects with a Dual-Frequency Tracker
- Event-based Autofocus
- Stabilizing an Event-based Stream using an IMU
- Crowd Monitoring for Low-power IoT Cameras
- Road Extraction from an Event-based Camera Mounted in a Car for Autonomous Driving
- Sign detection from an Event-based Camera Mounted in a Car for Autonomous Driving
- High-frequency Eye Tracking
Email with attached CV to Daniele Perrone at [email protected] .
Contact: Daniele Perrone
Object Detection in 3D Point Clouds
Today we have many 3D scanning techniques that allow us to capture the shape and appearance of objects. It is easier than ever to scan real 3D objects and transform them into a digital model for further processing, such as modeling, rendering or animation. However, the output of a 3D scanner is often a raw point cloud with little to no annotations. The unstructured nature of the point cloud representation makes it difficult for processing, e.g. surface reconstruction. One application is the detection and segmentation of an object of interest. In this project, the student is challenged to design a system that takes a point cloud (a 3D scan) as input and outputs the names of objects contained in the scan. This output can then be used to eliminate outliers or points that belong to the background. The approach involves collecting a large dataset of 3D scans and training a neural network on it.
Contact: Adrian Wälchli
Shape Reconstruction from a Single RGB Image or Depth Map
A photograph accurately captures the world in a moment of time and from a specific perspective. Since it is a projection of the 3D space to a 2D image plane, the depth information is lost. Is it possible to restore it, given only a single photograph? In general, the answer is no. This problem is ill-posed, meaning that many different plausible depth maps exist, and there is no way of telling which one is the correct one. However, if we cover one of our eyes, we are still able to recognize objects and estimate how far away they are. This motivates the exploration of an approach where prior knowledge can be leveraged to reduce the ill-posedness of the problem. Such a prior could be learned by a deep neural network, trained with many images and depth maps.
CNN Based Deblurring on Mobile
Deblurring finds many applications in our everyday life. It is particularly useful when taking pictures on handheld devices (e.g. smartphones) where camera shake can degrade important details. Therefore, it is desired to have a good deblurring algorithm implemented directly in the device. In this project, the student will implement and optimize a state-of-the-art deblurring method based on a deep neural network for deployment on mobile phones (Android). The goal is to reduce the number of network weights in order to reduce the memory footprint while preserving the quality of the deblurred images. The result will be a camera app that automatically deblurs the pictures, giving the user a choice of keeping the original or the deblurred image.
Depth from Blur
If an object in front of the camera or the camera itself moves while the aperture is open, the region of motion becomes blurred because the incoming light is accumulated in different positions across the sensor. If there is camera motion, there is also parallax. Thus, a motion blurred image contains depth information. In this project, the student will tackle the problem of recovering a depth-map from a motion-blurred image. This includes the collection of a large dataset of blurred- and sharp images or videos using a pair or triplet of GoPro action cameras. Two cameras will be used in stereo to estimate the depth map, and the third captures the blurred frames. This data is then used to train a convolutional neural network that will predict the depth map from the blurry image.
Unsupervised Clustering Based on Pretext Tasks
The idea of this project is that we have two types of neural networks that work together: There is one network A that assigns images to k clusters and k (simple) networks of type B perform a self-supervised task on those clusters. The goal of all the networks is to make the k networks of type B perform well on the task. The assumption is that clustering in semantically similar groups will help the networks of type B to perform well. This could be done on the MNIST dataset with B being linear classifiers and the task being rotation prediction.
Adversarial Data-Augmentation
The student designs a data augmentation network that transforms training images in such a way that image realism is preserved (e.g. with a constrained spatial transformer network) and the transformed images are more difficult to classify (trained via adversarial loss against an image classifier). The model will be evaluated for different data settings (especially in the low data regime), for example on the MNIST and CIFAR datasets.
Unsupervised Learning of Lip-reading from Videos
People with sensory impairment (hearing, speech, vision) depend heavily on assistive technologies to communicate and navigate in everyday life. The mass production of media content today makes it impossible to manually translate everything into a common language for assistive technologies, e.g. captions or sign language. In this project, the student employs a neural network to learn a representation for lip-movement in videos in an unsupervised fashion, possibly with an encoder-decoder structure where the decoder reconstructs the audio signal. This requires collecting a large dataset of videos (e.g. from YouTube) of speakers or conversations where lip movement is visible. The outcome will be a neural network that learns an audio-visual representation of lip movement in videos, which can then be leveraged to generate captions for hearing impaired persons.
Learning to Generate Topographic Maps from Satellite Images
Satellite images have many applications, e.g. in meteorology, geography, education, cartography and warfare. They are an accurate and detailed depiction of the surface of the earth from above. Although it is relatively simple to collect many satellite images in an automated way, challenges arise when processing them for use in navigation and cartography. The idea of this project is to automatically convert an arbitrary satellite image, of e.g. a city, to a map of simple 2D shapes (streets, houses, forests) and label them with colors (semantic segmentation). The student will collect a dataset of satellite image and topological maps and train a deep neural network that learns to map from one domain to the other. The data could be obtained from a Google Maps database or similar.
New Variables of Brain Morphometry: the Potential and Limitations of CNN Regression
Timo blattner · sept. 2022.
The calculation of variables of brain morphology is computationally very expensive and time-consuming. A previous work showed the feasibility of ex- tracting the variables directly from T1-weighted brain MRI images using a con- volutional neural network. We used significantly more data and extended their model to a new set of neuromorphological variables, which could become inter- esting biomarkers in the future for the diagnosis of brain diseases. The model shows for nearly all subjects a less than 5% mean relative absolute error. This high relative accuracy can be attributed to the low morphological variance be- tween subjects and the ability of the model to predict the cortical atrophy age trend. The model however fails to capture all the variance in the data and shows large regional differences. We attribute these limitations in part to the moderate to poor reliability of the ground truth generated by FreeSurfer. We further investigated the effects of training data size and model complexity on this regression task and found that the size of the dataset had a significant impact on performance, while deeper models did not perform better. Lack of interpretability and dependence on a silver ground truth are the main drawbacks of this direct regression approach.
Home Monitoring by Radar
Lars ziegler · sept. 2022.
Detection and tracking of humans via UWB radars is a promising and continuously evolving field with great potential for medical technology. This contactless method of acquiring data of a patients movement patterns is ideal for in home application. As irregularities in a patients movement patterns are an indicator for various health problems including neurodegenerative diseases, the insight this data could provide may enable earlier detection of such problems. In this thesis a signal processing pipeline is presented with which a persons movement is modeled. During an experiment 142 measurements were recorded by two separate radar systems and one lidar system which each consisted of multiple sensors. The models that were calculated on these measurements by the signal processing pipeline were used to predict the times when a person stood up or sat down. The predictions showed an accuracy of 72.2%.
Revisiting non-learning based 3D reconstruction from multiple images
Aaron sägesser · oct. 2021.
Arthroscopy consists of challenging tasks and requires skills that even today, young surgeons still train directly throughout the surgery. Existing simulators are expensive and rarely available. Through the growing potential of virtual reality(VR) (head-mounted) devices for simulation and their applicability in the medical context, these devices have become a promising alternative that would be orders of magnitude cheaper and could be made widely available. To build a VR-based training device for arthroscopy is the overall aim of our project, as this would be of great benefit and might even be applicable in other minimally invasive surgery (MIS). This thesis marks a first step of the project with its focus to explore and compare well-known algorithms in a multi-view stereo (MVS) based 3D reconstruction with respect to imagery acquired by an arthroscopic camera. Simultaneously with this reconstruction, we aim to gain essential measures to compare the VR environment to the real world, as validation of the realism of future VR tasks. We evaluate 3 different feature extraction algorithms with 3 different matching techniques and 2 different algorithms for the estimation of the fundamental (F) matrix. The evaluation of these 18 different setups is made with a reconstruction pipeline embedded in a jupyter notebook implemented in python based on common computer vision libraries and compared with imagery generated with a mobile phone as well as with the reconstruction results of state-of-the-art (SOTA) structure-from-motion (SfM) software COLMAP and Multi-View Environment (MVE). Our comparative analysis manifests the challenges of heavy distortion, the fish-eye shape and weak image quality of arthroscopic imagery, as all results are substantially worse using this data. However, there are huge differences regarding the different setups. Scale Invariant Feature Transform (SIFT) and Oriented FAST Rotated BRIEF (ORB) in combination with k-Nearest Neighbour (kNN) matching and Least Median of Squares (LMedS) present the most promising results. Overall, the 3D reconstruction pipeline is a useful tool to foster the process of gaining measurements from the arthroscopic exploration device and to complement the comparative research in this context.
Examination of Unsupervised Representation Learning by Predicting Image Rotations
Eric lagger · sept. 2020.
In recent years deep convolutional neural networks achieved a lot of progress. To train such a network a lot of data is required and in supervised learning algorithms it is necessary that the data is labeled. To label data there is a lot of human work needed and this takes a lot of time and money to be done. To avoid the inconveniences that come with this we would like to find systems that don’t need labeled data and therefore are unsupervised learning algorithms. This is the importance of unsupervised algorithms, even though their outcome is not yet on the same qualitative level as supervised algorithms. In this thesis we will discuss an approach of such a system and compare the results to other papers. A deep convolutional neural network is trained to learn the rotations that have been applied to a picture. So we take a large amount of images and apply some simple rotations and the task of the network is to discover in which direction the image has been rotated. The data doesn’t need to be labeled to any category or anything else. As long as all the pictures are upside down we hope to find some high dimensional patterns for the network to learn.
StitchNet: Image Stitching using Autoencoders and Deep Convolutional Neural Networks
Maurice rupp · sept. 2019.
This thesis explores the prospect of artificial neural networks for image processing tasks. More specifically, it aims to achieve the goal of stitching multiple overlapping images to form a bigger, panoramic picture. Until now, this task is solely approached with ”classical”, hardcoded algorithms while deep learning is at most used for specific subtasks. This thesis introduces a novel end-to-end neural network approach to image stitching called StitchNet, which uses a pre-trained autoencoder and deep convolutional networks. Additionally to presenting several new datasets for the task of supervised image stitching with each 120’000 training and 5’000 validation samples, this thesis also conducts various experiments with different kinds of existing networks designed for image superresolution and image segmentation adapted to the task of image stitching. StitchNet outperforms most of the adapted networks in both quantitative as well as qualitative results.
Facial Expression Recognition in the Wild
Luca rolshoven · sept. 2019.
The idea of inferring the emotional state of a subject by looking at their face is nothing new. Neither is the idea of automating this process using computers. Researchers used to computationally extract handcrafted features from face images that had proven themselves to be effective and then used machine learning techniques to classify the facial expressions using these features. Recently, there has been a trend towards using deeplearning and especially Convolutional Neural Networks (CNNs) for the classification of these facial expressions. Researchers were able to achieve good results on images that were taken in laboratories under the same or at least similar conditions. However, these models do not perform very well on more arbitrary face images with different head poses and illumination. This thesis aims to show the challenges of Facial Expression Recognition (FER) in this wild setting. It presents the currently used datasets and the present state-of-the-art results on one of the biggest facial expression datasets currently available. The contributions of this thesis are twofold. Firstly, I analyze three famous neural network architectures and their effectiveness on the classification of facial expressions. Secondly, I present two modifications of one of these networks that lead to the proposed STN-COV model. While this model does not outperform all of the current state-of-the-art models, it does beat several ones of them.
A Study of 3D Reconstruction of Varying Objects with Deformable Parts Models
Raoul grossenbacher · july 2019.
This work covers a new approach to 3D reconstruction. In traditional 3D reconstruction one uses multiple images of the same object to calculate a 3D model by taking information gained from the differences between the images, like camera position, illumination of the images, rotation of the object and so on, to compute a point cloud representing the object. The characteristic trait shared by all these approaches is that one can almost change everything about the image, but it is not possible to change the object itself, because one needs to find correspondences between the images. To be able to use different instances of the same object, we used a 3D DPM model that can find different parts of an object in an image, thereby detecting the correspondences between the different pictures, which we then can use to calculate the 3D model. To take this theory to practise, we gave a 3D DPM model, which was trained to detect cars, pictures of different car brands, where no pair of images showed the same vehicle and used the detected correspondences and the Factorization Method to compute the 3D point cloud. This technique leads to a completely new approach in 3D reconstruction, because changing the object itself was never done before.
Motion deblurring in the wild replication and improvements
Alvaro juan lahiguera · jan. 2019, coma outcome prediction with convolutional neural networks, stefan jonas · oct. 2018, automatic correction of self-introduced errors in source code, sven kellenberger · aug. 2018, neural face transfer: training a deep neural network to face-swap, till nikolaus schnabel · july 2018.
This thesis explores the field of artificial neural networks with realistic looking visual outputs. It aims at morphing face pictures of a specific identity to look like another individual by only modifying key features, such as eye color, while leaving identity-independent features unchanged. Prior works have covered the topic of symmetric translation between two specific domains but failed to optimize it on faces where only parts of the image may be changed. This work applies a face masking operation to the output at training time, which forces the image generator to preserve colors while altering the face, fitting it naturally inside the unmorphed surroundings. Various experiments are conducted including an ablation study on the final setting, decreasing the baseline identity switching performance from 81.7% to 75.8 % whilst improving the average χ2 color distance from 0.551 to 0.434. The provided code-based software gives users easy access to apply this neural face swap to images and videos of arbitrary crop and brings Computer Vision one step closer to replacing Computer Graphics in this specific area.
A Study of the Importance of Parts in the Deformable Parts Model
Sammer puran · june 2017, self-similarity as a meta feature, lucas husi · april 2017, a study of 3d deformable parts models for detection and pose-estimation, simon jenni · march 2015, amodal leaf segmentation, nicolas maier · nov. 2023.
Plant phenotyping is the process of measuring and analyzing various traits of plants. It provides essential information on how genetic and environmental factors affect plant growth and development. Manual phenotyping is highly time-consuming; therefore, many computer vision and machine learning based methods have been proposed in the past years to perform this task automatically based on images of the plants. However, the publicly available datasets (in particular, of Arabidopsis thaliana) are limited in size and diversity, making them unsuitable to generalize to new unseen environments. In this work, we propose a complete pipeline able to automatically extract traits of interest from an image of Arabidopsis thaliana. Our method uses a minimal amount of existing annotated data from a source domain to generate a large synthetic dataset adapted to a different target domain (e.g., different backgrounds, lighting conditions, and plant layouts). In addition, unlike the source dataset, the synthetic one provides ground-truth annotations for the occluded parts of the leaves, which are relevant when measuring some characteristics of the plant, e.g., its total area. This synthetic dataset is then used to train a model to perform amodal instance segmentation of the leaves to obtain the total area, leaf count, and color of each plant. To validate our approach, we create a small dataset composed of manually annotated real images of Arabidopsis thaliana, which is used to assess the performance of the models.
Assessment of movement and pose in a hospital bed by ambient and wearable sensor technology in healthy subjects
Tony licata · sept. 2022.
The use of automated systems describing the human motion has become possible in various domains. Most of the proposed systems are designed to work with people moving around in a standing position. Because such system could be interesting in a medical environment, we propose in this work a pipeline that can effectively predict human motion from people lying on beds. The proposed pipeline is tested with a data set composed of 41 participants executing 7 predefined tasks in a bed. The motion of the participants is measured with video cameras, accelerometers and pressure mat. Various experiments are carried with the information retrieved from the data set. Two approaches combining the data from the different measure technologies are explored. The performance of the different carried experiments is measured, and the proposed pipeline is composed with components providing the best results. Later on, we show that the proposed pipeline only needs to use the video cameras, which make the proposed environment easier to implement in real life situations.
Machine Learning Based Prediction of Mental Health Using Wearable-measured Time Series
Seyedeh sharareh mirzargar · sept. 2022.
Depression is the second major cause for years spent in disability and has a growing prevalence in adolescents. The recent Covid-19 pandemic has intensified the situation and limited in-person patient monitoring due to distancing measures. Recent advances in wearable devices have made it possible to record the rest/activity cycle remotely with high precision and in real-world contexts. We aim to use machine learning methods to predict an individual's mental health based on wearable-measured sleep and physical activity. Predicting an impending mental health crisis of an adolescent allows for prompt intervention, detection of depression onset or its recursion, and remote monitoring. To achieve this goal, we train three primary forecasting models; linear regression, random forest, and light gradient boosted machine (LightGBM); and two deep learning models; block recurrent neural network (block RNN) and temporal convolutional network (TCN); on Actigraph measurements to forecast mental health in terms of depression, anxiety, sleepiness, stress, sleep quality, and behavioral problems. Our models achieve a high forecasting performance, the random forest being the winner to reach an accuracy of 98% for forecasting the trait anxiety. We perform extensive experiments to evaluate the models' performance in accuracy, generalization, and feature utilization, using a naive forecaster as the baseline. Our analysis shows minimal mental health changes over two months, making the prediction task easily achievable. Due to these minimal changes in mental health, the models tend to primarily use the historical values of mental health evaluation instead of Actigraph features. At the time of this master thesis, the data acquisition step is still in progress. In future work, we plan to train the models on the complete dataset using a longer forecasting horizon to increase the level of mental health changes and perform transfer learning to compensate for the small dataset size. This interdisciplinary project demonstrates the opportunities and challenges in machine learning based prediction of mental health, paving the way toward using the same techniques to forecast other mental disorders such as internalizing disorder, Parkinson's disease, Alzheimer's disease, etc. and improving the quality of life for individuals who have some mental disorder.
CNN Spike Detector: Detection of Spikes in Intracranial EEG using Convolutional Neural Networks
Stefan jonas · oct. 2021.
The detection of interictal epileptiform discharges in the visual analysis of electroencephalography (EEG) is an important but very difficult, tedious, and time-consuming task. There have been decades of research on computer-assisted detection algorithms, most recently focused on using Convolutional Neural Networks (CNNs). In this thesis, we present the CNN Spike Detector, a convolutional neural network to detect spikes in intracranial EEG. Our dataset of 70 intracranial EEG recordings from 26 subjects with epilepsy introduces new challenges in this research field. We report cross-validation results with a mean AUC of 0.926 (+- 0.04), an area under the precision-recall curve (AUPRC) of 0.652 (+- 0.10) and 12.3 (+- 7.47) false positive epochs per minute for a sensitivity of 80%. A visual examination of false positive segments is performed to understand the model behavior leading to a relatively high false detection rate. We notice issues with the evaluation measures and highlight a major limitation of the common approach of detecting spikes using short segments, namely that the network is not capable to consider the greater context of the segment with regards to its origination. For this reason, we present the Context Model, an extension in which the CNN Spike Detector is supplied with additional information about the channel. Results show promising but limited performance improvements. This thesis provides important findings about the spike detection task for intracranial EEG and lays out promising future research directions to develop a network capable of assisting experts in real-world clinical applications.
PolitBERT - Deepfake Detection of American Politicians using Natural Language Processing
Maurice rupp · april 2021.
This thesis explores the application of modern Natural Language Processing techniques to the detection of artificially generated videos of popular American politicians. Instead of focusing on detecting anomalies and artifacts in images and sounds, this thesis focuses on detecting irregularities and inconsistencies in the words themselves, opening up a new possibility to detect fake content. A novel, domain-adapted, pre-trained version of the language model BERT combined with several mechanisms to overcome severe dataset imbalances yielded the best quantitative as well as qualitative results. Additionally to the creation of the biggest publicly available dataset of English-speaking politicians consisting of 1.5 M sentences from over 1000 persons, this thesis conducts various experiments with different kinds of text classification and sequence processing algorithms applied to the political domain. Furthermore, multiple ablations to manage severe data imbalance are presented and evaluated.
A Study on the Inversion of Generative Adversarial Networks
Ramona beck · march 2021.
The desire to use generative adversarial networks (GANs) for real-world tasks such as object segmentation or image manipulation is increasing as synthesis quality improves, which has given rise to an emerging research area called GAN inversion that focuses on exploring methods for embedding real images into the latent space of a GAN. In this work, we investigate different GAN inversion approaches using an existing generative model architecture that takes a completely unsupervised approach to object segmentation and is based on StyleGAN2. In particular, we propose and analyze algorithms for embedding real images into the different latent spaces Z, W, and W+ of StyleGAN following an optimization-based inversion approach, while also investigating a novel approach that allows fine-tuning of the generator during the inversion process. Furthermore, we investigate a hybrid and a learning-based inversion approach, where in the former we train an encoder with embeddings optimized by our best optimization-based inversion approach, and in the latter we define an autoencoder, consisting of an encoder and the generator of our generative model as a decoder, and train it to map an image into the latent space. We demonstrate the effectiveness of our methods as well as their limitations through a quantitative comparison with existing inversion methods and by conducting extensive qualitative and quantitative experiments with synthetic data as well as real images from a complex image dataset. We show that we achieve qualitatively satisfying embeddings in the W and W+ spaces with our optimization-based algorithms, that fine-tuning the generator during the inversion process leads to qualitatively better embeddings in all latent spaces studied, and that the learning-based approach also benefits from a variable generator as well as a pre-training with our hybrid approach. Furthermore, we evaluate our approaches on the object segmentation task and show that both our optimization-based and our hybrid and learning-based methods are able to generate meaningful embeddings that achieve reasonable object segmentations. Overall, our proposed methods illustrate the potential that lies in the GAN inversion and its application to real-world tasks, especially in the relaxed version of the GAN inversion where the weights of the generator are allowed to vary.
Multi-scale Momentum Contrast for Self-supervised Image Classification
Zhao xueqi · dec. 2020.
With the maturity of supervised learning technology, people gradually shift the research focus to the field of self-supervised learning. ”Momentum Contrast” (MoCo) proposes a new self-supervised learning method and raises the correct rate of self-supervised learning to a new level. Inspired by another article ”Representation Learning by Learning to Count”, if a picture is divided into four parts and passed through a neural network, it is possible to further improve the accuracy of MoCo. Different from the original MoCo, this MoCo variant (Multi-scale MoCo) does not directly pass the image through the encoder after the augmented images. Multi-scale MoCo crops and resizes the augmented images, and the obtained four parts are respectively passed through the encoder and then summed (upsampled version do not do resize to input but resize the contrastive samples). This method of images crop is not only used for queue q but also used for comparison queue k, otherwise the weights of queue k might be damaged during the moment update. This will further discussed in the experiments chapter between downsampled Multi-scale version and downsampled both Multi-scale version. Human beings also have the same principle of object recognition: when human beings see something they are familiar with, even if the object is not fully displayed, people can still guess the object itself with a high probability. Because of this, Multi-scale MoCo applies this concept to the pretext part of MoCo, hoping to obtain better feature extraction. In this thesis, there are three versions of Multi-scale MoCo, downsampled input samples version, downsampled input samples and contrast samples version and upsampled input samples version. The differences between these versions will be described in more detail later. The neural network architecture comparison includes ResNet50 , and the tested data set is STL-10. The weights obtained in pretext will be transferred to self-supervised learning, and in the process of self-supervised learning, the weights of other layers except the final linear layer are frozen without changing (these weights come from pretext).
Self-Supervised Learning Using Siamese Networks and Binary Classifier
Dušan mihajlov · march 2020.
In this thesis, we present several approaches for training a convolutional neural network using only unlabeled data. Our autonomously supervised learning algorithms are based on connections between image patch i. e. zoomed image and its original. Using the siamese architecture neural network we aim to recognize, if the image patch, which is input to the first neural network part, comes from the same image presented to the second neural network part. By applying transformations to both images, and different zoom sizes at different positions, we force the network to extract high level features using its convolutional layers. At the top of our siamese architecture, we have a simple binary classifier that measures the difference between feature maps that we extract and makes a decision. Thus, the only way that the classifier will solve the task correctly is when our convolutional layers are extracting useful representations. Those representations we can than use to solve many different tasks that are related to the data used for unsupervised training. As the main benchmark for all of our models, we used STL10 dataset, where we train a linear classifier on the top of our convolutional layers with a small amount of manually labeled images, which is a widely used benchmark for unsupervised learning tasks. We also combine our idea with recent work on the same topic, and the network called RotNet, which makes use of image rotations and therefore forces the network to learn rotation dependent features from the dataset. As a result of this combination we create a new procedure that outperforms original RotNet.
Learning Object Representations by Mixing Scenes
Lukas zbinden · may 2019.
In the digital age of ever increasing data amassment and accessibility, the demand for scalable machine learning models effective at refining the new oil is unprecedented. Unsupervised representation learning methods present a promising approach to exploit this invaluable yet unlabeled digital resource at scale. However, a majority of these approaches focuses on synthetic or simplified datasets of images. What if a method could learn directly from natural Internet-scale image data? In this thesis, we propose a novel approach for unsupervised learning of object representations by mixing natural image scenes. Without any human help, our method mixes visually similar images to synthesize new realistic scenes using adversarial training. In this process the model learns to represent and understand the objects prevalent in natural image data and makes them available for downstream applications. For example, it enables the transfer of objects from one scene to another. Through qualitative experiments on complex image data we show the effectiveness of our method along with its limitations. Moreover, we benchmark our approach quantitatively against state-of-the-art works on the STL-10 dataset. Our proposed method demonstrates the potential that lies in learning representations directly from natural image data and reinforces it as a promising avenue for future research.
Representation Learning using Semantic Distances
Markus roth · may 2019, zero-shot learning using generative adversarial networks, hamed hemati · dec. 2018, dimensionality reduction via cnns - learning the distance between images, ioannis glampedakis · sept. 2018, learning to play othello using deep reinforcement learning and self play, thomas simon steinmann · sept. 2018, aba-j interactive multi-modality tissue sectionto-volume alignment: a brain atlasing toolkit for imagej, felix meyenhofer · march 2018, learning visual odometry with recurrent neural networks, adrian wälchli · feb. 2018.
In computer vision, Visual Odometry is the problem of recovering the camera motion from a video. It is related to Structure from Motion, the problem of reconstructing the 3D geometry from a collection of images. Decades of research in these areas have brought successful algorithms that are used in applications like autonomous navigation, motion capture, augmented reality and others. Despite the success of these prior works in real-world environments, their robustness is highly dependent on manual calibration and the magnitude of noise present in the images in form of, e.g., non-Lambertian surfaces, dynamic motion and other forms of ambiguity. This thesis explores an alternative approach to the Visual Odometry problem via Deep Learning, that is, a specific form of machine learning with artificial neural networks. It describes and focuses on the implementation of a recent work that proposes the use of Recurrent Neural Networks to learn dependencies over time due to the sequential nature of the input. Together with a convolutional neural network that extracts motion features from the input stream, the recurrent part accumulates knowledge from the past to make camera pose estimations at each point in time. An analysis on the performance of this system is carried out on real and synthetic data. The evaluation covers several ways of training the network as well as the impact and limitations of the recurrent connection for Visual Odometry.
Crime location and timing prediction
Bernard swart · jan. 2018, from cartoons to real images: an approach to unsupervised visual representation learning, simon jenni · feb. 2017, automatic and large-scale assessment of fluid in retinal oct volume, nina mujkanovic · dec. 2016, segmentation in 3d using eye-tracking technology, michele wyss · july 2016, accurate scale thresholding via logarithmic total variation prior, remo diethelm · aug. 2014, novel techniques for robust and generalizable machine learning, abdelhak lemkhenter · sept. 2023.
Neural networks have transcended their status of powerful proof-of-concept machine learning into the realm of a highly disruptive technology that has revolutionized many quantitative fields such as drug discovery, autonomous vehicles, and machine translation. Today, it is nearly impossible to go a single day without interacting with a neural network-powered application. From search engines to on-device photo-processing, neural networks have become the go-to solution thanks to recent advances in computational hardware and an unprecedented scale of training data. Larger and less curated datasets, typically obtained through web crawling, have greatly propelled the capabilities of neural networks forward. However, this increase in scale amplifies certain challenges associated with training such models. Beyond toy or carefully curated datasets, data in the wild is plagued with biases, imbalances, and various noisy components. Given the larger size of modern neural networks, such models run the risk of learning spurious correlations that fail to generalize beyond their training data. This thesis addresses the problem of training more robust and generalizable machine learning models across a wide range of learning paradigms for medical time series and computer vision tasks. The former is a typical example of a low signal-to-noise ratio data modality with a high degree of variability between subjects and datasets. There, we tailor the training scheme to focus on robust patterns that generalize to new subjects and ignore the noisier and subject-specific patterns. To achieve this, we first introduce a physiologically inspired unsupervised training task and then extend it by explicitly optimizing for cross-dataset generalization using meta-learning. In the context of image classification, we address the challenge of training semi-supervised models under class imbalance by designing a novel label refinement strategy with higher local sensitivity to minority class samples while preserving the global data distribution. Lastly, we introduce a new Generative Adversarial Networks training loss. Such generative models could be applied to improve the training of subsequent models in the low data regime by augmenting the dataset using generated samples. Unfortunately, GAN training relies on a delicate balance between its components, making it prone mode collapse. Our contribution consists of defining a more principled GAN loss whose gradients incentivize the generator model to seek out missing modes in its distribution. All in all, this thesis tackles the challenge of training more robust machine learning models that can generalize beyond their training data. This necessitates the development of methods specifically tailored to handle the diverse biases and spurious correlations inherent in the data. It is important to note that achieving greater generalizability in models goes beyond simply increasing the volume of data; it requires meticulous consideration of training objectives and model architecture. By tackling these challenges, this research contributes to advancing the field of machine learning and underscores the significance of thoughtful design in obtaining more resilient and versatile models.
Automated Sleep Scoring, Deep Learning and Physician Supervision
Luigi fiorillo · oct. 2022.
Sleep plays a crucial role in human well-being. Polysomnography is used in sleep medicine as a diagnostic tool, so as to objectively analyze the quality of sleep. Sleep scoring is the procedure of extracting sleep cycle information from the wholenight electrophysiological signals. The scoring is done worldwide by the sleep physicians according to the official American Academy of Sleep Medicine (AASM) scoring manual. In the last decades, a wide variety of deep learning based algorithms have been proposed to automatise the sleep scoring task. In this thesis we study the reasons why these algorithms fail to be introduced in the daily clinical routine, with the perspective of bridging the existing gap between the automatic sleep scoring models and the sleep physicians. In this light, the primary step is the design of a simplified sleep scoring architecture, also providing an estimate of the model uncertainty. Beside achieving results on par with most up-to-date scoring systems, we demonstrate the efficiency of ensemble learning based algorithms, together with label smoothing techniques, in both enhancing the performance and calibrating the simplified scoring model. We introduced an uncertainty estimate procedure, so as to identify the most challenging sleep stage predictions, and to quantify the disagreement between the predictions given by the model and the annotation given by the physicians. In this thesis we also propose a novel method to integrate the inter-scorer variability into the training procedure of a sleep scoring model. We clearly show that a deep learning model is able to encode this variability, so as to better adapt to the consensus of a group of scorers-physicians. We finally address the generalization ability of a deep learning based sleep scoring system, further studying its resilience to the sleep complexity and to the AASM scoring rules. We can state that there is no need to train the algorithm strictly following the AASM guidelines. Most importantly, using data from multiple data centers results in a better performing model compared with training on a single data cohort. The variability among different scorers and data centers needs to be taken into account, more than the variability among sleep disorders.
Learning Representations for Controllable Image Restoration
Givi meishvili · march 2022.
Deep Convolutional Neural Networks have sparked a renaissance in all the sub-fields of computer vision. Tremendous progress has been made in the area of image restoration. The research community has pushed the boundaries of image deblurring, super-resolution, and denoising. However, given a distorted image, most existing methods typically produce a single restored output. The tasks mentioned above are inherently ill-posed, leading to an infinite number of plausible solutions. This thesis focuses on designing image restoration techniques capable of producing multiple restored results and granting users more control over the restoration process. Towards this goal, we demonstrate how one could leverage the power of unsupervised representation learning. Image restoration is vital when applied to distorted images of human faces due to their social significance. Generative Adversarial Networks enable an unprecedented level of generated facial details combined with smooth latent space. We leverage the power of GANs towards the goal of learning controllable neural face representations. We demonstrate how to learn an inverse mapping from image space to these latent representations, tuning these representations towards a specific task, and finally manipulating latent codes in these spaces. For example, we show how GANs and their inverse mappings enable the restoration and editing of faces in the context of extreme face super-resolution and the generation of novel view sharp videos from a single motion-blurred image of a face. This thesis also addresses more general blind super-resolution, denoising, and scratch removal problems, where blur kernels and noise levels are unknown. We resort to contrastive representation learning and first learn the latent space of degradations. We demonstrate that the learned representation allows inference of ground-truth degradation parameters and can guide the restoration process. Moreover, it enables control over the amount of deblurring and denoising in the restoration via manipulation of latent degradation features.
Learning Generalizable Visual Patterns Without Human Supervision
Simon jenni · oct. 2021.
Owing to the existence of large labeled datasets, Deep Convolutional Neural Networks have ushered in a renaissance in computer vision. However, almost all of the visual data we generate daily - several human lives worth of it - remains unlabeled and thus out of reach of today’s dominant supervised learning paradigm. This thesis focuses on techniques that steer deep models towards learning generalizable visual patterns without human supervision. Our primary tool in this endeavor is the design of Self-Supervised Learning tasks, i.e., pretext-tasks for which labels do not involve human labor. Besides enabling the learning from large amounts of unlabeled data, we demonstrate how self-supervision can capture relevant patterns that supervised learning largely misses. For example, we design learning tasks that learn deep representations capturing shape from images, motion from video, and 3D pose features from multi-view data. Notably, these tasks’ design follows a common principle: The recognition of data transformations. The strong performance of the learned representations on downstream vision tasks such as classification, segmentation, action recognition, or pose estimation validate this pretext-task design. This thesis also explores the use of Generative Adversarial Networks (GANs) for unsupervised representation learning. Besides leveraging generative adversarial learning to define image transformation for self-supervised learning tasks, we also address training instabilities of GANs through the use of noise. While unsupervised techniques can significantly reduce the burden of supervision, in the end, we still rely on some annotated examples to fine-tune learned representations towards a target task. To improve the learning from scarce or noisy labels, we describe a supervised learning algorithm with improved generalization in these challenging settings.
Learning Interpretable Representations of Images
Attila szabó · june 2019.
Computers represent images with pixels and each pixel contains three numbers for red, green and blue colour values. These numbers are meaningless for humans and they are mostly useless when used directly with classical machine learning techniques like linear classifiers. Interpretable representations are the attributes that humans understand: the colour of the hair, viewpoint of a car or the 3D shape of the object in the scene. Many computer vision tasks can be viewed as learning interpretable representations, for example a supervised classification algorithm directly learns to represent images with their class labels. In this work we aim to learn interpretable representations (or features) indirectly with lower levels of supervision. This approach has the advantage of cost savings on dataset annotations and the flexibility of using the features for multiple follow-up tasks. We made contributions in three main areas: weakly supervised learning, unsupervised learning and 3D reconstruction. In the weakly supervised case we use image pairs as supervision. Each pair shares a common attribute and differs in a varying attribute. We propose a training method that learns to separate the attributes into separate feature vectors. These features then are used for attribute transfer and classification. We also show theoretical results on the ambiguities of the learning task and the ways to avoid degenerate solutions. We show a method for unsupervised representation learning, that separates semantically meaningful concepts. We explain and show ablation studies how the components of our proposed method work: a mixing autoencoder, a generative adversarial net and a classifier. We propose a method for learning single image 3D reconstruction. It is done using only the images, no human annotation, stereo, synthetic renderings or ground truth depth map is needed. We train a generative model that learns the 3D shape distribution and an encoder to reconstruct the 3D shape. For that we exploit the notion of image realism. It means that the 3D reconstruction of the object has to look realistic when it is rendered from different random angles. We prove the efficacy of our method from first principles.
Learning Controllable Representations for Image Synthesis
Qiyang hu · june 2019.
In this thesis, our focus is learning a controllable representation and applying the learned controllable feature representation on images synthesis, video generation, and even 3D reconstruction. We propose different methods to disentangle the feature representation in neural network and analyze the challenges in disentanglement such as reference ambiguity and shortcut problem when using the weak label. We use the disentangled feature representation to transfer attributes between images such as exchanging hairstyle between two face images. Furthermore, we study the problem of how another type of feature, sketch, works in a neural network. The sketch can provide shape and contour of an object such as the silhouette of the side-view face. We leverage the silhouette constraint to improve the 3D face reconstruction from 2D images. The sketch can also provide the moving directions of one object, thus we investigate how one can manipulate the object to follow the trajectory provided by a user sketch. We propose a method to automatically generate video clips from a single image input using the sketch as motion and trajectory guidance to animate the object in that image. We demonstrate the efficiency of our approaches on several synthetic and real datasets.
Beyond Supervised Representation Learning
Mehdi noroozi · jan. 2019.
The complexity of any information processing task is highly dependent on the space where data is represented. Unfortunately, pixel space is not appropriate for the computer vision tasks such as object classification. The traditional computer vision approaches involve a multi-stage pipeline where at first images are transformed to a feature space through a handcrafted function and then consequenced by the solution in the feature space. The challenge with this approach is the complexity of designing handcrafted functions that extract robust features. The deep learning based approaches address this issue by end-to-end training of a neural network for some tasks that lets the network to discover the appropriate representation for the training tasks automatically. It turns out that image classification task on large scale annotated datasets yields a representation transferable to other computer vision tasks. However, supervised representation learning is limited to annotations. In this thesis we study self-supervised representation learning where the goal is to alleviate these limitations by substituting the classification task with pseudo tasks where the labels come for free. We discuss self-supervised learning by solving jigsaw puzzles that uses context as supervisory signal. The rational behind this task is that the network requires to extract features about object parts and their spatial configurations to solve the jigsaw puzzles. We also discuss a method for representation learning that uses an artificial supervisory signal based on counting visual primitives. This supervisory signal is obtained from an equivariance relation. We use two image transformations in the context of counting: scaling and tiling. The first transformation exploits the fact that the number of visual primitives should be invariant to scale. The second transformation allows us to equate the total number of visual primitives in each tile to that in the whole image. The most effective transfer strategy is fine-tuning, which restricts one to use the same model or parts thereof for both pretext and target tasks. We discuss a novel framework for self-supervised learning that overcomes limitations in designing and comparing different tasks, models, and data domains. In particular, our framework decouples the structure of the self-supervised model from the final task-specific finetuned model. Finally, we study the problem of multi-task representation learning. A naive approach to enhance the representation learned by a task is to train the task jointly with other tasks that capture orthogonal attributes. Having a diverse set of auxiliary tasks, imposes challenges on multi-task training from scratch. We propose a framework that allows us to combine arbitrarily different feature spaces into a single deep neural network. We reduce the auxiliary tasks to classification tasks and the multi-task learning to multi-label classification task consequently. Nevertheless, combining multiple representation space without being aware of the target task might be suboptimal. As our second contribution, we show empirically that this is indeed the case and propose to combine multiple tasks after the fine-tuning on the target task.
Motion Deblurring from a Single Image
Meiguang jin · dec. 2018.
With the information explosion, a tremendous amount photos is captured and shared via social media everyday. Technically, a photo requires a finite exposure to accumulate light from the scene. Thus, objects moving during the exposure generate motion blur in a photo. Motion blur is an image degradation that makes visual content less interpretable and is therefore often seen as a nuisance. Although motion blur can be reduced by setting a short exposure time, an insufficient amount of light has to be compensated through increasing the sensor’s sensitivity, which will inevitably bring large amount of sensor noise. Thus this motivates the necessity of removing motion blur computationally. Motion deblurring is an important problem in computer vision and it is challenging due to its ill-posed nature, which means the solution is not well defined. Mathematically, a blurry image caused by uniform motion is formed by the convolution operation between a blur kernel and a latent sharp image. Potentially there are infinite pairs of blur kernel and latent sharp image that can result in the same blurry image. Hence, some prior knowledge or regularization is required to address this problem. Even if the blur kernel is known, restoring the latent sharp image is still difficult as the high frequency information has been removed. Although we can model the uniform motion deblurring problem mathematically, it can only address the camera in-plane translational motion. Practically, motion is more complicated and can be non-uniform. Non-uniform motion blur can come from many sources, camera out-of-plane rotation, scene depth change, object motion and so on. Thus, it is more challenging to remove non-uniform motion blur. In this thesis, our focus is motion blur removal. We aim to address four challenging motion deblurring problems. We start from the noise blind image deblurring scenario where blur kernel is known but the noise level is unknown. We introduce an efficient and robust solution based on a Bayesian framework using a smooth generalization of the 0−1 loss to address this problem. Then we study the blind uniform motion deblurring scenario where both the blur kernel and the latent sharp image are unknown. We explore the relative scale ambiguity between the latent sharp image and blur kernel to address this issue. Moreover, we study the face deblurring problem and introduce a novel deep learning network architecture to solve it. We also address the general motion deblurring problem and particularly we aim at recovering a sequence of 7 frames each depicting some instantaneous motion of the objects in the scene.
Towards a Novel Paradigm in Blind Deconvolution: From Natural to Cartooned Image Statistics
Daniele perrone · july 2015.
In this thesis we study the blind deconvolution problem. Blind deconvolution consists in the estimation of a sharp image and a blur kernel from an observed blurry image. Because the blur model admits several solutions it is necessary to devise an image prior that favors the true blur kernel and sharp image. Recently it has been shown that a class of blind deconvolution formulations and image priors has the no-blur solution as global minimum. Despite this shortcoming, algorithms based on these formulations and priors can successfully solve blind deconvolution. In this thesis we show that a suitable initialization can exploit the non-convexity of the problem and yield the desired solution. Based on these conclusions, we propose a novel “vanilla” algorithm stripped of any enhancement typically used in the literature. Our algorithm, despite its simplicity, is able to compete with the top performers on several datasets. We have also investigated a remarkable behavior of a 1998 algorithm, whose formulation has the no-blur solution as global minimum: even when initialized at the no-blur solution, it converges to the correct solution. We show that this behavior is caused by an apparently insignificant implementation strategy that makes the algorithm no longer minimize the original cost functional. We also demonstrate that this strategy improves the results of our “vanilla” algorithm. Finally, we present a study of image priors for blind deconvolution. We provide experimental evidence supporting the recent belief that a good image prior is one that leads to a good blur estimate rather than being a good natural image statistical model. By focusing the attention on the blur estimation alone, we show that good blur estimates can be obtained even when using images quite different from the true sharp image. This allows using image priors, such as those leading to “cartooned” images, that avoid the no-blur solution. By using an image prior that produces “cartooned” images we achieve state-of-the-art results on different publicly available datasets. We therefore suggests a shift of paradigm in blind deconvolution: from modeling natural image statistics to modeling cartooned image statistics.
New Perspectives on Uncalibrated Photometric Stereo
Thoma papadhimitri · june 2014.
This thesis investigates the problem of 3D reconstruction of a scene from 2D images. In particular, we focus on photometric stereo which is a technique that computes the 3D geometry from at least three images taken from the same viewpoint and under different illumination conditions. When the illumination is unknown (uncalibrated photometric stereo) the problem is ambiguous: different combinations of geometry and illumination can generate the same images. First, we solve the ambiguity by exploiting the Lambertian reflectance maxima. These are points defined on curved surfaces where the normals are parallel to the light direction. Then, we propose a solution that can be computed in closed-form and thus very efficiently. Our algorithm is also very robust and yields always the same estimate regardless of the initial ambiguity. We validate our method on real world experiments and achieve state-of-art results. In this thesis we also solve for the first time the uncalibrated photometric stereo problem under the perspective projection model. We show that unlike in the orthographic case, one can uniquely reconstruct the normals of the object and the lights given only the input images and the camera calibration (focal length and image center). We also propose a very efficient algorithm which we validate on synthetic and real world experiments and show that the proposed technique is a generalization of the orthographic case. Finally, we investigate the uncalibrated photometric stereo problem in the case where the lights are distributed near the scene. In this case we propose an alternating minimization technique which converges quickly and overcomes the limitations of prior work that assumes distant illumination. We show experimentally that adopting a near-light model for real world scenes yields very accurate reconstructions.
- Main menu ( Acesskey 1)
- Sub menu ( Acesskey 2)
- Footer ( Acesskey 3)
- Search ( Acesskey 4)
- Startup-Center Services
- Fellows & Success Stories
- The 'Startup Salzburg' Initiative
- Team & Contact
- Service for Students
- Service for Companies
- Mentoring for female students
- Alumni Club
- Career Platform
- Alumni Stories
- Sponsors and partners
- "Wolfgang Gmachl" Library Urstein Campus
- Library Campus Kuchl
- Self-conception, Mission and Values
- FH Salzburg at a glance
- Cooperations with Companies
- Sustainability
- Innovative Teaching
- Gender & Diversity
- Share Holders and Supervisory Board
- University of Applied Sciences Board
- Service Departments
- Application
- Annual Reports
- FHS Logo and Corporate Design
- Photos & Videos
- In the media
Applied Image and Signal Processing (Joint Master)
Image and signal processing affect our daily lives in an ever-increasing way. Participate in designing this fascinating technology and shape its future function in business and society using AI empowered algorithms and methodology. Today‘s networked devices for image and signal generation provide a historically unmatched volume of raw data for automated decision making and control systems. The master programme Applied Image and Signal Processing enables you to design and implement professional data driven solutions in a range of exciting application areas.
We'd like to point out that after activation data may be sent to third parties. Further information can be found in our privacy statement .
Why study Applied Image and Signal Processing at Salzburg University of Applied Sciences?

Based on prior bachelor studies , the joint master programme for Applied Image and Signal Processing offers you thorough technical training at the cutting edge of research. With an unprecedented amount of raw data being generated by networked devices for image and signal generation, it has become vital to develop new tools and software programmes to distil useful information.
This master programme prepares you with an advanced ability for modelling, problem solving and optimisation. It familiarises you with formal and methodical basics as well as with diverse fields of application. Highly research-oriented courses and small groups provide an appropriate setting for creating innovative approaches and creative ideas.
Among other topics, you will learn about:
- artificial intelligence
- mathematical models and algorithms
- geometric modelling
- audio processing
- digital media formats
- IT project management skills
What you should know about the Applied Image and Signal Processing master programme

State of the Art Methodology
The master programme for Applied Image and Signal Processing provides you with a high degree of specialisation. The first year is devoted to a concise study of the theoretical foundations, the mathematical models and the algorithms used in image and signal processing. Those are complemented by an introduction to data science and machine learning, statistics, audio processing, digital media formats, and, in the third semester, computer vision and geometric modelling.
Choose your Elective Courses
Starting with the second year, specific application scenarios are discussed and corresponding technologies are investigated in a number of elective courses . Choose two such courses and complement those by free electives with a total sum of 6 ECTS in the 3rd or 4th semester.
Good to know : While it is recommended to take a third course from the electives , other lectures given in English on one of the two universities also qualify as free electives.
Develop your own Ideas
In the third semester, you also start researching on your master thesis. You will acquire profound skills in scientific research and paper writing as well as in agile project management. The fourth semester, finally, is dedicated to the completion of the master thesis. The accompanying master seminar provides a forum for presenting and defending one‘s approach to a solution and the results obtained, i.e. for scientific discourse with faculty and peers.

As part of your degree specialisation, you can choose from the following elective courses at two universities:
Studying abroad
With English as the language of instruction, the master programme has a highly international outlook. To complement your studies in Austria, you can choose to do a semester abroad at one of our numerous partner universities in the fourth semester.
Take a look into the study program
Simon Schindler, 2nd semester Master Applied Image and Signal Processing student gives insights into the study programme and career prospects.
Career prospects
This master programme is designed to provide you with an in-depth professional and scientific training based on research driven teaching. The sound knowledge and skills acquired qualify the alumni for diverse practical challenges in their professional work and empower them to contribute to future innovations in image and signal processing based on artificial intelligence. A lot of interesting research and development projects in the private and the public sectors are calling for your expertise. Alternatively, this degree will open up career tracks in universities and research labs by qualifying for applying to PhD programmes.
About Cookies
This website uses cookies. Those have two functions: On the one hand they are providing basic functionality for this website. On the other hand they allow us to improve our content for you by saving and analyzing anonymized user data. With the usage of the analysis cookies, your data will be probably transferred to the USA. You can redraw your consent to using these cookies at any time. Find more information regarding cookies on our Data Protection Declaration and regarding us on the Imprint .
These cookies are needed for a smooth operation of our website.
With the help of these cookies we strive to improve our offer for our users. By means of anonymized data of website users we can optimize the user flow. This enables us to improve website content.
These Cookies are needed to provide contacting us via live chat.
IMAGES
VIDEO
COMMENTS
Masters Thesis Digital image processing. Interest in digital image processing methods sterns from two principal application areas: improvement of pictorial information for human interpretation, and processing of scene data for autonomous machine perception. The applications of image processing techniques in the first category were used widely ...
These IP cores are capable of targeting specific structures within an FPGA, leading to. optimal use of resources. In the case of image processing algorithms, the major design constraint is the. tradeoff between parameters such as speed, area, and power consumption on one hand, and. image quality on the other hand.
Master Thesis Image Processing Projects is our world's utmost image processing research centre launch with our great motivation of give evergreen research zone for our students and research intellectuals. Recently, we guided 5000+ scholars in all over the world. Today, our students are widely-spread in world's popular countries.
Many students are going for this field for their master's thesis as well as for PhD thesis. There are various thesis topics in digital image processing for M.Tech, M.Phil and PhD students. The list of thesis topics in image processing are listed here. List of topics in image processing for thesis and research. 1.
Master Thesis Image Processing Projects reveals by us for our students to find different real world applications of image processing. We have a team of experts who are dedicated to work in advanced image processing concepts with all types of version software's. For our every student master thesis image processing projects, we also concentrate ...
Image Processing Software Developed With MATLAB® 9 1. Introduction As introduction for this master's thesis below are explained the context of the project as well as main goals and the structure of the document. 1.1 Context of the project Introducing the reader to the initial motivations of this work shall begin
image signal processor (ISP), which converts the RAW output of the camera sensor to a format that is useful for the human and computer vision. The resulting image is, then, ready to be processed by the image processing stage, which performs feature extraction and provides information about the car's environment to the image-based controller.
Simple image processing involves tasks such as: Image optimization [1]. Crop an image to fit a given aspect ratio [2]. Perform face detection on a photo and extract a person's portrait [3]. Take a full-page screenshot of a web page [4]. Analyze a web page and extract the most significant image [5].
Master Thesis on Automatic Information Recognition and Extraction based on Document Image Processing. The focus will be on the automation of information extraction in libraries based on Document Image Segmentation and Recognition. While artificial intelligence (AI) technologies, especially deep learning (DL) systems, have demonstrated state-of ...
This Master's Thesis discusses the different trade-offs a programmer needs to consider when constructing image processing systems. First, an overview of the different alternatives available is given followed by a focus on systems based on general hardware.
Students can go for this method for their master's thesis and research. 2. Image Enhancement: Image enhancement is one of the easiest and the most important areas of digital image processing. The core idea behind image enhancement is to find out information that is obscured or to highlight specific features according to the requirements of an ...
Bachelor/Master Theses - Image Processing. At the Lehrstuhl für Informatik 6 of the RWTH Aachen University bachelor/master/diploma theses are available in the field of image processing.Our work currently focusses on object recognition in cluttered scenes, image retrieval, optical character recognition, handwriting recognition, face recognition, gesture recognition, and recognition of sign ...
A wide variety of open topics is available. Upon request we would be happy to offer projects in Computer Vision, Machine Learning, and Pattern Recognition. Projects can focus on basic level research and/or interesting applications in other fields. Please contact: Timo Milbich to find out more ([email protected]). Current example projects: Large Scale GPU Programming for Visual ...
Title of the thesis: Design of an image acquisition and processing system using configurable devices Author: Miquel López Muñoz Advisor: Juan Manuel Moreno Aróstegui Abstract This thesis consists of the evaluation of the possibility to implement a Neural Network in an FPGA instead on the more used GPU. Theoretically, an FPGA is a better ...
If you are interested, send an email to Fred Hamprecht or Ullrich Köthe. Our topics are particularly suitable for students of physics, mathematics, and computer science, but motivated people from other fields are also welcome! Neuro SegmentationA major goal of neuro-science is the understanding of basic neural circuits. To this end, novel electron microscopic methods acquire 3-dimensional ...
In this thesis, a number of image processing techniques that involve cryptography on 2D images are proposed. The proposed cryptographic schemes employed include Cellular Automata, S-Boxes and ...
Deconvolution is an important image processing step in improving the quality of microscopy images for removing out-of-focus light, higher resolution, and beter signal to noise ratio. ... For this masters thesis we aim to make use of machine learning methods to predict mental health based on the data from the actigraph. The ability to predict ...
Master thesis Machine Learning Image Segmentation to Improve Object Recognition in Mixed Reality Guillermo Fernando Esquivel Tabares 2020. ... Object recognition represents an emerging technology in the field of image processing able to detect and label objects through the recognition of patterns in images. At the
The master programme Applied Image and Signal Processing enables you to design and implement professional data driven solutions in a range of exciting application areas. Study mode: full-time. Degree awarded: Master of Science in Engineering (MSc) Length of study: 4 semesters. Study places per year: 20.
Thesis (M.S.)--University of Tennessee, Knoxville, 1991. Vita. Includes bibliographical references (leaves [56]-58). Request PDF | On Apr 18, 2019, Bara W. Al-Mestarehi published Image Processing ...
The main goal of this study is to research image processing methods in attempts to develop a robust approach to image pre-preprocessing of Data Matrix barcode images that will improve barcode read rates in an open source fashion. This is demonstrated by element state classification to re-create the ideal binary matrix corresponding to the intended barcode layout through pattern recognition theory.
Master Thesis in Image Processing Final Year Master Thesis in Image Processing is your complete contribution of research. Our institution is The World Number One Institution created for students who are pursuing Master Degree Courses [M.E, M.Tech, MCA, M.Phil. and M.Sc.]. The most important issues of image processing are back-end technologies ...