- Scipy lecture notes »
- 3. Packages and applications »
- Edit Improve this page: Edit it on Github.

3.1. Statistics in Python ¶
Author : Gaël Varoquaux
Requirements
- Standard scientific Python environment (numpy, scipy, matplotlib)
- Statsmodels
To install Python and these dependencies, we recommend that you download Anaconda Python or Enthought Canopy , or preferably use the package manager if you are under Ubuntu or other linux.
- Bayesian statistics in Python : This chapter does not cover tools for Bayesian statistics. Of particular interest for Bayesian modelling is PyMC , which implements a probabilistic programming language in Python.
- Read a statistics book : The Think stats book is available as free PDF or in print and is a great introduction to statistics.
Why Python for statistics?
R is a language dedicated to statistics. Python is a general-purpose language with statistics modules. R has more statistical analysis features than Python, and specialized syntaxes. However, when it comes to building complex analysis pipelines that mix statistics with e.g. image analysis, text mining, or control of a physical experiment, the richness of Python is an invaluable asset.
- Data as a table
- The pandas data-frame
- Student’s t-test: the simplest statistical test
- Paired tests: repeated measurements on the same individuals
- “formulas” to specify statistical models in Python
- Multiple Regression: including multiple factors
- Post-hoc hypothesis testing: analysis of variance (ANOVA)
- Pairplot: scatter matrices
- lmplot: plotting a univariate regression
- Testing for interactions
- Full code for the figures
- Solutions to this chapter’s exercises
In this document, the Python inputs are represented with the sign “>>>”.
Disclaimer: Gender questions
Some of the examples of this tutorial are chosen around gender questions. The reason is that on such questions controlling the truth of a claim actually matters to many people.
3.1.1. Data representation and interaction ¶
3.1.1.1. data as a table ¶.
The setting that we consider for statistical analysis is that of multiple observations or samples described by a set of different attributes or features . The data can than be seen as a 2D table, or matrix, with columns giving the different attributes of the data, and rows the observations. For instance, the data contained in examples/brain_size.csv :
3.1.1.2. The pandas data-frame ¶
We will store and manipulate this data in a pandas.DataFrame , from the pandas module. It is the Python equivalent of the spreadsheet table. It is different from a 2D numpy array as it has named columns, can contain a mixture of different data types by column, and has elaborate selection and pivotal mechanisms.
Creating dataframes: reading data files or converting arrays ¶
It is a CSV file, but the separator is “;”
Reading from a CSV file: Using the above CSV file that gives observations of brain size and weight and IQ (Willerman et al. 1991), the data are a mixture of numerical and categorical values:
Missing values
The weight of the second individual is missing in the CSV file. If we don’t specify the missing value (NA = not available) marker, we will not be able to do statistical analysis.
Creating from arrays : A pandas.DataFrame can also be seen as a dictionary of 1D ‘series’, eg arrays or lists. If we have 3 numpy arrays:
We can expose them as a pandas.DataFrame :
Other inputs : pandas can input data from SQL, excel files, or other formats. See the pandas documentation .
Manipulating data ¶
data is a pandas.DataFrame , that resembles R’s dataframe:
For a quick view on a large dataframe, use its describe method: pandas.DataFrame.describe() .
groupby : splitting a dataframe on values of categorical variables:
groupby_gender is a powerful object that exposes many operations on the resulting group of dataframes:
Use tab-completion on groupby_gender to find more. Other common grouping functions are median, count (useful for checking to see the amount of missing values in different subsets) or sum. Groupby evaluation is lazy, no work is done until an aggregation function is applied.
What is the mean value for VIQ for the full population?
How many males/females were included in this study?
Hint use ‘tab completion’ to find out the methods that can be called, instead of ‘mean’ in the above example.
What is the average value of MRI counts expressed in log units, for males and females?
groupby_gender.boxplot is used for the plots above (see this example ).
Plotting data ¶
Pandas comes with some plotting tools ( pandas.tools.plotting , using matplotlib behind the scene) to display statistics of the data in dataframes:
Scatter matrices :
Two populations
The IQ metrics are bimodal, as if there are 2 sub-populations.
Plot the scatter matrix for males only, and for females only. Do you think that the 2 sub-populations correspond to gender?
3.1.2. Hypothesis testing: comparing two groups ¶
For simple statistical tests , we will use the scipy.stats sub-module of scipy :
Scipy is a vast library. For a quick summary to the whole library, see the scipy chapter.
3.1.2.1. Student’s t-test: the simplest statistical test ¶
1-sample t-test: testing the value of a population mean ¶.
scipy.stats.ttest_1samp() tests if the population mean of data is likely to be equal to a given value (technically if observations are drawn from a Gaussian distributions of given population mean). It returns the T statistic , and the p-value (see the function’s help):
With a p-value of 10^-28 we can claim that the population mean for the IQ (VIQ measure) is not 0.
2-sample t-test: testing for difference across populations ¶
We have seen above that the mean VIQ in the male and female populations were different. To test if this is significant, we do a 2-sample t-test with scipy.stats.ttest_ind() :
3.1.2.2. Paired tests: repeated measurements on the same individuals ¶
PIQ, VIQ, and FSIQ give 3 measures of IQ. Let us test if FISQ and PIQ are significantly different. We can use a 2 sample test:
The problem with this approach is that it forgets that there are links between observations: FSIQ and PIQ are measured on the same individuals. Thus the variance due to inter-subject variability is confounding, and can be removed, using a “paired test”, or “repeated measures test” :
This is equivalent to a 1-sample test on the difference:
T-tests assume Gaussian errors. We can use a Wilcoxon signed-rank test , that relaxes this assumption:
The corresponding test in the non paired case is the Mann–Whitney U test , scipy.stats.mannwhitneyu() .
- Test the difference between weights in males and females.
- Use non parametric statistics to test the difference between VIQ in males and females.
Conclusion : we find that the data does not support the hypothesis that males and females have different VIQ.
3.1.3. Linear models, multiple factors, and analysis of variance ¶
3.1.3.1. “formulas” to specify statistical models in python ¶, a simple linear regression ¶.
Given two set of observations, x and y , we want to test the hypothesis that y is a linear function of x . In other terms:
where e is observation noise. We will use the statsmodels module to:
- Fit a linear model. We will use the simplest strategy, ordinary least squares (OLS).
- Test that coef is non zero.
First, we generate simulated data according to the model:
“formulas” for statistics in Python
See the statsmodels documentation
Then we specify an OLS model and fit it:
We can inspect the various statistics derived from the fit:
Terminology:
Statsmodels uses a statistical terminology: the y variable in statsmodels is called ‘endogenous’ while the x variable is called exogenous. This is discussed in more detail here .
To simplify, y (endogenous) is the value you are trying to predict, while x (exogenous) represents the features you are using to make the prediction.
Retrieve the estimated parameters from the model above. Hint : use tab-completion to find the relevent attribute.
Categorical variables: comparing groups or multiple categories ¶
Let us go back the data on brain size:
We can write a comparison between IQ of male and female using a linear model:
Tips on specifying model
Forcing categorical : the ‘Gender’ is automatically detected as a categorical variable, and thus each of its different values are treated as different entities.
An integer column can be forced to be treated as categorical using:
Intercept : We can remove the intercept using - 1 in the formula, or force the use of an intercept using + 1 .
By default, statsmodels treats a categorical variable with K possible values as K-1 ‘dummy’ boolean variables (the last level being absorbed into the intercept term). This is almost always a good default choice - however, it is possible to specify different encodings for categorical variables ( http://statsmodels.sourceforge.net/devel/contrasts.html ).
Link to t-tests between different FSIQ and PIQ
To compare different types of IQ, we need to create a “long-form” table, listing IQs, where the type of IQ is indicated by a categorical variable:
We can see that we retrieve the same values for t-test and corresponding p-values for the effect of the type of iq than the previous t-test:
3.1.3.2. Multiple Regression: including multiple factors ¶
Consider a linear model explaining a variable z (the dependent variable) with 2 variables x and y :
Such a model can be seen in 3D as fitting a plane to a cloud of ( x , y , z ) points.
Example: the iris data ( examples/iris.csv )
Sepal and petal size tend to be related: bigger flowers are bigger! But is there in addition a systematic effect of species?
3.1.3.3. Post-hoc hypothesis testing: analysis of variance (ANOVA) ¶
In the above iris example, we wish to test if the petal length is different between versicolor and virginica, after removing the effect of sepal width. This can be formulated as testing the difference between the coefficient associated to versicolor and virginica in the linear model estimated above (it is an Analysis of Variance, ANOVA ). For this, we write a vector of ‘contrast’ on the parameters estimated: we want to test "name[T.versicolor] - name[T.virginica]" , with an F-test :
Is this difference significant?
Going back to the brain size + IQ data, test if the VIQ of male and female are different after removing the effect of brain size, height and weight.
3.1.4. More visualization: seaborn for statistical exploration ¶
Seaborn combines simple statistical fits with plotting on pandas dataframes.
Let us consider a data giving wages and many other personal information on 500 individuals ( Berndt, ER. The Practice of Econometrics. 1991. NY: Addison-Wesley ).
The full code loading and plotting of the wages data is found in corresponding example .
3.1.4.1. Pairplot: scatter matrices ¶
We can easily have an intuition on the interactions between continuous variables using seaborn.pairplot() to display a scatter matrix:
Categorical variables can be plotted as the hue:
Look and feel and matplotlib settings
Seaborn changes the default of matplotlib figures to achieve a more “modern”, “excel-like” look. It does that upon import. You can reset the default using:
To switch back to seaborn settings, or understand better styling in seaborn, see the relevent section of the seaborn documentation .
3.1.4.2. lmplot: plotting a univariate regression ¶
A regression capturing the relation between one variable and another, eg wage and eduction, can be plotted using seaborn.lmplot() :
Robust regression
Given that, in the above plot, there seems to be a couple of data points that are outside of the main cloud to the right, they might be outliers, not representative of the population, but driving the regression.
To compute a regression that is less sentive to outliers, one must use a robust model . This is done in seaborn using robust=True in the plotting functions, or in statsmodels by replacing the use of the OLS by a “Robust Linear Model”, statsmodels.formula.api.rlm() .
3.1.5. Testing for interactions ¶
Do wages increase more with education for males than females?
The plot above is made of two different fits. We need to formulate a single model that tests for a variance of slope across the two populations. This is done via an “interaction” .
Can we conclude that education benefits males more than females?
Take home messages
- Hypothesis testing and p-values give you the significance of an effect / difference.
- Formulas (with categorical variables) enable you to express rich links in your data.
- Visualizing your data and fitting simple models give insight into the data.
- Conditionning (adding factors that can explain all or part of the variation) is an important modeling aspect that changes the interpretation.
3.1.6. Full code for the figures ¶
Code examples for the statistics chapter.
Boxplots and paired differences
Plotting simple quantities of a pandas dataframe
Analysis of Iris petal and sepal sizes
Simple Regression
Multiple Regression
Test for an education/gender interaction in wages
Visualizing factors influencing wages
Air fares before and after 9/11
3.1.7. Solutions to this chapter’s exercises ¶
Relating Gender and IQ
Gallery generated by Sphinx-Gallery
Table Of Contents
- 3.1.1.1. Data as a table
- Creating dataframes: reading data files or converting arrays
- Manipulating data
- Plotting data
- 1-sample t-test: testing the value of a population mean
- 2-sample t-test: testing for difference across populations
- 3.1.2.2. Paired tests: repeated measurements on the same individuals
- A simple linear regression
- Categorical variables: comparing groups or multiple categories
- 3.1.3.2. Multiple Regression: including multiple factors
- 3.1.3.3. Post-hoc hypothesis testing: analysis of variance (ANOVA)
- 3.1.4.1. Pairplot: scatter matrices
- 3.1.4.2. lmplot: plotting a univariate regression
- 3.1.5. Testing for interactions
- 3.1.6. Full code for the figures
- 3.1.7. Solutions to this chapter’s exercises
Previous topic
3. Packages and applications
3.1.6.1. Boxplots and paired differences
- Show Source
Quick search

MachineLearningTutorials.org
Brief Machine Learning tutorials with examples.
Pandas Testing Tutorial (With Examples)
Introduction to pandas testing.
Testing is a critical aspect of software development that ensures the reliability and correctness of your code. When working with the pandas library in Python, testing becomes essential to validate the functionality of data manipulation and analysis operations. In this tutorial, we will explore various techniques and tools for testing pandas code to ensure that your data processing pipelines are robust and error-free.
Table of Contents
Installing required libraries, creating a test directory, writing test cases, running tests, test discovery, writing test functions, parametrized testing, running tests with pytest, checking data types, comparing dataframes, handling missing values, filtering and sorting, aggregation and grouping, merging and joining, interpreting test results, creating test data, advanced testing techniques.
- Keep Tests Independent
- Use Meaningful Test Names
- Test Edge Cases
- Test Performance
1. Setting Up Your Testing Environment
Before you start testing pandas code, make sure you have the required libraries installed. You will need pandas , unittest , and pytest . You can install them using pip :
To organize your tests effectively, create a separate directory for your test files. This directory can be named tests or anything similar. Inside this directory, you’ll create test scripts for different parts of your pandas code.
2. Unit Testing with unittest Module
The unittest module is a built-in testing framework in Python that allows you to write and run unit tests. Let’s see how to use it for testing pandas code.
Create a new Python script inside your test directory, e.g., test_dataframe_operations.py . Import the necessary modules and start writing your test cases.
In the example above, we define a test class TestDataFrameOperations that inherits from unittest.TestCase . Inside this class, you can write individual test methods, such as test_filtering and test_aggregation , to test different aspects of your pandas code.
To run your tests, navigate to the directory containing your test script and execute the following command:
This will execute all the test methods within the specified test class and display the test results.
The unittest module can automatically discover and run all the test scripts in your test directory. To enable test discovery, make sure your test script filenames follow the pattern test_*.py . For example, test_dataframe_operations.py .
Run test discovery using the following command:
3. Testing with pytest Framework
pytest is a popular testing framework that simplifies writing and running tests. It offers a more concise syntax and advanced features for testing.
Create a new Python script for your tests, e.g., test_dataframe_operations.py , inside the test directory. Write your test functions using the pytest syntax.
pytest allows you to perform parametrized testing by providing different inputs to a test function. This is particularly useful for testing the same operation with various datasets.
To run tests using pytest , navigate to your test directory and execute the following command:
pytest will automatically discover and run all the test functions in your test scripts. It provides detailed information about test outcomes and any assertion failures.
4. Testing DataFrames and Series
Testing pandas involves validating the correctness of DataFrame and Series objects resulting from data manipulation operations. Here are some techniques for testing these objects.
Before performing any complex tests, you can start by checking the data types of the columns in your DataFrame using the dtypes attribute. This helps ensure that the expected data types are present in the DataFrame.
When testing DataFrame transformations, you might want to compare the resulting DataFrame with an expected DataFrame. The equals method of DataFrames can be useful for this purpose.
Testing for missing values is crucial, as they can affect analysis and calculations. Use methods like isnull() , notnull() , and fillna() to handle missing values appropriately.
5. Testing Data Transformation Operations
Testing data transformation operations is essential to ensure the accuracy of your data processing pipelines. Let’s explore some examples of testing common transformation operations.
6. Example 1: Testing DataFrame Filtering and Aggregation
Consider a scenario where you have a DataFrame containing sales data and you want to test filtering and aggregation operations.
Run the tests using the pytest command:
If the tests pass, you’ll see an output indicating the number of tests that passed. If any test fails, pytest will provide detailed information about the failure, helping you identify the issue in your code.
7. Example 2: Testing Data Merging and Joining
Let’s assume you have two DataFrames representing customer data and order data. You want to test the merging and joining operations to ensure that customer information is correctly matched with orders.
Create a test script, e.g., test_merging_joining.py , and write test cases for merging and joining operations.
You can enhance your tests by introducing parametrization, edge cases, and more complex data scenarios. This helps ensure that your code is robust and handles various situations correctly.
8. Best Practices for Effective Testing
To create effective tests for your pandas code, follow these best practices:
- Keep Tests Independent : Each test should be independent of others and not rely on the results of previous tests.
- Use Meaningful Test Names : Give descriptive names to your test functions so that their purpose is clear.
- Test Edge Cases : Test scenarios that involve extreme or boundary values to ensure your code handles them correctly.
- Test Performance : If your code involves large datasets, consider testing its performance to ensure it’s efficient.
9. Conclusion
Testing your pandas code is essential to ensure that your data processing and analysis operations work as expected. By using the unittest module and the pytest framework, you can write comprehensive tests to validate your code’s functionality. By following best practices and testing different data scenarios, you can build robust and reliable data pipelines using pandas.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.

Visual Design.
Upgrade to get unlimited access ($10 one off payment).
7 Tips for Beginner to Future-Proof your Machine Learning Project

LLM Prompt Engineering Techniques for Knowledge Graph Integration

Develop a Data Analytics Web App in 3 Steps

What Does ChatGPT Say About Machine Learning Trend and How Can We Prepare For It?

- Apr 14, 2022
An Interactive Guide to Hypothesis Testing in Python
Updated: Jun 12, 2022

upgrade and grab the cheatsheet from our infographics gallery
What is hypothesis testing.
Hypothesis testing is an essential part in inferential statistics where we use observed data in a sample to draw conclusions about unobserved data - often the population.
Implication of hypothesis testing:
clinical research: widely used in psychology, biology and healthcare research to examine the effectiveness of clinical trials
A/B testing: can be applied in business context to improve conversions through testing different versions of campaign incentives, website designs ...
feature selection in machine learning: filter-based feature selection methods use different statistical tests to determine the feature importance
college or university: well, if you major in statistics or data science, it is likely to appear in your exams
For a brief video walkthrough along with the blog, check out my YouTube channel.
4 Steps in Hypothesis testing
Step 1. define null and alternative hypothesis.
Null hypothesis (H0) can be stated differently depends on the statistical tests, but generalize to the claim that no difference, no relationship or no dependency exists between two or more variables.
Alternative hypothesis (H1) is contradictory to the null hypothesis and it claims that relationships exist. It is the hypothesis that we would like to prove right. However, a more conservational approach is favored in statistics where we always assume null hypothesis is true and try to find evidence to reject the null hypothesis.
Step 2. Choose the appropriate test
Common Types of Statistical Testing including t-tests, z-tests, anova test and chi-square test

T-test: compare two groups/categories of numeric variables with small sample size
Z-test: compare two groups/categories of numeric variables with large sample size
ANOVA test: compare the difference between two or more groups/categories of numeric variables
Chi-Squared test: examine the relationship between two categorical variables
Correlation test: examine the relationship between two numeric variables
Step 3. Calculate the p-value
How p value is calculated primarily depends on the statistical testing selected. Firstly, based on the mean and standard deviation of the observed sample data, we are able to derive the test statistics value (e.g. t-statistics, f-statistics). Then calculate the probability of getting this test statistics given the distribution of the null hypothesis, we will find out the p-value. We will use some examples to demonstrate this in more detail.
Step 4. Determine the statistical significance
p value is then compared against the significance level (also noted as alpha value) to determine whether there is sufficient evidence to reject the null hypothesis. The significance level is a predetermined probability threshold - commonly 0.05. If p value is larger than the threshold, it means that the value is likely to occur in the distribution when the null hypothesis is true. On the other hand, if lower than significance level, it means it is very unlikely to occur in the null hypothesis distribution - hence reject the null hypothesis.
Hypothesis Testing with Examples
Kaggle dataset “ Customer Personality Analysis” is used in this case study to demonstrate different types of statistical test. T-test, ANOVA and Chi-Square test are sensitive to large sample size, and almost certainly will generate very small p-value when sample size is large . Therefore, I took a random sample (size of 100) from the original data:
T-test is used when we want to test the relationship between a numeric variable and a categorical variable.There are three main types of t-test.
one sample t-test: test the mean of one group against a constant value
two sample t-test: test the difference of means between two groups
paired sample t-test: test the difference of means between two measurements of the same subject
For example, if I would like to test whether “Recency” (the number of days since customer’s last purchase - numeric value) contributes to the prediction of “Response” (whether the customer accepted the offer in the last campaign - categorical value), I can use a two sample t-test.
The first sample would be the “Recency” of customers who accepted the offer:
The second sample would be the “Recency” of customers who rejected the offer:
To compare the “Recency” of these two groups intuitively, we can use histogram (or distplot) to show the distributions.

It appears that positive response have lower Recency compared to negative response. To quantify the difference and make it more scientific, let’s follow the steps in hypothesis testing and carry out a t-test.
Step1. define null and alternative hypothesis
null: there is no difference in Recency between the customers who accepted the offer in the last campaign and who did not accept the offer
alternative: customers who accepted the offer has lower Recency compared to customers who did not accept the offer
Step 2. choose the appropriate test
To test the difference between two independent samples, two-sample t-test is the most appropriate statistical test which follows student t-distribution. The shape of student-t distribution is determined by the degree of freedom, calculated as the sum of two sample size minus 2.
In python, simply import the library scipy.stats and create the t-distribution as below.
Step 3. calculate the p-value
There are some handy functions in Python calculate the probability in a distribution. For any x covered in the range of the distribution, pdf(x) is the probability density function of x — which can be represented as the orange line below, and cdf(x) is the cumulative density function of x — which can be seen as the cumulative area. In this example, we are testing the alternative hypothesis that — Recency of positive response minus the Recency of negative response is less than 0. Therefore we should use a one-tail test and compare the t-statistics we get against the lowest value in this distribution — therefore p-value can be calculated as cdf(t_statistics) in this case.
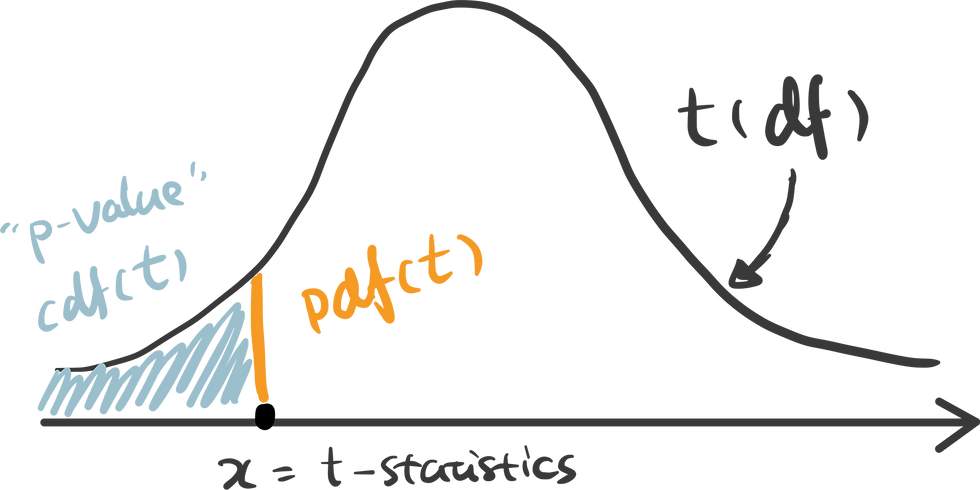
ttest_ind() is a handy function for independent t-test in python that has done all of these for us automatically. Pass two samples rececency_P and recency_N as the parameters, and we get the t-statistics and p-value.

Here I use plotly to visualize the p-value in t-distribution. Hover over the line and see how point probability and p-value changes as the x shifts. The area with filled color highlights the p-value we get for this specific test.
Check out the code in our Code Snippet section, if you want to build this yourself.
An interactive visualization of t-distribution with t-statistics vs. significance level.
Step 4. determine the statistical significance
The commonly used significance level threshold is 0.05. Since p-value here (0.024) is smaller than 0.05, we can say that it is statistically significant based on the collected sample. A lower Recency of customer who accepted the offer is likely not occur by chance. This indicates the feature “Response” may be a strong predictor of the target variable “Recency”. And if we would perform feature selection for a model predicting the "Recency" value, "Response" is likely to have high importance.
Now that we know t-test is used to compare the mean of one or two sample groups. What if we want to test more than two samples? Use ANOVA test.
ANOVA examines the difference among groups by calculating the ratio of variance across different groups vs variance within a group . Larger ratio indicates that the difference across groups is a result of the group difference rather than just random chance.
As an example, I use the feature “Kidhome” for the prediction of “NumWebPurchases”. There are three values of “Kidhome” - 0, 1, 2 which naturally forms three groups.
Firstly, visualize the data. I found box plot to be the most aligned visual representation of ANOVA test.

It appears there are distinct differences among three groups. So let’s carry out ANOVA test to prove if that’s the case.
1. define hypothesis:
null hypothesis: there is no difference among three groups
alternative hypothesis: there is difference between at least two groups
2. choose the appropriate test: ANOVA test for examining the relationships of numeric values against a categorical value with more than two groups. Similar to t-test, the null hypothesis of ANOVA test also follows a distribution defined by degrees of freedom. The degrees of freedom in ANOVA is determined by number of total samples (n) and the number of groups (k).
dfn = n - 1
dfd = n - k
3. calculate the p-value: To calculate the p-value of the f-statistics, we use the right tail cumulative area of the f-distribution, which is 1 - rv.cdf(x).
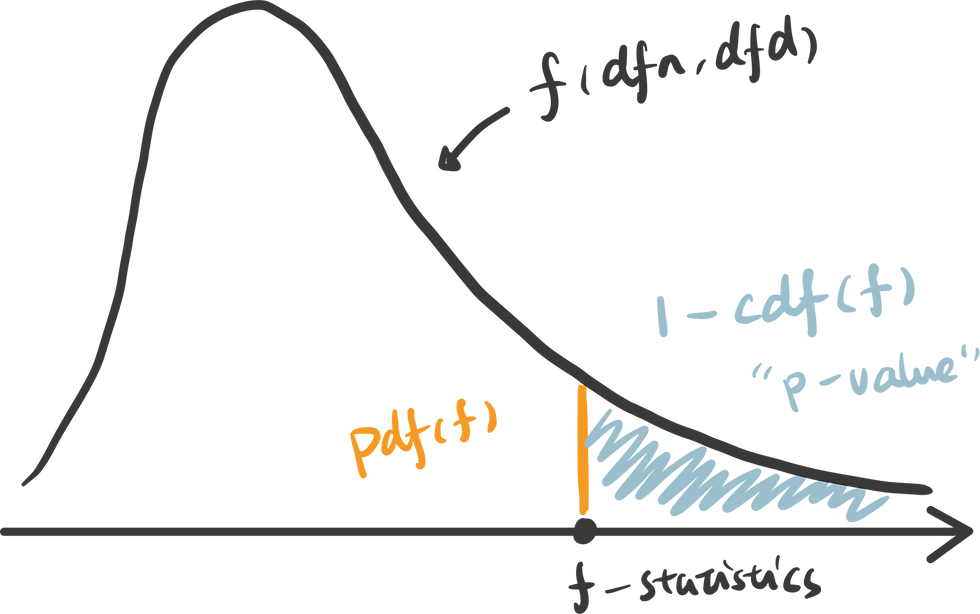
To easily get the f-statistics and p-value using Python, we can use the function stats.f_oneway() which returns p-value: 0.00040.
An interactive visualization of f-distribution with f-statistics vs. significance level. (Check out the code in our Code Snippet section, if you want to build this yourself. )
4. determine the statistical significance : Compare the p-value against the significance level 0.05, we can infer that there is strong evidence against the null hypothesis and very likely that there is difference in “NumWebPurchases” between at least two groups.
Chi-Squared Test
Chi-Squared test is for testing the relationship between two categorical variables. The underlying principle is that if two categorical variables are independent, then one categorical variable should have similar composition when the other categorical variable change. Let’s look at the example of whether “Education” and “Response” are independent.
First, use stacked bar chart and contingency table to summary the count of each category.
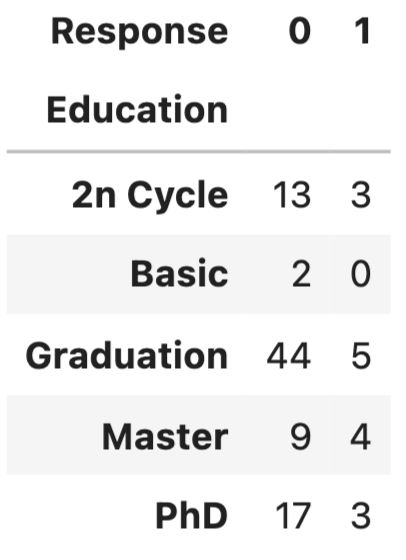
If these two variables are completely independent to each other (null hypothesis is true), then the proportion of positive Response and negative Response should be the same across all Education groups. It seems like composition are slightly different, but is it significant enough to say there is dependency - let’s run a Chi-Squared test.
null hypothesis: “Education” and “Response” are independent to each other.
alternative hypothesis: “Education” and “Response” are dependent to each other.
2. choose the appropriate test: Chi-Squared test is chosen and you probably found a pattern here, that Chi-distribution is also determined by the degree of freedom which is (row - 1) x (column - 1).
3. calculate the p-value: p value is calculated as the right tail cumulative area: 1 - rv.cdf(x).
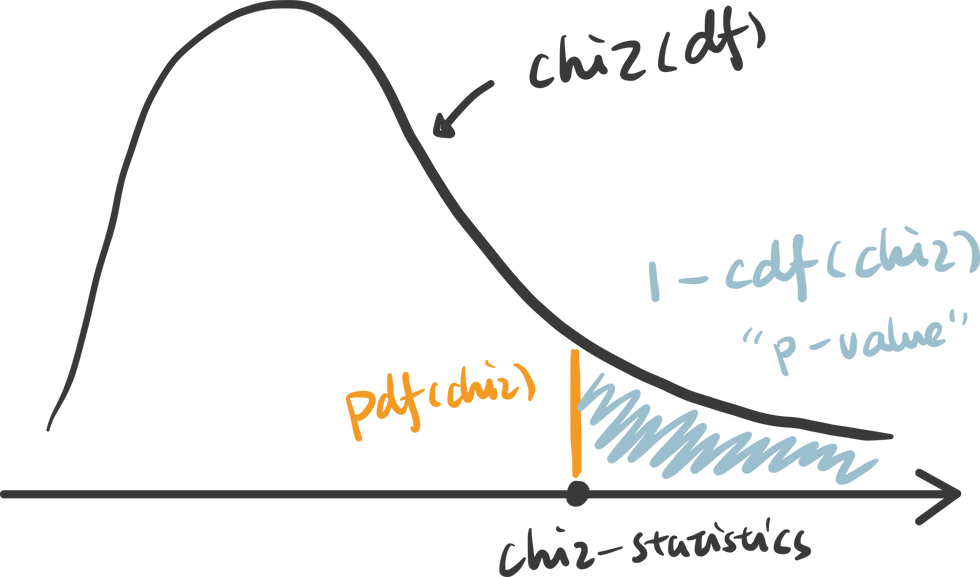
Python also provides a useful function to get the chi statistics and p-value given the contingency table.
An interactive visualization of chi-distribution with chi-statistics vs. significance level. (Check out the code in our Code Snippet section, if you want to build this yourself. )
4. determine the statistical significanc e: the p-value here is 0.41, suggesting that it is not statistical significant. Therefore, we cannot reject the null hypothesis that these two categorical variables are independent. This further indicates that “Education” may not be a strong predictor of “Response”.
Thanks for reaching so far, we have covered a lot of contents in this article but still have two important hypothesis tests that are worth discussing separately in upcoming posts.
z-test: test the difference between two categories of numeric variables - when sample size is LARGE
correlation: test the relationship between two numeric variables
Hope you found this article helpful. If you’d like to support my work and see more articles like this, treat me a coffee ☕️ by signing up Premium Membership with $10 one-off purchase.
Take home message.
In this article, we interactively explore and visualize the difference between three common statistical tests: t-test, ANOVA test and Chi-Squared test. We also use examples to walk through essential steps in hypothesis testing:
1. define the null and alternative hypothesis
2. choose the appropriate test
3. calculate the p-value
4. determine the statistical significance
- Data Science
Recent Posts
How to Self Learn Data Science in 2022
Python Companion to Statistical Thinking in the 21st Century
Hypothesis testing in Python
Hypothesis testing in python #.
In this chapter we will present several examples of using Python to perform hypothesis testing.
Simple example: Coin-flipping #
Let’s say that we flipped 100 coins and observed 70 heads. We would like to use these data to test the hypothesis that the true probability is 0.5. First let’s generate our data, simulating 100,000 sets of 100 flips. We use such a large number because it turns out that it’s very rare to get 70 heads, so we need many attempts in order to get a reliable estimate of these probabilties. This will take a couple of minutes to complete.
Now we can compute the proportion of samples from the distribution observed when the true proportion of heads is 0.5.
For comparison, we can also compute the p-value for 70 or more heads based on a null hypothesis of \(P_{heads}=0.5\) , using the binomial distribution.
compute the probability of 69 or fewer heads, when P(heads)=0.5
the probability of 70 or more heads is simply the complement of p_lt_70
Simulating p-values #
In this exercise we will perform hypothesis testing many times in order to test whether the p-values provided by our statistical test are valid. We will sample data from a normal distribution with a mean of zero, and for each sample perform a t-test to determine whether the mean is different from zero. We will then count how often we reject the null hypothesis; since we know that the true mean is zero, these are by definition Type I errors.
We should see that the proportion of samples with p < .05 is about 5%.

Statistics Made Easy
How to Perform t-Tests in Pandas (3 Examples)
The following examples show how to perform three different t-tests using a pandas DataFrame:
- Independent Two Sample t-Test
- Welch’s Two Sample t-Test
- Paired Samples t-Test
Example 1: Independent Two Sample t-Test in Pandas
An independent two sample t-test is used to determine if two population means are equal.
For example, suppose a professor wants to know if two different studying methods lead to different mean exam scores.
To test this, he recruits 10 students to use method A and 10 students to use method B.
The following code shows how to enter the scores of each student in a pandas DataFrame and then use the ttest_ind() function from the SciPy library to perform an independent two sample t-test:
From the output we can see:
- t test statistic: – 2.6034
- p-value: 0.0179
Since the p-value is less than .05, we reject the null hypothesis of the t-test and conclude that there is sufficient evidence to say that the two methods lead to different mean exam scores.
Example 2: Welch’s t-Test in Pandas
Welch’s t-test is similar to the independent two sample t-test, except it does not assume that the two populations that the samples came from have equal variance .
To perform Welch’s t-test on the exact same dataset as the previous example, we simply need to specify equal_var=False within the ttest_ind () function as follows:
- p-value: 0.0201
Since the p-value is less than .05, we reject the null hypothesis of Welch’s t-test and conclude that there is sufficient evidence to say that the two methods lead to different mean exam scores.
Example 3: Paired Samples t-Test in Pandas
A paired samples t-test is used to determine if two population means are equal in which each observation in one sample can be paired with an observation in the other sample.
To test this, he recruits 10 students to use method A and then take a test. Then, he lets the same 10 students used method B to prepare for and take another test of similar difficulty.
Since all of the students appear in both samples, we can perform a paired samples t-test in this scenario.
The following code shows how to enter the scores of each student in a pandas DataFrame and then use the ttest_rel() function from the SciPy library to perform a paired samples t-test:
- t test statistic: – 6.1620
- p-value: 0.0001
Since the p-value is less than .05, we reject the null hypothesis of the paired samples t-test and conclude that there is sufficient evidence to say that the two methods lead to different mean exam scores.
Additional Resources
The following tutorials explain how to perform other common tasks in Python:
How to Perform a Chi-Square Test of Independence in Python How to Perform a One-Way ANOVA in Python How to Perform Fisher’s Exact Test in Python
Hey there. My name is Zach Bobbitt. I have a Master of Science degree in Applied Statistics and I’ve worked on machine learning algorithms for professional businesses in both healthcare and retail. I’m passionate about statistics, machine learning, and data visualization and I created Statology to be a resource for both students and teachers alike. My goal with this site is to help you learn statistics through using simple terms, plenty of real-world examples, and helpful illustrations.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
scipy.stats.normaltest #
Test whether a sample differs from a normal distribution.
This function tests the null hypothesis that a sample comes from a normal distribution. It is based on D’Agostino and Pearson’s [1] , [2] test that combines skew and kurtosis to produce an omnibus test of normality.
The array containing the sample to be tested.
If an int, the axis of the input along which to compute the statistic. The statistic of each axis-slice (e.g. row) of the input will appear in a corresponding element of the output. If None , the input will be raveled before computing the statistic.
Defines how to handle input NaNs.
propagate : if a NaN is present in the axis slice (e.g. row) along which the statistic is computed, the corresponding entry of the output will be NaN.
omit : NaNs will be omitted when performing the calculation. If insufficient data remains in the axis slice along which the statistic is computed, the corresponding entry of the output will be NaN.
raise : if a NaN is present, a ValueError will be raised.
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
s^2 + k^2 , where s is the z-score returned by skewtest and k is the z-score returned by kurtosistest .
A 2-sided chi squared probability for the hypothesis test.
Beginning in SciPy 1.9, np.matrix inputs (not recommended for new code) are converted to np.ndarray before the calculation is performed. In this case, the output will be a scalar or np.ndarray of appropriate shape rather than a 2D np.matrix . Similarly, while masked elements of masked arrays are ignored, the output will be a scalar or np.ndarray rather than a masked array with mask=False .
D’Agostino, R. B. (1971), “An omnibus test of normality for moderate and large sample size”, Biometrika, 58, 341-348
D’Agostino, R. and Pearson, E. S. (1973), “Tests for departure from normality”, Biometrika, 60, 613-622
Shapiro, S. S., & Wilk, M. B. (1965). An analysis of variance test for normality (complete samples). Biometrika, 52(3/4), 591-611.
B. Phipson and G. K. Smyth. “Permutation P-values Should Never Be Zero: Calculating Exact P-values When Permutations Are Randomly Drawn.” Statistical Applications in Genetics and Molecular Biology 9.1 (2010).
Panagiotakos, D. B. (2008). The value of p-value in biomedical research. The open cardiovascular medicine journal, 2, 97.
Suppose we wish to infer from measurements whether the weights of adult human males in a medical study are not normally distributed [3] . The weights (lbs) are recorded in the array x below.
The normality test of [1] and [2] begins by computing a statistic based on the sample skewness and kurtosis.
(The test warns that our sample has too few observations to perform the test. We’ll return to this at the end of the example.) Because the normal distribution has zero skewness and zero (“excess” or “Fisher”) kurtosis, the value of this statistic tends to be low for samples drawn from a normal distribution.
The test is performed by comparing the observed value of the statistic against the null distribution: the distribution of statistic values derived under the null hypothesis that the weights were drawn from a normal distribution. For this normality test, the null distribution for very large samples is the chi-squared distribution with two degrees of freedom.

The comparison is quantified by the p-value: the proportion of values in the null distribution greater than or equal to the observed value of the statistic.

If the p-value is “small” - that is, if there is a low probability of sampling data from a normally distributed population that produces such an extreme value of the statistic - this may be taken as evidence against the null hypothesis in favor of the alternative: the weights were not drawn from a normal distribution. Note that:
The inverse is not true; that is, the test is not used to provide evidence for the null hypothesis.
The threshold for values that will be considered “small” is a choice that should be made before the data is analyzed [4] with consideration of the risks of both false positives (incorrectly rejecting the null hypothesis) and false negatives (failure to reject a false null hypothesis).
Note that the chi-squared distribution provides an asymptotic approximation of the null distribution; it is only accurate for samples with many observations. This is the reason we received a warning at the beginning of the example; our sample is quite small. In this case, scipy.stats.monte_carlo_test may provide a more accurate, albeit stochastic, approximation of the exact p-value.

Furthermore, despite their stochastic nature, p-values computed in this way can be used to exactly control the rate of false rejections of the null hypothesis [5] .
IMAGES
VIDEO
COMMENTS
It tests the null hypothesis that the population variances are equal (called homogeneity of variance or homoscedasticity). Suppose the resulting p-value of Levene's test is less than the significance level (typically 0.05).In that case, the obtained differences in sample variances are unlikely to have occurred based on random sampling from a population with equal variances.
Example 1: One Sample t-test in Python. A one sample t-test is used to test whether or not the mean of a population is equal to some value. For example, suppose we want to know whether or not the mean weight of a certain species of some turtle is equal to 310 pounds. To test this, we go out and collect a simple random sample of turtles with the ...
In this post, you will discover a cheat sheet for the most popular statistical hypothesis tests for a machine learning project with examples using the Python API. Each statistical test is presented in a consistent way, including: The name of the test. What the test is checking. The key assumptions of the test. How the test result is interpreted.
The pandas data-frame; Hypothesis testing: comparing two groups. Student's t-test: the simplest statistical test; ... from the pandas module. It is the Python equivalent of the spreadsheet table. ... Hypothesis testing and p-values give you the significance of an effect / difference.
Now Let's see some of widely used hypothesis testing type :-T Test ( Student T test) Z Test; ANOVA Test; Chi-Square Test; T- Test :- A t-test is a type of inferential statistic which is used to determine if there is a significant difference between the means of two groups which may be related in certain features.It is mostly used when the data sets, like the set of data recorded as outcome ...
In this article, we interactively explore and visualize the difference between three common statistical tests: T-test, ANOVA test and Chi-Squared test. We also use examples to walkthrough essential steps in hypothesis testing: 1. define the null and alternative hypothesis. 2. choose the appropriate test.
Image by Author. We use the boxplot() pandas function to create box plots for the compactness variable. Evidently, the Kama and Rosa varieties have similar quartiles, with median values that are nearly identical. In contrast, the Canadian variety appears to slightly differ from the rest, but we need to verify this with a hypothesis test.
Writing Test Functions. Create a new Python script for your tests, e.g., test_dataframe_operations.py, inside the test directory. Write your test functions using the pytest syntax. import pandas as pd def test_filtering(): # Your filtering code here pass def test_aggregation(): # Your aggregation code here pass Parametrized Testing
In this article, we interactively explore and visualize the difference between three common statistical tests: t-test, ANOVA test and Chi-Squared test. We also use examples to walk through essential steps in hypothesis testing: 1. define the null and alternative hypothesis. 2. choose the appropriate test.
Suppose we wish to test the null hypothesis that a sample is distributed according to the standard normal. We choose a confidence level of 95%; that is, we will reject the null hypothesis in favor of the alternative if the p-value is less than 0.05. When testing uniformly distributed data, we would expect the null hypothesis to be rejected.
Hypothesis testing in Python# ... import numpy as np import pandas as pd num_runs = 10000 def toss_coins_and_count_heads (num_coins = 100, p_heads = 0.5): ... In this exercise we will perform hypothesis testing many times in order to test whether the p-values provided by our statistical test are valid. We will sample data from a normal ...
Example 1: Independent Two Sample t-Test in Pandas. An independent two sample t-test is used to determine if two population means are equal. For example, suppose a professor wants to know if two different studying methods lead to different mean exam scores. To test this, he recruits 10 students to use method A and 10 students to use method B.
H1: There is a relationship between hot weather (greater than 28 degrees Celsius) and the number of car accidents. I am not sure of how to calculate the p-value for the above hypothesis in python. I did the following: import pandas as pd. from scipy.stats import ttest_ind.
For example, everything_except(int) returns a strategy that can generate anything that from_type() can ever generate, except for instances of int, and excluding instances of types added via register_type_strategy(). This is useful when writing tests which check that invalid input is rejected in a certain way. hypothesis.strategies. frozensets (elements, *, min_size = 0, max_size = None ...
scipy.stats.normaltest(a, axis=0, nan_policy='propagate', *, keepdims=False) [source] #. Test whether a sample differs from a normal distribution. This function tests the null hypothesis that a sample comes from a normal distribution. It is based on D'Agostino and Pearson's [1], [2] test that combines skew and kurtosis to produce an omnibus ...
3. I am trying to run a hypothesis test using model ols. I am trying to do this model Ols for tweet count based on four groups that I have in my data frame. The four groups are Athletes, CEOs, Politicians, and Celebrities. I have the four groups each labeled for each name in one column as a group. frames = [CEO_df, athletes_df, Celebrity_df ...
Welcome to Hypothesis! Hypothesis is a Python library for creating unit tests which are simpler to write and more powerful when run, finding edge cases in your code you wouldn't have thought to look for. It is stable, powerful and easy to add to any existing test suite. It works by letting you write tests that assert that something should be ...
Hypothesis for the scientific stack¶ numpy¶. Hypothesis offers a number of strategies for NumPy testing, available in the hypothesis[numpy] extra.It lives in the hypothesis.extra.numpy package.. The centerpiece is the arrays() strategy, which generates arrays with any dtype, shape, and contents you can specify or give a strategy for. To make this as useful as possible, strategies are ...
The basis of hypothesis testing has two attributes: (a) Null Hypothesis and (b) Alternative Hypothesis. The null hypothesis is, in general, the boring stuff i.e. it assumes that nothing interesting happens/happened.. The alternative hypothesis is, where the action is i.e. some observation/ phenomenon is real (i.e. not a fluke) and statistical analysis will give us more insights on that.
Pandera is a simple Python library for validating a pandas DataFrame. Validate Your pandas DataFrame with Pandera. Make Sure Your Data Matches Your Expectation. ... Hypothesis — Create Examples for Testing. Next, we will use hypothesis to create data for testing based on the constraints given by pandera.DataFrameSchema. Specifically, we will add:
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources